#cbs software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
So you've probably seen that I haven't been as active on tumblr lately. I'm currently raising a little gremlin. Anyways, I just saw this video where this guy said, "Little gremlins are constantly undergoing a software update. So don't install any dodgy external programs on them until the update is complete." Wash your hands before handling new baby gremlins and avoid altogether when sick. It is FINE to tell visitors to do so. It's not rude and if they think it is, tell them these are the rules of visitation!
#software updates lmaooo#but immature immune systems are no joke#one tiny virus and its 48 hours of sleepness nights#i'm hoping to be more active#but its unlikely#i have a lot of stuff happening in life#its just unfortunate it comes at a time where niki is in his prime#and i actually love the ateez cb#but such is life
8 notes
·
View notes
Text

#nobody fucken talk to me#i’m so mad @ myself#and also david cage and bryan dechart and clancy brown#but the dc hate is not the same as bd/cb make no mis kate i’ve read on the shit the fucker has publicly said#i swear i had no ill intentions and then bam#software instability amirite#the sunshine court#aftg#dbh#detroit become human
14 notes
·
View notes
Text

#Wizard of Wor#Bally Astrocade#Commodore 64#Atari 5200#CBS Electronics#Roklan#Midway Games#Commodore Japan Limited#Weird Science Software#Dave Nutting#arcade#1980
4 notes
·
View notes
Text
CB Ninja Review: New AI Creates Automated ClickBank Sites

Overview of CB Ninja
CB Ninja, powered by Bard AI and PaLM 2 technology, allows you to create fully automated ClickBank™ affiliate sites. These sites come preloaded with hot DFY (Done For You) AI content and AI-generated video reviews of high-profit products. The best part? These sites instantly rank themselves on Google, saving you time and effort.
CB Ninja Review: Features
First To Market Bard AI PaLM 2 Technology That Creates Fully Automated 100% Done For You ClickBank TM Affiliate Sites Like Never Before
Create Premium ClickBank TM Affiliate Sites That Get High Ranks On Google TM In 3 Easy Clicks Within Days
Use Artificial Intelligence To Automate Everything & Create Top-Notch Affiliate Sites On The Fly
Ensure Effortless Monetization Using Reviews & Videos For Top Products Like Never Before
Smartly Add JVzoo TM Affiliate Link To Any Keyword For Extra Monetization
Fill Your Sites With Daily Videos Reviews from AI On Top Trending Products Across ClickBank TM
We’re Using CBNinja To Make Tons Of Commissions From World’s Leading Affiliate Platform ClickBank TM
Create Sites For Any Offer In Any Niche With No Prior Tech Hassles Or Coding Skills
Use These Stunning Affiliate Sites To Create Multiple Set & Forget Passive Income Streams
Proprietary Tech Helps Join Thousands Of Marketers Who’re Making Billions Of Dollars On ClickBank TM
Never Worry About Paying Huge Money Monthly To Expensive Third Party Platforms
100% Easy To Use, Newbie Friendly Technology That’s Never Seen Before
>>>>Click Here To Grab CB Ninja
#affiliate marketing#CB Ninja Review#CB Ninja#Clickbank Marketing#Clickbank Affiliate Marketing#Clickbank Software#Make Money Online
1 note
·
View note
Text
CB Final Boss Spoilers Source: Trust Me Bro
Trying out Story Board Pro for the first time, Thought it would help out with my animation assignments since i use Toon Boom harmony to animate
So of course I do a shitpost with it to get used to the software
284 notes
·
View notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
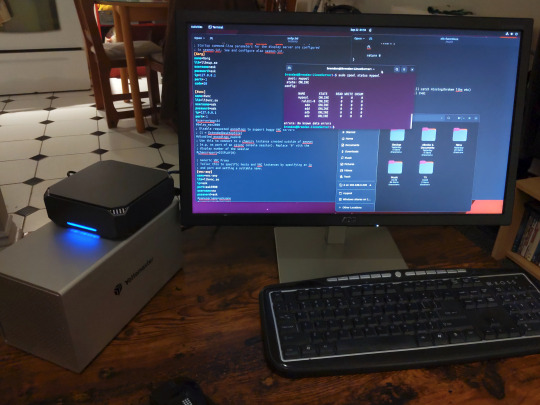
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
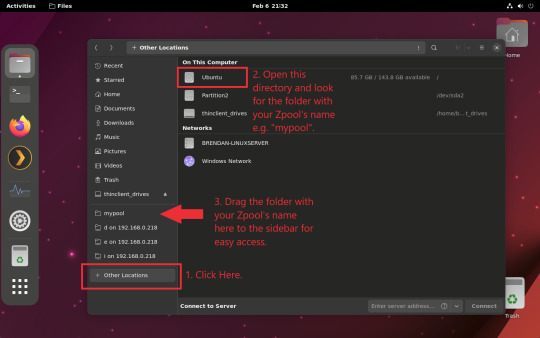
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
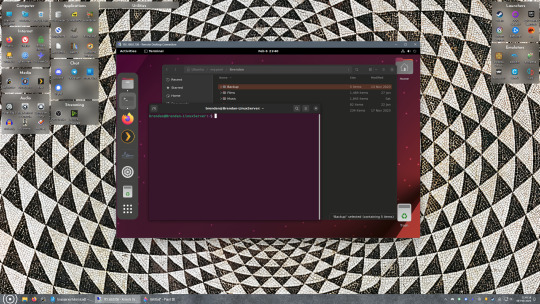
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
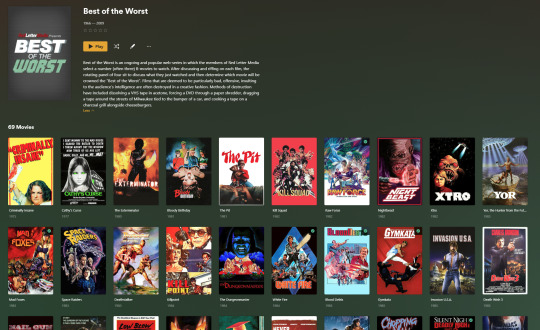
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
Future and Present
Trying to use Toon Boom for my animations, especially with trying to replicate CB style (lineless), so far Toon Boom is the easiest for me compared to other animation software that i've been using for years
I wish i can do more animation like this in the future, but of course i can't promise that cuz, life, lol
368 notes
·
View notes
Text
Bit of a traditional medium potential Furry AU design of CB and Dinah before I go to bed.

For Dinah I went for a cat. Sweet, gentle but can still do some damage if upset enough. I generally just thought of making the coaches felines of some kind and as a cat owner I thought a housecat fit Dinah best.
CB is a fox for various reasons but the main ones are that foxes are cute yet destructive, are canids but act somewhat feline(cat software on dog hardware is the common joke) which fits him as a brake van/caboose(a freight that has humans in him on the regular and can be put on a passenger run) and the colours if the red fox fits him well.
At first I thought of making CB an otter but thought making him a fox would work better. (Unfinished sketch of CB as an Otter and BV as a badger below cut)
If I ever continue this Elvis and his sister will be grey wolves and the Electras will be a Maned wolves.

CB would have been a river otter and BV a common American badger in the first though. This would have made Slick a European badger.
#starlight express#stex#cb the red caboose#stex red caboose#dinah the dining car#stex dinah#furry art#furry au#anthro fox#anthro cat
24 notes
·
View notes
Text

TRS-80 Microcomputer News September 1981
The CompuServe column in this issue promoted the online service's "CB Simulator" (online chat). There was also a VisiCalc column, bylined "Personal Software, Inc.", which began with "VisiCalc—The Product Which Made Desktop Computers Popular" and mentioned "other 'perceptive' advances which went before it—movable type, Jacquard Looms, steam power, gliding flight". A few letters explained that with a bit of tricky programming, you could use memory reserved for "the first graphics page" of a Color Computer for other information.
20 notes
·
View notes
Text
A United States Customs and Border Protection request for information this week revealed the agency’s plans to find vendors that can supply face recognition technology for capturing data on everyone entering the US in a vehicle like a car or van, not just the people sitting in the front seat. And a CBP spokesperson later told WIRED that the agency also has plans to expand its real-time face recognition capabilities at the border to detect people exiting the US as well—a focus that may be tied to the Trump administration’s push to get undocumented people to “self-deport” and leave the US.
WIRED also shed light this week on a recent CBP memo that rescinded a number of internal policies designed to protect vulnerable people—including pregnant women, infants, the elderly, and people with serious medical conditions���while in the agency’s custody. Signed by acting commissioner Pete Flores, the order eliminates four Biden-era policies.
Meanwhile, as the ripple effects of “SignalGate” continue, the communication app TeleMessage suspended “all services” pending an investigation after former US national security adviser Mike Waltz inadvertently called attention to the app, which subsequently suffered data breaches in recent days. Analysis of TeleMessage Signal’s source code this week appeared to show that the app sends users’ message logs in plaintext, undermining the security and privacy guarantees the service promised. After data stolen in one of the TeleMessage hacks indicated that CBP agents might be users of the app, CBP confirmed its use to WIRED, saying that the agency has “disabled TeleMessage as a precautionary measure.”
A WIRED investigation found that US director of national intelligence Tulsi Gabbard reused a weak password for years on multiple accounts. And researchers warn that an open source tool known as “easyjson” could be an exposure for the US government and US companies, because it has ties to the Russian social network VK, whose CEO has been sanctioned.
And there's more. Each week, we round up the security and privacy news we didn’t cover in depth ourselves. Click the headlines to read the full stories. And stay safe out there.
ICE’s Deportation Airline Hack Reveals Man “Disappeared” to El Salvador
Hackers this week revealed they had breached GlobalX, one of the airlines that has come to be known as “ICE Air” thanks to its use by the Trump administration to deport hundreds of migrants. The data they leaked from the airline includes detailed flight manifests for those deportation flights—including, in at least one case, the travel records of a man whose own family had considered him “disappeared” by immigration authorities and whose whereabouts the US government had refused to divulge.
On Monday, reporters at 404 Media said that hackers had provided them with a trove of data taken from GlobalX after breaching the company’s network and defacing its website. “Anonymous has decided to enforce the Judge's order since you and your sycophant staff ignore lawful orders that go against your fascist plans,” a message the hackers posted to the site read. That stolen data, it turns out, included detailed passenger lists for GlobalX’s deportation flights—including the flight to El Salvador of Ricardo Prada Vásquez, a Venezuelan man whose whereabouts had become a mystery to even his own family as they sought answers from the US government. US authorities had previously declined to tell his family or reporters where he had been sent—only that he had been deported—and his name was even excluded from a list of deportees leaked to CBS News. (The Department of Homeland Security later stated in a post to X that Prada was in El Salvador—but only after a New York Times story about his disappearance.)
The fact that his name was, in fact, included all along on a GlobalX flight manifest highlights just how opaque the Trump administration’s deportation process remains. According to immigrant advocates who spoke with 404 Media, it even raises questions about whether the government itself had deportation records as comprehensive as the airline whose planes it chartered. “There are so many levels at which this concerns me. One is they clearly did not take enough care in this to even make sure they had the right lists of who they were removing, and who they were not sending to a prison that is a black hole in El Salvador,” Michelle Brané, executive director of immigrant rights group Together and Free, told 404 Media. “They weren't even keeping accurate records of who they were sending there.”
The Computer of a DOGE Staffer With Sensitive Access Reportedly Infected With Malware
Elon Musk’s so-called Department of Governmental Efficiency has raised alarms not just due to its often reckless cuts to federal programs, but also the agency’s habit of giving young, inexperienced staffers with questionable vetting access to highly sensitive systems. Now security researcher Micah Lee has found that Kyle Schutt, a DOGE staffer who reportedly accessed the financial system of the Federal Emergency Management Agency, appears to have had infostealer malware on one of his computers. Lee discovered that four dumps of user data stolen by that kind of password-stealing malware included Schutt’s passwords and usernames. It’s far from clear when Schutt’s credentials were stolen, for what machine, or whether the malware would have posed any threat to any government agency’s systems, but the incident nonetheless highlights the potential risks posed by DOGE staffers’ unprecedented access.
Grok AI Will “Undress” Women in Public on X
Elon Musk has long marketed his AI tool Grok as a more freewheeling, less restricted alternative to other large language models and AI image generators. Now X users are testing the limits of Grok’s few safeguards by replying to images of women on the platform and asking Grok to “undress” them. While the tool doesn’t allow the generation of nude images, 404 Media and Bellingcat have found that it repeatedly responded to users’ “undress” prompts with pictures of women in lingerie or bikinis, posted publicly to the site. In one case, Grok apologized to a woman who complained about the practice, but the feature has yet to be disabled.
A Hacked School Software Company Paid a Ransom—but Schools Are Still Being Extorted
This week in don’t-trust-ransomware-gangs news: Schools in North Carolina and Canada warned that they’ve received extortion threats from hackers who had obtained students’ personal information. The likely source of that sensitive data? A ransomware breach last December of PowerSchool, one of the world’s biggest education software firms, according to NBC News. PowerSchool paid a ransom at the time, but the data stolen from the company nonetheless appears to be the same info now being used in the current extortion attempts. “We sincerely regret these developments—it pains us that our customers are being threatened and re-victimized by bad actors,” PowerSchool told NBC News in a statement. “As is always the case with these situations, there was a risk that the bad actors would not delete the data they stole, despite assurances and evidence that were provided to us.”
A Notorious Deepfake Porn Site Shuts Down After Its Creator Is Outed
Since its creation in 2018, MrDeepFakes.com grew into perhaps the world’s most infamous repository of nonconsensual pornography created with AI mimicry tools. Now it’s offline after the site’s creator was identified as a Canadian pharmacist in an investigation by CBC, Bellingcat, and the Danish news outlets Politiken and Tjekdet. The site’s pseudonymous administrator, who went by DPFKS on its forums and created at least 150 of its porn videos himself, left a trail of clues in email addresses and passwords found on breached sites that eventually led to the Yelp and Airbnb accounts of Ontario pharmacist David Do. After reporters approached Do with evidence that he was DPFKS, MrDeepFakes.com went offline. “A critical service provider has terminated service permanently. Data loss has made it impossible to continue operation,” reads a message on its homepage. “We will not be relaunching.”
14 notes
·
View notes
Text
Weaponizing violence. With alarming regularity, the nation continues to be subjected to spates of violence that terrorizes the public, destabilizes the country’s ecosystem, and gives the government greater justifications to crack down, lock down, and institute even more authoritarian policies for the so-called sake of national security without many objections from the citizenry.
Weaponizing surveillance, pre-crime and pre-thought campaigns. Surveillance, digital stalking and the data mining of the American people add up to a society in which there’s little room for indiscretions, imperfections, or acts of independence. When the government sees all and knows all and has an abundance of laws to render even the most seemingly upstanding citizen a criminal and lawbreaker, then the old adage that you’ve got nothing to worry about if you’ve got nothing to hide no longer applies. Add pre-crime programs into the mix with government agencies and corporations working in tandem to determine who is a potential danger and spin a sticky spider-web of threat assessments, behavioral sensing warnings, flagged “words,” and “suspicious” activity reports using automated eyes and ears, social media, behavior sensing software, and citizen spies, and you having the makings for a perfect dystopian nightmare. The government’s war on crime has now veered into the realm of social media and technological entrapment, with government agents adopting fake social media identities and AI-created profile pictures in order to surveil, target and capture potential suspects.
Weaponizing digital currencies, social media scores and censorship. Tech giants, working with the government, have been meting out their own version of social justice by way of digital tyranny and corporate censorship, muzzling whomever they want, whenever they want, on whatever pretext they want in the absence of any real due process, review or appeal. Unfortunately, digital censorship is just the beginning. Digital currencies (which can be used as “a tool for government surveillance of citizens and control over their financial transactions”), combined with social media scores and surveillance capitalism create a litmus test to determine who is worthy enough to be part of society and punish individuals for moral lapses and social transgressions (and reward them for adhering to government-sanctioned behavior). In China, millions of individuals and businesses, blacklisted as “unworthy” based on social media credit scores that grade them based on whether they are “good” citizens, have been banned from accessing financial markets, buying real estate or travelling by air or train.
Weaponizing compliance. Even the most well-intentioned government law or program can be—and has been—perverted, corrupted and used to advance illegitimate purposes once profit and power are added to the equation. The war on terror, the war on drugs, the war on COVID-19, the war on illegal immigration, asset forfeiture schemes, road safety schemes, school safety schemes, eminent domain: all of these programs started out as legitimate responses to pressing concerns and have since become weapons of compliance and control in the police state’s hands.
Weaponizing entertainment. For the past century, the Department of Defense’s Entertainment Media Office has provided Hollywood with equipment, personnel and technical expertise at taxpayer expense. In exchange, the military industrial complex has gotten a starring role in such blockbusters as Top Gun and its rebooted sequel Top Gun: Maverick, which translates to free advertising for the war hawks, recruitment of foot soldiers for the military empire, patriotic fervor by the taxpayers who have to foot the bill for the nation’s endless wars, and Hollywood visionaries working to churn out dystopian thrillers that make the war machine appear relevant, heroic and necessary. As Elmer Davis, a CBS broadcaster who was appointed the head of the Office of War Information, observed, “The easiest way to inject a propaganda idea into most people’s minds is to let it go through the medium of an entertainment picture when they do not realize that they are being propagandized.”
Weaponizing behavioral science and nudging. Apart from the overt dangers posed by a government that feels justified and empowered to spy on its people and use its ever-expanding arsenal of weapons and technology to monitor and control them, there’s also the covert dangers associated with a government empowered to use these same technologies to influence behaviors en masse and control the populace. In fact, it was President Obama who issued an executive order directing federal agencies to use “behavioral science” methods to minimize bureaucracy and influence the way people respond to government programs. It’s a short hop, skip and a jump from a behavioral program that tries to influence how people respond to paperwork to a government program that tries to shape the public’s views about other, more consequential matters. Thus, increasingly, governments around the world—including in the United States—are relying on “nudge units” to steer citizens in the direction the powers-that-be want them to go, while preserving the appearance of free will.
Weaponizing desensitization campaigns aimed at lulling us into a false sense of security. The events of recent years—the invasive surveillance, the extremism reports, the civil unrest, the protests, the shootings, the bombings, the military exercises and active shooter drills, the lockdowns, the color-coded alerts and threat assessments, the fusion centers, the transformation of local police into extensions of the military, the distribution of military equipment and weapons to local police forces, the government databases containing the names of dissidents and potential troublemakers—have conspired to acclimate the populace to accept a police state willingly, even gratefully.
Weaponizing fear and paranoia. The language of fear is spoken effectively by politicians on both sides of the aisle, shouted by media pundits from their cable TV pulpits, marketed by corporations, and codified into bureaucratic laws that do little to make our lives safer or more secure. Fear, as history shows, is the method most often used by politicians to increase the power of government and control a populace, dividing the people into factions, and persuading them to see each other as the enemy. This Machiavellian scheme has so ensnared the nation that few Americans even realize they are being manipulated into adopting an “us” against “them” mindset. Instead, fueled with fear and loathing for phantom opponents, they agree to pour millions of dollars and resources into political elections, militarized police, spy technology and endless wars, hoping for a guarantee of safety that never comes. All the while, those in power—bought and paid for by lobbyists and corporations—move their costly agendas forward, and “we the suckers” get saddled with the tax bills and subjected to pat downs, police raids and round-the-clock surveillance.
Weaponizing genetics. Not only does fear grease the wheels of the transition to fascism by cultivating fearful, controlled, pacified, cowed citizens, but it also embeds itself in our very DNA so that we pass on our fear and compliance to our offspring. It’s called epigenetic inheritance, the transmission through DNA of traumatic experiences. For example, neuroscientists observed that fear can travel through generations of mice DNA. As The Washington Post reports, “Studies on humans suggest that children and grandchildren may have felt the epigenetic impact of such traumatic events such as famine, the Holocaust and the Sept. 11, 2001, terrorist attacks.”
Weaponizing the future. With greater frequency, the government has been issuing warnings about the dire need to prepare for the dystopian future that awaits us. For instance, the Pentagon training video, “Megacities: Urban Future, the Emerging Complexity,” predicts that by 2030 (coincidentally, the same year that society begins to achieve singularity with the metaverse) the military would be called on to use armed forces to solve future domestic political and social problems. What they’re really talking about is martial law, packaged as a well-meaning and overriding concern for the nation’s security. The chilling five-minute training video paints an ominous picture of the future bedeviled by “criminal networks,” “substandard infrastructure,” “religious and ethnic tensions,” “impoverishment, slums,” “open landfills, over-burdened sewers,” a “growing mass of unemployed,” and an urban landscape in which the prosperous economic elite must be protected from the impoverishment of the have nots. “We the people” are the have-nots.
The end goal of these mind control campaigns—packaged in the guise of the greater good—is to see how far the American people will allow the government to go in re-shaping the country in the image of a totalitarian police state.
11 notes
·
View notes
Note
this is a genuine question not at all meant as a rude gotcha, but I feel like I've seen lots of people cite the relatively low barrier of entry as a huge advantage of podcasts as a medium, "if you have access to decent audio tech you can make a podcast" etc etc. So where does the need to sell a script come in? Is it a financial thing, and IP thing, something else?
this doesn't read like a rude gotcha at all, it's a really good question! there is a much lower barrier to entry when it comes to podcasts compared to tv, film, theater, etc. (though not as low as writing a book if we're talking about hard resources - you can technically write a book with just a laptop and a dream and then self publish! though as a writer who has written a lot of scripts and four books (3 published) writing a book is a much bigger psychological burden imo lol).
the need to sell a script, for me, is entirely a financial thing. if I had the money to produce podcasts at the level I want to entirely independently, I would! I know how to do it! but, unfortunately, I really only have the funds to produce something like @breakerwhiskey - a single narrator daily podcast that I make entirely on my own.
and that show is actually a great example of just how low the barrier is: I actually record the whole thing on a CB radio I got off of ebay for 30 bucks, my editing software is $50/month (I do a lot of editing, so this is an expense that isn't just for that show) and there are no hosting costs for it. the only thing it truly costs me is time and effort.
not every show I want to make is single narrator. a lot of the shows I've made involve large casts, full sound design, other writers, studio recording, scoring, and sometimes full cast albums (my first show, The Bright Sessions had all of those). I've worked on shows that have had budgets of 100 dollars and worked on shows that cost nearly half a million dollars. if anyone is curious about the nitty gritty of budgets, I made a huge amount of public, free resources about making audio drama earlier this year that has example budgets in these ranges!
back in the beginning of my career, I asked actors to work for free or sound designers to work for a tiny fee, because I was doing it all for free and we were all starting out. I don't like doing that anymore. so even if I'm making a show with only a few actors and a single sound designer...well, if you want an experienced sound designer and to pay everyone fairly (which I do!), it's going to cost you at least a few thousand dollars. when you're already writing something for free, it can be hard to justify spending that kind of money. I've sound designed in the past - and will be doing so again in the near future for another indie show of mine - but I'm not very good at it. that's usually the biggest expense that I want to have covered by an outside budget.
but if I'm being really honest, I want to be paid to write! while I do a lot of things - direct, produce, act, consult, etc. - writing is my main love and I want it to be the majority of my income. I'm really fortunate to be a full-time creative and I still do a lot of work independently for no money, but when I have a show that would be too expensive to produce on my own, ideally I want someone else footing the bill and paying me to write the scripts.
I love that audio fiction has the low barrier to entry it does, because I think hobbyists are incredible - it is a beautiful and generous thing to provide your labor freely to something creative and then share it with the world - but the barrier to being a professional audio drama writer is certainly higher. I'm very lucky to already be there, but, as every creative will tell you, even after you've had several successes and established yourself in the field, it can still be hard to make a living!
anyway, I hope this answers your question! I love talking about this stuff, so if anyone else is curious about this kind of thing, please ask away.
#lauren writes things#audio fiction#producing#also I say I don't like doing it anymore#but that's exactly what briggon andrew and I are working on#it's gonna be a show where we just split profits equally bc I can't afford to pay them lol#and I'll be sound designing it myself#so apologies in advance#also my GOD lauren can you be succinct once in your GODDAMN LIFE#why are all my posts so long i'm so sorry#also I don't get into it in this post#but using my book example as a jumping off point#obviously it is MUCH more complicated than that#bc self publishing/promoting/etc.#and writing the book in the first place!#is an ENORMOUS effort#as is making an audio drama!#also the grand irony in this#is that the show i was referencing in my original post is a show i first came up with to do independently lol#a two person show for briggon and andrew in fact#and then I happened to mention it to some producers I know and they liked it#so that's a show I COULD make for no money!#but they want to pitch it out and there's no harm in asking around#and in the meantime i just came up with another show for briggon and andrew haha#lauren answers things
64 notes
·
View notes
Text
ULTIMATE CBS MASTERPOST
(or, a general hub to answer a few questions that my followers who are here for other things that are not my passion projects might be curious about)
recently i've been really pushing hard into working on this revival project, so i thought it would be helpful to have a nice big post with links to all of my stuff inside it!

"what is care bear stars?"
care bear stars was a 2008-2009 fanime created, drawn, and animated by joshua click (known at the time as jcstars5). here's a general synopsis:
Care Bear Stars follows the story of Terry Rogers, who meets a magical anthropomorphic bear named True Heart Bear. She gives him a magical talisman, and with it, he transforms into Tender Heart Bear. Along with the other Care Bear Stars, they work to protect good feelings and love among humankind and fight the evil Professor Coldheart, alongside a rogues gallery of otherworldly foes.
for those who don't know exactly what a fanime is and what it entails, here's a good definition from TVtropes:
Fanime (a portmanteau of “fan” and “anime”) is a type of Web Animation typically created by young amateur artists that originated on YouTube around 2006, a year after the site's launch. ... In the past, many fanime were animesque cartoons based on pre-existing anime, especially Tokyo Mew Mew and other Magical Girl shows. Tracing was also common. Instead of using animation software, creators would usually draw frames in MS Paint or Photoshop and composite them in Windows Movie Maker. ... As fanime was predominately created by very young artists inexperienced in animation in the beginning, it gained a reputation for being bad. ... Following the mainstream popularity of Nyan~ Neko Sugar Girls, this type of fanime dominated the community for a long time, but creators attempting to create genuine shows still remain and the community has grown increasingly talented and creative throughout the years.
care bear stars was received pretty well for its time for fanime, receiving a decent amount of fanwork and discussions on websites like deviantArt. though it was far from the only fanime at the time with its premise, its generally considered one of the pillars of first generation fanime alongside series like elemental goddess, and stood out for having full TV length episodes (something that was unheard of at the time for fanime).
the project was cancelled in 2009 after the creator received a cease & desist letter from then (now defunct) owners of the care bear stars franchise, cookie jar group.
for a more in depth write up of my knowledge of CBS during its active period, joshua click's thoughts looking back on the series in adulthood, and where many of the VOs in the project are now, you can check out this document i've worked on and off on for 8 years
"why do you gaf?"
autism
i met some really great friends from the fanime community and now i've imprinted on this show in my mind more than any fanime that i'd ever watched
i love care bears
autism again
as a testament to said autism: here's a collection of all the care bears stars fanart i've ever found
"okay so what is care bear stars r?"
exactly what it sounds like. it's just a 1-to-1 remake of the premise, characters, etc with what i could find of the original project + what i would have done if it were me
for an in-depth (but WIP) write up of my revival, CARE BEAR STARS R, you can click here
you can also find all of my art & write-ups here , and all of my friends' fanart here , and all of the references for them here
other resources
my twitter thread that i consistently update
my tumblr tag for posting about care bear stars
the original series in chronological (series) order

thank you so much for reading!
31 notes
·
View notes
Note
I was a industry vet too I worked for jamdat mobile who owned Tetris then bought by ea mobile ,slaved as a temp gig worker for years at EA laid off finally got into software testing at cbs interactive for years they sold off any properties that weren’t streaming focus in 2020 . I got sold with that deal ( I didn’t even know till I got the actual offer letter bet you can guess how that felt) I also had a massive medical crisis which has now led me to transitioning at 46 (uglycrysobbing) after being sold and then onboarding their ad tech stack to all their properties the promptly laid us off ( it was all the old people lol) so from last June to about this July I was unemployed and literally about to be homeless on the street as my final few dollars of 401k disappeared. I was searching too,applying to everything from tech to Trader Joe’s it was so hard. I did find something after throwing a Hail Mary play help me find something post. I found a job and also a safe place to transition (in theory still trying to connect an endocrinologist and revel my self to work but the vibe is good ) I want to channel my good fortune into you as well as helping reblog and stuff.
I’m so happy your story has a happy conclusion and that you found a safe place to transition.
The industry, as a whole, is still so volatile and hateful toward trans folks (trans women especially) and having a safe place is worth it’s weight in gold.
38 notes
·
View notes
Text
Linkpowercharging: Leading the New Era of Electric Mobility

Founded in 2018, Linkpowercharging has been deeply engaged in the electric vehicle charging field for over 8 years. We specialize in providing comprehensive R&D solutions—including software, hardware, and design—for AC/DC charging stations, enabling our products to hit the ground running. With our expert team and relentless pursuit of innovation, Linkpowercharging has successfully delivered reliable products worth over $100 million to partners in more than 30 countries, including the United States, Canada, Germany, the United Kingdom, France, Singapore, Australia, and more.
Quality and Certification: With a team of over 60 skilled professionals, we have earned authoritative certifications such as ETL, FCC, CE, UKCA, CB, TR25, and RCM, ensuring that our products meet the strictest global safety and quality standards.
Technological Innovation: Our AC and DC fast chargers are powered by OCPP 1.6 software and have undergone rigorous testing with over 100 platform suppliers. We also support upgrades to the latest OCPP 2.0.1. In addition, by integrating IEC/ISO 15118 modules, we are actively advancing V2G (vehicle-to-grid) bidirectional charging technology.
Future Vision: Linkpowercharging is committed to driving the integration of clean energy and intelligent connectivity. In addition to offering high-performance EV charging solutions, we have also developed integrated systems that combine solar photovoltaic (PV) technology and lithium battery energy storage systems (BESS). Our mission is to build a greener, smarter future for global customers.
Whether you’re a forward-thinking business partner or an industry observer passionate about environmental innovation, Linkpowercharging is the trusted choice for your electric mobility transition. Let’s drive the future together and embark on this new era of electric mobility!
2 notes
·
View notes
Text
Excerpt from this story from EcoWatch:
Colorado State University (CSU) researchers are predicting an “above-average” Atlantic hurricane season this year, with a likelihood of more frequent storms, including nine hurricanes and 17 named storms.
The Tropical Cyclones, Radar, Atmospheric Modeling, and Software (TC-RAMS) Team within the Department of Atmospheric Science at CSU cited warmer than average sea surface temperatures in the subtropical eastern Atlantic Ocean and the Caribbean Sea as a primary factor in their prediction, a press release from CSU said.
Levi Silvers, one of the authors of the report and a research scientist in the Department of Atmospheric Science at CSU, said the increase in storm activity is significant, though slightly lower than last year’s forecast.
“It’s a noticeable and important difference, because it matters for people along the coastlines whenever we have an above average season,” Silvers told CBS News.
The tropical Pacific is currently experiencing weak La Niña conditions, but it is likely that they will transition to neutral El Niño-Southern Oscillation (ENSO) conditions in the next two months.
The odds of El Niño occurring this hurricane season are just 13 percent, according to the most recent NOAA outlook.
2 notes
·
View notes