#chained microservice design pattern
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Unlocking Insights with Cutting-Edge Big Data Analytics Services
In today's data-driven world, businesses generate vast amounts of information every second. Harnessing the power of this data is crucial for making informed decisions, gaining a competitive edge, and driving innovation. techcarrot's Big Data Analytics Services in Dubai and globally are designed to transform raw data into actionable insights, empowering your organization to thrive in the digital era.
Key Features:
· Data Integration and Aggregation:
Seamlessly integrate data from disparate sources.
Aggregate structured and unstructured data for a comprehensive view.
· Advanced Analytics:
Employ machine-learning algorithms for predictive analytics.
Identify patterns, trends, and anomalies for strategic decision-making.
· Scalable Infrastructure:
Utilize robust, scalable infrastructure to handle massive datasets.
Ensure performance and reliability, even with increasing data volumes.
· Real-time Analytics:
Enable real-time data processing for instant insights.
Quickly respond to changing market conditions and customer behavior.
· Data Security and Compliance:
Implement robust security measures to protect sensitive information.
Make sure that data protection regulations and industry standards are being followed.
Benefits:
Enhanced Decision-Making:
Make data-driven decisions backed by accurate and timely insights.
Improve strategic planning and resource allocation.
Operational Efficiency:
Streamline processes and operations through data optimization.
Identify and eliminate bottlenecks for improved efficiency.
Competitive Advantage:
Stay ahead of the competition with insights that drive innovation.
Identify emerging trends and market opportunities.
Customer Satisfaction:
Understand customer behavior and preferences.
Personalize offerings and enhance the overall customer experience.
Industries we serve:
Finance: Analyze market trends, manage risks, and optimize investment strategies.
Healthcare: Improve patient outcomes, streamline operations, and enhance healthcare delivery.
Retail: Optimize inventory, personalize marketing, and improve customer engagement.
Manufacturing: Enhance supply chain efficiency, predict maintenance needs, and improve quality control.
Why choose techcarrot for Big Data Analytics Services?
Expertise: Our team of seasoned data scientists and analysts brings extensive experience to the table.
Custom Solutions: Tailored analytics solutions to meet the unique needs of your business.
Scalability: Grow with confidence, knowing our solutions can scale with your evolving data requirements.
Client Success Stories: Discover how our services have transformed businesses in industry.
Get started today! Embrace the power of data with our big Data Analytics Services. Contact us to schedule a consultation and unlock the full potential of your data.
Check out our previous blogs:
Information Technology Consulting Service Middle East
🚀 Empower Your Business with Microservices Application Development Services!
Empowering Your Vision: Leading Mobile App Development Company
#data visualization services in dubai#big data consulting services in dubai#data intelligence company dubai#data intelligence service providers in dubai#big data#data#data analytics
0 notes
Text
IBM Deployment Path to accelerates release lifecycle: Part 1

IBM Deployment lifecycle
Many companies reduce technical debt and satisfy CapEx-to-OpEx goals by moving to the cloud. This includes microservices rearchitecting, lift-and-shift, replatforming, refactoring, replacing, and more. As DevOps, cloud native, serverless, and SRE mature, the focus shifts to automation, speed, agility, and business alignment with IT, which helps enterprise IT become engineering organizations.
Many companies struggle to get value from their cloud investments and overspend. Multiple researchers claim that over 90% of firms overpay in cloud, frequently without significant returns.
When business and IT collaborate to quickly create new capabilities, developer productivity and speed to market increase, creating actual value. Some goals require a target operating model. Rapid cloud application IBM Deployment requires development acceleration with continuous integration, deployment, and testing (CI/CD/CT) and supply chain lifecycle acceleration, which involves governance risk and compliance (GRC), change management, operations, resiliency, and reliability. Enterprises seek solutions to help product teams deliver faster than ever.
Focus on automation and DevSecOps
Instead of adopting fast and scalable lifecycle and delivery models, enterprises retrofit cloud transformation into current application supply chain processes. Companies that automate the application lifecycle enable engineering-driven product lifecycle acceleration that realizes cloud transition. Some examples are:
Pattern-based architecture that standardizes architecture and design while letting teams choose patterns and technologies or co-create new patterns.
Patterns that ensure security and compliance traceability.
Codifying various cross-cutting concerns with patterns-as-code enhances pattern maturity and reusability.
Lifecycle-wide DevOps pipeline activities.
Automatic data production for security and compliance evaluations.
Reviewing operational preparedness without manual intervention.
The route from development to production is crucial to customer value as organizations adopt cloud native and everything as code. The “pathway to deploy,” or series of procedures and decisions, can greatly impact an organization’s capacity to deliver software rapidly, consistently, and at scale. The IBM Deployment process includes architecture, design, code IBM Deployment , testing, deployment, and monitoring. Each stage brings distinct difficulties and opportunities. IBM can help you find the methods and goal state mode for a seamless and effective deployment as you manage today’s complexity.
They will examine best practices, technologies, and processes that help organizations optimize software delivery pipelines, minimize time-to-market, improve software quality, and ensure production-ready operations.
Enterprise cloud-native software development is constantly changing, thus the second part in this series gives a maturity model and building blocks to speed the software supply chain lifecycle.
The IBM Deployment path: Current views and challenges
The SDLC diagram below shows common gates for enterprise software development. The flow is self-explanatory, but the essential is to grasp that the software supply chain process combines waterfall and intermittent agile approaches. The problem is that manual first- and last-mile actions affect the build-deploy timeline for an application or iteration.
The main issues with classical SDLC are:
From architecture and design to development takes 4-8 weeks. The cause is:
Multiple first-mile reviews for privacy, data classification, business continuity, and regulatory compliance (most of which are manual).
Despite agile development concepts (e.g., environment provisioning only after full design approval), enterprise-wide SDLC processes are waterfall or semi-agile and require sequential execution.
Deep scrutiny and interventions with limited acceleration are applied to “unique” applications.
Institutionalizing patterns-based design and development is difficult due to lack of coherent effort and change agent driving, such as standardization.
Security controls and guidelines frequently require manual or semi-human operations, slowing development.
Development environment provision and CI/CD/CT tooling integration wait time owing to:
Semi-automated or manual environment provisioning.
Paper patterns are just prescriptive.
Fragmented DevOps tools that require assembly.
Post-development (last-mile) wait time before go-live is 6–8 weeks or more due to:
Manual evidence collection for security and compliance evaluations beyond SAST/SCA/DAST (security configuration, day 2 controls, tagging, etc.).
Manual evidence gathering for operation and resiliency reviews (cloud operations, business continuity).
Transition evaluations for IT service and issue management and resolution.
Launch path: Target state
A fast, efficient procedure that reduces bottlenecks and accelerates software supply chain transformation is needed to deliver goal state. The ideal IBM Deployment pathway integrates design (first mile), development, testing, platform engineering, and deployment (last mile) using agile and DevOps principles. With automated validations to production environments, code updates may be deployed quickly.
IBM’s target state integrates security checks and compliance validation into the CI/CD/CT pipeline to find and fix problems early. This concept promotes shared accountability across development, operations, reliability, and security teams. It also creates continual monitoring and feedback loops for improvement. The goal is to quickly deploy software upgrades and new features to end users with minimal manual intervention and high corporate stakeholder confidence.
Features of the cloud-native SDLC model include:
Enterprise-wide pattern-driven architecture and design.
Coded patterns that meet security, compliance, resiliency, and other enterprise policies.
Pattern-accelerated security and compliance reviews that explain the solution.
Core development, encompassing platform engineering corporate catalog-driven environments, pipelines, and service configuration.
A CI/CD/CT pipeline that links all actions in the IBM Deployment lifecycle.
Platform engineering embeds enterprise policies like encryption in platform policies while building, configuring, and managing platforms and services.
Security and compliance tooling (vulnerability scans, policy checks) and pipeline-integrated or self-service automation.
High-volume log, tool, and code scan data generation for multiple evaluations without operator involvement.
Tracking backlog, IBM Deployment , release notes, and change impact.
Exceptional interventions.
Clear, accountable, and traceable IBM Deployment pathway accelerates
Organizations can standardize supply chain lifecycle processes and ensure traceability and auditability by adopting a standardized IBM Deployment strategy. This gives stakeholders real-time visibility into the program’s development from design to deployment. Assigning ownership at each point of the deployment route makes team members accountable for their deliverables, makes it easier to manage contributions and modifications, and speeds up issue resolution with the correct amount of intervention. Data-driven insights from traceability to deployment improve future program procedures and efficiency. Each step of the deployment process is documented and retrievable, making compliance with industry rules and reporting easier.
Read more on Govindhtech.com
0 notes
Text
Accelerating Enterprise Software Development with RAD Studio: A Comprehensive Guide

What is Enterprise Software and its Types?
Enterprise software is a class of software solutions specifically designed to meet the unique needs of large organizations and businesses. These solutions are multifaceted and highly customizable, tailored to manage and automate critical business processes, data storage, and communication within an organization. They play a pivotal role in enhancing productivity and efficiency across various departments. Let's explore some of the common types:
Enterprise Resource Planning (ERP) Software: ERP systems integrate and manage various business processes, such as finance, HR, supply chain, and inventory, into a single software solution. Examples include SAP ERP and Oracle E-Business Suite.
Customer Relationship Management (CRM) Software: CRM software helps businesses manage their interactions and relationships with customers and prospects. It enables sales, marketing, and customer support teams to streamline their processes and improve customer engagement. Salesforce and HubSpot are popular CRM solutions.
Human Resource Management (HRM) Software: HRM software is designed to automate and optimize HR processes like employee onboarding, payroll, benefits management, and performance evaluations. Systems like Workday and BambooHR fall into this category.
Supply Chain Management (SCM) Software: SCM software optimizes the management of the supply chain, from procurement and inventory management to logistics and order fulfillment. Notable solutions include Oracle SCM Cloud and Kinaxis RapidResponse.
What are Enterprise Software Development Technologies?
Enterprise software development leverages a wide range of technologies to meet the diverse needs of organizations. These technologies include:
Databases: Enterprise software often relies on databases for data storage and retrieval. SQL (Structured Query Language) and NoSQL databases like MongoDB and Cassandra are commonly used.
Programming Languages: The choice of programming language depends on the specific project requirements. Java, C#, Python, and JavaScript are popular options. Java is widely used for its platform independence and robustness, while C# is common in the Microsoft ecosystem.
Web Development Frameworks: Web technologies like React, Angular, and Vue.js are employed to build user-friendly interfaces for enterprise applications.
Application Architecture Patterns: To create scalable and maintainable enterprise applications, developers use architectural patterns like microservices and service-oriented architecture (SOA). These patterns enable modular development and efficient resource utilization.
What is an Example of Enterprise Software?
One prime example of enterprise software is SAP ERP (Enterprise Resource Planning). This comprehensive solution assists organizations in managing various aspects of their business, including financials, supply chain, human resources, and customer relationships. SAP ERP offers features such as finance and accounting, procurement, production, sales, and analytics to support the overall operations of a business.
The 5 Stages of Enterprise Software Development
Enterprise software development is a complex process involving multiple stages. These stages ensure the successful creation and deployment of software solutions. Let's delve into each stage:
Planning and Requirements Analysis: This initial phase involves understanding the client's needs, objectives, and constraints. A detailed analysis of the project's scope is conducted to outline goals, features, and budget constraints.
Design and Architecture: During this stage, the software's architecture and design are conceptualized. The team creates a blueprint that outlines the structure, components, and functionalities of the software.
Development: In this phase, the actual coding and development of the software take place. Developers write the code based on the design specifications, ensuring it aligns with the project requirements.
Testing and Quality Assurance: Rigorous testing is essential to identify and fix bugs or issues in the software. This phase ensures that the software meets quality standards, is secure, and performs as expected.
Deployment and Maintenance: After thorough testing and validation, the software is deployed to the production environment. Ongoing maintenance, updates, and support are critical to keep the software running smoothly and up-to-date.
Best Practices in Enterprise Software Development
To ensure the success of enterprise software projects, developers and organizations should follow a set of best practices, including:
Clear Documentation: Comprehensive documentation ensures that all project stakeholders understand the software's functionality, codebase, and architecture. It facilitates collaboration and future maintenance.
Regular Communication: Effective communication with clients and team members is crucial. It helps manage expectations, address concerns, and adapt to changing requirements promptly.
Agile and DevOps Methodologies: Employing Agile or DevOps methodologies promotes iterative development, collaboration, and quick responses to evolving project needs. It allows for flexibility and faster deliveries.
The Top 3 Benefits of Enterprise Applications
Enterprise applications offer a multitude of advantages, contributing to the efficiency and productivity of organizations. Here are the top three benefits:
Efficiency: Enterprise applications streamline and automate business processes, reducing manual efforts and the risk of errors. This leads to increased efficiency across various departments, saving time and resources.
Data Management: These applications provide a centralized platform for storing, accessing, and analyzing data. This not only improves data accuracy but also facilitates data-driven decision-making.
Scalability: Enterprise applications are designed to grow with your business. They can adapt to the evolving needs of a growing organization, ensuring that the software remains relevant and effective.
5 Challenges Posed by Enterprise Applications
Enterprise software development is not without its challenges. Here are five common hurdles that organizations may encounter:
High Development Costs: Building custom enterprise software can be expensive, involving substantial development and maintenance costs.
Complex Integrations: Integrating enterprise software with existing systems and legacy applications can be complex and time-consuming.
Security Concerns: Enterprise applications often handle sensitive data, making them prime targets for cyberattacks. Security measures need to be robust and continuously updated.
User Adoption Hurdles: Employees may resist using new enterprise software, requiring thorough training and change management efforts.
Ongoing Updates and Maintenance: Keeping enterprise applications up-to-date and addressing issues requires ongoing commitment and resources.
Choosing the Right Language and Platform
The choice of programming language and platform in enterprise software development depends on project requirements, existing systems, and business goals:
Programming Language: Consider Java for its platform independence and maturity. C# is a strong choice for Windows-based ecosystems. Python is versatile and widely used in data-related applications.
Platform: Cloud-based solutions, such as AWS, Azure, and GCP, are favored for their scalability, cost-effectiveness, and flexibility. They provide infrastructure and services that enable the development, deployment, and scaling of enterprise applications with ease.
Discovering RAD Studio for Accelerated Development
If you're looking to expedite your enterprise software development projects, RAD Studio is a robust Integrated Development Environment (IDE) that can significantly enhance your productivity. RAD Studio supports various programming languages, including Delphi and C++, and offers a wide range of tools and components for building efficient and feature-rich enterprise applications. Its visual development approach allows for rapid prototyping and accelerated development cycles.
Frequently Asked Questions
Q: What is an enterprise application in simple words?
A: An enterprise application, in simple terms, is specialized software designed to help large organizations manage their operations and processes more efficiently. It often includes features like data storage, automation, and communication tools tailored to a business's unique needs.
Q: What is enterprise software experience? A: Enterprise software experience refers to how user-friendly and satisfying it is for employees or users within an organization to work with enterprise software. A positive experience leads to increased productivity and efficiency.
Q: What are enterprise software projects? A: Enterprise software projects are initiatives taken by organizations to develop, implement, and maintain customized software solutions that address their specific business needs. These projects aim to improve operational efficiency and effectiveness.
Q: What is the difference between enterprise software development and regular software development? A: The main difference lies in the focus and complexity. Enterprise software development tailors software to meet the specific needs of large organizations, making it more complex and specialized. Regular software development typically addresses broader user needs and is generally less complex. Enterprise software often involves extensive integration with existing systems and data sources.
1 note
·
View note
Video
youtube
Chained Microservice Design Pattern with Examples for Software Developers
Full Video Link https://youtu.be/66_yOKjeljc
Hello friends, new #video on #chainedmicroservice #designpattern for #microservices #tutorial with #examples is published on #codeonedigest #youtube channel. Learn #chained #microservice #designpattern #programming #coding with codeonedigest.
@java #java #aws #awscloud @awscloud @AWSCloudIndia #salesforce #Cloud #CloudComputing @YouTube #youtube #azure #msazure #chainedmicroservice #chainedmicroservicepattern #chainedmicroservicepatternmicroservices #chainedmicroservicepatternjava #chainedmicroservicepatterninsoftwareengineering #chainedmicroservicepatterntutorial #chainedmicroservicepatternexplained #chainedmicroservicepatternexample #chainedmicroservicedesignpattern #chainedmicroservicedesignpatternjava #chainedmicroservicedesignpatternspringboot #chainedmicroservicedesignpatternexample #chainedmicroservicedesignpatterntutorial #chainedmicroservicedesignpatternexplained #microservicedesignpatterns #microservicedesignpatterns #microservicedesignpatternsspringboot #microservicedesignpatternssaga #microservicedesignpatternsinterviewquestions #microservicedesignpatternsinjava #microservicedesignpatternscircuitbreaker #microservicedesignpatternsorchestration #decompositionpatternsmicroservices #decompositionpatterns #monolithicdecompositionpatterns #integrationpatterns #integrationpatternsinmicroservices #integrationpatternsinjava #integrationpatternsbestpractices #databasepatterns #databasepatternsmicroservices #microservicesobservabilitypatterns #observabilitypatterns #crosscuttingconcernsinmicroservices #crosscuttingconcernspatterns #servicediscoverypattern #healthcheckpattern #sagapattern #circuitbreakerpattern #cqrspattern #commandquerypattern #chainedmicroservicepattern #chainedmicroservicepattern #branchpattern #eventsourcingpattern #logaggregatorpattern
#youtube#chained microservice design pattern#chained pattern#microservice patterns#microservice design patterns#java design patterns#software design patterns#software patterns#java patterns
1 note
·
View note
Text
Application Modernization Trends to Watch in 2022
Corporate organizations have seen a boost in digital transformation as the pandemic has subsided. Legacy app modernization services provide business entities with the necessary competencies and abilities to respond to various dynamic developments. Software technologies are deployed and improved on a massive scale. The app modernization plan is used by corporate organizations to ensure business growth and continuity in the dynamic market.
Existing systems and app modernization are fantastic options for leveraging existing capital and avoiding unnecessary technological investments.
Application modernization is the activity of updating obsolete software for the latest computing approaches, including the latest frameworks, languages, and infrastructure platforms. Legacy app modernization and legacy modernization are terms used to describe this type of operation.
It contributes to the enhancement of structural integrity, safety, and efficiency. The legacy modernization increases the company's enterprise apps' lifespan. You can get information about application modernization trends in this article:
Application Modernization Trends
Businesses are subjected to a variety of external and internal pressures. During the COVID-19 crisis, it held up nicely. Since the supply chain will cause business turmoil, commercial businesses have seen a rapid loss of revenue. Regardless of the industry, businesses are losing patience with the legacy integration service's unfavorable business consequences and problems. The following are a few examples of application modernization trends:
Legacy apps stifle development.
The absence of integration can be costly.
Onboarding is thought to be more relevant.
The demands for innovative technology are continually increasing.
Assists you in developing customized services and features.
A wide range of businesses claims to generate software, which is a must for today's requirements. After the pandemic, change is the only constant. The app that works today may not work tomorrow. The most recent updates, releases, and patches may cause problems. Furthermore, it is difficult to meet shifting customer demands during a downturn in the economy.
Developing modern apps allows businesses to establish cutting-edge services and features that are in line with their long-term goals. Furthermore, such services and features are custom-built for the company, ensuring that the legacy software adds value to the company.
Patterns of application modernization
The following are examples of common modernization patterns:
Lift and Shift
Lift and shift, also known as rehosting, is an essential element of software development that involves relocating an existing app to a newly built infrastructure from a legacy environment. This pattern will lead you to the app, with no or little changes to the underlying architecture and code. Though it is the least time-consuming approach, it is not always the best, depending on the app.
Refactoring
Another term for restructuring or rewriting is rewriting. This method of app modernization entails adopting the legacy program, then retooling severe underlying code flaws so that it can run in the newer environment. Aside from the most recent codebase restructuring, this strategy entails rewriting the code. It is up to the development team to decide how to decouple the monolithic program into smaller sections. To maximize the benefits of cloud-native infrastructure, they should make proper use of microservices.
Replatforming
The platform can be viewed from the perspective of a midway point. It also serves as a middle ground between the refactoring, lifts, and shift strategies. It does not necessitate any significant changes to the design or code. It does, however, include recent changes that enable the legacy program to take advantage of the upcoming cloud platform, such as the replacement and modification of the app's back-end outbase.
App modernization technologies that are essential
There is a large array of overlapping technologies that are critical to app modernization:
Containers:
They're known as the cloud-centric method for deploying, packing, and running workloads and apps. Containerization has a wide range of advantages, including operational efficiency, portability, and scalability. It has a reputation for being a good fit for cloud architecture and a variety of hybrid and multi-cloud scenarios.
Cloud Computing
It is the process of migrating traditional software to run in the most recent cloud environments. Private clouds, public cloud platforms, and hybrid clouds are all included.
Microservices
Microservices allow you to decouple individual components into distinct and smaller codebases, referred to as monolithic development, rather than building and operating the app as a single codebase. You can then separate a wide range of components into separate and smaller bits, allowing you to operate, update, and deploy them independently.
Automation and orchestration
Software development orchestration aids in the automation of various operational processes associated with various containers, such as networking, scaling, and deployment. Automation is considered a crucial technology and principle. It ensures that security, operations, and development teams can manage the most recent apps as they scale. Modernizing legacy applications is critical to the success of the digital transformation. Businesses have a history of modernizing in a variety of ways. Legacy app modernization solutions are effective in increasing revenue by recognizing possibilities and identifying concerns.
There are numerous reasons why App Modernization is advised. For starters, it allows apps to work faster, resulting in improved performance. Furthermore, it provides the opportunity for personnel to seek improved cloud technology, which aids in efficiently serving clients. As a result, it's useful for discovering new business opportunities. Modernization is the first step in identifying new investment opportunities, such as using AI and different machine learning approaches and transferring data to a data lake. With cloud-native containerization and architecture adoption, you can design and deploy the most up-to-date services and apps.
How can Cambay Consulting help you?
We strive to be our customers' most valuable partner by expertly guiding them to the cloud and providing ongoing support. Cambay Consulting, a Microsoft Gold Partner offers "Work from Home" offerings to customers for them to quickly and efficiently deploy work from home tools, solutions, and best practices to mitigate downtime, ensure business continuity, and improve employee experience and productivity.
What role does Cambay Consulting play?
We achieve powerful results and outcomes that improve our clients ' businesses through our talented people, innovative culture, and technical and business expertise. We help them compete and succeed in today's digital world. We assist customers in achieving their digital transformation goals and objectives by providing services based on Microsoft technology, such as Managed Delivery, Project, and Change Management.
0 notes
Text
Overview of Design Patterns for Microservices

What is Microservice?
Microservice architecture has become the de facto choice for modern application development. I like the definition given by “Martin Fowler”.
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies. — Martin Fowler
Principles of microservice architecture:
Scalability
Availability
Resiliency
Independent, autonomous
Decentralized governance
Failure isolation
Auto-Provisioning
Continuous delivery through DevOps
What are design patterns?
Design patterns are commonly defined as time-tested solutions to recurring design problems. Design patterns are not limited to the software. Design patterns have their roots in the work of Christopher Alexander, a civil engineer who wrote about his experience in solving design issues as they related to buildings and towns. It occurred to Alexander that certain design constructs, when used time and time again, lead to the desired effect.
Why we need design patterns?
Design patterns have two major benefits. First, they provide you with a way to solve issues related to software development using a proven solution. Second, design patterns make communication between designers more efficient. Software professionals can immediately picture the high-level design in their heads when they refer the name of the pattern used to solve a particular issue when discussing system design.
Microservices is not just an architecture style, but also an organizational structure.
Do you know the “Conway’s Law”?
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure. — Melvin Conway, 1968
Microservices Design patterns:
Aggregator Pattern — It talks about how we can aggregate the data from different services and then send the final response to the consumer/frontend.
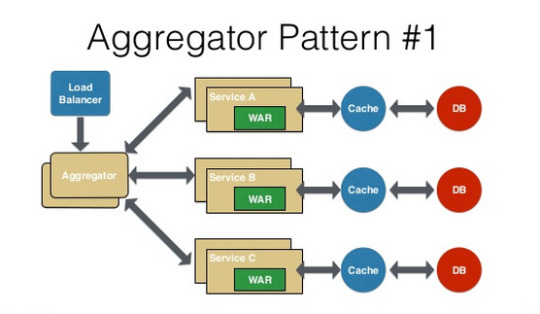
Proxy Pattern — Proxy just transparently transfers all the requests. It does not aggregate the data that is collected and sent to the client, which is the biggest difference between the proxy and the aggregator. The proxy pattern lets the aggregation of these data done by the frontend.

Chained Pattern — The chain design pattern is very common, where one service is making call to other service and so on. All these services are synchronous calls.

Branch Pattern — A microservice may need to get the data from multiple sources including other microservices. Branch microservice pattern is a mix of Aggregator & Chain design patterns and allows simultaneous request/response processing from two or more microservices.

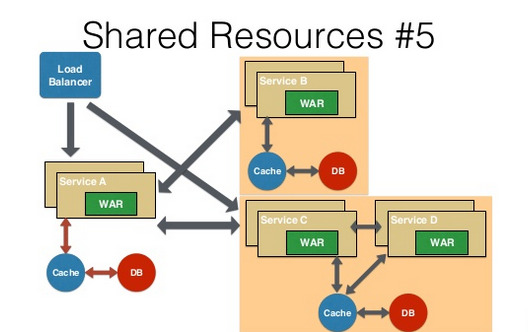
Shared Resources Pattern — One database per service being ideal for microservices. This is anti-pattern for microservices. But if the application is a monolith and trying to break into microservices, denormalization is not that easy. A shared database per service is not ideal, but that is the working solution for the above scenario.
Asynchronous Messaging Pattern — In an message based communication , the calling service or application publish a message instead of making a call directly to another API or a service. An message consuming application(s) then picks up this message and then carries out the task. This is asynchronous because the calling application or service is not aware of the consumer and the consumer isn’t aware of the called application as well.

There are many other patterns used with microservice architecture, like Sidecar, Event Sourcing Pattern, Continuous Delivery Patterns, and more. The list keeps growing as we get more experience with microservices.

Let me know what microservice patterns you are using.
Thank you for reading :)
Source:
#Design Patterns for Microservices#microservices#Mobile App Design#web design services#UI UX Design#WeCode Inc#Japan
0 notes
Text
Microservices in Healthcare Market Size by Emerging Trends - Global Forecast 2020-2025
The Global Microservices in Healthcare Market is expected to be around US$ 416.50 Billion by 2025 at a CAGR of 21.43% in the given forecast period.
A microservice is associate degree severally deployable service that provides new techniques in application programming interfaces (API). It helps in developing additional agile applications/software systems for purchasers. In alternative words, microservice is associate degree design that helps in developing advanced software package systems, accentuation on transcription single operate modules with precise actions and interfaces. The microservice design permits the constant distribution and readying of multifarious applications, so permitting health care organizations to boost their productivity and business processes. Major capabilities offered by microservices to health care organizations embody speed of delivery, fast innovation capabilities, and managing business operations with efficiency. The profits of microservice design, comparable their ability to spread overall strength and project sending speed, square measure the first thing that drives the market growth. However, considerations relating to security and regulative compliance and therefore the quality of design square measure expected to hinder the expansion of this market. Complication is the major restraint of the market. The global Microservices in Healthcare market is segregated on the basis of Component as Platforms and Services. Based on Deployment Model the global Microservices in Healthcare market is segmented in Cloud-Based Model and On-Premise Models. Based on End User the global Microservices in Healthcare market is segmented in Healthcare Providers, Healthcare Payers, Life Science Organizations, and Clinical Laboratories.
Request to Fill The Form To get Sample Copy of This Report: https://www.sdki.jp/sample-request-105879 The global Microservices in Healthcare market report provides geographic analysis covering regions, such as North America, Europe, Asia-Pacific, and Rest of the World. The Microservices in Healthcare market for each region is further segmented for major countries including the U.S., Canada, Germany, the U.K., France, Italy, China, India, Japan, Brazil, South Africa, and others. Competitive Rivalry Amazon Web Services, Inc., CA Technologies, Salesforce.Com, Inc., Microsoft, Pivotal Software, Inc., Infosys, IBM, Nginx, Inc., Oracle Corporation, Syntel, and others are among the major players in the global Microservices in Healthcare market. The companies are involved in several growth and expansion strategies to gain a competitive advantage. Industry participants also follow value chain integration with business operations in multiple stages of the value chain.
The report covers: Global Microservices in Healthcare market sizes from 2016 to 2025, along with CAGR for 2019-2025 Market size comparison for 2017 vs 2025, with actual data for 2017, estimates for 2018 and forecast from 2019 to 2025 Global Microservices in Healthcare market trends, covering comprehensive range of consumer trends & manufacturer trends Value chain analysis covering participants from raw material suppliers to the downstream buyer in the global Microservices in Healthcare market Major market opportunities and challenges in forecast timeframe to be focused Competitive landscape with analysis on competition pattern, portfolio comparisons, development trends and strategic management Comprehensive company profiles of the key industry players. Report Scope: The global Microservices in Healthcare market report scope includes detailed study covering underlying factors influencing the industry trends. The report covers analysis on regional and country level market dynamics. The scope also covers competitive overview providing company market shares along with company profiles for major revenue contributing companies. The report scope includes detailed competitive outlook covering market shares and profiles key participants in the global Microservices in Healthcare market share. Major industry players with significant revenue share include Amazon Web Services, Inc., CA Technologies, Salesforce.Com, Inc., Microsoft, Pivotal Software, Inc., Infosys, IBM, Nginx, Inc., Oracle Corporation, Syntel, and others. Reasons to Buy this Report: Gain detailed insights on the Microservices in Healthcare industry trends Find complete analysis on the market status Identify the Microservices in Healthcare market opportunities and growth segments Analyse competitive dynamics by evaluating business segments & product portfolios Facilitate strategy planning and industry dynamics to enhance decision making.
The dynamic nature of business environment in the current global economy is raising the need amongst business professionals to update themselves with current situations in the market. To cater such needs, Shibuya Data Count provides market research reports to various business professionals across different industry verticals, such as healthcare & pharmaceutical, IT & telecom, chemicals and advanced materials, consumer goods & food, energy & power, manufacturing & construction, industrial automation & equipment and agriculture & allied activities amongst others.
For more information, please contact:
Hina Miyazu
Shibuya Data Count Email: [email protected] Tel: + 81 3 45720790
0 notes
Text
Amdocs Voices
Learn about Amdocs’ catalyst projects, award nominations and speaking opportunities taking place at TM Forum’s Digital Transformation World 2020
*/

At TM Forum’s Digital Transformation World 2020, taking place online from October 7 – November 12, Amdocs will show how it’s taking the industry to the cloud and innovating in areas like 5G, cloud-native IT and artificial intelligence (AI). These advancements enable the effective and efficient managed digital and network transformation of communications and media companies. Here’s a snapshot of the activities Amdocs and customers are participating in. Keep an eye on Amdocs Blogs, Twitter and LinkedIn for more updates in the weeks to come.
Catalysts
Automating NaaS Wavelength (Lambda) Services Introduces a NaaS platform to enable “complex” network transformations for network monetization and decoupling OSS/BSS systems from the network. AI-Driven Business Assurance for 5G Demonstrates industry best-practices for using AI-driven business assurance innovations in multiple 5G-scenario use cases, including COVID-19-related eHealth services. Ecosystem Assurance This “mega catalyst” combines three projects around assuring trust in an ecosystem and demonstrates how a secure supply chain with repeatable patterns in a digital business marketplace can be constructed utilizing a plug-and-play design.
Amdocs is a finalist for three TM Forum Excellence Awards
CLOUD NATIVE IT & AGILITY AWARD
Sprint transformed to cloud-native architecture using a unique co-development approach with Amdocs, supported by Amdocs’ Microservices360 platform. Amdocs helped Sprint move from a heavily-siloed environment to a unified, simplified cloud-native architecture to deliver functionality in weeks instead of months, and enable digital, omnichannel experiences and continuous new, fast-to-market offerings.
HUMAN FACTOR AWARD
Amdocs transforms its own culture to help service providers move to the cloud. To accelerate the way it delivers value to customers, Amdocs’ highly successful top-down, company-wide transformation included moving to a cloud-native, microservices-based portfolio and services that can deliver new functionality and value to customers in rapid iterations.
CUSTOMER EXPERIENCE & TRUST AWARD
Three Ireland – a Hutchison Company – & Amdocs. Amdocs supported Three Ireland with their complex post-M&A BSS consolidation and customer-experience transformation, which used a “build-once-deploy-many” design-led approach and DevOps methodology to deliver a category-leading, omnichannel, digital-first experience across mobile, web, agent-driven channels and physical stores.
Catalyst Showcase Discussion
Thursday 22 October 2020 | Is business assurance critical in ecosystems?
Andreas Manolis - Head of Strategy & Innovation, BT; Gadi Solotorevsky – TM Forum Distinguished Fellow & Co-Head of Business Assurance group, CTO of Amdocs cVidya;
Amdocs speaker sessions by track
HEADLINER KEYNOTE
Wednesday, October 7 | Accelerating the journey to the cloud
Andre Fuetsch – President AT&T Labs and Chief Technology Officer, AT&T;
Anthony Goonetilleke – Group President – Strategy & Technology, Amdocs
AI, DATA & ANALYTICS
Wednesday, November 4 | Redefine your business with a whole new approach to AI
Dan Noel Natindim – Vice President & Head of Enterprise Data Office, Globe Telecom;
Gil Rosen – Chief Marketing Officer & Division President, amdocs:next
HUMAN FACTOR
Wednesday, October 21 | How to transform into a digital organism for complete business agility
Avishai Sharlin – Division President, Amdocs Technology
Thursday, November 12| LIVE MASTERCLASS: Utilizing the Diversity & Inclusion Maturity Model (with BT, Amdocs & Bain)
Idit Duvdevany – Head of Corporate Responsibility & Inclusion, Amdocs
CLOUD-NATIVE IT & AGILITY
Wednesday, October 21 | The migration dilemma
Ralf Hellebrand – Head of Solstice Transformation, Vodafone Germany;
Avishai Sharlin – President, Amdocs Technology
Wednesday, October 21| Solving the complicated integration challenges of a digital transformation
Meg Knauth – VP, Billing & Technical Product Solutions, T-Mobile US;
Josh Koenig – Head Of Client Solutions, Amdocs Digital Business Operations
Wednesday, November 4 | The 5G network platform – How to apply cloud business models to the network and edge for innovative monetization
Visu Sontam – Senior Partner Solutions Architect of Global Telecom Partner Technology, AWS;
Ron Porter – Product Marketing Lead, Monetization Solutions, Amdocs; David Hovey – Director of 5G Solutions and Strategy, Openet, an Amdocs company
AUTONOMOUS NETWORKS & THE EDGE
Wednesday, October 28 | Private enterprise networks panel – Why vertical enterprises are doing it for themselves
Alla Goldner – Chair of ONAP Use-Case Subcommittee, Linux Foundation, and Director, Technology, Strategy & Standardization, Amdocs
Wednesday, October 28 | From theory to practice – Making network slicing monetization a reality
Joe Hogan – Founder & CTO, Openet, an Amdocs Company;
Angela Logothetis – CTO, Amdocs Open Network;
Dereck Quinlan – VP Sales, North Asia & ANZ, Mavenir
Wednesday, October 29 | Satellite case study: Implementing the world’s first open, standards-based network-automation and service-orchestration NaaS platform on a public cloud
Gint Atkinson – Vice President, Network Strategy & Architecture, SES Networks;
Yogen Patel – Head of Solutions Marketing, Amdocs Open Network
BEYOND CONNECTIVITY
Wednesday, October 28 | LIVE MASTERCLASS: Moving to predictive business assurance in the age of AI
Gadi Solotorevsky – TM Forum Distinguished Fellow & Co-Head of Business Assurance group, and CTO of Amdocs cVidya
Wednesday, October 28 | LIVE MASTERCLASS: How Rogers are moving machine learning to an operational business-assurance functionality
Nurlan Karimov – Fraud Management Expert, Rogers Communications;
Gadi Solotorevsky – TM Forum Distinguished Fellow & Co-Head of Business Assurance group, and CTO of Amdocs cVidya
TM Forum Rising Stars & Talent Mentors Program
The new Rising Star program aims to recognize and showcase young diverse talent in the tech-communications sector. TM Forum has selected Amdocs Software Engineer, Gitika Sinha, as one of their Rising Stars, and will be broadcasting her story throughout the conference. TMF also selected Amdocs Head of Learning and Talent Development, Nomi Malka, as a TM Forum Talent Mentor. Her story of leading pioneering internal and external mentorship programs will also be broadcast throughout the conference. Communications service providers can register for TM Forum’s Digital Transformation World 2020 at no cost.
published first on https://jiohow.tumblr.com/
0 notes
Text
SENIOR DEVELOPPER . NET
Le recruteur : Le Senior Developper est responsable de la conception et du développement des applications en .Net. Il opère sous la responsabilité d’un Chef de Projet et peut prendre en charge le développement de l’ensemble de la chaine de production d’un logiciel. Le développeur doit posséder une expérience minimale de 3 ans en développement .Net et une bonne maa®trise des langages et des outils de développement Microsoft.
Poste a occuper : Compétences techniques requises
Langages et outils de développement : ASP.NET, ASP.NET Core, WCF, WPF, C#, SQL, HTML, CSS, javascript, Jquery, XSLT, HTML5, CSS3, React JS, Angular JS, Nodejs,
Méthodologies: Agile/Scrum, DevOps, Dev Sec Ops
Logiciels/ IDE : Visual studio, SQL Server Management Studio ,
Base de Données : SQL Server
Conception : design patterns (MVC, MVPâ¦) Sécurité Applicative, Stabilité Applicative,
Architecture serveurs (Microservices, SOAâ¦),
Aptitudes professionnelles et Soft Skills
Rigoureux, méthodique, efficace Esprit d’analyse et créativité dans la résolution des problèmes Dynamisme et capacité d’adaptation Rapidité d’exécution Esprit de collaboration et force de proposition Aisance relationnelle et rédactionnelle
Profil recherché : Responsabilités principales
Réaliser des développements selon les spécifications et la solution d’implémentation définie Intégrer les développements réalisés Garantir les livrables dans les délais selon les normes internes et spécifications client S’assurer de la qualité du code et participer aux revues de codes d’autres développeurs Analyser et réaliser des corrections d’anomalies logicielles Rédiger les documents techniques et assurer la formation et transfert de compétence Responsabilités Annexes
Participer a la spécification technique des produits Elaborer des solutions techniques pour répondre aux besoins fonctionnels Accompagner et encadrer les développeurs Jr et les faire monter en compétencesr
Secteur(s) d’activité :
Informatique / Internet / Multimedia
Métier(s) :
Informatique / Internet / Multimedia
Niveau d’expériences requis :
Junior (de 3 a 5 ans)
Niveau d’études exigé :
BAC+5 et plus
Langue(s) exigée(s) :
Francais
L’offre a été publiée il y a 2 semaines avant sur le site.
Salaire:
A négocier
https://ift.tt/3bj5gt3
0 notes
Text
The Decorator Pattern Tutorial with Java Example You've Been Waiting For | Compare it with Strategy Pattern
Full Video link https://youtu.be/CJ-EDREomJ0 Hello friends, #Decoratorpattern video in #JavaDesignPatterns is published on #codeonedigest #youtube channel. This video covers topics 1. What is #Decoratordesignpattern? 2. What is the use of Decorator #de
Decorator design pattern is to allow additional responsibility to object at the run time. Use Decorator pattern whenever sub-classing is not possible. Decorator pattern provides more flexibility than static inheritance. Decorator pattern simplifies the coding. Decorator design pattern allows the extension of object by adding new classes for new behavior or responsibility. Decorator pattern is a…

View On WordPress
#Decorator design pattern#Decorator design pattern java#Decorator design pattern java example#Decorator design pattern real world example#Decorator design pattern uml#Decorator Pattern#Decorator pattern explained#Decorator pattern in design pattern#Decorator pattern java#Decorator pattern java example#Decorator pattern javascript#Decorator pattern real world example#Decorator pattern vs chain of responsibility#design pattern interview questions#design patterns in java#design patterns in microservices#design patterns in software engineering#Design Patterns Tutorial#java design#java design pattern with examples#Java design patterns#java design patterns tutorial#java design principles#pattern
0 notes
Text
Vendrive: Backend Software Engineer

Headquarters: Amherst, MA URL: https://www.vendrive.com/
Description
Our mission is to standardize the B2B supply chain to allow for the more efficient operation of retailers, distributors and manufacturers alike. We've started with the automation and streamlining of day-to-day operations carried out by online retailers. Our price management software, Aura, proudly supports over 1,000 Amazon merchants and processes over 750-million price changes on the Amazon marketplace each month.
Our profitable bootstrapped company was founded in 2017 by a pair of Amazon sellers with a background in engineering. We're a team of die-hard nerds obsessed with big data and automation.
We're looking for a Backend Software Engineer with experience in distributed systems and an entrepreneurial mindset to join us.
Our growing team is remote-first, so it's important that you're able to communicate clearly and effectively in such an environment. We meet regularly, so we require that prospective team members' timezones are in alignment with ours (UTC-10 to UTC-4).
Responsibilities
Design and implement core backend microservices in Go
Design efficient SQL queries
Follow test-driven development practices
Conduct design and code reviews
Participate in daily standups and weekly all-hands meetings
Our Stack
Our backend follows an event-driven microservice architecture. Here are some of the technologies you'll be using:
Golang
PostgreSQL
Redis, Elastisearch
Several 3rd Party APIs
Benefits
Competitive salary
Fully remote position
Company sponsored health, vision and dental insurance
Flexible vacation policy
Equity in a profitable company
Bi-annual company retreats in locations around the world
Startup culture where you're encouraged to experiment
Requirements
B.S. in Computer Science or relevant field
Strong problem-solving and communication skills
Experience with relational databases (PostgreSQL) and ability to analyze and write efficient queries
Experience with Go in production-grade environments
Experience building REST APIs
Working knowledge of Git
Preferred Qualifications
Experience building distributed systems, event-driven microservice architecture, CQRS pattern
Previous remote work experience
Experience integrating with Amazon MWS (Marketplace Web Service)
Experience with Redshift, writing performant analytical queries
Experience collaborating via Git
Hands-on experience with highly concurrent production grade systems
Understanding of DevOps, CI/CD
Experience using AWS services (EC2, ECS, RDS, Redshift, SNS, SQS, etc.)
Understanding of the key metrics which drive a startup SaaS business (MRR, LTV, CAC, Churn, etc.)
Location
🇺🇸US-only
To apply: https://www.vendrive.com/careers/
from We Work Remotely: Remote jobs in design, programming, marketing and more https://ift.tt/2ZNXQrL from Work From Home YouTuber Job Board Blog https://ift.tt/2MTjcyE
0 notes
Photo

Using native modules in production today
#451 — August 23, 2019
Read on the Web
JavaScript Weekly
Using Native JavaScript Modules in Production Today — “now, thanks to some recent advances in bundler technology, it’s possible to deploy your production code as ES2015 modules—with both static and dynamic imports—and get better performance than all non-module options currently available.”
Philip Walton
Web Template Studio 2.0: Generate New Apps from VS Code Wizard-Style — Web Template Studio is an extension, from Microsoft, for Visual Studio Code that simplifies creating new full-stack apps in a ‘wizard’-esque style. It now supports Angular, Vue, and React.
Lea Akkari (Microsoft)
Free Webinar: Design Patterns for Microservice Architecture — If you're planning to design microservice architecture, make sure to learn the best design patterns first. We'll talk about API Gateway, BFF, Monorepo, gRPC and more. Everything based on real-life examples from successful SOA projects.
The Software House sponsor
▶ The State of JavaScript Frameworks in August 2019 — Every six months, Tracy Lee sits down with several representatives of different frameworks to get a brief update on how they’re doing. This hour long episode features Evan You (Vue.js), Minko Gechev (Angular), Michael Dawson (Node.js), Jen Weber (Cardstack), Manu Mtz.-Almeida (Ionic) and Marvin Hagemeister (Preact).
Tracy Lee
JavaScript to Know for React — Examples of which JavaScript features in particular you should be familiar with when learning and using React.
Kent C Dodds
date-fns 2.0: It's Like lodash But For Dates — A date utility library that provides an extensive and consistent API for manipulating dates, whether in the browser or in Node. After tree-shaking and minification, date-fns can be much more compact than moment.js. Homepage.
date-fns
Node v12.9.0 (Current) Released, Now on V8 7.6 — The upgrade to V8 7.6 opens up some new opportunities like Promise.allSettled(), JSON.parse and frozen/sealed array perf improvements, and BigInt now has a toLocaleString method for localized formatting of large numbers.
Node.js Foundation
💻 Jobs
Frontend Engineer at Scalable Capital (Munich) — Passionate about React and GraphQL? Join our Team of JavaScript Developers and shape the future of FinTech.
Scalable Capital GmbH
Have You Thought About Being a Web Developer in Robotics? — A unique opportunity to work on a high-powered engineering web application for a computer vision system combining 3D graphics and an intuitive user experience.
Veo Robotics
Get Hired Based on Your Skills Not Your CV — We’ll introduce you to over 1,500+ companies who’ll compete to hire you. You’re always hidden from your current employer and we’re trusted by over 100k developers.
hackajob
📘 Tutorials
An Introduction to Memoization in JavaScript — ‘Memoization’ is when you cache return values of functions based upon the arguments provided. Here’s an example of creating a separate function that can do this for existing functions.
Nick Scialli
Why is ('b'+'a'+ + 'a' + 'a').toLowerCase() 'banana'? — One of those fun little JavaScript “wat” moments.
Stack Overflow
The State of JavaScript: 2019 and Beyond. Get the Whitepaper — Read about the latest developments and trends in the JavaScript ecosystem, and how things will change in 2019 and beyond.
Progress Kendo UI sponsor
All The New ES2019 Tips and Tricks — An accessible, example-heavy roundup of new ES2019 features.
Laurie Barth
Exploring the Two-Sum Interview Question in JavaScript — There are two solutions, the straightforward ‘brute force’ way, and a more efficient solution that can demonstrate strong CS fundamentals..
Nick Scialli
Using Generators for Deep Recursion
Jason H Priestly
7 Ways to Make Your Angular App More Accessible
Chris Ward
▶ Is Modern JavaScript Tooling Too Complicated? — A podcast where two developers debate a point with two other developers, each group taking one side of the debate. Is modern JS tooling too complicated? Discuss!
JS Party podcast
🔧 Code and Tools
NodeGUI: A New Way to Build Native Desktop Apps with JavaScript — An interesting new alternative to something like Electron as it’s based around Qt, the cross platform widget toolkit, rather than a browser engine.
Atul R
Chart.xkcd: xkcd, Hand-Drawn-Style Charts — If you like your lines wiggly and rough, this might be for you. It tries to mimic the style of the fantastic xkcd comic.
Tim Qian
Browser Automation Experience Made Reliable and Less Flaky — Taiko is a free/open source browser automation tool that addresses the last mile to reliable testing.
ThoughtWorks - Taiko sponsor
FilePond: A Flexible File Uploader with a Smooth UI — It’s vanilla JavaScript but has adapters to make it easier to use with React, Vue, Angular, or even jQuery. v4.5 has just dropped. GitHub repo.
Rik Schennink
v8n: A 'Fluent Validation' Library — Chain together rules to make validations, e.g. v8n().some.not.uppercase().test("Hello");
Bruno C. Couto
file-type: Detect The File Type of a Buffer/Uint8Array — For example, give it the raw data from a PNG file, and it’ll tell you it’s a PNG file.
Sindre Sorhus
pagemap: A 'Mini Map' for Your Pages — A neat little idea that’s particularly useful on long pages. This adds a clickable/navigable overview of an entire page to the top right corner. Here’s the associated repo.
Lars Jung
Automated Code Reviews for 27 Languages, Directly from Your Workflow
Codacy sponsor
⚡️ Quick Releases
ESLint 2.6.1
d3 5.10 & 5.11 — the JavaScript data visualization library.
vue-cli 3.11
AVA 2.3 — popular test runner for Node.
The Lounge 3.2 — a JavaScript-powered IRC client.
by via JavaScript Weekly https://ift.tt/2HlYZ1S
0 notes
Text
Reducing Costs and Increasing Efficiency: Several Technical Architectures Help Linus Operate Transparently, Securely, and Efficiently
The development of Internet technology has realized the decentralized dissemination of information on a global scale, financial inclusion is developing rapidly, and people are more excited about the scenario of financial globalization. linus aims to provide a free, convenient and interesting digital asset trading platform for global users, gathering a number of advanced technologies, allowing global users to trade anytime and anywhere, and by participating in activities, enjoy the trading platform the huge dividends brought by the trading platform.

Linus Multi-Chain Hybrid Architecture
The Linus trading platform blockchain uses a multi-commons chain hybrid architecture that is designed to meet industry- and enterprise-level applications and support a variety of complex scenarios. One of the main goals of the hybrid architecture is to build a UTXO-enabled smart contract model based on the equity consensus mechanism (PoS). The hybrid architecture is compatible with the platform coin UTXO model and AAL-compliant virtual machines, the first compatible virtual machine is Ether's EVM, and the subsequent virtual machines of x86 architecture will be implemented to support the implementation of a variety of popular smart contract programming languages.
Diverse Functionality API & WebSocket
The Linus platform offers a variety of full-featured trading web application programming interfaces (APIs) that cover key trading functions while providing familiar entry points for different trading styles and user types. Users can use any of these APIs to gain read access to public market data and private APIs to gain private read access to accounts.
SpringCloud Microservices Architecture
The technical architecture of Linus trading platform mainly considers features such as security, distributed, easy scalability, fault tolerance, low latency, high concurrency, and various options such as melting mechanism, service registration and discovery, messaging service, service gateway, security authentication, in-memory database, and relational database. Therefore, based on the above technical selection requirements, the Linus platform, based on the SpringCloud microservices architecture development trading platform, provides developers with tools to quickly build some common patterns in distributed systems (e.g. configuration management, service discovery, circuit breaker, intelligent routing, microproxy, control bus).
Aggregate Transaction Engine
The Linus aggregation system uses a pooled bidding model. Since orders are not generated continuously in blockchain systems, but discrete by block-out intervals, Linus does not use continuous bidding algorithms for orders like most centralized exchanges, but periodically aggregates orders in a centralized bidding process by block-out intervals.
Wallet Interface and Extensibility
The Linus platform facilitates secure connections between a user's wallet and any DApp through the Wallet interface, which generates key pairs and creates sessions between the wallet and the DApp, facilitating end-to-end encrypted communication between the two clients. On the Linus platform, users can use the wallet to interact with any DApp without any permission, enabling a seamless experience with DApps on mobile devices.
SpringSecurity
Linus chose SpringSecurity technology to address platform security. springSecurity is based on the Spring framework and provides a complete solution for web application security.
Seata
Under the SpringCloud microservices architecture, the Linus platform leverages Seata technology for distributed transactions, an open source distributed transaction solution dedicated to providing high-performance and easy-to-use distributed transaction services in a microservices architecture.
Mongodb Data Warehouse
The Linus platform leverages the MongoDB data warehouse, a distributed file storage-based database written in C++ to provide a scalable, high-performance data storage solution for WEB applications, to store hyperscale data faster.
Conclusion
The development of the Linus platform cannot be achieved without the impetus of these advanced technologies, which ensure the transparent, secure and efficient operation of Linus and enable users to fully participate in it and enjoy the dividends brought by the digital era.
0 notes
Text
Top Ecommerce Trends You Must Know in 2020
Responsible for an age of customers that requests magnificent encounters over each channel, the eCommerce business is on the bleeding edge of advancement.
Because of the pace of progress in eCommerce website development, what’s to come isn’t something that numerous dealers have the advantage of getting ready for—it’s going on the present moment, surrounding us.
All in all, if the eventual fate of eCommerce is as of now upon us, what would merchants be able to expect throughout the following year? Magento’s biological system accomplices gave their considerations on the top eCommerce patterns to watch in 2020.
1. Ethical eCommerce Trends
Shopper consciousness of the natural and moral impression of their utilization is on the ascent. In 2019, we saw #climatestrike developments happening everywhere throughout the world as purchasers put focus on governments and enterprises to give supportable answers for address CO2 creation, plastic bundling, cultivating rehearses, squander decrease, etc.
An ongoing Nielsen study found that 81% of individuals feel unequivocally that organizations should help improve nature, and a different report found that 68% of online customers regarded item supportability a significant factor in making a buy. This enthusiasm for corporate obligation is shared across sexual orientation lines and ages. Twenty to thirty year olds, Gen Z, and Gen X are the most strong, yet their more seasoned partners aren’t a long ways behind.
Customer consciousness of nature and morally created things will ascend as an eCommerce pattern in 2020 as buyers will try to comprehend the genuine or concealed effects and expenses of eCommerce and seo company commercialization when all is said in done.
2. Consistent Omnichannel Experiences
In the event that vendors take a gander at their omnichannel methodology from just a business point of view, they’re passing up a significant eCommerce pattern. As the quantity of touchpoints required to settle on a choice develops, deals and advertising channels are progressively integral, setting off the requirement for predictable item encounters no matter how you look at it.
As indicated by PwC, 86% of purchasers are happy to pay more for an incredible client experience. Vendors with a decent comprehension of the effect of the different diverts in their client excursion can construct their item experience in like manner and flourish in the new omnichannel experience economy.
3. Personalization, No Conversion
The eventual fate of eCommerce personalization will use subjective answers for comprehend where clients are in their excursion and to distinguish various elements and characteristics to convey genuinely individualized encounters.
Fundamental personalization won’t stand the trial of time. In the event that shippers need to convey significant, customized encounters to everybody, the perfect method to do that is with computerized reasoning (AI). These new AI-fueled encounters will stretch out across channels, giving the most pertinent experiences dependent on the setting of a client’s association. Traders will think about who, yet where, when, and how a client is drawing in with them.
4. Transportation and Delivery Transformation
In 2020, a few advancements will keep on stirring up the eCommerce conveyance business. Delivery organizations are continually taking a gander at more approaches to utilize information to drive advancement, and AI’s latent capacity is unlimited: Data-driven inventory chains could bring already unbelievable degrees of improvement. Computer based intelligence is the eventual fate of transportation.
Indeed, McKinsey predicts a reality where self-sufficient vehicles convey 80% of bundles. Self-driving robots, which work like little storage spaces, are as of now being tried and will turn into an eCommerce pattern very soon. In only a couple of years, there is a decent possibility that online buys will show up at your entryway with no conveyance individual.
5. Headless Commerce
Headless structures and lean microservice stacks convey improved readiness and execution contrasted with solid frameworks. Furthermore, the advantages are conveyed very quickly.
With the capacity to create applications in equal, disengaging and scaling microservices is conceivable so new front-end encounters, including Progressive Web Applications (PWAs), can be propelled rapidly and productively.
Verifiably, if a client experience group approved an adjustment in plan that may support deals significantly, they’d need to sit on that change until a designer could find a good pace. The net impact is that shippers are more slow to develop. When showcasing and creatives have the opportunity and portability to execute transform, they’re ready to direct tests and examinations all the more every now and again, accumulating more extravagant bits of knowledge, which at last lead to higher changes
6. Progressive Web Apps (PWAs)
Versatile has been top-of-mind in eCommerce patterns for as long as not many years. PWAs are the following development of portable business and will turn into the standard in 2020.
Through PWAs, clients can cooperate with brands how they need and where they need in a totally consistent way. For example, clients visiting a furniture display will have their in-store understanding, versatile experience, and online experience all gave by the equivalent PWA to a consistent encounter that aides and supports shoppers from their first visit to the store completely through the conveyance of their new furnishings.
Because of their prevalence, the expense of PWAs will diminish, making them progressively available for more traders.
7. Small scale Animations to Boost Conversions
Liveliness like GIFs have been around since the beginning of the Internet, yet today their utilization is extending from images and diversion to turn into the most recent eCommerce pattern.
The use of enlivened symbols to the eCommerce development experience can underline the brand, improve the client experience, and lift changes.
8. Visual Search in eCommerce
The present buyers — particularly those between the ages of 18 and 20 and 21 and 34 — have indicated a developing enthusiasm for utilizing visual pursuit and picture acknowledgment so as to find new brands and items. By 2021, early adopter brands will overhaul their sites to help visual pursuit, bringing about a 30% expansion in computerized trade income and making it one of the greatest eCommerce patterns to watch.
With regards to eCommerce personalization, this exhibits a huge open door for brands to encourage further associations with their customers by making it simpler for them to discover the items they’re searching for.
9. Voice as an eCommerce Channel
While numerous individuals state we’re still in the beginning of voice, just about seventy five percent of individuals would prefer to utilize their voice as a contribution to look on web design development. What’s more, ongoing exploration shows that 76% of organizations have just acknowledged quantifiable advantages from voice and talk.
Indeed, this examination found that generally 20% of purchasers with astute speakers use them to shop, and that is relied upon to ascend to half in the following a year as this eCommerce pattern grabs hold.
10. NextGen B2B eCommerce
Just 14% of B2B organizations are client driven, and that is on the grounds that many don’t attempt to get inside the brain of the B2B purchaser. B2B brands ought to consider building a direct-to-customer channel. This would give them responsibility for information to upgrade the client experience over all channels and steps of the excursion.
In 2020, B2B advanced change will move from an item driven to a client driven core interest. We’ll see B2B associations investigate new chances and channels to improve the client encounter and extend their intended interest group.
11. Market Places
The eCommerce stage unrest will arrive at a tipping point in 2020, driven by purchasers looking for the simple, well-known, and seriously evaluated commercial center understanding. McKinsey predicts that in the following five years, stages could represent over 30% of worldwide corporate incomes. Furthermore, it’s not simply B2C. B2B dealers are going to stages too.
The main 100 online commercial centers as of now sell $1.8 trillion every year. The organizations that are leading the pack right now environment driven economy are seeing about twofold the income development of the organizations that avoid any and all risks. And keeping in mind that the open door is ready, there isn’t a lot of time left to turn into a first mover.
THE FUTURE IS HERE: WHAT CAN MERCHANTS DO?
What’s to come is now here. All these eCommerce patterns are in different phases of magento website development, with some being tried by early adopters and others well on their approach to turning out to be standard over the business.
Our biological system accomplices added to another eBook on eCommerce 2020. It’s pressed with subtleties and exhortation on what lies ahead in 2020 and past, and what vendors can do to get ready.
To know more about our services, please visit our website Rajasri System, our email id “[email protected]” and Skype “rajasrisystems1“.
#magento development india#magento web development#ecommerce web design agency#web developing company#progressive web apps
0 notes
Text
Building enterprise applications using Amazon DynamoDB, AWS Lambda, and Go
Amazon DynamoDB is a fully managed service that delivers single-digit millisecond performance at any scale. It is fully managed, highly available through behind-the-scene Multi-AZ data replication, supports native write-through caching with Amazon DynamoDB Accelerator (DAX) as well as multiple global secondary indexes. Developers can interact with DynamoDB using the AWS SDK in a rich set of programming languages, including Go, which is the focus of this post. This post addresses use cases specific to CRUD-intensive applications and how to handle them efficiently using DynamoDB, AWS Lambda, and Go. CRUD stands for create, read, update, delete (see Create, read, update, and delete on Wikipedia.). This terminology is common in applications that manage a large number of heterogeneous objects, in industries with complex business models, and high degrees of automation. This post uses an example from the hospitality industry, but the fundamental design principles apply to a wide variety of enterprise applications. This post is targeted at software engineers looking for good practices and examples to design and build enterprise applications using DynamoDB and Go. For more information, see the GitHub repo. The code in the GitHub repo is written for quick prototyping not recommended for production use. Prerequisites To complete this walkthrough, you must have an AWS account with AWS CLI access and have installed the AWS CDK. For more information, see Getting Started With the AWS CDK. For more information about building the API Gateway endpoints and Lambda function, see the GitHub repo. Use case and application design Modern hotel central reservation systems enable hotel chains and independent properties to administrate their content (such as pictures, videos, room descriptions, rooms and rates, and distribution rules) to make their products searchable and bookable through a wide variety of distribution channels (such as online travel agencies, chain websites, and internal booking engines). These specialized applications expose hundreds of use cases to a large number of users, from the hotel front desk agent to the final guest, along with the chain corporate employees and more. These use cases commonly fit into the following families: Administrative use cases – These typically allow hoteliers or corporate office employees to create, update, and delete objects such as CHAIN, BRAND, PROPERTY, ROOM, ROOM_TYPE, and PRICING_RULE, each consisting of a large set of interdependent attributes. Operational use cases – These allow mobile and web applications to search and book hotel products defined as a combination of the previously mentioned attributes, computed prices, and business rules results. Operational use cases have a limited set of flows and high traffic/low latency requirements, and some flows can withstand eventual consistency. Administrative use cases require consistent reads and a large number of small object CRUDs. Operational use cases Administrative use cases Use cases SearchHotelAvailability SearchRoomAvailability, BookRoom listHotels, saveHotel, getHotel, deleteHotel, addPicture, deletePicture, saveRooms, addSellable, addRoomType, addTag, deleteSellable, deleteRoomType, deleteTag, addSellablePicture, addRoomTypePicture, deleteSellablePicture, deleteRoomTypePicture, publishChanges Client Hotel chain, web site, Mobile booking Application, third party online travel agency…. Administration portal Persona Travel Agent, Hotelier, Guest Hotelier, Hotel Chain Corporate Employee Constraints High traffic Low latency Eventual consistency Medium to low traffic Strongly consistent Flexible datamodel Due to the large number of interdependent objects (easily mappable to classes with foreign keys), classic approaches to application design may identify administrative use cases as more suitable for relational database use. DynamoDB is also particularly useful in this set of use cases. It allows rapid data model evolution and provides independent object CRUD management, while exposing a natively efficient read use case. Additionally, despite object interdependencies, it avoids the use of joins and multiple parallel queries, which usually impede scalability and performance. To illustrate these use cases, this post presents a serverless application composed of a RESTful API on Amazon API Gateway, with a set of endpoints integrated with a Lambda function written in Go that accesses a DynamoDB table. The following diagram illustrates this architecture. The API Gateway layer manages the RESTful API definition and access control. It also defines the Lambda function called for each Method/REST endpoint combination along with a transformation template that allows the use of one single Lambda function for all the individual object managements. While these may seem against the principles of microservice design, keeping the management of many small interdependent simple objects in one Lambda application (and storage in one DB table) carries excellent benefits in terms of application operability and maintainability. The Lambda function translates the object model into a DynamoDB-optimized model. It is a good practice to decouple the two models because it helps better manage backward compatibility and provides an abstraction layer on top of the data store. This allows you to make changes more easily in the future. Another good practice is to build a wrapper on top of the DynamoDB SDK functions. This creates abstraction in case the data model changes and allows you to tailor function definitions to the use case, which greatly increases code readability and maintainability. Data model design A table in DynamoDB is composed of a partition key (PK) and an optional sort key (SK). The combination PK/SK constitutes the primary key of an item in the table. Also, the choice of partition key directly impacts the way items are distributed to the underlying database nodes, so you should choose a high cardinality set for PKs. There is a trade-off, however, because only SCAN operations can return items with different PKs. Because SCAN operations read the whole table, they are inefficient in comparison to QUERY operations, which only fetch the items for a given PK. Each hotel is identified by a code and has a master configuration record with the following model. type Hotel struct { Code string `json:"code"` //Unique identifier of the hotel Name string `json:"name"` //Hotel name Description string `json:"description"` //Hotel description CurrencyCode string `json:"currencyCode"` //Hotel currency code DefaultMarketting HotelMarketing `json:"defaultMarketting"` //Object containing marketing text Options HotelOptions `json:"options"` //Object containing transactional options (open for search, reservation?) Pictures []HotelPicture `json:"pictures"` //List of Picture object containing URL of image content and tags Buildings []HotelBuilding `json:"buildings"` //List of hotel building (each buildings has floors and rooms) RoomTypes []HotelRoomType `json:"roomTypes"` //List of Room types (Queen, Suite, presidential suite...) Tags []HotelRoomAttribute `json:"tags"` //List of tags impacting room type prices (such as Sea view or minibar) Sellables []HotelSellable `json:"sellables"` //List of sellable item (could be meals, excursion...) Rules []HotelBusinessRule `json:"businessRules"` //List of Business rules defining prices and availability of rooms, tags sellable PendingChanges []HotelConfigChange `json:"pendingChanges"` //List of Changes to the hotel configuration record } The master configuration object has a set of simple nested objects (fewer than 10 fields) with interdependencies. Industry use cases can typically have hundreds (in some cases thousands) of nested objects. The following diagram illustrates a partial version of such a data model using the classic UML. UML representation does not visually describe this post’s DynamoDB model very clearly. We prefer using a tabular representation, which describes the partition key, sort key, and dedicated attributes for each item. This representation is used later on in this post. Some of the administrative use cases to address with this model are: listHotels, saveHotel, getHotel, deleteHotel, addPicture, deletePicture, saveRooms, addSellable, addRoomType, addTag, deleteSellable, deleteRoomType, deleteTag, addSellablePicture, addRoomTypePicture, deleteSellablePicture, deleteRoomTypePicture, and publishChanges. One or several data access patterns correspond to each. To define a data model that corresponds to the preceding business model and efficiently performs with DynamoDB, you should review the constraints you must work with. Write operations To optimize for cost, performance, and application access patterns, split the objects into multiple items in the same table. When you need to read/write nested objects, you do not need the full object. To support these requirements, it makes sense to store the nested data in its own item. Because the nested objects defined previously are small (fewer than 10 fields), they are good candidates for the granularity of your items. Read operations The getHotel use case, which returns the whole hotel configuration, is likely to be the most frequent because this post doesn’t define more granular retrieve use cases (this design decision would benefit from further discussions, but this is beyond the scope of this post). You should therefore optimize it and avoid scan operations and multiple parallel queries. You can achieve this by using the hotel code as a partition key for all records and use the sort key as a way to identify the nested object the record corresponds to. Choosing the hotel code as the partition key works under the hypothesis that the administrative use case supports medium to low traffic. This is sensible because the traffic originates mostly from manual actions on an administration front-end. There are some critical differences between the way operational and administrative use cases use DynamoDB features. High throughput traffic from operational use cases would use DynamoDB for scalability and elasticity. Administrative use cases take advantage of the flexibility of adding and updating nested objects, the cost-efficiency of small write operations, and the serverless nature of DynamoDB. To design your DB model, use the following naming convention for your Sort Key: “cfg”-<”general” |”history” | nested_object_type>-<”picture”>- The following table shows a few mapping examples. Business object DynamoDB record sort key Hotel cfg-general HotelSellable cfg-sellable- HotelRoom cfg-room- HotelRoomAttribute cfg-tag- HotelRoomType cfg-roomType- HotelPicture cfg-general-picture- cfg-sellable-picture- cfg-roomType-picture- HotelConfigChange cfg-history- As mentioned previously, use the following tabular representation to translate the DynamoDB model visually. Lambda function architecture The following diagram illustrates the architecture of the Lambda function. Requests from API Gateway are passed to the handler, which picks the use case to run. Each use case interacts with the DynamoDB AWS SDK through an adapter layer to translate your business object model into the DynamoDB optimized model. In a scenario with multiple Lambda functions, you can make the Lambda core folder a shared GO component published in a separate repository. This allows you to jump-start your next Lambda function and reuse the same model and wrapper functions. Adapters use a set of wrapper functions built on top of the AWS SDK to simplify the code for the most frequent use cases. This post uses the following wrapper functions: Init – Create the connection struct Save – Upsert an item FindStartingWith – Find items for a given PK and an SK starting with a given string The following functions are also available in the GitHub repo: SaveMany – Save multiple items (it handles up to 25 items from the SDK BatchWriteItems) DeleteMany – Delete multiple items Delete – Delete one item by its PK and SK Get – Get an item by its PK and SK FindByGsi – Find items by the global secondary index Lambda function handler The Lambda function handler routes the requests from the API Gateway endpoint to the appropriate use case using the subFunction parameter in the request body that you mapped in your infrastructure script. See the following code: if(wrapper.SubFunction == FN_CONFIG_LIST_HOTEL) { log.Printf("Selected Use Case %v",FN_CONFIG_LIST_HOTEL) res, err = usecase.ListHotel(wrapper,configDb); } else if(wrapper.SubFunction == FN_CONFIG_SAVE_HOTEL) { log.Printf("Selected Use Case %v",FN_CONFIG_SAVE_HOTEL) res, err = usecase.SaveHotel(wrapper,configDb); } else if(wrapper.SubFunction == FN_CONFIG_GET_HOTEL) { log.Printf("Selected Use Case %v",FN_CONFIG_GET_HOTEL) res, err = usecase.GetHotel(wrapper,configDb); } else if(wrapper.SubFunction == FN_CONFIG_ADD_TOOM_TYPE) { log.Printf("Selected Use Case %v",FN_CONFIG_ADD_TOOM_TYPE) res, err = usecase.AddRoomType(wrapper,configDb); } else if(wrapper.SubFunction == FN_CONFIG_DELETE_ROOM_TYPE) { log.Printf("Selected Use Case %v",FN_CONFIG_DELETE_ROOM_TYPE) res, err = usecase.DeleteRoomType(wrapper,configDb); } else { log.Printf("No Use Case Found for %v",wrapper.SubFunction) err = errors.New("No Use Case Found for sub function " + wrapper.SubFunction) } It is a best practice to initialize the DynamoDB client outside of the Lambda function handler to allow Lambda to reuse connections. For more information, see Best Practices. See the following code: //It is a best practice to instanciate the Amazon DynamoDB client outside //of the AWS Lambda function handler. //https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Streams.Lambda.BestPracticesWithDynamoDB.html var configDb = db.Init(DB_TABLE_CONFIG_NAME,DB_TABLE_CONFIG_PK, DB_TABLE_CONFIG_SK) To implement it in the Lambda core package, see the following code: //init set up the session and define table name, primary key, and sort key func Init(tn string, pk string, sk string) DBConfig{ // Initialize a session that the SDK uses to load // credentials from the shared credentials file ~/.aws/credentials // and region from the shared configuration file ~/.aws/config. dbSession := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) // Create Amazon DynamoDB client return DBConfig{ DbService : dynamodb.New(dbSession), PrimaryKey : pk, SortKey : sk, TableName : tn, } } This step creates a client object to interact with a DynamoDB table. This strategy allows a single function to easily interact with multiple tables by maintaining multiple client objects. Get use case You can now write the GetHotel use case with the following code: func GetHotel(wrapper model.RqWrapper,configDb db.DBConfig) (model.ResWrapper, error) { dynRes := []model.DynamoHotelRec{} dbr := dbadapter.IdToDynamo(wrapper.Id) err := configDb.FindStartingWith(dbr.Code, dbadapter.ITEM_TYPE_CONFIG_PREFIX, &dynRes) return model.ResWrapper{Response: []model.Hotel{ dbadapter.DynamoListToBom(dynRes)}}, err } It uses the FindStartingWith wrapper function written in the core DB package. See the following code: func (dbc DBConfig) FindStartingWith(pk string, value string, data interface{}) error{ var queryInput = &dynamodb.QueryInput{ TableName: aws.String(dbc.TableName), KeyConditions: map[string]*dynamodb.Condition{ dbc.PrimaryKey: { ComparisonOperator: aws.String("EQ"), AttributeValueList: []*dynamodb.AttributeValue{ { S: aws.String(pk), }, }, }, dbc.SortKey: { ComparisonOperator: aws.String("BEGINS_WITH"), AttributeValueList: []*dynamodb.AttributeValue{ { S: aws.String(value), }, }, }, }, } var result, err = dbc.DbService.Query(queryInput) if err != nil { fmt.Println("DB:FindStartingWith> NOT FOUND") fmt.Println(err.Error()) return err } err = dynamodbattribute.UnmarshalListOfMaps(result.Items, data) if err != nil { panic(fmt.Sprintf("Failed to unmarshal Record, %v", err)) } return err } This wrapper function allows you to search all DynamoDB items for a given partition key and with a sort key starting with a given string. This implementation has the following important points: You use the SDK Query function (which is more efficient than Scans) This works because when following the preceding sort key convention, all sort keys start with a common prefix You can efficiently query any subpart of your nested structure by reflecting the depth of an object in the model hierarchy in the order of the components of the sort key The following is the DB adapter code: func DynamoListToBom(dbrList []model.DynamoHotelRec) model.Hotel{ var bom model.Hotel var hotelConfigChanges []model.HotelConfigChange = make([]model.HotelConfigChange,0,0) for _, dbr := range dbrList { if(strings.HasPrefix(dbr.ItemType,ITEM_TYPE_CONFIG_INVENTORY_ROOM_TYPE)) { bom.RoomTypes = append(bom.RoomTypes,DynamoToBomRoomType(dbr)) } else if(dbr.ItemType == ITEM_TYPE_CONFIG_GENERAL) { bom = DynamoToBom(dbr) } else if(strings.HasPrefix(dbr.ItemType,ITEM_TYPE_CONFIG_HISTORY)) { hotelConfigChanges = append(hotelConfigChanges,DynamoToBomConfigChange(dbr)) } } bom.PendingChanges = hotelConfigChanges return bom } The code iterates one time on all the records that DynamoDB returns and reconstructs the object piece by piece. You can reconstruct your entire object with one query as opposed to querying multiple tables or multiple times on one table and applying joints on the results. This does not come at the expense of less efficient write use cases because you can still write nested objects individually. This saves you write throughput costs and lowers the probability of concurrent access issues that you would encounter while storing one large configuration object. Write use case To directly write nested objects like RoomType, see the following code: func AddRoomType(wrapper model.RqWrapper,configDb db.DBConfig) (model.ResWrapper, error) { dbr := dbadapter.BomRoomTypeToDynamo(wrapper.Request, wrapper.UserInfo) _, err := configDb.Save(dbr) return model.ResWrapper{Response: []model.Hotel{wrapper.Request}},err } For the Save wrapper function, see the following code: func (dbc DBConfig) Save(prop interface{}) (interface{}, error){ av, err := dynamodbattribute.MarshalMap(prop) if err != nil { fmt.Println("Got error marshalling new property item:") fmt.Println(err.Error()) } input := &dynamodb.PutItemInput{ Item: av, TableName: aws.String(dbc.TableName), } _, err = dbc.DbService.PutItem(input) if err != nil { fmt.Println("Got error calling PutItem:") fmt.Println(err.Error()) } return prop, err } For the DB adapter function, see the following code: func BomRoomTypeToDynamo(bom model.Hotel, user core.User) model.DynamoRoomTypeRec{ return model.DynamoRoomTypeRec{ Code : bom.Code, Name : bom.RoomTypes[0].Name, Description : bom.RoomTypes[0].Description, LowPrice : bom.RoomTypes[0].LowPrice, MedPrice : bom.RoomTypes[0].MedPrice, HighPrice : bom.RoomTypes[0].HighPrice, ItemType: ITEM_TYPE_CONFIG_INVENTORY_ROOM_TYPE + "-" + bom.RoomTypes[0].Code, LastUpdatedBy : user.Username, } } Running the demo code If you are not interested in getting the CDK script working or are not planning to update the stack, you can use the AWS CloudFormation template from the GitHub repo. To build the infrastructure using CDK, complete the following steps: Clone the repository and run the install.sh script. This script installs all the required components (Node.js, CDK, Go, and packages). Run the deploy.sh script. This builds the Lambda handler code and creates the .zip file using the GO compiler and the AWS-provided packager. Then it creates and deploys the stack using the CDK CLI. See the following code: git clone [email protected]:aws-samples/aws-dynamodb-enterprise-application.git cd aws-dynamodb-enterprise-application sh install.sh sh deploy.sh If all is correct, you should receive the following output: CloudInfraDemoStack Outputs: CloudInfraDemoStack.awsCrudDemoEndpointE705E337 = https://3yv9bpbow0.execute-api.eu-west-1.amazonaws.com/prod/ Stack ARN: arn:aws:cloudformation:eu-west-1:XXXXXXXXXXXXX:stack/CloudInfraDemoStack/efcf48c0-bcc1-11e9-b902-06952668af9c You can now use this endpoint to perform calls to your newly created REST API using the curl utility software. Create a hotel, add a room type, and retrieve the full object. See the following code: curl -d '{"name" : "My First hotel","description" : "This is a great property"}' -H "Content-Type: application/json" -X POST https://3yv9bpbow0.execute-api.eu-west-1.amazonaws.com/prod/config You receive the following output: { "error": { "code": "", "msg": "" }, "subFunction": "", "response": [ { "code": "364425903", "name": "My First hotel", "description": "This is a great property", "currencyCode": "", "defaultMarketting": { "defaultTagLine": "", "defaultDescription": "" }, "options": { "bookable": false, "shoppable": false }, "pictures": null, "buildings": null, "roomTypes": null, "tags": null, "sellables": null, "businessRules": null, "pendingChanges": null } ] } Use the returned ID to perform the second call. See the following code: curl -d '{"code" : "364425903","roomTypes": [{"code" : "DBL","name" : "Room with Double Beds","description" : "Standard Room Type with double bed"}]}' -H "Content-Type: application/json" -X POST https://3yv9bpbow0.execute-api.eu-west-1.amazonaws.com/prod/config/364425903/rooms/type You should get a success 200 response. Perform a simple GET call. See the following code: curl https://3yv9bpbow0.execute-api.eu-west-1.amazonaws.com/prod/config/364425903 You can also paste the URL in a browser address bar. You receive the following code: { "error": { "code": "", "msg": "" }, "subFunction": "", "response": [ { "code": "364425903", "name": "My First hotel", "description": "This is a great property", "currencyCode": "", "defaultMarketting": { "defaultTagLine": "", "defaultDescription": "" }, "options": { "bookable": false, "shoppable": false }, "pictures": null, "buildings": null, "roomTypes": [ { "code": "DBL", "name": "Room with Double Beds", "lowPrice": 0, "medPrice": 0, "highPrice": 0, "description": "Standard Room Type with double bed", "pictures": null } ], "tags": null, "sellables": null, "businessRules": null, "pendingChanges": [] } ] } You can check that two records have been added to your DynamoDB table by logging in to the AWS Management Console for DynamoDB. Click on the Tables link and select the table named aws-crud-demo-config-$env (where $env is the name of the environment provided to the deploy.sh script.) The Items tab allows you to manage items and perform queries and scans. You should see two items with the sort key (SK) structure we discussed previously. Summary This post described an efficient way to build a serverless CRUD application on top of DynamoDB to enable administration use cases on large nested business object data models. The key takeaway is to use the same partition key for all nested objects and to use the sort key components order to reflect the nested object depths. This allows you to retrieve the full object in one query and allows efficient write use-cases for nested objects. This approach has the following benefits: It is aligned with DynamoDB pricing because read operations are cheaper than write operations. It lowers the probability of concurrent access issues because you write nested objects individually. It splits the object into smaller parts. This is an efficient handling of the 400 KB record side limit in DynamoDB. It allows you to retrieve the full object in one query, which takes advantage of DynamoDB single-digit millisecond response time. You can use a Query operation (and not a Scan) because you keep all nested objects under the same PK. Takeaways Some key takeways from building this demo: Use infrastructure as code – Use CloudFormation, CDK, or Amplify to script your architecture. Moving a large application infrastructure created manually through the AWS console to an infrastructure as code model is a tedious process. Sanitize your user inputs – Do this before using them as parameters to search for partition keys or sort keys. Otherwise, you could end up spending an hour debugging before finding logs with simple typographical errors. (beware the dreaded white space at the start of a PK or SK) Separate your storage model from your business model – This greatly increases code reusability. Build wrapper functions on top of AWS SDK – The DynamoDB SDK service team is constantly adding new features, so you can expect the SDK to become more complex over time. You do not necessarily need all its features at all times. Design simple wrapper functions of the most frequent use cases. This also allows you to reuse code for similar projects so you can jump-start a new project quicker. Beware of permissions settings – AWS provides a granular set of permissions capabilities through IAM. If something does not work out of the box, check first that your Amazon EC2 instance or Lambda function execution role has the appropriate permissions. Watch out for CORS settings. Don’t forget to enable CORS for the relevant endpoints in API Gateway. This is a frequent error during API design and often means extra back-and-forth exchanges between the front-end team and the back-end team. Going further To go further, you should explore how to use DynamoDB Streams to log the history of changes made on the business object. You can construct an audit log feature, which is a frequent requirement in large administration portals for compliance auditing. Tracking the list of changes in the business object models also allows you to apply a draft-and-publish model to the changes in the configuration object, whereby a user can make multiple changes to the Hotel configuration object and decide to only publish them together at a chosen (or scheduled) time. You can effectively implement this by publishing the fully constructed object to Amazon S3. You can use the published object as the latest snapshot for operational use cases such as searchHotelAvailability or BookRoom. The following diagram illustrates the simplified architecture of a hotel central reservation system. The Administration Use Case architecture matches this post’s demo code. The Operational Use Cases are also exposed as REST endpoints using Amazon API Gateway and AWS Lambda but use Amazon Aurora because using a SQL database in this use case is likely to be more cost-efficient due to the amount of write operations required for inventory updates. Amazon Elasticache can also be used to improve the response time of the SearchHotelAvailability use case. Finally, you can find advanced design pattern recommendations for DynamoDB (including tips on versioning your model) in an excellent presentation from AWS NoSQL Principal Technologist Rick Houlihan at 2018 AWS re:Invent. See the video of the presentation on YouTube. When building your Enterprise application on top of DynamoDB, follow DynamoDB best practices for the best performance and lowest costs! If you have questions or feedback about DynamoDB best practices, ping us on @DynamoDB on Twitter. About the Author Geoffroy Rollat is a Solutions Architect with Amazon Web Services supporting enterprise customers. Prior to AWS, Geoffroy spent close to ten years in the hospitality technology sector delivering software solutions to Hotel Chains and Travel Companies. https://probdm.com/site/ODA4OQ
0 notes
Text
The next integration evolution — blockchain
Bilgin Ibryam Contributor
Share on Twitter
Bilgin Ibryam is a principal architect at Red Hat, committer and member of Apache Software Foundation. He is an open-source evangelist, blogger, occasional speaker and the author of Kubernetes Patterns and Camel Design Patterns.
Here is one way to look at distributed ledger technologies (DLT) and blockchain in the context of integration evolution. Over the years, businesses and their systems are getting more integrated, forming industry-specific trustless networks, and blockchain technology is in the foundation of this evolutionary step.
Enterprise integration
Large organizations have a large number of applications running in separate silos that need to share data and functionality in order to operate in a unified and consistent way. The process of linking such applications within a single organization, to enable sharing of data and business processes, is called enterprise application integration (EAI).
Similarly, organizations also need to share data and functionality in a controlled way among themselves. They need to integrate and automate the key business processes that extend outside the walls of the organizations. The latter is an extension of EAI and achieved by exchanging structured messages using agreed upon message standards referred to as business-to-business (B2B) integration.
Fundamentally, both terms refer to the process of integrating data and functionality that spans across multiple systems and sometimes parties. The systems and business processes in these organizations are evolving, and so is the technology enabling B2B unification.
Evolution of integration
There isn’t a year when certain integration technologies became mainstream; they gradually evolved and built on top of each other. Rather than focusing on the specific technology and year, let’s try to observe the progression that happened over the decades and see why blockchain is the next technology iteration.
Evolution of integration technologies
Next we will explore briefly the main technological advances in each evolutionary step listed in the table above.
Data integration
This is one of the oldest mechanisms for information access across different systems with the following two primary examples:
Common database approach is used for system integration within organizations.
File sharing method is used for within and cross-organization data exchange. With universal protocols such as FTP, file sharing allows exchange of application data running across machines and operating systems.
But both approaches are non-real-time, batch-based integrations with limitations around scalability and reliability.
Functionality integration
While data integration provided non-real-time data exchange, the methods described here allow real-time data and importantly functionality exchange:
Remote procedure call provides significant improvements over low-level socket-based integration by hiding networking and data marshaling complexity. But it is an early generation, language-dependent, point-to-point, client-server architecture.
Object request broker architecture (with CORBA, DCOM, RMI implementations) introduces the broker component, which allows multiple applications in different languages to reuse the same infrastructure and talk to each other in a peer-to-peer fashion. In addition, the CORBA model has the notion of naming, security, concurrency, transactionality, registry and language-independent interface definition.
Messaging introduces temporal decoupling between applications and ensures guaranteed asynchronous message delivery.
So far we have seen many technology improvements, but they are primarily focused on system integration rather than application integration aspects. From batch to real-time data exchange, from point-to-point to peer-to-peer, from synchronous to asynchronous, these methods do not care or control what is the type of data they exchange, nor force or validate it. Still, this early generation integration infrastructure enabled B2B integrations by exchanging EDI-formatted data for example, but without any understanding of the data, nor the business process, it is part of.
With CORBA, we have early attempts of interface definitions, and services that are useful for application integration.
Service-oriented architecture
The main aspects of SOA that are relevant for our purpose are Web Services standards. XML providing language-independent format for exchange of data, SOAP providing common message format and WSDL providing an independent format for describing service interfaces, form the foundation of web services. These standards, combined with ESB and BPM implementations, made integrations focus on the business integration semantics, whereas the prior technologies were enabling system integration primarily.
Web services allowed systems not to exchange data blindly, but to have machine readable contracts and interface definitions. Such contracts would allow a system to understand and validate the data (up to a degree) before interacting with the other system.
I also include microservices architectural style here, as in its core, it builds and improves over SOA and ESBs. The primary evolution during this phase is around distributed system decomposition and transition from WS to REST-based interaction.
In summary, this is the phase where, on top of common protocols, distributed systems also got common standards and contracts definitions.
Blockchain-based integration
While exchanging data over common protocols and standards helps, the service contracts do not provide insight about the business processes hidden behind the contracts and running on remote systems. A request might be valid according to the contract, but invalid depending on the business processes’ current state. That is even more problematic when integration is not between two parties, as in the client-server model, but among multiple equally involved parties in a peer-to-peer model.
Sometimes multiple parties are part of the same business process, which is owned by no one party but all parties. A prerequisite for a proper functioning of such a multi-party interaction is transparency of the common business process and its current state. All that makes the blockchain technology very attractive for implementing distributed business processes among multiple parties.
This model extends the use of shared protocols and service contracts with shared business processes and contained state. With blockchain, all participating entities share the same business process in the form of smart contracts. But in order to validate the requests, process and come to the same conclusion, the business processes need also the same state, and that is achieved through the distributed ledger. Sharing all the past states of a smart contract is not a goal by itself, but a prerequisite of the shared business process runtime.
Looked at from this angle, blockchain can be viewed as the next step in the integration evolution. As we will see below, blockchain networks act as a kind of distributed ESB and BPM machinery that are not contained within a single business entity, but spanning multiple organizations.
Integration technology moving into the space between systems
First the protocols (such as FTP), then the API contracts (WSDL, SOAP) and now the business processes themselves (smart contracts) and their data are moving outside of the organizations, into the common shared space, and become part of the integration infrastructure. In some respect, this trend is analogous to how cross-cutting responsibilities of microservices are moving from within services into the supporting platforms.
With blockchain, common data models and now business processes are moving out of the organizations into the shared business networks. Something to note is that this move is not universally applicable and it is not likely to become a mainstream integration mechanism. Such a move is only possible when all participants in the network have the same understanding of data models and business processes; hence, it is applicable only in certain industries where the processes can be standardized, such as finance, supply chain, health care, etc.
Generations of integrations
Having done some chronological technology progression follow-up, let’s have a more broad look at the B2B integration evolution and its main stages.
First generation: system integration protocols
This is the generation of integration technology before CORBA and SOA, enabling mainly data exchange over common protocols but without an understanding of the data, contracts and business processes:
Integration model: client-server, where the server component is controlled by one party only; examples are databases, file servers, message brokers, etc.
Explicit, shared infrastructure: low-level system protocols and APIs such as FTP.
Implicit, not shared infrastructure: application contracts, data formats, business processes not part of the common integration infrastructure.
Second generation: application integration contracts
This generation of integration technology uses the system protocols from previous years and allows applications to share their APIs in the form of universal contracts. This is the next level of integration, where both applications understand the data, its structure, possible error conditions, but not the business process and current state behind it in the other systems:
Integration model: client-server model with APIs described by contracts.
Explicit, shared infrastructure: protocols, application contracts, and API definitions.
Implicit, not shared infrastructure: business processes and remote state are still private.
Third generation: distributed business processes
The blockchain-based generation, which still has to prove itself as a viable enterprise architecture, goes a step further. It uses peer-to-peer protocols, and shares business processes with state across multiple systems that are controlled by parties not trusting each other. While previous integration generations required shared understanding of protocol or APIs, this relies on common understanding of the full business process and its current state. Only then it makes sense and pays off to form a cross-organization distributed business process network:
Integration model: multi-party, peer-to-peer integration, by forming business networks with distributed business processes.
Explicit, shared infrastructure: business process and its required state.
Implicit, not shared infrastructure: other non-process related state.
There are many blockchain-based projects that are taking different approaches for solving the business integration challenges. In no particular, order here are some of the most popular and interesting permissioned open-source blockchain projects targeting the B2B integration space:
Hyperledger Fabric is one of the most popular and advanced blockchain frameworks, initially developed by IBM, and now part of Linux Foundation.
Hyperledger Sawtooth is another Linux Foundation distributed project developed initially by Intel. It is popular for its modularity and full component replaceability.
Quorum is an enterprise-focused distribution of Ethereum.
Corda is another project that builds on top of existing JVM-based middleware technologies and enables organizations to transact with contracts and exchange value.
There are already many business networks built with the above projects, enabling network member organizations to integrate and interact with each other using this new integration model.
In addition to these full-stack blockchain projects that provide network nodes, there also are hybrid approaches. For example, Unibright is a project that aims to connect internal business processes defined in familiar standards such as BPMN with existing blockchain networks by automatically generating smart contracts. The smart contracts can be generated for public or private blockchains, which can act as another integration pillar among organizations.
Recently, there are many blockchain experiments in many fields of life. While public blockchains generate all the hype by promising to change the world, private and permissioned blockchains are promising less, but are advancing steadily.
Conclusion
Enterprise integration has multiple nuances. Integration challenges within an organization, where all systems are controlled by one entity and participants have some degree of trust to each other, are mostly addressed by modern ESBs, BPMs and microservices architectures. But when it comes to multi-party B2B integration, there are additional challenges. These systems are controlled by multiple organizations, have no visibility of the business processes and do not trust each other. In these scenarios, we see organizations experimenting with a new breed of blockchain-based technology that relies not only on sharing of the protocols and contracts but sharing of the end-to-end business processes and state.
And this trend is aligned with the general direction integration has been evolving over the years: from sharing the very minimum protocols, to sharing and exposing more and more in the form of contracts, APIs and now business processes.
This shared integration infrastructure enables new transparent integration models where the previously private business processes are now jointly owned, agreed, built, maintained and standardized using the open-source collaboration model. This can motivate organizations to share business processes and form networks to benefit further from joint innovation, standardization and deeper integration in general.
source https://techcrunch.com/2019/02/05/blockchain-as-integration-evolution/
0 notes