#computeengine
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
H3 Virtual Machines: Compute Engine-Optimized Machine family

Compute Engine’s compute-optimized machine family
High performance computing (HPC) workloads and compute-intensive tasks are best suited for instances of compute-optimized virtual machines (VMs). With their architecture that makes use of characteristics like non-uniform memory access (NUMA) for optimal, dependable, consistent performance, compute-optimized virtual machines (VMs) provide the best performance per core.
This family of machines includes the following machine series:
Two 4th-generation Intel Xeon Scalable processors, code-named Sapphire Rapids, with an all-core frequency of 3.0 GHz power H3 virtual machines. 88 virtual cores (vCPUs) and 352 GB of DDR5 memory are features of H3 virtual machines.
The third generation AMD EPYC Milan CPU, which has a maximum boost frequency of 3.5 GHz, powers C2D virtual machines. Flexible scaling between 2 and 112 virtual CPUs and 2 to 8 GB of RAM per vCPU are features of C2D virtual machines.
The 2nd-generation Intel Xeon Scalable processor (Cascade Lake), which has a sustained single-core maximum turbo frequency of 3.9 GHz, powers C2 virtual machines. C2 provides virtual machines (VMs) with 4–60 vCPUs and 4 GB of memory per vCPU.
H3 machine series
The 4th generation Intel Xeon Scalable processors (code-named Sapphire Rapids), DDR5 memory, and Titanium offload processors power the H3 machine series and H3 virtual machines.
For applications involving compute-intensive high performance computing (HPC) in Compute Engine, H3 virtual machines (VMs) provide the highest pricing performance. The single-threaded H3 virtual machines (VMs) are perfect for a wide range of modeling and simulation tasks, such as financial modeling, genomics, crash safety, computational fluid dynamics, and general scientific and engineering computing. Compact placement, which is ideal for closely connected applications that grow over several nodes, is supported by H3 virtual machines.
There is only one size for the H3 series, which includes a whole host server. You can change the amount of visible cores to reduce licensing fees, but the VM still costs the same. H3 virtual machines (VMs) have a default network bandwidth rate of up to 200 Gbps and are able to utilize the full host network capacity. However, there is a 1 Gbps limit on the VM to internet bandwidth.
H3 virtual machines are unable to allow simultaneous multithreading (SMT). To guarantee optimal performance constancy, there is also no overcommitment.
H3 virtual machines can be purchased on-demand or with committed use discounts (CUDs) for one or three years. Google Kubernetes Engine can be utilized with H3 virtual machines.
H3 VMs Limitations
The following are the limitations of the H3 machine series:
Only a certain machine type is offered by the H3 machine series. No custom machine shapes are available.
GPUs cannot be used with H3 virtual machines.
There is a 1 Gbps limit on outgoing data transfer.
The performance limits for Google Cloud Hyperdisk and Persistent Disk are 240 MBps throughput and 15,000 IOPS.
Machine images are not supported by H3 virtual machines.
The NVMe storage interface is the only one supported by H3 virtual machines.
Disks cannot be created from H3 VM images.
Read-only or multi-writer disk sharing is not supported by H3 virtual machines.
Different types of H3 machines
Machine typesvCPUs*Memory (GB)Max network egress bandwidth†h3-standard-8888352Up to 200 Gbps
With no simultaneous multithreading (SMT), a vCPU represents a whole core. † The default egress bandwidth is limited to the specified value. The destination IP address and several variables determine the actual egress bandwidth. Refer to the network bandwidth.
Supported disk types for H3
The following block storage types are compatible with H3 virtual machines:
Balanced Persistent Disk (pd-balanced)
Hyperdisk Balanced (hyperdisk-balanced)
Hyperdisk Throughput (hyperdisk-throughput)
Capacity and disk limitations
With a virtual machine, you can employ a combination of persistent disk and hyperdisk volumes, however there are some limitations:
Each virtual machine can have no more than 128 hyperdisk and persistent disk volumes combined.
All disk types’ combined maximum total disk capacity (in TiB) cannot be greater than:
Regarding computer types with fewer than 32 virtual CPUs:
257 TiB for all Hyperdisk or all Persistent Disk
257 TiB for a mixture of Hyperdisk and Persistent Disk
For computer types that include 32 or more virtual central processors:
512 TiB for all Hyperdisk
512 TiB for a mixture of Hyperdisk and Persistent Disk
257 TiB for all Persistent Disk
H3 storage limits are described in the following table: Maximum number of disks per VMMachine typesAll disk types All Hyperdisk typesHyperdisk BalancedHyperdisk ThroughputHyperdisk ExtremeLocal SSDh3-standard-88128648640Not supported
Network compatibility for H3 virtual machines
gVNIC network interfaces are needed for H3 virtual machines. For typical networking, H3 allows up to 200 Gbps of network capacity.
Make sure the operating system image you use is fully compatible with H3 before moving to H3 or setting up H3 virtual machines. Even though the guest OS displays the gve driver version as 1.0.0, fully supported images come with the most recent version of the gVNIC driver. The VM may not be able to reach the maximum network bandwidth for H3 VMs if it is running an operating system with limited support, which includes an outdated version of the gVNIC driver.
The most recent gVNIC driver can be manually installed if you use a custom OS image with the H3 machine series. For H3 virtual machines, the gVNIC driver version v1.3.0 or later is advised. To take advantage of more features and bug improvements, Google advises using the most recent version of the gVNIC driver.
Read more on Govindhtech.com
#H3VMs#H3virtualmachines#computeengine#virtualmachine#VMs#Google#googlecloud#govindhtech#NEWS#TechNews#technology#technologytrends#technologynews
1 note
·
View note
Photo

Did you know Google has physical fiber optical cables across the globe, running through seabeds to connect their data center and cloud infrastructure to provide you with fast services? #power #speed #fast #google #fiberoptic #datacenter #googlecloud #gcp #googlecloudplatform #cloudcomputing #cloudengine #appengine #computeengine #Kubernetes #cloudfunctions #fastservice #cloud #CloudMigration #clouds (at Mississauga, Ontario)
#datacenter#gcp#power#google#cloudcomputing#clouds#cloud#googlecloudplatform#cloudengine#cloudmigration#googlecloud#cloudfunctions#fastservice#fast#speed#appengine#fiberoptic#computeengine#kubernetes
0 notes
Link

#cloudcomputing#google#cloud#googlecloud#gcp#googlecloudplatform#googlecloudcertified#gcpcloud#googlecloudpartners#cloudcertification#cloudtraining#googlecloudtraining#googlecloudplatformgcp#googlecloudpartner#gcloud#googlecloudcommunity#googlecloudcertification#ArchitectingwithGoogleComputeEngine#computeengine
0 notes
Photo

GCPで完結させたゲームプラットフォームのアーキテクチャ 開発期間は短くしつつ、自由度を失わないための工夫 https://ift.tt/35NodQR
2019年11月18日、グーグル・クラウド・ジャパン合同会社にて「第9回 Google Cloud INSIDE Games & Apps」が開催されました。ゲーム業界で活躍するインフラ、サーバーアプリケーションエンジニア、テクニカルリーダーを対象に開催される本イベント。今回は、GCPを活用するさまざまな企業が集まり、最新の活用事例を語りました。プレゼンテーション「これが新しいデザインパターン – mspoを支えるGCP&Looker」に登壇したのは、アイレット株式会社代表取締役社長の齋藤将平と、ガンホー・オンライン・エンターテイメント株式会社CTOの菊池貴則氏。ガンホーの子会社であるmspo株式会社における、GCPを用いたアーキテクチャについて、開発の舞台裏を語りました。
賞金がもらえるゲームプラットフォームの仕組み
菊池貴則氏(以下、菊池):こんにちは。ガンホーの菊池です。よろしくお願いします。弊社の紹介をさせていただきます。
最近はタイトルも充実してきましたが、もともとはPC向けオンラインゲームとして17年前に『ラグナロクオンライン』���発表しました。ですので、歴史的には古い部類に入ってきたかなと思います。

ゲームの技術も進歩する中で常に創造と挑戦をして、世界中の人々にエンターテインメントを通じて感動と楽しい経験を提供することをミッションに、ゲームの開発、運営、企画をしております。
齋藤将平(以下、齋藤):次は私の紹介をさせていただくのですが、アイレット株式会社を知っている方はいますか?
(会場挙手)
お、けっこういるんですね。ありがとうございます。

弊社はデザインからシステムの設計開発、クラウドの構築から運用保守のサービスとして「cloudpack(クラウドパック)」を提供しています。

ゲーム業界とのお付き合いも多く、モバイルのアプリからデータ分析基盤まで作っています。2017年からKDDIグループに参画いたしまして、エンタープライズ領域からゲーム領域まで幅広くやらせていただいています。
菊池:今日は弊社の子会社であるmspo株式会社が提供するゲームプラットフォームのアーキテクトについて説明させてください。まずmspoの紹介なんですが、昨年の4月に設立しまして、吉本興業株式会社とサイバーエージェント株式会社とのジョイントベンチャーです。
設立のきっかけは、弊社のグループ会社がUSにありまして、その会社はもともとモバイルの決済系プラットフォームを作っていて「m sports」というサービスをUS国内でHTML5ベースのゲームとしてリリースしました。
それを日本展開するための会社として、広告のプロであるサイバーエージェントさんに声をかけて、さらにご縁があってよしもとさんもゲームに力を入れていきたいということで、よしもとさんのプロモーション力を活用して展開するために、ジョイント・ベンチャーを作って始めました。
mspoというプラットフォームのビジネスロジックを説明します。
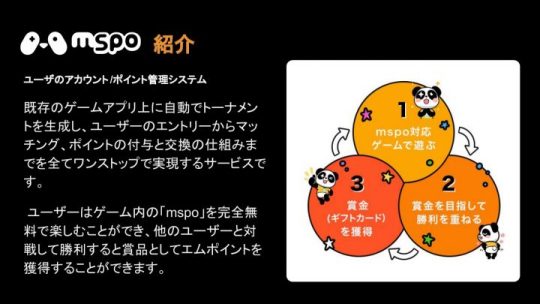
開発期間はできるだけ短く、自由度は担保する
菊池:そうしてやってきたのですが、6ヶ月ほど運営してみる中で、いろいろな問題が出てきました。例えば日米間で技術要件を詰めるといったことは、時差の関係でなかなかリアルタイムのコミュニケーションが難しいと感じました。
あとは、もともとそのUSのグループ会社には優秀な技術者がいたんですが、その分、日本のゲームの文化等をなかなか受け入れてくれなくて。それはなぜ必要なのかを理解してもらうために時間がかなりかかったことが、数回レベルではなくかなり起きてしまいました。
今年年明けに弊社のCEOである森下と話をして、一からガンホー主体でプラットフォームを作り直す話になり、2月頃にプロジェクトが始まりました。そこから開発パートナーを探すことにしました。
一番大きな特徴は、アプリのデベロッパーが容易に導入できるプラットフォームということです。もともとmspoはカジュアルゲームですので、空き時間に遊んでもらうのを目的として、1ゲームあたりマックス3分くらいのゲームがメインです。そういったゲームをこのプラットフォームに導入していくことができます。その中で、アプリの開発期間をできるだけ短くしたいという要望がmspoの社長からありました。1アプリあたり3ヶ月、長くても6ヶ月で出したい。プラットフォーム導入期間は短ければ短いほうがいいということで、そこが一番大きな要件でした。
とはいえ自由度も担保はしたかったので、バックエンドのAPIは基本的にはRESTにしました。mspoのプラットフォーム機能部分を、ゲーム内にREST APIで呼んでもらうのもありですし、開発したくないのであればプラットフォームとしてWebViewでも提供しています。
広告部分については、いろいろな広告のSDKがある中で、そこはひとまとめにしてSDK化して導入しています。あとは個人のデベロッパーの場合はマッチングサーバーまで作ってもらうのはけっこうつらいですが、要件的にはマッチングサーバーが必要になってしまうので、それもこちらで準備をしています。
また、広告とゲームとユーザーの行動を統合管理して一気に分析したい。それをまたゲームの中に戻すことをどうしてもやりたかったので、ここも技術要件に入れました。
個人的には、僕はもともとエンジニアをやっていたので、新しいサービスを作るときはなにかしら新しい要素を入れたい思いがあったので、このようなプラットフォームを開発しようと決めました。
システム構成はすべてをGCPで完結
齋藤:そんな技術要件がありまして、アイレットでできることは何かと考えました。mspoの技術的なチャレンジポイントについてお話します。
最近では当たり前のようになってるCloud SpannerとComputeEngineを組み合わせて、どんどん作っていくところもありましたが、なるべくマネージドサービスを使っていくことにしました。もちろん高い耐障害性を考えて開発を行っています。
また、認証基盤を開発するのもやめようということで、Firebaseによる認証を、Cloud Endpointsと連携させました。他には、アプリケーション用のデータベースと収集データを分析用DBにシームレスに連携することをすごく意識して作りました。DBが複数分かれたとしても、シームレスに連携するものを用意しようと思いました。
今回、菊池さんから「GCPでいくぞ」と連絡が入りましたので、すべてGCPで完結させる、と��ったことが技術的なチャレンジポイントになります。
こういった構成図になっています。
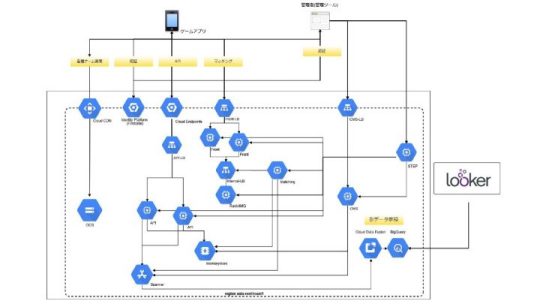
タイトルにもあるとおり、分析基盤としてLookerを使わせていただきました。最初、Lookerを使おうと考えていたときは、まだGoogleに買収されることが発表されていませんでした。後に「Looker社がGoogleに買収される」というニュースが出たのでちょっと驚きだったんですが、これはこれでGCP1つで完結するのでおもしろいのかなと思いました。
残念ながらまだGKEは使ってはいないんですが、基本的な構成としてはこのような構成を取っております。マッチングサーバーはElixirを使って連携しています。
クラウドストレージからSpannerのところでは、Cloud Data FusionによってBigQueryに入れ、そこでLookerが分析を行っています。
インスタンスの起動が早い一方、デメリットも 齋藤:GCPのメリットとデメリットについてです。本日会場にいらっしゃっている方々はすでにだいたい理解してるような内容になってしまうので申し訳ないんですが、僕らはとくにいろいろなクラウドを扱っているので、よかった部分としては、やはりバックエンドのハードウェアはライブマイグレーションがすごくよくできているなと感じました。

インスタンスのメンテナンス対応についても、ゲームを止めたくないという要件もありましたので、そこをしっかり解決できるイメージ��す。
あとはクラウドではあるあるですが、インターネット環境に開放されたサービスが多くて接続環境に縛られないところ。あとはGUIからのCloud Shellが意外と使いやすく、対応しやすかったです。
他には、やはりインスタンスの起動ですね。我々もいろいろ運用している中で、本当に早かったので、そこはメリットだと感じております。
一方、デメリットについてです。デメリットというほどの内容でもありませんが、「ツールに似た名称が多かった」とエンジニアチームは言ってます。あとはインスタンス名の初期設定をしたあとに変更できないという意見も少しありました。
ユーザサイドでの変更要素が多く、覚えなくてはいけない事項が若干多かったなという印象です。デメリットというより、まだうちのスキル不足もあるので、ぜんぜん解決できる問題でもあります。
多種多様なデータソースにつなげられる分析基盤「Looker」
菊池:先ほどもお話にあったとおり、僕のわがままもあり分析基盤にはLookerを採用してもらいました。ちなみにLookerを聞いたことのある方や、使っている方はどのくらいいますか?
(会場挙手)
まだ少ないですね。Looker自体はお世話になってる知り合いの方に紹介をしてもらいました。初めて知ったのは去年のre:Inventの直前くらいですね。re:InventでLookerのブースに行って、イケてるなとは思いつつ、自分でも情報収集をしていました。年明けにこのプロジェクトが始まったときに、なにか新しい要素の1つとして全然ありだなという感触はあったので入れました。

基本的にはこんな方針です。Lookerはみなさんが思っている以上に簡単に、多種多様なデータソースにつなぐことができます。もとも��BigQueryで全部まとめる方針ではありましたが、多種多様なデータソースにつなぐことができるので、他への移行もしやすいですし、ベンダーロックもかかりにくいのでLookerを採用しました。
齋藤:ビジュアル的にもいろいろ用意されています。
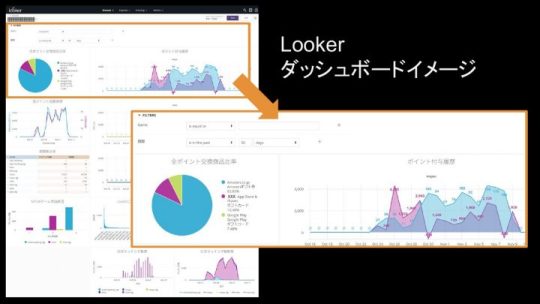
我々自身はとにかく開発に集中できて、分析側とうまく連携ができたと感じています。2行目に書いてあるアジャイル開発という意味では、1週間のスプリントでどんどんレポートが作られていく流れができたのがすごくいい面でした。よりプログラムライクに作られているプラットフォームなのかなと思います。
菊池:おっしゃるとおりです。
グローバル展開に向けて、さらに強力なプラットフォームにするために
齋藤:では、今後のチャレンジです。

菊池:今後、mspoのプラットフォームでやっていきたいことはまだまだいっぱいあるんですが、その一部を紹介します。先日Slackでクローズドなイベントでもお話しましたが、SlackとLookerとGCPの組み合わせがけっこう強力だなと感じています。
Lookerを入れようと決めた理由の1つで、わりと大きな要因なんですが、Slackとの連携がめちゃくちゃイケています。Slackのbotも作りやすいし、botから特定のダッシュボードの情報を引けたり、簡単なクエリが叩けたりします。

コスト面も考えると、ExcelかCSVか画像かPDFかを選んで、Lookerから毎日のレポートをSlackに投げることができます。また、そこに対してライセンスフィーはかからず、コスト面でも優位性が大きいので、Lookerを入れています。
まだそこが実装できていないところではあるので、今後、実装していけるかなと考えています。
齋藤:ちなみに、ちょっと宣伝になってしまいますが、我々はLookerのパートナーになりました。本日発表しましたので、なにかLookerのことで相談がありましたらよろしくお願いいたします。
(会場笑)
菊池:あとはプラットフォーム部分。まだGCEを使っていて、GKEをもっと最適化していいアーキテクトにできるはずなので、そこも来年手を入れたいなと思っています。
mspoは実はすでにリリースしていて、ファーストパーティーで今回2つのアプリを出しています。今月末からmspo自体のプロモーションもかけていって、来年末にはグローバル展開をしていきたいと考えています。その準備段階としてSpannerを採用しているので、そこに向けてもっと強力な基盤にしていきたいと考えています。
クイズの自動生成は、実は一番やりたいなと思っています。ファーストパーティーで作ってるものにクイズアプリがあるんですが、そこでなにかおもしろいことができないかとずっと考えています。
クイズアプリはけっこう単純だし広がりがないですし、なかなか難しいのですが、現場のプランナーと一緒に、ネットニュースなどいろいろな情報をキュレーションして、機械学習をかけて分析して、自動的にクイズの生成ができないかとふんわり考えています。
みなさんならなんとなくできそうじゃんと思うかもしれませんが、キュレーションの部分や、どうフィルタリングをかけるか、バズっているかどうかの判定が難しいので、そのあたりをうまくできたらとは思っています。
齋藤:では、少し短くなりましたが以上になります。ここからは、質疑応答の時間とさせていただきます。よろしくお願いします。
GCPは学習しやすいか?
司会者:いくつか質問いただいているので、人気のものから質問していきたいと思います。
「AWSの知識があってGCPにまだ慣れていないエンジニアの場合、どれくらいでキャッチアップできますか?」。とくにアイレットさんは他社クラウドさんにも強いと思うので、内部のエンジニア育成などをどうされていたか教えてください。
齋藤:AWSのエンジニアは相当強いですね(笑)。GCPに関しましては本当にまだまだ少ないのですが、実際にこういうかたちで案件に携わらせていただくと、学習スピードはかなり早かったと思っています。

正直1、2ヶ月もあればクラウドエンジニアなら問題ないかなと。覚えてしまえばそんなに大きく変わりません。それぞれのマネージドサービスをうまく利用して学習してもらいたいなと僕は思いますね。
ちなみに、エンジニアの採用は積極的に行なっていますので、よろしくお願いします。
(会場拍手)
司会者:ありがとうございます。菊池さんはいかがですか?
菊池:僕の知っている限り、ガンホーではGCPの導入はほとんどなくて。個人的にはGCPはAWSでCLI使っていたら、そんなにつらくないと思います。ですが、Webコンソールで作業してしまっているとGCPはコマンドラインでなければできないことがまだまだ多かったりするので、そこでつまずくパターンはあるかなって感じです。でも、そこも覚えてしまえばいいだけなので、やる気があればすぐ覚えられるじゃないかなぁって感じですね(笑)。
司会者:1、2ヶ月くらいで?
菊池:そうですね、そんなにつらくないと思います。全部わかる単語になっているので、学���コストはあまり変わらないと思います。
Data Fusionを選択した理由
司会者:ありがとうございます。では、次の質問にいきたいと思います。「SpannerからBQにデータを送る際にData Fusionを選択した理由を教えてください」。
菊池:選択肢はけっこういろいろあったんですが、一番の理由は設定が簡単だったからです。

Googleの方と相談しつついろいろなパターンを協議したんですが、結局Data Fusionは費用はちょっとかかるけれど、出たばかりでおもしろいサービスだし、使おうかなと思いました��実際使ってみると簡単に設定できましたし、よかったかなと思います。
司会者:ありがとうございます。比較的新しいプロダクトですが、Data Fusionの導入でなにか問題は発生しましたか?
菊池:いや、とくになかったですね。
司会者:お、すばらしいですね。ありがとうございます。では、Spannerに関する質問です。「最近Spannerの可用性はノード1つでも担保されるようになりましたが、その発表後、ノード数を減らしたりしていますか? ふだん何ノードくらい立ててますか?」という質問になります。言える限りで大丈夫です。
菊池:まだサービスして間もなく安全を取りたいので、テスト環境やステージングでは1ノードだけにしていて、プロダクションはミニマムで3ノードになってます。そこはとくに触っていません。パフォーマンスも問題なくて、「ちょっと余ってるかな」くらいの感じですが、たぶんそのままいくと思います。
プラットフォームなのであまり変更する気はなくて、これからユーザーがどれくらい来るかも読めていないプラットフォームなので、おそらくそこも触らないでいくかなと思ってます。
司会者:わかりました。ありがとうございます。では一旦質疑応答を締め切ります。菊池さん齋藤さんありがとうございました。
齋藤:ご清聴ありがとうございました。
菊池:ありがとうございます。
(会場拍手)
※提供:ログミー
December 24, 2019 at 12:07PM
0 notes
Text
Google Cloud Parallelstore Powering AI And HPC Workloads

Parallelstore
Businesses process enormous datasets, execute intricate simulations, and train generative models with billions of parameters using artificial intelligence (AI) and high-performance computing (HPC) applications for a variety of use cases, including LLMs, genomic analysis, quantitative analysis, and real-time sports analytics. Their storage systems are under a lot of performance pressure from these workloads, which necessitate high throughput and scalable I/O performance that keeps latencies under a millisecond even when thousands of clients are reading and writing the same shared file at the same time.
Google Cloud is thrilled to share that Parallelstore, which is unveiled at Google Cloud Next 2024, is now widely available to power these next-generation AI and HPC workloads. Parallelstore, which is based on the Distributed Asynchronous Object Storage (DAOS) architecture, combines a key-value architecture with completely distributed metadata to provide high throughput and IOPS.
Continue reading to find out how Google Parallelstore meets the demands of demanding AI and HPC workloads by enabling you to provision Google Kubernetes Engine and Compute Engine resources, optimize goodput and GPU/TPU utilization, and move data in and out of Parallelstore programmatically.
Optimize throughput and GPU/TPU use
It employs a key-value store architecture along with a distributed metadata management system to get beyond the performance constraints of conventional parallel file systems. Due to its high-throughput parallel data access, it may overwhelm each computing client’s network capacity while reducing latency and I/O constraints. Optimizing the expenses of AI workloads is dependent on maximizing good output to GPUs and TPUs, which is achieved through efficient data transmission. Google Cloud may also meet the needs of modest-to-massive AI and HPC workloads by continuously granting read/write access to thousands of virtual machines, graphics processing units, and TPUs.
The largest Parallelstore deployment of 100 TiB yields throughput scaling to around 115 GiB/s, with a low latency of ~0.3 ms, 3 million read IOPS, and 1 million write IOPS. This indicates that a large number of clients can benefit from random, dispersed access to small files on Parallelstore. According to Google Cloud benchmarks, Parallelstore’s performance with tiny files and metadata operations allows for up to 3.7x higher training throughput and 3.9x faster training timeframes for AI use cases when compared to native ML framework data loaders.
Data is moved into and out of Parallelstore using programming
For data preparation or preservation, cloud storage is used by many AI and HPC applications. You may automate the transfer of the data you want to import into Parallelstore for processing by using the integrated import/export API. With the help of the API, you may ingest enormous datasets into Parallelstore from Cloud Storage at a rate of about 20 GB per second for files bigger than 32 MB and about 5,000 files per second for smaller files.
gcloud alpha parallelstore instances import-data $INSTANCE_ID –location=$LOCATION –source-gcs-bucket-uri=gs://$BUCKET_NAME [–destination-parallelstore-path=”/”] –project= $PROJECT_ID
You can programmatically export results from an AI training task or HPC workload to Cloud Storage for additional evaluation or longer-term storage. Moreover, data pipelines can be streamlined and manual involvement reduced by using the API to automate data transfers.
gcloud alpha parallelstore instances export-data $INSTANCE_ID –location=$LOCATION –destination-gcs-bucket-uri=gs://$BUCKET_NAME [–source-parallelstore-path=”/”]
GKE resources are programmatically provisioned via the CSI driver
The Parallelstores GKE CSI driver makes it simple to effectively manage high-performance storage for containerized workloads. Using well-known Kubernetes APIs, you may access pre-existing Parallelstore instances in Kubernetes workloads or dynamically provision and manage Parallelstore file systems as persistent volumes within your GKE clusters. This frees you up to concentrate on resource optimization and TCO reduction rather than having to learn and maintain a different storage system.
ApiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: parallelstore-class provisioner: parallelstore.csi.storage.gke.io volumeBindingMode: Immediate reclaimPolicy: Delete allowedTopologies:
matchLabelExpressions:
key: topology.gke.io/zone values:
us-central1-a
The fully managed GKE Volume Populator, which automates the preloading of data from Cloud Storage straight into Parallelstore during the PersistentVolumeClaim provisioning process, will be available to preload data from Cloud Storage in the upcoming months. This helps guarantee that your training data is easily accessible, allowing you to maximize GPU and TPU use and reduce idle compute-resource time.
Utilizing the Cluster Toolkit, provide Compute Engine resources programmatically
With the Cluster Toolkit’s assistance, deploying Parallelstore instances for Compute Engine is simple. Cluster Toolkit is open-source software for delivering AI and HPC workloads; it was formerly known as Cloud HPC Toolkit. Using best practices, Cluster Toolkit allocates computing, network, and storage resources for your cluster or workload. With just four lines of code, you can integrate the Parallelstore module into your blueprint and begin using Cluster Toolkit right away. For your convenience, we’ve also included starter blueprints. Apart from the Cluster Toolkit, Parallelstore may also be deployed using Terraform templates, which minimize human overhead and support operations and provisioning processes through code.
Respo.vision
Leading sports video analytics company Respo. Vision is using it to speed up its real-time system’s transition from 4K to 8K video. Coaches, scouts, and fans can receive relevant information by having Respo.vision help gather and label granular data markers utilizing Parallelstore as the transport layer. Respo.vision was able to maintain low computation latency while managing spikes in high-performance video processing without having to make costly infrastructure upgrades because to Parallelstore.
The use of AI and HPC is expanding quickly. The storage solution you need to maintain the demanding GPU/TPUs and workloads is Parallelstore, with its novel architecture, performance, and integration with Cloud Storage, GKE, and Compute Engine.
Read more on govindhtech.com
#GoogleCloud#ParallelstorePoweringAI#AIworkloads#HPCWorkloads#artificialintelligence#AI#news#cloudstorage#GoogleCloudNext2024#ClusterToolkit#ComputeEngine#GoogleKubernetesEngine#technology#technews#GOVINDHTECH
0 notes
Text
Latest Updates For Confidential VMs Google In Compute Engine

Confidential virtual machine overview
Confidential VMs Google
One kind of Compute Engine virtual machine is a confidential virtual machine (VM). To help guarantee that your data and applications cannot be read or altered while in use, they employ hardware-based memory encryption.
Below are some advantages of confidential virtual machine instances:
Isolation: Only specialized hardware, unavailable to the hypervisor, generates and stores encryption keys.
Attestation: To ensure that important parts haven’t been tampered with, you can confirm the identity and condition of the virtual machine.
A Trusted Execution Environment is a term used to describe this kind of hardware isolation and attestation (TEE).
When you create a new virtual machine instance, you have the option to activate the Confidential VM service.
Confidential computing technology
Depending on the machine type and CPU platform you select, different Confidential Computing technologies can be employed while setting up a Confidential VM instance. Make sure the technology you select for Confidential Computing meets your budget and performance requirements.
AMD SEV
AMD Secure Encrypted Virtualization (SEV) on Confidential VM provides boot-time attestation using Google’s vTPM and hardware-based memory encryption via the AMD Secure Processor.
AMD SEV provides excellent performance for computationally intensive activities. Depending on the workload, the performance difference between a normal Compute Engine VM and a SEV Confidential VM can be negligible or nonexistent.
AMD SEV systems using the N2D machine type offer live migration, in contrast to other Confidential Computing technologies using Confidential VM.
AMD SEV-SNP
Adding hardware-based security to assist thwart malicious hypervisor-based attacks like data replay and memory remapping, AMD Secure Encrypted Virtualization-Secure Nested Paging (SEV-SNP) builds on SEV. Direct attestation results from the AMD Secure Processor are available upon request at any time.
Compared to SEV, AMD SEV-SNP requires greater resources due to its increased security measures. In instance, you may see higher network latency and decreased network bandwidth based on the demand.
TDX Intel
A hardware-based TEE is Intel Trust Domain Extensions (TDX). In order to manage and encrypt memory, TDX employs hardware extensions to establish an isolated trust domain (TD) inside of a virtual machine (VM).
By enhancing the defense of the TD against specific types of attacks that require physical access to the platform memory, such as active attacks of DRAM interfaces that involve splicing, aliasing, capturing, altering, relocating, and modifying memory contents, Intel TDX enhances the defense of the TD.
Confidential VM service
Confidential VM is used by the following Google Cloud services in addition to Compute Engine:
Secret All of your Google Kubernetes Engine nodes are required to use Confidential VM.
With a mutually agreed-upon workload, Confidential Space employs Confidential VM to allow parties to share sensitive data while maintaining ownership and confidentiality of that data.
Confidential VM-using Dataproc clusters are part of Dataproc Confidential Compute.
Features of Dataflow Confidential VM worker for dataflow confidential virtual machines.
Google Cloud is dedicated to keeping your data under your complete control and safe and secure. To start, use Confidential Computing to strengthen the Compute Engine virtual machines (VMs), which are the cornerstone of your compute architecture.
Using a hardware-based Trusted Execution Environment (TEE), Confidential Computing safeguards data throughout use and processing. TEEs are safe, segregated spaces that guard against illegal access to or alteration of data and applications while they’re in use.
Confidential Computing technologies and solutions have been early adopters and investments for us at Google. Google customers have been utilizing their expanded Confidential Computing products and new capabilities for over four years, utilizing them in creative ways to improve the security and confidentiality of their workloads. It was excited to announce the broad release of upgrades to the Google Cloud attestation service as well as numerous additional Confidential Computing choices.
Currently accessible to most people: Segmented virtual machine with AMD SEV on C3D platforms
It is pleased to inform you that Confidential VMs Google equipped with AMD Secure Encrypted Virtualization (AMD SEV) technology are now widely accessible on the general purpose C3D machine line. Using hardware-based memory encryption, Confidential VMs with AMD SEV technology help guarantee that your data and apps cannot be read or changed while in use. With Google’s Titanium hardware, the C3D machine series is built to provide optimal, dependable, and consistent performance, and is powered by the 4th generation AMD EPYC (Genoa) processor.
Prior to this, only the general-purpose N2D and C2D machine series offered Confidential VMs. The latest general purpose hardware with enhanced performance and data secrecy is now available to security-conscious customers with the expansion to the C3D machine line. Better performance comes from using the newest gear. Read more about the performance of the C3D machine series and confidential virtual machines here.
In any region and zone where C3D machines are available, confidential virtual machines featuring AMD SEV are accessible.
Now widely accessible: Intel TDX-powered confidential virtual machine on the C3 machine series
Confidential VMs Google equipped with Intel Trust Domain Extensions (Intel TDX) technology are now widely accessible on the general-purpose C3 machine series. Using hardware-based memory encryption, Confidential VMs with Intel TDX technology help guarantee that your data and apps cannot be read or changed while in use.
There are no code changes needed to enable confidential computing on a C3 virtual machine. You can use Intel Trust Authority’s remote attestation service or your own attestation provider to confirm that your hardened virtual machine (VM) is operating in a TEE. The 4th generation Intel Xeon Scalable CPUs (code-named Sapphire Rapids), DDR5 memory, and Google Titanium power the C3 machine line.
Intel AMX integrated CPU acceleration
By default, all C3 virtual machines (VMs), including Confidential VMs, have Intel Advanced Matrix Extensions (Intel AMX) enabled. To speed up workloads related to machine learning and artificial intelligence, Intel AMX is a novel expansion to the instruction set architecture (ISA). Two of the most popular processes in AI and ML are matrix multiplication and convolution, which may be carried out with the new instructions that AMX offers. You can execute AI/ML applications with an extra degree of protection by combining Intel AMX with Confidential VMs.
Asia-southeast1, US-central1, and Europe-west4 are the regions where Confidential VM with Intel TDX on the C3 machine series is accessible.
Confidential VM with AMD SEV-SNP on the N2D machine series is now widely accessible
Customers now have access to Confidential VMs with hardware-rooted attestation, data integrity, and data confidentiality thanks to the release of AMD Secure Encrypted Virtualization-Secure Nested Paging (AMD SEV-SNP) on the general purpose N2D machine series this past June. Prior to this, users could only access private VMs with AMD Secure Encrypted Virtualization (SEV), a private computing solution that guaranteed data confidentiality.
All Confidential VMs give users an extra line of defense and data protection against cloud administrators, operators, and insiders while also enabling them to retain control over their data in the public cloud and achieve cryptographic isolation in a multi-tenant environment. Confidential VMs with AMD SEV-SNP, on the other hand, come with further security measures that guard against harmful hypervisor-based assaults such memory remapping and data replay.
AMD SEV-SNP on the N2D machine series makes it simple and doesn’t require any code changes to create Confidential VMs. You also get the security advantages with less impact on performance.
Asia-southeast1, US-central1, Europe-west3, and Europe-west 4 are the regions where confidential virtual machines with AMD SEV-SNP on the N2D machine series are accessible.
Signed Intel TDX and AMD SEV-SNP UEFI binaries for Confidential Virtual Machines
With the addition of signed startup measures (UEFI binaries and initial state) to its Confidential VMs running AMD SEV-SNP and Intel TDX technologies, it is thrilled to announce a major security improvement. By signing these files, provided an additional degree of security against unauthorized changes or tampering with UEFI, the firmware that manages a computer’s startup procedure.
Gaining further transparency and confidence that the firmware operating on your Confidential VMs is authentic and uncompromised can be achieved by signing the UEFI and enabling you to validate the signatures. Your authenticated devices are operating in a secure and reliable environment if you can confirm the validity and integrity of the firmware.
Google intends to take other actions to create a system that is more verifiably reliable and secure.
AMD SEV Confidential VM is now supported by Google Cloud attestation
If your trust model permits it, you can use the Google Cloud attestation service in place of creating and executing an attestation verifier yourself. Use the Go-TPM tools to obtain an attestation quote from the vTPM of an AMD SEV Confidential VM instance, then transmit it to the Google Cloud Attestation service using the./go-tpm token command for verification.
You can verify whether or not the virtual machine (VM) can be trusted by comparing its details with your own policy once the Google Cloud Attestation has verified the attestation quote. Only AMD SEV is currently supported by Google’s attestation service.
Confidential VM costs
In addition to the Compute Engine price, there are additional expenses for Confidential VM. The cost of a Confidential VM instance is determined by several factors, including the type of Confidential Computing technology (such as AMD SEV, Intel TDX, or AMD SEV-SNP) and whether the instance is preemptible or on demand. The fees are flat rate per vCPU and per GB for Confidential VM.
See here for the price of the Confidential VM. See this page for Compute Engine’s price list.
Read more on Govindhtech.com
#ComputeEngine#virtualmachine#VMinstance#VMservice#ComputeEngineVM#TDXIntel#GoogleKubernetesEngine#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
How Can We Operate Airflow Apache On Google Cloud?
Apache Airflow on Google Cloud
Are you considering utilizing Google Cloud to run Apache Airflow? This is a well-liked option for managing intricate sequences of operations, such Extract, Transform, and Load (ETL) or pipelines for data analytics. Airflow Apache is a sophisticated tool for scheduling and dependency graphing. It employs a Directed Acyclic Graph (DAG) to arrange and relate many tasks for your workflows, including scheduling the required activity to run at a specific time.
What are the various configuration options for Airflow Apache on Google Cloud? Making the incorrect decision could result in lower availability or more expenses. You could need to construct multiple environments, such as dev, staging, and prod, or the infrastructure could fail. It will examine three methods for using Airflow Apache on Google Cloud in this post and go over the benefits and drawbacks of each. It offer Terraform code, which is available on GitHub, for every method so you may give it a try.
It should be noted that this article’s Terraform has a directory structure. The format of the files under modules is the same as that of the Terraform default code. Consider the modules directory to be a type of library if you work as a developer. The real business code is stored in the main.tf file. Assume you are working on development: begin with main.tf and save the shared code in folders such as modules, libraries, etc.)
Apache Airflow best practices
Let’s examine three methods for utilizing Airflow Apache.
Compute Engine
Installing and using Airflow directly on a Compute Engine virtual machine instance is a popular method for using Airflow on Google Cloud. The benefits of this strategy are as follows:
It costs less than the others.
All you need to know about virtual machines.
Nevertheless, there are drawbacks as well:
The virtual computer needs to be maintained by you.
There is less of it available.
Although there can be significant drawbacks, Compute Engine can be used to quickly prove of concept Airflow adoption.
First, use the following terraform code to construct a Compute Engine instance (some code has been eliminated for brevity). Allow is a firewall configuration. Since Airflow Web uses port 8080 by default, it ought to be open. You are welcome to modify the other options.
main.tf
module “gcp_compute_engine” { source = “./modules/google_compute_engine” service_name = local.service_name
region = local.region zone = local.zone machine_type = “e2-standard-4” allow = { … 2 = { protocol = “tcp” ports = [“22”, “8080”] } } }
The code and files that take the variables it handed in before and actually build an instance for it was found in the google_compute_engine directory, which it reference as source in main.tf above. Take note of how it takes in the machine_type.
modules/google_compute_engine/google_compute_instance.tf
resource “google_compute_instance” “default” { name = var.service_name machine_type = var.machine_type zone = var.zone … }
Use Terraform to run the code you wrote above:
$ terraform apply
A Compute Engine instance will be created after a short wait. The next step is to install Airflow by connecting to the instance; Launch Airflow after installation.
You can now use your browser to access Airflow! You will need to take extra precautions with your firewall settings if you intend to run Airflow on Compute Engine. It should only be accessible to authorized users, even in the event that the password is compromised. It has only made the sample accessible with the barest minimum of firewall settings.
You ought to get a screen similar after logging in. Additionally, an example DAG from Airflow is displayed. Examine the contents of the screen.
GKE Autopilot
Using Google Kubernetes Engine (GKE), Google’s managed Kubernetes service, running Airflow Apache on Google Cloud is made extremely simple. Additionally, you have the option to operate in GKE Autopilot mode, which will automatically scale your cluster according to your demands and assist you avoid running out of compute resources. You can manage your own Kubernetes nodes without having to do so because GKE Autopilot is serverless.
GKE Autopilot provides scalability and high availability. Additionally, you may make use of the robust Kubernetes ecosystem. For instance, you can monitor workloads in addition to other business services in your cluster using the kubectl command, which allows for fine-grained control over workloads. However, if you’re not particularly knowledgeable with Kubernetes, utilizing this method may result in you spending a lot of time managing Kubernetes rather than concentrating on Airflow.
Cloud Composer
Using Cloud Composer, a fully managed data workflow orchestration service on Google Cloud, is the third option. As a managed service, Cloud Composer simplifies the Airflow installation process, relieving you of the burden of maintaining the Airflow infrastructure. But it offers fewer choices. One unusual scenario is that storage cannot be shared throughout DAGs. Because you don’t have as much control over CPU and memory utilization, you might also need to make sure you balance those usages.
Conclude
Three considerations must be made if you plan to use Airflow in production: availability, performance, and cost. Three distinct approaches of running Airflow Apache on Google Cloud have been covered in this post; each has advantages and disadvantages of its own.
Remember that these are the requirements at the very least for selecting an Airflow environment. It could be enough to write some Python code to generate a DAG if you’re using Airflow for a side project. But in order to execute Airflow in production, you’ll also need to set up the Executor (LocalExecutor, CeleryExecutor, KubernetesExecutor, etc.), Airflow Core (concurrency, parallelism, SQL Pool size, etc.), and other components as needed.
Read more on Govindhtech.com
#Google#googlecloud#apacheairflow#computeengine#GKEautopilot#cloudcomposer#govindhtech#news#technews#Technology#technologynews#technologytrends
0 notes
Text
Backup vault For Cyber Resilience & Compute Engine Backups
Google Vault Backup
Data backup is more crucial than ever. Due to the rise in ransomware attacks, more customers are upgrading their protection to protect their data. Thus, security and usability are prioritized. Regarding security, the frequency of ransomware and other cyberattacks puts a company’s finances and reputation at serious danger. Simultaneously, there is a strong need to decrease operational burden and boost agility by streamlining backup management.
Google is introducing three significant updates to the Google Cloud Backup and Disaster Recovery (DR) service, all of which are now in preview, to better meet your changing needs:
- Advertisement -
The new backup vault storage feature protects your backups from manipulation and unwanted deletion by providing immutable (preventing modification) and indelible (preventing deletion) backups.
A completely managed end-to-end solution for centralized backup management that facilitates direct integration into resource management flows and makes data protection simple.
Integration with the Compute Engine virtual machine formation process, enabling application owners to implement backup policies at the time of VM creation.
Protect your backups from unapproved deletion and alteration
Backups are frequently the last line of defense for data recovery in situations where production data is compromised or unreliable, as occurs after a major user error or cyberattack. It’s imperative to secure your backups from later alteration and deletion in addition to backing up your important workloads. Backup vault enables you to confidently achieve the protection your organization needs by offering secure storage for backups made by the Backup and DR service.
How to Backup Vault
Air-gapped backup isolation makes sense
Data from your backup vault is conceptually air-gapped from your self-managed Google Cloud project and kept in a Google-managed project. Direct assaults against the underlying backup vault resources are prevented since they are not visible to or accessible by users within your business. The only way to access backup vault data is via the APIs and user interface of Google Cloud Backup and DR services.
Control and adherence: mandatory storage
You can stipulate while building a backup vault that vaulted backups have to be kept under strict security against deletion and modification until the administrator-specified minimum enforced retention period has passed. You can meet backup immutability and indelibility goals with this layered protection. Security initiatives and regulatory compliance requirements are common drivers of these goals.
Dependable and adaptable recuperation
Fully self-contained, vaulted backups allow for recovery even in the event that the original resource is unavailable. Furthermore, backup vaults can be established in a project that is distinct from the source project to guarantee that backups are still available in the event that the source project or resource is destroyed. You may therefore set up your backup policy to offer robust resistance against the deletion of the source project. In the event of a cyberattack, this facilitates the prompt recovery of production applications to projects that already exist or are freshly established. Recovery into projects set up as isolated recovery environments (IREs) for pre-recovery testing and forensics is also supported.
- Advertisement -
In the upcoming months, the backup vault feature will become broadly accessible after being made available in preview form today. Oracle and SQL Server databases, as well as Compute Engine and VMware Engine virtual machines, are all protected.
Utilize centralized, fully managed backup administration
Consumers frequently request an infrastructure-free, self-serving, and basic backup solution made for cloud applications. Customers want a more flexible strategy that gives app developers the ability to backup their virtual machines (VMs) while maintaining governance and monitoring by the central backup team. This is to ensure that critical operational components do not impede the agility that businesses need.
With a fully managed solution that simplifies data protection and provides an integrated, developer-centric, self-service approach for app developers, Google cloud new centralized backup management experience offers simplicity.
Store your vital Compute Engine virtual machine data in backup vaults
The new fully managed experience, which offers first support for managing Compute Engine VM protection, simplifies backup setup into three simple steps: 1) building a backup vault (storage), 2) defining your backup plan (schedule), and 3) initiating your VMs’ protection. Because of this approach’s ease of use, complicated setups are not necessary, allowing you to concentrate on your main business activities rather than managing backups.
Providing direct connection to empower application owners
Thanks to an integrated experience during VM formation, platform administrators now have the ability to backup Compute Engine virtual machines (VMs). This feature streamlines workflows and lessens the administrative load on IT and central backup teams by enabling teams to take charge of their own backup strategy right from the VM creation process. It is possible to guarantee that your data protection standards are followed consistently right from the start by including backup tasks in the VM provisioning process. Admins have freedom and control because of their integration with Google Cloud Identity and Access Management.
Centralized oversight, reporting, and monitoring
By providing centralized management over backup policies and enabling application owners to handle their own backup operations, the backup service improves governance as well as supervision. This dual-layer strategy strikes the ideal mix between operational flexibility and centralized control, ensuring consistency and compliance throughout the business.
The system offers extensive monitoring and reporting features to further fortify data protection:
Backup and restore jobs that are scheduled
Monitor the progress of these jobs to make sure they are proceeding according to plan. Track advancement, failure, and success of jobs with a single dashboard.
Customizable reports
Produce thorough reports on protected resources, compliance, storage utilization, failed and skipped jobs, and more. Customize these reports to your own requirements to acquire insightful knowledge about your backup environment.
Notifications and alerts
Configure alerts and notifications to be informed when important backup events occur. You’ll get timely notifications to take the necessary action, whether it’s about a failed job or other significant updates.
Automation simplicity: Integrate at-scale protection with your current systems
Effective cloud resource management requires automation, and new product works with the VM management tools you already have. Easy integration into your automation workflows is made possible by the Backup vault, regardless of whether you’re using Terraform, APIs, or the gcloud CLI. You will be able to use the UI and the gcloud CLI to secure Compute Engine virtual machines during the preview. You can use APIs and Terraform to integrate backup operations as code on top of your current infrastructure and integrate them into your larger VM management strategy once the offering is made broadly available. With this feature, you can be sure that your backup procedures are optimized for your current infrastructure and that they are also effective.
Read more on govindhtech.com
#Backupvault#ComputeEngine#GoogleCloud#cyberattacks#DisasterRecovery#APIs#SQLServer#VMwareEngine#virtualmachines#NEWS#TechNews#technology#technologynews#govindhtech
0 notes
Text
Google Cloud Advanced Performance Storage Pools Start Today

Block storage in Cloud
Hyperdisk Advanced Performance Storage Pools
Hyperdisk Storage Pools with Advanced Capacity, which help you reduce the Total Cost of Ownership (TCO) of your block storage capacity, were made generally available earlier this year. With Hyperdisk Storage Pools with Advanced Performance, Google is introducing that same breakthrough to block storage performance today. Now that you can provision IOPS and throughput aggregately, which Hyperdisk Storage Pools will dynamically allocate as your applications read and write data, you can significantly simplify performance planning and management and greatly boost resource usage.
With the Google Cloud console, you can begin using Advanced Performance Storage Pools right now.
The difficulty lies in allocating an appropriate quantity of performance resources
Clients have reported difficulties in striking a balance between making the most of all of their block storage performance resources and guaranteeing that their workloads have the resources necessary to be successful. This problem stems from what is known as the “sum of peaks” problem. Customers will provision their block storage at the maximum performance they have seen to guarantee that their workloads are never performance starved; nevertheless, in the majority of cases, their disks consume much less than that performance. This indicates that the performance usage of your disks is consistently low.
Utilizing Advanced Performance Storage Pools, reduce TCO by 40–50%
To address this issue, Google created Advanced Performance for Hyperdisk Storage Pools. You may now achieve high performance utilization and successful workloads simultaneously with Advanced Performance Storage Pools. When you provision performance in aggregate in a Hyperdisk Storage Pool with Advanced Performance, the Storage Pool intelligently divides those resources among the disks in the Pool as required. All without altering the behavior of drives, allowing your applications to function normally. Without compromising application success or resource efficiency, you can now more easily plan for your performance requirements and reduce your total cost of ownership.
To show how Hyperdisk Storage Pools with Advanced Performance can reduce your total cost of ownership, let’s examine a few workloads. Consider two workloads: a database workload that needs 75K IOPS at peak (such as when quarterly reports are due) but only 35K at steady state, and an enterprise application suite that needs 25K IOPS at peak (such as when all users are signed in simultaneously) but only 10K at steady state.
Since these workloads’ steady state performance would be around half of their allocated performance, they would function at 40–45% performance utilization outside of a pool. But because a Hyperdisk Storage Pool with Advanced Performance’s dynamic resource allocation guarantees that these workloads operate at about 80% utilization, the customer can supply far lower performance resources and reduce their TCO from 40–55% without modifying their applications.WorkloadPerformance RequirementsGCP Storage PoolsAlternative Cloud ProviderPools TCO SavingsEnterprise applicationsPeak IOPS: 25KAvg IOPS: 10KPeak Tput: 400 MiB/sAvg Tput: 160 MiB/s$33K/mo.$74K/mo.55%Databases (e.g. SQL Server)Peak IOPS: 75KAvg IOPS: 35KPeak Tput: 1.2 GiB/sAvg Tput: 560 MiB/s$15K/Mo.$25K/Mo.40%Price:IOPs – $.0095Throughput – $.076$81.92 / TiBIncludes: 1 TiB capacity, 5K IOPS, 200 MiB/s
Plan ahead and simplify block storage performance
A major advancement in performance resource provisioning is Advanced Performance Storage Pools. Infrastructure managers have historically had to decide between risking application failure by optimizing operational efficiency or accepting poor utilization. This implies that they must take on significant managerial effort and actively oversee each volume’s success.
Block storage performance management is made easy with Hyperdisk Advanced Performance Storage Pools. An Advanced Performance Storage Pool’s disk IOPS and throughput are “thin-provisioned.” To put it another way, you can provision up to five times the IOPS and throughput in a pool to the disks in the pool while maintaining resource-neutral performance at the disk level.
This results in great efficiency (because you no longer need to actively manage the IOPS and Throughput allocated to each disk) and eases deployment planning (since you no longer need to guess precisely what performance demands each disk should have). All you have to do is build the disks you need, as performanta as possible, and allow the Advanced Performance Storage Pool to provide resources as needed.
Early adopters of Advanced Performance Storage Pools, like REWE, have recognized the benefits of the product.
Start now
The same process used to create Hyperdisk Storage Pools can also be used to start Hyperdisk Advanced Performance Storage Pools. Go to Compute Engine by logging into the Google Cloud dashboard and selecting Storage. Next, establish your Storage Pool, choose Advanced Performance as the volume type (Balanced or Throughput), and enter the entire capacity and performance that the pool will require. Starting with the creation of new Hyperdisk volumes, you may start using the pool’s capacity as well as the extra advantage of dynamically sharing performance across your resources.
We believe that Advanced Performance Storage Pools will significantly enhance your ability to manage and get the optimal performance of your applications. The regions and zones that will receive Hyperdisk Advanced Performance Storage Pools are now being served. Start using Advanced Performance Storage Pools right now by opening the Google Cloud dashboard and navigating through Google Cloud’s documentation to establish, use, and maintain your pools.
Read more on govindhtech.com
#GoogleCloud#AdvancedPerformance#StoragePools#HyperdiskStoragePools#blockstorage#DATA#databaseworkload#disks#ComputeEngine#GOOGLE#technology#technews#news#govindhtech
0 notes
Text
Lightning-Fast Recovery: Instant Snapshots on Compute Engine

Take instant snapshots to guard against errors and corruption on Compute Engine workloads.
Consider yourself an application administrator updating a program within a scheduled maintenance window of one hour, and all of a sudden the update fails. This is the time to start your rollback processes. Recovering from routine snapshots is the standard procedure for rolling back; the duration of this process varies based on the amount of data that needs to be restored and can take several minutes. Alternatively, you may try to restore from a costly-to-maintain pre-upgrade replica of the program.
What if you had a disk-size-independent, incredibly quick, and affordable recovery solution that would let you take use of the whole maintenance window and provide a predictable rollback time?
Google is pleased to present instant snapshots for Compute Engine, which offer high-frequency, nearly immediate point-in-time checks of a disk that can be quickly restored as necessary.
Recovery time objective (RTO) in the tens of seconds and recovery point objective (RPO) of seconds are provided via instant snapshots. The only hyperscaler that provides high-performance checkpointing that enables instant recovery is Google Cloud. While competing hyperscalers may require tens of minutes or even hours for the workload to recover to full performance, your Compute Engine workload operates at full disk performance as soon as an instant snapshot is restored.
Compute Engine instant snapshots allow you to recover in cases when the data needs to be rolled back to an earlier state but the fundamental infrastructure is still intact. Typical usage cases include of:
Facilitating quick recovery from file system corruption, application software errors, and user mistake.
Backup verification routines that take regular snapshots and instantly restore them in order to perform data consistency checks, like those for database workloads.
Creating restore points prior to an application update allows for a quick rollback in case the scheduled maintenance doesn’t go as expected.
Apart from the aforementioned, employing immediate snapshots can also:
Boost developer productivity: Unintentional mistakes and build failures lengthen the time needed to finish tasks in fast development cycles with lengthy build times or complex code. You can benefit from quick restores using instant snapshots instead of relying on off-site backups.
Check the status before retreating: Make sure the backups you make are in the appropriate state and useable. Before starting a long-term backup, use quick snapshots to checkpoint and clone drives to validate on secondary machines.
Boost the frequency of backups: You can take regular backups of business-critical, high-volume databases that can’t afford long backup windows by using immediate snapshots.
Important aspects of instant snapshots
Compared to conventional snapshots, Compute Engine Instant snapshots have several advantages.
Backups that are made in-place: Instant snapshots are made on regional or zonal drives, and they are stored in the same location as the media type and source disk. This indicates that an immediate snapshot taken from an SDD (or HDD) disk shall be kept on the same disk. Instant snapshots have a fixed creation fee and additional storage costs are billed based on usage.
Quick and incremental: Only modified, incremental data blocks since the last instant snapshot are stored in each instant snapshot, which are prepared in a matter of seconds. Compared to backup snapshots, you can take snapshots far more frequently thanks to its high-frequency snapshotting capability.
Quick disk restore: Every instant snapshot can be quickly restored in a matter of seconds to a new disk. These new disks take on the disk type of the snapshot because they are in the same zone.
Convertible to backup or archive: For long-term, geo-redundant storage, you can migrate instant snapshots to a separate point of presence.
The operation of instant snapshots
Image credit to Google Cloud
Instant snapshots can be made in a matter of seconds since they only store the data that has changed since the initial checkpoint.
Thus, in the example above, instant snapshots generates a checkpoint at the time of creation, but they don’t actively store data until the disk’s third block is overwritten with fresh information. Keep in mind that adding data like Google Cloud doing here by writing to blocks 6 and 7 doesn’t necessitate using more storage on the checkpoint.
This results in both efficient performance and extremely high storage efficiency: As previously indicated, producing and restoring from an instant snapshot can be completed in a matter of seconds and has no effect on the underlying disk’s performance.
You can easily and effectively safeguard your workloads by integrating instant snapshots into your routine change-management and maintenance processes, thanks to their storage, performance, and cost-effectiveness.
Comparing different sorts of snapshots
An overview of the various performance attributes of instant snapshots in comparison to backup standard snapshots is provided here.Image credit to Google Cloud
An illustration of a use case
Maya, an administrator of applications, must update programs stored on persistent disk drives. She is allotted one hour to complete this maintenance window. If the volumes have the new software at the end of the window, it will be considered a successful upgrade; if not, it will be considered a rollback, and they will be in the exact same state as they were right before the maintenance window began.
Examine Maya’s process for taking instantaneous versus frequent snapshots:Image credit to Google Cloud
Make use of it now
Instant snapshots provide high-frequency backup and nearly instantaneous on-device point-in-time backups for quick restorations. They facilitate quick restores in the event of unsuccessful upgrades or user mistake, shorten the time needed for off-site backup, and improve program upgrade windows.
Read more on govindhtech.com
#LightningFastRecovery#InstantSnapshots#ComputeEngine#GoogleCloud#snapshots#hdd#disk#diskdrives#Importantaspects#Compute#google#technology#technews#news#govindhtech
0 notes
Text
Google Cloud Storage Client: Effective Information Planning

Cloud Storage client
Some of the workloads on Google Cloud Storage client that are expanding the fastest are data-intensive apps like analytics and AI/ML, but maintaining high throughput for these workloads can be difficult. By giving important client libraries the ability to parallelize uploads and downloads, Google Cloud Storage client library transfer manager increases throughput for your workloads.
To increase throughput, the new transfer manager module makes advantage of many workers in threads or processes. Although Cloud Storage command-line interfaces automatically parallelize downloads and uploads when appropriate, until recently, Google Cloud Storage client libraries did not offer fully controlled parallelism.
The Go transfer manager module is currently in preview and is usually accessible for Java, Node.js, and Python. More language support is being developed. We’ll provide some instances in this post of how Google Cloud Storage client library transfer manager features can significantly increase media operations performance over a sequential model.
Google Cloud Storage client library
How the client library does actions in parallel
Rather than looping over each file one at a time, the transfer manager in the Google Cloud Storage client library can perform concurrent actions on numerous files at once. The transfer manager has methods that accept file-blob pairs as well as ones that make it easy to upload or download entire directories at once. For further information, see the documentation found in the “Getting Started” section below.
The transfer manager offers a “divide-and-conquer” method for tasks involving huge files, which fragments the data in a file and transfers all the shards at once. Ranged reads are used to implement sharding downloads. Upload operations use either the XML multipart upload a API or the gRPC compose API, depending on which client library you choose.Image credit to Google cloud
Performance advantages Cloud Storage client
Transfer manager’s performance consequences are contingent upon various operating environments and workloads, which can be accommodated by configuring parallelism accordingly. Depending on the programming language, parallelism may use co-routines, threads, or processes.
When a large amount of data needs to be moved at once, switching from regular transfers to transfers handled by the transfer manager will have the biggest effect on your application. Your application will profit more the more there is to transfer, either in terms of quantity of objects, size of objects, or both.
For instance, on a c3-highcpu-8 Compute Engine instance, the Python library transfer manager module produced a 50x throughput boost over a single-worker solution when downloading a large number of files in less than 16Kbs employing 64 workers! Experiments revealed that very little files benefit most from having a big number of workers. Even though this example uses a disproportionately large number of workers for a small instance, using fewer workers still results in a notable increase in performance.
In the same case, the Google Cloud Storage client library transfer manager enhanced the throughput by 4.5x from a significantly higher beginning baseline when moving larger files of 64MB utilising only 8 workers. Similar performance was seen for sharded uploads and downloads with chunk sizes between 32 and 64 MB.
The best configuration for increasing throughput on a particular application depends on several parameters, such as memory, CPU type, and networking latency. Compute Engine instances, for instance, differ in terms of CPU and memory capacity as well as networking configurations. Similarly, using Cloud Storage from a location other than Compute Engine has very different limits on round-trip time and network throughput.
Client libraries explained
Using client libraries to access Google Cloud APIs from a supported language is simpler. Although you can utilise Google Cloud APIs directly by sending the server raw requests, client libraries simplify the process and cut down on the amount of code you have to write.
The various client libraries for Cloud APIs that Google offers are described in this paper. The documentation for your preferred product or language can also tell you more about the libraries that are available for it.
Libraries for Cloud Clients
When it comes to programmatically accessing Cloud APIs, Cloud Client Libraries are the suggested choice. Utilising the most recent client library concept, cloud client libraries also
To make Cloud APIs easy to use, provide idiomatic code in each language.
To make interacting with various Cloud services easier, provide all client libraries a uniform look and feel.
Take care of every little aspect involved in communicating with the server, such as establishing a Google account.
Is installable with well-known package management programmes like npm and pip.
Give you performance advantages in some situations by utilising gRPC. Refer to the gRPC APIs for additional details.
On the Client Libraries page for the Cloud APIs you’re using, you can discover installation guidelines and documentation for the Cloud Client Library. On the Cloud Client Libraries page, you will discover links to the reference material and an introduction to the Cloud Client Libraries.
Client Libraries for Google APIs
Not all languages have Cloud Client Libraries available for all Google Cloud APIs. You can still use the older type of client library, known as Google API Client Libraries, if you want to utilise one of these APIs and there isn’t a Cloud Client Library available for your favourite language. If you’re updating a project that already makes use of these libraries, you might also utilise them. These repositories:
Grant access to the REST interface of the API alone; gRPC is not accommodated.
Contain interface code written automatically, which may not be as intuitive as that of the Cloud Client Libraries.
Take care of every little aspect involved in communicating with the server, such as establishing a Google account.
Is installable with well-known package management programmes like npm and pip.
The Client Libraries page for the applicable Cloud APIs has links to these libraries.
Making use of the Firebase mobile app
The Google-wide method for creating mobile applications is called Firebase. It provides an SDK with client code that enables you to use iOS, Android, and Web apps to access Cloud APIs relevant to mobile devices. See the Firebase documentation for details on the available Cloud APIs and how to get started.
Read more on Govindhtech.com
#CloudStorage#GoogleCloudStorageclient#python#java#computeengineinstance#CPU#ComputeEngine#GoogleCloud#cloudapis#CloudClientLibraries#CloudServices#mobileapplication#mobiledevice#android#ios#news#TechNews#technologynews#technology#technologytrends#govindhtech
0 notes
Text
Reduce the Google Compute Engine Cost with 5 Tricks
Google Compute Engine Cost
Compute Engine provides several options for cutting expenses, such as optimising your infrastructure and utilising sales. Google Cloud is sharing some useful advice to help you save Google Compute Engine cost in this two-part blog post. This guide has something for everyone, regardless of whether you work for a huge organisation trying to optimise its budget or a small business just starting started with cloud computing.
Examine your present budgetary plan
It would be helpful to have a map of your present circumstances and spending structure before you embark on a journey to optimise your Google Compute Engine cost. This will allow you to make well-informed decisions regarding your next course of action. That billing panel is the Google Cloud console. It provides you with a detailed breakdown of your spending, tracking each expense to a specific SKU. It can be used to examine the overall financial picture of your company and to determine how much a given product will cost to use for a given project.
You can find resources you are no longer paying for but no longer require by taking a closer look at your spending. Nothing is a better method to save money than simply not spending it, after all.
Examine the automated suggestions
On the page where your virtual machines are listed, have you noticed the lightbulbs next to some of your machines? These are Google Cloud’s automated suggestions for things you could do to cut costs. The following project management categories cost, security, performance, reliability, management, and sustainability are addressed by Recommendation Hub, a new technology. The recommendations system can make suggestions for actions that you might think about based on its understanding of your fleet structure. Helping you cut costs without sacrificing fleet performance is Google Cloud’s main objective.Image credit to Google Cloud
The machine can be scaled down according to its utilisation, or the type of machine can be changed (e.g., from n1 to e2). You get a summary of the recommended modification along with the expected cost savings when you click on one of the recommendations. You have the option of applying the modification or not. Recall that the instance must be restarted in order for modifications to take effect.Image credit to Google Cloud
Check the types of discs you have
You must attach at least one persistent disc to each virtual machine in your fleet. Google Cloud offers a variety of disc formats with varying features and performance. The kinds that are offered are:
Hyperdisk
With a full range of data durability and administration features, Hyperdisk is a scalable, high-performance storage solution built for the most demanding mission-critical applications.
Hyperdisk Storage Pools
Hyperdisk Storage Pools are pre-aggregated volumes, throughput, and IOPS that you can reserve in advance and allocate to your apps as required.
Persistent Disk
Your virtual machines default storage option is called Persistent Disc. It may be regional or zonal. has four variations:
Standard
The desktop computer’s equivalent of an HDD disc. offers the least expensive storage with a slower I/O speed.
SSD
A speed-focused option with excellent I/O performance, albeit at a higher cost per gigabyte.
Balanced
The default setting for newly created compute instances; it strikes a compromise between “Standard” and “SSD.”
Extreme
Suitable for the hardest workloads. enables you to manage the disk’s IOPS in addition to its size.
Local SSD
An SSD that is physically attached to the host that powers your virtual machine is called a local SSD. incredibly quick but transient.
Since persistent disc storage is the most widely used type of storage, let’s concentrate on it. The Balanced disc, which offers a decent compromise between performance and cost, is the default disc type used when building a new virtual machine. Although this works well in a lot of situations, it might not be the ideal choice in every situation.
Fast I/O to disc is not needed, for instance, by stateless apps that are a component of auto-scaling deployments and keep all pertinent data in an external cache or database. These apps are excellent candidates for switching to Standard discs, which, depending on the region, can be up to three times less expensive per gigabyte than Balanced discs.
A list of the discs used in your project can be obtained using: the list of gcloud compute discs with the format “table(name, type, zone, sizeGb, users)”
You must clone the disc and make changes to the virtual machines that use it in order to start using the new disc in order to alter the disc type.
Free up any unused disc space
Moving on to storage, there are other factors besides disc type that influence price. You should also consider how much disc utilisation affects your budget.You will be paid for the full 100 GB of persistent disc space allocated for your project, whether you use 20%, 70%, or 100%. You may still want to monitor your boot discs closely even if your application does not use Persistent Discs for data storage.
If your stateless programme really needs a disc with many gigabytes of free space, think about reducing the size of the discs to match your actual needs. Because they enjoy round numbers, people frequently build 20 GB discs even when they only require 12 GB. Save money and act more like a machine.
Agree to make use of CUDs, or committed use discounts
Compute Engine is not the only product to which this advice is applicable. You can receive a significant discount if you can guarantee that you’ll use a specific number of virtual machines for three or more years, or at least a year! You can get substantially cheaper costs for local SSDs, GPUs, vCPUs, memory, sole-tenant nodes, and software licences by using a range of (CUDs). You are not even limited to allocating your vCPU and memory to a certain project, area, or machine series when using Flex CUDs.
Discounts for committed use are offered on a number of Google Cloud products. If you’re satisfied with Google Cloud and have no intention of switching providers anytime soon, you should seriously think about utilising CUDs whenever you can to save a lot of money. When it comes to computing, you can buy CUDs straight from the Google Cloud dashboard.
Read more on govindhtech.com
#GoogleComputeEngine#CPU#GoogleCloud#CloudComputing#hyperdisk#SSDs#GPU#VCPU#ComputeEngine#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
Blockchain Analytics startup architecture with Google Cloud

Blockchain Analytics
Globally, blockchain businesses are setting the standard in sectors including identity verification, financial services, and gaming as the technology finds practical uses in these domains. Blockchain infrastructure development and management, however, can be difficult and time-consuming.
Herein lies the role of Google Cloud
A wide range of services and products from Google Cloud are available to assist blockchain companies in developing, implementing, and maintaining their apps in a timely, safe, and effective manner.
Blockchain technology issues
Numerous elements of google cloud life could be transformed by blockchain technology. But in spite of its potential, blockchain still has to overcome the following obstacles before it can be widely used.
Scalability
Blockchain networks may slow down and fail as user and transaction volumes climb. Because every network node must confirm every transaction, it can take a long time.
Achievement
Another significant obstacle facing blockchain technology is achieving quick and dependable network performance, especially as the volume of users and transactions on the network increases.
Safety
Due to their ability to alter the network and store important data, blockchain nodes are a target for hackers.
Information
The massive amount of data that blockchains contain can make it difficult to scale, maintain privacy, and retrieve data quickly.
Google Cloud provides a wide range of services and products that are specifically designed to meet the demands of blockchain companies in order to assist you in addressing these difficulties. Let’s examine a few of the important choices.
Use infrastructure that is highly scalable to manage rising transaction volumes
With the help of Compute Engine and Google Cloud’s strong network, entrepreneurs may easily host their blockchain nodes and develop decentralised applications (dApps). Managed instance groups (MIGs) with autoscaling are another feature that Compute Engine offers. These MIGs may smoothly adjust to varying demand by automatically spinning up extra virtual machines (VMs) as needed and scaling down when demand decreases. Google Cloud virtual machines (VMs) start up quickly, so your dApps stay responsive and effective.
web3 applications
Another well-liked Google Cloud tool that facilitates the deployment and management of containerised applications is Google Cloud managed Kubernetes service, Google Kubernetes Engine (GKE). For organisations creating and overseeing Web3 applications, GKE is an excellent option since it streamlines node management for blockchain suppliers such as Blockdaemon and gives developers access to a scalable, self-healing infrastructure and detailed monitoring.
Blockchain Node Engine, Google Cloud newest blockchain node hosting service, is a fully managed solution created especially for Web3 development. It relieves developers of the burden of managing the underlying infrastructure by enabling them to quickly and simply create specialised blockchain nodes. You don’t have to worry about SRE jobs when using Blockchain Node Engine because Google Cloud takes care of them. Blockchain Node Engine is another tool that startups can utilise to jumpstart their dApp initiatives. For example, in less than an hour, entrepreneurs can access Etherum block data, and the public preview of support for Polygon and Solana is already underway.
Utilise high-performance infrastructure to optimise dApps
Google Cloud network services use automation, cutting-edge AI, and programmability to scale, secure, and optimise your infrastructure for startups seeking quick and secure transaction processing. Google Cloud gives you fine-grained control over your networking architecture, including firewall rules and IP addresses, in addition to location flexibility.
High-throughput, low-latency interconnects between blockchain nodes and your dApp are automatically established over Google’s high-performance private network. Google Cloud top priorities are security and access control. To that end, Google cloud provide Identity and Access Management (IAM) and Key Management Service (KMS) to guarantee adherence to user access roles and to facilitate the safe submission and approval of transactions involving digital assets through the use of encryption keys and signatures.
Examine blockchain information
Analytics Blockchain
BigQuery makes it simple to retrieve historical blockchain data with Google Cloud Blockchain Analytics, which streamlines SQL query data analysis. Developers can save time and resources by not having to manage nodes or create specialised indexers. Deeper insights into user behaviour and business operations can be obtained by developers by combining blockchain data with internal data and utilising BigQuery’s query engine.
Furthermore, BigQuery public datasets now feature 11 more blockchains in preview, meeting the increasing need for Web3-based comprehensive data access. Avalanche, Arbitrum, Cronos, Ethereum (Görli), Fantom (Opera), Near, Optimism, Polkadot, Polygon Mainnet, Polygon Mumbai, and Tron are among the recently added blockchains. BigQuery gives developers, researchers, and companies the ability to fully utilise blockchain technology by offering an easily accessible and all-inclusive source of blockchain data.
In a similar vein, Vertex AI enables entrepreneurs to unleash the full potential of blockchain data by fusing real-time processing, scalability, and Google’s deep AI and machine learning know-how to produce insights that are unmatched. Vertex AI’s state-of-the-art generative powers enhance data analysis and open up new avenues for exploring the blockchain’s potential. Some of these avenues include creating hyper-realistic simulations, creating synthetic data, or even using real data to create dynamic NFTs that can be used to interact with customers.
Develop and expand your blockchain enterprise
The goal of the Google Cloud Web3 startup programme is to help and expedite Web3 initiatives and businesses. By taking part in the programme, participants can access a multitude of advantages that can help Web3 startups succeed.
With large credits for Google Cloud services, the programme offers substantial financial support, relieving you of the burden of infrastructure expenditures and freeing you up to concentrate on innovation. In addition, the programme provides companies with exceptional learning opportunities that help them stay ahead of the curve in the rapidly changing Web3 ecosystem. Teams that join can take advantage of cutting-edge Google Cloud technologies, including early access to new products, and sophisticated hands-on labs.
Web3 and Google Cloud Advancing Blockchain Technologies
At Google Cloud, they are dedicated to advancing blockchain innovation and providing assistance to the Web3 community. We are assisting hundreds of blockchain firms in growing and developing ground-breaking new solutions that will play a significant role in shaping the future of the internet through Google Cloud Web3 startup programme and by offering cloud tools and resources that developers need to build and scale dApps securely.
Polygon
The Web3 ecosystem will expand more quickly because to the collaboration between Google Cloud and Polygon Labs, which will make it simpler for developers to create and use Polygon protocols. Building, launching, and expanding Web3 products and dApps is made easier for developers using tools and infrastructure from Google Cloud, a strategic cloud provider for Polygon protocols.
Developers can overcome the difficulties of setting up, managing, and running their own blockchain nodes with the aid of Blockchain Node Engine. To power dApps fast and simply, Google Cloud Marketplace also provides one-click deployment of a Polygon PoS node. To further aid in decision-making, Google Cloud gives developers access to the Polygon blockchain dataset on BigQuery, enabling them to examine real-time, on-chain, and cross-chain data.
Nansen
The blockchain analytics platform Nansen can handle and analyse up to 1 petabyte of blockchain data per day, and BigQuery is essential to this process. The capacity to process data in real-time is crucial for Nansen to give its consumers current information and help them make wise decisions in the quickly changing cryptocurrency market.
Furthermore, Nansen’s AI predictive modelling and recommendations approach has been influenced by Google Cloud’s machine learning technologies, including BigQuery ML and Cloud Inference API. Nansen has been able to create complex algorithms that can find hidden patterns and trends in blockchain data with the help of Google Cloud, giving users insightful analysis and prognostic suggestions.
Matter Research/zkSync
Matter Labs’ Layer-2 ZkSync protocol scales Ethereum with cutting-edge zero-knowledge (ZK) technology. It has become one of the fastest-growing ZK rollups worldwide since entering the mainnet in March 2023. Since its founding, Matter Labs has used Google Cloud, utilising GKE and additional services to meet the rapid expansion and high demand of the company. They have therefore tailored their proofing method to work with Google Cloud.
Matter Labs’ new hyperchain offering a new scaling solution for Ethereum and Google Cloud strengthened their partnership in 2024 to support the company’s next stage of expansion
Read more on govindhtech.com
#googlecloud#BlockchainAnalytics#blockchain#blockchaintechnology#ComputeEngine#googlekubernetesengine#sqlquery#BigQuery#news#technews#technologynews#technology#technologytrends#govindhtech
0 notes
Text
GDL Italia - Google Compute Engine overview
GDL Italia – Google Compute Engine overview

https://m.youtube.com/watch?v=ZJ6cLxGAeRs
We’ve been working for three Years on the virtualization technology and Compute Engine, So it’s not a copy of what you Can find in other places It’s really unique to Google So from the bottom up, You know what [ INAUDIBLE ] was Explaining that, because of our scale, we had to Build our product, We have to design our server, We have to build our Network…
View On WordPress
0 notes
Photo

Did you know Google has physical fiber optical cables across the globe, running through seabeds to connect their data center and cloud infrastructure to provide you with fast services? #power #speed #fast #google #fiberoptic #datacenter #googlecloud #gcp #googlecloudplatform #cloudcomputing #cloudengine #appengine #computeengine #Kubernetes #cloudfunctions #fastservice #cloud #CloudMigration #clouds (at Mississauga, Ontario)
#speed#cloud#power#fastservice#fiberoptic#googlecloudplatform#appengine#cloudmigration#fast#google#cloudengine#computeengine#kubernetes#cloudfunctions#cloudcomputing#clouds#googlecloud#datacenter#gcp
0 notes