#data mining company
Text
In today's fast-paced business landscape, Data Mining Services are essential for maintaining a competitive edge. By analyzing vast datasets, these services uncover patterns and insights that help businesses make informed decisions and predict future trends. Stay ahead in your industry by leveraging the power of data mining to enhance your strategic planning and operational efficiency. Learn more about how data mining can transform your business strategy by visiting our detailed blog post.
#data mining#data mining services#outsource data mining#data mining companies#data mining solutions#data mining company
0 notes
Text
The Power of Data Mining: Strategies for Business Transformation

With technology advancing rapidly, everything revolves around data-driven decision-making. Businesses rely on a wealth of information to understand industry trends, gain insights into their customers, and improve their overall performance. Data mining services provide valuable business intelligence by analyzing patterns, predicting outcomes, addressing issues, and identifying new opportunities. For more information, read the below blog.
0 notes
Link
Businesses of all sizes produce enormous volumes of data daily in today's data-driven environment. Data must be evaluated in order to yield insights that can be put to use. Data mining is the process of examining massive databases to spot trends and draw valuable conclusions that may be applied to decision-making. As data mining requires a lot of time and resources, many organisations choose to outsource their data mining needs to specialised suppliers. Let’s at the advantages of outsourcing data mining services for businesses
#Data Mining Company#Data Mining Process#Data Mining Services#data mining outsourcing#Outsourcing Data Mining
0 notes
Text

Data mining companies leverage the latest tools to predict patterns, find relations, make forecasts, and stay updated with the latest industry events. Hence, they can make informed decisions, map out effective strategies, perform effective competitor analysis, and expand paradigms.
0 notes
Text
Why Data Scraping Is Vital To The Healthcare Industry?
The healthcare industry is one of the largest generators and consumers of data. Its data analytics expense was US$29.1 Billion in 2021, and it is expected to grow at a CAGR of 21.5% between 2022-30. The large quantities of data that forms a part of every patient’s care, from a simple clinical visit to complex surgery, are responsible for this large analytics market.
Add to that the paperwork…

View On WordPress
#data#data mining company#data mining in healthcare#data scraping#data scraping services#database#healthcare data mining services
0 notes
Text
want to try ghostwriting because 1. i'm evil and i'm anti copyright/intellectual property 2. i like being anonymous. i hope i'm not a real person to you guys but just some pixels on the screen 3. i love writing. except for the fact every platform where ghostwriting happens needs me to plaster my face, my address, my phone number, my mother's maiden name, my kidney, my soul all over the digital town square.
#text#💚#tried to sign up on fb to check some groups and it needed my face to allow me to make an account#like... we don't even have to wait for AI#the internet is already 'taking our jobs'#by internet i mean humans btw#owners of tech companies that are always based in isr*el or silicon valley#& they platform sites only to data mine for more capitalistic ventures on stolen land#Pissed. Off.
4 notes
·
View notes
Text
Receiving 1 email about a service you are subscribed changing its terms of service: sus, they're likely trying to get more data from their users, i hate them.
Receiving emails about everyone changing its terms of service: chilll, its the EU smashing some data laws to those companies, wreck them actually, they should pass more data protection laws.
#i was surprised when everyone was changing their terms in early 2024#at the beginning it was alarming but then i realized it was something good#i hate those vague explanations of terms of service made easier#like those companies have already so much data#they should limit them more#but at least ita something#go go eu#next years it's gonna be ia related laws#mine#data#data privacy#rambling
2 notes
·
View notes
Text
observation-wise i do think it's interesting how enraged people were about how a giant query that returned pretty much everything ever posted (and unposted. drafts and unanswered asks and whatnot) on the site was done (which. to my knowledge. STILL doesn't have an answer regarding the question of whether or not the data included in that query was already sold) and that tumblr was going to start partnering with AI companies to train their models and then a couple of posts went around like "okie dokie guys NOW after that query was done we implemented an opt-out toggle <3 and we trust in Good Faith that the companies will respect this toggle <3" and then everyone was like Oh Okay <3 Yay <3 and suddenly everyone's fine again. 10/10 example of a collective sunk cost fallacy mentality. at this point it's kind of free entertainment to watch
#obviously if you post anything online you are implicitly acknowledging the risk of it being scraped. that isn't the point#the point is that a REALLY shitty dick move was pulled and like. nobody cares about it. at all#despite the fact that if this happened a year ago to another site like half the people posting about it would've been saying shit like#'haha that's what those idiots get for staying on a site that just wants to mine them for data. companies don't care about their users.#thank god tumblr is different <3' when it's like. guys. you realize tumblr hasn't been different for at least 6 years now. right.#you realize that the 'hellsite (affectionate)' marketing ploy was just that. a marketing ploy.#i realize some people will read this and go 'get off your high horse you're literally posting this on tumblr'#and i mean. yeah. that's the point HAHA
2 notes
·
View notes
Photo

#dead internet theory#dit#data mining#data collection company#dystopia#propaganda#cyberpunk#cyberculture#internet#tech
9 notes
·
View notes
Text
need to shell out for a new laptop before the end of the year - for a lot of reasons but mainly bc support ending for win8.1 makes fixing the current beast rather pointless :/ (and. admittedly. there is a lot to fix. she's old and she has suffered.)
but my current beastie is from the last gen of laptops with a disc drive and the thought of using an external/usb disc drive is enough to make me cry tears of blood
#really though it is time to upgrade#and i hate to say it because she /runs/ fine it's all hardware issues w parts that can absolutely be replaced#but if i can't use it to run the programs i need then shelling out the money for those parts would ultimately be a waste#but also the fact that this machine that runs fine is no longer worth fixing bc some google-based bullshit just won't support win8.1 anymor#is ALSO a fucking waste & a pile of planned obsolescence bullshit! and i hate it!#but uh. even though she runs fine and she totally does. she does need. uh.#new keyboard (only 1/3 of keys work; currently use usb keyboard)#new trackpad ribbon cable (trackpad does not currently work; using external usb mouse)#new power button and connecting ribbon cable (turning it on involves opening it up and causing an intentional short-circuit every time.)#(a problem largely solved by simply never turning her completely off- except she also needs)#a new battery (current battery does not charge at all; machine needs to be constantly plugged in or it shuts down immediately)#...ok i might be the 'this is fine' dog about this#but i am still upset! that i will no longer have a disc drive inside my damn laptop.#that's the disc drive's natural habitat; that's where it should be; it's weird and offputting to have it connected via usb!#ack. why do tech companies fuck everything up.#and that's without getting into the way new devices offer less harddrive space so people will use the fucking cloud or whatever???#yeah sorry no i'm not using your goddamn data mining corporate off-site storage i want to keep my shit on my own goddamn machine#go to actual hell if you're trying to sell me a pc with less than at least 500GB of storage i swear to fuck#...in essence you could say the whole process is leaving me rather grumpy
4 notes
·
View notes
Text
Explore our comprehensive guide on leveraging data mining to drive patient-centric healthcare services. This blog dives into innovative techniques for improving patient outcomes through effective data analysis. Understand the importance of data in transforming healthcare delivery and fostering personalized care. . Read now to enhance your knowledge and apply best practices in your organization.
0 notes
Text
Don’t know how I feel about Spotify Wrapped becoming A Phenomenon
#I do love Spotify wrapped and comparing with my friends#and I do love Spotify bc I like listening to a lot of artists and can’t afford to buy music for all of them#but I feel like wrapped is an uncomfortable reminder about the grip Spotify has on the music industry atm#plus a reminder of how much data big companies have on us#which is not necessarily good#but also. I enjoy it#do you see my problem#also i feel like ppl don’t realize the whole thing is a marketing ploy and you help it work by talking about it#the point is to make non-Spotify users feel left out#but am I still gonna post about mine? yeah#does that make me a hypocrite? probably
9 notes
·
View notes
Text
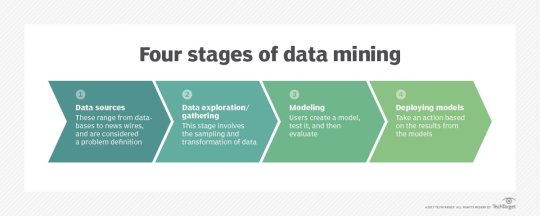
Data gathering. Relevant data for an analytics application is identified and assembled. The data may be located in different source systems, a data warehouse or a data lake, an increasingly common repository in big data environments that contain a mix of structured and unstructured data. External data sources may also be used. Wherever the data comes from, a data scientist often moves it to a data lake for the remaining steps in the process.
Data preparation. This stage includes a set of steps to get the data ready to be mined. It starts with data exploration, profiling and pre-processing, followed by data cleansing work to fix errors and other data quality issues. Data transformation is also done to make data sets consistent, unless a data scientist is looking to analyze unfiltered raw data for a particular application.
Mining the data. Once the data is prepared, a data scientist chooses the appropriate data mining technique and then implements one or more algorithms to do the mining. In machine learning applications, the algorithms typically must be trained on sample data sets to look for the information being sought before they're run against the full set of data.
Data analysis and interpretation. The data mining results are used to create analytical models that can help drive decision-making and other business actions. The data scientist or another member of a data science team also must communicate the findings to business executives and users, often through data visualization and the use of data storytelling techniques.
Types of data mining techniques
Various techniques can be used to mine data for different data science applications. Pattern recognition is a common data mining use case that's enabled by multiple techniques, as is anomaly detection, which aims to identify outlier values in data sets. Popular data mining techniques include the following types:
Association rule mining. In data mining, association rules are if-then statements that identify relationships between data elements. Support and confidence criteria are used to assess the relationships -- support measures how frequently the related elements appear in a data set, while confidence reflects the number of times an if-then statement is accurate.
Classification. This approach assigns the elements in data sets to different categories defined as part of the data mining process. Decision trees, Naive Bayes classifiers, k-nearest neighbor and logistic regression are some examples of classification methods.
Clustering. In this case, data elements that share particular characteristics are grouped together into clusters as part of data mining applications. Examples include k-means clustering, hierarchical clustering and Gaussian mixture models.
Regression. This is another way to find relationships in data sets, by calculating predicted data values based on a set of variables. Linear regression and multivariate regression are examples. Decision trees and some other classification methods can be used to do regressions, too
Data mining companies follow the procedure
#data enrichment#data management#data entry companies#data entry#banglore#monday motivation#happy monday#data analysis#data entry services#data mining
4 notes
·
View notes
Text
I grow weary of the app-ification of everything.
#today's edition of I'm So Fucking Tired is sponsored by 'I just had to download an app to my phone to login to work starting next week'#'because the company that manufactures the code generators we were using decided to switch to an app and phase out the physical devices'#all this to 'secure access to' a computer no one who isn't me is going to have any hope of logging into anyway#the internet of shit continues apace wiping out all manual inputs for something that can data-mine you and assumes you have a smartphone#bite maim rip tear bruise gouge rend shatter kill#do you know this bitch asked for camera and recording access? for what? It is a fucking access code generator! NO.#'oh it's ok to not give it camera permission don't worry' I wasn't worried. I was about to update my resume REAL quick if it wasn't ok tho.#had me about to try to figure out wtf my linkedin and indeed passwords are again for the first time in over two years
4 notes
·
View notes
Text
the tumblr checkmarks that you can't get rid of are a permanent mark of shame for those of us who are easily fooled by the glitz and glamor of capitalism. we were saying not to buy them the whole time you dumb fucks
#'bububu-but theyre funny!!! and tumblr is the underdog!!!!'#>automattic#>$8 for NOTHING you get NOTHING#giving money to company because you think it's funny is actually stupid! who could have known!#now these guys are mining your data and selling it. ya happy chief
5 notes
·
View notes
Last Seen Blogs

dredgenpride
Paradise Found

tembakmuka
Untitled

loveyru
jade

skeletonfromspace
WELL COME ON...BONE MAN

lozero-jv
JV | STREAMS | VIDEOS
INDIE | BETA | EARLY