#data science components
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Why choose USDSI®s data science certifications? As the global industry demand rises, it presses the need for qualified data science experts. Swipe through to explore the key benefits that can accelerate your career in 2025! Enroll today https://bit.ly/3WN1Kyv
#data science career#certified data science professional#data science trends#career in data science#data science components
0 notes
Text

HOW TO GAIN KNOWLEDGE IN DATA SCIENCE | INFOGRAPHIC
Data science is an interdisciplinary field and to succeed in your data science career path, you must have a strong knowledge in the foundational subjects and core disciplines of data science which are Mathematics and statistics, computer science, and domain or industry knowledge.
The knowledge of programming language, mathematical concepts like probability distribution, linear algebra, and business acumen will help you understand the business problem efficiently and develop accurate data science models.
Explore the core data science subjects that you must master before starting your career in data science and learn about specialized data science components like data analysis, data visualization, data engineering, and more in this detailed infographic.
0 notes
Text

As we enter the year 2024, we can find data science as one of the most promising career paths. The data science industry has been growing at a rapid pace and is evolving faster than ever. We can see new technologies making data science operations simpler and more advanced.
In 2024, the data science platform market is expected to reach a whopping $133.70 billion, as stated by the Mordor Intelligence report. This indicates organizations will spend a lot on data science infrastructure and skilled professionals. So, it is a great time for beginners to invest in gaining the latest data science skills.
But before you get started, it is important to understand what data science constitutes of. Therefore, USDSI® has designed a detailed infographic on “7 Popular Data Science Components to Master in 2024”. This guide will help you understand what data is, what is data engineering, the role of programming languages in data science, and many more.
Read the infographic and get started with your data science career journey.
0 notes
Text
Understanding Principal Component Analysis (PCA)

The world of data is vast and complex. Machine Learning thrives on this data, but with great power comes great responsibility (to manage all those features!). This is where Principal Component Analysis (PCA) steps in, offering a powerful technique for simplifying complex datasets in Machine Learning.
What is Principal Component Analysis?
Imagine a room filled with clothes. Each piece of clothing represents a feature in your data. PCA helps you organize this room by identifying the most important categories (like shirts, pants, dresses) and arranging them efficiently.
It does this by transforming your data into a lower-dimensional space while capturing the most significant information. This not only simplifies analysis but also improves the performance of Machine Learning algorithms.
Fundamentals of Principal Component Analysis (PCA)
At its core, Principal Component Analysis (PCA) is a technique used in Machine Learning for dimensionality reduction. Imagine a room filled with clothes, each piece representing a feature in your data.
PCA helps organize this room by identifying the most important categories (like shirts, pants, dresses) and arranging them efficiently in a smaller space. Here’s a breakdown of the fundamental steps involved in PCA:
Standardization
PCA assumes your data is centered around a mean of zero and has equal variances. Standardization ensures this by subtracting the mean from each feature and scaling them to have a unit variance. This creates a level playing field for all features, preventing biases due to different scales.
Covariance Matrix
This matrix captures the relationships between all features in your data. A high covariance value between two features indicates they tend to move together (e.g., height and weight). Conversely, a low covariance suggests they are relatively independent.
Eigenvectors and Eigenvalues
PCA finds a set of directions (eigenvectors) that explain the most variance in your data. Each eigenvector is associated with an eigenvalue, which represents the proportion of variance it captures.
Think of eigenvectors as new axes along which your data can be arranged, and eigenvalues as measures of how “important” those axes are in capturing the spread of your data points.
Component Selection
You choose the most informative eigenvectors (based on their corresponding eigenvalues) to create your new, lower-dimensional space. These eigenvectors are often referred to as “principal components” because they capture the essence of your original data.
By selecting the top eigenvectors with the highest eigenvalues, you retain the most important variations in your data while discarding less significant ones.
Understanding these fundamentals is crucial for effectively using PCA in your Machine Learning projects. It allows you to interpret the results and make informed decisions about the number of components to retain for optimal performance.
Applications of PCA in Machine Learning
PCA is a versatile tool with a wide range of applications:
Dimensionality Reduction
As mentioned earlier, PCA helps reduce the number of features in your data, making it easier to visualize, analyze, and use in Machine Learning models.
Feature Engineering
PCA creates new, uncorrelated features (principal components) that can be more informative than the originals for specific tasks.
Anomaly Detection
By identifying patterns in the principal components, PCA can help you detect outliers and unusual data points.
Image Compression
PCA plays a role in compressing images by discarding less important components, reducing file size without significant visual degradation.
Recommendation Systems
PCA can be used to analyze user preferences and recommend relevant products or services based on underlying patterns.
Implementing PCA in Machine Learning Projects
While the core concepts of PCA are crucial, its real power lies in its practical application. This section dives into how to implement PCA in your Machine Learning projects using Python libraries like Scikit-learn.
Prerequisites
Basic understanding of Python programming
Familiarity with Machine Learning concepts
Libraries
We’ll be using the following libraries:
Pandas: Data manipulation
Numpy: Numerical computations
Scikit-learn: Machine Learning algorithms (specifically PCA from decomposition)
Note: Make sure you have these libraries installed using pip install pandas, numpy, scikit-learn.
Sample Dataset
Let’s consider a dataset with customer information, including features like age, income, spending habits (various categories), and location. We want to use PCA to reduce dimensionality before feeding the data into a recommendation system.
Step 1: Import libraries and data
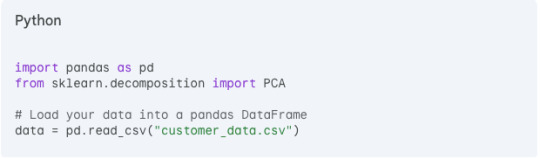
Step 2: Separate features and target (optional)
In this example, we’re focusing on dimensionality reduction, so we don’t necessarily need a target variable. However, if your task involves prediction, separate the features (explanatory variables) and target variable.

Step 3: Standardize the data
PCA is sensitive to the scale of features. Standardize the data using StandardScaler from scikit-learn.
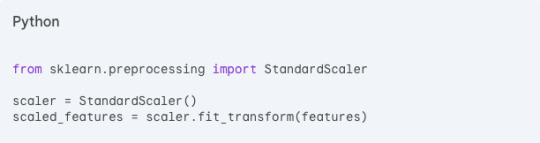
Step 4: Create the PCA object
Instantiate a PCA object, specifying the desired number of components (we’ll discuss this later) or leaving it blank for an initial analysis.

Step 5: Fit the PCA model
Train the PCA model on the standardized features.

Step 6: Analyze explained variance
PCA outputs the explained variance ratio (explained_variance_ratio_) for each principal component. This represents the proportion of variance captured by that component.

Step 7: Choose the number of components (n_components)
Here’s the crux of PCA implementation. You need to decide how many principal components to retain. There’s no single answer, but consider these factors:
Explained variance: Aim for components that capture a significant portion of the total variance (e.g., 80–90%).
Information loss: Retaining too few components might discard valuable information.
Model complexity: Using too many components might increase model complexity without significant benefit.
A common approach is to iteratively fit PCA models with different n_components and analyze the explained variance. You can also use tools like the scree plot to visualize the “elbow” where the explained variance plateaus.
Step 8: Transform the data
Once you’ve chosen the number of components, create a new PCA object with that specific value and transform the data into the principal component space.

Note: The transformed_data now contains your data projected onto the new, lower-dimensional space defined by the principal components.
Step 9: Use the transformed data
You can now use the transformed_data for further analysis or train your machine learning model with these reduced features.
Additional Tips:
Explore visualization techniques like plotting the principal components to understand the underlying structure of your data.
Remember that PCA assumes linear relationships between features. If your data exhibits non-linearity, consider alternative dimensionality reduction techniques.
By following these steps, you can effectively implement PCA in your machine learning projects to unlock the benefits of dimensionality reduction and enhance your models’ performance.
Frequently Asked Questions
How Much Dimensionality Reduction is Too Much?
There’s no one-size-fits-all answer. It depends on your data and the information you want to retain. Evaluation metrics can help you determine the optimal number of components.
Can PCA Handle Non-linear Relationships?
No, PCA works best with linear relationships between features. For non-linear data, consider alternative dimensionality reduction techniques.
Does PCA Improve Model Accuracy?
Not always directly. However, by simplifying data and reducing noise, PCA can often lead to better performing Machine Learning models.
Conclusion
PCA is a powerful tool that simplifies complex data, making it a valuable asset in your Machine Learning toolkit. By understanding its core concepts and applications, you can leverage PCA to unlock insights and enhance the performance of your Machine Learning projects.
Ready to take your Machine Learning journey further?
Enrol in our free introductory course on Machine Learning Fundamentals! Learn the basics, explore various algorithms, and unlock the potential of data in your projects.
0 notes
Text
25 Years of Exploring the Universe with NASA's Chandra Xray Observatory

Illustration of the Chandra telescope in orbit around Earth. Credit: NASA/CXC & J. Vaughan
On July 23, 1999, the space shuttle Columbia launched into orbit carrying NASA’s Chandra X-ray Observatory. August 26 marked 25 years since Chandra released its first images.
These were the first of more than 25,000 observations Chandra has taken. This year, as NASA celebrates the 25th anniversary of this telescope and the incredible data it has provided, we’re taking a peek at some of its most memorable moments.
About the Spacecraft
The Chandra telescope system uses four specialized mirrors to observe X-ray emissions across the universe. X-rays that strike a “regular” mirror head on will be absorbed, so Chandra’s mirrors are shaped like barrels and precisely constructed. The rest of the spacecraft system provides the support structure and environment necessary for the telescope and the science instruments to work as an observatory. To provide motion to the observatory, Chandra has two different sets of thrusters. To control the temperatures of critical components, Chandra's thermal control system consists of a cooling radiator, insulators, heaters, and thermostats. Chandra's electrical power comes from its solar arrays.
Learn more about the spacecraft's components that were developed and tested at NASA’s Marshall Space Flight Center in Huntsville, Alabama. Fun fact: If the state of Colorado were as smooth as the surface of the Chandra X-ray Observatory mirrors, Pike's Peak would be less than an inch tall.

Engineers in the X-ray Calibration Facility at NASA’s Marshall Space Flight Center in Huntsville, Alabama, integrating the Chandra X-ray Observatory’s High-Resolution Camera with the mirror assembly, in this photo taken March 16, 1997. Credit: NASA
Launch
When space shuttle Columbia launched on July 23, 1999, Chandra was the heaviest and largest payload ever launched by the shuttle. Under the command of Col. Eileen Collins, Columbia lifted off the launch pad at NASA’s Kennedy Space Center in Florida. Chandra was deployed on the mission’s first day.

Reflected in the waters, space shuttle Columbia rockets into the night sky from Launch Pad 39-B on mission STS-93 from Kennedy Space Center. Credit: NASA
First Light Images
Just 34 days after launch, extraordinary first images from our Chandra X-ray Observatory were released. The image of supernova remnant Cassiopeia A traces the aftermath of a gigantic stellar explosion in such captivating detail that scientists can see evidence of what is likely the neutron star.
“We see the collision of the debris from the exploded star with the matter around it, we see shock waves rushing into interstellar space at millions of miles per hour,” said Harvey Tananbaum, founding Director of the Chandra X-ray Center at the Smithsonian Astrophysical Observatory.
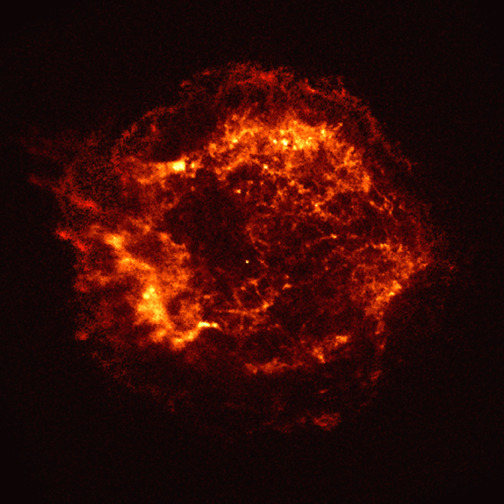
Cassiopeia A is the remnant of a star that exploded about 300 years ago. The X-ray image shows an expanding shell of hot gas produced by the explosion colored in bright orange and yellows. Credit: NASA/CXC/SAO
A New Look at the Universe
NASA released 25 never-before-seen views to celebrate the telescopes 25th anniversary. This collection contains different types of objects in space and includes a new look at Cassiopeia A. Here the supernova remnant is seen with a quarter-century worth of Chandra observations (blue) plus recent views from NASA’s James Webb Space Telescope (grey and gold).

This image features deep data of the Cassiopeia A supernova, an expanding ball of matter and energy ejected from an exploding star in blues, greys and golds. The Cassiopeia A supernova remnant has been observed for over 2 million seconds since the start of Chandra’s mission in 1999 and has also recently been viewed by the James Webb Space Telescope. Credit: NASA/CXC/SAO
Can You Hear Me Now?
In 2020, experts at the Chandra X-ray Center/Smithsonian Astrophysical Observatory (SAO) and SYSTEM Sounds began the first ongoing, sustained effort at NASA to “sonify” (turn into sound) astronomical data. Data from NASA observatories such as Chandra, the Hubble Space Telescope, and the James Webb Space Telescope, has been translated into frequencies that can be heard by the human ear.
SAO Research shows that sonifications help many types of learners – especially those who are low-vision or blind -- engage with and enjoy astronomical data more.
Click to watch the “Listen to the Universe” documentary on NASA+ that explores our sonification work: Listen to the Universe | NASA+

An image of the striking croissant-shaped planetary nebula called the Cat’s Eye, with data from the Chandra X-ray Observatory and Hubble Space Telescope. NASA’s Data sonification from Chandra, Hubble and/or Webb telecopes allows us to hear data of cosmic objects. Credit: NASA/CXO/SAO
Celebrate With Us!
Dedicated teams of engineers, designers, test technicians, and analysts at Marshall Space Flight Center in Huntsville, Alabama, are celebrating with partners at the Chandra X-ray Center and elsewhere outside and across the agency for the 25th anniversary of the Chandra X-ray Observatory. Their hard work keeps the spacecraft flying, enabling Chandra’s ongoing studies of black holes, supernovae, dark matter, and more.
Chandra will continue its mission to deepen our understanding of the origin and evolution of the cosmos, helping all of us explore the Universe.

The Chandra Xray Observatory, the longest cargo ever carried to space aboard the space shuttle, is shown in Columbia’s payload bay. This photo of the payload bay with its doors open was taken just before Chandra was tilted upward for release and deployed on July 23, 1999. Credit: NASA
Make sure to follow us on Tumblr for your regular dose of space: http://nasa.tumblr.com
2K notes
·
View notes
Text
I think something that's fascinating in the AI discussion is how non-creatives perceive AI versus how many creatives perceive AI.
For example, years before AI was a thing--I spoke with someone about my creative writing projects and they expressed to me how they found it unfathomable that I could just make up entire worlds far removed from our reality of existence. To them, it was like magic.
To me, it was the culmination of countless hours spent playing with words until they flowed into semi-coherent lines of thought and emotion. I remember being ten years old and laboring away on my "biggest" novel project ever--it was 5k words full of singular sentence-long paragraphs and garbled heaps of grammar atrocities to the English language.
If I hadn't written it, I wouldn't have come to learn how to create the basic foundations of a story.
But I do get the "it's magic" sentiment a bit--I'm that way with music. Theoretically, I understand the components of a music composition but it feels like magic to see a musician that can listen to a tune for the first time and play it perfectly due to years of honing in their craft.
That's the premise of that quote from Arthur C. Clarke: "Magic's just science we don't understand yet."
When it comes to anything we don't have countless hours of experience with, it feels like magic. It feels like something that's outside of our feeble human capabilities. It's not until we start to put in the time to learn a skill that it becomes more attainable inside our heads.
Generative AI presents a proposition to the non-creative: "What if you could skip past the 'learning process' and immediately create whatever art of your choosing?"
It's instant dopamine. In a world that preys upon our ever-decreasing attention spans and ways of farming short spikes of dopamine, was it ever a surprise that generative ai would be capitalized in this fashion?
So for the non-creative, when they use generative AI and see something resembling their prompt, it feels good. They are "writing" stories, they are "making" art in ways they could never do with their lack of skills.
(It is, in fact, really cool that we have technology that can do this. It's just incredibly shitty that it's exploitative of the human artists whose works were taken without permission as well as its existence threatening their livelihoods.)
What I think is equally concerning as the data scraping of generative ai is the threat that AI imposes on the education of the arts. More and more, you see an idea being pushed that you don't need knowledge/experience in how to create art, all you need to do is feed prompts into generative ai and let it do the "work" for you.
Generative AI pushes the idea that all art should be pristine, sleek and ready for capitalism consumption. There is no room for amateur artists struggling like foals to take their first steps in their creative journeys. We live in a world where time is money and why "waste" time learning when you can have instant success?
It's a dangerous concept because presents a potential loss in true understanding of how art works. It obscures it and makes it seem "impossible" to the average person, when art is one of the freest forms of expressions out there.
It's already happening--Nanowrimo, the writing challenge where the entire point was writing 50k original words in a single month regardless of how pretty it looked--coming out and saying that it is ableist and classist to be opposed to AI is the canary in the coalmine of what's to come.
For the non-creatives who enjoy the generative ai, it feels like a power fantasy come to life. But for creatives concerned about generative ai?
We're living in a horror movie.
386 notes
·
View notes
Text
Linguists deal with two kinds of theories or models.
First, you have grammars. A grammar, in this sense, is a model of an individual natural language: what sorts of utterances occur in that language? When are they used and what do they mean? Even assembling this sort of model in full is a Herculean task, but we are fairly successful at modeling sub-systems of individual languages: what sounds occur in the language, and how may they be ordered and combined?—this is phonology. What strings of words occur in the language, and what strings don't, irrespective of what they mean?—this is syntax. Characterizing these things, for a particular language, is largely tractable. A grammar (a model of the utterances of a single language) is falsified if it predicts utterances that do not occur, or fails to predict utterances that do occur. These situations are called "overgeneration" and "undergeneration", respectively. One of the advantages linguistics has as a science is that we have both massive corpora of observational data (text that people have written, databases of recorded phone calls), and access to cheap and easy experimental data (you can ask people to say things in the target language—you have to be a bit careful about how you do this—and see if what they say accords with your model). We have to make some spherical cow type assumptions, we have to "ignore friction" sometimes (friction is most often what the Chomskyans call "performance error", which you do not have to be a Chomskyan to believe in, but I digress). In any case, this lets us build robust, useful, highly predictive, and falsifiable, although necessarily incomplete, models of individual natural languages. These are called descriptive grammars.
Descriptive grammars often have a strong formal component—Chomsky, for all his faults, recognized that both phonology and syntax could be well described by formal grammars in the sense of mathematics and computer science, and these tools have been tremendously productive since the 60s in producing good models of natural language. I believe Chomsky's program sensu stricto is a dead end, but the basic insight that human language can be thought about formally in this way has been extremely useful and has transformed the field for the better. Read any descriptive grammar, of a language from Europe or Papua or the Amazon, and you will see (in linguists' own idiosyncratic notation) a flurry regexes and syntax trees (this is a bit unfair—the computer scientists stole syntax trees from us, also via Chomsky) and string rewrite rules and so on and so forth. Some of this preceded Chomsky but more than anyone else he gave it legs.
Anyway, linguists are also interested in another kind of model, which confusingly enough we call simply a "theory". So you have "grammars", which are theories of individual natural languages, and you have "theories", which are theories of grammars. A linguistic theory is a model which predicts what sorts of grammar are possible for a human language to have. This generally comes in the form of making claims about
the structure of the cognitive faculty for language, and its limitations
the pathways by which language evolves over time, and the grammars that are therefore attractors and repellers in this dynamical system.
Both of these avenues of research have seen some limited success, but linguistics as a field is far worse at producing theories of this sort than it is at producing grammars.
Capital-G Generativism, Chomsky's program, is one such attempt to produce a theory of human language, and it has not worked very well at all. Chomsky's adherents will say it has worked very well—they are wrong and everybody else thinks they are very wrong, but Chomsky has more clout in linguistics than anyone else so they get to publish in serious journals and whatnot. For an analogy that will be familiar to physics people: Chomskyans are string theorists. And they have discovered some stuff! We know about wh-islands thanks to Generativism, and we probably would not have discovered them otherwise. Wh-islands are weird! It's a good thing the Chomskyans found wh-islands, and a few other bits and pieces like that. But Generativism as a program has, I believe, hit a dead end and will not be recovering.
Right, Generativism is sort of, kind of attempting to do (1), poorly. There are other people attempting to do (1) more robustly, but I don't know much about it. It's probably important. For my own part I think (2) has a lot of promise, because we already have a fairly detailed understanding of how language changes over time, at least as regards phonology. Some people are already working on this sort of program, and there's a lot of work left to be done, but I do think it's promising.
Someone said to me, recently-ish, that the success of LLMs spells doom for descriptive linguistics. "Look, that model does better than any of your grammars of English at producing English sentences! You've been thoroughly outclassed!". But I don't think this is true at all. Linguists aren't confused about which English sentences are valid—many of us are native English speakers, and could simply tell you ourselves without the help of an LLM. We're confused about why. We're trying to distill the patterns of English grammar, known implicitly to every English speaker, into explicit rules that tell us something explanatory about how English works. An LLM is basically just another English speaker we can query for data, except worse, because instead of a human mind speaking a human language (our object of study) it's a simulacrum of such.
Uh, for another physics analogy: suppose someone came along with a black box, and this black box had within it (by magic) a database of every possible history of the universe. You input a world-state, and it returns a list of all the future histories that could follow on from this world state. If the universe is deterministic, there should only be one of them; if not maybe there are multiple. If the universe is probabilistic, suppose the machine also gives you a probability for each future history. If you input the state of a local patch of spacetime, the machine gives you all histories in which that local patch exists and how they evolve.
Now, given this machine, I've got a theory of everything for you. My theory is: whatever the machine says is going to happen at time t is what will happen at time t. Now, I don't doubt that that's a very useful thing! Most physicists would probably love to have this machine! But I do not think my theory of everything, despite being extremely predictive, is a very good one. Why? Because it doesn't tell you anything, it doesn't identify any patterns in the way the natural world works, it just says "ask the black box and then believe it". Well, sure. But then you might get curious and want to ask: are there patterns in the black box's answers? Are there human-comprehensible rules which seem to characterize its output? Can I figure out what those are? And then, presto, you're doing good old regular physics again, as if you didn't even have the black box. The black box is just a way to run experiments faster and cheaper, to get at what you really want to know.
General Relativity, even though it has singularities, and it's incompatible with Quantum Mechanics, is better as a theory of physics than my black box theory of everything, because it actually identifies patterns, it gives you some insight into how the natural world behaves, in a way that you, a human, can understand.
In linguistics, we're in a similar situation with LLMs, only LLMs are a lot worse than the black box I've described—they still mess up and give weird answers from time to time. And more importantly, we already have a linguistic black box, we have billions of them: they're called human native speakers, and you can find one in your local corner store or dry cleaner. Querying the black box and trying to find patterns is what linguistics already is, that's what linguists do, and having another, less accurate black box does very little for us.
Now, there is one advantage that LLMs have. You can do interpretability research on LLMs, and figure out how they are doing what they are doing. Linguists and ML researchers are kind of in a similar boat here. In linguistics, well, we already all know how to talk, we just don't know how we know how to talk. In ML, you have these models that are very successful, buy you don't know why they work so well, how they're doing it. We have our own version of interpretability research, which is neuroscience and neurolinguistics. And ML researchers have interpretability research for LLMs, and it's very possible theirs progresses faster than ours! Now with the caveat that we can't expect LLMs to work just like the human brain, and we can't expect the internal grammar of a language inside an LLM to be identical to the one used implicitly by the human mind to produce native-speaker utterances, we still might get useful insights out of proper scrutiny of the innards of an LLM that speaks English very well. That's certainly possible!
But just having the LLM, does that make the work of descriptive linguistics obsolete? No, obviously not. To say so completely misunderstands what we are trying to do.
79 notes
·
View notes
Text
Also preserved in our archive
New research indicates that people who contracted COVID-19 early in the pandemic faced a significantly elevated risk of heart attack, stroke, and death for up to three years post-infection.
Those with severe cases saw nearly quadruple the risk, especially in individuals with A, B, or AB blood types, while blood type O was associated with lower risk. This finding highlights long-term cardiovascular threats for COVID-19 patients and suggests that severe cases may need to be considered as a new cardiovascular risk factor. However, further studies on more diverse populations and vaccinated individuals are needed to validate these results.
Long-Term Cardiovascular Risks Linked to COVID-19 Infection A recent study supported by the National Institutes of Health (NIH) found that COVID-19 infection significantly increased the risk of heart attack, stroke, and death for up to three years in unvaccinated people who contracted the virus early in the pandemic. This risk was observed in individuals with and without pre-existing heart conditions and confirms earlier research linking COVID-19 infection to a higher chance of cardiovascular events. However, this study is the first to indicate that the heightened risk may last as long as three years, especially for those infected during the first wave of the pandemic.
The study, published in the journal Arteriosclerosis, Thrombosis, and Vascular Biology, revealed that individuals who had COVID-19 early in the pandemic were twice as likely to experience cardiovascular events compared to those with no history of infection. For those with severe cases, the risk was nearly quadrupled.
“This study sheds new light on the potential long-term cardiovascular effects of COVID-19, a still-looming public health threat,” said David Goff, M.D., Ph.D., director for the Division of Cardiovascular Sciences at NIH’s National Heart, Lung, and Blood Institute (NHLBI), which largely funded the study. “These results, especially if confirmed by longer term follow-up, support efforts to identify effective heart disease prevention strategies for patients who’ve had severe COVID-19. But more studies are needed to demonstrate effectiveness.”
Genetic Factors and Blood Type’s Role in COVID-19 Complications The study is also the first to show that an increased risk of heart attack and stroke in patients with severe COVID-19 may have a genetic component involving blood type. Researchers found that hospitalization for COVID-19 more than doubled the risk of heart attack or stroke among patients with A, B, or AB blood types, but not in patients with O types, which seemed to be associated with a lower risk of severe COVID-19.
Scientists studied data from 10,000 people enrolled in the UK Biobank, a large biomedical database of European patients. Patients were ages 40 to 69 at the time of enrollment and included 8,000 who had tested positive for the COVID-19 virus and 2,000 who were hospitalized with severe COVID-19 between Feb. 1, 2020, and Dec. 31, 2020. None of the patients had been vaccinated, as vaccines were not available during that period.
The researchers compared the two COVID-19 subgroups to a group of nearly 218,000 people who did not have the condition. They then tracked the patients from the time of their COVID-19 diagnosis until the development of either heart attack, stroke, or death, up to nearly three years.
Higher Cardiovascular Risk in Patients With Severe Cases Accounting for patients who had pre-existing heart disease – about 11% in both groups – the researchers found that the risk of heart attack, stroke, and death was twice as high among all the COVID-19 patients and four times as high among those who had severe cases that required hospitalization, compared to those who had never been infected. The data further show that, within each of the three follow-up years, the risk of having a major cardiovascular event was still significantly elevated compared to the controls – in some cases, the researchers said, almost as high or even higher than having a known cardiovascular risk factor, such as Type 2 diabetes.
“Given that more than 1 billion people worldwide have already experienced COVID-19 infection, the implications for global heart health are significant,” said study leader Hooman Allayee, Ph.D., a professor of population and public health sciences at the University of Southern California Keck School of Medicine in Los Angeles. “The question now is whether or not severe COVID-19 should be considered another risk factor for cardiovascular disease, much like type 2 diabetes or peripheral artery disease, where treatment focused on cardiovascular disease prevention may be valuable.”
Allayee notes that the findings apply mainly to people who were infected early in the pandemic. It is unclear whether the risk of cardiovascular disease is persistent or may be persistent for people who have had severe COVID-19 more recently (from 2021 to the present).
Need for Broader Studies and Vaccine Impact on Risks Scientists state that the study was limited due to the inclusion of patients from only the UK Biobank, a group that is mostly white. Whether the results will differ in a population with more racial and ethnic diversity is unclear and awaits further study. As the study participants were unvaccinated, future studies will be needed to determine whether vaccines influence cardiovascular risk. Studies on the connection between blood type and COVID-19 infection are also needed as the mechanism for the gene-virus interaction remains unclear.
Study link: www.ahajournals.org/doi/10.1161/ATVBAHA.124.321001
#mask up#covid#pandemic#public health#wear a mask#covid 19#wear a respirator#still coviding#coronavirus#sars cov 2#long covid#heart health#covidー19#covid conscious#covid is airborne#covid isn't over#covid pandemic#covid19
58 notes
·
View notes
Text
Because I am a fucking NERD, I read a medical journal article about testing the pharmacological properties of the Traditional Chinese Medicine (TCM) herb Atractylodes Macrocephala, aka Bai Zhu 白术 (after which our beautiful wife is named).
Here are some of the clinical findings! Sources linked at the end!
TLDR: Many of the traditional properties of Bai Zhu are rooted in good science! It is a versatile herb that can be used widely to treat many distinct ailments. The most amazing one for me is that Bai Zhu has anti-depressant properties! HE CAN LITERALLY ALLEVIATE OUR DEPRESSION.
Disclaimer: I have as many medical degrees as this guy, which is zero, firstly because he's an engineer not a medical doctor and secondly because he didn't even graduate.

I'll look at the TCM first and then highlight the salient points of the science article. Always consult a professional if trying TCM!
Bai Zhu flowers resemble those of a thistle, but it is in fact the sliced dried rhizome root that is used in TCM. It's categorised as one of the 'Tonic herbs for Qi Deficiency', ie strengthens the Qi. Bai Zhu is one of the components in the 'Four Gentlemen' Qi invigoration formula.


Bai Zhu is used quite widely in TCM as a core 'king' ingredient of many standardised formulas, some recipes going back to the 3rd century. It is also used to augment other herbs as an deputy or assistant ingredient.
Under TCM Five Phases Theory, the flavour profile of Bai Zhu is both bitter and sweet. Each flavour is said to target different organs and meridians in the body. Bitter ingredients alleviate 'dampness' in the body and encourages cleansing/elimination via urine/poop.
Sweet ingredients are said to detoxify the body, replenish Qi and blood, and slow down acute reactions. This is an interesting parallel with his story quest, where he formulates an antidote to what is essentially a poison.
Bai zhu is associated with relieving afflictions relating to the spleen and stomach. In TCM, the spleen has a huge role and impacts not just digestive health, but muscles, blood, saliva and raising of Qi. It houses the intellect, so is impacted by anxiety, affecting mental health

In TCM foods have different heat properties. Baizhu is a Warm ingredient, meaning it can alleviate Cold or Dampness in the body. Being vulnerable to Dampness, the spleen relies on it a lot. It's also used for immune/neurological issues said to arise from spleen dysfunction.
Bai Zhu is also believed to have anti-inflammatory properties. In addition, it is prescribed to assist with 'fetal safety' and reduce likelihood of premature birth.
Bai Zhu also has a 'drying' effect, helping the body to eliminate excess moisture and restore balance. This is an interesting quality when compared with his speciality dish 'Heat-Quelling Soup', which balances the natural 'Warm' and 'Drying' properties of the Bai Zhu herb.

In TCM, to assist the spleen, it is recommended to eat soft or easy to digest foods, preferably cooked. This is consistent with Baizhu's lines in 2.1 Moonchase.

NOW THE SCIENCE!
Gastrointestinal disorders
Bai Zhu decoction might greatly speed up the passage of the digestive tract and gastrointestinal contents. Also, improve the small intestinal smooth muscle's capacity to contract, amplify, and frequency, as well as its ability to prevent hypoxia.
Anti-osteoporotic activity
Further data is necessary, but there is evidence to suggest that Bai Zhu may be helpful in the treatment and prevention of osteoporosis.
Anti-inflammatory and immunomodulatory effects
Certain components of Bai Zhu were found scientifically to indeed have strong anti-inflammatory effects, reducing production of nitric oxide and TNF-α, as well as stopping TNF-α mRNA and inducible nitric oxide synthase from working.
Metabolic disorders
Some data suggests that it does indeed aid digestive metabolism, and can help the body better absorb nutrients from food and maintain proper metabolic functions. Furthermore, some studies suggest that it may have a role in regulating blood sugar levels.
Antibacterial activity
It has been shown that giving ethanol extracts to bacteria such as Shigella felxneri, Bacillus subtilis, Escherichia coli, and Staphylococcus aureus for a whole day significantly inhibits their development.
Neuroprotective properties
A component of Bai Zhu reduced the extent of brain infarcts, restored cerebral blood flow, and improved brain edema and neurological deficits.
It also ALLEVIATED DEPRESSION.
BAIZHU ALLEVIATES DEPRESSION!! SCIENTIFICALLY PROVEN!! (But we knew that)
Antioxidant activity
Some components of Bai Zhu may possess antioxidant and phytochemical properties and stimulate endogenous antioxidant enzymes. This can help reduce oxidative damage to cells and tissues, linked to neurodegenerative conditions like Alzheimer's and Parkinson's Disease.
Memory enhancement
It was found that Bai Zhu might help improve learning and memory problems in older people and could potentially be used as a therapeutic approach for improving cognitive function in aging individuals. This is adorable given the lore with Qiqi.
Preservation of smooth muscle functions in the uterus
Bai Zhu was found to be beneficial in reducing the frequency of uterine contractions in the latter stages of pregnancy, which decreased the chance of an early delivery. [Honestly, this one kind of blew my mind a little]
More studies are required but Bai Zhu is believed to have potential in many other areas as well, such as controlling blood cholesterol and glucose levels, anti-platelet aggregation agent, improve spleen and immune function, anti-tumour agent, easing side effects of chemotherapy.
So yeah, Bai Zhu can do a lot and while not a universal healer (because there's no such thing as a true panacea), it's extremely versatile and diverse in its application. Moreover, it still has a lot of untapped potential.
Here are the two main science articles I used, though their references contain many more, some of which I had fun reading:
https://sciencedirect.com/science/article/pii/S2667142524000381#bib0008…
https://pmc.ncbi.nlm.nih.gov/articles/PMC9452894/…
Here's an easy TCM overview of Bai Zhu with formula recipes: https://meandqi.com/herb-database/atractylodes-rhizome…
#baizhu#baizhu genshin impact#genshin baizhu#changsheng#TCM#traditional chinese medecine#nerd alert#白术#白朮#백출#長生
42 notes
·
View notes
Note
are hive men sentient in the same fashion we are? Do they experience the full range of subjectivity the modern homo sapiens does or was some of that excluded from their creation? It feels like it would have to in order to make them function well in an eusocial context. I'd be curious if you could expand on that
This is a question i've left a bit ambiguous for myself, because there is a wide range of answers.
In one version of the hive mind, a mass of human brains could be linked to become components of one huge brain (like the components of our own brains), with the individual completely subsumed into the whole. This angle is one that I want to play with later, as a biotech answer to making supercomputers...
For our martians, and the crew of the Hale-Bopp dyson Tree, I imagine there would be some of this at play, since my presumed method of communication in the hive is some sort of radio-telepathy - low-fi neural network stuff. Individual hive-men might have some agency of their own, though, in how they reacted to specific stimuli.
But you're right in that their subjective experience would be a lot different then ours, in part because they'd always be sharing in the data from the rest of the hive. There'd be little individual internal life for a hive member, since they'd always be picking up feelings and thoughts from their hive-mates.
In the story i first wanted to make about the hive-men, a big part of it was about an earthman finding himself inducted into the hive, and having the neural biotech grow inside him... and finding that all his individual neuroses, worries, etc, were obliterated as he found the sweet release of ego death, losing himself into the hive. Like when people surrender to a cult, basically, but this cult doesn't have a tyrannical leader, and operates as a super-organism... which to me seems a little more appealing.
Now, because this is science fiction, I like to think that the hive, as a collective mind, would be a bit more sophisticated than an ant colony, and perhaps capable of more abstract thought - daydreaming great symphonies, pondering philosophical and scientific problems with the brain power of the whole hive, that sort of thing. Not just reactive, but pro-active. But the rich, subjective internal life that is the heritage of all humans might not be as useful, or as possible, when you're sharing your thoughts and brainpower with ten thousand other people.
As a final little thought, I do imagine that these hive men would have began as a voluntary experiment by scientist types, somewhere out in the rings of saturn, far from the prying eyes of earth. Perhaps starting as a more traditional cultish organization, to start, but I'd like to think that the practical problems of living as a super-organism in deep space would temper the more extreme elements.
(but another story idea i would like to flesh out, one day, would be the bad side of other hive-people - non-biotech hive cults prone to mass religious mania, etc. There's a lot of room to play in...)
30 notes
·
View notes
Text
Soo I looked a bit into Dr.Stone some more. Still not too into it but I do love Senku’s personality.
So I decided to update the headcanons I wrote (here) with a more appropriate set. (I mean those still work but headcanons are ever changing!
————
(Y/N) being an unstoppable force of science and curiosity. Her seeing Hyrule as a goldmine of new discoveries.
Hylians, Zoras, Gorons, Ritos, fairies, magic, it’s all up for research. She treats every moment like an opportunity to advance scientific knowledge, and she refuses to be stopped.
Magic? Not real. :) It’s just science they haven’t figured out yet. The Chain gets so frustrated trying to explain magic to her. She just points at Wild’s Sheikah Slate and goes ‘That’s just ancient technology. You can’t tell me this isn’t science.’ (Wild doesn’t even argue that point cause he’s heard all that from Purah countless times.)
Warriors is her biggest headache. (….or is she his??) Every time she tries a new experiment, he’s there, yelling about how “this is insane” and “why do you need to study our bone density!?” He acts like her research is some grand threat to Hylian dignity. (Like like Hylians ever had dignity, have you SEEN the nonsense they get up to?)
Wild? The best test subject ever. He has zero self-preservation, an insane healing factor, and thinks everything she does is hilarious. If she tells him to drink a suspicious potion to test its effects, he’ll do it without question. (He probably has some instinctive memory from when he was guarding Zelda Pre-Calamity….and Purah, don’t forget Purah.)
Twilight, Time, and Four are skeptical. Twilight doesn’t like being poked at. Time just sighs and avoids her nonsense. Four, as a blacksmith, appreciates the concept of experimentation but thinks she’s a little unhinged.
Legend and Hyrule are terrified of her. Legend has been through way too much to trust someone who wants to test how “resilient” he is. Hyrule, being part fae, fears she’s trying to extract his blood for science. (She’s NEVER use it for malicious stuff but ya know…his situation with monsters after his blood is kinda traumatic if you think about it.)
Wind is… oddly encouraging? He doesn’t want to be tested on, but he’ll help her with experiments because he thinks it’s fun. Until she suggests launching him via trebuchet. Then he immediately bails.
Now…experiment ideas she would Absolutely ttempt:
1. Testing Hylians’ magic resistance.
(She straight-up douses Wild in fairy dust to see if he heals faster. He does. But now he won’t stop glowing.)
2. Figuring out why Twilight turns into a wolf.
(She follows him around, taking notes. Eventually just tries to pet him. He lets her and then bolts when she mutters about fur samples)
3. Trying to see how much weight Gorons can carry.
(Ends up building a scale just to measure how heavy Gorons actually are. )
4. Testing if fairies have any biological components.
(She somehow catches one and Wild (and Time and Hyrule, and Warriors) has to stop her before she dissects it.)
5. “Science-ing” Divine Beasts & Sheikah Tech.
(….She almost electrocutes herself messing with an inactive Guardian….and she actually gets electrocuted by Naboris)
6. Building a modern hot air balloon.
(It works. Wild and Wind immediately steal it. Crash it, she makes better with the data collected from their little joy ride.)
7. Trying to chemically analyze elixirs & potions.
(She drinks half of them herself. She starts tasting colors and seeing sounds.)
8. Seeing if magic weapons follow the law of thermodynamics.
(Almost burns herself with a fire sword.)
9. Figuring out what happens if someone eats a Korok seed.
(Wild tried it. It’s disgusting. And he hated everything that day.)
Look The Chain are both fascinated and terrified. They love her, she’s a fun gal, but they also know she is a menace and should NOT be allowed near other equally crazy scientists. (Looking at you Purah.)
21 notes
·
View notes
Text
Building robust data projects is a must to strengthen a business’s long-term growth trajectory. It is imperative to understand what goes into building a thriving and targeted project utilizing surefire data science components. This video aims to deliver a clear insight into what components play a crucial role in enhancing the quality of a data science project and ways to amplify your performance as a specialist. Understanding data quality, feature engineering, powerfully lucid data visualization, exploratory data analysis, model selection and training, and many other facets of project building get involved in successful delivery. If you wish to excel at building and strengthening your data project-building competencies, this is your calling. Begin with USDSI® today! bit.ly/40uXxSu
0 notes
Text

Before starting a career in data science, it is important to understand what it constitutes of. Explore different components of data science that you must master in 2024
0 notes
Text
Guide to Principal Component Analysis
Explore our comprehensive Guide to Principal Component Analysis (PCA) and transform your data analysis skills! This in-depth blog post covers everything you need to know about PCA, from the fundamental concepts to advanced applications. Learn how PCA can help you reduce dimensionality, identify patterns, and enhance your data visualization techniques. Perfect for data scientists, statisticians, and anyone keen on mastering this essential statistical tool. Dive into practical examples, step-by-step tutorials, and expert tips to make the most out of PCA in your projects. Don't miss out on this ultimate resource for mastering Principal Component Analysis!
0 notes
Text
get to know your tumblr mutuals tag!
i was tagged by @nfly5, thank you laura!! :))
1. what's the origin of your username?
i think wyll ravengard of bg3 fame and lae'zel also of bg3 fame should kiss and fall in love and ride dragons into the sunset (or, rather, the astral plane) together :)


2. otps + shipname
wyllzel 🥰 and vivwall (vivienne x blackwall dai) at the moment for sure!
i'm trying to think of more, but honestly i'm p easygoing when it comes to ships haha i'll take a peek at almost anything that seems compelling 🫣
3. song stuck in my head
"purple lace bra" by tate mcrae for uhhh no reason 🤫 and "feel it" by d4vd for also no reason LOL (🎶 you told me once that i was crazy i said babygirl i knooooowww but i can't let you gooo (away!) 🎶)
4. weirdest trait/habit
i have a growing aversion to cold drinks lol it's starting to feel odd drinking something that isn't hot... that's not that weird though, i think i'm just becoming a grandma LOL
5. hobbies
photoshop!! i like making gifs and edits and such :) i've also been writing a lot more recently which is crazy, i haven't felt this inspired or productive in forever :'D thank you DA lol 🩷
i am also v much a webtoon enjoyer (my all-time fave is "trash belongs in the trash can!" but i'm currently v invested in "nevermore," "i'm the queen in this life," "sisters at war," and "momfluencer"!), but i'll read manga (tatsuki fujimoto my GOAT) and comics (invincible also my GOAT)
6. if you work, what's your profession?
i write internal software documentation which means it's architectural, high-level design stuff... not so much code-specific, but the reasoning behind why software components are organized the way they are. it's not very fun, mostly mind-melting... i work closely w engineers and it's kind of a toss-up whether they'll be nice/patient or think i'm stupid lol
but my brain now contains so many company secrets :^) if you ever have any questions about data storage/virtualization i can possibly help lol
7. if you could have any job you wish, what would you have?
funny story—i applied for grad school, and i've been accepted to an english m.a. program that starts this fall!!! 🥹 we'll see where i go w that, but i'll likely enter education!
8. something you're good at?
uhh i suppose BG3 LOL i beat honor mode twice! 🎉 (i'm still trying to figure out how DA works 🤔 DA2 hard mode is chill idk if i'd ever do nightmare tho 😬)
9. something you hate?
ok it's not rly a "hate" thing but it does irk me when i see fandom claims/arguments that don't cite specific quotes/screenshots/instances lol (the english major in me activates and i am consumed by the thought "🚨‼️ where do you see this in the text 👁️👁️🫵" LOL)
10. something you forget?
the grief 😂🖐️ it creeps up on me! almost cried in my cubicle multiple times this week. haha.
11. your love language?
receiving is probably words of affirmation? giving is probably gifts, i like making silly things for my bestie (eg. fenris keychain lol) and finding weird stickers for my brother 🤡
12. favorite movies/shows?
my letterboxd top 4 are:
everything everywhere all at once (2022) (saw it twice in theaters and sobbed thru both times)
nope (2022) (BRILLIANT movie, so smart)
challengers (2024) (so fascinating!)
lust, caution (2007) (i need to rewatch this one expeditiously)
as for shows, i love succession (2018-23), invincible (2021-), and the twilight zone (1959-64)!
13. what were you like as a child?
apparently very friendly, outgoing, and extroverted! i would just run up to my fellow kids and yap at them?! i do nooot do that anymore lol
14. favorite subject in school?
english/literature!!
15. least favorite subject?
oh man, i was so bad at science, especially biology/chemistry... i could scrape by in physics bc i was decent at math, but it was still awful...
16. what's your best/worst character trait?
worst...??? according to my last annual review, i need to be more confident in the workplace LOL 💀 + sometimes i let my anxiety get the better of me... i think that's just a lifelong struggle thing though, but i know i can improve to be a better friend and such 💪
best... multiple reviews from mom-aged women say that i am a "nice" and "sweet" person so hopefully at least that means i can leave a good first impression haha
17. if you could change any detail of your life right now, what would it be?
i'm not a huge fan of what-if-ing personally, but i do wish i were on vacation 😆
18. if you could travel in time, who would you like to meet?
i'm currently very curious about my paternal grandparents... it's hard for me to conceptualize why they got married... and how my dad grew up... i guess i would want to witness some of that??
tagging: hello again haha!! @creaking-skull @andrewknightley @coolseabird @genderdotcom @bladeweave @grey-wardens @maironsbigboobs no pressure again :))
#chelle.txt#tag game#wow that was a lot of self-reflection!! :O#thank you again for the tag laura!! <3
18 notes
·
View notes
Text
DARK MATTER DOESN'T EXIST IN OUR UNIVERSE??
Blog#387
Wednesday, March 27th, 2024.
Welcome back,
The composition of the universe, as we currently understand it, is thought to comprise 'normal matter,' 'dark energy,' and 'dark matter.' However, a recent study from the University of Ottawa sheds new light on this notion, suggesting that dark matter might not actually be a necessary component.

Dark matter is a term used in cosmology to describe entities that don't interact with light or the electromagnetic field, and can only be inferred through gravitational effects. Essentially, it's invisible and its composition remains a mystery, yet it plays a crucial role in our comprehension of the behavior of galaxies, planets, and stars.

Professor Rajendra Gupta, from the Faculty of Science at the University of Ottawa, conducted this groundbreaking study. He utilized a blend of the covarying coupling constants (CCC) and "tired light" (TL) theories, amalgamating them into what's termed the CCC+TL model.
This model proposes that the forces of nature diminish over cosmic time and that light loses energy during its extensive travels.

Gupta's model has been rigorously tested against various observations, including the distribution of galaxies and the evolution of light from the early universe.
This study challenges the prevailing understanding of the universe, which posits that approximately 27% of its composition consists of dark matter, with less than 5% being ordinary matter, leaving the rest attributed to dark energy.

Gupta said, "The findings from our study affirm our prior research on the age of the universe, which concluded it to be approximately 26.7 billion years old, and demonstrate that the universe may not necessitate the presence of dark matter."
He further explains that while standard cosmology attributes the accelerated expansion of the universe to dark energy, it is actually the weakening of natural forces as the universe expands that drives this phenomenon, not dark energy.

The concept of "redshifts" plays a pivotal role in this study. Redshifts occur when light shifts towards the red end of the spectrum. Gupta scrutinized data from recent papers on galaxy distribution at low redshifts and the angular size of the sound horizon from literature at high redshifts.
Originally published on www.thebrighterside.news
COMING UP!!
(Saturday, March 30th, 2024)
"IS THERE GRAVITY IN SPACE??"
#astronomy#outer space#alternate universe#astrophysics#universe#spacecraft#white universe#space#parallel universe#astrophotography
104 notes
·
View notes