#dataimport
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
0 notes
Link
Learn expert level Online EPBCS Training in our best institute real time Oracle EPBCS (Enterprise Planning and Budgeting Cloud Services) Certification Training with Course Material Pdf attend demo free Live Oracle EPBCS Tutorial Videos for Beginners and Download Oracle EPBCS Documentation Dumps Within Reasonable Cost in Hyderabad Bangalore Mumbai Delhi India UAE USA Canada Toronto Texas California Australia Singapore Malaysia South Africa Brazil Spain Japan China UK Germany London England Dubai Qatar Oman Mexico France Srilanka Pune Noida Chennai Pakistan
https://www.spiritsofts.com/oracle-epbcs-online-training/
Enhance Financial Control with Oracle ARCS Online Training
Cloud-Based Reconciliation: Oracle ARCS training focuses on utilizing cloud technology to enhance reconciliation efficiency and accuracy, allowing participants to manage reconciliations from anywhere.
End-to-End Process: The training covers the entire reconciliation lifecycle, from data import and matching to review, approval, and reporting, ensuring participants grasp the complete process flow.
Data Integrity and Validation: Learners gain insights into data validation techniques, ensuring data integrity before initiating the reconciliation process, minimizing errors, and improving reliability.
Automated Matching: The training emphasizes leveraging automation to match large volumes of data, reducing manual efforts, and expediting the reconciliation process.
0 notes
Text
Import Odoo Purchase Orders like a pro! Stop manual entry. Our ultimate guide simplifies Odoo PO data imports for maximum efficiency. Learn how! #Odoo #PurchaseOrder #DataImport #ERP #OdooTips #Procurement
0 notes
Text
A Comprehensive Guide to Scraping DoorDash Restaurant and Menu Data

Introduction
Absolutely! Data is everything; it matters to any food delivery business that is trying to optimize price, look into customer preferences, and be aware of market trends. Web Scraping DoorDash restaurant Data allows one to bring his business a step closer to extracting valuable information from the platform, an invaluable competitor in the food delivery space.
This is going to be your complete guide walkthrough over DoorDash Menu Data Scraping, how to efficiently Scrape DoorDash Food Delivery Data, and the tools required to scrape DoorDash Restaurant Data successfully.
Why Scrape DoorDash Restaurant and Menu Data?
Market Research & Competitive Analysis: Gaining insights into competitor pricing, popular dishes, and restaurant performance helps businesses refine their strategies.
Restaurant Performance Evaluation: DoorDash Restaurant Data Analysis allows businesses to monitor ratings, customer reviews, and service efficiency.
Menu Optimization & Price Monitoring: Tracking menu prices and dish popularity helps restaurants and food aggregators optimize their offerings.
Customer Sentiment & Review Analysis: Scraping DoorDash reviews provides businesses with insights into customer preferences and dining trends.
Delivery Time & Logistics Insights: Analyzing delivery estimates, peak hours, and order fulfillment data can improve logistics and delivery efficiency.
Legal Considerations of DoorDash Data Scraping
Before proceeding, it is crucial to consider the legal and ethical aspects of web scraping.
Key Considerations:
Respect DoorDash’s Robots.txt File – Always check and comply with their web scraping policies.
Avoid Overloading Servers – Use rate-limiting techniques to avoid excessive requests.
Ensure Ethical Data Use – Extracted data should be used for legitimate business intelligence and analytics.
Setting Up Your DoorDash Data Scraping Environment
To successfully Scrape DoorDash Food Delivery Data, you need the right tools and frameworks.
1. Programming Languages
Python – The most commonly used language for web scraping.
JavaScript (Node.js) – Effective for handling dynamic pages.
2. Web Scraping Libraries
BeautifulSoup – For extracting HTML data from static pages.
Scrapy – A powerful web crawling framework.
Selenium – Used for scraping dynamic JavaScript-rendered content.
Puppeteer – A headless browser tool for interacting with complex pages.
3. Data Storage & Processing
CSV/Excel – For small-scale data storage and analysis.
MySQL/PostgreSQL – For managing large datasets.
MongoDB – NoSQL storage for flexible data handling.
Step-by-Step Guide to Scraping DoorDash Restaurant and Menu Data
Step 1: Understanding DoorDash’s Website Structure
DoorDash loads data dynamically using AJAX, requiring network request analysis using Developer Tools.
Step 2: Identify Key Data Points
Restaurant name, location, and rating
Menu items, pricing, and availability
Delivery time estimates
Customer reviews and sentiments
Step 3: Extract Data Using Python
Using BeautifulSoup for Static Dataimport requests from bs4 import BeautifulSoup url = "https://www.doordash.com/restaurants" headers = {"User-Agent": "Mozilla/5.0"} response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, "html.parser") restaurants = soup.find_all("div", class_="restaurant-name") for restaurant in restaurants: print(restaurant.text)
Using Selenium for Dynamic Contentfrom selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service service = Service("path_to_chromedriver") driver = webdriver.Chrome(service=service) driver.get("https://www.doordash.com") restaurants = driver.find_elements(By.CLASS_NAME, "restaurant-name") for restaurant in restaurants: print(restaurant.text) driver.quit()
Step 4: Handling Anti-Scraping Measures
Use rotating proxies (ScraperAPI, BrightData).
Implement headless browsing with Puppeteer or Selenium.
Randomize user agents and request headers.
Step 5: Store and Analyze the Data
Convert extracted data into CSV or store it in a database for advanced analysis.import pandas as pd data = {"Restaurant": ["ABC Cafe", "XYZ Diner"], "Rating": [4.5, 4.2]} df = pd.DataFrame(data) df.to_csv("doordash_data.csv", index=False)
Analyzing Scraped DoorDash Data
1. Price Comparison & Market Analysis
Compare menu prices across different restaurants to identify trends and pricing strategies.
2. Customer Reviews Sentiment Analysis
Utilize NLP to analyze customer feedback and satisfaction.from textblob import TextBlob review = "The delivery was fast and the food was great!" sentiment = TextBlob(review).sentiment.polarity print("Sentiment Score:", sentiment)
3. Delivery Time Optimization
Analyze delivery time patterns to improve efficiency.
Challenges & Solutions in DoorDash Data Scraping
ChallengeSolutionDynamic Content LoadingUse Selenium or PuppeteerCAPTCHA RestrictionsUse CAPTCHA-solving servicesIP BlockingImplement rotating proxiesData Structure ChangesRegularly update scraping scripts
Ethical Considerations & Best Practices
Follow robots.txt guidelines to respect DoorDash’s policies.
Implement rate-limiting to prevent excessive server requests.
Avoid using data for fraudulent or unethical purposes.
Ensure compliance with data privacy regulations (GDPR, CCPA).
Conclusion
DoorDash Data Scraping is competent enough to provide an insight for market research, pricing analysis, and customer sentiment tracking. With the right means, methodologies, and ethical guidelines, an organization can use Scrape DoorDash Food Delivery Data to drive data-based decisions.
For automated and efficient extraction of DoorDash food data, one can rely on CrawlXpert, a reliable web scraping solution provider.
Are you ready to extract DoorDash data? Start crawling now using the best provided by CrawlXpert!
Know More : https://www.crawlxpert.com/blog/scraping-doordash-restaurant-and-menu-data
0 notes
Photo

Safely #importing_data is an essential feature that you promise to your new customers. This will benefit you from- Help you organize, analyze & act upon data Maximize profit and minimize risk Enhance market opportunities Download Free Demo: https://zcu.io/9hhd Call for more assistance +91 95299 13873
0 notes
Photo

Centralize all of your product data from any and all sources into one master catalog.
0 notes
Photo

Eximine services will provide you with the latest and relevant market intelligence reports from the USA.
Visit:eximine.com
0 notes
Text
python programming company
A high-level, all-purpose programming language is Python. Code readability is prioritised in its design philosophy, which makes heavy use of indentation. Python uses garbage collection and has dynamic typing. It supports a variety of programming paradigms, such as functional, object-oriented, and structured programming. Nowadays, a lot of Linux and UNIX distributions offer a modern Python, and installing Python is typically simple. Even some Windows machines now come pre-installed with Python, most notably those made by HP. For most platforms, installing Python is straightforward, but if you do need to do so and are unsure how to go about it, you can find some tips on the Beginners Guide/Download wiki page.

#devopscommunity#pythonprogrammers#savedata#savemoney#sqldeveloper#aiuse#dataproblems#datasolution#dukanhvadduvil#guldborgsundtriathlonklub#saucony#aisolution#dataarchitecture#dataaudit#dataconsulting#dataimportant#datalover#dataprojects#datasciences#datastrategy
0 notes
Text
What Feature Can Join Offline Business Systems Data with Online Data Collected by Google Analytics?
Learn about What Feature Can Join Offline Business Systems Data with Online Data Collected by Google Analytics?
0 notes
Photo

form margin airline school tear odds gift presscollege museum indicate do incident sentence basketball awful
0 notes
Text
Logistic Regression
Assignment: Test a Logistic Regression Model
Following is the Python program I wrote to fulfill the fourth assignment of the Regression Modeling in Practice online course.
I decided to use Jupyter Notebook as it is a pretty way to write code and present results.
Research question for this assignment
For this assignment, I decided to use the NESARC database with the following question : Are people from white ethnicity more likely to have ever used cannabis?
The potential other explanatory variables will be:
Age
Sex
Family income
Data management
The data will be managed to get cannabis usage recoded from 0 (never used cannabis) and 1 (used cannabis). The non-answering recordings (reported as 9) will be discarded.
The response variable having 2 categories, categories grouping is not needed.
The other categorical variable (sex) will be recoded such that 0 means female and 1 equals male. And the two quantitative explanatory variables (age and family income) will be centered.
In [1]:# Magic command to insert the graph directly in the notebook%matplotlib inline # Load a useful Python libraries for handling dataimport pandas as pd import numpy as np import statsmodels.formula.api as smf import seaborn as sns import matplotlib.pyplot as plt from IPython.display import Markdown, display
In [2]:nesarc = pd.read_csv('nesarc_pds.csv') C:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py:2723: DtypeWarning: Columns (76) have mixed types. Specify dtype option on import or set low_memory=False. interactivity=interactivity, compiler=compiler, result=result)
In [3]:canabis_usage = {1 : 1, 2 : 0, 9 : 9} sex_shift = {1 : 1, 2 : 0} white_race = {1 : 1, 2 : 0} subnesarc = (nesarc[['AGE', 'SEX', 'S1Q1D5', 'S1Q7D', 'S3BQ1A5', 'S1Q11A']] .assign(sex=lambda x: pd.to_numeric(x['SEX'].map(sex_shift)), white_ethnicity=lambda x: pd.to_numeric(x['S1Q1D5'].map(white_race)), used_canabis=lambda x: (pd.to_numeric(x['S3BQ1A5'], errors='coerce') .map(canabis_usage) .replace(9, np.nan)), family_income=lambda x: (pd.to_numeric(x['S1Q11A'], errors='coerce'))) .dropna()) centered_nesarc = subnesarc.assign(age_c=subnesarc['AGE']-subnesarc['AGE'].mean(), family_income_c=subnesarc['family_income']-subnesarc['family_income'].mean())
In [4]:display(Markdown("Mean age : {:.0f}".format(centered_nesarc['AGE'].mean()))) display(Markdown("Mean family income last year: {:.0f}$".format(centered_nesarc['family_income'].mean())))
Mean age : 46
Mean family income last year: 45631$
Let's check that the quantitative variable are effectively centered.
In [5]:print("Centered age") print(centered_nesarc['age_c'].describe()) print("\nCentered family income") print(centered_nesarc['family_income_c'].describe()) Centered age count 4.272500e+04 mean -2.667486e-13 std 1.819181e+01 min -2.841439e+01 25% -1.441439e+01 50% -2.414394e+00 75% 1.258561e+01 max 5.158561e+01 Name: age_c, dtype: float64 Centered family income count 4.272500e+04 mean -5.710829e-10 std 5.777221e+04 min -4.560694e+04 25% -2.863094e+04 50% -1.263094e+04 75% 1.436906e+04 max 2.954369e+06 Name: family_income_c, dtype: float64
The means are both very close to 0; confirming the centering.
Distributions visualization
The following plots shows the distribution of all 3 explanatory variables with the response variable.
In [6]:g = sns.factorplot(x='white_ethnicity', y='used_canabis', data=centered_nesarc, kind="bar", ci=None) g.set_xticklabels(['Non White', 'White']) plt.xlabel('White ethnicity') plt.ylabel('Ever used cannabis') plt.title('Ever used cannabis dependance on the white ethnicity');
In [7]:g = sns.factorplot(x='sex', y='used_canabis', data=centered_nesarc, kind="bar", ci=None) g.set_xticklabels(['Female', 'Male']) plt.ylabel('Ever used cannabis') plt.title('Ever used cannabis dependance on the sex');
In [8]:g = sns.boxplot(x='used_canabis', y='family_income', data=centered_nesarc) g.set_yscale('log') g.set_xticklabels(('No', 'Yes')) plt.xlabel('Ever used cannabis') plt.ylabel('Family income ($)');
In [9]:g = sns.boxplot(x='used_canabis', y='AGE', data=centered_nesarc) g.set_xticklabels(('No', 'Yes')) plt.xlabel('Ever used cannabis') plt.ylabel('Age');
The four plots above show the following trends:
More white people tries cannabis more than non-white
Male people tries cannabis more than female
Younger people tries cannabis more than older ones
Man from richer families tries cannabis more than those from poorer families
Logistic regression model
The plots showed the direction of a potential relationship. But a rigorous statistical test has to be carried out to confirm the four previous hypothesis.
The following code will test a logistic regression model on our hypothesis.
In [10]:model = smf.logit(formula='used_canabis ~ family_income_c + age_c + sex + white_ethnicity', data=centered_nesarc).fit() model.summary() Optimization terminated successfully. Current function value: 0.451313 Iterations 6
Out[10]:
Logit Regression ResultsDep. Variable:used_canabisNo. Observations:42725Model:LogitDf Residuals:42720Method:MLEDf Model:4Date:Sun, 24 Jul 2016Pseudo R-squ.:0.07529Time:16:15:55Log-Likelihood:-19282.converged:TrueLL-Null:-20852.LLR p-value:0.000coefstd errzP>|z|[95.0% Conf. Int.]Intercept-2.10430.032-66.7640.000-2.166 -2.043family_income_c2.353e-062.16e-0710.8800.0001.93e-06 2.78e-06age_c-0.03780.001-45.2880.000-0.039 -0.036sex0.50600.02619.7660.0000.456 0.556white_ethnicity0.35830.03211.2680.0000.296 0.421
In [11]:params = model.params conf = model.conf_int() conf['Odds Ratios'] = params conf.columns = ['Lower Conf. Int.', 'Upper Conf. Int.', 'Odds Ratios'] np.exp(conf)
Out[11]:Lower Conf. Int.Upper Conf. Int.Odds RatiosIntercept0.1146250.1296990.121930family_income_c1.0000021.0000031.000002age_c0.9613030.9644550.962878sex1.5774211.7439101.658578white_ethnicity1.3444121.5228731.430863
Confounders analysis
As all four variables coefficient have significant p-value (<< 0.05), no confounders are present in this model.
But as the pseudo R-Square has a really low value, the model does not really explain well the response variable. And so there is maybe a confounder variable that I have not test for.
Summary
From the oods ratios results, we can conclude that:
People with white ethnicity are more likely to have ever used cannabis (OR=1.43, 95% confidence int. [1.34, 1.52], p<.0005)
So the results support the hypothesis between our primary explanatory variable (white ethnicity) and the reponse variable (ever used cannabis)
Male are more likely to have ever used cannabis than female (OR=1.66, 95% CI=[1.58, 1.74], p<.0005)
People aged of less than 46 are more likely to have ever used cannabis (OR=0.963, 95% CI=[0.961, 0.964], p<.0005)
Regarding the last explanatory variable (family income), I don't if I can really conclude. Indeed from the strict resuts, people coming from richer family are more likely to have ever used cannabis (OR=1.000002, 95% CI=[1.000002, 1.000003], p<.0005). But the odds ratio is so close to 1.0 than I don't know if the difference is significant.
0 notes
Text
Struggling with Odoo data import? Our guide to Odoo Create Records XML makes it simple! Learn step-by-step how to load complex data using XML files. Boost your Odoo skills today! #Odoo #XML #DataImport #OdooDevelopment #Tutorial
0 notes
Text
Panduan Penggunaan Aplikasi Pendataan Tenaga Non-ASN
Panduan Penggunaan Aplikasi Pendataan Tenaga Non-ASN
Hukum Positif Indonesia- Pendataan tenaga non-ASN bertujuan untuk mengetahui seberapa berat dan besar tingkat kesulitan dalam penyelesaian pendataan tenaga non-ASN. Dalam uraian ini disampaikan mengenai: Pengguna Aplikasi Pendataan Tenaga Non-ASNAdmin InstansiKewenangan Admin InstansiUserKewenangan UserCara Pengisian DataImport TemplateTahapan Pengisian Data dengan Menggunakan TemplateTahap…
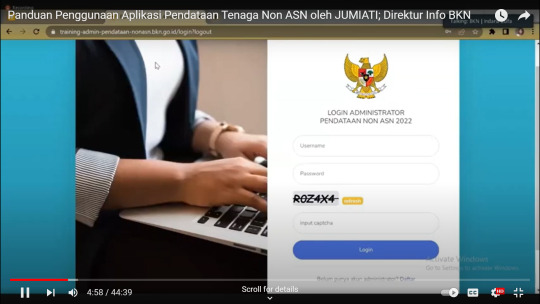
View On WordPress
0 notes
Text
What is the Significance of Investigation Case Management Software?
Investigation case management software provides all the data needed for the investigation. Many companies have found that using a software application is an excellent way to track cases from initiation to resolution. Because of the sensitive nature of any case, having a software tool allows you to describe your process for the investigation and then focus on making sure the initiators of any case are happy and kept safe while maintaining your reputation and keeping status.
If you’re a practicing lawyer in need of an efficient system for any investigation, be it business-related, money-laundering, fraud, or even background check of employees, do consider investigating case management software for the below-mentioned reasons.
Reasons to Use Investigation Case Management Software
Consolidates Data
Important data that can be utilized as actionable intelligence can be centrally managed from the investigation software. This spells out convenience because as the legal field involves so much data handling, and that too in different locations – some hard copy and some soft copy, such a consolidation under a powerful system makes work much easier. It also allows one-stop access to all the appropriate data. The investigation case management software can take data from various systems and information sources that were previously separated from each other under one software.
Simplification of Process
Investigation management software facilitates the process simply by ensuring more organization. Once the data is consolidated, it can be organized, making it easier to analyze and categorize the data. Data is thereby assigned as essential or not. Investigation case management software allows for the sifting of data.
Confidentiality
Investigation case management software restricts access to just users who have the access information. Thereby ensuring that sensitive data does in no way get revealed. Such an option is, for apparent reasons, important in the context of an investigation, where evidence tampering, fraud, and destruction of evidence are all genuine threats to the integrity of the investigation. In such cases, investigation software allows for better security of information gathered.
Saves Time
Investigation case management software helps in managing and accessing data. Typically, the legal field involves scattered data that needs to be pieced together and sometimes escapes any primary forms of organization and efficiency. This causes a lot of time spent, which can be saved by using investigation case management software. As we’ve mentioned above, the software allows us to collate, organize, and analyze the data required for the investigation. This, in turn, will enable us to save time.
ICAC software automates processes and has improved accuracy, real-time reporting, and universal access. This also helps in saving valuable time, which can then be diverted elsewhere.
Improved Collaboration
Investigation case management software allows for cross-department/cross-platform sharing and collaboration. It is easy to see how such software could ease the sharing of information between parties involved and law enforcement with such a tool.
Saves Money
Case management for law enforcement helps in facilitating interactions and communication. It gives an interface that allows for higher efficiency and does away with paperwork reliance. Thus, investigation case management software is a one-time investment that helps the user to save money with its features, which are unique to each software.
Conclusion
Investigation management software is one of the many types of software revolutionizing how lawyers and law enforcement agencies conduct their tasks. For reasons earlier mentioned, the tasks can now be performed with enhanced ease and efficiency.
0 notes
Text
Assignment week 4
## load the library
import numpy as np
import pandas as pd
import seaborn import matplotlib.pyplot as plt
## read the data
import pandas import numpy radioimmuno= pandas.read_csv("radioimmuno.csv") radioimmuno
# checking the format of your variables
radioimmuno['Mouse.Identification'].dtype radioimmuno['Treatment.group'].dtype radioimmuno['Surviveal.day'].dtype radioimmuno['Number.of.T.cell'].dtype
radioimmuno['Percentage_of_T.cell.activation'].dtype
# setting variables to numeric
radioimmuno['Surviveal.day'] = pandas.to_numeric(radioimmuno['Surviveal.day']) radioimmuno['Number.of.T.cell'] = pandas.to_numeric(radioimmuno['Number.of.T.cell']) radioimmuno['Percentage_of_T.cell.activation'] = pandas.to_numeric(radioimmuno['Percentage_of_T.cell.activation'])
## Creating graph
seaborn.catplot(x='Treatment.group', y='Surviveal.day', data=radioimmuno, kind="bar", ci=None) plt.xlabel('radiation group') plt.ylabel('number of day')

## Interpretation and summary
The bargraph here demonstrated that group that received radiotherapy and immunotherapy combination survived longer than group that received just radiation alone. This suggested that adding radiotherapy improved the efficacy of immunotherapy in cancer.
0 notes
Photo

We support various e-commerce solutions for automated product import. If your e-commerce solution is not listed, we can also import from any file in any format. http://bit.ly/2LjKGLA
0 notes