#dequeue in data structure using c
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
C Program to implement Deque using circular array
Implement Deque using circular array Write a C Program to implement Deque using circular array. Here’s simple Program to implement Deque using circular array in C Programming Language. What is Queue ? Queue is also an abstract data type or a linear data structure, in which the first element is inserted from one end called REAR, and the deletion of existing element takes place from the other end…
View On WordPress
#c data structures#c queue programs#dequeue in c using arrays#dequeue in data structure using c#dequeue in data structure with example#dequeue program in c using array#double ended queue in c#double ended queue in c using arrays#double ended queue in data structure#double ended queue in data structure program
0 notes
Text
300+ TOP SAP ABAP Objective Questions and Answers
SAP ABAP Multiple Choice Questions :-
1. This data type has a default length of one and a blank default value. A: I B: N C: C D: D Ans:C 2. A DATA statement may appear only at the top of a program, before START-OFSELECTION. A: True B: False Ans:B 3. If a field, NAME1, is declared as a global data object, what will be output by the following code? report zabaprg. DATA: name1 like KNA1-NAME1 value 'ABAP programmer'. name1 = 'Customer name'. CLEAR name1. perform write_name. FORM write_name. name1 = 'Material number'. WRITE name1. ENDFORM. A: Customer name B: ABAP programmer C: Material number D: None of the above Ans:C 4. All of these allow you to step through the flow of a program line-by-line except: A: Enter /h then execute B: Execute in debug mode C: Enter /i then execute D: Set a breakpoint Ans: C 5. Which of the following may NOT be modified using the ABAP Dictionary transaction? A: Type groups B: Search help C: Lock objects D: Function groups Ans:D 6. In a line of code, text-100, is an example of which type of text element? A: Text symbol B: Selection text C: Text title D: Text identifier Ans:A 7. The editor function that formats and indents the lines of code automatically is called ____. A: Auto align B: Pretty printer C: Generate version D: Syntax check Ans:B 8. A DO loop increments the system field ____. A: SY-LOOPI B: SY-TABIX C: SY-LSIND D: SY-INDEX Ans: D 9. The event that is processed after all data has been read but before the list is displayed is: A: END-OF-PAGE. B: START-OF-SELECTION. C: END-OF-SELECTION. D: AT LINE-SELECTION. Ans:A ? C 10. The field declared below is of what data type? DATA: new_fld(25). A: P B: N C: I D: C Ans: D

SAP ABAP MCQs 11. In regard to the INITIALIZATION event, which of the following is NOT a true statement? A: Executed before the selection screen is displayed. B: You should use SET PF-STATUS here. C: You can assign different values to PARAMETERS and SELECT-OPTIONS here. D: Executed one time when you start the report. Ans: B 12. The event AT SELECTION-SCREEN OUTPUT. occurs before the selection screen is displayed and is the best event for assigning default values to selection criteria. A: True B: False Ans: B 13. The business (non-technical) definition of a table field is determined by the field's ____. A: domain B: field name C: data type D: data element Ans: D 14. In regard to the three-tier client/server architecture, which of the following is a true statement? A: The presentation server processes the SAP program logic. B: An application server is responsible for updating database tables. C: Typically, there is a one-to-one ratio of database servers to presentation servers. D: The application server layer is the level between a presentation server and a database server. Ans: D,B 15. What will be output by the code below? DATA: alph type I value 3. write: alph. WHILE alph > 2. write: alph. alph = alph - 1. ENDWHILE. A: 3 B: 3 2 C: 3 3 2 D: 3 3 Ans: D 16. To allow the user to enter a single value on a selection screen, use the ABAP keyword ____. A: SELECT-OPTIONS. B: PARAMETERS. C: RANGES. D: DATA. Ans: B 17. What will be output by the following code? DATA: BEGIN OF itab OCCURS 0, fval type i, END OF itab. itab-fval = 1. APPEND itab. itab-fval = 2. APPEND itab. REFRESH itab. WRITE: /1 itab-fval. A: 1 B: 2 C: blank D: 0 Ans: B 18. You can define your own key fields when declaring an internal table. A: True B: False Ans: A 19. When modifying an internal table within LOOP AT itab. _ ENDLOOP. you must include an index number. A: True B: False Ans : B 20. If itab contains 20 rows, what will SY-TABIX equal when the program reaches the WRITE statement below? SY-TABIX = 10. LOOP AT itab. count_field = count_field + 1. ENDLOOP. WRITE: /1 count_field. A: 0 B: 10 C: 20 D: 30 Ans: C 21. Adding a COMMIT WORK statement between SELECT_ENDSELECT is a good method for improving performance. A: True B: False Ans:B 22. To select one record for a matching primary key, use ____. A: SELECT B: SELECT INTO C: SELECT SINGLE D: SELECT ENTRY Ans: C 23. In regard to MOVE-CORRESPONDING, which of the following is NOT a true statement? A: Moves the values of components with identical names. B: Fields without a match are unchanged. C: Corresponds to one or more MOVE statements. D: Moves the values of components according to their location. Ans: D 24. The ABAP keyword for adding authorizations to a program is ____. A: AUTH-CHECK B: AUTHORITY-CHECK C: AUTHORIZATION-CHECK D: AUTHORITY-OBJECT Ans:B 25. To read an exact row number of an internal table, use this parameter of the READ TABLE statement. A: INDEX B: TABIX C: ROW D: WHERE Ans: B ? A 26. To remove lines from a database table, use ____. A: UPDATE B: MODIFY C: ERASE D: DELETE Ans: D 27. Which table type would be most appropriate for accessing table rows using an index. A: Hashed table B: Standard table C: Sorted table D: None of these may be accessed using an index. Ans: C 28. The following code indicates: SELECTION-SCREEN BEGIN OF BLOCK B1. PARAMETERS: myparam(10) type C, Myparam2(10) type N, SELECTION-SCREEN END OF BLOCK. A: Draw a box around myparam and myparam2 on the selection screen. B: Allow myparam and myparam2 to be ready for input during an error dialog. C: Do not display myparam and myparam2 on the selection screen. D: Display myparam and myparam2 only if both fields have default values. Ans: A 29. The following code reorders the rows so that: DATA: itab LIKE kna1 OCCURS 0 WITH HEADER LINE. itab-name1 = 'Smith'. itab-ort01 = 'Miami'. APPEND itab. itab-name1 = 'Jones'. itab-ort01 = 'Chicago'. APPEND itab. itab-name1 = 'Brown'. itab-ort01 = 'New York'. APPEND itab. SORT itab BY name1 ort01. A: Smith appears before Jones B: Jones appears before Brown C: Brown appears before Jones D: Miami appears before New York Ans: C 30. If a table contains many duplicate values for a field, minimize the number of records returned by using this SELECT statement addition. A: MIN B: ORDER BY C: DISTINCT D: DELETE Ans:C 31. When writing a SELECT statement, you should place as much load as possible on the database server and minimize the load on the application server. A: True B: False Ans: B 32. All of the following pertain to interactive reporting in ABAP except: A: Call transactions and other programs from a list. B: Secondary list shows detail data. C: Good for processing lists in background. D: AT USER-COMMAND Ans:C 33. In regard to a function group, which of the following is NOT a true statement? A: Combines similar function modules. B: Shares global data with all its function modules. C: Exists within the ABAP workbench as an include program. D: Shares subroutines with all its function modules. Ans: D 34. Errors to be handled by the calling program are defined in a function module's ____. A: exceptions interface B: source code C: exporting interface D: main program Ans :A 35. In regard to the START-OF-SELECTION event, which of the following is a true statement? A: Executed before the selection screen is displayed. B: This is the only event in which a SELECT statement may be coded. C: Executed when the user double-clicks a list row. D: Automatically started by the REPORT statement. Ans:D 36. The order in which an event appears in the ABAP code determines when the event is processed. A: True B: False Ans: B 37. The SAP service that ensures data integrity by handling locking is called: A: Update B: Dialog C: Enqueue/Dequeue D: Spool Ans: C 38. What standard data type is the following user-defined type? TYPES: user_type. A: N B: C C: I D: Undefined Ans: B 39. Which ABAP program attribute provides access protection? A: Status B: Application C: Development class D: Authorization group Ans:D 40. Page headers for a secondary list should be coded in which event? A: TOP-OF-PAGE. B: START-OF-SELECTION. C: TOP-OF-PAGE DURING LINE-SELECTION. D: AT USER-COMMAND. Ans: C 41. Given: PERFORM subroutine USING var. The var field is known as what type of parameter? A: Formal B: Actual C: Static D: Value Ans:B 42. The following statement will result in a syntax error.DATA: price(3) type p decimals 2 value '100.23'. A: True B: False Ans: B 43. The following code indicates:CALL SCREEN 300. A: Start the PAI processing of screen 300. B: Jump to screen 300 without coming back. C: Temporarily branch to screen 300. * D: Exit screen 300. Ans:C 44. Which of the following would be stored in a table as master data? A: Customer name and address B: Sales order items C: Accounting invoice header D: Vendor credit memo Ans: A 45. In relation to an internal table as a formal parameter, because of the STRUCTURE syntax, it is possible to: A: Use the DESCRIBE statement within a subroutine. B: Loop through the internal table within a subroutine. C: Access the internal table fields within a subroutine. D: Add rows to the internal table within a subroutine. Ans: C 46. This data type has a default length of one and a default value = '0'. A: P B: C C: N D: I Ans: C 47. To prevent duplicate accesses to a master data field: A: Create an index on the master data field. B: Remove nested SELECT statements. C: Use SELECT SINGLE. D: Buffer the data in an internal table. Ans: A ? C 48. In regard to the code below, which of the following is not a true statement? TABLES: KNA1. GET KNA1. Write: /1 kna1-kunnr. END-OF-SELECTION. A: The GET event is processed while a logical database is running. B: All the fields from table KNA1 may be used in the GET event. C: You can code the GET event elsewhere in the same program. D: None of the above. Ans: D 49. The following code indicates: SELECT fld1 FROM tab1 INTO TABLE itab UP TO 100 ROWS WHERE fld7 = pfld7. A: Itab will contain 100 rows. B: Only the first 100 records of tab1 are read. C: If itab has less than 100 rows before the SELECT, SY-SUBRC will be set to 4. D: None of the above. Ans: D 50. To place a checkbox on a list, use A: WRITE CHECKBOX. B: FORMAT CHECKBOX ON. C: WRITE fld AS CHECKBOX. D: MODIFY LINE WITH CHECKBOX. Ans:C 51. Which of the following is NOT a true statement in regard to a sorted internal table type? A: May only be accessed by its key. B: Its key may be UNIQUE or NON-UNIQUE. C: Entries are sorted according to its key when added. D: A binary search is used when accessing rows by its key. Ans: A 52. The following code indicates: CALL SCREEN 9000 STARTING AT 10 5 ENDING AT 60 20 A: Screen 9000 is called with the cursor at coordinates (10,5)(60,20). B: Screen 9000 must be of type "Modal dialog box." C: Display screen 9000 in a full window. D: Screen 9000 may only contain an ABAP list. Ans:A 53. After a DESCRIBE TABLE statement SY-TFILL will contain A: The number of rows in the internal table. B: The current OCCURS value. C: Zero, if the table contains one or more rows. D: The length of the internal table row structure. Ans:A 54. Function module source code may not call a subroutine. A: True B: False Ans: B 55. This data type has a default length of eight and a default value = '00000000'. A: P B: D C: N D: C Ans: B 56. Within the source code of a function module, errors are handled via the keyword: A: EXCEPTION B: RAISE C: STOP D: ABEND Ans:B 57. Which of these is NOT a valid type of function module? A: Normal B: Update C: RFC D: Dialog Ans:D 58. To call a local subroutine named calculate answer, use this line of code: A: PERFORM calculate answer. B: CALL calculate answer. C: USING calculate answer. D: SUB calculate answer. Ans:A 59. Given: DO. Write: /1 'E equals MC squared.'. ENDDO. This will result in ____. A: output of 'E equals MC squared.' on a new line one time B: an endless loop that results in an abend error C: output of 'E equals MC squared.' on a new line many times D: a loop that will end when the user presses ESC Ans.B 60. The following code indicates write: /5 'I Love ABAP'. A: Output 'I Lov' on the current line B: Output 'I Love ABAP' starting at column 5 on the current line C: Output 'I Lov' on a new line D: Output 'I Love ABAP' starting at column 5 on a new line Ans: D 61. Which of the following is NOT a component of the default standard ABAP report header? A: Date and Time B: List title C: Page number D: Underline Ans: A 62. A select statement has built-in authorization checks. A: True B: False Ans:B 63. A BDC program is used for all of the following except: A: Downloading data to a local file B: Data interfaces between SAP and external systems C: Initial data transfer D: Entering a large amount of data Ans:B 64. Page footers are coded in the event: A: TOP-OF-PAGE. B: END-OF-SELECTION. C: NEW-PAGE. D: END-OF-PAGE. Ans:D 65. Page headers for a secondary/details list can be coded in the event: A: GET. B: INITIALIZATION. C: TOP-OF-PAGE DURING LINE-SELECTION. D: NEW-PAGE. Ans:C 66. To both add or change lines of a database table, use ____. A: INSERT B: UPDATE C: APPEND D: MODIFY Ans:D 67. To select one record for a matching primary key, use ____. A: SELECT B: SELECT INTO C: SELECT SINGLE D: SELECT ENTRY Ans:C 68. After adding rows to an internal table with COLLECT, you should avoid adding More rows with APPEND. A: True B: False Ans:A 69. The output for the following code will be report zabaprg. DATA: my_field type I value 99. my_field = my_field + 1. clear my_field. WRITE: 'The value is', my_field left-justified. A: The value is 99 B: The value is 100 C: The value is 0 D: None of the above Ans: C 70. If this code results in an error, the remedy is SELECT * FROM tab1 WHERE fld3 = pfld3. WRITE: /1 tab1-fld1, tab1-fld2. ENDSELECT. A: Add a SY-SUBRC check. B: Change the * to fld1 fld2. C: Add INTO (tab1-fld1, tab1-fld2). D: There is no error. Ans: C,D 71. To summarize the contents of several matching lines into a single line, use this SELECT statement clause. A: INTO B: WHERE C: FROM D: GROUP BY Ans:D 72. What is output by the following code? DATA: BEGIN OF itab OCCURS 0, letter type c, END OF itab. itab-letter = 'A'. APPEND itab. itab-letter = 'B'. APPEND itab. itab-letter = 'C'. APPEND itab. itab-letter = 'D'. APPEND itab. LOOP AT itab. SY-TABIX = 2. WRITE itab-letter. EXIT. ENDLOOP. A: A B: A B C D C: B D: B C D Ans: A 73. All of the following are considered to be valid ABAP modularization techniques except: A: Subroutine B: External subroutine C: Field-group D: Function module Ans:C 74. To create a list of the top 25 customers, you should use A: DELETE ADJACENT DUPLICATES B: READ TABLE itab INDEX 25 C: LOOP AT itab FROM 25 D: APPEND SORTED BY Ans:D 75. Which of these sentences most accurately describes the GET VBAK LATE. event? A: This event is processed before the second time the GET VBAK event is processed. B: This event is processed after all occurrences of the GET VBAK event are completed. C: This event will only be processed after the user has selected a basic list row. D: This event is only processed if no records are selected from table VBAK. Ans:B 76. In an R/3 environment, where is the work of a dialog program performed? A: On the application server using a dialog work process service. B: On the presentation server using a dialog work process service. C: On the database server using a dialog work process service. D: None of the above. Ans: A 77. In regard to Native SQL, which of the following is NOT a true statement? A: A CONNECT to the database is done automatically. B: You must specify the SAP client. C: The tables that you address do not have to exist in the ABAP Dictionary. D: Will run under different database systems. Ans:D 78. To change one or more lines of a database table, use ____. A: UPDATE B: INSERT C: INTO D: MOD Ans:A 79. Which is the correct sequence of events? A: AT SELECTION-SCREEN, TOP-OF-PAGE, INITIALIZATION B: START-OF-SELECTION, AT USER-COMMAND, GET dbtab C: INITIALIZATION, END-OF-SELECTION, AT LINE-SELECTION D: GET dbtab, GET dbtab LATE, START-OF-SELECTION Ans:B 80. Which of the following is NOT a numeric data type? A: I B: N C: P D: F Ans: B SAP ABAP Questions and Answers pdf Download Read the full article
2 notes
·
View notes
Text
The Collection Framework in Java

What is a Collection in Java?
Java collection is a single unit of objects. Before the Collections Framework, it had been hard for programmers to write down algorithms that worked for different collections. Java came with many Collection classes and Interfaces, like Vector, Stack, Hashtable, and Array.
In JDK 1.2, Java developers introduced theCollections Framework, an essential framework to help you achieve your data operations.
Why Do We Need Them?
Reduces programming effort & effort to study and use new APIs
Increases program speed and quality
Allows interoperability among unrelated APIs
Reduces effort to design new APIs
Fosters software reuse
Methods Present in the Collection Interface
NoMethodDescription1Public boolean add(E e)To insert an object in this collection.2Public boolean remove(Object element)To delete an element from the collection.3Default boolean removeIf(Predicate filter)For deleting all the elements of the collection that satisfy the specified predicate.4Public boolean retainAll(Collection c)For deleting all the elements of invoking collection except the specified collection.5Public int size()This return the total number of elements.6Publicvoid clear()This removes the total number of elements.7Publicboolean contains(Object element)It is used to search an element.8PublicIterator iterator()It returns an iterator.9PublicObject[] toArray()It converts collection into array.
Collection Framework Hierarchy
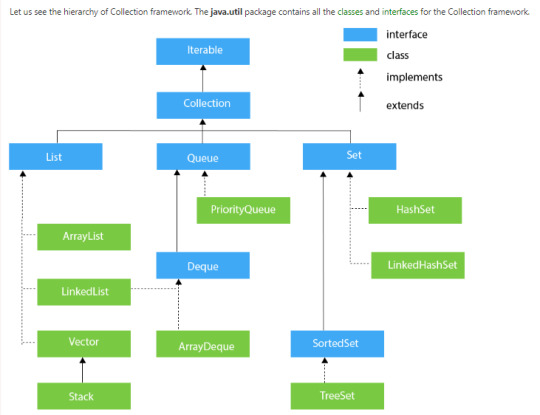
List Interface
This is the child interface of the collectioninterface. It is purely for lists of data, so we can store the ordered lists of the objects. It also allows duplicates to be stored. Many classes implement this list interface, including ArrayList, Vector, Stack, and others.
Array List
It is a class present in java. util package.
It uses a dynamic array for storing the element.
It is an array that has no size limit.
We can add or remove elements easily.
Linked List
The LinkedList class uses a doubly LinkedList to store elements. i.e., the user can add data at the initial position as well as the last position.
It allows Null insertion.
If we’d wish to perform an Insertion /Deletion operation LinkedList is preferred.
Used to implement Stacks and Queues.
Vector
Every method is synchronized.
The vector object is Thread safe.
At a time, one thread can operate on the Vector object.
Performance is low because Threads need to wait.
Stack
It is the child class of Vector.
It is based on LIFO (Last In First Out) i.e., the Element inserted in last will come first.
Queue
A queue interface, as its name suggests, upholds the FIFO (First In First Out) order much like a conventional queue line. All of the elements where the order of the elements matters will be stored in this interface. For instance, the tickets are always offered on a first-come, first-serve basis whenever we attempt to book one. As a result, the ticket is awarded to the requester who enters the queue first. There are many classes, including ArrayDeque, PriorityQueue, and others. Any of these subclasses can be used to create a queue object because they all implement the queue.
Dequeue
The queue data structure has only a very tiny modification in this case. The data structure deque, commonly referred to as a double-ended queue, allows us to add and delete pieces from both ends of the queue. ArrayDeque, which implements this interface. We can create a deque object using this class because it implements the Deque interface.
Set Interface
A set is an unordered collection of objects where it is impossible to hold duplicate values. When we want to keep unique objects and prevent object duplication, we utilize this collection. Numerous classes, including HashSet, TreeSet, LinkedHashSet, etc. implement this set interface. We can instantiate a set object with any of these subclasses because they all implement the set.
LinkedHashSet
The LinkedHashSet class extends the HashSet class.
Insertion order is preserved.
Duplicates aren’t allowed.
LinkedHashSet is non synchronized.
LinkedHashSet is the same as the HashSet except the above two differences are present.
HashSet
HashSet stores the elements by using the mechanism of Hashing.
It contains unique elements only.
This HashSet allows null values.
It doesn’t maintain insertion order. It inserted elements according to their hashcode.
It is the best approach for the search operation.
Sorted Set
The set interface and this interface are extremely similar. The only distinction is that this interface provides additional methods for maintaining the elements' order. The interface for handling data that needs to be sorted, which extends the set interface, is called the sorted set interface. TreeSet is the class that complies with this interface. This class can be used to create a SortedSet object because it implements the SortedSet interface.
TreeSet
Java TreeSet class implements the Set interface it uses a tree structure to store elements.
It contains Unique Elements.
TreeSet class access and retrieval time are quick.
It doesn’t allow null elements.
It maintains Ascending Order.
Map Interface
It is a part of the collection framework but does not implement a collection interface. A map stores the values based on the key and value Pair. Because one key cannot have numerous mappings, this interface does not support duplicate keys. In short, The key must be unique while duplicated values are allowed. The map interface is implemented by using HashMap, LinkedHashMap, and HashTable.
HashMap
Map Interface is implemented by HashMap.
HashMap stores the elements using a mechanism called Hashing.
It contains the values based on the key-value pair.
It has a unique key.
It can store a Null key and Multiple null values.
Insertion order isn’t maintained and it is based on the hash code of the keys.
HashMap is Non-Synchronized.
How to create HashMap.
LinkedHashMap
The basic data structure of LinkedHashMap is a combination of LinkedList and Hashtable.
LinkedHashMap is the same as HashMap except above difference.
HashTable
A Hashtable is an array of lists. Each list is familiar as a bucket.
A hashtable contains values based on key-value pairs.
It contains unique elements only.
The hashtable class doesn’t allow a null key as well as a value otherwise it will throw NullPointerException.
Every method is synchronized. i.e At a time one thread is allowed and the other threads are on a wait.
Performance is poor as compared to HashMap.
This blog illustrates the interfaces and classes of the java collection framework. Which is useful for java developers while writing efficient codes. This blog is intended to help you understand the concept better.
At Sanesquare Technologies, we provide end-to-end solutions for Development Services. If you have any doubts regarding java concepts and other technical topics, feel free to contact us.
0 notes
Text
BFS Algorithm
Breadth-First Search Algorithm
Breadth-First Search Algorithm or BFS is the most widely utilized method.
BFS is a graph traversal approach in which you start at a source node and layer by layer through the graph, analyzing the nodes directly related to the source node. Then, in BFS traversal, you must move on to the next-level neighbor nodes.
According to the BFS, you must traverse the graph in a breadthwise direction:
· To begin, move horizontally and visit all the current layer’s nodes.
· Continue to the next layer.
Breadth-First Search uses a queue data structure to store the node and mark it as “visited” until it marks all the neighboring vertices directly related to it. The queue operates on the First In First Out (FIFO) principle, so the node’s neighbors will be viewed in the order in which it inserts them in the node, starting with the node that was inserted first.
Read More
Why Do You Need Breadth-First Search Algorithm?
There are several reasons why you should use the BFS Algorithm to traverse graph data structure. The following are some of the essential features that make the BFS algorithm necessary:
· The BFS algorithm has a simple and reliable architecture.
· The BFS algorithm helps evaluate nodes in a graph and determines the shortest path to traverse nodes.
· The BFS algorithm can traverse a graph in the fewest number of iterations possible.
· The iterations in the BFS algorithm are smooth, and there is no way for this method to get stuck in an infinite loop.
· In comparison to other algorithms, the BFS algorithm’s result has a high level of accuracy.
In this tutorial, next, you will look at the pseudocode for the breadth-first search algorithm.
Pseudocode Of Breadth-First Search Algorithm
The breadth-first search algorithm’s pseudocode is:
Read More
Bredth_First_Serach( G, A ) // G ie the graph and A is the source node
Let q be the queue
q.enqueue( A ) // Inserting source node A to the queue
Mark A node as visited.
While ( q is not empty )
B = q.dequeue( ) // Removing that vertex from the queue, which will be visited by its neighbour
Processing all the neighbors of B
For all neighbors of C of B
If C is not visited, q. enqueue( C ) //Stores C in q to visit its neighbour
Mark C a visited
For a better understanding, you will look at an example of a breadth-first search algorithm later in this tutorial.
Example of Breadth-First Search Algorithm
In a tree-like structure, graph traversal requires the algorithm to visit, check, and update every single un-visited node. The sequence in which graph traversals visit the nodes on the graph categorizes them.
The BFS algorithm starts at the first starting node in a graph and travels it entirely. After traversing the first node successfully, it visits and marks the next non-traversed vertex in the graph.
Step 1: In the graph, every vertex or node is known. First, initialize a queue.
Step 2: In the graph, start from source node A and mark it as visited.
Step 3: Then you can observe B and E, which are unvisited nearby nodes from A. You have two nodes in this example, but here choose B, mark it as visited, and enqueue it alphabetically.
Step 4: Node E is the next unvisited neighboring node from A. You enqueue it after marking it as visited.
Step 5: A now has no unvisited nodes in its immediate vicinity. As a result, you dequeue and locate A.
Read More
Step 6: Node C is an unvisited neighboring node from B. You enqueue it after marking it as visited.
Step 7: Node D is an unvisited neighboring node from C. You enqueue it after marking it as visited.
Step 8: If all of D’s adjacent nodes have already been visited, remove D from the queue.
Step 9: Similarly, all nodes near E, B, and C nodes have already been visited; therefore, you must remove them from the queue.
Step 10: Because the queue is now empty, the bfs traversal has ended.
Complexity Of Breadth-First Search Algorithm
The time complexity of the breadth-first search algorithm : The time complexity of the breadth-first search algorithm can be stated as O(|V|+|E|) because, in the worst case, it will explore every vertex and edge. The number of vertices in the graph is |V|, while the edges are |E|.
The space complexity of the breadth-first search algorithm : You can define the space complexity as O(|V|), where |V| is the number of vertices in the graph, and different data structures are needed to determine which vertices have already been added to the queue. This is also the space necessary for the graph, which varies depending on the graph representation used by the algorithm’s implementation.
You will see some bfs algorithm applications now that you’ve grasped the complexity of the breadth-first search method.
Application Of Breadth-First Search Algorithm
The breadth-first search algorithm has the following applications:
· For Unweighted Graphs, You Must Use the Shortest Path and Minimum Spacing Tree.
Read More
The shortest path in an unweighted graph is the one with the fewest edges. You always reach a vertex from a given source using the fewest amount of edges when utilizing breadth-first. In unweighted graphs, any spanning tree is the Minimum Spanning Tree, and you can identify a spanning tree using either depth or breadth-first traversal.
· Peer to Peer Network
Breadth-First Search is used to discover all neighbor nodes in peer-to-peer networks like BitTorrent.
· Crawlers in Search Engine
Crawlers create indexes based on breadth-first. The goal is to start at the original page and follow all of the links there, then repeat. Crawlers can also employ Depth First Traversal. However, the benefit of breadth-first traversal is that the depth or layers of the created tree can be limited.
· Social Networking Websites
You can use a breadth-first search to identify persons within a certain distance ‘d’ from a person in social networks up to ‘d’s levels.
· GPS Navigation System
To find all nearby locations, utilize the breadth-first search method.
· Broadcasting Network
A broadcast packet in a network uses breadth-first search to reach all nodes.
· Garbage Collection
Cheney’s technique uses the breadth-first search for duplicating garbage collection. Because of the better locality of reference, breadth-first search is favored over the Depth First Search algorithm.
· Cycle Detection in Graph
Cycle detection in undirected graphs can be done using either Breadth-First Search or Depth First Search. BFS can also be used to find cycles in a directed graph.
· Identifying Routes
To see if there is a path between two vertices, you can use either Breadth-First or Depth First Traversal.
· Finding All Nodes Within One Connected Component
To locate all nodes reachable from a particular node, you can use either Breadth-First or Depth First Traversal.
Read More
Code Implementation of Breadth-First Search Algorithm
Breadth-First Search Algorithm Code Implementation:
#include<stdio.h>
#include<conio.h>
#include<stdlib.h>
int twodimarray[10][10],queue[10],visited[10],n,i,j,front=0,rear=-1;
void breadthfirstsearch(int vertex) // breadth first search function
{
for (i=1;i<=n;i++)
if(twodimarray[vertex][i] && !visited[i])
queue[++rear]=i;
if(front<=rear)
{
visited[queue[front]]=1;
breadthfirstsearch(queue[front++]);
}
}
int main() {
int x;
printf(“\n Enter the number of vertices:”);
scanf(“%d”,&n);
for (i=1;i<=n;i++) {
queue[i]=0;
visited[i]=0;
}
printf(“\n Enter graph value in form of matrix:\n”);
for (i=1;i<=n;i++)
for (j=1;j<=n;j++)
scanf(“%d”,&twodimarray[i][j]);
printf(“\n Enter the source node:”);
scanf(“%d”,&x);
breadthfirstsearch(x);
printf(“\n The nodes which are reachable are:\n”);
for (i=1;i<=n;i++)
if(visited[i])
printf(“%d\t”,i);
else
printf(“\n Breadth first search is not possible”);
getch();
}
1 note
·
View note
Text
BFS Algorithm
Breadth-First Search Algorithm
Breadth-First Search Algorithm or BFS is the most widely utilized method.
BFS is a graph traversal approach in which you start at a source node and layer by layer through the graph, analyzing the nodes directly related to the source node. Then, in BFS traversal, you must move on to the next-level neighbor nodes.
According to the BFS, you must traverse the graph in a breadthwise direction:
· To begin, move horizontally and visit all the current layer's nodes.
· Continue to the next layer.
Breadth-First Search uses a queue data structure to store the node and mark it as "visited" until it marks all the neighboring vertices directly related to it. The queue operates on the First In First Out (FIFO) principle, so the node's neighbors will be viewed in the order in which it inserts them in the node, starting with the node that was inserted first.
Read More
Why Do You Need Breadth-First Search Algorithm?
There are several reasons why you should use the BFS Algorithm to traverse graph data structure. The following are some of the essential features that make the BFS algorithm necessary:
· The BFS algorithm has a simple and reliable architecture.
· The BFS algorithm helps evaluate nodes in a graph and determines the shortest path to traverse nodes.
· The BFS algorithm can traverse a graph in the fewest number of iterations possible.
· The iterations in the BFS algorithm are smooth, and there is no way for this method to get stuck in an infinite loop.
· In comparison to other algorithms, the BFS algorithm's result has a high level of accuracy.
In this tutorial, next, you will look at the pseudocode for the breadth-first search algorithm.
Pseudocode Of Breadth-First Search Algorithm
The breadth-first search algorithm's pseudocode is:
Read More
Bredth_First_Serach( G, A ) // G ie the graph and A is the source node
Let q be the queue
q.enqueue( A ) // Inserting source node A to the queue
Mark A node as visited.
While ( q is not empty )
B = q.dequeue( ) // Removing that vertex from the queue, which will be visited by its neighbour
Processing all the neighbors of B
For all neighbors of C of B
If C is not visited, q. enqueue( C ) //Stores C in q to visit its neighbour
Mark C a visited
For a better understanding, you will look at an example of a breadth-first search algorithm later in this tutorial.
Example of Breadth-First Search Algorithm
In a tree-like structure, graph traversal requires the algorithm to visit, check, and update every single un-visited node. The sequence in which graph traversals visit the nodes on the graph categorizes them.
The BFS algorithm starts at the first starting node in a graph and travels it entirely. After traversing the first node successfully, it visits and marks the next non-traversed vertex in the graph.
Step 1: In the graph, every vertex or node is known. First, initialize a queue.
Step 2: In the graph, start from source node A and mark it as visited.
Step 3: Then you can observe B and E, which are unvisited nearby nodes from A. You have two nodes in this example, but here choose B, mark it as visited, and enqueue it alphabetically.
Step 4: Node E is the next unvisited neighboring node from A. You enqueue it after marking it as visited.
Step 5: A now has no unvisited nodes in its immediate vicinity. As a result, you dequeue and locate A.
Read More
Step 6: Node C is an unvisited neighboring node from B. You enqueue it after marking it as visited.
Step 7: Node D is an unvisited neighboring node from C. You enqueue it after marking it as visited.
Step 8: If all of D's adjacent nodes have already been visited, remove D from the queue.
Step 9: Similarly, all nodes near E, B, and C nodes have already been visited; therefore, you must remove them from the queue.
Step 10: Because the queue is now empty, the bfs traversal has ended.
Complexity Of Breadth-First Search Algorithm
The time complexity of the breadth-first search algorithm : The time complexity of the breadth-first search algorithm can be stated as O(|V|+|E|) because, in the worst case, it will explore every vertex and edge. The number of vertices in the graph is |V|, while the edges are |E|.
The space complexity of the breadth-first search algorithm : You can define the space complexity as O(|V|), where |V| is the number of vertices in the graph, and different data structures are needed to determine which vertices have already been added to the queue. This is also the space necessary for the graph, which varies depending on the graph representation used by the algorithm's implementation.
You will see some bfs algorithm applications now that you’ve grasped the complexity of the breadth-first search method.
Application Of Breadth-First Search Algorithm
The breadth-first search algorithm has the following applications:
· For Unweighted Graphs, You Must Use the Shortest Path and Minimum Spacing Tree.
Read More
The shortest path in an unweighted graph is the one with the fewest edges. You always reach a vertex from a given source using the fewest amount of edges when utilizing breadth-first. In unweighted graphs, any spanning tree is the Minimum Spanning Tree, and you can identify a spanning tree using either depth or breadth-first traversal.
· Peer to Peer Network
Breadth-First Search is used to discover all neighbor nodes in peer-to-peer networks like BitTorrent.
· Crawlers in Search Engine
Crawlers create indexes based on breadth-first. The goal is to start at the original page and follow all of the links there, then repeat. Crawlers can also employ Depth First Traversal. However, the benefit of breadth-first traversal is that the depth or layers of the created tree can be limited.
· Social Networking Websites
You can use a breadth-first search to identify persons within a certain distance 'd' from a person in social networks up to 'd's levels.
· GPS Navigation System
To find all nearby locations, utilize the breadth-first search method.
· Broadcasting Network
A broadcast packet in a network uses breadth-first search to reach all nodes.
· Garbage Collection
Cheney's technique uses the breadth-first search for duplicating garbage collection. Because of the better locality of reference, breadth-first search is favored over the Depth First Search algorithm.
· Cycle Detection in Graph
Cycle detection in undirected graphs can be done using either Breadth-First Search or Depth First Search. BFS can also be used to find cycles in a directed graph.
· Identifying Routes
To see if there is a path between two vertices, you can use either Breadth-First or Depth First Traversal.
· Finding All Nodes Within One Connected Component
To locate all nodes reachable from a particular node, you can use either Breadth-First or Depth First Traversal.
Read More
Code Implementation of Breadth-First Search Algorithm
Breadth-First Search Algorithm Code Implementation:
#include<stdio.h>
#include<conio.h>
#include<stdlib.h>
int twodimarray[10][10],queue[10],visited[10],n,i,j,front=0,rear=-1;
void breadthfirstsearch(int vertex) // breadth first search function
{
for (i=1;i<=n;i++)
if(twodimarray[vertex][i] && !visited[i])
queue[++rear]=i;
if(front<=rear)
{
visited[queue[front]]=1;
breadthfirstsearch(queue[front++]);
}
}
int main() {
int x;
printf("\n Enter the number of vertices:");
scanf("%d",&n);
for (i=1;i<=n;i++) {
queue[i]=0;
visited[i]=0;
}
printf("\n Enter graph value in form of matrix:\n");
for (i=1;i<=n;i++)
for (j=1;j<=n;j++)
scanf("%d",&twodimarray[i][j]);
printf("\n Enter the source node:");
scanf("%d",&x);
breadthfirstsearch(x);
printf("\n The nodes which are reachable are:\n");
for (i=1;i<=n;i++)
if(visited[i])
printf("%d\t",i);
else
printf("\n Breadth first search is not possible");
getch();
}
1 note
·
View note
Link
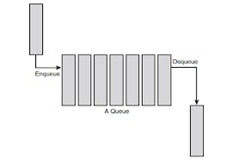
As the name suggests, the queue is the type of data structure that follows the FIFO (First In – First Out) mechanism. In simple words, it is a linear data structure that resembles somewhere like a stack but has the difference of entry and exit in the elements i.e unlike stacks. It is open at both ends. One end is used to insert data (enqueue) and the other end is used to remove data (dequeue).
Queues are just like lines at a ticket counter or a cash-counter where the first entering person is the first exiting person as well.
0 notes
Text
While studying computer science at University of Colorado Boulder, my data structures final project was to investigate different priority queue implementations to store the same data and compare their runtime when enqueuing and dequeuing elements. The data in this project was a list of hospital patients with a name, priority, and operation time. The priority of the patient represents the time until the patient goes into labor. The patients were ordered to have lowest priority first, and then ordered by least operation time if the patients had the same priority. The three implementations were a binary heap, linked list, and the c++ standard template library priority queue.
The binary heap priority queue uses an array to store the data while ordering the data in minimum heap property; every parent node is smaller than its child node. The binary heap insert function uses a swap helper function to keep swapping the inserted value with its greater child until the inserted value satisfies the min heap property. The dequeue function removes the root element because it is always the minimum and replaces it with the last element in the heap to keep the tree complete. The heap is then “heapified” or reordered to ensure the root is still the minimum value and the heap follows the min heap property.
The linked list priority queue uses a patient node structure that contains the address to the next priority element. The insert function traverses the list linearly until the inserted element is correctly ordered by its priority. The delete minimum function is very simple because the minimum is always stored at the head of the list so the function reassigns the head of the list to the second element and deletes the first element.
The standard template priority queue was implemented by creating a comparator struct and vector of the elements being prioritized. We do not necessarily know how the queue works because its source code is not available, but we can compare its runtime to the other implementations of the priority queue.
To test each implantation, the data was read into a array for quick access. A random section of the data with a specific size (100, 200… 800) was then copied into a new array. The different sized and random arrays were then enqueued and dequeued with the three priority queues. To calculate the runtime for enqueuing and dequeuing, the time in milliseconds was recorded before and after the loop with the function call and then stored in a matrix. The mean and standard deviations were then calculated for each queue and respective functions.
The code along with the data, charts and graphs for the mean enqueue and dequeue (writeup.pdf) can be found here on my github: https://github.com/jaq-h/priorityQueue
0 notes
Text
Understand about how to implement (fast) queue (#1)
Background
(I tried to write this blog post in Vietnamese, but after write half of the blog, I realized that half of written text is in english (ノ゚0゚)ノ~ ..)
Recently I wanted to understand better about queue, and how to make a better "unbounded, thread safe queue". If you don't know about queue, you could understand queue as a main data structure to share "work load" or "task" (in another word, producer consumer problem).
My system is written mostly in go. As a go user, the very obvious way to implement unbounded, thread safe is to use go channel
Go channel will serve us very well in most cases and workload, it's not very fast. The problem of slow throughput is pretty obvious since go channel using many centralize lock object, which cause much contention to happen. There is one way to resolve the problem (we're using this method), is to batch the workload into bigger one, to reduce queue contention.
However, since we're still happy with batched workload and go channel, the problem here is very interesting, so I'm realize that thread safe, bounded queue implementation is indeed very interesting topic because it touches many interesting fields in computer science. So that is, that's why I tried to write this blog series.
Implement a queue, why it's hard?
Some simple googling how to implement high performance queue bring me to go github discussion of whether to add decent implementation of unbounded queue to std (container/queue) or not.
The discussion could be summarized into few ideas of why making a queue is hard?:
Variation of situation we would want to use the queue (MPMC, SPMC, MPSC, SPSC)
Variation of features we would the queue to support (push-front or not (dequeue vs queue)? lock-free or not? performance requirement?)
Since we don't want a slow queue, let's presume we want to make it as fast as possible. There are multiple ways to implement a queue:
Linked list
Flat slice or Ring buffer (both could be implemented using array)
Linked-list implementation bring some advantages:
Better lock contention (since the lock contention is only high on tail or head (not both)
Dynamic resizing (since add / remove node require alloc/dealloc a single node only)
However it come in disadvantages:
Memory usage (need 64 bit pointer memory for singly linked-list and 128 bit pointer for doubly linked list per node)
Memory fragment (since alloc happen in realtime, the memory of nodes will not be continuous obviously)
GC pressure (since we will have a lot of pointers to manage, more pointers, more pressure for GC language (java/go))
In opposite, array-backed implementation has totally opposite advantage / disadvantage
Bad: Harder lock method (since we may need to lock the whole array for each enqueue / dequeue ))
Bad: Resizing cost. Most decent resizing method is to double array every time we short of memory, but that will cause high memcopy cost (which is linear to element count).
Good: Contiguous array make a very well performance tradeoff utilizing CPU cache line characteristic. And using array reduce GC pressure a lot, since we only have to manage single pointer of array head.
Grasp some ideas from the giants
Find the optimized implementation that could minimize above disadvantages is hard. Let's see how de-facto implementations of few major languages are doing it. TL;DR most of standard libs don't fancy trick, they just try to do very decent implementation that is bug free and fast enough for most of the cases.
Java's LinkedBlockingQueue
In my daily job, the most queue implementation i've been using is java std LinkedBlockingQueue.
As explained in source code, the queue implementation based on a technique called "two lock queue" with LinkedList backed queue.
https://github.com/openjdk-mirror/jdk7u-jdk/blob/master/src/share/classes/java/util/concurrent/LinkedBlockingQueue.java#L83-L93
A variant of the "two lock queue" algorithm. The putLock gates entry to put (and offer), and has an associated condition for waiting puts. Similarly for the takeLock.
The comment explain it all, we use 2 lock to control the the queue. putlock used to control write (enqueue) path, and takeLock used to control read (dequeue) path. The origin paper is here: Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms .
public boolean offer(E e) { ..... putLock.lock(); try { if (count.get() < capacity) { enqueue(node); .... } } finally { putLock.unlock(); } } public E take() throws InterruptedException { takeLock.lockInterruptibly(); try { x = dequeue(); ... } finally { takeLock.unlock(); } return x; }
The good thing of queue (compare to stack) is that the concern for read and write is separated, we have 2 different object head and last to control read and write path, we could just easily separate lock for those.
Beside the two-lock technique, the implementation also has some fine-grain control method to reduce lock time. One of the method is to control number of remain items so when producer side call offer (or put), it could signal on-waiting take (or poll) right away. The idea is written in source code as below:
to minimize need for puts to get takeLock and vice-versa, cascading notifies are used. When a put notices that it has enabled at least one take, it signals taker. That taker in turn signals others if more items have been entered since the signal. And symmetrically for takes signalling puts.
private final Condition notEmpty = takeLock.newCondition(); public boolean offer(E e) { ..... if (c == 0) notEmpty.signal(); ..... } public E take() throws InterruptedException { ..... try { while (count.get() == 0) { notEmpty.await(); } x = dequeue(); .... } .... }
So that is, LinkedBlockingQueue idea is so simple. To use the queue as MPMC task queue, LinkedBlockingQueue is definitely better than other implementation like ArrayBlockingQueue, since ArrayBlockingQueue try to lock the whole queue for every single put or take.
LinkedBlockingQueue serves us very well for years, even for now. LinkedBlockingQueue is also very convenient in term of specification, since it block consumer or producer when the queue is empty or full, which reduce cost for us to implement to spin wait ourself. However the question still remain, do we have better idea or implementation, which will be talked at next part of this serie, so stay tune :).
1 note
·
View note
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Text
Computing Machinery I Assignment 05 Solution
Computing Machinery I Assignment 05 Solution
Part A: Global Variables and Separate Compilation
A FIFO queue data structure can be implemented using an array, as shown in the following C program:
#include <stdio.h>
#include <stdlib.h>
#define QUEUESIZE
8
#define MODMASK
0x7
#define
FALSE
0
#define
TRUE
1
/* Function Prototypes */
void enqueue(int value);
int dequeue();
int queueFull();
int queueEmpty();
v…
View On WordPress
0 notes
Text
Computing Machinery I Assignment 05 Solution
Computing Machinery I Assignment 05 Solution
Part A: Global Variables and Separate Compilation
A FIFO queue data structure can be implemented using an array, as shown in the following C program:
#include <stdio.h>
#include <stdlib.h>
#define QUEUESIZE
8
#define MODMASK
0x7
#define
FALSE
0
#define
TRUE
1
/* Function Prototypes */
void enqueue(int value);
int dequeue();
int queueFull();
int queueEmpty();
v…
View On WordPress
0 notes
Link
Data Structures and Algorithms in C programming language – coding interviews questions/projects. Linked List, Recursion
DATA STRUCTURES
Created by Deepali Srivastava
Last updated 8/2019
English
English Subs [Auto-generated]
What you’ll learn
Understand the details of Data Structures and algorithms through animations
Learn to write programs for different Data Structures and Algorithms in C language
Get the confidence to face programming interviews
Test your knowledge with over 100 Quiz questions
Learn how to analyse algorithms
Get the ability to write and trace recursive algorithms
Requirements
Basic knowledge of programming in any language
Description
This “Data Structures and Algorithms In C” course is thoroughly detailed and uses lots of animations to help you visualize the concepts.
Subtitles are available for the first section only. Closed Captioning for rest of the sections is in progress and are available as [Auto-generated].
This “Data Structures and Algorithms in C” tutorial will help you develop a strong background in Data Structures and Algorithms. The course is broken down into easy to assimilate short lectures, and after each topic there is a quiz that can help you to test your newly acquired knowledge. The examples are explained with animations to simplify the learning of this complex topic. Complete working programs are shown for each concept that is explained.
This course provides a comprehensive explanation of structures like linked lists, stacks and queues, binary search trees, heap, searching, hashing. Various sorting algorithms with implementation and analysis are included in this tutorial. Concept of recursion is very important for designing and understanding certain algorithms so the process of recursion is explained with the help of several examples.
This course covers following topics with C language implementation :
Algorithm Analysis, Big O notation, Time complexity, Singly linked list, Reversing a linked list, Doubly linked list, Circular linked list, Linked list concatenation, Sorted linked list.
Stack, Queue, Circular Queue, Dequeue, Priority queue, Polish Notations, Infix to Postfix, Evaluation of Postfix, Binary Tree, Binary Search Tree, Tree Traversal (inorder, preorder, postorder, level order), Recursion, Heap, Searching, Hashing
Sorting : Selection, Bubble, Insertion, Shell, Merging, Recursive Merge, Iterative Merge, Quick, Heap, Binary tree, Radix, Address calculation sort
Throughout the course, a step by step approach is followed to make you understand different Data Structures and Algorithms. You will see implementation of different data structures in C language and algorithms are explained in step-wise manner. Through this course you can build a strong foundation and it will help you to crack Data Structures and Algorithms coding interviews questions and work on projects. Good foundation on Data Structures and Algorithms interview topics helps you to attempt tricky interview questions.
In this Data Structures and Algorithms course, C language is used for implementing various concepts, but you can easily implement them in any other programming languages like C++, C#, Java, Python.
What students are saying about this course-
“This is exactly how I hoped to learn data structure and algorithm, PLUS, it’s using C!!”
“Instructor is teaching in very well and efficient manner with a good pace ,clears every doubts and teaches concepts deeply.”
“Great class, explains topics very well, better than any college class I ever took.”
“yes this course has helped me a lot in discovering new topics and the example programs are also quite helpful.”
“I really appreciate the way the steps are broken down incrementally.”
“Deepali does a great job in explaining all the concept and the course is very well organized. First the concept is explained on paper and then there is a walk through of the code, and then execution of the code. I have learnt a great deal from this course.”
“I am taking notes and writing code side by side watching videos which makes it beneficial to understand the code and easier to grasp the concept of the topic rather than just copying the source code. Thank you Deepali Mam for not giving the source it was better to write the code by myself. The videos are informative, detailed and right on point with step by step code programs and I feel learned a lot taking your course then the class which I took at University. This course made my base of data structures in C pretty strong thank you for that.”
“This is an awesome course. If you need to understand then try to write every code yourself then try to analyze it. that’s how you can gain confidence.”
“I’m re-learning something what I am learn years ago, and this course is perfect for my need.”
“Its quite helpful, it nicely supplements what you have studied in the book.”
“Excellent presentation and content. Easily comprehensible. Since Data Structures and Algorithms are heart of computer science will give a 5 star for this kind of knowledge resource.”
“It is one of the best courses that I have ever taken in Structures and C.”
“Good foundation course covering the fundamentals of structures in C.”
“It’s definitely a good course for beginners who have basic knowledge in C and want to learn Data Structures and Algorithms. Really good explanation by the instructor with experience of even writing a book on Data structures.”
“Till now its above expectations.Mam I am also following your both book “C in Depth” and “Data Structure Using C”.”
“Great in depth explanations of the data structures and algorithms covered.”
“good and perfect teaching for basic levels for beginners in data structures.”
“Very good clarification and reference for common data structures and algorithms.”
This Data Structures and Algorithms In C online course on udemy will help software developers to refresh the concepts studied in book / pdf and also to students learning from referred book / pdf.
Who this course is for:
Programmers looking for jobs
Programmers wanting to write efficient code
Computer Science students having Data Structures as part of their curriculum
Non Computer science students wanting to enter IT industry
Size: 752MB
DOWNLOAD TUTORIAL
The post DATA STRUCTURES AND ALGORITHMS THROUGH C IN DEPTH appeared first on GetFreeCourses.Me.
0 notes
Text
Data Structures & Algorithms in Swift Full Release Now Available!
Hey, Swifties! The full release of our Data Structures & Algorithms in Swift book is now available!
The early access release of this book — complete with the theory of data structures and algorithms in Swift — debuted at our conference RWDevCon 2018. Since then, the team has been hard at work creating a robust catalogue of challenges — 18 chapters in all — to test what you’ve learned and grow your expertise. The book is structured with the theory chapters alternating with the challenge chapters to keep you on track to nail down the fundamental and more advanced concepts.
Why Do You Need This Book?
Understanding how data structures and algorithms work in code is crucial for creating efficient and scalable apps. Swift’s Standard Library has a small set of general purpose collection types, yet they don’t give you what you need for every case.
Moreover, you’ll find these concepts helpful for your professional and personal development as a developer.
When you interview for a software engineering position, chances are that you’ll be tested on data structures and algorithms. Having a strong foundation in data structures and algorithms is the “bar” for many companies with software engineering positions.
Knowing the strategies used by algorithms to solve tricky problems gives you ideas for improvements you can make to your own code. Knowing more data structures than just the standard array and dictionary also gives you a bigger collection of tools that you can use to build your own apps.
Here’s what’s contained in the full release of the book:
Section I: Introduction
Chapter 1: Why Learn Data Structures & Algorithms?: Data structures are a well-studied area, and the concepts are language agnostic; a data structure from C is functionally and conceptually identical to the same data structure in any other language, such as Swift. At the same time, the high-level expressiveness of Swift make it an ideal choice for learning these core concepts without sacrificing too much performance.
Chapter 2: Swift Standard Library: Before you dive into the rest of this book, you’ll first look at a few data structures that are baked into the Swift language. The Swift standard library refers to the framework that defines the core components of the Swift language. Inside, you’ll find a variety of tools and types to help build your Swift apps.
Section II: Elementary Data Structures
Chapter 3: Linked List: A linked list is a collection of values arranged in a linear unidirectional sequence. A linked list has several theoretical advantages over contiguous storage options such as the Swift Array, including constant time insertion and removal from the front of the list, and other reliable performance characteristics.
Chapter 5: Stacked Data Structure: The stack data structure is identical in concept to a physical stack of objects. When you add an item to a stack, you place it on top of the stack. When you remove an item from a stack, you always remove the topmost item. Stacks are useful, and also exceedingly simple. The main goal of building a stack is to enforce how you access your data.
Chapter 7: Queues: Lines are everywhere, whether you are lining up to buy tickets to your favorite movie, or waiting for a printer machine to print out your documents. These real-life scenarios mimic the queue data structure. Queues use first-in-first-out ordering, meaning the first element that was enqueued will be the first to get dequeued. Queues are handy when you need to maintain the order of your elements to process later.
Easy-to-understand examples show key concepts, such as trees!
Section III: Trees
Chapter 9: Trees: The tree is a data structure of profound importance. It is used to tackle many recurring challenges in software development, such as representing hierarchical relationships, managing sorted data, and facilitating fast lookup operations. There are many types of trees, and they come in various shapes and sizes.
Chapter 11: Binary Trees: In the previous chapter, you looked at a basic tree where each node can have many children. A binary tree is a tree where each node has at most two children, often referred to as the left and right children. Binary trees serve as the basis for many tree structures and algorithms. In this chapter, you’ll build a binary tree and learn about the three most important tree traversal algorithms.
Chapter 13: Binary Search Trees: A binary search tree facilitates fast lookup, addition, and removal operations. Each operation has an average time complexity of O(log n), which is considerably faster than linear data structures such as arrays and linked lists.
Chapter 15: AVL Trees: In the previous chapter, you learned about the O(log n) performance characteristics of the binary search tree. However, you also learned that unbalanced trees can deteriorate the performance of the tree, all the way down to O(n). In 1962, Georgy Adelson-Velsky and Evgenii Landis came up with the first self-balancing binary search tree: the AVL Tree.
Helpful visuals demonstrate how to organize and sort data!
Chapter 17: Tries: The trie (pronounced as “try”) is a tree that specializes in storing data that can be represented as a collection, such as English words. The benefits of a trie are best illustrated by looking at it in the context of prefix matching, which is what you’ll do in this chapter.
Chapter 19: Binary Search: Binary search is one of the most efficient searching algorithms with a time complexity of O(log n). This is comparable with searching for an element inside a balanced binary search tree. To perform a binary search, the collection must be able to perform index manipulation in constant time, and must be sorted.
Chapter 21: The Heap Data Structure: A heap is a complete binary tree, also known as a binary heap, that can be constructed using an array. Heaps come in two flavors: Max heaps and Min heaps. Have you seen the movie Toy Story, with the claw machine and the squeaky little green aliens? Imagine that the claw machine is operating on your heap structure, and will always pick the minimum or maximum value, depending on the flavor of heap.
Chapter 23: Priority Queue: Queues are simply lists that maintain the order of elements using first-in-first-out (FIFO) ordering. A priority queue is another version of a queue that, instead of using FIFO ordering, dequeues elements in priority order. A priority queue is especially useful when you need to identify the maximum or minimum value given a list of elements.
Section IV: Sorting Algorithms
Chapter 25: O(n²) Sorting Algorithms: O(n²) time complexity is not great performance, but the sorting algorithms in this category are easy to understand and useful in some scenarios. These algorithms are space efficient; they only require constant O(1) additional memory space. In this chapter, you’ll be looking at the bubble sort, selection sort, and insertion sort algorithms.us shapes and sizes.
Chapter 27: Merge Sort: In this chapter, you’ll look at a completely different model of sorting. So far, you’ve been relying on comparisons to determine the sorting order. Radix sort is a non-comparative algorithm for sorting integers in linear time. There are multiple implementations of radix sort that focus on different problems. To keep things simple, in this chapter you’ll focus on sorting base 10 integers while investigating the least significant digit (LSD) variant of radix sort.
Chapter 29: Radix Sort: A binary search tree facilitates fast lookup, addition, and removal operations. Each operation has an average time complexity of O(log n), which is considerably faster than linear data structures such as arrays and linked lists.
Chapter 31: Heapsort: Heapsort is another comparison-based algorithm that sorts an array in ascending order using a heap. This chapter builds on the heap concepts presented in Chapter 21, “The Heap Data Structure.” Heapsort takes advantage of a heap being, by definition, a partially sorted binary tree.
Chapter 33: Quicksort: Quicksort is another divide and conquer technique that introduces the concept of partitions and a pivot to implement high performance sorting. You‘ll see that while it is extremely fast for some datasets, for others it can be a bit slow.
Real-world examples help you apply the book’s concepts in a concrete and relevant way!
Section V: Graphs
Chapter 35: Graphs: What do social networks have in common with booking cheap flights around the world? You can represent both of these real-world models as graphs! A graph is a data structure that captures relationships between objects. It is made up of vertices connected by edges. In a weighted graph, every edge has a weight associated with it that represents the cost of using this edge. This lets you choose the cheapest or shortest path between two vertices.
Chapter 37: Breadth-First Search: In the previous chapter, you explored how graphs can be used to capture relationships between objects. Several algorithms exist to traverse or search through a graph’s vertices. One such algorithm is the breadth-first search algorithm, which can be used to solve a wide variety of problems, including generating a minimum spanning tree, finding potential paths between vertices, and finding the shortest path between two vertices.
Chapter 39: Depth-First Search: In the previous chapter, you looked at breadth-first search where you had to explore every neighbor of a vertex before going to the next level. In this chapter, you will look at depth-first search, which has applications for topological sorting, detecting cycles, path finding in maze puzzles, and finding connected components in a sparse graph.
Chapter 41: Dijkstra’s Algorithm: Have you ever used the Google or Apple Maps app to find the shortest or fastest from one place to another? Dijkstra’s algorithm is particularly useful in GPS networks to help find the shortest path between two places. Dijkstra’s algorithm is a greedy algorithm, which constructs a solution step-by-step, and picks the most optimal path at every step.
Chapter 43: Prim’s Algorithm: In previous chapters, you’ve looked at depth-first and breadth-first search algorithms. These algorithms form spanning trees. In this chapter, you will look at Prim’s algorithm, a greedy algorithm used to construct a minimum spanning tree. A minimum spanning tree is a spanning tree with weighted edges where the total weight of all edges is minimized. You’ll learn how to implement a greedy algorithm to construct a solution step-by-step, and pick the most optimal path at every step.
The book moves beyond fundamentals to more advanced concepts, such as Dijkstra’s Algorithm!
Data Structures and Algorithms in Swift will teach you how to implement the most popular and useful data structures, and when and why you should use one particular data structure or algorithm over another.
This set of basic data structures and algorithms will serve as an excellent foundation for building more complex and special-purpose constructs. And the high-level expressiveness of Swift makes it an ideal choice for learning these core concepts without sacrificing performance.
Get your own copy:
If you’ve pre-ordered Data Structures & Algorithms in Swift, you can log in to the store and download the final version here.
If you haven’t already bought this must-have addition to your development library, head over to our store page to grab your copy today!
Questions about the book? Ask them in the comments below!
The post Data Structures & Algorithms in Swift Full Release Now Available! appeared first on Ray Wenderlich.
Data Structures & Algorithms in Swift Full Release Now Available! published first on https://medium.com/@koresol
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
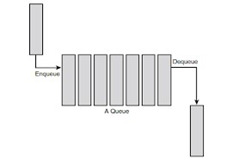
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
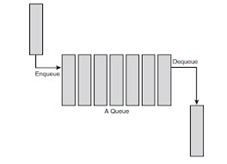
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
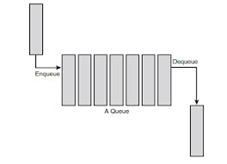
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes