#double ended queue in data structure
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Implementing Deques and Randomized Queues - Project 2
The purpose of this project is to implement elementary data structures using arrays and linked lists, and to introduce you to generics and iterators. Problem 1. (Deque) A double-ended queue or deque (pronounced \deck”) is a generalization of a stack and a queue that supports adding and removing items from either the front or the back of the data structure. Create a generic iterable data type…
0 notes
Text
Interactive Kiosk Market - Structure, Size, Trends, Analysis and Outlook 2022-2030
Interactive Kiosk Industry Overview
The global interactive kiosk market size was valued at USD 28.45 billion in 2021 and is projected to expand at a compound annual growth rate (CAGR) of 7.1% from 2022 to 2030.
Due to the high development in payment and security technologies, the market has witnessed rapid growth over the past few years. Many of the self-service kiosk manufacturers will continue to extract these technologies’ maximum potential and are expected to include them as an indispensable component of their product offering. Interactive kiosks help prevent long queues at public places, such as inquiry counters at railway stations, banks, and malls and check-in counters at airports. At places, such as hospitals and government offices, they help reduce the paperwork associated with visitor data collection and enhance visitors’ experiences.
Gather more insights about the market drivers, restrains and growth of the Interactive Kiosk Market
An increase in product adoption in the BFSI and retail segments is expected to be a major growth driver for the market. Some of the major manufacturers are already working on developing and integrating Artificial Intelligence (AI)-based technology in interactive kiosks. For instance, ViaTouch Media has introduced AI-based kiosks, which enable shoppers to examine the products before making a purchase. As products are removed from the retailer’s shelf, a video screen above displays product information to the customer. The growing problems due to the outbreak of COVID-19 have increased the adoption of self-checkout kiosks to avoid human interaction. As self-checkout kiosks ensure social distancing in stores, they pave the way for a little human interaction.
Looking forward to driving the adoption of and advantages offered by interactive kiosks to customers, the vendors operating in the market have launched various advanced solutions and technologies in response to the COVID-19 pandemic. The COVID-19 pandemic has doubled the R&D spending and innovation by the vendors. For instance, kiosk systems with temperature sensors, Personal Protective Equipment (PPE)-dispensing kiosks, smart kiosks that collect swab samples for COVID-19 tests, and mobile testing kiosks are some of the latest solutions launched by the vendors operating in the market. The vendors are expected to continue focusing on product innovation and development to gain a significant share in the years to come.
Interactive Kiosk Market Segmentation
Grand View Research has segmented the global interactive kiosk market report on the basis of component, type, end use, and region:
Component Outlook (Revenue, USD Million, 2017 - 2030)
Hardware
Display
Printer
Others
Software
Windows
Android
Linux
Others (iOS, Others)
Service
Integration & Deployment
Managed Services
Type Outlook (Revenue, USD Million, 2017 - 2030)
Automated Teller Machines (ATMs)
Retail Self-Checkout Kiosks
Self-Service Kiosks
Vending Kiosks
End Use Outlook (Revenue, USD Million, 2017 - 2030)
BFSI
Retail
Food & Beverage
Healthcare
Government
Travel & Tourism
Others
Regional Outlook (Revenue, USD Million, 2017 - 2030)
North America
US
Canada
Europe
UK
Germany
France
Asia Pacific
China
India
Japan
Singapore
Thailand
Indonesia
Malaysia
Vietnam
Australia
Latin America
Brazil
Middle East & Africa (MEA)
Browse through Grand View Research's Next Generation Technologies Industry Research Reports.
The global hybrid printing technologies market size was estimated at USD 4.59 billion in 2023 and is projected to grow at a CAGR of 12.3% from 2024 to 2030.
The global 4D printing market size was estimated at USD 156.8 million in 2023 and is anticipated to grow at a CAGR of 35.8% from 2024 to 2030.
Key Companies & Market Share Insights
The market is characterized by the presence of a few players accounting for significant industry share. New product launches and technology partnerships are some of the major strategies adopted by key companies to strengthen their market position. Key industry players are also heavily investing in research & development projects and focusing on establishing production infrastructure to develop and offer differentiated and cost-effective self-service solutions. The Meridian, Advanced Kiosk, and Kiosk Information System have a strong market presence due to the availability of a strong R&D department and production facilities. The companies mainly focus on product innovation and effective distribution through a strong network of partners in multiple countries, such as the U.S., Germany, India, and Brazil. Some of the key players in the global interactive kiosk market include:
NCR Corp.
Diebold Nixdorf AG
ZEBRA Technologies Corp.
Advanced Kiosks
Embross Group
GRGBanking
IER SAS
Order a free sample PDF of the Interactive Kiosk Market Intelligence Study, published by Grand View Research.
0 notes
Text
Difference between ArrayDeque and LinkedList in Java
The Deque interface represents a double-ended queue (Double Ended Queue), which allows operations at both ends of the queue, so it can realize both queue behavior and stack behavior.
6 notes
·
View notes
Text
Strangulating bare-metal infrastructure to Containers
Change is inevitable. Change for the better is a full-time job ~ Adlai Stevenson I
We run a successful digital platform for one of our clients. It manages huge amounts of data aggregation and analysis in Out of Home advertising domain.
The platform had been running successfully for a while. Our original implementation was focused on time to market. As it expanded across geographies and impact, we decided to shift our infrastructure to containers for reasons outlined later in the post. Our day to day operations and release cadence needed to remain unaffected during this migration. To ensure those goals, we chose an approach of incremental strangulation to make the shift.
Strangler pattern is an established pattern that has been used in the software industry at various levels of abstraction. Documented by Microsoft and talked about by Martin Fowler are just two examples. The basic premise is to build an incremental replacement for an existing system or sub-system. The approach often involves creating a Strangler Facade that abstracts both existing and new implementations consistently. As features are re-implemented with improvements behind the facade, the traffic or calls are incrementally routed via new implementation. This approach is taken until all the traffic/calls go only via new implementation and old implementation can be deprecated. We applied the same approach to gradually rebuild the infrastructure in a fundamentally different way. Because of the approach taken our production disruption was under a few minutes.
This writeup will explore some of the scaffolding we did to enable the transition and the approach leading to a quick switch over with confidence. We will also talk about tech stack from an infrastructure point of view and the shift that we brought in. We believe the approach is generic enough to be applied across a wide array of deployments.
The as-is
###Infrastructure
We rely on Amazon Web Service to do the heavy lifting for infrastructure. At the same time, we try to stay away from cloud-provider lock-in by using components that are open source or can be hosted independently if needed. Our infrastructure consisted of services in double digits, at least 3 different data stores, messaging queues, an elaborate centralized logging setup (Elastic-search, Logstash and Kibana) as well as monitoring cluster with (Grafana and Prometheus). The provisioning and deployments were automated with Ansible. A combination of queues and load balancers provided us with the capability to scale services. Databases were configured with replica sets with automated failovers. The service deployment topology across servers was pre-determined and configured manually in Ansible config. Auto-scaling was not built into the design because our traffic and user-base are pretty stable and we have reasonable forewarning for a capacity change. All machines were bare-metal machines and multiple services co-existed on each machine. All servers were organized across various VPCs and subnets for security fencing and were accessible only via bastion instance.
###Release cadence
Delivering code to production early and frequently is core to the way we work. All the code added within a sprint is released to production at the end. Some features can span across sprints. The feature toggle service allows features to be enabled/disable in various environments. We are a fairly large team divided into small cohesive streams. To manage release cadence across all streams, we trigger an auto-release to our UAT environment at a fixed schedule at the end of the sprint. The point-in-time snapshot of the git master is released. We do a subsequent automated deploy to production that is triggered manually.
CI and release pipelines
Code and release pipelines are managed in Gitlab. Each service has GitLab pipelines to test, build, package and deploy. Before the infrastructure migration, the deployment folder was co-located with source code to tag/version deployment and code together. The deploy pipelines in GitLab triggered Ansible deployment that deployed binary to various environments.

Figure 1 — The as-is release process with Ansible + BareMetal combination
The gaps
While we had a very stable infrastructure and matured deployment process, we had aspirations which required some changes to the existing infrastructure. This section will outline some of the gaps and aspirations.
Cost of adding a new service
Adding a new service meant that we needed to replicate and setup deployment scripts for the service. We also needed to plan deployment topology. This planning required taking into account the existing machine loads, resource requirements as well as the resource needs of the new service. When required new hardware was provisioned. Even with that, we couldn’t dynamically optimize infrastructure use. All of this required precious time to be spent planning the deployment structure and changes to the configuration.
Lack of service isolation
Multiple services ran on each box without any isolation or sandboxing. A bug in service could fill up the disk with logs and have a cascading effect on other services. We addressed these issues with automated checks both at package time and runtime however our services were always susceptible to noisy neighbour issue without service sandboxing.
Multi-AZ deployments
High availability setup required meticulous planning. While we had a multi-node deployment for each component, we did not have a safeguard against an availability zone failure. Planning for an availability zone required leveraging Amazon Web Service’s constructs which would have locked us in deeper into the AWS infrastructure. We wanted to address this without a significant lock-in.
Lack of artefact promotion
Our release process was centred around branches, not artefacts. Every auto-release created a branch called RELEASE that was promoted across environments. Artefacts were rebuilt on the branch. This isn’t ideal as a change in an external dependency within the same version can cause a failure in a rare scenario. Artefact versioning and promotion are more ideal in our opinion. There is higher confidence attached to releasing a tested binary.
Need for a low-cost spin-up of environment
As we expanded into more geographical regions rapidly, spinning up full-fledged environments quickly became crucial. In addition to that without infrastructure optimization, the cost continued to mount up, leaving a lot of room for optimization. If we could re-use the underlying hardware across environments, we could reduce operational costs.
Provisioning cost at deployment time
Any significant changes to the underlying machine were made during deployment time. This effectively meant that we paid the cost of provisioning during deployments. This led to longer deployment downtime in some cases.
Considering containers & Kubernetes
It was possible to address most of the existing gaps in the infrastructure with additional changes. For instance, Route53 would have allowed us to set up services for high availability across AZs, extending Ansible would have enabled multi-AZ support and changing build pipelines and scripts could have brought in artefact promotion.
However, containers, specifically Kubernetes solved a lot of those issues either out of the box or with small effort. Using KOps also allowed us to remained cloud-agnostic for a large part. We decided that moving to containers will provide the much-needed service isolation as well as other benefits including lower cost of operation with higher availability.
Since containers differ significantly in how they are packaged and deployed. We needed an approach that had a minimum or zero impact to the day to day operations and ongoing production releases. This required some thinking and planning. Rest of the post covers an overview of our thinking, approach and the results.
The infrastructure strangulation
A big change like this warrants experimentation and confidence that it will meet all our needs with reasonable trade-offs. So we decided to adopt the process incrementally. The strangulation approach was a great fit for an incremental rollout. It helped in assessing all the aspects early on. It also gave us enough time to get everyone on the team up to speed. Having a good operating knowledge of deployment and infrastructure concerns across the team is crucial for us. The whole team collectively owns the production, deployments and infrastructure setup. We rotate on responsibilities and production support.
Our plan was a multi-step process. Each step was designed to give us more confidence and incremental improvement without disrupting the existing deployment and release process. We also prioritized the most uncertain areas first to ensure that we address the biggest issues at the start itself.
We chose Helm as the Kubernetes package manager to help us with the deployments and image management. The images were stored and scanned in AWS ECR.
The first service
We picked the most complicated service as the first candidate for migration. A change was required to augment the packaging step. In addition to the existing binary file, we added a step to generate a docker image as well. Once the service was packaged and ready to be deployed, we provisioned the underlying Kubernetes infrastructure to deploy our containers. We could deploy only one service at this point but that was ok to prove the correctness of the approach. We updated GitLab pipelines to enable dual deploy. Upon code check-in, the binary would get deployed to existing test environments as well as to new Kubernetes setup.
Some of the things we gained out of these steps were the confidence of reliably converting our services into Docker images and the fact that dual deploy could work automatically without any disruption to existing work.
Migrating logging & monitoring
The second step was to prove that our logging and monitoring stack could continue to work with containers. To address this, we provisioned new servers for both logging and monitoring. We also evaluated Loki to see if we could converge tooling for logging and monitoring. However, due to various gaps in Loki given our need, we stayed with ElasticSearch stack. We did replace logstash and filebeat with Fluentd. This helped us address some of the issues that we had seen with filebeat our old infrastructure. Monitoring had new dashboards for the Kubernetes setup as we now cared about both pods as well in addition to host machine health.
At the end of the step, we had a functioning logging and monitoring stack which could show data for a single Kubernetes service container as well across logical service/component. It made us confident about the observability of our infrastructure. We kept new and old logging & monitoring infrastructure separate to keep the migration overhead out of the picture. Our approach was to keep both of them alive in parallel until the end of the data retention period.
Addressing stateful components
One of the key ingredients for strangulation was to make any changes to stateful components post initial migration. This way, both the new and old infrastructure can point to the same data stores and reflect/update data state uniformly.
So as part of this step, we configured newly deployed service to point to existing data stores and ensure that all read/writes worked seamlessly and reflected on both infrastructures.
Deployment repository and pipeline replication
With one service and support system ready, we extracted out a generic way to build images with docker files and deployment to new infrastructure. These steps could be used to add dual-deployment to all services. We also changed our deployment approach. In a new setup, the deployment code lived in a separate repository where each environment and region was represented by a branch example uk-qa,uk-prod or in-qa etc. These branches carried the variables for the region + environment. In addition to that, we provisioned a Hashicorp Vault to manage secrets and introduced structure to retrieve them by region + environment combination. We introduced namespaces to accommodate multiple environments over the same underlying hardware.
Crowd-sourced migration of services
Once we had basic building blocks ready, the next big step was to convert all our remaining services to have a dual deployment step for new infrastructure. This was an opportunity to familiarize the team with new infrastructure. So we organized a session where people paired up to migrate one service per pair. This introduced everyone to docker files, new deployment pipelines and infrastructure setup.
Because the process was jointly driven by the whole team, we migrated all the services to have dual deployment path in a couple of days. At the end of the process, we had all services ready to be deployed across two environments concurrently.
Test environment migration
At this point, we did a shift and updated the Nameservers with updated DNS for our QA and UAT environments. The existing domain started pointing to Kubernetes setup. Once the setup was stable, we decommissioned the old infrastructure. We also removed old GitLab pipelines. Forcing only Kubernetes setup for all test environments forced us to address the issues promptly.
In a couple of days, we were running all our test environments across Kubernetes. Each team member stepped up to address the fault lines that surfaced. Running this only on test environments for a couple of sprints gave us enough feedback and confidence in our ability to understand and handle issues.
Establishing dual deployment cadence
While we were running Kubernetes on the test environment, the production was still on old infrastructure and dual deployments were working as expected. We continued to release to production in the old style.
We would generate images that could be deployed to production but they were not deployed and merely archived.
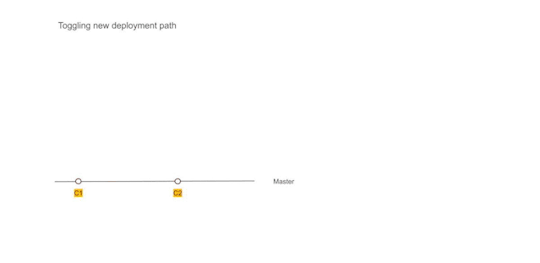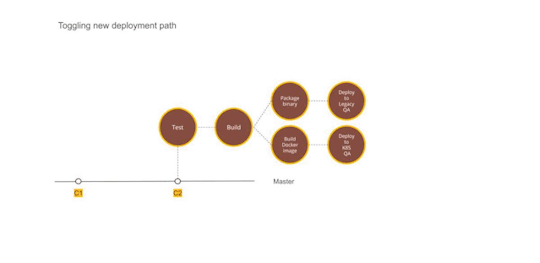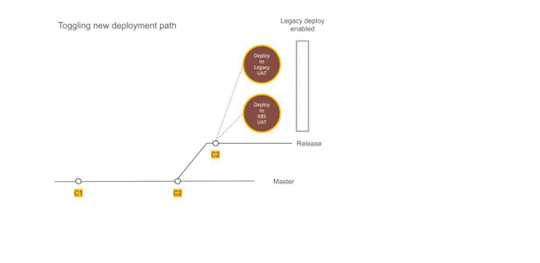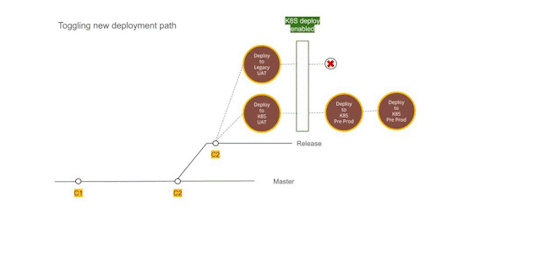
Figure 2 — Using Dual deployment to toggle deployment path to new infrastructure
As the test environment ran on Kubernetes and got stabilized, we used the time to establish dual deployment cadence across all non-prod environments.
Troubleshooting and strengthening
Before migrating to the production we spent time addressing and assessing a few things.
We updated the liveness and readiness probes for various services with the right values to ensure that long-running DB migrations don’t cause container shutdown/respawn. We eventually pulled out migrations into separate containers which could run as a job in Kubernetes rather than as a service.
We spent time establishing the right container sizing. This was driven by data from our old monitoring dashboards and the resource peaks from the past gave us a good idea of the ceiling in terms of the baseline of resources needed. We planned enough headroom considering the roll out updates for services.
We setup ECR scanning to ensure that we get notified about any vulnerabilities in our images in time so that we can address them promptly.
We ran security scans to ensure that the new infrastructure is not vulnerable to attacks that we might have overlooked.
We addressed a few performance and application issues. Particularly for batch processes, which were split across servers running the same component. This wasn’t possible in Kubernetes setup, as each instance of a service container feeds off the same central config. So we generated multiple images that were responsible for part of batch jobs and they were identified and deployed as separate containers.
Upgrading production passively
Finally, with all the testing we were confident about rolling out Kubernetes setup to the production environment. We provisioned all the underlying infrastructure across multiple availability zones and deployed services to them. The infrastructure ran in parallel and connected to all the production data stores but it did not have a public domain configured to access it. Days before going live the TTL for our DNS records was reduced to a few minutes. Next 72 hours gave us enough time to refresh this across all DNS servers.
Meanwhile, we tested and ensured that things worked as expected using an alternate hostname. Once everything was ready, we were ready for DNS switchover without any user disruption or impact.
DNS record update
The go-live switch-over involved updating the nameservers’ DNS record to point to the API gateway fronting Kubernetes infrastructure. An alternate domain name continued to point to the old infrastructure to preserve access. It remained on standby for two weeks to provide a fallback option. However, with all the testing and setup, the switch over went smooth. Eventually, the old infrastructure was decommissioned and old GitLab pipelines deleted.

Figure 3 — DNS record update to toggle from legacy infrastructure to containerized setup
We kept old logs and monitoring data stores until the end of the retention period to be able to query them in case of a need. Post-go-live the new monitoring and logging stack continued to provide needed support capabilities and visibility.
Observations and results
Post-migration, time to create environments has reduced drastically and we can reuse the underlying hardware more optimally. Our production runs all services in HA mode without an increase in the cost. We are set up across multiple availability zones. Our data stores are replicated across AZs as well although they are managed outside the Kubernetes setup. Kubernetes had a learning curve and it required a few significant architectural changes, however, because we planned for an incremental rollout with coexistence in mind, we could take our time to change, test and build confidence across the team. While it may be a bit early to conclude, the transition has been seamless and benefits are evident.
2 notes
·
View notes
Text
C Program to implement Deque using circular array
Implement Deque using circular array Write a C Program to implement Deque using circular array. Here’s simple Program to implement Deque using circular array in C Programming Language. What is Queue ? Queue is also an abstract data type or a linear data structure, in which the first element is inserted from one end called REAR, and the deletion of existing element takes place from the other end…
View On WordPress
#c data structures#c queue programs#dequeue in c using arrays#dequeue in data structure using c#dequeue in data structure with example#dequeue program in c using array#double ended queue in c#double ended queue in c using arrays#double ended queue in data structure#double ended queue in data structure program
0 notes
Text
Version 354
youtube
windows
zip
exe
os x
app
linux
tar.gz
source
tar.gz
I had a great week. The first duplicates storage update is done, and I got some neat misc fixes in as well.
false positives and alternates
The first version of the duplicates system did not store 'false positive' and 'alternates' relationships very efficiently. Furthermore, it was not until we really used it in real scenarios that we found the way we wanted to logically apply these states was also not being served well. This changes this week!
So, 'false positive' (up until recently called 'not dupes') and 'alternates' (which are 'these files are related but not duplicates', and sitting in a holding pattern for a future big job that will allow us to process them better) are now managed in a more intelligent storage system. On update, your existing relationships will be auto-converted.
This system uses significantly less space, particularly for large groups of alts like many game cg collections, and applies relationships transitively by its very structure. Alternates are now completely transitive, so if you have a A-alt-B set (meaning one group of duplicate files A has an alternate relationship to another group of duplicate files B) and then apply A-alt-C, the relationship B-alt-C will also apply without you having to do anything. False positive relationships are more tricky, but they are stored significantly more efficiently and also apply on an 'alternates' level, so if you have A-alt-B and add A-fp-M, B-fp-M will be automatically inferred. It may sound odd at first to think that something that is false positive to A could be nothing but false positive to B, but consider: if our M were same/better/worse to B, it would be in B and hence transitively alternate to A, which it cannot be as we already determined it was not related to A.
Mistakenly previously allowable states, such as a false positive relationship within an alternates group, will be corrected on the update. Alternates will take precedence, and any subsequently invalid false positives will be considered mistakes and discarded. If you know there are some problems here, there is unfortunately no easy way at the moment to cancel or undo an alternate or false positive relationship, but once the whole duplicates system is moved over I will be able to write a suite of logically correct and more reliable reset/break/dissolve commands for all the various states in which files can be related with each other. These 'reset/set none' tools never worked well in the old system.
The particularly good news about these changes is it cuts down on filtering time. Many related 'potential' duplicates can be auto-resolved from a single alternate or false positive decision, and if you have set many alts or false positives previously, you will see your pending potentials queue shrink considerably after update, and as you continue to process.
With this more logically consistent design, alternate and false positive counts and results are more sensible and consistent when searched for or opened from the advanced mode thumbnail right-click menu. All the internal operations are cleaner, and I feel much better about working on an alternates workflow in future so we can start setting 'WIP' and 'costume change'-style labels to our alternates and browsing them more conveniently in the media viewer.
The actual remaining duplicate relations, 'potential', 'same quality', and 'this is better', are still running on the old inefficient system. They will be the next to work on. I would like to have 'same quality' and 'this is better' done for 356, after E3.
the rest
The tag blacklists in downloaders' tag import options now apply to the page's tags after tag sibling processing. So, if you banned 'high heels', say, but the site suddenly starts delivering 'high-heel shoes', then as long as that 'high-heel shoes' gets mapped to 'high-heels' in one of your tag services, it should now be correctly filtered. The unprocessed tags are still checked as before, so this is really a double-round of checking to cover more valid ground. If you were finding you were chasing many different synonyms of the tags you do not like, please let me know how this now works for you.
The annoying issue where a handful of thumbnails would sometimes stop fading in during heavy scrolling seems to be fixed! Also, the thumbnail 'waterfall' system is now cleverer about how it schedules thumbnails that need regeneration. You may notice the new file maintenance manager kicking in more often with thumbnail work.
Another long-term annoying issue was the 'pending' menu update-flickering while a lot of tag activity was going on. It would become difficult to interact with. I put some time into this this week, cleaning up a bunch of related code, and I think I figured out a reliable way to make the menus on the main gui stop updating as long as one is open. It won't flicker and should let you start a tags commit even when other things are going on. The other menus (like the 'services' menu, which will update on various service update info) will act the same way. Overall menu-related system stability should be improved for certain Linux users as well.
The new 'fix siblings and parents' button on manage tags is now a menu button that lets you apply siblings and parents from all services or just from the service you are looking at. These commands overrule your 'apply sibs/parents across all services' settings. So, if you ever accidentally applied a local sibling to the PTR or vice versa, please try the specific-service option here.
full list
duplicates important:
duplicates 'false positive' and 'alternates' pairs are now stored in a new more efficient structure that is better suited for larger groups of files
alternate relationships are now implicitly transitive--if A is alternate B and A is alternate C, B is now alternate C
false positive relationships remain correctly non-transitive, but they are now implicitly shared amongst alternates--if A is alternate B and A is false positive with C, B is now false positive with C. and further, if C alt D, then A and B are implicitly fp D as well!
your existing false positive and alternates relationships will be migrated on update. alternates will apply first, so in the case of conflicts due to previous non-excellent filtering workflow, formerly invalid false positives (i.e. false positives between now-transitive alternates) will be discarded. invalid potentials will also be cleared out
attempting to set a 'false positives' or 'alternates' relationship to files that already have a conflicting relation (e.g. setting false positive to two files that already have alternates) now does nothing. in future, this will have graceful failure reporting
the false positive and alternate transitivity clears out potential dupes at a faster rate than previously, speeding up duplicate filter workflow and reducing redundancy on the human end
unfortunately, as potential and better/worse/same pairs have yet to be updated, the system may report that a file has the same alternate as same quality partner. this will be automatically corrected in the coming weeks
when selecting 'view this file's duplicates' from thumbnail right-click, the focus file will now be the first file displayed in the next page
.
duplicates boring details:
setting 'false positive' and 'alternates' status now accounts for the new data storage, and a variety of follow-on assumptions and transitive properties (such as implying other false positive relationships or clearing out potential dupes between two groups of merging alternates) are now dealt with more rigorously (and moreso when I move the true 'duplicate' file relationships over)
fetching file duplicate status counts, file duplicate status hashes, and searching for system:num_dupes now accounts for the new data storage r.e. false positives and alternates
new potential dupes are culled when they conflict with the new transitive alternate and false positive relationships
removed the code that fudges explicit transitive 'false positive' and 'alternate' relationships based on existing same/better/worse pairs when setting new dupe pairs. this temporary gap will be filled back in in the coming weeks (clearing out way more potentials too)
several specific advanced duplicate actions are now cleared out to make way for future streamlining of the filter workflow:
removed the 'duplicate_media_set_false_positive' shortcut, which is an action only appropriate when viewing confirmed potentials through the duplicate filter (or after the ' show random pairs' button)
removed the 'duplicate_media_remove_relationships' shortcut and menu action ('remove x pairs ... from the dupes system'), which will return as multiple more precise and reliable 'dissolve' actions in the coming weeks
removed the 'duplicate_media_reset_to_potential' shortcut and menu action ('send the x pairs ... to be compared in the duplicates filter') as it was always buggy and lead to bloating of the filter queue. it is likely to return as part of the 'dissolve'-style reset commands as above
fixed an issue where hitting 'duplicate_media_set_focused_better' shortcut with no focused thumb would throw an error
started proper unit tests for the duplicates system and filled in the phash search, basic current better/worse, and false positive and alternate components
various incidences of duplicate 'action options' and similar phrasing are now unified to 'metadata merge options'
cleaned up 'unknown/potential' phrasing in duplicate pair code and some related duplicate filter code
cleaned up wording and layout of the thumbnail duplicates menu
.
the rest:
tag blacklists in downloaders' tag import options now apply to the parsed tags both before and after a tag sibling collapse. it uses the combined tag sibling rules, so feedback on how well this works irl would be appreciated
I believe I fixed the annoying issue where a handful of thumbnails would sometimes inexplicitly not fade in after during thumbgrid scrolling (and typically on first thumb load--this problem was aggravated by scroll/thumb-render speed ratio)
when to-be-regenerated thumbnails are taken off the thumbnail waterfall queue due to fast scrolling or page switching, they are now queued up in the new file maintenance system for idle-time work!
the main gui menus will now no longer try to update while they are open! uploading pending tags while lots of new tags are coming in is now much more reliable. let me know if you discover a way to get stuck in this frozen state!
cleaned up some main gui menu regeneration code, reducing the total number of stub objects created and deleted, particularly when the 'pending' menu refreshes its label frequently while uploading many pending tags. should be a bit more stable for some linux flavours
the 'fix siblings and parents' button on manage tags is now a menu button with two options--for fixing according to the 'all services combined' siblings and parents or just for the current panel's service. this overrides the 'apply sibs/parents across all services' options. this will be revisited in future when more complicated sibling application rules are added
the 'hide and anchor mouse' check under 'options->media' is no longer windows-only, if you want to test it, and the previous touchscreen-detecting override (which unhid and unanchored on vigorous movement) is now optional, defaulting to off
greatly reduced typical and max repository pre-processing disk cache time and reworked stop calculations to ensure some work always gets done
fixed an issue with 'show some random dupes' thumbnails not hiding on manual trashing, if that option is set. 'show some random dupes' thumbnail panels will now inherit their file service from the current duplicate search domain
repository processing will now never run for more than an hour at once. this mitigates some edge-case disastrous ui-hanging outcomes and generally gives a chance for hydrus-level jobs like subscriptions and even other programs like defraggers to run even when there is a gigantic backlog of processing to do
added yet another CORS header to improve Client API CORS compatibility, and fixed an overauthentication problem
setting a blank string on the new local booru external port override option will now forego the host:port colon in the resultant external url. a tooltip on the control repeats this
reworded and coloured the pause/play sync button in review services repository panel to be more clear about current paused status
fixed a problem when closing the gui when the popup message manager is already closed by clever OS-specific means
misc code cleanup
updated sqlite on windows to 3.28.0
updated upnpc exe on windows to 2.1
next week
The duplicates work this week took more time than I expected. I still have many small jobs I want to catch up on, so I am shunting my rotating schedule down a week and doing a repeat. I will add some new shortcuts, some new tab commands, and hopefully a clipboard URL watcher and a new way of adding OR search predicates.
1 note
·
View note
Text
C++ Deque
Deque stands for double ended queue. It generalizes the queue data structure i.e insertion and deletion can be performed from both the ends either front or back.
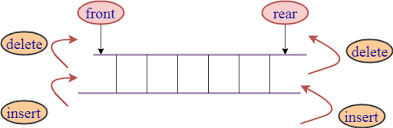
0 notes
Text
The Collection Framework in Java

What is a Collection in Java?
Java collection is a single unit of objects. Before the Collections Framework, it had been hard for programmers to write down algorithms that worked for different collections. Java came with many Collection classes and Interfaces, like Vector, Stack, Hashtable, and Array.
In JDK 1.2, Java developers introduced theCollections Framework, an essential framework to help you achieve your data operations.
Why Do We Need Them?
Reduces programming effort & effort to study and use new APIs
Increases program speed and quality
Allows interoperability among unrelated APIs
Reduces effort to design new APIs
Fosters software reuse
Methods Present in the Collection Interface
NoMethodDescription1Public boolean add(E e)To insert an object in this collection.2Public boolean remove(Object element)To delete an element from the collection.3Default boolean removeIf(Predicate filter)For deleting all the elements of the collection that satisfy the specified predicate.4Public boolean retainAll(Collection c)For deleting all the elements of invoking collection except the specified collection.5Public int size()This return the total number of elements.6Publicvoid clear()This removes the total number of elements.7Publicboolean contains(Object element)It is used to search an element.8PublicIterator iterator()It returns an iterator.9PublicObject[] toArray()It converts collection into array.
Collection Framework Hierarchy
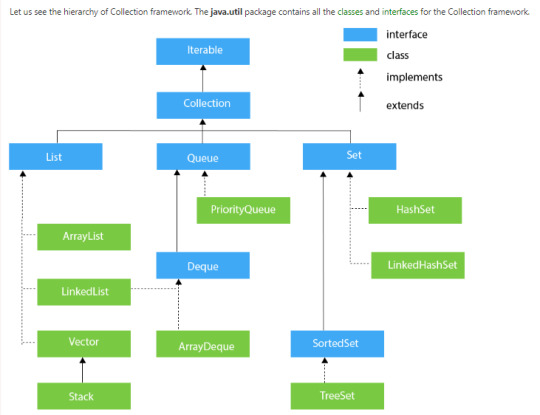
List Interface
This is the child interface of the collectioninterface. It is purely for lists of data, so we can store the ordered lists of the objects. It also allows duplicates to be stored. Many classes implement this list interface, including ArrayList, Vector, Stack, and others.
Array List
It is a class present in java. util package.
It uses a dynamic array for storing the element.
It is an array that has no size limit.
We can add or remove elements easily.
Linked List
The LinkedList class uses a doubly LinkedList to store elements. i.e., the user can add data at the initial position as well as the last position.
It allows Null insertion.
If we’d wish to perform an Insertion /Deletion operation LinkedList is preferred.
Used to implement Stacks and Queues.
Vector
Every method is synchronized.
The vector object is Thread safe.
At a time, one thread can operate on the Vector object.
Performance is low because Threads need to wait.
Stack
It is the child class of Vector.
It is based on LIFO (Last In First Out) i.e., the Element inserted in last will come first.
Queue
A queue interface, as its name suggests, upholds the FIFO (First In First Out) order much like a conventional queue line. All of the elements where the order of the elements matters will be stored in this interface. For instance, the tickets are always offered on a first-come, first-serve basis whenever we attempt to book one. As a result, the ticket is awarded to the requester who enters the queue first. There are many classes, including ArrayDeque, PriorityQueue, and others. Any of these subclasses can be used to create a queue object because they all implement the queue.
Dequeue
The queue data structure has only a very tiny modification in this case. The data structure deque, commonly referred to as a double-ended queue, allows us to add and delete pieces from both ends of the queue. ArrayDeque, which implements this interface. We can create a deque object using this class because it implements the Deque interface.
Set Interface
A set is an unordered collection of objects where it is impossible to hold duplicate values. When we want to keep unique objects and prevent object duplication, we utilize this collection. Numerous classes, including HashSet, TreeSet, LinkedHashSet, etc. implement this set interface. We can instantiate a set object with any of these subclasses because they all implement the set.
LinkedHashSet
The LinkedHashSet class extends the HashSet class.
Insertion order is preserved.
Duplicates aren’t allowed.
LinkedHashSet is non synchronized.
LinkedHashSet is the same as the HashSet except the above two differences are present.
HashSet
HashSet stores the elements by using the mechanism of Hashing.
It contains unique elements only.
This HashSet allows null values.
It doesn’t maintain insertion order. It inserted elements according to their hashcode.
It is the best approach for the search operation.
Sorted Set
The set interface and this interface are extremely similar. The only distinction is that this interface provides additional methods for maintaining the elements' order. The interface for handling data that needs to be sorted, which extends the set interface, is called the sorted set interface. TreeSet is the class that complies with this interface. This class can be used to create a SortedSet object because it implements the SortedSet interface.
TreeSet
Java TreeSet class implements the Set interface it uses a tree structure to store elements.
It contains Unique Elements.
TreeSet class access and retrieval time are quick.
It doesn’t allow null elements.
It maintains Ascending Order.
Map Interface
It is a part of the collection framework but does not implement a collection interface. A map stores the values based on the key and value Pair. Because one key cannot have numerous mappings, this interface does not support duplicate keys. In short, The key must be unique while duplicated values are allowed. The map interface is implemented by using HashMap, LinkedHashMap, and HashTable.
HashMap
Map Interface is implemented by HashMap.
HashMap stores the elements using a mechanism called Hashing.
It contains the values based on the key-value pair.
It has a unique key.
It can store a Null key and Multiple null values.
Insertion order isn’t maintained and it is based on the hash code of the keys.
HashMap is Non-Synchronized.
How to create HashMap.
LinkedHashMap
The basic data structure of LinkedHashMap is a combination of LinkedList and Hashtable.
LinkedHashMap is the same as HashMap except above difference.
HashTable
A Hashtable is an array of lists. Each list is familiar as a bucket.
A hashtable contains values based on key-value pairs.
It contains unique elements only.
The hashtable class doesn’t allow a null key as well as a value otherwise it will throw NullPointerException.
Every method is synchronized. i.e At a time one thread is allowed and the other threads are on a wait.
Performance is poor as compared to HashMap.
This blog illustrates the interfaces and classes of the java collection framework. Which is useful for java developers while writing efficient codes. This blog is intended to help you understand the concept better.
At Sanesquare Technologies, we provide end-to-end solutions for Development Services. If you have any doubts regarding java concepts and other technical topics, feel free to contact us.
0 notes
Text
Linked list stack implememntation using two queues 261

Linked list stack implememntation using two queues 261 code#
Fortunately, JavaScript arrays implement this for us in the form of the length property. algorithms (sorting, using stacks and queues, tree exploration algorithms, etc.). A common additional operation for collection data structures is the size, as it allows you to safely iterate the elements and find out if there are any more elements present in the data structure. Data structures: Abstract data types (ADTs), vector, deque, list, queue. Again, it doesn't change the index of the other items in the array, so it is O(1). Similarly, on pop, we simply pop the last value from the array. As it doesn't change the index of the current items, this is O(1). On push, we simply push the new item into the array. Therefore, we can simply implement the operations of this data structure using an array. Fortunately, in JavaScript implementations, array functions that do not require any changes to the index of the current items have an average runtime of O(1). First node have null in link field and second node link have first node address in link field and so on and last node address in. which is head of the stack where pushing and popping items happens at the head of the list. In stack Implementation, a stack contains a top pointer. You will use only one C file (stackfromqueue.c)containing all the functions to design the entire interface. The objective is to implement these push and pop operations such that they operate in O(1) time. A stack can be easily implemented using the linked list. Part 3: Linked List Stack Implementation Using Two Queues Inthis part, you will use two instances of Queue ADT to implement aStack ADT. This fact can be modeled into the type system by using a union of T and undefined. If there are no more items, we can return an out-of-bound value, for example, undefined. The other key operation pops an item from the stack, again in O(1). The first one is push, which adds an item in O(1). StdOut.java A list implemented with a doubly linked list. js is the open source HTML5 audio player. The stack data structure has two key operations. js, a JavaScript library with the goal of making coding accessible to artists, designers, educators, and beginners. We can model this easily in TypeScript using the generic class for items of type T. Using Python, create an implementation of Deque (double-ended queue) with linked list nodes.
Linked list stack implememntation using two queues 261 code#
So deleting of the middle element can be done in O(1) if we just pop the element from the front of the deque.A stack is a last-in/first-out data structure with key operations having a time complexity of O(1). I encountered this question as I am preparing for my code interview. The stack functions worked on from Worksheet 17 were re-implemented using the queue functions worked on from Worksheet 18. Overview: This program is an implementation of a stack using two instances of a queue. Here each new node will be dynamically allocated, so overflow is not possible unless memory is exhausted. Using an array will restrict the maximum capacity of the array, which can lead to stack overflow. You must use only standard operations of a queue - which means only push to back, peek/pop from front, size, and is empty operations are valid. The advantage of using a linked list over arrays is that it is possible to implement a stack that can grow or shrink as much as needed. empty () - Return whether the stack is empty. We will see that the middle element is always the front element of the deque. Stack With Two Queues (Linked List) Zedrimar. pop () - Removes the element on top of the stack. If after the pop operation, the size of the deque is less than the size of the stack, we pop an element from the top of the stack and insert it back into the front of the deque so that size of the deque is not less than the stack. The pop operation on myStack will remove an element from the back of the deque. The number of elements in the deque stays 1 more or equal to that in the stack, however, whenever the number of elements present in the deque exceeds the number of elements in the stack by more than 1 we pop an element from the front of the deque and push it into the stack. Insert operation on myStack will add an element into the back of the deque. We will use a standard stack to store half of the elements and the other half of the elements which were added recently will be present in the deque. Method 2: Using a standard stack and a deque ISRO CS Syllabus for Scientist/Engineer Exam.ISRO CS Original Papers and Official Keys.GATE CS Original Papers and Official Keys.
0 notes
Text
COMP 3006 Programming Assignment 4
Assignment 4.1: Instantiate an object of the class Counter (import it from collections) and use it to determine the three most common numbers that appear when you simulate 100 rolls of a fair six-sided die. Display them along with how many times they appeared. Assignment 4.2: Instantiate a double ended queue data structure (deque). Fill it with six given names of movie stars. Insert new names in…
0 notes
Text
Teque Solution
Problem Description You have probably heard about the deque (double-ended queue) data structure, which allows for efficient pushing and popping of elements from both the front and back of the queue. Depending on the implementation, it also allows for efficient random access to any index element of the queue as well. Now, we want you to bring this data structure up to the next level, the teque…

View On WordPress
0 notes
Text
Programming Project 2 Notation Converter Solution
Programming Project 2 Notation Converter Solution
Instructions For Programming Project 2, you will implement a Deque (Double-Ended Queue) and use that data structure to write a class that can convert between the three common mathematical notation for arithmetic. The three notations are: Postfix (Reverse Polish) Notation: Operators are written after operands A B – C + == (A – B) + C Infix Notation: The standard notation we use where the operator…

View On WordPress
0 notes
Text

Double Ended Queue is also a Queue data structure in which the insertion and deletion operations are performed at both the ends (front and rear)💻 The Deque data structure supports clockwise and anticlockwise rotations in O(1) time which can be useful in certain applications.👩💻
Do follow for more such amazing content 👉 @tutort-academy
0 notes
Text
Everything You Need to Know about Apache Storm
Data is everywhere, and as the world becomes more digital, new issues in data management and processing emerge every day. The ever-increasing development in Big Data production and analytics continues to create new problems, which data scientists and programmers calmly accept by always enhancing the solutions they develop.
When I say simple, I mean we'll focus on the most basic concepts without getting bogged down in details, and we'll keep it short. One of these issues was real-time streaming. Streaming data is any type of data that can be read without having to open and close the input like a regular data file.
Apache Storm: An Overview
Apache Storm is a distributed real-time computation system for processing data streams that is open-source. Apache Storm is a real-time, distributed computing system that is widely used in Big Data Analytics. Apache Storm performs unlimited streams of data in a reliable manner, similar to what Hadoop does for batch processing. It is an open-source platform as well as free.
In a fraction of a second, Apache Storm can handle over a million jobs on a single node.
To get better throughputs, it is connected with Hadoop. Apache Storm is well-known for its incredible speed.
It's very simple to set up and also can work with any kind of programming language. It processes over a million tuples per second per node, making it significantly quicker than Apache Spark.
Nathan Marz created the storm as a back-type project, which was later acquired by Twitter in 2011. Apache Storm prioritizes scalability, fault tolerance, and the processing of your data. The storm was made public by Twitter in 2013 when it was uploaded to GitHub. The storm was then accepted into the Apache Software Foundation as an incubator project in the same year, delivering high-end applications. Apache is simple to install and use, and it can work with any programming language. Since then, Apache Storm has been able to meet the needs of Big Data Analytics.
Components for Apache Storm
Turple
A tuple, like a database row, is an ordered list of named values. The basic data structure in Storm is the tuple.
The data type of each field in the tuple can be dynamic.
It's a list of elements in a particular order.
Any data type, including string, integer, float, double, boolean, and byte array, can be used in the field.
A Tuple supports all data types by default. In tuples, user-defined data types are also permitted.
It's usually represented as a list of comma-separated values and sent to a Storm cluster.
Stream
The stream, which is an unbounded pipeline of tuples, is one of the most basic abstractions in Storm architecture.
A stream is a tuple sequence that is not in any particular order.
Spouts
The source of the stream is quite the spouts. Storm receives data from a variety of raw data sources, including the Twitter Streaming API, Apache Kafka queue, Kestrel queue, and others.
It is the topology's entry point or source of streams.
It is in charge of connecting to the actual data source, continuously receiving data, translating the data into a stream of tuples, and eventually passing the data to bolts to be processed as well.
You can technically use spouts to read data from data sources if you don't want to use spouts so well.
The primary interface for implementing spouts is "ISpout." IRichSpout, BaseRichSpout, KafkaSpout, and other particular interfaces are examples.
Bolts
Bolts are logical processing units. They're in charge of accepting a variety of input streams, processing them, and then producing new streams for processing.
Spouts send information to the bolts and bolts process, which results in a new output stream.
They can execute functions, filter tuples, aggregate and join streams, and connect to databases, among other things.
Filtering, aggregating, joining, and interfacing with data sources and databases are all possible using Bolts.
Conclusion
So that's the certain gist of it. Apache Storm is not only a market leader in the software business, but it also has a wide range of applications in areas such as telecommunications, social media platforms, weather forecasting, and more, making it one of the most in-demand technologies today. Data that isn't analyzed at the right moment might quickly become obsolete for businesses.
Now that you've learned everything there is to know about Apache Storm, you should focus on mastering the Big Data and data science ecosystem as a whole. It is necessary to analyze data in order to uncover trends that can benefit the firm. If you're new to Big Data and data science, Learnbay's data science course Certification is a good place to start. Organizations developed several analytics tools in response to the needs and benefits of evaluating real-time data. This certification course will help you master the most in-demand Apache Spark skills and earn a competitive edge in your Data Scientist profession.
#data science certification courses#Data Science Courses In Bangalore#data science course bangalore#best data science course#Best data science institute in bangalore#Online Course on Data Science
0 notes
Text
Transcriptions:
List operations:
access any item
-- insert item at beginning, middle, or end
delete item at beginning, middle, or end
--
--
Why linked list: if one item is removed, we need to move all items after it up an index (so we don't have blank index) In a normal array, we need to move every single item individually, which is costly when you have thousands of items - Using linked list, we don't need to do this
- Linked list: instead of keeping items in array, we link each item to the next
- Each item has a pointer to the memory address of next item
In linked list, instead of each item needing to be right next to the other in memory, they can be anywhere in memory, because we have the address of next item stored First item in linked list is called "head node" - we need to have reference to this
- We need to take care of the linking ourselves: if item is removed, we need to link previous item to next item
- examples of linked list:
tabs in chrome/firefox
songs in youtube playlist
computer internal: stack, queue, process scheduling
--
--
linked list should have interation, search, insert, and remove operations
- iteration/count operation is also known as traversal
for iteration, linked list is costly; some other data structures are better for iterating through elements
without a reference to the head, there is no way to locate that node, or the rest of the list
- last node: tail - the node with null as next reference
tail can be found by traversing the list - starting at the beginning and going until the end (also called link hopping or pointer hopping)
- but it's common to make an explicit reference for the tail as well
also common to keep count of items in list
- to create a new head: set new node's next pointer to point to previous head, set new node as head (then increment node count) similar process to create new tail
to remove head, just set head to current head's next node
- no easy way to remove tail - you'd have to go through the whole list until the second-last element and set its next to null
- good methods to implement: size(), isEmpty(), first(), last(), addFirst(e), addLast(e), removeFirst()
Photo 2:
Java syntax:
//to define object public class TShirtAsNode {
public double price;
// to point to another tshirt
public TShirtAsNode next;
}
//to instantiate
TShirtAsNode firstshirt = new TShirtAsNode(); firstshirt.price= 0;
TShirtAsNode secondShirt = new TShirtAsNode(); secondshirt.price= 1;
etc.
//to link them
firstshirt.next = secondShirt; secondshirt.next = thirdshirt; //keep reference of first one TShirtAsNode head = firstshirt;
//to iterate thru array TShirtAsNode current = head;
int counter = 0;
while (current) {
}
// do operations counter++;
current = current.next;
💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎
🌱 Sunday 🌱 4/16/2023 🌱
💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎
16. show us some revision resources you’ve made recently
As someone currently stuck in gen-ed hell, I do more assignments than actual revision and tests. But here's some of my notes about linked lists from early in the semester when I was actually trying. I can't guarantee that they're right, please do your own research!


💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎
Today:
- writing assignment
💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎💚💙🤎
4 notes
·
View notes
Text
COMP 3006 Programming Assignment 4 Solution
Assignment 4.1: Instantiate an object of the class Counter (import it from collections) and use it to determine the three most common numbers that appear when you simulate 100 rolls of a fair six-sided die. Display them along with how many times they appeared. Assignment 4.2: Instantiate a double ended queue data structure (deque). Fill it with six given names of movie stars. Insert new names in…
0 notes