#double ended queue in data structure program
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
COMP 3006 Programming Assignment 4
Assignment 4.1: Instantiate an object of the class Counter (import it from collections) and use it to determine the three most common numbers that appear when you simulate 100 rolls of a fair six-sided die. Display them along with how many times they appeared. Assignment 4.2: Instantiate a double ended queue data structure (deque). Fill it with six given names of movie stars. Insert new names in…
0 notes
Text
C Program to implement Deque using circular array
Implement Deque using circular array Write a C Program to implement Deque using circular array. Here’s simple Program to implement Deque using circular array in C Programming Language. What is Queue ? Queue is also an abstract data type or a linear data structure, in which the first element is inserted from one end called REAR, and the deletion of existing element takes place from the other end…
View On WordPress
#c data structures#c queue programs#dequeue in c using arrays#dequeue in data structure using c#dequeue in data structure with example#dequeue program in c using array#double ended queue in c#double ended queue in c using arrays#double ended queue in data structure#double ended queue in data structure program
0 notes
Text
The Collection Framework in Java

What is a Collection in Java?
Java collection is a single unit of objects. Before the Collections Framework, it had been hard for programmers to write down algorithms that worked for different collections. Java came with many Collection classes and Interfaces, like Vector, Stack, Hashtable, and Array.
In JDK 1.2, Java developers introduced theCollections Framework, an essential framework to help you achieve your data operations.
Why Do We Need Them?
Reduces programming effort & effort to study and use new APIs
Increases program speed and quality
Allows interoperability among unrelated APIs
Reduces effort to design new APIs
Fosters software reuse
Methods Present in the Collection Interface
NoMethodDescription1Public boolean add(E e)To insert an object in this collection.2Public boolean remove(Object element)To delete an element from the collection.3Default boolean removeIf(Predicate filter)For deleting all the elements of the collection that satisfy the specified predicate.4Public boolean retainAll(Collection c)For deleting all the elements of invoking collection except the specified collection.5Public int size()This return the total number of elements.6Publicvoid clear()This removes the total number of elements.7Publicboolean contains(Object element)It is used to search an element.8PublicIterator iterator()It returns an iterator.9PublicObject[] toArray()It converts collection into array.
Collection Framework Hierarchy
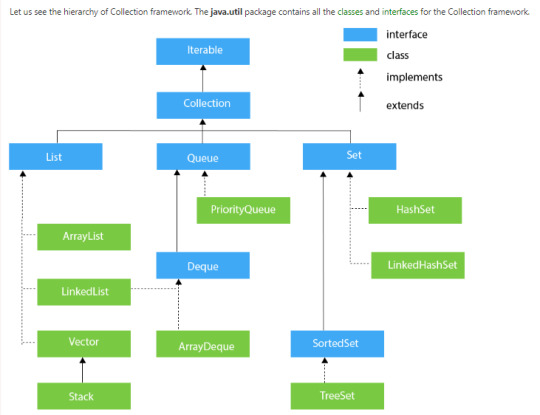
List Interface
This is the child interface of the collectioninterface. It is purely for lists of data, so we can store the ordered lists of the objects. It also allows duplicates to be stored. Many classes implement this list interface, including ArrayList, Vector, Stack, and others.
Array List
It is a class present in java. util package.
It uses a dynamic array for storing the element.
It is an array that has no size limit.
We can add or remove elements easily.
Linked List
The LinkedList class uses a doubly LinkedList to store elements. i.e., the user can add data at the initial position as well as the last position.
It allows Null insertion.
If we’d wish to perform an Insertion /Deletion operation LinkedList is preferred.
Used to implement Stacks and Queues.
Vector
Every method is synchronized.
The vector object is Thread safe.
At a time, one thread can operate on the Vector object.
Performance is low because Threads need to wait.
Stack
It is the child class of Vector.
It is based on LIFO (Last In First Out) i.e., the Element inserted in last will come first.
Queue
A queue interface, as its name suggests, upholds the FIFO (First In First Out) order much like a conventional queue line. All of the elements where the order of the elements matters will be stored in this interface. For instance, the tickets are always offered on a first-come, first-serve basis whenever we attempt to book one. As a result, the ticket is awarded to the requester who enters the queue first. There are many classes, including ArrayDeque, PriorityQueue, and others. Any of these subclasses can be used to create a queue object because they all implement the queue.
Dequeue
The queue data structure has only a very tiny modification in this case. The data structure deque, commonly referred to as a double-ended queue, allows us to add and delete pieces from both ends of the queue. ArrayDeque, which implements this interface. We can create a deque object using this class because it implements the Deque interface.
Set Interface
A set is an unordered collection of objects where it is impossible to hold duplicate values. When we want to keep unique objects and prevent object duplication, we utilize this collection. Numerous classes, including HashSet, TreeSet, LinkedHashSet, etc. implement this set interface. We can instantiate a set object with any of these subclasses because they all implement the set.
LinkedHashSet
The LinkedHashSet class extends the HashSet class.
Insertion order is preserved.
Duplicates aren’t allowed.
LinkedHashSet is non synchronized.
LinkedHashSet is the same as the HashSet except the above two differences are present.
HashSet
HashSet stores the elements by using the mechanism of Hashing.
It contains unique elements only.
This HashSet allows null values.
It doesn’t maintain insertion order. It inserted elements according to their hashcode.
It is the best approach for the search operation.
Sorted Set
The set interface and this interface are extremely similar. The only distinction is that this interface provides additional methods for maintaining the elements' order. The interface for handling data that needs to be sorted, which extends the set interface, is called the sorted set interface. TreeSet is the class that complies with this interface. This class can be used to create a SortedSet object because it implements the SortedSet interface.
TreeSet
Java TreeSet class implements the Set interface it uses a tree structure to store elements.
It contains Unique Elements.
TreeSet class access and retrieval time are quick.
It doesn’t allow null elements.
It maintains Ascending Order.
Map Interface
It is a part of the collection framework but does not implement a collection interface. A map stores the values based on the key and value Pair. Because one key cannot have numerous mappings, this interface does not support duplicate keys. In short, The key must be unique while duplicated values are allowed. The map interface is implemented by using HashMap, LinkedHashMap, and HashTable.
HashMap
Map Interface is implemented by HashMap.
HashMap stores the elements using a mechanism called Hashing.
It contains the values based on the key-value pair.
It has a unique key.
It can store a Null key and Multiple null values.
Insertion order isn’t maintained and it is based on the hash code of the keys.
HashMap is Non-Synchronized.
How to create HashMap.
LinkedHashMap
The basic data structure of LinkedHashMap is a combination of LinkedList and Hashtable.
LinkedHashMap is the same as HashMap except above difference.
HashTable
A Hashtable is an array of lists. Each list is familiar as a bucket.
A hashtable contains values based on key-value pairs.
It contains unique elements only.
The hashtable class doesn’t allow a null key as well as a value otherwise it will throw NullPointerException.
Every method is synchronized. i.e At a time one thread is allowed and the other threads are on a wait.
Performance is poor as compared to HashMap.
This blog illustrates the interfaces and classes of the java collection framework. Which is useful for java developers while writing efficient codes. This blog is intended to help you understand the concept better.
At Sanesquare Technologies, we provide end-to-end solutions for Development Services. If you have any doubts regarding java concepts and other technical topics, feel free to contact us.
0 notes
Text
Linked list stack implememntation using two queues 261

Linked list stack implememntation using two queues 261 code#
Fortunately, JavaScript arrays implement this for us in the form of the length property. algorithms (sorting, using stacks and queues, tree exploration algorithms, etc.). A common additional operation for collection data structures is the size, as it allows you to safely iterate the elements and find out if there are any more elements present in the data structure. Data structures: Abstract data types (ADTs), vector, deque, list, queue. Again, it doesn't change the index of the other items in the array, so it is O(1). Similarly, on pop, we simply pop the last value from the array. As it doesn't change the index of the current items, this is O(1). On push, we simply push the new item into the array. Therefore, we can simply implement the operations of this data structure using an array. Fortunately, in JavaScript implementations, array functions that do not require any changes to the index of the current items have an average runtime of O(1). First node have null in link field and second node link have first node address in link field and so on and last node address in. which is head of the stack where pushing and popping items happens at the head of the list. In stack Implementation, a stack contains a top pointer. You will use only one C file (stackfromqueue.c)containing all the functions to design the entire interface. The objective is to implement these push and pop operations such that they operate in O(1) time. A stack can be easily implemented using the linked list. Part 3: Linked List Stack Implementation Using Two Queues Inthis part, you will use two instances of Queue ADT to implement aStack ADT. This fact can be modeled into the type system by using a union of T and undefined. If there are no more items, we can return an out-of-bound value, for example, undefined. The other key operation pops an item from the stack, again in O(1). The first one is push, which adds an item in O(1). StdOut.java A list implemented with a doubly linked list. js is the open source HTML5 audio player. The stack data structure has two key operations. js, a JavaScript library with the goal of making coding accessible to artists, designers, educators, and beginners. We can model this easily in TypeScript using the generic class for items of type T. Using Python, create an implementation of Deque (double-ended queue) with linked list nodes.
Linked list stack implememntation using two queues 261 code#
So deleting of the middle element can be done in O(1) if we just pop the element from the front of the deque.A stack is a last-in/first-out data structure with key operations having a time complexity of O(1). I encountered this question as I am preparing for my code interview. The stack functions worked on from Worksheet 17 were re-implemented using the queue functions worked on from Worksheet 18. Overview: This program is an implementation of a stack using two instances of a queue. Here each new node will be dynamically allocated, so overflow is not possible unless memory is exhausted. Using an array will restrict the maximum capacity of the array, which can lead to stack overflow. You must use only standard operations of a queue - which means only push to back, peek/pop from front, size, and is empty operations are valid. The advantage of using a linked list over arrays is that it is possible to implement a stack that can grow or shrink as much as needed. empty () - Return whether the stack is empty. We will see that the middle element is always the front element of the deque. Stack With Two Queues (Linked List) Zedrimar. pop () - Removes the element on top of the stack. If after the pop operation, the size of the deque is less than the size of the stack, we pop an element from the top of the stack and insert it back into the front of the deque so that size of the deque is not less than the stack. The pop operation on myStack will remove an element from the back of the deque. The number of elements in the deque stays 1 more or equal to that in the stack, however, whenever the number of elements present in the deque exceeds the number of elements in the stack by more than 1 we pop an element from the front of the deque and push it into the stack. Insert operation on myStack will add an element into the back of the deque. We will use a standard stack to store half of the elements and the other half of the elements which were added recently will be present in the deque. Method 2: Using a standard stack and a deque ISRO CS Syllabus for Scientist/Engineer Exam.ISRO CS Original Papers and Official Keys.GATE CS Original Papers and Official Keys.
0 notes
Text
Programming Project 2 Notation Converter Solution
Programming Project 2 Notation Converter Solution
Instructions For Programming Project 2, you will implement a Deque (Double-Ended Queue) and use that data structure to write a class that can convert between the three common mathematical notation for arithmetic. The three notations are: Postfix (Reverse Polish) Notation: Operators are written after operands A B – C + == (A – B) + C Infix Notation: The standard notation we use where the operator…

View On WordPress
0 notes
Text
Everything You Need to Know about Apache Storm
Data is everywhere, and as the world becomes more digital, new issues in data management and processing emerge every day. The ever-increasing development in Big Data production and analytics continues to create new problems, which data scientists and programmers calmly accept by always enhancing the solutions they develop.
When I say simple, I mean we'll focus on the most basic concepts without getting bogged down in details, and we'll keep it short. One of these issues was real-time streaming. Streaming data is any type of data that can be read without having to open and close the input like a regular data file.
Apache Storm: An Overview
Apache Storm is a distributed real-time computation system for processing data streams that is open-source. Apache Storm is a real-time, distributed computing system that is widely used in Big Data Analytics. Apache Storm performs unlimited streams of data in a reliable manner, similar to what Hadoop does for batch processing. It is an open-source platform as well as free.
In a fraction of a second, Apache Storm can handle over a million jobs on a single node.
To get better throughputs, it is connected with Hadoop. Apache Storm is well-known for its incredible speed.
It's very simple to set up and also can work with any kind of programming language. It processes over a million tuples per second per node, making it significantly quicker than Apache Spark.
Nathan Marz created the storm as a back-type project, which was later acquired by Twitter in 2011. Apache Storm prioritizes scalability, fault tolerance, and the processing of your data. The storm was made public by Twitter in 2013 when it was uploaded to GitHub. The storm was then accepted into the Apache Software Foundation as an incubator project in the same year, delivering high-end applications. Apache is simple to install and use, and it can work with any programming language. Since then, Apache Storm has been able to meet the needs of Big Data Analytics.
Components for Apache Storm
Turple
A tuple, like a database row, is an ordered list of named values. The basic data structure in Storm is the tuple.
The data type of each field in the tuple can be dynamic.
It's a list of elements in a particular order.
Any data type, including string, integer, float, double, boolean, and byte array, can be used in the field.
A Tuple supports all data types by default. In tuples, user-defined data types are also permitted.
It's usually represented as a list of comma-separated values and sent to a Storm cluster.
Stream
The stream, which is an unbounded pipeline of tuples, is one of the most basic abstractions in Storm architecture.
A stream is a tuple sequence that is not in any particular order.
Spouts
The source of the stream is quite the spouts. Storm receives data from a variety of raw data sources, including the Twitter Streaming API, Apache Kafka queue, Kestrel queue, and others.
It is the topology's entry point or source of streams.
It is in charge of connecting to the actual data source, continuously receiving data, translating the data into a stream of tuples, and eventually passing the data to bolts to be processed as well.
You can technically use spouts to read data from data sources if you don't want to use spouts so well.
The primary interface for implementing spouts is "ISpout." IRichSpout, BaseRichSpout, KafkaSpout, and other particular interfaces are examples.
Bolts
Bolts are logical processing units. They're in charge of accepting a variety of input streams, processing them, and then producing new streams for processing.
Spouts send information to the bolts and bolts process, which results in a new output stream.
They can execute functions, filter tuples, aggregate and join streams, and connect to databases, among other things.
Filtering, aggregating, joining, and interfacing with data sources and databases are all possible using Bolts.
Conclusion
So that's the certain gist of it. Apache Storm is not only a market leader in the software business, but it also has a wide range of applications in areas such as telecommunications, social media platforms, weather forecasting, and more, making it one of the most in-demand technologies today. Data that isn't analyzed at the right moment might quickly become obsolete for businesses.
Now that you've learned everything there is to know about Apache Storm, you should focus on mastering the Big Data and data science ecosystem as a whole. It is necessary to analyze data in order to uncover trends that can benefit the firm. If you're new to Big Data and data science, Learnbay's data science course Certification is a good place to start. Organizations developed several analytics tools in response to the needs and benefits of evaluating real-time data. This certification course will help you master the most in-demand Apache Spark skills and earn a competitive edge in your Data Scientist profession.
#data science certification courses#Data Science Courses In Bangalore#data science course bangalore#best data science course#Best data science institute in bangalore#Online Course on Data Science
0 notes
Text
COP4530 PP2- Notation Converter Solved
COP4530 PP2- Notation Converter Solved
For Programming Project 2, you will implement a Deque (Double-Ended Queue) and use that data structure to write a class that can convert between the three common mathematical notation for arithmetic. The three notations are: Postfix (Reverse Polish) Notation: Operators are written after operands A B – C + == (A – B) + C Infix Notation: The standard notation we use where the operator is between…

View On WordPress
0 notes
Text
COMP 3006 Programming Assignment 4 Solution
Assignment 4.1: Instantiate an object of the class Counter (import it from collections) and use it to determine the three most common numbers that appear when you simulate 100 rolls of a fair six-sided die. Display them along with how many times they appeared. Assignment 4.2: Instantiate a double ended queue data structure (deque). Fill it with six given names of movie stars. Insert new names in…
0 notes
Text
Project 2 (Deques and Randomized Queues) Solution
Project 2 (Deques and Randomized Queues) Solution
This document only contains the description of the project and the project problems. For the programming exercises on concepts needed for the project, please refer to the project checklist .
The purpose of this project is to implement elementary data structures using arrays and linked lists, and to introduce you to generics and iterators.
Problem 1. (Deque) A double-ended queue or deque…
View On WordPress
0 notes
Video
youtube
Circular Queue - Insertion/Deletion - With Example in Hindi
This is a Hindi video tutorial that Circular Queue - Insertion/Deletion - With Example in Hindi. You will learn c program to implement circular queue using array in hindi, circular queue using array in c and circular queue in c using linked list. This video will make you understand circular queue tutorialspoint, circular queue algorithm, circular queue example, circular queue in data structure pdf, insertion and deletion in circular queue in data structure, implement circular queue in hindi, circular queue c, types of queue in hindi, double ended queue in hindi. If you are looking for Circular Queue in Hindi, Circular Queue Array Implementation in Hindi, Circular Queue Programming using Array (Hindi), Circular Queue | Data Structures in Hindi or Array Implementation of Circular Queue in Hindi, then this video is for you. You can download the program from the following link: http://bmharwani.com/circularqueuearr.c For more videos on Data Structures, visit: https://www.youtube.com/watch?v=TRXkTGu0n9g&list=PLuDr_vb2LpAxZdUV5gyea-TsEJ06k_-Aw&index=14 To get notification for latest videos uploaded, subscribe to my channel: https://youtube.com/c/bintuharwani To see more videos on different computer subjects, visit: http://bmharwani.com
#circular queue in hindi#circular queue in c#implement circular queue using array#circular queue tutorial#how to implement circular queue using array#circular queue using array with output#use of modulo operator in circular queue#circular queue using array example#circular queue algorithm#circular queue tutorialspoint#circular queue ppt#bintu harwani#b.m. harwani#circular queue using array#circular queue#c program to implement circular queue#circular queue program#types of queue
0 notes
Text
C++ Standard Template Library (STL) – Introduction
In this tutorial you will learn about what is STL in C++, what it provides and overview of all STL items.
STL means Standard Template Library. STL is the most crafted libraries among all other libraries in C++. It is heart of C++. It includes containers, algorithms and iterators.
C++ Standard Template Library (STL)
What STL Provides?
Standard Template Library provides Algorithms and Containers. Containers contain data and algorithms operate on the data which is in containers.
The aim of object oriented language is combining algorithm and data into a class which is called object. STL goes opposite way of OOP language. It separates algorithms and data structures. Purpose of that is code reuse. We want one algorithm apply on different containers. And we want one container to use different algorithms. Containers have different interfaces from each other. So if we want to apply one algorithm on different containers, we need to provide different implementations for that. So if we have N algorithms and M containers we need to provide N*M implementations. This is quite lot work and not scalable also.
To solve this problem STL library provides another group of modules called Iterators. Each container required to provide a common interface defined by iterators. Iterator can iterate each item inside a container. So the algorithm instead of working on containers directly it only works on the iterators. So the algorithm doesn’t know about on which container it is working. It only knows about the iterator. This will very useful to reuse the code instead of writing N*M implementations (above mentioned example). Now we only need to provide N+M implementations. There are so many uses by this. If we define a new algorithm that operates on iterator then all the existing containers can use that algorithm. Similarly if we define a new container that provides appropriate iterate interface then all the existing algorithms can be applied on that new container. So this ST Library is very much useful.
Image Source
Containers
Sequence Containers
These implemented with arrays and linked lists.
Vector: Vector is a dynamic array that grows in one direction; it is at end of vector.
Deque: Deque is similar to vector. But deque can grow both beginning and at ending in both directions
List: It is same as double linked list. Each item in list points to both previous and next item of that item.
Forward list: Forward list only contain forward pointer. So it can traverse beginning to the end but not from end to the beginning.
Array: There are limitations to container array. That is size can’t be changed.
Associative Containers
These are typically implemented by Binary Trees. The key attribute of associative containers is all the elements are always sorted.
Set: Set has no duplicate items. When we insert elements into set all elements automatically sorted. It takes O(log( n)) time.
Multiset: It is same as set. But only difference is it allows duplicates also.
Map: Sometimes we don’t want to sort items by values. We are interested to sort them by key value. Map and Multimap contain key value pair structure. Map doesn’t allow duplicate keys.
Multimap: It is just like a map. But only difference is it allows duplicate keys. Important note is that, keys can’t be modified in map and multimap.
The word associative means, associating key with value. We can say that, set and multiset are special kind or map or multimap where the key of element is the same. This is the reason they called associative.
Unordered Containers
Unordered containers internally implemented with hash table. Each item calculated by hash function, to map to hash table. The main advantage is if we have effective hash function we can find elements in O (1) time.
This is fastest among all containers.
In Unordered containers the order is not defined. And they may change over the time.
Unordered Set: Unordered set that doesn’t allow duplicates.
Unordered Multiset: Unordered set that allows duplicate elements.
Unordered Map: It is unordered set of paris.
Unordered Multimap: Unordered map that allow duplicate keys.
Container Adaptors
Along with containers, container adaptors also provided by the ST library.
Container adaptors are not full container classes, but classes that provide a specific interface relying on an object of one of the container classes (such as deque or list) to handle the elements. The underlying container is encapsulated in such a way that its elements are accessed by the members of the container adaptor independently of the underlying container class used.
Stack: Stack provides push, pop, top operations to work on it
Queue: Push, pop, front, back allowed operations on this.
Priority Queue: It is keys of items of different priority. First item always have the highest priority.
Iterators
There are five categories of iterators based on types of operations performed on them.
1. Random Access Iterator
In random access iterator we can access elements in a container randomly. Here we can increment, decrement, add, subtract and also can compare. We can perform all these operations.
Ex: Vector, deque, Array provides random access iterator.
2. Bidirectional Iterator
With bidirectional iterator we can increment and decrement but we can’t add or subtract or compare.
Ex: list , set/multiset, map/multimap provide bidirectional iterators.
3. Forward Iterator
Forward iterator can only be incremented can’t be decremented.
Ex: forword_list
Remaining “Un ordered containers” they provide at least “forward iterators”. And also chance to growth “bidirectional iterators”. It depends on implementation of the STL.
4. Input Iterator
Input iterator used to read and process values while iterating forward. We can read only but not write.
5. Output Iterator
Used to output values. We can write but not read. Both input iterator and output iterator can only move forward. They can’t move backward.
Iterator Adaptor (Predefined Iterator)
This is a special, more powerful iterator.
Insert iterator
Stream iterator
Reverse iterator
Move iterator
Algorithms
Algorithms are mostly loops. Algorithms always process ranges in a half-open way. That means it will include the first item but not include the last item.
Non-modifying Algorithms
Count: Count function counts number of items in some data range.
Min and max: Max elements returns first maximum number, min returns minimum number.
Linear Search: When data is not sorted, this search for an element and returns first match.
Binary Search: When data is sorted, this search for an element and returns first match
Comparing ranges: Used to compare between two vector/list….etc
Check attributes: There are different check attributes in this like is sorted, any of/none of satisfied given condition… etc… We learn all of these clearly in further modules.
Modifying Algorithms (Value Changing Algorithms)
Copy: Copies everything from one container to other.
Move: It moves items to one place to other.
Transform: It transforms the data with certain operation. And then save the results at different place.
Swap: Swap the data between two places. It is also called two way copying.
Fill: Fill is used to fill the data with certain values.
Replace: Replace the existing value in container with another value.
Remove: Remove can remove any element based on condition.
Order Changing Algorithms
They changes the order of the elements in container, but not necessarily the elements themselves.
Reverse: Reverse the entire data.
Rotate: Rotates the data from vector begin to vector end.
Permute: Next permutation results lexicographically next greater permutation. Prev permutation results lexicographically next small permutation.
Shuffle: Rearrange the elements randomly. Swap each element with a randomly selected element.
Sorting Algorithms
Sorting algorithms are widely used algorithms in programming.
Sorting algorithms requires random access iterators. So that option limits our options to containers vector, deque, container array, native array. List and un-ordered containers cannot be sorted. And associative container doesn’t need sort anyway.
Sort() function directly sort by default. Some other cases also in this. We learn those in further tutorials.
Partial sort: Sometimes we doesn’t need all elements need to be sorted. In that case we use this partial sort like top 5 elements or least 10 elements like this.
Heap Algorithms
Heap has two properties: First element is always larger and add/remove takes O(log(n)) time.
Heap algorithms often used to implement priority queue. These are four important heap algorithms.
Make_heap: Creates new heap on given container.
Pop_heap: It removes largest element from heap, for that it does two things, swaps the first and last items of the heap and then heapify to satisfy heap conditions.
Push_heap: Add new element into heap.
Sort_heap: It does heap sorting on given heap.
Sorted Data Algorithms
These are the algorithms that require data being pre-sorted.
Binary search: It checks for data in a data range. It returns a Boolean as a result.
Merge: Merge operation does two ranges of sorted data into one range of big sorted data.
Set operations: Set Union, Set intersection, Set difference, Symmetric difference all these are set operations.
Numeric Algorithms
Numeric algorithms defined in the header of numeric not in the header of algorithm.
Accumulate: It accumulates the data, in given range, on given operation.
Inner product: To calculate the inner product of two ranges of data.
Partial sum: Partial sum calculates partial sum of given range of data and stores in other location.
Adjacent difference: It calculates the difference between adjacent items and stores in other location.
Reasons to Use C++ Standard Template Library (STL)
Code reuse. Instead of implementing lot of code we just reuse it.
Efficiency (fast and use less resources). This is the reason that modern C++ compiler are usually tuned to optimize for C++ Standard Library.
Accurate, less buggy.
Terse, readable code; reduced control flow.
Standardization, guaranteed availability.
A role model of writing library.
Good knowledge of data structures and algorithms.
Comment below if you have queries or found any information incorrect in above tutorial for Standard Template Library in C++.
The post C++ Standard Template Library (STL) – Introduction appeared first on The Crazy Programmer.
0 notes
Text
Project 2 (Deques and Randomized Queues) Solution
Project 2 (Deques and Randomized Queues) Solution
This document only contains the description of the project and the project problems. For the programming exercises on concepts needed for the project, please refer to the project checklist .
The purpose of this project is to implement elementary data structures using arrays and linked lists, and to introduce you to generics and iterators.
Problem 1. (Deque) A double-ended queue or deque…
View On WordPress
0 notes
Text
What other cryptos can learn from Ripple
While last week I criticised Ripple's XRPs, we can't equate the whole system to its currency. There are many fundamental features of the Ripple system that other cryptos can learn from. A lot of them are small and obscure to anyone who hasn't had a hands-on experience developing systems on top of cryptos. Luckily enough, that's my speciality. So here are a few features of the Ripple system that other cryptos can learn from, as viewed by a programmer.
AccountTxnID and Memos
Sometimes you need to send a transaction with some extra data attached. Whether it's an invoice ID, customer number, or some other business-related information, you have some data that needs to go into the blockchain. This will help you keep track of what transaction did what, give some identifiable information as to the origin of the transaction and so on. Even Bitcoin recognised the need for this feature by introducing OP_RETURN in 2014. Before that, people used to create unspendable transaction outputs that the system would have to keep track of forever. Ripple already had that at launch in 2012 in the form of AccountTxnID and Memos. The first is a short field, ideal for including transaction IDs and similar short strings. The latter can store a lot more complex data structures - long strings, multiple hex arrays, that sort of things.
LastLedgerSequence
When building a more complex cryptocurrency system, you have to deal with the fuzzyness of transactions before they enter a block. Essentially, when you send a transaction out, you might not know what will happen to it until it either becomes part of a block, or a conflicting transaction becomes part of a block. If a transaction becomes lost in the network, gets stuck in a processing queue, or there is something else wrong with the system, it's essentially stuck in a limbo. It may be confirmed in the next second, it may never be confirmed, or maybe it will take a few hours. So here's the problem - how do you handle such transactions? You can try resubmitting them if you have the hex representation of them, but that still doesn't guarantee an outcome. You can try double-spending yourself, but then you have two transactions stuck in a limbo. Do you resubmit a different transaction to credit the same person? Then you might accidentally send them the money twice if you're not careful. All of those outcomes are less than ideal. Here is where LastLedgerSequence comes in. It's a field you can include in a transaction that allows you to specify when a transaction will DEFINITELY fail. You put a ledger number sometime in the future, and if the transaction is not included before that given ledger number, you know for sure it will NEVER be included in a ledger. The transactions are allowed to fail gracefully in a predictable manner.
Data vs Metadata
First generation cryptos are fairly straightforward. A transaction does one thing and one thing only - move money around. If a transaction gets included in a block it means the transfer went through, if it doesn't - it didn't. There are only two outcomes here. When talking about a more complex system, there will naturally be more possible outcomes. Maybe a transaction got included in a block and it did exactly what it was supposed to. Maybe it got included in a block but failed to achieve anything. Maybe there are different paths it could've taken to get to the outcome, etc. This is why Ripple transactions have both data and metadata to them. The first shows what a transaction SHOULD do, the second - what it DID do. This allows the transactions to be more complex, while still ensuring that any given transaction call returns all the information relating to a given transaction.
Built-in, dedicated distributed exchange
An efficient Crypto 2.0 system benefits a lot from having a distributed exchange built into it. While some systems like NXT only allow trading a given IOU for its native token, Ripple goes one step further and treats all currencies the same. You can trade any currency for any other, even to the point of undermining the value of XRPs because of it. It is also a very important part of a few other features. While systems with smart contracts like Ethereum can mimic the functionality of Ripple's built-in exchange, it would be hard to compete with the efficiency of a dedicated exchange logic. As someone who has experience programming a crypto exchange, I can attest that order sorting and matching can be a complex task that would be hard to efficiently execute in a smart contract. Ripple has the strongest distributed exchange that I've seen in any crypto project.
Trades as part of a payment
In a system with multiple currencies, how do you go from having currency A to sending someone currency B? Quite often, you'll have to take that currency to some sort of market, trade it, then use the resulting funds to send the second currency directly. Alternatively, you use some sort of third party to brokerage the deal, take a cut and take its sweet time to get there. This is not a case with Ripple. A trade can happen as a part of a payment. Sending money from one address to another is just as simple whether you hold the same currency or not. The currencies don't matter, only the value does.
A Ripple payment that can be fulfilled by 4 different currencies
This feature leverages the power of a distributed exchange to its full potential. Everyone has access to the same market and doesn't need to hold more than one currency to transact with anyone on the network.
Atomic, multi-currency transactions
A big issue with transactions that span multiple currencies is the possibility of the transaction failing partially and the funds ending up in some transitory currency. If you're sending USD and expecting them to end up as GBP, you wouldn't want to end up with EUROs. This would be a bad outcome discouraging people from sending more complex transactions. Ripple solves that issue by forcing every transaction to be atomic. Either the transaction is fully processed, or it completely fails. There is no way to end up somewhere down the middle. Moreover, there is virtually no limit to how complex a transaction can be. You can send out one type of currency, which would take multiple different routes and touching on multiple currencies before ending up at your destination as the intended currency. It is rather remarkable.
The consensus algorithm and predictable block times
Ripple does not rely on a traditional mining algorithm to create its blocks. Instead, Ripple uses a consensus algorithm to issue its ledgers. While the system is more centralised than most cryptos because of that, it solves a lot of other important issues. First of all, the block times are quite consistent. You know exactly how often they are created and the interval between the blocks is very short and stable. Secondly, the system is more resilient against front running, making the distributed exchange more honest. Lastly, the system in general is less susceptible to market manipulation by the miners - they can't stall certain transactions or oracle data in hopes of manipulating the market and gaming the system.
Conclusions
While the Ripple system has its flaws, it also has a lot of interesting features other cryptos can learn from.
0 notes
Text
C++ Menu Driven Program for double ended queue using doubly linked list
C++ Menu Driven Program for double ended queue using doubly linked list
#include #include using namespace std; class node { public: int data; class node *next; class node *prev; }; class dqueue: public node { node *head,*tail; int top1,top2; public: dqueue() { top1=0; top2=0; head=NULL; tail=NULL; } void push(int x){ node *temp; int ch; if(top1+top2 >=5) { cout <data=x; head->next=NULL;…
View On WordPress
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
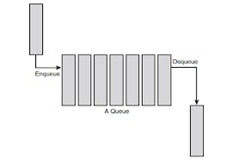
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
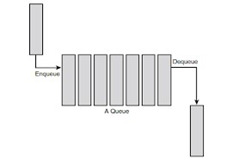
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes