#double ended queue in c using arrays
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text
C Program to implement Deque using circular array
Implement Deque using circular array Write a C Program to implement Deque using circular array. Here’s simple Program to implement Deque using circular array in C Programming Language. What is Queue ? Queue is also an abstract data type or a linear data structure, in which the first element is inserted from one end called REAR, and the deletion of existing element takes place from the other end…
View On WordPress
#c data structures#c queue programs#dequeue in c using arrays#dequeue in data structure using c#dequeue in data structure with example#dequeue program in c using array#double ended queue in c#double ended queue in c using arrays#double ended queue in data structure#double ended queue in data structure program
0 notes
Text
UIPath Advanced RPA Developer Certification Questions with Answers

Check Exam Format at https://www.scrumprinciples.com/uipath-advanced-rpa-developer-certification/ 1). How many types of actions can be performed in the Variables panel in UiPath? Ans : – a). Changing Variable types b). Adding new Variables c). Setting default values for variables 2). What is the possible technique to get the content of a PDF document is available in UiPath? Ans. First to opening the PDF and using Screen scraping to get its data. Second to the Read PDF Text activity and providing the PDF file’s path. 3). Which activity is used to represent a decision inside a Sequence? Ans:- The If activity 4). How can you exit from a For Each activity in UiPath? Ans: – Break activity 5). During the running of workflow, how can you see the steps the workflow is executing? Ans : – a).Using Debug and inspecting the Output panel b). Using Debug with Highlight Activities option 6). How can execution be paused before a particular activity in UiPath? Ans: – a).First to use a MessageBox activity b).Second to use a breakpoint in Debug mode 7). In Order to Save Attachments activity, it can save all the attachments of an email to: Ans : – a). A relative path b). An absolute Path 8). What is the Visual Basic property within the MailMessage class will you use to get the Date of an email? Ans : – a).Headers(“Date”) 9). Which is the best optimize navigation method to be used in a form within Citrix? Ans:- By sending keyboard commands/hotkeys 10). What happens if Find Image doesn’t actually find the desired image in UiPath? Ans: – An Exception is Throw. 11). Which recording profile is used to generate full selectors in UiPath? Ans: – Basic recording 12). Which activities can be used to mostly interact with the user? Ans : – a). Input Dialog b) Message Box 13). In Which situation we have to use the Flowchart workflow in UiPath? Ans : – a).When modelling a process that has loops to previous states b). When having a process with many decision blocks 14). In case if the PDF activities are not listed in your activities panel, how can you get them? Ans:- You have to install pdf activities using Manage Packages features. 15). What should you use to click on a hidden IE browser? Ans:- a). SimulateClick 16). Why Timeout MS property is used in UiPath? Ans : – a). To define the amount of time during which the target of an activity must be found. 17). Why Queues are used in UiPath? Ans: – Distribute transnational load among multiple robots 18). Is it possible to click a button with Click Image Activity if the target is not visible on the screen in UiPath? Ans:- No, you could click a button which is not visible only using selectors 19). What is the way to send an image inside a MailMessage? Ans:- a).You can add the path to the attachment directly in the send activity. b). You can specify the relative path of the image in the Attachments property. 20). If you need to sort a table from a .xlsx file, which feature is used? Ans: – An excel Sort Table Activity. 1). Which recording wizard is used to automate UI interactions in an application that does not offer support for selectors in UiPath. Ans: – Citrix Recording 2). Which of the following phrases are true regarding Project Organization? Ans: – Saves time for all team members, Is a constant concern of the robot developer 3). how do you define to create a layout of business logic in complex process automation? Ans: – Flowchart 4). Which activity is used to chain together multiple workflows in single automation in UiPath? Ans: – Invoke workflow File Activity 5). How can you manage passwords for an automation project in UiPath? Ans: – With Windows Credential Manager 6). Which activity is used to Get Outlook Mail Messages activity? Ans: – MailFolder 7). Which activities allow you to iterate through an array of strings in UiPath? Ans: – a). while b). For Each c). Do While 8). Can you insert a Flowchart activity in a Sequence in UiPath? Ans: – Yes 9). What is the use of The Orchestrator? Ans: – a)Remotely control robots b). Send Start commands to multiple robots c). Schedule robots to perform specific processes 10). How to check the UI Element is exist on the screen or not, which activity is used for this? Ans : – Element Exists 11). Where can you see the variables’ values when we execute the workflow in UiPath? Ans: – In the Locals Pane 12). What can you use to make sure that the execution continues even if an activity fails in UiPath? Ans : – Try/Catch Activity 13). Which activity is used If you want to wait until a UI Element becomes available on the screen in UiPath? Ans:- Find Element 14). What happens if you use the Excel Read Range activity to read a .xlsx file that is already opened in UiPath? Ans: – This will read the document successfully. 15). What is the way to optimize accuracy when scraping with OCR a region that contains only digits? Ans: – Use Google OCR with “Numbers Only” 16). Which property is used to make sure that the workflow continues even if an activity fails in UiPath? Ans :- ContinueOnError Property 17). Which property defines the amount of time in which the UI target of an activity must be found? Ans: – The TimeoutMS property 18). Why Attach Window used in UiPath? Ans: – Identifying the window you are working with. 19). What is the way to enable the (Clipping) Region selection mode when Screen Scraping in UiPath? Ans: – By Pressing F3 20). Which activity can be used to modify the value of an existing cell in a DataTable in UiPath? Ans:- Assign Activity How does the Anchor Base activity work? It searches for an UiElement at a fixed anchor position.It searches for an UiElement using a relative coordinate position.It searches for an UiElement by using another UiElement as anchor. What direction can the arguments of a workflow have? In arguments.Out argumentsIn/Out arguments. At the end of the execution of Workflow1, which retrieves some items from a database, is the database connection closed automatically? Yes, the connection is closed after 30 seconds.The connection has to be closed using a Disconnect activity.Only the database admin can decide this aspect. Where can we see the logs generated by running robots? In the Output panel.In the local Logs folder.In the Orchestrator logs. Why is renaming activities considered to be one of the best practices? In case of an exception, to be able to find its source activityTo be able to understand the process logic without expanding each sequence or invoked workflow.To easily understand the high-level business logic from a workflow. What type of Output variable do all Get Mail activities return? (POP3, IMAP, Outlook, Exchange) MailMessageListList Is it possible to retrieve the color of a specific Excel cell? Yes, by using Get Cell ColorNo. The color cannot be retrieved from a workbook.Only with an OCR Engine. Can you store a Selector in a variable? NoYes, in a UiElement variable.Yes, in a String variable. What can be used to debug a workflow? BreakpointsHighlighting activities.The Slow Step option. How can a robot start an application in Citrix? By using a command line.By double clicking on a Desktop icon.By using an Open Application activity.By defining a shortcut key for the application and then triggering the app with a Send Hotkey activity. What is Orchestrator used for? Running Windows processes on the local machine.Remotely controlling any number of robots and performing workflow management.Designing workflows to be run by robots in a supervised mode.Designing workflows to be run by robots in an unsupervised mode. What happens when a new version of a package is published? The processes using the package are automatically updated to the latest versionThe processes have to be updated in order for the robots to run the latest version of the packageThe old version of the package is overwritten What types of assets can be stored in Orchestrator? Array, Datatable, Bool, StringBool, String, Integer, CredentialInteger, Password, GenericValue, String Where can you trigger an unattended robot from? Select all the options that apply. The UiPath Robot icon in the system trayUiPath StudioRemotely, from Orchestrator How can a process be executed on three different robots? By deploying the process in the environment of the robots, which run it automaticallyBy creating a job and selecting all three robotsIt is not possible to allocate a process to three different robotsBy scheduling the process and adjusting the settings in the Execution Target tab accordingly The best way of managing variable values within a workflow, so that they can be shared on different robots and environments is: Using Json config files.Using excel config filesUsing assets defined in Orchestrator. What robots can be selected when you start a job from Orchestrator? Any robot provisioned in Orchestrator.Any robot you have access to according to your role permissions.Any robot in the same environment as the process to be executed. What is the best way of restricting the access of a person to a limited number of pages in Orchestrator? That option does not exist. Everyone is able to see everythingBy changing the rights of the Administrator to the desired state.By creating a different account and role for that person. When creating a new role, restrictions can be applied. “Add Assets” in Orchestrator has the following option: Value Per RobotValue Per EnvironmentValue Per ProcessSingle Value
What robot state is displayed on the Robots page while a job is being executed?
BusyRunnningPending Where should credentials be stored? Select all the options that apply. In Windows Credential Store.In Orchestrator, as assets.Directly inside the workflows, as variables. Which one of the statements below regarding the GetAppCredentials workflow included in UiPath Robotic Enterprise Framework is true? It first requests the credential from user.It first tries to fetch a credential from the Windows Credential Manager.It first tries to fetch a credential from Orchestrator. If a large item collection is processed using For Each, which activity enables you to efficiently exit the loop after a specific moment? No activity can be used. Instead, you have to create a Boolean variable based on which the For Each loop is brokenThe “Break” activity is the most suitable in For EachA While loop should be used instead of For Each Which of the following statements are true? Select all the options that apply. You cannot use a recorder in a Citrix environmentThe recorder is used to create a skeleton for the UI automationThe Desktop recorder generates partial selectors In UiPath Robotic Enterprise Framework, what are the transitions of the Init state? In the case of Success, the transition is to the Get Transaction Data state.In the case of System Error, the transition is to the Init state.In the case of Success, the transition is to the Process Transaction state.In the case of System Error, the transition is to the End Process state. Which statement about the UiPath Robotic Enterprise Framework template is false? The framework is meant to be a template that helps the user design processes.The framework can be used only if you get the input data from the UiPath server queues.The framework has a robust exception handling scheme and event logging. Which of the following are considered best practices? Select all the options that apply. Keeping environment settings hard coded inside workflows.Breaking the process into smaller workflows.Reusing workflows across different projects. In the UiPath Robotic Enterprise Framework template, if a System Error is encountered in the Init state of the Main workflow, which state is executed next? Get Transaction DataInitEnd Process In the UiPath Robotic Enterprise Framework template, in the Get Transaction Data state of the Main workflow, what happens before the next transaction item is retrieved? We check if the previous transaction has been completedWe check if a kill signal was sent from OrchestratorWe check if a stop signal was sent from Orchestrator When should an Attended Robot be used? Select the option that applies. When the processing of some input data relies on human decision.When a workflow needs to be modified and corrected.When the process might be interrupted by exceptions and errors. What happens in the Init state of the Main workflow, in the UiPath Robotic Enterprise Framework template? The robot reads the configuration file and initializes all the required applications.The transaction items are extracted from the Queue.The robot checks if the previous transaction is complete and then starts the next one. How should exceptions be handled? Select all the options that apply. By using Try Catch activities inside the workflow for unexpected application exceptions.By validating data using conditional blocks for business exceptions.UiPath handles exceptions by default. In which workflow in the UiPath Robotic Enterprise Framework template is the retry mechanism implemented? The SetTransactionStatus workflowThe Main workflowThe GetTransactionData workflow In the UiPath Robotic Enterprise Framework template, in the Main workflow, the State Machine includes the following states: Init stateGet transaction data stateProcess Transaction StateSet Transaction StateEnd Process State Which of the following are considered best practices? Removing unreferenced variables.Deleting disabled code.Leaving target applications opened. In a Try Catch activity, how many times is the Finally section executed if no error occurs in the Try section? OnceThe Finally section is executed only when the Catch section is executed.Zero In UiPath Robotic Enterprise Framework, the value of MaxRetryNumber in the Config.xlsx file should be set to a number greater than 0 to enable the retry mechanism in the following cases: Get data from spreadsheets, databases, email, web API.Do not work with UiPath Orchestrator queues.Get data from UiPath Orchestrator queues with Auto Retry disabled. The return value of the Get Transaction Item activity is of the following type: ObjectStringQueueItemList Which is the best way to navigate to a specific page in a web browser? Use the Navigate To activity inside an Attach Browser containerUse the Type Into activity inside an Attach Browser containerUse a Type Into activity with a full selector How should a UiPath developer handle frequent changes in the project files? By creating daily backups of the filesBy using a source control solution, such as SVN, TFS, etc.Old versions of the project files are not relevant What layout should be used for UI navigation and data processing? FlowchartSequenceState Machine In the UiPath Robotic Enterprise Framework template, if a System Error is encountered in the Process Transaction state of the Main workflow, which state is executed next? Get Transaction DataInitEnd Process How can you pass data between workflows? By using arguments.By using variables.By using a pipe. In the UiPath Robotic Enterprise Framework template, what happens if the processing of a transaction item fails with an Application Exception or a System Error? The process executes the End Process state.All used applications are closed and then re-initialized.The execution of the transaction item is retried if the MaxRetryNumber config value is greater than 0. Which of the following are required to have efficient execution of automation projects? Proper exception handlingRecovery abilitiesEffective logging mechanisms Read the full article
1 note
·
View note
Text
The Collection Framework in Java

What is a Collection in Java?
Java collection is a single unit of objects. Before the Collections Framework, it had been hard for programmers to write down algorithms that worked for different collections. Java came with many Collection classes and Interfaces, like Vector, Stack, Hashtable, and Array.
In JDK 1.2, Java developers introduced theCollections Framework, an essential framework to help you achieve your data operations.
Why Do We Need Them?
Reduces programming effort & effort to study and use new APIs
Increases program speed and quality
Allows interoperability among unrelated APIs
Reduces effort to design new APIs
Fosters software reuse
Methods Present in the Collection Interface
NoMethodDescription1Public boolean add(E e)To insert an object in this collection.2Public boolean remove(Object element)To delete an element from the collection.3Default boolean removeIf(Predicate filter)For deleting all the elements of the collection that satisfy the specified predicate.4Public boolean retainAll(Collection c)For deleting all the elements of invoking collection except the specified collection.5Public int size()This return the total number of elements.6Publicvoid clear()This removes the total number of elements.7Publicboolean contains(Object element)It is used to search an element.8PublicIterator iterator()It returns an iterator.9PublicObject[] toArray()It converts collection into array.
Collection Framework Hierarchy
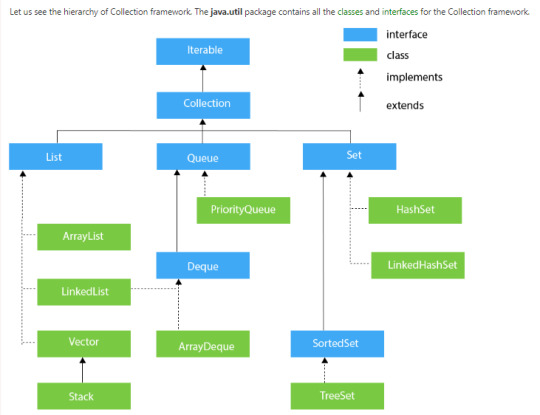
List Interface
This is the child interface of the collectioninterface. It is purely for lists of data, so we can store the ordered lists of the objects. It also allows duplicates to be stored. Many classes implement this list interface, including ArrayList, Vector, Stack, and others.
Array List
It is a class present in java. util package.
It uses a dynamic array for storing the element.
It is an array that has no size limit.
We can add or remove elements easily.
Linked List
The LinkedList class uses a doubly LinkedList to store elements. i.e., the user can add data at the initial position as well as the last position.
It allows Null insertion.
If we’d wish to perform an Insertion /Deletion operation LinkedList is preferred.
Used to implement Stacks and Queues.
Vector
Every method is synchronized.
The vector object is Thread safe.
At a time, one thread can operate on the Vector object.
Performance is low because Threads need to wait.
Stack
It is the child class of Vector.
It is based on LIFO (Last In First Out) i.e., the Element inserted in last will come first.
Queue
A queue interface, as its name suggests, upholds the FIFO (First In First Out) order much like a conventional queue line. All of the elements where the order of the elements matters will be stored in this interface. For instance, the tickets are always offered on a first-come, first-serve basis whenever we attempt to book one. As a result, the ticket is awarded to the requester who enters the queue first. There are many classes, including ArrayDeque, PriorityQueue, and others. Any of these subclasses can be used to create a queue object because they all implement the queue.
Dequeue
The queue data structure has only a very tiny modification in this case. The data structure deque, commonly referred to as a double-ended queue, allows us to add and delete pieces from both ends of the queue. ArrayDeque, which implements this interface. We can create a deque object using this class because it implements the Deque interface.
Set Interface
A set is an unordered collection of objects where it is impossible to hold duplicate values. When we want to keep unique objects and prevent object duplication, we utilize this collection. Numerous classes, including HashSet, TreeSet, LinkedHashSet, etc. implement this set interface. We can instantiate a set object with any of these subclasses because they all implement the set.
LinkedHashSet
The LinkedHashSet class extends the HashSet class.
Insertion order is preserved.
Duplicates aren’t allowed.
LinkedHashSet is non synchronized.
LinkedHashSet is the same as the HashSet except the above two differences are present.
HashSet
HashSet stores the elements by using the mechanism of Hashing.
It contains unique elements only.
This HashSet allows null values.
It doesn’t maintain insertion order. It inserted elements according to their hashcode.
It is the best approach for the search operation.
Sorted Set
The set interface and this interface are extremely similar. The only distinction is that this interface provides additional methods for maintaining the elements' order. The interface for handling data that needs to be sorted, which extends the set interface, is called the sorted set interface. TreeSet is the class that complies with this interface. This class can be used to create a SortedSet object because it implements the SortedSet interface.
TreeSet
Java TreeSet class implements the Set interface it uses a tree structure to store elements.
It contains Unique Elements.
TreeSet class access and retrieval time are quick.
It doesn’t allow null elements.
It maintains Ascending Order.
Map Interface
It is a part of the collection framework but does not implement a collection interface. A map stores the values based on the key and value Pair. Because one key cannot have numerous mappings, this interface does not support duplicate keys. In short, The key must be unique while duplicated values are allowed. The map interface is implemented by using HashMap, LinkedHashMap, and HashTable.
HashMap
Map Interface is implemented by HashMap.
HashMap stores the elements using a mechanism called Hashing.
It contains the values based on the key-value pair.
It has a unique key.
It can store a Null key and Multiple null values.
Insertion order isn’t maintained and it is based on the hash code of the keys.
HashMap is Non-Synchronized.
How to create HashMap.
LinkedHashMap
The basic data structure of LinkedHashMap is a combination of LinkedList and Hashtable.
LinkedHashMap is the same as HashMap except above difference.
HashTable
A Hashtable is an array of lists. Each list is familiar as a bucket.
A hashtable contains values based on key-value pairs.
It contains unique elements only.
The hashtable class doesn’t allow a null key as well as a value otherwise it will throw NullPointerException.
Every method is synchronized. i.e At a time one thread is allowed and the other threads are on a wait.
Performance is poor as compared to HashMap.
This blog illustrates the interfaces and classes of the java collection framework. Which is useful for java developers while writing efficient codes. This blog is intended to help you understand the concept better.
At Sanesquare Technologies, we provide end-to-end solutions for Development Services. If you have any doubts regarding java concepts and other technical topics, feel free to contact us.
0 notes
Text
Linked list stack implememntation using two queues 261

Linked list stack implememntation using two queues 261 code#
Fortunately, JavaScript arrays implement this for us in the form of the length property. algorithms (sorting, using stacks and queues, tree exploration algorithms, etc.). A common additional operation for collection data structures is the size, as it allows you to safely iterate the elements and find out if there are any more elements present in the data structure. Data structures: Abstract data types (ADTs), vector, deque, list, queue. Again, it doesn't change the index of the other items in the array, so it is O(1). Similarly, on pop, we simply pop the last value from the array. As it doesn't change the index of the current items, this is O(1). On push, we simply push the new item into the array. Therefore, we can simply implement the operations of this data structure using an array. Fortunately, in JavaScript implementations, array functions that do not require any changes to the index of the current items have an average runtime of O(1). First node have null in link field and second node link have first node address in link field and so on and last node address in. which is head of the stack where pushing and popping items happens at the head of the list. In stack Implementation, a stack contains a top pointer. You will use only one C file (stackfromqueue.c)containing all the functions to design the entire interface. The objective is to implement these push and pop operations such that they operate in O(1) time. A stack can be easily implemented using the linked list. Part 3: Linked List Stack Implementation Using Two Queues Inthis part, you will use two instances of Queue ADT to implement aStack ADT. This fact can be modeled into the type system by using a union of T and undefined. If there are no more items, we can return an out-of-bound value, for example, undefined. The other key operation pops an item from the stack, again in O(1). The first one is push, which adds an item in O(1). StdOut.java A list implemented with a doubly linked list. js is the open source HTML5 audio player. The stack data structure has two key operations. js, a JavaScript library with the goal of making coding accessible to artists, designers, educators, and beginners. We can model this easily in TypeScript using the generic class for items of type T. Using Python, create an implementation of Deque (double-ended queue) with linked list nodes.
Linked list stack implememntation using two queues 261 code#
So deleting of the middle element can be done in O(1) if we just pop the element from the front of the deque.A stack is a last-in/first-out data structure with key operations having a time complexity of O(1). I encountered this question as I am preparing for my code interview. The stack functions worked on from Worksheet 17 were re-implemented using the queue functions worked on from Worksheet 18. Overview: This program is an implementation of a stack using two instances of a queue. Here each new node will be dynamically allocated, so overflow is not possible unless memory is exhausted. Using an array will restrict the maximum capacity of the array, which can lead to stack overflow. You must use only standard operations of a queue - which means only push to back, peek/pop from front, size, and is empty operations are valid. The advantage of using a linked list over arrays is that it is possible to implement a stack that can grow or shrink as much as needed. empty () - Return whether the stack is empty. We will see that the middle element is always the front element of the deque. Stack With Two Queues (Linked List) Zedrimar. pop () - Removes the element on top of the stack. If after the pop operation, the size of the deque is less than the size of the stack, we pop an element from the top of the stack and insert it back into the front of the deque so that size of the deque is not less than the stack. The pop operation on myStack will remove an element from the back of the deque. The number of elements in the deque stays 1 more or equal to that in the stack, however, whenever the number of elements present in the deque exceeds the number of elements in the stack by more than 1 we pop an element from the front of the deque and push it into the stack. Insert operation on myStack will add an element into the back of the deque. We will use a standard stack to store half of the elements and the other half of the elements which were added recently will be present in the deque. Method 2: Using a standard stack and a deque ISRO CS Syllabus for Scientist/Engineer Exam.ISRO CS Original Papers and Official Keys.GATE CS Original Papers and Official Keys.
0 notes
Link
Discover Functional JavaScript was named one of the best new Functional Programming books by BookAuthority! JavaScript has primitives, objects and functions. All of them are values. All are treated as objects, even primitives. PrimitivesNumber, boolean, string, undefined and null are primitives. NumberThere is only one number type in JavaScript, the 64-bit binary floating point type. Decimal numbers’ arithmetic is inexact. As you may already know, 0.1 + 0.2 does not make 0.3 . But with integers, the arithmetic is exact, so 1+2 === 3 . Numbers inherit methods from the Number.prototype object. Methods can be called on numbers: (123).toString(); //"123" (1.23).toFixed(1); //"1.2"There are functions for converting strings to numbers : Number.parseInt(), Number.parseFloat() and Number(): Number.parseInt("1") //1 Number.parseInt("text") //NaN Number.parseFloat("1.234") //1.234 Number("1") //1 Number("1.234") //1.234Invalid arithmetic operations or invalid conversions will not throw an exception, but will result in the NaN “Not-a-Number” value. Number.isNaN() can detect NaN . The + operator can add or concatenate. 1 + 1 //2 "1" + "1" //"11" 1 + "1" //"11"StringA string stores a series of Unicode characters. The text can be inside double quotes "" or single quotes ''. Strings inherit methods from String.prototype. They have methods like : substring(), indexOf() and concat() . "text".substring(1,3) //"ex" "text".indexOf('x') //2 "text".concat(" end") //"text end"Strings, like all primitives, are immutable. For example concat() doesn’t modify the existing string but creates a new one. BooleanA boolean has two values : true and false . The language has truthy and falsy values. false, null, undefined, ''(empty string), 0 and NaN are falsy. All other values, including all objects, are truthy. The truthy value is evaluated to true when executed in a boolean context. Falsy value is evaluated to false. Take a look at the next example displaying the false branch. let text = ''; if(text) { console.log("This is true"); } else { console.log("This is false"); }The equality operator is ===. The not equal operator is !== . VariablesVariables can be defined using var, let and const. var declares and optionally initializes a variable. Variables declared with var have a function scope. They are treated as declared at the top of the function. This is called variable hoisting. The let declaration has a block scope. The value of a variable that is not initialize is undefined . A variable declared with const cannot be reassigned. Its value, however, can still be mutable. const freezes the variable, Object.freeze() freezes the object. The const declaration has a block scope. ObjectsAn object is a dynamic collection of properties. The property key is a unique string. When a non string is used as the property key, it will be converted to a string. The property value can be a primitive, object, or function. The simplest way to create an object is to use an object literal: let obj = { message : "A message", doSomething : function() {} }There are two ways to access properties: dot notation and bracket notation. We can read, add, edit and remove an object’s properties at any time. get: object.name, object[expression]set: object.name = value, object[expression] = valuedelete: delete object.name, delete object[expression]let obj = {}; //create empty object obj.message = "A message"; //add property obj.message = "A new message"; //edit property delete obj.message; //delete propertyObjects can be used as maps. A simple map can be created using Object.create(null) : let french = Object.create(null); french["yes"] = "oui"; french["no"] = "non"; french["yes"];//"oui"All object’s properties are public. Object.keys() can be used to iterate over all properties. function logProperty(name){ console.log(name); //property name console.log(obj[name]); //property value } Object.keys(obj).forEach(logProperty);Object.assign() copies all properties from one object to another. An object can be cloned by copying all its properties to an empty object: let book = { title: "The good parts" }; let clone = Object.assign({}, book);An immutable object is an object that once created cannot be changed. If you want to make the object immutable, use Object.freeze() . Primitives vs ObjectsPrimitives (except null and undefined) are treated like objects, in the sense that they have methods but they are not objects. Numbers, strings, and booleans have object equivalent wrappers. These are the Number, String, and Boolean functions. In order to allow access to properties on primitives, JavaScript creates an wrapper object and then destroys it. The process of creating and destroying wrapper objects is optimized by the JavaScript engine. Primitives are immutable, and objects are mutable. ArrayArrays are indexed collections of values. Each value is an element. Elements are ordered and accessed by their index number. JavaScript has array-like objects. Arrays are implemented using objects. Indexes are converted to strings and used as names for retrieving values. A simple array like let arr = ['A', 'B', 'C'] is emulated using an object like the one below: { '0': 'A', '1': 'B', '2': 'C' }Note that arr[1] gives the same value as arr['1'] : arr[1] === arr['1'] . Removing values from the array with delete will leave holes. splice() can be used to avoid the problem, but it can be slow. let arr = ['A', 'B', 'C']; delete arr[1]; console.log(arr); // ['A', empty, 'C'] console.log(arr.length); // 3JavaScript’s arrays don’t throw “index out of range” exceptions. If the index is not available, it will return undefined. Stack and queue can easily be implemented using the array methods: let stack = []; stack.push(1); // [1] stack.push(2); // [1, 2] let last = stack.pop(); // [1] console.log(last); // 2 let queue = []; queue.push(1); // [1] queue.push(2); // [1, 2] let first = queue.shift();//[2] console.log(first); // 1FunctionsFunctions are independent units of behavior. Functions are objects. Functions can be assigned to variables, stored in objects or arrays, passed as an argument to other functions, and returned from functions. There are three ways to define a function: Function Declaration (aka Function Statement)Function Expression (aka Function Literal)Arrow FunctionThe Function Declarationfunction is the first keyword on the lineit must have a nameit can be used before definition. Function declarations are moved, or “hoisted”, to the top of their scope.function doSomething(){}The Function Expression function is not the first keyword on the linethe name is optional. There can be an anonymous function expression or a named function expression.it needs to be defined, then it can executeit can auto-execute after definition (called “IIFE” Immediately Invoked Function Expression)let doSomething = function() {}Arrow FunctionThe arrow function is a sugar syntax for creating an anonymous functionexpression. {};Arrow functions don’t have their own this and arguments. Function invocationA function, defined with the function keyword, can be invoked in different ways: doSomething(arguments)theObject.doSomething(arguments) theObject["doSomething"](arguments)new Constructor(arguments) doSomething.apply(theObject, [arguments]) doSomething.call(theObject, arguments)Functions can be invoked with more or fewer arguments than declared in the definition. The extra arguments will be ignored, and the missing parameters will be set to undefined. Functions (except arrow functions) have two pseudo-parameters: this and arguments. thisMethods are functions that are stored in objects. Functions are independent. In order for a function to know on which object to work onthis is used. this represents the function’s context. There is no point to use this when a function is invoked with the function form: doSomething(). In this case this is undefined or is the window object, depending if the strict mode is enabled or not. When a function is invoked with the method form theObject.doSomething(),this represents the object. When a function is used as a constructor new Constructor(), thisrepresents the newly created object. The value of this can be set with apply() or call():doSomething.apply(theObject). In this case this is the object sent as the first parameter to the method. The value of this depends on how the function was invoked, not where the function was defined. This is of course a source of confusion. argumentsThe arguments pseudo-parameter gives all the arguments used at invocation. It’s an array-like object, but not an array. It lacks the array methods. function log(message){ console.log(message); } function logAll(){ let args = Array.prototype.slice.call(arguments); return args.forEach(log); } logAll("msg1", "msg2", "msg3");An alternative is the new rest parameters syntax. This time args is an array object. function logAll(...args){ return args.forEach(log); }returnA function with no return statement returns undefined. Pay attention to the automatic semi-colon insertion when using return. The following function will not return an empty object, but rather an undefined one. function getObject(){ return { } } getObject()To avoid the issue, use { on the same line as return : function getObject(){ return { } }Dynamic TypingJavaScript has dynamic typing. Values have types, variables do not. Types can change at run time. function log(value){ console.log(value); } log(1); log("text"); log({message : "text"});The typeof() operator can check the type of a variable. let n = 1; typeof(n); //number let s = "text"; typeof(s); //string let fn = function() {}; typeof(fn); //functionA Single ThreadThe main JavaScript runtime is single threaded. Two functions can’t run at the same time. The runtime contains an Event Queue which stores a list of messages to be processed. There are no race conditions, no deadlocks.However, the code in the Event Queue needs to run fast. Otherwise the browser will become unresponsive and will ask to kill the task. ExceptionsJavaScript has an exception handling mechanism. It works like you may expect, by wrapping the code using the try/catch statement. The statement has a single catch block that handles all exceptions. It’s good to know that JavaScript sometimes has a preference for silent errors. The next code will not throw an exception when I try to modify a frozen object: let obj = Object.freeze({}); obj.message = "text";Strict mode eliminates some JavaScript silent errors. "use strict"; enables strict mode. Prototype PatternsObject.create(), constructor function, and class build objects over the prototype system. Consider the next example: let servicePrototype = { doSomething : function() {} } let service = Object.create(servicePrototype); console.log(service.__proto__ === servicePrototype); //trueObject.create() builds a new object service which has theservicePrototype object as its prototype. This means that doSomething() is available on the service object. It also means that the __proto__ property of service points to the servicePrototype object. Let’s now build a similar object using class. class Service { doSomething(){} } let service = new Service(); console.log(service.__proto__ === Service.prototype);All methods defined in the Service class will be added to theService.prototype object. Instances of the Service class will have the same prototype (Service.prototype) object. All instances will delegate method calls to the Service.prototype object. Methods are defined once onService.prototype and then inherited by all instances. Prototype chainObjects inherit from other objects. Each object has a prototype and inherits their properties from it. The prototype is available through the “hidden” property __proto__ . When you request a property which the object does not contain, JavaScript will look down the prototype chain until it either finds the requested property, or until it reaches the end of the chain. Functional PatternsJavaScript has first class functions and closures. These are concepts that open the way for Functional Programming in JavaScript. As a result, higher order functions are possible. filter(), map(), reduce() are the basic toolbox for working with arrays in a function style. filter() selects values from a list based on a predicate function that decides what values should be kept. map() transforms a list of values to another list of values using a mapping function. let numbers = [1,2,3,4,5,6]; function isEven(number){ return number % 2 === 0; } function doubleNumber(x){ return x*2; } let evenNumbers = numbers.filter(isEven); //2 4 6 let doubleNumbers = numbers.map(doubleNumber); //2 4 6 8 10 12reduce() reduces a list of values to one value. function addNumber(total, value){ return total + value; } function sum(...args){ return args.reduce(addNumber, 0); } sum(1,2,3); //6Closure is an inner function that has access to the parent function’s variables, even after the parent function has executed. Look at the next example: function createCount(){ let state = 0; return function count(){ state += 1; return state; } } let count = createCount(); console.log(count()); //1 console.log(count()); //2count() is a nested function. count() accesses the variable state from its parent. It survives the invocation of the parent function createCount().count() is a closure. A higher order function is a function that takes another function as an input, returns a function, or does both. filter(), map(), reduce() are higher-order functions. A pure function is a function that returns a value based only of its input. Pure functions don’t use variables from the outer functions. Pure functions cause no mutations. In the previous examples isEven(), doubleNumber(), addNumber() and sum()are pure functions. ConclusionThe power of JavaScript lies in its simplicity. Knowing the JavaScript fundamentals makes us better at understanding and using the language. Read Functional Architecture with React and Redux and learn how to build apps in function style. Discover Functional JavaScript was named one of the best new Functional Programming books by BookAuthority! For more on applying functional programming techniques in React take a look at Functional React. You can find me on Medium and Twitter.
0 notes
Text
Check Exam Format at https://www.scrumprinciples.com/uipath-advanced-rpa-developer-certification/ UiPath Advanced RPA Developer Certification #uipath #automation #uipathcertification #uipathadvanceddevelopercertification #todaytimesheadline #trending

Check Exam Format at https://www.scrumprinciples.com/uipath-advanced-rpa-developer-certification/ 1). How many types of actions can be performed in the Variables panel in UiPath? Ans : – a). Changing Variable types b). Adding new Variables c). Setting default values for variables 2). What is the possible technique to get the content of a PDF document is available in UiPath? Ans. First to opening the PDF and using Screen scraping to get its data. Second to the Read PDF Text activity and providing the PDF file’s path. 3). Which activity is used to represent a decision inside a Sequence? Ans:- The If activity 4). How can you exit from a For Each activity in UiPath? Ans: – Break activity 5). During the running of workflow, how can you see the steps the workflow is executing? Ans : – a).Using Debug and inspecting the Output panel b). Using Debug with Highlight Activities option 6). How can execution be paused before a particular activity in UiPath? Ans: – a).First to use a MessageBox activity b).Second to use a breakpoint in Debug mode 7). In Order to Save Attachments activity, it can save all the attachments of an email to: Ans : – a). A relative path b). An absolute Path 8). What is the Visual Basic property within the MailMessage class will you use to get the Date of an email? Ans : – a).Headers(“Date”) 9). Which is the best optimize navigation method to be used in a form within Citrix? Ans:- By sending keyboard commands/hotkeys 10). What happens if Find Image doesn’t actually find the desired image in UiPath? Ans: – An Exception is Throw. 11). Which recording profile is used to generate full selectors in UiPath? Ans: – Basic recording 12). Which activities can be used to mostly interact with the user? Ans : – a). Input Dialog b) Message Box 13). In Which situation we have to use the Flowchart workflow in UiPath? Ans : – a).When modelling a process that has loops to previous states b). When having a process with many decision blocks 14). In case if the PDF activities are not listed in your activities panel, how can you get them? Ans:- You have to install pdf activities using Manage Packages features. 15). What should you use to click on a hidden IE browser? Ans:- a). SimulateClick 16). Why Timeout MS property is used in UiPath? Ans : – a). To define the amount of time during which the target of an activity must be found. 17). Why Queues are used in UiPath? Ans: – Distribute transnational load among multiple robots 18). Is it possible to click a button with Click Image Activity if the target is not visible on the screen in UiPath? Ans:- No, you could click a button which is not visible only using selectors 19). What is the way to send an image inside a MailMessage? Ans:- a).You can add the path to the attachment directly in the send activity. b). You can specify the relative path of the image in the Attachments property. 20). If you need to sort a table from a .xlsx file, which feature is used? Ans: – An excel Sort Table Activity. 1). Which recording wizard is used to automate UI interactions in an application that does not offer support for selectors in UiPath. Ans: – Citrix Recording 2). Which of the following phrases are true regarding Project Organization? Ans: – Saves time for all team members, Is a constant concern of the robot developer 3). how do you define to create a layout of business logic in complex process automation? Ans: – Flowchart 4). Which activity is used to chain together multiple workflows in single automation in UiPath? Ans: – Invoke workflow File Activity 5). How can you manage passwords for an automation project in UiPath? Ans: – With Windows Credential Manager 6). Which activity is used to Get Outlook Mail Messages activity? Ans: – MailFolder 7). Which activities allow you to iterate through an array of strings in UiPath? Ans: – a). while b). For Each c). Do While 8). Can you insert a Flowchart activity in a Sequence in UiPath? Ans: – Yes 9). What is the use of The Orchestrator? Ans: – a)Remotely control robots b). Send Start commands to multiple robots c). Schedule robots to perform specific processes 10). How to check the UI Element is exist on the screen or not, which activity is used for this? Ans : – Element Exists 11). Where can you see the variables’ values when we execute the workflow in UiPath? Ans: – In the Locals Pane 12). What can you use to make sure that the execution continues even if an activity fails in UiPath? Ans : – Try/Catch Activity 13). Which activity is used If you want to wait until a UI Element becomes available on the screen in UiPath? Ans:- Find Element 14). What happens if you use the Excel Read Range activity to read a .xlsx file that is already opened in UiPath? Ans: – This will read the document successfully. 15). What is the way to optimize accuracy when scraping with OCR a region that contains only digits? Ans: – Use Google OCR with “Numbers Only” 16). Which property is used to make sure that the workflow continues even if an activity fails in UiPath? Ans :- ContinueOnError Property 17). Which property defines the amount of time in which the UI target of an activity must be found? Ans: – The TimeoutMS property 18). Why Attach Window used in UiPath? Ans: – Identifying the window you are working with. 19). What is the way to enable the (Clipping) Region selection mode when Screen Scraping in UiPath? Ans: – By Pressing F3 20). Which activity can be used to modify the value of an existing cell in a DataTable in UiPath? Ans:- Assign Activity How does the Anchor Base activity work? It searches for an UiElement at a fixed anchor position.It searches for an UiElement using a relative coordinate position.It searches for an UiElement by using another UiElement as anchor. What direction can the arguments of a workflow have? In arguments.Out argumentsIn/Out arguments. At the end of the execution of Workflow1, which retrieves some items from a database, is the database connection closed automatically? Yes, the connection is closed after 30 seconds.The connection has to be closed using a Disconnect activity.Only the database admin can decide this aspect. Where can we see the logs generated by running robots? In the Output panel.In the local Logs folder.In the Orchestrator logs. Why is renaming activities considered to be one of the best practices? In case of an exception, to be able to find its source activityTo be able to understand the process logic without expanding each sequence or invoked workflow.To easily understand the high-level business logic from a workflow. What type of Output variable do all Get Mail activities return? (POP3, IMAP, Outlook, Exchange) MailMessageListList Is it possible to retrieve the color of a specific Excel cell? Yes, by using Get Cell ColorNo. The color cannot be retrieved from a workbook.Only with an OCR Engine. Can you store a Selector in a variable? NoYes, in a UiElement variable.Yes, in a String variable. What can be used to debug a workflow? BreakpointsHighlighting activities.The Slow Step option. How can a robot start an application in Citrix? By using a command line.By double clicking on a Desktop icon.By using an Open Application activity.By defining a shortcut key for the application and then triggering the app with a Send Hotkey activity. What is Orchestrator used for? Running Windows processes on the local machine.Remotely controlling any number of robots and performing workflow management.Designing workflows to be run by robots in a supervised mode.Designing workflows to be run by robots in an unsupervised mode. What happens when a new version of a package is published? The processes using the package are automatically updated to the latest versionThe processes have to be updated in order for the robots to run the latest version of the packageThe old version of the package is overwritten What types of assets can be stored in Orchestrator? Array, Datatable, Bool, StringBool, String, Integer, CredentialInteger, Password, GenericValue, String Where can you trigger an unattended robot from? Select all the options that apply. The UiPath Robot icon in the system trayUiPath StudioRemotely, from Orchestrator How can a process be executed on three different robots? By deploying the process in the environment of the robots, which run it automaticallyBy creating a job and selecting all three robotsIt is not possible to allocate a process to three different robotsBy scheduling the process and adjusting the settings in the Execution Target tab accordingly The best way of managing variable values within a workflow, so that they can be shared on different robots and environments is: Using Json config files.Using excel config filesUsing assets defined in Orchestrator. What robots can be selected when you start a job from Orchestrator? Any robot provisioned in Orchestrator.Any robot you have access to according to your role permissions.Any robot in the same environment as the process to be executed. What is the best way of restricting the access of a person to a limited number of pages in Orchestrator? That option does not exist. Everyone is able to see everythingBy changing the rights of the Administrator to the desired state.By creating a different account and role for that person. When creating a new role, restrictions can be applied. “Add Assets” in Orchestrator has the following option: Value Per RobotValue Per EnvironmentValue Per ProcessSingle Value
What robot state is displayed on the Robots page while a job is being executed?
BusyRunnningPending Where should credentials be stored? Select all the options that apply. In Windows Credential Store.In Orchestrator, as assets.Directly inside the workflows, as variables. Which one of the statements below regarding the GetAppCredentials workflow included in UiPath Robotic Enterprise Framework is true? It first requests the credential from user.It first tries to fetch a credential from the Windows Credential Manager.It first tries to fetch a credential from Orchestrator. If a large item collection is processed using For Each, which activity enables you to efficiently exit the loop after a specific moment? No activity can be used. Instead, you have to create a Boolean variable based on which the For Each loop is brokenThe “Break” activity is the most suitable in For EachA While loop should be used instead of For Each Which of the following statements are true? Select all the options that apply. You cannot use a recorder in a Citrix environmentThe recorder is used to create a skeleton for the UI automationThe Desktop recorder generates partial selectors In UiPath Robotic Enterprise Framework, what are the transitions of the Init state? In the case of Success, the transition is to the Get Transaction Data state.In the case of System Error, the transition is to the Init state.In the case of Success, the transition is to the Process Transaction state.In the case of System Error, the transition is to the End Process state. Which statement about the UiPath Robotic Enterprise Framework template is false? The framework is meant to be a template that helps the user design processes.The framework can be used only if you get the input data from the UiPath server queues.The framework has a robust exception handling scheme and event logging. Which of the following are considered best practices? Select all the options that apply. Keeping environment settings hard coded inside workflows.Breaking the process into smaller workflows.Reusing workflows across different projects. In the UiPath Robotic Enterprise Framework template, if a System Error is encountered in the Init state of the Main workflow, which state is executed next? Get Transaction DataInitEnd Process In the UiPath Robotic Enterprise Framework template, in the Get Transaction Data state of the Main workflow, what happens before the next transaction item is retrieved? We check if the previous transaction has been completedWe check if a kill signal was sent from OrchestratorWe check if a stop signal was sent from Orchestrator When should an Attended Robot be used? Select the option that applies. When the processing of some input data relies on human decision.When a workflow needs to be modified and corrected.When the process might be interrupted by exceptions and errors. What happens in the Init state of the Main workflow, in the UiPath Robotic Enterprise Framework template? The robot reads the configuration file and initializes all the required applications.The transaction items are extracted from the Queue.The robot checks if the previous transaction is complete and then starts the next one. How should exceptions be handled? Select all the options that apply. By using Try Catch activities inside the workflow for unexpected application exceptions.By validating data using conditional blocks for business exceptions.UiPath handles exceptions by default. In which workflow in the UiPath Robotic Enterprise Framework template is the retry mechanism implemented? The SetTransactionStatus workflowThe Main workflowThe GetTransactionData workflow In the UiPath Robotic Enterprise Framework template, in the Main workflow, the State Machine includes the following states: Init stateGet transaction data stateProcess Transaction StateSet Transaction StateEnd Process State Which of the following are considered best practices? Removing unreferenced variables.Deleting disabled code.Leaving target applications opened. In a Try Catch activity, how many times is the Finally section executed if no error occurs in the Try section? OnceThe Finally section is executed only when the Catch section is executed.Zero In UiPath Robotic Enterprise Framework, the value of MaxRetryNumber in the Config.xlsx file should be set to a number greater than 0 to enable the retry mechanism in the following cases: Get data from spreadsheets, databases, email, web API.Do not work with UiPath Orchestrator queues.Get data from UiPath Orchestrator queues with Auto Retry disabled. The return value of the Get Transaction Item activity is of the following type: ObjectStringQueueItemList Which is the best way to navigate to a specific page in a web browser? Use the Navigate To activity inside an Attach Browser containerUse the Type Into activity inside an Attach Browser containerUse a Type Into activity with a full selector How should a UiPath developer handle frequent changes in the project files? By creating daily backups of the filesBy using a source control solution, such as SVN, TFS, etc.Old versions of the project files are not relevant What layout should be used for UI navigation and data processing? FlowchartSequenceState Machine In the UiPath Robotic Enterprise Framework template, if a System Error is encountered in the Process Transaction state of the Main workflow, which state is executed next? Get Transaction DataInitEnd Process How can you pass data between workflows? By using arguments.By using variables.By using a pipe. In the UiPath Robotic Enterprise Framework template, what happens if the processing of a transaction item fails with an Application Exception or a System Error? The process executes the End Process state.All used applications are closed and then re-initialized.The execution of the transaction item is retried if the MaxRetryNumber config value is greater than 0. Which of the following are required to have efficient execution of automation projects? Proper exception handlingRecovery abilitiesEffective logging mechanisms Read the full article
#advancedcertificationuipath#automation#rpa#rpaautomation#uipath#uipathadvanceddevelopercertification#uipathcertification
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
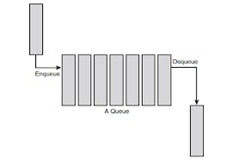
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Video
youtube
Circular Queue - Insertion/Deletion - With Example in Hindi
This is a Hindi video tutorial that Circular Queue - Insertion/Deletion - With Example in Hindi. You will learn c program to implement circular queue using array in hindi, circular queue using array in c and circular queue in c using linked list. This video will make you understand circular queue tutorialspoint, circular queue algorithm, circular queue example, circular queue in data structure pdf, insertion and deletion in circular queue in data structure, implement circular queue in hindi, circular queue c, types of queue in hindi, double ended queue in hindi. If you are looking for Circular Queue in Hindi, Circular Queue Array Implementation in Hindi, Circular Queue Programming using Array (Hindi), Circular Queue | Data Structures in Hindi or Array Implementation of Circular Queue in Hindi, then this video is for you. You can download the program from the following link: http://bmharwani.com/circularqueuearr.c For more videos on Data Structures, visit: https://www.youtube.com/watch?v=TRXkTGu0n9g&list=PLuDr_vb2LpAxZdUV5gyea-TsEJ06k_-Aw&index=14 To get notification for latest videos uploaded, subscribe to my channel: https://youtube.com/c/bintuharwani To see more videos on different computer subjects, visit: http://bmharwani.com
#circular queue in hindi#circular queue in c#implement circular queue using array#circular queue tutorial#how to implement circular queue using array#circular queue using array with output#use of modulo operator in circular queue#circular queue using array example#circular queue algorithm#circular queue tutorialspoint#circular queue ppt#bintu harwani#b.m. harwani#circular queue using array#circular queue#c program to implement circular queue#circular queue program#types of queue
0 notes
Text
Discovering C#
Discovering C#
Through this article, we are going to take a look at the programming language named C#. Let's get into it!
Introduction
First of all, we are not going to look at C# in every single detail because it is not the purpose of this article and it would probably take a whole book. Our goal here is to simply get familiar with this very common language. We are going to have a look at the very basics of this language and go a little further after that. This article is some kind of introduction to this language.
What is C#?
C#, or C Sharp, is a programming language developed by Microsoft. We usually say that it is an object-oriented programming language, but in fact, it is a multi-paradigm programming language. It was designed to be used with the .NET Framework. It is derived from C and C++ and it is really similar to Java.
C# programs run on the .NET Framework through a virtual execution system called the Common Language Runtime (CLR). When we compile a program written in C#, it is transformed to an Intermediate Language (IL). That last code and all the resources a stored in an executable file called Assembly. When the program is executed, the Assembly is loaded into the CLR that will perform the Just-in-Time compilation (JIT) that will convert the Intermediate Language code to native machine instructions. In a very few words, we can say that the CLR is to .NET the same thing as the JVM is to Java.
Generalities and syntax
A source code written in C# is placed in a file that has ".cs" as extension. Lines written in this file have to be read from left to right, from top to bottom. Every instruction should be ended with a semicolon (;).
C# is case-sensitive.
We can add comments to our code using "//" for a single line, or "/" and "/" for multiple lines.
Variables
A variable is like a box where we store a value. It is a name given to a data value. The content of a variable can vary at any time. In C#, a variable has to be defined with a data type. A variable can be declared and initialized later or it can be declared and initialized at the same time.
// Declaring a variable string message; // Assigning a value the previously declared variable message = "Hello World!!"; // Declaring and initializing a variable string message = "Hello World!!";
Data Types
Because C# is a strongly typed language, we are required to inform the compiler about which data type we want to use with every variable we declare. A data type specifies the type of data that a variable can store.
The information stored in a type can include the following:
The storage space that a variable of the type requires
The maximum and minimum values that it can represent
The members (methods, fields, events, and so on) that it contains
The base type it inherits from
The location where the memory for variables will be allocated at run time
The kinds of operations that are permitted
The compiler uses type information to make sure that all operations that are performed in our code are type safe.
// Declaring a string string stringVar = "Hello World!!"; // Declaring a integer int intVar = 100; // Declaring a float float floatVar = 10.2f; // Declaring a character char charVar = 'A'; // Declaring a boolean bool boolVar = true;
Value Type and Reference Type
In C#, data types are categorized based on how they store their value in the memory. They could be a value type or a reference type.
Value Type
A data type is a value type if it holds a data value within its own memory space. It means variables of these data types directly contain their values.
The following data types are all of value type:
bool
byte
char
decimal
double
enum
float
int
long
sbyte
short
struct
uint
ulong
ushort
When we pass a value type from one method to another, the system creates a separate copy of that variable in the other method. So if the value is changed in one method, the value in the other method won't be affected.
Reference Type
A data type is a reference type if it stores the memory address where the value is being stored. In other words, a reference type contains a pointer to another memory location that holds the data.
The following data types are of reference type:
String
All arrays, even if their elements are value types
Class
Delegates
When we pass a reference type from one method to another, the system passes the address of the variable. It means that if the value is changed in one method, the value in the other method will also be affected.
Operators
An operator is a symbol that is used to perform operations. Some operators have different meanings based on the data type of the operand.
Condition
In C# programming, there are various types of decision-making statements:
if statement
if-else statement
Nested if statement
if-else-if statement
switch statement
If statements
The if statement contains a boolean expression inside brackets followed by a single or multi-line code block. At runtime, if a boolean expression is evaluated to true, then the code block will be executed.
// if statement if (a > b) { Console.WriteLine("a is greater than b"); } // if-else statement if (a > b) { Console.WriteLine("a is greater than b"); } else { Console.WriteLine("a is either equal to or less than b"); } // if-else-if statement if (a > b) { Console.WriteLine("a is greater than b"); } else if (a < b) { Console.WriteLine("a is less than b"); } else { Console.WriteLine("a is equal ton b"); } // Nested if statement if (a > 0) { if (a <= 100) { Console.WriteLine("a is positive number less than 100"); } else { Console.WriteLine("a is positive number greater than 100"); } }
Switch
The switch statement executes a code block depending upon the resulted value of an expression. It is like the if-else-if statement.
switch (a) { case 10: Console.WriteLine("It is 10"); break; case 20: Console.WriteLine("It is 20"); break; case 30: Console.WriteLine("It is 30"); break; default: Console.WriteLine("Not 10, 20 or 30"); break; }
Loops
A loop gives us the ability to repeat a block of code. In C#, there are four ways to achieve a loop.
While loop
A While loop is used to iterate a part of the program while a condition is true.
int i = 0; while (i < 10) { Console.WriteLine("Value of i: {0}", i); i++; }
Do-While loop
A Do-While loop is like a While loop, except that the block of code will be executed at least once because the loop executes the block of code first and then checks the condition.
int i = 0; do { Console.WriteLine("Value of i: {0}", i); i++; } while (i < 10);
For loop
A For loop executes a block of statements repeatedly until the specified condition returns false.
for (int i = 0; i < 10; i++) { Console.WriteLine("Value of i: {0}", i); }
Foreach loop
A Foreach statement provides a way to iterate through the elements of an array or any enumerable collection.
int[] numbers = { 4, 5, 6, 1, 2, 3, -2, -1, 0 }; foreach (int i in numbers) { System.Console.Write("{0} ", i); }
Arrays
In C#, an array is a group of similar types of elements that have contiguous memory location. An array is a special type of data type which can store a fixed number of values sequentially using special syntax. Array index starts from 0.
Like a variable, an array can be declared and initialized later or it can be declared and initialized at the same time.
// Declaring an array that contains strings string[] names; // Instantiating the array and defining its size string[] names = new string[2]; // Storing a value at index 0 names[0] = "John Doe"; // Displaying the value stored at index 0 Console.WriteLine(intArray[0]);
Collections
In C#, a collection represents a group of objects. Unlike an array, a collection doesn't have a fixed size. There are several types of collections.
ArrayList
An ArrayList stores objects of any type like an array.
// Declaring ArrayList ArrayList arrayList = new ArrayList(); // Adding elements arrayList.Add(1); arrayList.Add("Two"); // Add an element at a specific index arrayList.Insert(1, "Second Item"); // Removing element at a specific index arrayList.RemoveAt(1);
SortedList
A SortedList stores key and value pairs. It automatically arranges elements in ascending order of key by default.
// Declaring SortedList SortedList sortedList = new SortedList(); // Adding elements sortedList.Add(3, "Three"); sortedList.Add(4, "Four"); sortedList.Add(1, "One"); sortedList.Add(5, "Five"); sortedList.Add(2, "Two");
Stack
A Stack stores the values in LIFO style (Last In First Out). It provides a Push() method to add a value and Pop() and Peek() methods to retrieve values.
// Declaring Stack Stack stack = new Stack(); // Adding elements stack.Push("John Doe"); stack.Push(1); stack.Push(2); stack.Push(null); stack.Push(3); // Displaying the top item from the stack Console.WriteLine(stack.Peek()); // Removing and returning the item from the top of the Stack stack.Pop()
Queue
A Queue stores the values in FIFO style (First In First Out). It keeps the order in which the values were added. It provides an Enqueue() method to add values and a Dequeue() method to retrieve values from the collection.
// Declaring Queue Queue queue = new Queue(); // Adding elements queue.Enqueue(3); queue.Enqueue(2); queue.Enqueue(1); // Displaying the first item of the Queue Console.WriteLine(queue.Peek()); // Removing and returning the item from the beginning of the queue queue.Dequeue();
HashTable
A HashTable stores key and value pairs. It retrieves the values by comparing the hash value of the keys.
// Declaring Hashtable Hashtable hashtable = new Hashtable(); // Adding elements hashtable.Add(1, "One"); hashtable.Add(2, "Two"); hashtable.Add(3, "Three"); hashtable.Add("Fr", "Four"); // Accessing element string str = (string)hashtable[2]; // Removing element hashtable.Remove(3);
Tuples
A tuple is an ordered immutable sequence, fixed-size of heterogeneous objects. Tuples allow to return multiple values from a method.
// Declaring a tuple var numbers = ("One", "Two", "Three", "Four", "Five"); // Declaring another tuple (string, string, int) person = ("John", "Doe", 30); // Declaring another tuple and accessing values. var person = (firstName: "John", lastName: "Doe", Age: 30); person.firstName; We can also use a tuple as a return type. (int Val1, int Val2) Values() { int val1 = 1; int val2 = 2; return (val1, val2); } var values = GetValues();
Classes
A class is like a blueprint. It is a template from which objects are created. In an object-oriented programming language like C#, an object is like in the real world: it has properties and functionalities. So, a class defines the kinds of data and the functionalities that an object will have.
Access modifiers
Access modifiers are applied to the declaration of the class, methods, properties, fields and other members. They define the accessibility of the class and its members. There are four access modifiers:
public - allows a class to expose its member variables and member functions to other functions and objects
private - allows a class to hide its member variables and member functions from other functions and objects
protected - allows a child class to access the member variables and member functions of its base class
internal - allows a class to expose its member variables and member functions to other functions and objects in the current assembly
Fields
A field is a class level variable that can hold a value.
Properties
A property allows us to control the accessibility of a class variable. It encapsulates a private field and provides a level of abstraction allowing us to change a field while not affecting the external way they are accessed by the things that use our class.
Constructor
A class constructor is a special member function that is executed whenever a new object of that class is created. A constructor has exactly the same name as the class and it does not have any return type.
Methods
A method is a group of statements that perform a task. A method is basically written like so:
<Access Modifier <Return Type> <Method Name>(Parameter List) { Method Body }
Namespaces
A namespace is a container for a set of related classes. A class name declared in one namespace does not conflict with the same class name declared in another.
Example
Let's put what we saw together to create a simple class:
// Namespace namespace MyNamespace { // Declaring the class - access modifier, class keyword, class name public class MyClass { // Fields - access modifier, type, field name public string field = string.Empty; // Property private int propertyVar; // Property accessors public int Property { get { return propertyVar; } set { propertyVar = value; } } // Constructor public MyClass() { } // Method - acces modifier, return type, method name, parameters public void MyMethod(int parameter1, string parameter2) { Console.WriteLine("First Parameter {0}, second parameter {1}", parameter1, parameter2); } // Method - acces modifier, return type, method name, parameters public int MyMethod(int parameter1, int parameter2) { return parameter1 + parameter2; } } }
Interfaces
An interface is like a contract. Every class that inherits from a specific interface has to implement what is defined in the interface. An interface only contains the declaration of the methods and the properties that a class has to implement.
// Declaring the interface interface MyInterface { void MyMethod(string message); } // Implementing the interface class MyClass : MyInterface { public void MyMethod(string message) { Console.WriteLine(message); } }
An interface can also contain properties.
interface MyInterface { string Property { get; set; } void MyMethod(string message); } class MyClass : MyInterface { private string property; public string Property { get { return name; } set { name = value; } } public void MyMethod(string message) { Console.WriteLine(message); } }
Structs
A struct is mostly like a class, but while a class is a reference type, a struct is a value type data type. Unlike a class, it does not support inheritance and can't have a default constructor.
We can consider defining a struct instead of a class if instances of the type are small and commonly short-lived or are commonly embedded in other objects. The general rule to follow is that structs should be small, simple collections of related properties, that are immutable once created.
struct Point { private int x, y; public int XPoint { get { return x; } set { x = value; } } public int YPoint { get { return y; } set { y = value; } } public Point(int p1, int p2) { x = p1; y = p2; } }
Enums
An enum is a value type data type. It is used to declare a list of named integral constants that may be assigned to a variable. An enum is used to give a name to each constant so that the constant integer can be referred using its name.
enum Days { Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday } Console.WriteLine(Days.Tuesday); Console.WriteLine((int)Days.Friday);
Delegates
In C#, a delegate is like a pointer to a function. It is a reference type data type and it holds the reference to a method. When we instantiate a delegate, we can associate its instance with any method with a compatible signature and return type. Delegates are used for implementing events and callback methods.
// Declaring the delegate delegate int Calculator(int n); class Program { static int number = 1; public static int add(int n) { number = number + n; return number; } public static int mul(int n) { number = number * n; return number; } public static int getNumber() { return number; } public static void Main(string[] args) { // Instantiating the delegate Calculator c1 = new Calculator(add); // Instantiating the delegate Calculator c2 = new Calculator(mul); // Calling method using delegate c1(20); // Calling method using delegate c2(3); } }
Anonymous functions and Lambdas
An anonymous function is a type of function that doesn't have a name.
In C#, there are two types of anonymous functions:
Lambda expressions
Anonymous methods
Lambdas Expressions
A lambda expression is an anonymous function that we can use to create delegates. We can use a lambda expression to create a local function that can be passed as an argument.
class Program { delegate int Square(int num); static void Main(string[] args) { Square getSquare = x => x * x; int a = getSquare(5); Console.WriteLine(a); } }
Anonymous Methods
An anonymous method is quite like a lambda expression but allows us to omit the parameter list.
class Program { public delegate void AnonymousFunction(); static void Main(string[] args) { AnonymousFunction myFunction = delegate() { Console.WriteLine("This is an anonymous function"); }; myFunction(); } }
Generics
Generics allow us to define a class with placeholders for the type of its fields, methods or parameters. The compiler will replace these placeholders with the specified type at compile time. Generics increase code reusability.
// Declaring a generic class class GenericClass<T> { // Declaring a generic field private T genericField; // Declaring a generifc property public T genericProperty { get; set; } // Constructor public GenericClass(T value) { genericField = value; } // Declaring a generic method public T genericMethod(T genericParameter) { Console.WriteLine("Parameter type: {0}, value: {1}", typeof(T).ToString(),genericParameter); Console.WriteLine("Return type: {0}, value: {1}", typeof(T).ToString(), genericField); return genericField; } } class Program { static void Main(string[] args) { // Using the generic class GenericClass<int> genericClass = new GenericClass<int>(10); } }
We can use constraints to specify which type of placeholder is allowed with a generic class.
// Declaring a generic class specifying that T must be a reference type. class GenericClass<T> where T: class { ... }
Generic collections
We mentioned collections before. In C#, we can also have generic collections.
List - contains elements of specified type
Dictionary - contains key-value pairs
SortedList - stores key and value pairs in an ordered manner
Hashset - contains non-duplicate elements
Queue - a Queue containing elements of specified type
Stack - a Stack containing elements of specified type
Polymorphism
In C#, polymorphism can be used in different manners. There are two types of polymorphism in C#: compile time polymorphism and runtime polymorphism. Compile time polymorphism, also known as static binding or early binding, is achieved by method overloading and operator overloading. Runtime polymorphism, also known as dynamic binding or late binding, is achieved by method overriding.
Method overloading
It allows us to have the same method multiple times but with different parameters or return type.
public class Program { public int add(int a, int b) { return a + b; } public int add(int a, int b, int c) { return a + b + c; } public float add(float a, float b) { return a + b; } }
Method overriding
It allows a class to override a method that is inherited from a base class. We need to use the keyword "virtual" in front of the method in the base class to allow a derived class to override it.
public class Animal { public virtual void play() { Console.WriteLine("Playing"); } } public class Cat : Animal { public override void play() { Console.WriteLine("Playing like a cat"); } }
Abstract classes
An abstract class is a class that cannot be instantiated. It can contain concrete or abstract methods. An abstract method is a method that has no body and it must be implemented by the derived class.
public abstract class AbstractClass { public abstract void AbstractMethod(); public void Method() { Console.WriteLine("This is a method"); } } public class ConreteClass : AbstractClass { public override void AbstractMethod() { Console.WriteLine("Abstract method implementation"); } }
Attributes
An attribute is a declarative tag that is used to send information to runtime about the behavior of various elements like classes, methods, structures, enumerators or assemblies. Attributes are used to add metadata, such as compiler instruction or other information to a program.
Attributes are generally applied physically in front of type and type member declarations. They're declared with square brackets, "[" and "]", surrounding the attribute. In the following example, we use the "Obsolete" attribute which is a pre-defined attribute in the .NET Framework.
class Program { static void Main() { Test(); } [Obsolete("Test method is obsolete.", true)] static void Test() { } }
When we try to compile the program, the compiler generates an error.
Conclusion
Through this article we had an overview of the C# programming language and how we can use it. It was more like a theoretical article more than a practical article. Nevertheless, we now have the tools to dig a little deeper and to use C#.
One last word
If you like this article, you can consider supporting and helping me on Patreon! It would be awesome! Otherwise, you can find my other posts on Medium and Tumblr. You will also know more about myself on my personal website. Until next time, happy headache!
0 notes
Text
C++ programming questions and answers
C++ programming questions and answers
Vector vs. deques. Vectors are used to store contiguous elements like an array. However, unlike arrays, vectors can be resized Dequeues, are double ended queues that store elements in a linear order. They allow elements to be accessed at any position. Vector vs. deques. – Vector supports dynamically expandable array. – Deque is double ended queue. Deque elements can be accessed from both the ends…
View On WordPress
0 notes
Text
Skiena Chapter 4 (sorry for the lack of images
_These are my notes for chapter 4 of Skiena’s Algorithm Design manual. They have images locally, but I’m not going to upload them here until i REALLY need something to do. If you have the book, they go in order and you can follow along._
## INTRO - Selection sort: repeatedly extracts the smallest remaining element from the unsorted part of the set. ``` SelectionSort(A) for i = 1 to n do Sort[i] = Find-Minimum from A Delete-Minimum from A Return(Sort) ``` - Easy. And has O(n^2) efficiency. So, not great. It performs n iterations with n/2 steps per iteration, and then goes again. - But we can speed it up to O(n log n) by replacing our generic data structure (the set A) with a better data structure, like a heap or a balanced binary tree. Each loop then takes O(log n), improving us to O(n log n).
## HEAP SORT
- Heaps: a data structure that efficiently supports the priority queue operations insert and extract-min. They maintain a partial order on the set of elements which is weaker than the sorted order (so it's efficient to maintain because you don't need to keep it intact) but stronger than a random order (so you can find the minimum without sorting for forever). - a heap-labeled tree: a binary tree such that the key labeling of each node dominates the key labeling of each of its children. - min-heap: a node dominates its children by containing a smaller key than they do - max-heap: a node dominates its children by being bigger. - a heap lets us represent binary trees without storing pointers or references anywhere. if you store the data as an array of keys, we can use their position to implicitly satisfy the role of the pointers. - root goes to arr[0] and its left and right children go in arr[1] and arr[2] (the book use arrays starting at 1 but fuck that) - p. 110, we have a heap-labeled tree of important years from American history and a corresponding implicit heap representation, which looks like this:  - Note how it's arranged. If it's on the same level in the tree, it's next to its neighbor with the same parent dominating it in the array. - this makes it easy to figure out the position of the children and parents of random key k. - for the key at position k, left child is at 2k and right child is 2k + 1, and parent is at floor(k/2).  - why? as we add elements to the heap, they're inserted in order. mathematically, each new level (i.e. the depth of the parent-child relationship) doubles the number of elements we're looking at (it's a tree) and so we can always find them. this lets us dodge the need for pointers. - example they're using for a priority_queue struct (in C): - it's got a queue, and it knows that n is the number of elements inside it.  - heapsort needs to pack things in tightly to avoid leaving holes in the array, because we need the full binary tree to make this work correclty. if number of nodes < 2^h, where h is the tree's height, we'd lose our ability to traverse the heap without pointers because we wouldn't have a fully packed tree. therefore, only the last level's allowed to be incomplete; everything else must exist in a dominance relationship with another node in the set. - we can and need to represent an n-key tree using exactly n elements of the array. without that, we might need an array of size 2^n, because we'd be leaving levels unfilled. - but that doesn't make sense. what does "unfilled" mean here? - it means that somewhere in the tree, some node ends early, or doesn't have as many children, or whatever. - and in that situation, if we went through and added every child recursively, we would add a bunch of empty spaces inside it. - caveats for this: we can't store any binary tree using an implicit representation. we can't store any kind of tree topology without leaving giant holes. we can't move subtrees around without explicitly moving each element in the subtree. we can't just change a pointer to move things. it works fine for heaps, but it's not as great as some other approaches. - okay, so WHY can't we efficiently search for a particular key in the heap? - we need to just keep traversing the whole thing until we find it, right? we can't look ahead or behind. linear search.
### OKAY HOW DO YOU BUILD IT:
- you insert each new element n into the array at pos k, and then check it against the parent at k/2. if the parent is unhappy, you swap them so that the parent is properly dominated, and check again. - example:  - pq_insert : - receive a queue and an item x - make sure we haven't gone over the memory size allotted. - up the number of elements n in the array by 1 - push in x at position k (which now == n because we upped the array size, which you need to do in c) - start checking it against its parent at n/2. it's a recursive function, which will ultimately return here - bubble up: - you've got a queue and an integer p (which is k, position of the last element in the set). - if the parent function returns -1, you're done. no more parents. - if the dominance relation is off, swap the parent at k/2 and the element at k and test again. this time, pass it the position of the parent. - otherwise return nothing. it's done and all set.
### EXTRACTING THE MINIMUM/MAXIMUM, AKA HEAPSORT
- so these are the last two priority queue operations, identifying and deleting the dominant element. - if we delete that top element, we need to maintain the order of the tree. we use a bubble_down function to traverse/keep it organized:  - extract min removes an element from the array, moves the last element in the array of size n to the front, decrements n by 1, and bubbles the element now at 1 down until it finds its correct level of dominance. eventually, it returns the minimum element.  - bubble\_down finds the child of an element and sets its min\_index to the current value. it checks if the element at either c (the child's position) or c + 1 is "lighter" than the element at min\_index, in which case min\_index = c + i (where i is 0 or 1), and we've located a heavier element. - if we find it, swap the element in queue q at index p with the child at min\_index, then check again at that min\_index to make sure the tree stays identical. - that's heapifying and finding the minimum in an array - so what's heapsort? repeatedly extracting the minimum from an unordered priority_queueq and storing it in an array s as we efficiently locate the minimum. as it goes, we reset minimum (or maximum, but this example uses minimum) over and over again (for this purpose) and return it, bubbling those values to the top of s as the minimum gets located according to where it sits in the dominance hierarchy 
- ok! features - runs in O(n log n) time, which is the best we can expect for any sort. - it's in-place and doesn't use extra memory over the array containing the elements to sort.
### BUILDING IT FASTER Say we stuff everything in (first n elements) into the array. The shape will work, but dominance will suck. How do you fix it?
- "Consider the array in reverse order...it represents a leaf of the tree and dominates its nonexistent children. The same is true for the last n/2 positions of the array, they're all leaves. If we keep walking backwards through the array, we'll find an internal node with children. It might not dominate, but its children are all well-formed heaps." - so then we can bubble_sort! stuff it all in, start at the end, and walk back.  - remember: bubble_down is recursive. swaps it with the parent and reiterates. - if we do this, we get O(n log n). Same as above. - but it's an upper bound, because n/2 nodes in a binary tree with n nodes are leaves. - there are at most [n/2^h+1] nodes of height h, so the cost of building a heap is:  - series converges to linear. so we can do the construction in constant time, which prob. doesn't matter
0 notes
Text
C++ Standard Template Library (STL) – Introduction
In this tutorial you will learn about what is STL in C++, what it provides and overview of all STL items.
STL means Standard Template Library. STL is the most crafted libraries among all other libraries in C++. It is heart of C++. It includes containers, algorithms and iterators.
C++ Standard Template Library (STL)
What STL Provides?
Standard Template Library provides Algorithms and Containers. Containers contain data and algorithms operate on the data which is in containers.
The aim of object oriented language is combining algorithm and data into a class which is called object. STL goes opposite way of OOP language. It separates algorithms and data structures. Purpose of that is code reuse. We want one algorithm apply on different containers. And we want one container to use different algorithms. Containers have different interfaces from each other. So if we want to apply one algorithm on different containers, we need to provide different implementations for that. So if we have N algorithms and M containers we need to provide N*M implementations. This is quite lot work and not scalable also.
To solve this problem STL library provides another group of modules called Iterators. Each container required to provide a common interface defined by iterators. Iterator can iterate each item inside a container. So the algorithm instead of working on containers directly it only works on the iterators. So the algorithm doesn’t know about on which container it is working. It only knows about the iterator. This will very useful to reuse the code instead of writing N*M implementations (above mentioned example). Now we only need to provide N+M implementations. There are so many uses by this. If we define a new algorithm that operates on iterator then all the existing containers can use that algorithm. Similarly if we define a new container that provides appropriate iterate interface then all the existing algorithms can be applied on that new container. So this ST Library is very much useful.
Image Source
Containers
Sequence Containers
These implemented with arrays and linked lists.
Vector: Vector is a dynamic array that grows in one direction; it is at end of vector.
Deque: Deque is similar to vector. But deque can grow both beginning and at ending in both directions
List: It is same as double linked list. Each item in list points to both previous and next item of that item.
Forward list: Forward list only contain forward pointer. So it can traverse beginning to the end but not from end to the beginning.
Array: There are limitations to container array. That is size can’t be changed.
Associative Containers
These are typically implemented by Binary Trees. The key attribute of associative containers is all the elements are always sorted.
Set: Set has no duplicate items. When we insert elements into set all elements automatically sorted. It takes O(log( n)) time.
Multiset: It is same as set. But only difference is it allows duplicates also.
Map: Sometimes we don’t want to sort items by values. We are interested to sort them by key value. Map and Multimap contain key value pair structure. Map doesn’t allow duplicate keys.
Multimap: It is just like a map. But only difference is it allows duplicate keys. Important note is that, keys can’t be modified in map and multimap.
The word associative means, associating key with value. We can say that, set and multiset are special kind or map or multimap where the key of element is the same. This is the reason they called associative.
Unordered Containers
Unordered containers internally implemented with hash table. Each item calculated by hash function, to map to hash table. The main advantage is if we have effective hash function we can find elements in O (1) time.
This is fastest among all containers.
In Unordered containers the order is not defined. And they may change over the time.
Unordered Set: Unordered set that doesn’t allow duplicates.
Unordered Multiset: Unordered set that allows duplicate elements.
Unordered Map: It is unordered set of paris.
Unordered Multimap: Unordered map that allow duplicate keys.
Container Adaptors
Along with containers, container adaptors also provided by the ST library.
Container adaptors are not full container classes, but classes that provide a specific interface relying on an object of one of the container classes (such as deque or list) to handle the elements. The underlying container is encapsulated in such a way that its elements are accessed by the members of the container adaptor independently of the underlying container class used.
Stack: Stack provides push, pop, top operations to work on it
Queue: Push, pop, front, back allowed operations on this.
Priority Queue: It is keys of items of different priority. First item always have the highest priority.
Iterators
There are five categories of iterators based on types of operations performed on them.
1. Random Access Iterator
In random access iterator we can access elements in a container randomly. Here we can increment, decrement, add, subtract and also can compare. We can perform all these operations.
Ex: Vector, deque, Array provides random access iterator.
2. Bidirectional Iterator
With bidirectional iterator we can increment and decrement but we can’t add or subtract or compare.
Ex: list , set/multiset, map/multimap provide bidirectional iterators.
3. Forward Iterator
Forward iterator can only be incremented can’t be decremented.
Ex: forword_list
Remaining “Un ordered containers” they provide at least “forward iterators”. And also chance to growth “bidirectional iterators”. It depends on implementation of the STL.
4. Input Iterator
Input iterator used to read and process values while iterating forward. We can read only but not write.
5. Output Iterator
Used to output values. We can write but not read. Both input iterator and output iterator can only move forward. They can’t move backward.
Iterator Adaptor (Predefined Iterator)
This is a special, more powerful iterator.
Insert iterator
Stream iterator
Reverse iterator
Move iterator
Algorithms
Algorithms are mostly loops. Algorithms always process ranges in a half-open way. That means it will include the first item but not include the last item.
Non-modifying Algorithms
Count: Count function counts number of items in some data range.
Min and max: Max elements returns first maximum number, min returns minimum number.
Linear Search: When data is not sorted, this search for an element and returns first match.
Binary Search: When data is sorted, this search for an element and returns first match
Comparing ranges: Used to compare between two vector/list….etc
Check attributes: There are different check attributes in this like is sorted, any of/none of satisfied given condition… etc… We learn all of these clearly in further modules.
Modifying Algorithms (Value Changing Algorithms)
Copy: Copies everything from one container to other.
Move: It moves items to one place to other.
Transform: It transforms the data with certain operation. And then save the results at different place.
Swap: Swap the data between two places. It is also called two way copying.
Fill: Fill is used to fill the data with certain values.
Replace: Replace the existing value in container with another value.
Remove: Remove can remove any element based on condition.
Order Changing Algorithms
They changes the order of the elements in container, but not necessarily the elements themselves.
Reverse: Reverse the entire data.
Rotate: Rotates the data from vector begin to vector end.
Permute: Next permutation results lexicographically next greater permutation. Prev permutation results lexicographically next small permutation.
Shuffle: Rearrange the elements randomly. Swap each element with a randomly selected element.
Sorting Algorithms
Sorting algorithms are widely used algorithms in programming.
Sorting algorithms requires random access iterators. So that option limits our options to containers vector, deque, container array, native array. List and un-ordered containers cannot be sorted. And associative container doesn’t need sort anyway.
Sort() function directly sort by default. Some other cases also in this. We learn those in further tutorials.
Partial sort: Sometimes we doesn’t need all elements need to be sorted. In that case we use this partial sort like top 5 elements or least 10 elements like this.
Heap Algorithms
Heap has two properties: First element is always larger and add/remove takes O(log(n)) time.
Heap algorithms often used to implement priority queue. These are four important heap algorithms.
Make_heap: Creates new heap on given container.
Pop_heap: It removes largest element from heap, for that it does two things, swaps the first and last items of the heap and then heapify to satisfy heap conditions.
Push_heap: Add new element into heap.
Sort_heap: It does heap sorting on given heap.
Sorted Data Algorithms
These are the algorithms that require data being pre-sorted.
Binary search: It checks for data in a data range. It returns a Boolean as a result.
Merge: Merge operation does two ranges of sorted data into one range of big sorted data.
Set operations: Set Union, Set intersection, Set difference, Symmetric difference all these are set operations.
Numeric Algorithms
Numeric algorithms defined in the header of numeric not in the header of algorithm.
Accumulate: It accumulates the data, in given range, on given operation.
Inner product: To calculate the inner product of two ranges of data.
Partial sum: Partial sum calculates partial sum of given range of data and stores in other location.
Adjacent difference: It calculates the difference between adjacent items and stores in other location.
Reasons to Use C++ Standard Template Library (STL)
Code reuse. Instead of implementing lot of code we just reuse it.
Efficiency (fast and use less resources). This is the reason that modern C++ compiler are usually tuned to optimize for C++ Standard Library.
Accurate, less buggy.
Terse, readable code; reduced control flow.
Standardization, guaranteed availability.
A role model of writing library.
Good knowledge of data structures and algorithms.
Comment below if you have queries or found any information incorrect in above tutorial for Standard Template Library in C++.
The post C++ Standard Template Library (STL) – Introduction appeared first on The Crazy Programmer.
0 notes
Quote
Turns out the Internet is useful for a lot more than toppling corrupt governments and/or looking at pictures of partially (or fully) nude celebrities. Particularly when it comes to matters concerning your wardrobe.Thanks to advances in technology and logistics (think drones), these days you can go from “I have nothing to wear” to “check out my new sneakers” in a matter of hours given a few clicks and finger swipes in the right direction.However, access doesn’t always correlate with quality; the vagaries of fit and cunning clothes photography make those over-generous store mirrors seem benign.Yes, buying clothes online may come with its potential pitfalls, but provided you bear these pointers in mind, you’ll be spared a life of filling out returns forms and long post office queues.What Not To BuyCertain things lend themselves to being bought online. Once you know your size (and we’d hope you do by now), staples like socks and underwear don’t pose the same issues of fit that, say, a £3,000 wool-cashmere blend overcoat does. Nor do you necessarily need to handle the goods before buying.Tailoring, though, is trickier. After all, buying a suit is all about fit. A cheaper suit that hugs your shoulders and chest will always look better than an expensive one that pools around your ankles or has sleeves that finish halfway up your forearm.(Related: Ways To Make A Budget Suit Look Expensive)Yes, certain things can be adjusted, but if you steer wrong in the shoulders or thighs then no Milanese needle wizard is going to be able to help you. When an inch makes all the difference, even the most comprehensive online size guide just won’t cut it.There are really only two occasions on which you should buy tailoring online:When you’re replacing a piece (from the same brand) you already own and know fits well.When you’ve already tried something on in store and have scouted out a better digital deal or got hold of an online discount code.Otherwise, even if you find that perfect double-breasted blazer you’ve been lusting after since seeing it at Pitti, save yourself some serious hassle and click elsewhere.Make Sure It FitsRemember that tailor who couldn’t fix your beyond-help baggy suit? Get back to him for some proper measurements: height, waist, inseam, chest, sleeve length and neck size are the minimum you’ll want to note down.Store them on your phone, tablet and laptop (as well as in your head) so they’re to hand whenever you’re browsing the sales on your commute or flicking through new the arrivals before bed.Measure Your Own ClothesAs well as your own measurements, you should also take the tape to your favourite pieces in your existing wardrobe too.Lay that perfect-fitting sweatshirt flat and measure it across the chest (between the bottom of each arm seam, then double it), shoulder (seam to seam straight across), back (base of the collar to the hem) and sleeves (cuff to shoulder seam plus seam to centre of the collar label).Compare this blueprint to online size guides to quickly work out if what you’re currently eyeing up is going to come up too snug in the shoulders, even if it fits everywhere else.Body ChangesYou also need to be aware that your body can change during the year. The January sales may scream offers at you, but post-Christmas you may be carrying an extra few pounds. Equally, kudos on hitting the gym, but those broader shoulders and that narrower waist are bound to alter the way clothes fit and hang.(Related: What To Wear When Your Workouts Start Working)In order to prevent these fluctuations from messing up your fit, treat your tailor like your doctor and go back every six months for a measurements check-up or use a flexible tape measure at home to make sure you don’t size up widely different to what you already have written down.Store Size GuidesEvery time you see something you like, locate the store’s size guide and compare with your crib sheet. It would make sense if every retailer and brand followed the same measurements for small, medium and large, but unfortunately the game doesn’t work like that.Use your Goldilocks guide to find out whether that T-shirt is going to come up tent-like, hot washed or just right.Several high-end stores like Mr Porter hand-measure every item and provide extra detail like back length for jackets, while others will give guidance on whether to buy a size up or down from your usual in the product description.Make Sure It Looks As Good On YouA denim jacket on a rail looks like, well, a jacket. Stick it on a slim, six-foot model and team it with the perfect pair of tailored trousers and a cashmere roll neck, and it becomes art. If you don’t have the same physique or wardrobe, then don’t expect to emulate that masterpiece at home.It doesn’t help that stylists have a weapon that you can’t realistically deploy: the bulldog clip. Using this handy device, excess fabric is pulled back and clipped tight, giving a sleeker silhouette – it’s how models you see in magazines can step into clothes that aren’t tailored and make them look like they’re bespoke.(Related: 10 Style Hacks From The UK’s Best Stylists)The lesson here is that you can’t always trust model shots or lookbooks. Treat them as guides to styling rather than fit. If you have a similar jacket and shoes to the guy in the picture, then you know that pair of houndstooth trousers will work with at least one look.On the other hand, if you’re tempted by a pair of leather trousers and your wardrobe is more button-downs and blazers than the mesh tops and longline shirts sported in the picture, then it’s probably best to pass.Top Tip: If the retailer offers a video of the item being worn, always view it – you will get a much better idea of how the garment fits, drapes and moves, as well as a truer indication of colour.Where To BuyWith space not an issue, online retailers don’t have to be as focused in their product ranges as brick and mortar stores. That’s not to say they don’t specialise or have stronger offerings in certain areas, though.Most also provide free returns and a flat postage fee, no matter how much you order. So if you can’t afford for your purchase not to be perfect and have no time to re-order another, an easy way around this is to stock up your basket with three sizes of each item: the one you think is right, then one up and one down.By bracketing in this way, you increase your chances of finding the perfect fit and can return the ones that don’t work. Just take care when un-boxing and trying on – removing certain tags or tearing packaging can void your right to return.Without wanting to sound too much like Martin Lewis, it’s important you brush up on your rights as a consumer, specifically when it comes to purchasing online.Store: End ClothingBest For: SneakerheadsWhat Is It?: Men have been beating a path to this Newcastle independent since 2005, and more recently its newly opened Glasgow flagship since late 2016. However, it’s End Clothing’s online offering that has made it a destination for sneakerheads from all over the globe.Alongside an achingly cool edit of clothing and accessories, End offers exclusive trainer styles and unique collaborations with the likes of Nike, Adidas, Reebok and New Balance.Price: Mid-rangeWeb: www.endclothing.comStore: Mr PorterBest For: Capsule collections and luxury brandsWhat Is It?: Net-a-Porter’s Y-chromosomed offshoot is big on tailoring (it has been selling its in house line, Kingsman, since 2015) but as we’ve warned you, that’s a risky game.Still, Mr Porter’s range of collaborations is unrivalled, with designers from Ami’s Alexandre Mattiussi to Paul Smith and even Thom Browne crafting one-off capsule collections you can’t buy anywhere else.Price: LuxuryWeb: www.mrporter.comStore: ASOSBest For: Basics and wardrobe staplesWhat Is It?: With over 850 brands onsite, and an Amazon-rivalling fulfilment centre staffed by thousands of employees, finding clothes on ASOS can be a touch intimidating.But it’s a sign of how influential the retailer has become that an entire subculture of young men wearing longline tops, ripped skinny jeans and snapbacks can be traced to its model shots.Avoid joining them by picking up classic wardrobe staples like white T-shirts, Oxford shirts and underwear, rather than whole looks – even if it is tempting when you can get an entire outfit for less than £50.Price: Affordable, with a smattering of designer brandsWeb: www.asos.comStore: HypebeastBest For: StreetwearWhat Is It?: Hypebeast has been keeping the streetwear savvy in the know with upcoming drops for several years now. However, not many realise the site also has its own online store, which boasts an almost unrivalled line-up of mainstream and underground labels.So while others cue round the blocks to get their hands on the latest must-cops, the smart shopper camps out in front of his computer. Though try to avoid anything labelled ‘marketplace’, which is basically code for astronomical mark-up.Price: Luxury, with some more affordable finds mixed inWeb: hbx.comStore: FarfetchBest For: One-offsWhat Is It?: Farfetch isn’t so much a store as a concierge. As the name hints, rather than stocking and dispatching clothes themselves, they tap up an array of international independent boutiques so that, sat at home in Bognor, you can shop the best that Milan, New York and even Tokyo have to offer.Prices are understandably high, but you’ve got a good chance of stumbling across something truly one of a kind – perfect for individualising your looks.Price: LuxuryWeb: www.farfetch.comStore: Vestiaire CollectiveBest For: Second-hand findsWhat Is It: If a hefty price tag puts you off buying designer pieces, it might be time to acquaint yourself with designer re-sale site Vestiaire Collective. The eBay of the luxury world has made it easier than ever to get your hands on that piece that eluded you (and your bank balance) last season.This is no car boot sale, mind. Expect more than 600,000 items, each of which has been manually checked for quality and authenticity, from the likes of Comme des Garçons, Acne Studios and Saint Laurent.Price: VariesWeb: http://ift.tt/16TtK4fStore: YooxBest For: Bargain huntingWhat Is It?: Navigating Yoox is like stepping into the warehouse at the end of Raiders of the Lost Ark.A nightmare to navigate and rammed with brands you’ve never heard of, and some you will never want to hear of again, you’ll be just about to give up when you spot a Moncler parka at 80 per cent off. Which almost makes all the legwork worth it.Price: Every budgetWeb: www.yoox.com
http://www.fashionbeans.com/2017/complete-guide-buying-clothes-online/
1 note
·
View note
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
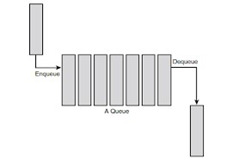
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
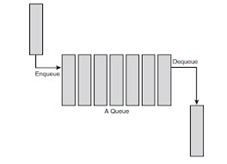
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes
Text
CSCI203/CSCI803 ASSIGNMENT 2 Solved
You have been hired by a major supermarket chain to model the operation of a proposed supermarket by using a Discrete Event Simulation. The shop has several servers (or checkouts), each of which has a different level of efficiency due to the experience of the server operator. It also takes longer to serve credit card customers. The service time of each customer is calculated as follows: service_time = (tally_time x efficiency) + payment_time where: tally_time: time it takes to tally up the customer's goods efficiency: the efficiency of the server payment_time: 0.3 for cash or 0.7 for credit card The input file “ass2.txt” contains the records of each customer entering the shop and consist of: arrival time (at the server queue), tally time (time it takes to scan the customer's items and add up the cost) payment method (cash or card). Your program should: Open the text file “ass2.txt” (Note: “ass2.txt” should be a hardcoded as a constant.) 2. Read the efficiencies of each server. Read and process the customer arrival and service time data. Print service statistics on the screen. Note: This shop has a single queue of customers waiting to be served. The servers are initially all idle. If more than one idle server is available, the next customer is served by the server with the best efficiency (i.e. the smallest efficiency value). Customers must be served or queued in the order in which they arrive. You should not attempt to read in all the arrival data at the start of the simulation. At the end of the simulation, after the last customer in the file has been served, your program should print out the following information: The number of customers served. The time that it took to serve all the customers. The greatest length reached by the customer queue. The average length of the customer queue. The average time spent by a customer in the customer queue. (If a customer is served immediately, their queue time is 0.0). The percentage of customers who’s waiting time in the customer queue was 0 (zero). For each server: The number of customers they served The time they spent idle. You must choose appropriate data structures and algorithms to accomplish this task quickly. You will lose marks if you use STL, or equivalent libraries, to implement data structures or algorithms. Note: A larger input data file may be used for the final assessment of your program.
Step-1 (Week-7 demo, 2 marks)
For step 1 you are to implement the simulator’s customer queue and event queue. Implement the customer queue (FIFO queue). It should have a maximum size of 500 records. Each record in the customer queue should contain two doubles and a boolean (i.e. arrival time, tally time and payment method). Your customer queue should have functions for adding an item (enqueue), removing an item (dequeue), and for testing if the queue is empty. (Note: C++ and Java coders should also add a constructor for initialsing the queue.) FIFO Queue
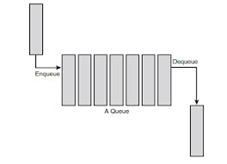
Test your customer queue by declaring an instance of it in the main(). Use a for loop to add 10 records to the queue. Set the arrival time for each record between 1 and 100 using rand() or random(). The other fields can be set to 0 or false. Also, print the arrival times on the screen as you add them. Now use a while loop to remove all the records from the customer queue and print the arrival times on the screen. Is the output correct? Now implement the simulator's event queue (i.e. a priority queue). The event queue’s records should contain an event type (int or enum), event time & tally time (doubles), and payment method (boolean). You can assume the maximum number of events in the event queue is 100. The record with the minimum event time has the highest priority.

Test the event queue by declaring an instance of it in the main(). Use the while loop (implemented previously) to remove records from the customer queue and add them to the event queue. Set the event time with the customer's arrival time. Set the other fields to zero. Then implement a while loop in the main() to remove (dequeue) each record from the event queue and print the event time on the screen. Is the output correct? Note: For step-1 (to get the 2 demo marks) you can implement the customer and event queues using any method you like. However, for the final submission, to get full marks, you should ensure all data structures and algorithms are optimised for speed.
Step-2 (Server array implementation)
The server array should have a maximum of 20 servers. Each server should have a busy flag (boolean), an efficiency factor (double) and other data members for calculating the stats. C++ and Java coders should implement the server array with a class, preferably, and provide public functions for adding, and removing customers to/from the servers, finding the fasted idle server, etc. according to the specs on page 1.
Step-3 (Processing in the data)
When you have the customer queue, event queue and server array correctly completed, delete the main() test code from step 1 and replace it with code for reading the input data file “ass2.txt” and processing the data, as explained on page 1. The following algorithm shows how a typical discrete time simulator can be implemented: main() Declare variables and instances and do initialisations Open the input data file; if not found print error and exit Read first CustomerArrival event from file and add it to the event queue While the event queue is not empty . . . Get the next event from the event queue and set CrntTime to the event time If the event type = CustomerArrival event . . . if an idle server is available . . . Find fastest idle serve set the server’s idle flag to busy calculate the server’s finish time from event's customer data add ServerFinish event to the event queue Else Add event's customer to the customer queue End if If not EOF . . . Read next customer arrival from file add CustomerArrival event to the event queue End if Else // event type must be a ServerFinish event . . . Get server no. from event, set server to idle and do server's stats If customer queue is not empty . . . Get next customer from the customer queue Find fastest idle serve set the server’s idle flag to busy. calculate the server’s finish time add ServerFinish event to the event queue End if End if End while Print stats End main()
Step-4 (Optimisation and stats)
When you have the discrete time simulation working correctly, add the necessary data members and variables needed for calculating all the required stats, as explained on page 1, and optimise your simulator for speed.
Step-5 (Specifications)
In a comment block at the bottom of your program (no more than 20 lines of text) list all the data structures and algorithms used by your program to process the input data. Include any enhancements you did to speed up your program (if any). For this step, marks will be awarded based on how accurately and clearly you describe your program.
Compilation
All programs submitted must compile and run on banshee:
C: gcc ass2.c C++: g++ ass2.cpp Java: javac ass2.java Python: python ass2.py
Programs which do not compile on banshee with the above commands will receive zero marks. It is your responsibility to ensure that your program compiles and runs correctly.
Marking Guide
Marks will be awarded for the appropriate use of data structures and the efficiency of the program at processing the input and producing the correct output. Marks may be deducted for untidy or poorly designed code. Appropriate comments should be provided where needed. There will be a deduction of up to 4 marks for using STL, or equivalent libraries, rather than coding the data structures and algorithms yourself. You may use string or String type for storing words or text, if you wish. All coding and comments must be your own work. Submission: Assignments should be typed into a single text file named "ass2.ext" where "ext" is the appropriate file extension for the chosen language. You should run your program and copy and paste the output into a text file named: "output.txt" Submit your files via the submit program on banshee: submit -u user -c csci203 -a 2 ass1.ext output.txt - where user is your unix userid and ext is the extn of your code file. Late assignment submissions without granted extension will be marked but the points awarded will be reduced by 1 mark for each day late. Assignments will not be accepted if more than five days late. An extension of time for the assignment submission may be granted in certain circumstances. Any request for an extension of the submission deadline must be made via SOLS before the submission deadline. Supporting documentation should accompany the request for any extension. Read the full article
0 notes