#etl testing training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text

#Our ETL testing training program in Hyderabad covers comprehensive topics such as ETL testing#certification#data testing#specialized courses
0 notes
Text
Essential Predictive Analytics Techniques
With the growing usage of big data analytics, predictive analytics uses a broad and highly diverse array of approaches to assist enterprises in forecasting outcomes. Examples of predictive analytics include deep learning, neural networks, machine learning, text analysis, and artificial intelligence.
Predictive analytics trends of today reflect existing Big Data trends. There needs to be more distinction between the software tools utilized in predictive analytics and big data analytics solutions. In summary, big data and predictive analytics technologies are closely linked, if not identical.
Predictive analytics approaches are used to evaluate a person's creditworthiness, rework marketing strategies, predict the contents of text documents, forecast weather, and create safe self-driving cars with varying degrees of success.
Predictive Analytics- Meaning
By evaluating collected data, predictive analytics is the discipline of forecasting future trends. Organizations can modify their marketing and operational strategies to serve better by gaining knowledge of historical trends. In addition to the functional enhancements, businesses benefit in crucial areas like inventory control and fraud detection.
Machine learning and predictive analytics are closely related. Regardless of the precise method, a company may use, the overall procedure starts with an algorithm that learns through access to a known result (such as a customer purchase).
The training algorithms use the data to learn how to forecast outcomes, eventually creating a model that is ready for use and can take additional input variables, like the day and the weather.
Employing predictive analytics significantly increases an organization's productivity, profitability, and flexibility. Let us look at the techniques used in predictive analytics.
Techniques of Predictive Analytics
Making predictions based on existing and past data patterns requires using several statistical approaches, data mining, modeling, machine learning, and artificial intelligence. Machine learning techniques, including classification models, regression models, and neural networks, are used to make these predictions.
Data Mining
To find anomalies, trends, and correlations in massive datasets, data mining is a technique that combines statistics with machine learning. Businesses can use this method to transform raw data into business intelligence, including current data insights and forecasts that help decision-making.
Data mining is sifting through redundant, noisy, unstructured data to find patterns that reveal insightful information. A form of data mining methodology called exploratory data analysis (EDA) includes examining datasets to identify and summarize their fundamental properties, frequently using visual techniques.
EDA focuses on objectively probing the facts without any expectations; it does not entail hypothesis testing or the deliberate search for a solution. On the other hand, traditional data mining focuses on extracting insights from the data or addressing a specific business problem.
Data Warehousing
Most extensive data mining projects start with data warehousing. An example of a data management system is a data warehouse created to facilitate and assist business intelligence initiatives. This is accomplished by centralizing and combining several data sources, including transactional data from POS (point of sale) systems and application log files.
A data warehouse typically includes a relational database for storing and retrieving data, an ETL (Extract, Transfer, Load) pipeline for preparing the data for analysis, statistical analysis tools, and client analysis tools for presenting the data to clients.
Clustering
One of the most often used data mining techniques is clustering, which divides a massive dataset into smaller subsets by categorizing objects based on their similarity into groups.
When consumers are grouped together based on shared purchasing patterns or lifetime value, customer segments are created, allowing the company to scale up targeted marketing campaigns.
Hard clustering entails the categorization of data points directly. Instead of assigning a data point to a cluster, soft clustering gives it a likelihood that it belongs in one or more clusters.
Classification
A prediction approach called classification involves estimating the likelihood that a given item falls into a particular category. A multiclass classification problem has more than two classes, unlike a binary classification problem, which only has two types.
Classification models produce a serial number, usually called confidence, that reflects the likelihood that an observation belongs to a specific class. The class with the highest probability can represent a predicted probability as a class label.
Spam filters, which categorize incoming emails as "spam" or "not spam" based on predetermined criteria, and fraud detection algorithms, which highlight suspicious transactions, are the most prevalent examples of categorization in a business use case.
Regression Model
When a company needs to forecast a numerical number, such as how long a potential customer will wait to cancel an airline reservation or how much money they will spend on auto payments over time, they can use a regression method.
For instance, linear regression is a popular regression technique that searches for a correlation between two variables. Regression algorithms of this type look for patterns that foretell correlations between variables, such as the association between consumer spending and the amount of time spent browsing an online store.
Neural Networks
Neural networks are data processing methods with biological influences that use historical and present data to forecast future values. They can uncover intricate relationships buried in the data because of their design, which mimics the brain's mechanisms for pattern recognition.
They have several layers that take input (input layer), calculate predictions (hidden layer), and provide output (output layer) in the form of a single prediction. They are frequently used for applications like image recognition and patient diagnostics.
Decision Trees
A decision tree is a graphic diagram that looks like an upside-down tree. Starting at the "roots," one walks through a continuously narrowing range of alternatives, each illustrating a possible decision conclusion. Decision trees may handle various categorization issues, but they can resolve many more complicated issues when used with predictive analytics.
An airline, for instance, would be interested in learning the optimal time to travel to a new location it intends to serve weekly. Along with knowing what pricing to charge for such a flight, it might also want to know which client groups to cater to. The airline can utilize a decision tree to acquire insight into the effects of selling tickets to destination x at price point y while focusing on audience z, given these criteria.
Logistics Regression
It is used when determining the likelihood of success in terms of Yes or No, Success or Failure. We can utilize this model when the dependent variable has a binary (Yes/No) nature.
Since it uses a non-linear log to predict the odds ratio, it may handle multiple relationships without requiring a linear link between the variables, unlike a linear model. Large sample sizes are also necessary to predict future results.
Ordinal logistic regression is used when the dependent variable's value is ordinal, and multinomial logistic regression is used when the dependent variable's value is multiclass.
Time Series Model
Based on past data, time series are used to forecast the future behavior of variables. Typically, a stochastic process called Y(t), which denotes a series of random variables, are used to model these models.
A time series might have the frequency of annual (annual budgets), quarterly (sales), monthly (expenses), or daily (daily expenses) (Stock Prices). It is referred to as univariate time series forecasting if you utilize the time series' past values to predict future discounts. It is also referred to as multivariate time series forecasting if you include exogenous variables.
The most popular time series model that can be created in Python is called ARIMA, or Auto Regressive Integrated Moving Average, to anticipate future results. It's a forecasting technique based on the straightforward notion that data from time series' initial values provides valuable information.
In Conclusion-
Although predictive analytics techniques have had their fair share of critiques, including the claim that computers or algorithms cannot foretell the future, predictive analytics is now extensively employed in virtually every industry. As we gather more and more data, we can anticipate future outcomes with a certain level of accuracy. This makes it possible for institutions and enterprises to make wise judgments.
Implementing Predictive Analytics is essential for anybody searching for company growth with data analytics services since it has several use cases in every conceivable industry. Contact us at SG Analytics if you want to take full advantage of predictive analytics for your business growth.
2 notes
·
View notes
Text
iceDQ Training: Learn ETL Testing and Data Governance
Manual testing won’t cut it in today’s high-volume data environments. The Introduction to iceDQ v1.0 course introduces you to a smarter way to manage quality across your entire data stack.
What’s inside the course:
🧠 Deep dive into the logic of rule creation
🔄 Understand execution and test cycles
📊 Learn to audit BI dashboards and warehouse data
🛠️ Discover scalable data QA strategies
Ideal for:
QA professionals tired of writing SQL scripts for validation
Analysts needing reliable reporting
Developers building ETL pipelines
Businesses requiring continuous data monitoring
Top skills you’ll gain:
Automated data validation
Data observability implementation
Data governance fundamentals
📚 Let automation handle your data quality. Start the Introduction to iceDQ v1.0 Course today and streamline your testing.

#iceDQ#DataQuality#ETLTesting#DataValidation#DataGovernance#DataMonitoring#DataObservability#AutomatedTesting#DataAnalytics#BItesting#DataEngineer#DataAnalyst#DataTesting
0 notes
Text
A Technical Guide to Test Mock Data: Levels, Tools, and Best Practices

Mock data is the backbone of modern software development and testing. It allows developers to simulate real-world scenarios without relying on production data, ensuring security, efficiency, and reliability. Whether you’re testing APIs, building UIs, or stress-testing databases, mock data helps you isolate components, accelerate development, and catch bugs early.
In this blog, we’ll cover: - Why mock data matters (with real-world examples from Tesla, Netflix, and more) - Different levels of mock data (from foo/bar to synthetic AI-generated datasets) - Best tools for generating mock data (Mockaroo, Faker, JSONPlaceholder) - Code samples in Python & JavaScript (executable examples) - Common pitfalls & how to avoid them
Why Mock Data is Essential for Developers
Real-World Example: Tesla’s Self-Driving AI
Tesla trains its autonomous driving algorithms with massive amounts of labelled mock data. Instead of waiting for real-world accidents, Tesla simulates edge cases (e.g., pedestrians suddenly crossing) using synthetic data. This helps improve safety without risking lives
Key Benefits for Developers
No Dependency on Live APIs – Frontend devs can build UIs before the backend is ready.
Data Privacy Compliance – Avoid GDPR/HIPAA violations by never using real PII.
Faster Debugging – Reproduce bugs with controlled datasets.
Performance Testing – Simulate 10,000 users hitting your API without crashing prod.
Levels of Mock Data (From Simple to Production-Grade)
Level 1: Static Mock Data (foo/bar Placeholders)
Use Case: Quick unit tests.# Python Example: Hardcoded user data user = { "id": 1, "name": "Test User", "email": "[email protected]" }
✅ Pros: Simple, fast. ❌ Cons: Not scalable, lacks realism.
Best Practices & Tips
Keep it minimal. Only mock the fields your unit under test actually needs.
Group your fixtures. Store them in a /tests/fixtures/ folder for re-use across test suites.
Version-pin schema. If you change your real schema, bump a “fixture version” so stale mocks break fast.
Level 2: Dynamic Mock Data (Faker.js, Mockaroo)
Use Case: Integration tests, demo environments.// JavaScript Example: Faker.js for realistic fake data import { faker } from '@faker-js/faker'; const mockUser = { id: faker.string.uuid(), name: faker.person.fullName(), email: faker.internet.email() }; console.log(mockUser);
Tools & Techniques
Faker libraries:
JavaScript: @faker-js/faker
Python: Faker
Ruby: faker
Mock servers:
Mockaroo for CSV/JSON exports
JSON Server for spinning up a fake REST API
Seeding:
Always pass a fixed seed in CI (e.g. faker.seed(1234)) so CI failures are reproducible.
Level 3: Sanitized Production Data
Use Case: Performance testing, security audits.-- SQL Example: Anonymized production data SELECT user_id, CONCAT('user_', id, '@example.com') AS email, -- Masked PII '***' AS password_hash FROM production_users;
✅ Pros: Realistic, maintains referential integrity. ❌ Cons: Requires strict governance to avoid leaks.
Governance & Workflow
Anonymization pipeline: Use tools like Aircloak Insights or write ETL-scripts to strip or hash PII.
Subset sampling: Don’t pull the entire production table—sample 1–5% uniformly or by stratified key to preserve distributions without bloat.
Audit logs:Track which team member pulled which snapshot and when; enforce retention policies.
Best Tools for Generating Mock Data
1. Mockaroo (Web-Based, Customizable Datasets)
Supports CSV, JSON, SQL exports.
REST API mocking (simulate backend responses).
# Python Example: Generate 100 fake users via Mockaroo API import requests API_KEY = "YOUR_API_KEY" response = requests.get(f"https://api.mockaroo.com/api/users?count=100&key={API_KEY}") users = response.json()
📌 Use Case: Load testing, prototyping 56.
2. Faker.js (Programmatic Fake Data)
// JavaScript Example: Generate fake medical records import { faker } from '@faker-js/faker'; const patient = { id: faker.string.uuid(), diagnosis: faker.helpers.arrayElement(['COVID-19', 'Diabetes', 'Hypertension']), lastVisit: faker.date.past() };
📌 Use Case: Frontend dev, demo data 210.
3. JSONPlaceholder (Free Fake REST API)
# Example: Fetch mock posts curl https://jsonplaceholder.typicode.com/posts/1
📌 Use Case: API testing, tutorials 910.
Advanced Mocking: Stateful APIs & AI-Generated Data
Example: Netflix’s Recommendation System
Netflix uses synthetic user behavior data to test recommendation algorithms before deploying them. This avoids spoiling real user experiences with untested models.
Mocking a Stateful API (Python + Flask)
from flask import Flask, jsonify app = Flask(__name__) users_db = [] @app.route('/users', methods=['POST']) def add_user(): new_user = {"id": len(users_db) + 1, "name": "Mock User"} users_db.append(new_user) return jsonify(new_user), 201 @app.route('/users', methods=['GET']) def get_users(): return jsonify(users_db)
📌 Use Case: Full-stack testing without a backend.
Common Pitfalls & How to Avoid Them
Pitfall
Solution
Mock data is too simplistic
Use tools like Faker for realism.
Hardcoded data breaks tests
Use builders (e.g., PersonBuilder pattern) 2.
Ignoring edge cases
Generate outliers (e.g. age: -1, empty arrays).
Mock != Real API behavior
Contract testing (Pact, Swagger).
Conclusion
Mock data is not just a testing tool—it’s a development accelerator. By leveraging tools like Mockaroo, Faker, and JSONPlaceholder, developers can: - Build much faster (no backend dependencies). - Stay compliant (avoid PII risks). - Find Bugs sooner (simulate edge cases).
FAQ
What is mock data?Mock data is synthetic or anonymized data used in place of real production data for testing, development, and prototyping. It helps developers: ✅ Test APIs without hitting live servers. ✅ Build UIs before the backend is ready. ✅ Avoid exposing sensitive information (PII).
When should I use mock data?
Unit/Integration Testing → Simple static mocks (foo/bar).
UI Development → Dynamic fake data (Faker.js).
Performance Testing → Large-scale synthetic datasets (Mockaroo).
Security Testing → Sanitized production data (masked PII).
What’s the difference between mock data and real data?Mock DataReal DataGenerated artificiallyComes from actual usersSafe for testing (no PII)May contain sensitive infoCan simulate edge casesLimited to real-world scenarios
0 notes
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes
Text

Test Your Guidewire Knowledge! Are you ready to challenge yourself and grow in the world of insurance tech? Take part in our quick quiz and see how much you really know about Guidewire tools!
📌 Question: Which tool in Guidewire helps with ETL and reporting? A) Guidewire Edge B) DataHub C) Guidewire Live D) Portal
💬 Drop your answers in the comments and tag a friend to take the quiz too! This is a great way to engage, learn, and connect with fellow Guidewire learners.
🚀 Want to become a Guidewire Expert? Join the industry-focused training at Guidewire Masters and elevate your career!
📞 Contact: +91 9885118899 🌐 Website: www.guidewiremasters.in
#Guidewire#GuidewireMasters#GuidewireTraining#InsuranceTech#InsurTech#DataHub#ETLTools#PolicyCenter#BillingCenter#ClaimCenter#TechQuiz#QuizTime#CareerInTech#LearnGuidewire#GuidewireExperts
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
Best Informatica Cloud | Informatica Training in Ameerpet
How Does Dynamic Mapping Work in CDI?
Informatica Cloud Data Integration (CDI) provides robust ETL and ELT capabilities, enabling enterprises to manage and transform their data efficiently. One of its most powerful features is Dynamic Mapping, which allows organizations to create reusable and flexible data integration solutions without modifying mappings manually for each change in source or target structures.

What is Dynamic Mapping?
Dynamic Mapping in CDI is a feature that allows mappings to automatically adjust to changes in source and target schemas. Instead of hardcoding column names and data types, users can define mappings that dynamically adapt, making data pipelines more scalable and resilient to structural changes. Informatica IDMC Training
Key Benefits of Dynamic Mapping
Flexibility – Easily accommodate changes in source or target structures without redesigning mappings.
Reusability – Use the same mapping logic across multiple datasets without creating separate mappings.
Reduced Maintenance Effort – Eliminates the need for frequent manual updates when schemas evolve.
Improved Efficiency – Reduces development time and enhances agility in managing data integration workflows.
How Dynamic Mapping Works in CDI
Dynamic Mapping operates using several key components that allow it to function efficiently: Informatica Cloud Training
1. Dynamic Schema Handling
In CDI, you can configure mappings to fetch metadata dynamically from the source system. This means that when a new column is added, modified, or removed, the mapping can recognize the changes and adjust accordingly.
2. Dynamic Ports
Dynamic ports allow you to handle varying schemas without specifying each field manually. You can use parameterized field rules to determine which fields should be included, excluded, or renamed dynamically.
3. Parameterized Transformations
Transformations like Aggregator, Filter, and Expression can be parameterized, meaning they can adapt dynamically based on incoming metadata. This ensures that business rules applied to the data remain relevant, even when structures change.
4. Use of Parameter Files
Dynamic mappings often leverage parameter files, which store variable values such as connection details, field rules, and transformation logic. These files can be updated externally without modifying the core mapping, ensuring greater adaptability.
5. Dynamic Target Mapping
When working with dynamic targets, CDI allows mappings to adjust based on target metadata. This is particularly useful for handling data lakes, data warehouses, and cloud storage, where new tables or columns might be added frequently.
Steps to Implement Dynamic Mapping in CDI
To configure a Dynamic Mapping in CDI, follow these steps: Informatica IDMC Training
Create a Mapping – Define a new mapping in Informatica CDI.
Enable Dynamic Schema Handling – Select the option to read metadata dynamically from the source.
Use Dynamic Ports – Configure the mapping to recognize new or changing columns automatically.
Parameterize Transformations – Define business rules that adapt dynamically to the dataset.
Leverage Parameter Files – Store mapping configurations externally to avoid hardcoding values.
Deploy and Test – Execute the mapping to verify that it dynamically adjusts to changes.
Use Cases for Dynamic Mapping in CDI: Informatica Cloud IDMC Training
Multi-Source Data Integration – Load data from different databases, cloud storage, or APIs with varying schemas.
Data Warehousing and ETL Automation – Streamline ETL pipelines by accommodating schema evolution.
Schema Drift Management – Handle changes in incoming data structures without breaking existing workflows.
Metadata-Driven Data Pipelines – Automate data processing in environments with frequently changing datasets.
Conclusion
Dynamic Mapping in Informatica CDI is a game-changer for organizations dealing with evolving data structures. By enabling mappings to adapt automatically, it enhances flexibility, reduces maintenance effort, and streamlines data integration processes. Businesses leveraging this capability can significantly improve efficiency, ensuring that their data pipelines remain robust and scalable in dynamic environments.
For More Information about Informatica Cloud Online Training
Contact Call/WhatsApp: +91 7032290546
Visit: https://www.visualpath.in/informatica-cloud-training-in-hyderabad.html
#Informatica Training in Hyderabad#IICS Training in Hyderabad#IICS Online Training#Informatica Cloud Training#Informatica Cloud Online Training#Informatica IICS Training#Informatica IDMC Training#Informatica Training in Ameerpet#Informatica Online Training in Hyderabad#Informatica Training in Bangalore#Informatica Training in Chennai#Informatica Training in India#Informatica Cloud IDMC Training
0 notes
Text
Implementing the Tableau to Power BI Migration: A Strategic Approach for Transition
migrating from Tableau to Power BI offers organizations an opportunity to unlock new levels of analytics performance, cost-efficiency, and integration within the Microsoft ecosystem. However, transitioning from one BI tool to another is a complex process that requires careful planning and execution. In this guide, we explore the essential steps and strategies for a successful Tableau to Power BI migration, ensuring smooth data model conversion, optimized performance, robust security implementation, and seamless user adoption. Whether you're looking to modernize your analytics environment or improve cost management, understanding the key components of this migration is crucial to achieving long-term success.
Understanding the Tableau to Power BI migration Landscape
When planning a Tableau to Power BI migration , organizations must first understand the fundamental differences between these platforms. The process requires careful consideration of various factors, including data architecture redesign and cross-platform analytics transition. A successful Tableau to Power BI migration starts with a thorough assessment of your current environment.
Strategic Planning and Assessment
The foundation of any successful Tableau to Power BI migration lies in comprehensive planning. Organizations must conduct a thorough migration assessment framework to understand their current Tableau implementation. This involves analyzing existing reports, dashboards, and data sources while documenting specific requirements for the transition.
Technical Implementation Framework
Data Architecture and Integration
The core of Tableau to Power BI migration involves data model conversion and proper database connection transfer. Organizations must implement effective data warehouse integration strategies while ensuring proper data gateway configuration. A successful Tableau to Power BI migration requires careful attention to ETL process migration and schema migration planning.
Development and Conversion Process
During the Tableau to Power BI migration, special attention must be paid to DAX formula conversion and LOD expression transformation. The process includes careful handling of calculated field migration and implementation of proper parameter configuration transfer. Organizations should establish a robust development environment setup to ensure smooth transitions.
Performance Optimization Strategy
A critical aspect of Tableau to Power BI migration involves implementing effective performance tuning methods. This includes establishing proper query performance optimization techniques and memory usage optimization strategies. Organizations must focus on resource allocation planning and workload distribution to maintain optimal performance.
Security Implementation
Security remains paramount during Tableau to Power BI migration. Organizations must ensure proper security model transfer and implement robust access control implementation. The process includes setting up row-level security migration and establishing comprehensive data protection protocols.
User Management and Training
Successful Tableau to Power BI migration requires careful attention to user access migration and license transfer process. Organizations must implement effective group policy implementation strategies while ensuring proper user mapping strategy execution. This includes developing comprehensive user training materials and establishing clear knowledge transfer plans.
Testing and Quality Assurance
Implementing thorough migration testing protocols ensures successful outcomes. Organizations must establish comprehensive validation framework setup procedures and implement proper quality assurance methods. This includes conducting thorough user acceptance testing and implementing effective dashboard testing strategy procedures.
Maintenance and Support Planning
Post-migration success requires implementing effective post-migration monitoring systems and establishing proper system health checks. Organizations must focus on performance analytics and implement comprehensive usage monitoring setup procedures to ensure continued success.
Ensuring Long-term Success and ROI
A successful Tableau to Power BI migration requires ongoing attention to maintenance and optimization. Organizations must establish proper maintenance scheduling procedures and implement effective backup procedures while ensuring comprehensive recovery planning.
Partner with DataTerrain for Migration Excellence
At DataTerrain, we understand the complexities of Tableau to Power BI migration. Our team of certified professionals brings extensive experience in managing complex migrations, ensuring seamless transitions while maintaining business continuity. We offer:
Comprehensive Migration Services: Our expert team handles every aspect of your migration journey, from initial assessment to post-migration support.
Technical Excellence: With deep expertise in both Tableau and Power BI, we ensure optimal implementation of all technical components.
Proven Methodology: Our structured approach, refined through numerous successful migrations, ensures predictable outcomes and minimal disruption.
Transform your business intelligence capabilities with DataTerrain's expert Tableau to Power BI migration services. Contact us today for a free consultation and discover how we can guide your organization through a successful migration journey.
1 note
·
View note
Text
Preparing Data for Training in Machine Learning
Preparing data is a crucial step in building a machine learning model. Poorly processed data can lead to inaccurate predictions and inefficient models.
Below are the key steps involved in preparing data for training.
Understanding and Collecting Data Before processing, ensure that the data is relevant, diverse, and representative of the problem you’re solving.
✅ Sources — Data can come from databases, APIs, files (CSV, JSON), or real-time streams.
✅ Data Types — Structured (tables, spreadsheets) or unstructured (text, images, videos).
✅ Labeling — For supervised learning, ensure data is properly labeled.
2. Data Cleaning and Preprocessing
Raw data often contains errors, missing values, and inconsistencies that must be addressed. Key Steps:
✔ Handling Missing Values — Fill with mean/median (numerical) or mode (categorical), or drop incomplete rows.
✔ Removing Duplicates — Avoid bias by eliminating redundant records.
✔ Handling Outliers — Use statistical methods (Z-score, IQR) to detect and remove extreme values.
✔ Data Type Conversion — Ensure consistency in numerical, categorical, and date formats.
3. Feature Engineering Transforming raw data into meaningful features improves model performance.
Techniques:
📌 Normalization & Standardization — Scale numerical features to bring them to the same range.
📌 One-Hot Encoding — Convert categorical variables into numerical form.
📌 Feature Selection — Remove irrelevant or redundant features using correlation analysis or feature importance.
📌 Feature Extraction — Create new features (e.g., extracting time-based trends from timestamps). 4. Splitting Data into Training, Validation, and Testing Sets To evaluate model performance effectively, divide data into: Training Set (70–80%) — Used for training the model.
Validation Set (10–15%) — Helps tune hyperparameters and prevent overfitting. Test Set (10–15%) — Evaluates model performance on unseen data.
📌 Stratified Sampling — Ensures balanced distribution of classes in classification tasks.
5. Data Augmentation (For Image/Text Data)
If dealing with images or text, artificial expansion of the dataset can improve model generalization.
✔ Image Augmentation — Rotate, flip, zoom, adjust brightness.
✔ Text Augmentation — Synonym replacement, back-translation, text shuffling.
6. Data Pipeline Automation For large datasets,
use ETL (Extract, Transform, Load) pipelines or tools like Apache Airflow, AWS Glue, or Pandas to automate data preparation.
WEBSITE: https://www.ficusoft.in/deep-learning-training-in-chennai/
0 notes
Text

#Visualpath offers the Best Online DBT Courses, designed to help you excel in data transformation and analytics. Our expert-led #DBT Online Training covers tools like Matillion, Snowflake, ETL, Informatica, Data Warehousing, SQL, Talend, Power BI, Cloudera, Databricks, Oracle, SAP, and Amazon Redshift. With flexible schedules, recorded sessions, and hands-on projects, we provide a seamless learning experience for global learners. Master advanced data engineering skills, prepare for DBT certification, and elevate your career. Call +91-9989971070 for a free demo and enroll today!
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
Visit: https://www.visualpath.in/online-data-build-tool-training.html
#visualpathedu #testing #automation #selenium #git #github #JavaScript #Azure #CICD #AzureDevOps #playwright #handonlearning #education #SoftwareDevelopment #onlinelearning #newtechnology #software #education #ITskills #training #trendingcourses #careers #students #typescript
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
SAP implementation projects are complex and can face various challenges. Here’s an overview of the main challenges and potential ways to address them:
1. Inadequate Planning and Scope Definition
Challenge: Lack of a clear plan or improper scope definition can lead to delays, cost overruns, or incomplete implementations.
Solution:Conduct thorough requirement gathering and analysis.Use a phased implementation approach.Clearly define project scope, timelines, and deliverables in the project charter.
2. Resistance to Change
Challenge: Employees may resist adopting the new system due to unfamiliarity, fear of job displacement, or comfort with legacy systems.
Solution:Develop a robust change management strategy.Involve key stakeholders early in the process.Provide training sessions and ongoing support to build confidence.
3. Data Migration Issues
Challenge: Migrating data from legacy systems to SAP can be complex, leading to data integrity and compatibility issues.
Solution:Perform a comprehensive data audit before migration.Use SAP’s data migration tools like SAP Data Services or third-party ETL tools.Test data migration extensively in a sandbox environment.
4. Customization vs. Standardization
Challenge: Excessive customization to fit legacy processes can lead to higher costs and maintenance complexity.
Solution:Assess whether the business can adapt its processes to SAP’s standard functionalities.Use customization sparingly and only when it adds significant value.
5. Inadequate Training
Challenge: Users may find the system challenging to use without proper training, leading to poor adoption.
Solution:Offer role-based training tailored to different user groups.Create detailed user manuals and provide hands-on workshops.Leverage SAP Learning Hub and other online resources.
6. Integration Challenges
Challenge: Ensuring seamless integration with other systems (e.g., third-party applications, existing ERP modules) can be difficult.
Solution:Use middleware tools like SAP PI/PO or SAP Integration Suite.Engage technical experts to address complex integration requirements.Conduct regular integration testing.
7. Project Budget and Timeline Overruns
Challenge: Misestimating costs and timelines can derail the project.
Solution:Break the project into manageable phases using methodologies like SAP Activate.Regularly monitor the budget and progress using KPIs and dashboards.Allocate contingency funds for unforeseen issues.
8. Lack of Skilled Resources
Challenge: Insufficient availability of SAP-skilled professionals can slow down implementation.
Solution:Partner with experienced SAP implementation partners.Upskill internal teams with relevant SAP certifications.Hire contract consultants for specialized roles.
9. System Performance Issues
Challenge: Poor performance due to inadequate infrastructure can affect user satisfaction.
Solution:Conduct infrastructure readiness assessments before implementation.Ensure hardware and network setups align with SAP’s requirements.Regularly monitor and optimize system performance.
10. Regulatory and Compliance Challenges
Challenge: Non-compliance with legal or industry-specific regulations can result in fines or operational disruptions.
Solution:Leverage SAP’s compliance modules (e.g., SAP GRC).Regularly consult legal and compliance experts during the project.Keep the system updated to meet evolving regulatory requirements.
By addressing these challenges proactively with detailed planning, stakeholder engagement, and leveraging SAP best practices, organizations can significantly improve the likelihood of a successful SAP implementation.
Mail us on [email protected]
Website: Anubhav Online Trainings | UI5, Fiori, S/4HANA Trainings
youtube
0 notes
Text
Azure Databricks: Unleashing the Power of Big Data and AI
Introduction to Azure Databricks
In a world where data is considered the new oil, managing and analyzing vast amounts of information is critical. Enter Azure Databricks, a unified analytics platform designed to simplify big data and artificial intelligence (AI) workflows. Developed in partnership between Microsoft and Databricks, this tool is transforming how businesses leverage data to make smarter decisions.
Azure Databricks combines the power of Apache Spark with Azure’s robust ecosystem, making it an essential resource for businesses aiming to harness the potential of data and AI.
Core Features of Azure Databricks
Unified Analytics Platform
Azure Databricks brings together data engineering, data science, and business analytics in one environment. It supports end-to-end workflows, from data ingestion to model deployment.
Support for Multiple Languages
Whether you’re proficient in Python, SQL, Scala, R, or Java, Azure Databricks has you covered. Its flexibility makes it a preferred choice for diverse teams.
Seamless Integration with Azure Services
Azure Databricks integrates effortlessly with Azure’s suite of services, including Azure Data Lake, Azure Synapse Analytics, and Power BI, streamlining data pipelines and analysis.

How Azure Databricks Works
Architecture Overview
At its core, Azure Databricks leverages Apache Spark’s distributed computing capabilities. This ensures high-speed data processing and scalability.
Collaboration in a Shared Workspace
Teams can collaborate in real-time using shared notebooks, fostering a culture of innovation and efficiency.
Automated Cluster Management
Azure Databricks simplifies cluster creation and management, allowing users to focus on analytics rather than infrastructure.
Advantages of Using Azure Databricks
Scalability and Flexibility
Azure Databricks automatically scales resources based on workload requirements, ensuring optimal performance.
Cost Efficiency
Pay-as-you-go pricing and resource optimization help businesses save on operational costs.
Enterprise-Grade Security
With features like role-based access control (RBAC) and integration with Azure Active Directory, Azure Databricks ensures data security and compliance.
Comparing Azure Databricks with Other Platforms
Azure Databricks vs. Apache Spark
While Apache Spark is the foundation, Azure Databricks enhances it with a user-friendly interface, better integration, and managed services.
Azure Databricks vs. AWS Glue
Azure Databricks offers superior performance and scalability for machine learning workloads compared to AWS Glue, which is primarily an ETL service.
Key Use Cases for Azure Databricks
Data Engineering and ETL Processes
Azure Databricks simplifies Extract, Transform, Load (ETL) processes, enabling businesses to cleanse and prepare data efficiently.
Machine Learning Model Development
Data scientists can use Azure Databricks to train, test, and deploy machine learning models with ease.
Real-Time Analytics
From monitoring social media trends to analyzing IoT data, Azure Databricks supports real-time analytics for actionable insights.
Industries Benefiting from Azure Databricks
Healthcare
By enabling predictive analytics, Azure Databricks helps healthcare providers improve patient outcomes and optimize operations.
Retail and E-Commerce
Retailers leverage Azure Databricks for demand forecasting, customer segmentation, and personalized marketing.
Financial Services
Banks and financial institutions use Azure Databricks for fraud detection, risk assessment, and portfolio optimization.

Getting Started with Azure Databricks
Setting Up an Azure Databricks Workspace
Begin by creating an Azure Databricks workspace through the Azure portal. This serves as the foundation for your analytics projects.
Creating Clusters
Clusters are the computational backbone. Azure Databricks makes it easy to create and configure clusters tailored to your workload.
Writing and Executing Notebooks
Use notebooks to write, debug, and execute your code. Azure Databricks’ notebook interface is intuitive and collaborative.
Best Practices for Using Azure Databricks
Optimizing Cluster Performance
Select the appropriate cluster size and configurations to balance cost and performance.
Managing Data Storage Effectively
Integrate with Azure Data Lake for efficient and scalable data storage solutions.
Ensuring Data Security and Compliance Implement RBAC, encrypt data at rest, and adhere to industry-specific compliance standards.
Challenges and Solutions in Using Azure Databricks
Managing Costs
Monitor resource usage and terminate idle clusters to avoid unnecessary expenses.
Handling Large Datasets Efficiently
Leverage partitioning and caching to process large datasets effectively.
Debugging and Error Resolution
Azure Databricks provides detailed logs and error reports, simplifying the debugging process.
Future Trends in Azure Databricks
Enhanced AI Capabilities
Expect more advanced AI tools and features to be integrated, empowering businesses to solve complex problems.
Increased Automation
Automation will play a bigger role in streamlining workflows, from data ingestion to model deployment.
Real-Life Success Stories
Case Study: How a Retail Giant Scaled with Azure Databricks
A leading retailer improved inventory management and personalized customer experiences by utilizing Azure Databricks for real-time analytics.
Case Study: Healthcare Advancements with Predictive Analytics
A healthcare provider reduced readmission rates and enhanced patient care through predictive modeling in Azure Databricks.
Learning Resources and Support
Official Microsoft Documentation
Access in-depth guides and tutorials on the Microsoft Azure Databricks documentation.
Online Courses and Certifications
Platforms like Coursera, Udemy, and LinkedIn Learning offer courses to enhance your skills.
Community Forums and Events
Join the Databricks and Azure communities to share knowledge and learn from experts.
Conclusion
Azure Databricks is revolutionizing the way organizations handle big data and AI. Its robust features, seamless integrations, and cost efficiency make it a top choice for businesses of all sizes. Whether you’re looking to improve decision-making, streamline processes, or innovate with AI, Azure Databricks has the tools to help you succeed.
FAQs
1. What is the difference between Azure Databricks and Azure Synapse Analytics?
Azure Databricks focuses on big data analytics and AI, while Azure Synapse Analytics is geared toward data warehousing and business intelligence.
2. Can Azure Databricks handle real-time data processing?
Yes, Azure Databricks supports real-time data processing through its integration with streaming tools like Azure Event Hubs.
3. What skills are needed to work with Azure Databricks?
Knowledge of data engineering, programming languages like Python or Scala, and familiarity with Azure services is beneficial.
4. How secure is Azure Databricks for sensitive data?
Azure Databricks offers enterprise-grade security, including encryption, RBAC, and compliance with standards like GDPR and HIPAA.
5. What is the pricing model for Azure Databricks?
Azure Databricks uses a pay-as-you-go model, with costs based on the compute and storage resources used.
0 notes
Text
Streamlining Data Integration with SAP CDC
Efficient data integration is a cornerstone of modern business success. SAP Change Data Capture (CDC) ensures real-time synchronization and data accuracy across platforms, improving decision-making and operational efficiency.
What is SAP CDC?
SAP CDC is a mechanism to track changes—like inserts, updates, and deletes—in SAP and non-SAP systems. These changes are captured and made available to downstream applications, ensuring data consistency.
Advantages of SAP CDC
Real-Time Data Sync: Keeps all systems updated instantly.
Improved ETL Processes: Reduces latency and improves pipeline efficiency.
Lower Overhead: Operates with minimal impact on system performance.
Enhanced Reporting: Provides up-to-date data for analytics tools.
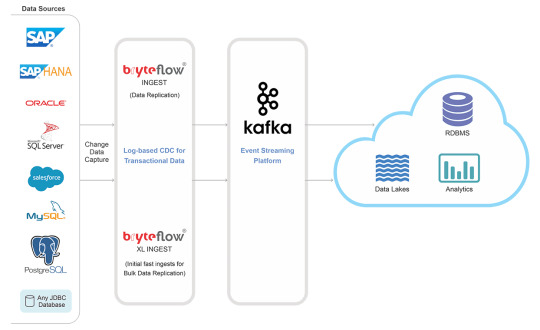
How SAP CDC Works
Log-Based Capture: Monitors changes via database logs.
Event Streaming: Sends change events to target systems in real time.
ETL Integration: Integrates seamlessly with data pipelines for further processing.
Applications of SAP CDC
Data Replication: Keep multiple databases synchronized.
Data Lakes and Warehousing: Feed real-time data into analytical environments.
Cloud Migration: Smoothly transfer data from legacy systems to modern platforms.
Advanced Use Cases
SAP CDC is especially valuable for companies operating across multiple regions. By ensuring data consistency and real-time availability, businesses can support global operations more effectively. SAP CDC also plays a vital role in machine learning workflows, providing up-to-date training data for AI models.
Getting Started with SAP CDC
Begin by identifying the source systems and changes you want to capture. Set up the integration using SAP tools or connectors, then test the pipeline to ensure accuracy. Focus on configuring alerts for failures to ensure continuous operations.
SAP CDC transforms how businesses manage data, providing a foundation for agile, data-driven operations. It’s the perfect solution for organizations seeking to stay ahead in today’s fast-paced digital landscape. Its real-time capabilities and flexibility make it indispensable for modern enterprises.
0 notes
Text
Azure Data Engineering Training in Hyderabad
Master Data Engineering with RS Trainings – The Best Data Engineering Training in Hyderabad
In today’s data-driven world, Data Engineering plays a crucial role in transforming raw data into actionable insights. As organizations increasingly rely on data for decision-making, the demand for skilled data engineers is at an all-time high. If you are looking to break into this exciting field or elevate your existing data skills, RS Trainings offers the best Data Engineering training in Hyderabad, providing you with the knowledge and practical experience needed to excel.

What is Data Engineering?
Data Engineering is the process of designing, building, and maintaining the infrastructure that enables data generation, collection, storage, and analysis. It involves the creation of pipelines that transfer and transform data for use in analytics, reporting, and machine learning applications. Data engineers are responsible for building scalable systems that support big data analytics and help businesses gain meaningful insights from massive data sets.
Why Choose Data Engineering?
Data Engineers are highly sought after due to their ability to bridge the gap between data science and operations. With companies across industries relying on data to drive strategies, the demand for data engineers continues to grow. Learning data engineering will equip you with the skills to design robust data architectures, optimize data processes, and handle vast amounts of data in real time.
Why RS Trainings is the Best for Data Engineering Training in Hyderabad
RS Trainings stands out as the best place to learn Data Engineering in Hyderabad for several reasons. Here’s what makes it the top choice for aspiring data engineers:
1. Industry-Experienced Trainers
At RS Trainings, you will learn from industry experts who have hands-on experience in top-tier organizations. These trainers bring real-world insights into the classroom, offering practical examples and cutting-edge techniques that are directly applicable to today’s data engineering challenges.
2. Comprehensive Curriculum
RS Trainings offers a comprehensive Data Engineering curriculum that covers all aspects of the field, including:
Data Pipeline Design: Learn how to build, test, and optimize efficient data pipelines.
Big Data Technologies: Gain proficiency in tools such as Apache Hadoop, Spark, Kafka, and more.
Cloud Platforms: Master cloud-based data engineering with AWS, Azure, and Google Cloud.
Data Warehousing and ETL: Understand how to manage large-scale data warehouses and build ETL processes.
Data Modeling: Learn the principles of designing scalable and efficient data models for complex data needs.
Real-Time Data Processing: Get hands-on with real-time data processing frameworks like Apache Flink and Spark Streaming.
3. Hands-On Training with Real-Time Projects
RS Trainings focuses on providing practical experience, ensuring that students work on real-time projects during their training. You will build and manage real-world data pipelines, giving you a deeper understanding of the challenges data engineers face and how to overcome them.
4. Flexible Learning Options
Whether you are a working professional or a recent graduate, RS Trainings provides flexible learning schedules, including weekend batches, online classes, and fast-track programs, to accommodate everyone’s needs.
5. Certification and Placement Assistance
On completing your Data Engineering course, RS Trainings offers a globally recognized certification. This certification will help you stand out in the job market. In addition, RS Trainings provides placement assistance, connecting you with top companies seeking data engineering talent.
Who Should Join Data Engineering Training at RS Trainings?
Aspiring Data Engineers: Anyone looking to start a career in Data Engineering.
Software Engineers/Developers: Professionals looking to transition into the data engineering domain.
Data Analysts/Scientists: Analysts or data scientists who want to enhance their data pipeline and big data skills.
IT Professionals: Anyone in the IT field who wants to gain expertise in handling data at scale.
Why Hyderabad?
Hyderabad is quickly becoming one of India’s top IT hubs, housing some of the world’s largest tech companies and a thriving data engineering community. Learning Data Engineering at RS Trainings in Hyderabad positions you perfectly to tap into this booming job market.
Conclusion
As data continues to grow in importance for organizations worldwide, skilled data engineers are in high demand. If you are looking for the best Data Engineering training in Hyderabad, RS Trainings is the ideal place to start your journey. With its industry-experienced trainers, practical approach to learning, and comprehensive curriculum, RS Trainings will equip you with the tools you need to succeed in the field of Data Engineering.
Enroll today and take the first step toward a rewarding career in data engineering!
RS Trainings: Empowering you with real-world data engineering skills.
#azure data engineering training in hyderabad#azure data engineer course online#azure data engineer training with placement#azure data engineering online training#azure online training#azure data online training#data engineering online training#best azure training in hyderabad#best tableau training in hyderabad
0 notes
Text
Top ETL Testing Course with Placement – Start Your Data Testing Career Today!
ETL (Extract, Transform, Load) testing is a critical process in data warehousing and business intelligence. With businesses relying on data-driven decisions, the demand for skilled ETL testers has skyrocketed. At Trendnologies Institute, we offer ETL Testing Certification Training designed to help students and professionals build a strong foundation in data validation, data transformation, and automation testing.

ETL Testing Certification – Unlock Your Career in Data Engineering
Why Choose Our ETL Testing Course?
✔ Comprehensive Curriculum – Covers SQL, Data Warehousing, ETL Tools (Informatica, Talend), Automation Testing, and more ✔ 100% Placement Assistance – Get placed in top IT companies after course completion ✔ Industry-Expert Trainers – Learn from professionals with real-world experience in ETL testing & data engineering ✔ Hands-on Projects & Case Studies – Work on real-time projects to gain practical experience ✔ Flexible Learning Options – Online & Offline classes available in Chennai, Coimbatore & Bangalore
What You Will Learn in ETL Testing Certification?
🔹 ETL Process – Learn how data is extracted, transformed, and loaded into databases 🔹 SQL & Database Testing – Understand queries, data validation, and performance testing 🔹 ETL Testing Tools – Hands-on training on Informatica, Talend, SSIS, and more 🔹 Data Warehouse Concepts – Understand OLAP, OLTP, Data Marts, and Data Lakes 🔹 Automation Testing in ETL – Learn how to automate ETL test cases using Selenium & Python
Who Can Join This Course?
✅ Freshers & IT Graduates looking for a career in software testing & data analytics ✅ Manual Testers & QA Engineers who want to upgrade to ETL testing ✅ Data Analysts & Developers looking to expand their skills in data validation & transformation ✅ Working Professionals who want to switch to a high-paying ETL testing role
Enroll Now & Start Your Journey in ETL Testing!
At Trendnologies, we ensure that our students get the best training & career support to help them succeed in the data engineering & software testing industry. Join our ETL Testing Certification Course today and get ready to land a high-paying job in top MNCs.
📞 Contact Us Today:
🌍 Website: www.trendnologies.com
📍 Locations: Chennai | Coimbatore | Bangalore
📧 Email ID : [email protected]
0 notes