#flatmap vs map
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Kotlin: 100 Simple Codes

Kotlin: 100 Simple Codes
beginner-friendly collection of easy-to-understand Kotlin examples.

Each code snippet is designed to help you learn programming concepts step by step, from basic syntax to simple projects. Perfect for students, self-learners, and anyone who wants to practice Kotlin in a fun and practical way.
Codes:
1. Hello World
2. Variables and Constants
3. If-Else Statement
4. When Statement (Switch)
5. For Loop
6. While Loop
7. Functions
8. Return Value from Function
9. Array Example
10. List Example
===
11. Mutable List
12. Map Example
13. Mutable Map
14. Class Example
15. Constructor with Default Value
16. Nullable Variable
17. Safe Call Operator
18. Elvis Operator
19. Data Class
20. Loop with Index
===
21. Lambda Function
22. Higher-Order Function
23. Filter a List
24. Map a List
25. String Interpolation
26. String Templates with Expressions
27. Read-Only vs Mutable List
28. Check Element in List
29. Exception Handling
30. Null Check with let
===
31. For Loop with Step
32. For Loop in Reverse
33. Break in Loop
34. Continue in Loop
35. Check String Empty or Not
36. Compare Two Numbers
37. Array Access by Index
38. Loop Through Map
39. Default Parameters in Function
40. Named Arguments
===
41. Range Check
42. Function Returning Unit
43. Multiple Return Statements
44. Chained Method Calls
45. Function Inside Function
46. Function Expression Syntax
47. Array Size
48. String to Int Conversion
49. Safe String to Int Conversion
50. Repeat Block
===
51. Sealed Class
52. Object Expression (Anonymous Object)
53. Singleton using Object Keyword
54. Extension Function
55. Enum Class
56. Use Enum in When Statement
57. Type Alias
58. Destructuring Declarations
59. Companion Object
60. Simple Interface Implementation
===
61. Abstract Class
62. Lateinit Variable
63. Initialization Block
64. Secondary Constructor
65. Nested Class
66. Inner Class
67. Generic Function
68. Generic Class
69. Custom Getter
70. Custom Setter
===
71. String Equality
72. Loop with Range Until
73. Using Pair
74. Triple Example
75. Check Type with is
76. Smart Cast
77. Type Casting with as
78. Safe Casting with as?
79. Loop Through Characters of String
80. Sum of List
===
81. Min and Max of List
82. Sort List
83. Reverse List
84. Count Items in List
85. All / Any Conditions
86. Check if List is Empty
87. Join List to String
88. Take and Drop
89. Zipping Lists
90. Unzipping Pairs
===
91. Chunked List
92. Windowed List
93. Flatten List
94. FlatMap
95. Remove Duplicates
96. Group By
97. Associate By
98. Measure Execution Time
99. Repeat with Index
100. Create Range and Convert to List
===
0 notes
Text
FlatMap In Angular
FlatMap In Angular
This Article is about FlatMap In Angular. Let’s say we wanted to implement an AJAX search feature in which every keypress in a text field will automatically perform a search and update the page with the results. How would this look? Well we would have an Observablesubscribed to events coming from an input field, and on every change of input we want to perform some HTTP…
View On WordPress
#best jquery plugins 2019#best jquery plugins with code examples#FlatMap#flatmap example#FlatMap In Angular#flatmap java#flatmap javascript#flatmap scala#flatmap vs map#free jquery plugins 2019
0 notes
Text
Week 301
Happy Thursday! Swift 5.1 is officially released, which brings module stability, and we already know details about the Swift 5.2 Release Process, which is “meant to include significant quality and performance enhancements”. I’m so looking forward to that :).
Marius Constantinescu
Articles
Flux pattern in Swift, by @theillbo
Redux-like state container in SwiftUI. Part 2, by @mecid
iOS 13, by @mattt
Transforming Operators in Swift Combine Framework: Map vs FlatMap vs SwitchToLatest, by @V8tr
Supporting Low Data Mode In Your App, by @donnywals
Swift 5.1 Property Wrappers, by @adamwaite
Advanced SwiftUI Transitions, by @SwiftUILab
Business/Career
Dark Side of the App Store by @fassko
Subscribers Are Your True Fans, by @drbarnard
UI/UX
Designing for iOS 13, by Belen Vazquez
Videos
Redux with CombineFeedback and SwiftUI Part 1 and Part 2, by @peres
Credits
Daniele Bogo, mecid, kean, peres, fassko, adamwaite, Donny Wals
1 note
·
View note
Text
Useful JavaScript things (or awful corner cases) that I’ve seen people not know
Enumerability and ownership of properties (the spread operator isn’t listed here, but only handles enumerable owned properties)
Prototypal inheritance
Labeled break/continue (useful for nested for/while loops)
IIFEs (mostly outdated now)
Array#flatMap() (which both map() and filter() can be implemented in terms of - I didn’t know this was a thing until last week)
Hoisting and block vs. function scope (grepping `var` in a sufficiently modern codebase will give you a list of neat scope tricks)
Private and protected members (outdated, but an example of a neat scope trick)
Automatic semicolon insertion ambiguity (more common in TypeScript - e.g. `let a = foo[1] \n (b as any)._enfuckerate(a)`)
0 notes
Text
Spark map() vs flatMap() with Examples
Spark map() vs flatMap() with Examples
What is the difference between Spark map() vs flatMap() is a most asked interview question, if you are taking an interview on Spark (Java/Scala/PySpark), so let’s understand the differences with examples? Regardless of an interview, you have to know the differences as this is also one of the most used Spark transformations. map() – Spark map() transformation applies a function to each row in a…
View On WordPress
0 notes
Text
3 набора данных в Spark SQL для аналитики Big Data: что такое dataframe, dataset и RDD

Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-инструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и ��ереляционными хранилищами информации. Начнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и чем они отличаются друг от друга.
Что такое Spark SQL и как он работает
Прежде всего, напомним, что Spark SQL – это модуль Apache Spark для работы со структурированными данными. На практике такая задача возникает при работе с реляционными базами данных, где хранится нужная информация, например, если требуется избирательное изучение пользовательского поведения на основании серверных логов. Однако, в случае множества СУБД и файловых хранилищ необходимо работать с каждой схемой данных в отдельности, что потребует множества ресурсов [1]. Spark SQL позволяет реализовать декларативные запросы посредством универсального доступа к данным, предоставляя общий способ доступа к различным источникам данных: Apache Hive, AVRO, Parquet, ORC, JSON и JDBC/ODBC. При этом можно смешивать данные, полученные из разных источников, организуя таким образом бесшовную интеграцию между Big Data системами. Работать с разными схемами (форматами данных), таблицами и записями, позволяет SchemaRDD в качестве временной таблицы [2]. Для такого взаимодействия с внешними источниками данных Spark SQL использует не функциональную структуру данных RDD (Resilient Distributed Dataset, надежную распределенную коллекцию типа таблицы), а SQL или Dataset API. Отметим, способ реализации (API или язык программирования) не влияет на внутренний механизм выполнения вычислений. Поэтому разработчик может выбрать интерфейс, наиболее подходящий для преобразования выражений в каждом конкретном случае [2]. DataFrame используется при реляционных преобразованиях, а также для создания временного представления, которое позволяет применять к данным SQL-запросы. При запуске SQL-запроса из другого языка программирования результаты будут возвращены в виде Dataset/DataFrame. По сути, интерфейс DataFrame предоставляет предметно-ориентированный язык для работы со структурированными данными, хранящимися в файлах Parquet, JSON, AVRO, ORC, а также в СУБД Cassandra, Apache Hive и пр. [2]. Например, чтобы отобразить на экране содержимое JSON-файла с данными в виде датафрейма, понадобится несколько строк на языке Java [2]: import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; Dataset df = spark.read().json("resources/people.json"); df.show();// Displays the content of the DataFrame to stdout
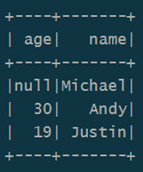
Пример датафрейма Spark SQL Следующий набор Java-инструкций показывает пару типичных SQL-операций над данными: инкрементирование численных значений, выбор по условию и подсчет строк [2]: import static org.apache.spark.sql.functions.col; // col("...") is preferable to df.col("...") df.select(col("name"), col("age").plus(1)).show();// Select everybody, but increment the age by 1 df.filter(col("age").gt(21)).show();// Select people older than 21 df.groupBy("age").count().show();// Count people by age

Примеры SQL-операций над датафреймом в Spark
Что такое dataframe, dataset и RDD в Apache Spark
Поясним разницу между понятиями датасет (dataset), датафрейм (dataframe) и RDD. Все они представляют собой структуры данных для доступа к определенному информационному набору и операций с ним. Тем не менее, представление данных в этих абстракциях отличается друг от друга: · RDD – это распределенная коллекция данных, размещенных на узлах кластера, набор объектов Java или Scala, представляющих данные [3]. · DataFrame – это распределенная коллекция данных, организованная в именованные стол��цы. Концептуально он соответствует таблице в реляционной базе данных с улучшенной оптимизаций для распределенных вычислений [3]. DataFrame доступен в языках программирования Scala, Java, Python и R. В Scala API и Java API DataFrame представлен как Dataset[Row] и Dataset соответственно [2]. · DataSet – это расширение API DataFrame, добавленный в Spark 1.6. Он обеспечивает функциональность объектно-ориентированного RDD-API (строгая типизация, лямбда-функции), производительность оптимизатора запросов Catalyst и механизм хранения вне кучи API DataFrame [3]. Dataset может быть построен из JVM-объектов и изменен с помощью функциональных преобразований (map, flatMap, filter и т. д.). Dataset API доступен в Scala и Java. Dataset API не поддерживается R и Python в версии Spark 2.1.1, но, благодаря динамическому характеру этих языков программирования, в них доступны многие возможности Dataset API. В частности, обращение к полю в строке по имени [2].
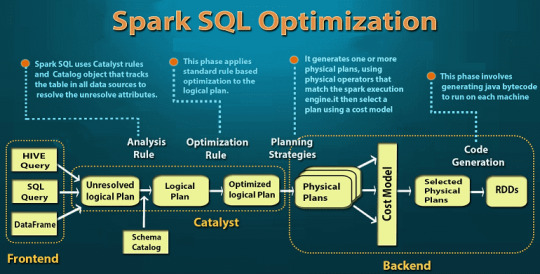
Как связаны dataset, dataframe и RDD в Apache Spark: SQL-оптимизация Более подробно о сходствах и различиях этих понятий (RDD, Dataset, DataFrame) мы расскажем в следующей статье, сравнив их по основным критериям (форматы данных, емкость памяти, оптимизация и т.д.). А все тонкости прикладной работы с ними вы узнаете на нашем практическом курсе SPARK2: Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://habr.com/ru/company/wrike/blog/275567/ 2. https://ru.bmstu.wiki/Spark_SQL 3. https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/ Read the full article
0 notes
Text
RxAndroid Learnings.
RxAndroid is a library that handles any asynchronous data streams.
What r async data streams:
click event
push notifications
keyboard input
reading a file
database access
device sensor updates
They happen at anytime and outside of normal flow of program execution.
Benefits of Rx:
Chaining
Abstraction
Threading
Non-blocking
Composable
avoid callbacks
data transformation
Function map does data transformation.
Example of Observable with data transformation:
Observable.just( 5, 6, 7 ) .map { “;-) “.repeat(it) } .subscribe { println(it) }
Result:
;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-) ;-)
Example of Observable with chaining:
Observable.just( 5, 6, 7 ) .map { “;-) “.repeat(it) } .filter { it.length < 24 } .subscribe { println(it) }
Result:
;-) ;-) ;-) ;-) ;-)
E.g. kotlin collections
Example:
listOf ( 5, 6, 7 ) .map { it * 5 } .filter { it > 25 }
Process:
5 6 7 map into
25 30 35
filter into
30 35
Disadvantage:
extra overhead
blocking async manner
LAZY - will not create intermediate list with same result.
listOf ( 5, 6, 7 ) .asSequence() .map { it * 5 } .filter { it > 25 } .toList()
RxJava vs Kotlin
in Rx is ok to not have any data initially. Rx is also lazy
Rx has flexible threading model. Can choose thread to do the work on by using Schedulers.
3 Basic of Rx (3o’s)
Observer
Observables
Operators
Observable
U can think of this as producing a stream of events that you are interested in knowing bout.
Observable can be Hot or Cold manner Hot: Start doing work as soon as it gets created. It is not waiting for anyone else before getting “busy”. Example: Click events
Cold: They dont work until someone shows interest. It doesnt work when it gets observable. Example: Reading a file - dont needa do work until someone wants to read a file
Observable.create<Int> { subscriber -> }
Observable.just( item1, item2, item3 )
Observable.interval( 2, TimeUnit.SECODNS )
@Test fun testCreate_withNoSubscriber() {
val observable = Observable.create<Int> { subscriber ->
Logger.log(”create”) subscriber.onNext(4) subscriber.onNext(5) subscriber.onNext(6)
Logger.log(”complete”)
}
Logger.log(”done”) }
================= main: done ================= it only prints “done”
@Test fun testCreate_withSubscriber() {
val observable = Observable.create<Int> { subscriber ->
Logger.log(”create”) subscriber.onNext(4) subscriber.onNext(5) subscriber.onNext(6)
Logger.log(”complete”)
} observable.subscribe { Logger.log( “next: $it” ) }
Logger.log(”done”) }
================= main: create main: next: 4 main: next: 5 main: next: 6 main: complete main: done ================= it only prints “done”
Observer
Observer is the abstraction that Rx java uses for listening to or observing the various items or events that the observable is producing.
interface Observer <T> {
fun onError( e: Throwable )
fun Complete()
fun onNext( t: T )
fun onSubscribe( d: Disposable )
}

Sometimes observer dont rly care bout other things.
interface Consumer <T> { fun accept( t: T ) }
accept method is like the onNext method
Observers: have a lifecycle. Subscribe, Next, Error, Complete
Operator
Operators are what help you to transform and combine / create observable
map()


Observable.just( 5, 6, 7) .map { “ ;-) ”.repeat( it ) } .subscribe { println( it ) }
function map expanded:

flatmap ()
flatmap transform an item into an Observable of different item for long running async task
e.g.

Flowable, Singles, Maybe, BackPressure, Completable, Disposable???
Should you use Rx?
do you like Function programming?
Process items asynchronously?
Compose data?
Handle errors gracefully?
If yes to most of this qns > it depends Rx java can be too complex to handle things u need.
src: https://www.youtube.com/watch?v=YPf6AYDaYf8 useful links: www.adavis.info
0 notes
Link
In our previous blog – Future vs. CompletableFuture – #1, we compared Java 5’s Future with Java 8’s CompletableFuture on the basis of two categories i.e. manual completion and attaching a callable method. Now, we will be comparing them on the basis of next 3 categories i.e.
Combining 2 CompletableFutures together
Combining multiple CompletableFutures together
Exception Handling
Let’s have a look at each one of them.
3. Combining 2 CompletableFutures together
In case of Future, there is no way to create asynchronous workflow i.e. long running computation. But CompletableFuture provides us with 2 methods to achieve this functionality:
i) thenCompose()
It is a method of combining 2 dependent futures together. This method takes a function that returns a CompletableFuture instance. The argument of this function is the result of the previous computation step. This allows us to use this value inside the next CompletableFuture‘s lambda.
For example:
Let’s compare this with the supplier method, thenApply() :
As you can see, the thenCompose() method is returning a value of type CompletableFuture whereas thenApply() is returning the value of type CompletableFuture in the same scenario.
Note: The thenCompose method together with thenApply implement basic building blocks of the monadic pattern. They closely relate to the map and flatMap methods of Stream and Optional classes also available in Java 8.
ii) thenCombine()
It is a method of combining 2 independent futures together and do something with there result after both of them are complete. Combining is accomplished by taking 2 successful CompletionStages and having the results from both used as parameters to a BiFunction to produce another result. For example:
iii) thenAcceptBoth()
It is used when you want to perform some operation with two independent Future’s result but don’t need to pass any resulting value down a Future chain. For example:
4. Combining multiple CompletableFutures together
What if there comes a scenario where you want to combine 100 different Futures that you want to run in parallel and then run some function after all of them completes. Future does not provide us any way in order to achieve this functionality but CompletableFuture does. There are two methods of implementing this:
i) CompletableFuture.allOf()
CompletableFuture.allOf() static method is used in scenarios when you have a List of independent futures that you want to run in parallel and do something after all of them are complete.
Limitation:
The limitation of this method is that the return type is CompletableFuture i.e. it does not return the combined results of all Futures. Instead you have to manually get results from Futures.
Fortunately, CompletableFuture.join() method and Java 8 Streams API helps to resolve this issue:
Note :
The CompletableFuture.join() method is similar to the CompletableFuture.get() method, but it throws an unchecked exception in case the Future does not complete normally. This makes it possible to use it as a method reference in the Stream.map() method.
ii) CompletableFuture.anyOf()
CompletableFuture.anyOf() as the name suggests, returns a new CompletableFuture which is completed when any of the given CompletableFutures complete, with the same result. CompletableFuture.anyOf() takes a varargs of Futures and returns CompletableFuture.
Limitation:The problem with CompletableFuture.anyOf() is that if you have CompletableFuture that return results of different types, then you won’t know the type of your final CompletableFuture.
5. Exception Handling
Let’s first understand how errors are propagated in a callback chain. Consider the following CompletableFuture callback chain –
If an error occurs in the original supplyAsync() task, then none of the thenApply() callbacks will be called and future will be resolved with the exception occurred. If an error occurs in first thenApply() callback then 2nd and 3rd callbacks won’t be called and the future will be resolved with the exception occurred, and so on.
So, there are 2 ways in order to handle this scenario:
i) Handle exceptions using exceptionally() callback
exceptionally() gives us a chance to recover by returning a default value or taking an alternative function that will be executed if preceding calculation fails with an exception.
ii) Handle exceptions using the generic handle() method
The API also provides a more generic method – handle() to recover from exceptions. It is called whether or not an exception occurs. If an exception occurs, then the result argument will be null, otherwise, the ex argument will be null.
The link for the above demo code is : https://github.com/jasmine-k/completableFutureDemo
Here is the link for my previous blog.
References :
http://www.baeldung.com/java-completablefuture
https://www.callicoder.com/java-8-completablefuture-tutorial/
http://www.deadcoderising.com/java8-writing-asynchronous-code-with-completablefuture/
0 notes
Text
Transforming enterprise integration with reactive streams
Build a more scalable, composable, and functional architecture for interconnecting systems and applications.
Software today is not typically a single program—something that is executed by an operator or user, producing a result to that person—but rather a service: something that runs for the benefit of its consumers, a provider of value. So, software is a part of a greater whole, and typically multiple generations of technologies must coexist peacefully and purposefully to provide a viable service. In addition to that, software is increasingly dependent on other software to provide its functionality, be it WebServices, HTTP APIs, databases, or even external devices such as sensors.
Software must also consume data from many potential sources and destinations of information—apps, websites, APIs, files, databases, proprietary services, and so on—and because of this, there’s plenty of incentives to do that well. We refer to this aspect as "integration" of different sources and destinations of information. In this article, we will discuss the need for—and how to achieve—modernization in the field of enterprise integration. We will start by reviewing the current state of enterprise integration and its challenges, and then demonstrate how organizations can achieve more scalable, composable, and functional architecture for interconnecting systems and applications by adopting a reactive and stream-based mindset and tools.
Welcome to a new world of data-driven systems
Today, data needs to be available at all times, serving its users—both humans and computer systems—across all time zones, continuously, in close to real time. As traditional architectures, techniques, and tools prove unresponsive, not scalable, or unavailable, many companies are turning toward the principles of reactive systems and real-time streaming as a way to gain insight into massive amounts of data quickly in a predictable, scalable, and resilient fashion.
Although the ideas of reactive and streaming are nowhere near new, and keeping in mind that mere novelty doesn’t imply greatness, it is safe to say they have proven themselves and matured enough to see many programming languages, platforms, and infrastructure products embrace them fully. Working with never-ending streams of data necessitates continuous processing of it, ensuring the system keeps up with the load patterns it is exposed to, and always provides real-time, up-to-date information.
One of the key aspects—as trivial as it is profound—is that data is coming from somewhere, and ends up somewhere else. Let’s dive into this concept for a bit.
The most common programming task in the world
The most common programming task that a typical software developer has to deal with is: receiving input, transforming it, and producing output.
While that statement seems obvious, it has a few subtle but important implications.
First of all, when we, programmers, write a method or a function, we do not specify where the input parameters come from, or where the output return value goes to. Sadly, it is very common to write logic that deeply couples the notion of IO with the processing of that IO. This is mixing concerns and leads to code that becomes strongly coupled, monolithic, hard to write, hard to read, hard to evolve, hard to test, and hard to reuse.
Since integrating different pieces of software, different systems, different data sources and destinations, and different formats and encodings is becoming so prevalent, this quintessential work deserves better tools.
The past and present of enterprise integration
Service-oriented architecture (SOA) was hyped in the mid-2000s as a modern take on distributed systems architecture, which through modular design would provide productivity through loose coupling between collaborative services—so-called "WebServices"—communicating through externally published APIs.
The problem was that the fundamental ideas of SOA were most often misunderstood and misused, resulting in complicated systems where an enterprise service bus (ESB) was used to hook up multiple monoliths, communicating through complicated, inefficient, and inflexible protocols—across a single point of failure: the ESB.
Anne Thomas[1] captures this very well in her article "SOA is Dead; Long Live Services":
Although the word 'SOA' is dead, the requirement for service-oriented architecture is stronger than ever. But perhaps that’s the challenge: the acronym got in the way. People forgot what SOA stands for. They were too wrapped up in silly technology debates (e.g., 'what’s the best ESB?' or 'WS-* vs. REST'), and they missed the important stuff: architecture and services.
Successful SOA (i.e., application re-architecture) requires disruption to the status quo. SOA is not simply a matter of deploying new technology and building service interfaces to existing applications; it requires a redesign of the application portfolio. And it requires a massive shift in the way IT operates.
What eventually led to the demise of SOAs was that not only did it get too focused on implementation details, but it completely misunderstood the architecture aspect of itself. Some of the problems were:
The lack of mature testing tools made interoperability a nightmare, especially when services stopped adhering to their own self-published service contracts.
WebServices, unfortunately, failed to deliver on the distributed systems front by having virtually all implementations using synchronous/blocking calls—which we all know is a recipe for scaling disaster.
Schema evolution practices were rarely in place.
Service discovery was rarely—if ever—used, which led to hardcoded endpoint addresses, leading to brittle setups with almost guaranteed downtime on redeployments.
Scaling the ESBs was rarely attempted, leading to a single point of failure and a single point of bottleneck.
Furthermore, the deployment tooling was not ready for SOA. The provisioning of new machines was not done on-demand: physical servers would take a long time to get delivered and set up, and virtual servers were slow to start, and often ran on oversubscribed machines, with poor performance as a result (something that has improved drastically in the past years with the advent of technologies such as Docker, Kubernetes, and more). Orchestration tooling was also not ready for SOA, with manual deployment scripts being one of the most common ways of deploying new versions.
The rise of enterprise integration patterns
In 2003, Gregor Hohpe and Bobby Woolf released their book Enterprise Integration Patterns. Over the last 15 years, it has become a modern classic, providing a catalog with 65 different patterns of integration between components in systems, and has formed the basis for the pattern language and vocabulary that we now use when talking about system integration.
Over the years, these patterns have been implemented by numerous products, ranging from commercial ESBs and enterprise message buses to open source libraries and products.
Most well-known is probably Apache Camel. Created in 2007, and described as "a versatile open source integration framework based on known enterprise integration patterns," it is a very popular Java library for system integration, offering implementations of most (if not all) of the standard enterprise integration patterns (EIP). It has a large community around it that, over the years, has implemented connectors to most standard protocols and products in the Java industry. Many see it as the defacto standard for enterprise integration in Java.
Breaking the Camel’s back?
Unfortunately, most of Apache Camel’s connectors are implemented in a synchronous and/or blocking fashion, without first-class support for streaming—working with data that never ends—leading to inefficient use of resources and limited scalability due to high contention for shared resources. Its strategies for flow control are either stop-and-wait (i.e., blocking), discarding data, or none—which can lead to resilience problems, poor performance, or worse: rapid unscheduled disassembly in production. Also, fan-in/fan-out patterns tend to be either poorly supported—requiring emulation[2]; static—requiring knowing all inputs/outputs at creation[3]; or, lowest-common-denominator—limiting throughput to the slowest producer/consumer[4].
The need for reactive enterprise integration
There is clearly a need to improve over the status quo: what can be done differently, given what we’ve learned in the past decades as an industry, and given what tooling is now available to us? What if we could fully embrace the concept of streaming, and redesign system integration from a reactive—asynchronous, non-blocking, scalable, and resilient perspective? What would that look like?
Streaming as a first-class concept
First of all, we need to have streams as a first-class programming concept. A stream can be defined as a potentially unbounded (“infinite”) sequence of data. Since it is potentially unbounded, we can’t wait—buffer elements—until we have received all data before we act upon it, but need to do so in an incremental fashion—ideally without overwhelming ourselves, or overwhelming those who consume the data we produce or incur a too-high processing latency.
By first-class concept, we mean that we need to be able to reason about streams as values, manipulate streams, join streams, or split them apart. Ideally, we need to land on a set of different patterns for stream processing and integration, along the same lines as the classic EIP.
Functional programming lends itself very well to stream transformation, and it is no coincidence the industry has standardized on a simple set of functional combinators that any modern stream-based DSL needs to support. Examples of these include map, flatMap, filter, groupBy, and zip, and together they form a core part of our pattern language and vocabulary for stream processing.
What is interesting is that these functional combinators—let’s call them "shapes"—are so high level, generic, powerful, composable, and reusable that the need for relying on explicit APIs and abstractions for EIP vanish[5]. Instead, the necessary integration patterns can be composed on an as-needed basis using our reusable shapes for stream processing.
From one perspective, stream processing is all about integration: ingest data from different sources and try to mine knowledge from it in real time before pushing it out to interested parties. But each implementation is doing it differently, which makes interoperability hard.
What we are lacking is a standardized way to integrate stream processing products, databases, traditional standardized protocols, and legacy enterprise products.
The need for flow control
One of the key realizations one develops when integrating components of unequal capacities is that flow control is not optional, but mandatory.
Flow control is essential for the system to stay responsive, ensuring that the sender does not send data downstream faster than the receiver is able to process. Failing to do so can, among other things, result in running out of resources, taking down the whole node, or filling up buffers, stalling the system as a whole. Therefore, flow control, especially through backpressure (see Figure 1), is essential in order to achieve resilience in a stream/integration pipeline.
Figure 1. Illustrates the flow of data and backpressure in a stream topology.
Also, during an inability to send or receive data, processing resources must be handed back and made available to other parts of the system, allowing the system to scale to many concurrent integration pipelines.
Reactive streams: A call to arms
To address the problem of flow control, an initiative called reactive streams was created in late 2013 to “provide a standard for asynchronous stream processing with non-blocking backpressure.”
Reactive streams is a set of four Java interfaces (publisher, subscriber, subscription, and processor), a specification for their interactions, and a technology compatibility kit (TCK) to aid and verify implementations.
The reactive streams specification has many implementations and was recently adopted into JDK 9 as the Flow API. Crucially, it provides the assurance that connecting publishers, processors, and subscribers—no matter who implemented them—will provide the flow control needed. When it comes to flow control, all components in the processing pipeline need to participate.
Toward reusable shapes for integration
We need to be able to reason about transformational shapes (see Figure 2)—how data is processed (separately from the sources and sinks), where data comes from and ends up. We also need to decouple the notion of representational shape from sources and sinks so we can disconnect internal representation from external representation.
Figure 2. Description of relationships between shapes—sources, flows, and sinks.
Furthermore, we want to be able to reuse the encoding and decoding of data separately from the transformation. That means encryption/decryption, compression/decompression, and other data representational concerns ought to be reusable and not depend on the medium used to facilitate the transfer of information/data.
Getting started with reactive integration
The Alpakka project is an open source library initiative to implement stream-aware, reactive, integration pipelines for Java and Scala. It is built on top of Akka Streams, and has been designed from the ground up to understand streaming natively and provide a DSL for reactive and stream-oriented programming, with built-in support for backpressure through implementing the reactive streams standard.
The DSL allows for designing reusable "graph blueprints" of data processing schematics—built from the reusable shapes—that can then be materialized[6] into running stream processing graphs.
The basic shapes in Akka Streams, which Alpakka is built with, are:
Source<Out, M>—which represents a producer of data items of type "Out", and yields a value of type "M" when materialized.
Sink<In, M>—which represents a consumer of data items of type "In", and yields a value of type "M" when materialized.
Flow<In, Out, M>—which represents a consumer of data items of type "In" and a producer of data items of type "Out", and yields a value of type "M" when materialized.
Alpakka has a sizeable and growing set of connectors[7] implementing support for most standard enterprise protocols (i.e., HTTP, TCP, FTP, MQTT, JMS), databases (i.e., JDBC, Cassandra, HBase, MongoDB) and infrastructure products (i.e., AWS, Kafka, Google Cloud, Spring, ElasticSearch).
From one-off scripts to reusable blueprints
Using shell scripts for integration work is a rather old and common practice; that being said, it is unfortunately suffering from a couple of different problems: those scripts are rarely tested, rarely version-controlled, typically “stringly-typed” throughout (communication using sequences of characters), and rarely composable in functionality but composable on the outside—via files or similar.
Wouldn’t it be cool if your typical integration workloads could be reusable, composable blueprints that aren’t tied to the nature of where the data comes from or goes to?
Let’s take a look at a code snippet of a simple streaming pipeline to better understand how these pieces fit together. This piece of Java code is using Alpakka to produce a series of integers ranging from 1 to 100 (a source), run each integer through a pair of transformation flows (using the map function) that turns it into a string, before passing the strings down to a sink that prints them out, one by one:
final RunnableGraph<NotUsed> blueprint = Source.range(1, 100) .map(e -> e.toString()) .map(s -> s + s) .to(Sink.foreach(s -> System.out.println(s))); // Materializes the blueprint and runs it asynchronously. blueprint.run(materializer);
If we break this snippet down into its constituents we get three distinct reusable pieces (shapes):
Source.range(1, 100): is the source stage that is producing/ingesting the data, and is of type Source<Int, NotUsed>
map(e -> e.toString): is a flow stage that is performing a transformation—turning Integers into Strings—and is of type Flow<Int, String, NotUsed>
map(s -> s + s): is a flow stage that is performing a transformation—concatenating Strings—and is of type Flow<String, String, NotUsed>
to(Sink.foreach(s -> System.out.println(s)): is the sink stage that is receiving the transformed output and potentially running side-effects, and is of type Sink<String, CompletionStage<Done>>
When all inputs and outputs have been attached, the result is a RunnableGraph<NotUsed>, which means that the blueprint is now ready to be materialized, and upon materialization, it will start executing the pipeline asynchronously and return, in this case[8], an instance of NotUsed[9] to the caller.
As we’ve discussed previously, most of the time, coupling between sources, transformations, and sinks impair composability and reusability, so if we break the example up into its constituents, we end up with the following:
final Source<Integer, NotUsed> source = Source.range(1, 100); final Flow<Integer, String, NotUsed> transformation1 = Flow.of(Integer.class).map(e -> e.toString()); final Flow<String, String, NotUsed> transformation2 = Flow.of(String.class).map(s -> s + s); final Sink<String, CompletionStage<Done>> sink = Sink.foreach(s -> System.out.println(s)); final RunnableGraph<NotUsed> blueprint = source // elements flow from the source .via(transformation1) // then via (through) transformation1 .via(transformation2) // then via (through) transformation2 .to(sink); // then to the sink blueprint.run(materializer);
As you can see, the composability of the stream pipeline is driven by the types and is verified at compile time by the type system. If we want to reuse the transformation, or extend it, we can now do so without duplication of logic. Different sources, and sinks, can be used—and reused—effortlessly, in a fully typesafe manner.
Connecting all the things!
Enough with theory and conceptual discussions—it’s time to take a practical problem and see how we can solve it using a reactive and stream-native approach to enterprise integration. We will take a look at how to design a simple integration system connecting orders to invoices, allowing us to hook up orders from various sources, transform them, and perform business logic, before creating invoices that are pushed downstream into a pluggable set of sinks.
The sample project can be found on GitHub, in case you are interested in cloning it and running or modifying it.
Create the domain objects
Let’s start by creating domain objects for our sample project, starting with a very rudimentary Order class.
final public class Order { public final long customerId; public final long orderId; // More fields would go here, omitted for brevity of the example @JsonCreator public Order( @JsonProperty("customerId") long customerId, @JsonProperty("orderId") long orderId) { this.customerId = customerId; this.orderId = orderId; } // toString, equals & hashCode omitted for brevity }
We're going to be receiving orders, and from those orders we'll want to create invoices. So, let's create a bare-minimum Invoice class[10].
final public class Invoice { public final long customerId; public final long orderId; public final long invoiceId; @JsonCreator public Invoice( @JsonProperty("customerId") long customerId, @JsonProperty("orderId") long orderId, @JsonProperty("invoiceId") long invoiceId) { this.customerId = customerId; this.orderId = orderId; this.invoiceId = invoiceId; } // toString, equals & hashCode omitted for brevity }
Let’s also create a Transport[11] enumeration so we can easily instruct the main method where we want to read our orders from, and where we want to produce our invoices to.
enum Transport { file, jms, test; }
Bootstrap the system
Now, let’s create a “main method” so we can execute this example from a command line. As arguments, the invoker will have to specify which transport is going to be used from the input, as well as the output, of the program.
public static void main(final String[] args) throws Exception { if (args.length < 2) throw new IllegalArgumentException( "Syntax: [file, jms, test](source) [file, jms, test](sink)"); final Transport inputTransport = Transport.valueOf(args[0]); final Transport outputTransport = Transport.valueOf(args[1]); ... }
Since we're going to use Alpakka, which is based on Akka, to construct our integration pipeline, we first need to create what's called an ActorSystem—the main entrypoint to Akka-based applications.
final ActorSystem system = ActorSystem.create("integration");
Now we need to create an ActorMaterializer that will be responsible for taking the blueprints of our integration pipelines and..
from FEED 10 TECHNOLOGY http://ift.tt/2D93tDX
0 notes
Text
Transforming enterprise integration with reactive streams
Transforming enterprise integration with reactive streams
Build a more scalable, composable, and functional architecture for interconnecting systems and applications.
Software today is not typically a single program—something that is executed by an operator or user, producing a result to that person—but rather a service: something that runs for the benefit of its consumers, a provider of value. So, software is a part of a greater whole, and typically multiple generations of technologies must coexist peacefully and purposefully to provide a viable service. In addition to that, software is increasingly dependent on other software to provide its functionality, be it WebServices, HTTP APIs, databases, or even external devices such as sensors.
Software must also consume data from many potential sources and destinations of information—apps, websites, APIs, files, databases, proprietary services, and so on—and because of this, there’s plenty of incentives to do that well. We refer to this aspect as "integration" of different sources and destinations of information. In this article, we will discuss the need for—and how to achieve—modernization in the field of enterprise integration. We will start by reviewing the current state of enterprise integration and its challenges, and then demonstrate how organizations can achieve more scalable, composable, and functional architecture for interconnecting systems and applications by adopting a reactive and stream-based mindset and tools.
Welcome to a new world of data-driven systems
Today, data needs to be available at all times, serving its users—both humans and computer systems—across all time zones, continuously, in close to real time. As traditional architectures, techniques, and tools prove unresponsive, not scalable, or unavailable, many companies are turning toward the principles of reactive systems and real-time streaming as a way to gain insight into massive amounts of data quickly in a predictable, scalable, and resilient fashion.
Although the ideas of reactive and streaming are nowhere near new, and keeping in mind that mere novelty doesn’t imply greatness, it is safe to say they have proven themselves and matured enough to see many programming languages, platforms, and infrastructure products embrace them fully. Working with never-ending streams of data necessitates continuous processing of it, ensuring the system keeps up with the load patterns it is exposed to, and always provides real-time, up-to-date information.
One of the key aspects—as trivial as it is profound—is that data is coming from somewhere, and ends up somewhere else. Let’s dive into this concept for a bit.
The most common programming task in the world
The most common programming task that a typical software developer has to deal with is: receiving input, transforming it, and producing output.
While that statement seems obvious, it has a few subtle but important implications.
First of all, when we, programmers, write a method or a function, we do not specify where the input parameters come from, or where the output return value goes to. Sadly, it is very common to write logic that deeply couples the notion of IO with the processing of that IO. This is mixing concerns and leads to code that becomes strongly coupled, monolithic, hard to write, hard to read, hard to evolve, hard to test, and hard to reuse.
Since integrating different pieces of software, different systems, different data sources and destinations, and different formats and encodings is becoming so prevalent, this quintessential work deserves better tools.
The past and present of enterprise integration
Service-oriented architecture (SOA) was hyped in the mid-2000s as a modern take on distributed systems architecture, which through modular design would provide productivity through loose coupling between collaborative services—so-called "WebServices"—communicating through externally published APIs.
The problem was that the fundamental ideas of SOA were most often misunderstood and misused, resulting in complicated systems where an enterprise service bus (ESB) was used to hook up multiple monoliths, communicating through complicated, inefficient, and inflexible protocols—across a single point of failure: the ESB.
Anne Thomas[1] captures this very well in her article "SOA is Dead; Long Live Services":
Although the word 'SOA' is dead, the requirement for service-oriented architecture is stronger than ever. But perhaps that’s the challenge: the acronym got in the way. People forgot what SOA stands for. They were too wrapped up in silly technology debates (e.g., 'what’s the best ESB?' or 'WS-* vs. REST'), and they missed the important stuff: architecture and services.
Successful SOA (i.e., application re-architecture) requires disruption to the status quo. SOA is not simply a matter of deploying new technology and building service interfaces to existing applications; it requires a redesign of the application portfolio. And it requires a massive shift in the way IT operates.
What eventually led to the demise of SOAs was that not only did it get too focused on implementation details, but it completely misunderstood the architecture aspect of itself. Some of the problems were:
The lack of mature testing tools made interoperability a nightmare, especially when services stopped adhering to their own self-published service contracts.
WebServices, unfortunately, failed to deliver on the distributed systems front by having virtually all implementations using synchronous/blocking calls—which we all know is a recipe for scaling disaster.
Schema evolution practices were rarely in place.
Service discovery was rarely—if ever—used, which led to hardcoded endpoint addresses, leading to brittle setups with almost guaranteed downtime on redeployments.
Scaling the ESBs was rarely attempted, leading to a single point of failure and a single point of bottleneck.
Furthermore, the deployment tooling was not ready for SOA. The provisioning of new machines was not done on-demand: physical servers would take a long time to get delivered and set up, and virtual servers were slow to start, and often ran on oversubscribed machines, with poor performance as a result (something that has improved drastically in the past years with the advent of technologies such as Docker, Kubernetes, and more). Orchestration tooling was also not ready for SOA, with manual deployment scripts being one of the most common ways of deploying new versions.
The rise of enterprise integration patterns
In 2003, Gregor Hohpe and Bobby Woolf released their book Enterprise Integration Patterns. Over the last 15 years, it has become a modern classic, providing a catalog with 65 different patterns of integration between components in systems, and has formed the basis for the pattern language and vocabulary that we now use when talking about system integration.
Over the years, these patterns have been implemented by numerous products, ranging from commercial ESBs and enterprise message buses to open source libraries and products.
Most well-known is probably Apache Camel. Created in 2007, and described as "a versatile open source integration framework based on known enterprise integration patterns," it is a very popular Java library for system integration, offering implementations of most (if not all) of the standard enterprise integration patterns (EIP). It has a large community around it that, over the years, has implemented connectors to most standard protocols and products in the Java industry. Many see it as the defacto standard for enterprise integration in Java.
Breaking the Camel’s back?
Unfortunately, most of Apache Camel’s connectors are implemented in a synchronous and/or blocking fashion, without first-class support for streaming—working with data that never ends—leading to inefficient use of resources and limited scalability due to high contention for shared resources. Its strategies for flow control are either stop-and-wait (i.e., blocking), discarding data, or none—which can lead to resilience problems, poor performance, or worse: rapid unscheduled disassembly in production. Also, fan-in/fan-out patterns tend to be either poorly supported—requiring emulation[2]; static—requiring knowing all inputs/outputs at creation[3]; or, lowest-common-denominator—limiting throughput to the slowest producer/consumer[4].
The need for reactive enterprise integration
There is clearly a need to improve over the status quo: what can be done differently, given what we’ve learned in the past decades as an industry, and given what tooling is now available to us? What if we could fully embrace the concept of streaming, and redesign system integration from a reactive—asynchronous, non-blocking, scalable, and resilient perspective? What would that look like?
Streaming as a first-class concept
First of all, we need to have streams as a first-class programming concept. A stream can be defined as a potentially unbounded (“infinite”) sequence of data. Since it is potentially unbounded, we can’t wait—buffer elements—until we have received all data before we act upon it, but need to do so in an incremental fashion—ideally without overwhelming ourselves, or overwhelming those who consume the data we produce or incur a too-high processing latency.
By first-class concept, we mean that we need to be able to reason about streams as values, manipulate streams, join streams, or split them apart. Ideally, we need to land on a set of different patterns for stream processing and integration, along the same lines as the classic EIP.
Functional programming lends itself very well to stream transformation, and it is no coincidence the industry has standardized on a simple set of functional combinators that any modern stream-based DSL needs to support. Examples of these include map, flatMap, filter, groupBy, and zip, and together they form a core part of our pattern language and vocabulary for stream processing.
What is interesting is that these functional combinators—let’s call them "shapes"—are so high level, generic, powerful, composable, and reusable that the need for relying on explicit APIs and abstractions for EIP vanish[5]. Instead, the necessary integration patterns can be composed on an as-needed basis using our reusable shapes for stream processing.
From one perspective, stream processing is all about integration: ingest data from different sources and try to mine knowledge from it in real time before pushing it out to interested parties. But each implementation is doing it differently, which makes interoperability hard.
What we are lacking is a standardized way to integrate stream processing products, databases, traditional standardized protocols, and legacy enterprise products.
The need for flow control
One of the key realizations one develops when integrating components of unequal capacities is that flow control is not optional, but mandatory.
Flow control is essential for the system to stay responsive, ensuring that the sender does not send data downstream faster than the receiver is able to process. Failing to do so can, among other things, result in running out of resources, taking down the whole node, or filling up buffers, stalling the system as a whole. Therefore, flow control, especially through backpressure (see Figure 1), is essential in order to achieve resilience in a stream/integration pipeline.
Figure 1. Illustrates the flow of data and backpressure in a stream topology.
Also, during an inability to send or receive data, processing resources must be handed back and made available to other parts of the system, allowing the system to scale to many concurrent integration pipelines.
Reactive streams: A call to arms
To address the problem of flow control, an initiative called reactive streams was created in late 2013 to “provide a standard for asynchronous stream processing with non-blocking backpressure.”
Reactive streams is a set of four Java interfaces (publisher, subscriber, subscription, and processor), a specification for their interactions, and a technology compatibility kit (TCK) to aid and verify implementations.
The reactive streams specification has many implementations and was recently adopted into JDK 9 as the Flow API. Crucially, it provides the assurance that connecting publishers, processors, and subscribers—no matter who implemented them—will provide the flow control needed. When it comes to flow control, all components in the processing pipeline need to participate.
Toward reusable shapes for integration
We need to be able to reason about transformational shapes (see Figure 2)—how data is processed (separately from the sources and sinks), where data comes from and ends up. We also need to decouple the notion of representational shape from sources and sinks so we can disconnect internal representation from external representation.
Figure 2. Description of relationships between shapes—sources, flows, and sinks.
Furthermore, we want to be able to reuse the encoding and decoding of data separately from the transformation. That means encryption/decryption, compression/decompression, and other data representational concerns ought to be reusable and not depend on the medium used to facilitate the transfer of information/data.
Getting started with reactive integration
The Alpakka project is an open source library initiative to implement stream-aware, reactive, integration pipelines for Java and Scala. It is built on top of Akka Streams, and has been designed from the ground up to understand streaming natively and provide a DSL for reactive and stream-oriented programming, with built-in support for backpressure through implementing the reactive streams standard.
The DSL allows for designing reusable "graph blueprints" of data processing schematics—built from the reusable shapes—that can then be materialized[6] into running stream processing graphs.
The basic shapes in Akka Streams, which Alpakka is built with, are:
Source<Out, M>—which represents a producer of data items of type "Out", and yields a value of type "M" when materialized.
Sink<In, M>—which represents a consumer of data items of type "In", and yields a value of type "M" when materialized.
Flow<In, Out, M>—which represents a consumer of data items of type "In" and a producer of data items of type "Out", and yields a value of type "M" when materialized.
Alpakka has a sizeable and growing set of connectors[7] implementing support for most standard enterprise protocols (i.e., HTTP, TCP, FTP, MQTT, JMS), databases (i.e., JDBC, Cassandra, HBase, MongoDB) and infrastructure products (i.e., AWS, Kafka, Google Cloud, Spring, ElasticSearch).
From one-off scripts to reusable blueprints
Using shell scripts for integration work is a rather old and common practice; that being said, it is unfortunately suffering from a couple of different problems: those scripts are rarely tested, rarely version-controlled, typically “stringly-typed” throughout (communication using sequences of characters), and rarely composable in functionality but composable on the outside—via files or similar.
Wouldn’t it be cool if your typical integration workloads could be reusable, composable blueprints that aren’t tied to the nature of where the data comes from or goes to?
Let’s take a look at a code snippet of a simple streaming pipeline to better understand how these pieces fit together. This piece of Java code is using Alpakka to produce a series of integers ranging from 1 to 100 (a source), run each integer through a pair of transformation flows (using the map function) that turns it into a string, before passing the strings down to a sink that prints them out, one by one:
final RunnableGraph<NotUsed> blueprint = Source.range(1, 100) .map(e -> e.toString()) .map(s -> s + s) .to(Sink.foreach(s -> System.out.println(s))); // Materializes the blueprint and runs it asynchronously. blueprint.run(materializer);
If we break this snippet down into its constituents we get three distinct reusable pieces (shapes):
Source.range(1, 100): is the source stage that is producing/ingesting the data, and is of type Source<Int, NotUsed>
map(e -> e.toString): is a flow stage that is performing a transformation—turning Integers into Strings—and is of type Flow<Int, String, NotUsed>
map(s -> s + s): is a flow stage that is performing a transformation—concatenating Strings—and is of type Flow<String, String, NotUsed>
to(Sink.foreach(s -> System.out.println(s)): is the sink stage that is receiving the transformed output and potentially running side-effects, and is of type Sink<String, CompletionStage<Done>>
When all inputs and outputs have been attached, the result is a RunnableGraph<NotUsed>, which means that the blueprint is now ready to be materialized, and upon materialization, it will start executing the pipeline asynchronously and return, in this case[8], an instance of NotUsed[9] to the caller.
As we’ve discussed previously, most of the time, coupling between sources, transformations, and sinks impair composability and reusability, so if we break the example up into its constituents, we end up with the following:
final Source<Integer, NotUsed> source = Source.range(1, 100); final Flow<Integer, String, NotUsed> transformation1 = Flow.of(Integer.class).map(e -> e.toString()); final Flow<String, String, NotUsed> transformation2 = Flow.of(String.class).map(s -> s + s); final Sink<String, CompletionStage<Done>> sink = Sink.foreach(s -> System.out.println(s)); final RunnableGraph<NotUsed> blueprint = source // elements flow from the source .via(transformation1) // then via (through) transformation1 .via(transformation2) // then via (through) transformation2 .to(sink); // then to the sink blueprint.run(materializer);
As you can see, the composability of the stream pipeline is driven by the types and is verified at compile time by the type system. If we want to reuse the transformation, or extend it, we can now do so without duplication of logic. Different sources, and sinks, can be used—and reused—effortlessly, in a fully typesafe manner.
Connecting all the things!
Enough with theory and conceptual discussions—it’s time to take a practical problem and see how we can solve it using a reactive and stream-native approach to enterprise integration. We will take a look at how to design a simple integration system connecting orders to invoices, allowing us to hook up orders from various sources, transform them, and perform business logic, before creating invoices that are pushed downstream into a pluggable set of sinks.
The sample project can be found on GitHub, in case you are interested in cloning it and running or modifying it.
Create the domain objects
Let’s start by creating domain objects for our sample project, starting with a very rudimentary Order class.
final public class Order { public final long customerId; public final long orderId; // More fields would go here, omitted for brevity of the example @JsonCreator public Order( @JsonProperty("customerId") long customerId, @JsonProperty("orderId") long orderId) { this.customerId = customerId; this.orderId = orderId; } // toString, equals & hashCode omitted for brevity }
We're going to be receiving orders, and from those orders we'll want to create invoices. So, let's create a bare-minimum Invoice class[10].
final public class Invoice { public final long customerId; public final long orderId; public final long invoiceId; @JsonCreator public Invoice( @JsonProperty("customerId") long customerId, @JsonProperty("orderId") long orderId, @JsonProperty("invoiceId") long invoiceId) { this.customerId = customerId; this.orderId = orderId; this.invoiceId = invoiceId; } // toString, equals & hashCode omitted for brevity }
Let’s also create a Transport[11] enumeration so we can easily instruct the main method where we want to read our orders from, and where we want to produce our invoices to.
enum Transport { file, jms, test; }
Bootstrap the system
Now, let’s create a “main method” so we can execute this example from a command line. As arguments, the invoker will have to specify which transport is going to be used from the input, as well as the output, of the program.
public static void main(final String[] args) throws Exception { if (args.length < 2) throw new IllegalArgumentException( "Syntax: [file, jms, test](source) [file, jms, test](sink)"); final Transport inputTransport = Transport.valueOf(args[0]); final Transport outputTransport = Transport.valueOf(args[1]); ... }
Since we're going to use Alpakka, which is based on Akka, to construct our integration pipeline, we first need to create what's called an ActorSystem—the main entrypoint to Akka-based applications.
final ActorSystem system = ActorSystem.create("integration");
Now we need to create an ActorMaterializer that will be responsible for taking the blueprints of our integration pipelines and..
http://ift.tt/2D93tDX
0 notes