#flatmap scala
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Apache Spark flatMap transformation
Apache Spark flatMap transformation
Apache Spark flatMap transformation Apache Spark In our previous post, we talked about the Map transformation in Spark. In this post we will learn the flatMap transformation. As per Apache Spark documentation, flatMap(func) is similar to map, but each input item can be mapped to 0 or more output items That means the func should return a scala.collection.Seq rather than a single item. Let’s…

View On WordPress
0 notes
Text
FlatMap In Angular
FlatMap In Angular
This Article is about FlatMap In Angular. Let’s say we wanted to implement an AJAX search feature in which every keypress in a text field will automatically perform a search and update the page with the results. How would this look? Well we would have an Observablesubscribed to events coming from an input field, and on every change of input we want to perform some HTTP…
View On WordPress
#best jquery plugins 2019#best jquery plugins with code examples#FlatMap#flatmap example#FlatMap In Angular#flatmap java#flatmap javascript#flatmap scala#flatmap vs map#free jquery plugins 2019
0 notes
Text
POLYMORPHISM UNBOUND

Bruce Eckel
AUTHOR/CONSULTANT
@BruceEckel
Bruce was studying at the oceanography school at UW!
Cfront was a type of C++ sent to schools on tapes that would generate code to run through a C compiler.
Cfront had virtual classes and dynamic binding.
Simula67 was the first OO language. The common thing you need to do is send messages to step simulations forward.
Smalltalk evolved from Simula to introduce code reuse through inheritance. But Smalltalk is inherently dynamic: it is part of its nature.
Alan Kay regrets not calling OOP Message-oriented Programming. Since OOP is really all about message passing.
C++ took the idea of inheritance and dynamic binding and expanded it. C++ was statically typed…for safety!
With C++, you don't have to use objects if you don't want to.
Then Java came along to say: if objects are good, then objects are the best. Everything is an object! And Static typing is also the best! But…inheritance was a mistake.
What is polymorphism? A type that represents multiple types. Usually as a function parameter. Why would you do this??!?
We are somehow fitting a group of types into a single type.
Ad-hoc polymorphism, aka Overloading. The same function taking different arguments. Under the hood, this is jus two different functions.
Kotlin by default makes all functions final, use the open keyword to make them open.
Overloading is in a lot of languages: Java, C++, Kotlin, etc.
Subtype Polymorphism: "Classic" inheritance. Follows the Liskov Substitution Principle.
Multiple Inheritance: forces an existing set of types into a hierarchy. This is useful if you are handed classes that you cannot change. But…it gets messy.
Multiple inheritance is really just composition in the guise of inheritance.
But true composition is much cleaner than multiple inheritance for code reuse and readability.
C++ is private by default, and it allows you to do private inheritance. It is not used very often.
Parametric Polymorphism: Generics in Java, Templates in C++
Now you have a parameter that creates a class of types instead of just one type. Mostly used for standard libraries for generic use cases.
Parametirc polymorphism allows you to introduce pattern matching! (Which we are getting with Java 19, LET'S GO!)
Kotlin has reified generics, Scala has that too.
Duck Typing: In dynamically typed languages, we can just throw a method at an object, and if it works, it works! "If it quacks like a duck, it is a duck!"
C++ has duck typing through templates. The templates do function overloading for you!
Union Types, aka Sum Types: creating anonymous types by combining multiple types (Type1 | Type2 | Type3)
Union types allow you to get errors at type check time instead of run or compile time (aka faster)
Go has a version of union types, but they are composed differently.
C++ has union types, too, but it is not pretty
Protocols: another way to mash your types together. Now you can have interfaces that invert the control of your inheritance.
Algebraic Data Types (ADTs). Martin was all about Enums in Scala 3. ADTs become case classes in Scala. The ADT makes sure the pattern match is exhaustive.
Type Classes: Type classes allow you to extend generic functions to, again, invert control of execution. A type class is an adapter that is taken care of at compile time.
Multiple Dispatching (need more info here)
Takeaways:
Why do we want to treat multiple types into a single type: capturing and reusing concepts.
Don’t do it without questioning!
Was OO a mistake? No, sometimes it is quite useful, just not ALL THE TIME.
Ad-hoc polymorphism is used all over the place: map, foldLeft, FoldRight, flatMap, etc.
Thank you, Bruce, for the great talk!
0 notes
Text
Adv LAB 5- SCALA FUNCTIONAL PROGRAMMING TECHNIQUES Solved
Adv LAB 5- SCALA FUNCTIONAL PROGRAMMING TECHNIQUES Solved
In this lab you will gain further practice in functional programming in Scala and learn how to create a simple menu-driven application in Scala. You will work with partial function application and currying, and see examples of the use of map, flatMap and for comprehensions. For this lab you should create an IntelliJ Scala project lab5project. Tasks 1 and 2 can be done with Scala worksheets, while…

View On WordPress
0 notes
Text
Spark map() vs flatMap() with Examples
Spark map() vs flatMap() with Examples
What is the difference between Spark map() vs flatMap() is a most asked interview question, if you are taking an interview on Spark (Java/Scala/PySpark), so let’s understand the differences with examples? Regardless of an interview, you have to know the differences as this is also one of the most used Spark transformations. map() – Spark map() transformation applies a function to each row in a…
View On WordPress
0 notes
Text
300+ TOP SCALA Interview Questions and Answers
SCALA Interview Questions for freshers experienced :-
1. What is Scala? Scala is a Java-based Hybrid programming language which is the fusion of both Functional and Object-Oriented Programming Language features. It can integrate itself with Java Virtual Machine and compile the code written. 2. How Scala is both Functional and Object-oriented Programming Language? Scala treats every single value as an Object which even includes Functions. Hence, Scala is the fusion of both Object-oriented and Functional programming features. 3.Write a few Frameworks of Scala Some of the Frameworks supported by Scala are as follows: Akka Framework Spark Framework Play Framework Scalding Framework Neo4j Framework Lift Framework Bowler Framework 4. Explain the types of Variables in Scala? And What is the difference between them? The Variables in Scala are mainly of two types: Mutable Variables We Declare Mutable Variables by using the var keyword. The values in the Mutable Variables support Changes Immutable Variables We declare Immutable Variables using the val keyword. The values in Immutable Variables do not support changes. 5. Explain Streams in Scala. In simple words, we define Stream as a Lazy list which evaluates the elements only when it needs to. This sort of lazy computation enhances the Performance of the program. 6. Mention the Advantages of Scala Some of the major Advantages of Scala are as follows: It is highly Scalable It is highly Testable It is highly Maintainable and Productive It facilitates Concurrent programming It is both Object-Oriented and Functional It has no Boilerplate code Singleton objects are a cleaner solution than Static Scala Arrays use regular Generics Scala has Native Tuples and Concise code 7. Explain the Operators in Scala The following are the Operators in Scala: Arithmetic Operators Relational Operators Logical Operators Bitwise Operators Assignment Operators 8. What is Recursion tail in Scala? ‘Recursion’ is a function that calls itself. For example, a function ‘A’ calls function ‘B’, which calls the function ‘C’. It is a technique used frequently in Functional programming. In order for a Tail recursive, the call back to the function must be the last function to be performed. 9. Explain the use of Tuples in Scala? Scala tuples combine a Finite number of items together so that the programmer can Pass a tuple around as a Whole. Unlike an Array or List, a tuple is Immutable and can hold objects with different Datatypes. 10. How is a Class different from an Object? Class combines the data and its methods whereas an Object is one particular Instance in a class.

SCALA Interview Questions 11. Why do we need App in Scala? App is a helper class that holds the main method and its Members together. The App trait can be used to quickly turn Objects into Executable programs. We can have our classes extend App to render the executable code. object Edureka extends App{ println("Hello World") } 12. What are Higher-order functions? A Higher-order function is a function that does at least one of the following: takes one or more Functions as Arguments, returns a Function as its result. 13. Explain the scope provided for variables in Scala. There are three different scopes depending upon their use. Namely: Fields: Fields are variables declared inside an object and they can be accessed anywhere inside the program depending upon the access modifiers. Fields can be declared using var as well as val. Method Parameters: Method parameters are strictly Immutable. Method parameters are mainly used to Pass values to the methods. These are accessed inside a method, but it is possible to access them from outside the method provided by a Reference. Local Variables: Local variables are declared inside a method and they are accessible only inside the method. They can be accessed if you return them from the method. 14. What is a Closure? Closure is considered as a Function whose return value is Dependent upon the value of one or more variables declared outside the closure function. Course Curriculum Apache Spark and Scala Certification Training Instructor-led SessionsReal-life Case StudiesAssessmentsLifetime Access Example: val multiplier = (i:Int) => i * 10 Here the only variable used in the function body, i * 10 , is i, which is defined as a parameter to the function 15. Explain Traits in Scala. A Trait can be defined as a unit which Encapsulates the method and its variables or fields. The following example will help us understand in a better way. trait Printable{ def print() } class A4 extends Printable{ def print(){ println("Hello") } } object MainObject{ def main(args:Array){ var a = new A4() a.print() } } 16. Mention how Scala is different from Java A few scenarios where Scala differs from Java are as follows: All values are treated as Objects. Scala supports Closures Scala Supports Concurrency. It has Type-Inference. Scala can support Nested functions. It has DSL support Traits 17. Explain extend Keyword You can extend a base Scala class and you can design an Inherited class in the same way you do it in Java by using extends keyword, but there are two restrictions: method Overriding requires the override keyword, and only the Primary constructor can pass parameters to the base Constructor. Let us understand by the following example println("How to extend abstract class Parent and define a sub-class of Parent called Child") class Child=(name:String)extends Parent(name){ override def printName:Unit= println(name) } object Child { def apply(name:String):Parent={ new Child(name) } } 18. Explain implicit classes with syntax Implicit classes allow Implicit conversations with the class’s Primary constructor when the class is in scope. Implicit class is a class marked with the “implicit” keyword. This feature was introduced in with Scala 2.10 version. //Syntax: object { implicit class Data type) { def Unit = xyz } } 19. Explain the access Modifiers available in Scala There are mainly three access Modifiers available in Scala. Namely, Private: The Accessibility of a private member is restricted to the Class or the Object in which it declared. The following program will explain this in detail. class Outer { class Inner { private def f() { println("f") } class InnerMost { f() // OK } } (new Inner).f() // Error: f is not accessible } Protected: A protected member is only Accessible from Subclasses of the class in which the member is defined. The following program will explain this in detail. package p class Super { protected def f() { println("f") } } class Sub extends Super { f() } class Other { (new Super).f() // Error: f is not accessible } } Public: Unlike Private and Protected members, it is not required to specify Public keyword for Public members. There is no explicit modifier for public members. Such members can be accessed from Anywhere. Following is the example code snippet to explain Public member class Outer { class Inner { def f() { println("f") } class InnerMost { f() // OK } } (new Inner).f() // OK because now f() is public } 20. What is a Monad in Scala? A Monad is an object that wraps another object. You pass the Monad mini-programs, i.e functions, to perform the data manipulation of the underlying object, instead of manipulating the object directly. Monad chooses how to apply the program to the underlying object. 21. Explain the Scala Anonymous Function. In the Source code, Anonymous functions are called ‘Function literals’ and at run time, function literals are instantiated into objects called Function values. Scala provides a relatively easy Syntax for defining Anonymous functions. //Syntax (z:Int, y:Int)=> z*y Or (_:Int)*(_Int) 22. How do I Append data in a list? In Scala to Append into a List, We have the following methods: use “:+” single value var myList = List.empty myList :+= "a" 23. Why Scala prefers Immutability? Scala prefers Immutability in design and in many cases uses it as default. Immutability can help when dealing with Equality issues or Concurrent programs. 24. Give some examples of Packages in Scala The three important and default Packages in Scala are as follows: Java.lang._ : Java.lang._ package in Java. Provides classes that are fundamental to the design of the Java programming language. Java.io._ : Java.io._ Package used to import every class in Scala for input-output resources. PreDef: Predef provides type aliases for types which are commonly used, such as the immutable collection types Map, Set, and the List constructors 25. Why is an Option used in Scala? Option in Scala is used to Wrap the Missing value. 26. Mention the Identifiers in Scala. There are four types of Scala Identifiers: Alphanumeric identifiers Operator identifiers Mixed identifiers Literal identifiers //Scala program to demonstrate Identifiers in Scala. object Main { //Main method def main(args: Array) { //Valid Identifiers var 'name = "Hari"' var age = 20; var Branch = "Computer Science" println() println() println() } } 27. How do you define a function in Scala? def keyword is used to define the Function in Scala. object add { def addInt( a:Int, b:Int ) : Int = { var sum:Int = 0 sum = a + b return sum } } 28. How is the Scala code compiled? Code is written in Scala IDE or a Scala REPL, Later, the code is converted into a Byte code and transferred to the JVM or Java Virtual Machine for compilation. Big Data Training 29. Explain the functionality of Yield. Yield is used with a loop, Yield produces a value for each iteration. Another way to do is to use map/flatMap and filter with nomads. for (i "#FF0000", "azure" -> "#F0FFFF") 39. Explain Exception Handling in Scala Throw Exception: Throwing an exception looks the same as in Java. You create an exception object and then you throw it with the throw keyword as follows. Throw new IllegalArgumentException Catching an Exception: Scala allows you to try/catch any exception in a single block and then perform pattern matching against it using case blocks. Try the following example program to handle the exception. Example: import java.io.FileReader import java.io.FileNotFoundException import java.io.IOException object Demo { def main(args: Array) { try { val f = new FileReader("input.txt") } catch { case ex: FileNotFoundException ={ println("Missing file exception") } case ex: IOException = { println("IO Exception") } } } } So, with this, we finished some questions on the Intermediate Level. Now, Let us move to the next level of interview questions which happen to be the Advanced Level Interview Questions. 40. Explain Pattern Matching in Scala through an example A Pattern match includes a sequence of alternatives, each starting with the Keyword case. Each alternative includes a Pattern and one or more Expressions, Scala evaluates whenever a pattern matches. An arrow symbol => separates the pattern from the expressions. Try the following example program, which shows how to match against an integer value. object Demo { def main(args: Array) { println(matchTest(3)) } def matchTest(x: Int): String = x match { case 1 = "one" case 2 = "two" case _ = "other" } } 41. Explain Extractors in Scala Course Curriculum Apache Spark and Scala Certification Training Weekday / Weekend Batches An Extractor in Scala is an object that has a method called unapply as one of its members. The purpose of that unapply method is to match the value and take it apart. 42. What is the result of x+y*z and why? Similar to any other programming language, Scala also follows Presidency and Priority tables. According to the tables, Scala Performs the operations as follows. Scala evaluates y*z first. Then adds (y*z) with x 43. What is an Auxiliary constructor We use Auxiliary constructor in Scala for Constructor Overloading. The Auxiliary Constructor must call either previously defined auxiliary constructors or primary constructor in the first line of its body. 44. Explain recursion through a program def factorial_loop(i: BigInt): BigInt = { var result = BigInt(1) for (j- 2 to i.intValue) result *= j result } for (i - 1 to 10) format("%s: %sn", i, factorial_loop(i)) 45. Explain Que with example Queue is a Data Structure similar to Stack except, it follows First In First Out procedure for data processing. In Scala, to work with Queues, you need to import a library called, import scala.collection.mutable.Queue val empty = new Queue SCALA Questions and Answers Pdf Download Read the full article
0 notes
Text
3 набора данных в Spark SQL для аналитики Big Data: что такое dataframe, dataset и RDD

Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-��нструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и нереляционными хранилищами информации. Начнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и чем они отличаются друг от друга.
Что такое Spark SQL и как он работает
Прежде всего, напомним, что Spark SQL – это модуль Apache Spark для работы со структурированными данными. На практике такая задача возникает при работе с реляционными базами данных, где хранится нужная информация, например, если требуется избирательное изучение пользовательского поведения на основании серверных логов. Однако, в случае множества СУБД и файловых хранилищ необходимо работать с каждой схемой данных в отдельности, что потребует множества ресурсов [1]. Spark SQL позволяет реализовать декларативные запросы посредством универсального доступа к данным, предоставляя общий способ доступа к различным источникам данных: Apache Hive, AVRO, Parquet, ORC, JSON и JDBC/ODBC. При этом можно смешивать данные, полученные из разных источников, организуя таким образом бесшовную интеграцию между Big Data системами. Работать с разными схемами (форматами данных), таблицами и записями, позволяет SchemaRDD в качестве временной таблицы [2]. Для такого взаимодействия с внешними источниками данных Spark SQL использует не функциональную структуру данных RDD (Resilient Distributed Dataset, надежную распределенную коллекцию типа таблицы), а SQL или Dataset API. Отметим, способ реализации (API или язык программирования) не влияет на внутренний механизм выполнения вычислений. Поэтому разработчик может выбрать интерфейс, наиболее подходящий для преобразования выражений в каждом конкретном случае [2]. DataFrame используется при реляционных преобразованиях, а также для создания временного представления, которое позволяет применять к данным SQL-запросы. При запуске SQL-запроса из другого языка программирования результаты будут возвращены в виде Dataset/DataFrame. По сути, интерфейс DataFrame предоставляет предметно-ориентированный язык для работы со структурированными данными, хранящимися в файлах Parquet, JSON, AVRO, ORC, а также в СУБД Cassandra, Apache Hive и пр. [2]. Например, чтобы отобразить на экране содержимое JSON-файла с данными в виде датафрейма, понадобится несколько строк на языке Java [2]: import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; Dataset df = spark.read().json("resources/people.json"); df.show();// Displays the content of the DataFrame to stdout
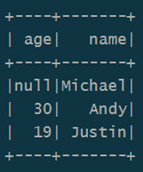
Пример датафрейма Spark SQL Следующий набор Java-инструкций показывает пару типичных SQL-операций над данными: инкрементирование численных значений, выбор по условию и подсчет строк [2]: import static org.apache.spark.sql.functions.col; // col("...") is preferable to df.col("...") df.select(col("name"), col("age").plus(1)).show();// Select everybody, but increment the age by 1 df.filter(col("age").gt(21)).show();// Select people older than 21 df.groupBy("age").count().show();// Count people by age

Примеры SQL-операций над датафреймом в Spark
Что такое dataframe, dataset и RDD в Apache Spark
Поясним разницу между понятиями датасет (dataset), датафрейм (dataframe) и RDD. Все они представляют собой структуры данных для доступа к определенному информационному набору и операций с ним. Тем не менее, представление данных в этих абстракциях отличается друг от друга: · RDD – это распределенная коллекция данных, размещенных на узлах кластера, набор объектов Java или Scala, представляющих данные [3]. · DataFrame – это распределенная коллекция данных, организованная в именованные столбцы. Концептуально он соответствует таблице в реляционной базе данных с улучшенной оптимизаций для распределенных вычислений [3]. DataFrame доступен в языках программирования Scala, Java, Python и R. В Scala API и Java API DataFrame представлен как Dataset[Row] и Dataset соответственно [2]. · DataSet – это расширение API DataFrame, добавленный в Spark 1.6. Он обеспечивает функциональность объектно-ориентированного RDD-API (строгая типизация, лямбда-функции), производительность оптимизатора запросов Catalyst и механизм хранения вне кучи API DataFrame [3]. Dataset может быть построен из JVM-объектов и изменен с помощью функциональных преобразований (map, flatMap, filter и т. д.). Dataset API доступен в Scala и Java. Dataset API не поддерживается R и Python в версии Spark 2.1.1, но, благодаря динамическому характеру этих языков программирования, в них доступны многие возможности Dataset API. В частности, обращение к полю в строке по имени [2].
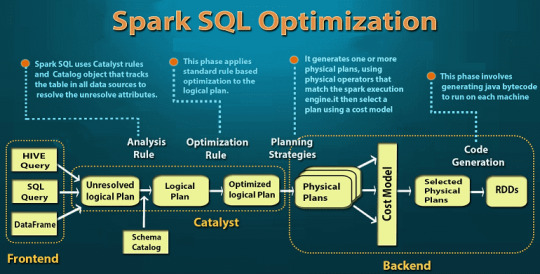
Как связаны dataset, dataframe и RDD в Apache Spark: SQL-оптимизация Более подробно о сходствах и различиях этих понятий (RDD, Dataset, DataFrame) мы расскажем в следующей статье, сравнив их по основным критериям (форматы данных, емкость памяти, оптимизация и т.д.). А все тонкости прикладной работы с ними вы узнаете на нашем практическом курсе SPARK2: Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist��ов и аналитиков Big Data) в Москве.

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://habr.com/ru/company/wrike/blog/275567/ 2. https://ru.bmstu.wiki/Spark_SQL 3. https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/ Read the full article
0 notes
Text
map(), flatMap() on Futures & Options in scala
map(), flatMap() on Futures & Options in scala

In this blog, we would be looking at how map() and flatMap() operations work with Option and Future of scala, literally speaking both Futures and Options are very effective features of scala, A Future lets us have a value from some task on a differnt thread and Option provides us a hand from null of java as using null in scala is seen a very bad approach in functional programming.
In my previous…
View On WordPress
0 notes
Text
RustでEitherを実装する(している) - Qiita [はてなブックマーク]
RustでEitherを実装する(している) - Qiita
きっかけ 最近、Rustを始めて標準でEitherがないのは不便と思ったので、実装しています。 元々、Scalaをやっていたので実装はScalaに合わせています。 ソース https://ift.tt/2IeHz55 困っていること flatMapの実装 今回の実装 https://github.com/ry...
kjw_junichi あとで読む
from kjw_junichiのブックマーク https://ift.tt/2pMyaer
0 notes
Text
Why Kotlin language, Android? Why did Google choose Kotlin ?
Why Kotlin language?
If today I was asked what is one of the characteristics that distinguishes the development of Android applications from the rest of the fields, I would not hesitate to answer that the possibility of executing the same application on devices with a different hardware in a native way is one of them; but … how is this possible? And today I would like to start my series of Kotlin language articles, explaining the language and the benefits of it.
At this point no one is surprised to see the same web application running on any device and on any platform (Android, iOS, Windows, MacOS …), we all know that these applications are slower and more unstable than any native application; but in exchange we only have to develop one application for all platforms. A similar problem would arise when talking about the number of different devices on which Android works right now; and I say would if it wasn’t because of Java. The power of Java and the fact that it is used in billions of devices today, it’s ability to work on any device regardless of its hardware and software, as long as it has an interpreter of the pseudo-compiled code generated by the Java compiler (The official Java interpreter is the Java Virtual Machine, although on Android Dalvik was used in the first versions and ART today).
Does this mean that Java is the solution to all evils? Unfortunately, nothing is further from the truth … Although Java solves the problem of interoperability between devices, it opens a new range of headaches that we would like to be able to remove from the equation, some of them *:
* Note: Many of these problems, although resolved in Java 8 and 9, are not available in the Android SDK below API 24, which makes them practically unusable)
There is no native support for optionals (although we do have it for immutable collections). Although there is the Optional <T> class, its use implies the generation of a large amount of boilerplate code, which we could save if the support for the options was built within the language itself and not as an extension of it.
There is no native support for functional programming: In Java there is the Stream Api (Once again it only has support in Android starting from API 24), but its integration in the language is similar to the one of Optional, it exists poorly in the objects associated with primitive types (IntStream, DoubleStream …), and through a Stream class <T> for all other objects.
Support for anonymous functions (Lambdas). Although Java 8 incorporates support for Lambda functions, these are not first-class citizens; this means that, although we can use lambdas to implement anonymously interfaces with a single method, Java does not support passing functions as arguments to a method. In addition, the lack of type inference makes the statement of Lambdas quite uncomfortable, especially in the attempt to simulate functions such as composition of functions or currying; lack of support for them in the language.
Type nullability: Although this can be included within the section referring to the optional, the dimension of this problem deserves a special mention. How many Java programmers didn’t fill their code with if (foo! = Null) to try to fight the dreaded NullPointerException? (Actually, it’s creator apologised for what he calls a “billion-dollar mistake”) And how many of those check ups are more than patches to avoid a crash in our application?
Binding of manual views: Although this problem is specific to Android as a Platform, and not Java as a language, it is also worth pointing out the amount of boilerplate code needed to obtain a reference to an Android view. Although we have managed to eliminate the hated findViewById (int id) thanks to dataBinding, we still have to store a reference to that binding.
It is more general, but not less important, Java is a very verbose language, it requires writing a large amount of code for any operation, as well as generating a large number of files (one per class). The first problem can lead us to a code more expensive to maintain and more prone to errors. The second is a problem of class proliferation.
Why Kotlin language breaks with all this?
It is for all these reasons that, today, Java is considered as a language that, at least in Android development, does not evolve at the speed that the industry does.
As time passes, the need to have a language with real and native support for everything mentioned above becomes more imperative, as well as maintaining the main feature of Android exposed at the beginning of this article, its ability, writing and compiling a single application, make it work on any device and version of it. In this direction many possibilities have been explored, some of them being the use of Swift or Scala, although none has been very promising.
All this changed with the appearance of Kotlin language. Kotlin is a language designed and developed by Jetbrains, focused on being a modern language, in constant evolution and, above all, that can be executed on the JVM. This makes it a perfect candidate to be used on Android.
To begin to demonstrate it, we can list down all the cons we face with Java and how Kotlin language acts in front of them:
Optionals. They’re built in inside Kotlin, all you have to do is declare the type of a variable ending in a question mark ? so it becomes an optional type. Kotlin language also provides the possibility of safely unwrapping those optionals listener?.onSuccess() without checking if there’s a value for this optional, and also provides the Elvis Operator.
Functional programming: In Kotlin we find native support to work with collections and datasets like Streams. We can directly call .flatMap {} in a collection, as well as .filter {}, .map {}, and many more. The inference of types makes the use of Lambdas especially manageable.
Lambdas and high order functions: The previous point is completed with the fact that in Kotlin language, the functions are first class citizens. We can define functions that receive other functions as parameters. An example of this is the definition of the map function itself:
inline fun <T, R> Iterable.map(transform: (T) -> R): List (source)
Although at first sight this code may seem a bit chaotic, the part that interests us is
transform: (T) -> R
This means, the map function has a parameter called transform, which is itself a function that has an input parameter of type T and returns an object of type R.
Thanks to this native support for lambdas, in Kotlin language we can use the map function such that:
collection.map { item -> aTransformation(item) }
This code snippet will return a collection of elements of the type returned by aTransformation.
Type nullability: In Kotlin language, since there is an integrated support in the language for optionals, we should have the minimum possible number of nullables in our code. But even so, if it exists, Kotlin offers us tools to deal with them easier than in Java. For example we have the operator safe call (?) to avoid NullPointerException when accessing an optional, or with the operator safe cast to protect us in case of wanting to perform a casting. The compiler of Kotlin, in addition, forces to control the types that could have null value, and even introduces runtime checks in case of compatibility with Java code.
Binding of views: This being a specific Android problem, Jetbrains offers us Kotlin Android Extensions; an official support library to simplify this problem (and some other) through a gradle plugin.
Verbosity of language:
Java
Public interface Listener { void success(int result); void error(Exception ex); } Public void someMethod(Listener listener) { int rand = new Random().nextInt(); If (listener != null) { if (rand <= 0) { listener.onError(new ValueNotSupportedException()); } else { listener.success(rand); } } Public void fun(Type1 param1) { param1.someMethod(new Listener() { @Override public void success(int result) { println(“Success” + result); } @Override public void error(Exception ex) { ex.printStackTrace(); } } }
Kotlin
fun someMethod(success: (Int) -> Unit, error: (Exception) -> Unit) { val rand = Random().nextInt() if (rand <= 0) { error(ValueNotSupportedException()) else { success(rand) } }
Or even, using expressions:
fun someMethod(success: (Int) -> Unit, error: (Exception) -> Unit) { val rand = Random().nextInt() if (rand <= 0) error(ValueNotSupportedException()) else success(rand) }
It is up to the reader to decide which of the two snippets is easier to write and interpret.
All the discussed above, along with another large number of features that did not fit in this article or that were not the ones that really matter to us shows us that Kotlin language seems the most promising bet for the next few years in the world of mobile development. In my next articles, we will study more in detail what benefits we get by using Kotlin in Android development and its impact on the industry.
And if you are interested in mobile development, I highly recommend you to subscribe to our monthly newsletter by clicking here.
If you found this article about Kotlin language interesting, you might like…
iOS Objective-C app: sucessful case study
Mobile app development trends of the year
Banco Falabella wearable case study
Mobile development projects
Viper architecture advantages for iOS apps
MVP pattern in iOS
The post Why Kotlin language, Android? Why did Google choose Kotlin ? appeared first on Apiumhub.
Why Kotlin language, Android? Why did Google choose Kotlin ? published first on http://ift.tt/2w7iA1y
0 notes
Text
JWT authentication with Akka HTTP
The authentication of RESTful APIs is quite an often asked question, so I decided to demonstrate basic authentication via JWT (JSON Web Token) in an example of an API built with Akka HTTP.
JWT working concept
Before we start with the actual coding, we should briefly recap how the mechanism of JWT authentication works. JWT itself is composed of three parts:
Header
Payload
Signature
Header contains a hashing algorithm (RSA, SHA256…) and token type. The payload section is going to be of most interest to you. The payload contains claims. And they usually contain information about the user along with some metadata. Lastly, JWT contains the signature which is used to verify the authenticity of the token sender. The token authentication process and access to secured resources is displayed in the following image.
RESTful APIs are stateless. Upon authentication, there is no a secured session which is generated on server and held in the context of the application followed by the cookie which is being returned and stored on the client side. In case of JWT authentication, we sign in using our credentials, the server generates an access token and we save it on the client side. In order to access secured content on the server, we have to send the access token upon each request (usually as a value of the authorization header). Then the server simply tries to verify the provided access token with a secret key. If the verification is successful, the server provides access to a secured resource. Otherwise, it rejects the request since the user is unauthorized. Our RESTful API remains stateless since the token is not stored anywhere on the server side. Also notice that payload is encoded. Therefore, it’s not smart to put sensitive data into the payload of your JWT! All this sounds great, but what about logging out? The answer is: There is no real logout. Or so to say: There is no immediate invalidation of the access token. And you will probably wonder: “But what if someone steals my access token?”. The best approach is to make your JWT access token expirable. The general rule is to make the access token short-lived and to use a refresh token (“remember me” token) for long lived sessions. Refresh token is stored as a resource (e.g. in database). When the access token expires, a refresh token is sent and checked in order to obtain a new access token. When you delete the refresh token from the data store (upon logout) and when the access token expires, then you will simply have to login again in order to obtain a new refresh and access token. For the sake of simplicity, we will only implement authentication with expirable an access token.
Akka HTTP implementation
In this example, beside the Akka HTTP library, we will use authentikat-jwt which is one of JWT implementations for Scala. Also, we will use circe and akka-http-circe JSON libraries for content unmarshalling. First, let’s create a new Scala class and its companion object – HttpApi. In the companion object, we will create a case class which will represent our login request:
final case class LoginRequest(username: String, password: String)
And we will define few properties for JWT:
private val tokenExpiryPeriodInDays = 1 private val secretKey = "super_secret_key" private val header = JwtHeader("HS256")
Expiry period will be part of claims. Now let’s add “login” route:
private def login = post { entity(as[LoginRequest]) { case lr @ LoginRequest("admin", "admin") => val claims = setClaims(lr.username, tokenExpiryPeriodInDays) respondWithHeader(RawHeader("Access-Token", JsonWebToken(header, claims, secretKey))) { complete(StatusCodes.OK) } case LoginRequest(_, _) => complete(StatusCodes.Unauthorized) } }
Let’s take a deeper look into this method. We are sending credentials as JSON content. Again, for the sake of simplicity, we will just check whether the username is “admin” and the password is “admin”, too. Regularly, this data should be checked in a separate service. If the credentials are incorrect, we simply return “unauthorized” HTTP status code. If the credentials are correct, we respond with “OK” status code and the JWT (the access token). JWT contains two properties in its claims:
user – which is just a username
expiredAt – the period after the JWT will not be valid anymore
Where “setClaims” method looks like this:
private def setClaims(username: String, expiryPeriodInDays: Long) = JwtClaimsSet( Map("user" -> username, "expiredAt" -> (System.currentTimeMillis() + TimeUnit.DAYS .toMillis(expiryPeriodInDays))) )
The login curl command looks like this:
curl -i -X POST localhost:8000 -d '{"username": "admin", "password": "admin"}' -H "Content-Type: application/json"
And response looks something like this:
HTTP/1.1 200 OK Access-Token: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjoiYWRtaW4iLCJleHBpcmVkQXQiOjE1MDI0NTkyNzUzMTV9.fgg-H47A3GswZF92Bwtvr0avkezg3TcPhCb_maYSLUY Server: akka-http/10.0.9 Date: Thu, 10 Aug 2017 13:47:55 GMT Content-Type: text/plain; charset=UTF-8 Content-Length: 2 OK%
And that’s it when the login mechanism comes in. Pretty simple.
The JWT can be obtained from the “Access-Token” header and saved on client side. Upon each request, we will have to send the JWT as a value of the “authorization” header in order to access secured resources. Now, we are going to make a special directive method “authenticated” which will check JWT validity.
private def authenticated: Directive1[Map[String, Any]] = optionalHeaderValueByName("Authorization").flatMap { case Some(jwt) if isTokenExpired(jwt) => complete(StatusCodes.Unauthorized -> "Token expired.") case Some(jwt) if JsonWebToken.validate(jwt, secretKey) => provide(getClaims(jwt).getOrElse(Map.empty[String, Any])) case _ => complete(StatusCodes.Unauthorized) }
The method first tries to obtain value from the “authorization” header. If it fails to obtain that value, it will simply respond with the status “unauthorized”. If it obtains the JWT, first it is going to check whether the token expired. If the token has expired, it is going to respond with “unauthorized” status code and the “token expired” message. If the token has not expired, it will check the validity of the token and if it is valid, it will “provide” claims so that we can use them further (e.g. for authorization). In all other cases, the method will return the “unauthorized” status code. This is what the “isTokenExpired” method looks like:
private def isTokenExpired(jwt: String) = getClaims(jwt) match { case Some(claims) => claims.get("expiredAt") match { case Some(value) => value.toLong < System.currentTimeMillis() case None => false } case None => false }
And this is how “getClaims” method looks like:
private def getClaims(jwt: String) = jwt match { case JsonWebToken(_, claims, _) => claims.asSimpleMap.toOption case _ => None }
Finally, we can apply our “authenticated” directive on some route which will make it secured requiring access token:
private def securedContent = get { authenticated { claims => complete(s"User ${claims.getOrElse("user", "")} accessed secured content!") } }
Final route will look like this:
def routes: Route = login ~ securedContent
In order to access resources returned by the “securedContent” route, we will have to provide the JWT we got upon login as a value of “Authorization” header:
curl -i localhost:8000 -H "Authorization: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjoiYWRtaW4iLCJleHBpcmVkQXQiOjE1MDI0NTkyNzUzMTV9.fgg-H47A3GswZF92Bwtvr0avkezg3TcPhCb_maYSLUY"
And the response will look like this:
HTTP/1.1 200 OK Server: akka-http/10.0.9 Date: Thu, 10 Aug 2017 14:08:28 GMT Content-Type: application/json Content-Length: 38 "User admin accessed secured content!"%
After we have finished with the building of routes, we are going to finally add the code in the HttpApi class which is going to be an actor used to “spawn” Akka HTTP server:
final class HttpApi(host: String, port: Int) extends Actor with ActorLogging { import HttpApi._ import context.dispatcher private implicit val materializer = ActorMaterializer() Http(context.system).bindAndHandle(routes, host, port).pipeTo(self) override def receive: Receive = { case ServerBinding(address) => log.info("Server successfully bound at {}:{}", address.getHostName, address.getPort) case Failure(cause) => log.error("Failed to bind server", cause) context.system.terminate() } }
A full working example can be found here.
The post JWT authentication with Akka HTTP appeared first on codecentric AG Blog.
JWT authentication with Akka HTTP published first on http://ift.tt/2vCN0WJ
0 notes
Text
JWT authentication with Akka HTTP
The authentication of RESTful APIs is quite an often asked question, so I decided to demonstrate basic authentication via JWT (JSON Web Token) in an example of an API built with Akka HTTP.
JWT working concept
Before we start with the actual coding, we should briefly recap how the mechanism of JWT authentication works. JWT itself is composed of three parts:
Header
Payload
Signature
Header contains a hashing algorithm (RSA, SHA256…) and token type. The payload section is going to be of most interest to you. The payload contains claims. And they usually contain information about the user along with some metadata. Lastly, JWT contains the signature which is used to verify the authenticity of the token sender. The token authentication process and access to secured resources is displayed in the following image.
RESTful APIs are stateless. Upon authentication, there is no a secured session which is generated on server and held in the context of the application followed by the cookie which is being returned and stored on the client side. In case of JWT authentication, we sign in using our credentials, the server generates an access token and we save it on the client side. In order to access secured content on the server, we have to send the access token upon each request (usually as a value of the authorization header). Then the server simply tries to verify the provided access token with a secret key. If the verification is successful, the server provides access to a secured resource. Otherwise, it rejects the request since the user is unauthorized. Our RESTful API remains stateless since the token is not stored anywhere on the server side. Also notice that payload is encoded. Therefore, it’s not smart to put sensitive data into the payload of your JWT! All this sounds great, but what about logging out? The answer is: There is no real logout. Or so to say: There is no immediate invalidation of the access token. And you will probably wonder: “But what if someone steals my access token?”. The best approach is to make your JWT access token expirable. The general rule is to make the access token short-lived and to use a refresh token (“remember me” token) for long lived sessions. Refresh token is stored as a resource (e.g. in database). When the access token expires, a refresh token is sent and checked in order to obtain a new access token. When you delete the refresh token from the data store (upon logout) and when the access token expires, then you will simply have to login again in order to obtain a new refresh and access token. For the sake of simplicity, we will only implement authentication with expirable an access token.
Akka HTTP implementation
In this example, beside the Akka HTTP library, we will use authentikat-jwt which is one of JWT implementations for Scala. Also, we will use circe and akka-http-circe JSON libraries for content unmarshalling. First, let’s create a new Scala class and its companion object – HttpApi. In the companion object, we will create a case class which will represent our login request:
final case class LoginRequest(username: String, password: String)
And we will define few properties for JWT:
private val tokenExpiryPeriodInDays = 1 private val secretKey = "super_secret_key" private val header = JwtHeader("HS256")
Expiry period will be part of claims. Now let’s add “login” route:
private def login = post { entity(as[LoginRequest]) { case lr @ LoginRequest("admin", "admin") => val claims = setClaims(lr.username, tokenExpiryPeriodInDays) respondWithHeader(RawHeader("Access-Token", JsonWebToken(header, claims, secretKey))) { complete(StatusCodes.OK) } case LoginRequest(_, _) => complete(StatusCodes.Unauthorized) } }
Let’s take a deeper look into this method. We are sending credentials as JSON content. Again, for the sake of simplicity, we will just check whether the username is “admin” and the password is “admin”, too. Regularly, this data should be checked in a separate service. If the credentials are incorrect, we simply return “unauthorized” HTTP status code. If the credentials are correct, we respond with “OK” status code and the JWT (the access token). JWT contains two properties in its claims:
user – which is just a username
expiredAt – the period after the JWT will not be valid anymore
Where “setClaims” method looks like this:
private def setClaims(username: String, expiryPeriodInDays: Long) = JwtClaimsSet( Map("user" -> username, "expiredAt" -> (System.currentTimeMillis() + TimeUnit.DAYS .toMillis(expiryPeriodInDays))) )
The login curl command looks like this:
curl -i -X POST localhost:8000 -d '{"username": "admin", "password": "admin"}' -H "Content-Type: application/json"
And response looks something like this:
HTTP/1.1 200 OK Access-Token: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjoiYWRtaW4iLCJleHBpcmVkQXQiOjE1MDI0NTkyNzUzMTV9.fgg-H47A3GswZF92Bwtvr0avkezg3TcPhCb_maYSLUY Server: akka-http/10.0.9 Date: Thu, 10 Aug 2017 13:47:55 GMT Content-Type: text/plain; charset=UTF-8 Content-Length: 2 OK%
And that’s it when the login mechanism comes in. Pretty simple.
The JWT can be obtained from the “Access-Token” header and saved on client side. Upon each request, we will have to send the JWT as a value of the “authorization” header in order to access secured resources. Now, we are going to make a special directive method “authenticated” which will check JWT validity.
private def authenticated: Directive1[Map[String, Any]] = optionalHeaderValueByName("Authorization").flatMap { case Some(jwt) if isTokenExpired(jwt) => complete(StatusCodes.Unauthorized -> "Token expired.") case Some(jwt) if JsonWebToken.validate(jwt, secretKey) => provide(getClaims(jwt).getOrElse(Map.empty[String, Any])) case _ => complete(StatusCodes.Unauthorized) }
The method first tries to obtain value from the “authorization” header. If it fails to obtain that value, it will simply respond with the status “unauthorized”. If it obtains the JWT, first it is going to check whether the token expired. If the token has expired, it is going to respond with “unauthorized” status code and the “token expired” message. If the token has not expired, it will check the validity of the token and if it is valid, it will “provide” claims so that we can use them further (e.g. for authorization). In all other cases, the method will return the “unauthorized” status code. This is what the “isTokenExpired” method looks like:
private def isTokenExpired(jwt: String) = getClaims(jwt) match { case Some(claims) => claims.get("expiredAt") match { case Some(value) => value.toLong < System.currentTimeMillis() case None => false } case None => false }
And this is how “getClaims” method looks like:
private def getClaims(jwt: String) = jwt match { case JsonWebToken(_, claims, _) => claims.asSimpleMap.toOption case _ => None }
Finally, we can apply our “authenticated” directive on some route which will make it secured requiring access token:
private def securedContent = get { authenticated { claims => complete(s"User ${claims.getOrElse("user", "")} accessed secured content!") } }
Final route will look like this:
def routes: Route = login ~ securedContent
In order to access resources returned by the “securedContent” route, we will have to provide the JWT we got upon login as a value of “Authorization” header:
curl -i localhost:8000 -H "Authorization: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjoiYWRtaW4iLCJleHBpcmVkQXQiOjE1MDI0NTkyNzUzMTV9.fgg-H47A3GswZF92Bwtvr0avkezg3TcPhCb_maYSLUY"
And the response will look like this:
HTTP/1.1 200 OK Server: akka-http/10.0.9 Date: Thu, 10 Aug 2017 14:08:28 GMT Content-Type: application/json Content-Length: 38 "User admin accessed secured content!"%
After we have finished with the building of routes, we are going to finally add the code in the HttpApi class which is going to be an actor used to “spawn” Akka HTTP server:
final class HttpApi(host: String, port: Int) extends Actor with ActorLogging { import HttpApi._ import context.dispatcher private implicit val materializer = ActorMaterializer() Http(context.system).bindAndHandle(routes, host, port).pipeTo(self) override def receive: Receive = { case ServerBinding(address) => log.info("Server successfully bound at {}:{}", address.getHostName, address.getPort) case Failure(cause) => log.error("Failed to bind server", cause) context.system.terminate() } }
A full working example can be found here.
The post JWT authentication with Akka HTTP appeared first on codecentric AG Blog.
JWT authentication with Akka HTTP published first on http://ift.tt/2fA8nUr
0 notes
Link
I can hear you say “but if there’s no actual unit() method in Scala (since we said that apply() in monad’s companion object serves as unit), what did you mean by saying “return in Haskell, unit in Scala? What, unit is a name for a function that doesn’t exist?” That’s a good observation, and yes, you are quite right. “Unit” is merely a convention for referencing monad’s identity operation in Scala. You can create a perfectly good custom monad and call its methods galvanize and dropTheBass instead of unit and flatMap if you wish. As long as they have proper signatures and do what they’re supposed to, it will conceptually be a monad.
0 notes
Text
MONAD I LOVE YOU NOW GET OUT OF MY TYPE SYSTEM

Gjeta Gjyshinca
SOFTWARE DEVELOPER, MORGAN STANLEY
A monad is a container that abstracts away execution.
Today we will concentrate on Futures, which allow us to write sync and non-blocking code. But they invade our type system.
The problem with most systems is the bottleneck of sequential code. What is a solution: Futures!
Scala gives you a for/yield comprehension abstraction to fix this, BUT it is just syntactic sugar for map ad flatMap. But if you move executions out of the for comprehension, they can ne lazily evaluated async. But now your code is double the size, and much less clear than declarative styles of programming.
Execution concerns have leaked into our type systems! VERY NO!
We want to solve the business problem, but we have to build a lot of structure around it to get it to run the way we want it. That's annoying.
If you have a blocking call that makes async futures, the blocking call is STILL blocking, you have to wait still, the block issue isn't solved.
Where does composability and debugging comes in? I don't want a future of what I want, I just want what I want.
What if you want more than one thing, you have to get sequences of future, now you need cancellable futures, now you can have Future[Seq[CancellableFuture[Metrics]]]. Now it is getting silly. But this is real code!
Type acrobatics are not fun! Why are we spending our mental energy playing with the type system.
A possible solution is 'free' Monads. Make all your code lazy, nothing runs until it is needed.
What about applicatives with effects, though? People don't want to deal with that. You cannot only hire phDs! It is hard enough hiring ANYBODY!
Multicore is here. Why isn't FP winning? IT is immutable! That solves thread safety! Referential transparency! That is repeatable execution: same input same output every time. Portability! Cacheable results! Purity! No side effects! Compossibility! You can map higher order functions to others.
FP is not doing well because it is not the code you want to write.
The problem is the platform. But category theory has provided a solution, but it is absurdly complicated, so 'free' monads really doesn't solve it.
If the solution requires a phD to understand, it is not a good solution.
Check out blog "What color is your function"
Does C++ solve memory management? NO! Does the JVM manage concurrency? NO!
What is a language that natively solves concurrency? SQL!!!!!! (shock!)
SQL solves for concurrency.
What is the runtime?
Garbage collectors allowed us to stop thinking about pointers. The runtime can give you a lot back. Can we make a runtime that makes it so you never hav to think about concurrency? Like SQL?
MorganStanley introduces the @node annotation to Scala. @node tells the runtime that the function is referentially transparent. The @node annotation turns the function into an async state machine. The developer doesn't have to think about futures, etc. anymore.
The @node annotation will behind the scenes batch data calls together if they re going to the same datastore. Since the reads on data stores are referentially transparent, the data is cacheable at a fixed point, so the @node automatically caches sequential call results.
The @node is a monad, but you as the developer do not have to THINK about it being a monad. And that is a HUGE win.
Thanks for the great talk, Gjeta!
0 notes
Text
300+ TOP PYSPARK Interview Questions and Answers
PYSPARK Interview Questions for freshers experienced :-
1. What is Pyspark? Pyspark is a bunch figuring structure which keeps running on a group of item equipment and performs information unification i.e., perusing and composing of wide assortment of information from different sources. In Spark, an undertaking is an activity that can be a guide task or a lessen task. Flash Context handles the execution of the activity and furthermore gives API’s in various dialects i.e., Scala, Java and Python to create applications and quicker execution when contrasted with MapReduce. 2. How is Spark not quite the same as MapReduce? Is Spark quicker than MapReduce? Truly, Spark is quicker than MapReduce. There are not many significant reasons why Spark is quicker than MapReduce and some of them are beneath: There is no tight coupling in Spark i.e., there is no compulsory principle that decrease must come after guide. Spark endeavors to keep the information “in-memory” however much as could be expected. In MapReduce, the halfway information will be put away in HDFS and subsequently sets aside longer effort to get the information from a source yet this isn’t the situation with Spark. 3. Clarify the Apache Spark Architecture. How to Run Spark applications? Apache Spark application contains two projects in particular a Driver program and Workers program. A group supervisor will be there in the middle of to communicate with these two bunch hubs. Sparkle Context will stay in contact with the laborer hubs with the assistance of Cluster Manager. Spark Context resembles an ace and Spark laborers resemble slaves. Workers contain the agents to run the activity. In the event that any conditions or contentions must be passed, at that point Spark Context will deal with that. RDD’s will dwell on the Spark Executors. You can likewise run Spark applications locally utilizing a string, and on the off chance that you need to exploit appropriated conditions you can take the assistance of S3, HDFS or some other stockpiling framework. 4. What is RDD? RDD represents Resilient Distributed Datasets (RDDs). In the event that you have enormous measure of information, and isn’t really put away in a solitary framework, every one of the information can be dispersed over every one of the hubs and one subset of information is called as a parcel which will be prepared by a specific assignment. RDD’s are exceptionally near information parts in MapReduce. 5. What is the job of blend () and repartition () in Map Reduce? Both mix and repartition are utilized to change the quantity of segments in a RDD however Coalesce keeps away from full mix. On the off chance that you go from 1000 parcels to 100 segments, there won’t be a mix, rather every one of the 100 new segments will guarantee 10 of the present allotments and this does not require a mix. Repartition plays out a blend with mix. Repartition will result in the predefined number of parcels with the information dispersed utilizing a hash professional. 6. How would you determine the quantity of parcels while making a RDD? What are the capacities? You can determine the quantity of allotments while making a RDD either by utilizing the sc.textFile or by utilizing parallelize works as pursues: Val rdd = sc.parallelize(data,4) val information = sc.textFile(“path”,4) 7. What are activities and changes? Changes make new RDD’s from existing RDD and these changes are sluggish and won’t be executed until you call any activity. Example:: map(), channel(), flatMap(), and so forth., Activities will return consequences of a RDD. Example:: lessen(), tally(), gather(), and so on., 8. What is Lazy Evaluation? On the off chance that you make any RDD from a current RDD that is called as change and except if you consider an activity your RDD won’t be emerged the reason is Spark will defer the outcome until you truly need the outcome in light of the fact that there could be a few circumstances you have composed something and it turned out badly and again you need to address it in an intuitive manner it will expand the time and it will make un-essential postponements. Additionally, Spark improves the required figurings and takes clever choices which is beyond the realm of imagination with line by line code execution. Sparkle recoups from disappointments and moderate laborers. 9. Notice a few Transformations and Actions Changes map (), channel(), flatMap() Activities diminish(), tally(), gather() 10. What is the job of store() and continue()? At whatever point you need to store a RDD into memory with the end goal that the RDD will be utilized on different occasions or that RDD may have made after loads of complex preparing in those circumstances, you can exploit Cache or Persist. You can make a RDD to be continued utilizing the persevere() or store() works on it. The first occasion when it is processed in an activity, it will be kept in memory on the hubs. When you call persevere(), you can indicate that you need to store the RDD on the plate or in the memory or both. On the off chance that it is in-memory, regardless of whether it ought to be put away in serialized organization or de-serialized position, you can characterize every one of those things. reserve() resembles endure() work just, where the capacity level is set to memory as it were.

11. What are Accumulators? Collectors are the compose just factors which are introduced once and sent to the specialists. These specialists will refresh dependent on the rationale composed and sent back to the driver which will total or process dependent on the rationale. No one but driver can get to the collector’s esteem. For assignments, Accumulators are compose as it were. For instance, it is utilized to include the number blunders seen in RDD crosswise over laborers. 12. What are Broadcast Variables? Communicate Variables are the perused just shared factors. Assume, there is a lot of information which may must be utilized on various occasions in the laborers at various stages. 13. What are the enhancements that engineer can make while working with flash? Flash is memory serious, whatever you do it does in memory. Initially, you can alter to what extent flash will hold up before it times out on every one of the periods of information region information neigh borhood process nearby hub nearby rack neighborhood Any. Channel out information as ahead of schedule as could be allowed. For reserving, pick carefully from different capacity levels. Tune the quantity of parcels in sparkle. 14. What is Spark SQL? Flash SQL is a module for organized information handling where we exploit SQL questions running on the datasets. 15. What is a Data Frame? An information casing resembles a table, it got some named sections which composed into segments. You can make an information outline from a document or from tables in hive, outside databases SQL or NoSQL or existing RDD’s. It is practically equivalent to a table. 16. How might you associate Hive to Spark SQL? The principal significant thing is that you need to place hive-site.xml record in conf index of Spark. At that point with the assistance of Spark session object we can develop an information outline as, 17. What is GraphX? Ordinarily you need to process the information as charts, since you need to do some examination on it. It endeavors to perform Graph calculation in Spark in which information is available in documents or in RDD’s. GraphX is based on the highest point of Spark center, so it has got every one of the abilities of Apache Spark like adaptation to internal failure, scaling and there are numerous inbuilt chart calculations too. GraphX binds together ETL, exploratory investigation and iterative diagram calculation inside a solitary framework. You can see indistinguishable information from the two charts and accumulations, change and unite diagrams with RDD effectively and compose custom iterative calculations utilizing the pregel API. GraphX contends on execution with the quickest diagram frameworks while holding Spark’s adaptability, adaptation to internal failure and convenience. 18. What is PageRank Algorithm? One of the calculation in GraphX is PageRank calculation. Pagerank measures the significance of every vertex in a diagram accepting an edge from u to v speaks to a supports of v’s significance by u. For exmaple, in Twitter if a twitter client is trailed by numerous different clients, that specific will be positioned exceptionally. GraphX accompanies static and dynamic executions of pageRank as techniques on the pageRank object. 19. What is Spark Streaming? At whatever point there is information streaming constantly and you need to process the information as right on time as could reasonably be expected, all things considered you can exploit Spark Streaming. 20. What is Sliding Window? In Spark Streaming, you need to determine the clump interim. In any case, with Sliding Window, you can indicate what number of last clumps must be handled. In the beneath screen shot, you can see that you can indicate the clump interim and what number of bunches you need to process. 21. Clarify the key highlights of Apache Spark. Coming up next are the key highlights of Apache Spark: Polyglot Speed Multiple Format Support Lazy Evaluation Real Time Computation Hadoop Integration Machine Learning 22. What is YARN? Like Hadoop, YARN is one of the key highlights in Spark, giving a focal and asset the executives stage to convey adaptable activities over the bunch. YARN is a conveyed holder chief, as Mesos for instance, while Spark is an information preparing instrument. Sparkle can keep running on YARN, a similar way Hadoop Map Reduce can keep running on YARN. Running Spark on YARN requires a double dispersion of Spark as based on YARN support. 23. Do you have to introduce Spark on all hubs of YARN bunch? No, in light of the fact that Spark keeps running over YARN. Flash runs autonomously from its establishment. Sparkle has a few alternatives to utilize YARN when dispatching employments to the group, as opposed to its very own inherent supervisor, or Mesos. Further, there are a few arrangements to run YARN. They incorporate ace, convey mode, driver-memory, agent memory, agent centers, and line. 24. Name the parts of Spark Ecosystem. Spark Core: Base motor for huge scale parallel and disseminated information handling Spark Streaming: Used for handling constant spilling information Spark SQL: Integrates social handling with Spark’s useful programming API GraphX: Graphs and chart parallel calculation MLlib: Performs AI in Apache Spark 25. How is Streaming executed in Spark? Clarify with precedents. Sparkle Streaming is utilized for handling constant gushing information. Along these lines it is a helpful expansion deeply Spark API. It empowers high-throughput and shortcoming tolerant stream handling of live information streams. The crucial stream unit is DStream which is fundamentally a progression of RDDs (Resilient Distributed Datasets) to process the constant information. The information from various sources like Flume, HDFS is spilled lastly handled to document frameworks, live dashboards and databases. It is like bunch preparing as the information is partitioned into streams like clusters. 26. How is AI executed in Spark? MLlib is adaptable AI library given by Spark. It goes for making AI simple and adaptable with normal learning calculations and use cases like bunching, relapse separating, dimensional decrease, and alike. 27. What record frameworks does Spark support? The accompanying three document frameworks are upheld by Spark: Hadoop Distributed File System (HDFS). Local File framework. Amazon S3 28. What is Spark Executor? At the point when SparkContext associates with a group chief, it obtains an Executor on hubs in the bunch. Representatives are Spark forms that run controls and store the information on the laborer hub. The last assignments by SparkContext are moved to agents for their execution. 29. Name kinds of Cluster Managers in Spark. The Spark system underpins three noteworthy sorts of Cluster Managers: Standalone: An essential administrator to set up a group. Apache Mesos: Generalized/regularly utilized group administrator, additionally runs Hadoop MapReduce and different applications. YARN: Responsible for asset the board in Hadoop. 30. Show some utilization situations where Spark beats Hadoop in preparing. Sensor Data Processing: Apache Spark’s “In-memory” figuring works best here, as information is recovered and joined from various sources. Real Time Processing: Spark is favored over Hadoop for constant questioning of information. for example Securities exchange Analysis, Banking, Healthcare, Telecommunications, and so on. Stream Processing: For preparing logs and identifying cheats in live streams for cautions, Apache Spark is the best arrangement. Big Data Processing: Spark runs upto multiple times quicker than Hadoop with regards to preparing medium and enormous estimated datasets. 31. By what method can Spark be associated with Apache Mesos? To associate Spark with Mesos: Configure the sparkle driver program to associate with Mesos. Spark paired bundle ought to be in an area open by Mesos. Install Apache Spark in a similar area as that of Apache Mesos and design the property ‘spark.mesos.executor.home’ to point to the area where it is introduced. 32. How is Spark SQL not the same as HQL and SQL? Flash SQL is a unique segment on the Spark Core motor that supports SQL and Hive Query Language without changing any sentence structure. It is conceivable to join SQL table and HQL table to Spark SQL. 33. What is ancestry in Spark? How adaptation to internal failure is accomplished in Spark utilizing Lineage Graph? At whatever point a progression of changes are performed on a RDD, they are not assessed promptly, however languidly. At the point when another RDD has been made from a current RDD every one of the conditions between the RDDs will be signed in a diagram. This chart is known as the ancestry diagram. Consider the underneath situation Ancestry chart of every one of these activities resembles: First RDD Second RDD (applying map) Third RDD (applying channel) Fourth RDD (applying check) This heredity diagram will be helpful on the off chance that if any of the segments of information is lost. Need to set spark.logLineage to consistent with empower the Rdd.toDebugString() gets empowered to print the chart logs. 34. What is the contrast between RDD , DataFrame and DataSets? RDD : It is the structure square of Spark. All Dataframes or Dataset is inside RDDs. It is lethargically assessed permanent gathering objects RDDS can be effectively reserved if a similar arrangement of information should be recomputed. DataFrame : Gives the construction see ( lines and segments ). It tends to be thought as a table in a database. Like RDD even dataframe is sluggishly assessed. It offers colossal execution due to a.) Custom Memory Management – Data is put away in off load memory in twofold arrangement .No refuse accumulation because of this. Optimized Execution Plan – Query plans are made utilizing Catalyst analyzer. DataFrame Limitations : Compile Time wellbeing , i.e no control of information is conceivable when the structure isn’t known. DataSet : Expansion of DataFrame DataSet Feautures – Provides best encoding component and not at all like information edges supports arrange time security. 35. What is DStream? Discretized Stream (DStream) Apache Spark Discretized Stream is a gathering of RDDS in grouping . Essentially, it speaks to a flood of information or gathering of Rdds separated into little clusters. In addition, DStreams are based on Spark RDDs, Spark’s center information reflection. It likewise enables Streaming to flawlessly coordinate with some other Apache Spark segments. For example, Spark MLlib and Spark SQL. 36. What is the connection between Job, Task, Stage ? Errand An errand is a unit of work that is sent to the agent. Each stage has some assignment, one undertaking for every segment. The Same assignment is done over various segments of RDD. Occupation The activity is parallel calculation comprising of numerous undertakings that get produced in light of activities in Apache Spark. Stage Each activity gets isolated into littler arrangements of assignments considered stages that rely upon one another. Stages are named computational limits. All calculation is impossible in single stage. It is accomplished over numerous stages. 37. Clarify quickly about the parts of Spark Architecture? Flash Driver: The Spark driver is the procedure running the sparkle setting . This driver is in charge of changing over the application to a guided diagram of individual strides to execute on the bunch. There is one driver for each application. 38. How might you limit information moves when working with Spark? The different manners by which information moves can be limited when working with Apache Spark are: Communicate and Accumilator factors 39. When running Spark applications, is it important to introduce Spark on every one of the hubs of YARN group? Flash need not be introduced when running a vocation under YARN or Mesos in light of the fact that Spark can execute over YARN or Mesos bunches without influencing any change to the group. 40. Which one will you decide for an undertaking – Hadoop MapReduce or Apache Spark? The response to this inquiry relies upon the given undertaking situation – as it is realized that Spark utilizes memory rather than system and plate I/O. In any case, Spark utilizes enormous measure of RAM and requires devoted machine to create viable outcomes. So the choice to utilize Hadoop or Spark changes powerfully with the necessities of the venture and spending plan of the association. 41. What is the distinction among continue() and store() endure () enables the client to determine the capacity level while reserve () utilizes the default stockpiling level. 42. What are the different dimensions of constancy in Apache Spark? Apache Spark naturally endures the mediator information from different mix tasks, anyway it is regularly proposed that clients call persevere () technique on the RDD on the off chance that they intend to reuse it. Sparkle has different tirelessness levels to store the RDDs on circle or in memory or as a mix of both with various replication levels. 43. What are the disservices of utilizing Apache Spark over Hadoop MapReduce? Apache Spark’s in-memory ability now and again comes a noteworthy barrier for cost effective preparing of huge information. Likewise, Spark has its own record the board framework and consequently should be incorporated with other cloud based information stages or apache hadoop. 44. What is the upside of Spark apathetic assessment? Apache Spark utilizes sluggish assessment all together the advantages: Apply Transformations tasks on RDD or “stacking information into RDD” isn’t executed quickly until it sees an activity. Changes on RDDs and putting away information in RDD are languidly assessed. Assets will be used in a superior manner if Spark utilizes sluggish assessment. Lazy assessment advances the plate and memory utilization in Spark. The activities are activated just when the information is required. It diminishes overhead. 45. What are advantages of Spark over MapReduce? Because of the accessibility of in-memory handling, Spark executes the preparing around 10 to multiple times quicker than Hadoop MapReduce while MapReduce utilizes diligence stockpiling for any of the information handling errands. Dissimilar to Hadoop, Spark gives inbuilt libraries to play out numerous errands from a similar center like cluster preparing, Steaming, Machine learning, Interactive SQL inquiries. Be that as it may, Hadoop just backings cluster handling. Hadoop is very plate subordinate while Spark advances reserving and in-memory information stockpiling. 46. How DAG functions in Spark? At the point when an Action is approached Spark RDD at an abnormal state, Spark presents the heredity chart to the DAG Scheduler. Activities are separated into phases of the errand in the DAG Scheduler. A phase contains errand dependent on the parcel of the info information. The DAG scheduler pipelines administrators together. It dispatches task through group chief. The conditions of stages are obscure to the errand scheduler.The Workers execute the undertaking on the slave. 47. What is the hugeness of Sliding Window task? Sliding Window controls transmission of information bundles between different PC systems. Sparkle Streaming library gives windowed calculations where the changes on RDDs are connected over a sliding window of information. At whatever point the window slides, the RDDs that fall inside the specific window are consolidated and worked upon to create new RDDs of the windowed DStream. 48. What are communicated and Accumilators? Communicate variable: On the off chance that we have an enormous dataset, rather than moving a duplicate of informational collection for each assignment, we can utilize a communicate variable which can be replicated to every hub at one timeand share similar information for each errand in that hub. Communicate variable assistance to give a huge informational collection to every hub. Collector: Flash capacities utilized factors characterized in the driver program and nearby replicated of factors will be produced. Aggregator are shared factors which help to refresh factors in parallel during execution and offer the outcomes from specialists to the driver. 49. What are activities ? An activity helps in bringing back the information from RDD to the nearby machine. An activity’s execution is the aftereffect of all recently made changes. lessen() is an activity that executes the capacity passed over and over until one esteem assuming left. take() move makes every one of the qualities from RDD to nearby hub. 50. Name kinds of Cluster Managers in Spark. The Spark system bolsters three noteworthy kinds of Cluster Managers: Independent : An essential administrator to set up a bunch. Apache Mesos : Summed up/ordinarily utilized group director, additionally runs Hadoop MapReduce and different applications. PYSPARK Questions and Answers Pdf Download Read the full article
0 notes
Text
Back2Basics: For Expression Served From Scala Magic Box - I.
Back2Basics: For Expression Served From Scala Magic Box – I.
In Scala, lots of the things are kind of a magic for Java developers. Sometimes this magic amazes the code but sometimes it has ruined the developer’s life. Today we are going to discuss one of the magic called “For Expression“, “For Comprehension” or as per Java developers like me called “For Loop“.
Scala developers familiar with for comprehension and most of them have the idea, how this for com…
View On WordPress
#compiler#flatMap#for#forexpression#Functional Programming#map#opensource#scala#technology#withFilter#yield
0 notes