#hadoop installation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Note
We used Hadoop at school today. We had 4 hours. We spent 2 of those installing, you guessed it, Java™ 8. Some poor soul did everything with the JRE instead of the JDK and had to start over. I have so much respect for people who deal with java in their actual job, i can't stand the damn thing.
thanks, that means a lot.
🙏
4 notes
·
View notes
Text
How to Make AI: A Guide to An AI Developer’s Tech Stack
Globally, artificial intelligence (AI) is revolutionizing a wide range of industries, including healthcare and finance. Knowing the appropriate tools and technologies is crucial if you want to get into AI development. A well-organized tech stack can make all the difference, regardless of your level of experience as a developer. The top IT services in Qatar can assist you in successfully navigating AI development if you require professional advice.

Knowing the Tech Stack for AI Development
Programming languages, frameworks, cloud services, and hardware resources are all necessary for AI development. Let's examine the key elements of a tech stack used by an AI developer. 1. Programming Languages for the Development of AI
The first step in developing AI is selecting the appropriate programming language. Among the languages that are most frequently used are:
Because of its many libraries, including TensorFlow, PyTorch, and Scikit-Learn, Python is the most widely used language for artificial intelligence (AI) and machine learning (ML). • R: Perfect for data analysis and statistical computing. • Java: Used in big data solutions and enterprise AI applications. • C++: Suggested for AI-powered gaming apps and high-performance computing. Integrating web design services with AI algorithms can improve automation and user experience when creating AI-powered web applications.
2. Frameworks for AI and Machine Learning
AI/ML frameworks offer pre-built features and resources to speed up development. Among the most widely utilized frameworks are: • TensorFlow: Google's open-source deep learning application library. • PyTorch: A versatile deep learning framework that researchers prefer. • Scikit-Learn: Perfect for conventional machine learning tasks such as regression and classification.
Keras is a high-level TensorFlow-based neural network API. Making the most of these frameworks is ensured by utilizing AI/ML software development expertise in order to stay ahead of AI innovation.
3. Tools for Data Processing and Management Large datasets are necessary for AI model training and optimization. Pandas, a robust Python data manipulation library, is one of the most important tools for handling and processing AI data. • Apache Spark: A distributed computing platform designed to manage large datasets. • Google BigQuery: An online tool for organizing and evaluating sizable datasets. Hadoop is an open-source framework for processing large amounts of data and storing data in a distributed manner. To guarantee flawless performance, AI developers must incorporate powerful data processing capabilities, which are frequently offered by the top IT services in Qatar.

4. AI Development Cloud Platforms
Because it offers scalable resources and computational power, cloud computing is essential to the development of AI. Among the well-known cloud platforms are Google Cloud AI, which provides AI development tools, AutoML, and pre-trained models. • Microsoft Azure AI: This platform offers AI-driven automation, cognitive APIs, and machine learning services. • Amazon Web Services (AWS) AI: Offers computing resources, AI-powered APIs, and deep learning AMIs. Integrating cloud services with web design services facilitates the smooth deployment and upkeep of AI-powered web applications.
5. AI Hardware and Infrastructure
The development of AI demands a lot of processing power. Important pieces of hardware consist of: • GPUs (Graphics Processing Units): Crucial for AI training and deep learning. • Tensor Processing Units (TPUs): Google's hardware accelerators designed specifically for AI. • Edge Computing Devices: These are used to install AI models on mobile and Internet of Things devices.
To maximize hardware utilization, companies looking to implement AI should think about hiring professionals to develop AI/ML software.
Top Techniques for AI Development
1. Choosing the Appropriate AI Model Depending on the needs of your project, select between supervised, unsupervised, and reinforcement learning models.
2. Preprocessing and Augmenting Data
To decrease bias and increase model accuracy, clean and normalize the data.
3. Constant Model Training and Improvement
For improved performance, AI models should be updated frequently with fresh data.
4. Ensuring Ethical AI Procedures
To avoid prejudice, maintain openness, and advance justice, abide by AI ethics guidelines.
In conclusion
A strong tech stack, comprising cloud services, ML frameworks, programming languages, and hardware resources, is necessary for AI development. Working with the top IT services in Qatar can give you the know-how required to create and implement AI solutions successfully, regardless of whether you're a business or an individual developer wishing to use AI. Furthermore, combining AI capabilities with web design services can improve automation, productivity, and user experience. Custom AI solutions and AI/ML software development are our areas of expertise at Aamal Technology Solutions. Get in touch with us right now to find out how AI can transform your company!
#Best IT Service Provider in Qatar#Top IT Services in Qatar#IT services in Qatar#web designing services in qatar#web designing services#Mobile App Development#Mobile App Development services in qatar
0 notes
Text
Big Data Analytics Training - Learn Hadoop, Spark

Big Data Analytics Training – Learn Hadoop, Spark & Boost Your Career
Meta Title: Big Data Analytics Training | Learn Hadoop & Spark Online Meta Description: Enroll in Big Data Analytics Training to master Hadoop and Spark. Get hands-on experience, industry certification, and job-ready skills. Start your big data career now!
Introduction: Why Big Data Analytics?
In today’s digital world, data is the new oil. Organizations across the globe are generating vast amounts of data every second. But without proper analysis, this data is meaningless. That’s where Big Data Analytics comes in. By leveraging tools like Hadoop and Apache Spark, businesses can extract powerful insights from large data sets to drive better decisions.
If you want to become a data expert, enrolling in a Big Data Analytics Training course is the first step toward a successful career.
What is Big Data Analytics?
Big Data Analytics refers to the complex process of examining large and varied data sets—known as big data—to uncover hidden patterns, correlations, market trends, and customer preferences. It helps businesses make informed decisions and gain a competitive edge.
Why Learn Hadoop and Spark?
Hadoop: The Backbone of Big Data
Hadoop is an open-source framework that allows distributed processing of large data sets across clusters of computers. It includes:
HDFS (Hadoop Distributed File System) for scalable storage
MapReduce for parallel data processing
Hive, Pig, and Sqoop for data manipulation
Apache Spark: Real-Time Data Engine
Apache Spark is a fast and general-purpose cluster computing system. It performs:
Real-time stream processing
In-memory data computing
Machine learning and graph processing
Together, Hadoop and Spark form the foundation of any robust big data architecture.
What You'll Learn in Big Data Analytics Training
Our expert-designed course covers everything you need to become a certified Big Data professional:
1. Big Data Basics
What is Big Data?
Importance and applications
Hadoop ecosystem overview
2. Hadoop Essentials
Installation and configuration
Working with HDFS and MapReduce
Hive, Pig, Sqoop, and Flume
3. Apache Spark Training
Spark Core and Spark SQL
Spark Streaming
MLlib for machine learning
Integrating Spark with Hadoop
4. Data Processing Tools
Kafka for data ingestion
NoSQL databases (HBase, Cassandra)
Data visualization using tools like Power BI
5. Live Projects & Case Studies
Real-time data analytics projects
End-to-end data pipeline implementation
Domain-specific use cases (finance, healthcare, e-commerce)
Who Should Enroll?
This course is ideal for:
IT professionals and software developers
Data analysts and database administrators
Engineering and computer science students
Anyone aspiring to become a Big Data Engineer
Benefits of Our Big Data Analytics Training
100% hands-on training
Industry-recognized certification
Access to real-time projects
Resume and job interview support
Learn from certified Hadoop and Spark experts
SEO Keywords Targeted
Big Data Analytics Training
Learn Hadoop and Spark
Big Data course online
Hadoop training and certification
Apache Spark training
Big Data online training with certification
Final Thoughts
The demand for Big Data professionals continues to rise as more businesses embrace data-driven strategies. By mastering Hadoop and Spark, you position yourself as a valuable asset in the tech industry. Whether you're looking to switch careers or upskill, Big Data Analytics Training is your pathway to success.
0 notes
Text
Creating a Scalable Amazon EMR Cluster on AWS in Minutes

Minutes to Scalable EMR Cluster on AWS
AWS EMR cluster
Spark helps you easily build up an Amazon EMR cluster to process and analyse data. This page covers Plan and Configure, Manage, and Clean Up.
This detailed guide to cluster setup:
Amazon EMR Cluster Configuration
Spark is used to launch an example cluster and run a PySpark script in the course. You must complete the “Before you set up Amazon EMR” exercises before starting.
While functioning live, the sample cluster will incur small per-second charges under Amazon EMR pricing, which varies per location. To avoid further expenses, complete the tutorial’s final cleaning steps.
The setup procedure has numerous steps:
Amazon EMR Cluster and Data Resources Configuration
This initial stage prepares your application and input data, creates your data storage location, and starts the cluster.
Setting Up Amazon EMR Storage:
Amazon EMR supports several file systems, but this article uses EMRFS to store data in an S3 bucket. EMRFS reads and writes to Amazon S3 in Hadoop.
This lesson requires a specific S3 bucket. Follow the Amazon Simple Storage Service Console User Guide to create a bucket.
You must create the bucket in the same AWS region as your Amazon EMR cluster launch. Consider US West (Oregon) us-west-2.
Amazon EMR bucket and folder names are limited. Lowercase letters, numerals, periods (.), and hyphens (-) can be used, but bucket names cannot end in numbers and must be unique across AWS accounts.
The bucket output folder must be empty.
Small Amazon S3 files may incur modest costs, but if you’re within the AWS Free Tier consumption limitations, they may be free.
Create an Amazon EMR app using input data:
Standard preparation involves uploading an application and its input data to Amazon S3. Submit work with S3 locations.
The PySpark script examines 2006–2020 King County, Washington food business inspection data to identify the top ten restaurants with the most “Red” infractions. Sample rows of the dataset are presented.
Create a new file called health_violations.py and copy the source code to prepare the PySpark script. Next, add this file to your new S3 bucket. Uploading instructions are in Amazon Simple Storage Service’s Getting Started Guide.
Download and unzip the food_establishment_data.zip file, save the CSV file to your computer as food_establishment_data.csv, then upload it to the same S3 bucket to create the example input data. Again, see the Amazon Simple Storage Service Getting Started Guide for uploading instructions.
“Prepare input data for processing with Amazon EMR” explains EMR data configuration.
Create an Amazon EMR Cluster:
Apache Spark and the latest Amazon EMR release allow you to launch the example cluster after setting up storage and your application. This may be done with the AWS Management Console or CLI.
Console Launch:
Launch Amazon EMR after login into AWS Management Console.
Start with “EMR on EC2” > “Clusters” > “Create cluster”. Note the default options for “Release,” “Instance type,” “Number of instances,” and “Permissions”.
Enter a unique “Cluster name” without <, >, $, |, or `. Install Spark from “Applications” by selecting “Spark”. Note: Applications must be chosen before launching the cluster. Check “Cluster logs” to publish cluster-specific logs to Amazon S3. The default destination is s3://amzn-s3-demo-bucket/logs. Replace with S3 bucket. A new ‘logs’ subfolder is created for log files.
Select your two EC2 keys under “Security configuration and permissions”. For the instance profile, choose “EMR_DefaultRole” for Service and “EMR_EC2_DefaultRole” for IAM.
Choose “Create cluster”.
The cluster information page appears. As the EMR fills the cluster, its “Status” changes from “Starting” to “Running” to “Waiting”. Console view may require refreshing. Status switches to “Waiting” when cluster is ready to work.
AWS CLI’s aws emr create-default-roles command generates IAM default roles.
Create a Spark cluster with aws emr create-cluster. Name your EC2 key pair –name, set –instance-type, –instance-count, and –use-default-roles. The sample command’s Linux line continuation characters () may need Windows modifications.
Output will include ClusterId and ClusterArn. Remember your ClusterId for later.
Check your cluster status using aws emr describe-cluster –cluster-id myClusterId>.
The result shows the Status object with State. As EMR deployed the cluster, the State changed from STARTING to RUNNING to WAITING. When ready, operational, and up, the cluster becomes WAITING.
Open SSH Connections
Before connecting to your operating cluster via SSH, update your cluster security groups to enable incoming connections. Amazon EC2 security groups are virtual firewalls. At cluster startup, EMR created default security groups: ElasticMapReduce-slave for core and task nodes and ElasticMapReduce-master for main.
Console-based SSH authorisation:
Authorisation is needed to manage cluster VPC security groups.
Launch Amazon EMR after login into AWS Management Console.
Select the updateable cluster under “Clusters”. The “Properties” tab must be selected.
Choose “Networking” and “EC2 security groups (firewall)” from the “Properties” tab. Select the security group link under “Primary node”.
EC2 console is open. Select “Edit inbound rules” after choosing “Inbound rules”.
Find and delete any public access inbound rule (Type: SSH, Port: 22, Source: Custom 0.0.0.0/0). Warning: The ElasticMapReduce-master group’s pre-configured rule that allowed public access and limited traffic to reputable sources should be removed.
Scroll down and click “Add Rule”.
Choose “SSH” for “Type” to set Port Range to 22 and Protocol to TCP.
Enter “My IP” for “Source” or a range of “Custom” trustworthy client IP addresses. Remember that dynamic IPs may need updating. Select “Save.”
When you return to the EMR console, choose “Core and task nodes” and repeat these steps to provide SSH access to those nodes.
Connecting with AWS CLI:
SSH connections may be made using the AWS CLI on any operating system.
Use the command: AWS emr ssh –cluster-id –key-pair-file <~/mykeypair.key>. Replace with your ClusterId and the full path to your key pair file.
After connecting, visit /mnt/var/log/spark to examine master node Spark logs.
The next critical stage following cluster setup and access configuration is phased work submission.
#AmazonEMRcluster#EMRcluster#DataResources#SSHConnections#AmazonEC2#AWSCLI#technology#technews#technologynews#news#govindhtech
0 notes
Text
The emergence of Big Data as the new-age technology has changed the landscape of data science. And, one of the most extensively used and popular Big Data frameworks is Hadoop. Some of the top players in the industry, including Apple, Facebook, Microsoft, Intel, Yahoo, eBay, Amazon, and Hortonworks, use Hadoop for all their Big Data needs. Developed by Doug Cutting and Michale J., Hadoop is an open-source, Java-based framework for storing and processing large datasets. It is a collection of libraries that provide the framework for processing massive datasets across thousands of computers in clusters.Consisting of both hardware and software services used for mining structured and unstructured data for extracting hidden patterns, Hadoop can serve as a backbone for any Big Data operation. Being a highly scalable and inexpensive option, Hadoop is steadily gaining traction in the industry. This is not only escalating the demand for skilled Hadoop developers but also increasing the craze for Hadoop certification training courses.Who is a Hadoop developer?A Hadoop developer is a professional coder and programmer with extensive knowledge in Big Data tools and technologies. They know the Hadoop framework inside out and are responsible for the design and development, configuration, installation and implementation of the Hadoop framework. To put it in simple words, a Hadoop developer is just like a software developer, but the field of expertise is Big Data.Today, there is a huge demand for Hadoop developers in the market. According to recent studies, it is estimated that 80% of all Fortune 500 companies will have adopted Hadoop by 2020. Companies across various sectors of the industry are hiring skilled Hadoop developers to solve complex analytical challenges related to Big Data. Apart from designing and developing the Hadoop framework to fit company objectives and client demands, Hadoop developers can also fix wrongly configured Hadoop clusters.Armed with the requisite knowledge of Big Data tools and technologies, Hadoop Developers can help companies uncover the potential of Big Data to enhance business value. They can build scalable and flexible Big Data solutions for companies that can be deployed both onsite or on cloud platforms according to client needs. By and large, a Hadoop developer is the answer to all the business challenges associated with distributed data processing on a vast scale. How to Become a Hadoop developer?According to a recent report by Allied Market Research, by 2021, the global Hadoop Market is predicted to expand exponentially to reach $84.6 billion at a compound annual growth rate of 63.4%. What does this mean? It only goes to show that the demand for Hadoop developers is to increase significantly in the years to come. So, if you are ready to strike when the iron is hot, here’s the pathway to becoming a Hadoop developer.1. Get Your Education RightThe good thing about Hadoop is that it doesn’t require a bachelor’s degree in computer science. You could be a graduate in statistics, mathematics, analytics, physics or any other science stream to explore opportunities in the Hadoop domain. What is mandatory is the sound knowledge of more than one programming language and distributed systems. Most companies recruiting Hadoop developers always look for candidates who are skilled coders/programmers with a good grasp on languages like Python, R, Java, SQL, and Scala. If you are well-versed in databases like NoSQL, MySQL, Oracle, and MongoDB, then the better are your chances of being hired. 2. Acquire Hadoop and Related Domain KnowledgeA Hadoop developer must have an in-depth understanding of the Hadoop ecosystem, including HDFS, YARN (Yet Another Resource Negotiator) and MapReduce. Apart from this, a Hadoop developer must:be proficient in back-end programming, particularly Java, JS, Node.js and OOAD.be well-versed in database structures, theories, principles, and practices.be familiar with data loading tools like Flume and Sqoop.
be able to write high-performance, scalable and reliable codes.be well-versed in Hadoop, HBase, Hive, Pig, and HBase.be able to write MapReduce jobs.be able to write Pig Latin scripts.have hands-on working experience in HiveQL.have sound knowledge of data warehouse infrastructure.have a basic understanding of operating systems (Linux, Windows, and iOS).have in-depth knowledge of multi-threading and concurrency concepts.3. Build on the other Essential SkillsTo be a successful Hadoop developer, you must also have the following skills:Analytical skills - Hadoop developers must understand and analyze the needs of customers and design solutions accordingly. Creativity - Just like software developers, Hadoop developers must be creative and innovative in their workspace.Detail-Oriented - Software development takes place in parts and phases. Hence, attention to detail at every stage is essential to build well-designed and integrated products.Problem-Solving Skills - Hadoop developers must be expert problem solvers who can resolve issues as and when they arise in the course of the product development process. Communication Skills - Since Hadoop developers work as a part of a team, they must communicate effectively with other team members. This makes the development process seamless and smooth. Also, they should be able to explain to customers about the working of software solutions and respond to their queries.4. Get a Hadoop CertificationCertifications are an excellent way to hone your knowledge and skill set. You get to focus on a particular domain and learn about the new concepts and latest trends in the same. Thankfully, there are plenty of platforms offering Hadoop certifications with Cloudera, MapR, IBM, and Hortonworks being the top few.Being a Hadoop-certified professional has numerous advantages:Having a Hadoop certification allows you to stand out amongst your peers. Besides, you become a valuable asset for your organization as you can add value to your company through the application of your newly gained skills and expertise.Certifications add credibility to your education and knowledge, thereby revamping your resume. This makes you a more appealing candidate to potential employers. You will receive better employment opportunities, thanks to your advanced domain knowledge and Big Data skills.Although the pathway to becoming a Hadoop developer is pretty straightforward and simple, you need the right guidance and training for it. The best way to gain the requisite training is to take up a Hadoop training course. Learning from expert mentors in the field and engaging in a productive exchange of ideas with your peers will help set you on the right path for becoming a successful Hadoop developer.
0 notes
Text
Techmindz – The Premier Data Science Institute in Kerala for Future-Ready Professionals
In today's data-driven world, the demand for skilled data science professionals is soaring across industries. From healthcare to finance, organizations are harnessing the power of data to make smarter decisions and gain a competitive edge. As the need for data science expertise grows, so does the importance of choosing the right training ground. If you're looking for the best Data Science Institute in Kerala, look no further than Techmindz.
Why Choose Techmindz?
Techmindz, located in the heart of Kerala’s growing tech ecosystem, stands out as a leading institute offering industry-aligned data science training. Here’s why it’s becoming the top choice for aspiring data scientists in Kerala:
1. Industry-Curated Curriculum
Techmindz offers a comprehensive data science curriculum designed by industry experts. The course covers all essential topics including:
Python and R Programming
Data Analysis and Visualization
Machine Learning and Deep Learning
SQL and NoSQL Databases
Big Data Tools (Hadoop, Spark)
AI and Model Deployment
The program blends theoretical knowledge with practical, real-world applications to ensure students are job-ready from day one.
2. Experienced Trainers
At Techmindz, you learn from experienced professionals who have worked on real-time data science projects. These trainers bring years of domain expertise and provide valuable mentorship throughout your learning journey.
3. Live Projects and Internships
Techmindz believes in learning by doing. Students get to work on live industry projects and gain hands-on experience through internships with reputed tech companies. This not only enhances their practical knowledge but also boosts their confidence and portfolio.
4. State-of-the-Art Infrastructure
The institute is equipped with modern labs, collaborative learning spaces, and high-performance computing systems. Whether you prefer classroom sessions or hybrid learning, Techmindz offers flexible options to suit your style.
5. Placement Assistance
One of Techmindz’s strongest pillars is its dedicated placement support. The institute has tie-ups with leading companies in India and abroad. Resume building, mock interviews, and career counseling sessions are conducted regularly to ensure students secure high-paying roles as data scientists, analysts, and AI engineers.
6. Affordable and Accessible
Techmindz offers one of the most cost-effective data science courses in Kerala without compromising on quality. Easy installment options and scholarships make it accessible to a wide range of students.
Student Success Stories
Hundreds of students from diverse academic backgrounds have successfully transitioned into data science roles after completing their course at Techmindz. From fresh graduates to working professionals, learners have praised the institute for its hands-on approach and career-focused training.
Join the Best Data Science Institute in Kerala Today
If you're serious about building a future in data science, enrolling at Techmindz – the top-rated Data Science Institute in Kerala – could be your best career move. With expert mentorship, real-world projects, and placement support, Techmindz prepares you for the challenges and opportunities in the ever-evolving world of data.
0 notes
Link
Author(s): Niklas Lang Originally published on Towards AI. A comprehensive guide covering Hadoop setup, HDFS commands, MapReduce, debugging, advantages, challenges, and the future of big data technologies.Photo by Nam Anh on Unsplash Nowadays, a lar #AI #ML #Automation
0 notes
Text
CSC 4760/6760, DSCI 4760 Big Data Programming Assignment 1
1. (100 points) (Setting up Hadoop on Ubuntu Linux and running the WordCount example) This assignment aims at letting you setup Hadoop on Ubuntu Linux – via the command line. After the installation of Hadoop, you need to run the WordCount example. Source Code and Datasets: The java source code is given in the file “WordCount.java”. You need to run it on two…
0 notes
Text

Data Science Course in Tirupati
Takeoffupskill brings you an all-inclusive Data Science Course in Tirupati to keep you up-skilled for working in the world of data. This course would be aptly suited for all students, working professionals, or enthusiasts looking for a career buildup or career upgrade in data science. Here is what the curriculum entails
Data analysis and visualization Techniques in Machine learning Statistical modelling Python and R programming
Learn with practical training on big data tools like Hadoop and Spark with real-world projects and expert support. Analyze data, discover insights, and make smart decisions. No matter if its finance, healthcare, retail, or tech, all the specializations shall find their perfect starting point here.
Why choose Takeoffupskill?
Experienced instructors with industry expertise Flexible learning schedules to fit your needs Affordable fees with instalment options Internship opportunities for practical experience
Join our Data Science Course in Tirupati today and change your career. Only limited seats are available. So don't miss the opportunity to upskill yourself in one of the most in-demand fields of the 21st century. For more information or to register, contact us today!
#datasciencecourse#dataanalysis#machinelearning#trainingcourse#takeoffupskill#https://takeoffupskill.com/data-science-course
0 notes
Text
Oracle Analytics vs Jaspersoft: A Detailed Comparison of BI Powerhouses
Overview of Oracle Analytics and Jaspersoft
Oracle Analytics offers a full suite of business intelligence solutions, providing predictive analytics, modern data visualization, and reporting. It is designed for businesses that need strong analytics features and smooth integration with other Oracle products.
On the other hand, Jaspersoft is a flexible and reasonably priced business intelligence platform. Its ability to deliver robust reporting, dashboarding, and data integration features makes it a popular choice for businesses of all sizes.
oracle Analytics vs. Jaspersoft — Feature Comparison
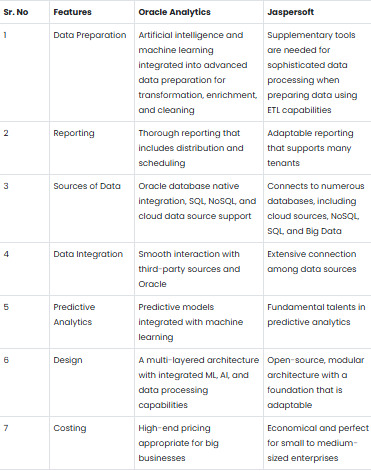
In-Depth Analysis of Oracle Analytics and JaspersoftInformation Perception
Oracle Analytics excels at data integration, particularly for companies already using Oracle products. It supports a variety of SQL, NoSQL databases, cloud data sources, and third-party applications, with seamless integration to Oracle databases.
Jaspersoft also supports a wide range of databases, including NoSQL, SQL, Big Data sources like Hadoop, and cloud platforms such as AWS and Azure. While it offers flexible options for data integration, more complex scenarios may require additional configuration.
Features
Oracle Analytics provides a feature-rich reporting solution, including automated scheduling, distribution, and a wide range of formatting options. This makes it a powerful tool for businesses needing regular and professional report generation.
Jaspersoft, on the other hand, has a powerful reporting engine that supports multiple tenants, which is highly useful for SaaS applications. It is a flexible tool for companies seeking a customizable reporting solution.
Data Integration
Oracle Analytics shines in data integration, especially for enterprises already part of the Oracle ecosystem. It ensures smooth data flow across systems by offering seamless connectivity with third-party sources and Oracle databases and applications.
Jaspersoft’s strength lies in its on-premises integration capabilities. While not as efficient as Oracle Analytics, it is ideal for small-scale operations.
Analytics
Oracle Analytics offers advanced predictive analytics through its integrated machine-learning models, enabling businesses to predict trends and make data-driven decisions.
Jaspersoft, however, only offers basic predictive analytics, which may not be sufficient for businesses requiring more advanced capabilities. Oracle Analytics has an edge when it comes to advanced analytics.
Design
Oracle Analytics’ multi-layered design is built to handle complex data situations. Its architecture is optimized for high performance, supporting real-time analytics and large-scale data processing.
Jaspersoft’s design is based on an open-source, modular architecture that offers flexibility and customization. It particularly benefits SaaS providers and businesses requiring a scalable BI solution, supporting both on-premises and cloud installations.
Cost Analysis
A significant distinction between the two platforms is cost. With its enterprise-grade functionality and premium features, Oracle Analytics is more expensive and better suited for larger enterprises.
Jaspersoft’s pricing is economical, making it the ideal choice for small to medium-sized businesses.
DataTerrain Automated Migration Solutions for Jaspersoft & Oracle Analytics
Businesses considering migrating to Jaspersoft or Oracle Analytics from existing BI tools should take advantage of DataTerrain’s Ai driven and effective migration solutions. Our expertise in business intelligence systems ensures a seamless transition, minimizing downtime and ensuring accurate and efficient transfer of your data and reports.
We have completed numerous migration projects, helping our clients optimize their existing data analytics workflows and uncover new opportunities.
Choosing Between Oracle Analytics and Jaspersoft
The distinct specialties of Jaspersoft and Oracle Analytics are clear. For large businesses that need enterprise-grade scalability, seamless integration, and advanced analytics, Oracle Analytics is the preferred choice.
Conversely, Jaspersoft offers a flexible and reasonably priced solution, ideal for small to medium-sized businesses or those requiring a high degree of customization.
The choice between the two ultimately depends on the unique requirements of your company’s current system. DataTerrain provides reliable and effective Automated migration services for businesses looking to switch to Jaspersoft or Oracle Analytics from existing BI systems.
0 notes
Text
Apache Storm Tutorial: Real-Time Analytics and Stream Processing Explained

Apache Storm is a powerful tool for real-time data processing, making it ideal for applications that need instant data insights. Whether you’re analyzing social media feeds, processing transactions, or managing sensor data, Apache Storm can help handle vast amounts of data efficiently.
To get started, you need to understand a few key concepts. Apache Storm is designed around “spouts” and “bolts”. Spouts are the entry points that fetch data from sources like social media streams or databases. Bolts, on the other hand, are the processors, responsible for analyzing and transforming the data received from spouts. Together, these components create a "topology," which defines how data flows through the system.
Setting up Apache Storm requires installing Java and setting up ZooKeeper, which coordinates the various components in a distributed environment. Once installed, you can start creating and deploying topologies. Each topology runs indefinitely until you decide to stop it, allowing for continuous data processing.
One of Apache Storm’s biggest strengths is its scalability. It can process millions of messages per second, which makes it perfect for real-time analytics. Additionally, Apache Storm works well with other big data tools like Apache Hadoop, making it versatile for various data projects.
If you’re looking to learn more about using Apache Storm, check out the complete Apache Storm Tutorial from TAE. This guide provides detailed insights and examples to help you master Apache Storm and start building powerful data-driven applications.
0 notes
Text
What are the benefits of Amazon EMR? Drawbacks of AWS EMR

Benefits of Amazon EMR
Amazon EMR has many benefits. These include AWS's flexibility and cost savings over on-premises resource development.
Cost-saving
Amazon EMR costs depend on instance type, number of Amazon EC2 instances, and cluster launch area. On-demand pricing is low, but Reserved or Spot Instances save much more. Spot instances can save up to a tenth of on-demand costs.
Note
Using Amazon S3, Kinesis, or DynamoDB with your EMR cluster incurs expenses irrespective of Amazon EMR usage.
Note
Set up Amazon S3 VPC endpoints when creating an Amazon EMR cluster in a private subnet. If your EMR cluster is on a private subnet without Amazon S3 VPC endpoints, you will be charged extra for S3 traffic NAT gates.
AWS integration
Amazon EMR integrates with other AWS services for cluster networking, storage, security, and more. The following list shows many examples of this integration:
Use Amazon EC2 for cluster nodes.
Amazon VPC creates the virtual network where your instances start.
Amazon S3 input/output data storage
Set alarms and monitor cluster performance with Amazon CloudWatch.
AWS IAM permissions setting
Audit service requests with AWS CloudTrail.
Cluster scheduling and launch with AWS Data Pipeline
AWS Lake Formation searches, categorises, and secures Amazon S3 data lakes.
Its deployment
The EC2 instances in your EMR cluster do the tasks you designate. When you launch your cluster, Amazon EMR configures instances using Spark or Apache Hadoop. Choose the instance size and type that best suits your cluster's processing needs: streaming data, low-latency queries, batch processing, or big data storage.
Amazon EMR cluster software setup has many options. For example, an Amazon EMR version can be loaded with Hive, Pig, Spark, and flexible frameworks like Hadoop. Installing a MapR distribution is another alternative. Since Amazon EMR runs on Amazon Linux, you can manually install software on your cluster using yum or the source code.
Flexibility and scalability
Amazon EMR lets you scale your cluster as your computing needs vary. Resizing your cluster lets you add instances during peak workloads and remove them to cut costs.
Amazon EMR supports multiple instance groups. This lets you employ Spot Instances in one group to perform jobs faster and cheaper and On-Demand Instances in another for guaranteed processing power. Multiple Spot Instance types might be mixed to take advantage of a better price.
Amazon EMR lets you use several file systems for input, output, and intermediate data. HDFS on your cluster's primary and core nodes can handle data you don't need to store beyond its lifecycle.
Amazon S3 can be used as a data layer for EMR File System applications to decouple computation and storage and store data outside of your cluster's lifespan. EMRFS lets you scale up or down to meet storage and processing needs independently. Amazon S3 lets you adjust storage and cluster size to meet growing processing needs.
Reliability
Amazon EMR monitors cluster nodes and shuts down and replaces instances as needed.
Amazon EMR lets you configure automated or manual cluster termination. Automatic cluster termination occurs after all procedures are complete. Transitory cluster. After processing, you can set up the cluster to continue running so you can manually stop it. You can also construct a cluster, use the installed apps, and manually terminate it. These clusters are “long-running clusters.”
Termination prevention can prevent processing errors from terminating cluster instances. With termination protection, you can retrieve data from instances before termination. Whether you activate your cluster by console, CLI, or API changes these features' default settings.
Security
Amazon EMR uses Amazon EC2 key pairs, IAM, and VPC to safeguard data and clusters.
IAM
Amazon EMR uses IAM for permissions. Person or group permissions are set by IAM policies. Users and groups can access resources and activities through policies.
The Amazon EMR service uses IAM roles, while instances use the EC2 instance profile. These roles allow the service and instances to access other AWS services for you. Amazon EMR and EC2 instance profiles have default roles. By default, roles use AWS managed policies generated when you launch an EMR cluster from the console and select default permissions. Additionally, the AWS CLI may construct default IAM roles. Custom service and instance profile roles can be created to govern rights outside of AWS.
Security groups
Amazon EMR employs security groups to control EC2 instance traffic. Amazon EMR shares a security group for your primary instance and core/task instances when your cluster is deployed. Amazon EMR creates security group rules to ensure cluster instance communication. Extra security groups can be added to your primary and core/task instances for more advanced restrictions.
Encryption
Amazon EMR enables optional server-side and client-side encryption using EMRFS to protect Amazon S3 data. After submission, Amazon S3 encrypts data server-side.
The EMRFS client on your EMR cluster encrypts and decrypts client-side encryption. AWS KMS or your key management system can handle client-side encryption root keys.
Amazon VPC
Amazon EMR launches clusters in Amazon VPCs. VPCs in AWS allow you to manage sophisticated network settings and access functionalities.
AWS CloudTrail
Amazon EMR and CloudTrail record AWS account requests. This data shows who accesses your cluster, when, and from what IP.
Amazon EC2 key pairs
A secure link between the primary node and your remote computer lets you monitor and communicate with your cluster. SSH or Kerberos can authenticate this connection. SSH requires an Amazon EC2 key pair.
Monitoring
Debug cluster issues like faults or failures utilising log files and Amazon EMR management interfaces. Amazon EMR can archive log files on Amazon S3 to save records and solve problems after your cluster ends. The Amazon EMR UI also has a task, job, and step-specific debugging tool for log files.
Amazon EMR connects to CloudWatch for cluster and job performance monitoring. Alarms can be set based on cluster idle state and storage use %.
Management interfaces
There are numerous Amazon EMR access methods:
The console provides a graphical interface for cluster launch and management. You may examine, debug, terminate, and describe clusters to launch via online forms. Amazon EMR is easiest to use via the console, requiring no scripting.
Installing the AWS Command Line Interface (AWS CLI) on your computer lets you connect to Amazon EMR and manage clusters. The broad AWS CLI includes Amazon EMR-specific commands. You can automate cluster administration and initialisation with scripts. If you prefer command line operations, utilise the AWS CLI.
SDK allows cluster creation and management for Amazon EMR calls. They enable cluster formation and management automation systems. This SDK is best for customising Amazon EMR. Amazon EMR supports Go, Java,.NET (C# and VB.NET), Node.js, PHP, Python, and Ruby SDKs.
A Web Service API lets you call a web service using JSON. A custom SDK that calls Amazon EMR is best done utilising the API.
Complexity:
EMR cluster setup and maintenance are more involved than with AWS Glue and require framework knowledge.
Learning curve
Setting up and optimising EMR clusters may require adjusting settings and parameters.
Possible Performance Issues:
Incorrect instance types or under-provisioned clusters might slow task execution and other performance.
Depends on AWS:
Due to its deep interaction with AWS infrastructure, EMR is less portable than on-premise solutions despite cloud flexibility.
#AmazonEMR#AmazonEC2#AmazonS3#AmazonVirtualPrivateCloud#EMRFS#AmazonEMRservice#Technology#technews#NEWS#technologynews#govindhtech
0 notes
Text
MongoDB: A Comprehensive Guide to the NoSQL Powerhouse
In the world of databases, MongoDB has emerged as a popular choice, especially for developers looking for flexibility, scalability, and performance. Whether you're building a small application or a large-scale enterprise solution, MongoDB offers a versatile solution for managing data. In this blog, we'll dive into what makes MongoDB stand out and how you can leverage its power for your projects.
What is MongoDB?
MongoDB is a NoSQL database that stores data in a flexible, JSON-like format called BSON (Binary JSON). Unlike traditional relational databases that use tables and rows, MongoDB uses collections and documents, allowing for more dynamic and unstructured data storage. This flexibility makes MongoDB ideal for modern applications where data types and structures can evolve over time.
Key Features of MongoDB
Schema-less Database: MongoDB's schema-less design means that each document in a collection can have a different structure. This allows for greater flexibility when dealing with varying data types and structures.
Scalability: MongoDB is designed to scale horizontally. It supports sharding, where data is distributed across multiple servers, making it easy to manage large datasets and high-traffic applications.
High Performance: With features like indexing, in-memory storage, and advanced query capabilities, MongoDB ensures high performance even with large datasets.
Replication and High Availability: MongoDB supports replication through replica sets. This means that data is copied across multiple servers, ensuring high availability and reliability.
Rich Query Language: MongoDB offers a powerful query language that supports filtering, sorting, and aggregating data. It also supports complex queries with embedded documents and arrays, making it easier to work with nested data.
Aggregation Framework: The aggregation framework in MongoDB allows you to perform complex data processing and analysis, similar to SQL's GROUP BY operations, but with more flexibility.
Integration with Big Data: MongoDB integrates well with big data tools like Hadoop and Spark, making it a valuable tool for data-driven applications.
Use Cases for MongoDB
Content Management Systems (CMS): MongoDB's flexibility makes it an excellent choice for CMS platforms where content types can vary and evolve.
Real-Time Analytics: With its high performance and support for large datasets, MongoDB is often used in real-time analytics and data monitoring applications.
Internet of Things (IoT): IoT applications generate massive amounts of data in different formats. MongoDB's scalability and schema-less nature make it a perfect fit for IoT data storage.
E-commerce Platforms: E-commerce sites require a database that can handle a wide range of data, from product details to customer reviews. MongoDB's dynamic schema and performance capabilities make it a great choice for these platforms.
Mobile Applications: For mobile apps that require offline data storage and synchronization, MongoDB offers solutions like Realm, which seamlessly integrates with MongoDB Atlas.
Getting Started with MongoDB
If you're new to MongoDB, here are some steps to get you started:
Installation: MongoDB offers installation packages for various platforms, including Windows, macOS, and Linux. You can also use MongoDB Atlas, the cloud-based solution, to start without any installation.
Basic Commands: Familiarize yourself with basic MongoDB commands like insert(), find(), update(), and delete() to manage your data.
Data Modeling: MongoDB encourages a flexible approach to data modeling. Start by designing your documents to match the structure of your application data, and use embedded documents and references to maintain relationships.
Indexing: Proper indexing can significantly improve query performance. Learn how to create indexes to optimize your queries.
Security: MongoDB provides various security features, such as authentication, authorization, and encryption. Make sure to configure these settings to protect your data.
Performance Tuning: As your database grows, you may need to tune performance. Use MongoDB's monitoring tools and best practices to optimize your database.
Conclusion
MongoDB is a powerful and versatile database solution that caters to the needs of modern applications. Its flexibility, scalability, and performance make it a top choice for developers and businesses alike. Whether you're building a small app or a large-scale enterprise solution, MongoDB has the tools and features to help you manage your data effectively.
If you're looking to explore MongoDB further, consider trying out MongoDB Atlas, the cloud-based version, which offers a fully managed database service with features like automated backups, scaling, and monitoring.
Happy coding!
For more details click www.hawkstack.com
#redhatcourses#docker#linux#information technology#containerorchestration#container#kubernetes#containersecurity#dockerswarm#aws#hawkstack#hawkstack technologies
0 notes
Link
Author(s): Niklas Lang Originally published on Towards AI. A comprehensive guide covering Hadoop setup, HDFS commands, MapReduce, debugging, advantages, challenges, and the future of big data technologies.Photo by Nam Anh on Unsplash Nowadays, a lar #AI #ML #Automation
0 notes
Text
CSC 4760/6760, DSCI 4760 Big Data Programming Assignment 1
1. (100 points) (Setting up Hadoop on Ubuntu Linux and running the WordCount example) This assignment aims at letting you setup Hadoop on Ubuntu Linux – via the command line. After the installation of Hadoop, you need to run the WordCount example. Source Code and Datasets: The java source code is given in the file “WordCount.java”. You need to run it on two…

View On WordPress
0 notes