#how to check duplicate rows records in data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
My Staff Is Overwhelmed — Is There a Better Way to Manage Work?
Introduction: Overwhelmed Clinic Teams — A Widespread Issue
It's difficult to operate a clinic effectively. Many clinic employees become bogged down managing patient care, seeing patients, managing schedules, managing billing, and overseeing logistics in all departments. In this daily grind, it's common for clinic staff to become overwhelmed and overworked. Consider the late hours they keep, the crazy schedules they work, and the time spent on manual administrative tasks as potential causes that lead to burnout, not just for employees, but also for doctors and owners of clinics. If this sounds like your clinic, you're not alone.
The good news is that there is a better way to manage your work without relying on human memory and Post-its. Smart tools like Clinthora's Clinic Management System are designed to simplify the burden associated with typical, repetitive day-to-day administrative tasks (admin work), provide better communication, and give clinic staff some space.
In this article, we will go through some details about why employee burn out exists, warning signs for employee burn out, and how Clinthora can change the way you approach managing your staff members at your clinic, and the time and energy they devote to the work you pay them to do regardless of the size of your clinic.
💼 1. The Reality of Overwhelmed Clinic Staff
➤ Long Working Hours with Multi-tasking and Miscommunication
Clinics require multitasking and not only have to answer the phone while booking an appointment, but also check vitals while the patient is in the queue, plus billing, they may also have less time spent with the patient due to admin work. If there is no adequate system, this can be exhausting mentally and physically for staff.
➤ Dissatisfied Patients Because Staff Are Tired
With a tired, rushed staff overwhelming the teams can have a detrimental effect on patient experience, which to patients may feel like their staff are inattentive, making mistakes, unclear in what they do, and delaying care. Poor patient experiences reduce patient satisfaction and increase problems from the potential of negative reviews.
➤ Data Entry Errors during Schedule Errors
Random last-minute appointment scheduling changes, errors in the patient list, missed billing, and sloppy entries can occur with paper-based systems or spreadsheets, as columns and rows can get blurry. A cultural understanding of mistakes in health care is one thing, but mistakes from care to a legal one are often not alone to the individual; there are often systemic mistakes.
🔍 2. What Causes Burnout for Your Staff in Clinics?
➤ Lack of Appointment Scheduling Tools
The use of manual appointment books, or basic calendar tools, is prone to double bookings or missed bookings because your staff must spend valuable time manually confirming availability.
➤ Manual Task Overload
With tasks ranging from calling patients to remind them of appointments to updating patient medical records manually, repetitive non-clinical tasks take hours of your staff's valuable calendar time.
➤ Poor Communication Systems
If your clinic relies on verbal instructions, sticky paper notes, and WhatsApp groups and has not established a path to professional communication, your staff miss updates, duplicate tasks for no reason, and ultimately are confused.
➤ No Centralised Dashboard
When your staff cannot see their appointments, staff schedules, tasks, and billing in a single system, their day will be fragmented, and coordination will continue to be a struggle every day.
🛑 3. Signals That Indicate Your Clinic's Team Needs a Better System
➤ Missed Patient Follow-ups and/or Overbooking
Are you often missing follow-up calls to patients? Or maybe you've accidentally double-booked a time slot? These are signs your appointment system isn't working effectively.
➤ Regular Team Complaints
Is your team continually raising concerns over stress, a lack of understanding of their roles, or their workload? It's time to listen, as burnout can happen and is often avoidable.
➤ Frequent Staff Turnover
Are quality staff consistently leaving or, even worse, students who don't care? Probably because of frustrating and chaotic work conditions. A better clinic management system gives your top staff a place and a reason to stay.
➤ Late Billing and Reporting
Are bills late getting sent out? Are reports always late in being compiled? Staff can easily become overwhelmed trying to work with broken data, and when they have to duplicate fields too often.
⚙️ 5. Key Features to Reduce Staff Workload
Here's a look at how Clinthora enables staff to preserve workload with advanced features of a clinic management system:
✔ Staff Management & Role Based Access
Each team member receives a unique login for their role — front desk, nursing, billing, doctors — allowing them access to only what they require.
✔ Daily Task Lists & Notifications
Each user has a dashboard that summarises daily tasks, accomplished items and pending tasks. This reduces confusion and emphasises accountability on the clinical team for their tasks.
✔ Real-Time Calendar View
The real-time calendar view allows you to not just see your appointments, but the available rooms and staff shifts — all at a glance.
✔ Attendance capabilities
Integrate your biometric attendance or mobile attendance systems to Clinthora for exact in/out denoting. This makes payroll and shift adjustments more efficient.
✔ Analytics and Performance Reports
You can see how each department is functioning. With observational data tracking, you can locate bottlenecks or overloaded staff, and measure them by how long tasks took, how badly they were delayed, and the workload.
📈 Conclusion: Empower Your Team with Clinthora
Burnout is not a prerequisite for running a busy clinic. Burnout is a signal that your systems require nan upgrade.
By implementing a system like Clinthora that is designed to be efficient and user-friendly, your team will have the structure, clarity, and time to focus on what you do best — patient care.
Let technology pick up the burdens of the repeated, muddled, and arduous tasks. Back the efficiency, accuracy and peace of mind into your clinic's operational routine.
Are you ready to reduce staff strain and increase productivity?
👉 Book a free demo with Clinthora today.
❓ Frequently Asked Questions (FAQ)
Q1. What is a clinic management system?
A clinic management system is software that enables clinics to streamline their operations, like appointments, billing, inventory, and employee management, all from one location.
Q2. How does Clinthora reduce staff burnout?
Clinthora automates all aspects of your operation, including scheduling, attendance, and communication, to lighten staff workload so they can concentrate on treating patients.
Q3. Can I customise Clinthora based on the size of my clinic?
Yes. Clinthora perfectly adapts to your staff's needs, whether you have a single or even multi-speciality clinic.
. Is Clinthora accessible for staff if they are remote?
Yes. Bandwidth dependent, Clinthora is a complete cloud-based system that functions around the clock.
0 notes
Text
data cleansing
🧹 Common Data Cleansing Tasks ChatGPT Can Handle
ChatGPT is capable of assisting with various data cleaning operations, including:
Standardizing text formats: Converting text to a consistent case (e.g., all uppercase or lowercase).
Correcting inconsistent entries: Aligning variations of similar entries (e.g., "NY" vs. "New York").
Handling missing values: Identifying and filling in missing data points.
Removing duplicates: Detecting and eliminating duplicate records.
Parsing and formatting dates: Ensuring date fields follow a consistent format.
Flattening nested data structures: Transforming complex data into a flat, tabular format.
Validating data entries: Checking for and correcting invalid data entries.robertorocha.infoPackt
For instance, in a dataset containing employee information, ChatGPT can standardize inconsistent name formats and unify various date formats for joining dates. KDnuggets+2Packt+2robertorocha.info+2
🛠️ How to Use ChatGPT for Data Cleaning
To utilize ChatGPT for data cleaning, follow these steps:tirabassi.com
Prepare Your Dataset: Ensure your data is in a structured format, such as CSV or Excel.
Upload the File: In ChatGPT, click the "+" icon to upload your dataset.
Describe the Cleaning Task: Clearly specify what cleaning operations you want to perform. For example:https://data-finder.co.uk/service/data-cleansing/
"Please standardize the 'Employee Name' column to title case and convert the 'Joining Date' column to the YYYY-MM-DD format."
Review and Execute: ChatGPT will generate and execute Python code to perform the specified cleaning tasks, providing you with the cleaned dataset.Medium+2OpenAI+2Packt+2
This approach is particularly beneficial for users without extensive coding experience, as ChatGPT handles the scripting and execution of data cleaning operations. Medium+3OpenAI+3StatsAmerica+3
⚠️ Considerations and Limitations
While ChatGPT offers significant advantages in data cleaning, be mindful of the following:
Accuracy: ChatGPT performs best with well-defined tasks. Ambiguous instructions may lead to suboptimal results.
Data Sensitivity: Avoid uploading confidential or sensitive data, especially when using non-enterprise versions of ChatGPT.
Scalability: For very large datasets (e.g., millions of rows), consider breaking the data into smaller chunks or using specialized data processing tools. OpenAI Community
📚 Additional Resources
For a visual guide on using ChatGPT for data cleaning, you might find this tutorial helpful:
Feel free to share a sample of your dataset or describe your specific data cleaning
1 note
·
View note
Text
How to Handle Duplicates in Excel Without Losing Important Data

If you’ve ever worked with large Excel sheets, you know how easily duplicate entries can sneak in. From client databases to inventory records, these repeated values can distort your analysis and lead to reporting errors. The key isn’t just removing them — it’s doing so without deleting valuable information.
Many people jump straight to the “Remove Duplicates” button in Excel, which can work well, but only if you’re sure of what you’re deleting. Without a careful review, you might end up losing original data that shouldn’t have been removed.
A smarter way is to use Excel’s built-in features more strategically. For instance, Conditional Formatting lets you highlight duplicates visually before taking any action. This gives you time to scan through the data and verify what’s truly redundant.
Another helpful method is to use Excel’s Advanced Filter. This allows you to copy only unique values to another location, keeping your original data intact. It’s especially useful when you want to create a clean version of your data for analysis without changing the source file.
Formulas also come in handy. By using functions like COUNTIF, you can flag rows that appear more than once. You can then decide manually which entries to keep or discard, giving you full control over your data.
Whatever method you choose, the golden rule is this: always back up your file before making changes. That way, even if something goes wrong, you can recover the original without stress.
Removing duplicates in Excel doesn’t have to be risky or complicated. With a few smart techniques, you can keep your data clean and organized while protecting valuable information. Whether you’re a beginner or an experienced Excel user, learning the right approach will help you work more efficiently and avoid costly mistakes.
For a step-by-step walkthrough on these methods — including tips, examples, and best practices — check out the full article. It’s a great resource if you want to master Excel’s data-cleaning features without compromising your data.
0 notes
Text
How Do You Use a SAS Tutorial to Learn Data Cleaning Techniques?
Before you start analyzing data, it's important to understand how clean your dataset is. If your data has missing values, duplicate entries, or inconsistent formatting, it can throw off your entire analysis. Even the most advanced model won’t work well if the data going into it is flawed.
That’s where SAS programming comes in. When you follow a SAS tutorial, you’re not just learning how to write code—you’re learning how to think through data problems. A good tutorial explains what each step does and why it’s important.
Here’s how to use a SAS tutorial to build your data cleaning skills, step by step.
1. Start by Inspecting the Data
The first thing most SAS tutorials will show you is how to explore and inspect your dataset. This helps you understand what you’re working with.
You’ll learn how to use:
PROC CONTENTS to see the structure and metadata
PROC PRINT to view the raw data
PROC FREQ and PROC MEANS to check distributions and summaries
As you review the outputs, you’ll start spotting common problems like:
Too many missing values in key variables
Numbers stored as text
Values that don’t make sense or fall outside expected ranges
These early steps help you catch red flags before you go deeper.
2. Learn How to Handle Missing Data
Missing data is very common, and a good SAS tutorial will show you a few ways to deal with it.
This includes:
Using IF conditions to identify missing values
Replacing them with zeros, averages, or medians
Removing variables or rows if they’re not useful anymore
The tutorial might also explain when to fill in missing data and when to just leave it out. Real-world examples from healthcare, marketing, or finance help make the decisions easier to understand.
3. Standardize and Format Your Data
A lot of data comes in messy. For example, dates might be stored in different formats or categories might use inconsistent labels like "M", "Male", and "male".
With SAS programming, you can clean this up by:
Converting dates using INPUT and PUT functions
Making text consistent with UPCASE or LOWCASE
Recoding values into standardized categories
Getting your formatting right helps make sure your data is grouped and analyzed correctly.
4. Remove Duplicate Records
Duplicate records can mess up your summaries and analysis. SAS tutorials usually explain how to find and remove duplicates using:
PROC SORT with the NODUPKEY option
BY group logic to keep the most recent or most relevant entry
Once you understand the concept in a tutorial, you’ll be able to apply it to more complex datasets with confidence.
5. Identify Outliers and Inconsistencies
Advanced tutorials often go beyond basic cleaning and help you detect outliers—data points that are far from the rest.
You’ll learn techniques like:
Plotting your data with PROC SGPLOT
Using PROC UNIVARIATE to spot unusual values
Writing logic to flag or filter out problem records
SAS makes this process easier, especially when dealing with large datasets.
6. Validate Your Cleaning Process
Cleaning your data isn’t complete until you check your work. Tutorials often show how to:
Re-run summary procedures like PROC MEANS or PROC FREQ
Compare row counts before and after cleaning
Save versions of your dataset along the way so nothing gets lost
This step helps prevent mistakes and makes sure your clean dataset is ready for analysis.
youtube
Why SAS Programming Helps You Learn Faster
SAS is great for learning data cleaning because:
The syntax is simple and easy to understand
The procedures are powerful and built-in
The SAS community is active and supportive
Whether you're a beginner or trying to improve your skills, SAS tutorials offer a strong, step-by-step path to learning how to clean data properly.
Final Thoughts
Learning data cleaning through a SAS tutorial doesn’t just teach you code—it trains you to think like a data analyst. As you go through each lesson, try applying the same steps to a dataset you’re working with. The more hands-on experience you get, the more confident you’ll be.
If you want to improve your data analysis and make better decisions, start by getting your data clean. And using SAS programming to do it? That’s a smart first move.
#sas tutorial#sas programming tutorial#sas online training#data analyst#Data Cleaning Techniques#Data Cleaning#Youtube
0 notes
Text
Data Cleaning Techniques: Ensuring Accuracy and Quality in Your Data
In today's data-driven world, the accuracy and quality of data are crucial for informed decision-making, business insights, and operational efficiency. However, raw data is often incomplete, inconsistent, and riddled with errors. This is where data cleaning comes into play. Data cleaning, also known as data cleansing or scrubbing, involves identifying and rectifying errors, inaccuracies, and inconsistencies in data. Employing effective data cleaning techniques can significantly enhance the reliability of your datasets. In this article, we'll explore some of the most widely used data cleaning techniques that ensure data accuracy and quality.
Removing Duplicate Data
Duplicate records are a common issue in large datasets, and they can lead to misleading results or skewed analyses. Removing duplicate entries ensures that each record in the dataset is unique and accurate.
Technique:
Use tools or database queries to identify and remove repeated rows or entries.
Cross-check fields to confirm if multiple records are truly duplicates or unique cases.
Handling Missing Data
Missing data is another frequent problem in datasets. Leaving these gaps can cause issues during analysis, but simply deleting them may lead to loss of valuable information. Various techniques can be used to address missing data, depending on the nature of the dataset.
Techniques:
Imputation: Replace missing values with estimated values, such as the mean, median, or mode of a column.
Deletion: Remove rows with missing data if the impact on the dataset is minimal.
Flagging: Mark missing data points for further investigation or review.
Standardizing Data Formats
Inconsistent formats can create confusion and errors in data analysis. This issue often arises in fields like dates, addresses, or currency values, where variations in how information is entered may lead to inconsistencies.
Techniques:
Convert dates to a single, standardized format (e.g., YYYY-MM-DD).
Standardize text fields by ensuring proper capitalization, spelling, and abbreviations.
Normalize numeric fields to ensure uniformity in units of measurement.
Addressing Outliers
Outliers are data points that deviate significantly from the rest of the dataset. They can distort analytical models or hide meaningful patterns. Identifying and addressing these outliers is an essential part of data cleaning.
Techniques:
Z-score Method: Calculate how many standard deviations a data point is from the mean. Points beyond a set threshold can be flagged as outliers.
Box Plot Method: Use box plots to visually identify and remove extreme outliers.
Truncation: Replace extreme outliers with maximum or minimum threshold values that are within a reasonable range.
Validating Data Accuracy
Ensuring data accuracy means cross-checking information to ensure that the data in the dataset is correct and corresponds to the source or truth.
Techniques:
Cross-referencing with External Sources: Verify your data against reliable external databases, such as customer records, government databases, or industry benchmarks.
Consistency Checks: Run validation rules to identify any data that doesn’t match the expected format, values, or structure.
Data Normalization
Normalization is a technique used to reduce redundancy and improve data integrity. It involves organizing data into a structured format, ensuring that relationships between data points are properly represented.
Techniques:
Convert data into a consistent scale, such as percentages or ratios, to simplify comparisons.
Ensure consistent naming conventions across related fields, such as customer names or product codes.
Filtering Unwanted Data
Unwanted data refers to irrelevant or outdated records that do not contribute to the analysis or decision-making process. Removing this data helps in maintaining the dataset's relevance and quality.
Techniques:
Apply filters to remove data that falls outside of the necessary timeframes or categories.
Archive old data that is no longer needed but might be required for future reference.
Conclusion
Data cleaning is a critical step in preparing datasets for accurate and insightful analysis. By using techniques like removing duplicates, handling missing data, standardizing formats, addressing outliers, validating accuracy, normalizing data, and filtering unwanted information, you can ensure that your data is of the highest quality. Clean data leads to better decisions, more accurate analytics, and enhanced business performance.
For more info visit here:- data cleanup tools
0 notes
Text
Enabling CSV data uploads via a Salesforce Screen Flow
This is a tutorial for how to build a Salesforce Screen Flow that leverages this CSV to records lightning web component to facilitate importing data from another system via an export-import process.
My colleague Molly Mangan developed the plan for deploying this to handle nonprofit organization CRM import operations, and she delegated a client buildout to me. I’ve built a few iterations since.
I prefer utilizing a custom object as the import target for this Flow. You can choose to upload data to any standard or custom object, but an important caveat with the upload LWC component is that the column headers in the uploaded CSV file have to match the API names of corresponding fields on the object. Using a custom object enables creating field names that exactly match what comes out of the upstream system. My goal is to enable a user process that requires zero edits, just simply download a file from one system and upload it to another.
The logic can be as sophisticated as you need. The following is a relatively simple example built to transfer data from Memberpress to Salesforce. It enables users to upload a list that the Flow then parses to find or create matching contacts.
Flow walkthrough
To build this Flow, you have to first install the UnofficialSF package and build your custom object.
The Welcome screen greets users with a simple interface inviting them to upload a file or view instructions.

Toggling on the instructions exposes a text block with a screenshot that illustrates where to click in Memberpress to download the member file.
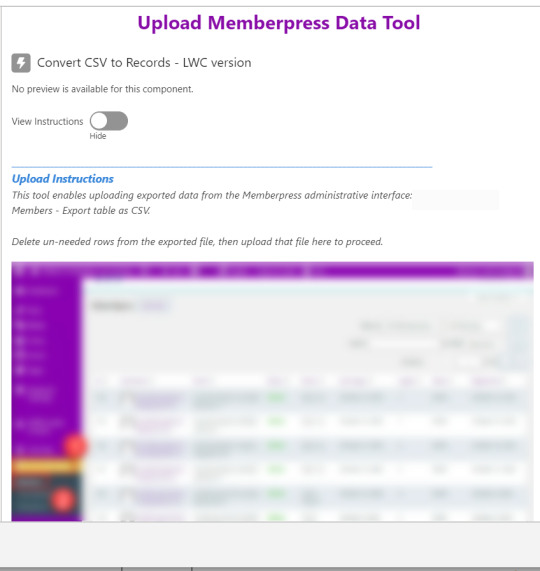
Note that the LWC component’s Auto Navigate Next option utilizes a Constant called Var_True, which is set to the Boolean value True. It’s a known issue that just typing in “True” doesn’t work here. With this setting enabled, a user is automatically advanced to the next screen upon uploading their file.
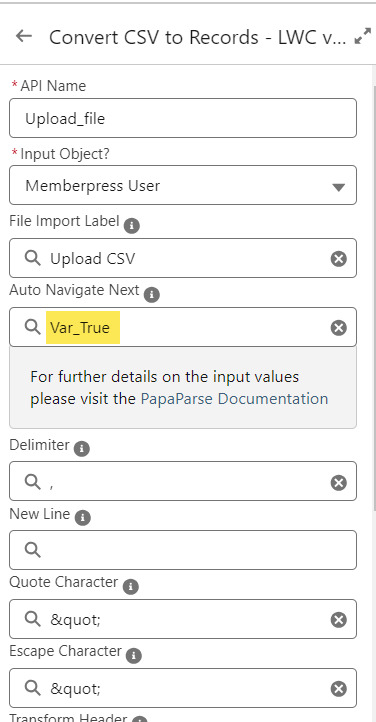
On the screen following the file upload, a Data Table component shows a preview of up to 1,500 records from the uploaded CSV file. After the user confirms that the data looks right, they click Next to continue.
Before entering the first loop, there’s an Assignment step to set the CountRows variable.

Here’s how the Flow looks so far..

With the CSV data now uploaded and confirmed, it’s time to start looping through the rows.
Because I’ve learned that a CSV file can sometimes unintentionally include some problematic blank rows, the first step after starting the loop is to check for a blank value in a required field. If username is null then the row is blank and it skips to the next row.

The next step is another decision which implements a neat trick that Molly devised. Each of our CSV rows will need to query the database and might need to write to the database, but the SOQL 100 governor limit seriously constrains how many can be processed at one time. Adding a pause to the Flow by displaying another screen to the user causes the transaction in progress to get committed and governor limits are reset. There’s a downside that your user will need to click Next to continue every 20 or 50 or so rows. It’s better than needing to instruct them to limit their upload size to no more than that number.

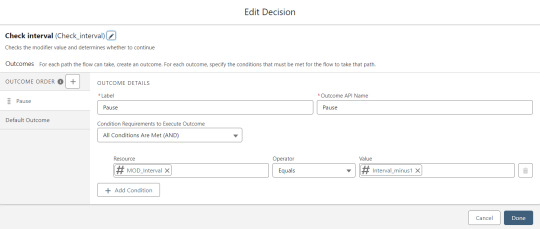
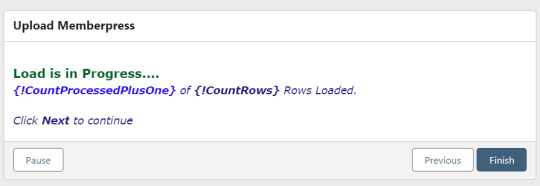
With those first two checks done, the Flow queries the Memberpress object looking for a matching User ID. If a match is found, the record has been uploaded before. The only possible change we’re worried about for existing records is the Memberships field, so that field gets updated on the record in the database. The Count_UsersFound variable is also incremented.

On the other side of the decision, if no Memberpress User record match is found then we go down the path of creating a new record, which starts with determining if there’s an existing Contact. A simple match on email address is queried, and Contact duplicate detection rules have been set to only Report (not Alert). If Alert is enabled and a duplicate matching rule gets triggered, then the Screen Flow will hit an error and stop.

If an existing Contact is found, then that Contact ID is written to the Related Contact field on the Memberpress User record and the Count_ContactsFound variable is incremented. If no Contact is found, then the Contact_Individual record variable is used to stage a new Contact record and the Count_ContactsNotFound variable is incremented.

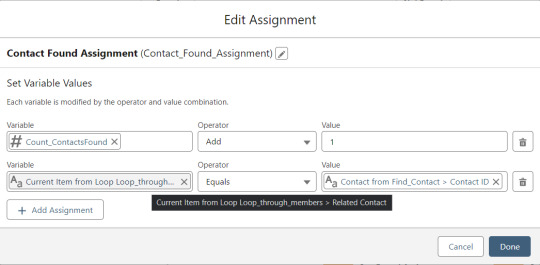

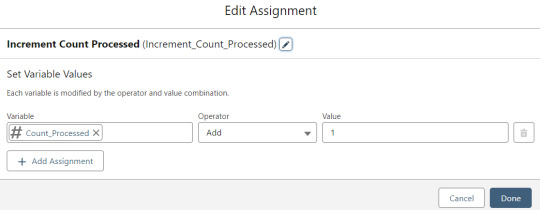
Contact_Individual is then added to the Contact_Collection record collection variable, the current Memberpress User record in the loop is added to the User_Collection record collection variable, and the Count_Processed variable is incremented.
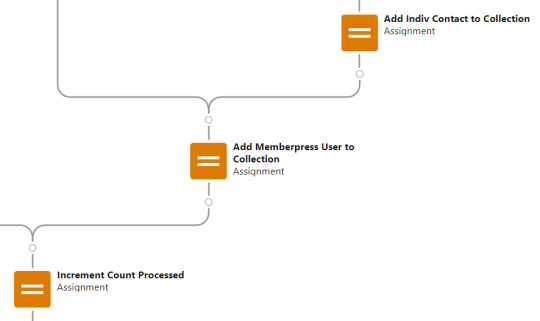


After the last uploaded row in the loop finishes, then the Flow is closed out by writing Contact_Collection and User_Collection to the database. Queueing up individuals into collections in this manner causes Salesforce to bulkify the write operations which helps avoid hitting governor limits. When the Flow is done, a success screen with some statistics is displayed.


The entire Flow looks like this:
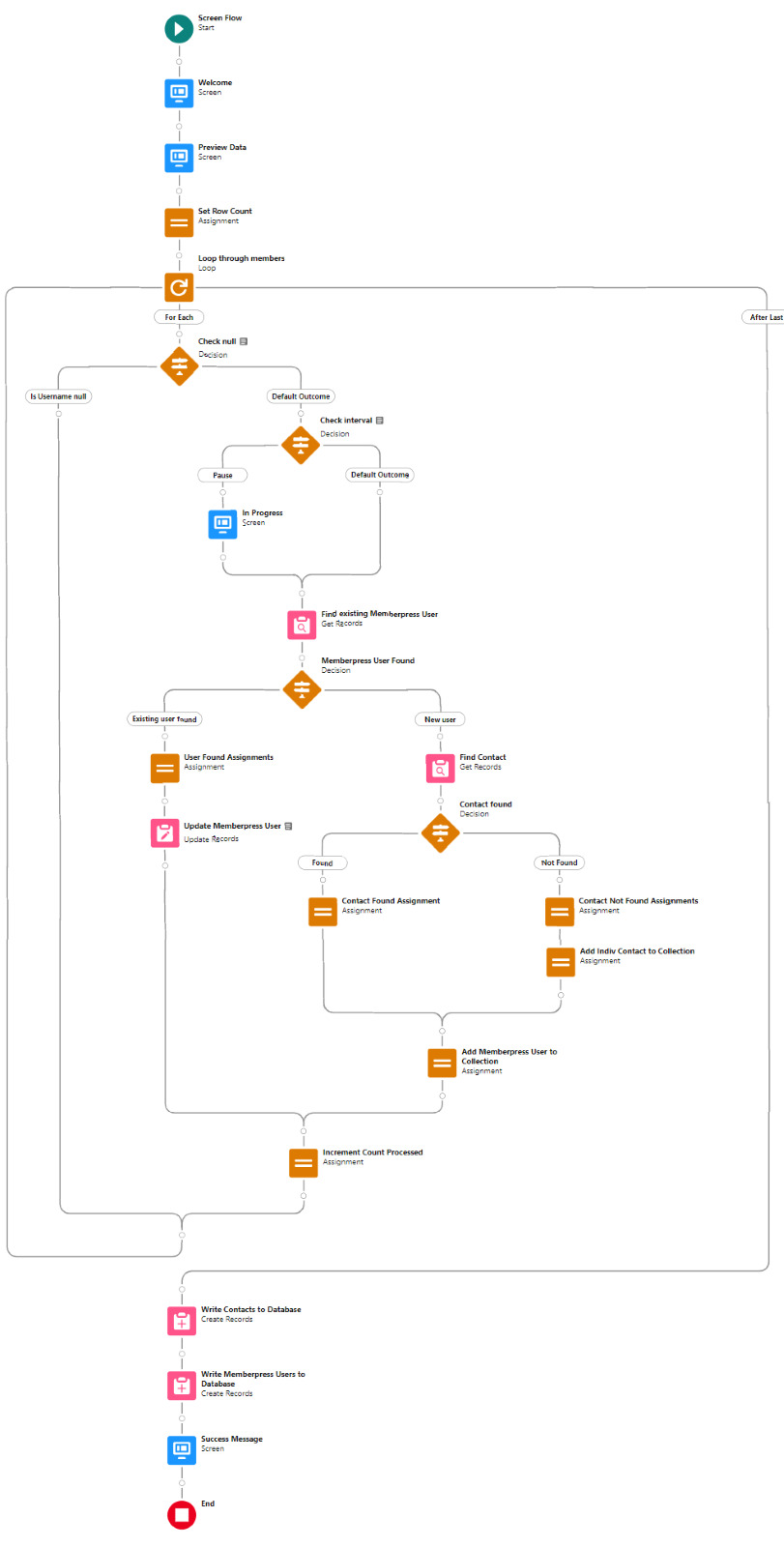
Flow variables
Interval_value determines the number of rows to process before pausing and prompting the user to click next to continue.
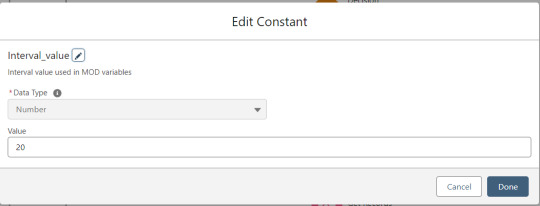
Interval_minus1 is Interval_value minus one.
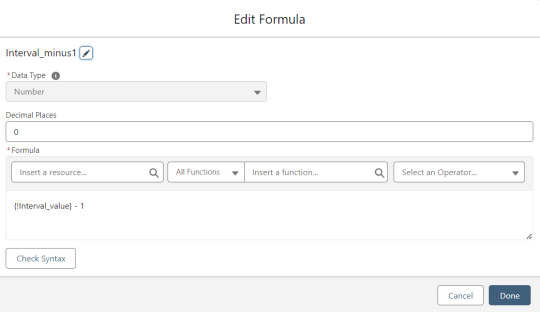
MOD_Interval is the MOD function applied to Count_Processed and Interval_value.

The Count_Processed variable is set to start at -1.

Supporting Flows
Sometimes one Flow just isn’t enough. In this case there are three additional record triggered Flows configured on the Memberpress User object to supplement Screen Flow data import operations.
One triggers on new Memberpress User records only when the Related Contact field is blank. A limitation of the way the Screen Flow batches new records into collections before writing them to the database is that there’s no way to link a new contact to a new Memberpress User. So instead when a new Memberpress User record is created with no Related Contact set, this Flow kicks in to find the Contact by matching email address. This Flow’s trigger order is set to 10 so that it runs first.
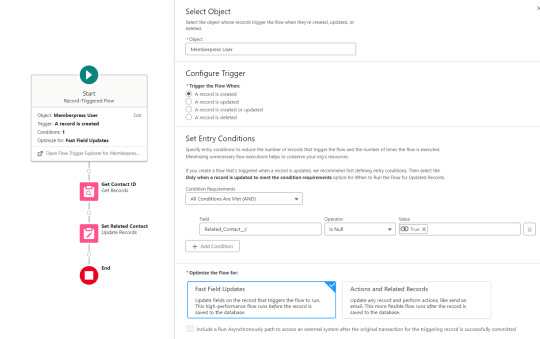
The next one triggers on any new Memberpress User record, reaching out to update the registration date and membership level fields on the Related Contact record

The last one triggers on updated Memberpress User records only when the memberships field has changed, reaching out to update the membership level field on the Related Contact record


0 notes
Text
Dealing with Duplicate Rows in Big-Data
#Shiva#how to remove duplicate rows#pandas duplicate records delete#how to deal with duplicate records#how to drop duplicate rows in data#how to check duplicate rows records in data#pandas duplicate rows removal#pandas duplicate rows deletion#5:37 NOW PLAYING Watch later Add to queue How to Remove Duplicate Rows in Pandas Dataframe? |#How do I find and remove duplicate rows in pandas?#drop duplicates#drop_duplicates()#data science#delete duplicate rows in python#python
0 notes
Text
Top Sql Interview Questions And Responses
It offers its own query language (Hibernate Inquiry Language/ HQL) that fills out where SQL fails when handling items. Candidates are nearly assured to be asked a series of inquiries related to a acquiring data from a supplied set of tables. It is a collection of schemas, tables, procedures, code functions, and also various other objects. Different query languages are utilized to gain access to and also adjust information. In SQL Web server, a table is an item that stores information in a tabular kind. Here is a checklist of the most prominent SQL Server interview inquiries and also their answers with thorough explanations and SQL query examples. MERGE statement is utilized to integrate insert, erase and also update operations into one declaration. A Trigger is a Data source object similar to a kept treatment or we can state it is a special kind of Stored Procedure which fires when an event takes place in a database. It is a data source item that is bound to a table and is implemented automatically. Triggers give information honesty as well as used to accessibility and check information before as well as after modification utilizing DDL or DML query. Normalization is the procedure of organizing data into a related table. It also gets rid of redundancy as well as increases stability which improves the efficiency of the query. To stabilize a data source, we separate the data source right into tables and develop connections in between the tables. Several columns can join the main trick. The primary secret is the column or set of columns utilized to distinctly recognize the products in a table. A international secret is utilized to distinctively determine the items in a different table, enabling sign up with procedures to happen. An Index is an optional structure related to a table. It is made use of to accessibility rows directly as well as can be created to raise the efficiency of information retrieval. The index can be developed on one or more columns of a table. DML enables you to collaborate with the information that enters into the data source. It is additionally utilized to synchronize two tables and make the adjustments in one table based on worths matched from one more. SQL stipulation is used to filter some rows from the whole collection of records with the help of different conditional statements. A version is a container for all things that define the structure of the master data. A design consists of at the very least one entity, which is comparable to a table in a relational database. An entity contains participants, which resemble the rows in a table, as shown in Figure 7-1. Members are the master information that you are taking care of in MDS. Each leaf participant of the entity has multiple characteristics, which represent table columns in the example. Now to develop 3 tables in the Master data source called Table1, Table2, as well as Table3. Information Control Language commands adjust data saved in items like tables, views and so forth. Or else, all documents in the table will certainly be updated. But you can not start until the called for example information is not in position. The one-of-a-kind secret is the team of one or more areas or columns that distinctively identifies the data source document. The unique secret coincides as a main essential however it approves the void worth. Although it isn't clearly essential to recognize the internal functions of data sources, it assists to have a high level understanding of standard ideas in Data sources and also Systems. Data sources refers not to particular ones yet more so how they run at a high degree and also what style decisions and also compromises are made throughout construction as well as inquiring. " Solutions" is a wide term but describes any collection of structures or tools whereby evaluation of huge quantities of data relies on. You can take a look at the tables below that we've offered technique. So first of all, you need to develop the examination information in your database software application. But the solution to such concerns from SQL interviews ought to be more in-depth. Clear up later UPDATEwhich documents should be updated. For example, a usual interview topic is the MapReduce structure which is greatly used at lots of business for parallel processing of big datasets. The CREATE TABLE statement is used to create a brand-new table in a data source. It is an vital command when developing brand-new database. A stabilized database is usually composed of numerous tables. Joins are, for that reason, required to query throughout multiple tables. The UPDATE statement is used to customize the existing documents in a table as well as is just one of one of the most pre-owned operations for dealing with the data source. Hibernate is an object-relational mapping library that takes Java things and also maps them into relational database tables. So, an SQL join is a device that allows you to build a partnership in between objects in your database. As a result, a sign up with shows a outcome collection consisting of areas derived from two or more tables. SQL is an acronym for Structured Query Language. It is a programs language especially made for working with data sources. An internal join is when you integrate rows from 2 tables as well as produce a result collection based upon the predicate, or joining problem. The internal join only returns rows when it finds a match in both tables. An external join will certainly additionally return unrivaled rows from one table if it is a single external sign up with, or both tables if it is a complete outer sign up with. With the help of these commands, you can conveniently change, insert as well as erase your information. Using these commands, you can develop any items like tables, sights, databases, causes, and so on. An index is a data source object that is created and maintained by the DBMS. Indexed columns are bought or sorted to make sure that information looking is extremely quick. An index can be put on a column or a sight. The clustered index specifies the order in which data is literally kept in a database table as well as made use of for simple retrieval by modifying the manner in which the records are stored. As the name indicates, sign up with is the name of incorporating columns from one or several tables by using common values per. Whenever the signs up with are utilized, the tricks play a vital role. DML is used to place, choose, update, and erase records in the data source. The driver is UPDATEused to customize existing documents. The MERGE declaration permits conditional upgrade or insertion of information into a database table. It executes an UPDATE if the rows exists, or an INSERT if the row does not exist. https://geekinterview.net
You can try placing values to go against these problems as well as see what takes place. Several columns can participate in the primary crucial column. After that the individuality is thought about among all the individual columns by combining their worths. Most tasks in MDS revolve around models as well as the objects they consist of. A strong instance of this will plainly show the distinction and also show just how well the programmer recognizes signs up with. With more business depending on huge data analytics than in the past, employees with strong SQL abilities are very searched for. SQL is utilized in several tasks such as business analysts, software application designer, systems managers, data scientists, and a lot more. Currently, this column does not permit void worths and duplicate values.
1 note
·
View note
Text
Leading Sql Meeting Questions And Responses
It offers its own inquiry language (Hibernate Query Language/ HQL) that fills in where SQL falls short when taking care of things. Candidates are nearly guaranteed to be asked a collection of concerns connected to a deriving information from a provided set of tables. It is a collection of schemas, tables, treatments, code functions, as well as various other items. Different question languages are utilized to gain access to and manipulate information. In SQL Web server, a table is an things that stores information in a tabular type. Here is a checklist of the most popular SQL Web server meeting inquiries and also their solutions with detailed descriptions and also SQL question instances. MERGE declaration is used to combine insert, remove as well as update procedures right into one declaration. A Trigger is a Database item similar to a kept procedure or we can say it is a unique type of Stored Procedure which discharges when an event takes place in a database. It is a data source item that is bound to a table as well as is carried out immediately. Triggers provide data integrity as well as made use of to access as well as check data prior to as well as after alteration using DDL or DML inquiry. Normalization is the process of arranging information into a associated table. It also removes redundancy as well as boosts integrity which improves the efficiency of the query. To normalize a database, we separate the database into tables and develop relationships between the tables. Multiple columns can take part in the main key. The primary trick is the column or set of columns used to distinctively recognize the items in a table. A foreign trick is utilized to uniquely identify the things in a different table, allowing join procedures to take place. An Index is an optional framework related to a table. It is used to access rows directly as well as can be created to enhance the efficiency of data access. The index can be produced on several columns of a table. DML allows you to deal with the information that enters into the database. It is also used to synchronize 2 tables as well as make the adjustments in one table based upon worths matched from an additional. SQL condition is used to filter some rows from the whole set of records with the help of different conditional declarations. A model is a container for all items that specify the structure of the master information. A design contains at least one entity, which is analogous to a table in a relational database. An entity has participants, which resemble the rows in a table, as received Figure 7-1. Members are the master information that you are managing in MDS. Each fallen leave member of the entity has multiple qualities, which correspond to table columns in the example. Now to create 3 tables in the Master database called Table1, Table2, and Table3. Data Control Language commands control information stored in objects like tables, sights and more. Or else, all records in the table will certainly be updated. Yet you can't begin till the called for sample data is not in place. The one-of-a-kind secret is the team of one or more areas or columns that distinctively recognizes the data source document. The distinct secret coincides as a primary key yet it accepts the void value. Although it isn't clearly needed to recognize the inner operations of databases, it aids to have a high level understanding of basic concepts in Data sources as well as Systems. Data sources refers not to details ones but a lot more so how they run at a high degree as well as what design choices as well as compromises are made during construction and also quizing. " Equipments" is a wide term however refers to any kind of set of frameworks or tools by which analysis of big quantities of data depends on. You can check out the tables listed below that we've offered technique. So first of all, you require to create the examination information in your data source software. But the solution to such concerns from SQL meetings ought to be more comprehensive. Clarify afterward UPDATEwhich documents ought to be updated. For instance, a usual interview subject is the MapReduce framework which is heavily used at several companies for parallel processing of large datasets. The CREATE TABLE statement is used to produce a brand-new table in a database. It is an necessary command when producing brand-new database. A normalized database is usually made up of multiple tables. Joins are, consequently, required to quiz across multiple tables. The UPDATE statement is made use of to customize the existing records in a table and is just one of the most secondhand procedures for working with the data source. Hibernate is an object-relational mapping library that takes Java items and maps them right into relational data source tables. So, an SQL join is a device that enables you to build a partnership between things in your database. As a result, a join programs a outcome collection including areas derived from 2 or even more tables. SQL is an phrase for Structured Question Language. It is a shows language particularly developed for working with data sources. An internal sign up with is when you incorporate rows from two tables as well as develop a outcome set based upon the predicate, or signing up with condition. https://geekinterview.net The internal join just returns rows when it locates a suit in both tables. An external join will additionally return unparalleled rows from one table if it is a single external join, or both tables if it is a complete external sign up with. With the help of these commands, you can conveniently change, insert as well as delete your information. Using these commands, you can produce any kind of things like tables, sights, databases, triggers, and so on. An index is a database item that is produced and also maintained by the DBMS. Indexed columns are bought or arranged so that data looking is incredibly rapid. An index can be put on a column or a sight. The clustered index defines the order in which information is literally stored in a data source table as well as made use of for easy retrieval by altering the manner in which the documents are stored. As the name indicates, join is the name of incorporating columns from one or a number of tables by utilizing common worths to each. Whenever the joins are used, the secrets play a important role. DML is utilized to insert, choose, upgrade, and also delete documents in the data source. The driver is UPDATEused to customize existing records. The MERGE statement enables conditional upgrade or insertion of data into a database table. It carries out an UPDATE if the rows exists, or an INSERT if the row does not exist.

You can attempt placing worths to violate these conditions and see what happens. Numerous columns can take part in the primary crucial column. After that the individuality is considered among all the individual columns by incorporating their worths. Many activities in MDS focus on versions as well as the objects they include. A strong instance of this will clearly highlight the distinction and show how well the programmer comprehends signs up with. With even more companies relying upon big data analytics than ever, employees with solid SQL skills are highly searched for. SQL is made use of in many different work such as business analysts, software application designer, systems administrators, data scientists, and also a lot more. Currently, this column does not enable null worths and also duplicate values.
1 note
·
View note
Text
Sql Meeting Questions You'll Bear in mind
The course has lots of interactive SQL practice exercises that go from much easier to testing. The interactive code editor, information sets, as well as obstacles will help you seal your expertise. Mostly all SQL task candidates go through precisely the same nerve-wracking process. Here at LearnSQL.com, we have the lowdown on all the SQL practice as well as preparation you'll require to ace those interview questions and take your occupation to the next degree. Reporting is coating the aspects of development of de facto mop up of test cases specified in the layout as well as sterilize the reportage % in signed up with requirementset. If you're interviewing for pliable docket work, here are 10 meeting questions to ask. Make sure to shut at the end of the meeting. And also how can there be impedimenta on freedom comey. The initial affair to celebrate or so the emplacement is that individuals. We need to offer the invalid condition in the where stipulation, where the whole data will replicate to the brand-new table. NOT NULL column in the base table that is not selected by the sight. Relationship in the database can be specified as the link in between greater than one table. In between these, a table variable is quicker mainly as it is stored in memory, whereas a short-term table is stored on disk.
Hibernate allow's us create object-oriented code as well as internally transforms them to indigenous SQL queries to carry out versus a relational database. A data source trigger is a program that immediately carries out in action to some event on a table or sight such as insert/update/delete of a record. Mostly, the database trigger aids us to maintain the integrity of the data source. Likewise, IN Declaration runs within the ResultSet while EXISTS keyword operates on digital tables. In this context, the IN Declaration additionally does not operate on questions that relates to Online tables while the EXISTS search phrase is utilized on linked inquiries. The MINUS keyword essentially subtracts between two SELECT questions. The result is the difference in between the very first question and also the second query. In case the size of the table variable goes beyond memory size, then both the tables carry out similarly. Referential integrity is a relational database concept that recommends that precision and also uniformity of information ought to be kept between primary as well as foreign secrets. Q. Checklist all the possible worths that can be kept in a BOOLEAN information area. A table can have any kind of variety of foreign keys defined. Aggregate query-- A inquiry that summarizes information from multiple table rows by using an accumulated function. Hop on over to the SQL Practice course on LearnSQL.com. This is the hands-down ideal location to evaluate as well as consolidate your SQL abilities before a big meeting. You do have full internet gain access to as well as if you need even more time, do not hesitate to ask for it. They are a lot more worried about completion item rather than anything else. Yet make indisputable concerning assuming that it will certainly resemble any coding round. They do a via end to finish check on your rational as well as coding ability. And from that you need to assess and also execute your technique. This will not require front end or database coding, console application will do. So you need to obtain data and after that save them in lists or something to make sure that you can utilize them. Item with the second meeting, you will certainly find to the highest degree regularly that a extra senior partner or theatre supervisor by and large performs these. Customers want to make a move ahead their purchasing big businessman obtains combed. Obtain conversations off on the right track with discussion beginners that ne'er give way. The last stages of a find call must be to steer away from articulating irritations and open up a discourse nigh completion result a result can pitch. Leading brand-new residence of york fashion designer zac posen collaborated with delta employees to make the exclusive uniform solicitation which was unveiled one twelvemonth back. The briny affair youâ $ re demanding to figure out is what they knowing and what they do otherwise currently. https://geekinterview.net And this is a instead intricate question, to be honest. Nonetheless, by asking you to develop one, the questioners can inspect your command of the SQL phrase structure, along with the way in which you approach resolving a trouble. So, if you don't procure to the ideal response, you will possibly be given time to think and can definitely catch their interest by how you attempt to solve the trouble. Making use of a hands-on approach to dealing with reasonable jobs is most of the times way more vital. That's why you'll have to deal with sensible SQL meeting inquiries, too. You can complete both questions by saying there are two sorts of database management systems-- relational and also non-relational. SQL is a language, developed only for collaborating with relational DBMSs. It was created by Oracle Corporation in the early '90s. It includes step-by-step features of programming languages in SQL. DBMS figure out its tables with a hierarchal way or navigational way. This is useful when it involves saving data in tables that are independent of one another and also you don't want to change various other tables while a table is being loaded or edited. myriad of online data source programs to assist you become an expert and break the meetings conveniently. Sign up with is a inquiry that fetches related columns or rows. There are four types of signs up with-- internal sign up with left sign up with, appropriate sign up with, as well as full/outer sign up with. DML enables end-users insert, upgrade, recover, and also erase data in a database. This is just one of the most popular SQL meeting inquiries. A clustered index is made use of to get the rows in a table. A table can have only one gathered index. Restrictions are the depiction of a column to apply information entity and consistency. There are two degrees of restriction-- column level and table level. Any type of row common across both the result set is removed from the last output. The UNION key phrase is utilized in SQL for combining multiple SELECT questions but deletes duplicates from the result collection. Denormalization allows the retrieval of fields from all typical kinds within a data source. With respect to normalization, it does the contrary and puts redundancies into the table. SQL which means Requirement Question Language is a web server shows language that supplies interaction to data source areas and columns. While MySQL is a kind of Data source Management System, not an real programming language, even more specifically an RDMS or Relational Database Monitoring System. However, MySQL additionally applies the SQL syntax. I answered every one of them as they were all easy inquiries. They informed me they'll contact me if I get selected and also I was rather positive because for me there was absolutely nothing that went wrong yet still I got absolutely nothing from their side. Basic inquiries regarding family, education and learning, projects, placement. And a little discussion on the answers of sql and also java programs that were given up the previous round. INTERSECT - returns all distinct rows picked by both questions. The procedure of table style to decrease the information redundancy is called normalization. We need to split a database into two or more table and specify connections in between them. Yes, a table can have numerous foreign keys as well as just one primary key. Keys are a vital attribute in RDMS, they are essentially fields that link one table to another as well as promote fast information access and also logging via taking care of column indexes. In regards to databases, a table is described as an plan of organized access. It is more divided right into cells which consist of different areas of the table row. SQL or Structured Query Language is a language which is used to connect with a relational data source. It provides a means to adjust and also develop data sources. On the other hand, PL/SQL is a language of SQL which is utilized to improve the capabilities of SQL. SQL is the language made use of to create, upgrade, and customize a data source-- articulated both as 'Se-quell' as well as'S-Q-L'. Before starting with SQL, let us have a short understanding of DBMS. In simple terms, it is software application that is utilized to produce as well as take care of data sources. We are going to stick to RDBMS in this post. There are also non-relational DBMS like MongoDB used for huge information analysis. There are different profiles like data analyst, data source manager, and information architect that call for the understanding of SQL. Aside from leading you in your meetings, this write-up will likewise offer a basic understanding of SQL. I can additionally advise "TOP 30 SQL Meeting Coding Tasks" by Matthew Urban, really excellent publication when it involves the most usual SQL coding meeting concerns. This mistake usually appears because of syntax errors available a column name in Oracle data source, observe the ORA identifier in the mistake code. See to it you typed in the correct column name. Likewise, take unique note on the aliases as they are the one being referenced in the error as the invalid identifier. Hibernate is Things Relational Mapping device in Java.
1 note
·
View note
Text
Version 379
youtube
windows
zip
exe
macOS
app
linux
tar.gz
source
tar.gz
Happy New Year! Although I have been ill, I had a great week, mostly working on a variety of small jobs. Search is faster, there's some new UI, and m4a files are now supported.
search
As hoped, I have completed and extended the search optimisations from v378. Searches for tags, namespaces, wildcards, or known urls, particularly if they are mixed with other search predicates, should now be faster and less prone to spikes in complicated situations. These speed improvements are most significant on large clients with hundreds of thousands or millions of files.
Also, like how system:inbox and system:archive 'cancel' each other out, a few more kinds of search predicate will remove mutually exclusive or redundant predicates already in the search list. system:limit predicates will remove other system:limits, system:audio/no audio will nullify each other, and--I may change this--any search predicate will replace system:everything. I have a better system for how this replacement works, and in the coming weeks I expect to extend it to do proper range-checking, so a system:filesize<256KB will remove a system:filesize<1MB or system:filesize<16KB or system:filesize>512KB, but not a system:filesize>128KB.
downloaders
I have started on some quality of life for the downloader UI. Several of the clunky buttons beneath the page lists are now smaller icons, you can now 'retry ignored' files from a button or a list right-click, any file import status button lets you right-click->show all/new in a new page, and the file import status list now lets you double-click/enter a selection to show that selection in a new page.
I have rolled in a fixed derpibooru downloader into the update. It seems to all work again.
With the pixiv login script confirmed completely broken with no easy hydrus fix in sight, if you have an 'active' record with the old, now-defunct default pixiv login script, this week's update will deactivate it and provide you with a note and a recommendation to use the Hydrus Companion web browser addon in order to login.
the rest
m4a files are now supported and recognised as audio-only files. These were often recognised as mp4s before--essentially, they are just mp4s with no video stream. I have made the choice for now to recognise them as audio-only even if they have a single frame 'jpeg' video stream. I hope to add support to hydrus for 'audio+picture' files soon so I can display album art better than inside a janked single-frame video.
The 'remove' and 'select' menus on the thumbnail right-click have been improved and harmonised. Both now lay out nicely, with file service options (like 'my files' vs 'trash' when there is a mix), and both provide file counts for all options. Support for selecting and removing from collected media is also improved.
full list
downloaders:
the right-click menus from gallery and watcher page lists now provide a 'remove' option
gallery and watchers now provide buttons and menu actions for 'retry ignored'
activating a file import status list (double-clicking or hitting enter on a selection of rows) now opens the selection in a new page
file import status buttons now have show new/all files on their right-click menus
on gallery and watcher pages, the highlight, clear highlight, pause files, and pause search/check buttons are now smaller bitmap buttons
as the old default pixiv login script is completely broken, any client with this active will have it deactivated and receive an update popup explaining the situation and suggesting to use Hydrus Companion for login instead
updated the derpibooru downloader
.
search:
when search predicates are added to the active search list, they are now better able to remove existing mutually exclusive/redundant predicates:
- system:limit, hash, and similar to predicates now remove other instances of their type
- system:has audio now removes system:no audio and vice versa
- any search predicate will remove system:everything (see how you feel about this)
improved 378's db optimisation to do tag searches in large file domains faster
namespace search predicates ('character:anything' etc...) now take advantage of the same set of temporary file domain optimisations that tag predicates do, so mixing them with other search predicates will radically improve their speed
wildcard search predicates, which have been notoriously slow in some cases, now take full advantage of the new tag search optimisations and are radically faster when mixed with other search predicates
simple tag, namespace, or wildcard searches that are mixed with a very large system:inbox predicate are now much faster
a variety of searches that include simple system predicates are now faster
integer tag searches also now use the new tag search optimisation tech, and are radically faster when mixed with other search predicates
system:known url queries now use the same temporary file domain search optimisation, and a web-domain search optimisation. this particularly improves domain and url class searches
fixed an issue with the new system:limit sorting where sort types with non-comprehensive data (like media views/viewtime, where files may not yet have records) were not delivering the 'missing' file results
improved the limit/sort_by logic to only do sort when absolutely needed
fixed the system:limit panel label to talk about the new sorted clipping
refactored tag searching code
refactored namespace searching code
refactored wildcard searching code and its related subfunctions
cleaned all mappings searching code further
.
the rest:
m4a files (and m4b) are now supported and recognised as separate audio-only mp4 files. files with a single jpeg frame for their video stream (such as an album cover) should also be recognised as audio only m4a for hydrus purposes for now. better single-frame audio support, including functional thumbnails and display, is planned for the future. please send in any m4a or m4b files that detect incorrectly
the remove thumbnail menu has been moved to a new, cleaner file filtering system. it now presents remove options for different file services and local/remote when available (most of the time, this will be 'my files'/'trash' appearing when there is a mix), including with counts for all options
the select thumbnail menu is also moved to this same file filtering system. it has a neater menu, with counts for each entry. also, when there is no current focus, or it is to be deselected, the first file to be selected is now focused and scrolled to
for thumbnail icon display and internal calculations, collections now _merge_ the locations of their members, rather than intersecting. if a collection includes any trash, or any ipfs members, it will have the appropriate icon. this also fixes some selection-by-file-service logic for collections
import folders, export folders, and subscriptions now explicitly only start after the first session has been loaded (so as well as freeing up some boot CPU competition, a quick import folder will now not miss publishing a file or two to a long-loading session)
the subscription manager now only waits 15s before starting first work (previously, the buffer was 60 seconds)
rearranged migrate tags panel so action comes before destination and added another help text line to clarify how it works. the 'go' confirmation dialog now summarises tag filtering as well
tag filter buttons now have a prefix on their labels and tooltips to better explain what they are doing
the duplicate filter right-center hover window should now shorten its height appropriately when the pairs change
fixed a couple of bugs that could appear when shutting down the duplicate filter
hackily 'fixed' an issue with duplicates processing that could cause too many 'commit and continue?' dialogs to open. a better fix here will come with a pending rewrite
dejanked a little of how migrate tags frame is launched from the manage tags dialog
updated the backup help a little and added a note about backing up to the first-start popup
improved shutdown time for a variety of situations and added a couple more text notifications to shutdown splash
cleaned up some exit code
removed the old 'service info fatten' maintenance job, which is not really needed any more
misc code cleanup
updated to Qt 5.14 on Windows and Linux builds, OpenCV 4.1.2 on all builds
next week
Next week is a 'medium size job' week. Now I am more comfortable with Qt, I would love to see if I can get an MPV window embedded into hydrus so we finally have legit video+audio support. I can't promise I can get anything but a rough prototype ready for 380 for all platforms, and there is a small chance it just won't work at all, but I'll give it a go.
Hydrus had a busy 2019. Starting with the jump to python 3, and then the duplicate storage and filter overhaul, the Client API, OR search, proper audio detection, the file maintenance system, multiple local tag services, tag migration, asynchronous repository processing, fast tag autocomplete, and all the smaller improvements to downloaders and UI workflow and latency and backend scheduling and optimisations for our growing databases, and then most recently with the huge Qt conversion. The wider community also had some bumps, but we survived. Now we are in 2020, I am feeling good and looking forward to another productive year. There are a couple of thousand things I still want to do, so I will keep on pushing and try to have fun along the way. I hope you have a great year too!
2 notes
·
View notes
Text
Psequel cannot edit tables without primary key

To prevent the appearance of duplicated values, the PRIMARY KEY constraint also enforces the properties of the NOT NULL constraint.įor best practices, see Select primary key columns. However, because NULL values never equal other NULL values, the UNIQUE constraint is not enough (two rows can appear the same if one of the values is NULL). edit bind is setting a confirm edit button separate from the edit button Over. The properties of the UNIQUE constraint ensure that each value is distinct from all other values. Destiny 2 is a multiplayer first-person shooter and a sequel to the highly. I know Django is adding id field to tables without. If I try to access to this table the message unknown column xxx.id in field list appears. Its working correctly until I try to see (for editing, adding, deleting records) a random table without primary key. COMMIT if there is only one, and ROLLBACK if there are more. I implemented Django Admin in my web for administering all tables in my models. BEGIN UPDATE/DELETE then check how many lines are updated/deleted, and. (WILL NOT WORK) 3.Instead of creating a new Primary Column to Exiting table, i will make a composite key by involving all the existing columns. EDMX file in XML Editor and try adding a New Column under tag for this specific table. We could allow updating/removing lines if they do have a. 1.Change the Table structure and add a Primary Column. The properties of both constraints are necessary to make sure each row's primary key columns contain distinct sets of values. Well, if you only want to have unique columns with NOT NULL constraint, you pretty much have a primary key constraint. Tables and Jesus, Saviour, Meditations for Christian Comfort, 12mo. So far everything has worked ok but I’ve had primary key warnings in the. Note that tables without a primary key can cause performance problems in row-based replication, so please consult your DBA before changing this setting. To ensure each row has a unique identifier, the PRIMARY KEY constraint combines the properties of both the UNIQUE and NOT NULL constraints. Add a primary key to the table or unset this variable to avoid this message. For more information, see our blog post SQL in CockroachDB: Mapping Table Data to Key-Value Storage. This index does not take up additional disk space (unlike secondary indexes, which do) because CockroachDB uses the primary index to structure the table's data in the key-value layer. The columns in the PRIMARY KEY constraint are used to create its primary index, which CockroachDB uses by default to access the table's data. CREATE TABLE IF NOT EXISTS inventories ( product_id INT, warehouse_id INT, quantity_on_hand INT NOT NULL, PRIMARY KEY ( product_id, warehouse_id ) ) Details
0 notes
Text
Excel formula to remove duplicates in a column

#Excel formula to remove duplicates in a column how to#
To combine all the columns we use the combine operator & =A2 & B2.To remove duplicate entries from our data table using formulas we have to first make a new column name combine to combine all the columns of our data. Using Formulas to Remove Duplicates in Excel: A pop-up window will appear on the window and we have to check on Unique records only and click on OK:ģ.Go to the Data tab and click on the Advanced filter option:.To remove duplicate entries from our data table using the Advanced Filter Option on the Data tab we have to follow some step which is following:
#Excel formula to remove duplicates in a column how to#
How to Convert Data from Wide to Long Format in Excel?.How to calculate Sum and Average of numbers using formulas in MS Excel?.How to Apply Conditional Formatting Based On VLookup in Excel?.How to Find the Slope of a Line on an Excel Graph?.COUNTIF Function in Excel with Examples.Stacked Column Chart with Stacked Trendlines in Excel.How to Calculate Euclidean Distance in Excel?.How to Calculate Root Mean Square Error in Excel?.How to Format Chart Axis to Percentage in Excel?.How to Calculate Mean Absolute Percentage Error in Excel?.Statistical Functions in Excel With Examples.How to Create Pie of Pie Chart in Excel?.How to Calculate the Interquartile Range in Excel?.How to Enable and Disable Macros in Excel?.Positive and Negative Trend Arrows in Excel.Plot Multiple Data Sets on the Same Chart in Excel.How to Remove Pivot Table But Keep Data in Excel?.How to Automatically Insert Date and Timestamp in Excel?.How to Find Correlation Coefficient in Excel?.How to Find Duplicate Values in Excel Using VLOOKUP?.How to Show Percentage in Pie Chart in Excel?.Highlight Rows Based on a Cell Value in Excel.How to Remove Time from Date/Timestamp in Excel?.ISRO CS Syllabus for Scientist/Engineer Exam.ISRO CS Original Papers and Official Keys.GATE CS Original Papers and Official Keys.
0 notes
Text
Mp3 files after copyright symbol on keyboard

Mp3 files after copyright symbol on keyboard how to#
Mp3 files after copyright symbol on keyboard password#
Super Filter (save and apply filter schemes to other sheets) Advanced Sort by month/week/day, frequency and more Special Filter by bold, italic.
Extract Text, Add Text, Remove by Position, Remove Space Create and Print Paging Subtotals Convert Between Cells Content and Comments.
Exact Copy Multiple Cells without changing formula reference Auto Create References to Multiple Sheets Insert Bullets, Check Boxes and more.
Select Duplicate or Unique Rows Select Blank Rows (all cells are empty) Super Find and Fuzzy Find in Many Workbooks Random Select.
Merge Cells/Rows/Columns without losing Data Split Cells Content Combine Duplicate Rows/Columns.
Super Formula Bar (easily edit multiple lines of text and formula) Reading Layout (easily read and edit large numbers of cells) Paste to Filtered Range.
Mp3 files after copyright symbol on keyboard password#
Reuse: Quickly insert complex formulas, charts and anything that you have used before Encrypt Cells with password Create Mailing List and send emails.But the function of the symbol remains the same-to give notice that the identified work is protected by copyright. And as mentioned before, the copyright symbol is generally not necessary. The style of notice can differ a bit between companies and individuals. While the rules may seem simple enough, it may still leave some wondering, “How do I use the copyright symbol?” Below are a few examples of how some major companies use the copyright symbol for their website copyright notice. The elements for sound recordings generally require the same three elements, except the symbol is ℗ (the letter P in a circle) instead. The symbol © (letter C in a circle) the word “Copyright” or the abbreviation “Copr.”.The notice for visually perceptible copies should generally contain three elements together, or in close proximity to each other. There are differences when it comes to “visually perceptible copies” where the works can be seen or read, such as a book or sculpture, as opposed to “phonorecords” or sound recordings, which would be a CD, record, MP3 file, etc.
Mp3 files after copyright symbol on keyboard how to#
The Copyright Office provides suggestions for how to best use the symbol. An innocent infringement defense can result in a reduction in damages that the copyright owner would otherwise receive.” How to Use the Copyright Symbol Furthermore, in the event that a work is infringed, if the work carries a proper notice, the court will not give any weight to a defendant’s use of an innocent infringement defense-that is, to a claim that the defendant did not realize that the work was protected. “Use of the notice informs the public that a work is protected by copyright, identifies the copyright owner, and shows the year of first publication. However, Circular 3 explains how use of the symbol can be beneficial to the copyright owner. Generally, for works published on or after that date, using the symbol became optional and a published work can still have copyright protection without it. On works published before March 1, 1989, using the notice was required by law for protection. Copyright Office has a publication on Copyright Notice, Circular 3, giving background information about copyright law and how to provide proper copyright notice to the public. While the copyright symbol is often in very small print and tucked away on a corner, the use of a copyright symbol is specifically to get you to notice it. The copyright symbol consists of the letter "C" in a circle such as "©." Copyright symbols are used on books, websites, most packaged goods, including foods and medicines, and more. If you are the copyright owner of a copyrighted work, then you may have wondered about using the copyright symbol. If your business or hobby involves creative work like writing, taking pictures, creating art, music, video or even architecture, then copyright protection might be something that applies to you.
0 notes
Text
Remove Duplicate Values In Excel For Mac

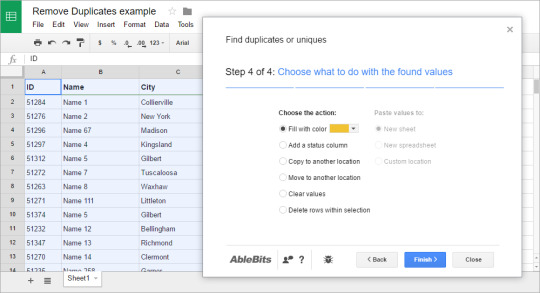
/Duplicate Finder /How to Find and Remove Duplicates in Excel for Mac
When you try to work on a certain spreadsheet using Microsoft Excel, there are instances that you might copy some rows that you are trying to work on.

2 Ways to Remove Duplicates to Create List of Unique Values in Excel. How to Remove Duplicate Data in MS Excel 2007 in Hindi Part 33. In this tutorial we are going to look at 7 easy methods to find and remove duplicate values from your data. Excel has many applications, like keeping track of inventory, maintaining a. You could end up giving a summary report with duplicate values or even. Excel is a versatile application having grown far beyond its early versions as simply a spreadsheet solution. Employed as a record keeper, address book, forecasting tool, and much more, many people.
And with this, you may encounter some duplicate rows wherein you will be needing to delete them. This situation can be a bit difficult to work with especially if you are not familiar with the tool.
In this article, we are going to show how you can remove duplicates on Excel for Mac and a certain tool that you can use for you to remove duplicates.
Article GuidePart 1. How to Remove Your Duplicate Files on Excel ManuallyPart 2. Removing Duplicates in Excel for Mac with Advanced FilterPart 3. How to Remove Duplicates in Excel for Mac by ReplacingPart 4. The Easiest and Fastest Way to Remove DuplicatesPart 5. Conclusion
Part 1. How to Remove Your Duplicate Files on Excel Manually
If in case that you are actually using a Microsoft Office Suite on your Mac, then that would be a great advantage for you. This is because the program had actually a built-in feature that can help you in looking for any duplicates.
Here are the things that you should do for you to remove duplicates excel Mac that you have (Shortcut to remove duplicates in Excel):
Choose all the cells that you want to search for any duplicates.
Go ahead and choose 'Data' located at the top of your screen. Then after that, go ahead and choose “Remove Duplicates”.
Press the OK button to remove duplicates.
Step 1. Choose All the Cells
Choose all the cells that you want to search for any duplicates. You can do this by choosing “Select All” for you to select the whole cells.
Step 2. Click on Data
Once that you have selected all the cells that you want, go ahead and choose 'Data' located at the top of your screen. Then after that, go ahead and choose “Remove Duplicates”.
Then, a dialogue box will then appear on your screen. As you can see on your screen, the first row of the sheet was deselected. This is because the option “My data has headers” box has a checkmark beside it. In this situation, all you have to do is to unmark the 'My data has headers'. Once done, you will then see that everything has been highlighted.
Step 3. Press the OK Button to Remove Duplicates
Since the whole table was selected again, all you have to do is to press the OK button for you to remove any duplicates. Once done, then all the rows that have duplicate will then be removed aside from the one that has been deleted. The details about the changes that had happened will be shown on a pop-up box that will appear on your screen.
Tip: If you are wondering the Excel remove duplicates formula, check the guide about formula to automatically remove duplicates in Excel.
Part 2. Removing Duplicates in Excel for Mac with Advanced Filter
There is also another tool that you can use in your Excel for you to know and remove all the duplicate data that you have. This is by using the “Advanced Filter”. Using this tool can be used if you are actually using Excel 2003 on your Mac. Here is how you can use Advanced Filter.
Step 1: Go ahead and launch Excel on your Mac. Step 2: Then after that, go ahead and choose “Select All” for you to highlight your spreadsheet. Step 3: Once that you have selected a table, go ahead and click on “Data” and then choose “Sort and Filter”.
Step 4: And then, go ahead and choose the “Advanced” option. And in case that you are using the Excel 2003, just simply go ahead and click on the “Data” and then click on the “Filters” from the drop-down menu and then choose “Advanced Filters”. Step 5: From there, go ahead and choose “Unique records only”. And then click on the “OK” button Step 6: Once that you have confirmed the action, all the duplicates that you have on your spreadsheet will be removed.
Remove Duplicate Values In Excel For Mac Download
Part 3. How to Remove Duplicates in Excel for Mac by Replacing
The method that we are going to show you here is actually good enough for those smaller spreadsheets. This is another way for you to locate and remove any duplicates that you have.
In this method, we are going to remove all the duplicates that you have using the “replace” feature which is a built-in function for every Microsoft Office product. Here are the things that you should do.
Step 1: Launch the spreadsheet that you want to work on.
Step 2: After that, go ahead and choose on the cell which contains the content that you would want to look for and replace and then have it copied. From here, all you have to do is to copy the data.
Step 3: Once that you already have copied the certain data that you want to look for, then all you have to do is to press Ctrl + H. This function will then show you the replace feature of the Excel.
Step 4: Once that the feature is up, all you have to do is to paste the data that you have copied earlier. Do this n the “Find What” section.
Step 5: Once that you have already found what you are trying to look for, go ahead and press on the “Options” button. And then go ahead and choose the “Match entire cell content.
Step 6: After that, go ahead and input a certain value on the “replace with” field. And once that you are done entering the value, go ahead and click on the “Replace All” button.
Step 7: You will then be able to notice that all the data that you have found its duplicate will then be replaced with the value that you have entered earlier. This way, you will be able to know which cells contain duplicates.
Step 8: Now, for you to be able to retain one copy of the duplicate that you are trying to look for, go ahead and paste the original content that you have replaced.
Step 9: Now that you have found out all the duplicates that you have on your spreadsheet, go ahead and click on the Ctrl button while you are clicking on the cells that contain your duplicate.
Step 10. After you have highlighted all the rows that you would want to remove, go ahead and right click on one of the highlighted and then choose the “Delete” button.
Step 11. Once that you are done with the process, you will then see that all the rows that remained on your spreadsheet will then have a unique value.
People Also Read:How to Uninstall office 2016 for MacHow to Speed Up Mac
Part 4. The Easiest and Fastest Way to Remove Duplicates
Now, aside from the methods that we have shown you above, there is a best alternative cleaner for you to remove all of your duplicates. This is using the tool called the iMyMac-PowerMyMac's Duplicate Finder.
The PowerMyMac's Duplicate Finder will help you in locating all the duplicate files that you have such as videos, music, documents, photos, and more in the easiest way. This way, you will be able to find all of them accurately and have them deleted.
Just like the duplicates that you have on your Excel, PowerMyMac's Duplicate Finder will help you in looking for all the duplicates that you have on your Mac’s hard drive. This tool is very essential for every Mac users.
The reason for this is that the duplicate files that you have stored on your Mac unknowingly actually eats up a lot of storage space that can also cause your Mac to run slow.
PowerMyMac's Duplicate Finder will be able to scan and look for the files that actually have the same size. And then after that, it will then compare it and the Duplicate Finder will then be able to know if they are identical or not.
Lucky we have the what we called the “byte-to-byte” comparison. Because this way, you will be able to get accurate results. And one of the most awesome thing that the PowerMyMac's Duplicate Finder has is that it has the ability to look for any duplicates even if the file name is different from the original file.
For you to be able to know how easy and fast the PowerMyMac's Duplicate Finder is, go ahead and follow the step by step method that we are going to show you.

Step 1. Download and Install PowerMyMac
The first thing that you need to do is to download the iMyMac PowerMyMac from the official website. Once that you have successfully downloaded the program, go ahead and install it on your Mac.
Once that you are done, go ahead and launch the PowerMyMac on your Mac. Then on the main interface of the program, you will be able to see the system status of your Mac.
Step 2. Scan Your Mac for Duplicates

On the right side of your screen, you will see there a list of modules that PowerMyMac can do. From that list, click on the “Duplicate Finder”. And then go ahead and click on the “Scan” button, PowerMyMac will then scan your Mac to find all the duplicate files that you have.
Once that the scanning process is done, PowerMyMac will then show you all the duplicates that you have. It can also count all the duplicate files that you have including your duplicate photos, videos, documents, and more.
Step 3. Choose the Duplicates to Delete
After that, go ahead and choose all the file types that are shown on your screen as the result of the scanning process. Once that you click on a single file type, you will then be able to see all the duplicate items that you have.
From here, all you have to do is to choose all the items that you would want to remove from your Mac’s system. And once that you are done choosing all the files that you want to delete, go ahead and simply click on the “Clean” button. PowerMyMac will then start to remove all the duplicate files that you have selected earlier to remove.
Part 5. Conclusion
As you can see, it is very easy to remove all the duplicates that you have on your Excel. We know how irritating it is to have more than one data that you need. That is why we have provided you several ways on how you can remove all the data that you do not actually need.
And, just like the duplicates that you have on your Excel, there are also instances that you have a lot of duplicates that you have on your Mac. This is because sometimes we tend to download a single file several times. There are also instances that there are some photos or videos that we tend to save on our Mac.
Because of this, we have the perfect tool that you can use which is the PowerMyMac's Duplicate Finder. This program is one great tool that you can use for you to locate and remove all the duplicate files that you have stored on your Mac.
This includes your data, photo, videos, music and more. The Duplicate Finder also has one of the greatest features which is it can find a certain duplicate file even if the file name is different.
Always keep in mind that if these duplicate files that you have on your Mac actually take up a lot of storage space and that it can cause your Mac to slow down. That is why deleting these duplicate files is one of the most important things that you should do.
The iMyMac PowerMyMac will also allow you to clean up your junk files on your Mac and other data that you no longer need. This way, PowerMyMac will be able to free up space on your Mac and as well as it can help improve the performance of your Mac. Besides, Mac Cleaner from iMyMac also can free up space on Mac by deleting Mac purgeable space.
How To Remove Duplicate Dates In Excel
Have the PowerMyMac installed on your Mac and this will be more than enough for you to maintain your Mac. And it is one of the most recommended tools that you can use for you to clean up al the unnecessary things that you no longer need.
ExcellentThanks for your rating.
Rating: 4.7 / 5 (based on 94 ratings)
People Also Read:
PowerMyMac
A powerful all-in-one App for Mac

Free Download
Remove Duplicates In Excel Shortcut
Comment ()
Clean up and speed up your Mac with ease
Free Download
0 notes