#json filter sum
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
MySQL in Data Science: A Powerful Tool for Managing and Analyzing Data

Data science relies on large-scale ability in information collection, storage, and analysis. Strong emphasis on advanced generation through machine learning and artificial intelligence disregards the fundamental steps involved in the process-data management. MySQL is a popular relational database management system that is used significantly in structured data organizations and management.
In this article, we will dive into the relevance of MySQL for data science and its features and applications. Furthermore, we shall explain why each aspiring data professional should master this. Whether one is looking for learning data science from scratch or searching for the best data analytics courses, one must understand the importance of mastering MySQL.
What is MySQL?
MySQL is an open source, RDBMS, which allows users to store and administer structured data in a very efficient manner. It executes operations such as inserting, updating, deleting, and retrieving data using SQL.
Since structured data is a must for data analysis, MySQL provides a well-structured way of managing large datasets before they are processed for insights. Many organizations use MySQL to store and retrieve structured data for making decisions.
Why is MySQL Important in Data Science?
Efficient Data Storage and Management
MySQL helps in storing vast amounts of structured data in an optimized manner, ensuring better accessibility and security.
Data Extraction and Preprocessing
Before data analysis, raw data must be cleaned and structured. MySQL allows data scientists to filter, sort, and process large datasets efficiently using SQL queries.
Integration with Data Science Tools
MySQL seamlessly integrates with Python, R, and other data science tools through connectors, enabling advanced data analysis and visualization.
Scalability for Large Datasets
Organizations dealing with massive amounts of data use MySQL to handle large-scale databases without compromising performance.
Security and Reliability
MySQL provides authentication, encryption, and access control, so that data is kept safe and secure for analysis purposes.
Key Features of MySQL for Data Science
SQL Queries for Data Manipulation
SQL makes it easy to interact with the database for any data scientist. Some of the most common SQL queries are as follows:
SELECT – Retrieves data
WHERE – Filters results
GROUP BY – Groups records
JOIN – Merges data from multiple tables
Indexing for Faster Queries
It uses indexes for speeding up data retrieval. Querying large data is efficient, using MySQL.
Stored Procedures and Functions
These facilitate automation of repetitive tasks. Efficiency in working with big data is enhanced by these techniques.
Data Aggregation
Support for functions SUM, COUNT, AVG, MIN, and MAX is there in MySQL to sum up the data prior to actual analysis.
Data Export and Integration
Data scientists can export MySQL data in formats like CSV, JSON, and Excel for further processing in Python or R.
Applications of MySQL in Data Science
Exploratory Data Analysis (EDA)
MySQL helps data scientists explore datasets, filter records, and detect trends before applying statistical or machine learning techniques.
Building Data Pipelines
Many organizations use MySQL in ETL (Extract, Transform, Load) processes to collect and structure data before analysis.
Customer Behavior Analysis
Businesses study customer purchase behavior and interaction data housed in MySQL to customize marketing campaigns.
Real-Time Analytics
MySQL can monitor real-time data in finance and e-commerce fields.
Data Warehousing
Businesses use MySQL databases to store historical data. This type of data can be used by firms to analyze long-term business trends and performance metrics.
How to Learn MySQL for Data Science
Mastering MySQL is the first step for anyone interested in data science. A step-by-step guide on how to get started is as follows:
SQL Basic Learning
Start with fundamental SQL commands and learn how to build, query, and manipulate databases.
Practice with Real Datasets
Work on open datasets and write SQL queries to extract meaningful insights.
Integrate MySQL with Python
Leverage Python libraries like Pandas and SQLAlchemy to connect with MySQL for seamless data analysis.
Work on Data Projects
Apply MySQL in projects like sales forecasting, customer segmentation, and trend analysis.
Explore the Best Data Analytics Courses
This means that you will be able to master MySQL as well as other advanced analytics concepts.
Conclusion
MySQL is a vital tool in data science because it offers effective data storage, management, and retrieval capabilities. Whether you're analyzing business performance or building predictive models, MySQL is a foundational skill. With the continued development of data science, mastering MySQL will give you a competitive advantage in handling structured datasets and extracting meaningful insights.
By adding MySQL to your skill set, you can unlock new opportunities in data-driven industries and take a significant step forward in your data science career.
0 notes
Text
Python Full Stack Development Course AI + IoT Integrated | TechEntry
Join TechEntry's No.1 Python Full Stack Developer Course in 2025. Learn Full Stack Development with Python and become the best Full Stack Python Developer. Master Python, AI, IoT, and build advanced applications.
Why Settle for Just Full Stack Development? Become an AI Full Stack Engineer!
Transform your development expertise with our AI-focused Full Stack Python course, where you'll master the integration of advanced machine learning algorithms with Python’s robust web frameworks to build intelligent, scalable applications from frontend to backend.
Kickstart Your Development Journey!
Frontend Development
React: Build Dynamic, Modern Web Experiences:
What is Web?
Markup with HTML & JSX
Flexbox, Grid & Responsiveness
Bootstrap Layouts & Components
Frontend UI Framework
Core JavaScript & Object Orientation
Async JS promises, async/await
DOM & Events
Event Bubbling & Delegation
Ajax, Axios & fetch API
Functional React Components
Props & State Management
Dynamic Component Styling
Functions as Props
Hooks in React: useState, useEffect
Material UI
Custom Hooks
Supplement: Redux & Redux Toolkit
Version Control: Git & Github
Angular: Master a Full-Featured Framework:
What is Web?
Markup with HTML & Angular Templates
Flexbox, Grid & Responsiveness
Angular Material Layouts & Components
Core JavaScript & TypeScript
Asynchronous Programming Promises, Observables, and RxJS
DOM Manipulation & Events
Event Binding & Event Bubbling
HTTP Client, Ajax, Axios & Fetch API
Angular Components
Input & Output Property Binding
Dynamic Component Styling
Services & Dependency Injection
Angular Directives (Structural & Attribute)
Routing & Navigation
Reactive Forms & Template-driven Forms
State Management with NgRx
Custom Pipes & Directives
Version Control: Git & GitHub
Backend
Python
Python Overview and Setup
Networking and HTTP Basics
REST API Overview
Setting Up a Python Environment (Virtual Environments, Pip)
Introduction to Django Framework
Django Project Setup and Configuration
Creating Basic HTTP Servers with Django
Django URL Routing and Views
Handling HTTP Requests and Responses
JSON Parsing and Form Handling
Using Django Templates for Rendering HTML
CRUD API Creation and RESTful Services with Django REST Framework
Models and Database Integration
Understanding SQL and NoSQL Database Concepts
CRUD Operations with Django ORM
Database Connection Setup in Django
Querying and Data Handling with Django ORM
User Authentication Basics in Django
Implementing JSON Web Tokens (JWT) for Security
Role-Based Access Control
Advanced API Concepts: Pagination, Filtering, and Sorting
Caching Techniques for Faster Response
Rate Limiting and Security Practices
Deployment of Django Applications
Best Practices for Django Development
Database
MongoDB (NoSQL)
Introduction to NoSQL and MongoDB
Understanding Collections and Documents
Basic CRUD Operations in MongoDB
MongoDB Query Language (MQL) Basics
Inserting, Finding, Updating, and Deleting Documents
Using Filters and Projections in Queries
Understanding Data Types in MongoDB
Indexing Basics in MongoDB
Setting Up a Simple MongoDB Database (e.g., MongoDB Atlas)
Connecting to MongoDB from a Simple Application
Basic Data Entry and Querying with MongoDB Compass
Data Modeling in MongoDB: Embedding vs. Referencing
Overview of Aggregation Framework in MongoDB
SQL
Introduction to SQL (Structured Query Language)
Basic CRUD Operations: Create, Read, Update, Delete
Understanding Tables, Rows, and Columns
Primary Keys and Unique Constraints
Simple SQL Queries: SELECT, WHERE, and ORDER BY
Filtering Data with Conditions
Using Aggregate Functions: COUNT, SUM, AVG
Grouping Data with GROUP BY
Basic Joins: Combining Tables (INNER JOIN)
Data Types in SQL (e.g., INT, VARCHAR, DATE)
Setting Up a Simple SQL Database (e.g., SQLite or MySQL)
Connecting to a SQL Database from a Simple Application
Basic Data Entry and Querying with a GUI Tool
Data Validation Basics
Overview of Transactions and ACID Properties
AI and IoT
Introduction to AI Concepts
Getting Started with Python for AI
Machine Learning Essentials with scikit-learn
Introduction to Deep Learning with TensorFlow and PyTorch
Practical AI Project Ideas
Introduction to IoT Fundamentals
Building IoT Solutions with Python
IoT Communication Protocols
Building IoT Applications and Dashboards
IoT Security Basics
TechEntry Highlights
In-Office Experience: Engage in a collaborative in-office environment (on-site) for hands-on learning and networking.
Learn from Software Engineers: Gain insights from experienced engineers actively working in the industry today.
Career Guidance: Receive tailored advice on career paths and job opportunities in tech.
Industry Trends: Explore the latest software development trends to stay ahead in your field.
1-on-1 Mentorship: Access personalized mentorship for project feedback and ongoing professional development.
Hands-On Projects: Work on real-world projects to apply your skills and build your portfolio.
What You Gain:
A deep understanding of Front-end React.js and Back-end Python.
Practical skills in AI tools and IoT integration.
The confidence to work on real-time solutions and prepare for high-paying jobs.
The skills that are in demand across the tech industry, ensuring you're not just employable but sought-after.
Frequently Asked Questions
Q: What is Python, and why should I learn it?
A: Python is a versatile, high-level programming language known for its readability and ease of learning. It's widely used in web development, data science, artificial intelligence, and more.
Q: What are the prerequisites for learning Angular?
A: A basic understanding of HTML, CSS, and JavaScript is recommended before learning Angular.
Q: Do I need any prior programming experience to learn Python?
A: No, Python is beginner-friendly and designed to be accessible to those with no prior programming experience.
Q: What is React, and why use it?
A: React is a JavaScript library developed by Facebook for building user interfaces, particularly for single-page applications. It offers reusable components, fast performance, and one-way data flow.
Q: What is Django, and why should I learn it?
A: Django is a high-level web framework for building web applications quickly and efficiently using Python. It includes many built-in features for web development, such as authentication and an admin interface.
Q: What is the virtual DOM in React?
A: The virtual DOM represents the real DOM in memory. React uses it to detect changes and update the real DOM as needed, improving UI performance.
Q: Do I need to know Python before learning Django?
A: Yes, a basic understanding of Python is essential before diving into Django.
Q: What are props in React?
A: Props in React are objects used to pass information to a component, allowing data to be shared and utilized within the component.
Q: Why should I learn Angular?
A: Angular is a powerful framework for building dynamic, single-page web applications. It enhances your ability to create scalable and maintainable web applications and is highly valued in the job market.
Q: What is the difference between class-based components and functional components with hooks in React?
A: Class-based components maintain state via instances, while functional components use hooks to manage state, making them more efficient and popular.
For more, visit our website:
https://techentry.in/courses/python-fullstack-developer-course
0 notes
Text
json nesnesi içerisinde toplama yaptırmak
aşağıdaki örnek json dosyasında expense olanları ayrı, income olanların amount değerlerini type alanlarına göre ayı olarak toplamak istiyorum. Şöyle yapıyoruz
getListOfBudget :{ budgetData: [ { amount: 1, category: 'house', budgetDate: 2021-09-21T21:00:00.000Z, description: '123', type: 'expense', createdDate: 2021-09-22T07:39:13.002Z, budgetId: 123123 }, { amount: 2, category: 'house', budgetDate: 2021-09-17T21:00:00.000Z, description: '123123', type: 'expense', createdDate: 2021-09-22T07:39:13.002Z, budgetId: 123123 }, { amount: 91, category: 'life', budgetDate: 2021-09-17T21:00:00.000Z, description: '123123', type: 'income', createdDate: 2021-09-22T07:39:13.002Z, budgetId: 3123123 } ], _id: 61489f246cf7653d286ac26b, userID: 124124, __v: 0 }
Kod şu şekilde
let r = getListOfBudget.budgetData.reduce((pv,cv) => { if(pv[cv.type]){ pv[cv.type] += cv.amount; } else { pv[cv.type] = cv.amount; } return pv; }, {})
çıktısı
{ expense: 3, income: 91 }
0 notes
Text
Google’s Newest Way to Manage Custom Cloud Monitoring

Google Cloud has GitHub repository that contains 30 dashboard templates to manage custom cloud monitoring. The new product targets specific Google Cloud services that focus on compute, storage, data processing, networking, database, tooling and microservice demo application.
The GitHub repository offers sample dashboards. Firstly, the customers can study the purpose of each dashboard sample through a README file. The file is on each folder that sums up the content and metrics used. The Google Teams created the GitHub repository by aggregating some of the data based on specific use cases. After that, the data was put in sample dashboards that will make easier for the users.
Take a look at the following examples. The dashboard for CPU utilization and memory usage is by default not aggregated. While for network egress and ingress, the Google Teams used sum for aggregation for the widgets on the dashboard for showing the goal to catch total bytes. In the GitHub Repository, you can manage custom cloud monitoring because you will have a holistic view on your workload state by grouping related services.
There are some steps that you need to take to manage custom cloud monitoring though these dashboard templates. You can firstly check on the templates through the GitHub repo via the gcloud CLI, Terraform or Deployment Manager. After that, follow the procedures for further actions.
You need to check it out from GitHub then apply the gcloud monitoring dashboards create command to set up a dashboard. You can either choose Terraform to utilize the dashboards. Apply a script under the terraform folder that contains the dashboard module to display this step.
Else, you can choose Cloud Deployment Manager to utilize the dashboards using the scripts under the dm folder. Those channels make your efforts easier for integrating dashboard development and deployment into an automated pipeline. One practice that you can try includes checking your dashboard JSON files into a Git repository and updating the repository can lead to a Cloud Build process. In turn, this will make changes in the Cloud Monitoring.
After the GitHub repository, Google Cloud is working on improving the template library. It is examining on more Google Cloud services, extending the dashboard templates so that they can cover multiple services under one dashboard and accommodating customer insight through built-in data filter and aggregation capability. Link: https://sotech.co.id/manage-custom-cloud-monitoring/
1 note
·
View note
Text
Sparkster source code review
Sparkster has finally opened its code repositories to the public, and as the project has been somewhat in the centre of discussion in the crypto community, as well as marketed by one of the high profile crypto influencers, we have been quite curious to see the result of their efforts.

The fundamental idea of the project is to provide a high-throughput decentralized cloud computing platform, with software developer kit (SDK) on top with no requirement for programming expertise (coding is supposed to be done in plain English). The idea of plain English coding is far from new and has been emerging more than a few times over the years, but never gotten any widespread traction. The reason in our opinion is that professional developers are not drawn to simplified drag & drop plain language programming interfaces, and non-developers (which is one of the potential target groups for Sparkster) are, well, most probably just not interested in software development altogether.
However the focus of this article is not to scrutinize the use case scenarios suggested by Sparkster (which do raise some question marks) but rather to take a deep look into the code they have produced. With a team counting 14 software developers and quite a bit of runway passed since their ICO in July 2018, our expectations are high.
Non-technical readers are advised to skip to the end for conclusions.
Source code review Sparkster initially published four public repositories in their github (of which one (Sparkster) was empty). We noticed a lack of commit history which we assume is due to a transfer of the repos from a private development environment into github. Three of the above repositories were later combined into a single one containing subfolders for each system element.
The first impression from browsing the repositories is decent after recent cleanups by the team. Readme has been added to the main repository with information on the system itself and installation instructions (Windows x64 only, no Linux build is available yet)
However, we see no copyright notes anywhere in the code developed by Sparkster, which is quite unusual for an open source project released to the public.
Below is a walk-thru of the three relevant folders containing main system components under the Decentralized-Cloud repository and a summary of our impression.
Master-Node folder The source code is written in C++. Everything we see is very basic. In total there are is not a lot of unique code (we expected much more given the development time spent) and a lot of the recently added code is GNU/forks from other projects (all according to the copyright notes for these parts).
An interesting part is, that if this master node spawned the compute node for this transaction, the master node will request the compute node to commit the transaction. The master nodes takes the control over more or less all communication to stakeholders such as clients. The master node will send a transaction to 20 other master nodes.
The lock mechanism during voting is standard: nodes booting in the middle of voting are locked and cannot participate to avoid incorrect results.
We cannot see anything in the code that differentiates the node and makes it special in any way, i.e. this is blockchain 101.
Compute-Node folder All source files sum up to a very limited amount of code. As the master node takes over a lot of control, the compute node focuses on the real work. A minimalistic code is generally recommended in a concept like this, but this is far less than expected.
We found the “gossip” to 21 master nodes before the memory gets erased and the compute node falls back to listen mode.
The concept of 21 master nodes is defined in the block producer. Every hour a new set of 21 master nodes become the master node m21.
“At any given point in time, 21 Master Nodes will exist that facilitate consensus on transactions and blocks; we will call these master nodes m21. The nodes in m21 are selected every hour through an automated voting process”
(Source: https://github.com/sparkster-me/Decentralized-Cloud)
The compute node is somewhat the heart of the project but is yet again standard without any features giving it high performance capability.
Storage-Node folder The source code is again very basic. Apart from this, the code is still at an experimental stage with e.g. buffer overflow disabling being utilized, something that should not be present at this stage of development.
Overall the storage uses json requests and supports/uses the IPFS (InterPlanetary File System). IPFS is an open source project and used for storing and sharing hypermedia in a distributed file system. The storage node not only handles the storage of data, it also responds to some client filter requests.
Conclusion In total Sparkster has produced a limited amount of very basic code, with a team of 14 developers at their disposal. As their announcement suggests that this is the complete code for their cloud platform mainnet, we must assume that the productivity of the team has been quite low over the months since funds were raised, since none of the envisioned features for high performance are yet implemented.
The current repository is not on par with standards for a mainnet release and raises some serious question marks about the intention of the project altogether. The impression is that the team has taken a very basic approach and attempted to use short cuts in order to keep their timelines towards the community, rather than develop something that is actually unique and useful. This is further emphasized by the fact that the Sparkster website and blockchain explorer is built on stock templates. We don’t see any sign of advanced development capability this far.
Based on what we see in this release Sparkster is currently not a platform for ”full scale support to build AI powered apps” as their roadmap suggest and we are puzzled by the progress and lack of provisioning of any type of SDK plugin. The Sparkster team has a lot to work on to even be close to their claims and outlined roadmap.
Note: we have been in contact with the Sparkster team prior to publishing this review, in order to provide opportunity for them to comment on our observations. Their answers are listed below but doesn’t change our overall conclusions of the current state of Sparkster development.
“We use several open source libraries in our projects. These include OpenDHT, WebSocket++, Boost, and Ed25519. In other places, we’ve clearly listed where code is adapted from in the cases where we’ve borrowed code from other sources. We’ve used borrowed code for things like getting the time from a time server: a procedure that is well documented and for which many working code examples already exist, so it is not necessary for us to reinvent the wheel. However, these cases cover a small portion of our overall code base.
Our alpha net supports one cell, and our public claims are that one cell can support 1,000 TPS. These are claims that we have tested and validated, so the mainnet is in spec. You will see that multi cell support is coming in our next release, as mentioned in our readme. Our method of achieving multi cell support is with a well understood and documented methodology, specifically consistent hashing. However, an optimization opportunity, we’re investiging LSH over CS. This is an optimization that was recommended by a member of our Tech Advisory Board, who is a PHD in Computer Science at the University of Cambridge.
Our code was made straightforward on purpose. Most of its simplicity comes from its modular design: we use a common static library in which we’ve put common functionality, and this library is rightfully called BlockChainCommon.lib. This allows us to abstract away from the individual nodes the inner workings of the core components of our block chain, hence keeping the code in the individual nodes small. This allows for a high level of code reusability. In fact, in some cases this modular design has reduced a node to a main function with a series of data handlers, and that’s all there is to it. It allows us to design a common behavior pattern among nodes: start up OpenDHT, register data handlers using a mapping between the ComandType command and the provided lambda function, call the COMM_PROTOCOL_INIT macro, enter the node’s forever loop. This way, all incoming data packets and command processors are handled by BlockChainCommon, and all nodes behave similarly: wait for a command, act on the command. So while this design gives the impression of basic code, we prefer simplicity over complexity because it allows us to maintain the code and even switch out entire communications protocols within a matter of days should we choose to do so. As far as the Compute Node is concerned, we use V8 to execute the javascript which has a proven track record of being secure, fast and efficient.
We’ve specifically disabled warning 4996 because we are checking for buffer overflows ourselves, and unless we’re in debug mode, we don’t need the compiler to warn about these issues. This also allows our code to be portable, since taking care of a lot of these warnings the way the VCC compiler wants us to will mean using Microsoft-specific functions are portable (other platforms don’t provide safe alternatives with the _s suffix, and even Microsoft warns about this fact here: https://docs.microsoft.com/en-us/cpp/error-messages/compiler-warnings/compiler-warning-level-3-c4996?view=vs-2017.) To quote: “However, the updated names are Microsoft-specific. If you need to use the existing function names for portability reasons, you can turn these warnings off.”
1 note
·
View note
Text
Download mongodb 4.0

Download mongodb 4.0 how to#
Download mongodb 4.0 for mac os x#
Download mongodb 4.0 code#
The cursor.not(operator-expression) method performs a logical NOT operation on the specified “operator-expression” and selects the documents that do not match the “operator-expression”. MongoBooser integrates node-fetch to bring window.fetch to MongoDB Script.Ĭonsole.log( await( await(fetch( '')).text())) Ĭonsole.log( await( await(fetch( '')).json())) Minor Enhancement More Useful MongoDB Shell Extensions Global fetch() method
Download mongodb 4.0 how to#
Out of the box, Ctrl-Space, Alt-Space are acceptable triggers.Ĭlick here to learn how to use Node.js Modules in Your Script You can always manually trigger it with Ctrl-Shift-Space. The IntelliSense suggestions will pop up as you type and automatically complete Javascript method names, variables, etc. Within this release, MongoBooster also offers Intellisense experience for Node.js required packages. Intellisense for Node.js Required Packages The above example can be written with the MongoBooster await function. Note this await function is different from es7 await, this await function may be used in functions without the async keyword marked. It can await a promise or a promise array. Within this release, we have also added support for ES7 Async/Await in MongoBooster shell.Īs a comparison, MongoBooster has a build-in function await which is a common js method, not a keyword. See the features and SQL examples supported by the MongoBooster. Autocomplete for keywords, MongoDB collection names, field names and SQL functions.Provide a programming interface (mb.runSQLQuery) that can be integrated into your script.Aggregation Pipeline Operators as SQL Functions (dateToString, toUpper, split, substr…).SQL Functions (COUNT, SUM, MAX, MIN, AVG).Access data via SQL including WHERE filters, ORDER BY, GROUP BY, HAVING, DISTINCT, LIMIT.The Equivalent MongoDB Query can be viewed in console.log tab.Ĭlick here to learn how to run SQL SELECT Query against MongoDB SQL Query Features The SQL query is validated and translated into a MongoDB query and executed by MongoBooster. SQL features are not natively supported by MongoDB.If you want the results not to be edited directly, you can enable the “read-only” mode by clicking the lock button in the toolbar.Pressing shortcut “Esc” will return the previous value and exit the editor. Double-click on any value or array element to edit. MongoBooster supports in-place editing in result tree view.You can always manually trigger the auto-complete feature with Ctrl-Shift-Space. The IntelliSense suggestions will pop up as you type. The build-in SQL language service knows all possible completions, SQL functions, keywords, MongoDB collection names and field names.Just Click on the “console.log/print” tab to show the equivalent MongoDB query: Just type a snippet prefix “run”, and enter “tab” to insert this snippet, then press “Command-Enter” to execute it and get the result.
Download mongodb 4.0 code#
MongoBooster also offers a “runSQLQuery” code snippets. Open a shell tab, enter the above script. SELECT department, SUM(salary) AS total FROM employees GROUP BY department You can query MongoDB by using old SQL which you probably already know 1 Instead of writing the MongoDB query which is represented as a JSON-like structure 1 Let’s look at how to use the GROUP BY clause with the SUM function in SQL. SQL support includes functions, expressions, aggregation for collections with nested objects and arrays. With MongoBooster V4, you can run SQL SELECT Query against MongoDB.
Download mongodb 4.0 for mac os x#
This major upgrade includes Query MongoDB with SQL, ES7 Async/Await support and more.Īlthough we are showing screenshots of MongoBooster for Windows, all these new features are available for Mac OS X and Linux as well. Today, we are extremely pleased to announce the release of MongoBooster 4.0.
0 notes
Text
How to Get Free Malware Samples and Reports?

Malware hunters often look for malicious objects to investigate threat features and build protection strategies. The hindrance for striving cybersecurity specialists is to access new malicious code samples to practice on. ANY.RUN is an excellent resource for obtaining malware for free. In this post, we will tell you how to do it.
Where can you get malware samples?
ANY.RUN is an online interactive sandbox with a vast malware sample database of 3,780,111 public submissions. Each registered user can make use of these tasks to rerun and analyze a sample, get reports and IOCs, and other options. Fresh samples are delivered constantly. Researchers worldwide comprise this collection and run more than 9000 tasks every day.
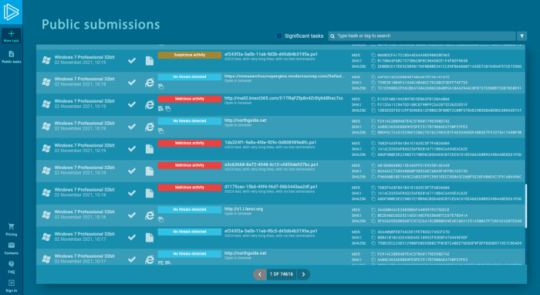
The “Public submissions” window is where you can dive into fresh malware samples and explore malware techniques. Here you can go through all the tasks that service users upload publicly. Users of premium subscriptions have an opportunity to analyze their tasks privately. So the window above includes only public submissions that a user chose to share with the community.
How to find a specific malware sample?
During the research, you may need an exact malicious program. To save your time in the search, ANY.RUN service has a helpful filter system. You can navigate through numerous samples using the following parameters:
Object
Hash
Run type of analyzed object (URL or file)
Extensions
Country
Verdict
You can also filter submissions using the sample’s threat level status and the verdict. There are three types of verdicts:
Malicious. Malicious activity is detected.
Suspicious. Suspicious activity was detected, and there is a possibility of the file being malicious, but it isn’t proven.
No threats detected. ANY.RUN has detected no malicious or suspicious activity.
Specified tag
You can find a sample by a malware name, family, technique, and vulnerabilities that the malicious program exploits. Read our blog post to check the list of tags and get more details about them. All the trending tags are displayed on the dashboard.
Context
You can type the sample’s unique data like a file hash, domain, IP address, MITRE ATT&CK, and Suricata SID in the context part.
Apply one or several parameters to find a specific malicious example. Try it yourself with a possibly infected IOC — use the filter, and similar cases will be displayed.

Once you find the sample you need, you see the analysis results immediately. They are shown in the visual form of a video or a screenshot slideshow.

What reports can you get?
Different reports on our malware samples site can help you examine the malicious object.

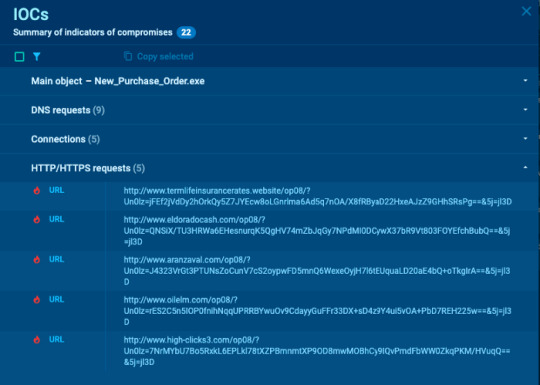
IOCs
Summary of indicators of compromise. Check out the object’s hash sums, DNS requests, connections, and HTTP/HTTPS requests. The window allows you to copy the necessary data and filter information. Icons and the number of IOCs let you run through the report and understand what you are dealing with at once.
Text report

The text reports are convenient. The most significant data is at the top, so you won’t miss anything. A detailed report contains general information about a sample, behavior activities, screenshots, data about the process, registry, files, network, debug output, etc.
You can also export or print this report in a preferable form — hide blocks by clicking on the “eye” icon.
The export in different formats is also available:
JSON Summary
JSON IOC
HTML Document
Export Process Graph (SVG)
JSON MISP format
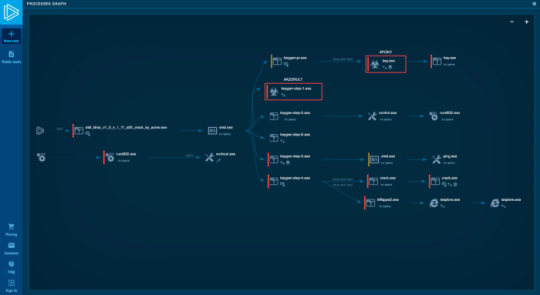
Process graph
The best overview of a sample is to examine its events in the process graph. A brief look, and you already know what is going on here.
MITRE ATT&CK matrix
The more information you have, the better analysis you perform. MITRE ATT&CK matrix gives a full view of the investigated malware’s tactics.

Of course, that is not all the details that you get. Each process has descriptive information about network stream, static discovering, and advanced information about events. You can find it out during the analysis or go through our guide on how to use ANY.RUN.
PCAP files
You can download PCAP files from the tasks to further analyze the network traffic in programs such as Wireshark. If the task was started with HTTPS MITM Proxy on, then the SSL Key Log file will also be available for download that allows you to decrypt HTTPS traffic.
Rerun a task that you have found in the public submissions and watch the process by yourself. With ANY.RUN’s premium subscriptions — Searcher and Hunter, you get extra features: customize configurations and see malware behavior on VM in a different environment. Check out a video to watch these plans in action:
Be attentive if you want to submit a malware sample and research files with sensitive information. A Community account’s investigation is available to the public by default.
ANY.RUN is an online sandbox. But it is also a service for education and research. If you are interested in malware trends, you can take a look at our Malware Trends Tracker to monitor malicious activity daily with its dynamic articles.
Check out the public submissions and start your analysis of malware samples with detailed reports now!
The malware samples used in the post: https://app.any.run/tasks/064e8183-009b-486c-9e5b-6d549a568612/ and https://app.any.run/tasks/a76e4684-0d7b-46de-af71-0538a5cde0f8/
0 notes
Text
Top 10 Data Analytics Tools
The developing interest and significance of information examination in the market have produced numerous openings around the world. It turns out to be marginally difficult to waitlist the top information investigation apparatuses as the Data structure and algorithm are more well known, easy to understand and execution situated than the paid variant. There are many open source apparatuses which doesn't need a lot/any coding and figures out how to convey preferable outcomes over paid renditions for example - R programming in information mining and Tableau public, Python in information representation. The following is the rundown of top 10 of information investigation apparatuses, both open source and paid rendition, in view of their fame, learning and execution.
1. R Programming
R is the main investigation apparatus in the business and generally utilized for measurements and information demonstrating. It can without much of a stretch control your information and present in an unexpected way. It has surpassed SAS from multiple points of view like limit of information, execution and result. R incorporates and runs on a wide assortment of stages viz - UNIX, Windows and MacOS. It has 11,556 bundles and permits you to peruse the bundles by classifications. R likewise gives apparatuses to consequently introduce all bundles according to client necessity, which can likewise be very much gathered with Big information.
2. Scene Public:
Scene Public is a free programming that interfaces any information source be it corporate Data Warehouse, Microsoft Excel or electronic information, and makes information representations, maps, dashboards and so on with ongoing updates introducing on web. They can likewise be shared through web-based media or with the customer. It permits the admittance to download the document in various arrangements. On the off chance that you need to see the force of scene, we should have excellent information source. Scene's Big Data abilities makes them significant and one can dissect and envision information better than some other information perception programming on the lookout.

3. Python
Python is an article arranged scripting language which is not difficult to peruse, compose, keep up and is a free open-source apparatus. It was created by Guido van Rossum in late 1980's which upholds both useful and organized programming strategies.
Python is not difficult to learn as it is fundamentally the same as JavaScript, Ruby, and PHP. Likewise, Python has excellent AI libraries viz. Scikitlearn, Theano, Tensorflow and Keras. Another significant component of Python is that it very well may be amassed on any stage like SQL worker, a MongoDB information base or JSON. Python can likewise deal with text information quite well.
4. SAS
Sas is a programming climate and language for information control and an innovator in examination, created by the SAS Institute in 1966 and further created in 1980's and 1990's. SAS is effectively open, managable and can dissect information from any sources. SAS presented an enormous arrangement of items in 2011 for client insight and various SAS modules for web, online media and showcasing examination that is generally utilized for profiling clients and possibilities. It can likewise foresee their practices, oversee, and advance interchanges.
5. Apache Spark
The University of California, Berkeley's AMP Lab, created Apache in 2009. Apache Spark is a quick enormous scope information preparing motor and executes applications in Hadoop groups multiple times quicker in memory and multiple times quicker on circle. Flash is based on information science and its idea makes information science easy. Sparkle is additionally well known for information pipelines and AI models improvement.
Sparkle additionally incorporates a library - MLlib, that gives a reformist arrangement of machine calculations for dreary information science strategies like Classification, Regression, Collaborative Filtering, Clustering, and so on
6. Dominate
Dominate is an essential, mainstream and generally utilized scientific apparatus practically on the whole businesses. Regardless of whether you are a specialist in Sas, R or Tableau, you will in any case have to utilize Excel. Dominate becomes significant when there is a prerequisite of examination on the customer's interior information. It breaks down the intricate errand that sums up the information with a review of rotate tables that helps in separating the information according to customer necessity. Dominate has the development business examination alternative which helps in demonstrating capacities which have prebuilt choices like programmed relationship recognition, a making of DAX measures and time gathering.
7. RapidMiner:
RapidMiner is an incredible coordinated information science stage created by the very organization that performs prescient examination and other progressed investigation like information mining, text examination, AI and visual examination with no programming. RapidMiner can join with any information source types, including Access, Excel, Microsoft SQL, Tera information, Oracle, Sybase, IBM DB2, Ingres, MySQL, IBM SPSS, Dbase and so on The apparatus is exceptionally amazing that can create examination dependent on genuine information change settings, for example you can handle the organizations and informational indexes for prescient investigation.
8. KNIME
KNIME Developed in January 2004 by a group of programmers at University of Konstanz. KNIME is driving open source, detailing, and incorporated examination apparatuses that permit you to break down and model the information through visual programming, it coordinates different segments for information mining and AI by means of its measured information pipelining idea.
9. QlikView
QlikView has numerous one of a kind highlights like protected innovation and has in-memory information handling, which executes the outcome extremely quick to the end clients and stores the information in the actual report. Information relationship in QlikView is consequently kept up and can be packed to practically 10% from its unique size. Information relationship is envisioned utilizing colors - a particular tone is given to related information and another tone for non-related information.
10. Splunk:
Splunk is an apparatus that examines and search the machine-created information. Splunk pulls all content based log information and gives a basic method to look through it, a client can pull on the whole sort of information, and play out such a fascinating measurable investigation on it, and present it in various organizations.
For More Details, Visit Us:
data structures in java
system design interview questions
Google interview questions
cracking the coding interview python
0 notes
Text
success
fail
Feb MAR Apr 23 2018 2019 2020
26 captures
21 Jan 2016 - 27 Sep 2019
About this capture
COLLECTED BY
Organization: Alexa Crawls
Starting in 1996, Alexa Internet has been donating their crawl data to the Internet Archive. Flowing in every day, these data are added to the Wayback Machine after an embargo period.
Collection: Alexa Crawls
Starting in 1996, Alexa Internet has been donating their crawl data to the Internet Archive. Flowing in every day, these data are added to the Wayback Machine after an embargo period.
TIMESTAMPS
__wm.bt(625,27,25,2,"web","http://nbanalytics.tumblr.com/","20190323161114",1996,"/_static/",["/_static/css/banner-styles.css?v=HyR5oymJ","/_static/css/iconochive.css?v=qtvMKcIJ"]); NBAnalyticsfigure{margin:0}.tmblr-iframe{position:absolute}.tmblr-iframe.hide{display:none}.tmblr-iframe--amp-cta-button{visibility:hidden;position:fixed;bottom:10px;left:50%;transform:translateX(-50%);z-index:100}.tmblr-iframe--amp-cta-button.tmblr-iframe--loaded{visibility:visible;animation:iframe-app-cta-transition .2s ease-out} /* If this option is selected, the theme will use a solid background instead of an image */ body { background: #000000 url(http://web.archive.org/web/20190323161114im_/http://static.tumblr.com/06e5dcbee1eebcb1fc08923a0dbbdf9e/deauzpq/9Mumzs7m4/tumblr_static_maxresdefault.jpg) fixed top left; } /* If this option is selected, the theme will use a solid background instead of an image */ var enableAudiostream = false; var audioplayerTagFilter = false; var enableDisqus = false; var enableTwitter = false; var enableFlickr = false; var enableInstagram = false; var totalBlogPages = '1'; {"@type":"ItemList","url":"http:\/\/web.archive.org\/web\/20190323161114\/http:\/\/nbanalytics.tumblr.com","itemListElement":[{"@type":"ListItem","position":1,"url":"http:\/\/web.archive.org\/web\/20190323161114\/http:\/\/nbanalytics.tumblr.com\/post\/75952859870\/ranking-the-nba-teams-with-a-genetic-ml-algorithm"},{"@type":"ListItem","position":2,"url":"http:\/\/web.archive.org\/web\/20190323161114\/http:\/\/nbanalytics.tumblr.com\/post\/74366758922\/what-team-benefits-the-most-from-home-cooking"}],"@context":"http:\/\/web.archive.org\/web\/20190323161114\/http:\/\/schema.org"}
Now Playing Tracks
NBAnalytics
Facebook
Twitter
Google
Tumblr
Ranking the NBA Teams with a Genetic ML Algorithm
Which team is the best in the NBA? A question that most of us basketball fans think we know the answer to yet often we find it so hard to come to a consensus. In the ever-popular world of basketball analytics, I would argue that mathematical team rankings are probably the most popular and contentious problem that people try to “solve”. About two years ago I attacked this topic of debate in my very first foray into the world of basketball analytics. I was naive and inexperienced at the time, but my eventual failure led me to continue to explore the world of basketball data, statistics and machine learning…
From a math point of view there are lots of ways to approach the problem developing a computer ranking system. I will begin by establishing that the goal of any NBA ranking system should be to predict playoff success. If two teams are paired together in a playoff bracket, the higher ranked team should win more often. Additionally, the larger the difference in rating scores, the more likely the favorite team should win the playoff series. Here are a couple of simple models one might use to predict playoff success. I will use these as baseline models to which I compare my own ranking system.
The most basic way to measure team quality from the regular season is winning percentage. Below we see a plot of playoff wins versus regular season winning percentage.

There is definitely a positive and statistically significant correlation of 0.571, but can we do better? The percent of the variance in playoff success explained by regular season success alone is only 33%. Not to mention that half of the NBA champion teams fall outside of the 95% confidence interval for prediction. Obviously there are other factors that should be taken into account when predicting postseason success.
Another way to measure team quality and a popular one with computational ranking systems is average margin of victory. Below is a plot of the average margin of victory versus playoff wins.

This metric also has a positive correlation with playoff success with a statistically significant value of 0.599, which is slightly better than using regular season wins to predict playoff wins. The percent of the variance explained is also slightly better for margin of victory at 36%. However, this model also fails to include many of the champions in the 95% confidence band.
So how can be expand our ranking system to better predict postseason success? Similar to my take on measuring home court advantage, I believe that any ranking system needs to take into account the various strengths of the opponents that each teams play as well as the quality of performance in each of those games relative to an average team would against the same opponents.
From this simple criteria I developed 10 performance measures that could be included in the ranking of every team in two different categories for every game they play:
Strength of opponent
Total opponent winning percentage at time of the game
Opponent winning percentage at site of game (home/away) at time of the game
Opponent’s avg. margin of victory
Opponent’s avg. margin of victory at site of game (home/away)
Opponent’s winning percentage in last X games
Quality of play in each game compared to expected performance
Margin of victory
Over/under opponent’s points against avg.
Over/under opponent’s points for avg.
Over/under opponent’s points against avg. at site (home/away)
Over/under opponent’s points for avg. at site (home/away)
I added a few other factors to consider in the ranking algorithm as well. Overall winning percentage was included because it is a standard baseline for team rankings. Additionally, the opponent’s recent level of play could be factored into the strength of the opponent, as well a discount factor for how long ago games were played.
From these factors I created a linear function to combine the Strength of Opponent factors and Quality of Play factors with coefficients.


These two larger factors are then linearly combined with how recent the game was to the current point in time and the overall team winning percentage, again, with coefficients.

For a final team ranking, the score of every game is summed and the teams ordered from highest to lowest.
The value of each of these factors and how I combined them is debatable. Any ranking system is going to have some inherent subjectivity and assumptions based on the system designer and the data feed into it. The reason that I support this model is not because of the factors it takes into account, but rather that the factors can be combined in an infinite number of ways in an effort to fit the model to historical results. The theory behind the model is that the coefficients will shed light into what actually matters in winning basketball games. If defense is more important than offense the the coefficient X with be fit to be larger than the coefficient W. If performance on the road or performance at home matters, then the site specific coefficients with be large and they will be close to zero if site-specific performance is irrelevant.
This raises the question of how to best train the coefficients on historical data. At the time that I did this study, I had zero training in machine learning, so I hacked together an algorithm of my own creation that would generate random starting coefficients and search through the infinitely sized set of coefficients looking for the most predictive set. I was inspired by nature’s own machine learning technique and used breeding, mutation and natural selection to move through the coefficient search space.
The steps of the genetic algorithm were as follows:
I populated a number of “parent” sets of coefficients. I used my basketball knowledge to create coefficients I assumed would be near the optimal values for some of the parents, but randomly generated others so that my population would attack the problem from multiple “perspectives” as my intuition is not necessary what is best.
The parent sets were then “breed” with each other, two at a time, to create a large population of “children.” Each child received half of the coefficients from two different parents.
Each coefficient for every child was given the opportunity to “mutate” into a value other than that of the child’s parents.
Each child set of coefficients was then used to calculate the end of season ranking for every playoff team during the 2002-2003 through 2011-2012 NBA seasons. These rankings were used to see if the children accurately predicted the winner of each of the 150 different playoff series that occurred during those ten seasons with extra weight given to predicting the eventual champion.
The top 10 most predictive children sets were “naturally selected” to be the parent sets for the next “generation” of the algorithm.
The algorithm stopped when it accurately predicts all 10 NBA champions or reaches a pre-specified maximum number of generations.
After creating the algorithm I sat back and let it run for a while to see what kind of results would pop out. It was good to see that my “expertly” chosen coefficients accurately predicted the result of most playoff series but the algorithm quickly found a better combination. In general, the the algorithm asymptotes very quickly just above 70% prediction accuracy for all playoff series. However after just a few generations, it struggles to improve itself and never seems to predict more than 4 out of the 10 championship teams before the start of the playoffs, but it does predict 8 out of the 10 winners given the Finals match-up.

More importantly it appears that the set of coefficients that produce relatively high accuracy has many local maxima, as very different sets of coefficients produce very similar accuracy results. It was interesting to see these various formulas that my genetic algorithm converged on. Perhaps this sheds some light into being able to forecast post-season success. Either some playoff series are easy to predict (this makes sense for first round match-ups, but not for later rounds) or there are many ways to create quality teams. To avoid getting stuck at the first local maxima encountered, the algorithm allows for every child to have a random mutation that differs from either of the parents. Just as in nature this allows for innovation and diversification of the population. Along these same lines, one of the keys for arriving at the best model in light of many local maxima is to have a suitably large population to breed from. The more parents in the population, the more diverse the population, and the more opportunity the algorithm has of finding the true most-predictive model.
I investigated the impact of having a larger population, in spite of the extra computation time, by increasing the parent population size and the number of children produced each generation. As an example, here is a plot of the progression of the model over each generation with a population of 100, rather than the 10 shown above.

The variance in the population of models accuracy increases any time the population size is increased. It also takes more generations for the population to converge toward a homogeneous level of accuracy. More importantly, changing the population size does not increase the models ability to converge to a global optima as the total accuracy does not change much for any population size of at least 10. It was disappointing that the model very quickly reaches its most optimum set of coefficients regardless of the model parameters.
I after investigating the effect of changing the population and it’s effect on convergence, I ran the model one last time and the genetic algorithm found the most predictive model. Here is the final rankings of the model compared to the baseline models’ rankings for the 2012-2013 season.

Overall the rankings of all three are pretty similar. This is not too surprising given that my model is linear combinations of values that are for the most part derived from winning percentage and margin of victory. The teams with the largest changes in my ranking from the baseline rankings are either teams that were doing much better or much worse in their most recent games. So this is how the teams fall into order during regular season, but does it translate into playoff prediction?
Here are the predictions for the 2013 NBA playoffs for he three models along side what actually went down….

In this particular season, my model is no better than the simple predictive models based on regular season wins and regular season margin of victory. Only the wins model was able to predict the champion by ranking Miami first before the start of the playoffs. However, the goal is not to have the highest accuracy in a single season but have the model generalize to be the most predictive in any future season. Here is how the my ranking model predicts the results over the ten seasons to which the model was fit. The assumption of a linear relationship was used just as with the baseline models earlier.

My ranking system scales each team’s score to fall between 0 and 100 where the 30th ranked team has a score of 0 and the top ranked team a score of 100. As expected this team score is positively correlated with playoff success with a statistically significant value of 0.525. This is unfortunately worse than the baseline models despite being the model that the genetic algorithm found to be most predictive of postseason success. The percent of the variance explained is also worse at only 28%. But, it turns out that the team’s score it not the best metric from my ranking system for predicting playoff success because team scores are scaled based on the teams’ stats for that season. So scores can not be accurately compared with one another across seasons, and it is more realistic to predict playoff success based on the teams’ rank for that season.

This performs better, as expected, but it is still worse than the baseline models of regular season wins and regular season margin of victory. The correlation is only 0.553 and the percent of variance explained only 31%.
In light of these results, there are certainly areas where this model could be improved. Because of computation time, many of the algorithm iterations were done with too small a population and converged on local optima too soon. I did not play with any of the parameters around the randomization of the coefficients to mutate or how the parents that were “mated” were chosen. I suspect that there are ways to create population clusters or engineer other algorithm features to make the genetic algorithm converge on the best optima quicker. However, the real problem with the model has to do with the choice of a genetic algorithm to begin with.
If I were to re-do this analysis with my skill set today, I would use a different method to optimize the linear model coefficients. Ordinary least squares optimization would converge more quickly to the best-fit coefficient values, but it unclear how to set up the data set to accommodate this method and a squared error penalization may not be the best assumption in this situation. Another option would be to use an expectation maximization algorithm to converge the parameters to the best fit values from my initial assumption values. This would be an interesting experiment and is more similar to my original concept. Of course, something more powerful such as Random Forests or Neural Networks could prove more accurate with enough input information, but these methods are not for fitting parameters to an assumed model structure, but rather black-box model generators that sacrifice model interpretability. My choice of a genetic algorithm was driven by personal curiosity, and as a novice in machine learning I was unaware of what tool would be best suited to the task.
One last way to improve model would be to include more information such as, number of days rest, injuries and how types of teams match-up with one another.
In conclusion, it seems noble in the scientific sense to try and put a formula of the results of the NBA playoffs and be able to measure the quality of a basketball team, but the truth is really the old cliché, basketball games and trophies aren’t won on paper, but rather, on the hardwood. I learned a few analytics lessons. More complex models are not guaranteed be better than the simpler models they hope to improve upon, and any data scientist needs to know when to use the right model for the given problem. While I never expected a genetic algorithm to be the best way to fit my model, it turns out that it was never properly suited to the task given my evaluation measure and the computation time involved.
As fan of the sport I have come to realize that this is actually an encouraging result. It should not be easy to change conventional wisdom or predict the future. I am glad that there is the white noise randomness of blown charging calls and streak-shooting that make each game dramatic and exciting. Sure there are better measures of the true quality of a team beyond winning percentage or margin of victory, but if we knew with any certainty the outcome of a basketball, why would we even bother to watch?
This analysis was done in Matlab and the results processed in a combination of Matlab and R.
All of the data was courtesy of basketball-reference.com
More general information about genetic algorithms can be found at http://en.wikipedia.org/wiki/Genetic_algorithm
Other computer ranking systems for NBA teams can be found at:
http://www.usatoday.com/sports/nba/sagarin/
http://www.teamrankings.com/nba/ranking/overall-power-ranking-by-team
http://espn.go.com/nba/hollinger/powerrankings
Feb 7
Facebook
Twitter
Google
Tumblr
What team benefits the most from home cooking?
Basketball just like any spectator sport is subject the phenomenon we all know and love as “Home Court Advantage.” Even the casual sports fan knows that their favorite team has a better chance of winning in their home arena than they do in somebody else’s. In the NBA, the rule of thumb is that the home team tends to do about 3 points better than they would if the game were played at a neutral site. That means that there is a whopping 6 point swing depending on whose gym the game is being played in which is significant considering that the average margin of victory in the NBA is only 3.3 points.
So what is the cause of this crowd pleasing phenomenon? The standard theories include: the home crowd support, player’s sleeping in their own bed, the home game routine, and the additional rest home teams enjoy courtesy of the typical NBA season (see endnote references). I’m sure in reality that it is some combination of all of these factors, but who’s to say that all home court advantages were created equal?
Awhile ago, I spent a day investigating this very topic because the best home court advantage in the NBA is a pretty frequent subject in national TV telecasts. The media and coaches love to point to how are it is to win in places like the Pepsi Center in the mile-high altitude of Denver or beneath the raucous crowds at Oracle Arena in Oakland. So do the numbers back up these usual candidates for toughest places to play in the NBA? First, a clear definition of home court advantage needs to be established.
I care about consistent fan bases and a home court advantage that is independent of individual players or particular team rosters in a given year, so it is important to study the impact of home court advantage over a number of seasons. I chose to study all NBA games from the 2002-2003 season through the 2011-2012 season, a period of time that is long enough for NBA rosters to have completely turned over during that time frame and for most to have had both good and bad years. Also, calculating a team’s benefit from playing at home should be more sophisticated than simply subtracting each teams away margin of victory from their home margin of victory. This simple metric does not take into account the different schedules that each team plays or the imbalance in the number home vs. away games that teams play against each other (see endnote references). A team like the Houston Rockets that have 26 homes against the stronger eastern conference whereas the Toronto Raptors have only 15 home games against Western conference foes. This season at least, the Raptors play one game home and one road game against the Rockets compared to the the much weaker Orlando Magic against whom they play two home games and only one away game. Toronto’s home margin would be expect to be ballooned slightly by having an easier home schedule than road schedule since the other road game is most likely against a team of higher quality that the Magic.
Therefore, I attempted to insulate my calculation of home court advantage against the different schedules that every team experiences and the differences in schedules across NBA seasons. This is done by calculating the average points for and against for all visiting teams and then comparing that to how that team does in all of the the 30 NBA arenas. The strength of a home court advantage is based on how many more points the home team tends to win by against its opponents compared to how many points the visiting teams tend to lose by. This normalizes the home margin of victory against the strength of the visiting opponents for all teams. This value can then be compared to how well the same team does on the road to create the average benefit that each team gets from playing at home.
In essence, the best home court advantage does not belong to the team that wins the highest percentage of their home games (That was San Antonio at 72% during the 10 seasons of study). Nor is it the team that has the largest increase in home winning percentage over road winning percentage (That was Washington with over a 40% increase). It is the team whose expected point differential for home games performance increases the most in expected point differential between home games and away games relative to the average point differential of the opposing team.
As an example. Let’s study the games between Houston and Toronto from the 2012-2013 season. Houston averaged 106.0 points per game and allows 102.5 points per game for a average margin of victory of 3.5 points. Toronto averaged 97.2 points per game and allows 98.7 points per game for an average margin of victory of -1.5 points. In the first game, in Houston, the Rockets won 117-101. Toronto prevailed at home in the rematch 103-96. Assuming both of the games had been at a neutral site,we would have expected Houston to win both games by about 2.5 points (given that both teams had played teams of equal quality of course). To calculate the advantage of home court between Toronto and Houston I looked at the change in the expect value for margin of victory. Houston increased their expected margin from 2.5 to 16 for an increase of 13.5 points at home. The road margin dropped from the 2.5 expected to -7 for a -9.5 points. In this match up, home court was worth a whopping 23 points to the Houston Rockets and, via symmetry, to Toronto as well. I performed this calculation for all of the 29 head-to-head matched between teams for each season and then averaged the increases to find an average increase in margin of victory for each team over the whole season. To reduce the variation that is expected from season to season, I then average then ten seasons of study to create an estimate for the standard home court advantage expected in all 30 NBA arenas.
So now for the results of the study which is what we all want to see…
Below is a ranked chart of each team with the changes in Winning Percentage, Points For, Points Against, and Margin of Victory between home and away from the 2002-2003 to 2011-2012 seasons.

Unsurprisingly, the usual suspects rise to the top. However notice that often forgotten Utah gains the most from playing at home. I suspect this is for having an elevation only 1,000 feet lower than Denver and better than average crowd that loves their only major pro-sports team in town.
As I claim that my analyses are grounded in math and science, I must ask whether these results are statistically significant. First let’s look at a plot of the three best and three worst teams’ home advantage over the ten seasons compare to the average home court advantage that year.

While I admit that there is a lot of noise from season to season, there is a clear difference between Utah, Denver, and Golden State compared to Minnesota, Philadelphia and Boston. The former teams almost always have above average home court advantages while the latter teams almost always under perform at home.
But are these claims statistically significant? Boston’s league worst home court advantage of 4.67 is statisitically different from the assumption that home court advantage does not exist with a p-value of 2.1x10-9, a really small number. So, I conclude that home court advantage does indeed exist, as well all expected. I then looked to see whether Boston’s and Utah’s advantages were statistically different than the league average. The resulting p-values were 0.004 and 0.001 respectively, so yes Utah can be considered a more difficult environment to play in compared to Boston, given the quality of the teams are the same. But the question we all care about is: Can we definitely say that Utah has the greatest home court advantage in the NBA? Namely, is the Jazz’s league lead 9.3 point advantage better than Denver’s 8.8 point advantage?
Well, we can not really make such a claim, as the p-value for the hypothesis test to whether Utah’s average home court advantage is greater than Denver’s is a rather large 0.37. In fact, I had to go all the way down to Sacramento with the sixth best advantage to be able to even claim that Utah has a significant advantage over the King’s with even a 90% confidence level. Essentially, all of the usual suspects can make an argument that they place is the toughest to play, and there is no clear cut winner. In reality, it probably varies year to year based on the players on the roster and other factors like rest and injuries.
In conclusion, the effect of home court advantage is real. There is a clear difference in the effect of home court across the NBA as Utah’s advantage is twice that of Boston’s. However because there is a lot of variation in relative home court advantage from season to season there is no clear “hardest place to play” in the NBA. Much of the effect of home court advantage can be clouded by the unbalanced strength of schedule in the NBA, but this can be accounted for by factoring in the opponent’s strength. It is also unclear what individual variables contribute to this phenomenon but it appears that crowd support and altitude have an effect.
I also want to point out further points of research that could be done with this data include: investigating the relationship between team record and home court advantage or whether these variables are independent, why some teams advantage is primarily on offense or defense, why the increase in winning percentage is only loosely correlated to increase in margin of victory, and investigating if home court advantage is consistently around 3.2 every year or has an identifiable trend.
This analysis was done in Matlab and the results processed in R.
All of the data was courtesy of basketball-reference.com
Below are a few links to related material:
Days Rest’s effect on Home Court Advantage-
http://www.amstat.org/chapters/boston/nessis07/presentation_material/Dylan_Small.pdf
How the NBA creates it’s schedule and the imbalances-
http://www.nbastuffer.com/component/option,com_glossary/Itemid,90/catid,44/func,view/term,How%20the%20NBA%20Schedule%20is%20Made/
Jan 23
1
Random post
Browse the Archive
Get the RSS
About

What started out at a hobby trying to separate basketball facts from opinion has led me to a career in data analytics. Perhaps I should share some of my mathematical musings...
Ask me anything
Connect
Linkedin
tumblrNotesInserted = function(notes_html) { $('.notes .note:not(.processed) img').each(function(i){ var note = $(this).parent().parent(); var avaurl = $(this).attr("src"); avaurl = avaurl.replace('16.gif','64.gif'); avaurl = avaurl.replace('16.png','64.png'); avaurl = avaurl.replace('16.jpg','64.jpg'); $(this).attr('src', avaurl).parent().addClass('avatar-wrap'); note.append($('<span class="ir note-glyph">')).addClass('processed'); }); $('.more_notes_link').prepend($('<div>',{'class':'more-notes-icon'})); } var _gaq=[['_setAccount','UA-43477248-2'],['_trackPageview']]; (function(d,t){var g=d.createElement(t),s=d.getElementsByTagName(t)[0]; g.src=('https:'==location.protocol?'//web.archive.org/web/20190323161114/http://ssl':'//web.archive.org/web/20190323161114/http://www')+'.google-analytics.com/ga.js'; s.parentNode.insertBefore(g,s)}(document,'script')); var themeTitle = "Fluid Neue Theme"; var url = "http://web.archive.org/web/20190323161114/http://fluid-theme.pixelunion.net"; (function() { var pxu = document.createElement('script'); pxu.type = 'text/javascript'; pxu.async = true; pxu.src = 'http://web.archive.org/web/20190323161114/http://cdn.pixelunion.net/customize/pxucm.js'; var isCustomize = (window.location.href.indexOf('/customize_preview_receiver.html') >= 0) ? true: false; var isDemo = (window.location.href.indexOf(url) >= 0) ? true: false; (isCustomize || isDemo) && ((document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(pxu)); })(); var pxuConversionLabel = "ex5HCJmipgIQ58Wg4gM"; var pxuDemoURL = "fluid-theme.pixelunion.net"; var pxuIsDemo = (window.location.href.indexOf(pxuDemoURL) != -1); var pxuTriggerConversion = (document.referrer.indexOf(pxuConversionLabel) != -1); if (pxuTriggerConversion && !pxuIsDemo) { /* <![CDATA[ */ var google_conversion_id = 1011360487; var google_conversion_language = "en"; var google_conversion_format = "3"; var google_conversion_color = "ffffff"; var google_conversion_label = pxuConversionLabel; var google_conversion_value = 40; /* ]]> */ }
(function(){ var analytics_frame = document.getElementById('ga_target'); var analytics_iframe_loaded; var user_logged_in; var blog_is_nsfw = 'No'; var addthis_enabled = false; var eventMethod = window.addEventListener ? "addEventListener" : "attachEvent"; var eventer = window[eventMethod]; var messageEvent = eventMethod == "attachEvent" ? "onmessage" : "message"; eventer(messageEvent,function(e) { var message = (e.data && e.data.split) ? e.data.split(';') : ''; switch (message[0]) { case 'analytics_iframe_loaded': analytics_iframe_loaded = true; postCSMessage(); postGAMessage(); postATMessage(); postRapidMessage(); break; case 'user_logged_in': user_logged_in = message[1]; postGAMessage(); postATMessage(); break; } }, false); analytics_frame.src = "http://web.archive.org/web/20190323161114/https://assets.tumblr.com/analytics.html?dfab06320413a6a34dbca419c4c70f2c#" + "http://web.archive.org/web/20190323161114/http://nbanalytics.tumblr.com"; function postGAMessage() { if (analytics_iframe_loaded && user_logged_in) { var is_ajax = false; analytics_frame.contentWindow.postMessage(['tick_google_analytics', is_ajax, user_logged_in, blog_is_nsfw, '/?route=%2F'].join(';'), analytics_frame.src.split('/analytics.html')[0]); } } function postCSMessage() { COMSCORE = true; analytics_frame.contentWindow.postMessage('enable_comscore;' + window.location, analytics_frame.src.split('/analytics.html')[0]); } function postATMessage() { if (addthis_enabled && analytics_iframe_loaded) { analytics_frame.contentWindow.postMessage('enable_addthis', analytics_frame.src.split('/analytics.html')[0]); } } function postRapidMessage() { if (analytics_iframe_loaded) { var is_ajax = ''; var route = '/'; var tumblelog_id = 't:XtTapjYtMmgXGemxL-VsnQ'; var yahoo_space_id = '1197719229'; var rapid_client_only = '1'; var apv = '1'; var rapid_ex = ''; analytics_frame.contentWindow.postMessage( [ 'tick_rapid', is_ajax, route, user_logged_in, tumblelog_id, yahoo_space_id, rapid_client_only, apv, rapid_ex ].join(';'), analytics_frame.src.split('/analytics.html')[0] ); } } })(); !function(s){s.src='http://web.archive.org/web/20190323161114/https://px.srvcs.tumblr.com/impixu?T=1553357474&J=eyJ0eXBlIjoidXJsIiwidXJsIjoiaHR0cDovL25iYW5hbHl0aWNzLnR1bWJsci5jb20vIiwicmVxdHlwZSI6MCwicm91dGUiOiIvIn0=&U=MNAPGBOLOM&K=5b3670896fe7836d54aac5bc1d96f7ffd6748f245e27eae2e1c41110d05db005&R='.replace(/&R=[^&$]*/,'').concat('&R='+escape(document.referrer)).slice(0,2000).replace(/%.?.?$/,'');}(new Image());
(function (w,d) { 'use strict'; var l = function(el, type, listener, useCapture) { el.addEventListener ? el.addEventListener(type, listener, !!useCapture) : el.attachEvent && el.attachEvent('on' + type, listener, !!useCapture); }; var a = function () { if (d.getElementById('tumblr-cdx')) { return; } var s = d.createElement('script'); var el = d.getElementsByTagName('script')[0]; s.async = true; s.src = 'http://web.archive.org/web/20190323161114/http://assets.tumblr.com/assets/scripts/vendor/cedexis/1-13960-radar10.min.js?_v=8d32508b0a251bebecb4853c987c5015'; s.type = 'text/javascript'; s.id = 'tumblr-cdx'; d.body.appendChild(s); }; l(w,'load',a); }(window, document)); !function(s){s.src='http://web.archive.org/web/20190323161114/https://px.srvcs.tumblr.com/impixu?T=1553357474&J=eyJ0eXBlIjoicG9zdCIsInVybCI6Imh0dHA6Ly9uYmFuYWx5dGljcy50dW1ibHIuY29tLyIsInJlcXR5cGUiOjAsInJvdXRlIjoiLyIsInBvc3RzIjpbeyJwb3N0aWQiOiI3NTk1Mjg1OTg3MCIsImJsb2dpZCI6IjE2NzQzMDY0NiIsInNvdXJjZSI6MzN9LHsicG9zdGlkIjoiNzQzNjY3NTg5MjIiLCJibG9naWQiOiIxNjc0MzA2NDYiLCJzb3VyY2UiOjMzfV19&U=FAHMBNNFHH&K=c8c29950492c11442d56bbbc69d51452c56935b7e4a6538331f6d3c3f6b3ed2a&R='.replace(/&R=[^&$]*/,'').concat('&R='+escape(document.referrer)).slice(0,2000).replace(/%.?.?$/,'');}(new Image());
0 notes
Link
As usual, Spring arrives early for the Salesforce world, and with it, our latest release. During this prerelease cycle, the developer evangelist team has been busy updating our gallery of sample apps with the latest and greatest features. Here’s a list of items that you can find if you pull down the latest from GitHub. What is the Sample Gallery? The sample gallery is a set of reference apps that showcase a range of low-code to pro-code developer features of the Salesforce platform. Each sample app takes an idea and implements it in the Salesforce platform along with other related apps and features e.g. mobile apps, external-facing web apps, integrations, etc. You can read about all the apps on the Sample Gallery landing page, which also contains links to source repos for each app. LWC Properties Are Automatically Reactive In Spring ‘20, the Lightning Web Component core framework has an added feature that makes all properties reactive without the need to be explicitly decorated as such. In the past, where you would have seen @track used to trigger a DOM refresh in LWC, this becomes no longer necessary. To address this, we’ve removed the @track decorator. The code below from the todoList component in the LWC Recipes app shows one instance of how this looks in our sample apps. Previously, the filteredTodos array property was decorated with @track. @track filteredTodos = []; Again, with the new “all properties are reactive” feature, this is no longer necessary; with one important exception. You must use @track to observe changes in the properties of an object or elements of an array. In other words, if you mutate an object or array in place and you want to update the DOM based on that, @track is required. Understanding array or object mutation in JavaScript is not always straightforward. However, every instance of our sample apps follows the practice of not mutating objects or arrays in place, but rather reassigning them when we need to change their state. In the filteredTodos example above, we have removed @track. todo.priority === true ); } else { this.filteredTodos = this._todos; } } ... } When the filterTodos() function is invoked, we use the Array.prototype.filter() higher order function on the “master” list of todo items in the private _todos array. The filter function always returns a new array instance, meaning the line this.filteredTodos = this._todos.filter... will always cause a new object to be assigned to this.filteredTodos and trigger the now implicit reactivity of that property. But be careful, some higher-order array functions (like Array.prototype.sort()) modify an array in place. If you find yourself using one of these, you might want to look into explicitly creating a new array or alternatively, actually use the @track decorator on that array. For more on the implementation of reactive data types in LWC, we recommend reading the documentation on that topic from the LWC open source project. Lightning Pages on Desktop and Mobile Prior to Spring ‘20, there was no easy way to bring Lightning Pages to mobile. Now, you can design your Lightning Pages for mobile as well as desktop. This includes some of the standard templates, but you can also raise the bar by creating your own custom templates. To bring this to life, we updated the custom Lightning page template in the Dreamhouse app. Custom page templates are implemented in Aura today. Above you can see the markup used to define whether the template will use a layout that supports desktop or mobile, based on information provided by the browser. We reviewed components and modified any we needed to in order for them to work in a small form factor. In addition to ensuring the components themselves were responsive, we also needed to configure the metadata file to indicate which form factors a given component supports. Finally, we configured the app as well as several record pages to be available for mobile, and we were now all set for our pages to work in both mobile and desktop. Check In Your Community For developers working with Communities, the Communities Experience Bundle is a long awaited improvement to your application lifecycle management. This new way to store your community configuration creates a bundle of files which allows you to build, configure, and customize your community as well as check the entire configuration in version control, in a JSON-based format. No more binary .site file! This change also now makes it possible to create and test your community in a scratch org and manage its deployment from the Salesforce CLI. The experience bundle feature has been in closed pilot… until now. In moving to being generally available, the experience bundle feature adds support for unlocked packages, as well as support for additional Communities configurations that weren’t in the pilot. You can see this in use and test it out in the e-bikes sample app. Please note that the effort to migrate an existing community to the experience bundle format varies greatly between orgs. If you decide to make the transition, be sure to budget time to investigate how this change will impact you. If you would like to read more about using the experience bundle, be sure to check out the Communities developer guide, or read about the implementation specs in the Metadata API developer guide. You can also watch this segment on experience bundles from the release readiness live webinar. SOQL SECURITY_ENFORCED Queries Apex has been introducing some exciting new features, and nothing is more exciting to you (and your compliance team) than more secure data access. While some of these are still in beta, we’re pleased to include the new SOQL WITH SECURITY_ENFORCED clause in most Apex classes that use SOQL (where the SOQL fits the restrictions of that feature) Here’s an example: findContacts(String searchKey) { String key = '%' + searchKey + '%'; return [ SELECT Id, Name, Title, Phone, Email, Picture__c FROM Contact WHERE Name LIKE :key AND Picture__c != null WITH SECURITY_ENFORCED LIMIT 10 ]; } The WITH SECURITY_ENFORCED clause allows you to bring object and field security into your Apex SOQL queries with one simple statement. There are a few rules around using it correctly, so be sure to check out the documentation and the release notes for implementation details. A segment from the release readiness webinar that covers the new Apex security features can be seen here. Navigating to New Records with Default Values The term ��url hack” has long been fabled in the annals of Salesforce developer lore as a by-the-seat-of-your-pants “pattern”. Well, hack no longer! In Lightning, both Aura and LWC components support the ability to navigate to a new record with default values. We’ve implemented this in its own recipe in the LWC Recipes app. import { LightningElement } from 'lwc'; import { NavigationMixin } from 'lightning/navigation'; import { encodeDefaultFieldValues } from 'lightning/pageReferenceUtils'; export default class NavToNewRecord extends NavigationMixin(LightningElement) { navigateToNewContactWithDefaults() { // get encoded default values const defaultValues = encodeDefaultFieldValues({ FirstName: 'Morag', LastName: 'de Fault', LeadSource: 'Other', AccountId: '011xxxxxxxxxxxxXXX' }); console.log(defaultValues); this[NavigationMixin.Navigate]({ type: 'standard__objectPage', attributes: { objectApiName: 'Contact', actionName: 'new' }, state: { // assign default values for nav pageReference defaultFieldValues: defaultValues } }); } } Note that for the time being, sfdx-lwc-jest framework does not support the lightning/pageReferenceUtils package, so we’ve implemented a dummy test. We will however be updating this once a better solution appears. When initiating navigation, the PageReference supports a state value to set default values, and the lightning/pageReferenceUtils utility has been added to correctly encode and decode default values. In Aura, this utility is referenced in markup as a component called Other Items of Note Coming Changes to the sample apps We’re constantly working to improve our sample apps for you. Some great things are planned to ship throughout this year. If you want to get a sneak peak of one of these you should check out Trailhead Live, where developer evangelist Kevin Poorman codes live on…drumroll…Apex Recipes! Stay tuned! You too can contribute If you have an idea for a feature to add to a sample app, or see a bug or potential improvement, we welcome your contributions to the sample apps! Details for how to contribute are located in each sample app repo. So if you see something, file an issue and we can discuss it with you; if you can write the solution, we welcome the PRs. Summing It Up As always, releases are a bit like a birthday present that comes three times a year. We hope you enjoy exploring these features in our gallery of sample apps as we all welcome Spring ‘20 to our orgs.
0 notes
Text
Spying On Google: 5 Ways to Use Log File Analysis To Reveal Invaluable SEO Insights

Log File Analysis should be a part of every SEO pro’s tool belt, but most SEOs have never conducted one. Which means most SEOs are missing out on unique and invaluable insights that regular crawling tools just can’t produce. Let's demystify Log File Analysis so it's not so intimidating. If you’re interested in the wonderful world of log files and what they can bring to your site audits, this guide is definitely for you.
What are Log Files?
Log Files are files containing detailed logs on who and what is making requests to your website server. Every time a bot makes a request to your site, data (such as the time, date IP address, user agent, etc.) is stored in this log. This valuable data allows any SEO to find out what Googlebot and other crawlers are doing on your site. Unlike regular crawlings, such as with the Screaming Frog SEO Spider, this is real-world data — not an estimation of how your site is being crawled. It is an exact overview of how your site is being crawled. Having this accurate data can help you identify areas of crawl budget waste, easily find access errors, understand how your SEO efforts are affecting crawling and much, much more. The best part is that, in most cases, you can do this with simple spreadsheet software. In this guide, we will be focussing on Excel to perform Log File Analysis, but I’ll also discuss other tools such as Screaming Frog’s less well-known Log File Analyser which can just make the job a bit easier and faster by helping you manage larger data sets. Note: owning any software other than Excel is not a requirement to follow this guide or get your hands dirty with Log Files.
How to Open Log Files
Rename .log to .csv When you get a log file with a .log extension, it is really as easy as renaming the file extension .csv and opening the file in spreadsheet software. Remember to set your operating system to show file extensions if you want to edit these. How to open split log files Log files can come in either one big log or multiple files, depending on the server configuration of your site. Some servers will use server load balancing to distribute traffic across a pool or farm of servers, causing log files to be split up. The good news is that it's really easy to combine, and you can use one of these three methods to combine them and then open them as normal: Use the command line in Windows by Shift + right-clicking in the folder containing your log files and selecting “Run Powershell from here”
Then run the following command: copy *.log mylogfiles.csv You can now open mylogfile.csv and it will contain all your log data. Or if you are a Mac user, first use the cd command to go to the directory of your log files: cd Documents/MyLogFiles/ Then, use the cat or concatenate command to join up your files: cat *.log > mylogfiles.csv 2) Using the free tool, Log File Merge, combine all the log files and then edit the file extension to .csv and open as normal. 3) Open the log files with the Screaming Frog Log File Analyser, which is as simple as dragging and dropping the log files:
Splitting Strings (Please note: This step isn’t required if you are using Screaming Frog’s Log File Analyser) Once you have your log file open, you’re going to need to split the cumbersome text in each cell into columns for easier sorting later. Excel’s Text to Column function comes in handy here, and is as easy as selecting all the filled cells (Ctrl / Cmd + A) and going to Excel > Data > Text to Columns and selecting the “Delimited” option, and the delimiter being a Space character. Once you’ve separated this out, you may also want to sort by time and date — you can do so in the Time and Date stamp column, commonly separating the data with the “:” colon delimiter. Your file should look similar to the one below:
As mentioned before, don’t worry if your log file doesn’t look exactly the same — different log files have different formats. As long as you have the basic data there (time and date, URL, user-agent, etc.) you’re good to go!
Understanding Log Files
Now that your log files are ready for analysis, we can dive in and start to understand our data. There are many formats that log files can take with multiple different data points, but they generally include the following: Server IP Date and time Server request method (e.g. GET / POST) Requested URL HTTP status code User-agent More details on the common formats can be found below if you’re interested in the nitty gritty details: WC3 Apache and NGINX Amazon Elastic Load Balancing HA Proxy JSON
How to quickly reveal crawl budget waste
As a quick recap, Crawl Budget is the number of pages a search engine crawls upon every visit of your site. Numerous factors affect crawl budget, including link equity or domain authority, site speed, and more. With Log File Analysis, we will be able to see what sort of crawl budget your website has and where there are problems causing crawl budget to be wasted. Ideally, we want to give crawlers the most efficient crawling experience possible. Crawling shouldn’t be wasted on low-value pages and URLs, and priority pages (product pages for example) shouldn’t have slower indexation and crawl rates because a website has so many dead weight pages. The name of the game is crawl budget conservation, and with good crawl budget conversion comes better organic search performance. See crawled URLs by user agent Seeing how frequently URLs of the site are being crawled can quickly reveal where search engines are putting their time into crawling. If you’re interested in seeing the behavior of a single user agent, this is easy as filtering out the relevant column in excel. In this case, with a WC3 format log file, I’m filtering the cs(User-Agent) column by Googlebot:
And then filtering the URI column to show the number of times Googlebot crawled the home page of this example site:
This is a fast way of seeing if there are any problem areas by URI stem for a singular user-agent. You can take this a step further by looking at the filtering options for the URI stem column, which in this case is cs-uri-stem:
From this basic menu, we can see what URLs, including resource files, are being crawled to quickly identify any problem URLs (parameterized URLs that shouldn’t be being crawled for example). You can also do broader analyses with Pivot tables. To get the number of times a particular user agent has crawled a specific URL, select the whole table (Ctrl/cmd + A), go to Insert > Pivot Table and then use the following options:
All we’re doing is filtering by User Agent, with the URL stems as rows, and then counting the number of times each User-agent occurs. With my example log file, I got the following:
Then, to filter by specific User-Agent, I clicked the drop-down icon on the cell containing “(All)," and selected Googlebot:
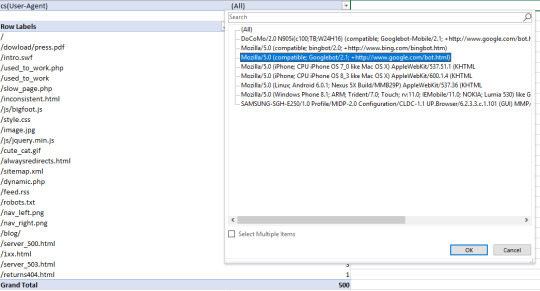
Understanding what different bots are crawling, how mobile bots are crawling differently to desktop, and where the most crawling is occurring can help you see immediately where there is crawl budget waste and what areas of the site need improvement. Find low-value add URLs Crawl budget should not be wasted on Low value-add URLs, which are normally caused by session IDs, infinite crawl spaces, and faceted navigation. To do this, go back to your log file, and filter by URLs that contain a “?” or question mark symbols from the URL column (containing the URL stem). To do this in Excel, remember to use “~?” or tilde question mark, as shown below:
A single “?” or question mark, as stated in the auto filter window, represents any single character, so adding the tilde is like an escape character and makes sure to filter out the question mark symbol itself. Isn’t that easy? Find duplicate URLs Duplicate URLs can be a crawl budget waste and a big SEO issue, but finding them can be a pain. URLs can sometimes have slight variants (such as a trailing slash vs a non-trailing slash version of a URL). Ultimately, the best way to find duplicate URLs is also the least fun way to do so — you have to sort by site URL stem alphabetically and manually eyeball it. One way you can find trailing and non-trailing slash versions of the same URL is to use the SUBSTITUTE function in another column and use it to remove all forward slashes: =SUBSTITUTE(C2, “/”, “”) In my case, the target cell is C2 as the stem data is on the third column. Then, use conditional formatting to identify duplicate values and highlight them.
However, eyeballing is, unfortunately, the best method for now. See the crawl frequency of subdirectories Finding out which subdirectories are getting crawled the most is another quick way to reveal crawl budget waste. Although keep in mind, just because a client’s blog has never earned a single backlink and only gets three views a year from the business owner’s grandma doesn’t mean you should consider it crawl budget waste — internal linking structure should be consistently good throughout the site and there might be a strong reason for that content from the client’s perspective. To find out crawl frequency by subdirectory level, you will need to mostly eyeball it but the following formula can help: =IF(RIGHT(C2,1)="/",SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"/","")))/LEN("/")+SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"=","")))/LEN("=")-2, SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"/","")))/LEN("/")+SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"=","")))/LEN("=")-1) The above formula looks like a bit of a doozy, but all it does is check if there is a trailing slash, and depending on the answer, count the number of trailing slashes and subtract either 2 or 1 from the number. This formula could be shortened if you remove all trailing slashes from your URL list using the RIGHT formula — but who has the time. What you’re left with is subdirectory count (starting from 0 from as the first subdirectory). Replace C2 with the first URL stem / URL cell and then copy the formula down your entire list to get it working.

Make sure you replace all of the C2s with the appropriate starting cell and then sort the new subdirectory counting column by smallest to largest to get a good list of folders in a logical order, or easily filter by subdirectory level. For example, as shown in the below screenshots:
The above image is subdirectories sorted by level.

The above image is subdirectories sorted by depth. If you’re not dealing with a lot of URLs, you could simply sort the URLs by alphabetical order but then you won’t get the subdirectory count filtering which can be a lot faster for larger sites. See crawl frequency by content type Finding out what content is getting crawled, or if there are any content types that are hogging crawl budget, is a great check to spot crawl budget waste. Frequent crawling on unnecessary or low priority CSS and JS files, or how crawling is occurring on images if you are trying to optimize for image search, can easily be spotted with this tactic. In Excel, seeing crawl frequency by content type is as easy as filtering by URL or URI stem using the Ends With filtering option.
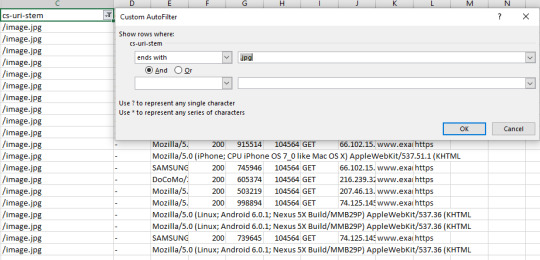
Quick Tip: You can also use the “Does Not End With” filter and use a .html extension to see how non-HTML page files are being crawled — always worth checking in case of crawl budget waste on unnecessary js or css files, or even images and image variations (looking at you Wordpress). Also, remember if you have a site with trailing and non-trailing slash URLs to take that into account with the “or” operator with filtering.
Spying on bots: Understand site crawl behavior
Log File Analysis allows us to understand how bots behave by giving us an idea of how they prioritize. How do different bots behave in different situations? With this knowledge, you can not only deepen your understanding of SEO and crawling, but also give you a huge leap in understanding the effectiveness of your site architecture. See most and least crawled URLs This strategy has been touched up previously with seeing crawled URLs by user-agent, but it’s even faster. In Excel, select a cell in your table and then click Insert > Pivot Table, make sure the selection contains the necessary columns (in this case, the URL or URI stem and the user-agent) and click OK.
Once you have your pivot table created, set the rows to the URL or URI stem, and the summed value as the user-agent.
From there, you can right-click in the user-agent column and sort the URLs from largest to smallest by crawl count:
Now you’ll have a great table to make charts from or quickly review and look for any problematic areas:

A question to ask yourself when reviewing this data is: Are the pages you or the client would want being crawled? How often? Frequent crawling doesn’t necessarily mean better results, but it can be an indication as to what Google and other content user-agents prioritize most. Crawl frequency per day, week, or month Checking the crawling activity to identify issues where there has been loss of visibility around a period of time, after a Google update or in an emergency can inform you where the problem might be. This is as simple as selecting the “date” column, making sure the column is in the “date” format type, and then using the date filtering options on the date column. If you’re looking to analyze a whole week, just select the corresponding days with the filtering options available.
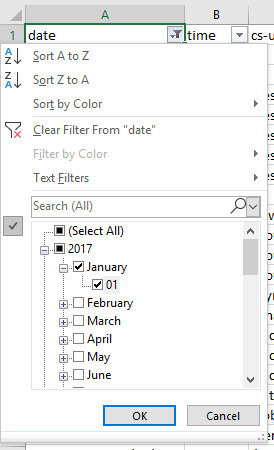
Crawl frequency by directive Understanding what directives are being followed (for instance, if you are using a disallow or even a no-index directive in robots.txt) by Google is essential to any SEO audit or campaign. If a site is using disallows with faceted navigation URLs, for example, you’ll want to make sure these are being obeyed. If they aren’t, recommend a better solution such as on-page directives like meta robots tags. To see crawl frequency by directive, you’ll need to combine a crawl report with your log file analysis. (Warning: We’re going to be using VLOOKUP, but it’s really not as complicated as people make it out to be) To get the combined data, do the following: Get the crawl from your site using your favorite crawling software. I might be biased, but I’m a big fan of the Screaming Frog SEO Spider, so I’m going to use that. If you’re also using the spider, follow the steps verbatim, but otherwise, make your own call to get the same results. Export the Internal HTML report from the SEO Spider (Internal Tab > “Filter: HTML”) and open up the “internal_all.xlsx” file.

From there, you can filter the “Indexability Status” column and remove all blank cells. To do this, use the “does not contain” filter and just leave it blank. You can also add the “and” operator and filter out redirected URLs by making the filter value equal “does not contain → “Redirected” as shown below:
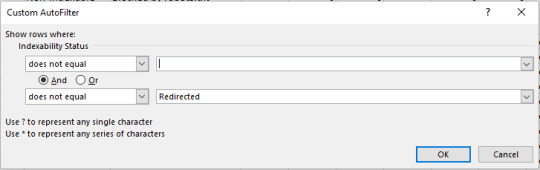
This will show you canonicalized, no-index by meta robots and canonicalized URLs. Copy this new table out (with just the Address and Indexability Status columns) and paste it in another sheet of your log file analysis export. Now for some VLOOKUP magic. First, we need to make sure the URI or URL column data is in the same format as the crawl data. Log Files don’t generally have the root domain or protocol in the URL, so we either need to remove the head of the URL using "Find and Replace" in our newly made sheet, or make a new column in your log file analysis sheet append the protocol and root domain to the URI stem. I prefer this method because then you can quickly copy and paste a URL that you are seeing problems with and take a look. However, if you have a massive log file, it is probably a lot less CPU intensive with the "Find and Replace" method. To get your full URLs, use the following formula but with the URL field changed to whatever site you are analyzing (and make sure the protocol is correct as well). You'll also want to change D2 to the first cell of your URL column ="https://www.example.com"&D2 Drag down the formula to the end of your Log file table and get a nice list of full URLs:
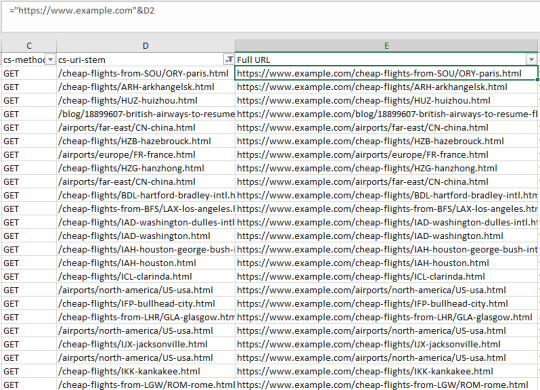
Now, create another column and call it “Indexability Status”. In the first cell, use a VLOOKUP similar to the following: =VLOOKUP(E2,CrawlSheet!A$1:B$1128,2,FALSE). Replace E2 with the first cell of you "Full URL" column, then make the lookup table into your new. crawl sheet. Remember to sue the dollar signs so that the lookup table doesn't change as you. apply the formula to further roles. Then, select the correct column (1 would be the first column of the index table, so number 2 is the one we are after). Use the FALSE range lookup mode for exact matching. Now you have a nice tidy list of URLs and their indexability status matched with crawl data:
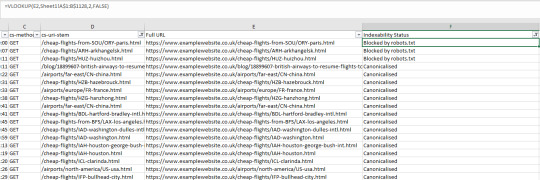
Crawl frequency by depth and internal links This analysis allows us to see how a site’s architecture is performing in terms of crawl budget and crawlability. The main aim is to see if you have far more URLs than you do requests — and if you do then you have a problem. Bots shouldn’t be “giving up” on crawling your entire site and not discovering important content or wasting crawl budget on content that is not important. Tip: It is also worth using a crawl visualization tool alongside this analysis to see the overall architecture of the site and see where there are “off-shoots” or pages with poor internal linking. To get this all-important data, do the following: Crawl your site with your preferred crawling tool and export whichever report has both the click depth and number of internal links with each URL. In my case, I’m using the Screaming Frog SEO Spider, going exporting the Internal report:
Use a VLOOKUP to match your URL with the Crawl Depth column and the number of Inlinks, which will give you something like this:
Depending on the type of data you want to see, you might want to filter out only URLs returning a 200 response code at this point or make them filterable options in the pivot table we create later. If you’re checking an e-commerce site, you might want to focus solely on product URLs, or if you’re optimizing crawling of images you can filter out by file type by filtering the URI column of your log file using the “Content-Type” column of your crawl export and making an option to filter with a pivot table. As with all of these checks, you have plenty of options! Using a pivot table, you can now analyze crawl rate by crawl depth (filtering by the particular bot in this case) with the following options:
To get something like the following:
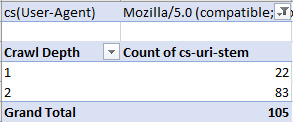
Better data than Search Console? Identifying crawl issues
Search Console might be a go-to for every SEO, but it certainly has flaws. Historical data is harder to get, and there are limits on the number of rows you can view (at this time of writing it is 1000). But, with Log File Analysis, the sky’s the limit. With the following checks, we’re going to be discovered crawl and response errors to give your site a full health check. Discover Crawl Errors An obvious and quick check to add to your arsenal, all you have to do is filter the status column of your log file (in my case “sc-status” with a W3C log file type) for 4xx and 5xx errors:
Find inconsistent server responses A particular URL may have varying server responses over time, which can either be normal behavior, such as when a broken link has been fixed or a sign there is a serious server issue occurring such as when heavy traffic to your site causes a lot more internal server errors and is affecting your site’s crawlability. Analyzing server responses is as easy as filtering by URL and by Date:
Alternatively, if you want to quickly see how a URL is varying in response code, you can use a pivot table with the rows set to the URL, the columns set to the response codes and counting the number of times a URL has produced that response code. To achieve this setup create a pivot table with the following settings:
This will produce the following:
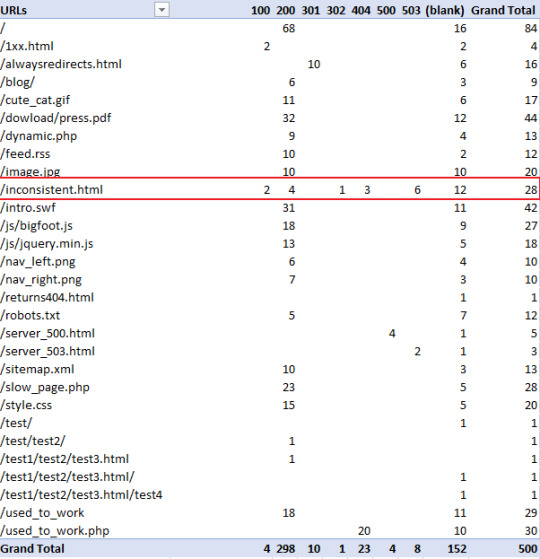
As you can see in the above table, you can clearly see “/inconcistent.html” (highlighted in the red box) has varying response codes. View Errors by Subdirectory To find which subdirectories are producing the most problems, we just need to do some simple URL filtering. Filter out the URI column (in my case “cs-uri-stem”) and use the “contains” filtering option to select a particular subdirectory and any pages within that subdirectory (with the wildcard *):
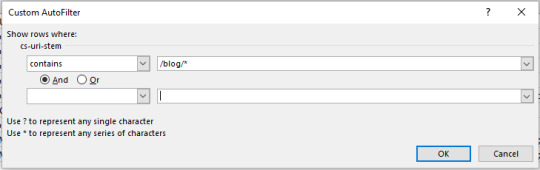
For me, I checked out the blog subdirectory, and this produced the following:
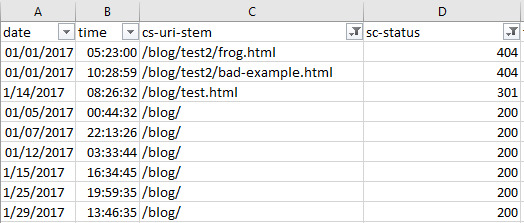
View Errors by User Agent Finding which bots are struggling can be useful for numerous reasons including seeing the differences in website performance for mobile and desktop bots, or which search engines are best able to crawl more of your site. You might want to see which particular URLs are causing issues with a particular bot. The easiest way to do this is with a pivot table that allows for filtering the number of times a particular response code occurs per URI. To achieve this make a pivot table with the following settings:
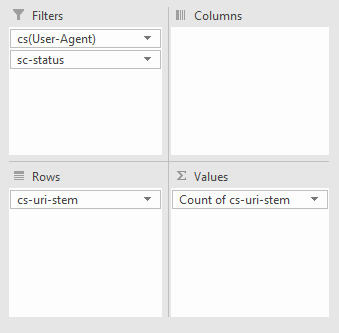
From there, you can filter by your chosen bot and response code type, such as image below, where I'm filtering for Googlebot desktop to seek out 404 errors:
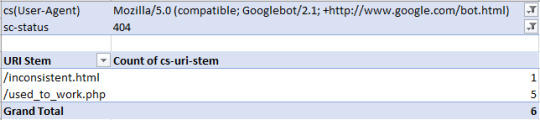
Alternatively, you can also use a pivot table to see how many times a specific bot produces different response codes as a whole by creating a pivot table that filters by bot, counts by URI occurrence, and uses response codes as rows. To achieve this use the settings below:
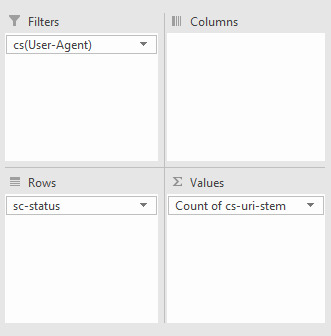
For example, in the pivot table (below), I’m looking at how many of each response code Googlebot is receiving:
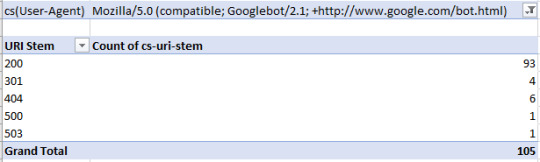
Diagnose on-page problems
Websites need to be designed not just for humans, but for bots. Pages shouldn’t be slow loading or be a huge download, and with log file analysis, you can see both of these metrics per URL from a bot’s perspective. Find slow & large pages While you can sort your log file by the “time taken” or “loading time” column from largest to smallest to find the slowest loading pages, it’s better to look at the average load time per URL as there could be other factors that might have contributed to a slow request other than the web page’s actual speed. To do this, create a pivot table with the rows set to the URI stem or URL and the summed value set to the time taken to load or load time:
Then using the drop-down arrow, in this case, where it says “Sum of time-taken” and go to “Value Field Settings”:
In the new window, select “Average” and you’re all set:
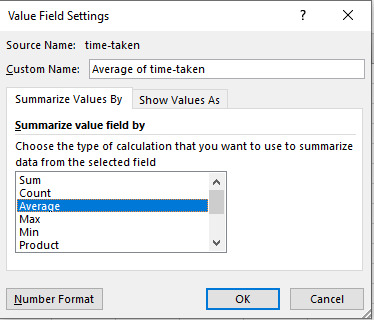
Now you should have something similar to the following when you sort the URI stems by largest to smallest and average time taken:
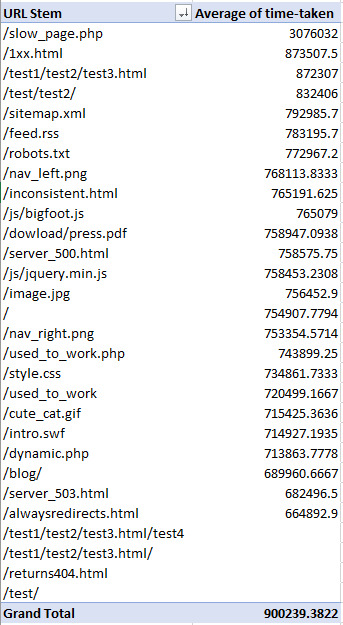
Find large pages You can now add the download size column (in my case “sc-bytes”) using the settings shown below. Remember that the set the size to the average or sum depending on what you would like to see. For me, I’ve done the average:
And you should get something similar to the following:

Bot behavior: Verifying and analyzing bots
The best and easiest way to understand bot and crawl behavior is with log file analysis as you are again getting real-world data, and it’s a lot less hassle than other methods. Find un-crawled URLs Simply take the crawl of your website with your tool of choice, and then take your log file an compare the URLs to find unique paths. You can do this with the “Remove Duplicates” feature of Excel or conditional formatting, although the former is a lot less CPU intensive especially for larger log files. Easy! Identify spam bots Unnecessary server strain from spam and spoof bots is easily identified with log files and some basic command line operators. Most requests will also have an IP associated with it, so using your IP column (in my case, it is titled “c-ip” in a W3C format log), remove all duplicates to find each individual requesting IP. From there, you should follow the process outlined in Google’s document for verifying IPs (note: For Windows users, use the nslookup command): https://support.google.com/webmasters/answer/80553?hl=en Or, if you’re verifying a bing bot, use their handy tool: https://www.bing.com/toolbox/verify-bingbot
Conclusion: Log Files Analysis — not as scary as it sounds
With some simple tools at your disposal, you can dive deep into how Googlebot behaves. When you understand how a website handles crawling, you can diagnose more problems than you can chew — but the real power of Log File Analysis lies in being able to test your theories about Googlebot and extending the above techniques to gather your own insights and revelations. What theories would you test using log file analysis? What insights could you gather from log files other than the ones listed above? Let me know in the comments below. Read the full article
0 notes
Text
R intro part 1
Hola, hola.
As another part of my studying experience I want to sum up my weekend entertainment, which is learning R. This sum up is going to be in the form of a note with links to documentation.
First of all, let me tell you what R is.
R is a programming language (interpreted language, which is a language that for most of the implementations execute instructions without previously compiling a program), created in the 90s for data analysis and as a teaching aid for learning statistics. As it was an open-source project, R easily became popular and even now many users are engaged into developing R and in working on new packages and libraries. Thanks to that, R has a lot of useful functions and is used for statistical calculations, data visualization, data analysis and data science.
Data types, objects:
Basic object type in R is a vector. Elements of the vector have the same data type, one of the following: numeric, integer, character or logical. Except vectors we have matrix, data frame, and list.
Matrix – all of the columns must have the same type and same length.
Data Frames – used for storing data tables, and it is a list of vectors with equal length, columns might have different data type.
List – object that contains element of different types.
Factors – used to represent categorical data, are stored as integers and have labels associated with these unique integers, R sorts levels in alphabetical order.
Arrays – object that can store data in more than two dimensions.
Tibble - is a data frame providing a nicer printing method, useful when working with large data sets.
Useful functions:
class() - will return in a class of the object, names() - will assign names to values of the vector/colnames and rownames accordingly for matrices, cbind() – adding new vector to matrix or merging matrices, by columns ,rbind() – combines vector, martix, data frame by row, levels(), summary(), str() - display the structure of an arbitrary R object, head().
LIBRARIES worth to know:
ggplot2 – data visualization package and „most elegant and aesthetically pleasing graphics framework available in R”.
dplyr - is a grammar of data manipulation, providing a consistent set of verbs that help you solve the most common data manipulation challenges (like select, mutate, filter, arrange, %>% !pipelines!).
readr – provide a fast and friendly way to read rectangular data (like csv, tsv, and fwf) (read_csv, read_tsv, read_delim etc.)
readxl – makes it easy to get data out of Excel and into R, has no external dependencies and is designed to work with tabular data (read_excel, excel_sheets etc.)
XLConnect – comprehensive and cross-platform R package for manipulating Microsoft Excel files from within R.
DBI – a database interface definition for communication between R and relational database management systems.
httr – useful tools for working with HTTP organized by HTTP verbs (GET(), POST(), etc). Configuration functions make it easy to control additional request components (authenticate(), add_headers() and so on).
jsonlite – a fast JSON parser and generator optimized for statistical data and the web.
haven – enables R to read and write various data formats used by other statistical packages (SAS, SPSS, STATA).
foreign – another package to read and write data formats such as SAS, SPSS, STATA.
tidyr - the goal of tidyr is to help you create tidy data, functions such as gather, spread, separate, unite, extract.
lubridate – provides easy and fast parsing of date-times, simple functions to get and set components of a date-time help to handle time zones (y, m, d, h, m, s)
stringr – provide a cohesive set of functions designed to make working with strings as easy as possible (str_detect, str_replace).
tidyverse - set of packages that work in harmony because they share common data representations and API design, such as ggplot2, dplyr, tidyr, readr, purrr, tibble, haven, stringr.
Todo for now, will get to you with more soon!
szarki9
0 notes
Text
MERN/MEAN Full Stack Developer Course with AI & IoT Integrated
Join TechEntry's MERN/MEAN Full Stack Development Course. Learn to build advanced web applications with AI and IoT integration. Master Node.js, Angular, React, and MongoDB. Enroll now to kickstart your successful career!
Why Settle for Just Full Stack Development? Become an AI Full Stack Engineer!
The tech industry is evolving fast, and companies are no longer just looking for MERN/MEAN stack developers. They want professionals who can integrate cutting edge technologies like AI and IoT into their development processes. This is where TechEntry stands out.
Kickstart Your Development Journey!
Frontend Development:
React: Build Dynamic, Modern Web Experiences:
What is Web?
Markup with HTML & JSX
Flexbox, Grid & Responsiveness
Bootstrap Layouts & Components
Frontend UI Framework
Core JavaScript & Object Orientation
Async JS promises, async/await
DOM & Events
Event Bubbling & Delegation
Ajax, Axios & fetch API
Functional React Components
Props & State Management
Dynamic Component Styling
Functions as Props
Hooks in React : useState, useEffect
Material UI
Custom Hooks
Supplement: Redux & Redux Toolkit
Version Control: Git & Github
Angular: Master a FullFeatured Framework:
What is Web?
Markup with HTML & Angular Templates
Flexbox, Grid & Responsiveness
Angular Material Layouts & Components
Core JavaScript & TypeScript
Asynchronous Programming Promises, Observables, and RxJS
DOM Manipulation & Events
Event Binding & Event Bubbling
HTTP Client, Ajax, Axios & Fetch API
Angular Components
Input & Output Property Binding
Dynamic Component Styling
Services & Dependency Injection
Angular Directives (Structural & Attribute)
Routing & Navigation
Reactive Forms & Templatedriven Forms
State Management with NgRx
Custom Pipes & Directives
Version Control: Git & GitHub
Backend:
Node.js: Power Your BackEnd with JavaScript:
Networking and HTTP
REST API overview
Node.js and NPM setup
Creating basic HTTP servers
JavaScript for Backend
Node.js modules and file handling
Process management in Node.js
Asynchronous programming: callbacks, Promises, async/await
Building APIs with Express.js
Express server setup and routing
Handling HTTP requests and responses
JSON parsing and form handling
Templating engines (EJS, Handlebars)
CRUD API creation and RESTful services
Middleware setup and error handling
Database Integration:
SQL and NoSQL database basics
CRUD operations with SQL and NoSQL
Database connection setup (e.g., MongoDB, PostgreSQL)
Querying and data handling
Authentication & Authorization:
User authentication basics
JSON Web Tokens (JWT) for security
Rolebased access control
Advanced API Concepts:
Pagination, filtering, and sorting
Caching techniques for faster response
Rate limiting and security practices
Database:
MongoDB (NoSQL)
Introduction to NoSQL and MongoDB
Understanding Collections and Documents
Basic CRUD Operations in MongoDB
MongoDB Query Language (MQL) Basics
Inserting, Finding, Updating, and Deleting Documents
Using Filters and Projections in Queries
Understanding Data Types in MongoDB
Indexing Basics in MongoDB
Setting Up a Simple MongoDB Database (e.g., MongoDB Atlas)
Connecting to MongoDB from a Simple Application
Basic Data Entry and Querying with MongoDB Compass
Data Modeling in MongoDB: Embedding vs. Referencing
Overview of Aggregation Framework in MongoDB
SQL
Introduction to SQL (Structured Query Language)
Basic CRUD Operations: Create, Read, Update, Delete
Understanding Tables, Rows, and Columns
Primary Keys and Unique Constraints
Simple SQL Queries: SELECT, WHERE, and ORDER BY
Filtering Data with Conditions
Using Aggregate Functions: COUNT, SUM, AVG
Grouping Data with GROUP BY
Basic Joins: Combining Tables (INNER JOIN)
Data Types in SQL (e.g., INT, VARCHAR, DATE)
Setting Up a Simple SQL Database (e.g., SQLite or MySQL)
Connecting to a SQL Database from a Simple Application
Basic Data Entry and Querying with a GUI Tool
Data Validation Basics
Overview of Transactions and ACID Properties
AI and IoT:
Introduction to AI Concepts
Getting Started with Node.js for AI
Machine Learning Basics with TensorFlow.js
Introduction to Natural Language Processing
Practical AI Project Ideas
Introduction to IoT Fundamentals
Building IoT Solutions with Node.js
IoT Communication Protocols
Building IoT Applications and Dashboards
IoT Security Basics
You're Ready to Become an IT Professional
Master the Skills and Launch Your Career: Upon mastering Frontend, Backend, Database, AI, and IoT, you’ll be fully equipped to launch your IT career confidently.
TechEntry Highlights
InOffice Experience: Engage in a collaborative inoffice environment (onsite) for handson learning and networking.
Learn from Software Engineers: Gain insights from experienced engineers actively working in the industry today.
Career Guidance: Receive tailored advice on career paths and job opportunities in tech.
Industry Trends: Explore the latest software development trends to stay ahead in your field.
1on1 Mentorship: Access personalized mentorship for project feedback and ongoing professional development.
HandsOn Projects: Work on realworld projects to apply your skills and build your portfolio.
What You Gain:
A deep understanding of Frontend React.js and Backend Node.js.
Practical skills in AI tools and IoT integration.
The confidence to work on realtime solutions and prepare for highpaying jobs.
The skills that are in demand across the tech industry, ensuring you're not just employable but soughtafter.
Frequently Asked Questions
Q: What is Node.js, and what is it used for?
A: Node.js is a runtime environment that allows you to execute JavaScript code outside of a web browser, typically on a server. It is used for building scalable server side applications, handling I/Oheavy operations, realtime applications, APIs, and microservices.
Q: What is the difference between class based components and functional components with hooks in React?
A: Class based components maintain state via instances, while functional components use hooks for state management and other side effects. Hooks have made functional components more popular due to their simplicity and flexibility.
Q: What are the popular frameworks for building web applications with Node.js?
A: Popular frameworks include Express.js, Koa.js, and Nest.js. They provide higher level abstractions and utilities to simplify building web applications.
Q: What is Angular, and why should I learn it?
A: Angular is a powerful framework for building dynamic, single page web applications. It provides a comprehensive solution with builtin tools for routing, forms, and dependency injection, making it highly valued in the job market.
Q: Why is Express.js preferred for beginners?
A: Express.js has a minimalistic and straightforward approach, making it easier for beginners to grasp core web development concepts without being overwhelmed by too many builtin features. It also has a large community and abundant resources.
Q: What are Angular’s life cycle hooks, and how are they used?
A: Angular’s life cycle hooks are methods that allow you to tap into specific moments in a component’s life cycle (e.g., initialization, change detection, destruction). Examples include ngOnInit, ngOnChanges, and ngOnDestroy.
Q: What is React, and why is it popular?
A: React is a JavaScript library for building user interfaces, particularly for single page applications. It is popular due to its reusable components, fast performance with virtual DOM, and one way data flow, making the code predictable and easy to debug.
Q: What are the job roles available for someone skilled in Node.js, Express.js, React, and Angular?
A: Job roles include Backend Developer, Frontend Developer, Full Stack Developer, API Developer, UI/UX Developer, DevOps Engineer, and Systems Architect.
Q: What is JSX in React?
A: JSX is a syntax extension of JavaScript used to create React elements. It allows you to write HTML elements and JavaScript together, making it easier to structure components and manage the user interface.
Q: What are some realworld applications built with these technologies?
A: Realworld applications include platforms like Netflix, LinkedIn, and PayPal (Node.js and Express.js); dynamic singlepage applications (React); and enterpriselevel applications (Angular). These technologies are used to handle high traffic, realtime features, and complex user interfaces.
For more, visit our website:
https://techentry.in/courses/nodejs-fullstack-mean-mern-course
0 notes
Text
What are the best app development tools for Sharepoint?
In today’s world, it’s all regarding speed and accuracy and SharePoint development isn't any totally different during this. to assist the SharePoint developer community an outsized range of tools and utilities have return up and evolved into what we have a tendency to decision ‘must-have tools’ for a SharePoint developer. we have a tendency to performed varied internal searches among our development team and variety of such powerful tools were listed out. when a careful analysis and consideration on the deserves of victimization tools here area unit the highest six listed:
1. SharePoint Search query tool
2. SharePoint Manager 2013
3. CAML query builder
4. ULS Viewer
5. Fiddler
6. CKS Dev
1. SharePoint Search Query Tool
Searching and looking for the relevant data is that the most vital for each project. SharePoint isn't any totally different in building and sharing data in large volume. For building this economical search, it's perpetually difficult to jot down queries for the developers. this can be long and might even result in undesirable results. This tool comes with a predefined set of question choices. The developers will build still because of the queries and their leads to the required format between JSON and XML, on the go whereas performing on immense SharePoint farm. Therefore, these tools modify your search needs.
2. SharePoint Manager 2013
Exploring SharePoint Object Model of the project is a clear task whereas performing on any resolution. This tool helps in seeing the SharePoint farm structure. This helps in visualizing the schema hold on within the information. The users with server access will solely use this tool, which may be wont to see the whole object structure and underline properties and their values.
Also Read: a way to Optimize Your Sharepoint application development?
3. CAML Query Builder
There is no custom development project in SharePoint that doesn't involve actuation knowledge from SharePoint list and libraries. this may be finished the assistance of CAML queries. a big a part of the event effort goes in writing and optimizing the CAML Queries. an efficient CAML question builder tool, together with saving your development time may validate your results as you're writing the queries.
4. ULS Viewer
While performing on comes SharePoint log files have a large range of logs on every request. Therefore, it becomes arduous to spot and right the matter manually. ULS Viewer helps to perform this job in an exceedingly} very short time. It provides multiple filters to refine the logs and find the required lines of a statement supported correlation id and levels. Summing up, if you're configuring, deploying or debugging the SharePoint project, then the ULS Log Viewer helps to look the logs instantly and so saves the time in partitioning the errors.
Also Read: Sharepoint Is rattling than You Ever Thought!
5. Fiddler
Debugging the shopper-facet interface for all the requests and responses could be a long method for a developer. looking for the assorted net sessions, their responses traffic etc area unit terribly tedious tasks. With Fiddler, you'll simply analyze the statistics of the request and downloaded knowledge that helps US in rising the performance of the web site. The request traffic may be recorded for more use. Therefore, if you're trying to find a tool for fast debugging and client-side testing you'll use Fiddler.
6. CKS Dev
This could be a plugin for Visual Studio that is a killer feature that you just will later while not. This has been engineered by a team of awful of us within the community as associate degree extension to Visual Studio and currently, it's support for 2013 still. It permits you to manage your development routines a lot of with efficiency whereas you're on the committal to writing the journey. It conjointly adds a bunch of recent projects things for your SharePoint comes associate degreed it contributes to an overall satisfactory SharePoint development story.
Also Read: Things to contemplate whereas designing your SharePoint computer network
The preceding area unit the six must-have SharePoint development tools we might wish to mention. we have a tendency to area unit happy to share our expertise in having used these tools, which may facilitate the in increasing our potency. although their area unit several tools offered on the market we might like these tools to be used extensively that area unit a section of our comes and success stories. you'll refer and suggest a lot of tools you're victimization and in what varied ways in which they're tributary. Let’s share this and find the most advantage to make the SharePoint development team a lot of economical and productive.
Rajasri systems may be a SharePoint development company that provides a large vary of SharePoint services to supply our international shoppers with user-friendly, feature-rich SharePoint applications investment Microsoft SharePoint functionalities.
Let's connect wih us : rajasri.com
Email: [email protected]
#sharepoint application development#sharepointwebsite sharepointdevelopment developmentcompany rajasrisystems
0 notes
Photo

Cursor-based Pagination な API を RxJS でリアクティブに処理してみる http://bit.ly/2SZaz6W
この記事は 俺でもわかるシリーズ Advent Calendar 2018 の14日目です。本当に申し訳ありません。
前置き
たとえば、全件をまとめて取得するのが殆ど不可能であるがゆえに、1回の呼び出しで最大1,000件のアイテム群が返ってくる API があったとしよう。
次のページを取得するためには、現在のページのレスポンスに含まれる情報(カーソル)を使って再度リクエストをするという仕組みであり、
そして、あなたはその最大1,000件ずつ取得するアイテム群に対して、何らかの処理をしたい。そういう状況であったとすると、
何らかの処理というのは非常に多岐に渡っていて、ざっくり考えただけでも
何らかの条件に応じてアイテムを取得したい
全件を取得したい
1件だけ取得したい
n件まで取得したい
合致するまでの全件を取得したい
取得されたアイテムに何らかの処理をしたい
データ形式を変換したい
n件ずつのサブグループにしたい
合計とか平均とか、それらを使って1つのデータを作りたい
取得元は複数ある(API を叩く条件が複数とか)が、取得されたアイテムに対する処理は共通化したい
アイテムが取得されたら、探索が終わってからでなく取得された瞬間から次の処理に渡したい
これを地道に実装しようとすると、次ページを取得する部分とアイテムに対して処理をする部分が混ざり、非常に見通しが悪そう。
しかし、コレ、なんか見覚えがあるよな……


というわけで RxJS を使って、例として S3 の ListObjectsV2 API をラップしてみるというネタです。
前提条件・ソースコード
Observable を静的型なしに扱うと脳が爆発四散するので TypeScript で書きました。
"aws-sdk": "^2.377.0"
"rxjs": "^6.3.3"
"typescript": "^3.2.2"
ソースは y13i/s3-observable-example に置いてます。
ListObjectsV2 を Observable 化する
こんな感じにしてみました。
listObjectsAsObservable.ts
import { Observable } from "rxjs"; import { S3 } from "aws-sdk"; type Request = S3.ListObjectsV2Request; export function listObjectsAsObservable( s3: S3, request: Request ): Observable<S3.ListObjectsV2Output> { return Observable.create((observer: any) => { let finished = false; let continuationToken: string | undefined = undefined; (async () => { try { do { const req: Request = { ...request, ContinuationToken: continuationToken }; const result = await s3.listObjectsV2(req).promise(); continuationToken = result.NextContinuationToken; observer.next(result); } while (continuationToken && !finished); } catch (error) { observer.error(error); } observer.complete(); })(); return () => (finished = true); }); }
n 回繰り返し API 呼び出しのメソッドを呼び出してその結果を流す Observable を作るには Observable.create() を使えば良さそうです。
Observable.create() の引数であるサブスクライバー関数の仮引数 observer のメソッド next() に何らかの値を引数として与えて実行すると、その値が流れてくるようになります。 error(), complete() はそれぞれ、ストリームのエラー値とストリーム終了時の値に対応しています。
s3.listObjectV2() API の、次ページを指し示すカーソルは ContinuationToken という名前です。レスポンスに含まれる NextContinuationToken の値を次回のリクエストに ContinuationToken として含めると、次ページの結果を得られます。
async, await を使うとループ回数が不明な場合の処理を再帰なしに書けるので脳にやさしいですね。
サブスクライバー関数は、ストリームが中断(dispose)された時の処理を行う関数を返します。例えば10個の値が流れてくるストリームに対し、 take(5) すると5個取った時点で残りは流れてこなくてよい、というような場合です。今回の例ではそうなった場合は以降のページのリクエストを行わない、としています。
試してみる
1. まずは簡単な例
適当に130個ほどダミーオブジェクトを置いておき、それを50個ずつ一覧してみます。本来 listObjectV2() は1回で1,000件まで取得できるのですが、時間短縮のためわざと件数を少なめで試しています。
await listObjectsAsObservable(s3, { Bucket: bucket, Prefix: prefix, MaxKeys: 50 }) .pipe( tap(listObjectsResult => { console.log( `!!! list contains ${listObjectsResult.Contents!.length} items.` ); }) ) .toPromise();
AWS SDK のデバッグ出力を有効にして実行してみました。出力結果は以下です。
[AWS s3 200 0.096s 0 retries] listObjectsV2({ Bucket: 's3-observable-example', Prefix: 'test1/', MaxKeys: 50, ContinuationToken: undefined }) !!! list contains 50 items. [AWS s3 200 0.076s 0 retries] listObjectsV2({ Bucket: 's3-observable-example', Prefix: 'test1/', MaxKeys: 50, ContinuationToken: '1KI8JxWWj6YE3WmkKojZ2JeionQ3wtMNsZDGPXICX4e0wk0jhsiYZFh1EjUao850UqILlYHBZUVn45tLUh0bkcA==' }) !!! list contains 50 items. [AWS s3 200 0.073s 0 retries] listObjectsV2({ Bucket: 's3-observable-example', Prefix: 'test1/', MaxKeys: 50, ContinuationToken: '1MQ1MDhm6mD4vblrhuvafELPq5mKZQA1V6gHy0wxjfjWB8nSP+DkTdEG5XHLZUjWCkqMBEDnDXyggNokdHMKRig==' }) !!! list contains 30 items.
listObjectsV2() が計3回呼び出され、それぞれのリストの長さは50, 50, 30件になっていることがわかります。期待通りの挙動っぽい。
2. ストリームを変形する
listObjectsAsObservable() は S3.ListObjectsV2Output が流れてくるように実装しましたが、実際取りたいのはオブジェクトの情報だけなんじゃ! という事はままあるでしょう。
そんな時は Observable.from(), mergeMap() を使うと簡単にオブジェクト情報(型定義の名前では S3.Object���のストリームに変換できます。
const divisibleBy13Count = await listObjectsAsObservable(s3, { Bucket: bucket, Prefix: prefix, MaxKeys: 50 }) .pipe( mergeMap(listObjectsResult => { return from(listObjectsResult.Contents!); }), filter(object => { const match = object.Key!.match(/(\d+)\.json$/); if (!match) return false; const number = parseInt(match[1]!); return number % 13 === 0; }), tap(object => { console.log( `The timestamp in object key ${object.Key} is divisible by 13` ); }), count() ) .toPromise(); console.log( `There are ${divisibleBy13Count} objects with 13-divisible-timestamps.` );
この例ではストリームを Observable<S3.Object> に変換した後、オブジェクトキーに含まれるタイムスタンプが13の倍数のものだけを抽出・出力して、さらにその個数をカウントする、としてみました。出力結果はこんな感じ。
The timestamp in object key test1/113-1545384463792.json is divisible by 13 The timestamp in object key test1/15-1545384453717.json is divisible by 13 The timestamp in object key test1/90-1545384461985.json is divisible by 13 There are 3 objects with 13-divisible-timestamps.
3. 非同期処理を重ねて、その結果をまとめてみる
ダミーオブジェクトは {"value":47} のような形式で100未満の数字が書いてある JSON です。
この数字を取得するためにはlistObjectsV2() だけでなく getObject() でオブジェクト内容を取得する必要があります。
最後にこれをやってみましょう。
await listObjectsAsObservable(s3, { Bucket: bucket, Prefix: prefix, MaxKeys: 50 }) .pipe( mergeMap(listObjectsResult => { return from(listObjectsResult.Contents!); }), filter(object => { const match = object.Key!.match(/(\d+)\.json$/); if (!match) return false; const number = parseInt(match[1]!); return number % 7 === 0; }), take(7), mergeMap(object => { return s3.getObject({ Bucket: bucket, Key: object.Key! }).promise(); }), map(getObjectResult => { const parsed: { value: number } = JSON.parse( getObjectResult.Body!.toString() ); return parsed.value; }), scan((acc, x) => { return acc + x; }, 0), tap(currentSum => console.log( `The current sum of values in objects with 7-divisible-timestamps is ${currentSum}` ) ) ) .toPromise();
別の非同期処理を挟み込む場合も mergeMap() を使います。 Promise を自動で Observable に変換してくれてありがたい。
ついでにストリームっぽく、最初の7つの、7の倍数のタイムスタンプを持つオブジェクトの中の値(なげーな)が流れてくるたびに「その時点での合計値」を出力するようにしてみました。
The current sum of values in the first 7 objects with 7-divisible-timestamps is 51 The current sum of values in the first 7 objects with 7-divisible-timestamps is 94 The current sum of values in the first 7 objects with 7-divisible-timestamps is 179 The current sum of values in the first 7 objects with 7-divisible-timestamps is 257 The current sum of values in the first 7 objects with 7-divisible-timestamps is 285 The current sum of values in the first 7 objects with 7-divisible-timestamps is 315 The current sum of values in the first 7 objects with 7-divisible-timestamps is 379
まとめ
NextContinuationToken が続く限り次ページをリクエストし続ける、という処理を listObjectsAsObservable() の中に閉じ込めることができ、そうして取得してきたデータに対する処理と混ぜずに書けることがわかりました。
場合によっては役に立つかもしれないですね。
あと Observable/RxJS をもっとわかりたいと思いました。おわり
元記事はこちら
「Cursor-based Pagination な API を RxJS でリアクティブに処理してみる」
January 16, 2019 at 12:00PM
0 notes
Text
crypto code review
Sparkster has finally opened its code repositories to the public, and as the project has been somewhat in the centre of discussion in the crypto community, as well as marketed by one of the high profile crypto influencers, we have been quite curious to see the result of their efforts.
The fundamental idea of the project is to provide a high-throughput decentralized cloud computing platform, with software developer kit (SDK) on top with no requirement for programming expertise (coding is supposed to be done in plain English). The idea of plain English coding is far from new and has been emerging more than a few times over the years, but never gotten any widespread traction. The reason in our opinion is that professional developers are not drawn to simplified drag & drop plain language programming interfaces, and non-developers (which is one of the potential target groups for Sparkster) are, well, most probably just not interested in software development altogether.

However the focus of this article is not to scrutinize the use case scenarios suggested by Sparkster (which do raise some question marks) but rather to take a deep look into the code they have produced. With a team counting 14 software developers and quite a bit of runway passed since their ICO in July 2018, our expectations are high.
Non-technical readers are advised to skip to the end for conclusions.
crypto code review Sparkster initially published four public repositories in their github (of which one (Sparkster) was empty). We noticed a lack of commit history which we assume is due to a transfer of the repos from a private development environment into github. Three of the above repositories were later combined into a single one containing subfolders for each system element.
The first impression from browsing the repositories is decent after recent cleanups by the team. Readme has been added to the main repository with information on the system itself and installation instructions (Windows x64 only, no Linux build is available yet)
However, we see no copyright notes anywhere in the code developed by Sparkster, which is quite unusual for an open source project released to the public.
Below is a walk-thru of the three relevant folders containing main system components under the Decentralized-Cloud repository and a summary of our impression.
Master-Node folder The source code is written in C++. Everything we see is very basic. In total there are is not a lot of unique code (we expected much more given the development time spent) and a lot of the recently added code is GNU/forks from other projects (all according to the copyright notes for these parts).
An interesting part is, that if this master node spawned the compute node for this transaction, the master node will request the compute node to commit the transaction. The master nodes takes the control over more or less all communication to stakeholders such as clients. The master node will send a transaction to 20 other master nodes.
The lock mechanism during voting is standard: nodes booting in the middle of voting are locked and cannot participate to avoid incorrect results.
We cannot see anything in the code that differentiates the node and makes it special in any way, i.e. this is blockchain 101.
Compute-Node folder All source files sum up to a very limited amount of code. As the master node takes over a lot of control, the compute node focuses on the real work. A minimalistic code is generally recommended in a concept like this, but this is far less than expected.
We found the “gossip” to 21 master nodes before the memory gets erased and the compute node falls back to listen mode.
The concept of 21 master nodes is defined in the block producer. Every hour a new set of 21 master nodes become the master node m21.
“At any given point in time, 21 Master Nodes will exist that facilitate consensus on transactions and blocks; we will call these master nodes m21. The nodes in m21 are selected every hour through an automated voting process”
(Source: https://github.com/sparkster-me/Decentralized-Cloud)
The compute node is somewhat the heart of the project but is yet again standard without any features giving it high performance capability.
Storage-Node folder The source code is again very basic. Apart from this, the code is still at an experimental stage with e.g. buffer overflow disabling being utilized, something that should not be present at this stage of development.
Overall the storage uses json requests and supports/uses the IPFS (InterPlanetary File System). IPFS is an open source project and used for storing and sharing hypermedia in a distributed file system. The storage node not only handles the storage of data, it also responds to some client filter requests.
Conclusion In total Sparkster has produced a limited amount of very basic code, with a team of 14 developers at their disposal. As their announcement suggests that this is the complete code for their cloud platform mainnet, we must assume that the productivity of the team has been quite low over the months since funds were raised, since none of the envisioned features for high performance are yet implemented.
The current repository is not on par with standards for a mainnet release and raises some serious question marks about the intention of the project altogether. The impression is that the team has taken a very basic approach and attempted to use short cuts in order to keep their timelines towards the community, rather than develop something that is actually unique and useful. This is further emphasized by the fact that the Sparkster website and blockchain explorer is built on stock templates. We don’t see any sign of advanced development capability this far.
Based on what we see in this release Sparkster is currently not a platform for ”full scale support to build AI powered apps” as their roadmap suggest and we are puzzled by the progress and lack of provisioning of any type of SDK plugin. The Sparkster team has a lot to work on to even be close to their claims and outlined roadmap.
Note: we have been in contact with the Sparkster team prior to publishing this review, in order to provide opportunity for them to comment on our observations. Their answers are listed below but doesn’t change our overall conclusions of the current state of Sparkster development.
“We use several open source libraries in our projects. These include OpenDHT, WebSocket++, Boost, and Ed25519. In other places, we’ve clearly listed where code is adapted from in the cases where we’ve borrowed code from other sources. We’ve used borrowed code for things like getting the time from a time server: a procedure that is well documented and for which many working code examples already exist, so it is not necessary for us to reinvent the wheel. However, these cases cover a small portion of our overall code base.
Our alpha net supports one cell, and our public claims are that one cell can support 1,000 TPS. These are claims that we have tested and validated, so the mainnet is in spec. You will see that multi cell support is coming in our next release, as mentioned in our readme. Our method of achieving multi cell support is with a well understood and documented methodology, specifically consistent hashing. However, an optimization opportunity, we’re investiging LSH over CS. This is an optimization that was recommended by a member of our Tech Advisory Board, who is a PHD in Computer Science at the University of Cambridge.
Our code was made straightforward on purpose. Most of its simplicity comes from its modular design: we use a common static library in which we’ve put common functionality, and this library is rightfully called BlockChainCommon.lib. This allows us to abstract away from the individual nodes the inner workings of the core components of our block chain, hence keeping the code in the individual nodes small. This allows for a high level of code reusability. In fact, in some cases this modular design has reduced a node to a main function with a series of data handlers, and that’s all there is to it. It allows us to design a common behavior pattern among nodes: start up OpenDHT, register data handlers using a mapping between the ComandType command and the provided lambda function, call the COMM_PROTOCOL_INIT macro, enter the node’s forever loop. This way, all incoming data packets and command processors are handled by BlockChainCommon, and all nodes behave similarly: wait for a command, act on the command. So while this design gives the impression of basic code, we prefer simplicity over complexity because it allows us to maintain the code and even switch out entire communications protocols within a matter of days should we choose to do so. As far as the Compute Node is concerned, we use V8 to execute the javascript which has a proven track record of being secure, fast and efficient.
We’ve specifically disabled warning 4996 because we are checking for buffer overflows ourselves, and unless we’re in debug mode, we don’t need the compiler to warn about these issues. This also allows our code to be portable, since taking care of a lot of these warnings the way the VCC compiler wants us to will mean using Microsoft-specific functions are portable (other platforms don’t provide safe alternatives with the _s suffix, and even Microsoft warns about this fact here: https://docs.microsoft.com/en-us/cpp/error-messages/compiler-warnings/compiler-warning-level-3-c4996?view=vs-2017.) To quote: “However, the updated names are Microsoft-specific. If you need to use the existing function names for portability reasons, you can turn these warnings off.”
0 notes