#kubernetes cluster Platform
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/deploying-large-language-models-on-kubernetes-a-comprehensive-guide/
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
Large Language Models (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation.
However, deploying LLMs can be a challenging task due to their immense size and computational requirements. Kubernetes, an open-source container orchestration system, provides a powerful solution for deploying and managing LLMs at scale. In this technical blog, we’ll explore the process of deploying LLMs on Kubernetes, covering various aspects such as containerization, resource allocation, and scalability.
Understanding Large Language Models
Before diving into the deployment process, let’s briefly understand what Large Language Models are and why they are gaining so much attention.
Large Language Models (LLMs) are a type of neural network model trained on vast amounts of text data. These models learn to understand and generate human-like language by analyzing patterns and relationships within the training data. Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet.
LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. However, their massive size and computational requirements pose significant challenges for deployment and inference.
Why Kubernetes for LLM Deployment?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It provides several benefits for deploying LLMs, including:
Scalability: Kubernetes allows you to scale your LLM deployment horizontally by adding or removing compute resources as needed, ensuring optimal resource utilization and performance.
Resource Management: Kubernetes enables efficient resource allocation and isolation, ensuring that your LLM deployment has access to the required compute, memory, and GPU resources.
High Availability: Kubernetes provides built-in mechanisms for self-healing, automatic rollouts, and rollbacks, ensuring that your LLM deployment remains highly available and resilient to failures.
Portability: Containerized LLM deployments can be easily moved between different environments, such as on-premises data centers or cloud platforms, without the need for extensive reconfiguration.
Ecosystem and Community Support: Kubernetes has a large and active community, providing a wealth of tools, libraries, and resources for deploying and managing complex applications like LLMs.
Preparing for LLM Deployment on Kubernetes:
Before deploying an LLM on Kubernetes, there are several prerequisites to consider:
Kubernetes Cluster: You’ll need a Kubernetes cluster set up and running, either on-premises or on a cloud platform like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
GPU Support: LLMs are computationally intensive and often require GPU acceleration for efficient inference. Ensure that your Kubernetes cluster has access to GPU resources, either through physical GPUs or cloud-based GPU instances.
Container Registry: You’ll need a container registry to store your LLM Docker images. Popular options include Docker Hub, Amazon Elastic Container Registry (ECR), Google Container Registry (GCR), or Azure Container Registry (ACR).
LLM Model Files: Obtain the pre-trained LLM model files (weights, configuration, and tokenizer) from the respective source or train your own model.
Containerization: Containerize your LLM application using Docker or a similar container runtime. This involves creating a Dockerfile that packages your LLM code, dependencies, and model files into a Docker image.
Deploying an LLM on Kubernetes
Once you have the prerequisites in place, you can proceed with deploying your LLM on Kubernetes. The deployment process typically involves the following steps:
Building the Docker Image
Build the Docker image for your LLM application using the provided Dockerfile and push it to your container registry.
Creating Kubernetes Resources
Define the Kubernetes resources required for your LLM deployment, such as Deployments, Services, ConfigMaps, and Secrets. These resources are typically defined using YAML or JSON manifests.
Configuring Resource Requirements
Specify the resource requirements for your LLM deployment, including CPU, memory, and GPU resources. This ensures that your deployment has access to the necessary compute resources for efficient inference.
Deploying to Kubernetes
Use the kubectl command-line tool or a Kubernetes management tool (e.g., Kubernetes Dashboard, Rancher, or Lens) to apply the Kubernetes manifests and deploy your LLM application.
Monitoring and Scaling
Monitor the performance and resource utilization of your LLM deployment using Kubernetes monitoring tools like Prometheus and Grafana. Adjust the resource allocation or scale your deployment as needed to meet the demand.
Example Deployment
Let’s consider an example of deploying the GPT-3 language model on Kubernetes using a pre-built Docker image from Hugging Face. We’ll assume that you have a Kubernetes cluster set up and configured with GPU support.
Pull the Docker Image:
bashCopydocker pull huggingface/text-generation-inference:1.1.0
Create a Kubernetes Deployment:
Create a file named gpt3-deployment.yaml with the following content:
apiVersion: apps/v1 kind: Deployment metadata: name: gpt3-deployment spec: replicas: 1 selector: matchLabels: app: gpt3 template: metadata: labels: app: gpt3 spec: containers: - name: gpt3 image: huggingface/text-generation-inference:1.1.0 resources: limits: nvidia.com/gpu: 1 env: - name: MODEL_ID value: gpt2 - name: NUM_SHARD value: "1" - name: PORT value: "8080" - name: QUANTIZE value: bitsandbytes-nf4
This deployment specifies that we want to run one replica of the gpt3 container using the huggingface/text-generation-inference:1.1.0 Docker image. The deployment also sets the environment variables required for the container to load the GPT-3 model and configure the inference server.
Create a Kubernetes Service:
Create a file named gpt3-service.yaml with the following content:
apiVersion: v1 kind: Service metadata: name: gpt3-service spec: selector: app: gpt3 ports: - port: 80 targetPort: 8080 type: LoadBalancer
This service exposes the gpt3 deployment on port 80 and creates a LoadBalancer type service to make the inference server accessible from outside the Kubernetes cluster.
Deploy to Kubernetes:
Apply the Kubernetes manifests using the kubectl command:
kubectl apply -f gpt3-deployment.yaml kubectl apply -f gpt3-service.yaml
Monitor the Deployment:
Monitor the deployment progress using the following commands:
kubectl get pods kubectl logs <pod_name>
Once the pod is running and the logs indicate that the model is loaded and ready, you can obtain the external IP address of the LoadBalancer service:
kubectl get service gpt3-service
Test the Deployment:
You can now send requests to the inference server using the external IP address and port obtained from the previous step. For example, using curl:
curl -X POST http://<external_ip>:80/generate -H 'Content-Type: application/json' -d '"inputs": "The quick brown fox", "parameters": "max_new_tokens": 50'
This command sends a text generation request to the GPT-3 inference server, asking it to continue the prompt “The quick brown fox” for up to 50 additional tokens.
Advanced topics you should be aware of
While the example above demonstrates a basic deployment of an LLM on Kubernetes, there are several advanced topics and considerations to explore:
_*]:min-w-0″ readability=”131.72387362124″>
1. Autoscaling
Kubernetes supports horizontal and vertical autoscaling, which can be beneficial for LLM deployments due to their variable computational demands. Horizontal autoscaling allows you to automatically scale the number of replicas (pods) based on metrics like CPU or memory utilization. Vertical autoscaling, on the other hand, allows you to dynamically adjust the resource requests and limits for your containers.
To enable autoscaling, you can use the Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). These components monitor your deployment and automatically scale resources based on predefined rules and thresholds.
2. GPU Scheduling and Sharing
In scenarios where multiple LLM deployments or other GPU-intensive workloads are running on the same Kubernetes cluster, efficient GPU scheduling and sharing become crucial. Kubernetes provides several mechanisms to ensure fair and efficient GPU utilization, such as GPU device plugins, node selectors, and resource limits.
You can also leverage advanced GPU scheduling techniques like NVIDIA Multi-Instance GPU (MIG) or AMD Memory Pool Remapping (MPR) to virtualize GPUs and share them among multiple workloads.
3. Model Parallelism and Sharding
Some LLMs, particularly those with billions or trillions of parameters, may not fit entirely into the memory of a single GPU or even a single node. In such cases, you can employ model parallelism and sharding techniques to distribute the model across multiple GPUs or nodes.
Model parallelism involves splitting the model architecture into different components (e.g., encoder, decoder) and distributing them across multiple devices. Sharding, on the other hand, involves partitioning the model parameters and distributing them across multiple devices or nodes.
Kubernetes provides mechanisms like StatefulSets and Custom Resource Definitions (CRDs) to manage and orchestrate distributed LLM deployments with model parallelism and sharding.
4. Fine-tuning and Continuous Learning
In many cases, pre-trained LLMs may need to be fine-tuned or continuously trained on domain-specific data to improve their performance for specific tasks or domains. Kubernetes can facilitate this process by providing a scalable and resilient platform for running fine-tuning or continuous learning workloads.
You can leverage Kubernetes batch processing frameworks like Apache Spark or Kubeflow to run distributed fine-tuning or training jobs on your LLM models. Additionally, you can integrate your fine-tuned or continuously trained models with your inference deployments using Kubernetes mechanisms like rolling updates or blue/green deployments.
5. Monitoring and Observability
Monitoring and observability are crucial aspects of any production deployment, including LLM deployments on Kubernetes. Kubernetes provides built-in monitoring solutions like Prometheus and integrations with popular observability platforms like Grafana, Elasticsearch, and Jaeger.
You can monitor various metrics related to your LLM deployments, such as CPU and memory utilization, GPU usage, inference latency, and throughput. Additionally, you can collect and analyze application-level logs and traces to gain insights into the behavior and performance of your LLM models.
6. Security and Compliance
Depending on your use case and the sensitivity of the data involved, you may need to consider security and compliance aspects when deploying LLMs on Kubernetes. Kubernetes provides several features and integrations to enhance security, such as network policies, role-based access control (RBAC), secrets management, and integration with external security solutions like HashiCorp Vault or AWS Secrets Manager.
Additionally, if you’re deploying LLMs in regulated industries or handling sensitive data, you may need to ensure compliance with relevant standards and regulations, such as GDPR, HIPAA, or PCI-DSS.
7. Multi-Cloud and Hybrid Deployments
While this blog post focuses on deploying LLMs on a single Kubernetes cluster, you may need to consider multi-cloud or hybrid deployments in some scenarios. Kubernetes provides a consistent platform for deploying and managing applications across different cloud providers and on-premises data centers.
You can leverage Kubernetes federation or multi-cluster management tools like KubeFed or GKE Hub to manage and orchestrate LLM deployments across multiple Kubernetes clusters spanning different cloud providers or hybrid environments.
These advanced topics highlight the flexibility and scalability of Kubernetes for deploying and managing LLMs.
Conclusion
Deploying Large Language Models (LLMs) on Kubernetes offers numerous benefits, including scalability, resource management, high availability, and portability. By following the steps outlined in this technical blog, you can containerize your LLM application, define the necessary Kubernetes resources, and deploy it to a Kubernetes cluster.
However, deploying LLMs on Kubernetes is just the first step. As your application grows and your requirements evolve, you may need to explore advanced topics such as autoscaling, GPU scheduling, model parallelism, fine-tuning, monitoring, security, and multi-cloud deployments.
Kubernetes provides a robust and extensible platform for deploying and managing LLMs, enabling you to build reliable, scalable, and secure applications.
#access control#Amazon#Amazon Elastic Kubernetes Service#amd#Apache#Apache Spark#app#applications#apps#architecture#Artificial Intelligence#attention#AWS#azure#Behavior#BERT#Blog#Blue#Building#chatbots#Cloud#cloud platform#cloud providers#cluster#clusters#code#command#Community#compliance#comprehensive
0 notes
Text
using git and a … wikipedia says that the generic term for what github and gitlab are is 'software forge' for document editing is pretty great
you can use your favorite text editor! you can track a multi-file project! the default workflow encourages you to keep copies both on your computer and in the cloud! you can log what changes you're making!
if you accidentally edit with the wrong account you can go edit the history, it'll be a pain but you can.
the other options for "edit a document and show it to your friends as you edit" are, like:
google docs. it's a weird proprietary format and if you export to html it will be a horrible mess of html that needs cleanup. you don't by default end up with your file constantly up to date on your computer. it's super easy to end up viewing a doc with the wrong account.
edit in some platform on your computer and upload files to share them with your friends. you will have to upload the files a lot to lots of people if you want to keep them all up to date.
use some weird other web text service. it might also randomly go down and delete everything and there's way less of a robust advice ecosystem
unfortunately if you use a software forge they might ask you if you want to add a kubernetes cluster. and also they often won't enable word wrap on plaintext.
(im currently writing stuff on gitgud.io which has a fairly lenient ToS)
7 notes
·
View notes
Text
A3 Ultra VMs With NVIDIA H200 GPUs Pre-launch This Month

Strong infrastructure advancements for your future that prioritizes AI
To increase customer performance, usability, and cost-effectiveness, Google Cloud implemented improvements throughout the AI Hypercomputer stack this year. Google Cloud at the App Dev & Infrastructure Summit:
Trillium, Google’s sixth-generation TPU, is currently available for preview.
Next month, A3 Ultra VMs with NVIDIA H200 Tensor Core GPUs will be available for preview.
Google’s new, highly scalable clustering system, Hypercompute Cluster, will be accessible beginning with A3 Ultra VMs.
Based on Axion, Google’s proprietary Arm processors, C4A virtual machines (VMs) are now widely accessible
AI workload-focused additions to Titanium, Google Cloud’s host offload capability, and Jupiter, its data center network.
Google Cloud’s AI/ML-focused block storage service, Hyperdisk ML, is widely accessible.
Trillium A new era of TPU performance
Trillium A new era of TPU performance is being ushered in by TPUs, which power Google’s most sophisticated models like Gemini, well-known Google services like Maps, Photos, and Search, as well as scientific innovations like AlphaFold 2, which was just awarded a Nobel Prize! We are happy to inform that Google Cloud users can now preview Trillium, our sixth-generation TPU.
Taking advantage of NVIDIA Accelerated Computing to broaden perspectives
By fusing the best of Google Cloud’s data center, infrastructure, and software skills with the NVIDIA AI platform which is exemplified by A3 and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs it also keeps investing in its partnership and capabilities with NVIDIA.
Google Cloud announced that the new A3 Ultra VMs featuring NVIDIA H200 Tensor Core GPUs will be available on Google Cloud starting next month.
Compared to earlier versions, A3 Ultra VMs offer a notable performance improvement. Their foundation is NVIDIA ConnectX-7 network interface cards (NICs) and servers equipped with new Titanium ML network adapter, which is tailored to provide a safe, high-performance cloud experience for AI workloads. A3 Ultra VMs provide non-blocking 3.2 Tbps of GPU-to-GPU traffic using RDMA over Converged Ethernet (RoCE) when paired with our datacenter-wide 4-way rail-aligned network.
In contrast to A3 Mega, A3 Ultra provides:
With the support of Google’s Jupiter data center network and Google Cloud’s Titanium ML network adapter, double the GPU-to-GPU networking bandwidth
With almost twice the memory capacity and 1.4 times the memory bandwidth, LLM inferencing performance can increase by up to 2 times.
Capacity to expand to tens of thousands of GPUs in a dense cluster with performance optimization for heavy workloads in HPC and AI.
Google Kubernetes Engine (GKE), which offers an open, portable, extensible, and highly scalable platform for large-scale training and AI workloads, will also offer A3 Ultra VMs.
Hypercompute Cluster: Simplify and expand clusters of AI accelerators
It’s not just about individual accelerators or virtual machines, though; when dealing with AI and HPC workloads, you have to deploy, maintain, and optimize a huge number of AI accelerators along with the networking and storage that go along with them. This may be difficult and time-consuming. For this reason, Google Cloud is introducing Hypercompute Cluster, which simplifies the provisioning of workloads and infrastructure as well as the continuous operations of AI supercomputers with tens of thousands of accelerators.
Fundamentally, Hypercompute Cluster integrates the most advanced AI infrastructure technologies from Google Cloud, enabling you to install and operate several accelerators as a single, seamless unit. You can run your most demanding AI and HPC workloads with confidence thanks to Hypercompute Cluster’s exceptional performance and resilience, which includes features like targeted workload placement, dense resource co-location with ultra-low latency networking, and sophisticated maintenance controls to reduce workload disruptions.
For dependable and repeatable deployments, you can use pre-configured and validated templates to build up a Hypercompute Cluster with just one API call. This include containerized software with orchestration (e.g., GKE, Slurm), framework and reference implementations (e.g., JAX, PyTorch, MaxText), and well-known open models like Gemma2 and Llama3. As part of the AI Hypercomputer architecture, each pre-configured template is available and has been verified for effectiveness and performance, allowing you to concentrate on business innovation.
A3 Ultra VMs will be the first Hypercompute Cluster to be made available next month.
An early look at the NVIDIA GB200 NVL72
Google Cloud is also awaiting the developments made possible by NVIDIA GB200 NVL72 GPUs, and we’ll be providing more information about this fascinating improvement soon. Here is a preview of the racks Google constructing in the meantime to deliver the NVIDIA Blackwell platform’s performance advantages to Google Cloud’s cutting-edge, environmentally friendly data centers in the early months of next year.
Redefining CPU efficiency and performance with Google Axion Processors
CPUs are a cost-effective solution for a variety of general-purpose workloads, and they are frequently utilized in combination with AI workloads to produce complicated applications, even if TPUs and GPUs are superior at specialized jobs. Google Axion Processors, its first specially made Arm-based CPUs for the data center, at Google Cloud Next ’24. Customers using Google Cloud may now benefit from C4A virtual machines, the first Axion-based VM series, which offer up to 10% better price-performance compared to the newest Arm-based instances offered by other top cloud providers.
Additionally, compared to comparable current-generation x86-based instances, C4A offers up to 60% more energy efficiency and up to 65% better price performance for general-purpose workloads such as media processing, AI inferencing applications, web and app servers, containerized microservices, open-source databases, in-memory caches, and data analytics engines.
Titanium and Jupiter Network: Making AI possible at the speed of light
Titanium, the offload technology system that supports Google’s infrastructure, has been improved to accommodate workloads related to artificial intelligence. Titanium provides greater compute and memory resources for your applications by lowering the host’s processing overhead through a combination of on-host and off-host offloads. Furthermore, although Titanium’s fundamental features can be applied to AI infrastructure, the accelerator-to-accelerator performance needs of AI workloads are distinct.
Google has released a new Titanium ML network adapter to address these demands, which incorporates and expands upon NVIDIA ConnectX-7 NICs to provide further support for virtualization, traffic encryption, and VPCs. The system offers best-in-class security and infrastructure management along with non-blocking 3.2 Tbps of GPU-to-GPU traffic across RoCE when combined with its data center’s 4-way rail-aligned network.
Google’s Jupiter optical circuit switching network fabric and its updated data center network significantly expand Titanium’s capabilities. With native 400 Gb/s link rates and a total bisection bandwidth of 13.1 Pb/s (a practical bandwidth metric that reflects how one half of the network can connect to the other), Jupiter could handle a video conversation for every person on Earth at the same time. In order to meet the increasing demands of AI computation, this enormous scale is essential.
Hyperdisk ML is widely accessible
For computing resources to continue to be effectively utilized, system-level performance maximized, and economical, high-performance storage is essential. Google launched its AI-powered block storage solution, Hyperdisk ML, in April 2024. Now widely accessible, it adds dedicated storage for AI and HPC workloads to the networking and computing advancements.
Hyperdisk ML efficiently speeds up data load times. It drives up to 11.9x faster model load time for inference workloads and up to 4.3x quicker training time for training workloads.
With 1.2 TB/s of aggregate throughput per volume, you may attach 2500 instances to the same volume. This is more than 100 times more than what big block storage competitors are giving.
Reduced accelerator idle time and increased cost efficiency are the results of shorter data load times.
Multi-zone volumes are now automatically created for your data by GKE. In addition to quicker model loading with Hyperdisk ML, this enables you to run across zones for more computing flexibility (such as lowering Spot preemption).
Developing AI’s future
Google Cloud enables companies and researchers to push the limits of AI innovation with these developments in AI infrastructure. It anticipates that this strong foundation will give rise to revolutionary new AI applications.
Read more on Govindhtech.com
#A3UltraVMs#NVIDIAH200#AI#Trillium#HypercomputeCluster#GoogleAxionProcessors#Titanium#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
2 notes
·
View notes
Text
CNAPP Explained: The Smartest Way to Secure Cloud-Native Apps with EDSPL

Introduction: The New Era of Cloud-Native Apps
Cloud-native applications are rewriting the rules of how we build, scale, and secure digital products. Designed for agility and rapid innovation, these apps demand security strategies that are just as fast and flexible. That’s where CNAPP—Cloud-Native Application Protection Platform—comes in.
But simply deploying CNAPP isn’t enough.
You need the right strategy, the right partner, and the right security intelligence. That’s where EDSPL shines.
What is CNAPP? (And Why Your Business Needs It)
CNAPP stands for Cloud-Native Application Protection Platform, a unified framework that protects cloud-native apps throughout their lifecycle—from development to production and beyond.
Instead of relying on fragmented tools, CNAPP combines multiple security services into a cohesive solution:
Cloud Security
Vulnerability management
Identity access control
Runtime protection
DevSecOps enablement
In short, it covers the full spectrum—from your code to your container, from your workload to your network security.
Why Traditional Security Isn’t Enough Anymore
The old way of securing applications with perimeter-based tools and manual checks doesn’t work for cloud-native environments. Here’s why:
Infrastructure is dynamic (containers, microservices, serverless)
Deployments are continuous
Apps run across multiple platforms
You need security that is cloud-aware, automated, and context-rich—all things that CNAPP and EDSPL’s services deliver together.
Core Components of CNAPP
Let’s break down the core capabilities of CNAPP and how EDSPL customizes them for your business:
1. Cloud Security Posture Management (CSPM)
Checks your cloud infrastructure for misconfigurations and compliance gaps.
See how EDSPL handles cloud security with automated policy enforcement and real-time visibility.
2. Cloud Workload Protection Platform (CWPP)
Protects virtual machines, containers, and functions from attacks.
This includes deep integration with application security layers to scan, detect, and fix risks before deployment.
3. CIEM: Identity and Access Management
Monitors access rights and roles across multi-cloud environments.
Your network, routing, and storage environments are covered with strict permission models.
4. DevSecOps Integration
CNAPP shifts security left—early into the DevOps cycle. EDSPL’s managed services ensure security tools are embedded directly into your CI/CD pipelines.
5. Kubernetes and Container Security
Containers need runtime defense. Our approach ensures zero-day protection within compute environments and dynamic clusters.
How EDSPL Tailors CNAPP for Real-World Environments
Every organization’s tech stack is unique. That’s why EDSPL never takes a one-size-fits-all approach. We customize CNAPP for your:
Cloud provider setup
Mobility strategy
Data center switching
Backup architecture
Storage preferences
This ensures your entire digital ecosystem is secure, streamlined, and scalable.
Case Study: CNAPP in Action with EDSPL
The Challenge
A fintech company using a hybrid cloud setup faced:
Misconfigured services
Shadow admin accounts
Poor visibility across Kubernetes
EDSPL’s Solution
Integrated CNAPP with CIEM + CSPM
Hardened their routing infrastructure
Applied real-time runtime policies at the node level
✅ The Results
75% drop in vulnerabilities
Improved time to resolution by 4x
Full compliance with ISO, SOC2, and GDPR
Why EDSPL’s CNAPP Stands Out
While most providers stop at integration, EDSPL goes beyond:
🔹 End-to-End Security: From app code to switching hardware, every layer is secured. 🔹 Proactive Threat Detection: Real-time alerts and behavior analytics. 🔹 Customizable Dashboards: Unified views tailored to your team. 🔹 24x7 SOC Support: With expert incident response. 🔹 Future-Proofing: Our background vision keeps you ready for what’s next.
EDSPL’s Broader Capabilities: CNAPP and Beyond
While CNAPP is essential, your digital ecosystem needs full-stack protection. EDSPL offers:
Network security
Application security
Switching and routing solutions
Storage and backup services
Mobility and remote access optimization
Managed and maintenance services for 24x7 support
Whether you’re building apps, protecting data, or scaling globally, we help you do it securely.
Let’s Talk CNAPP
You’ve read the what, why, and how of CNAPP — now it’s time to act.
📩 Reach us for a free CNAPP consultation. �� Or get in touch with our cloud security specialists now.
Secure your cloud-native future with EDSPL — because prevention is always smarter than cure.
0 notes
Text
Enterprise Kubernetes Storage with Red Hat OpenShift Data Foundation (DO370)
In the era of cloud-native transformation, data is the fuel powering everything from mission-critical enterprise apps to real-time analytics platforms. However, as Kubernetes adoption grows, many organizations face a new set of challenges: how to manage persistent storage efficiently, reliably, and securely across distributed environments.
To solve this, Red Hat OpenShift Data Foundation (ODF) emerges as a powerful solution — and the DO370 training course is designed to equip professionals with the skills to deploy and manage this enterprise-grade storage platform.
🔍 What is Red Hat OpenShift Data Foundation?
OpenShift Data Foundation is an integrated, software-defined storage solution that delivers scalable, resilient, and cloud-native storage for Kubernetes workloads. Built on Ceph and Rook, ODF supports block, file, and object storage within OpenShift, making it an ideal choice for stateful applications like databases, CI/CD systems, AI/ML pipelines, and analytics engines.
🎯 Why Learn DO370?
The DO370: Red Hat OpenShift Data Foundation course is specifically designed for storage administrators, infrastructure architects, and OpenShift professionals who want to:
✅ Deploy ODF on OpenShift clusters using best practices.
✅ Understand the architecture and internal components of Ceph-based storage.
✅ Manage persistent volumes (PVs), storage classes, and dynamic provisioning.
✅ Monitor, scale, and secure Kubernetes storage environments.
✅ Troubleshoot common storage-related issues in production.
🛠️ Key Features of ODF for Enterprise Workloads
1. Unified Storage (Block, File, Object)
Eliminate silos with a single platform that supports diverse workloads.
2. High Availability & Resilience
ODF is designed for fault tolerance and self-healing, ensuring business continuity.
3. Integrated with OpenShift
Full integration with the OpenShift Console, Operators, and CLI for seamless Day 1 and Day 2 operations.
4. Dynamic Provisioning
Simplifies persistent storage allocation, reducing manual intervention.
5. Multi-Cloud & Hybrid Cloud Ready
Store and manage data across on-prem, public cloud, and edge environments.
📘 What You Will Learn in DO370
Installing and configuring ODF in an OpenShift environment.
Creating and managing storage resources using the OpenShift Console and CLI.
Implementing security and encryption for data at rest.
Monitoring ODF health with Prometheus and Grafana.
Scaling the storage cluster to meet growing demands.
🧠 Real-World Use Cases
Databases: PostgreSQL, MySQL, MongoDB with persistent volumes.
CI/CD: Jenkins with persistent pipelines and storage for artifacts.
AI/ML: Store and manage large datasets for training models.
Kafka & Logging: High-throughput storage for real-time data ingestion.
👨🏫 Who Should Enroll?
This course is ideal for:
Storage Administrators
Kubernetes Engineers
DevOps & SRE teams
Enterprise Architects
OpenShift Administrators aiming to become RHCA in Infrastructure or OpenShift
🚀 Takeaway
If you’re serious about building resilient, performant, and scalable storage for your Kubernetes applications, DO370 is the must-have training. With ODF becoming a core component of modern OpenShift deployments, understanding it deeply positions you as a valuable asset in any hybrid cloud team.
🧭 Ready to transform your Kubernetes storage strategy? Enroll in DO370 and master Red Hat OpenShift Data Foundation today with HawkStack Technologies – your trusted Red Hat Certified Training Partner. For more details www.hawkstack.com
0 notes
Text
Unlocking SRE Success: Roles and Responsibilities That Matter
In today’s digitally driven world, ensuring the reliability and performance of applications and systems is more critical than ever. This is where Site Reliability Engineering (SRE) plays a pivotal role. Originally developed by Google, SRE is a modern approach to IT operations that focuses strongly on automation, scalability, and reliability.

But what exactly do SREs do? Let’s explore the key roles and responsibilities of a Site Reliability Engineer and how they drive reliability, performance, and efficiency in modern IT environments.
🔹 What is a Site Reliability Engineer (SRE)?
A Site Reliability Engineer is a professional who applies software engineering principles to system administration and operations tasks. The main goal is to build scalable and highly reliable systems that function smoothly even during high demand or failure scenarios.
🔹 Core SRE Roles
SREs act as a bridge between development and operations teams. Their core responsibilities are usually grouped under these key roles:
1. Reliability Advocate
Ensures high availability and performance of services
Implements Service Level Objectives (SLOs), Service Level Indicators (SLIs), and Service Level Agreements (SLAs)
Identifies and removes reliability bottlenecks
2. Automation Engineer
Automates repetitive manual tasks using tools and scripts
Builds CI/CD pipelines for smoother deployments
Reduces human error and increases deployment speed
3. Monitoring & Observability Expert
Sets up real-time monitoring tools like Prometheus, Grafana, and Datadog
Implements logging, tracing, and alerting systems
Proactively detects issues before they impact users
4. Incident Responder
Handles outages and critical incidents
Leads root cause analysis (RCA) and postmortems
Builds incident playbooks for faster recovery
5. Performance Optimizer
Analyzes system performance metrics
Conducts load and stress testing
Optimizes infrastructure for cost and performance
6. Security and Compliance Enforcer
Implements security best practices in infrastructure
Ensures compliance with industry standards (e.g., ISO, GDPR)
Coordinates with security teams for audits and risk management
7. Capacity Planner
Forecasts traffic and resource needs
Plans for scaling infrastructure ahead of demand
Uses tools for autoscaling and load balancing
🔹 Day-to-Day Responsibilities of an SRE
Here are some common tasks SREs handle daily:
Deploying code with zero downtime
Troubleshooting production issues
Writing automation scripts to streamline operations
Reviewing infrastructure changes
Managing Kubernetes clusters or cloud services (AWS, GCP, Azure)
Performing system upgrades and patches
Running game days or chaos engineering practices to test resilience
🔹 Tools & Technologies Commonly Used by SREs
Monitoring: Prometheus, Grafana, ELK Stack, Datadog
Automation: Terraform, Ansible, Chef, Puppet
CI/CD: Jenkins, GitLab CI, ArgoCD
Containers & Orchestration: Docker, Kubernetes
Cloud Platforms: AWS, Google Cloud, Microsoft Azure
Incident Management: PagerDuty, Opsgenie, VictorOps
🔹 Why SRE Matters for Modern Businesses
Reduces system downtime and increases user satisfaction
Improves deployment speed without compromising reliability
Enables proactive problem solving through observability
Bridges the gap between developers and operations
Drives cost-effective scaling and infrastructure optimization
🔹 Final Thoughts
Site Reliability Engineering roles and responsibilities are more than just monitoring systems—it’s about building a resilient, scalable, and efficient infrastructure that keeps digital services running smoothly. With a blend of coding, systems knowledge, and problem-solving skills, SREs play a crucial role in modern DevOps and cloud-native environments.
📥 Click Here: Site Reliability Engineering certification training program
0 notes
Text
Kubernetes cost visibility is an organizational responsibility. Your teams must rethink how they measure, share, and act on usage data within containerized environments.
Whether you're running production LLMs, supporting internal dev teams, or building multicloud services, improving Kubernetes cost attribution is foundational to scaling responsibly.
The goal isn't just more data. It's making cloud costs legible to every stakeholder, from platform teams to product leads to finance. And that starts by building visibility directly into your infrastructure, not as an afterthought.
Gain total control over multicloud expenses. No surprises, just savings. Discover More
0 notes
Text
Kubernetes Cluster Management at Scale: Challenges and Solutions
As Kubernetes has become the cornerstone of modern cloud-native infrastructure, managing it at scale is a growing challenge for enterprises. While Kubernetes excels in orchestrating containers efficiently, managing multiple clusters across teams, environments, and regions presents a new level of operational complexity.
In this blog, we’ll explore the key challenges of Kubernetes cluster management at scale and offer actionable solutions, tools, and best practices to help engineering teams build scalable, secure, and maintainable Kubernetes environments.
Why Scaling Kubernetes Is Challenging
Kubernetes is designed for scalability—but only when implemented with foresight. As organizations expand from a single cluster to dozens or even hundreds, they encounter several operational hurdles.
Key Challenges:
1. Operational Overhead
Maintaining multiple clusters means managing upgrades, backups, security patches, and resource optimization—multiplied by every environment (dev, staging, prod). Without centralized tooling, this overhead can spiral quickly.
2. Configuration Drift
Cluster configurations often diverge over time, causing inconsistent behavior, deployment errors, or compliance risks. Manual updates make it difficult to maintain consistency.
3. Observability and Monitoring
Standard logging and monitoring solutions often fail to scale with the ephemeral and dynamic nature of containers. Observability becomes noisy and fragmented without standardization.
4. Resource Isolation and Multi-Tenancy
Balancing shared infrastructure with security and performance for different teams or business units is tricky. Kubernetes namespaces alone may not provide sufficient isolation.
5. Security and Policy Enforcement
Enforcing consistent RBAC policies, network segmentation, and compliance rules across multiple clusters can lead to blind spots and misconfigurations.
Best Practices and Scalable Solutions
To manage Kubernetes at scale effectively, enterprises need a layered, automation-driven strategy. Here are the key components:
1. GitOps for Declarative Infrastructure Management
GitOps leverages Git as the source of truth for infrastructure and application deployment. With tools like ArgoCD or Flux, you can:
Apply consistent configurations across clusters.
Automatically detect and rollback configuration drifts.
Audit all changes through Git commit history.
Benefits:
�� Immutable infrastructure
· Easier rollbacks
· Team collaboration and visibility
2. Centralized Cluster Management Platforms
Use centralized control planes to manage the lifecycle of multiple clusters. Popular tools include:
Rancher – Simplified Kubernetes management with RBAC and policy controls.
Red Hat OpenShift – Enterprise-grade PaaS built on Kubernetes.
VMware Tanzu Mission Control – Unified policy and lifecycle management.
Google Anthos / Azure Arc / Amazon EKS Anywhere – Cloud-native solutions with hybrid/multi-cloud support.
Benefits:
· Unified view of all clusters
· Role-based access control (RBAC)
· Policy enforcement at scale
3. Standardization with Helm, Kustomize, and CRDs
Avoid bespoke configurations per cluster. Use templating and overlays:
Helm: Define and deploy repeatable Kubernetes manifests.
Kustomize: Customize raw YAMLs without forking.
Custom Resource Definitions (CRDs): Extend Kubernetes API to include enterprise-specific configurations.
Pro Tip: Store and manage these configurations in Git repositories following GitOps practices.
4. Scalable Observability Stack
Deploy a centralized observability solution to maintain visibility across environments.
Prometheus + Thanos: For multi-cluster metrics aggregation.
Grafana: For dashboards and alerting.
Loki or ELK Stack: For log aggregation.
Jaeger or OpenTelemetry: For tracing and performance monitoring.
Benefits:
· Cluster health transparency
· Proactive issue detection
· Developer fliendly insights
5. Policy-as-Code and Security Automation
Enforce security and compliance policies consistently:
OPA + Gatekeeper: Define and enforce security policies (e.g., restrict container images, enforce labels).
Kyverno: Kubernetes-native policy engine for validation and mutation.
Falco: Real-time runtime security monitoring.
Kube-bench: Run CIS Kubernetes benchmark checks automatically.
Security Tip: Regularly scan cluster and workloads using tools like Trivy, Kube-hunter, or Aqua Security.
6. Autoscaling and Cost Optimization
To avoid resource wastage or service degradation:
Horizontal Pod Autoscaler (HPA) – Auto-scales pods based on metrics.
Vertical Pod Autoscaler (VPA) – Adjusts container resources.
Cluster Autoscaler – Scales nodes up/down based on workload.
Karpenter (AWS) – Next-gen open-source autoscaler with rapid provisioning.
Conclusion
As Kubernetes adoption matures, organizations must rethink their management strategy to accommodate growth, reliability, and governance. The transition from a handful of clusters to enterprise-wide Kubernetes infrastructure requires automation, observability, and strong policy enforcement.
By adopting GitOps, centralized control planes, standardized templates, and automated policy tools, enterprises can achieve Kubernetes cluster management at scale—without compromising on security, reliability, or developer velocity.
0 notes
Text
7 Skills You'll Build in Top AI Certification Courses
You're considering AI certification courses to advance your career, but what exactly will you learn? These programs pack tremendous value by teaching practical skills that translate directly to real-world applications. Let's explore the seven key capabilities you'll develop through quality AI certification courses.
1. Machine Learning Fundamentals
Your journey begins with understanding how machines learn from data. You'll master supervised and unsupervised learning techniques, working with algorithms like linear regression, decision trees, and clustering methods. These foundational concepts form the backbone of AI systems, and you'll practice implementing them through hands-on projects that simulate actual business scenarios.
2. Deep Learning and Neural Networks
Building on machine learning basics, you will dive into neural networks and deep learning architectures. You will construct and train models using frameworks like TensorFlow and PyTorch, understanding how layers, activation functions, and backpropagation work together. Through AI certification courses, you will gain confidence working with convolutional neural networks for image processing and recurrent neural networks for sequential data.
3. Natural Language Processing (NLP)
You will develop skills to make computers understand and generate human language. This includes text preprocessing, sentiment analysis, named entity recognition, and building chatbots. You'll work with transformer models and learn how technologies like GPT and BERT revolutionize language understanding. These NLP skills are increasingly valuable as businesses seek to automate customer service and content analysis.
4. Data Preprocessing and Feature Engineering
Raw data rarely comes ready for AI models. You'll learn to clean, transform, and prepare datasets effectively. This includes handling missing values, encoding categorical variables, scaling features, and creating new meaningful features from existing data. You'll understand why data scientists spend 80% of their time on data preparation and master techniques to streamline this crucial process.
5. Model Evaluation and Optimization
Creating an AI model is just the beginning. You'll learn to evaluate model performance using metrics like accuracy, precision, recall, and F1-score. You'll master techniques for preventing overfitting, including cross-validation, regularization, and dropout. AI certification courses teach you to fine-tune hyperparameters and optimize models for production environments, ensuring your solutions perform reliably in real-world conditions.
6. Ethical AI and Responsible Development
You'll explore the critical aspects of AI ethics, including bias detection and mitigation, fairness in algorithms, and privacy considerations. You'll learn frameworks for responsible AI development and understand regulatory requirements like GDPR's right to explanation. This knowledge positions you as a thoughtful practitioner who can navigate the complex ethical landscape of artificial intelligence.
7. AI Deployment and MLOps
Finally, you'll bridge the gap between development and production. You'll learn to deploy models using cloud platforms, create APIs for model serving, and implement monitoring systems to track performance over time. You'll understand containerization with Docker, orchestration with Kubernetes, and continuous integration/continuous deployment (CI/CD) pipelines for machine learning projects.
Conclusion
These seven skills represent a comprehensive toolkit for AI practitioners. The best AI certification courses combine theoretical knowledge with practical application, ensuring you can immediately apply what you've learned.
As you progress through your chosen program, you'll notice how these skills interconnect – from data preprocessing through model development to ethical deployment. This holistic understanding distinguishes certified AI professionals and provides the foundation for a successful career in artificial intelligence.
For more information, visit: https://www.ascendientlearning.com/it-training/vmware
0 notes
Text

Comparison of Ubuntu, Debian, and Yocto for IIoT and Edge Computing
In industrial IoT (IIoT) and edge computing scenarios, Ubuntu, Debian, and Yocto Project each have unique advantages. Below is a detailed comparison and recommendations for these three systems:
1. Ubuntu (ARM)
Advantages
Ready-to-use: Provides official ARM images (e.g., Ubuntu Server 22.04 LTS) supporting hardware like Raspberry Pi and NVIDIA Jetson, requiring no complex configuration.
Cloud-native support: Built-in tools like MicroK8s, Docker, and Kubernetes, ideal for edge-cloud collaboration.
Long-term support (LTS): 5 years of security updates, meeting industrial stability requirements.
Rich software ecosystem: Access to AI/ML tools (e.g., TensorFlow Lite) and databases (e.g., PostgreSQL ARM-optimized) via APT and Snap Store.
Use Cases
Rapid prototyping: Quick deployment of Python/Node.js applications on edge gateways.
AI edge inference: Running computer vision models (e.g., ROS 2 + Ubuntu) on Jetson devices.
Lightweight K8s clusters: Edge nodes managed by MicroK8s.
Limitations
Higher resource usage (minimum ~512MB RAM), unsuitable for ultra-low-power devices.
2. Debian (ARM)
Advantages
Exceptional stability: Packages undergo rigorous testing, ideal for 24/7 industrial operation.
Lightweight: Minimal installation requires only 128MB RAM; GUI-free versions available.
Long-term support: Up to 10+ years of security updates via Debian LTS (with commercial support).
Hardware compatibility: Supports older or niche ARM chips (e.g., TI Sitara series).
Use Cases
Industrial controllers: PLCs, HMIs, and other devices requiring deterministic responses.
Network edge devices: Firewalls, protocol gateways (e.g., Modbus-to-MQTT).
Critical systems (medical/transport): Compliance with IEC 62304/DO-178C certifications.
Limitations
Older software versions (e.g., default GCC version); newer features require backports.
3. Yocto Project
Advantages
Full customization: Tailor everything from kernel to user space, generating minimal images (<50MB possible).
Real-time extensions: Supports Xenomai/Preempt-RT patches for μs-level latency.
Cross-platform portability: Single recipe set adapts to multiple hardware platforms (e.g., NXP i.MX6 → i.MX8).
Security design: Built-in industrial-grade features like SELinux and dm-verity.
Use Cases
Custom industrial devices: Requires specific kernel configurations or proprietary drivers (e.g., CAN-FD bus support).
High real-time systems: Robotic motion control, CNC machines.
Resource-constrained terminals: Sensor nodes running lightweight stacks (e.g., Zephyr+FreeRTOS hybrid deployment).
Limitations
Steep learning curve (BitBake syntax required); longer development cycles.
4. Comparison Summary
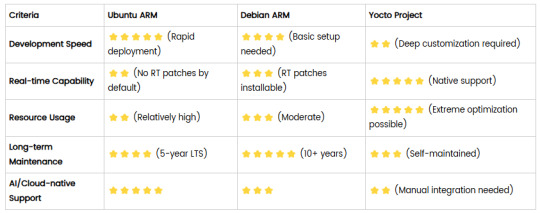
5. Selection Recommendations
Choose Ubuntu ARM: For rapid deployment of edge AI applications (e.g., vision detection on Jetson) or deep integration with public clouds (e.g., AWS IoT Greengrass).
Choose Debian ARM: For mission-critical industrial equipment (e.g., substation monitoring) where stability outweighs feature novelty.
Choose Yocto Project: For custom hardware development (e.g., proprietary industrial boards) or strict real-time/safety certification (e.g., ISO 13849) requirements.
6. Hybrid Architecture Example
Smart factory edge node:
Real-time control layer: RTOS built with Yocto (controlling robotic arms)
Data processing layer: Debian running OPC UA servers
Cloud connectivity layer: Ubuntu Server managing K8s edge clusters
Combining these systems based on specific needs can maximize the efficiency of IIoT edge computing.
0 notes
Text
North America Cloud Security Market Size, Revenue, End Users And Forecast Till 2028
The North America cloud security market is expected to grow from US$ 17,168.84 million in 2022 to US$ 42,944.12 million by 2028. It is estimated to grow at a CAGR of 16.5% from 2022 to 2028.
Surging Managed Container Services is fueling the growth of North America cloud security market
The use of containers in the IT sector has increased exponentially in recent years. A large number of businesses use managed or native Kubernetes orchestration; the well-known managed cloud services used by these enterprises include Amazon Elastic Container Service for Kubernetes, Azure Kubernetes Service, and Google Kubernetes Engine. These managed service platforms have simplified the management, deployment, and scaling of use cases. With the increasing use of containers, enterprises need to ensure that the right security solutions are in place to prevent security issues. For instance, the pods of Kubernetes clusters might receive traffic from any source, raising security issues throughout the company. To prevent attacks on vulnerable networks, enterprises implement network policies for their managed Kubernetes services. Thus, the adoption of managed container services is bolstering the growth of the North America cloud security market.
Grab PDF To Know More @ https://www.businessmarketinsights.com/sample/BMIRE00028041
North America Cloud Security Market Overview
The US, Canada, and Mexico are among the major economies in North America. With higher penetration of large and mid-sized companies, there is a growing frequency of cyber-attacks and the increasing number of hosted servers. Moreover, growing number of cyber crime and the production of new cyber attacks, as well as surge in usage of cloud-based solutions are all becoming major factor propelling the adoption of cloud security solutions and services. In addition, to enhance IT infrastructure and leverage the benefits of technologies such as AI and ML, there is a growing adoption of cloud security and therefore, becoming major factors contributing towards the market growth. Furthermore, there is huge growth potential in industries such as energy, manufacturing, and utilities, as they are continuously migrating towards digital-transformed methods of operations and focusing on data protection measures. Major companies such as Microsoft, Google, Cisco, McAfee, Palo Alto Networks, FireEye, and Fortinet and start-ups in the North America cloud security market provide cloud security solutions and services.
North America Cloud Security Strategic Insights
Strategic insights for the North America Cloud Security provides data-driven analysis of the industry landscape, including current trends, key players, and regional nuances. These insights offer actionable recommendations, enabling readers to differentiate themselves from competitors by identifying untapped segments or developing unique value propositions. Leveraging data analytics, these insights help industry players anticipate the market shifts, whether investors, manufacturers, or other stakeholders. A future-oriented perspective is essential, helping stakeholders anticipate market shifts and position themselves for long-term success in this dynamic region. Ultimately, effective strategic insights empower readers to make informed decisions that drive profitability and achieve their business objectives within the market.
Market leaders and key company profiles
Amazon Web Services
Microsoft Corp
International Business Machines Corp
Oracle Corp
Trend Micro Incorporated
VMware, Inc.
Palo Alto Networks, Inc.
Cisco Systems Inc
Check Point Software Technologies Ltd.
Google LLC
North America Cloud Security Regional Insights
The geographic scope of the North America Cloud Security refers to the specific areas in which a business operates and competes. Understanding local distinctions, such as diverse consumer preferences (e.g., demand for specific plug types or battery backup durations), varying economic conditions, and regulatory environments, is crucial for tailoring strategies to specific markets. Businesses can expand their reach by identifying underserved areas or adapting their offerings to meet local demands. A clear market focus allows for more effective resource allocation, targeted marketing campaigns, and better positioning against local competitors, ultimately driving growth in those targeted areas.
North America Cloud Security Market Segmentation
The North America cloud security market is segmented into service model, deployment model, enterprise size, solution type, industry vertical, and country. Based on service model, the North America cloud security market is segmented into infrastructure as a service (IaaS), platform as a service (PaaS) and software as a service (SaaS). The software-as-a-service (SaaS)segment registered the largest market share in 2022.
Based on deployment model, the North America cloud security market is segmented into public cloud, private cloud, and hybrid cloud. The public cloud segment registered the largest market share in 2022.Based on enterprise size, the North America cloud security market is segmented into small and medium-sized enterprises (SMEs), and large enterprises. The large enterprises segment registered a larger market share in 2022.
About Us:
Business Market Insights is a market research platform that provides subscription service for industry and company reports. Our research team has extensive professional expertise in domains such as Electronics & Semiconductor; Aerospace & Defence; Automotive & Transportation; Energy & Power; Healthcare; Manufacturing & Construction; Food & Beverages; Chemicals & Materials; and Technology, Media, & Telecommunications.
0 notes
Text
Trending Cloud Services to Consider in 2025
The cloud services landscape is evolving rapidly, offering businesses innovative solutions to enhance productivity and efficiency. Here are some trending cloud services that organizations should consider incorporating into their strategies this year.
For those looking to enhance their skills, Cloud Computing Course With Placement programs offer comprehensive education and job placement assistance, making it easier to master this tool and advance your career.

1. Serverless Computing
AWS Lambda
Serverless computing allows developers to run code without provisioning or managing servers. AWS Lambda is leading the way, enabling businesses to focus on application logic rather than infrastructure management. This approach reduces costs and accelerates deployment times.
Azure Functions
Similar to AWS Lambda, Azure Functions offers event-driven serverless computing. It integrates seamlessly with other Azure services, making it ideal for businesses utilizing the Microsoft ecosystem.
2. Multi-Cloud Solutions
IBM Multicloud Management
As more organizations adopt multi-cloud strategies, services like IBM Multicloud Management facilitate the management of applications across multiple cloud environments. This flexibility helps businesses avoid vendor lock-in and optimize costs.
Google Anthos
Google Anthos enables organizations to manage applications across on-premises and cloud environments. Its ability to run Kubernetes clusters consistently across platforms makes it a powerful tool for hybrid cloud strategies.
3. AI and Machine Learning Services
Azure Machine Learning
With the growing importance of data-driven decision-making, Azure Machine Learning provides robust tools for building, training, and deploying machine learning models. Its user-friendly interface allows businesses to leverage AI without extensive technical expertise.
Google AI Platform
Google’s AI Platform supports businesses in developing their AI applications. From data preparation to model deployment, it offers comprehensive solutions tailored to various industries.
It’s simpler to master this tool and progress your profession with the help of Best Online Training & Placement programs, which provide thorough instruction and job placement support to anyone seeking to improve their talents.

4. Cloud Security Solutions
Palo Alto Networks Prisma Cloud
As cyber threats evolve, robust cloud security solutions are essential. Prisma Cloud provides comprehensive security for cloud-native applications and protects against vulnerabilities across multi-cloud environments.
Cloudflare Zero Trust
Cloudflare’s Zero Trust security model ensures that access is granted based on user identity and device security rather than network location. This approach enhances security in today’s remote work environment.
5. Collaborative Tools
Microsoft Teams
As remote work continues to be a norm, Microsoft Teams has emerged as a leading collaborative platform. Its integration with Microsoft 365 allows for seamless communication and collaboration among teams.
Slack
Slack remains a favorite for team communication, offering various integrations that enhance productivity. Its user-friendly interface and ability to streamline workflows make it essential for modern businesses.
6. Data Analytics Platforms
Tableau
Tableau is a powerful analytics platform that allows businesses to visualize data and gain insights. Its cloud capabilities enable teams to collaborate on data analysis in real-time.
Looker
Part of Google Cloud, Looker offers robust data analytics and business intelligence solutions. Its ability to integrate with various data sources makes it ideal for businesses looking to derive actionable insights from their data.
Conclusion
In 2025, these trending cloud services are set to redefine how businesses operate and innovate. By adopting serverless computing, multi-cloud solutions, AI services, and enhanced security measures, organizations can stay competitive in an ever-evolving landscape. Embracing these technologies will not only streamline operations but also empower businesses to make data-driven decisions for future growth. Stay ahead of the curve by considering these cloud services as you plan for the year ahead!
0 notes
Text
Why GPU PaaS Is Incomplete Without Infrastructure Orchestration and Tenant Isolation
GPU Platform-as-a-Service (PaaS) is gaining popularity as a way to simplify AI workload execution — offering users a friendly interface to submit training, fine-tuning, and inferencing jobs. But under the hood, many GPU PaaS solutions lack deep integration with infrastructure orchestration, making them inadequate for secure, scalable multi-tenancy.
If you’re a Neocloud, sovereign GPU cloud, or an enterprise private GPU cloud with strict compliance requirements, you are probably looking at offering job scheduling of Model-as-a-Service to your tenants/users. An easy approach is to have a global Kubernetes cluster that is shared across multiple tenants. The problem with this approach is poor security as the underlying OS kernel, CPU, GPU, network, and storage resources are shared by all users without any isolation. Case-in-point, in September 2024, Wiz discovered a critical GPU container and Kubernetes vulnerability that affected over 35% of environments. Thus, doing just Kubernetes namespace or vCluster isolation is not safe.
You need to provision bare metal, configure network and fabric isolation, allocate high-performance storage, and enforce tenant-level security boundaries — all automated, dynamic, and policy-driven.
In short: PaaS is not enough. True GPUaaS begins with infrastructure orchestration.
The Pitfall of PaaS-Only GPU Platforms
Many AI platforms stop at providing:
A web UI for job submission
A catalog of AI/ML frameworks or models
Basic GPU scheduling on Kubernetes
What they don’t offer:
Control over how GPU nodes are provisioned (bare metal vs. VM)
Enforcement of north-south and east-west isolation per tenant
Configuration and Management of Infiniband, RoCE or Spectrum-X fabric
Lifecycle Management and Isolation of External Parallel Storage like DDN, VAST, or WEKA
Per-Tenant Quota, Observability, RBAC, and Policy Governance
Without these, your GPU PaaS is just a thin UI on top of a complex, insecure, and hard-to-scale backend.
What Full-Stack Orchestration Looks Like
To build a robust AI cloud platform — whether sovereign, Neocloud, or enterprise — the orchestration layer must go deeper.
How aarna.ml GPU CMS Solves This Problem
aarna.ml GPU CMS is built from the ground up to be infrastructure-aware and multi-tenant-native. It includes all the PaaS features you would expect, but goes beyond PaaS to offer:
BMaaS and VMaaS orchestration: Automated provisioning of GPU bare metal or VM pools for different tenants.
Tenant-level network isolation: Support for VXLAN, VRF, and fabric segmentation across Infiniband, Ethernet, and Spectrum-X.
Storage orchestration: Seamless integration with DDN, VAST, WEKA with mount point creation and tenant quota enforcement.
Full-stack observability: Usage stats, logs, and billing metrics per tenant, per GPU, per model.
All of this is wrapped with a PaaS layer that supports Ray, SLURM, KAI, Run:AI, and more, giving users flexibility while keeping cloud providers in control of their infrastructure and policies.
Why This Matters for AI Cloud Providers
If you're offering GPUaaS or PaaS without infrastructure orchestration:
You're exposing tenants to noisy neighbors or shared vulnerabilities
You're missing critical capabilities like multi-region scaling or LLM isolation
You’ll be unable to meet compliance, governance, and SemiAnalysis ClusterMax1 grade maturity
With aarna.ml GPU CMS, you deliver not just a PaaS, but a complete, secure, and sovereign-ready GPU cloud platform.
Conclusion
GPU PaaS needs to be a complete stack with IaaS — it’s not just a model serving interface!
To deliver scalable, secure, multi-tenant AI services, your GPU PaaS stack must be expanded to a full GPU cloud management software stack to include automated provisioning of compute, network, and storage, along with tenant-aware policy and observability controls.
Only then is your GPU PaaS truly production-grade.
Only then are you ready for sovereign, enterprise, and commercial AI cloud success.
To see a live demo or for a free trial, contact aarna.ml
This post orginally posted on https://www.aarna.ml/
0 notes
Text
Master Multicluster Kubernetes with DO480: Red Hat OpenShift Platform Plus Training
In today’s enterprise landscape, managing multiple Kubernetes clusters across hybrid or multi-cloud environments is no longer optional — it’s essential. Whether you’re scaling applications globally, ensuring high availability, or meeting regulatory compliance, multicluster management is the key to consistent, secure, and efficient operations.
That’s where Red Hat OpenShift Platform Plus and the DO480 course come in.
🔍 What is DO480?
DO480: Multicluster Management with Red Hat OpenShift Platform Plus is an advanced, hands-on course designed for platform engineers, cluster admins, and DevOps teams. It teaches how to manage and secure Kubernetes clusters at scale using Red Hat’s enterprise-grade tools like:
Red Hat Advanced Cluster Management (ACM) for Kubernetes
Red Hat Advanced Cluster Security (ACS) for Kubernetes
OpenShift GitOps and Pipelines
Multi-cluster observability
📌 Why Should You Learn DO480?
As enterprises adopt hybrid and multi-cloud strategies, the complexity of managing Kubernetes clusters increases. DO480 equips you with the skills to:
✅ Deploy, govern, and automate multiple clusters ✅ Apply security policies consistently across all clusters ✅ Gain centralized visibility into workloads, security posture, and compliance ✅ Use GitOps workflows to streamline multicluster deployments ✅ Automate Day-2 operations like backup, disaster recovery, and patch management
👨💻 What Will You Learn?
The DO480 course covers key topics, including:
Installing and configuring Red Hat ACM
Creating and managing cluster sets, placement rules, and application lifecycle
Using OpenShift GitOps for declarative deployment
Integrating ACS for runtime and build-time security
Enforcing policies and handling compliance at scale
All these are practiced through hands-on labs in a real-world environment.
🎯 Who Should Attend?
This course is ideal for:
Platform engineers managing multiple clusters
DevOps professionals building GitOps-based automation
Security teams enforcing policies across cloud-native environments
Anyone aiming to become a Red Hat Certified Specialist in Multicluster Management
🔒 Certification Path
Completing DO480 helps prepare you for the Red Hat Certified Specialist in Multicluster Management exam — a valuable addition to your Red Hat Certified Architect (RHCA) journey.
🚀 Ready to Master Multicluster Kubernetes? Enroll in DO480 – Multicluster Management with Red Hat OpenShift Platform Plus and gain the skills needed to control, secure, and scale your OpenShift environment like a pro.
🔗 Talk to HawkStack today to schedule your corporate or individual training. 🌐 www.hawkstack.com
0 notes
Text
SRE Roadmap: Your Complete Guide to Becoming a Site Reliability Engineer in 2025
In today’s rapidly evolving tech landscape, Site Reliability Engineering (SRE) has become one of the most in-demand roles across industries. As organizations scale and systems become more complex, the need for professionals who can bridge the gap between development and operations is critical. If you’re looking to start or transition into a career in SRE, this comprehensive SRE roadmap will guide you step by step in 2025.

Why Follow an SRE Roadmap?
The field of SRE is broad, encompassing skills from DevOps, software engineering, cloud computing, and system administration. A well-structured SRE roadmap helps you:
Understand what skills are essential at each stage.
Avoid wasting time on non-relevant tools or technologies.
Stay up to date with industry standards and best practices.
Get job-ready with the right certifications and hands-on experience.
SRE Roadmap: Step-by-Step Guide
🔹 Phase 1: Foundation (Beginner Level)
Key Focus Areas:
Linux Fundamentals – Learn the command line, shell scripting, and process management.
Networking Basics – Understand DNS, HTTP/HTTPS, TCP/IP, firewalls, and load balancing.
Version Control – Master Git and GitHub for collaboration.
Programming Languages – Start with Python or Go for scripting and automation tasks.
Tools to Learn:
Git
Visual Studio Code
Postman (for APIs)
Recommended Resources:
"The Linux Command Line" by William Shotts
GitHub Learning Lab
🔹 Phase 2: Core SRE Skills (Intermediate Level)
Key Focus Areas:
Configuration Management – Learn tools like Ansible, Puppet, or Chef.
Containers & Orchestration – Understand Docker and Kubernetes.
CI/CD Pipelines – Use Jenkins, GitLab CI, or GitHub Actions.
Monitoring & Logging – Get familiar with Prometheus, Grafana, ELK Stack, or Datadog.
Cloud Platforms – Gain hands-on experience with AWS, GCP, or Azure.
Certifications to Consider:
AWS Certified SysOps Administrator
Certified Kubernetes Administrator (CKA)
Google Cloud Professional SRE
🔹 Phase 3: Advanced Practices (Expert Level)
Key Focus Areas:
Site Reliability Principles – Learn about SLIs, SLOs, SLAs, and Error Budgets.
Incident Management – Practice runbooks, on-call rotations, and postmortems.
Infrastructure as Code (IaC) – Master Terraform or Pulumi.
Scalability and Resilience Engineering – Understand fault tolerance, redundancy, and chaos engineering.
Tools to Explore:
Terraform
Chaos Monkey (for chaos testing)
PagerDuty / OpsGenie
Real-World Experience Matters
While theory is important, hands-on experience is what truly sets you apart. Here are some tips:
Set up your own Kubernetes cluster.
Contribute to open-source SRE tools.
Create a portfolio of automation scripts and dashboards.
Simulate incidents to test your monitoring setup.
Final Thoughts
Following this SRE roadmap will provide you with a clear and structured path to break into or grow in the field of Site Reliability Engineering. With the right mix of foundational skills, real-world projects, and continuous learning, you'll be ready to take on the challenges of building reliable, scalable systems.
Ready to Get Certified?
Take your next step with our SRE Certification Course and fast-track your career with expert training, real-world projects, and globally recognized credentials.
0 notes