#labelbox
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
#machine learning#Data Labeling#cogito ai#ai data annotation#V7 Darwin#Labelbox#Scale AI#Dataloop#SuperAnnotate
0 notes
Text
The Best Labelbox Alternatives for Data Labeling in 2025
Whether you're training machine learning models, building AI applications, or working on computer vision projects, effective data labeling is critical for success. Labelbox has been a go-to platform for enterprises and teams looking to manage their data labeling workflows efficiently. However, it may not suit everyone’s needs due to high pricing, lack of certain features, or compatibility issues with specific use cases.
If you're exploring alternatives to Labelbox, you're in the right place. This blog dives into the top Labelbox alternatives, highlights the key features to consider when choosing a data labeling platform, and provides insights into which option might work best for your unique requirements.
What Makes a Good Data Labeling Platform?
Before we explore alternatives, let's break down the features that define a reliable data labeling solution. The right platform should help optimize your labeling workflow, save time, and ensure precision in annotations. Here are a few key features you should keep in mind:
Scalability: Can the platform handle the size and complexity of your dataset, whether you're labeling a few hundred samples or millions of images?
Collaboration Tools: Does it offer features that improve collaboration among team members, such as user roles, permissions, or integration options?
Annotation Capabilities: Look for robust annotation tools that support bounding boxes, polygons, keypoints, and semantic segmentation for different data types.
AI-Assisted Labeling: Platforms with auto-labeling capabilities powered by AI can significantly speed up the labeling process while maintaining accuracy.
Integration Flexibility: Can the platform seamlessly integrate with your existing workflows, such as TensorFlow, PyTorch, or custom ML pipelines?
Affordability: Pricing should align with your budget while delivering a strong return on investment.
With these considerations in mind, let's explore the best alternatives to Labelbox, including their strengths and weaknesses.
Top Labelbox Alternatives
1. Macgence
Strengths:
Offers a highly customizable end-to-end solution that caters to specific workflows for data scientists and machine learning engineers.
AI-powered auto-labeling to accelerate labeling tasks.
Proven expertise in handling diverse data types, including images, text, and video annotations.
Seamless integration with popular machine learning frameworks like TensorFlow and PyTorch.
Known for its attention to data security and adherence to compliance standards.
Weaknesses:
May require time for onboarding due to its vast range of features.
Limited online community documentation compared to Labelbox.
Ideal for:
Organizations that value flexibility in their workflows and need an AI-driven platform to handle large-scale, complex datasets efficiently.
2. Supervisely
Strengths:
Strong collaboration tools, making it easy to assign tasks and monitor progress across teams.
Extensive support for complex computer vision projects, including 3D annotation.
A free plan that’s feature-rich enough for small-scale projects.
Intuitive user interface with drag-and-drop functionality for ease of use.
Weaknesses:
Limited scalability for larger datasets unless opting for the higher-tier plans.
Auto-labeling tools are slightly less advanced compared to other platforms.
Ideal for:
Startups and research teams looking for a low-cost option with modern annotation tools and collaboration features.
3. Amazon SageMaker Ground Truth
Strengths:
Fully managed service by AWS, allowing seamless integration with Amazon's cloud ecosystem.
Uses machine learning to create accurate annotations with less manual effort.
Pay-as-you-go pricing, making it cost-effective for teams already on AWS.
Access to a large workforce for outsourcing labeling tasks.
Weaknesses:
Requires expertise in AWS to set up and configure workflows.
Limited to AWS ecosystem, which might pose constraints for non-AWS users.
Ideal for:
Teams deeply embedded in the AWS ecosystem that want an AI-powered labeling workflow with access to a scalable workforce.
4. Appen
Strengths:
Combines advanced annotation tools with a global workforce for large-scale projects.
Offers unmatched accuracy and quality assurance with human-in-the-loop workflows.
Highly customizable solutions tailored to specific enterprise needs.
Weaknesses:
Can be expensive, particularly for smaller organizations or individual users.
Requires external support for integration into custom workflows.
Ideal for:
Enterprises with complex projects that require high accuracy and precision in data labeling.
Use Case Scenarios: Which Platform Fits Best?
For startups with smaller budgets and less complex projects, Supervisely offers an affordable and intuitive entry point.
For enterprises requiring precise accuracy on large-scale datasets, Appen delivers unmatched quality at a premium.
If you're heavily integrated with AWS, SageMaker Ground Truth is a practical, cost-effective choice for your labeling needs.
For tailored workflows and cutting-edge AI-powered tools, Macgence stands out as the most flexible platform for diverse projects.
Finding the Best Labelbox Alternative for Your Needs
Choosing the right data labeling platform depends on your project size, budget, and technical requirements. Start by evaluating your specific use cases—whether you prioritize cost efficiency, advanced AI tools, or integration capabilities.
For those who require a customizable and AI-driven data labeling solution, Macgence emerges as a strong contender to Labelbox, delivering robust capabilities with high scalability. No matter which platform you choose, investing in the right tools will empower your team and set the foundation for successful machine learning outcomes.
Source: - https://technologyzon.com/blogs/436/The-Best-Labelbox-Alternatives-for-Data-Labeling-in-2025
0 notes
Text

2023.08.31
i have no idea what i'm doing!
learning computer vision concepts on your own is overwhelming, and it's even more overwhelming to figure out how to apply those concepts to train a model and prepare your own data from scratch.
context: the public university i go to expects the students to self-study topics like AI, machine learning, and data science, without the professors teaching anything TT
i am losing my mind
based on what i've watched on youtube and understood from articles i've read, i think i have to do the following:
data collection (in my case, images)
data annotation (to label the features)
image augmentation (to increase the diversity of my dataset)
image manipulation (to normalize the images in my dataset)
split the training, validation, and test sets
choose a model for object detection (YOLOv4?)
training the model using my custom dataset
evaluate the trained model's performance
so far, i've collected enough images to start annotation. i might use labelbox for that. i'm still not sure if i'm doing things right 🥹
if anyone has any tips for me or if you can suggest references (textbooks or articles) that i can use, that would be very helpful!
56 notes
·
View notes
Text
Techmeme: Scale AI's rivals like Snorkel AI Labelbox and Turing report rising interest from clients concerned about Scale's independence after Meta's $14.3B investment (Bloomberg)
Bloomberg: Scale AI's rivals like Snorkel AI, Labelbox, and Turing report rising interest from clients concerned about Scale's independence after Meta's $14.3B investment — Alex Ratner was trying to get in a few hours of work after putting his kids to bed when news broke that Meta Platforms Inc. planned … June 18, 2025 at 10:45PM
0 notes
Text
Title: Image Annotation Services Explained: Tools, Techniques & Use Cases
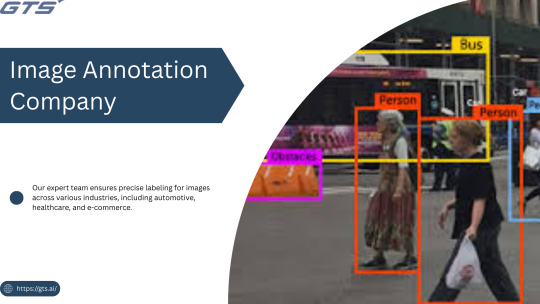
Introduction
In the fast-paced realm of artificial intelligence, Image Annotation Company serve as the foundation for effective computer vision models. Whether you are creating a self-driving vehicle, an AI-driven medical diagnostic application, or a retail analytics solution, the availability of high-quality annotated images is crucial for training precise and dependable machine learning models. But what precisely are image annotation services, how do they function, and what tools and methodologies are utilized? Let us explore this in detail.
What Is Image Annotation?
Image annotation refers to the practice of labeling or tagging images to facilitate the training of machine learning and deep learning models. This process includes the identification of objects, boundaries, and features within images, enabling AI systems to learn to recognize these elements in real-world applications. Typically, this task is carried out by specialized image annotation firms that employ a combination of manual and automated tools to guarantee precision, consistency, and scalability.
Common Image Annotation Techniques
The appropriate annotation method is contingent upon the specific requirements, complexity, and nature of the data involved in your project. Among the most prevalent techniques are:
Bounding Boxes:
Utilized for identifying and localizing objects by encasing them in rectangular boxes, this method is frequently applied in object detection for autonomous vehicles and security systems.
Polygon Annotation:
Best suited for objects with irregular shapes, such as trees, buildings, or road signs, this technique allows for precise delineation of object edges, which is essential for detailed recognition tasks.
Semantic Segmentation:
This approach assigns a label to every pixel in an image according to the object class, commonly employed in medical imaging, robotics, and augmented/virtual reality environments.
Instance Segmentation:
An advancement over semantic segmentation, this method distinguishes between individual objects of the same class, such as recognizing multiple individuals in a crowd.
Keypoint Annotation:
This technique involves marking specific points on objects and is often used in facial recognition, human pose estimation, and gesture tracking.
3D Cuboids:
This method enhances depth perception in annotation by creating three-dimensional representations, which is vital for applications like autonomous navigation and augmented reality.
Popular Image Annotation Tools
Image annotation can be executed utilizing a diverse array of platforms and tools. Notable examples include:
LabelImg: An open-source tool designed for bounding box annotations,
CVAT: A web-based application created by Intel for intricate tasks such as segmentation and tracking,
SuperAnnotate: A robust tool that merges annotation and collaboration functionalities,
Labelbox: A comprehensive platform featuring AI-assisted labeling, data management, and analytics,
VGG Image Annotator (VIA): A lightweight tool developed by Oxford for efficient annotations.
Prominent annotation service providers like GTS.AI frequently employ a blend of proprietary tools and enterprise solutions, seamlessly integrated with quality assurance workflows to fulfill client-specific needs.
Real-World Use Cases of Image Annotation
Image annotation services play a vital role in various sectors, including:
Autonomous Vehicles
Object detection for identifying pedestrians, vehicles, traffic signs, and road markings.
Lane detection and semantic segmentation to facilitate real-time navigation.
Healthcare
Annotating medical images such as X-rays and MRIs to identify tumors, fractures, or other abnormalities.
Training diagnostic tools to enhance early disease detection.
Retail and E-commerce:
Implementing product identification and classification for effective inventory management.
Monitoring customer behavior through in-store camera analytics.
Agriculture:
Assessing crop health, detecting pests, and identifying weeds using drone imagery.
Forecasting yield and optimizing resource allocation.
Geospatial Intelligence:
Classifying land use and mapping infrastructure.
Utilizing annotated satellite imagery for disaster response.
Why Work with a Professional Image Annotation Company?
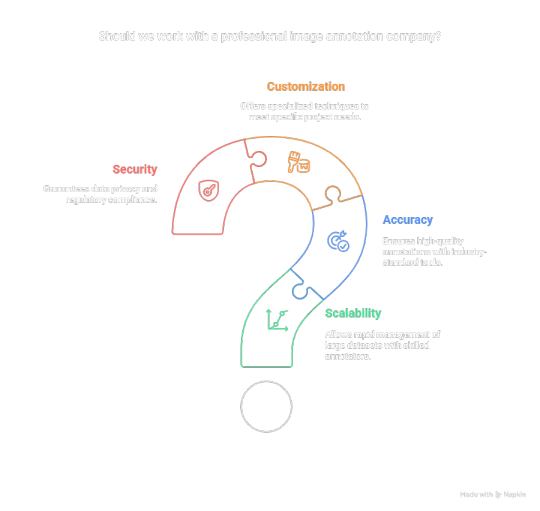
Although in-house annotation may initially appear feasible, expanding it necessitates significant time, resources, and a comprehensive quality assurance process. This is the reason businesses collaborate with providers such as GTS.AI:
Scalability : Allows for the rapid management of extensive datasets through skilled annotators;
Accuracy : Is ensured with industry-standard tools and quality assurance measures;
Customization : Coffers specialized annotation techniques to meet specific project objectives; and
Security : Guarantees adherence to data privacy regulations for sensitive data.
Final Thoughts
With the expansion of AI and computer vision applications, the necessity for high-quality annotated data has become increasingly vital. Image annotation services have evolved from being merely supportive functions to becoming strategic assets essential for developing dependable AI systems. If you aim to enhance your AI projects through professional data labeling, consider Globose Technology Solution .AI’s Image and Video Annotation Services to discover how they can effectively assist you in achieving your objectives with accuracy, efficiency, and scalability.
0 notes
Text
How Data Annotation Tools Are Paving the Way for Advanced AI and Autonomous Systems
The global data annotation tools market size was estimated at USD 1.02 billion in 2023 and is anticipated to grow at a CAGR of 26.3% from 2024 to 2030. The growth is majorly driven by the increasing adoption of image data annotation tools in the automotive, retail, and healthcare sectors. The data annotation tools enable users to enhance the value of data by adding attribute tags to it or labeling it. The key benefit of using annotation tools is that the combination of data attributes enables users to manage the data definition at a single location and eliminates the need to rewrite similar rules in multiple places.
The rise of big data and a surge in the number of large datasets are likely to necessitate the use of artificial intelligence technologies in the field of data annotations. The data annotation industry is also expected to have benefited from the rising demands for improvements in machine learning as well as in the rising investment in advanced autonomous driving technology.
Technologies such as the Internet of Things (IoT), Machine Learning (ML), robotics, advanced predictive analytics, and Artificial Intelligence (AI) generate massive data. With changing technologies, data efficiency proves to be essential for creating new business innovations, infrastructure, and new economics. These factors have significantly contributed to the growth of the industry. Owing to the rising potential of growth in data annotation, companies developing AI-enabled healthcare applications are collaborating with data annotation companies to provide the required data sets that can assist them in enhancing their machine learning and deep learning capabilities.
For instance, in November 2022, Medcase, a developer of healthcare AI solutions, and NTT DATA, formalized a legally binding agreement. Under this partnership, the two companies announced their collaboration to offer data discovery and enrichment solutions for medical imaging. Through this partnership, customers of Medcase will gain access to NTT DATA's Advocate AI services. This access enables innovators to obtain patient studies, including medical imaging, for their projects.
However, the inaccuracy of data annotation tools acts as a restraint to the growth of the market. For instance, a given image may have low resolution and include multiple objects, making it difficult to label. The primary challenge faced by the market is issues related to inaccuracy in the quality of data labeled. In some cases, the data labeled manually may contain erroneous labeling and the time to detect such erroneous labels may vary, which further adds to the cost of the entire annotation process. However, with the development of sophisticated algorithms, the accuracy of automated data annotation tools is improving thus reducing the dependency on manual annotation and the cost of the tools.
Global Data Annotation Tools Market Report Segmentation
Grand View Research has segmented the global data annotation tools market report based on type, annotation type, vertical, and region:
Type Outlook (Revenue, USD Million, 2017 - 2030)
Text
Image/Video
Audio
Annotation Type Outlook (Revenue, USD Million, 2017 - 2030)
Manual
Semi-supervised
Automatic
Vertical Outlook (Revenue, USD Million, 2017 - 2030)
IT
Automotive
Government
Healthcare
Financial Services
Retail
Others
Regional Outlook (Revenue, USD Million, 2017 - 2030)
North America
US
Canada
Mexico
Europe
Germany
UK
France
Asia Pacific
China
Japan
India
South America
Brazil
Middle East and Africa (MEA)
Key Data Annotation Tools Companies:
The following are the leading companies in the data annotation tools market. These companies collectively hold the largest market share and dictate industry trends.
Annotate.com
Appen Limited
CloudApp
Cogito Tech LLC
Deep Systems
Labelbox, Inc
LightTag
Lotus Quality Assurance
Playment Inc
Tagtog Sp. z o.o
CloudFactory Limited
ClickWorker GmbH
Alegion
Figure Eight Inc.
Amazon Mechanical Turk, Inc
Explosion AI GMbH
Mighty AI, Inc.
Trilldata Technologies Pvt Ltd
Scale AI, Inc.
Google LLC
Lionbridge Technologies, Inc
SuperAnnotate LLC
Recent Developments
In November 2023, Appen Limited, a high-quality data provider for the AI lifecycle, chose Amazon Web Services (AWS) as its primary cloud for AI solutions and innovation. As Appen utilizes additional enterprise solutions for AI data source, annotation, and model validation, the firms are expanding their collaboration with a multi-year deal. Appen is strengthening its AI data platform, which serves as the bridge between people and AI, by integrating cutting-edge AWS services.
In September 2023, Labelbox launched Large Language Model (LLM) solution to assist organizations in innovating with generative AI and deepen the partnership with Google Cloud. With the introduction of large language models (LLMs), enterprises now have a plethora of chances to generate new competitive advantages and commercial value. LLM systems have the ability to revolutionize a wide range of intelligent applications; nevertheless, in many cases, organizations will need to adjust or finetune LLMs in order to align with human preferences. Labelbox, as part of an expanded cooperation, is leveraging Google Cloud's generative AI capabilities to assist organizations in developing LLM solutions with Vertex AI. Labelbox's AI platform will be integrated with Google Cloud's leading AI and Data Cloud tools, including Vertex AI and Google Cloud's Model Garden repository, allowing ML teams to access cutting-edge machine learning (ML) models for vision and natural language processing (NLP) and automate key workflows.
In March 2023, has released the most recent version of Enlitic Curie, a platform aimed at improving radiology department workflow. This platform includes Curie|ENDEX, which uses natural language processing and computer vision to analyze and process medical images, and Curie|ENCOG, which uses artificial intelligence to detect and protect medical images in Health Information Security.
In November 2022, Appen Limited, a global leader in data for the AI Lifecycle, announced its partnership with CLEAR Global, a nonprofit organization dedicated to ensuring access to essential information and amplifying voices across languages. This collaboration aims to develop a speech-based healthcare FAQ bot tailored for Sheng, a Nairobi slang language.
Order a free sample PDF of the Market Intelligence Study, published by Grand View Research.
0 notes
Text
The Data Collection And Labeling Market was valued at USD 3.0 Billion in 2023 and is expected to reach USD 29.2 Billion by 2032, growing at a CAGR of 28.54% from 2024-2032.
The data collection and labeling market is witnessing transformative growth as artificial intelligence (AI), machine learning (ML), and deep learning applications continue to expand across industries. As organizations strive to unlock the value of big data, the demand for accurately labeled datasets has surged, making data annotation a critical component in developing intelligent systems. Companies in sectors such as healthcare, automotive, retail, and finance are investing heavily in curated data pipelines that drive smarter algorithms, more efficient automation, and personalized customer experiences.
Data Collection and Labeling Market Fueled by innovation and technological advancement, the data collection and labeling market is evolving to meet the growing complexities of AI models. Enterprises increasingly seek comprehensive data solutions—ranging from image, text, audio, and video annotation to real-time sensor and geospatial data labeling—to power mission-critical applications. Human-in-the-loop systems, crowdsourcing platforms, and AI-assisted labeling tools are at the forefront of this evolution, ensuring the creation of high-quality training datasets that minimize bias and improve predictive performance.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/5925
Market Keyplayers:
Scale AI – Scale Data Engine
Appen – Appen Data Annotation Platform
Labelbox – Labelbox AI Annotation Platform
Amazon Web Services (AWS) – Amazon SageMaker Ground Truth
Google – Google Cloud AutoML Data Labeling Service
IBM – IBM Watson Data Annotation
Microsoft – Azure Machine Learning Data Labeling
Playment (by TELUS International AI) – Playment Annotation Platform
Hive AI – Hive Data Labeling Platform
Samasource – Sama AI Data Annotation
CloudFactory – CloudFactory Data Labeling Services
SuperAnnotate – SuperAnnotate AI Annotation Tool
iMerit – iMerit Data Enrichment Services
Figure Eight (by Appen) – Figure Eight Data Labeling
Cogito Tech – Cogito Data Annotation Services
Market Analysis The market's growth is driven by the convergence of AI deployment and the increasing demand for labeled data to support supervised learning models. Startups and tech giants alike are intensifying their focus on data preparation workflows. Strategic partnerships and outsourcing to data labeling service providers have become common approaches to manage scalability and reduce costs. The competitive landscape features a mix of established players and emerging platforms offering specialized labeling services and tools, creating a highly dynamic ecosystem.
Market Trends
Increasing adoption of AI and ML across diverse sectors
Rising preference for cloud-based data annotation tools
Surge in demand for multilingual and cross-domain data labeling
Expansion of video and 3D image annotation for autonomous systems
Growing emphasis on ethical AI and reduction of labeling bias
Integration of AI-assisted labeling to accelerate workflows
Outsourcing of labeling processes to specialized firms for scalability
Enhanced use of synthetic data for model training and validation
Market Scope The data collection and labeling market serves as the foundation for AI applications across verticals. From autonomous vehicles requiring high-accuracy image labeling to chatbots trained on annotated customer interactions, the scope encompasses every industry where intelligent automation is pursued. As AI maturity increases, the need for diverse, structured, and domain-specific datasets will further elevate the relevance of comprehensive labeling solutions.
Market Forecast The market is expected to maintain strong momentum, driven by increasing digital transformation initiatives and investment in smart technologies. Continuous innovation in labeling techniques, enhanced platform capabilities, and regulatory compliance for data privacy are expected to shape the future landscape. Organizations will prioritize scalable, accurate, and cost-efficient data annotation solutions to stay competitive in an AI-driven economy. The role of data labeling is poised to shift from a support function to a strategic imperative.
Access Complete Report: https://www.snsinsider.com/reports/data-collection-and-labeling-market-5925
Conclusion The data collection and labeling market is not just a stepping stone in the AI journey—it is becoming a strategic cornerstone that determines the success of intelligent systems. As enterprises aim to harness the full potential of AI, the quality, variety, and scalability of labeled data will define the competitive edge. Those who invest early in refined data pipelines and ethical labeling practices will lead in innovation, relevance, and customer trust in the evolving digital world.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
0 notes
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes
Text
AI Trainer for Biology (College Degree Required)
is a community of subject matter experts from several disciplines who align AI models by creating high-quality data in their field of expertise to build the future of Generative AI. Alignerr is operated by Labelbox. Labelbox is the leading data-centric AI platform for building intelligent applications. Teams looking to capitalize on the latest advances in generative AI and LLMs use the Labelbox…
0 notes
Text
Step-by-Step Breakdown of AI Video Analytics Software Development: Tools, Frameworks, and Best Practices for Scalable Deployment
AI Video Analytics is revolutionizing how businesses analyze visual data. From enhancing security systems to optimizing retail experiences and managing traffic, AI-powered video analytics software has become a game-changer. But how exactly is such a solution developed? Let’s break it down step by step—covering the tools, frameworks, and best practices that go into building scalable AI video analytics software.

Introduction: The Rise of AI in Video Analytics
The explosion of video data—from surveillance cameras to drones and smart cities—has outpaced human capabilities to monitor and interpret visual content in real-time. This is where AI Video Analytics Software Development steps in. Using computer vision, machine learning, and deep neural networks, these systems analyze live or recorded video streams to detect events, recognize patterns, and trigger automated responses.
Step 1: Define the Use Case and Scope
Every AI video analytics solution starts with a clear business goal. Common use cases include:
Real-time threat detection in surveillance
Customer behavior analysis in retail
Traffic management in smart cities
Industrial safety monitoring
License plate recognition
Key Deliverables:
Problem statement
Target environment (edge, cloud, or hybrid)
Required analytics (object detection, tracking, counting, etc.)
Step 2: Data Collection and Annotation
AI models require massive amounts of high-quality, annotated video data. Without clean data, the model's accuracy will suffer.
Tools for Data Collection:
Surveillance cameras
Drones
Mobile apps and edge devices
Tools for Annotation:
CVAT (Computer Vision Annotation Tool)
Labelbox
Supervisely
Tip: Use diverse datasets (different lighting, angles, environments) to improve model generalization.
Step 3: Model Selection and Training
This is where the real AI work begins. The model learns to recognize specific objects, actions, or anomalies.
Popular AI Models for Video Analytics:
YOLOv8 (You Only Look Once)
OpenPose (for human activity recognition)
DeepSORT (for multi-object tracking)
3D CNNs for spatiotemporal activity analysis
Frameworks:
TensorFlow
PyTorch
OpenCV (for pre/post-processing)
ONNX (for interoperability)
Best Practice: Start with pre-trained models and fine-tune them on your domain-specific dataset to save time and improve accuracy.
Step 4: Edge vs. Cloud Deployment Strategy
AI video analytics can run on the cloud, on-premises, or at the edge depending on latency, bandwidth, and privacy needs.
Cloud:
Scalable and easier to manage
Good for post-event analysis
Edge:
Low latency
Ideal for real-time alerts and privacy-sensitive applications
Hybrid:
Initial processing on edge devices, deeper analysis in the cloud
Popular Platforms:
NVIDIA Jetson for edge
AWS Panorama
Azure Video Indexer
Google Cloud Video AI
Step 5: Real-Time Inference Pipeline Design
The pipeline architecture must handle:
Video stream ingestion
Frame extraction
Model inference
Alert/visualization output
Tools & Libraries:
GStreamer for video streaming
FFmpeg for frame manipulation
Flask/FastAPI for inference APIs
Kafka/MQTT for real-time event streaming
Pro Tip: Use GPU acceleration with TensorRT or OpenVINO for faster inference speeds.
Step 6: Integration with Dashboards and APIs
To make insights actionable, integrate the AI system with:
Web-based dashboards (using React, Plotly, or Grafana)
REST or gRPC APIs for external system communication
Notification systems (SMS, email, Slack, etc.)
Best Practice: Create role-based dashboards to manage permissions and customize views for operations, IT, or security teams.
Step 7: Monitoring and Maintenance
Deploying AI models is not a one-time task. Performance should be monitored continuously.
Key Metrics:
Accuracy (Precision, Recall)
Latency
False Positive/Negative rate
Frame per second (FPS)
Tools:
Prometheus + Grafana (for monitoring)
MLflow or Weights & Biases (for model versioning and experiment tracking)
Step 8: Security, Privacy & Compliance
Video data is sensitive, so it’s vital to address:
GDPR/CCPA compliance
Video redaction (blurring faces/license plates)
Secure data transmission (TLS/SSL)
Pro Tip: Use anonymization techniques and role-based access control (RBAC) in your application.
Step 9: Scaling the Solution
As more video feeds and locations are added, the architecture should scale seamlessly.
Scaling Strategies:
Containerization (Docker)
Orchestration (Kubernetes)
Auto-scaling with cloud platforms
Microservices-based architecture
Best Practice: Use a modular pipeline so each part (video input, AI model, alert engine) can scale independently.
Step 10: Continuous Improvement with Feedback Loops
Real-world data is messy, and edge cases arise often. Use real-time feedback loops to retrain models.
Automatically collect misclassified instances
Use human-in-the-loop (HITL) systems for validation
Periodically retrain and redeploy models
Conclusion
Building scalable AI Video Analytics Software is a multi-disciplinary effort combining computer vision, data engineering, cloud computing, and UX design. With the right tools, frameworks, and development strategy, organizations can unlock immense value from their video data—turning passive footage into actionable intelligence.
0 notes
Text
Data Matters: How to Curate and Process Information for Your Private LLM
In the era of artificial intelligence, data is the lifeblood of any large language model (LLM). Whether you are building a private LLM for business intelligence, customer service, research, or any other application, the quality and structure of the data you provide significantly influence its accuracy and performance. Unlike publicly trained models, a private LLM requires careful curation and processing of data to ensure relevance, security, and efficiency.
This blog explores the best practices for curating and processing information for your private LLM, from data collection and cleaning to structuring and fine-tuning for optimal results.
Understanding Data Curation
Importance of Data Curation
Data curation involves the selection, organization, and maintenance of data to ensure it is accurate, relevant, and useful. Poorly curated data can lead to biased, irrelevant, or even harmful responses from an LLM. Effective curation helps improve model accuracy, reduce biases, enhance relevance and domain specificity, and strengthen security and compliance with regulations.
Identifying Relevant Data Sources
The first step in data curation is sourcing high-quality information. Depending on your use case, your data sources may include:
Internal Documents: Business reports, customer interactions, support tickets, and proprietary research.
Publicly Available Data: Open-access academic papers, government databases, and reputable news sources.
Structured Databases: Financial records, CRM data, and industry-specific repositories.
Unstructured Data: Emails, social media interactions, transcripts, and chat logs.
Before integrating any dataset, assess its credibility, relevance, and potential biases.
Filtering and Cleaning Data
Once you have identified data sources, the next step is cleaning and preprocessing. Raw data can contain errors, duplicates, and irrelevant information that can degrade model performance. Key cleaning steps include removing duplicates to ensure unique entries, correcting errors such as typos and incorrect formatting, handling missing data through interpolation techniques or removal, and eliminating noise such as spam, ads, and irrelevant content.
Data Structuring for LLM Training
Formatting and Tokenization
Data fed into an LLM should be in a structured format. This includes standardizing text formats by converting different document formats (PDFs, Word files, CSVs) into machine-readable text, tokenization to break down text into smaller units (words, subwords, or characters) for easier processing, and normalization by lowercasing text, removing special characters, and converting numbers and dates into standardized formats.
Labeling and Annotating Data
For supervised fine-tuning, labeled data is crucial. This involves categorizing text with metadata, such as entity recognition (identifying names, locations, dates), sentiment analysis (classifying text as positive, negative, or neutral), topic tagging (assigning categories based on content themes), and intent classification (recognizing user intent in chatbot applications). Annotation tools like Prodigy, Labelbox, or Doccano can facilitate this process.
Structuring Large Datasets
To improve retrieval and model efficiency, data should be stored in a structured format such as vector databases (using embeddings and vector search for fast retrieval like Pinecone, FAISS, Weaviate), relational databases (storing structured data in SQL-based systems), or NoSQL databases (storing semi-structured data like MongoDB, Elasticsearch). Using a hybrid approach can help balance flexibility and speed for different query types.
Processing Data for Model Training
Preprocessing Techniques
Before feeding data into an LLM, preprocessing is essential to ensure consistency and efficiency. This includes data augmentation (expanding datasets using paraphrasing, back-translation, and synthetic data generation), stopword removal (eliminating common but uninformative words like "the," "is"), stemming and lemmatization (reducing words to their base forms like "running" → "run"), and encoding and embedding (transforming text into numerical representations for model ingestion).
Splitting Data for Training
For effective training, data should be split into a training set (80%) used for model learning, a validation set (10%) used for tuning hyperparameters, and a test set (10%) used for final evaluation. Proper splitting ensures that the model generalizes well without overfitting.
Handling Bias and Ethical Considerations
Bias in training data can lead to unfair or inaccurate model predictions. To mitigate bias, ensure diverse data sources that provide a variety of perspectives and demographics, use bias detection tools such as IBM AI Fairness 360, and integrate human-in-the-loop review to manually assess model outputs for biases. Ethical AI principles should guide dataset selection and model training.
Fine-Tuning and Evaluating the Model
Transfer Learning and Fine-Tuning
Rather than training from scratch, private LLMs are often fine-tuned on top of pre-trained models (e.g., GPT, Llama, Mistral). Fine-tuning involves selecting a base model that aligns with your needs, using domain-specific data to specialize the model, and training with hyperparameter optimization by tweaking learning rates, batch sizes, and dropout rates.
Model Evaluation Metrics
Once the model is trained, its performance must be evaluated using metrics such as perplexity (measuring how well the model predicts the next word), BLEU/ROUGE scores (evaluating text generation quality), and human evaluation (assessing outputs for coherence, factual accuracy, and relevance). Continuous iteration and improvement are crucial for maintaining model quality.
Deployment and Maintenance
Deploying the Model
Once the LLM is fine-tuned, deployment considerations include choosing between cloud vs. on-premise hosting depending on data sensitivity, ensuring scalability to handle query loads, and integrating the LLM into applications via REST or GraphQL APIs.
Monitoring and Updating
Ongoing maintenance is necessary to keep the model effective. This includes continuous learning by regularly updating with new data, model drift detection to identify and correct performance degradation, and user feedback integration to use feedback loops to refine responses. A proactive approach to monitoring ensures sustained accuracy and reliability.
Conclusion
Curating and processing information for a private LLM is a meticulous yet rewarding endeavor. By carefully selecting, cleaning, structuring, and fine-tuning data, you can build a robust and efficient AI system tailored to your needs. Whether for business intelligence, customer support, or research, a well-trained private LLM can offer unparalleled insights and automation, transforming the way you interact with data.
Invest in quality data, and your model will yield quality results.
#ai#blockchain#crypto#ai generated#dex#cryptocurrency#blockchain app factory#ico#ido#blockchainappfactory
0 notes
Text
More thoughts on final project
3/31/25
presentation: cognition versus computation in models of vision
I'll be using the MultiModal Co-Lab built for Gemini, that I was given access to my Marcelo. I'm using this to detect objects in images, and then processing the bounding box outputs through LabelBox. I'll be presenting a few key examples as part of my presentation, as well as testing the humans in the room in what they see in various images / videos, comparing that to the computational data I will have found.
things we're bad at: optical illusions (noise in videos we miss things, length of lines, color constancy, perceived speed of cars)
things we're good at: semantic reasoning gained from images, instant decisions based on lots of noise (driving), seeing depth, object permanency.
change blindness / counting vs optical illusions / semantics
show GPT model trying to get semantic information, trying to count, trying to identify objects, trying to keep track of object permanency
give a comparison of human test results vs computational ones
Predictive brain versus computational brain. So much of computer vision is bottom up - pixel by pixel, counting dimensions / proportionality - versus human vision gut reaction. Sometimes we pick out minute details (6 fingers), but often we just have an instant reaction that something is wrong.
0 notes
Video
youtube
$100K Data Annotation Jobs From Home!Data annotation, huh? It sounds a bit dry at first, doesn't it? But let me tell you, it's one of those hidden gems in the data science world that can open up a whole new realm of opportunities-especially if you're diving into machine learning and AI. So, let's break it down, shall we? First off, what is data annotation? In simple terms, it's the process of labeling or tagging data-think text, images, videos, or audio-so that machine learning models can actually make sense of it. It's like teaching a child to recognize a dog by showing them pictures and saying, "This is a dog." There are different types of annotation, too. With images, you might be drawing bounding boxes around objects, segmenting parts of the image, or detecting specific items. When it comes to text, you could be diving into sentiment analysis, identifying named entities, or tagging parts of speech. And don't even get me started on audio and video annotations-those involve transcribing sounds, identifying speakers, tracking objects, and even recognizing actions. It's a whole universe of data waiting to be explored! Now, once you've wrapped your head around what data annotation is, it's time to get your hands dirty with some tools. There are some fantastic annotation tools out there. For instance, Labelbox is great for handling images, videos, and texts, while Supervisely focuses on image annotation with deep learning features. Prodigy is a go-to for text annotation, especially if you're into natural language processing. And if you're looking to annotate images or videos, VoTT is a solid choice. The best part? Many of these tools offer free versions or trials, so you can practice without breaking the bank. Speaking of practice, let's talk about online courses and tutorials. Platforms like DataCamp and Coursera have a treasure trove of courses on data annotation and supervised learning. If you're on a budget, Udemy is your friend, offering affordable courses that cover various data labeling techniques. And don't overlook Kaggle; they have micro-courses that touch on data preparation and annotation practices. This is where you can really build your skills and confidence.
0 notes
Text
Not everyone I really and truly like is a friend the dynamics humans can have go far beyond categorizing connection under more recognized labelboxes
0 notes
Text
Best Image Annotation Companies Compared: Features, Pricing, and Accuracy

Introduction
As applications powered by artificial intelligence, such as self-driving cars, healthcare diagnostics, and online retail, expand, image annotation has emerged as a crucial component in developing effective machine learning models. However, with numerous providers offering annotation services, how can one select the most suitable Image Annotation Companies for their requirements? In this article, we evaluate several leading image annotation companies in 2025, considering their features, pricing, and accuracy, to assist you in identifying the best match for your project.
1. GTS.AI – Enterprise-Grade Accuracy with Custom Workflows
GTS.AI is renowned for its flexible annotation pipelines, stringent enterprise security standards, and its ability to cater to various sectors such as the automotive, healthcare, and retail industries.
Key Features:
Supports various annotation types including bounding boxes, polygons, keypoints, segmentation, and video annotation.
Offers a scalable workforce that includes human validation.
Integrates seamlessly with major machine learning tools.
Adheres to ISO-compliant data security protocols.
Pricing:
Custom pricing is determined based on the volume of data, type of annotation, and required turnaround time.
Offers competitive rates for datasets requiring high accuracy.
Accuracy:
Achieves over 98% annotation accuracy through a multi-stage quality control process.
Provides annotator training programs and conducts regular audits.
Best for: Companies in need of scalable, highly accurate annotation services across various industries.
2. Labelbox – Platform Flexibility and AI-Assisted Tools
Labelbox provides a robust platform for teams seeking to manage their annotation processes effectively, featuring capabilities that cater to both internal teams and external outsourcing.
Key Features
Include a powerful data labeling user interface and software development kits,
Automation through model-assisted labeling,
Seamless integration with cloud storage and machine learning workflows.
Pricing
Options consist of a freemium tier,
Custom pricing for enterprises,
Pay-per-usage model for annotations.
Accuracy
May vary based on whether annotators are in-house or outsourced, with strong quality
Control tools that necessitate internal supervision.
This platform is ideal for machine learning teams in need of versatile labeling tools and integration possibilities.
3. Scale AI – Enterprise-Level Services for Complex Use Cases
Scale AI is a leading provider in the market for extensive and complex annotation tasks, such as 3D perception, LiDAR, and autonomous vehicle data.
Key Features:
Offers a wide range of annotation types, including 3D sensor data.
Utilizes an API-first platform that integrates with machine learning.
Provides dedicated project managers for large clients.
Pricing
Premium pricing, particularly for high-complexity data.
Offers project-based quotes.
Accuracy:
Renowned for top-tier annotation accuracy.
Implements multi-layered quality checks and human review.
Best for: Projects in autonomous driving, defense, and robotics that require precision and scale.
4. CloudFactory – Human-Centric Approach with Ethical Sourcing
CloudFactory offers a unique blend of skilled human annotators and ethical AI practices, positioning itself as an excellent choice for companies prioritizing fair labor practices and high data quality.
Key Features:
The workforce is trained according to industry-specific guidelines.
It supports annotation for images, videos, audio, and documents.
There's a strong focus on data ethics and the welfare of the workforce.
Pricing
Pricing is based on volume and is moderately priced compared to other providers.
Contracts are transparent.
Accuracy
There are multiple stages of human review.
Continuous training and feedback loops are implemented.
Best for: Companies looking for socially responsible and high-quality annotation services.
5. Appen – Global Crowd with AI Integration

Appen boasts one of the largest international crowds for data annotation, offering extensive support for various AI training data types, such as natural language processing and computer vision.
Key Features
Include a diverse global crowd with multilingual capabilities,
Automated workflows, and data validation tools,
As well as high data throughput suitable for large-scale projects.
Pricing
Appen provides competitive rates for bulk annotation tasks,
With options for pay-as-you-go and contract models.
Accuracy
The quality of data can fluctuate based on project management,
Although the workflows are robust, necessitating a quality control setup.
Best for: This service is ideal for global brands and research teams that need support across multiple languages and domains.
Conclusion: Choosing the Right Partner
The ideal image annotation company for your project is contingent upon your specific requirements:
If you require enterprise-level quality with adaptable services, Globose Technology Solution.AI is recommended.
For those seeking comprehensive control over labeling processes, Labelbox is an excellent choice.
If your project involves intricate 3D or autonomous data, Scale AI is specifically designed for such tasks.
If ethical sourcing and transparency are priorities, CloudFactory should be considered.
For multilingual and scalable teams, Appen may be the right fit.
Prior to selecting a vendor, it is essential to assess your project's scale, data type, necessary accuracy, and compliance requirements. A strategic partner will not only assist in labeling your data but also enhance your entire AI development pipeline.
0 notes
Text
How to Choose the Right Data Annotation Tools for Your AI Project

Introduction
In the fast-paced domain of artificial intelligence (AI), the availability of high-quality labeled data is essential for developing precise and dependable machine learning models. The selection of an appropriate Data Annotation tool can greatly influence the success of your project by promoting efficiency, accuracy, and scalability. This article will provide guidance on the important factors to evaluate when choosing the most suitable data annotation tool for your AI initiative.
Understanding Data Annotation Tools
Data annotation tools play a crucial role in the labeling of datasets intended for machine learning models. These tools offer user-friendly interfaces that enable annotators to tag, segment, classify, and organize data, thereby rendering it interpretable for artificial intelligence algorithms. Depending on the specific application, these annotation tools can accommodate a range of data types, such as images, text, audio, and video.
Key Considerations When Selecting a Data Annotation Tool
1. Nature of Data to be Annotated
Various AI initiatives necessitate distinct forms of annotated data. Prior to selecting a tool, it is crucial to identify whether the annotation pertains to images, text, videos, or audio. Some tools are tailored for specific data types, while others provide capabilities for multi-modal annotation.
2. Features for Accuracy and Quality Control
To guarantee high-quality annotations, seek tools that offer:
Integrated validation mechanisms
Consensus-driven labeling
Automated error detection
Quality assurance processes
3. Scalability and Automation Features
As AI projects expand, manual annotation may become less efficient. Opting for a tool that includes automation features such as AI-assisted labeling, pre-annotation, and active learning can greatly enhance the speed of the process while ensuring accuracy.
4. Compatibility with Machine Learning Pipelines
It is vital for the tool to integrate smoothly with current machine learning workflows. Verify whether the tool supports APIs, SDKs, and data format compatibility with platforms like TensorFlow, PyTorch, or cloud-based machine learning services.
5. Cost and Pricing Models
Annotation tools are available with various pricing options, which include:
Pay-per-use (suitable for smaller projects)
Subscription-based (best for ongoing initiatives)
Enterprise solutions (designed for extensive AI implementations)
Evaluate your financial resources and select a tool that provides optimal value while maintaining quality.
6. Security and Compliance
In projects that handle sensitive information, security and compliance are paramount. Verify that the tool complies with industry standards such as GDPR, HIPAA, or SOC 2 certification. Features such as encryption, access controls, and data anonymization can enhance security measures.
7. User Experience and Collaboration Features
A user-friendly interface and collaborative capabilities can significantly boost productivity. Look for tools that provide:
Role-based access control
Real-time collaboration
Intuitive dashboards
8. Support and Community
Dependable customer support and an active user community are essential for addressing technical challenges and enhancing workflow. Investigate tools that offer comprehensive documentation, training materials, and responsive support teams.
Widely Utilized Data Annotation Tools
The following are some prominent data annotation tools designed to meet various requirements:
Labelbox (Comprehensive and scalable solution)
SuperAnnotate (AI-enhanced annotation for images and videos)
V7 Labs (Optimal for medical and scientific datasets)
Prodigy (Ideal for natural language processing projects)
Amazon SageMaker Ground Truth (Highly scalable with AWS integration)
Conclusion
Choosing the appropriate data annotation tool is essential for the success of your AI initiative. By evaluating aspects such as data type, accuracy, scalability, integration, cost, security, and user experience, you can select a tool that fits your project specifications. The right choice will not only enhance annotation efficiency but also improve the overall effectiveness of your AI model.
For professional advice on data annotation solutions, please visit GTS AI Services.
0 notes