#managed streaming for apache kafka
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
AWS MSK Create & List Topics
Problem I needed to created topics in Amazon Web Services(AWS) Managed Streaming for Apache Kafka(MSK) and I wanted to list out the topics after they were created to verify. Solution This solution is written in python using the confluent-kafka package. It connects to the Kafka cluster and adds the new topics. Then it prints out all of the topics for verification This file contains…

View On WordPress
#amazon web services#apache kafka#aws#confluent-kafka#create#kafka#kafka topic#list#managed streaming for apache kafka#msk#python#topic
0 notes
Link
0 notes
Text
How AI Is Revolutionizing Contact Centers in 2025
As contact centers evolve from reactive customer service hubs to proactive experience engines, artificial intelligence (AI) has emerged as the cornerstone of this transformation. In 2025, modern contact center architectures are being redefined through AI-based technologies that streamline operations, enhance customer satisfaction, and drive measurable business outcomes.
This article takes a technical deep dive into the AI-powered components transforming contact centers—from natural language models and intelligent routing to real-time analytics and automation frameworks.
1. AI Architecture in Modern Contact Centers
At the core of today’s AI-based contact centers is a modular, cloud-native architecture. This typically consists of:
NLP and ASR engines (e.g., Google Dialogflow, AWS Lex, OpenAI Whisper)
Real-time data pipelines for event streaming (e.g., Apache Kafka, Amazon Kinesis)
Machine Learning Models for intent classification, sentiment analysis, and next-best-action
RPA (Robotic Process Automation) for back-office task automation
CDP/CRM Integration to access customer profiles and journey data
Omnichannel orchestration layer that ensures consistent CX across chat, voice, email, and social
These components are containerized (via Kubernetes) and deployed via CI/CD pipelines, enabling rapid iteration and scalability.
2. Conversational AI and Natural Language Understanding
The most visible face of AI in contact centers is the conversational interface—delivered via AI-powered voice bots and chatbots.
Key Technologies:
Automatic Speech Recognition (ASR): Converts spoken input to text in real time. Example: OpenAI Whisper, Deepgram, Google Cloud Speech-to-Text.
Natural Language Understanding (NLU): Determines intent and entities from user input. Typically fine-tuned BERT or LLaMA models power these layers.
Dialog Management: Manages context-aware conversations using finite state machines or transformer-based dialog engines.
Natural Language Generation (NLG): Generates dynamic responses based on context. GPT-based models (e.g., GPT-4) are increasingly embedded for open-ended interactions.
Architecture Snapshot:
plaintext
CopyEdit
Customer Input (Voice/Text)
↓
ASR Engine (if voice)
↓
NLU Engine → Intent Classification + Entity Recognition
↓
Dialog Manager → Context State
↓
NLG Engine → Response Generation
↓
Omnichannel Delivery Layer
These AI systems are often deployed on low-latency, edge-compute infrastructure to minimize delay and improve UX.
3. AI-Augmented Agent Assist
AI doesn’t only serve customers—it empowers human agents as well.
Features:
Real-Time Transcription: Streaming STT pipelines provide transcripts as the customer speaks.
Sentiment Analysis: Transformers and CNNs trained on customer service data flag negative sentiment or stress cues.
Contextual Suggestions: Based on historical data, ML models suggest actions or FAQ snippets.
Auto-Summarization: Post-call summaries are generated using abstractive summarization models (e.g., PEGASUS, BART).
Technical Workflow:
Voice input transcribed → parsed by NLP engine
Real-time context is compared with knowledge base (vector similarity via FAISS or Pinecone)
Agent UI receives predictive suggestions via API push
4. Intelligent Call Routing and Queuing
AI-based routing uses predictive analytics and reinforcement learning (RL) to dynamically assign incoming interactions.
Routing Criteria:
Customer intent + sentiment
Agent skill level and availability
Predicted handle time (via regression models)
Customer lifetime value (CLV)
Model Stack:
Intent Detection: Multi-label classifiers (e.g., fine-tuned RoBERTa)
Queue Prediction: Time-series forecasting (e.g., Prophet, LSTM)
RL-based Routing: Models trained via Q-learning or Proximal Policy Optimization (PPO) to optimize wait time vs. resolution rate
5. Knowledge Mining and Retrieval-Augmented Generation (RAG)
Large contact centers manage thousands of documents, SOPs, and product manuals. AI facilitates rapid knowledge access through:
Vector Embedding of documents (e.g., using OpenAI, Cohere, or Hugging Face models)
Retrieval-Augmented Generation (RAG): Combines dense retrieval with LLMs for grounded responses
Semantic Search: Replaces keyword-based search with intent-aware queries
This enables agents and bots to answer complex questions with dynamic, accurate information.
6. Customer Journey Analytics and Predictive Modeling
AI enables real-time customer journey mapping and predictive support.
Key ML Models:
Churn Prediction: Gradient Boosted Trees (XGBoost, LightGBM)
Propensity Modeling: Logistic regression and deep neural networks to predict upsell potential
Anomaly Detection: Autoencoders flag unusual user behavior or possible fraud
Streaming Frameworks:
Apache Kafka / Flink / Spark Streaming for ingesting and processing customer signals (page views, clicks, call events) in real time
These insights are visualized through BI dashboards or fed back into orchestration engines to trigger proactive interventions.
7. Automation & RPA Integration
Routine post-call processes like updating CRMs, issuing refunds, or sending emails are handled via AI + RPA integration.
Tools:
UiPath, Automation Anywhere, Microsoft Power Automate
Workflows triggered via APIs or event listeners (e.g., on call disposition)
AI models can determine intent, then trigger the appropriate bot to complete the action in backend systems (ERP, CRM, databases)
8. Security, Compliance, and Ethical AI
As AI handles more sensitive data, contact centers embed security at multiple levels:
Voice biometrics for authentication (e.g., Nuance, Pindrop)
PII Redaction via entity recognition models
Audit Trails of AI decisions for compliance (especially in finance/healthcare)
Bias Monitoring Pipelines to detect model drift or demographic skew
Data governance frameworks like ISO 27001, GDPR, and SOC 2 compliance are standard in enterprise AI deployments.
Final Thoughts
AI in 2025 has moved far beyond simple automation. It now orchestrates entire contact center ecosystems—powering conversational agents, augmenting human reps, automating back-office workflows, and delivering predictive intelligence in real time.
The technical stack is increasingly cloud-native, model-driven, and infused with real-time analytics. For engineering teams, the focus is now on building scalable, secure, and ethical AI infrastructures that deliver measurable impact across customer satisfaction, cost savings, and employee productivity.
As AI models continue to advance, contact centers will evolve into fully adaptive systems, capable of learning, optimizing, and personalizing in real time. The revolution is already here—and it's deeply technical.
#AI-based contact center#conversational AI in contact centers#natural language processing (NLP)#virtual agents for customer service#real-time sentiment analysis#AI agent assist tools#speech-to-text AI#AI-powered chatbots#contact center automation#AI in customer support#omnichannel AI solutions#AI for customer experience#predictive analytics contact center#retrieval-augmented generation (RAG)#voice biometrics security#AI-powered knowledge base#machine learning contact center#robotic process automation (RPA)#AI customer journey analytics
0 notes
Text
The Ultimate Roadmap to AIOps Platform Development: Tools, Frameworks, and Best Practices for 2025
In the ever-evolving world of IT operations, AIOps (Artificial Intelligence for IT Operations) has moved from buzzword to business-critical necessity. As companies face increasing complexity, hybrid cloud environments, and demand for real-time decision-making, AIOps platform development has become the cornerstone of modern enterprise IT strategy.

If you're planning to build, upgrade, or optimize an AIOps platform in 2025, this comprehensive guide will walk you through the tools, frameworks, and best practices you must know to succeed.
What Is an AIOps Platform?
An AIOps platform leverages artificial intelligence, machine learning (ML), and big data analytics to automate IT operations—from anomaly detection and event correlation to root cause analysis, predictive maintenance, and incident resolution. The goal? Proactively manage, optimize, and automate IT operations to minimize downtime, enhance performance, and improve the overall user experience.
Key Functions of AIOps Platforms:
Data Ingestion and Integration
Real-Time Monitoring and Analytics
Intelligent Event Correlation
Predictive Insights and Forecasting
Automated Remediation and Workflows
Root Cause Analysis (RCA)
Why AIOps Platform Development Is Critical in 2025
Here’s why 2025 is a tipping point for AIOps adoption:
Explosion of IT Data: Gartner predicts that IT operations data will grow 3x by 2025.
Hybrid and Multi-Cloud Dominance: Enterprises now manage assets across public clouds, private clouds, and on-premises.
Demand for Instant Resolution: User expectations for zero downtime and faster support have skyrocketed.
Skill Shortages: IT teams are overwhelmed, making automation non-negotiable.
Security and Compliance Pressures: Faster anomaly detection is crucial for risk management.
Step-by-Step Roadmap to AIOps Platform Development
1. Define Your Objectives
Problem areas to address: Slow incident response? Infrastructure monitoring? Resource optimization?
KPIs: MTTR (Mean Time to Resolution), uptime percentage, operational costs, user satisfaction rates.
2. Data Strategy: Collection, Integration, and Normalization
Sources: Application logs, server metrics, network traffic, cloud APIs, IoT sensors.
Data Pipeline: Use ETL (Extract, Transform, Load) tools to clean and unify data.
Real-Time Ingestion: Implement streaming technologies like Apache Kafka, AWS Kinesis, or Azure Event Hubs.
3. Select Core AIOps Tools and Frameworks
We'll explore these in detail below.
4. Build Modular, Scalable Architecture
Microservices-based design enables better updates and feature rollouts.
API-First development ensures seamless integration with other enterprise systems.
5. Integrate AI/ML Models
Anomaly Detection: Isolation Forest, LSTM models, autoencoders.
Predictive Analytics: Time-series forecasting, regression models.
Root Cause Analysis: Causal inference models, graph neural networks.
6. Implement Intelligent Automation
Use RPA (Robotic Process Automation) combined with AI to enable self-healing systems.
Playbooks and Runbooks: Define automated scripts for known issues.
7. Deploy Monitoring and Feedback Mechanisms
Track performance using dashboards.
Continuously retrain models to adapt to new patterns.
Top Tools and Technologies for AIOps Platform Development (2025)
Data Ingestion and Processing
Apache Kafka
Fluentd
Elastic Stack (ELK/EFK)
Snowflake (for big data warehousing)
Monitoring and Observability
Prometheus + Grafana
Datadog
Dynatrace
Splunk ITSI
Machine Learning and AI Frameworks
TensorFlow
PyTorch
scikit-learn
H2O.ai (automated ML)
Event Management and Correlation
Moogsoft
BigPanda
ServiceNow ITOM
Automation and Orchestration
Ansible
Puppet
Chef
SaltStack
Cloud and Infrastructure Platforms
AWS CloudWatch and DevOps Tools
Google Cloud Operations Suite (formerly Stackdriver)
Azure Monitor and Azure DevOps
Best Practices for AIOps Platform Development
1. Start Small, Then Scale
Begin with a few critical systems before scaling to full-stack observability.
2. Embrace a Unified Data Strategy
Ensure that your AIOps platform ingests structured and unstructured data across all environments.
3. Prioritize Explainability
Build AI models that offer clear reasoning for decisions, not black-box results.
4. Incorporate Feedback Loops
AIOps platforms must learn continuously. Implement mechanisms for humans to approve, reject, or improve suggestions.
5. Ensure Robust Security and Compliance
Encrypt data in transit and at rest.
Implement access controls and audit trails.
Stay compliant with standards like GDPR, HIPAA, and CCPA.
6. Choose Cloud-Native and Open-Source Where Possible
Future-proof your system by building on open standards and avoiding vendor lock-in.
Key Trends Shaping AIOps in 2025
Edge AIOps: Extending monitoring and analytics to edge devices and remote locations.
AI-Enhanced DevSecOps: Tight integration between AIOps and security operations (SecOps).
Hyperautomation: Combining AIOps with enterprise-wide RPA and low-code platforms.
Composable IT: Building modular AIOps capabilities that can be assembled dynamically.
Federated Learning: Training models across multiple environments without moving sensitive data.
Challenges to Watch Out For
Data Silos: Incomplete data pipelines can cripple AIOps effectiveness.
Over-Automation: Relying too much on automation without human validation can lead to errors.
Skill Gaps: Building an AIOps platform requires expertise in AI, data engineering, IT operations, and cloud architectures.
Invest in cross-functional teams and continuous training to overcome these hurdles.
Conclusion: Building the Future with AIOps
In 2025, the enterprises that invest in robust AIOps platform development will not just survive—they will thrive. By integrating the right tools, frameworks, and best practices, businesses can unlock proactive incident management, faster innovation cycles, and superior user experiences.
AIOps isn’t just about reducing tickets—it’s about creating a resilient, self-optimizing IT ecosystem that powers future growth.
0 notes
Text
Why You Should Hire Scala Developers for Your Next Big Data Project

As big data drives decision-making across industries, the demand for technologies that can handle large-scale processing is on the rise. Scala, is a high-level language that blends object-oriented and functional programming and has emerged as a go-to choice for developing robust and scalable data systems.
It’s no wonder that tech companies are looking to hire software engineers skilled in Scala to support their data pipelines, streamline applications, and real-time analytics platforms. If your next project is about processing massive datasets or working with tools like Apache Spark, Scala would be the strategic advantage that you need.
Scalable Code, Powerful Performance, and Future-Ready Solutions
If you are wondering why Scala, let's first answer that thought.
Scala is ideal for big data systems since it was created to be succinct, expressive, and scalable. It is more effective at creating intricate data transformations or concurrent operations since it runs on the Java Virtual Machine (JVM), which makes it compatible with Java.
Scala is preferred by many tech businesses because:
It easily combines with Akka, Kafka, and Apache Spark.
It facilitates functional programming, which produces code that is more dependable and testable.
It manages concurrency and parallelism better than many alternatives.
Its community is expanding, and its environment for data-intensive applications is robust.
Top Reasons to Hire Scala Developers
Hiring Scala developers means bringing in experts who are aware of the business implications of data as well as its technical complexity. They are skilled at creating distributed systems that scale effectively and maintain dependability when put under stress.
When should you think about recruiting Scala developers?
You currently use Apache Spark or intend to do so in the future.
Your app manages complicated event streaming or real-time data processing.
Compared to conventional Java-based solutions, you want more manageable, succinct code.
You're developing pipelines for machine learning that depend on effective batch or stream processing.
In addition to writing code, a proficient Scala developer will assist in the design of effective, fault-tolerant systems that can grow with your data requirements.
Finding the Right Talent
Finding the appropriate fit can be more difficult with Scala because it is more specialized than some other programming languages. For this reason, it's critical to explicitly identify the role: Does the developer work on real-time dashboards, back-end services, or Spark jobs?
You can use a salary benchmarking tool to determine the current market rate after your needs are clear. Because of their specialized knowledge and familiarity with big data frameworks, scala engineers typically charge higher pay. This is why setting up a proper budget early on is essential to luring in qualified applicants.
Have you tried the Uplers salary benchmarking tool? If not, give it a shot as it’s free and still offers you relevant real-time salary insights related to tech and digital roles. This helps global companies to align their compensation with the industry benchmarks.
Final Thoughts
Big data projects present unique challenges, ranging from system stability to processing speed. Selecting the appropriate development team and technology stack is crucial. Hiring Scala developers gives your team the resources and know-how they need to create scalable, high-performance data solutions.
Scala is more than simply another language for tech organizations dealing with real-time analytics, IoT data streams, or large-scale processing workloads; it's a competitive edge.
Hiring Scala talent for your next big data project could be the best choice you make, regardless of whether you're creating a system from the ground up or enhancing an existing one.
0 notes
Text
Unlocking the Power of AI-Ready Customer Data

In today’s data-driven landscape, AI-ready customer data is the linchpin of advanced digital transformation. This refers to structured, cleaned, and integrated data that artificial intelligence models can efficiently process to derive actionable insights. As enterprises seek to become more agile and customer-centric, the ability to transform raw data into AI-ready formats becomes a mission-critical endeavor.
AI-ready customer data encompasses real-time behavior analytics, transactional history, social signals, location intelligence, and more. It is standardized and tagged using consistent taxonomies and stored in secure, scalable environments that support machine learning and AI deployment.
The Role of AI in Customer Data Optimization
AI thrives on quality, contextual, and enriched data. Unlike traditional CRM systems that focus on collecting and storing customer data, AI systems leverage this data to predict patterns, personalize interactions, and automate decisions. Here are core functions where AI is transforming customer data utilization:
Predictive Analytics: AI can forecast future customer behavior based on past trends.
Hyper-personalization: Machine learning models tailor content, offers, and experiences.
Customer Journey Mapping: Real-time analytics provide visibility into multi-touchpoint journeys.
Sentiment Analysis: AI reads customer feedback, social media, and reviews to understand emotions.
These innovations are only possible when the underlying data is curated and processed to meet the strict requirements of AI algorithms.
Why AI-Ready Data is a Competitive Advantage
Companies equipped with AI-ready customer data outperform competitors in operational efficiency and customer satisfaction. Here’s why:
Faster Time to Insights: With ready-to-use data, businesses can quickly deploy AI models without the lag of preprocessing.
Improved Decision Making: Rich, relevant, and real-time data empowers executives to make smarter, faster decisions.
Enhanced Customer Experience: Businesses can anticipate needs, solve issues proactively, and deliver customized journeys.
Operational Efficiency: Automation reduces manual interventions and accelerates process timelines.
Data maturity is no longer optional — it is foundational to innovation.
Key Steps to Making Customer Data AI-Ready
1. Centralize Data Sources
The first step is to break down data silos. Customer data often resides in various platforms — CRM, ERP, social media, call center systems, web analytics tools, and more. Use Customer Data Platforms (CDPs) or Data Lakes to centralize all structured and unstructured data in a unified repository.
2. Data Cleaning and Normalization
AI demands high-quality, clean, and normalized data. This includes:
Removing duplicates
Standardizing formats
Resolving conflicts
Filling in missing values
Data should also be de-duplicated and validated regularly to ensure long-term accuracy.
3. Identity Resolution and Tagging
Effective AI modeling depends on knowing who the customer truly is. Identity resolution links all customer data points — email, phone number, IP address, device ID — into a single customer view (SCV).
Use consistent metadata tagging and taxonomies so that AI models can interpret data meaningfully.
4. Privacy Compliance and Security
AI-ready data must comply with GDPR, CCPA, and other regional data privacy laws. Implement data governance protocols such as:
Role-based access control
Data anonymization
Encryption at rest and in transit
Consent management
Customers trust brands that treat their data with integrity.
5. Real-Time Data Processing
AI systems must react instantly to changing customer behaviors. Stream processing technologies like Apache Kafka, Flink, or Snowflake allow for real-time data ingestion and processing, ensuring your AI models are always trained on the most current data.
Tools and Technologies Enabling AI-Ready Data
Several cutting-edge tools and platforms enable the preparation and activation of AI-ready data:
Snowflake — for scalable cloud data warehousing
Segment — to collect and unify customer data across channels
Databricks — combines data engineering and AI model training
Salesforce CDP — manages structured and unstructured customer data
AWS Glue — serverless ETL service to prepare and transform data
These platforms provide real-time analytics, built-in machine learning capabilities, and seamless integrations with marketing and business intelligence tools.
AI-Driven Use Cases Empowered by Customer Data
1. Personalized Marketing Campaigns
Using AI-ready customer data, marketers can build highly segmented and personalized campaigns that speak directly to the preferences of each individual. This improves conversion rates and increases ROI.
2. Intelligent Customer Support
Chatbots and virtual agents can be trained on historical support interactions to deliver context-aware assistance and resolve issues faster than traditional methods.
3. Dynamic Pricing Models
Retailers and e-commerce businesses use AI to analyze market demand, competitor pricing, and customer buying history to adjust prices in real-time, maximizing margins.
4. Churn Prediction
AI can predict which customers are likely to churn by monitoring usage patterns, support queries, and engagement signals. This allows teams to launch retention campaigns before it’s too late.
5. Product Recommendations
With deep learning algorithms analyzing user preferences, businesses can deliver spot-on product suggestions that increase basket size and customer satisfaction.
Challenges in Achieving AI-Readiness
Despite its benefits, making data AI-ready comes with challenges:
Data Silos: Fragmented data hampers visibility and integration.
Poor Data Quality: Inaccuracies and outdated information reduce model effectiveness.
Lack of Skilled Talent: Many organizations lack data engineers or AI specialists.
Budget Constraints: Implementing enterprise-grade tools can be costly.
Compliance Complexity: Navigating international privacy laws requires legal and technical expertise.
Overcoming these obstacles requires a cross-functional strategy involving IT, marketing, compliance, and customer experience teams.
Best Practices for Building an AI-Ready Data Strategy
Conduct a Data Audit: Identify what customer data exists, where it resides, and who uses it.
Invest in Data Talent: Hire or train data scientists, engineers, and architects.
Use Scalable Cloud Platforms: Choose infrastructure that grows with your data needs.
Automate Data Pipelines: Minimize manual intervention with workflow orchestration tools.
Establish KPIs: Measure data readiness using metrics such as data accuracy, processing speed, and privacy compliance.
Future Trends in AI-Ready Customer Data
As AI matures, we anticipate the following trends:
Synthetic Data Generation: AI can create artificial data sets for training models while preserving privacy.
Federated Learning: Enables training models across decentralized data without sharing raw data.
Edge AI: Real-time processing closer to the data source (e.g., IoT devices).
Explainable AI (XAI): Making AI decisions transparent to ensure accountability and trust.
Organizations that embrace these trends early will be better positioned to lead their industries.
0 notes
Text
h
Technical Skills (Java, Spring, Python)
Q1: Can you walk us through a recent project where you built a scalable application using Java and Spring Boot? A: Absolutely. In my previous role, I led the development of a microservices-based system using Java with Spring Boot and Spring Cloud. The app handled real-time financial transactions and was deployed on AWS ECS. I focused on building stateless services, applied best practices like API versioning, and used Eureka for service discovery. The result was a 40% improvement in performance and easier scalability under load.
Q2: What has been your experience with Python in data processing? A: I’ve used Python for ETL pipelines, specifically for ingesting large volumes of compliance data into cloud storage. I utilized Pandas and NumPy for processing, and scheduled tasks with Apache Airflow. The flexibility of Python was key in automating data validation and transformation before feeding it into analytics dashboards.
Cloud & DevOps
Q3: Describe your experience deploying applications on AWS or Azure. A: Most of my cloud experience has been with AWS. I’ve deployed containerized Java applications to AWS ECS and used RDS for relational storage. I also integrated S3 for static content and Lambda for lightweight compute tasks. In one project, I implemented CI/CD pipelines with Jenkins and CodePipeline to automate deployments and rollbacks.
Q4: How have you used Docker or Kubernetes in past projects? A: I've containerized all backend services using Docker and deployed them on Kubernetes clusters (EKS). I wrote Helm charts for managing deployments and set up autoscaling rules. This improved uptime and made releases smoother, especially during traffic spikes.
Collaboration & Agile Practices
Q5: How do you typically work with product owners and cross-functional teams? A: I follow Agile practices, attending sprint planning and daily stand-ups. I work closely with product owners to break down features into stories, clarify acceptance criteria, and provide early feedback. My goal is to ensure technical feasibility while keeping business impact in focus.
Q6: Have you had to define technical design or architecture? A: Yes, I’ve been responsible for defining the technical design for multiple features. For instance, I designed an event-driven architecture for a compliance alerting system using Kafka, Java, and Spring Cloud Streams. I created UML diagrams and API contracts to guide other developers.
Testing & Quality
Q7: What’s your approach to testing (unit, integration, automation)? A: I use JUnit and Mockito for unit testing, and Spring’s Test framework for integration tests. For end-to-end automation, I’ve worked with Selenium and REST Assured. I integrate these tests into Jenkins pipelines to ensure code quality with every push.
Behavioral / Cultural Fit
Q8: How do you stay updated with emerging technologies? A: I subscribe to newsletters like InfoQ and follow GitHub trending repositories. I also take part in hackathons and complete Udemy/Coursera courses. Recently, I explored Quarkus and Micronaut to compare their performance with Spring Boot in cloud-native environments.
Q9: Tell us about a time you challenged the status quo or proposed a modern tech solution. A: At my last job, I noticed performance issues due to a legacy monolith. I advocated for a microservices transition. I led a proof-of-concept using Spring Boot and Docker, which gained leadership buy-in. We eventually reduced deployment time by 70% and improved maintainability.
Bonus: Domain Experience
Q10: Do you have experience supporting back-office teams like Compliance or Finance? A: Yes, I’ve built reporting tools for Compliance and data reconciliation systems for Finance. I understand the importance of data accuracy and audit trails, and have used role-based access and logging mechanisms to meet regulatory requirements.
0 notes
Text
Best Azure Data Engineer Course In Ameerpet | Azure Data
Understanding Delta Lake in Databricks
Introduction
Delta Lake, an open-source storage layer developed by Databricks, is designed to address these challenges. It enhances Apache Spark's capabilities by providing ACID transactions, schema enforcement, and time travel, making data lakes more reliable and efficient. In modern data engineering, managing large volumes of data efficiently while ensuring reliability and performance is a key challenge.

What is Delta Lake?
Delta Lake is an optimized storage layer built on Apache Parquet that brings the reliability of a data warehouse to big data processing. It eliminates the limitations of traditional data lakes by adding ACID transactions, scalable metadata handling, and schema evolution. Delta Lake integrates seamlessly with Azure Databricks, Apache Spark, and other cloud-based data solutions, making it a preferred choice for modern data engineering pipelines. Microsoft Azure Data Engineer
Key Features of Delta Lake
1. ACID Transactions
One of the biggest challenges in traditional data lakes is data inconsistency due to concurrent read/write operations. Delta Lake supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable data updates without corruption. It uses Optimistic Concurrency Control (OCC) to handle multiple transactions simultaneously.
2. Schema Evolution and Enforcement
Delta Lake enforces schema validation to prevent accidental data corruption. If a schema mismatch occurs, Delta Lake will reject the data, ensuring consistency. Additionally, it supports schema evolution, allowing modifications without affecting existing data.
3. Time Travel and Data Versioning
Delta Lake maintains historical versions of data using log-based versioning. This allows users to perform time travel queries, enabling them to revert to previous states of data. This is particularly useful for auditing, rollback, and debugging purposes. Azure Data Engineer Course
4. Scalable Metadata Handling
Traditional data lakes struggle with metadata scalability, especially when handling billions of files. Delta Lake optimizes metadata storage and retrieval, making queries faster and more efficient.
5. Performance Optimizations (Data Skipping and Caching)
Delta Lake improves query performance through data skipping and caching mechanisms. Data skipping allows queries to read only relevant data instead of scanning the entire dataset, reducing processing time. Caching improves speed by storing frequently accessed data in memory.
6. Unified Batch and Streaming Processing
Delta Lake enables seamless integration of batch and real-time streaming workloads. Structured Streaming in Spark can write and read from Delta tables in real-time, ensuring low-latency updates and enabling use cases such as fraud detection and log analytics.
How Delta Lake Works in Databricks?
Delta Lake is tightly integrated with Azure Databricks and Apache Spark, making it easy to use within data pipelines. Below is a basic workflow of how Delta Lake operates: Azure Data Engineering Certification
Data Ingestion: Data is ingested into Delta tables from multiple sources (Kafka, Event Hubs, Blob Storage, etc.).
Data Processing: Spark SQL and PySpark process the data, applying transformations and aggregations.
Data Storage: Processed data is stored in Delta format with ACID compliance.
Query and Analysis: Users can query Delta tables using SQL or Spark.
Version Control & Time Travel: Previous data versions are accessible for rollback and auditing.
Use Cases of Delta Lake
ETL Pipelines: Ensures data reliability with schema validation and ACID transactions.
Machine Learning: Maintains clean and structured historical data for training ML models. Azure Data Engineer Training
Real-time Analytics: Supports streaming data processing for real-time insights.
Data Governance & Compliance: Enables auditing and rollback for regulatory requirements.
Conclusion
Delta Lake in Databricks bridges the gap between traditional data lakes and modern data warehousing solutions by providing reliability, scalability, and performance improvements. With ACID transactions, schema enforcement, time travel, and optimized query performance, Delta Lake is a powerful tool for building efficient and resilient data pipelines. Its seamless integration with Azure Databricks and Apache Spark makes it a preferred choice for data engineers aiming to create high-performance and scalable data architectures.
Trending Courses: Artificial Intelligence, Azure AI Engineer, Informatica Cloud IICS/IDMC (CAI, CDI),
Visualpath stands out as the best online software training institute in Hyderabad.
For More Information about the Azure Data Engineer Online Training
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text
Top 15 Data Collection Tools in 2025: Features, Benefits

In the data-driven world of 2025, the ability to collect high-quality data efficiently is paramount. Whether you're a seasoned data scientist, a marketing guru, or a business analyst, having the right data collection tools in your arsenal is crucial for extracting meaningful insights and making informed decisions. This blog will explore 15 of the best data collection tools you should be paying attention to this year, highlighting their key features and benefits.
Why the Right Data Collection Tool Matters in 2025:
The landscape of data collection has evolved significantly. We're no longer just talking about surveys. Today's tools need to handle diverse data types, integrate seamlessly with various platforms, automate processes, and ensure data quality and compliance. The right tool can save you time, improve accuracy, and unlock richer insights from your data.
Top 15 Data Collection Tools to Watch in 2025:
Apify: A web scraping and automation platform that allows you to extract data from any website. Features: Scalable scraping, API access, workflow automation. Benefits: Access to vast amounts of web data, streamlined data extraction.
ParseHub: A user-friendly web scraping tool with a visual interface. Features: Easy point-and-click interface, IP rotation, cloud-based scraping. Benefits: No coding required, efficient for non-technical users.
SurveyMonkey Enterprise: A robust survey platform for large organizations. Features: Advanced survey logic, branding options, data analysis tools, integrations. Benefits: Scalable for complex surveys, professional branding.
Qualtrics: A comprehensive survey and experience management platform. Features: Advanced survey design, real-time reporting, AI-powered insights. Benefits: Powerful analytics, holistic view of customer experience.
Typeform: Known for its engaging and conversational survey format. Features: Beautiful interface, interactive questions, integrations. Benefits: Higher response rates, improved user experience.
Jotform: An online form builder with a wide range of templates and integrations. Features: Customizable forms, payment integrations, conditional logic. Benefits: Versatile for various data collection needs.
Google Forms: A free and easy-to-use survey tool. Features: Simple interface, real-time responses, integrations with Google Sheets. Benefits: Accessible, collaborative, and cost-effective.
Alchemer (formerly SurveyGizmo): A flexible survey platform for complex research projects. Features: Advanced question types, branching logic, custom reporting. Benefits: Ideal for in-depth research and analysis.
Formstack: A secure online form builder with a focus on compliance. Features: HIPAA compliance, secure data storage, integrations. Benefits: Suitable for regulated industries.
MongoDB Atlas Charts: A data visualization tool with built-in data collection capabilities. Features: Real-time data updates, interactive charts, MongoDB integration. Benefits: Seamless for MongoDB users, visual data exploration.
Amazon Kinesis Data Streams: A scalable and durable real-time data streaming service. Features: High throughput, real-time processing, integration with AWS services. Benefits: Ideal for collecting and processing streaming data.
Apache Kafka: A distributed streaming platform for building real-time data pipelines. Features: High scalability, fault tolerance, real-time data processing. Benefits: Robust for large-scale streaming data.
Segment: A customer data platform that collects and unifies data from various sources. Features: Data integration, identity resolution, data governance. Benefits: Holistic view of customer data, improved data quality.
Mixpanel: A product analytics platform that tracks user interactions within applications. Features: Event tracking, user segmentation, funnel analysis. Benefits: Deep insights into user behavior within digital products.
Amplitude: A product intelligence platform focused on understanding user engagement and retention. Features: Behavioral analytics, cohort analysis, journey mapping. Benefits: Actionable insights for product optimization.
Choosing the Right Tool for Your Needs:
The best data collection tool for you will depend on the type of data you need to collect, the scale of your operations, your technical expertise, and your budget. Consider factors like:
Data Type: Surveys, web data, streaming data, product usage data, etc.
Scalability: Can the tool handle your data volume?
Ease of Use: Is the tool user-friendly for your team?
Integrations: Does it integrate with your existing systems?
Automation: Can it automate data collection processes?
Data Quality Features: Does it offer features for data cleaning and validation?
Compliance: Does it meet relevant data privacy regulations?
Elevate Your Data Skills with Xaltius Academy's Data Science and AI Program:
Mastering data collection is a crucial first step in any data science project. Xaltius Academy's Data Science and AI Program equips you with the fundamental knowledge and practical skills to effectively utilize these tools and extract valuable insights from your data.
Key benefits of the program:
Comprehensive Data Handling: Learn to collect, clean, and prepare data from various sources.
Hands-on Experience: Gain practical experience using industry-leading data collection tools.
Expert Instructors: Learn from experienced data scientists who understand the nuances of data acquisition.
Industry-Relevant Curriculum: Stay up-to-date with the latest trends and technologies in data collection.
By exploring these top data collection tools and investing in your data science skills, you can unlock the power of data and drive meaningful results in 2025 and beyond.
1 note
·
View note
Text
How Data Engineering Consultancy Builds Scalable Pipelines
To drive your business growth and make informed decision making, data integration, transformation, and its analysis is very crucial. How well you collect, transfer, analyze and utilize your data impacts your business or organization’s success. So, it becomes essential to partner with a professional data engineering consultancy to ensure your important data is managed effectively using scalable data pipelines.
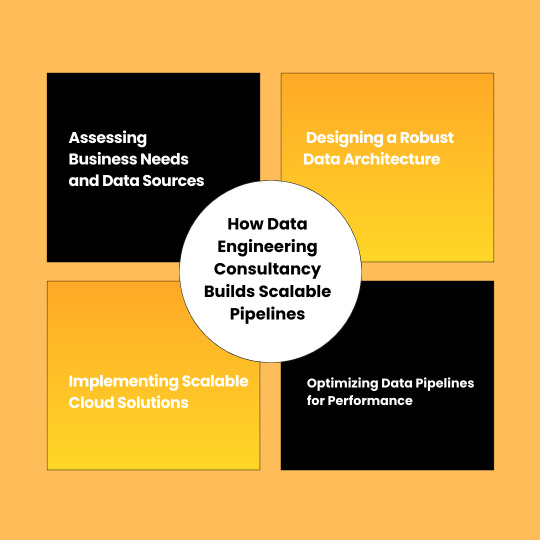
What are these scalable data pipelines? How does a Data Engineering Consultancy build them? The role of Google Analytics consulting? Let’s discuss all these concerns in this blog.
What are Scalable Data Pipelines?
Scalable data pipelines are the best approach used for moving and processing data from various sources to analytical platforms. This approach increases data volume and complexity while the performance remains consistent. Data Engineering Consultancy designs these data pipelines that handle massive data sets which is also known as the backbone of modern data infrastructure.
Key Components of a Scalable Data Pipeline
The various key components of a scalable data pipelines are:
Data Ingestion – Collect data from multiple sources. These sources are APIs, cloud services, databases and third-party applications.
Data Processing – Clean, transform, and structure raw data for analysis. These tools are Apache Spark, Airflow, and cloud-based services.
Storage & Management – Store and manage data in scalable cloud-based solutions. These solutions are Google BigQuery, Snowflake, and Amazon S3.
Automation & Monitoring – Implement automated workflows and monitor systems to ensure smooth operations and detect potential issues.
These are the various key components of scalable data pipelines that are used by Data Engineering Consultancy. These data pipelines ensure businesses manage their data efficiently, allow faster insights, and improved decision-making.
How Data Engineering Consultancy Builds Scalable Pipelines
Data Engineering Consultancy builds scalable pipelines in step by step process, let’s explore these steps.
1. Assessing Business Needs and Data Sources
Step 1 is accessing your business needs and data sources. We start by understanding your data requirements and specific business objectives. Our expert team determines the best approach for data integration by analyzing data sources such as website analytics tools, third-party applications, and CRM platforms.
2. Designing a Robust Data Architecture
Step 2 is designing a robust data plan. Our expert consultants create a customized data plan based on your business needs. We choose the most suitable technologies and frameworks by considering various factors such as velocity, variety, and data volume.
3. Implementing Scalable Cloud Solutions
Step 3 is implementing scalable cloud based solutions. We implement solutions like Azure, AWS, and Google Cloud to ensure efficiency and cost-effectiveness. Also, these platforms provide flexibility of scale storage and computing resources based on real-time demand.
4. Optimizing Data Pipelines for Performance
Step 4 is optimizing data pipelines for performance. Our Data Engineering Consultancy optimizes data pipelines by automating workflows and reducing latency. Your business can achieve near-instant data streaming and processing capabilities by integrating tools like Apache Kafka and Google Dataflow.
5. Google Analytics Consulting for Data Optimization
Google Analytics consulting plays an important role for data optimization as it understands the user behaviors and website performance.. With our Google Analytics consulting your businesses can get actionable insights by -
Setting up advanced tracking mechanisms.
Integrating Google Analytics data with other business intelligence tools.
Enhancing reporting and visualization for better decision-making.
Data Engineering Consultancy - What Are Their Benefits?
Data engineering consultancy offers various benefits,let's explore them.
Improve Data Quality and Reliability
Enhance Decision-Making
Cost and Time Efficiency
Future-Proof Infrastructure
With Data engineering consultancy, you can get access to improved data quality and reliability. This helps you to get accurate data with no errors.
You can enhance your informed decision-making using real-time and historical insights.This helps businesses to make informed decisions.
Data Engineering consultancy reduces manual data handling and operational costs as it provides cost and time efficiency.
Data Engineering consultancy provides future proof infrastructure. Businesses can scale their data operations seamlessly by using latest and exceptional technologies.
Conclusion: Boost Business With Expert & Top-Notch Data Engineering Solutions
Let’s boost business growth with exceptional and top-notch data engineering solutions. We at Kaliper help businesses to get the full potential of their valuable data to make sustainable growth of their business. Our expert and skilled team can assist you to thrive your business performance by extracting maximum value from your data assets. We can help you to gain valuable insights about your user behavior. To make informed decisions, and get tangible results with our top-notch and innovative Google Analytics solutions.
Kaliper ensures your data works smarter for you by integrating with data engineering consultancy. We help you to thrive your business with our exceptional data engineering solutions. Schedule a consultation with Kaliper today and let our professional and expert team guide you toward your business growth and success.
0 notes
Text
Hadoop Big Data Analytics Market Demand, Key Trends, and Future Projections 2032
The Hadoop Big Data Analytics Market size was valued at USD 11.22 billion in 2023 and is expected to Reach USD 62.86 billion by 2032 and grow at a CAGR of 21.11% over the forecast period of 2024-2032
The Hadoop Big Data Analytics market is expanding rapidly as businesses increasingly rely on data-driven decision-making. With the exponential growth of structured and unstructured data, organizations seek scalable and cost-effective solutions to process and analyze vast datasets. Hadoop has emerged as a key technology, offering distributed computing capabilities to manage big data efficiently.
The Hadoop Big Data Analytics market continues to thrive as industries recognize its potential to enhance operational efficiency, customer insights, and business intelligence. Companies across sectors such as healthcare, finance, retail, and manufacturing are leveraging Hadoop’s open-source framework to extract meaningful patterns from massive datasets. As data volumes continue to grow, businesses are investing in Hadoop-powered analytics to gain a competitive edge and drive innovation.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3517
Market Keyplayers:
Cloudera Inc. (Cloudera Data Platform)
Hortonworks, Inc. (Hortonworks Data Platform)
Hadapt, Inc. (Hadapt)
Amazon Web Services LLC (Amazon EMR)
Outerthought (Outerthought Hadoop)
MapR Technologies, Inc. (MapR Converged Data Platform)
Platform Computing (Platform Symphony)
Karmasphere, Inc. (Karmasphere Analytics)
Greenplum, Inc. (Greenplum Database)
Hstreaming LLC (Hstreaming)
Pentaho Corporation (Pentaho Data Integration)
Zettaset, Inc. (Zettaset Orchestrator)
IBM Corporation (IBM BigInsights)
Microsoft Corporation (Azure HDInsight)
Teradata Corporation (Teradata Analytics Platform)
SAP SE (SAP HANA)
Oracle Corporation (Oracle Big Data Appliance)
Dell Technologies (Dell EMC Isilon)
SAS Institute Inc. (SAS Viya)
Qlik Technologies (Qlik Sense)
Market Trends Driving Growth
1. Increasing Adoption of AI and Machine Learning
Hadoop is being widely integrated with AI and machine learning models to process complex data structures, enabling predictive analytics and automation.
2. Growth in Cloud-Based Hadoop Solutions
The demand for cloud-based Hadoop solutions is rising as businesses look for flexible, scalable, and cost-effective data management options. Leading cloud providers are offering Hadoop-as-a-Service (HaaS) to simplify deployment.
3. Real-Time Data Processing and Streaming Analytics
Organizations are increasingly focusing on real-time data analysis for instant decision-making, leading to the adoption of Hadoop-powered stream processing frameworks like Apache Kafka and Spark.
4. Industry-Specific Hadoop Implementations
Sectors like banking, healthcare, and retail are implementing Hadoop to enhance fraud detection, patient care analytics, and customer behavior analysis, respectively.
5. Growing Demand for Data Security and Governance
With the rise in cybersecurity threats and data privacy regulations, businesses are adopting Hadoop for secure, compliant, and well-governed big data storage and processing.
Enquiry of This Report: https://www.snsinsider.com/enquiry/3517
Market Segmentation:
By Component
Software
Services
By Application
Risk & Fraud Analytics
Internet of Things (IoT)
Customer Analytics
Security Intelligence
Distributed Coordination Service
Merchandising Coordination Service
Merchandising & Supply Chain Analytics
Others
By End-User
BFSI
IT & Telecommunication
Retail
Government & Defense
Manufacturing
Transportation & Logistics
Healthcare
Others
Market Analysis and Current Landscape
Surging data volumes from IoT, social media, and enterprise applications.
Growing enterprise investment in big data infrastructure.
Advancements in cloud computing, making Hadoop deployments more accessible.
Rising need for cost-effective and scalable data storage solutions.
Challenges such as Hadoop’s complex deployment, data security concerns, and the need for skilled professionals persist. However, innovations in automation, cloud integration, and managed Hadoop services are addressing these issues.
Future Prospects: What Lies Ahead?
1. Advancements in Edge Computing and IoT Analytics
Hadoop is expected to play a key role in processing data from IoT devices at the edge, reducing latency and improving real-time insights.
2. Expansion of Hadoop in Small and Medium Enterprises (SMEs)
As Hadoop-as-a-Service gains popularity, more SMEs will adopt big data analytics without the need for large-scale infrastructure investments.
3. Enhanced Integration with Blockchain Technology
Hadoop and blockchain integration will help improve data security, traceability, and regulatory compliance in industries like finance and healthcare.
4. Automation and No-Code Hadoop Solutions
The emergence of no-code and low-code platforms will simplify Hadoop deployments, making big data analytics more accessible to non-technical users.
5. Continued Growth in Hybrid and Multi-Cloud Hadoop Deployments
Organizations will increasingly adopt hybrid cloud and multi-cloud strategies, leveraging Hadoop for seamless data processing across different cloud environments.
Access Complete Report: https://www.snsinsider.com/reports/hadoop-big-data-analytics-market-3517
Conclusion
The Hadoop Big Data Analytics market is poised for sustained growth as businesses continue to harness big data for strategic decision-making. With advancements in AI, cloud computing, and security frameworks, Hadoop’s role in enterprise data analytics will only strengthen. Companies investing in scalable and innovative Hadoop solutions will be well-positioned to unlock new insights, improve efficiency, and drive digital transformation in the data-driven era.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Hadoop Big Data Analytics market#Hadoop Big Data Analytics market Analysis#Hadoop Big Data Analytics market Scope#Hadoop Big Data Analytics market Share#Hadoop Big Data Analytics market Growth
0 notes
Text
Discuss ADF’s role in the evolving data landscape.
The Evolving Role of Azure Data Factory in Modern Data Engineering
The data landscape is evolving rapidly, driven by the exponential growth of data, the rise of cloud computing, and the increasing need for real-time analytics. Organizations are shifting from traditional ETL (Extract, Transform, Load) pipelines to more agile, cloud-native, and scalable data integration solutions. In this transformation, Azure Data Factory (ADF) has emerged as a key player, enabling businesses to streamline their data workflows while embracing new trends like serverless computing, hybrid data integration, and AI-driven automation.
Why Azure Data Factory is Critical in the Evolving Data Landscape
1. The Shift to Cloud and Hybrid Data Integration
With businesses leveraging multiple cloud providers and on-premises systems, seamless data movement is crucial. ADF simplifies hybrid data integration by connecting on-premises databases, cloud storage, SaaS applications, and big data platforms like Azure Synapse, Snowflake, and AWS S3. The Self-hosted Integration Runtime (SHIR) allows organizations to securely transfer on-premises data to the cloud without opening firewall ports, making cloud adoption smoother.
2. Serverless and Scalable Data Pipelines
The demand for serverless computing is growing, as enterprises look for cost-effective, auto-scalable solutions. ADF offers serverless data orchestration, eliminating the need for infrastructure management. It efficiently handles both batch processing and real-time data ingestion, automatically scaling resources based on demand, ensuring performance and cost efficiency.
3. Unified ETL and ELT Capabilities
ADF supports both traditional ETL (Extract, Transform, Load) and modern ELT (Extract, Load, Transform) approaches. With data flows powered by Apache Spark, users can process large datasets without managing clusters. For ELT workflows, ADF integrates seamlessly with Azure Synapse Analytics and SQL Data Warehouse, pushing transformation logic to the database layer for optimized performance.
4. Real-Time and Streaming Data Integration
Real-time analytics is becoming a business necessity. ADF works with Azure Event Hubs, Azure Stream Analytics, and Apache Kafka to process streaming data from IoT devices, web applications, and business intelligence tools. This enables organizations to make data-driven decisions instantly, enhancing customer experiences and operational efficiencies.
5. Low-Code and No-Code Data Integration
The demand for self-service data engineering is growing, allowing non-technical users to build pipelines without deep coding expertise. ADF’s drag-and-drop UI and Data Flow activities enable users to create data transformation workflows visually, reducing development time and lowering the barrier to entry for data integration.
6. AI and Automation in Data Orchestration
Automation is at the core of modern data workflows. ADF leverages Azure Machine Learning and AI-powered monitoring to optimize pipeline execution. Features like data-driven triggers, parameterized pipelines, and error-handling mechanisms ensure automated and resilient data workflows.
7. Security, Compliance, and Governance
With data privacy regulations like GDPR, CCPA, and HIPAA, enterprises must prioritize data security and compliance. ADF provides end-to-end encryption, managed identity authentication, role-based access control (RBAC), and data masking to protect sensitive information. Integration with Azure Purview also ensures robust data lineage tracking and governance.
Conclusion:
ADF’s Future in the Data-Driven World
As enterprises continue to modernize their data ecosystems, Azure Data Factory will remain a cornerstone for data integration and orchestration. Its ability to adapt to cloud-first architectures, support real-time analytics, and integrate AI-driven automation makes it an indispensable tool for modern data engineering.
With Microsoft continuously enhancing ADF with new features, its role in the evolving data landscape will only grow stronger. Whether for batch processing, real-time analytics, or AI-driven workflows, ADF provides the flexibility and scalability that today’s businesses need to turn data into actionable insights.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
How to Integrate Hadoop with Machine Learning & AI
Introduction
With the explosion of big data, businesses are leveraging Machine Learning (ML) and Artificial Intelligence (AI) to gain insights and improve decision-making. However, handling massive datasets efficiently requires a scalable storage and processing solution—this is where Apache Hadoop comes in. By integrating Hadoop with ML and AI, organizations can build powerful data-driven applications. This blog explores how Hadoop enables ML and AI workflows and the best practices for seamless integration.
1. Understanding Hadoop’s Role in Big Data Processing
Hadoop is an open-source framework designed to store and process large-scale datasets across distributed clusters. It consists of:
HDFS (Hadoop Distributed File System): A scalable storage system for big data.
MapReduce: A parallel computing model for processing large datasets.
YARN (Yet Another Resource Negotiator): Manages computing resources across clusters.
Apache Hive, HBase, and Pig: Tools for data querying and management.
Why Use Hadoop for ML & AI?
Scalability: Handles petabytes of data across multiple nodes.
Fault Tolerance: Ensures data availability even in case of failures.
Cost-Effectiveness: Open-source and works on commodity hardware.
Parallel Processing: Speeds up model training and data processing.
2. Integrating Hadoop with Machine Learning & AI
To build AI/ML applications on Hadoop, various integration techniques and tools can be used:
(a) Using Apache Mahout
Apache Mahout is an ML library that runs on top of Hadoop.
It supports classification, clustering, and recommendation algorithms.
Works with MapReduce and Apache Spark for distributed computing.
(b) Hadoop and Apache Spark for ML
Apache Spark’s MLlib is a powerful machine learning library that integrates with Hadoop.
Spark processes data 100x faster than MapReduce, making it ideal for ML workloads.
Supports supervised & unsupervised learning, deep learning, and NLP applications.
(c) Hadoop with TensorFlow & Deep Learning
Hadoop can store large-scale training datasets for TensorFlow and PyTorch.
HDFS and Apache Kafka help in feeding data to deep learning models.
Can be used for image recognition, speech processing, and predictive analytics.
(d) Hadoop with Python and Scikit-Learn
PySpark (Spark’s Python API) enables ML model training on Hadoop clusters.
Scikit-Learn, TensorFlow, and Keras can fetch data directly from HDFS.
Useful for real-time ML applications such as fraud detection and customer segmentation.
3. Steps to Implement Machine Learning on Hadoop
Step 1: Data Collection and Storage
Store large datasets in HDFS or Apache HBase.
Use Apache Flume or Kafka for streaming real-time data.
Step 2: Data Preprocessing
Use Apache Pig or Spark SQL to clean and transform raw data.
Convert unstructured data into a structured format for ML models.
Step 3: Model Training
Choose an ML framework: Mahout, MLlib, or TensorFlow.
Train models using distributed computing with Spark MLlib or MapReduce.
Optimize hyperparameters and improve accuracy using parallel processing.
Step 4: Model Deployment and Predictions
Deploy trained models on Hadoop clusters or cloud-based platforms.
Use Apache Kafka and HDFS to feed real-time data for predictions.
Automate ML workflows using Oozie and Airflow.
4. Real-World Applications of Hadoop & AI Integration
1. Predictive Analytics in Finance
Banks use Hadoop-powered ML models to detect fraud and analyze risk.
Credit scoring and loan approval use HDFS-stored financial data.
2. Healthcare and Medical Research
AI-driven diagnostics process millions of medical records stored in Hadoop.
Drug discovery models train on massive biomedical datasets.
3. E-Commerce and Recommendation Systems
Hadoop enables large-scale customer behavior analysis.
AI models generate real-time product recommendations using Spark MLlib.
4. Cybersecurity and Threat Detection
Hadoop stores network logs and threat intelligence data.
AI models detect anomalies and prevent cyber attacks.
5. Smart Cities and IoT
Hadoop stores IoT sensor data from traffic systems, energy grids, and weather sensors.
AI models analyze patterns for predictive maintenance and smart automation.
5. Best Practices for Hadoop & AI Integration
Use Apache Spark: For faster ML model training instead of MapReduce.
Optimize Storage: Store processed data in Parquet or ORC formats for efficiency.
Enable GPU Acceleration: Use TensorFlow with GPU-enabled Hadoop clusters for deep learning.
Monitor Performance: Use Apache Ambari or Cloudera Manager for cluster performance monitoring.
Security & Compliance: Implement Kerberos authentication and encryption to secure sensitive data.
Conclusion
Integrating Hadoop with Machine Learning and AI enables businesses to process vast amounts of data efficiently, train advanced models, and deploy AI solutions at scale. With Apache Spark, Mahout, TensorFlow, and PyTorch, organizations can unlock the full potential of big data and artificial intelligence.
As technology evolves, Hadoop’s role in AI-driven data processing will continue to grow, making it a critical tool for enterprises worldwide.
Want to Learn Hadoop?
If you're looking to master Hadoop and AI, check out Hadoop Online Training or contact Intellimindz for expert guidance.
Would you like any refinements or additional details? 🚀
0 notes
Text
Essential Skills Needed to Become a Data Scientist
Introduction
The demand for data scientists is skyrocketing, making it one of the most sought-after careers in the tech industry. However, succeeding in this field requires a combination of technical, analytical, and business skills. Whether you're an aspiring data scientist or a business looking to hire top talent, understanding the key skills needed is crucial.
In this article, we'll explore the must-have skills for a data scientist and how they contribute to solving real-world business problems.
1. Programming Skills
A strong foundation in programming is essential for data manipulation, analysis, and machine learning implementation. The most popular languages for data science include:
✔ Python – Preferred for its extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow. ✔ R – Ideal for statistical computing and data visualization. ✔ SQL – Essential for querying and managing structured databases.
2. Mathematics & Statistics
Data science is built on mathematical models and statistical methods. Key areas include:
✔ Linear Algebra – Used in machine learning algorithms. ✔ Probability & Statistics – Helps in hypothesis testing, A/B testing, and predictive modeling. ✔ Regression Analysis – Essential for making data-driven predictions.
3. Data Wrangling & Preprocessing
Raw data is often messy and unstructured. Data wrangling is the process of cleaning and transforming it into a usable format. A data scientist should be skilled in:
✔ Handling missing values and duplicate records. ✔ Data normalization and transformation. ✔ Feature engineering to improve model performance.
4. Machine Learning & Deep Learning
Machine learning is at the core of predictive analytics. A data scientist should understand:
✔ Supervised Learning – Regression & classification models. ✔ Unsupervised Learning – Clustering, dimensionality reduction. ✔ Deep Learning – Neural networks, NLP, and computer vision using frameworks like TensorFlow & PyTorch.
5. Big Data Technologies
With businesses dealing with large volumes of data, knowledge of big data tools is a plus:
✔ Apache Hadoop & Spark – For distributed data processing. ✔ Kafka – Real-time data streaming. ✔ NoSQL Databases – MongoDB, Cassandra for handling unstructured data.
6. Data Visualization & Storytelling
Data-driven insights must be presented in an understandable way. Visualization tools help in storytelling, making complex data more accessible. Common tools include:
✔ Tableau & Power BI – For interactive dashboards. ✔ Matplotlib & Seaborn – For statistical visualizations. ✔ Google Data Studio – For business intelligence reporting.
7. Business Acumen & Domain Knowledge
A data scientist must understand business problems and align data insights with strategic goals. This includes:
✔ Industry-specific knowledge (Finance, Healthcare, Marketing, etc.). ✔ Understanding KPIs and decision-making processes. ✔ Communicating technical insights to non-technical stakeholders.
8. Soft Skills: Communication & Problem-Solving
Technical skills alone aren’t enough—effective communication and problem-solving skills are key. A data scientist should:
✔ Explain complex models in simple terms. ✔ Collaborate with cross-functional teams. ✔ Think critically to solve business challenges.
How Adzguru Can Help Businesses with Data Science
At Adzguru, we provide expert Data Science as a Service (DSaaS) to help businesses leverage data for growth. Our offerings include:
✔ AI & Machine Learning Solutions – Custom predictive analytics models. ✔ Big Data Integration – Scalable and real-time data processing. ✔ Business Intelligence & Data Visualization – Actionable insights for better decision-making.
Conclusion
Becoming a successful data scientist requires a blend of technical expertise, analytical thinking, and business acumen. By mastering these skills, professionals can unlock exciting career opportunities, and businesses can harness the power of data-driven decision-making.
Want to explore how data science can transform your business? Check out our Data Science Services today!
0 notes
Text
What to Look for When Hiring Remote Scala Developers

Scala is a popular choice if you as a SaaS business are looking to build scalable, high-performance applications. Regarded for its functional programming potential and seamless integration with Java, Scala is widely implemented in data-intensive applications, distributed systems, and backend development.
However, to identify and hire skilled remote software developers with Scala proficiency can be challenging. An understanding of the needed key skills and qualifications can help you find the right fit. Operating as a SaaS company makes efficiency and scalability vital, which is why the best Scala developers can ensure smooth operations and future-proof applications.
Key Skills and Qualities to Look for When Hiring Remote Scala Developers
Strong knowledge of Scala and functional programming
A Scala developer's proficiency with the language is the most crucial consideration when hiring them. Seek applicants with:
Expertise in Scala's functional programming capabilities, such as higher-order functions and immutability.
Strong knowledge of object-oriented programming (OOP) principles and familiarity with Scala frameworks such as Play, Akka, and Cats.
You might also need to hire backend developers who are adept at integrating Scala with databases and microservices if your project calls for a robust backend architecture.
Experience in distributed systems and big data
Scala is widely used by businesses for large data and distributed computing applications. The ideal developer should be familiar with:
Kafka for real-time data streaming.
Apache Spark, a top framework for large data analysis.
Proficiency in NoSQL databases, such as MongoDB and Cassandra.
Hiring a Scala developer with big data knowledge guarantees effective processing and analytics for SaaS organizations managing massive data volumes.
Ability to operate in a remote work environment
Hiring remotely is challenging since it poses several obstacles. Therefore, remote developers must be able to:
Work independently while still communicating with the team.
Use collaboration technologies like Jira, Slack, and Git for version control.
Maintain productivity while adjusting to distinct time zones.
Employing engineers with excellent communication skills guarantees smooth project management for companies transitioning to a remote workspace.
Knowledge of JVM and Java interoperability
Scala's interoperability with Java is one of its main benefits. Make sure the developer has experience with Java libraries and frameworks and is knowledgeable about JVM internals and performance tuning before employing them. They must be able to work on projects that call for integration between Java and Scala. Businesses switching from Java-based apps to Scala will find this very helpful.
Problem-solving and code optimization skills
Writing clear, effective, and maintainable code is a must for any competent Scala developer. Seek applicants who can:
Optimize and debug code according to best practices.
Refactor current codebases to increase performance.
Possess expertise in continuous integration and test-driven development (TDD).
Conclusion
It takes more than just technical know-how to choose and hire the best Scala developer. Seek out experts who can work remotely, have experience with distributed systems, and have good functional programming abilities. Long-term success will result from hiring developers with the appropriate combination of skills and expertise. Investing in top Scala talent enables SaaS organizations to create high-performing, scalable applications that propel business expansion.
0 notes
Text
How can real-time updates and scores be integrated into fantasy baseball app development?
Fantasy baseball has become a highly engaging and competitive industry, requiring real-time updates and scores to enhance user experience. Integrating these features into a fantasy baseball app can improve user retention, increase engagement, and provide players with up-to-the-minute insights on their selected teams. This article explores the various methods and technologies used to integrate real-time updates and scores into fantasy baseball app development.
1. Importance of Real-Time Updates in Fantasy Baseball
Real-time updates and live scoring are crucial for fantasy baseball apps as they provide users with instant feedback on player performances. Key benefits include:
Enhanced User Engagement: Real-time scoring keeps users actively involved in their teams.
Competitive Edge: Apps with faster updates attract more users.
Strategic Decision Making: Players can make timely changes based on live statistics.
2. Data Sources for Real-Time Updates
To ensure accurate real-time updates, fantasy baseball apps need reliable data sources, such as:
Official MLB APIs – Major League Baseball provides APIs with real-time game stats and player performance data.
Third-Party Sports Data Providers – Companies like Sportradar, STATS Perform, and FantasyData offer real-time feeds.
Web Scraping Techniques – In some cases, apps use web scraping to extract live scores from sports websites.
3. Technologies Used for Real-Time Data Integration
Several technologies and frameworks can be used to integrate real-time updates and scores into fantasy baseball apps:
WebSockets: Enables real-time bidirectional communication between the server and client.
RESTful APIs & GraphQL: Used for fetching and delivering data efficiently.
Firebase Realtime Database: Provides seamless real-time syncing across devices.
Cloud Computing Services: AWS, Google Cloud, and Azure offer scalable data processing for real-time updates.
4. Backend Infrastructure for Real-Time Processing
Developing a robust backend infrastructure is crucial for handling live data updates efficiently. Key components include:
Data Streaming Pipelines: Technologies like Apache Kafka and RabbitMQ help manage large-scale real-time data.
Database Optimization: Using NoSQL databases like MongoDB or Redis enhances performance.
Load Balancing: Ensures smooth data flow and prevents server overload.
5. Frontend Implementation for Live Scores
User experience is critical for fantasy baseball apps. The frontend should be designed to display real-time updates effectively:
Push Notifications: Instant alerts for player stats and match results.
Live Score Widgets: Interactive components that show real-time scores.
Dynamic UI Updates: Implement frameworks like React or Vue.js for smooth real-time rendering.
6. Handling Latency and Performance Optimization
Minimizing latency is key to providing seamless real-time updates. Strategies include:
Content Delivery Networks (CDN): Distributes data efficiently to reduce lag.
Efficient API Caching: Reduces server load and speeds up response times.
Edge Computing: Processes data closer to the user, minimizing delays.
7. Security and Data Integrity Measures
Ensuring the security and accuracy of real-time updates is vital:
Data Encryption: Protects sensitive user and player information.
Access Control: Prevents unauthorized API access.
Data Validation: Regularly checks data accuracy to prevent discrepancies.
8. Testing and Monitoring Real-Time Features
Rigorous testing ensures smooth operation of live updates:
Load Testing: Evaluates app performance under high traffic.
User Testing: Collects feedback to improve usability.
Monitoring Tools: Services like New Relic and Datadog track real-time data issues.
9. Monetization Opportunities with Real-Time Data
Real-time updates can be monetized to increase revenue:
Premium Subscriptions: Offer exclusive live data features for paying users.
In-App Advertisements: Display targeted ads during live updates.
Sponsorship Deals: Partner with sports brands to sponsor real-time scoring features.
Conclusion
Fantasy baseball app development enhances user experience, engagement, and monetization opportunities. By leveraging advanced technologies, optimizing backend infrastructure, and ensuring security, developers can create a dynamic and competitive fantasy baseball platform. As the demand for real-time fantasy sports apps continues to grow, investing in real-time integration remains a key strategy for success.
#Fantasy Baseball Software Development#Fantasy Baseball App Developer#Fantasy Baseball App Development#Fantasy Baseball Solution
0 notes