#median function in pandas
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
What is The Median Function Used For in Pandas?
Within Python, the programming language, libraries can be used to extend the functionality of code. One popular library is Pandas, stylized as Pandas. This library allows data scientists to manipulate and transform data in a variety of ways, but certain functions can be used to filter and sort data as well.
The MEDIAN function in pandas is an example of a function that does just that. Using the MEDIAN function in pandas, you’re able to call out the median number in a series or dataframe. A dataframe is like a spreadsheet within Python that contains an X-axis and a Y-axis.
Data from this table can be difficult to sort by sight, particularly when working with a large volume of data. Sorting via the MEDIAN function helps data scientists quickly ascertain the median number from a large group of number data.
How Can the MEDIAN Function Be Used?
You can use the MEDIAN function for a variety of things. For instance, if you were concerned about anomalies in your data, you could use the MEDIAN function to establish the median. This result will be most likely to represent a consistent trend among all the number data in a series or dataframe. With the median established in a dataset, you can establish thresholds to more easily identify anomalies in the future.
You can also use the MEDIAN function to determine the median cost of things like homes. A Realtor could work with a data scientist to establish the median home price in a particular area when working with tabular data. Realtors often gather data from their own internal sales as well as figures reported to national associations and public information provided to local governments.
This data could be imported from Excel or another spreadsheet program. Traditionally, the Realtor would need to go through each line by hand to determine the median value within the data, but the MEDIAN function can return this value instantly. Armed with this information, the Realtor can more accurately represent properties and guide buyers and sellers to the right opportunities.
Read a similar article about Excel functions in Python here at this page.
0 notes
Text
How much Python should one learn before beginning machine learning?
Before diving into machine learning, a solid understanding of Python is essential. :

Basic Python Knowledge:
Syntax and Data Types:
Understand Python syntax, basic data types (strings, integers, floats), and operations.
Control Structures:
Learn how to use conditionals (if statements), loops (for and while), and list comprehensions.
Data Handling Libraries:
Pandas:
Familiarize yourself with Pandas for data manipulation and analysis. Learn how to handle DataFrames, series, and perform data cleaning and transformations.
NumPy:
Understand NumPy for numerical operations, working with arrays, and performing mathematical computations.
Data Visualization:
Matplotlib and Seaborn:
Learn basic plotting with Matplotlib and Seaborn for visualizing data and understanding trends and distributions.
Basic Programming Concepts:
Functions:
Know how to define and use functions to create reusable code.
File Handling:
Learn how to read from and write to files, which is important for handling datasets.
Basic Statistics:
Descriptive Statistics:
Understand mean, median, mode, standard deviation, and other basic statistical concepts.
Probability:
Basic knowledge of probability is useful for understanding concepts like distributions and statistical tests.
Libraries for Machine Learning:
Scikit-learn:
Get familiar with Scikit-learn for basic machine learning tasks like classification, regression, and clustering. Understand how to use it for training models, evaluating performance, and making predictions.
Hands-on Practice:
Projects:
Work on small projects or Kaggle competitions to apply your Python skills in practical scenarios. This helps in understanding how to preprocess data, train models, and interpret results.
In summary, a good grasp of Python basics, data handling, and basic statistics will prepare you well for starting with machine learning. Hands-on practice with machine learning libraries and projects will further solidify your skills.
To learn more drop the message…!
2 notes
·
View notes
Text
Statistics Programming and Data Analysis

Statistics programming is a key part of data analysis and decision-making in fields ranging from business to science. By combining statistical knowledge with programming, developers can uncover patterns, test hypotheses, and make data-driven decisions effectively.
What is Statistical Programming?
Statistical programming is the use of programming languages to perform statistical analysis on data. It involves techniques like data cleaning, descriptive analysis, hypothesis testing, modeling, and visualization.
Popular Languages for Statistical Programming
R: A language built specifically for statistical computing and graphics.
Python: Widely used with libraries like pandas, numpy, scipy, and statsmodels.
SAS: Often used in healthcare and enterprise environments.
Julia: A newer language offering high-performance data processing.
Basic Concepts in Statistical Analysis
Descriptive Statistics (mean, median, mode, variance)
Probability Distributions
Hypothesis Testing (t-tests, chi-square)
Regression Analysis
ANOVA (Analysis of Variance)
Python Example: Descriptive Stats
import pandas as pd data = [23, 45, 12, 67, 34, 89, 22] df = pd.Series(data) print("Mean:", df.mean()) print("Median:", df.median()) print("Standard Deviation:", df.std())
Essential Libraries for Data Analysis
pandas: Data manipulation and analysis
numpy: Numerical computations
matplotlib/seaborn: Visualization
scipy: Scientific and statistical functions
statsmodels: Statistical models and tests
Applications of Statistical Programming
Market and Customer Analysis
Scientific Research and Experiments
Financial Forecasting
Healthcare Analytics
Sports Performance Analysis
Best Practices
Always clean and validate your data before analysis.
Understand the assumptions behind each statistical test.
Visualize your data to identify patterns or outliers.
Automate your workflows using scripts or notebooks.
Document your analysis for reproducibility.
Conclusion
Statistical programming gives developers the power to transform raw data into actionable insights. Whether you're a beginner or an experienced analyst, learning how to combine statistics with code will supercharge your data analysis skills and open up endless opportunities across industries.
0 notes
Text
How do you handle missing data in a dataset?
Handling missing data is a crucial step in data preprocessing, as incomplete datasets can lead to biased or inaccurate analysis. There are several techniques to deal with missing values, depending on the nature of the data and the extent of missingness.
1. Identifying Missing Data Before handling missing values, it is important to detect them using functions like .isnull() in Python’s Pandas library. Understanding the pattern of missing data (random or systematic) helps in selecting the best strategy.
2. Removing Missing Data
If the missing values are minimal (e.g., less than 5% of the dataset), you can remove the affected rows using dropna().
If entire columns contain a significant amount of missing data, they may be dropped if they are not crucial for analysis.
3. Imputation Techniques
Mean/Median/Mode Imputation: For numerical data, replacing missing values with the mean, median, or mode of the column ensures continuity in the dataset.
Forward or Backward Fill: For time-series data, forward filling (ffill()) or backward filling (bfill()) propagates values from previous or next entries.
Interpolation: Using methods like linear or polynomial interpolation estimates missing values based on trends in the dataset.
Predictive Modeling: More advanced techniques use machine learning models like K-Nearest Neighbors (KNN) or regression to predict and fill missing values.
4. Using Algorithms That Handle Missing Data Some machine learning algorithms, like decision trees and random forests, can handle missing values internally without imputation.
By applying these techniques, data quality is improved, leading to more accurate insights. To master such data preprocessing techniques, consider enrolling in the best data analytics certification, which provides hands-on training in handling real-world datasets.
0 notes
Text
Ensuring Data Accuracy with Cleaning
Ensuring data accuracy with cleaning is an essential step in data preparation. Here’s a structured approach to mastering this process:
1. Understand the Importance of Data Cleaning
Data cleaning is crucial because inaccurate or inconsistent data leads to faulty analysis and incorrect conclusions. Clean data ensures reliability and robustness in decision-making processes.
2. Common Data Issues
Identify the common issues you might face:
Missing Data: Null or empty values.
Duplicate Records: Repeated entries that skew results.
Inconsistent Formatting: Variations in date formats, currency, or units.
Outliers and Errors: Extreme or invalid values.
Data Type Mismatches: Text where numbers should be or vice versa.
Spelling or Casing Errors: Variations like “John Doe” vs. “john doe.”
Irrelevant Data: Data not needed for the analysis.
3. Tools and Libraries for Data Cleaning
Python: Libraries like pandas, numpy, and pyjanitor.
Excel: Built-in cleaning functions and tools.
SQL: Using TRIM, COALESCE, and other string functions.
Specialized Tools: OpenRefine, Talend, or Power Query.
4. Step-by-Step Process
a. Assess Data Quality
Perform exploratory data analysis (EDA) using summary statistics and visualizations.
Identify missing values, inconsistencies, and outliers.
b. Handle Missing Data
Imputation: Replace with mean, median, mode, or predictive models.
Removal: Drop rows or columns if data is excessive or non-critical.
c. Remove Duplicates
Use functions like drop_duplicates() in pandas to clean redundant entries.
d. Standardize Formatting
Convert all text to lowercase/uppercase for consistency.
Standardize date formats, units, or numerical scales.
e. Validate Data
Check against business rules or constraints (e.g., dates in a reasonable range).
f. Handle Outliers
Remove or adjust values outside an acceptable range.
g. Data Type Corrections
Convert columns to appropriate types (e.g., float, datetime).
5. Automate and Validate
Automation: Use scripts or pipelines to clean data consistently.
Validation: After cleaning, cross-check data against known standards or benchmarks.
6. Continuous Improvement
Keep a record of cleaning steps to ensure reproducibility.
Regularly review processes to adapt to new challenges.
Would you like a Python script or examples using a specific dataset to see these principles in action?
0 notes
Text
What will we study in Data Science with Python and AI with Python, and what is its scope in the future?
Data Science using Python and AI is an up-and-coming field that merges the power of Python programming with superior AI techniques to extract insightful information from big data.
Key Areas of Study
Python Programming
Fundamentals: Variables, data types, control flow, functions, modules.
Libraries: NumPy, Pandas, Matplotlib, Seaborn for data manipulation, analysis, and visualization.
Statistics and Mathematics
Descriptive Statistics: Mean, median, mode, standard deviation.
Probability: Distributions, hypothesis testing.
Linear Algebra: Matrices, vectors, operations.
Calculus: Derivatives, integrals.
Machine Learning
Supervised Learning: Regression-Linear, logistic; classification-decision trees, random forests, support vector machines.
Unsupervised Learning: Clustering, K-means, hierarchical; dimensionality reduction, PCA, t-SNE.
Deep Learning: Neural networks-convolutional, recurrent; TensorFlow, PyTorch.
Data Cleaning and Preprocessing
Handling Missing Values: Imputation techniques
Outlier Detection: Identification and treatment
Feature Engineering: New feature creation from existing ones.
Natural Language Processing
Text Preprocessing: Tokenization; stemming; lemmatization
Sentiment Analysis: Determining the sentiment of a text.
Text Classification: Categorization of texts into predefined categories.
Computer Vision
Image Processing: Filtering, Segmentation, Feature Extraction
Object Detection: The capability of recognizing objects from images and videos.
Image Classification: Classifying images into groups based on their content.
Future Scope of Data Science with Python and AI Automation: AI will perform routine tasks from the data scientist and will leave them for more significant roles to play.
Deep Learning: Breakthroughs in deep learning will make the models' architecture even more complicated and enable them to be more accurate.
Ethics: Bias, Privacy, and explainability are some of the crucial concerns for AI applications.
Interdisciplinary Applications: Data Science integrated with healthcare, finance, and manufacturing.
Emerging Technologies: A foray into new areas of generative AI, reinforcement learning, and quantum machine learning.
Conceptual clarity on these topics and an update on the current trends could take you far towards a really rewarding career in data science and AI.
0 notes
Text
What is data cleaning with pandas
Data cleaning with Pandas involves using the library's powerful functions to prepare and transform raw data into a format suitable for analysis. Raw datasets often contain inconsistencies, missing values, duplicates, or incorrect data types, which can skew results if not properly handled.
Key steps in data cleaning with Pandas include:
Handling Missing Data: Missing values can be addressed using methods such as fillna() to replace them with a default value or the mean/median of a column, or by using dropna() to remove rows or columns with missing values.
Removing Duplicates: Duplicated rows can be identified and removed using drop_duplicates(), which ensures each record is unique and prevents skewed analysis.
Data Type Conversion: Incorrect data types can cause issues during analysis. The astype() function allows you to convert columns to appropriate types, such as changing strings to dates or numbers.
Filtering and Renaming Columns: You can filter or rename columns using filter() or rename(), making the dataset easier to manage and understand.
Standardizing Data: Inconsistent formatting, such as varying text capitalization, can be standardized using methods like str.lower() or str.strip(). Handling Outliers: Pandas can also help in identifying and handling outliers by applying functions like describe() to detect unusual values.
0 notes
Text
Comprehensive Breakdown of a Data Science Curriculum: What to Expect from Start to Finish
Comprehensive Breakdown of a Data Science Curriculum: What to Expect from Start to Finish
A Data Science course typically covers a broad range of topics, combining elements from statistics, computer science, and domain-specific knowledge. Here’s a breakdown of what you can expect from a comprehensive Data Science curriculum:
1. Introduction to Data Science
Overview of Data Science: Understanding what Data Science is and its significance.
Applications of Data Science: Real-world examples and case studies.
2. Mathematics and Statistics
Linear Algebra: Vectors, matrices, eigenvalues, and eigenvectors.
Calculus: Derivatives and integrals, partial derivatives, gradient descent.
Probability and Statistics: Probability distributions, hypothesis testing, statistical inference, sampling, and data distributions.
3. Programming for Data Science
Python/R: Basics and advanced concepts of programming using Python or R.
Libraries and Tools: NumPy, pandas, Matplotlib, seaborn for Python; dplyr, ggplot2 for R.
Data Manipulation and Cleaning: Techniques for preprocessing, cleaning, and transforming data.
4. Data Visualization
Principles of Data Visualization: Best practices, visualization types.
Tools and Libraries: Tableau, Power BI, and libraries like Matplotlib, seaborn, Plotly.
5. Data Wrangling
Data Collection: Web scraping, APIs.
Data Cleaning: Handling missing data, data types, normalization.
6. Exploratory Data Analysis (EDA)
Descriptive Statistics: Mean, median, mode, standard deviation.
Data Exploration: Identifying patterns, anomalies, and visual exploration.
7. Machine Learning
Supervised Learning: Linear regression, logistic regression, decision trees, random forests, support vector machines.
Unsupervised Learning: K-means clustering, hierarchical clustering, PCA (Principal Component Analysis).
Model Evaluation: Cross-validation, bias-variance tradeoff, ROC/AUC.
8. Deep Learning
Neural Networks: Basics of neural networks, activation functions.
Deep Learning Frameworks: TensorFlow, Keras, PyTorch.
Applications: Image recognition, natural language processing.
9. Big Data Technologies
Introduction to Big Data: Concepts and tools.
Hadoop and Spark: Ecosystem, HDFS, MapReduce, PySpark.
10. Data Engineering
ETL Processes: Extract, Transform, Load.
Data Pipelines: Building and maintaining data pipelines.
11. Database Management
SQL and NoSQL: Database design, querying, and management.
Relational Databases: MySQL, PostgreSQL.
NoSQL Databases: MongoDB, Cassandra.
12. Capstone Project
Project Work: Applying the concepts learned to real-world data sets.
Presentation: Communicating findings effectively.
13. Ethics and Governance
Data Privacy: GDPR, data anonymization.
Ethical Considerations: Bias in data, ethical AI practices.
14. Soft Skills and Career Preparation
Communication Skills: Presenting data findings.
Team Collaboration: Working in data science teams.
Job Preparation: Resume building, interview preparation.
Optional Specializations
Natural Language Processing (NLP)
Computer Vision
Reinforcement Learning
Time Series Analysis
Tools and Software Commonly Used:
Programming Languages: Python, R
Data Visualization Tools: Tableau, Power BI
Big Data Tools: Hadoop, Spark
Databases: MySQL, PostgreSQL, MongoDB, Cassandra
Machine Learning Libraries: Scikit-learn, TensorFlow, Keras, PyTorch
Data Analysis Libraries: NumPy, pandas, Matplotlib, seaborn
Conclusion
A Data Science course aims to equip students with the skills needed to collect, analyze, and interpret large volumes of data, and to communicate insights effectively. The curriculum is designed to be comprehensive, covering both theoretical concepts and practical applications, often culminating in a capstone project that showcases a student’s ability to apply what they've learned.
Acquire Skills and Secure a Job with best package in a reputed company in Ahmedabad with the Best Data Science Course Available
Or contact US at 1802122121 all Us 18002122121
Call Us 18002122121
Call Us 18002122121
Call Us 18002122121
Call Us 18002122121
0 notes
Text
Battle of the Programming Languages: R vs Python

Battle of the Programming Languages: R vs Python
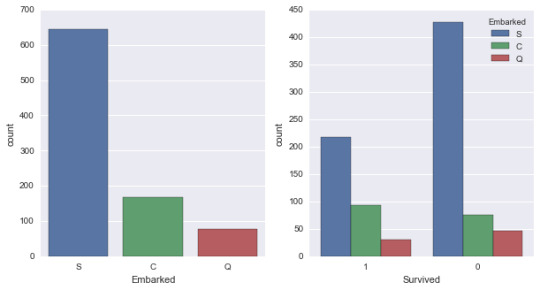
We are going to compare Functions exist in both R and Python for same operations. And for this we took the Titanic dataset which contains the Passenger details. Importing a CSV Reading Data in both the languages is similar, but the only difference is for python we have to import pandas library for reading the Data. Once the importing is done we can look into the data by applying the below functions.RPythontitanicimport pandas as pd
titanic = pd.read_csv("train.csv")
Dimension and Shape If we want to look the Dimension of the above imported Data. You can get it from the below functions.RPythondim(titanic)titanic.shape[1] 891 12(891, 12)
The above code brings you the number of passengers in titanic ship and the number of columns present in data. Head and Tail If you want to see some of the data like top rows (Any number of rows by default it gets 5 rows) or bottom rows form the Data frame. There are functions in similar functions in both R and Python.RPythonhead(titanic,2)titanic.head(2)PassengerId Survived Pclass
1 1 0 3
2 2 1 1
PassengerId Survived Pclass 0 1 0 3 1 2 1 1tail(titanic,2)titanic.tail(2) PassengerId Survived Pclass
890 890 1 1
891 891 0 3
PassengerId Survived Pclass 889 890 1 1
890 891 0 3
Here head and tail functions applied on Titanic dataset to look at the first two rows of Data. If you observe clearly the index values are different in both R and Python. It is because Python index starts with '0'. Basic Statistics of Data (Summary and Describe)RPythonsummary(titanic)titanic.describe()PassengerId SurvivedPassengerId SurvivedMin. : 1.0 Min. :0.0000
1st Qu.:223.5 1st Qu.:0.0000
Median :446.0 Median :0.0000
Mean :446.0 Mean :0.3838
3rd Qu.:668.5 3rd Qu.:1.0000
Max. : 891.0 Max. :1.0000count 891.000000 891.000000
mean 446.000000 0.383838
std 257.353842 0.486592
min 1.000000 0.000000
25% 223.500000 0.000000
50% 446.000000 0.000000
75% 668.500000 1.000000
max 891.000000 1.000000
The above two functions are for determining some basic statistics column wise. Whereas python gives two more statistic values compared to R function. The main difference between these functions is R contains Separate functions and for Python we have to call the required methods on the Data as it is more of object oriented type programming. Slicing the Datatitanic[1:5,1:3]titanic.iloc[0:5,0:3]PassengerId Survived Pclass
1 1 0 3
2 2 1 1
3 3 1 3
4 4 1 1
5 5 0 3PassengerId Survived Pclass
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Sub setting Data Here in this case for sub setting the Data I took only some columns from the titanic Dataset. For the convenience of displaying the output. Using sam_data sam_data = titanic[['PassengerId', 'Survived','Sex','Age']] for Python I created sam_data for applying subset function. subset(sam_data,Survived == 1& Sex == 'male')sam_data[(sam_data.Sex == 'male') & (sam_data.Survived ==1)].head(2)PassengerId Survived Sex Age
18 18 1 male NA 22 22 1 male 34 24 24 1 male 28 37 37 1 male NA 56 56 1 male NA 66 66 1 male NAPassengerId Survived Sex Age
17 18 1 male NaN 21 22 1 male 34.00 23 24 1 male 28.00 36 37 1 male NaN 55 56 1 male NaN 65 66 1 male NaN
The important thing here is the representation of NA in Python is NaN. Ordering the Data We ordered the Sample Dataset By arrange(sam_data, Survived, desc(Age))sam_data.sort_index(by=['Survived', 'Age'], ascending=[True, False])PassengerId Survived Sex Age 1 852 0 male 74.0 2 97 0 male 71.0 3 494 0 male 71.0 4 117 0 male 70.5 5 673 0 male 70.0 6 746 0 male 70.0PassengerId Survived Sex Age 851 852 0 male 74.0 493 494 0 male 71.0 96 97 0 male 71.0 116 117 0 male 70.5 672 673 0 male 70.0 745 746 0 male 70.0
Joins For Performing join operations we created three different data frames from the titanic Dataset df_Survived df_Sex df_Age df_Survived = sam_data[['PassengerId', 'Survived']] df_Sex = sam_data [['PassengerId', 'Sex']] df_Age = sam_data [[ 'PassengerId', 'Age']] Inner
JoinTable_Inner_J = merge ( merge(df_Survived, df_Sex, key = "PassengerId" ),
df_Age ,
key = "PassengerId")Table_Inner_J = pd.merge ( pd.merge(df_Survived, df_Sex, on = "PassengerId" , how = "inner" ),
df_Age ,
on = "PassengerId" , how = "inner")Outer JoinTable_Outer_J = merge ( merge(df_Survived, df_Sex, key = "PassengerId" , all =TRUE),
df_Age ,
key = "PassengerId", all = TRUE)Table_Outer_J = pd.merge ( pd.merge(df_Survived, df_Sex, on = "PassengerId" , how = "outer"),
df_Age ,
on = "PassengerId", how = "outer")Left
JoinTable_Left_J = merge ( merge(df_Survived, df_Sex, key = "PassengerId" , all.x =TRUE),
df_Age ,
key = "PassengerId", all.x = TRUE)Table_Left_J = pd.merge ( pd.merge(df_Survived, df_Sex, on = "PassengerId" , how = "left"),
df_Age ,
on = "PassengerId" , how = "left")Right
JoinTable_Right_J = merge ( merge(df_Survived, df_Sex, key = "PassengerId", all.y = TRUE),
df_Age ,
key = "PassengerId", all.y = TRUE )Table_Right_J = pd.merge ( pd.merge(df_Survived, df_Sex, on = "PassengerId" , how = "right"),
df_Age ,
on = "PassengerId" , how = "right")
The major Difference in R and Python for joining operation is both can be done using merge function. But for python we have to import pandas library for using the merge function to perform these join functions. We can join three Data frames at a time by applying merge function two times. Missing Values Treatment: In Missing Values treatment first thing we have to do is identify the NA values by running the first block of code in below table. After getting the variables where missing values are there then you can impute them with the mean value of that respective column. Here, second block of code replaces the NA values with the respective mean values. tail(is.na(sam_data))sam_data.isnull().tail()PassengerId Survived Sex Age [886,] FALSE FALSE FALSE FALSE [887,] FALSE FALSE FALSE FALSE [888,] FALSE FALSE FALSE FALSE [889,] FALSE FALSE FALSE TRUE [890,] FALSE FALSE FALSE FALSE [891,] FALSE FALSE FALSE FALSEPassengerId Survived Sex Age 886 False False False False 887 False False False False 888 False False False False 889 False False False True 890 False False False Falsesam_data["Age"][is.na(sam_data["Age"])]meanAge = np.mean(sam_data.Age)
sam_data.Age = sam_data.Age.fillna(meanAge)PassengerId Survived Sex Age
[886,] FALSE FALSE FALSE FALSE
[887,] FALSE FALSE FALSE FALSE
[888,] FALSE FALSE FALSE FALSE
[889,] FALSE FALSE FALSE FALSE
[890,] FALSE FALSE FALSE FALSE
[891,] FALSE FALSE FALSE FALSEPassengerId Survived Sex Age
886 False False False False
887 False False False False
888 False False False False
889 False False False False
890 False False False False

About Rang Technologies: Headquartered in New Jersey, Rang Technologies has dedicated over a decade delivering innovative solutions and best talent to help businesses get the most out of the latest technologies in their digital transformation journey. Read More...
0 notes
Text
Demystifying Data Science: Essential Concepts for Beginners
In today's data-driven world, the field of data science stands out as a beacon of opportunity. With Python programming as its cornerstone, data science opens doors to insights, predictions, and solutions across countless industries. If you're a beginner looking to dive into this exciting realm, fear not! This article will serve as your guide, breaking down essential concepts in a straightforward manner.
1. Introduction to Data Science
Data science is the art of extracting meaningful insights and knowledge from data. It combines aspects of statistics, computer science, and domain expertise to analyze complex data sets.
2. Why Python?
Python has emerged as the go-to language for data science, and for good reasons. It boasts simplicity, readability, and a vast array of libraries tailored for data manipulation, analysis, and visualization.
3. Setting Up Your Python Environment
Before we dive into coding, let's ensure your Python environment is set up. You'll need to install Python and a few key libraries such as Pandas, NumPy, and Matplotlib. These libraries will be your companions throughout your data science journey.
4. Understanding Data Types
In Python, everything is an object with a type. Common data types include integers, floats (decimal numbers), strings (text), booleans (True/False), and more. Understanding these types is crucial for data manipulation.
5. Data Structures in Python
Python offers versatile data structures like lists, dictionaries, tuples, and sets. These structures allow you to organize and work with data efficiently. For instance, lists are sequences of elements, while dictionaries are key-value pairs.
6. Introduction to Pandas
Pandas is a powerhouse library for data manipulation. It introduces two main data structures: Series (1-dimensional labeled array) and DataFrame (2-dimensional labeled data structure). These structures make it easy to clean, transform, and analyze data.
7. Data Cleaning and Preprocessing
Before diving into analysis, you'll often need to clean messy data. This involves handling missing values, removing duplicates, and standardizing formats. Pandas provides functions like dropna(), fillna(), and replace() for these tasks.
8. Basic Data Analysis with Pandas
Now that your data is clean, let's analyze it! Pandas offers a plethora of functions for descriptive statistics, such as mean(), median(), min(), and max(). You can also group data using groupby() and create pivot tables for deeper insights.
9. Data Visualization with Matplotlib
They say a picture is worth a thousand words, and in data science, visualization is key. Matplotlib, a popular plotting library, allows you to create various charts, histograms, scatter plots, and more. Visualizing data helps in understanding trends and patterns.
Conclusion
Congratulations! You've embarked on your data science journey with Python as your trusty companion. This article has laid the groundwork, introducing you to essential concepts and tools. Remember, practice makes perfect. As you explore further, you'll uncover the vast possibilities data science offers—from predicting trends to making informed decisions. So, grab your Python interpreter and start exploring the world of data!
In the realm of data science, Python programming serves as the key to unlocking insights from vast amounts of information. This article aims to demystify the field, providing beginners with a solid foundation to begin their journey into the exciting world of data science.
0 notes
Text
Navigating the Data Science Journey: A Step-by-Step Guide
Are you captivated by the realm of data science but find yourself daunted by its vastness? Fear not, you're not alone. Data science is an exhilarating and swiftly evolving discipline that amalgamates statistics, programming, and domain expertise to extract insights and knowledge from data. Whether you're a novice or seeking to refine your skills, adopting a step-by-step approach can simplify the journey and infuse it with enjoyment. If you want to advance your career at the Data Science Training in Pune, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path.

Let's delineate the process:
Step 1: Grasp the Fundamentals Before delving into the technical intricacies of data science, it's imperative to grasp the basics. Familiarize yourself with elementary statistical concepts such as mean, median, and standard deviation. Acquaint yourself with diverse data types and their characteristics, encompassing categorical and numerical data. For those looking to excel in Data Science, Data Science Online Training is highly suggested. Look for classes that align with your preferred programming language and learning approach.
Step 2: Acquire Proficiency in Programming Languages Python and R stand as the foremost programming languages in data science. Begin by mastering the rudiments of one of these languages. Concentrate on comprehending data structures, control flow, and functions. Abundant online tutorials and resources are available for free to aid in your initiation.
Step 3: Explore Data Analysis and Visualization Once you've attained proficiency in programming basics, delve into data analysis and visualization libraries within your chosen language. Learn to load and manipulate datasets, conduct descriptive statistics, and craft visual representations utilizing tools like pandas, matplotlib, and seaborn in Python, or ggplot2 in R. Visualizing data facilitates insight generation and effective communication of findings.
Step 4: Hone Machine Learning Concepts Machine learning serves as the crux of data science, empowering computers to glean insights from data and make predictions or decisions. Begin by comprehending the manifold machine learning algorithms, spanning supervised and unsupervised learning. Familiarize yourself with training and evaluating models using libraries such as scikit-learn in Python or caret in R. Experiment with diverse algorithms to discern their optimal applications.
Step 5: Delve into Advanced Topics As you accrue experience, delve into advanced data science topics such as deep learning, natural language processing, and big data technologies. Given their perpetual evolution, maintaining curiosity and staying abreast of the latest advancements is paramount. Engage with online communities, attend workshops, and participate in hackathons to broaden your horizons and network with fellow data aficionados.
Step 6: Apply Your Skills The most efficacious approach to solidify your understanding of data science concepts is through their practical application. Seek opportunities to engage in real-world data science projects, whether through internships, freelance endeavors, or personal initiatives. Cultivating a portfolio of projects not only showcases your abilities to potential employers but also deepens your comprehension of data science principles.
Step 7: Persist in Learning and Advancing Data science is an expansive domain teeming with opportunities for continual learning and growth. Maintain a sense of inquisitiveness, explore novel techniques and technologies, and never cease your pursuit of knowledge. Whether it entails attending conferences, enrolling in online courses, or perusing research papers, there's perpetually something new to uncover in the realm of data science.

In conclusion, embarking on the journey of learning data science necessitates dedication, patience, and an unwavering commitment to perpetual learning. By adhering to these sequential guidelines and remaining steadfast in your aspirations, you can embark on a gratifying career in data science and effectuate meaningful contributions to the field. So roll up your sleeves, plunge in, and relish the adventure!
#data science#data science course#data science training#data science certification#data scientist#data science online course
0 notes
Text
The Foundation of Clean Data Analysis
Clean data is the cornerstone of accurate and reliable data analysis. A robust foundation in data cleaning ensures that your insights are valid, consistent, and actionable. Here’s an outline of the foundational steps for clean data analysis:
1. Understanding the Dataset
Familiarize Yourself with the Data Understand the context of the dataset, including its purpose, variables, and expected outcomes. Tools: Data dictionaries, documentation, or domain expertise.
Inspect the Data Use methods like .head(), .info(), and .describe() in Python to gain an overview of the dataset's structure and summary statistics.
2. Identifying and Handling Missing Data
Locate Missing Data Identify missing values using functions like .isnull().sum() in Python. Visualization: Heatmaps (e.g., Seaborn) can highlight missing data patterns.
Strategies to Handle Missing Data
Removal: Drop rows or columns with excessive missing values.
Imputation: Fill missing values using statistical methods (mean, median, mode) or predictive models.
3. Addressing Outliers
Detect Outliers Use visualizations like boxplots or statistical methods like Z-scores and IQR to identify outliers.
Handle Outliers Options include capping, transformation, or removal, depending on the context of the analysis.
4. Resolving Inconsistencies
Standardize Data Formats Ensure consistency in formats (e.g., date formats, text capitalization, units of measurement). Example: Converting all text to lowercase using .str.lower() in Python.
Validate Entries Check for and correct invalid entries like negative ages or typos in categorical data.
5. Dealing with Duplicates
Detect Duplicates Use methods like .duplicated() to identify duplicate rows.
Handle Duplicates Drop duplicates unless they are meaningful for the analysis.
6. Ensuring Correct Data Types
Verify Data Types Check that variables have appropriate types (e.g., integers for counts, strings for categories).
Convert Data Types Use type-casting functions like astype() in Python to fix mismatched data types.
7. Data Transformation
Feature Scaling Apply normalization or standardization for numerical features used in machine learning. Techniques: Min-Max scaling or Z-score normalization.
Encoding Categorical Variables Use one-hot encoding or label encoding for categorical features.
Key Tools for Data Cleaning:
Libraries: Pandas, NumPy, Seaborn, Matplotlib (for Python users).
Software: Excel, OpenRefine, or specialized ETL tools like Talend or Alteryx.
By mastering these foundational steps, you’ll ensure your data is clean, consistent, and ready for exploration and analysis. Would you like more detailed guidance or code examples for any of these steps?
0 notes
Text
A Beginner's Guide to Data Preprocessing in Machine Learning: Cleaning and Preparing Data for Analysis

Introduction:
Data is the fuel that powers the world of machine learning, but it's rarely in perfect shape when we first get our hands on it. Raw data is often messy, containing missing values, outliers, and inconsistencies that can negatively impact the performance of machine learning models. That's where data preprocessing comes in – a crucial step in the machine learning pipeline that involves cleaning and preparing the data to ensure it's in a suitable format for analysis. In this blog, we'll walk through the basics of data preprocessing and introduce some popular libraries to help you get started on your machine learning journey.
1. Importing the Necessary Libraries:
Before diving into data preprocessing, let's make sure we have the right tools at our disposal. We'll need to import the following libraries in Python:
- Pandas: For data manipulation and analysis.
- NumPy: For numerical operations and array processing.
- Matplotlib and Seaborn: For data visualization.
- Scikit-learn: For machine learning algorithms and additional preprocessing functions.
You can install these libraries using pip by running the following commands:
pip install pandas numpy matplotlib seaborn scikit-learn
2. Understanding the Data:
The first step in data preprocessing is to gain an understanding of the data you're working with. Look for the following aspects:
- The dimensions of the dataset (rows and columns).
- The types of features present (numerical, categorical, text, etc.).
- The presence of any missing values.
- Distribution of the target variable (for supervised learning tasks).
3. Handling Missing Data:
Missing data is a common issue in datasets and can lead to biased results if not handled properly. There are several approaches to deal with missing values:
- **Removal**: Remove rows or columns with missing values. However, this should be done with caution as it may result in a loss of valuable information.
- **Imputation**: Fill in missing values using various techniques such as mean, median, mode, or advanced imputation methods like K-nearest neighbors.
We can use Pandas to perform these operations:
import pandas as pd
# Load the dataset
data = pd.read_csv('your_dataset.csv')
# Check for missing values
print(data.isnull().sum())
# Impute missing values with mean
data.fillna(data.mean(), inplace=True)
4. Handling Categorical Data:
Machine learning models typically work with numerical data, so we need to convert categorical data into numerical form. One common technique is one-hot encoding, where each category becomes a binary column.
# One-hot encoding using pandas
data = pd.get_dummies(data, columns=['categorical_column'])
5. Feature Scaling:
Feature scaling ensures that all numerical features are on a similar scale, preventing certain features from dominating others during model training. Two popular scaling techniques are Min-Max scaling and Standardization.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Min-Max Scaling
scaler = MinMaxScaler()
data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']])
# Standardization
scaler = StandardScaler()
data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']])
6. Handling Outliers:
Outliers can significantly impact model performance. You can visualize them using box plots and handle them using various techniques like truncation or capping.
import seaborn as sns
# Box plot to identify outliers
sns.boxplot(data=data[['feature1', 'feature2']])
7. Splitting the Data:
Before training the model, we need to split the data into training and testing sets. This allows us to evaluate the model's performance on unseen data.
from sklearn.model_selection import train_test_split
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Conclusion:
Data preprocessing is a critical step in the machine learning workflow, as it ensures that the data is cleaned and transformed into a suitable format for model training. In this blog, we covered the basics of data preprocessing, including handling missing data, categorical data, feature scaling, and outliers. By using libraries like Pandas, NumPy, Matplotlib, Seaborn, and Scikit-learn, you can effectively preprocess your data and set the foundation for building powerful machine learning models.
Remember that data preprocessing is not a one-size-fits-all process. Different datasets may require different preprocessing techniques, so always be prepared to explore and adapt your approach accordingly. Happy learning and good luck on your machine learning journey!
@TalentServe
#DataPreprocessing #MachineLearning #Cleaning #Analysis
0 notes
Text
Dealing with missing data in Pandas

Data Pre-processing can be referred as the manipulation of data before it is being used so as to ensure performance and it is a very important step to be done as a Data Scientist. Data Pre-processing can be generally classified as Data cleaning, Data Transformation, and Data Reduction.
The data we get is essentially raw, and can have many irrelevant and missing parts. To handle these parts, Data Cleaning is done. It involves handling of missing data, filtering out noisy data etc.
Data Cleaning and preparation is the most time consuming part of any Data Science project. Thankfully, there are many powerful tools to speedup this process. One of them is Pandas package which is a widely used library in Python for Data Analysis. Handling missing data is an essential part of data cleaning because all the real row data in real life will definitely have missing values.
Standard missing values are represented as np.nan, None and NaT, for datatime64[ns] types, for python. The representation np.nan is float so if we use them in a column that contains integers, they will be converted to floating points datatypes.
To clean up missing values, first we have to recognize them. So, for finding missing data points, pandas provides isnull( ), isna( ) as functions to detect missing values. We can also choose to use notna( ) which ithe just opposite of isna( ). isna( ).any( ) return a Boolean output for each column. If there is atlieast one missing value in that column, the result will be True.
Once we have found out the missing values, we are supposed to clean it up. But, the problem is that not all missing values come in beautiful format of np.nan or None. Sometimes, “?” or “- -” characters come into action while representing the missing data points.
However, these characters cannot be effectively identified by Pandas as missing data. In these situation, we can use replace( ) function in pandas to handle these values.
There is no optimal way to handle missing values. Depending on the characteristics of the data and task at hand, we can opt to either Drop the missing values or to replace missing values.
To drop a row or column with missing values, we can use dropna( ) function. The “how” parameter is set condition to drop: “any” to drop if there is any missing values and “all” to drop if all values are missing.
Data is very valuable that we cannot easily drop the data points on our every whim. Machine learning models tend to perform better with more data for training. So, depending on the situation, we can choose to replace the missing value instead of dropping.
The fillna( ) function in pandas beautifully handles the missing data by replacing them by a special value or aggregate value such as mean or median.
A deep understanding in Data Pre-processing and thereby in Data Cleaning is very important as a Data Scientist and suitable training in the Data Science training in Kerala makes a huge difference. The right kind of training when dealing with the Data is very important as the conversion of raw, real life data to processed data is the key to Data Analysis and such training can be availed by extensive course provided by Data Science training institute in Kochi.
Author:
STEPS
Written by: STEPS
#DATA SCIENCE COURSES IN KOCHI
#DATA SCIENCE TRAINING IN KOCHI
2 notes
·
View notes
Link
Data Pre-processing can be referred as the manipulation of data before it is being used so as to ensure performance and it is a very important step to be done as a Data Scientist. Data Pre-processing can be generally classified as Data cleaning, Data Transformation, and Data Reduction.
The data we get is essentially raw, and can have many irrelevant and missing parts. To handle these parts, Data Cleaning is done. It involves handling of missing data, filtering out noisy data etc.
Data Cleaning and preparation is the most time consuming part of any Data Science project. Thankfully, there are many powerful tools to speedup this process. One of them is Pandas package which is a widely used library in Python for Data Analysis. Handling missing data is an essential part of data cleaning because all the real row data in real life will definitely have missing values.
Standard missing values are represented as np.nan, None and NaT, for datatime64[ns] types, for python. The representation np.nan is float so if we use them in a column that contains integers, they will be converted to floating points datatypes.
To clean up missing values, first we have to recognize them. So, for finding missing data points, pandas provides isnull( ), isna( ) as functions to detect missing values. We can also choose to use notna( ) which ithe just opposite of isna( ). isna( ).any( ) return a Boolean output for each column. If there is atlieast one missing value in that column, the result will be True.
Once we have found out the missing values, we are supposed to clean it up. But, the problem is that not all missing values come in beautiful format of np.nan or None. Sometimes, “?” or “- -” characters come into action while representing the missing data points.
However, these characters cannot be effectively identified by Pandas as missing data. In these situation, we can use replace( ) function in pandas to handle these values.
There is no optimal way to handle missing values. Depending on the characteristics of the data and task at hand, we can opt to either Drop the missing values or to replace missing values.
To drop a row or column with missing values, we can use dropna( ) function. The “how” parameter is set condition to drop: “any” to drop if there is any missing values and “all” to drop if all values are missing.
Data is very valuable that we cannot easily drop the data points on our every whim. Machine learning models tend to perform better with more data for training. So, depending on the situation, we can choose to replace the missing value instead of dropping.
The fillna( ) function in pandas beautifully handles the missing data by replacing them by a special value or aggregate value such as mean or median.
A deep understanding in Data Pre-processing and thereby in Data Cleaning is very important as a Data Scientist and suitable training in the Data Science training in Kerala makes a huge difference. The right kind of training when dealing with the Data is very important as the conversion of raw, real life data to processed data is the key to Data Analysis and such training can be availed by extensive course provided by Data Science training institute in Kochi.
Author:
STEPS
Written by: STEPS
#DATA SCIENCE COURSES IN KOCHI
#DATA SCIENCE TRAINING IN KOCHI
Tweet
1 note
·
View note
Text
How and with what to analyze the connections of cryptocurrency pairs?
Author: Evgenii Bodiagin
From author: Cooperation proposal for the supply of data
How to analyze the relationship of cryptocurrencies? What are the laws governing the movement of cryptocurrencies? What are the features in the movements of the crypt?

Content:
Introduction.
Is everything all right with your distribution?….
Extraction of data on cryptocurrencies. Active cryptopairs.
How is the crypto market moving? ...
A nonparametric tool for analyzing relationships between pairs of cryptocurrencies.
Conclusion.
Introduction
Not so long ago, our world was replenished with another phenomenon: cryptocurrencies. At first, they were treated as a tool that only geeks are interested in. Today it is obvious that the "crypt" is becoming a backbone. Its mysteriousness, frightening volatility attracts more and more people: from speculators to lovers of conspiracy theory. There is a natural desire to understand the movement of the crypt. The urge to organize and "put everything on the shelves" forces you to turn to data processing tools. Very often these tools are used not quite, to put it mildly, correctly.
For example, in the flow of information about cryptocurrency markets, a lot of attention is paid to the research of cryptocurrency connections. Which cryptocurrencies rise / fall at the same time (have the same movement vector)? AND…. on the contrary - which have the opposite direction. The answers to these questions can enrich the investor in the truest sense of the word. This task is a classic task of correlation analysis. It would seem ... we take the quotes of cryptocurrencies ... a package of spreadsheets. "Go" and done. But ... I remember a phrase from an advertisement: "not all yoghurts are equally useful."
The subtleties, as they say, are in the details. The fact is that the methods for calculating correlations are different. Spreadsheets use Pearson's correlation, although it is referred to simply as "correlation." But there is one but. Pearson's correlation is only possible if the data we are trying to analyze is normally distributed.
Is everything all right with your distribution?….
Let's remember what the normal distribution is. First there will be boring formulas, then an entertaining example. So, a one-dimensional random variable that corresponds to a normal distribution has the following probability density function:
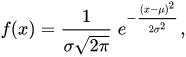
Behind the eyes, it is also called the Gaussian function;) It has only two parameters. First: µ is the mathematical expectation (mean), median and distribution mode. Second parameter: σ - standard deviation (σ2 - variance) of the distribution. The probability density function has the following graphical representation:

In order to describe the normal distribution without formulas, consider, for example, the height of the people around us. Think of your friends, acquaintances, work colleagues. Are there many giants among them? Are there many people of extremely small stature among them? The most common value is likely to be "average height".
The normal distribution has another remarkable property. We measure three standard deviations down from the average height. We measure three standard deviations up from the average height. 99.73% of your subjects will be within this range. In other words, the lion's share of the sample is within the "three sigma" range.
Imagine now that we are in the fabulous Middle Ages. In addition to people, other creatures live on earth: giants, gnomes. Dragons hover in the sky. Elves lurk in the woods. Let's form a sample of the growth of fantastic creatures. As you can see, the histogram has heavy tails.

Why? It's simple - a meeting with a gnome or a giant is not so rare. The distribution of the height of the inhabitants of the fairy forest differs significantly from the normal one.
It is especially worth noting that if a random variable is affected by many random variables that are practically independent of each other, the behavior of such a random variable is described by a normal distribution. The normal distribution is fairly well understood. A lot of data processing techniques are based on it. The Pearson correlation, which requires normality, is only one in a thousand instruments. And here a fundamental question arises. What is the distribution of price changes in cryptocurrencies?
Mining data about cryptocurrencies. Active crypto pairs.
We will consider the Binance crypto exchange as a source of data on cryptocurrency pairs. We will use Python 3.7.7 as processing tools. We use libraries such as: scipy, numpy, pandas, plotly.
At the time of this writing, we have historical data on 600 cryptocurrency pairs. We will consider daily data. Data mining is done using the Binance API. The sample size is 90 days. The subject of consideration will be the following indicator:
Growth_rate_Close = Close temp day / Close last day
Those. if, for example, this ratio is 1.015, the closing price has increased by 1.5%. If the value, for example, is 0.98, then the price has dropped by 2%. Thus, we analyze not the absolute values of the closing prices of cryptocurrency pairs, but their gains.
Note that not all crypto pairs are actively traded. Let's select the most liquid ones. There are two criteria for activity - the number of transactions or the volume of trade. Let's choose the number of deals. So, if you sort all cryptocurrency pairs by the number of transactions, and display it on the chart, you get the following.

Let's take the 35 most actively traded cryptocurrencies. They are shown in red on the graph. All data on cryptocurrency pairs are displayed in blue. The graph shows that the most active part of cryptocurrencies is only 6% of the entire list of cryptocurrencies.
0,05833 = 35 / 600
Yes, that's a fact. These are the realities of the crypto market.
How is the crypto market moving? ...
What does the histogram of price increases for these most active 35 positions look like? How is the crypto market moving? Something like this:

Testing for compliance with the normal distribution is performed both by visual compliance with the normal distribution graph and by calculating statistics. How close is this picture to a normal distribution? Visually? Doubtful ...
Additionally, we will conduct the Shapiro - Wilk test. This test is used to determine whether a sample fits a normal distribution. The following results were obtained:

Only 10 out of 35 crypto pairs have p, which turned out to be higher than the alpha level of Shapiro - Wilk. This means that, technically, we cannot reject the hypothesis that the samples are normally distributed. Here's what the histogram of the 10 mentioned crypto pairs looks like:

To what extent does their appearance correspond to the normal distribution? Despite the significance of the Shapiro-Wilk statistic, it is highly doubtful. Thickened tails are visible on both the right and left. Let's remember about gnomes and giants;)
Cryptocurrency pairs do not live according to the laws of normal distribution! This fact has an important consequence. It is necessary to use such analysis tools that would be free of distribution type. We are talking about nonparametric statistics. And ... researching relationships is also possible there!
A nonparametric tool for analyzing relationships between cryptocurrency pairs
The nonparametric analogue of the Pearson coefficient is the Spearman coefficient. In general, its calculation refers to the methods of rank correlation. But ... rank correlation is applicable to real variables as well. Calculating the Spearman coefficient between cryptocurrency pairs in each case, we get two values: the coefficient itself, as well as the value p, which allows us to assess the significance level of the Spearman coefficient itself.
At the time of the research, we identified only 35 pairs of instruments where there is an interesting and statistically significant relationship. Why is the term interestingused here? Not strong ... not weak? Because the value of the correlation is not the only parameter that indicates how interesting the relationship is in terms of making a profit. You can read the research "Guide indicators in cryptocurrency trading or the Truman effect in action. Weak correlations are in the arsenal of a trader." at www.cryptosensors.info, which will tell you about the nuances of researching relationships.
The cryptocurrency market is volatile, but ... our monitoring software processing works with it. You can find out what relationships exist between cryptocurrency pairs at this time (we are not talking about the time of writing these lines; but about the time when you read these lines) at www.cryptosensors.info.
Conclusion
Cryptocurrency pairs do not behave according to the laws of normal distribution. When choosing a tool for analyzing cryptocurrency connections, you must use the right tool. Spearman's correlation coefficient can be used to analyze the crypto market, since it is a nonparametric criterion.
From author: Cooperation proposal for the supply of data
You may be interested in research / data:
Research: Guide Indicators in Cryptocurrency Trading or the Truman Effect in Action. Weak correlations are in the arsenal of a trader.
Research: Cryptocurrency quotes. Collection and processing. What should a trader know about?
Research: Candlestick analysis efficiency statistics for cryptocurrency trading. Patterns: bullish hammer, bearish hammer.
Data: Cryptopairs quotes in xlsx format.
Data: Comparable data for ten well-known cryptopairs.
Data: Exchange candlestick analysis. Evaluating the use and effectiveness of patterns. Patterns: Bull hammer Bear hammer.
Data: Search data for Truman zones ALMOST ALL (guide indicators for cryptocurrency pairs).
Data: Cryptopairs-relationships.
Send your questions and suggestions to [email protected]. We are open for cooperation!
#cryptocurreny trading#crypto market#how the crypto market moves#nonparametric analysis of cryptocurrencies#histogram#cryptocurrency distribution#cryptocurrency relationships#data processing
1 note
·
View note