#onehotencoding
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text

🎯 Data Transformation Methods help prepare raw data for analysis.
🔹 Normalization
🔹 Standardization
🔹 One-Hot Encoding
🔹 Log Transformation
✅ Why Choose Us?
✔️ 100% practical training
✔️ Real-time projects & case studies
✔️ Expert mentors with industry experience
✔️ Certification & job assistance
✔️ Easy-to-understand Telugu + English mix classes
📍 Institute Address:
3rd Floor, Dr. Atmaram Estates, Metro Pillar No. A690,
Beside Siri Pearls & Jewellery, near JNTU Metro Station,
Hyder Nagar, Vasantha Nagar, Hyderabad, Telangana – 500072
📞 Contact: +91 9948801222
📧 Email: [email protected]
🌐 Website: https://dataanalyticsmasters.in
#DataTransformation#DataAnalytics#DataAnalyticsMasters#DataScience#DataPreparation#MachineLearning#AnalyticsTraining#DataScienceTips#Normalization#Standardization#OneHotEncoding#LogTransformation#DataCleaning#LearnDataAnalytics#UpskillNow
0 notes
Text
Dummy Variables & One Hot Encoding

Handling Categorical Variables with One-Hot Encoding in Python
Introduction:
Machine learning models are powerful tools for predicting outcomes based on numerical data. However, real-world datasets often include categorical variables, such as city names, colors, or types of products. Dealing with categorical data in machine learning requires converting them into numerical representations. One common technique to achieve this is one-hot encoding. In this tutorial, we will explore how to use pandas and scikit-learn libraries in Python to perform one-hot encoding and avoid the dummy variable trap.
1. Understanding Categorical Variables and One-Hot Encoding:
Categorical variables are those that represent categories or groups, but they lack a numerical ordering or scale. Simple label encoding assigns numeric values to categories, but this can lead to incorrect model interpretations. One-hot encoding, on the other hand, creates binary columns for each category, representing their presence or absence in the original data.
2. Using pandas for One-Hot Encoding:
To demonstrate the process, let's consider a dataset containing information about home prices in different towns.
import pandas as pd
# Assuming you have already loaded the data
df = pd.read_csv("homeprices.csv")
print(df.head())
The dataset looks like this:
town area price
0 monroe township 2600 550000
1 monroe township 3000 565000
2 monroe township 3200 610000
3 monroe township 3600 680000
4 monroe township 4000 725000
Now, we will use `pd.get_dummies` to perform one-hot encoding for the 'town' column:
dummies = pd.get_dummies(df['town'])
merged = pd.concat([df, dummies], axis='columns')
final = merged.drop(['town', 'west windsor'], axis='columns')
print(final.head())
The resulting DataFrame will be:
area price monroe township robinsville
0 2600 550000 1 0
1 3000 565000 1 0
2 3200 610000 1 0
3 3600 680000 1 0
4 4000 725000 1 0
3. Dealing with the Dummy Variable Trap:
The dummy variable trap occurs when there is perfect multicollinearity among the encoded variables. To avoid this, we drop one of the encoded columns. However, scikit-learn's `OneHotEncoder` automatically handles the dummy variable trap. Still, it's good practice to handle it manually.
# Manually handle dummy variable trap
final = final.drop(['west windsor'], axis='columns')
print(final.head())
The updated DataFrame after dropping the 'west windsor' column will be:
area price monroe township robinsville
0 2600 550000 1 0
1 3000 565000 1 0
2 3200 610000 1 0
3 3600 680000 1 0
4 4000 725000 1 0
4. Using sklearn's OneHotEncoder:
Alternatively, we can use scikit-learn's `OneHotEncoder` to handle one-hot encoding:
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# Assuming 'df' is loaded with town names already label encoded
X = df[['town', 'area']].values
y = df['price'].values
# Specify the column(s) to one-hot encode
ct = ColumnTransformer([('town', OneHotEncoder(), [0])], remainder='passthrough')
X = ct.fit_transform(X)
# Remove one of the encoded columns to avoid the trap
X = X[:, 1:]
5. Building a Linear Regression Model:
Finally, we build a linear regression model using the one-hot encoded data:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X, y)
# Predicting home prices for new samples
sample_1 = [[0, 1, 3400]]
sample_2 = [[1, 0, 2800]]
Conclusion:
One-hot encoding is a valuable technique to handle categorical variables in machine learning models. It converts categorical data into a numerical format, enabling the use of these variables in various algorithms. By understanding the dummy variable trap and appropriately encoding the data, we can build accurate predictive models. In this tutorial, we explored how to perform one-hot encoding using both pandas and scikit-learn libraries, providing clear examples and code snippets for easy implementation.
@talentserve
0 notes
Text
RANDOM FOREST
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.preprocessing import OneHotEncoder from sklearn.metrics import accuracy_score, classification_report
#Improvise a dataset
np.random.seed(42) # for reproducibility n_samples = 200
#Explanatory variables
temperature = np.random.uniform(15, 35, n_samples) humidity = np.random.uniform(40, 90, n_samples) wind_speed = np.random.uniform(5, 30, n_samples) location = np.random.choice(['Urban', 'Rural', 'Suburban'], n_samples)
#Create a binary response variable based on some (arbitrary) combination of features
probability_of_event = 1 / (1 + np.exp(-(0.2 * temperature - 0.05 * humidity + 0.1 * wind_speed + (location == 'Urban') * 1 - (location == 'Rural') * 0.5))) response = np.random.binomial(1, probability_of_event)
#Create a pandas DataFrame
data = pd.DataFrame({ 'temperature': temperature, 'humidity': humidity, 'wind_speed': wind_speed, 'location': location, 'event_occurred': response # Binary response variable })
#Separate features (X) and target (y)
X = data.drop('event_occurred', axis=1) y = data['event_occurred']
#Handle categorical explanatory variable ('location') using One-Hot Encoding
encoder = OneHotEncoder(handle_unknown='ignore', sparse_output=False) X_encoded = encoder.fit_transform(X[['location']]) X_encoded_df = pd.DataFrame(X_encoded, columns=encoder.get_feature_names_out(['location'])) X = pd.concat([X.drop('location', axis=1).reset_index(drop=True), X_encoded_df], axis=1)
#Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize and train the Random Forest Classifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42) rf_classifier.fit(X_train, y_train)
#Evaluate model performance
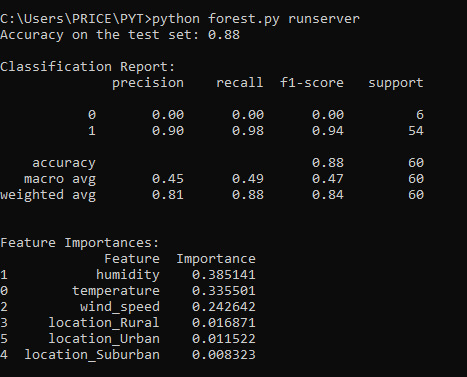
y_pred = rf_classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(f"Accuracy on the test set: {accuracy:.2f}") print("\nClassification Report:") print(classification_report(y_test, y_pred))
#Evaluate Feature Importance
feature_importances = rf_classifier.feature_importances_ feature_names = X_train.columns
#Create a DataFrame to display feature importances
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importances}) importance_df = importance_df.sort_values(by='Importance', ascending=False)
print("\nFeature Importances:") print(importance_df)
0 notes
Text
SOBRE CHICAGO....
Este código em Python realiza uma análise de clusterização geo-temporal de eventos de violência armada, simulados para a cidade de Chicago. O objetivo principal é identificar padrões espaciais e temporais nesses eventos, agrupando-os em clusters com base em sua proximidade geográfica, temporal e outras características relevantes.
Funcionalidades e Melhorias:
Simulação de Dados:
O código inicia com a geração de um conjunto de dados simulados, representando eventos de violência armada. Esses dados incluem coordenadas geográficas (latitude e longitude), hora do evento, calibre da arma utilizada, proximidade de escolas e bares, taxa de desemprego e data do ocorrido.
Uma melhoria significativa foi a adição de variáveis temporais (dia da semana e mês) e uma simulação de densidade populacional, tornando a análise mais rica.
Engenharia de Features:
As variáveis categóricas (calibre, proximidade de escolas e bares) são transformadas em variáveis numéricas usando a técnica de "one-hot encoding".
Todas as variáveis numéricas são padronizadas usando o StandardScaler para garantir que tenham a mesma escala, o que é crucial para o algoritmo de clusterização.
Clusterização DBSCAN:
O algoritmo DBSCAN (Density-Based Spatial Clustering of Applications with Noise) é utilizado para agrupar os eventos. Este algoritmo é eficaz na identificação de clusters de formas arbitrárias e na detecção de outliers.
Uma melhoria importante é a otimização do parametro "eps" do DBSCAN, atraves do metodo do joelho.
Validação de Clusterização:
O código inclui métricas de avaliação (índice de silhueta e índice de Calinski-Harabasz) para quantificar a qualidade dos clusters gerados. Essas métricas fornecem informações sobre a coesão e separação dos clusters.
Visualização:
Os resultados da clusterização são visualizados usando a biblioteca Seaborn, mostrando a distribuição dos clusters no mapa de Chicago.
Para melhorar a visualização foi adicionado o plotly express, para uma melhor visualização da densidade dos incidentes.
Os dados são exportados em formato GeoJSON para facilitar a visualização em ferramentas de mapeamento geoespacial como Kepler.gl.
Considerações Importantes:
O código utiliza dados simulados, que podem não refletir a complexidade dos dados reais de violência urbana. A aplicação deste código a dados reais do Chicago Data Portal ou de outras fontes relevantes é essencial para obter resultados significativos.
A análise de violência urbana é um tema sensível, e é crucial considerar aspectos éticos e de justiça algorítmica ao trabalhar com esses dados. A atenção ao viés de dados e a proteção da privacidade são fundamentais.
É importante lembrar que esses dados já carregam consigo muitos vieses da sociedade, portanto muita cautela é mandatório ao analisar os resultados gerados pelos modelos.
Em resumo, este código fornece uma base sólida para a análise geo-temporal de eventos de violência armada. Ao incorporar dados reais e considerar as implicações éticas, ele pode ser uma ferramenta valiosa para entender e abordar esse problema complexo.
import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.cluster import DBSCAN from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from datetime import datetime from geopy.distance import geodesic import matplotlib.pyplot as plt import seaborn as sns import geopandas as gpd from sklearn.metrics import silhouette_score, calinski_harabasz_score from sklearn.neighbors import NearestNeighbors import plotly.express as px
Simulação de Dados Melhorada
np.random.seed(42) n = 1200 data = pd.DataFrame({ 'latitude': np.random.uniform(41.75, 41.85, n), 'longitude': np.random.uniform(-87.75, -87.60, n), 'hora': np.random.randint(0, 24, n), 'calibre': np.random.choice(['9mm', '.40', '.45', '.380'], n), 'proximidade_escola': np.random.choice(['Sim', 'Nao'], n, p=[0.2, 0.8]), 'proximidade_bar': np.random.choice(['Sim', 'Nao'], n, p=[0.5, 0.5]), 'desemprego': np.random.uniform(5, 25, n), 'data': pd.to_datetime(np.random.choice(pd.date_range('2023-01-01', '2023-12-31'), n)) })
Engenharia de Variáveis Melhorada
data['dia_semana'] = data['data'].dt.dayofweek data['mes'] = data['data'].dt.month data['densidade_populacional'] = np.random.poisson(lam=1500, size=n)
encoder = ColumnTransformer([ ('onehot', OneHotEncoder(), ['calibre', 'proximidade_escola', 'proximidade_bar']) ], remainder='passthrough')
Normalização e Pipeline
scaler = StandardScaler() pipeline = Pipeline([ ('encode', encoder), ('scale', scaler) ])
X = pipeline.fit_transform(data[['calibre', 'proximidade_escola', 'proximidade_bar', 'hora', 'desemprego', 'dia_semana', 'mes', 'densidade_populacional']])
Otimização de Parâmetros (Knee Method)
neigh = NearestNeighbors(n_neighbors=15) nbrs = neigh.fit(X) distances, _ = nbrs.kneighbors(X) distances = np.sort(distances[:, 14]) plt.plot(distances) plt.xlabel('Points') plt.ylabel('Distance') plt.title('Knee Method for Epsilon Selection') plt.show()
Clusterização DBSCAN com epsilon otimizado
eps = 1.5 # Ajuste com base no método do Knee db = DBSCAN(eps=eps, min_samples=15).fit(X) data['cluster'] = db.labels_
Validação de Clusterização
if len(np.unique(data.cluster)) > 1: print(f"Silhouette: {silhouette_score(X, data.cluster)}") print(f"Calinski-Harabasz: {calinski_harabasz_score(X, data.cluster)}") else: print("Métricas não aplicáveis - muito poucos clusters")
Visualização com Seaborn
plt.figure(figsize=(10, 8)) sns.scatterplot(data=data, x='longitude', y='latitude', hue='cluster', palette='tab10') plt.title('Clusterização de Tiroteios em Chicago - Simulação Melhorada') plt.xlabel('Longitude') plt.ylabel('Latitude') plt.legend(title='Cluster') plt.grid(True) plt.tight_layout() plt.show()
Visualização com Plotly Express
fig = px.density_mapbox(data, lat='latitude', lon='longitude', radius=5, zoom=9, mapbox_style='carto-darkmatter', title='Densidade de Tiroteios Simulados - Chicago') fig.show()
Exportação GeoJSON
gdf = gpd.GeoDataFrame(data, geometry=gpd.points_from_xy(data.longitude, data.latitude)) gdf.to_file('clusters_chicago_simulado_melhorado.geojson', driver='GeoJSON')
0 notes
Text
Construção de Modelos de Machine Learning com o Dataset Adult.csv

Introdução
Este artigo reúne em um só lugar todos os posts do projeto de construção de modelos de Machine Learning usando o dataset adult.csv. Ao compilar todos os textos, oferecemos uma visão completa e integrada, facilitando o acesso dos leitores e permitindo que o projeto seja referenciado com apenas um link, sem a necessidade de adicionar novos links conforme mais artigos são publicados. Acompanhar o projeto de Machine Learning fica mais prático, garantindo uma experiência mais organizada e fluida para os leitores interessados em aprender e aplicar esses conceitos.
Posts Apresentados
Aplicação de Machine Learning: Um Guia para Iniciar com Modelos em Classificação
Explorando a Classificação em Machine Learning: Tipos de Variáveis
Explorando o Google Colab: Seu Aliado para Codificar Modelos de Machine Learning
Explorando Dados com Python no Google Colab: Um Guia Prático Utilizando o Dataset adult.csv
Desmistificando a Divisão de Previsores e Classe e o Tratamento de Atributos Categóricos com LabelEncoder e OneHotEncoder
Escalonamento de Dados: A Base para Modelos Eficientes
Aprenda a Dividir em Treinamento e Teste os Dados de um Dataset Utilizando Python
Como Utilizar o Naive Bayes para Prever Salários com o Dataset adult.csv
Como fazer uma previsão de renda usando Árvores de Decisão: um tutorial com código Python
1 — Aplicação de Machine Learning: Um Guia para Iniciar com Modelos em Classificação

Neste artigo, iniciaremos uma série de textos focados na aplicação de Machine Learning, especificamente no método preditivo de classificação. Exploraremos, em detalhes, a importância do pré-processamento de dados, as etapas necessárias para preparar um dataset para análise, e como diferentes modelos de classificação podem ser aplicados e comparados. Utilizaremos a base de dados “Adult”, disponível no UC Irvine Machine Learning Repository, para demonstrar como essas técnicas podem ser aplicadas na prática. LER O TEXTO COMPLETO.
2 — Explorando a Classificação em Machine Learning: Tipos de Variáveis

Este artigo é o segundo de uma série sobre a aplicação de métodos de Machine Learning em uma base de dados, com foco no método preditivo de Classificação. Discutiremos o pré-processamento de dados e a importância de compreender os tipos de variáveis — numéricas e categóricas — antes de aplicar qualquer modelo. Este conhecimento é crucial para adaptar os dados aos requisitos de cada algoritmo, garantindo previsões mais precisas. LER O TEXTO COMPLETO.
3 — Explorando o Google Colab: Seu Aliado para Codificar Modelos de Machine Learning

Neste artigo, você descobrirá o que precisa saber sobre o Google Colab, uma ferramenta poderosa para codificar e executar modelos de Machine Learning diretamente no navegador. Abordaremos o que é o Google Colab, suas funcionalidades, vantagens, e como começar a utilizá-lo, além de apresentar um tutorial simples para criação e execução de células de código Python. Este é o primeiro de uma sequência de artigos focados na construção de modelos preditivos usando Machine Learning no Colab. LER O TEXTO COMPLETO.
4 — Explorando Dados com Python no Google Colab: Um Guia Prático Utilizando o Dataset adult.csv

Neste artigo, vamos explorar o processo de manipulação e visualização de dados usando o Google Colab, com foco no dataset “adult.csv”. Você aprenderá como importar bibliotecas, carregar o dataset, verificar suas informações e criar gráficos para visualizar os dados. Ao final, terá uma compreensão sólida de como explorar um dataset em Python e como o Colab facilita o trabalho com grandes conjuntos de dados. LER O TEXTO COMPLETO.
5 — Desmistificando a Divisão de Previsores e Classe e o Tratamento de Atributos Categóricos com LabelEncoder e OneHotEncoder

Neste artigo, vamos abordar a divisão entre previsores e classe em um conjunto de dados e como tratar atributos categóricos usando as técnicas de LabelEncoder e OneHotEncoder. A compreensão desses conceitos �� fundamental para aplicar corretamente algoritmos de Machine Learning que requerem dados numéricos. Vamos apresentar o código Python passo a passo para garantir que você entenda como cada transformação é aplicada, preparando seus dados para uso em modelos preditivos. LER O TEXTO COMPLETO.
6 — Escalonamento de Dados: A Base para Modelos Eficientes

Neste artigo, abordaremos a importância do escalonamento de dados em Machine Learning, discutindo por que é essencial para muitos algoritmos. Vamos explorar as técnicas de Standardisation (padronização) e Normalization (normalização), explicando suas diferenças e aplicações práticas. Além disso, você verá o código completo para aplicar a padronização no dataset ‘adult.csv’ usando o StandardScaler do sklearn. Este é um passo crucial para garantir que os modelos de aprendizado tratem os atributos com equidade, evitando vieses baseados em escalas desiguais entre os dados. LER O TEXTO COMPLETO.
7 — Aprenda a Dividir em Treinamento e Teste os Dados de um Dataset Utilizando Python

Este artigo ensina como dividir um dataset em dados de treinamento e teste e salvar essa divisão em um arquivo .pkl, essencial para treinar e avaliar modelos de Machine Learning de forma organizada. O processo usa a biblioteca sklearn e pickle, permitindo reutilizar os dados processados em projetos futuros. Este artigo é o próximo passo de uma série de tutoriais sobre pré-processamento de dados. LER O TEXTO COMPLETO.
8 — Como Utilizar o Naive Bayes para Prever Salários com o Dataset adult.csv

Neste artigo, vamos explorar o modelo de Machine Learning Naive Bayes, aplicando-o para prever se uma pessoa ganha mais ou menos de 50 mil dólares por ano, utilizando a base de dados adult.csv. O artigo começa com uma explicação teórica detalhada sobre o Naive Bayes e a correção Laplaciana, passa pela implementação do modelo em Python, com avaliação de acurácia e matriz de confusão, e conclui com uma análise das vantagens e desvantagens do modelo. Essa leitura é essencial para entender os pontos fortes e limitações do Naive Bayes em bases de dados grandes. LER O TEXTO COMPLETO.
9 — Como fazer uma previsão de renda usando Árvores de Decisão: um tutorial com código Python

Este tutorial apresenta o modelo de Árvores de Decisão aplicado para prever se uma pessoa ganha mais ou menos de 50 mil dólares por ano usando o dataset adult.csv. Ao longo do texto, abordaremos conceitos como estrutura de árvores, entropia, ganho de informação, poda, viés e variância, além de vantagens e desvantagens das Árvores de Decisão. Finalizamos com um exemplo prático em Python, incluindo treinamento, avaliação do modelo e explicação dos resultados com matriz de confusão e acurácia. LER O TEXTO COMPLETO.
Conclusão
Seguir a sequência dos posts apresentados neste compilado é fundamental para compreender o processo completo de construção de modelos de Machine Learning. Este artigo facilita o aprendizado, reunindo todos os textos em um único local, o que torna a experiência mais organizada e a consulta mais prática.
Livros que Indico
Estatística Prática para Cientistas de dados — neste link tem uma análise bem completa do livro.
Introdução à Computação Usando Python
2041: Como a Inteligência Artificial Vai Mudar Sua Vida nas Próximas Décadas — neste link tem uma análise completa do livro.
Curso Intensivo de Python — neste link tem uma análise completa do livro.
Entendendo Algoritmos. Um guia Ilustrado Para Programadores e Outros Curiosos
Inteligência Artificial a Nosso Favor
Novos Kindles
Fiz uma análise detalhada dos novos Kindles lançados este ano, destacando suas principais inovações e benefícios para os leitores digitais. Confira o texto completo no link a seguir: O Fascinante Mundo da Leitura Digital: Vantagens de Ter um Kindle.
Amazon Prime
Entrar no Amazon Prime oferece uma série de vantagens, incluindo acesso ilimitado a milhares de filmes, séries e músicas, além de frete grátis em milhões de produtos com entrega rápida.
Se você tiver interesse, entre pelo link a seguir: AMAZON PRIME, que me ajuda a continuar na divulgação da inteligência artificial e programação de computadores.
0 notes
Link
original source : https://medium.com/@contactsunny/label-encoder-vs-one-hot-encoder-in-machine-learning-3fc273365621
These two encoders are parts of the SciKit Learn library in Python, and they are used to convert categorical data, or text data, into numbers, which our predictive models can better understand.
Label Encoding
nd to convert this kind of categorical text data into model-understandable numerical data, we use the Label Encoder class. So all we have to do, to label encode the first column, is import the LabelEncoder class from the sklearn library, fit and transform the first column of the data, and then replace the existing text data with the new encoded data. Let’s have a look at the code.
from sklearn.preprocessing import LabelEncoder labelencoder = LabelEncoder() x[:, 0] = labelencoder.fit_transform(x[:, 0])
We’ve assumed that the data is in a variable called ‘x’. After running this piece of code, if you check the value of x, you’ll see that the three countries in the first column have been replaced by the numbers 0, 1, and 2.
That’s all label encoding is about. But depending on the data, label encoding introduces a new problem. For example, we have encoded a set of country names into numerical data. This is actually categorical data and there is no relation, of any kind, between the rows.
The problem here is, since there are different numbers in the same column, the model will misunderstand the data to be in some kind of order, 0 < 1 < 2. But this isn’t the case at all. To overcome this problem, we use One Hot Encoder.
One Hot Encoder
If you’re interested in checking out the documentation, you can find it here. Now, as we already discussed, depending on the data we have, we might run into situations where, after label encoding, we might confuse our model into thinking that a column has data with some kind of order or hierarchy, when we clearly don’t have it. To avoid this, we ‘OneHotEncode’ that column.
What one hot encoding does is, it takes a column which has categorical data, which has been label encoded, and then splits the column into multiple columns. The numbers are replaced by 1s and 0s, depending on which column has what value. In our example, we’ll get three new columns, one for each country — France, Germany, and Spain.
For rows which have the first column value as France, the ‘France’ column will have a ‘1’ and the other two columns will have ‘0’s. Similarly, for rows which have the first column value as Germany, the ‘Germany’ column will have a ‘1’ and the other two columns will have ‘0’s.
The Python code for one hot encoding is also pretty simple:
from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder(categorical_features = [0]) x = onehotencoder.fit_transform(x).toarray()
0 notes
Photo

The math behind One-Hot Encoding is ridiculous. The math behind Cross Entropy is even more ridiculous. Deep learning is difficult. Sometimes I don’t even know what to answer. -Has anyone else been getting into all the free online knowledge from Edx, Udacity, Google, etc? -Does anyone pay for these classes/nanodegrees? -Do they hold any water with employers? Asking for a friend.... #DeepLearning #OneHotEncoding #Udacity (at Mesa, Arizona)
0 notes
Link
0 notes
Text
Data Cleaning and Preprocessing for Beginners

When our team’s project scored first in the text subtask of this year’s CALL Shared Task challenge, one of the key components of our success was careful preparation and cleaning of data. Data cleaning and preparation is the most critical first step in any AI project. As evidence shows, most data scientists spend most of their time — up to 70% — on cleaning data.
In this blog post, we’ll guide you through these initial steps of data cleaning and preprocessing in Python, starting from importing the most popular libraries to actual encoding of features.
Data cleansing or data cleaning is the process of detecting and correcting (or removing) corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. //Wikipedia
Step 1. Loading the data set

Importing libraries
The absolutely first thing you need to do is to import libraries for data preprocessing. There are lots of libraries available, but the most popular and important Python libraries for working on data are Numpy, Matplotlib, and Pandas. Numpy is the library used for all mathematical things. Pandas is the best tool available for importing and managing datasets. Matplotlib (Matplotlib.pyplot) is the library to make charts.
To make it easier for future use, you can import these libraries with a shortcut alias:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Loading data into pandas
Once you downloaded your data set and named it as a .csv file, you need to load it into a pandas DataFrame to explore it and perform some basic cleaning tasks removing information you don’t need that will make data processing slower.
Usually, such tasks include:
Removing the first line: it contains extraneous text instead of the column titles. This text prevents the data set from being parsed properly by the pandas library:
my_dataset = pd.read_csv(‘data/my_dataset.csv’, skiprows=1, low_memory=False)
Removing columns with text explanations that we won’t need, url columns and other unnecessary columns:
my_dataset = my_dataset.drop([‘url’],axis=1)
Removing all columns with only one value, or have more than 50% missing values to work faster (if your data set is large enough that it will still be meaningful):
my_dataset = my_dataset.dropna(thresh=half_count,axis=1)
It’s also a good practice to name the filtered data set differently to keep it separate from the raw data. This makes sure you still have the original data in case you need to go back to it.
Step 2. Exploring the data set

Understanding the data
Now you have got your data set up, but you still should spend some time exploring it and understanding what feature each column represents. Such manual review of the data set is important, to avoid mistakes in the data analysis and the modelling process.
To make the process easier, you can create a DataFrame with the names of the columns, data types, the first row’s values, and description from the data dictionary.
As you explore the features, you can pay attention to any column that:
is formatted poorly,
requires more data or a lot of pre-processing to turn into useful a feature, or
contains redundant information,since these things can hurt your analysis if handled incorrectly.
You should also pay attention to data leakage, which can cause the model to overfit. This is because the model will be also learning from features that won’t be available when we’re using it to make predictions. We need to be sure our model is trained using only the data it would have at the point of a loan application.
Deciding on a target column
With a filtered data set explored, you need to create a matrix of dependent variables and a vector of independent variables. At first you should decide on the appropriate column to use as a target column for modelling based on the question you want to answer. For example, if you want to predict the development of cancer, or the chance the credit will be approved, you need to find a column with the status of the disease or loan granting ad use it as the target column.
For example, if the target column is the last one, you can create the matrix of dependent variables by typing:
X = dataset.iloc[:, :-1].values
That first colon (:) means that we want to take all the lines in our dataset. : -1 means that we want to take all of the columns of data except the last one. The .values on the end means that we want all of the values.
To have a vector of independent variables with only the data from the last column, you can type
y = dataset.iloc[:, -1].values
Step 3. Preparing the Features for Machine Learning

Finally, it’s time to do the preparatory work to feed the features for ML algorithms. To clean the data set, you need to handle missing values and categorical features, because the mathematics underlying most machine learning models assumes that the data is numerical and contains no missing values. Moreover, the scikit-learn library returns an error if you try to train a model like linear regression and logistic regression using data that contain missing or non-numeric values.
Dealing with Missing Values
Missing data is perhaps the most common trait of unclean data. These values usually take the form of NaN or None.
here are several causes of missing values: sometimes values are missing because they do not exist, or because of improper collection of data or poor data entry. For example, if someone is under age, and the question applies to people over 18, then the question will contain a missing value. In such cases, it would be wrong to fill in a value for that question.
There are several ways to fill up missing values:
you can remove the lines with the data if you have your data set is big enough and the percentage of missing values is high (over 50%, for example);
you can fill all null variables with 0 is dealing with numerical values;
you can use the Imputer class from the scikit-learn library to fill in missing values with the data’s (mean, median, most_frequent)
you can also decide to fill up missing values with whatever value comes directly after it in the same column.
These decisions depend on the type of data, what you want to do with the data, and the cause of values missing. In reality, just because something is popular doesn’t necessarily make it the right choice. The most common strategy is to use the mean value, but depending on your data you may come up with a totally different approach.
Handling categorical data
Machine learning uses only numeric values (float or int data type). However, data sets often contain the object data type than needs to be transformed into numeric. In most cases, categorical values are discrete and can be encoded as dummy variables, assigning a number for each category. The simplest way is to use One Hot Encoder, specifying the index of the column you want to work on:
from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder(categorical_features = [0])X = onehotencoder.fit_transform(X).toarray()
Dealing with inconsistent data entry
Inconsistency occurs, for example, when there are different unique values in a column which are meant to be the same. You can think of different approaches to capitalization, simple misprints and inconsistent formats to form an idea. One of the ways to remove data inconsistencies is by to remove whitespaces before or after entry names and by converting all cases to lower cases.
If there is a large number of inconsistent unique entries, however, it is impossible to manually check for the closest matches. You can use the Fuzzy Wuzzy package to identify which strings are most likely to be the same. It takes in two strings and returns a ratio. The closer the ratio is to 100, the more likely you will unify the strings.
Handling Dates and Times
A specific type of data inconsistency is inconsistent format of dates, such as dd/mm/yy and mm/dd/yy in the same columns. Your date values might not be in the right data type, and this will not allow you effectively perform manipulations and get insight from it. This time you can use the datetime package to fix the type of the date.
Scaling and Normalization
Scaling is important if you need to specify that a change in one quantity is not equal to another change in another. With the help of scaling you ensure that just because some features are big they won’t be used as a main predictor. For example, if you use the age and the salary of a person in prediction, some algorithms will pay attention to the salary more because it is bigger, which does not make any sense.
Normalization involves transforming or converting your dataset into a normal distribution. Some algorithms like SVM converge far faster on normalized data, so it makes sense to normalize your data to get better results.
There are many ways to perform feature scaling. In a nutshell, we put all of our features into the same scale so that none are dominated by another. For example, you can use the StandardScaler class from the sklearn.preprocessing package to fit and transform your data set:
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)As you don’t need to fit it to your test set, you can just apply transformation.sc_y = StandardScaler() y_train = sc_y.fit_transform(y_train)
Save to CSV
To be sure that you still have the raw data, it is a good practice to store the final output of each section or stage of your workflow in a separate csv file. In this way, you’ll be able to make changes in your data processing flow without having to recalculate everything.
As we did previously, you can store your DataFrame as a .csv using the pandas to_csv() function.
my_dataset.to_csv(“processed_data/cleaned_dataset.csv”,index=False)
Conclusion
These are the very basic steps required to work through a large data set, cleaning and preparing the data for any Data Science project. There are other forms of data cleaning that you might find useful. But for now we want you to understand that you need to properly arrange and tidy up your data before the formulation of any model. Better and cleaner data outperforms the best algorithms. If you use a very simple algorithm on the cleanest data, you will get very impressive results. And, what is more, it is not that difficult to perform basic preprocessing!
0 notes
Text
Machine Learning for Data Analysis: Lasso Regression
This blog post is about Lasso Regression algorithm on the Iris dataset obtained from Kaggle.
In the given dataset, the dataset the predictor variables used are: Sepal Length in cm, Sepal Width in cm, Petal Length in cm and Petal Width in cm.
The target variable in this dataset is the name of the species, which was label encoded due to its string format and 3 values.
The python code for the regression is given below:
#Importing the libraries import pandas as pd import numpy as np import matplotlib.pylab as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LassoLarsCV
#Load the dataset data = pd.read_csv("Iris.csv")
#upper-case all DataFrame column names data.columns = map(str.upper, data.columns)
#select predictor variables and target variable as separate data sets predvar= data[['SEPALLENGTHCM', 'SEPALWIDTHCM', 'PETALLENGTHCM', 'PETALWIDTHCM']]
target = data.SPECIES
# standardize predictors to have mean=0 and sd=1 predictors = predvar.copy()
from sklearn.preprocessing import LabelEncoder,OneHotEncoder labelencoder_Y = LabelEncoder() target = labelencoder_Y.fit_transform(target)
# # split data into train and test sets pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, target, test_size=.3, random_state=123)
# specify the lasso regression model model = LassoLarsCV(cv=10, precompute=False).fit(pred_train,tar_train)
# print variable names and regression coefficients dict(zip(predictors.columns, model.coef_))
# plot coefficient progression m_log_alphas = -np.log10(model.alphas_) ax = plt.gca() plt.plot(m_log_alphas, model.coef_path_.T) plt.axvline(-np.log10(model.alpha_), linestyle='--', color='k', label='alpha CV') plt.ylabel('Regression Coefficients') plt.xlabel('-log(alpha)') plt.title('Regression Coefficients Progression for Lasso Paths') plt.show()
#plot mean square error for each fold m_log_alphascv = -np.log10(model.cv_alphas_)
plt.plot(m_log_alphascv, model.mse_path_, ':') plt.plot(m_log_alphascv, model.mse_path_.mean(axis=-1), 'k', label='Average across the folds', linewidth=2) plt.axvline(-np.log10(model.alpha_), linestyle='--', color='k', label='alpha CV') plt.legend() plt.xlabel('-log(alpha)') plt.ylabel('Mean squared error') plt.title('Mean squared error on each fold') plt.show()
from sklearn.metrics import mean_squared_error train_error = mean_squared_error(tar_train, model.predict(pred_train)) test_error = mean_squared_error(tar_test, model.predict(pred_test)) print ('training data MSE') print(train_error) print ('test data MSE') print(test_error)
# R-square from training and test data rsquared_train=model.score(pred_train,tar_train) rsquared_test=model.score(pred_test,tar_test) print ('training data R-square') print(rsquared_train) print ('test data R-square') print(rsquared_test)
The output of the above code was:
training data MSE 0.048419013706674695 test data MSE 0.04428800087556087 training data R-square 0.9217732083651687 test data R-square 0.9430221081492943


The accuracy score on the test data came out to be 94.3 percent which is considerably good. In addition to this, the mean squared error for the test data was 0.044. Furthermore, the MSE was lowest when the negative logarithm of alpha was tending towards 2.
0 notes
Photo

"[P] comparing accuracy between two encoded datasets"- Detail: I have two datasets that I ran a label encoder and onehotencoder on. A is the actual and B is the prediction.I would like to be able to come up with the accuracy between the two. For example in B, the last row is different so I would like calculate an accuracy of 75%.Is there a nice pythonian way of doing this?A010100001100B010100001010. Caption by rxo85. Posted By: www.eurekaking.com
0 notes
Text
ColumnTransformer in SciKit for LabelEncoding and OneHotEncoding in Machine Learning
http://bit.ly/2NXiaT6
0 notes
Text
Como fazer uma previsão de renda usando Árvores de Decisão: um tutorial com código Python

Resumo: Este tutorial apresenta o modelo de Árvores de Decisão aplicado para prever se uma pessoa ganha mais ou menos de 50 mil dólares por ano usando o dataset adult.csv. Ao longo do texto, abordaremos conceitos como estrutura de árvores, entropia, ganho de informação, poda, viés e variância, além de vantagens e desvantagens das Árvores de Decisão. Finalizamos com um exemplo prático em Python, incluindo treinamento, avaliação do modelo e explicação dos resultados com matriz de confusão e acurácia.
Principais Tópicos
Introdução ao uso do modelo de Árvores de Decisão
Estrutura e termos fundamentais de uma árvore em computação
Teoria do modelo de Árvores de Decisão
Cálculo da entropia e ganho de informação
Split e poda no algoritmo de árvore de decisão
Explicação sobre viés, variância e overfitting
Vantagens e desvantagens do modelo de Árvores de Decisão
Implementação prática com código Python
Acurácia e análise da matriz de confusão
Conclusão e sequência de posts
Importante: Para seguir este artigo, leia primeiro os artigos abaixo na sequência sugerida. Cada artigo fornece a base necessária para compreender o próximo, garantindo que você entenda todo o fluxo de trabalho até este ponto.
Artigo 1: Aplicação de Machine Learning: Um Guia para Iniciar como Modelos em Classificação
Artigo 2: Explorando a Classificação em Machine Learning: Tipos de Variáveis
Artigo 3: Explorando o Google Colab: Seu Aliado para Codificar Modelos de Machine Learning
Artigo 4: Explorando Dados com Python no Google Colab: Um Guia Prático Utilizando o Dataset adult.csv
Artigo 5: Desmistificando a Divisão de Previsores e Classe e o Tratamento de Atributos Categóricos com LabelEncoder e OneHotEncoder
Artigo 6: Escalonamento de Dados: A Base para Modelos Eficientes
Artigo 7: Aprenda a Dividir em Treinamento e Teste os Dados de um Dataset Utilizando Python
Artigo 8: Como Utilizar o Naive Bayes para Prever Salários com o Dataset adult.csv
Iniciando o processo no Google Colab
Antes de qualquer coisa, acesse este link do notebook e selecione Arquivo > Salvar uma cópia no Drive. Lembre-se de que o dataset (adult.csv) precisa ser carregado novamente a cada novo post (mais informações no Artigo 4 acima), pois cada tutorial cria um notebook novo, adicionando apenas o código necessário apresentado neste artigo, porém o notebook está com todo o código gerado até o momento. Uma cópia do notebook será salva no Google Drive, dentro da pasta Colab Notebooks, mantendo o processo organizado e contínuo.
Introdução
Neste artigo, você aprenderá a utilizar o modelo de Árvores de Decisão para prever se uma pessoa ganha mais ou menos de 50 mil dólares por ano, usando o famoso dataset adult.csv. Esse modelo de Machine Learning é conhecido por sua estrutura hierárquica que facilita a interpretação dos resultados e pode ser utilizado em várias tarefas de classificação e regressão. Neste tutorial, exploraremos desde os conceitos básicos até a implementação em Python, possibilitando que você aplique e compreenda essa poderosa técnica preditiva.
Estrutura de uma Árvore em Computação
Em computação, uma árvore é uma estrutura hierárquica composta por nós conectados por arestas. A partir do nó raiz, a árvore se ramifica em nós filhos, até atingir os nós folhas, que não possuem descendentes. Os principais termos incluem:
Nó Raiz: O ponto de partida da árvore.
Nó Interno: Um nó que possui filhos.
Nó Folha: Um nó terminal que não possui filhos.
Aresta: Conexão entre dois nós.
Profundidade: Distância do nó raiz até o nó folha mais distante.
Esses termos ajudam a compreender como a árvore de decisão é construída e como toma decisões com base nos dados de entrada.
Teoria das Árvores de Decisão
O modelo de Árvores de Decisão é uma técnica de classificação e regressão que utiliza uma estrutura em forma de árvore para dividir o espaço de decisão em regiões específicas. Ele começa no nó raiz e desce pela árvore, fazendo perguntas sobre os dados e dividindo-os em grupos com base nos valores dos atributos mais relevantes.
Cada divisão é feita de maneira a maximizar a separação entre classes, utilizando o conceito de “ganho de informação”. Os atributos que estão no topo da árvore são considerados mais importantes, pois causam maior impacto nas previsões.
Cálculo da Entropia e do Ganho de Informação
O cálculo da entropia e do ganho de informação é essencial para definir os pontos de divisão (splits) no modelo de árvore.
Entropia: Medida da desordem ou imprevisibilidade dentro de um conjunto de dados. A entropia é calculada pela fórmula:

Onde pi é a probabilidade de cada classe.
Ganho de Informação: Representa a redução de incerteza após dividir os dados. É calculado pela diferença entre a entropia do conjunto original e a soma ponderada das entropias dos subconjuntos divididos:

Split e Poda no Algoritmo de Árvore de Decisão
O split refere-se ao processo de dividir os dados em ramificações na árvore. Já a poda reduz o tamanho da árvore removendo ramos irrelevantes ou redundantes, o que pode melhorar a generalização e reduzir o overfitting.
Benefícios da Poda: Reduz a complexidade do modelo e ajuda a evitar o overfitting.
Prejuízos da Poda: Pode remover informações úteis, o que reduz a precisão em alguns casos.
Viés e Variância
Bias (Viés): Erros decorrentes de uma simplificação excessiva do modelo, como ao subestimar a complexidade dos dados.
Variância: Erros resultantes de uma alta sensibilidade a pequenas mudanças nos dados de treinamento. Árvores grandes podem sofrer de overfitting, o que ocorre quando o modelo se ajusta demais aos dados de treinamento e perde a capacidade de generalizar para novos dados.
Vantagens e Desvantagens das Árvores de Decisão
Vantagens:
Fácil interpretação.
Não requer normalização ou padronização.
Rápido para classificar novos registros.
Desvantagens:
Pode gerar árvores muito complexas.
Pequenas mudanças nos dados podem alterar a estrutura da árvore.
A construção de uma árvore é um problema NP-completo — isto é, requer muito tempo computacional conforme o número de combinações de dados cresce.
Implementação Prática com Código Python
Nesta seção, vamos apresentar o código em Python para a construção e avaliação de um modelo de árvore de decisão.from sklearn.tree import DecisionTreeClassifier import pickle from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, ConfusionMatrixDisplay
# Carregando os dados with open('adult.pkl', 'rb') as fl: X_adult_treinamento, y_adult_treinamento, X_adult_teste, y_adult_teste = pickle.load(fl) # Verificando o formato dos dados print(X_adult_treinamento.shape, y_adult_treinamento.shape) print(X_adult_teste.shape, y_adult_teste.shape)
# Realizando o treinamento adult_tree = DecisionTreeClassifier(criterion='entropy', random_state=0) adult_tree.fit(X_adult_treinamento, y_adult_treinamento)
# Fazendo a previsão com os dados de teste prev_tree = adult_tree.predict(X_adult_teste) print(prev_tree)
# Apresentando os valores corretos das previsões print(y_adult_teste)
# Calculando a acurácia accuracy = accuracy_score(y_adult_teste, prev_tree) print("Acurácia:", accuracy)
# Gerando a matriz de confusão cm_tree = confusion_matrix(y_adult_teste, prev_tree) print("Matriz de Confusão:\n", cm_tree) ConfusionMatrixDisplay(cm_tree).plot()
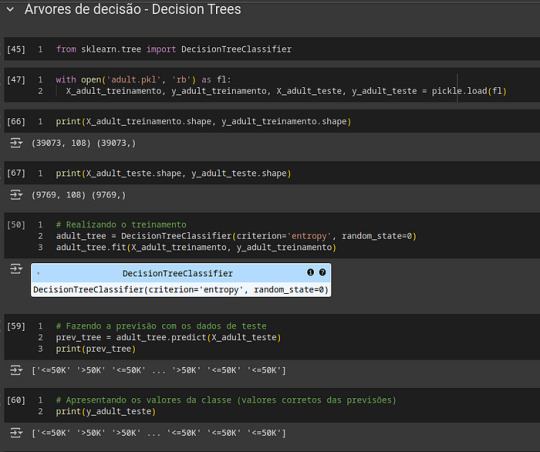
Neste código, usamos DecisionTreeClassifier para treinar e prever dados. A precisão é avaliada pela acurácia, e a matriz de confusão nos permite analisar os erros de classificação.
Acurácia e Matriz de Confusão

indica o número de previsões corretas e incorretas para cada classe.
Conclusão
Neste tutorial, exploramos o modelo de Árvores de Decisão para prever se uma pessoa ganha mais ou menos de 50 mil dólares, utilizando o dataset adult.csv. Ao longo deste texto, discutimos desde os fundamentos de árvores até a implementação em Python, passando por conceitos essenciais de viés, variância e overfitting. Em breve, abordaremos outros modelos de classificação e comparações entre eles para aprofundar o entendimento do leitor sobre Machine Learning.
Livros que Indico
Estatística Prática para Cientistas de dados — neste link tem uma análise bem completa do livro.
Introdução à Computação Usando Python
2041: Como a Inteligência Artificial Vai Mudar Sua Vida nas Próximas Décadas — neste link tem uma análise completa do livro.
Curso Intensivo de Python — neste link tem uma análise completa do livro.
Entendendo Algoritmos. Um guia Ilustrado Para Programadores e Outros Curiosos
Inteligência Artificial a Nosso Favor
Novos Kindles
Fiz uma análise detalhada dos novos Kindles lançados este ano, destacando suas principais inovações e benefícios para os leitores digitais. Confira o texto completo no link a seguir: O Fascinante Mundo da Leitura Digital: Vantagens de Ter um Kindle.
Amazon Prime
Entrar no Amazon Prime oferece uma série de vantagens, incluindo acesso ilimitado a milhares de filmes, séries e músicas, além de frete grátis em milhões de produtos com entrega rápida.
Se você tiver interesse, entre pelo link a seguir: AMAZON PRIME, que me ajuda a continuar na divulgação da inteligência artificial e programação de computadores.
0 notes
Text
Multiple Regression using Python
# Multiple Linear Regression
# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd import seaborn as sns from statsmodels.formula.api import ols import matplotlib.pyplot as plt import pylab import scipy.stats as stats import statsmodels.api as sm import statsmodels.formula.api as smf # Importing the dataset dataset = pd.read_csv('C:/Users/Janani/Desktop/50_Startups.csv') dataset.columns = ('RDSpend','Administration','MarketingSpend','State','Profit')
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values # Encoding categorical data from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder = LabelEncoder() X[:, 3] = labelencoder.fit_transform(X[:, 3]) onehotencoder = OneHotEncoder(categorical_features = [3]) X = onehotencoder.fit_transform(X).toarray() # Avoiding the Dummy Variable Trap X = X[:, 1:] # Splitting the dataset into the Training set and Test set from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) # Fitting Multiple Linear Regression to the Training set from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) # Predicting the Test set results y_pred = regressor.predict(X_test)
stats.probplot(y_pred, dist='norm', plot=pylab) pylab.show()
model = smf.ols(formula='Profit ~ RDSpend + Administration + MarketingSpend + State' , data=dataset).fit()
model.summary()
OLS Regression Results ============================================================================== Dep. Variable: Profit R-squared: 0.951 Model: OLS Adj. R-squared: 0.945 Method: Least Squares F-statistic: 169.9 Date: Sun, 11 Nov 2018 Prob (F-statistic): 1.34e-27 Time: 23:00:19 Log-Likelihood: -525.38 No. Observations: 50 AIC: 1063. Df Residuals: 44 BIC: 1074. Df Model: 5 Covariance Type: nonrobust ===================================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------------- Intercept 5.013e+04 6884.820 7.281 0.000 3.62e+04 6.4e+04 State[T.Florida] 198.7888 3371.007 0.059 0.953 -6595.030 6992.607 State[T.New York] -41.8870 3256.039 -0.013 0.990 -6604.003 6520.229 RDSpend 0.8060 0.046 17.369 0.000 0.712 0.900 Administration -0.0270 0.052 -0.517 0.608 -0.132 0.078 MarketingSpend 0.0270 0.017 1.574 0.123 -0.008 0.062 ============================================================================== Omnibus: 14.782 Durbin-Watson: 1.283 Prob(Omnibus): 0.001 Jarque-Bera (JB): 21.266 Skew: -0.948 Prob(JB): 2.41e-05 Kurtosis: 5.572 Cond. No. 1.45e+06 ==============================================================================
model_fitted_y = model.fittedvalues plt.hist(model_fitted_y.pearson_resid) model_residuals = model.resid model_norm_residuals = model.get_influence().resid_studentized_internal model_norm_residuals_abs_sqrt = np.sqrt(np.abs(model_norm_residuals)) model_abs_resid = np.abs(model_residuals)
model_leverage = model.get_influence().hat_matrix_diag model_cooks = model.get_influence().cooks_distance[0] stats.probplot(model, dist="norm", plot=pylab) pylab.show()
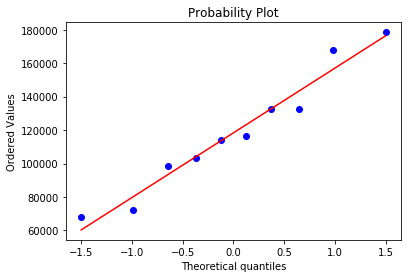
#Q-Q plot for normality fig4=sm.qqplot(model.resid, line='r')

The qq-plot clearly displays the points lie along the line and it clearly indicates there are no skewness. There are no outliers.
fig, ax = plt.subplots(figsize=(12,8)) fig = sm.graphics.influence_plot(model, ax=ax, criterion="cooks")
Influence Leverage Plot:
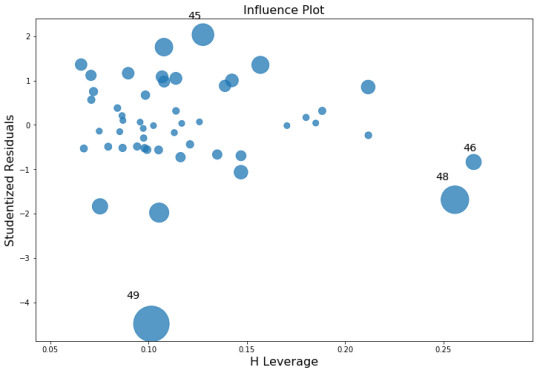
There are only three outliers hence there are not many influencers to skew the data.
# simple plot of residuals
stdres=pd.DataFrame(model.resid_pearson) plt.plot(stdres, 'o', ls='None') l = plt.axhline(y=0, color='r') plt.ylabel('Standardized Residual') plt.xlabel('Observation Number')

After adjusting for potential confounding factors R&D Spend, Administration, Marketing, State), Profit significantly increased.
0 notes
Text
Veri Analizi Proje Yönetimi ve Problem Tipleri
#1. kutuphaneler import numpy as np import matplotlib.pyplot as plt import pandas as pd
#2.1. Veri Yukleme veriler = pd.read_csv('dosya_adı.csv') #pd.read_csv("veriler.csv")
#eksik veriler
from sklearn.preprocessing import Imputer
imputer= Imputer(missing_values='NaN', strategy = 'mean', axis=0 )
Yas = veriler.iloc[:,1:4].values print(Yas) imputer = imputer.fit(Yas[:,1:4]) Yas[:,1:4] = imputer.transform(Yas[:,1:4]) print(Yas)
#encoder: Kategorik -> Numeric ulke = veriler.iloc[:,0:1].values print(ulke) from sklearn.preprocessing import LabelEncoder le = LabelEncoder() ulke[:,0] = le.fit_transform(ulke[:,0]) print(ulke)
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(categorical_features='all') ulke=ohe.fit_transform(ulke).toarray() print(ulke)
#numpy dizileri dataframe donusumu sonuc = pd.DataFrame(data = ulke, index = range(22), columns=['fr','tr','us'] ) print(sonuc)
sonuc2 =pd.DataFrame(data = Yas, index = range(22), columns = ['boy','kilo','yas']) print(sonuc2)
cinsiyet = veriler.iloc[:,-1].values print(cinsiyet)
sonuc3 = pd.DataFrame(data = cinsiyet , index=range(22), columns=['cinsiyet']) print(sonuc3)
#dataframe birlestirme islemi s=pd.concat([sonuc,sonuc2],axis=1) print(s)
s2= pd.concat([s,sonuc3],axis=1) print(s2)
#verilerin egitim ve test icin bolunmesi from sklearn.cross_validation import train_test_split x_train, x_test,y_train,y_test = train_test_split(s,sonuc3,test_size=0.33, random_state=0)
#verilerin olceklenmesi from sklearn.preprocessing import StandardScaler
sc = StandardScaler() X_train = sc.fit_transform(x_train) X_test = sc.fit_transform(x_test)
#verilerin olceklenmesi#verilerin egitim ve test icin bolunmesi#dataframe birlestirme islemi#numpy dizileri dataframe donusumu
0 notes
Text
Como Utilizar o Naive Bayes para Prever Salários com o Dataset adult.csv

Resumo
Neste artigo, vamos explorar o modelo de Machine Learning Naive Bayes, aplicando-o para prever se uma pessoa ganha mais ou menos de 50 mil dólares por ano, utilizando a base de dados adult.csv. O artigo começa com uma explicação teórica detalhada sobre o Naive Bayes e a correção Laplaciana, passa pela implementação do modelo em Python, com avaliação de acurácia e matriz de confusão, e conclui com uma análise das vantagens e desvantagens do modelo. Essa leitura é essencial para entender os pontos fortes e limitações do Naive Bayes em bases de dados grandes.
Principais Tópicos Abordados
Introdução ao Naive Bayes
Teoria e Funcionamento do Naive Bayes
Correção Laplaciana no Naive Bayes
Probabilidades Apriori e Posteriori
Vantagens e Desvantagens do Naive Bayes
Implementação em Python com Código Explicado
Acurácia e Matriz de Confusão
Conclusão e Próximos Passos
Importante: Para seguir este artigo, leia primeiro os artigos abaixo na sequência sugerida. Cada artigo fornece a base necessária para compreender o próximo, garantindo que você entenda todo o fluxo de trabalho até este ponto.
Artigo 1: Aplicação de Machine Learning: Um Guia para Iniciar como Modelos em Classificação
Artigo 2: Explorando a Classificação em Machine Learning: Tipos de Variáveis
Artigo 3: Explorando o Google Colab: Seu Aliado para Codificar Modelos de Machine Learning
Artigo 4: Explorando Dados com Python no Google Colab: Um Guia Prático Utilizando o Dataset adult.csv
Artigo 5: Desmistificando a Divisão de Previsores e Classe e o Tratamento de Atributos Categóricos com LabelEncoder e OneHotEncoder
Artigo 6: Escalonamento de Dados: A Base para Modelos Eficientes
Artigo 7: Aprenda a Dividir em Treinamento e Teste os Dados de um Dataset Utilizando Python
Iniciando o processo no Google Colab
Antes de qualquer coisa, acesse este link do notebook e selecione Arquivo > Salvar uma cópia no Drive. Lembre-se de que o dataset (adult.csv) precisa ser carregado novamente a cada novo post (mais informações no Artigo 4 acima), pois cada tutorial cria um notebook novo, adicionando apenas o código necessário apresentado neste artigo, porém o notebook está com todo o código gerado até o momento. Uma cópia do notebook será salva no Google Drive, dentro da pasta Colab Notebooks, mantendo o processo organizado e contínuo.
Introdução
Neste artigo, você aprenderá a utilizar o modelo Naive Bayes para prever se uma pessoa ganha mais ou menos de 50 mil dólares por ano. Utilizaremos a base de dados adult.csv e exploraremos o funcionamento do Naive Bayes, seu potencial e suas limitações. Com uma abordagem prática, vamos implementar o modelo em Python e avaliar o desempenho. Esta leitura lhe dará uma visão ampla sobre como o Naive Bayes trabalha e quando ele é uma boa opção para suas aplicações de Machine Learning.
Explicação Teórica sobre o Modelo Naive Bayes
O Naive Bayes é um modelo de Machine Learning probabilístico, baseado no Teorema de Bayes, que calcula a probabilidade de uma amostra pertencer a uma determinada classe. Sua abordagem se destaca por transformar dados em uma tabela de probabilidades, conhecida como tabela de frequência ou de probabilidade condicional. No Naive Bayes, os atributos são considerados independentes uns dos outros (daí o “naive” ou ingênuo), o que torna o modelo simples e rápido.

Nessa tabela, o modelo calcula probabilidades para cada combinação de atributos, multiplicando as probabilidades de cada variável, considerando-as independentes. Assim, ele estima a probabilidade de uma amostra pertencer a uma classe específica.
Correção Laplaciana: Evitando Zeros nas Probabilidades
A correção Laplaciana é aplicada para evitar que, durante a multiplicação das probabilidades, algum valor zerado no conjunto de dados leve o modelo a um resultado incorreto. Em vez de usar um valor zero, adicionamos um pequeno valor, geralmente “1”, a cada contagem, ajustando a probabilidade para um valor mínimo e evitando que a multiplicação resulte em zero.
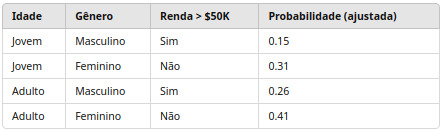
Neste exemplo, aplicamos a correção para aumentar as probabilidades sem alterar muito o resultado final.
Raio (Temor Radius), Probabilidade Apriori e Posteriori
Raio (Temor Radius): Refere-se ao intervalo dentro do qual o modelo “Naive” assume independência condicional entre variáveis.
Probabilidade Apriori: Representa a probabilidade inicial de cada classe antes de observar os dados. No exemplo da renda, seria a probabilidade de uma pessoa ganhar mais de 50 mil dólares sem observar os demais fatores.
Probabilidade Posteriori: Esta é a probabilidade final após considerar os dados observados (idade, gênero, etc.). Ela indica a probabilidade de uma pessoa ganhar mais de 50 mil dólares dado seu perfil.
Esses conceitos são fundamentais para entender como o Naive Bayes calcula as probabilidades das classes.
Vantagens e Desvantagens do Modelo Naive Bayes
Vantagens:
Rapidez e Simplicidade: O Naive Bayes é rápido e fácil de interpretar.
Alta Dimensionalidade: Lida bem com datasets de alta dimensionalidade.
Eficácia em Datasets Pequenos: Performances elevadas em datasets de 200 a 2000 linhas.
Desvantagens:
Assunção de Independência: A independência entre atributos nem sempre é válida na prática.
Bases de Dados Grandes: Em bases grandes, como “adult.csv”, seu desempenho pode diminuir.
Implementação em Python: Treinamento, Acurácia e Matriz de Confusão
Nesta seção, vamos treinar o modelo Naive Bayes com Python e avaliar sua performance em termos de acurácia e matriz de confusão.import pickle from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay, classification_report
with open('adult.pkl', 'rb') as fl: X_adult_treinamento, y_adult_treinamento, X_adult_teste, y_adult_teste = pickle.load(fl)
# Verificando as dimensões dos dados print(X_adult_treinamento.shape, y_adult_treinamento.shape) print(X_adult_teste.shape, y_adult_teste.shape)
# Instanciando e treinando o modelo Naive Bayes naive_adult = GaussianNB() naive_adult.fit(X_adult_treinamento, y_adult_treinamento)
# Realizando previsões prev = naive_adult.predict(X_adult_teste) print(y_adult_teste) # Valores reais
# Acurácia e Matriz de Confusão print("Acurácia:", accuracy_score(y_adult_teste, prev)) cm = confusion_matrix(y_adult_teste, prev) print("Matriz de Confusão:\n", cm)
cm_display = ConfusionMatrixDisplay(cm, display_labels=['<=50K', '>50K']).plot() print("Relatório de Classificação:\n", classification_report(y_adult_teste, prev))
No código, carregamos as variáveis, treinamos o modelo e fazemos previsões. O accuracy_score calcula a acurácia, enquanto confusion_matrix e classification_report nos dão uma visão detalhada dos acertos e erros do modelo.
Acurácia e Matriz de Confusão
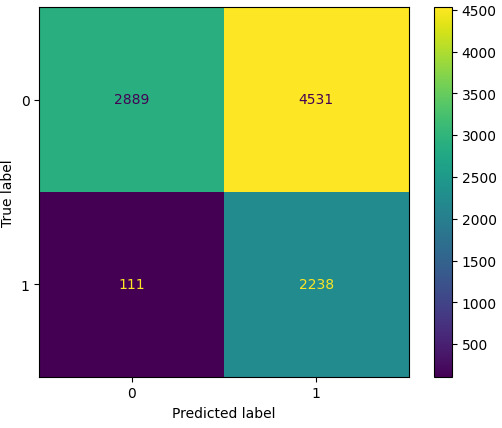
Isso significa que o modelo previu corretamente 2889 pessoas com renda menor e 2238 com renda maior. No entanto, houve 4531 erros para a classe de renda maior, destacando que o Naive Bayes não lida bem com a base adult.csv devido ao tamanho dos dados. Ainda assim, sem o escalonamento, a acurácia poderia subir para cerca de 70%, mas nosso foco é demonstrar o Naive Bayes em sua forma pura.
Conclusão
O modelo Naive Bayes, como demonstrado, é uma ferramenta rápida e poderosa em datasets menores e de alta dimensionalidade, mas apresenta limitações em bases maiores devido à sua suposição de independência entre variáveis. Apesar disso, a simplicidade do Naive Bayes o torna uma opção valiosa para iniciantes e para casos onde o tempo de processamento é uma prioridade.
Em artigos futuros, vamos comparar o Naive Bayes com outros modelos para analisar a performance e a adequação de cada um a diferentes tipos de dados. Fique atento para os próximos posts com detalhes e insights adicionais.
Livros que Indico
Estatística Prática para Cientistas de dados — neste link tem uma análise bem completa do livro.
Introdução à Computação Usando Python
2041: Como a Inteligência Artificial Vai Mudar Sua Vida nas Próximas Décadas — neste link tem uma análise completa do livro.
Curso Intensivo de Python — neste link tem uma análise completa do livro.
Entendendo Algoritmos. Um guia Ilustrado Para Programadores e Outros Curiosos
Novos Kindles
Fiz uma análise detalhada dos novos Kindles lançados este ano, destacando suas principais inovações e benefícios para os leitores digitais. Confira o texto completo no link a seguir: O Fascinante Mundo da Leitura Digital: Vantagens de Ter um Kindle.
Amazon Prime
Entrar no Amazon Prime oferece uma série de vantagens, incluindo acesso ilimitado a milhares de filmes, séries e músicas, além de frete grátis em milhões de produtos com entrega rápida. Os membros também desfrutam de ofertas exclusivas, acesso antecipado a promoções e benefícios em serviços como Prime Video, Prime Music e Prime Reading, tornando a experiência de compra e entretenimento muito mais conveniente e rica.
Se você tiver interesse, entre pelo link a seguir: AMAZON PRIME, que me ajuda a continuar na divulgação da inteligência artificial e programação de computadores.
0 notes