#oracle dba commands list
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
Database change management tools are of great help to developers and database administrators. These tools increase the efficiency of their work. Earlier database administrators used command lines to delete, create and edit databases. However now with the introduction of Database Change Management tools, the work load of the DBA’s has reduced considerably. Below are given different types of open source database change management tools which are of great help to the DBA’s: LIQUIBASE Liquibase is an open source (Apache 2.0 Licensed), database-independent library for tracking, managing and applying database changes. LIQUIBASE is used by developers in locating and making amendments in the database. The track of all these changes are maintained in an XML file (database changelog file) which serves to overview the list of changes made. It is compatible with any database which java can easily connect to. Key Features Efficiently manage multiple databases Extensible to make changes Able to keep a track record of database changes Execution can take place through Maven, command line, Ant etc. Download is available at https://www.liquibase.org/download DBDeploy Designed by a team of professionals at “Thoughworks”, this database change management tool is basically used by developers to manage and enhance their database designs. It is much more useful for those who refactor their database more often. Dbdeploy has employed java for its code construction and unifies with Sybase and Hypersonic SQL databases, Apache Ant build tool supporting Oracle. Key Features Simple to use Works well with Ant Download is available at http://code.google.com/p/dbdeploy/downloads/list Ruckusing This database tool is a frame of reference written in PHP5. Its use is to create and manage “database migrations”. These “database migrations” are files that define the present status of a database like its indexes, columns etc. The salient feature of this database is that multiple users can simultaneously work on the same application. In case of a crash by an individual the other users shall not be disrupted. The idea of the framework was influenced from the migration system built into Ruby on Rails. Any one who is familiar with Migrations in RoR will be able to use this quickly Key Features Portability: The migration files are initially written in PHP5 which are further translated to appropriate SQL during runtime. Thus providing an option of supporting any RDBMS with a single migration file. The ability to move (up and down) to particular migration state Download is available at DBSource Tools This database management tool is in there in form of a GUI service. Its use is to bring SQL server database under source control. Key Features Can be used to compare schemas Strong database scripter Download is available at Nextep Open Designer This IDE is used as a remedial measure for the deployment and development of the database as well as automating you test processes and your deployment. This software is available for free and its installation has many advantages. NeXtep Open Designer uses a centralized version control repository to track any change you make on your database model, source code (PL/SQL, T-SQL, etc.) and reference data. This repository is a simple database schema that can be automatically deployed to any supported database. Key Features Ease of merging database during development Helps in integrating deployment processes Download is available at http://www.nextep-softwares.com/index.php/products Tasks like maintaining and updating the relational databases are done by these tools very quickly and efficiently. These tools also help in maintaining the complex projects thus making the task easier for developers. Thus if you wish to increase your efficiency then these Database Management Tools are highly recommended. Hope you found this list useful! What are the tools you have used for database management? Please don't forget to share with us in comments.
Article Updates Article Updated on September 2021. Some HTTP links are updated to HTTPS. Updated broken links with latest URLs. Some minor text updates done. Content validated and updated for relevance in 2021.
0 notes
Text
Steps to Enable Archive Log Mode in Oracle RAC Database
You need to be logged in as a user with DBA privileges. 1) Check Current Archive Log Mode Status Archive log list; 2) Shutdown the RAC database on each instance or simply shutdown from SRVCTL command: srvctl stop database -d ORCL Or - Need to run on each instance of RAC database. so use srvctl for shutdown Shutdown immediate 3) Start the Oracle RAC Database in Mount Mode srvctl start…
0 notes
Text
Useful Linux commands for DBA
Useful Linux commands for ORACLE DBA
Here we learn some useful Linux commands for dba. Read: How to add SWAP Space in Linux PWD: show the present working directory. $pwd /home/oracle ls: list all files and directories from a given location, if the location is not given it shows the list from the current directory. $ls $ls /u01 $ls -l (list file details) $ls -a (show hidden files) cd: change directory or switch directory. $cd…

View On WordPress
#aix commands for oracle dba#basic linux commands#dba commands in sql#important unix commands for oracle dba#linux commands for oracle dba pdf#oracle commands#oracle database administration on linux#oracle dba commands cheat sheet#oracle dba commands list#oracle dba commands pdf#oracle linux commands cheat sheet#shripal singh#solaris commands for oracle dba
0 notes
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
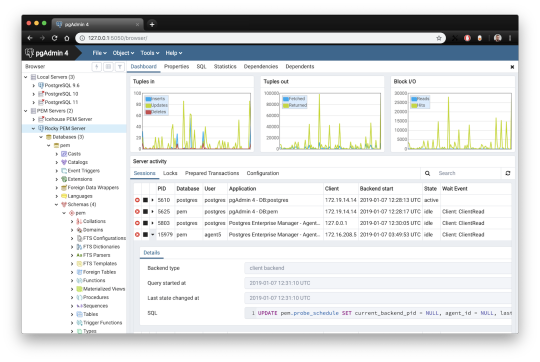
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
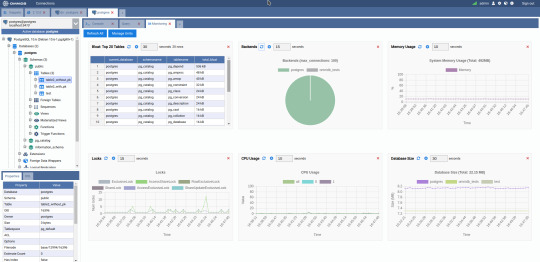
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
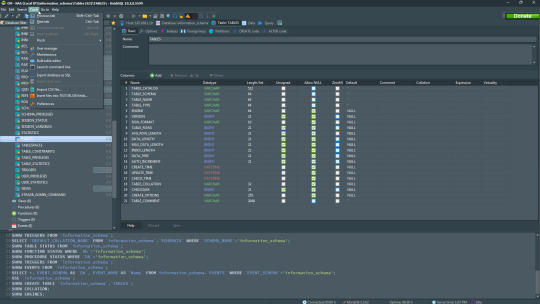
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
Sql Tools For Mac

Download SQL Server Data Tools (SSDT) for Visual Studio.; 6 minutes to read +32; In this article. APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL Data Warehouse) Parallel Data Warehouse SQL Server Data Tools (SSDT) is a modern development tool for building SQL Server relational databases, databases in Azure SQL, Analysis Services (AS) data models, Integration. SQLite's code is in the public domain, which makes it free for commercial or private use. I use MySQL GUI clients mostly for SQL programming, and I often keep SQL in files. My current favorites are: DBVisualizer Not free but I now use. Oracle SQL Developer is a free, development environment that simplifies the management of Oracle Database in both traditional and Cloud deployments. It offers development of your PL/SQL applications, query tools, a DBA console, a reports interface, and more.
Full MySQL Support
Sequel Pro is a fast, easy-to-use Mac database management application for working with MySQL databases.
Perfect Web Development Companion
Whether you are a Mac Web Developer, Programmer or Software Developer your workflow will be streamlined with a native Mac OS X Application!
Flexible Connectivity
Sequel Pro gives you direct access to your MySQL Databases on local and remote servers.
Easy Installation
Simply download, and connect to your database. Use these guides to get started:
Get Involved
Sequel Pro is open source and built by people like you. We’d love your input – whether you’ve found a bug, have a suggestion or want to contribute some code.
Get Started
New to Sequel Pro and need some help getting started? No problem.
-->
APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL Data Warehouse) Parallel Data Warehouse
SQL Server Data Tools (SSDT) is a modern development tool for building SQL Server relational databases, databases in Azure SQL, Analysis Services (AS) data models, Integration Services (IS) packages, and Reporting Services (RS) reports. With SSDT, you can design and deploy any SQL Server content type with the same ease as you would develop an application in Visual Studio.
SSDT for Visual Studio 2019
Changes in SSDT for Visual Studio 2019
The core SSDT functionality to create database projects has remained integral to Visual Studio.
With Visual Studio 2019, the required functionality to enable Analysis Services, Integration Services, and Reporting Services projects has moved into the respective Visual Studio (VSIX) extensions only.
Note
There's no SSDT standalone installer for Visual Studio 2019.
Install SSDT with Visual Studio 2019
If Visual Studio 2019 is already installed, you can edit the list of workloads to include SSDT. If you don’t have Visual Studio 2019 installed, then you can download and install Visual Studio 2019 Community.
To modify the installed Visual Studio workloads to include SSDT, use the Visual Studio Installer.

Launch the Visual Studio Installer. In the Windows Start menu, you can search for 'installer'.
In the installer, select for the edition of Visual Studio that you want to add SSDT to, and then choose Modify.
Select SQL Server Data Tools under Data storage and processing in the list of workloads.

For Analysis Services, Integration Services, or Reporting Services projects, you can install the appropriate extensions from within Visual Studio with Extensions > Manage Extensions or from the Marketplace.
SSDT for Visual Studio 2017
Changes in SSDT for Visual Studio 2017
Sql Server Data Tools For Mac
Starting with Visual Studio 2017, the functionality of creating Database Projects has been integrated into the Visual Studio installation. There's no need to install the SSDT standalone installer for the core SSDT experience.
Now to create Analysis Services, Integration Services, or Reporting Services projects, you still need the SSDT standalone installer.
Install SSDT with Visual Studio 2017
To install SSDT during Visual Studio installation, select the Data storage and processing workload, and then select SQL Server Data Tools.
Sql Management Studio For Mac
If Visual Studio is already installed, use the Visual Studio Installer to modify the installed workloads to include SSDT.
Launch the Visual Studio Installer. In the Windows Start menu, you can search for 'installer'.
In the installer, select for the edition of Visual Studio that you want to add SSDT to, and then choose Modify.
Select SQL Server Data Tools under Data storage and processing in the list of workloads.
Install Analysis Services, Integration Services, and Reporting Services tools
To install Analysis Services, Integration Services, and Reporting Services project support, run the SSDT standalone installer.
The installer lists available Visual Studio instances to add SSDT tools. If Visual Studio isn't already installed, selecting Install a new SQL Server Data Tools instance installs SSDT with a minimal version of Visual Studio, but for the best experience, we recommend using SSDT with the latest version of Visual Studio.
SSDT for VS 2017 (standalone installer)
Important
Before installing SSDT for Visual Studio 2017 (15.9.6), uninstall Analysis Services Projects and Reporting Services Projects extensions if they are already installed, and close all VS instances.
Removed the inbox component Power Query Source for SQL Server 2017. Now we have announced Power Query Source for SQL Server 2017 & 2019 as out-of-box component, which can be downloaded here.
To design packages using Oracle and Teradata connectors and targeting an earlier version of SQL Server prior to SQL 2019, in addition to the Microsoft Oracle Connector for SQL 2019 and Microsoft Teradata Connector for SQL 2019, you need to also install the corresponding version of Microsoft Connector for Oracle and Teradata by Attunity.
Release Notes
For a complete list of changes, see Release notes for SQL Server Data Tools (SSDT).
System requirements
Microsoft Sql Tools For Mac
SSDT for Visual Studio 2017 has the same system requirements as Visual Studio.
Available Languages - SSDT for VS 2017
Sql Server Tools For Mac
This release of SSDT for VS 2017 can be installed in the following languages:
Considerations and limitations
You can’t install the community version offline
To upgrade SSDT, you need to follow the same path used to install SSDT. For example, if you added SSDT using the VSIX extensions, then you must upgrade via the VSIX extensions. If you installed SSDT via a separate install, then you need to upgrade using that method.
Offline install
To install SSDT when you’re not connected to the internet, follow the steps in this section. For more information, see Create a network installation of Visual Studio 2017.
First, complete the following steps while online:
Download the SSDT standalone installer.
Download vs_sql.exe.
While still online, execute one of the following commands to download all the files required for installing offline. Using the --layout option is the key, it downloads the actual files for the offline installation. Replace <filepath> with the actual layouts path to save the files.
For a specific language, pass the locale: vs_sql.exe --layout c:<filepath> --lang en-us (a single language is ~1 GB).
For all languages, omit the --lang argument: vs_sql.exe --layout c:<filepath> (all languages are ~3.9 GB).
After completing the previous steps, the following steps below can be done offline:
Run vs_setup.exe --NoWeb to install the VS2017 Shell and SQL Server Data Project.
From the layouts folder, run SSDT-Setup-ENU.exe /install and select SSIS/SSRS/SSAS.a. For an unattended installation, run SSDT-Setup-ENU.exe /INSTALLALL[:vsinstances] /passive.
For available options, run SSDT-Setup-ENU.exe /help
Note
If using a full version of Visual Studio 2017, create an offline folder for SSDT only, and run SSDT-Setup-ENU.exe from this newly created folder (don’t add SSDT to another Visual Studio 2017 offline layout). If you add the SSDT layout to an existing Visual Studio offline layout, the necessary runtime (.exe) components are not created there.
Supported SQL versions
Project TemplatesSQL Platforms SupportedRelational databasesSQL Server 2005* - SQL Server 2017 (use SSDT 17.x or SSDT for Visual Studio 2017 to connect to SQL Server on Linux) Azure SQL Database Azure Synapse Analytics (supports queries only; database projects aren't yet supported) * SQL Server 2005 support is deprecated, move to an officially supported SQL versionAnalysis Services models Reporting Services reportsSQL Server 2008 - SQL Server 2017Integration Services packagesSQL Server 2012 - SQL Server 2019
DacFx
SSDT for Visual Studio 2015 and 2017 both use DacFx 17.4.1: Download Data-Tier Application Framework (DacFx) 17.4.1.
Previous versions
Unix Tools For Mac
To download and install SSDT for Visual Studio 2015, or an older version of SSDT, see Previous releases of SQL Server Data Tools (SSDT and SSDT-BI).
See Also
Next steps
After installing SSDT, work through these tutorials to learn how to create databases, packages, data models, and reports using SSDT.
Get help
1 note
·
View note
Text
Datagrip sql

Datagrip sql driver#
Datagrip sql full#
Datagrip sql software#
Datagrip sql trial#
Datagrip sql full#
The SQL syntax is standard Spark SQL so we are free to use the full capabilities of the language. This style of working makes it really easy to explore our data as we're building our pipelines. Click on a table to view the records from that component.The DataGrip catalog should be filled in, with each Dataflow should be present as a different schema with each component mapped as a table.
Datagrip sql trial#
DOWNLOAD A 30-DAY TRIAL FOR DATAGRIP One of the most important activities for anyone working with databases is writing SQL. It supports PostgreSQL, MySQL, SQL Server, Oracle, and many other databases. It even analyzes your existing databases and helps you write. DataGrip is a universal tool for dealing with databases. It has auto completion support for SQL language. Although this article will go through the setup. DataGrip is a SQL database IDE from JetBrains. Click the database connection, select “ All schemas”, then hit the "Refresh" icon. Using Ascends JDBC / ODBC Connection, developers can query Ascend directly from SQL tools like DataGrip.
By default DataGrip does not include any schemas.
Switch to the Options tab to enable the connection as "Read-only".
Test the connection to ensure the setup is correct.
Enter the Username and Password from an API Token linked to a Service Account.
Fill in the host with your Ascend domain in the format.
If you encounter difficult connecting, you will likely need to download the Hive Standalone JAR for 2.3.7 from Maven Central and use that JAR instead of the one embedded in DataGrip.
Datagrip sql driver#
The Apache Hive Driver that ships with DataGrip is version 3 and Spark is only compatible up to version 2.3.7. For the data source type, prefer Apache Spark if present, otherwise use Apache Hive. "You get what you pay for" - The paid tools are worth the cost if you can use it to full extent. You can get a connection to SQLite going very easily though, and unlike other databases it doesn't require a server per se (or to be more correct the server is self contained in the driver). To create an instance, run SqlLocalDB create 'DEVELOPMENT' 14.0 -s. A cross-platform IDE that is aimed at DBAs and developers working with SQL databases. You will see a list of available LocalDB instances on the server. What is DataGrip A database IDE for professional SQL developers. Locate SqllocalDB.exe and run the SqllocalDB.exe i command in a terminal. And as a first step, check if your LocalDB instance is ready for a connection. dBeaver - SSMS, Azure Data Studio, Oracle development studio - Snowflake UI, GBQ Builtin UI DataGrip is still a great tool for learning SQL, but there's generally some additional setup involved in getting a server running that they simply don't cover. You can easily connect to your LocalDB instance with DataGrip. The tools native to the system are more than enough. Select the Databricks driver that you added in the preceding step. On the Data Sources tab, click the + ( Add) button. VSCode - Pycharm + DataGripįree tools should not be ignored as they get the job done well. Use DataGrip to connect to the cluster or SQL warehouse that you want to use to access the databases in your Databricks workspace. This means, the development environment should cater to general needs and/or scripting. I'll summarize some of the response:įor general DE needs, a scripted approach seems to be consensus.
Datagrip sql software#
MY RECOMMENDED READING LIST FOR SOFTWARE DEVEL. Toad, data grip, dbeaver etc.Īny recommendations / opinions on IDE & why?Įdit: Thanks for the feedback. Wondering if you should buy Jetbrains DataGrip Learn if its worth the price tag in this super quick review. I have been using sublime and atom as text editors with syntax highlighting but I have been looking into full fledged IDEs e.g. Just curious about the IDE's that other people use.
0 notes
Text
Actual Odbc Driver
Advertisement
DTM ODBC Driver List v.2011DTM ODBCDriver List is a free command line tool that enumerates or export to text file the list of installed ODBC drivers. Generated text file is ready to open by Microsoft Excel. It is handy tool for DBA and advanced users who works with ODBC.
Actual ODBC Driver for OpenBase for Mac OS v.2.2Now you can access data from your OpenBase database using Microsoft Excel and FileMaker Pro. With the Actual ODBCDriver for OpenBase, you can connect quickly and easily to your database. Unlike other solutions, this driver installs completely on ...
NetSuite ODBC Driver (32/64-bit) v.1.3Devart ODBCDriver for NetSuite provides high-performance and feature-rich connectivity solution for ODBC-based applications to access NetSuite ERP from Windows, both 32-bit and 64-bit.
Devart ODBC Driver for NetSuite v.2.0Devart ODBCDriver for NetSuite provides high-performance and feature-rich connectivity solution for ODBC-based applications to access NetSuite ERP from Windows, both 32-bit and 64-bit.
Devart ODBC Driver for NexusDB v.1.0Devart ODBCDriver for NexusDB provides a high-performance and feature-rich connectivity solution for ODBC-based applications to access NexusDB databases from Windows, both 32-bit and 64-bit.
Devart ODBC Driver for Oracle v.4.0.1Devart ODBCDriver for Oracle provides high-performance and feature-rich connectivity solution for ODBC-based applications to access Oracle databases from Windows, Linux and Mac OS X, both 32-bit and 64-bit.
Devart ODBC Driver for SQL Server v.3.1Devart ODBCDriver for SQL Server provides high-performance and feature-rich connectivity solution for ODBC-based applications to access SQL Server databases from Windows, Linux and Mac OS X, both 32-bit and 64-bit.
Devart ODBC Driver for PostgreSQL v.3.2Devart ODBCDriver for PostgreSQL provides high-performance and feature-rich connectivity solution for ODBC-based applications to access PostgreSQL databases from Windows, Linux and Mac OS X, both 32-bit and 64-bit.
Devart ODBC Driver for InterBase v.2.2Devart ODBCDriver for InterBase provides high-performance and feature-rich connectivity solution for ODBC-based applications to access InterBase databases from Windows, both 32-bit and 64-bit.
Devart ODBC Driver for Firebird v.3.0.4Devart ODBCDriver for Firebird provides a high-performance and feature-rich connectivity solution for ODBC-compliant applications to access Firebird databases from Windows, macOS, and Linux, both 32-bit and 64-bit.
Devart ODBC Driver for SQL Azure v.3.1Devart ODBCDriver for SQL Azure provides high-performance and feature-rich connectivity solution for ODBC-based applications to access SQL Azure databases from Windows, both 32-bit and 64-bit.
Devart ODBC Driver for SQLite v.4.0.1Devart ODBCDriver for SQLite provides a high-performance and feature-rich connectivity solution for ODBC-compliant applications to access SQLite databases from Windows, macOS, and Linux, both 32-bit and 64-bit.
Salesforce Marketing Cloud (ExactTarget) ODBC Driver (32/64 bit) v.1.3.Devart ODBCDriver for Salesforce Marketing Cloud (formerly known as ExactTarget) provides high-performance and feature-rich connectivity solution for ODBC-based applications to access Salesforce Marketing Cloud databases from Windows 32-bit & 64-bit ...
Dynamics CRM ODBC Driver (32/64 bit) v.1.4Devart ODBCDriver for Dynamics CRM provides high-performance and feature-rich connectivity solution for ODBC-based applications to access Dynamics CRM cloud databases from Windows, both 32-bit and 64-bit.
SugarCRM ODBC Driver (32/64 bit) v.1.3Devart ODBCDriver for SugarCRM provides high-performance and feature-rich connectivity solution for ODBC-based applications to access SugarCRM cloud databases from Windows, both 32-bit and 64-bit.
Zoho CRM ODBC Driver (32/64 bit) v.1.3.Devart ODBCDriver for Zoho CRM provides high-performance and feature-rich connectivity solution for ODBC-based applications to access Zoho CRM cloud databases from Windows, both 32-bit and 64-bit.
QuickBooks ODBC Driver (32/64 bit) v.1.3Devart ODBCDriver for QuickBooks provides high-performance and feature-rich connectivity solution for ODBC-based applications to access QuickBooks cloud databases from Windows, both 32-bit and 64-bit.
FreshBooks ODBC Driver (32/64 bit) v.2.1Devart ODBCDriver for FreshBooks provides high-performance and feature-rich connectivity solution for ODBC-based applications to access FreshBooks cloud databases from Windows, both 32-bit and 64-bit.
MailChimp ODBC Driver (32/64 bit) v.1.3Devart ODBCDriver for MailChimp provides high-performance and feature-rich connectivity solution for ODBC-based applications to access MailChimp cloud databases from Windows, both 32-bit and 64-bit.
BigCommerce ODBC Driver (32/64 bit) v.1.4Devart ODBCDriver for BigCommerce provides high-performance and feature-rich connectivity solution for ODBC-based applications to access BigCommerce cloud databases from Windows, both 32-bit and 64-bit.
Actual ODBC Driver for SQL Server v.2.6The Actual SQLServer ODBC Driver lets you access your companys Microsoft SQLServer database from within Microsoft Excel. You can connect to any database you are authorized to use, and work with the data just like your Windows-using co-workers. Jan 05, 2009 The Actual SQL Server ODBC Driver lets you access your company's Microsoft SQL Server and Sybase databases from within Microsoft Excel and FileMaker Pro. You can connect to any database you are.
Excel Odbc Driver software by TitlePopularityFreewareLinuxMac
Today's Top Ten Downloads for Excel Odbc Driver
Devart ODBC Driver for Oracle Devart ODBC Driver for Oracle provides high-performance
BigCommerce ODBC Driver (32/64 bit) Devart ODBC Driver for BigCommerce provides
SQLite ODBC driver (32/64 bit) Devart ODBC Driver for SQLite provides high-performance
DTM ODBC Driver List DTM ODBC Driver List is a free command line tool that
Actual ODBC Driver for OpenBase for Mac OS Now you can access data from your OpenBase database using
Actual ODBC Driver for Access With the ODBC driver for Access, you can connect to
Dynamics CRM ODBC Driver (32/64 bit) Devart ODBC Driver for Dynamics CRM provides
MySQL ODBC driver (32/64 bit) Devart ODBC Driver for MySQL provides high-performance
Devart ODBC Driver for InterBase Devart ODBC Driver for InterBase provides
FreshBooks ODBC Driver (32/64 bit) Devart ODBC Driver for FreshBooks provides
Visit HotFiles@Winsite for more of the top downloads here at WinSite!-->
Applies to: SQL Server (all supported versions) Azure SQL Database Azure SQL Managed Instance Azure Synapse Analytics Parallel Data Warehouse
Microsoft ODBC Driver for SQL Server is a single dynamic-link library (DLL) containing run-time support for applications using native-code APIs to connect to SQL Server. Use Microsoft ODBC Driver 17 for SQL Server to create new applications or enhance existing applications that need to take advantage of newer SQL Server features.
Download for Windows
The redistributable installer for Microsoft ODBC Driver 17 for SQL Server installs the client components, which are required during run time to take advantage of newer SQL Server features. It optionally installs the header files needed to develop an application that uses the ODBC API. Starting with version 17.4.2, the installer also includes and installs the Microsoft Active Directory Authentication Library (ADAL.dll).
Version 17.8.1 is the latest general availability (GA) version. If you have a previous version of Microsoft ODBC Driver 17 for SQL Server installed, installing 17.8.1 upgrades it to 17.8.1.
Download Microsoft ODBC Driver 17 for SQL Server (x64) Download Microsoft ODBC Driver 17 for SQL Server (x86)
Version information
Release number: 17.8.1.1
Released: July 30, 2021
Note
Actual Odbc Driver
If you are accessing this page from a non-English language version, and want to see the most up-to-date content, please select Read in English at the top of this page. You can download different languages from the US-English version site by selecting available languages.
Available languages
This release of Microsoft ODBC Driver for SQL Server can be installed in the following languages:
Microsoft ODBC Driver 17.8.1 for SQL Server (x64): Chinese (Simplified) | Chinese (Traditional) | English (United States) | French | German | Italian | Japanese | Korean | Portuguese (Brazil) | Russian | Spanish
Microsoft ODBC Driver 17.8.1 for SQL Server (x86): Chinese (Simplified) | Chinese (Traditional) | English (United States) | French | German | Italian | Japanese | Korean | Portuguese (Brazil) | Russian | Spanish
Actual Odbc Driver For Access
Release notes for Windows
For details about this release on Windows, see the Windows release notes.
Previous releases for Windows
To download previous releases for Windows, see previous Microsoft ODBC Driver for SQL Server releases.
Download for Linux and macOS
The Microsoft ODBC Driver for SQL Server can be downloaded and installed using package managers for Linux and macOS using the relevant installation instructions: Install ODBC for SQL Server (Linux) Install ODBC for SQL Server (macOS)
Actual Odbc Drivers
If you need to download the packages for offline installation, all versions are available via the below links.
Note
Packages named msodbcsql17-* are the latest version. Packages named msodbcsql-* are version 13 of the driver.
Alpine
17.8.1.1 Alpine package (PGP Signature)
17.7.2.1 Alpine package (PGP Signature)
17.7.1.1 Alpine package (PGP Signature)
17.6.1.1 Alpine package (PGP Signature)
17.5.2.2 Alpine package (PGP Signature)
17.5.2.1 Alpine package (PGP Signature)
17.5.1.1 Alpine package (PGP Signature)
Debian
Red Hat
Actual Odbc Driver Update
Suse

Ubuntu
See also Installing the Linux driver.
macOS
See the Homebrew formulae for details.
See also Installing the macOS driver.
Older Linux releases
Actual Odbc Driver Windows 10
Red Hat Enterprise Linux 5 and 6 (64-bit) - Download Microsoft ODBC Driver 11 for SQL Server - Red Hat Linux
SUSE Linux Enterprise 11 Service Pack 2 (64-bit) - Download Microsoft ODBC Driver 11 Preview for SQL Server - SUSE Linux
Release notes for Linux and macOS
Actual Odbc Driver Free
For details about releases for Linux and macOS, see the Linux and macOS release notes.
0 notes
Text
Design Workshop Lite Free Software Download

Design Workshop Lite free. software download Windows 10
Workshop Design Software
Workshop Design Software Free
Tf3dm 3d Models
Design Workshop Lite free. software download Cnet
License: All 1 2 | Free

Welcome to Design Workshop. We are dedicated to creating quality landscapes that meet today’s needs and endure for future generations. We use landscape architecture, urban design, planning and strategic services to create a resilient legacy for our clients, our communities and the well-being of our planet. Design Workshop, free design workshop software downloads. File Name: design-icons.zip Author: Aha-soft License: Demo ($129.00) File Size: 4.41 Mb Runs on: WinXP.
Using novaPDF Lite you can easily create high quality searchable PDF files in an affordable and reliable way from any Windows application. It installs as a printer driver and helps you generate the PDF files by simply selecting the 'print' command from any application (you can convert your Word documents, Excel sheets, PowerPoint presentations, AutoCad drawings, company’s reports,...
Category: Business & Finance / Business Finance Publisher: Softland, License: Shareware, Price: USD $19.95, File Size: 1.6 MB Platform: Windows
Colorful Music Editor Lite Version is a very easy to used music edit tools, you can join, split, and add any audio effect to you music file to create a new music.You can save part of audio file into new audio file and add audio effect to output file such as zoom in , zoom out and so on. Large number of audio format are supported. What's Features 1. Join parts of any audio file into...
Category: Audio Publisher: Colorful Software, License: Shareware, Price: USD $19.90, File Size: 6.6 MB Platform: Windows
Looking for a smart, powerfull and easy to use DJ software? Look no more! Meet FutureDecks Lite - the affordable professional DJ mixing software With FutureDecks Lite you can mix your songs like a pro DJ. Beat-matching is just a click away and also are seamless beat-aware loops and many other things. All theese thanks to the precise automatic BPM counter. You have a...
Category: Audio / All-in-One Jukeboxes Publisher: XYLIO INFO SRL, License: Demo, Price: USD $39.50, EUR29.5, File Size: 4.4 MB Platform: Windows, Mac
3D Topicscape Lite uses the concept-mapping or mindmapping approach to allow ideas and information to be organized, but in place of the usual 2D sheet, it works in 3D. This lets you plan your work as the ideas flow and see your to do list in an unlimited 3D mindmapping landscape. ( Comparison of Lite and Pro versions: http://www.topicscape.com/Pro-features.php ). If you think...
Category: Business & Finance Publisher: 3d-Scape Limited, License: Shareware, Price: USD $49.99, File Size: 26.2 MB Platform: Windows
Cross-Database Comparator Lite is a powerful easy-to-use ODBC based tool for comparison of heterogeneous databases, used by thousands DBAs, developers and testers all over the world. Product has earned this position owing to its high performance and friendly user interface, combined with rich functionality and wide features spectrum. Cross-Database Comparator Lite is intended for...
Category: Business & Finance Publisher: dbBalance Ltd., License: Shareware, Price: USD $299.00, File Size: 6.3 MB Platform: Windows
Using novaPDF Server Lite you can easily create high quality searchable PDF files in an affordable and reliable way from any Windows application. It installs as a printer driver and helps you generate the PDF files by simply selecting the 'print' command from any application (you can convert your Word documents, Excel sheets, PowerPoint presentations, AutoCad drawings, emails or web...
Category: Business & Finance Publisher: Softland, License: Shareware, Price: USD $19.95, File Size: 1.7 MB Platform: Windows
PDF-XChange Lite is a reduced version of PDF-XChange Standard that contains basic features for use when printing documents virtually. It combines high quality conversion with optimized compression to create professional documents that are comparatively small in size. It installs in the same manner as a standard printer and can be selected as desired to print/convert documents into...
Category: Utilities / Printers Publisher: Tracker Software Products Ltd, License: Freeware, Price: USD $0.00, File Size: 31.4 MB Platform: Windows
Program supports all voice modems. . .
Category: Business & Finance Publisher: Phone Server Lite, License: Shareware, Price: USD $99.95, File Size: 273.4 KB Platform: Windows
RiskyProject Lite is a schedule risk analysis software. RiskyProject Lite is seamlessly integrated with Microsoft Project and can be also executed as a standalone application. You can define project schedule in RiskyProject Lite, Microsoft Project, or can import it from other project management software including Oracle Primavera, Safran Project, MindManager, or other...
Category: Business & Finance / Project Management Publisher: Intaver Institute Inc., License: Demo, Price: USD $999.00, CAD999, File Size: 14.7 MB Platform: Windows
Timesheets Lite is our multi user timesheet program that is free for single database connections (2-3 users). It is ideally suited to a project based environment where you need to track and bill your employees time against projects. Key features of Timesheets Lite include: An older version is completely free for use for single connections (up to 3 users) Simple to use...
Category: Business & Finance Publisher: Timesheets MTS Software, License: Shareware, Price: USD $29.00, File Size: 4.3 MB Platform: Windows
Customer data, sales data, order data, classification data, sales results, budget administration, various testing data, questionarie tabulation, etc. Transforms data to fit your needs while simplifying everyday data processing with just one click. Waha! Transformer Lite is a tool that frees you from messy data conversions without any programming. This automatic data transformer can...
Category: Business & Finance Publisher: Beacon Information Technology Inc., License: Demo, Price: USD $99.95, File Size: 15.7 MB Platform: Windows
Multilizer Lite for Developers is an easy-to-use tool for localizing software developed with the most common software development tools. Multilizer Lite for Developers enables localization of standard Windows binaries (.exe, .ocs, .dll, ...), VCL binaries (binaries compiled with Delphi/C++Builder), Visual Studio .NET solutions and projects, and .resx files.
Category: Software Development Publisher: Multilizer (Rex Partners Oy), License: Demo, Price: USD $375.00, File Size: 5.9 MB Platform: Windows
Multilizer Lite for Documents is an easy-to-use tool for localizing documents in the most common document formats. Multilizer Lite for Documents enables localization of typical text documents, such as HTML (.html, .htm, .php, .asp, etc.) including embedded scripts (JScript for example), XML (.xml, .svg, and all others), and any other text files with regular expressions.
Category: Software Development Publisher: Multilizer (Rex Partners Oy), License: Demo, Price: USD $375.00, File Size: 2.6 MB Platform: Windows
AD Picture Viewer Lite is a compact, easy-to-use image viewer. It's support all popular image file formats and have many useful features such as opening images in folder with or without subfolders, viewing them in slide-show mode, a flexible and powerful image printing tool and so on. AD Picture Viewer Lite has many powerful features: a easy-to-use and intuitively user...
Category: Multimedia & Design / Graphics Viewers Publisher: Abroad Design, License: Shareware, Price: USD $19.95, File Size: 1.6 MB Platform: Windows
SignGo Lite signmaking software has everything you need to make professional signs. Create text, shapes and freehand graphics at any size to cut in vinyl. SignGo Lite includes essential sign making tools such as InlineOutline, welding, text on arc and node editor. Import or paste graphics from your favourite graphics program and use the powerful cutting utility to drive your...
Category: Multimedia & Design Publisher: Wissen UK Inc. Ltd., License: Shareware, Price: USD $139.00, File Size: 9.2 MB Platform: Windows
Absolute Log Analyzer Lite is an ideal website analysis tool for small websites (up to 5 domains). Priced at only $50, it contains 90 reports that let you evaluate your website performance, see where your visitors come from, analyze which keywords and keyphrases are most effective. The program automatically detects the format of your log files, keeps the database of old log files,...
Design Workshop Lite free. software download Windows 10
Category: Internet Publisher: BitStrike Software, License: Shareware, Price: USD $49.95, File Size: 1.4 MB Platform: Windows
Safety above all - and we guard our computers with antivirus programs, firewalls, etc. Privacy is essential - and we... enter the Internet without giving a tiniest thought to protecting our private information. Your IP address, in other words your computer ID, as well as the location of your computer, the language your OS uses and other details are monitored and very often logged for future use...

Category: Internet Publisher: ThankSoft, License: Shareware, Price: USD $25.00, File Size: 1.5 MB Platform: Windows
JitBit Macro Recorder Lite is a simple and low cost automation system to record keyboard, record mouse movement, record mouse clicks. All recorded keystrokes and mouse activity can be replayed or saved to disk for later use. This utility will save you a lot of time on repetitive tasks. Use it to automate ANY activity in ANY windows application, record on-screen presentations and...
Category: Utilities Publisher: JitBit Software, License: Shareware, Price: USD $27.85, File Size: 1.1 MB Platform: Windows
All-in-one MIDI musical instrument with Arpeggiator and MIDI / MIDI Karaoke Player (Lite version). Allows to play piano on PC keyboard, play with any MIDI file and sing at the same time. Works with any hardware or software synthesizer installed in your computer. Includes 'basic' Java Soundbank, which can be easily upgraded to 'deluxe' Soundbank. Easy to learn and use for inexperienced...
Category: Audio Publisher: ArptonSoft, LLC, License: Shareware, Price: USD $24.95, File Size: 1.3 MB Platform: Windows
Brainstorm Lite is a very restrictive brainstorming application that forces you to follow some core brainstorming rules thus achieving better results in less time. The software tracks brainstorming time and prohibits the user from entering new ideas after the time is up. This is used to inspire creativity because everyone knows how much time is left to generate new ideas and that there...
Workshop Design Software
Category: Business & Finance Publisher: Computer Systems Odessa, License: Freeware, Price: USD $0.00, File Size: 579.9 KB Platform: Mac
Task Fields: Task Number (auto assigned), Description, Long Description, Status (lookup, ie: New, Open, Closed, Dependancy), Status Note (reason for Status), Severity (Low, Medium, High, Urgent), Category (lookup, ie: Bug, Enhancement, File Change), Module (lookup, ie: A/R, Payroll, G/L, A/P), Received (date task entered/received), Phase (lookup, ie: Requirements, Analysis, Design), %...
Category: Business & Finance Publisher: Berthume Software, License: Shareware, Price: USD $27.00, File Size: 5.1 MB Platform: Windows
EMS SQL Manager for MySQL is a high performance tool for MySQL Database Server administration and development. SQL Manager for MySQL works with any MySQL versions from 3.23 to 5.2 and supports all of the latest MySQL features including views, stored procedures and functions, InnoDB foreign keys and so on. It offers plenty of powerful tools for experienced users to satisfy all their needs. SQL...
Category: Business & Finance Publisher: EMS Database Management Solutions, Inc, License: Freeware, Price: USD $0.00, File Size: 21.6 MB Platform: Windows
EMS SQL Manager for PostgreSQL is a powerful tool for PostgreSQL Database Server administration and development. PostgreSQL Manager works with any PostgreSQL versions up to 8.2 and supports all of the latest PostgreSQL features including tablespaces, argument names in functions, and so on. It offers plenty of powerful tools for experienced users such as Visual Database Designer, Visual Query...
Category: Business & Finance Publisher: EMS Database Management Solutions, Inc, License: Freeware, Price: USD $0.00, File Size: 17.6 MB Platform: Windows
Gold Calculator Lite Computes Gold, in Kilos, Oz, Dwt, grams, and grains to market price. A Must For All Jewelry Professionals, Pawnbrokers, Jewelers, Refineries, Investers, Laylmen. Just enter Gold Spot or Market Price and Gold Calculator Lite will do the rest. No system requirements. Uses virtually No system resources. The latest Runtime files are included with the application....
Workshop Design Software Free
Category: Business & Finance Publisher: Gold Calculator, License: Freeware, Price: USD $0.00, File Size: 1.6 MB Platform: Windows
Tf3dm 3d Models
Tm Desktop Utilities Pack. Includes 3 freeware utilities: Desktop Metric Conversion Calculator, Desktop Loan Repayment Calculator, Desktop Credit Card Validator in one program. All of them have an intuitive interface and simple to learn and use.
Design Workshop Lite free. software download Cnet
Category: Business & Finance Publisher: TM Services, License: Freeware, Price: USD $0.00, File Size: 465.5 KB Platform: Windows
0 notes
Text
Setting up Amazon CloudWatch alarms for AWS DMS resources using the AWS CLI
For very large migrations, AWS Database Migration Service (AWS DMS) replication can run for hours or days depending on the data being replicated. It’s advisable to monitor the AWS DMS resources for a smooth migration. Monitoring your resources can help you detect anomalies and trigger notifications based on the threshold metrics configured. You can use Amazon CloudWatch to collect, track, and monitor AWS resources using metrics. With CloudWatch, you can create alarms that watch metrics and send notifications when a threshold is breached. You can configure CloudWatch to monitor your replication using the AWS Management Console, the AWS Command Line Interface (AWS CLI), or AWS DMS API. AWS DMS replication is set up between two databases with multiple tasks performing full load or change data capture (CDC). With AWS DMS, you can perform one-time migrations and replicate ongoing changes to keep sources and targets in sync. These replication tasks run for hours or days, and can run into various replication issues, such as the following: Low memory – The replication instance is running low on memory High CPU – CPU is used at capacity Excessive swap usage – Not enough memory is allocated Network disruptions – Network failure between source and target instances To avoid these replication issues and redundant activities by DBAs, which can delay the migration timelines, it’s recommended to identify and detect these failures ahead of time to avoid any replication disruption. Setting up the CloudWatch monitoring alarms on AWS DMS replication and its tasks helps you alert proactively, so that you can act accordingly. This post describes how to set up and configure the monitoring of AWS DMS resources. You can implement the solution with the AWS CLI or the console. For this post, we use the AWS CLI to create our CloudWatch alarms. Solution overview The AWS CLI is an open-source tool that enables you to interact with AWS services using commands in your command line shell. For more information about installing and configuring the AWS CLI, see Installing the AWS CLI. AWS DMS helps you migrate databases to AWS securely. It supports homogeneous and heterogeneous migrations between different database platforms, such as Oracle to Amazon Aurora. AWS DMS supports continuous data replication while maintaining high availability, and has been widely adopted for database migrations because it’s easy to configure. For more information, see What Is AWS Database Migration Service? To use AWS DMS, you need to create a DMS replication instance, create a source endpoint that connects the source database to read data, and create a target endpoint that connects to the target database and loads the data. You can create one or more replication tasks to replicate and migrate your data between source and target databases. In this post, we describe the metrics that you can monitor on your AWS DMS resources. An AWS DMS replication instance is an Amazon Elastic Compute Cloud (Amazon EC2) instance that performs the actual data migration between source and target databases. The replication instance also caches the changes during the migration, which is very CPU and memory intensive. You can set up various metrics for AWS DMS replication. For this post, we set up the following: CPUUtilization FreeableMemory FreeStorageSpace WriteIOPS AWS DMS replication tasks are responsible for migrating and replicating data between the source and target endpoints. For this post, we set up the following key metrics: FullLoadThroughputRowsSource FullLoadThroughputRowsTarget CDCThroughputRowsSource CDCThroughputRowsTarget Prerequisites To follow along with this solution, you need the following resources: An AWS account with permissions to access resources in AWS DMS and CloudWatch Access to a Linux/Unix machine installed and configured with the AWS CLI Necessary AWS Identity and Access Management (IAM) permissions granted to the EC2 instance for accessing the CloudWatch alarms An AWS DMS replication instance running in your AWS account Setting up your replication instance To set up monitoring, it’s a best practice to name your CloudWatch alarm metrics uniquely. For this post, we create an AWS DMS replication instance (sample-dms-replication-instance) and AWS DMS tasks (dms-task-1) and configure its source and target endpoints. Complete the following steps: On the AWS DMS console, choose Replication instances. Choose your desired instance (for this post, we use sample-dms-replication-instance). To name your alarm uniquely, use the following parameters: team_tag_value – The parameter should be unique tag value resource_name – The unique resource name of your choice (this post uses dms_instance) metric_name – The alarm metrics replicaton_instance_identifier – The replication_instance_identifier name (for this post, we use sample-dms-replication-instance) region – The Region of your AWS DMS replication instance replication_instance_arn – The ARN of your replication instance (for this post, it’s arn:aws:dms:us-east-1:999999999999:rep:G7EBKJQL2EBNETCOE352XV77K4) Run the following commands on any Linux/Unix system to set up the environment variables referring to the preceding parameters: export team_tag_value=team1 export resource_name=dms_instance export replication_instance_identifier=sample-dms-replication-instance export region=us-east-1 export replication_instance_arn=arn:aws:dms:us-east-1:999999999999:rep:G7EBKJQL2EBNETCOE352XV77K4 To check all the available metrics on your AWS DMS resource, enter the following code: aws cloudwatch list-metrics --namespace AWS/DMS --dimensions "Name=ReplicationInstanceIdentifier,Value=$replication_instance_identifier" --region $region Output: { "Metrics": [ { "Namespace": "AWS/DMS", "MetricName": "FullLoadThroughputBandwidthSource", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "FullLoadThroughputRowsTarget", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "RunCounter", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, . . . . . . . . { "Namespace": "AWS/DMS", "MetricName": "CDCLatencyTarget", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "CDCLatencySource", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "CDCThroughputRowsTarget", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "FullLoadThroughputRowsSource", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "CDCChangesMemorySource", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] }, { "Namespace": "AWS/DMS", "MetricName": "CDCChangesMemoryTarget", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" }, { "Name": "ReplicationTaskIdentifier", "Value": "TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ" } ] } ] } Setting up AWS DMS replication instance CloudWatch metrics The following are some of the significant CloudWatch metrics for monitoring the AWS DMS replication instance: CPUUtilization – Amount of CPU used FreeStorageSpace – Amount of available storage space in bytes FreeableMemory – Amount of available random-access memory WriteIOPS – Average number of disk write I/O operations per second To set up an alarm for CPU utilization, run the following command, which creates a CloudWatch alarm for the replication instance when the CPU utilization is more than 70 percent for a period of 5 minutes for 3 data points: $ aws cloudwatch put-metric-alarm --alarm-name ${team_tag_value}-${resource_name}-cpu --alarm-description "alarm when cpu is more than threshold" --metric-name CPUUtilization --namespace AWS/DMS --statistic Average --period 300 --threshold 70 --comparison-operator GreaterThanThreshold --dimensions "Name=ReplicationInstanceIdentifier,Value=$replication_instance_identifier" --evaluation-periods 3 --unit Percent --region=$region To check the allocated storage (in GB) for your running AWS DMS instance, run the following command: $ aws dms describe-replication-instances --filters Name=replication-instance-arn,Values=$replication_instance_arn --query "ReplicationInstances[:].{AllocatedStorage:AllocatedStorage}" --region=$region Output: [ { "AllocatedStorage": 50 } ] To set up an alarm for free storage space (in bytes), run the following command: $ aws cloudwatch put-metric-alarm --alarm-name ${team_tag_value}-${resource_name}-FreeStorage --alarm-description "when less than 20% of the allocated storage" --metric-name FreeStorageSpace --namespace AWS/DMS --statistic Average --period 300 --threshold 1.0e+09 --comparison-operator LessThanOrEqualToThreshold --dimensions "Name=ReplicationInstanceIdentifier,Value= $replication_instance_identifier" --evaluation-periods 1 --unit Bytes --region=$region FreeableMemory Freeable memory is memory that can be freed and used for other processes; it’s the amount of cache used on the replication instance. Although the FreeableMemory metric doesn’t reflect actual free memory available, the combination the FreeableMemory and SwapUsage metrics can indicate if the replication instance is overloaded. To set up an alarm for freeable memory less than 1 GB, run the following command: $ aws cloudwatch put-metric-alarm --alarm-name ${team_tag_value}-${resource_name}-FreeableMemory --alarm-description "Free Memory is lower than 1GB" --metric-name "FreeableMemory" --namespace "AWS/DMS" --statistic Average --period 300 --threshold 1.0e+09 --comparison-operator LessThanOrEqualToThreshold --dimensions "Name=ReplicationInstanceIdentifier,Value= $replication_instance_identifier" --evaluation-periods 3 --unit Bytes --region=$region WriteIOPS To set up the alarm for the average number of WriteIOPS, run the following command: $ aws cloudwatch put-metric-alarm --alarm-name ${team_tag_value}-${resource_name}-WriteIOPS --alarm-description "High Write IOPs ALARM: More than 1000/Secs" --metric-name WriteIOPS --namespace "AWS/DMS" --statistic Average --period 120 --threshold 1000 --comparison-operator GreaterThanOrEqualToThreshold --evaluation-periods 2 --unit Count/Second --dimensions "Name=ReplicationInstanceIdentifier,Value= $replication_instance_identifier" --region=$region After you set up these metrics, you can see the alarms in CloudWatch. The following screenshot shows the alarms set up for sample-dms-replication-instance with the state OK. To describe the alarm that you configured, run the following command (the following code checks the alarm for WriteIOPS): $ export metric_name=WriteIOPS $ aws cloudwatch describe-alarms --alarm-names ${team_tag_value}-${resource_name}-${metric_name} --region=$region Output: { "MetricAlarms": [ { "AlarmName": "team1-dms_instance-WriteIOPS", "AlarmArn": "arn:aws:cloudwatch:us-east-1:999999999999:alarm:team1-dms_instance-WriteIOPS", "AlarmDescription": "High Write IOPs ALARM: More than 1000/Secs", "AlarmConfigurationUpdatedTimestamp": "2020-10-29T15:43:36.545Z", "ActionsEnabled": true, "OKActions": [], "AlarmActions": [], "InsufficientDataActions": [], "StateValue": "OK", "StateReason": "Threshold Crossed: 2 datapoints [0.0 (29/10/20 15:42:00), 0.10833333333333334 (29/10/20 15:40:00)] were not greater than or equal to the threshold (1000.0).", "StateReasonData": "{"version":"1.0","queryDate":"2020-10-29T15:44:38.061+0000","startDate":"2020-10-29T15:40:00.000+0000","unit":"Count/Second","statistic":"Average","period":120,"recentDatapoints":[0.10833333333333334,0.0],"threshold":1000.0}", "StateUpdatedTimestamp": "2020-10-29T15:44:38.066Z", "MetricName": "WriteIOPS", "Namespace": "AWS/DMS", "Statistic": "Average", "Dimensions": [ { "Name": "ReplicationInstanceIdentifier", "Value": "sample-dms-replication-instance" } ], "Period": 120, "Unit": "Count/Second", "EvaluationPeriods": 2, "Threshold": 1000.0, "ComparisonOperator": "GreaterThanOrEqualToThreshold" } ], "CompositeAlarms": [] } Setting up an alarm for replication tasks After you configure the AWS DMS replication alarms, you set up the replication tasks. On the AWS DMS console, choose Database migration tasks. Choose the task you want to set up an alarm for. You need the following parameters to name your alarm uniquely: replication_task_identifier – Replication task identifier replication_task_arn – Replication task ARN task_name – Name of the replication task Run the following commands on any Linux/Unix system to set up the CloudWatch metrics: $ export task_name=dms-task-1 $ export replication_task_identifier=TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ $ export replication_task_arn=arn:aws:dms:us-east-1:99999999999:task:TKTVOIKYZJY665F72C5OLEZJ4HYQX7USNHTZSRQ To check the available metrics for your task, run the following command: $ aws cloudwatch list-metrics --namespace AWS/DMS --dimensions "Name=ReplicationInstanceIdentifier,Value=$replication_instance_identifier " "Name=ReplicationTaskIdentifier,Value=$replication_task_identifier " --region=$region Setting up AWS DMS replication tasks CloudWatch metrics The following are some of the significant metrics for monitoring AWS DMS replication tasks: CDCThroughputRowsTarget – Outgoing task changes for the target in rows per second CDCThroughputRowsSource – Incoming task changes from the source in rows per second To describe the task the ReplicationInstanceIdentifier and ReplicationTaskIdentifier, enter the following code: $ aws dms describe-replication-tasks --filters Name=replication-task-arn,Values=$replication_task_arn --query "ReplicationTasks[:].{ReplicationTaskIdentifier:ReplicationTaskIdentifier,ReplicationInstanceArn:ReplicationInstanceArn,ReplicationTaskArn:ReplicationTaskArn}" --region=$region To set up the alarm for CDCThroughputRowsTarget, run the following command: $ aws cloudwatch put-metric-alarm --alarm-name ${team_tag_value}-${task_name}-cdcthroughputrowssource --alarm-description "Outgoing task changes for the target is more than 1000 rows per second" --metric-name CDCThroughputRowsSource --namespace "AWS/DMS" --statistic Average --period 60 --threshold 1000 --comparison-operator GreaterThanOrEqualToThreshold --evaluation-periods 1 --dimensions "Name=ReplicationInstanceIdentifier,Value=$replication_instance_identifier" "Name=ReplicationTaskIdentifier,Value=$replication_task_identifier" --region=$region To set up the alarm for CDCThroughputRowsSource, run the following command: $ aws cloudwatch put-metric-alarm --alarm-name ${team_tag_value}-${task_name}-cdcthroughputrowstarget --alarm-description "Outgoing task changes for the target is more than 1000 rows per second" --metric-name CDCThroughputRowsTarget --namespace "AWS/DMS" --statistic Average --period 60 --threshold 1000 --comparison-operator GreaterThanOrEqualToThreshold --evaluation-periods 1 --dimensions "Name=ReplicationInstanceIdentifier,Value=$replication_instance_identifier" "Name=ReplicationTaskIdentifier,Value=$replication_task_identifier" --region=$region These alarms aren’t initialized until the task is started. The following screenshot shows the alarms configured after running the alarm setup commands. To describe the alarms for this task, run the following command: $ export metric_name=cdcthroughputrowssource $ aws cloudwatch describe-alarms --alarm-names ${team_tag_value}-${task_name}-${metric_name} --query "MetricAlarms[:].{AlarmArn:AlarmArn,Dimensions:Dimensions,StateReason:StateReason}" --region=$region You can set up additional alarms based on your requirements, such as the following: CDCLatencySource – The gap, in seconds, between the last event captured from the source endpoint and current system timestamp of the AWS DMS instance. If no changes have been captured from the source due to task scoping, AWS DMS sets this value to zero. CDCLatencyTarget – The gap, in seconds, between the first event timestamp waiting to commit on the target and the current timestamp of the AWS DMS instance. Target latency should never be smaller than the source latency. NetworkTransmitThroughput – The outgoing (transmit) network traffic on the replication instance, including customer database traffic and AWS DMS traffic used for monitoring and replication. NetworkReceiveThroughput – The incoming (receive) network traffic on the replication instance, including customer database traffic and AWS DMS traffic used for monitoring and replication. Summary: This post discussed some of the CloudWatch metrics you can use to monitor your AWS DMS replication instance and replication tasks. For information about debugging AWS DMS, see Debugging Your AWS DMS Migrations: What to Do When Things Go Wrong (Part 1) and Debugging Your AWS DMS Migrations: What to Do When Things Go Wrong (Part 2). Try this approach in your environment and see the benefits. We hope this post helps you with your AWS DMS replication monitoring. Please reach out with questions or feature requests via the comments. About the Authors Jeevith Anumalla is an Oracle Database Cloud Architect with the Professional Services team at Amazon Web Services. He works as database migration specialist to help internal and external Amazon customers to move their on-premises database environment to AWS data stores. Sagar Patel is a Database Specialty Architect with the Professional Services team at Amazon Web Services. He works as a database migration specialist to provide technical guidance and help Amazon customers to migrate their on-premises databases to AWS. https://aws.amazon.com/blogs/database/setting-up-amazon-cloudwatch-alarms-for-aws-dms-resources-using-the-aws-cli/
0 notes
Text
300+ TOP ORACLE Database Interview Questions and Answers
ORACLE Database Interview Questions for freshers experienced :-
1. What Is Oracle? Oracle is a company. Oracle is also a database server, which manages data in a very structured way. It allows users to store and retrieve related data in a multiuser environment so that many users can concurrently access the same data. All this is accomplished while delivering high performance. A database server also prevents unauthorized access and provides efficient solutions for failure recovery. 2. What Is an Oracle Database? An Oracle database is a collection of data treated as a big unit in the database server. 3. What Is an Oracle Instance? Every running Oracle database is associated with an Oracle instance. When a database is started on a database server (regardless of the type of computer), Oracle allocates a memory area called the System Global Area (SGA) and starts one or more Oracle processes. This combination of the SGA and the Oracle processes is called an Oracle instance. The memory and processes of an instance manage the associated database's data efficiently and serve the one or multiple users of the database. 4. What Is a Parameter File in Oracle? A parameter file is a file that contains a list of initialization parameters and a value for each parameter. You specify initialization parameters in a parameter file that reflect your particular installation. Oracle supports the following two types of parameter files: * Server Parameter Files - Binary version. Persistent. * Initialization Parameter Files - Text version. Not persistent. 5. What Is a Server Parameter File in Oracle? A server parameter file is a binary file that acts as a repository for initialization parameters. The server parameter file can reside on the machine where the Oracle database server executes. Initialization parameters stored in a server parameter file are persistent, in that any changes made to the parameters while an instance is running can persist across instance shutdown and startup. 6. What Is a Initialization Parameter File in Oracle? An initialization parameter file is a text file that contains a list of initialization parameters. The file should be written in the client's default character set. Sample initialization parameter files are provided on the Oracle distribution medium for each operating system. A sample file is sufficient for initial use, but you will probably want to modify the file to tune the database for best performance. Any changes will take effect after you completely shut down and restart the instance. 7. What is System Global Area (SGA) in Oracle? The System Global Area (SGA) is a memory area that contains data shared between all database users such as buffer cache and a shared pool of SQL statements. The SGA is allocated in memory when an Oracle database instance is started, and any change in the value will take effect at the next startup. 8. What is Program Global Area (PGA) in Oracle? A Program Global Area (PGA) is a memory buffer that is allocated for each individual database session and it contains session specific information such as SQL statement data or buffers used for sorting. The value specifies the total memory allocated by all sessions, and changes will take effect as new sessions are started. 9. What Is a User Account in Oracle? A user account is identified by a user name and defines the user's attributes, including the following: Password for database authentication Privileges and roles Default tablespace for database objects Default temporary tablespace for query processing work space 10. What Is the Relation of a User Account and a Schema in Oracle? User accounts and schemas have a one-to-one relation. When you create a user, you are also implicitly creating a schema for that user. A schema is a logical container for the database objects (such as tables, views, triggers, and so on) that the user creates. The schema name is the same as the user name, and can be used to unambiguously refer to objects owned by the user.

ORACLE Database Interview Questions 11. What Is a User Role in Oracle? A user role is a group of privileges. Privileges are assigned to users through user roles. You create new roles, grant privileges to the roles, and then grant roles to users. 12. What is a Database Schema in Oracle? A schema is a collection of logical structures of data, or schema objects. A schema is owned by a database user and has the same name as that user. Each user owns a single schema. Schema objects can be created and manipulated with SQL and include: tables, views, and other types of data objects. 13. What Is a Database Table in Oracle? A database table is a basic unit of data logical storage in an Oracle database. Data is stored in rows and columns. You define a table with a table name, such as employees, and a set of columns. You give each column a column name, such as employee_id, last_name, and job_id; a datatype, such as VARCHAR2, DATE, or NUMBER; and a width. The width can be predetermined by the datatype, as in DATE. If columns are of the NUMBER datatype, define precision and scale instead of width. A row is a collection of column information corresponding to a single record. 14. What Is a Table Index in Oracle? Index is an optional structure associated with a table that allow SQL statements to execute more quickly against a table. Just as the index in this manual helps you locate information faster than if there were no index, an Oracle Database index provides a faster access path to table data. You can use indexes without rewriting any queries. Your results are the same, but you see them more quickly. 15. What Is an Oracle Tablespace? An Oracle tablespace is a big unit of logical storage in an Oracle database. It is managed and used by the Oracle server to store structures data objects, like tables and indexes. 16. What Is an Oracle Data File? An Oracle data file is a big unit of physical storage in the OS file system. One or many Oracle data files are organized together to provide physical storage to a single Oracle tablespace. 17. What Is a Static Data Dictionary in Oracle? Data dictionary tables are not directly accessible, but you can access information in them through data dictionary views. To list the data dictionary views available to you, query the view DICTIONARY. Many data dictionary tables have three corresponding views: * An ALL_ view displays all the information accessible to the current user, including information from the current user's schema as well as information from objects in other schemas, if the current user has access to those objects by way of grants of privileges or roles. * A DBA_ view displays all relevant information in the entire database. DBA_ views are intended only for administrators. They can be accessed only by users with the SELECT ANY TABLE privilege. This privilege is assigned to the DBA role when the system is initially installed. * A USER_ view displays all the information from the schema of the current user. No special privileges are required to query these views. 18. What Is a Dynamic Performance View in Oracle? Oracle contains a set of underlying views that are maintained by the database server and accessible to the database administrator user SYS. These views are called dynamic performance views because they are continuously updated while a database is open and in use, and their contents relate primarily to performance. Although these views appear to be regular database tables, they are not. These views provide data on internal disk structures and memory structures. You can select from these views, but you can never update or alter them. 19. What Is a Recycle Bin in Oracle? Recycle bin is a logical storage to hold the tables that have been dropped from the database, in case it was dropped in error. Tables in recycle bin can be recovered back into database by the Flashback Drop action. Oracle database recycle save the same purpose as the recycle bin on your Windows desktop. Recycle bin can be turned on or off in the recyclebin=on/off in your parameter file. 20. What Is SQL*Plus? SQL*Plus is an interactive and batch query tool that is installed with every Oracle Database Server or Client installation. It has a command-line user interface, a Windows Graphical User Interface (GUI) and the iSQL*Plus web-based user interface. 21. What Is Transport Network Substrate (TNS) in Oracle? TNS, Transport Network Substrate, is a foundation technology, built into the Oracle Net foundation layer that works with any standard network transport protocol. 22. What Is Open Database Communication (ODBC) in Oracle? ODBC, Open Database Communication, a standard API (application program interface) developed by Microsoft for Windows applications to communicate with database management systems. Oracle offers ODBC drivers to allow Windows applications to connect Oracle server through ODBC. 23. What is Oracle Database 10g Express Edition? Based on Oracle Web site: Oracle Database 10g Express Edition (Oracle Database XE) is an entry-level, small-footprint database based on the Oracle Database 10g Release 2 code base that's free to develop, deploy, and distribute; fast to download; and simple to administer. Oracle Database XE is a great starter database for: Developers working on PHP, Java, .NET, and Open Source applications DBAs who need a free, starter database for training and deployment Independent Software Vendors (ISVs) and hardware vendors who want a starter database to distribute free of charge Educational institutions and students who need a free database for their curriculum 24. What Are the Limitations Oracle Database 10g XE? Oracle Database XE is free for runtime usage with the following limitations: Supports up to 4GB of user data (in addition to Oracle system data) Single instance only of Oracle Database XE on any server May be installed on a multiple CPU server, but only executes on one processor in any server May be installed on a server with any amount of memory, but will only use up to 1GB RAM of available memory 25. What Operating Systems Are Supported by Oracle Database 10g XE? Oracle Database 10g Express Edition is available for two types of operating Systems: Linux x86 - Debian, Mandriva, Novell, Red Hat and Ubuntu Microsoft Windows 26. How To Download Oracle Database 10g XE? If you want to download a copy of Oracle Database 10g Express Edition, visit http://www.oracle.com/technology/software/products/database/xe/. If you are using Windows systems, there are downloads available for you: Oracle Database 10g Express Edition (Western European) - Single-byte LATIN1 database for Western European language storage, with the Database Homepage user interface in English only. Oracle Database 10g Express Edition (Universal) - Multi-byte Unicode database for all language deployment, with the Database Homepage user interface available in the following languages: Brazilian Portuguese, Chinese (Simplified and Traditional), English, French, German, Italian, Japanese, Korean and Spanish. Oracle Database 10g Express Client You need to download the universal edition, OracleXEUniv.exe, (216,933,372 bytes) and client package, OracleXEClient.exe (30,943,220 bytes). 27. How To Install Oracle Database 10g XE? To install 10g universal edition, double click, OracleXEUniv.exe, the install wizard starts. It will guide you to finish the installation process. You should take notes about: The SYSTEM password you selecte: atoztarget. Database server port: 1521. Database HTTP port: 8080. MS Transaction Server port: 2030. The directory where 10g XE is installed: oraclexe Hard disk space taken: 1655MB. 28. How To Check Your Oracle Database 10g XE Installation? If you want to check your fresh installation of 10g Express Edition without using any special client programs, you can use a Web browser with this address, http://localhost:8080/apex/. You will see the login page. Enter SYSTEM as the user name, and the password (atoztarget), you selected during the installation to log into the server. Visit different areas on your 10g XE server home page to make sure your server is running OK. You can also get to your 10g XE server home page by going through the start menu. Select All Programs, then Oracle Database 10g Express Edition, and then Go To Database Home Page 29. How To Shutdown Your 10g XE Server? If you want to shutdown your 10g Express Edition server, go to the Services manager in the control panel. You will a service called OracleServiceXE, which represents your 10g Express Edition server. Select OracleServiceXE, and use the right mouse click to stop this service. This will shutdown your 10g Express Edition server. You can also shutdown your 10g XE server through the start menu. Select All Programs, then Oracle Database 10g Express Edition, and then Stop Database. 30. How To Start Your 10g XE Server? Go to the Start menu, select All Programs, Oracle Database 10g Express Edition, and Start Database. 31. How Much Memory Your 10g XE Server Is Using? Your 10g XE Server is using about 180MB of memory even there is no users on the server. The server memory usage is displayed on your server home page, if you log in as SYSTEM. 32. How To Start Your 10g XE Server from Command Line? You can start your 10g XE server from command line by: Open a command line window. Change directory to oraclexeapporacleproduct10.2.0serverBIN. Run StartDB.bat. The batch file StartDB.bat contains: net start OracleXETNSListener net start OracleServiceXE @oradim -startup -sid XE -starttype inst > nul 2>&1 33. How To Shutdown Your 10g XE Server from Command Line? You can shutdown your 10g XE server from command line by: Open a command line window. Change directory to oraclexeapporacleproduct10.2.0serverBIN. Run StopDB.bat. The batch file StopDB.bat contains: net stop OracleServiceXE 34. How To Unlock the Sample User Account in Oracle? Your 10g XE server comes with a sample database user account called HR. But this account is locked. You must unlock it before you can use it: Log into the server home page as SYSTEM. Click the Administration icon, and then click Database Users. Click the HR schema icon to display the user information for HR. Enter a new password (hr) for HR, and change the status to Unlocked. Click Alter User to save the changes. Now user account HR is ready to use. 35. How To Change System Global Area (SGA) in Oracle? Your 10g XE server has a default setting for System Global Area (SGA) of 140MB. The SGA size can be changed to a new value depending on how many concurrent sessions connecting to your server. If you are running this server just for yourself to improve your DBA skill, you should change the SGA size to 32MB by: Log into the server home page as SYSTEM. Go to Administration, then Memory. Click Configure SGA. Enter the new memory size: 32 Click Apply Changes to save the changes. Re-start your server. 36. How To Change Program Global Area (PGA) in Oracle? Your 10g XE server has a default setting for Program Global Area (PGA) of 40MB. The PGA size can be changed to a new value depending on how much data a single session should be allocated. If you think your session will be short with a small amount of data, you should change the PGA size to 16MB by: Log into the server home page as SYSTEM. Go to Administration, then Memory. Click Configure PGA. Enter the new memory size: 16 Click Apply Changes to save the changes. Re-start your server. 37. What Happens If You Set the SGA Too Low in Oracle? Let's you made a mistake and changed to SGA to 16MB from the SYSTEM admin home page. When you run the batch file StartDB.bat, it will return a message saying server stated. However, if you try to connect to your server home page: http://localhost:8080/apex/, you will get no response. Why? Your server is running, but the default instance XE was not started. If you go the Control Panel and Services, you will see service OracleServiceXE is listed not in the running status. 38. What To Do If the StartBD.bat Failed to Start the XE Instance? If StartBD.bat failed to start the XE instance, you need to try to start the instance with other approaches to get detail error messages on why the instance can not be started. One good approach to start the default instance is to use SQL*Plus. Here is how to use SQL*Plus to start the default instance in a command window: >cd (OracleXE home directory) >.binstartdb >.binsqlplus Enter user-name: SYSTEM Enter password: atoztarget ERROR: ORA-01034: ORACLE not available ORA-27101: shared memory realm does not exist The first "cd" is to move the current directory the 10g XE home directory. The second command ".binstartdb" is to make sure the TNS listener is running. The third command ".binsqlplus" launches SQL*Plus. The error message "ORA-27101" tells you that there is a memory problem with the default instance. So you can not use the normal login process to the server without a good instance. See other tips on how to log into a server without any instance. 39. How To Login to the Server without an Instance? If your default instance is in trouble, and you can not use the normal login process to reach the server, you can use a special login to log into the server without any instance. Here is how to use SQL*Plus to log in as as a system BDA: >cd (OracleXE home directory) >.binstartdb >.binsqlplus Enter user-name: SYSTEM/atoztarget AS SYSDBA Connected to an idle instance SQL> show instance instance "local" The trick is to put user name, password and login options in a single string as the user name. "AS SYSDBA" tells the server to not start any instance, and connect the session the idle instance. Log in as SYSDBA is very useful for performing DBA tasks. 40. How To Use "startup" Command to Start Default Instance? If you logged in to the server as a SYSDBA, you start the default instance with the "startup" command. Here is how to start the default instance in SQL*Plus in SYSDBA mode: >.binsqlplus Enter user-name: SYSTEM/atoztarget AS SYSDBA Connected to an idle instance SQL> show instance instance "local" SQL> startup ORA-00821: Specified value of sga_target 16M is too small, needs to be at least 20M Now the server is telling you more details about the memory problem on your default instance: your SGA setting of 16MB is too small. It must be increased to at least 20MB. 41. Where Are the Settings Stored for Each Instance in Oracle? Settings for each instance are stored in a file called Server Parameter File (SPFile). Oracle supports two types of parameter files, Text type, and Binary type. parameter files should be located in $ORACLE_HOMEdatabase directory. A parameter file should be named like "init$SID.ora", where $SID is the instance name. 42. What To Do If the Binary SPFile Is Wrong for the Default Instance? Let's say the SPFile for the default instance is a binary file, and some settings are wrong in the SPFile, like SGA setting is bellow 20MB, how do you change a setting in the binary file? This seems to be a hard task, because the binary SPFile is not allowed to be edited manually. It needs to be updated by the server with instance started. But you can not start the instance because the SPFile has a wrong setting. One way to solve the problem is to stop using the binary SPFile, and use a text version of the a parameter file to start the instance. Here is an example of how to use the backup copy (text version) of the parameter file for the default instance to start the instance: >.binsqlplus Enter user-name: SYSTEM/atoztarget AS SYSDBA Connected to an idle instance 43. How To Check the Server Version in Oracle? Oracle server version information is stored in a table called: PRODUCT_COMPONENT_VERSION. You can use a simple SELECT statement to view the version information like this: >.binsqlplus Enter user-name: SYSTEM/atoztarget AS SYSDBA Connected to an idle instance SQL> COL PRODUCT FORMAT A35 SQL> COL VERSION FORMAT A15 SQL> COL STATUS FORMAT A15 SQL> SELECT * FROM PRODUCT_COMPONENT_VERSION; PRODUCT VERSION STATUS ----------------------------------- ----------- ---------- NLSRTL 10.2.0.1.0 Production Oracle Database 10g Express Edition 10.2.0.1.0 Product PL/SQL 10.2.0.1.0 Production TNS for 32-bit Windows: 10.2.0.1.0 Production 44. Explain What Is SQL*Plus? SQL*Plus is an interactive and batch query tool that is installed with every Oracle Database Server or Client installation. It has a command-line user interface, a Windows Graphical User Interface (GUI) and the iSQL*Plus web-based user interface. SQL*Plus has its own commands and environment, and it provides access to the Oracle Database. It enables you to enter and execute SQL, PL/SQL, SQL*Plus and operating system commands to perform the following: Format, perform calculations on, store, and print from query results Examine table and object definitions Develop and run batch scripts Perform database administration You can use SQL*Plus to generate reports interactively, to generate reports as batch processes, and to output the results to text file, to screen, or to HTML file for browsing on the Internet. You can generate reports dynamically using the HTML output facility of SQL*Plus, or using the dynamic reporting capability of iSQL*Plus to run a script from a web page. 45. How To Start the Command-Line SQL*Plus? f you Oracle server or client installed on your windows system, you can start the command-line SQL*Plus in two ways: 1. Click Start > All Programs > Oracle ... > Start SQL Command Line. The SQL*Plus command window will show up with a message like this: SQL*Plus: Release 10.2.0.1.0 - Production on Tue ... Copyright (c) 1982, 2005, Oracle. All rights reserved. SQL> 2. Click Start > Run..., enter "cmd" and click OK. A Windows command window will show up. You can then use Windows commands to start the command-line SQL*Plus as shown in the tutorial exercise below: >cd c:oraclexeapporacleproduct10.2.0server >.binsqlplus /nolog SQL*Plus: Release 10.2.0.1.0 - Production on Tue ... Copyright (c) 1982, 2005, Oracle. All rights reserved. 46. How To Get Help at the SQL Prompt? Once SQL*Plus is started, you will get a SQL prompt like this: SQL>. This where you can enter commands for SQL*Plus to run. To get help information at the SQL prompt, you can use the HELP command as shown in the following tutorial example: SQL> HELP INDEX Enter Help for help. @ COPY PAUSE SHUTDOWN @@ DEFINE PRINT SPOOL / DEL PROMPT SQLPLUS ACCEPT DESCRIBE QUIT START APPEND DISCONNECT RECOVER STARTUP ARCHIVE LOG EDIT REMARK STORE ATTRIBUTE EXECUTE REPFOOTER TIMING BREAK EXIT REPHEADER TTITLE ... COMPUTE LIST SET XQUERY CONNECT PASSWORD SHOW SQL> HELP CONNECT CONNECT ------ 47. What Information Is Needed to Connect SQL*Plus an Oracle Server? If you want to connect your SQL*Plus session to an Oracle server, you need to know the following information about this server: The network hostname, or IP address, of the Oracle server. The network port number where the Oracle server is listening for incoming connections. The name of the target database instance managed by the Oracle server. The name of your user account predefined on in the target database instance. The password of your user account predefined on in the target database instance. 48. What Is a Connect Identifier? A "connect identifier" is an identification string of a single set of connection information to a specific target database instance on a specific Oracle server. Connect identifiers are defined and stored in a file called tnsnames.ora located in $ORACLE_HOME/network/admin/ directory. Here is one example of a "connect identifier" definition: ggl_XE = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP) (HOST = www.atoztarget.com) (PORT = 1521) ) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE) ) ) The above "connect identifier" defines "TNS_XE" with the following connection information: * The network hostname: www.atoztarget.com. * The network port number: 1521. * The name of the target database instance: XE. 49. How To Connect a SQL*Plus Session to an Oracle Server? In order to connect a SQL*Plus session to an Oracle server, you need to: 1. Obtain the connection information from the Oracle server DBA. 2. Define a new "connect identifier" called "ggl_XE" in your tnsnames.org file with the given connection information. 3. Run the CONNECT command in SQL*Plus as shown in the tutorial exercise below: >cd c:oraclexeapporacleproduct10.2.0server >.binsqlplus /nolog SQL*Plus: Release 10.2.0.1.0 - Production on Tue ... Copyright (c) 1982, 2005, Oracle. All rights reserved. SQL> CONNECT ggl/retneclgg@ggl_XE; Connected. SQL> SELECT SYSDATE FROM DUAL; SYSDATE --------- 05-MAR-06 50. What Happens If You Use a Wrong Connect Identifier? Of course, you will get an error, if you use a wrong connect identifier. Here is an example of how SQL*Plus react to a wrong connect identifier: SQL> CONNECT ggl/retneclgg@WRONG; ERROR: ORA-12154: TNS:could not resolve the connect identifier specified Warning: You are no longer connected to ORACLE. What you need to do in this case: Check the CONNECT command to make sure that the connect identifier is entered correctly. Check the tnsnames.ora file to make sure that the connect identifier is defined correctly. Check the tnsnames.ora file to make sure that there is no multiple definitions of the same connect identifier. Check your files system to see if you have multiple copies of tnsnames.ora in different Oracle home directories, because you installed multiple versions of Oracle. If you do have multiple copies, make sure your SQL*Plus session is picking up the correct copy of tnsnames.ora. 51. What To Do If DBA Lost the SYSTEM Password? If the DBA lost the password of the SYSTEM user account, he/she can go to the Oracle server machine, and run SQL*Plus on server locally with the operating system authentication method to gain access to the database. The tutorial exercise below shows you how: (Terminal server to the Oracle server machine) (Start SQL*Plus) SQL>CONNECT / AS SYSDBA Connected. SQL> ALTER USER SYSTEM IDENTIFIED BY ssap_lgg; User altered. Notice that the (/) in the CONNECT command tells SQL*Plus to use the current user on local operating system as the connection authentication method. 52. What Types of Commands Can Be Executed in SQL*Plus? There are 4 types of commands you can run at the SQL*Plus command line prompt: 1. SQL commands - Standard SQL statements to be executed on target database on the Oracle server. For example: "SELECT * FROM ggl_faq;" is a SQL command. 2. PL/SQL commands - PL/SQL statements to be executed by the Oracle server. For example: "EXECUTE DBMS_OUTPUT.PUT_LINE('Welcome to www.atoztarget.com')" runs a PL/SQL command. SQL*Plus commands - Commands to be executed by the local SQL*Plus program itself. For example: "SET NULL 'NULL'" is a SQL*Plus command. OS commands - Commands to be executed by the local operating system. For example: "HOST dir" runs an operating system command on the local machine. 53. How To Run SQL Commands in SQL*Plus? If you want to run a SQL command in SQL*Plus, you need to enter the SQL command in one or more lines and terminated with (;). The tutorial exercise below shows a good example: SQL> SELECT 'Welcome!' FROM DUAL; 'WELCOME -------- Welcome! SQL> SELECT 'Welcome to atoztarget.com tutorials!' 2 FROM DUAL 3 ; 'WELCOMETOatoztarget.COMTUTORIALS!' ----------------------------------- Welcome to atoztarget.com tutorials! 54. How To Run PL/SQL Statements in SQL*Plus? If you want to run a single PL/SQL statement in SQL*Plus, you need to use the EXECUTE command as shown in the following tutorial example: SQL> SET SERVEROUTPUT ON SQL> EXECUTE DBMS_OUTPUT.PUT_LINE('Welcome to atoztarget!') Welcome to atoztarget! PL/SQL procedure successfully completed. 55. How To Change SQL*Plus System Settings? SQL*Plus environment is controlled a big list of SQL*Plus system settings. You can change them by using the SET command as shown in the following list: * SET AUTOCOMMIT OFF - Turns off the auto-commit feature. * SET FEEDBACK OFF - Stops displaying the "27 rows selected." message at the end of the query output. * SET HEADING OFF - Stops displaying the header line of the query output. * SET LINESIZE 256 - Sets the number of characters per line when displaying the query output. * SET NEWPAGE 2 - Sets 2 blank lines to be displayed on each page of the query output. * SET NEWPAGE NONE - Sets for no blank lines to be displayed on each page of the query output. * SET NULL 'null' - Asks SQL*Plus to display 'null' for columns that have null values in the query output. * SET PAGESIZE 60 - Sets the number of lines per page when displaying the query output. * SET TIMING ON - Asks SQL*Plus to display the command execution timing data. * SET WRAP OFF - Turns off the wrapping feature when displaying query output. 56. How To Look at the Current SQL*Plus System Settings? If you want to see the current values of SQL*Plus system settings, you can use the SHOW command as shown in the following tutorial exercise: SQL> SHOW AUTOCOMMIT autocommit OFF SQL> SHOW HEADING heading ON SQL> SHOW LINESIZE linesize 80 SQL> SHOW PAGESIZE pagesize 14 SQL> SHOW FEEDBACK FEEDBACK ON for 6 or more rows SQL> SHOW TIMING timing OFF SQL> SHOW NULL null "" SQL> SHOW ALL appinfo is OFF and set to "SQL*Plus" arraysize 15 autocommit OFF autoprint OFF autorecovery OFF autotrace OFF blockterminator "." (hex 2e) cmdsep OFF colsep " " compatibility version NATIVE concat "." (hex 2e) copycommit 0 COPYTYPECHECK is ON define "&" (hex 26) describe DEPTH 1 LINENUM OFF INDENT ON echo OFF 57. What Are SQL*Plus Environment Variables? Behaviors of SQL*Plus are also controlled a some environment variables predefined on the local operating system. Here are some commonly used SQL*Plus environment variables: * ORACLE_HOME - The home directory where your Oracle client application is installed. * PATH - A list of directories where SQL*Plus will search for executable or DLL files. PATH should include $ORACLE_HOMEbin. * SQLPLUS - The directory where localization messages are stored. SQLPLUS should be set to $ORACLE_HOMEsqlplusmesg * TNS_ADMIN - The directory where the connect identifier file, tnsnames.ora is located. TNS_ADMIN should be set to $ORACLE_HOME/network/admin. 58. How To Generate Query Output in HTML Format? If you want your query output to be generated in HTML format, you can use the "SET MARKUP HTML ON" to turn on the HTML feature. The following tutorial exercise gives you a good example: SQL> connect HR/retneclgg SQL> SET MARKUP HTML ON SQL> SELECT FIRST_NAME, LAST_NAME, HIRE_DATE 2 FROM EMPLOYEES WHERE FIRST_NAME LIKE 'Joh%'; FIRST_NAME LAST_NAME HIRE_DATE John Seo 12-FEB-98 John Russell 01-OCT-96 59. What Is Output Spooling in SQL*Plus? The output spooling a nice feature of the command-line SQL*Plus tool. If the spooling feature is turned on, SQL*Plus will send a carbon copy of the everything on your screen to a specified local file. Output spooling is used mostly for quick dump of data to local files. Here are the commands to turn on and off output spooling in SQL*Plus: * SPOOL fileName - Turning on output spooling with the specified file. * SPOOL OFF - Turning off output spooling and close the spool file. 60. How To Save Query Output to a Local File? Normally, when you run a SELECT statement in SQL*Plus, the output will be displayed on your screen. If you want the output to be saved to local file, you can use the "SPOOL fileName" command to specify a local file and start the spooling feature. When you are done with your SELECT statement, you need to close the spool file with the "SPOOL OFF" command. The following tutorial exercise gives you a good example: SQL> connect HR/retneclgg SQL> SET HEADING OFF SQL> SET FEEDBACK OFF SQL> SET LINESIZE 1000 SQL> SPOOL tempemployees.lst SQL> SELECT * FROM EMPLOYEES; ...... SQL> SPOOL OFF You should get all records in employees.lst with fixed length fields. 61. What Is Input Buffer in SQL*Plus? Input buffer is a nice feature of the command-line SQL*Plus tool. It allows you to revise a multiple-line command and re-run it with a couple of simple commands. By default, input buffer is always turned on in SQL*Plus. The last SQL statement is always stored in the buffer. All you need is to remember to following commonly used commands: * LIST - Displays the SQL statement (the last executed SQL statement) in the buffer. * RUN - Runs the SQL statement in the buffer again. ";" is a quick command equivalent to RUN. * CLEAR BUFFER - Removes the SQL statement in the buffer. * INPUT line - Adds a new line into the buffer. * APPEND text - Appends more text to the last line in the buffer. * DEL - Deletes one line from the buffer. * CHANGE /old/new - Replaces 'old' text with 'new' text in the buffer. 62. How To Revise and Re-Run the Last SQL Command? If executed a long SQL statement, found a mistake in the statement, and you don't want enter that long statement again, you can use the input buffer commands to the correct last statement and re-run it. The following tutorial exercise gives you a good example: SQL> connect HR/retneclgg SQL> SELECT FIRST_NAME, LAST_NAME, HIRE_DATE 2 FROM EMPLOYEE WHERE FIRST_NAME LIKE 'Joh%'; FROM EMPLOYEE WHERE FIRST_NAME LIKE 'Joh%' * ERROR at line 2: ORA-00942: table or view does not exist SQL> LIST 1 SELECT FIRST_NAME, LAST_NAME, HIRE_DATE 2* FROM EMPLOYEES WHERE FIRST_NAME LIKE 'Joh%' SQL> CHANGE /EMPLOYEE/EMPLOYEES/ 2* FROM EMPLOYEES WHERE FIRST_NAME LIKE 'Joh%' SQL> RUN (Query output) SQL> INPUT ORDER BY FIRE_DATE SQL> LIST 1 SELECT FIRST_NAME, LAST_NAME, HIRE_DATE 2 FROM EMPLOYEE WHERE FIRST_NAME LIKE 'Joh%' 3* ORDER BY HIRE_DATE SQL> RUN (Query output) SQL> CLEAR BUFFER buffer cleared SQL> LIST SP2-0223: No lines in SQL buffer. 63. How Run SQL*Plus Commands That Are Stored in a Local File? If you have a group of commands that you need to run them repeatedly every day, you can save those commands in a file (called SQL script file), and using the "@fileName" command to run them in SQL*Plus. If you want to try this, create a file called tempinput.sql with: SELECT 'Welcome to' FROM DUAL; SELECT 'atoztarget.com!' FROM DUAL; Then run the "@" command in SQL*Plus as: SQL> connect HR/retneclgg SQL> @tempinput.sql 'WELCOMETO ---------- Welcome to 'atoztarget.COM -------------- atoztarget.com! 64. How To Use SQL*Plus Built-in Timers? If you don't have a stopwatch/timer and want to measure elapsed periods of time, you can SQL*Plus Built-in Timers with the following commands: * TIMING - Displays number of timers. * TIMING START - Starts a new timer with or without a name. * TIMING SHOW - Shows the current time of the named or not-named timer. * TIMING STOP - Stops the named or not-named timer. The following tutorial exercise shows you a good example of using SQL*Plus built-in timers: SQL> TIMING START timer_1 (some seconds later) SQL> TIMING START timer_2 (some seconds later) SQL> TIMING START timer_3 (some seconds later) SQL> TIMING SHOW timer_1 timing for: timer_2 Elapsed: 00:00:19.43 (some seconds later) SQL> TIMING STOP timer_2 timing for: timer_2 Elapsed: 00:00:36.32 SQL> TIMING 2 timing elements in use 65. What Is Oracle Server Autotrace in Oracle? Autotrace is Oracle server feature that generates two statement execution reports very useful for performance tuning: * Statement execution path - Shows you the execution loop logic of a DML statement. * Statement execution statistics - Shows you various execution statistics of a DML statement. To turn on the autotrace feature, the Oracle server DBA need to: * Create a special table called PLAN_TABLE. * Create a special security role called PLUSTRACE. * Grant PLUSTRACE role your user account. 66. How To Set Up Autotrace for a User Account? If an Oracle user wants to use the autotrace feature, you can use the tutorial as an example to create the required table PLAN_TABLE, the required security role PLUSTRACE, and grant the role to that user: SQL> CONNECT HR/retneclgg SQL> @oraclexeapporacleproduct10.2.0server RDBMSADMINUTLXPLAN.SQL Table (HR.PLAN_TABLE) created. SQL> CONNECT / AS SYSDBA SQL> @C:oraclexeapporacleproduct10.2.0server SQLPLUSADMINPLUSTRCE.SQL SQL> drop role plustrace; Role (PLUSTRACE) dropped. SQL> create role plustrace; Role (PLUSTRACE) created. SQL> grant plustrace to dba with admin option; Grant succeeded. SQL> GRANT PLUSTRACE TO HR; Grant succeeded. Remember that PLAN_TABLE table must be created under the user schema HR. 67. How To Get Execution Path Reports on Query Statements? If your user account has autotrace configured by the DBA, you can use the "SET AUTOTRACE ON EXPLAIN" command to turn on execution path reports on query statements. The tutorial exercise bellow shows you a good example: SQL> CONNECT HR/retneclgg SQL> SET AUTOTRACE ON EXPLAIN SQL> SELECT E.LAST_NAME, E.SALARY, J.JOB_TITLE 2 FROM EMPLOYEES E, JOBS J 3 WHERE E.JOB_ID=J.JOB_ID AND E.SALARY>12000; LAST_NAME SALARY JOB_TITLE ----------------- ---------- ----------------------------- King 24000 President Kochhar 17000 Administration Vice President De Haan 17000 Administration Vice President Russell 14000 Sales Manager Partners 13500 Sales Manager Hartstein 13000 Marketing Manager 6 rows selected. 68. How To Get Execution Statistics Reports on Query Statements? If your user account has autotrace configured by the DBA, you can use the "SET AUTOTRACE ON STATISTICS" command to turn on execution statistics reports on query statements. The tutorial exercise bellow shows you a good example: SQL> CONNECT HR/retneclgg SQL> SET AUTOTRACE ON STATISTICS SQL> SELECT E.LAST_NAME, E.SALARY, J.JOB_TITLE 2 FROM EMPLOYEES E, JOBS J 3 WHERE E.JOB_ID=J.JOB_ID AND E.SALARY>12000; LAST_NAME SALARY JOB_TITLE ----------------- ---------- ----------------------------- King 24000 President Kochhar 17000 Administration Vice President De Haan 17000 Administration Vice President Russell 14000 Sales Manager Partners 13500 Sales Manager Hartstein 13000 Marketing Manager 6 rows selected. 69. What Is SQL in Oracle? SQL, SEQUEL (Structured English Query Language), is a language for RDBMS (Relational Database Management Systems). SQL was developed by IBM Corporation. 70. How Many Categories of Data Types in Oracle? Oracles supports the following categories of data types: * Oracle Built-in Datatypes. * ANSI, DB2, and SQL/DS Datatypes. * User-Defined Types. * Oracle-Supplied Types. 71. What Are the Oracle Built-in Data Types? There are 20 Oracle built-in data types, divided into 6 groups: * Character Datatypes - CHAR, NCHAR, NVARCHAR2, VARCHAR2 * Number Datatypes - NUMBER, BINARY_FLOAT, BINARY_DOUBLE * Long and Row Datatypes - LONG, LONG RAW, RAW * Datetime Datatypes - DATE, TIMESTAMP, INTERVAL YEAR TO MONTH, INTERVAL DAY TO SECOND * Large Object Datatypes - BLOB, CLOB, NCLOB, BFILE * Row ID Datatypes - ROWID, UROWID 72. What Are the Differences between CHAR and NCHAR in Oracle? Both CHAR and NCHAR are fixed length character data types. But they have the following differences: * CHAR's size is specified in bytes by default. * NCHAR's size is specified in characters by default. A character could be 1 byte to 4 bytes long depending on the character set used. * NCHAR stores characters in Unicode. 73. What Are the Differences between CHAR and VARCHAR2 in Oracle? The main differences between CHAR and VARCHAR2 are: * CHAR stores values in fixed lengths. Values are padded with space characters to match the specified length. * VARCHAR2 stores values in variable lengths. Values are not padded with any characters. 74. What Are the Differences between NUMBER and BINARY_FLOAT in Oracle? The main differences between NUMBER and BINARY_FLOAT in Oracle are: * NUMBER stores values as fixed-point numbers using 1 to 22 bytes. * BINARY_FLOAT stores values as single precision floating-point numbers. 75. What Are the Differences between DATE and TIMESTAMP in Oracle? The main differences between DATE and TIMESTAMP in Oracle are: * DATE stores values as century, year, month, date, hour, minute, and second. * TIMESTAMP stores values as year, month, day, hour, minute, second, and fractional seconds. 76. What Are the Differences between INTERVAL YEAR TO MONTH and INTERVAL DAY TO SECOND? The main differences between INTERVAL YEAR TO MONTH and INTERVAL DAY TO SECOND are: * INTERVAL YEAR TO MONTH stores values as time intervals at the month level. * INTERVAL DAY TO SECOND stores values as time intervals at the fractional seconds level. 77. What Are the Differences between BLOB and CLOB in Oracle? The main differences between BLOB and CLOB in Oracle are: * BLOB stores values as LOB (Large OBject) in bitstreams. * CLOB stores values as LOB (Large OBject) in character steams. 78. What Are the ANSI Data Types Supported in Oracle? The following ANSI data types are supported in Oracle: * CHARACTER(n) / CHAR(n) * CHARACTER VARYING(n) / CHAR VARYING(n) * NATIONAL CHARACTER(n) / NATIONAL CHAR(n) / NCHAR(n) * NATIONAL CHARACTER VARYING(n) / NATIONAL CHAR VARYING(n) / NCHAR VARYING(n) * NUMERIC(p,s) * DECIMAL(p,s) * INTEGER / INT * SMALLINT * FLOAT * DOUBLE PRECISION * REAL 79. How To Write Text Literals in Oracle? There are several ways to write text literals as shown in the following samples: SELECT 'atoztarget.com' FROM DUAL -- The most common format atoztarget.com SELECT 'It''s Sunday!' FROM DUAL -- Single quote escaped It's Sunday! SELECT N'Allo, C''est moi.' FROM DUAL -- National chars Allo, C'est moi. SELECT Q'/It's Sunday!/' FROM DUAL -- Your own delimiter It's Sunday! 80. How To Write Numeric Literals in Oracle? Numeric literals can coded as shown in the following samples: SELECT 255 FROM DUAL -- An integer 255 SELECT -6.34 FROM DUAL -- A regular number -6.34 SELECT 2.14F FROM DUAL -- A single-precision floating point 2.14 SELECT -0.5D FROM DUAL -- A double-precision floating point -0.5 81. How To Write Date and Time Literals in Oracle? Date and time literals can coded as shown in the following samples: SELECT DATE '2002-10-03' FROM DUAL -- ANSI date format 03-OCT-07 SELECT TIMESTAMP '0227-01-31 09:26:50.124' FROM DUAL 31-JAN-07 09.26.50.124000000 AM -- This is ANSI format 82. How To Write Date and Time Interval Literals in Oracle? Date and time interval literals can coded as shown in the following samples: SELECT DATE '2002-10-03' + INTERVAL '123-2' YEAR(3) TO MONTH FROM DUAL -- 123 years and 2 months is added to 2002-10-03 03-DEC-25 SELECT DATE '2002-10-03' + INTERVAL '123' YEAR(3) FROM DUAL -- 123 years is added to 2002-10-03 03-OCT-25 SELECT DATE '2002-10-03' + INTERVAL '299' MONTH(3) FROM DUAL -- 299 months years is added to 2002-10-03 03-SEP-27 SELECT TIMESTAMP '1997-01-31 09:26:50.124' + INTERVAL '4 5:12:10.222' DAY TO SECOND(3) FROM DUAL 04-FEB-97 02.39.00.346000000 PM SELECT TIMESTAMP '1997-01-31 09:26:50.124' + INTERVAL '4 5:12' DAY TO MINUTE FROM DUAL 04-FEB-97 02.38.50.124000000 PM SELECT TIMESTAMP '1997-01-31 09:26:50.124' + INTERVAL '400 5' DAY(3) TO HOUR FROM DUAL 07-MAR-98 02.26.50.124000000 PM SELECT TIMESTAMP '1997-01-31 09:26:50.124' + INTERVAL '400' DAY(3) FROM DUAL 07-MAR-98 09.26.50.124000000 AM SELECT TIMESTAMP '1997-01-31 09:26:50.124' + INTERVAL '11:12:10.2222222' HOUR TO SECOND(7) FROM DUAL 31-JAN-97 08.39.00.346222200 PM 83. How To Convert Numbers to Characters in Oracle? You can convert numeric values to characters by using the TO_CHAR() function as shown in the following examples: SELECT TO_CHAR(4123.4570) FROM DUAL 123.457 SELECT TO_CHAR(4123.457, '$9,999,999.99') FROM DUAL $4,123.46 SELECT TO_CHAR(-4123.457, '9999999.99EEEE') FROM DUAL -4.12E+03 84. How To Convert Characters to Numbers in Oracle? You can convert characters to numbers by using the TO_NUMBER() function as shown in the following examples: SELECT TO_NUMBER('4123.4570') FROM DUAL 4123.457 SELECT TO_NUMBER(' $4,123.46','$9,999,999.99') FROM DUAL 4123.46 SELECT TO_NUMBER(' -4.12E+03') FROM DUAL -4120 85. How To Convert Dates to Characters in Oracle? You can convert dates to characters using the TO_CHAR() function as shown in the following examples: SELECT TO_CHAR(SYSDATE, 'DD-MON-YYYY') FROM DUAL; -- SYSDATE returns the current date 07-MAY-2006 SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD') FROM DUAL; 2006/05/07 SELECT TO_CHAR(SYSDATE, 'MONTH DD, YYYY') FROM DUAL; MAY 07, 2006 SELECT TO_CHAR(SYSDATE, 'fmMONTH DD, YYYY') FROM DUAL; May 7, 2006 SELECT TO_CHAR(SYSDATE, 'fmDAY, MONTH DD, YYYY') FROM DUAL; SUNDAY, MAY 7, 2006 86. How To Convert Characters to Dates in Oracle? You can convert dates to characters using the TO_DATE() function as shown in the following examples: SELECT TO_DATE('07-MAY-2006', 'DD-MON-YYYY') FROM DUAL; 07-MAY-06 SELECT TO_DATE('2006/05/07 ', 'YYYY/MM/DD') FROM DUAL; 07-MAY-06 SELECT TO_DATE('MAY 07, 2006', 'MONTH DD, YYYY') FROM DUAL; 07-MAY-06 SELECT TO_DATE('May 7, 2006', 'fmMONTH DD, YYYY') FROM DUAL; 07-MAY-06 SELECT TO_DATE('SUNDAY, MAY 7, 2006', 'fmDAY, MONTH DD, YYYY') FROM DUAL; 07-MAY-06 87. How To Convert Times to Characters in Oracle? You can convert dates to characters using the TO_CHAR() function as shown in the following examples: SELECT TO_CHAR(SYSDATE, 'HH:MI:SS') FROM DUAL; 04:49:49 SELECT TO_CHAR(SYSDATE, 'HH24:MI:SS.FF') FROM DUAL; -- Error: SYSDATE has no fractional seconds SELECT TO_CHAR(SYSTIMESTAMP, 'HH24:MI:SS.FF9') FROM DUAL; 16:52:57.847000000 SELECT TO_CHAR(SYSDATE, 'SSSSS') FROM DUAL; -- Seconds past midnight 69520 88. How To Convert Characters to Times in Oracle? You can convert dates to characters using the TO_CHAR() function as shown in the following examples: SELECT TO_CHAR(TO_DATE('04:49:49', 'HH:MI:SS'), 'DD-MON-YYYY HH24:MI:SS') FROM DUAL; -- Default date is the first day of the current month 01-MAY-2006 04:49:49 SELECT TO_CHAR(TO_TIMESTAMP('16:52:57.847000000', 'HH24:MI:SS.FF9'), 'DD-MON-YYYY HH24:MI:SS.FF9') FROM DUAL; 01-MAY-2006 16:52:57.847000000 SELECT TO_CHAR(TO_DATE('69520', 'SSSSS'), 'DD-MON-YYYY HH24:MI:SS') FROM DUAL; 01-MAY-2006 19:18:40 89. What Is NULL value in Oracle? NULL is a special value representing "no value" in all data types. NULL can be used on in operations like other values. But most operations has special rules when NULL is involved. The tutorial exercise below shows you some examples: SET NULL 'NULL'; -- Make sure NULL is displayed SELECT NULL FROM DUAL; N - N U L L SELECT NULL + NULL FROM DUAL; NULL+NULL ---------- NULL SELECT NULL + 7 FROM DUAL; NULL+7 ---------- NULL SELECT NULL * 7 FROM DUAL; NULL*7 ---------- NULL SELECT NULL || 'A' FROM DUAL; N - A SELECT NULL + SYSDATE FROM DUAL; NULL+SYSD --------- NULL 90. How To Use NULL as Conditions in Oracle? If you want to compare values against NULL as conditions, you should use the "IS NULL" or "IS NOT NULL" operator. Do not use "=" or "" against NULL. The sample script below shows you some good examples: SELECT 'A' IS NULL FROM DUAL; -- Error: Boolean is not data type. -- Boolean can only be used as conditions SELECT CASE WHEN 'A' IS NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; FALSE SELECT CASE WHEN '' IS NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN 0 IS NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; FALSE SELECT CASE WHEN NULL IS NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN 'A' = NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; -- Do not use "=" FALSE SELECT CASE WHEN 'A' NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; -- Do not use "" FALSE SELECT CASE WHEN NULL = NULL THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; -- Do not use "=" FALSE 91. How To Concatenate Two Text Values in Oracle? There are two ways to concatenate two text values together: * CONCAT() function. * '||' operation. Here is some examples on how to use them: SELECT 'ggl' || 'Center' || '.com' FROM DUAL; atoztarget.com SELECT CONCAT('atoztarget','.com') FROM DUAL; atoztarget.com 92. How To Increment Dates by 1 in Oracle? If you have a date, and you want to increment it by 1. You can do this by adding the date with a date interval. You can also do this by adding the number 1 directly on the date. The tutorial example below shows you how to adding numbers to dates, and take date differences: SELECT TO_DATE('30-APR-06') + 1 FROM DUAL; -- Adding 1 day to a date 01-MAY-06 SELECT TO_DATE('01-MAY-06') - TO_DATE('30-APR-06') FROM DUAL; -- Taking date differences 1 SELECT SYSTIMESTAMP + 1 FROM DUAL; -- The number you add is always in days. 08-MAY-06 SELECT TO_CHAR(SYSTIMESTAMP+1,'DD-MON-YYYY HH24:MI:SS.FF3') FROM DUAL; -- Error: Adding 1 to a timestamp makes it a date. 93. How To Calculate Date and Time Differences in Oracle? If you want to know how many years, months, days and seconds are there between two dates or times, you can use the date and time interval expressions: YEAR ... TO MONTH and DAY ... TO SECOND. The tutorial exercise below gives you some good examples: SELECT (TO_DATE('01-MAY-2006 16:52:57','DD-MON-YYYY HH24:MI:SS') - TO_DATE('31-JAN-1897 09:26:50','DD-MON-YYYY HH24:MI:SS')) YEAR(4) TO MONTH FROM DUAL; -- 109 years and 3 months 109-3 SELECT (TO_DATE('01-MAY-2006 16:52:57','DD-MON-YYYY HH24:MI:SS') - TO_DATE('31-JAN-1897 09:26:50','DD-MON-YYYY HH24:MI:SS')) DAY(9) TO SECOND FROM DUAL; -- 39901 days and some seconds 39901 7:26:7.0 SELECT (TO_TIMESTAMP('01-MAY-2006 16:52:57.847', 'DD-MON-YYYY HH24:MI:SS.FF3') - TO_TIMESTAMP('31-JAN-1897 09:26:50.124', 'DD-MON-YYYY HH24:MI:SS.FF3')) YEAR(4) TO MONTH FROM DUAL; -- 109 years and 3 months 109-3 SELECT (TO_TIMESTAMP('01-MAY-2006 16:52:57.847', 'DD-MON-YYYY HH24:MI:SS.FF3') - TO_TIMESTAMP('31-JAN-1897 09:26:50.124','DD-MON-YYYY HH24:MI:SS.FF3')) DAY(9) TO SECOND FROM DUAL; -- 39 94. How To Use IN Conditions in Oracle? An IN condition is single value again a list of values. It returns TRUE, if the specified value is in the list. Otherwise, it returns FALSE. Some examples are given in the script below: SELECT CASE WHEN 3 IN (1,2,3,5) THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN 3 NOT IN (1,2,3,5) THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; FALSE SELECT CASE WHEN 'Y' IN ('F','Y','I') THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE 95. How To Use LIKE Conditions in Oracle? LIKE condition is also called pattern patch. There 3 main rules on using LIKE condition: * '_' is used in the pattern to match any one character. * '%' is used in the pattern to match any zero or more characters. * ESCAPE clause is used to provide the escape character in the pattern. The following script provides you some good pattern matching examples: SELECT CASE WHEN 'atoztarget.com' LIKE '%Center%' THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN 'atoztarget.com' LIKE '%CENTER%' THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; -- Case sensitive by default FALSE SELECT CASE WHEN 'atoztarget.com' LIKE '%Center_com' THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN '100% correct' LIKE '100% %' ESCAPE '' THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE 96. How To Use Regular Expression in Pattern Match Conditions in Oracle? If you have a pattern that is too complex for LIKE to handle, you can use the regular expression pattern patch function: REGEXP_LIKE(). The following script provides you some good examples: SELECT CASE WHEN REGEXP_LIKE ('atoztarget.com', '.*ggl.*','i') THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN REGEXP_LIKE ('atoztarget.com', '.*com$','i') THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE SELECT CASE WHEN REGEXP_LIKE ('atoztarget.com', '^F.*','i') THEN 'TRUE' ELSE 'FALSE' END FROM DUAL; TRUE 97. What Are DDL Statements in Oracle? DDL (Data Definition Language) statements are statements to create and manage data objects in the database. The are 3 primary DDL statements: CREATE - Creating a new database object. ALTER - Altering the definition of an existing data object. DROP - Dropping an existing data object. 98. How To Create a New Table in Oracle? If you want to create a new table in your own schema, you can log into the server with your account, and use the CREATE TABLE statement. The following script shows you how to create a table: >.binsqlplus /nolog SQL> connect HR/atoztarget Connected. SQL> CREATE TABLE tip (id NUMBER(5) PRIMARY KEY, subject VARCHAR(80) NOT NULL, description VARCHAR(256) NOT NULL, create_date DATE DEFAULT (sysdate)); Table created. This scripts creates a testing table called "tip" with 4 columns in the schema associated with the log in account "HR". 99. How To Create a New Table by Selecting Rows from Another Table? Let's say you have a table with many data rows, now you want to create a backup copy of this table of all rows or a subset of them, you can use the CREATE TABLE...AS SELECT statement to do this. Here is an example script: >.binsqlplus /nolog SQL> connect HR/atoztarget Connected. SQL> CREATE TABLE emp_dept_10 2 AS SELECT * FROM employees WHERE department_id=10; Table created. SQL> SELECT first_name, last_name, salary 2 FROM emp_dept_10; FIRST_NAME LAST_NAME SALARY -------------------- ------------------------- ---------- Jennifer Whalen 4400 As you can see, this SQL scripts created a table called "emp_dept_10" using the same column definitions as the "employees" table and copied data rows of one department. This is really a quick and easy way to create a table. 100. How To Add a New Column to an Existing Table in Oracle? If you have an existing table with existing data rows, and want to add a new column to that table, you can use the ALTER TABLE ... ADD statement to do this. Here is an example script: SQL> connect HR/atoztarget Connected. SQL> CREATE TABLE emp_dept_110 2 AS SELECT * FROM employees WHERE department_id=110; Table created. SQL> ALTER TABLE emp_dept_110 ADD (vacation NUMBER); Table altered. SQL> SELECT first_name, last_name, vacation 2 FROM emp_dept_110; FIRST_NAME LAST_NAME VACATION -------------------- ------------------------- ---------- Shelley Higgins William Gietz This SQL script added a new column called "vacation" to the "emp_dept_110" table. NULL values were added to this column on all existing data rows. ORACLE Database Questions and Answers Pdf Download Read the full article
0 notes
Text
Studying for 1Z0-460: Oracle Linux 6 Implementation Essentials
The 1Z0-460: Oracle Linux 6 Implementation Essentials exam covers basic installation and configuration tasks of an OL6 system. Passing the exam will earn candidates the Oracle Linux 6 Certified Implementation Specialist certification. This test is largely geared toward employees of companies that are Oracle Partners. However, anyone can take the exam and earn the certification. 1Z0-460 shares a number of topics with the OCA-level exam 1Z0-100: Oracle Linux 5 and 6 System Administration. The OCA exam covers a significant number of subjects beyond those covered by the implementation essentials test.
The 1Z0-460 exam is meant to ensure that individuals understand the differences between Oracle Linux and other Linux distributions and that they are able to perform installation and initial configuration tasks. Oracle's Linux distribution is starting to be used on an increasing number of servers that host Oracle databases, They have modified the Red Hat Enterprise Linux distribution to improve its suitability as a database platform. Becoming familiar with Oracle's most recent distribution of Linux 6 has the potential to enhance the careers of Linux system administrators that work with Oracle database or with database administrators that also perform system administration tasks. When preparing for any Oracle certification exam, your first step should be to visit the Oracle Education website. There is a list of topics available for every Oracle certification exam. The list will provide you with a clear set of goals that should guide your preparation. Oracle exams will never contain any question about topics outside those on the list. The Oracle Linux 6 Implementation Essentials exam will have seventy-one multiple-choice or multiple-answer questions and you will have 120 minutes to complete it.

The passing score is sixty-two percent. There is no partial credit for the multiple-answer questions -- every question is either right or wrong. Any questions on the exam that are left blank will count as incorrect. You should provide an answer to every question, even if you simply pick one at random, because otherwise it is certain the question will count against your score. If you are already familiar with installing Linux and performing basic system administration tasks, much of the material in this exam will be a review for you, This is true even if you have not worked specifically with Oracle Linux, The vast majority of commands covered behave identically from one distribution to the next, If you have worked with Red Hat Enterprise Linux or with Fedora, Oracle Linux is nearly identical, Only about twenty percent of the exam is on topics that are specific to Oracle Linux for one reason or another. The Oracle manuals are always a good source for candidates who are studying for Oracle certification tests. The documentation is very good and they can all be freely downloaded.
The information in the manuals is definitive. Oracle University develops their tests from them, so the answers on the exam will always match what the manuals indicate. The following titles provide the majority of the information you will need for 1Z0-460: Oracle Linux 6 Installation Guide Oracle Linux 6 Administrator's Guide Oracle Linux 6 Security Guide Oracle Linux Ksplice User's Guide The 1Z0-460 exam covers a fairly large number of topics -- seventy-nine in all. Because this is an 'essentials' exam, you might expect the questions to be fairly broad and generic -- asking about the purpose of a given command, for example. That is not the case. You will be expected to be quite familiar with commands and be able to provide the options that will perform specific functions. You might also be given a goal and have to answer which Linux utility would best be able to meet that goal. This exam concentrates on a relatively narrow set of Linux commands and functionality.
However, you need to understand the aspects of Linux that it does cover to a fair degree of detail. Prior to scheduling your exam, you should have spent a significant amount of time working with Oracle Linux 6. I highly recommend that you get Oracle's VM Virtualbox software (freely downloadable) and use it to create a virtual machine that you can install the operating system on. Having a Linux system handy to try out commands, investigate filesystems, and view configuration files while you are studying for the exam will help to make what you are studying more real. Good luck on the test. Matthew is an experienced DBA and developer. He holds Oracle DBA Certifications for releases 7, 8i, 9i, 10G and 11G; Oracle Expert Certifications for SQL, SQL Tuning and Application Express; is an Oracle Advanced PL/SQL Developer Certified Professional and an Oracle Linux 6 Certified Implementation Specialist. He is the author of several Oracle certification guides including one for 1Z0-460. His Web site, www.troytec.com, is dedicated to providing links to resources for Oracle certification preparation.
Formore: https://www.troytec.com/exam/1z0-460-exams
0 notes
Link
Get Hired — Linux Engineering 2019 ##realdiscount ##udemycoupon #Engineering #Hired #Linux Get Hired — Linux Engineering 2019 If you're looking for the ONE course that'll get you hired as a Linux Admin, read on... Hello. My name is Agaba Philip and I'm Linux Admin, Consultant & Pilot.I started my IT career in 2009 as an Oracle on Linux administrator,and I'll be sharing my real-world experience with you throughout this course. By the end of this course you will have gone from Linux fundamentals, to beingable to configure and maintain complex Linux-based services and systems.If you've been searching for the ONE course that'll take you from beginner tosenior-level Linux admin, your search is over.This course does not assume any prior Linux experience.You will be guided step-by-step from Linux novice, to the level of RHCE and beyond.Following, is a listing of some of the Skills you'll master.LINUX: Essential Tools & Commands Basic Administration KVM Virtualization Server Hardening File Sharing with NFS & Samba Centralized Authentication with LDAP & Kerberos Centralized Authentication with FreeIPA iSCSI Storage Area Networks Network Teaming & Bridging Apache Web service Postfix Mail service DNS & DHCP MariaDB Network Time Protocol Shell Scripting ORACLE: Basic SQL Advanced SQL Database Essentials RMAN Backup & Recovery Performance Tuning & Optimization Oracle Cloud Database Security ANSIBLE: Fundamentals Playbooks Variables, Inclusions & Task control Flow control & Conditionals Jinja2 templates DevOps with Vagrant AWS: Features EC2 Instances SSH Identities Availability Zones Static IPs Block Storage Object Storage Database Services ENROLL IN THIS COURSE AND STACK YOUR RESUME WITH JOB-READY SKILLS. Who this course is for: Anyone who wants to become a Paid Linux administrator. Students wishing to become Oracle DBAs. Anyone wanting to master Ansible configuration management. IT pros who want to learn cloud computing with Amazon Web Services. Anyone looking for a pay raise OR a change of jobs. 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/get-hired-linux-engineering-2019/
0 notes
Text
Frequently used OS (Linux/Solaris/AIX) Command for DBA
As a DBA you need to use frequent OS command or alt least how to query the OS and its hardware. Usually we do it before fresh install upgrade, migrate of database/operating system. Here is some of the useful frequently used day to day OS command for DBA. To find and delete files older than N number of days: find . -name ‘*.*’ -mtime + -exec rm {} ; Example : find . -mtime +5 -exec rm {} ; The above command is specially useful to delete log, trace, tmp file To list files modified in last N days: find . -mtime - -exec ls -lt {} ; Example: find . -mtime +3 -exec ls -lt {} ;1 The above command will find files modified in last 3 days To sort files based on Size of file: ls -l | sort -nk 5 | more useful to find large files in log directory to delete in case disk is full To find files changed in last N days : find -mtime -N –print Example: find -mtime -2 -print To find CPU & Memory detail of linux: cat /proc/cpuinfo (CPU) cat /proc/meminfo (Memory) Linux: cat /proc/cpuinfo|grep processor|wc -l HP: ioscan -fkn -C processor|tail +3|wc -l Solaris: psrinfo -v|grep "Status of processor"|wc –l psrinfo -v|grep "Status of processor"|wc –l lscfg -vs|grep proc | wc -l To find if Operating system in 32 bit or 64 bit: ON Linux: uname -m On 64-bit platform, you will get: x86_64 and on 32-bit patform , you will get:i686 On HP: getconf KERNEL_BITS On Solaris: /usr/bin/isainfo –kv On 64-bit patform, you will get: 64-bit sparcv9 kernel modules and on 32-bit, you will get: 32-bit sparc kernel modules. For solaris you can use directly: isainfo -v If you see out put like: "32-bit sparc applications" that means your O.S. is only 32 bit but if you see output like "64-bit sparcv9 applications" that means youe OS is 64 bit & can support both 32 & 64 bit applications. To find if any service is listening on particular port or not: netstat -an | grep {port no} Example: netstat -an | grep 1523 To find Process ID (PID) associated with any port: This command is useful if any service is running on a particular port (389, 1521..) and that is run away process which you wish to terminate using kill command lsof | grep {port no.} (lsof should be installed and in path) How to kill all similar processes with single command: ps -ef | grep opmn |grep -v grep | awk ‘{print $2}’ |xargs -i kill -9 {} Locating Files under a particular directory: find . -print |grep -i test.sql To remove a specific column of output from a UNIX command: For example to determine the UNIX process Ids for all Oracle processes on server (second column) ps -ef |grep -i oracle |awk '{ print $2 }' Changing the standard prompt for Oracle Users: Edit the .profile for the oracle user PS1="`hostname`*$ORACLE_SID:$PWD>" Display top 10 CPU consumers using the ps command: /usr/ucb/ps auxgw | head -11 Show number of active Oracle dedicated connection users for a particular ORACLE_SID ps -ef | grep $ORACLE_SID|grep -v grep|grep -v ora_|wc -l Display the number of CPU’s in Solaris: psrinfo -v | grep "Status of processor"|wc -l Display the number of CPU’s in AIX: lsdev -C | grep Process|wc -l Display RAM Memory size on Solaris: prtconf |grep -i mem Display RAM memory size on AIX: First determine name of memory device: lsdev -C |grep mem then assuming the name of the memory device is ‘mem0’ then the command is: lsattr -El mem0 Swap space allocation and usage: Solaris : swap -s or swap -l Aix : lsps -a Total number of semaphores held by all instances on server: ipcs -as | awk '{sum += $9} END {print sum}' View allocated RAM memory segments: ipcs -pmb Manually deallocate shared memeory segments: ipcrm -m '' Show mount points for a disk in AIX: lspv -l hdisk13 Display occupied space (in KB) for a file or collection of files in a directory or sub-directory: du -ks * | sort -n| tail Display total file space in a directory: du -ks . Cleanup any unwanted trace files more than seven days old: find . *.trc -mtime +7 -exec rm {} ; Locate Oracle files that contain certain strings: find . -print | xargs grep rollback Locate recently created UNIX files: find . -mtime -1 -print Finding large files on the server: find . -size +102400 -print Crontab Use: To submit a task every Tuesday (day 2) at 2:45PM 45 14 2 * * /opt/oracle/scripts/tr_listener.sh > /dev/null 2>&1 To submit a task to run every 15 minutes on weekdays (days 1-5) 15,30,45 * 1-5 * * /opt/oracle/scripts/tr_listener.sh > /dev/null 2>&1 To submit a task to run every hour at 15 minutes past the hour on weekends (days 6 and 0) 15 * 0,6 * * opt/oracle/scripts/tr_listener.sh > /dev/null 2>&1 For more related Linux/Solaris Basic command click on the link: Basic Linux/Solaris Command
0 notes
Text
DBA interview Question and Answer part 23
What is basic difference between V$ view to GV$ or V$ and V_$ view?The V_$ (V$ is the public synonym for V_$ views) view are called dynamic performance views. They are continuously updated while a database is open in use and their contents related primary to performance.Select object_type from '%SESSION' 'V%';OWNER OBJECT_NAME OBJECT_TYPE----- ----------- -------------SYS V_$HS_SESSION VIEWSYS V_$LOGMNR_SESSION VIEWSYS V_$PX_SESSION VIEWSYS V_$SESSION VIEWWhere as GV$ views are called Global dynamic performance view and retrieve information about all started instance accessing one RAC database in contrast with dynamic performance views which retrieves information about local instance only. The GV$ views having the additional column INST_ID which indicates the instance in RAC environment.GV$ views use a special form of parallel execution. The parallel execution co-ordinator runs on the instance that the client connects to and one slave is allocated in each instance to query the underlying V$ view for that instance.What is the Purpose of default Tablespace in oracle database?Each user should have a default tablespace. When a user creates a schema objects and specifies no tablespace to contain it, oracle database stores the object in default user tablespace.The default setting for default tablespace of all users is the SYSTEM tablespace. If a user likely to create any type of objects then you should specify and assign the user a default tablespace. Note: Using the tablespace other than SYSTEM reduces contention between data dictionary objects and the user objects for the same data files. Thus it is not advisable for user data to be stored in the SYSTEM tablesapce.SELECT USERNAME, DEFAULT_TABLESPACE FROM DBA_USERS WHERE USERNAME='EDSS';SQL> Alter user EDSS default tablespace XYZ;SELECT USERNAME, DEFAULT_TABLESPACE FROM DBA_USERS WHERE USERNAME='EDSS';Once you change the tablespace for a user the previous/existing objects stay the same,I suppose that you never specified a tablespace when you created the objects and let to use the default tablespace from the user, the objects stay stored in the previous tablespace(tablespace A) and new objects will be created in the new default tablespace (tablespace B). Like in the example above, the objects for EDSS stay in the ORAJDA_DB tablespace and any new object will be stored in the ORAJDA_DB1 tablespace.What is Identity Columns Feature in oracle 12c?Before Oracle 12c there was no direct equivalent of the AutoNumberor Identityfunctionality, when needed it will implemented using a combination of sequences and triggers. The oracle 12c database introduces the ability to define an identity clause for a table column defined using a numeric type. Using ALWAYS keyword will force the use of the identity.GENERATED ]AS IDENTITY Using BY DEFAULT allows you to use the identity if the column isn't referenced in the insert statement.Using BY DEFAULT ON NULL allows the identity to be used even when the identity column is referenced and NULL value is specified.How to find Truncated Table user information?If you have already configure the data mining concept with your database then there is nothing to do you can query with v$logmnr_contents view and find the list, otherwise you need to do some more step to configure it first with your database.Why used Materialized view instead of Table?Materialized views are basically used to increase query performance since it contains results of a query. They should be used for reporting instead of a table for a faster execution.How does Session communicate with the server process?Server processes executes SQL received from user processes.Which SGA memory structure cannot re-size dynamically after instance startup?Log BufferWhich Activity will generate less UNDO data?InsertWhat happens when a user issue a COMMIT?The LGWR flushes the log buffer to the online redo log.When the SMON processes perform ICR?Only at the time of startup after abort shutdown.What is the purpose of synonym in oracle?Synonym permits application to function without modification regardless of which user owns table or view or regardless of which database holds the table or view. It masks the real name and owner of an object and provides location transparency for tables, views or program units of a remote database.CREATE SYNONYM pay_payment_master FOR HRMS.pay_payment_master;CREATE PUBLIC SYNONYM pay_payment_master FOR [email protected];How many memory layers are in the shared pool?The shared pool of SGA having three layers: Library cache which contains parsed sql statement, cursor information, execution plan etc; dictionary cache contains cache user account information, privilege information, datafiles, segments and extent information; buffer for parallel execution messages and control structure.What is the cache hit ratio, what impact does it have on performance?It calculates how often a requested block has been found in the buffer cache without requiring disk space. This ratio is computed using view V$SYSSTAT. The buffer cache hit ratio can be used to verify the physical I/O as predicted by V$DB_CACHE_ADVICE.select From in 'physical reads');The cache-hit ratio can be calculated as follows: Hit ratio = 1 – (physical reads / (db block gets + consistent gets)) If the cache-hit ratio goes below 90% then: increase the initialization parameter DB_CACHE_SIZE.Which environment variables are critical to run OUI?ORACLE_BASE; ORACLE_HOME; ORACLE_SIDWhat is Cluster verification utility in RAC env.The cluster verification utility (CVU) is a validation tools that you can use to check all the important component that need to verified at different stage of deployment in a RAC environment.How to identify the voting disk in RAC env. and why it is always in odd number?As we know every node are interconnected with each other and pinging voting disk in cluster to check whether they are alive. If voting disks are in even count then both nodes are survival node and it is created multiple brains in same cluster. If it is odd number in that case only one node ping greater count of voting disk and cluster can be saved from multiple brain syndrome. You can identify voting disk by using the below command line:#crsctl query css votediskWhat are the components of physical database structure? What is the use of control files?Oracle database consists of three main categories of files: one or more datafiles, two or more redo log files; one or more control files.When an instance of an Oracle database is started, its control file is used to identify the database and redo log files that must be opened for database operation to proceed. It is also used in database recovery.What is difference between database Refreshing and Cloning?DB refreshing means the data in the target environment has been synchronized with a copy of production. This can be done by restoring with a backup of production database where as cloning means that an identical copy of production has been taken and restore to the target environment.When we need to Clone or Refresh the database? There are a couple of scenarios when cloning should be performed: 1. Creating a new environment with the same or different DBNAME. 2. Sometimes we need to apply patches or other major configuration changes thus a copy of environment is needed to test the effect of this change.3. Normally in software development environment before any major development efforts take place, it is always good to re-clone dev, test environments to keep environment sync. The refreshment is needed only when you sure that the environment are already sync and you need to apply only change of latest data.What is OERR utility?The OERR (Oracle Error) utility is provided only with Oracle databases on UNIX platforms. OERR is not an executable, but instead, a shell script that retrieves messages from installed message files. OERR is an Oracle utility that extracts error messages with suggested actions from the standard Oracle message files. This utility is very useful as it can extract OS-specific errors that are not in the generic Error Messages and Codes Manual.What do you mean by logfile mirroring?The Process of having copy of redolog file is called mirroring. It is done by creating group by log file together. This ensures that LGWR automatically writes them to all the member of the current online redo log group. In case a group fails the database automatically switch over the next group. It diminishes the performance.What is the use of large pool? Which case you need to use the large pool?You need to set large pool if you are using multi thread server and RMAN backup. It prevents RMAN and MTS server from competing with other subsystem for the same memory. RMAN uses the large pool for backup & restore when you set the DBWR_IO_SLAVES or BACKUP_TAPE_IO_SLAVES parameters to simulate asynchronous I/O. If neither of these parameters is enabled then oracle allocates backup buffers from local process memory rather than shared memory. Then there is no use of large pool.What will be your first steps if you get the message Application is running slow?Gather the statistics (statspack, AWR) report to find TOP 5 wait event or run a Top command in Linux to see CPU usage. Later run VMSTAT, SAR and PRSTAT command to get more information on CPU and Memory usage and possible blocking.If poor written statements then run EXPLAIN PLAN on these statements and see whether new index or use of HINT brings the cost of SQL down.How do you add more or subsequent block size specification? Re-create the CONTROLFILE to specify the new BLOCK SIZE for specific data files or Take the database OFFLINE and bring back online with a new BLOCK SIZE specification.
0 notes
Text
DBA Daily/Weekly/Monthly or Quarterly Checklist
In response of some fresher DBA I am giving quick checklist for a production DBA. Here I am including reference of some of the script which I already posted as you know each DBA have its own scripts depending on database environment too. Please have a look on into daily, weekly and quarterly checklist. Note: I am not responsible of any of the script is harming your database so before using directly on Prod DB. Please check it on Test environment first and make sure then go for it.Please send your corrections, suggestions, and feedback to me. I may credit your contribution. Thank you.------------------------------------------------------------------------------------------------------------------------Daily Checks:Verify all database, instances, Listener are up, every 30 Min. Verify the status of daily scheduled jobs/daily backups in the morning very first hour.Verify the success of archive log backups, based on the backup interval.Check the space usage of the archive log file system for both primary and standby DB. Check the space usage and verify all the tablespace usage is below critical level once in a day. Verify Rollback segments.Check the database performance, periodic basis usually in the morning very first hour after the night shift schedule backup has been completed.Check the sync between the primary database and standby database, every 20 min. Make a habit to check out the new alert.log entry hourly specially if getting any error.Check the system performance, periodic basis.Check for the invalid objectsCheck out the audit files for any suspicious activities. Identify bad growth projections.Clear the trace files in the udump and bdump directory as per the policy.Verify all the monitoring agent, including OEM agent and third party monitoring agents.Make a habit to read DBA Manual.Weekly Checks:Perform level 0 or cold backup as per the backup policy. Note the backup policy can be changed as per the requirement. Don’t forget to check out the space on disk or tape before performing level 0 or cold backup.Perform Export backups of important tables.Check the database statistics collection. On some databases this needs to be done every day depending upon the requirement.Approve or plan any scheduled changes for the week.Verify the schedule jobs and clear the output directory. You can also automate it.Look for the object that break rule. Look for security policy violation. Archive the alert logs (if possible) to reference the similar kind of error in future. Visit the home page of key vendors.Monthly or Quarterly Checks:Verify the accuracy of backups by creating test databases.Checks for the critical patch updates from oracle make sure that your systems are in compliance with CPU patches.Checkout the harmful growth rate. Review Fragmentation. Look for I/O Contention. Perform Tuning and Database Maintenance.Verify the accuracy of the DR mechanism by performing a database switch over test. This can be done once in six months based on the business requirements.------------------------------------------------------------------------------------------------------------------------------------------------------- Below is the brief description about some of the important concept including important SQL scripts. You can find more scripts on my different post by using blog search option.Verify all instances are up: Make sure the database is available. Log into each instance and run daily reports or test scripts. You can also automate this procedure but it is better do it manually. Optional implementation: use Oracle Enterprise Manager's 'probe' event.Verify DBSNMP is running:Log on to each managed machine to check for the 'dbsnmp' process. For Unix: at the command line, type ps –ef | grep dbsnmp. There should be two dbsnmp processes running. If not, restart DBSNMP.Verify success of Daily Scheduled Job:Each morning one of your prime tasks is to check backup log, backup drive where your actual backup is stored to verify the night backup. Verify success of database archiving to tape or disk:In the next subsequent work check the location where daily archiving stored. Verify the archive backup on disk or tape.Verify enough resources for acceptable performance:For each instance, verify that enough free space exists in each tablespace to handle the day’s expected growth. As of , the minimum free space for : . When incoming data is stable, and average daily growth can be calculated, then the minimum free space should be at least days’ data growth. Go to each instance, run query to check free mb in tablespaces/datafiles. Compare to the minimum free MB for that tablespace. Note any low-space conditions and correct it.Verify rollback segment:Status should be ONLINE, not OFFLINE or FULL, except in some cases you may have a special rollback segment for large batch jobs whose normal status is OFFLINE. Optional: each database may have a list of rollback segment names and their expected statuses.For current status of each ONLINE or FULL rollback segment (by ID not by name), query on V$ROLLSTAT. For storage parameters and names of ALL rollback segment, query on DBA_ROLLBACK_SEGS. That view’s STATUS field is less accurate than V$ROLLSTAT, however, as it lacks the PENDING OFFLINE and FULL statuses, showing these as OFFLINE and ONLINE respectively.Look for any new alert log entries:Connect to each managed system. Use 'telnet' or comparable program. For each managed instance, go to the background dump destination, usually $ORACLE_BASE//bdump. Make sure to look under each managed database's SID. At the prompt, use the Unix ‘tail’ command to see the alert_.log, or otherwise examine the most recent entries in the file. If any ORA-errors have appeared since the previous time you looked, note them in the Database Recovery Log and investigate each one. The recovery log is in .Identify bad growth projections.Look for segments in the database that are running out of resources (e.g. extents) or growing at an excessive rate. The storage parameters of these segments may need to be adjusted. For example, if any object reached 200 as the number of current extents, upgrade the max_extents to unlimited. For that run query to gather daily sizing information, check current extents, current table sizing information, current index sizing information and find growth trendsIdentify space-bound objects:Space-bound objects’ next_extents are bigger than the largest extent that the tablespace can offer. Space-bound objects can harm database operation. If we get such object, first need to investigate the situation. Then we can use ALTER TABLESPACE COALESCE. Or add another datafile. Run spacebound.sql. If all is well, zero rows will be returned.Processes to review contention for CPU, memory, network or disk resources:To check CPU utilization, go to =>system metrics=>CPU utilization page. 400 is the maximum CPU utilization because there are 4 CPUs on phxdev and phxprd machine. We need to investigate if CPU utilization keeps above 350 for a while.Make a habit to Read DBA Manual:Nothing is more valuable in the long run than that the DBA be as widely experienced, and as widely read, as possible. Readingsshould include DBA manuals, trade journals, and possibly newsgroups or mailing lists.Look for objects that break rules:For each object-creation policy (naming convention, storage parameters, etc.) have an automated check to verify that the policy is being followed. Every object in a given tablespace should have the exact same size for NEXT_EXTENT, which should match the tablespace default for NEXT_EXTENT. As of 10/03/2012, default NEXT_EXTENT for DATAHI is 1 gig (1048576 bytes), DATALO is 500 mb (524288 bytes), and INDEXES is 256 mb (262144 bytes). To check settings for NEXT_EXTENT, run nextext.sql. To check existing extents, run existext.sqlAll tables should have unique primary keys:To check missing PK, run no_pk.sql. To check disabled PK, run disPK.sql. All primary key indexes should be unique. Run nonuPK.sql to check. All indexes should use INDEXES tablespace. Run mkrebuild_idx.sql. Schemas should look identical between environments, especially test and production. To check data type consistency, run datatype.sql. To check other object consistency, run obj_coord.sql.Look for security policy violations:Look in SQL*Net logs for errors, issues, Client side logs, Server side logs and Archive all Alert Logs to historyVisit home pages of key vendors:For new update information made a habit to visit home pages of key vendors such as: Oracle Corporation: http://www.oracle.com, http://technet.oracle.com, http://www.oracle.com/support, http://www.oramag.com Quest Software: http://www.quests.comSun Microsystems: http://www.sun.com Look for Harmful Growth Rates:Review changes in segment growth when compared to previous reports to identify segments with a harmful growth rate. Review Tuning Opportunities and Perform Tuning Maintainance:Review common Oracle tuning points such as cache hit ratio, latch contention, and other points dealing with memory management. Compare with past reports to identify harmful trends or determine impact of recent tuning adjustments. Make the adjustments necessary to avoid contention for system resources. This may include scheduled down time or request for additional resources.Look for I/O Contention:Review database file activity. Compare to past output to identify trends that could lead to possible contention.Review Fragmentation:Investigate fragmentation (e.g. row chaining, etc.), Project Performance into the FutureCompare reports on CPU, memory, network, and disk utilization from both Oracle and the operating system to identify trends that could lead to contention for any one of these resources in the near future. Compare performance trends to Service Level Agreement to see when the system will go out of bounds. -------------------------------------------------------------------------------------------- Useful Scripts: -------------------------------------------------------------------------------------------- Script: To check free, pct_free, and allocated space within a tablespace SELECT tablespace_name, largest_free_chunk, nr_free_chunks, sum_alloc_blocks, sum_free_blocks , to_char(100*sum_free_blocks/sum_alloc_blocks, '09.99') || '%' AS pct_free FROM ( SELECT tablespace_name, sum(blocks) AS sum_alloc_blocks FROM dba_data_files GROUP BY tablespace_name), ( SELECT tablespace_name AS fs_ts_name, max(blocks) AS largest_free_chunk , count(blocks) AS nr_free_chunks, sum(blocks) AS sum_free_blocks FROM dba_free_space GROUP BY tablespace_name ) WHERE tablespace_name = fs_ts_name; Script: To analyze tables and indexes BEGIN dbms_utility.analyze_schema ( '&OWNER', 'ESTIMATE', NULL, 5 ) ; END ; Script: To find out any object reaching SELECT e.owner, e.segment_type , e.segment_name , count(*) as nr_extents , s.max_extents , to_char ( sum ( e.bytes ) / ( 1024 * 1024 ) , '999,999.90') as MB FROM dba_extents e , dba_segments s WHERE e.segment_name = s.segment_name GROUP BY e.owner, e.segment_type , e.segment_name , s.max_extents HAVING count(*) > &THRESHOLD OR ( ( s.max_extents - count(*) ) < &&THRESHOLD ) ORDER BY count(*) desc; The above query will find out any object reaching level extents, and then you have to manually upgrade it to allow unlimited max_extents (thus only objects we expect to be big are allowed to become big. Script: To identify space-bound objects. If all is well, no rows are returned. SELECT a.table_name, a.next_extent, a.tablespace_name FROM all_tables a,( SELECT tablespace_name, max(bytes) as big_chunk FROM dba_free_space GROUP BY tablespace_name ) f WHERE f.tablespace_name = a.tablespace_name AND a.next_extent > f.big_chunk; Run the above query to find the space bound object . If all is well no rows are returned if found something then look at the value of next extent. Check to find out what happened then use coalesce (alter tablespace coalesce;). and finally, add another datafile to the tablespace if needed. Script: To find tables that don't match the tablespace default for NEXT extent. SELECT segment_name, segment_type, ds.next_extent as Actual_Next , dt.tablespace_name, dt.next_extent as Default_Next FROM dba_tablespaces dt, dba_segments ds WHERE dt.tablespace_name = ds.tablespace_name AND dt.next_extent !=ds.next_extent AND ds.owner = UPPER ( '&OWNER' ) ORDER BY tablespace_name, segment_type, segment_name; Script: To check existing extents SELECT segment_name, segment_type, count(*) as nr_exts , sum ( DECODE ( dx.bytes,dt.next_extent,0,1) ) as nr_illsized_exts , dt.tablespace_name, dt.next_extent as dflt_ext_size FROM dba_tablespaces dt, dba_extents dx WHERE dt.tablespace_name = dx.tablespace_name AND dx.owner = '&OWNER' GROUP BY segment_name, segment_type, dt.tablespace_name, dt.next_extent; The above query will find how many of each object's extents differ in size from the tablespace's default size. If it shows a lot of different sized extents, your free space is likely to become fragmented. If so, need to reorganize this tablespace. Script: To find tables without PK constraint SELECT table_name FROM all_tables WHERE owner = '&OWNER' MINUS SELECT table_name FROM all_constraints WHERE owner = '&&OWNER' AND constraint_type = 'P'; Script: To find out which primary keys are disabled SELECT owner, constraint_name, table_name, status FROM all_constraints WHERE owner = '&OWNER' AND status = 'DISABLED' AND constraint_type = 'P'; Script: To find tables with nonunique PK indexes. SELECT index_name, table_name, uniqueness FROM all_indexes WHERE index_name like '&PKNAME%' AND owner = '&OWNER' AND uniqueness = 'NONUNIQUE' SELECT c.constraint_name, i.tablespace_name, i.uniqueness FROM all_constraints c , all_indexes i WHERE c.owner = UPPER ( '&OWNER' ) AND i.uniqueness = 'NONUNIQUE' AND c.constraint_type = 'P' AND i.index_name = c.constraint_name; Script: To check datatype consistency between two environments SELECT table_name, column_name, data_type, data_length,data_precision,data_scale,nullable FROM all_tab_columns -- first environment WHERE owner = '&OWNER' MINUS SELECT table_name,column_name,data_type,data_length,data_precision,data_scale,nullable FROM all_tab_columns@&my_db_link -- second environment WHERE owner = '&OWNER2' order by table_name, column_name; Script: To find out any difference in objects between two instances SELECT object_name, object_type FROM user_objects MINUS SELECT object_name, object_type FROM user_objects@&my_db_link; For more about script and Daily DBA Task or Monitoring use the search concept to check my other post. Follow the below link for important Monitoring Script: http://shahiddba.blogspot.com/2012/04/oracle-dba-daily-checklist.html
0 notes
Text
Selenium Training Institute in VAISHALI
About Selenium
This is a platform for testing software for web applications. Selenium provides a playback tool (previously also writing) to develop tests without having to learn the scripting language. It also provides a domain specific test language for writing tests in several programming languages, including C #, Groovy, Java, Perl, PHP, Python, Ruby and Scale. Then the tests can work against most modern web browsers. Testing of selenium is deployed on Windows, Linux and OS X. It is an open source software released under the Apache 2.0 license: web developers can download and use it without charge. Companies can run critical workloads or sensitive applications on private selenium by using public selenium tests or batch loads that need to be scaled on demand. Selenium training Institute of Education in Vaishali Delhi
History of selenium
Selenium was originally developed by Jason Huggins in 2004 as an internal tool of ThoughtWorks. Later, they were joined by other programmers and testers at ThoughtWorks before Paul Hammant joined the team and led the development of the second mode of operation, which later becomes "Selenium Remote Control." This year the instrument was opened.
In 2005, Dan Fabulich and Nelson Sproul suggested adopting a series of patches that would turn Selenium-RC into what was best known. At the same meeting in Selenium, the management of selenium as a project will continue as a committee, and Huggins and Hammant will be representatives of "Thoughts".
In 2007, Huggins joined Google. Together with others, such as Jennifer Bevan, he continued to develop and stabilize Selenium RC. At the same time, Simon Stewart at ThoughtWorks developed an excellent browser automation tool called WebDriver. In 2009, after a meeting of developers at the Google Test Automation Conference, it was decided to combine two projects and name the new project Selenium WebDriver for Selenium 2.0.
Components of selenium testing
There are some components of selenium.
Selenium IDE
Selenium IDE(Integrated Development Environment) is a complete integrated development environment (IDE) for Selenium tests. It is implemented as Firefox Add On and allows you to record using software, editing and debugging tests. Previously it was known as Selenium Recorder. It was originally created by Shinya Kasatani and transferred to the Selenium project in 2006. It is little supported and is compatible with Selenium RC, which was obsolete.
Selenium client API
The second component is selenium. As an alternative to writing tests in Selenium, tests can also be written in different programming languages. These tests are then linked to Selenium, calling methods in the Selenium Client API and testing selenium. Currently, Selenium provides client APIs for Java, C #, Ruby, JavaScript, and Python.
Selenium Remote Control
Selenium Remote Control (RC) is a component of selenium testing. This is a server written in Java, which accepts commands for the browser via HTTP. Selenium Remote Control allows you to write automatic tests for a web application in any programming language, which allows you to better integrate Selenium into existing modular test environments. To simplify the writing of tests, the Selenium project currently provides client drivers for PHP, Python, Ruby, .NET, Perl and Java. The Java driver can also be used with JavaScript. And a copy of the selenium RC server is required to run the test script html - this means that the port must be different for each parallel launch.
Selenium Grid
This is the last thing that is connected with the components of selenium. Selenium Grid is a server that allows you to test instances of a web browser running on remote computers. With Selenium Grid, one server acts as a hub. Tests communicate with the hub to access browser instances. The hub has a list of servers that provide access to browser instances, and allows you to test these instances. Thus, the Selenium Grid section allows you to run tests on several computers in parallel and centrally manage different versions of the browser and browser configurations.
Advantages
The first advantage is Selenium - a set of tools that helps automate only web applications. The Selenium IDE software is a plug-in for Firefox that allows testers to record their actions following the technological process that they need to test. Selenium WebDriver is the successor to Selenium RC, which sends commands directly to the browser and retrieves the results.
Disadvantages
supports only web based applications.
No IDE, so the script development won't be fast
Cannot access controls within the browser.
No default test report generation.
If you are looking for the Best Selenium Training Institute in Vaishali then you can contact to Webtrackker Technology. Because webtrackker is providing the real time working trainer of all sap modules for their all students
Our other courses:
Java training institute in Vaishali
Dot net training institute in vaishali
Php training institute in vaishali
Oracle dba training Institute in Vaishali
Sap training institute in vaishali
Selenium training institute in vaishali
Web design training institute in vaishali
Hadoop training institute in vaishali
AngularJS training in vaishali
Ios Training institute in vaishali
SAS Training institute in vaishali
0 notes