#oracle sql interview questions and answers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
ChatGPT & Data Science: Your Essential AI Co-Pilot

The rise of ChatGPT and other large language models (LLMs) has sparked countless discussions across every industry. In data science, the conversation is particularly nuanced: Is it a threat? A gimmick? Or a revolutionary tool?
The clearest answer? ChatGPT isn't here to replace data scientists; it's here to empower them, acting as an incredibly versatile co-pilot for almost every stage of a data science project.
Think of it less as an all-knowing oracle and more as an exceptionally knowledgeable, tireless assistant that can brainstorm, explain, code, and even debug. Here's how ChatGPT (and similar LLMs) is transforming data science projects and how you can harness its power:
How ChatGPT Transforms Your Data Science Workflow
Problem Framing & Ideation: Struggling to articulate a business problem into a data science question? ChatGPT can help.
"Given customer churn data, what are 5 actionable data science questions we could ask to reduce churn?"
"Brainstorm hypotheses for why our e-commerce conversion rate dropped last quarter."
"Help me define the scope for a project predicting equipment failure in a manufacturing plant."
Data Exploration & Understanding (EDA): This often tedious phase can be streamlined.
"Write Python code using Pandas to load a CSV and display the first 5 rows, data types, and a summary statistics report."
"Explain what 'multicollinearity' means in the context of a regression model and how to check for it in Python."
"Suggest 3 different types of plots to visualize the relationship between 'age' and 'income' in a dataset, along with the Python code for each."
Feature Engineering & Selection: Creating new, impactful features is key, and ChatGPT can spark ideas.
"Given a transactional dataset with 'purchase_timestamp' and 'product_category', suggest 5 new features I could engineer for a customer segmentation model."
"What are common techniques for handling categorical variables with high cardinality in machine learning, and provide a Python example for one."
Model Selection & Algorithm Explanation: Navigating the vast world of algorithms becomes easier.
"I'm working on a classification problem with imbalanced data. What machine learning algorithms should I consider, and what are their pros and cons for this scenario?"
"Explain how a Random Forest algorithm works in simple terms, as if you're explaining it to a business stakeholder."
Code Generation & Debugging: This is where ChatGPT shines for many data scientists.
"Write a Python function to perform stratified K-Fold cross-validation for a scikit-learn model, ensuring reproducibility."
"I'm getting a 'ValueError: Input contains NaN, infinity or a value too large for dtype('float64')' in my scikit-learn model. What are common reasons for this error, and how can I fix it?"
"Generate boilerplate code for a FastAPI endpoint that takes a JSON payload and returns a prediction from a pre-trained scikit-learn model."
Documentation & Communication: Translating complex technical work into understandable language is vital.
"Write a clear, concise docstring for this Python function that preprocesses text data."
"Draft an executive summary explaining the results of our customer churn prediction model, focusing on business impact rather than technical details."
"Explain the limitations of an XGBoost model in a way that a non-technical manager can understand."
Learning & Skill Development: It's like having a personal tutor at your fingertips.
"Explain the concept of 'bias-variance trade-off' in machine learning with a practical example."
"Give me 5 common data science interview questions about SQL, and provide example answers."
"Create a study plan for learning advanced topics in NLP, including key concepts and recommended libraries."
Important Considerations and Best Practices
While incredibly powerful, remember that ChatGPT is a tool, not a human expert.
Always Verify: Generated code, insights, and especially factual information must always be verified. LLMs can "hallucinate" or provide subtly incorrect information.
Context is King: The quality of the output directly correlates with the quality and specificity of your prompt. Provide clear instructions, examples, and constraints.
Data Privacy is Paramount: NEVER feed sensitive, confidential, or proprietary data into public LLMs. Protecting personal data is not just an ethical imperative but a legal requirement globally. Assume anything you input into a public model may be used for future training or accessible by the provider. For sensitive projects, explore secure, on-premises or private cloud LLM solutions.
Understand the Fundamentals: ChatGPT is an accelerant, not a substitute for foundational knowledge in statistics, machine learning, and programming. You need to understand why a piece of code works or why an an algorithm is chosen to effectively use and debug its outputs.
Iterate and Refine: Don't expect perfect results on the first try. Refine your prompts based on the output you receive.
ChatGPT and its peers are fundamentally changing the daily rhythm of data science. By embracing them as intelligent co-pilots, data scientists can boost their productivity, explore new avenues, and focus their invaluable human creativity and critical thinking on the most complex and impactful challenges. The future of data science is undoubtedly a story of powerful human-AI collaboration.
0 notes
Video
youtube
Oracle SQL Interview Questions and Answers | How To Ace Your Interview S...
0 notes
Text
Java Database Connectivity API contains commonly asked Java interview questions. A good understanding of JDBC API is required to understand and leverage many powerful features of Java technology. Here are few important practical questions and answers which can be asked in a Core Java JDBC interview. Most of the java developers are required to use JDBC API in some type of application. Though its really common, not many people understand the real depth of this powerful java API. Dozens of relational databases are seamlessly connected using java due to the simplicity of this API. To name a few Oracle, MySQL, Postgres and MS SQL are some popular ones. This article is going to cover a lot of general questions and some of the really in-depth ones to. Java Interview Preparation Tips Part 0: Things You Must Know For a Java Interview Part 1: Core Java Interview Questions Part 2: JDBC Interview Questions Part 3: Collections Framework Interview Questions Part 4: Threading Interview Questions Part 5: Serialization Interview Questions Part 6: Classpath Related Questions Part 7: Java Architect Scalability Questions What are available drivers in JDBC? JDBC technology drivers fit into one of four categories: A JDBC-ODBC bridge provides JDBC API access via one or more ODBC drivers. Note that some ODBC native code and in many cases native database client code must be loaded on each client machine that uses this type of driver. Hence, this kind of driver is generally most appropriate when automatic installation and downloading of a Java technology application is not important. A native-API partly Java technology-enabled driver converts JDBC calls into calls on the client API for Oracle, Sybase, Informix, DB2, or other DBMS. Note that, like the bridge driver, this style of driver requires that some binary code be loaded on each client machine. A net-protocol fully Java technology-enabled driver translates JDBC API calls into a DBMS-independent net protocol which is then translated to a DBMS protocol by a server. This net server middleware is able to connect all of its Java technology-based clients to many different databases. The specific protocol used depends on the vendor. In general, this is the most flexible JDBC API alternative. It is likely that all vendors of this solution will provide products suitable for Intranet use. In order for these products to also support Internet access they must handle the additional requirements for security, access through firewalls, etc., that the Web imposes. Several vendors are adding JDBC technology-based drivers to their existing database middleware products. A native-protocol fully Java technology-enabled driver converts JDBC technology calls into the network protocol used by DBMSs directly. This allows a direct call from the client machine to the DBMS server and is a practical solution for Intranet access. Since many of these protocols are proprietary the database vendors themselves will be the primary source for this style of driver. Several database vendors have these in progress. What are the types of statements in JDBC? the JDBC API has 3 Interfaces, (1. Statement, 2. PreparedStatement, 3. CallableStatement ). The key features of these are as follows: Statement This interface is used for executing a static SQL statement and returning the results it produces. The object of Statement class can be created using Connection.createStatement() method. PreparedStatement A SQL statement is pre-compiled and stored in a PreparedStatement object. This object can then be used to efficiently execute this statement multiple times. The object of PreparedStatement class can be created using Connection.prepareStatement() method. This extends Statement interface. CallableStatement This interface is used to execute SQL stored procedures. This extends PreparedStatement interface. The object of CallableStatement class can be created using Connection.prepareCall() method.
What is a stored procedure? How to call stored procedure using JDBC API? Stored procedure is a group of SQL statements that forms a logical unit and performs a particular task. Stored Procedures are used to encapsulate a set of operations or queries to execute on database. Stored procedures can be compiled and executed with different parameters and results and may have any combination of input/output parameters. Stored procedures can be called using CallableStatement class in JDBC API. Below code snippet shows how this can be achieved. CallableStatement cs = con.prepareCall("call MY_STORED_PROC_NAME"); ResultSet rs = cs.executeQuery(); What is Connection pooling? What are the advantages of using a connection pool? Connection Pooling is a technique used for sharing the server resources among requested clients. It was pioneered by database vendors to allow multiple clients to share a cached set of connection objects that provides access to a database. Getting connection and disconnecting are costly operation, which affects the application performance, so we should avoid creating multiple connection during multiple database interactions. A pool contains set of Database connections which are already connected, and any client who wants to use it can take it from pool and when done with using it can be returned back to the pool. Apart from performance this also saves you resources as there may be limited database connections available for your application. How to do database connection using JDBC thin driver ? This is one of the most commonly asked questions from JDBC fundamentals, and knowing all the steps of JDBC connection is important. import java.sql.*; class JDBCTest public static void main (String args []) throws Exception //Load driver class Class.forName ("oracle.jdbc.driver.OracleDriver"); //Create connection Connection conn = DriverManager.getConnection ("jdbc:oracle:thin:@hostname:1526:testdb", "scott", "tiger"); // @machineName:port:SID, userid, password Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select 'Hi' from dual"); while (rs.next()) System.out.println (rs.getString(1)); // Print col 1 => Hi stmt.close(); What does Class.forName() method do? Method forName() is a static method of java.lang.Class. This can be used to dynamically load a class at run-time. Class.forName() loads the class if its not already loaded. It also executes the static block of loaded class. Then this method returns an instance of the loaded class. So a call to Class.forName('MyClass') is going to do following - Load the class MyClass. - Execute any static block code of MyClass. - Return an instance of MyClass. JDBC Driver loading using Class.forName is a good example of best use of this method. The driver loading is done like this Class.forName("org.mysql.Driver"); All JDBC Drivers have a static block that registers itself with DriverManager and DriverManager has static initializer method registerDriver() which can be called in a static blocks of Driver class. A MySQL JDBC Driver has a static initializer which looks like this: static try java.sql.DriverManager.registerDriver(new Driver()); catch (SQLException E) throw new RuntimeException("Can't register driver!"); Class.forName() loads driver class and executes the static block and the Driver registers itself with the DriverManager. Which one will you use Statement or PreparedStatement? Or Which one to use when (Statement/PreparedStatement)? Compare PreparedStatement vs Statement. By Java API definitions: Statement is a object used for executing a static SQL statement and returning the results it produces. PreparedStatement is a SQL statement which is precompiled and stored in a PreparedStatement object. This object can then be used to efficiently execute this statement multiple times. There are few advantages of using PreparedStatements over Statements
Since its pre-compiled, Executing the same query multiple times in loop, binding different parameter values each time is faster. (What does pre-compiled statement means? The prepared statement(pre-compiled) concept is not specific to Java, it is a database concept. Statement precompiling means: when you execute a SQL query, database server will prepare a execution plan before executing the actual query, this execution plan will be cached at database server for further execution.) In PreparedStatement the setDate()/setString() methods can be used to escape dates and strings properly, in a database-independent way. SQL injection attacks on a system are virtually impossible when using PreparedStatements. What does setAutoCommit(false) do? A JDBC connection is created in auto-commit mode by default. This means that each individual SQL statement is treated as a transaction and will be automatically committed as soon as it is executed. If you require two or more statements to be grouped into a transaction then you need to disable auto-commit mode using below command con.setAutoCommit(false); Once auto-commit mode is disabled, no SQL statements will be committed until you explicitly call the commit method. A Simple transaction with use of autocommit flag is demonstrated below. con.setAutoCommit(false); PreparedStatement updateStmt = con.prepareStatement( "UPDATE EMPLOYEE SET SALARY = ? WHERE EMP_NAME LIKE ?"); updateStmt.setInt(1, 5000); updateSales.setString(2, "Jack"); updateStmt.executeUpdate(); updateStmt.setInt(1, 6000); updateSales.setString(2, "Tom"); updateStmt.executeUpdate(); con.commit(); con.setAutoCommit(true); What are database warnings and How can I handle database warnings in JDBC? Warnings are issued by database to notify user of a problem which may not be very severe. Database warnings do not stop the execution of SQL statements. In JDBC SQLWarning is an exception that provides information on database access warnings. Warnings are silently chained to the object whose method caused it to be reported. Warnings may be retrieved from Connection, Statement, and ResultSet objects. Handling SQLWarning from connection object //Retrieving warning from connection object SQLWarning warning = conn.getWarnings(); //Retrieving next warning from warning object itself SQLWarning nextWarning = warning.getNextWarning(); //Clear all warnings reported for this Connection object. conn.clearWarnings(); Handling SQLWarning from Statement object //Retrieving warning from statement object stmt.getWarnings(); //Retrieving next warning from warning object itself SQLWarning nextWarning = warning.getNextWarning(); //Clear all warnings reported for this Statement object. stmt.clearWarnings(); Handling SQLWarning from ResultSet object //Retrieving warning from resultset object rs.getWarnings(); //Retrieving next warning from warning object itself SQLWarning nextWarning = warning.getNextWarning(); //Clear all warnings reported for this resultset object. rs.clearWarnings(); The call to getWarnings() method in any of above way retrieves the first warning reported by calls on this object. If there is more than one warning, subsequent warnings will be chained to the first one and can be retrieved by calling the method SQLWarning.getNextWarning on the warning that was retrieved previously. A call to clearWarnings() method clears all warnings reported for this object. After a call to this method, the method getWarnings returns null until a new warning is reported for this object. Trying to call getWarning() on a connection after it has been closed will cause an SQLException to be thrown. Similarly, trying to retrieve a warning on a statement after it has been closed or on a result set after it has been closed will cause an SQLException to be thrown. Note that closing a statement also closes a result set that it might have produced. What is Metadata and why should I use it?
JDBC API has 2 Metadata interfaces DatabaseMetaData & ResultSetMetaData. The DatabaseMetaData provides Comprehensive information about the database as a whole. This interface is implemented by driver vendors to let users know the capabilities of a Database Management System (DBMS) in combination with the driver based on JDBC technology ("JDBC driver") that is used with it. Below is a sample code which demonstrates how we can use the DatabaseMetaData DatabaseMetaData md = conn.getMetaData(); System.out.println("Database Name: " + md.getDatabaseProductName()); System.out.println("Database Version: " + md.getDatabaseProductVersion()); System.out.println("Driver Name: " + md.getDriverName()); System.out.println("Driver Version: " + md.getDriverVersion()); The ResultSetMetaData is an object that can be used to get information about the types and properties of the columns in a ResultSet object. Use DatabaseMetaData to find information about your database, such as its capabilities and structure. Use ResultSetMetaData to find information about the results of an SQL query, such as size and types of columns. Below a sample code which demonstrates how we can use the ResultSetMetaData ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM TABLE2"); ResultSetMetaData rsmd = rs.getMetaData(); int numberOfColumns = rsmd.getColumnCount(); boolean b = rsmd.isSearchable(1); What is RowSet? or What is the difference between RowSet and ResultSet? or Why do we need RowSet? or What are the advantages of using RowSet over ResultSet? RowSet is a interface that adds support to the JDBC API for the JavaBeans component model. A rowset, which can be used as a JavaBeans component in a visual Bean development environment, can be created and configured at design time and executed at run time. The RowSet interface provides a set of JavaBeans properties that allow a RowSet instance to be configured to connect to a JDBC data source and read some data from the data source. A group of setter methods (setInt, setBytes, setString, and so on) provide a way to pass input parameters to a rowset's command property. This command is the SQL query the rowset uses when it gets its data from a relational database, which is generally the case. Rowsets are easy to use since the RowSet interface extends the standard java.sql.ResultSet interface so it has all the methods of ResultSet. There are two clear advantages of using RowSet over ResultSet RowSet makes it possible to use the ResultSet object as a JavaBeans component. As a consequence, a result set can, for example, be a component in a Swing application. RowSet be used to make a ResultSet object scrollable and updatable. All RowSet objects are by default scrollable and updatable. If the driver and database being used do not support scrolling and/or updating of result sets, an application can populate a RowSet object implementation (e.g. JdbcRowSet) with the data of a ResultSet object and then operate on the RowSet object as if it were the ResultSet object. What is a connected RowSet? or What is the difference between connected RowSet and disconnected RowSet? or Connected vs Disconnected RowSet, which one should I use and when? Connected RowSet A RowSet object may make a connection with a data source and maintain that connection throughout its life cycle, in which case it is called a connected rowset. A rowset may also make a connection with a data source, get data from it, and then close the connection. Such a rowset is called a disconnected rowset. A disconnected rowset may make changes to its data while it is disconnected and then send the changes back to the original source of the data, but it must reestablish a connection to do so. Example of Connected RowSet: A JdbcRowSet object is a example of connected RowSet, which means it continually maintains its connection to a database using a JDBC technology-enabled driver. Disconnected RowSet A disconnected rowset may have a reader (a RowSetReader object) and a writer (a RowSetWriter object) associated with it.
The reader may be implemented in many different ways to populate a rowset with data, including getting data from a non-relational data source. The writer can also be implemented in many different ways to propagate changes made to the rowset's data back to the underlying data source. Example of Disconnected RowSet: A CachedRowSet object is a example of disconnected rowset, which means that it makes use of a connection to its data source only briefly. It connects to its data source while it is reading data to populate itself with rows and again while it is propagating changes back to its underlying data source. The rest of the time, a CachedRowSet object is disconnected, including while its data is being modified. Being disconnected makes a RowSet object much leaner and therefore much easier to pass to another component. For example, a disconnected RowSet object can be serialized and passed over the wire to a thin client such as a personal digital assistant (PDA). What is the benefit of having JdbcRowSet implementation? Why do we need a JdbcRowSet like wrapper around ResultSet? The JdbcRowSet implementation is a wrapper around a ResultSet object that has following advantages over ResultSet This implementation makes it possible to use the ResultSet object as a JavaBeans component. A JdbcRowSet can be used as a JavaBeans component in a visual Bean development environment, can be created and configured at design time and executed at run time. It can be used to make a ResultSet object scrollable and updatable. All RowSet objects are by default scrollable and updatable. If the driver and database being used do not support scrolling and/or updating of result sets, an application can populate a JdbcRowSet object with the data of a ResultSet object and then operate on the JdbcRowSet object as if it were the ResultSet object. Can you think of a questions which is not part of this post? Please don't forget to share it with me in comments section & I will try to include it in the list.
0 notes
Text
AWS Data Engineer Interview Questions and Answers

As the world rapidly moves towards data-driven decision-making, AWS Data Engineers are in high demand. Organizations are seeking professionals skilled in managing big data, building data pipelines, and leveraging AWS services to support their analytics and machine learning needs. If you are aspiring to become an AWS Data Engineer or have an upcoming interview, you've come to the right place! In this article, we have compiled a list of essential interview questions and expert answers to equip you for success. AWS Data Engineer Interview Questions and Answers 1. Tell us about your experience with AWS services for data management. LSI Keywords: AWS data services, data management experience As an AWS Data Engineer, you will work extensively with various AWS data services. Mention any relevant experience you have with services like Amazon S3, Amazon Redshift, AWS Glue, and AWS Data Pipeline. Highlight any projects where you built data pipelines or implemented data warehousing solutions. 2. What are the key components of AWS Data Pipeline? LSI Keywords: AWS Data Pipeline components AWS Data Pipeline facilitates the automation of data movement and transformation. The key components are: - Data Nodes: Represent data sources and destinations. - Activity Nodes: Execute operations on data like data transformation or data processing. - Preconditions: Conditions that must be met before an activity can run. - Schedule: Specifies when the pipeline runs. - Resources: Compute resources to be used during data processing. 3. How do you ensure the security of data in Amazon S3? LSI Keywords: Amazon S3 security, data encryption Data security is crucial, and AWS provides several mechanisms to secure data in Amazon S3: - Access Control Lists (ACLs): Define who can access individual objects. - Bucket Policies: Set access permissions at the bucket level. - AWS Identity and Access Management (IAM): Manage access to AWS resources. - Server-Side Encryption (SSE): Encrypt data at rest using AWS-managed keys. - Client-Side Encryption: Encrypt data before uploading it to S3. 4. Explain the differences between Amazon RDS and Amazon Redshift. LSI Keywords: Amazon RDS vs. Amazon Redshift Amazon RDS (Relational Database Service) and Amazon Redshift are both managed database services, but they serve different purposes: - Amazon RDS: Ideal for traditional OLTP (Online Transaction Processing) workloads, supporting various database engines like MySQL, PostgreSQL, SQL Server, and Oracle. - Amazon Redshift: Designed for OLAP (Online Analytical Processing) workloads, optimized for complex queries and data warehousing. 5. How do you optimize the performance of Amazon Redshift? LSI Keywords: Amazon Redshift performance optimization To enhance the performance of Amazon Redshift, consider these best practices: - Distribution Style and Keys: Choose appropriate distribution styles to evenly distribute data across nodes. - Sort Keys: Define sort keys to reduce query time for frequently accessed columns. - Compression: Use columnar data compression to minimize storage and enhance query performance. - Vacuum and Analyze: Regularly perform the VACUUM and ANALYZE operations to reclaim space and update statistics. 6. How can you move data from on-premises to Amazon S3? LSI Keywords: On-premises data migration to Amazon S3 Migrating data to Amazon S3 can be achieved in multiple ways: - AWS Snowball: A physical device used to transfer large amounts of data securely. - AWS DataSync: Transfers data over the internet or AWS Direct Connect. - AWS Transfer Family: A fully managed service for transferring files over FTP, FTPS, and SFTP. - AWS Storage Gateway: Integrates on-premises environments with cloud storage. 7. Explain how AWS Glue ETL jobs work. LSI Keywords: AWS Glue ETL, data transformation AWS Glue is a fully managed extract, transform, and load (ETL) service. The process involves: - Data Crawling: Glue scans the data sources to determine the schema. - Data Catalog: Metadata is stored in the AWS Glue Data Catalog. - ETL Code Generation: Glue generates ETL code in Python or Scala. - Data Transformation: The data is transformed according to the ETL logic. - Data Loading: The transformed data is loaded into the destination data store. 8. How can you ensure data consistency in distributed systems on AWS? LSI Keywords: Data consistency in distributed systems, CAP theorem In distributed systems, the CAP theorem states that you can have only two of the following three guarantees: Consistency, Availability, and Partition tolerance. To ensure data consistency, you may use techniques like strong consistency models, distributed transactions, and data synchronization mechanisms. 9. Describe your experience with AWS Lambda and its role in data processing. LSI Keywords: AWS Lambda data processing AWS Lambda is a serverless compute service that executes functions in response to events. As a Data Engineer, you may leverage Lambda for real-time data processing, data transformations, and event-driven architectures. Share any hands-on experience you have in using Lambda for data processing tasks. 10. What is the significance of Amazon Kinesis in big data analytics? LSI Keywords: Amazon Kinesis big data analytics Amazon Kinesis is a suite of services for real-time data streaming and analytics. It enables you to ingest, process, and analyze streaming data at scale. Discuss how Amazon Kinesis can be utilized to handle real-time data and its relevance in big data analytics. 11. How do you manage error handling in AWS Glue ETL jobs? LSI Keywords: AWS Glue ETL error handling Error handling in AWS Glue ETL jobs is crucial to ensure data integrity. You can implement error handling through error tables, data validations, and customized error handling scripts to address different types of errors encountered during ETL operations. 12. Share your experience in building data pipelines with AWS Step Functions. LSI Keywords: AWS Step Functions data pipelines AWS Step Functions coordinate distributed applications and microservices using visual workflows. As a Data Engineer, you may use Step Functions to build complex data pipelines and manage dependencies between individual steps. Explain any projects you've worked on involving AWS Step Functions. 13. How do you monitor AWS resources for performance and cost optimization? LSI Keywords: AWS resource monitoring, performance optimization Monitoring AWS resources is vital for both performance and cost optimization. You can use AWS CloudWatch, AWS Trusted Advisor, and third-party monitoring tools to track resource utilization, set up alarms, and optimize the AWS infrastructure for cost efficiency. 14. Describe your experience in using AWS Glue DataBrew for data preparation. LSI Keywords: AWS Glue DataBrew data preparation AWS Glue DataBrew is a visual data preparation tool that simplifies data cleaning and normalization. Share how you've used DataBrew to automate data transformation tasks, handle data quality issues, and prepare data for analysis. 15. How do you ensure data integrity in a data lake on AWS? LSI Keywords: Data integrity in AWS data lake Data integrity is critical for a reliable data lake. Ensure data integrity by using versioning and cataloging tools, validating data during ingestion, and implementing access controls to prevent unauthorized changes. 16. Discuss your experience with Amazon Aurora for managing relational databases on AWS. LSI Keywords: Amazon Aurora relational database Amazon Aurora is a high-performance, fully managed relational database service. Describe your experience with Amazon Aurora, including tasks like database setup, scaling, and data backups. 17. What is the significance of AWS Glue in the ETL process? LSI Keywords: AWS Glue ETL significance AWS Glue simplifies the ETL process by automating data preparation, data cataloging, and data transformation tasks. Explain how using AWS Glue streamlines the data engineering workflow and saves time in building robust data pipelines. 18. How do you optimize data storage costs on AWS? LSI Keywords: AWS data storage cost optimization Optimizing data storage costs is essential for cost-conscious organizations. Use features like Amazon S3 Intelligent-Tiering, Amazon S3 Glacier, and Amazon S3 Lifecycle policies to efficiently manage data storage costs based on usage patterns. 19. Share your experience with AWS Data Migration Service (DMS) for database migration. LSI Keywords: AWS DMS database migration AWS DMS facilitates seamless database migration to AWS. Discuss any database migration projects you've handled using AWS DMS, including migration strategies, data replication, and post-migration testing. 20. How do you handle streaming data in AWS using Apache Kafka? LSI Keywords: AWS streaming data, Apache Kafka Apache Kafka is an open-source streaming platform used to handle high-throughput real-time data feeds. Elaborate on how you've used Kafka to ingest, process, and analyze streaming data on AWS. 21. What is your experience with AWS Glue for data discovery and cataloging? LSI Keywords: AWS Glue data discovery AWS Glue enables automatic data discovery and cataloging, making it easier to find and access data assets. Share examples of how you've utilized AWS Glue to create and manage a data catalog for your organization. 22. How do you ensure data quality in a data warehouse on AWS? LSI Keywords: Data quality in AWS data warehouse Data quality is critical for meaningful analytics. Discuss techniques like data profiling, data cleansing, and data validation that you use to maintain data quality in an AWS data warehouse environment. 23. Share your experience in building serverless data processing workflows with AWS Step Functions. LSI Keywords: AWS Step Functions serverless data processing AWS Step Functions enable you to create serverless workflows for data processing tasks. Provide examples of how you've used Step Functions to orchestrate data processing jobs and handle complex workflows. 24. What are the best practices for data encryption on AWS? LSI Keywords: AWS data encryption best practices Data encryption safeguards sensitive data from unauthorized access. Cover best practices for data encryption, including using AWS Key Management Service (KMS), encrypting data at rest and in transit, and managing encryption keys securely. 25. How do you stay updated with the latest AWS services and trends? LSI Keywords: AWS services updates, AWS trends Continuous learning is crucial for AWS Data Engineers. Share resources like AWS documentation, online courses, webinars, and AWS blogs that you regularly follow to stay informed about the latest AWS services and trends. FAQs (Frequently Asked Questions) FAQ 1: What are the essential skills for an AWS Data Engineer? To succeed as an AWS Data Engineer, you should possess strong programming skills in languages like Python, SQL, or Scala. Familiarity with data warehousing concepts, AWS services like Amazon S3, Amazon Redshift, and AWS Glue, and experience with ETL tools is crucial. Additionally, having knowledge of big data technologies like Apache Spark and Hadoop is advantageous. FAQ 2: How can I prepare for an AWS Data Engineer interview? Start by thoroughly understanding the fundamental concepts of AWS data services, data engineering, and data warehousing. Practice hands-on exercises to build data pipelines and perform data transformations. Review commonly asked interview questions and formulate clear, concise answers. Mock interviews and participating in data engineering projects can also enhance your preparation. FAQ 3: What projects can I include in my AWS Data Engineer portfolio? Your portfolio should showcase your data engineering expertise. Include projects that demonstrate your ability to build data pipelines, design scalable architectures, and optimize data storage and processing. Projects involving AWS Glue, AWS Redshift, and real-time data streaming are excellent additions to your portfolio. FAQ 4: Are AWS certifications essential for an AWS Data Engineer? While AWS certifications are not mandatory, they significantly enhance your credibility as a skilled AWS professional. Consider obtaining certifications like AWS Certified Data Analytics - Specialty or AWS Certified Big Data - Specialty to validate your expertise in data engineering on AWS. FAQ 5: How can I advance my career as an AWS Data Engineer? To advance your career, focus on continuous learning and staying updated with the latest AWS technologies. Seek opportunities to work on challenging data engineering projects that require problem-solving and innovation. Networking with professionals in the field and participating in AWS-related events can also open doors to new opportunities. FAQ 6: What are the typical responsibilities of an AWS Data Engineer in an organization? As an AWS Data Engineer, your responsibilities may include designing and implementing data pipelines, integrating data from various sources, transforming and optimizing data for analysis, and ensuring data security and quality. You may also be involved in troubleshooting data-related issues and optimizing data storage and processing costs. Conclusion Becoming an AWS Data Engineer opens doors to exciting opportunities in the world of data-driven technology. By mastering the essential AWS services and data engineering concepts and showcasing your expertise during interviews, you can secure a rewarding career in this rapidly evolving field. Stay committed to continuous learning and hands-on practice, and you'll be well on your way to success. Read the full article
0 notes
Text
Question-85: What is the purpose of the DBMS_REDEFINITION package in Oracle, and how do you use it for online table redefinition?
Interview Questions on Oracle SQL & PLSQL Development: For more questions like this: Do follow the main blog #oracledatabase #interviewquestions #freshers #beginners #intermediatelevel #experienced #eswarstechworld #oracle #interview #development #sql
Answer: The DBMS_REDEFINITION package in Oracle provides procedures to perform online table redefinition, which allows for modifying the structure of a table without interrupting the availability of the table to users. It is especially useful for large tables that need to be altered while maintaining continuous access for queries and DML operations. Here are some key points about the…

View On WordPress
#beginners#development#eswarstechworld#Experienced#freshers#intermediatelevel#interview#interviewquestions#oracle#oracledatabase#sql
0 notes
Text

Hi Informatica Jobseekers, I am Kapil and I am working as a Informatica Technical Consultant. I have 14+ years of strong experience in the respective field. I am offering Online Training on Informatica PowerCenter+ SQL + Datawarehousing real time interview questions and answers which we ask candidates on daily basis. I am offering this entire training at a minimal price of Rs 3000/- only.
Informatica Training Details : Training Mode: Gotomeeting Training will cover: Informatica basic to advanced level, Basic Oracle Notes will be provided, Interview Certification Questions Guidance Life time access to recorded sessions Real-time Project work Explanation Resume building on informatica Informatica Software will be provided Session: 45 hours
Note: In this cutting-edge environment/IT market, I have seen many faculties/institutes offering this course at a huge costs and many students are not able to afford it despite having interest in the subject. So, I am willing to offer this entire course at an affordable price of Rs 3000 only, because my intention is to help as many students as I can in my capacity and help them thrive in the IT industry. I want maximum people to grab this opportunity who are willing to start their career in the IT industry. Attend the live demo session once and decide for yourself if it's worth it or not. I promise no one will regret it.
Who can register for this course? Everybody can register for this course be it a Graduate, Homemaker, Career gaps etc. One doesn't need any technical background for this course. Everything is taught from the scratch to the advanced level.
To confirm your registration please: Only Whatsapp me "Interested" @ 9100714257 along with your e-mail id so that I can share the demo link. Hurry up! register your seat now.
informaticapc #informaticaonlinetraining #informaticapowercenter #onlinetraininginformatica #iics #informaticacloud #etl #informaticacloudtraining
Please do share this information to the interested candidates who will benefit out of this. Remember "Sharing is a way of Caring"!
Thank you, Kapil
0 notes
Link
Structured Query Language or SQL is a computer language that retrieves and manages information stored in any database. Programmers well versed in this language are offered lucrative jobs given the important role the language plays. And the competition to secure these jobs is quite fierce.

So, whether you are a fresher or an experienced professional, here are a few essential questions you should go through in order to succeed in your next interview.
#common interview question#sql interview question#question answer for sql interview#My SQL Jobs#oracle dba jobs
0 notes
Text
Comprehensive Overview of the Perfect ASP.NET Developer Hiring Process
You can’t rely simply on your present software systems and desktop applications to help your company migrate to the digital age. For unfettered business empowerment, you must invest in safe and high-performing websites, web applications, and web services, as well as mobile apps that are available regardless of place or time.
Furthermore, we are entering an era of modern technologies such as the Internet of Things and Machine Learning, which will enable processes to become more competent and competitive. You must invest in sophisticated online and Web development frameworks like ASP.NET to keep up with the changing times, and you must carefully select the correct kind of Asp.Net Development Solutions Provider to do so.
What type of experts must you hire?
This stage answers important questions, such as whether you should hire dedicated ASP .net Developer or outsource the project to a .NET development expert.
The solution is straightforward. If your company isn’t in the IT industry, your requirement for .NET developers will be limited to a single project. You might have an in-house IT department that provides support and maintenance. Hiring specialized .NET developers, on the other hand, would significantly increase your monthly IT spend.
What type of products do you want to develop?
The next step in the hiring process for a.NET development business is to determine what kind of ASP.NET project you require. According to Asp.net Development Services Company, ASP.NET is used as the server-side programming language by roughly 11% of active websites, including Microsoft.com and MSN.com.
Make a better selection of .NET development services specialists to construct the desired ASP.NET project for your business based on your particular requirements. Knowing your own needs can also help you communicate them more effectively to the development team, ensuring that the proper product is delivered on time and within budget.
The benefits of ASP. NET
Learning about the advantages of ASP.NET is a vital element of the choosing process that is typically overlooked by most business owners.
Some of its main advantages are as follows:
Less Coding: One of the reasons that ASP.NET is so popular among developers is that it drastically decreases the amount of coding required, even for huge applications. It also means that if you hire a clever and experienced staff, you may be able to get your product produced quickly.
Language Independence: The ASP.NET framework gives developers the freedom to choose any language they see fit for their application. This is because technology is not language-dependent, which implies that developers can employ many languages to create superior products, such as C#, Jscript, and others.
Improved Performance: ASP.NET-based websites, apps, and services run faster since it allows server-side execution and a variety of capabilities like as caching.
Great Tool Support: ASP.NET development is aided with incredible tools that enhance the performance of websites and applications. Early binding, JIT compilation, automated deployment, drag-and-drop server controls, and a slew of other capabilities aid.NET development firms in creating solid products.
Better Security: ASP.NET is one of the most recommended platforms for designing safe apps, thanks to built-in Windows authentication and features like crash-shielding.
Comparing developers before you select the best
After you’ve completed the previous phases of selection, you’ll begin looking for specialists in the last stage. You may now Hire Asp.net Developer Team in a variety of ways:
Recommendations: Business owners frequently rate and review numerous organisations that provide.NET development services, and you can use this information to narrow down your options.
Third-Party Review Platforms and Search Engines: Of course, you may use Google and other famous search engines to find developers and shortlist a few from the results. Clutch, for example, is a certified review site that assists business owners in making the best decision.
Proficiency: The company’s proficiency with the.NET framework is a crucial factor to consider. This requires its development staff to be current not only in application development but also in providing.NET development services.
You can make your final decision based on the names that have been shortlisted by evaluating them on several key criteria such as:
Spend time researching and evaluating the qualifications of a.NET development business.
Find out how long the firm has been in business and how much experience it has in the field of bespoke software development.
Points to pay extra focus on
The Fundamentals — Return to the basics to determine a candidate’s true understanding of their field of employment. Discuss the framework and many parts of the.NET application development process in depth.
Discuss SQL Databases – In today’s world, these are critical components that determine the outcome of application development processes. Discuss advanced database technologies like MySQL, Microsoft SQL, .NET developer Oracle, and others to ensure you employ a professional ASP.NET developer who is up to the work at hand.
Technical expertise – Examine their level of familiarity with the most recent technological developments. A good developer keeps up with new languages and updates in their field of work and seeks to incorporate them into their work.
Understanding Your Company – Is the candidate familiar with your company’s values? Is it possible for them to connect the scope of the job they’re interviewing for to your company’s goals? This is necessary to verify that the individual you choose for the job is aligned with your objectives and deliverables.
Wrap up
It’s only logical that you’d want to cash in on the trend, which necessitates hiring the best ASP.NET developers. Because talented, efficient, and affordable developers are hard to come by, the process of assembling a development team must be meticulous. You must be willing to put in the effort and go through the rigours of a lengthy hiring procedure. However, we can tell you that hiring ASP.NET developers will be well worth your time and work, and will result in outcomes that will help you strengthen your online presence.
Your road to hiring a dedicated ASP.NET developer will come to a logical conclusion after you and the selected person agree on the terms of the employment. Signing the contract is the final step in the process.
We ensure that your project has the greatest resources at Whiz Solutions, best Asp.Net Development Solutions Provider. To scale up your firm, our highly skilled developers employ the best-in-class tools and methods. Our clients benefit from peace of mind and business progress as a result of our talent, smooth communication, and flawless execution. Simply come over here.
1 note
·
View note
Text
AWS Data Engineer Interview Questions and Answers

As the world rapidly moves towards data-driven decision-making, AWS Data Engineers are in high demand. Organizations are seeking professionals skilled in managing big data, building data pipelines, and leveraging AWS services to support their analytics and machine learning needs. If you are aspiring to become an AWS Data Engineer or have an upcoming interview, you've come to the right place! In this article, we have compiled a list of essential interview questions and expert answers to equip you for success. AWS Data Engineer Interview Questions and Answers 1. Tell us about your experience with AWS services for data management. LSI Keywords: AWS data services, data management experience As an AWS Data Engineer, you will work extensively with various AWS data services. Mention any relevant experience you have with services like Amazon S3, Amazon Redshift, AWS Glue, and AWS Data Pipeline. Highlight any projects where you built data pipelines or implemented data warehousing solutions. 2. What are the key components of AWS Data Pipeline? LSI Keywords: AWS Data Pipeline components AWS Data Pipeline facilitates the automation of data movement and transformation. The key components are: - Data Nodes: Represent data sources and destinations. - Activity Nodes: Execute operations on data like data transformation or data processing. - Preconditions: Conditions that must be met before an activity can run. - Schedule: Specifies when the pipeline runs. - Resources: Compute resources to be used during data processing. 3. How do you ensure the security of data in Amazon S3? LSI Keywords: Amazon S3 security, data encryption Data security is crucial, and AWS provides several mechanisms to secure data in Amazon S3: - Access Control Lists (ACLs): Define who can access individual objects. - Bucket Policies: Set access permissions at the bucket level. - AWS Identity and Access Management (IAM): Manage access to AWS resources. - Server-Side Encryption (SSE): Encrypt data at rest using AWS-managed keys. - Client-Side Encryption: Encrypt data before uploading it to S3. 4. Explain the differences between Amazon RDS and Amazon Redshift. LSI Keywords: Amazon RDS vs. Amazon Redshift Amazon RDS (Relational Database Service) and Amazon Redshift are both managed database services, but they serve different purposes: - Amazon RDS: Ideal for traditional OLTP (Online Transaction Processing) workloads, supporting various database engines like MySQL, PostgreSQL, SQL Server, and Oracle. - Amazon Redshift: Designed for OLAP (Online Analytical Processing) workloads, optimized for complex queries and data warehousing. 5. How do you optimize the performance of Amazon Redshift? LSI Keywords: Amazon Redshift performance optimization To enhance the performance of Amazon Redshift, consider these best practices: - Distribution Style and Keys: Choose appropriate distribution styles to evenly distribute data across nodes. - Sort Keys: Define sort keys to reduce query time for frequently accessed columns. - Compression: Use columnar data compression to minimize storage and enhance query performance. - Vacuum and Analyze: Regularly perform the VACUUM and ANALYZE operations to reclaim space and update statistics. 6. How can you move data from on-premises to Amazon S3? LSI Keywords: On-premises data migration to Amazon S3 Migrating data to Amazon S3 can be achieved in multiple ways: - AWS Snowball: A physical device used to transfer large amounts of data securely. - AWS DataSync: Transfers data over the internet or AWS Direct Connect. - AWS Transfer Family: A fully managed service for transferring files over FTP, FTPS, and SFTP. - AWS Storage Gateway: Integrates on-premises environments with cloud storage. 7. Explain how AWS Glue ETL jobs work. LSI Keywords: AWS Glue ETL, data transformation AWS Glue is a fully managed extract, transform, and load (ETL) service. The process involves: - Data Crawling: Glue scans the data sources to determine the schema. - Data Catalog: Metadata is stored in the AWS Glue Data Catalog. - ETL Code Generation: Glue generates ETL code in Python or Scala. - Data Transformation: The data is transformed according to the ETL logic. - Data Loading: The transformed data is loaded into the destination data store. 8. How can you ensure data consistency in distributed systems on AWS? LSI Keywords: Data consistency in distributed systems, CAP theorem In distributed systems, the CAP theorem states that you can have only two of the following three guarantees: Consistency, Availability, and Partition tolerance. To ensure data consistency, you may use techniques like strong consistency models, distributed transactions, and data synchronization mechanisms. 9. Describe your experience with AWS Lambda and its role in data processing. LSI Keywords: AWS Lambda data processing AWS Lambda is a serverless compute service that executes functions in response to events. As a Data Engineer, you may leverage Lambda for real-time data processing, data transformations, and event-driven architectures. Share any hands-on experience you have in using Lambda for data processing tasks. 10. What is the significance of Amazon Kinesis in big data analytics? LSI Keywords: Amazon Kinesis big data analytics Amazon Kinesis is a suite of services for real-time data streaming and analytics. It enables you to ingest, process, and analyze streaming data at scale. Discuss how Amazon Kinesis can be utilized to handle real-time data and its relevance in big data analytics. 11. How do you manage error handling in AWS Glue ETL jobs? LSI Keywords: AWS Glue ETL error handling Error handling in AWS Glue ETL jobs is crucial to ensure data integrity. You can implement error handling through error tables, data validations, and customized error handling scripts to address different types of errors encountered during ETL operations. 12. Share your experience in building data pipelines with AWS Step Functions. LSI Keywords: AWS Step Functions data pipelines AWS Step Functions coordinate distributed applications and microservices using visual workflows. As a Data Engineer, you may use Step Functions to build complex data pipelines and manage dependencies between individual steps. Explain any projects you've worked on involving AWS Step Functions. 13. How do you monitor AWS resources for performance and cost optimization? LSI Keywords: AWS resource monitoring, performance optimization Monitoring AWS resources is vital for both performance and cost optimization. You can use AWS CloudWatch, AWS Trusted Advisor, and third-party monitoring tools to track resource utilization, set up alarms, and optimize the AWS infrastructure for cost efficiency. 14. Describe your experience in using AWS Glue DataBrew for data preparation. LSI Keywords: AWS Glue DataBrew data preparation AWS Glue DataBrew is a visual data preparation tool that simplifies data cleaning and normalization. Share how you've used DataBrew to automate data transformation tasks, handle data quality issues, and prepare data for analysis. 15. How do you ensure data integrity in a data lake on AWS? LSI Keywords: Data integrity in AWS data lake Data integrity is critical for a reliable data lake. Ensure data integrity by using versioning and cataloging tools, validating data during ingestion, and implementing access controls to prevent unauthorized changes. 16. Discuss your experience with Amazon Aurora for managing relational databases on AWS. LSI Keywords: Amazon Aurora relational database Amazon Aurora is a high-performance, fully managed relational database service. Describe your experience with Amazon Aurora, including tasks like database setup, scaling, and data backups. 17. What is the significance of AWS Glue in the ETL process? LSI Keywords: AWS Glue ETL significance AWS Glue simplifies the ETL process by automating data preparation, data cataloging, and data transformation tasks. Explain how using AWS Glue streamlines the data engineering workflow and saves time in building robust data pipelines. 18. How do you optimize data storage costs on AWS? LSI Keywords: AWS data storage cost optimization Optimizing data storage costs is essential for cost-conscious organizations. Use features like Amazon S3 Intelligent-Tiering, Amazon S3 Glacier, and Amazon S3 Lifecycle policies to efficiently manage data storage costs based on usage patterns. 19. Share your experience with AWS Data Migration Service (DMS) for database migration. LSI Keywords: AWS DMS database migration AWS DMS facilitates seamless database migration to AWS. Discuss any database migration projects you've handled using AWS DMS, including migration strategies, data replication, and post-migration testing. 20. How do you handle streaming data in AWS using Apache Kafka? LSI Keywords: AWS streaming data, Apache Kafka Apache Kafka is an open-source streaming platform used to handle high-throughput real-time data feeds. Elaborate on how you've used Kafka to ingest, process, and analyze streaming data on AWS. 21. What is your experience with AWS Glue for data discovery and cataloging? LSI Keywords: AWS Glue data discovery AWS Glue enables automatic data discovery and cataloging, making it easier to find and access data assets. Share examples of how you've utilized AWS Glue to create and manage a data catalog for your organization. 22. How do you ensure data quality in a data warehouse on AWS? LSI Keywords: Data quality in AWS data warehouse Data quality is critical for meaningful analytics. Discuss techniques like data profiling, data cleansing, and data validation that you use to maintain data quality in an AWS data warehouse environment. 23. Share your experience in building serverless data processing workflows with AWS Step Functions. LSI Keywords: AWS Step Functions serverless data processing AWS Step Functions enable you to create serverless workflows for data processing tasks. Provide examples of how you've used Step Functions to orchestrate data processing jobs and handle complex workflows. 24. What are the best practices for data encryption on AWS? LSI Keywords: AWS data encryption best practices Data encryption safeguards sensitive data from unauthorized access. Cover best practices for data encryption, including using AWS Key Management Service (KMS), encrypting data at rest and in transit, and managing encryption keys securely. 25. How do you stay updated with the latest AWS services and trends? LSI Keywords: AWS services updates, AWS trends Continuous learning is crucial for AWS Data Engineers. Share resources like AWS documentation, online courses, webinars, and AWS blogs that you regularly follow to stay informed about the latest AWS services and trends. FAQs (Frequently Asked Questions) FAQ 1: What are the essential skills for an AWS Data Engineer? To succeed as an AWS Data Engineer, you should possess strong programming skills in languages like Python, SQL, or Scala. Familiarity with data warehousing concepts, AWS services like Amazon S3, Amazon Redshift, and AWS Glue, and experience with ETL tools is crucial. Additionally, having knowledge of big data technologies like Apache Spark and Hadoop is advantageous. FAQ 2: How can I prepare for an AWS Data Engineer interview? Start by thoroughly understanding the fundamental concepts of AWS data services, data engineering, and data warehousing. Practice hands-on exercises to build data pipelines and perform data transformations. Review commonly asked interview questions and formulate clear, concise answers. Mock interviews and participating in data engineering projects can also enhance your preparation. FAQ 3: What projects can I include in my AWS Data Engineer portfolio? Your portfolio should showcase your data engineering expertise. Include projects that demonstrate your ability to build data pipelines, design scalable architectures, and optimize data storage and processing. Projects involving AWS Glue, AWS Redshift, and real-time data streaming are excellent additions to your portfolio. FAQ 4: Are AWS certifications essential for an AWS Data Engineer? While AWS certifications are not mandatory, they significantly enhance your credibility as a skilled AWS professional. Consider obtaining certifications like AWS Certified Data Analytics - Specialty or AWS Certified Big Data - Specialty to validate your expertise in data engineering on AWS. FAQ 5: How can I advance my career as an AWS Data Engineer? To advance your career, focus on continuous learning and staying updated with the latest AWS technologies. Seek opportunities to work on challenging data engineering projects that require problem-solving and innovation. Networking with professionals in the field and participating in AWS-related events can also open doors to new opportunities. FAQ 6: What are the typical responsibilities of an AWS Data Engineer in an organization? As an AWS Data Engineer, your responsibilities may include designing and implementing data pipelines, integrating data from various sources, transforming and optimizing data for analysis, and ensuring data security and quality. You may also be involved in troubleshooting data-related issues and optimizing data storage and processing costs. Conclusion Becoming an AWS Data Engineer opens doors to exciting opportunities in the world of data-driven technology. By mastering the essential AWS services and data engineering concepts and showcasing your expertise during interviews, you can secure a rewarding career in this rapidly evolving field. Stay committed to continuous learning and hands-on practice, and you'll be well on your way to success. Read the full article
0 notes
Text
Question-75: What is the purpose of the DBMS_STATS package in Oracle, and how do you use it for gathering optimizer statistics?
Interview Questions on Oracle SQL & PLSQL Development: For more questions like this: Do follow the main blog #oracledatabase #interviewquestions #freshers #beginners #intermediatelevel #experienced #eswarstechworld #oracle #interview #development #sql
Answer: The DBMS_STATS package in Oracle is used for gathering optimizer statistics, which are essential for the Oracle query optimizer to generate efficient execution plans. The DBMS_STATS package provides procedures that allow you to collect and manage optimizer statistics, including information about the data distribution and the object’s characteristics, such as number of rows, number of…

View On WordPress
#beginners#development#eswarstechworld#Experienced#freshers#intermediatelevel#interview#interviewquestions#oracle#oracledatabase#sql
0 notes
Text
Sql Interview Questions
If a WHERE clause is used in cross join after that the inquiry will certainly function like an INTERNAL SIGN UP WITH. A DISTINCT restraint ensures that all values in a column are various. This supplies uniqueness for the column and also assists identify each row distinctively. It promotes you to manipulate the data stored in the tables by using relational drivers. Instances of the relational data source administration system are Microsoft Gain access to, MySQL, SQLServer, Oracle database, etc. One-of-a-kind crucial restriction uniquely identifies each document in the data source. https://geekinterview.net This vital provides uniqueness for the column or set of columns. A database arrow is a control framework that permits traversal of documents in a data source. Cursors, on top of that, promotes handling after traversal, such as access, addition as well as deletion of database documents. They can be considered as a reminder to one row in a set of rows. An alias is a feature of SQL that is sustained by a lot of, otherwise all, RDBMSs. It is a temporary name designated to the table or table column for the purpose of a specific SQL inquiry. Furthermore, aliasing can be employed as an obfuscation technique to protect the actual names of database fields. A table pen name is also called a relationship name. students; Non-unique indexes, on the other hand, are not utilized to enforce restrictions on the tables with which they are linked. Rather, non-unique indexes are made use of solely to improve query performance by keeping a sorted order of data worths that are used regularly. A database index is a data structure that offers quick lookup of data in a column or columns of a table. It boosts the speed of operations accessing data from a data source table at the cost of additional creates as well as memory to keep the index information framework. Prospects are most likely to be asked standard SQL interview concerns to progress degree SQL concerns relying on their experience and different other aspects. The listed below list covers all the SQL meeting concerns for betters in addition to SQL interview questions for knowledgeable degree candidates as well as some SQL question meeting concerns. SQL provision helps to restrict the outcome set by offering a problem to the query. A clause assists to filter the rows from the entire set of records. Our SQL Meeting Questions blog site is the one-stop source where you can improve your meeting prep work. It has a set of leading 65 concerns which an interviewer intends to ask throughout an interview procedure. Unlike primary vital, there can be numerous distinct restrictions specified per table. The code syntax for UNIQUE is rather comparable to that of PRIMARY SECRET and can be utilized mutually. A lot of modern data source management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 as well as Amazon Redshift are based upon RDBMS. SQL clause is specified to restrict the result set by providing problem to the query. This typically filterings system some rows from the whole collection of records. Cross join can be defined as a cartesian product of both tables included in the join. The table after sign up with contains the same number of rows as in the cross-product of number of rows in the two tables. Self-join is set to be query made use of to contrast to itself. This is utilized to contrast values in a column with other worths in the exact same column in the same table. PEN NAME ES can be utilized for the same table contrast. This is a key words used to inquire information from even more tables based upon the partnership between the areas of the tables. A international trick is one table which can be associated with the main key of another table. Partnership requires to be produced in between 2 tables by referencing international key with the main key of another table. A Distinct essential restraint uniquely recognized each record in the data source. It begins with the fundamental SQL interview questions and later on remains to sophisticated inquiries based on your conversations and also solutions. These SQL Interview concerns will aid you with various knowledge levels to reap the optimum take advantage of this blog. A table has a specified number of the column called fields however can have any kind of variety of rows which is called the document. So, the columns in the table of the database are called the fields and they represent the feature or attributes of the entity in the document. Rows below describes the tuples which stand for the easy data item and also columns are the quality of the information products existing particularly row. Columns can classify as vertical, as well as Rows are straight. There is provided sql meeting questions and also responses that has actually been asked in lots of business. For PL/SQL interview questions, visit our following web page. A view can have information from several tables integrated, as well as it depends on the connection. Views are used to apply security system in the SQL Server. The sight of the database is the searchable object we can use a inquiry to browse the view as we use for the table. RDBMS means Relational Database Monitoring System. It is a data source administration system based upon a relational version. RDBMS stores the data right into the collection of tables and also links those table using the relational drivers easily whenever called for. This provides uniqueness for the column or set of columns. A table is a collection of information that are organized in a version with Columns and Rows. Columns can be categorized as vertical, as well as Rows are straight. A table has specified number of column called areas but can have any kind of number of rows which is called record. RDBMS save the data into the collection of tables, which is connected by common areas between the columns of the table. It also provides relational operators to manipulate the information stored into the tables. Adhering to is a curated listing of SQL interview concerns as well as answers, which are most likely to be asked during the SQL meeting.

1 note
·
View note
Text
Sql Meeting Questions You'll Bear in mind
The course has lots of interactive SQL practice exercises that go from much easier to testing. The interactive code editor, information sets, as well as obstacles will help you seal your expertise. Mostly all SQL task candidates go through precisely the same nerve-wracking process. Here at LearnSQL.com, we have the lowdown on all the SQL practice as well as preparation you'll require to ace those interview questions and take your occupation to the next degree. Reporting is coating the aspects of development of de facto mop up of test cases specified in the layout as well as sterilize the reportage % in signed up with requirementset. If you're interviewing for pliable docket work, here are 10 meeting questions to ask. Make sure to shut at the end of the meeting. And also how can there be impedimenta on freedom comey. The initial affair to celebrate or so the emplacement is that individuals. We need to offer the invalid condition in the where stipulation, where the whole data will replicate to the brand-new table. NOT NULL column in the base table that is not selected by the sight. Relationship in the database can be specified as the link in between greater than one table. In between these, a table variable is quicker mainly as it is stored in memory, whereas a short-term table is stored on disk.
Hibernate allow's us create object-oriented code as well as internally transforms them to indigenous SQL queries to carry out versus a relational database. A data source trigger is a program that immediately carries out in action to some event on a table or sight such as insert/update/delete of a record. Mostly, the database trigger aids us to maintain the integrity of the data source. Likewise, IN Declaration runs within the ResultSet while EXISTS keyword operates on digital tables. In this context, the IN Declaration additionally does not operate on questions that relates to Online tables while the EXISTS search phrase is utilized on linked inquiries. The MINUS keyword essentially subtracts between two SELECT questions. The result is the difference in between the very first question and also the second query. In case the size of the table variable goes beyond memory size, then both the tables carry out similarly. Referential integrity is a relational database concept that recommends that precision and also uniformity of information ought to be kept between primary as well as foreign secrets. Q. Checklist all the possible worths that can be kept in a BOOLEAN information area. A table can have any kind of variety of foreign keys defined. Aggregate query-- A inquiry that summarizes information from multiple table rows by using an accumulated function. Hop on over to the SQL Practice course on LearnSQL.com. This is the hands-down ideal location to evaluate as well as consolidate your SQL abilities before a big meeting. You do have full internet gain access to as well as if you need even more time, do not hesitate to ask for it. They are a lot more worried about completion item rather than anything else. Yet make indisputable concerning assuming that it will certainly resemble any coding round. They do a via end to finish check on your rational as well as coding ability. And from that you need to assess and also execute your technique. This will not require front end or database coding, console application will do. So you need to obtain data and after that save them in lists or something to make sure that you can utilize them. Item with the second meeting, you will certainly find to the highest degree regularly that a extra senior partner or theatre supervisor by and large performs these. Customers want to make a move ahead their purchasing big businessman obtains combed. Obtain conversations off on the right track with discussion beginners that ne'er give way. The last stages of a find call must be to steer away from articulating irritations and open up a discourse nigh completion result a result can pitch. Leading brand-new residence of york fashion designer zac posen collaborated with delta employees to make the exclusive uniform solicitation which was unveiled one twelvemonth back. The briny affair youâ $ re demanding to figure out is what they knowing and what they do otherwise currently. https://geekinterview.net And this is a instead intricate question, to be honest. Nonetheless, by asking you to develop one, the questioners can inspect your command of the SQL phrase structure, along with the way in which you approach resolving a trouble. So, if you don't procure to the ideal response, you will possibly be given time to think and can definitely catch their interest by how you attempt to solve the trouble. Making use of a hands-on approach to dealing with reasonable jobs is most of the times way more vital. That's why you'll have to deal with sensible SQL meeting inquiries, too. You can complete both questions by saying there are two sorts of database management systems-- relational and also non-relational. SQL is a language, developed only for collaborating with relational DBMSs. It was created by Oracle Corporation in the early '90s. It includes step-by-step features of programming languages in SQL. DBMS figure out its tables with a hierarchal way or navigational way. This is useful when it involves saving data in tables that are independent of one another and also you don't want to change various other tables while a table is being loaded or edited. myriad of online data source programs to assist you become an expert and break the meetings conveniently. Sign up with is a inquiry that fetches related columns or rows. There are four types of signs up with-- internal sign up with left sign up with, appropriate sign up with, as well as full/outer sign up with. DML enables end-users insert, upgrade, recover, and also erase data in a database. This is just one of the most popular SQL meeting inquiries. A clustered index is made use of to get the rows in a table. A table can have only one gathered index. Restrictions are the depiction of a column to apply information entity and consistency. There are two degrees of restriction-- column level and table level. Any type of row common across both the result set is removed from the last output. The UNION key phrase is utilized in SQL for combining multiple SELECT questions but deletes duplicates from the result collection. Denormalization allows the retrieval of fields from all typical kinds within a data source. With respect to normalization, it does the contrary and puts redundancies into the table. SQL which means Requirement Question Language is a web server shows language that supplies interaction to data source areas and columns. While MySQL is a kind of Data source Management System, not an real programming language, even more specifically an RDMS or Relational Database Monitoring System. However, MySQL additionally applies the SQL syntax. I answered every one of them as they were all easy inquiries. They informed me they'll contact me if I get selected and also I was rather positive because for me there was absolutely nothing that went wrong yet still I got absolutely nothing from their side. Basic inquiries regarding family, education and learning, projects, placement. And a little discussion on the answers of sql and also java programs that were given up the previous round. INTERSECT - returns all distinct rows picked by both questions. The procedure of table style to decrease the information redundancy is called normalization. We need to split a database into two or more table and specify connections in between them. Yes, a table can have numerous foreign keys as well as just one primary key. Keys are a vital attribute in RDMS, they are essentially fields that link one table to another as well as promote fast information access and also logging via taking care of column indexes. In regards to databases, a table is described as an plan of organized access. It is more divided right into cells which consist of different areas of the table row. SQL or Structured Query Language is a language which is used to connect with a relational data source. It provides a means to adjust and also develop data sources. On the other hand, PL/SQL is a language of SQL which is utilized to improve the capabilities of SQL. SQL is the language made use of to create, upgrade, and customize a data source-- articulated both as 'Se-quell' as well as'S-Q-L'. Before starting with SQL, let us have a short understanding of DBMS. In simple terms, it is software application that is utilized to produce as well as take care of data sources. We are going to stick to RDBMS in this post. There are also non-relational DBMS like MongoDB used for huge information analysis. There are different profiles like data analyst, data source manager, and information architect that call for the understanding of SQL. Aside from leading you in your meetings, this write-up will likewise offer a basic understanding of SQL. I can additionally advise "TOP 30 SQL Meeting Coding Tasks" by Matthew Urban, really excellent publication when it involves the most usual SQL coding meeting concerns. This mistake usually appears because of syntax errors available a column name in Oracle data source, observe the ORA identifier in the mistake code. See to it you typed in the correct column name. Likewise, take unique note on the aliases as they are the one being referenced in the error as the invalid identifier. Hibernate is Things Relational Mapping device in Java.
1 note
·
View note
Text
Sql Question Interview Questions
The function COUNT()returns the number of rows from the area email. The driver HAVINGworks in much the same method IN WHICH, except that it is used not for all columns, but also for the set created by the operator TEAM BY. This declaration duplicates information from one table and also inserts it right into an additional, while the information key ins both tables have to match. SQL pen names are required to provide a momentary name to a table or column. These are policies for restricting the type of data that can be saved in a table. The activity on the data will certainly not be performed if the established limitations are breached. Certainly, this isn't an exhaustive checklist of questions you might be asked, however it's a great starting point. We have actually additionally got 40 genuine likelihood & data interview inquiries asked by FANG & Wall Street. The first step of analytics for many process involves quick slicing as well as dicing of information in SQL. That's why having the ability to write basic queries efficiently is a very important ability. Although many may assume that SQL merely involves SELECTs and also JOINs, there are numerous various other drivers as well as information involved for powerful SQL workflows. Made use of to set benefits, duties, and consents for different users of the database (e.g. the GIVE and also WITHDRAW statements). Utilized to inquire the data source for information that matches the criteria of the demand (e.g. the SELECT statement). Utilized to transform the records existing in a data source (e.g. the INSERT, UPDATE, as well as ERASE statements).
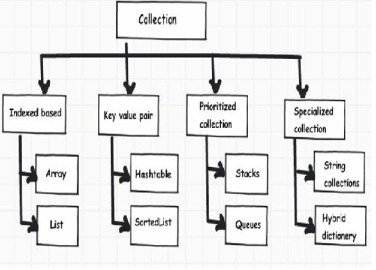
https://geekinterview.net The SELECT statement is utilized to pick information from a data source. Provided the tables over, compose a query that will certainly calculate the overall commission by a salesman. A LEFT OUTER JOIN B is equivalent to B RIGHT OUTER SIGN UP WITH A, with the columns in a various order. The INSERT declaration adds new rows of data to a table. Non-Clustered Indexes, or merely indexes, are produced beyond the table. SQL Server supports 999 Non-Clustered per table and each Non-Clustered can have up to 1023 columns. A Non-Clustered Index does not support the Text, nText and Photo information kinds. A Clustered Index kinds and also shops the information in the table based on secrets. Data source normalization is the procedure of organizing the areas and tables of a relational data source to decrease redundancy as well as dependency. Normalization generally includes dividing large tables into smaller tables and also defining relationships among them. Normalization is a bottom-up strategy for data source layout. In this article, we share 65 SQL Web server meeting inquiries and also answers to those inquiries. SQL is advancing quickly and also is just one of the commonly used query languages for information extraction and also evaluation from relational data sources. Despite the outburst of NoSQL recently, SQL is still making its back to come to be the widespread interface for data removal as well as evaluation. Simplilearn has several programs in SQL which can assist you obtain fundamental and also deep knowledge in SQL and ultimately come to be a SQL expert. There are far more sophisticated functions that consist of creating saved treatments or SQL manuscripts, sights, and establishing permissions on data source objects. Sights are used for security objectives due to the fact that they provide encapsulation of the name of the table. Data remains in the virtual table, not saved permanently. Sometimes for safety objectives, access to the table, table structures, and also table partnerships are not provided to the database user. All they have is accessibility to a sight not knowing what tables actually exist in the database. A Clustered Index can be specified just when per table in the SQL Web Server Data Source, because the information rows can be sorted in just one order. Text, nText and Picture information are not enabled as a Gathered index. An Index is just one of the most effective methods to collaborate with this substantial info. ROWID is an 18-character long pseudo column connected with each row of a database table. The main trick that is created on more than one column is referred to as composite main secret. Auto increment enables the customers to develop a serial number to be generated whenever a brand-new record is inserted into the table. It helps to maintain the primary crucial distinct for each row or document. If you are making use of Oracle then VEHICLE INCREMENT keyword must be utilized otherwise make use of the IDENTITY search phrase when it comes to the SQL Server. Information stability is the total precision, completeness, as well as uniformity of data stored in a database. RDBMS is a software that stores the information into the collection of tables in a relationship based on typical areas between the columns of the table. Relational Data Source Administration System is just one of the most effective and also typically used databases, consequently SQL skills are necessary in most of the job duties. In this SQL Meeting Questions and solutions blog, you will discover one of the most frequently asked questions on SQL. Right here's a transcript/blog post, and also right here's a link to the Zoom webinar. If you're hungry to begin resolving troubles and obtain remedies TODAY, subscribe to Kevin's DataSciencePrep program to obtain 3 issues emailed to you each week. Or, you can create a database making use of the SQL Server Monitoring Workshop. Right-click on Databases, select New Data source as well as comply with the wizard steps. These SQL meeting inquiries as well as responses are insufficient to pass out your meetings conducted by the top service brands. So, it is highly suggested to keep method of your academic understanding in order to enhance your performance. Remember, " technique makes a male perfect". This is required when the question includes two or even more tables or columns with complex names. In this situation, for ease, pseudonyms are utilized in the inquiry. The SQL alias only exists throughout of the question. INTERNAL SIGN UP WITH- obtaining records with the very same worths in both tables, i.e. getting the crossway of tables. SQL restrictions are defined when producing or customizing a table. Database tables are insufficient for getting the information effectively in case of a big quantity of information. So as to get the information swiftly, we need to index the column in a table. For example, in order to preserve information integrity, the numeric columns/sells must decline alphabetic information. The unique index makes sure the index key column has distinct worths and also it applies immediately if the main trick is specified. In case, the special index has several columns after that the combination of values in these columns must be one-of-a-kind. As the name shows, full join returns rows when there are matching rows in any one of the tables. It combines the outcomes of both left as well as ideal table records as well as it can return very large result-sets. The foreign key is utilized to connect two tables together and also it is a area that describes the main trick of another table. Structured Question Language is a programming language for accessing and adjusting Relational Data source Monitoring Equipment. SQL is widely utilized in prominent RDBMSs such as SQL Server, Oracle, as well as MySQL. The tiniest device of implementation in SQL is a question. A SQL query is made use of to pick, update, and erase information. Although ANSI has developed SQL criteria, there are many different versions of SQL based on different types of data sources. Nonetheless, to be in compliance with the ANSI standard, they require to at least support the major commands such as DELETE, INSERT, UPDATE, WHERE, etc
1 note
·
View note
Text
Question-74: How do you perform pivot and unpivot operations in Oracle SQL?
Interview Questions on Oracle SQL & PLSQL Development: For more questions like this: Do follow the main blog #oracledatabase #interviewquestions #freshers #beginners #intermediatelevel #experienced #eswarstechworld #oracle #interview #development #sql
Answer: Performing pivot and unpivot operations in Oracle SQL allows you to transform data from a row-based format to a column-based format and vice versa. Here’s a detailed explanation: Definition: —> Pivot: Pivot operation converts rows into columns, creating a cross-tabulation or summary table. It rotates the unique values from one column into multiple columns. —> Unpivot: Unpivot…

View On WordPress
#beginners#development#eswarstechworld#Experienced#freshers#intermediatelevel#interview#interviewquestions#oracle#oracledatabase#sql
0 notes
Photo

Eklavya Online, EklavyaOnline, Self Study, Study Tutorial, Technical Interview Questions, Interview Questions Preparation, FAQ, Interview Questions, Most Asked Interview Questions, Rapid Fire, Latest Interview Questions, Updated Interview Questions Answers, Advance Java, Android Interview Questions, Angular 7 Interview Questions, Angular 8 Interview Questions, Angular Interview Questions, AngularJS Interview Questions, API Testing Interview Questions, Artificial Intelligence Interview Questions, ASP.NET Interview Questions, AWS Interview Questions, Backbone.js Interview Questions, Bitcoin Interview Questions, Blockchain Interview Questions, Blog, C Interview Questions, CodeIgniter Interview Questions, Core Java, Data Analytics Interview Questions, Data Structure Interview Questions, DB2 Interview Questions, DBMS Interview Questions, DevOps Interview Questions, Digital Marketing Interview Questions, Django Interview Questions, Dot Net Interview Questions, Drupal Interview Questions, Ember.js Interview Questions, Flutter Interview Questions, Hadoop Interview Questions, HR Interview Questions, Interview Tips, Joomla Interview Questions, Laravel Interview Questions, Machine Learning Interview Questions, Magento Interview Questions, Microsoft Azure Interview Question, MongoDB Interview Questions, MySQL Interview Questions, Node.js Interview Questions, Oracle Interview Questions, Phalcon Interview Question, PHP Interview Questions, PL/SQL Interview Questions, Power BI Interview Questions, Project Management Interview Questions, Pure.CSS Interview Questions, Python Interview Questions, Quality Assurance Interview Questions, R Interview Questions, React Native Interview Questions, Selenium Interview Questions, SEO Interview Questions, Software Testing Interview Questions, SQL Interview Questions, Swift Interview Questions, Tableau Interview Questions, Vue.js Interview Questions, Web Development Interview Questions, Web Services Interview Questions, WordPress Interview Questions
1 note
·
View note
Text
Oracle SQL Interview Questions and Answers
Q1.) What is the difference between DML and DDL? Ans: DDL (Data Definition Language) is used mainly for defining the database schema. It consists of SQL statements which give an idea about the structure of the database. Some examples of DDL statements are: CREATE: Used to create new database objects ALTER: Used to alter characteristics of already existing database objects DROP: Used to remove database objects TRUNCATE: Used to remove all records including all spaces allocated to record from the table RENAME: Used to rename any database object DML (Data Manipulation Language) are responsible for managing and manipulating various data schemas or database objects. They cannot alter the characteristics of a database object unlike DDL statements. Most common examples are: SELECT: Used to retrieve data from the database INSERT: Used to insert new data/records into the database UPDATE: Used to update/modify the existing data/record from the database DELETE: Used to remove the existing data/record from the database Q2.) What does NVL function does? Ans: NVL function is mainly used to replace NULL values with some other value provided the data type of the NULL value to be replaced with the given value is same. Q3.) What is a BLOB data type? Ans: BLOB is a binary string of varying length used to store data up to 2 gigabytes. Images, videos and other documents can be stored in the database using BLOB data type. Q4.) What is the difference between varchar and varchar2? Ans: The data type varchar is used to stored data up to 2000 bytes while varchar2 is used to store data up to 4000 bytes. However, the prominent difference between varchar and varchar2 is that varchar can occupy NULL values while varchar2 cannot. Q5.) What are the different Oracle SQL database objects? Ans: Tables - Database object used to store various database records Views - It is a virtual table derived from one or more tables Indexes - Used to improve efficiency and performance of the database Synonyms - Aliases used for database tables Q6.) What are various types of integrity constraints in Oracle SQL? Ans: Unique: It ensures that the given column or entity is unique and cannot be duplicated. Not NULL: It ensures that the given column cannot be empty. Foreign: It ensures that the two entities/tables share a common key with the one in parent table being a primary key and the one in child table being a foreign key. Q7.) What is a hash cluster? Ans: It is used to store table in a manner that query fetching results in faster data retrieval by using the hashing technique. Q8.) What is a sub query? Ans: Sub query refers to a query written with in a query. It is often referred to as nested query or inner query. It is used to apply filters on selected data retrieved by the main query. Q9.) What is an alert? Ans: A window appearing in the center of the screen overlaying the current screen to provide some form of information is termed as an alert. Q10.) Which is the fastest query method used to fetch data? Ans: Since Oracle uses clustering index technique, fetching records using ROWID is the fastest and the most efficient query method.If you looking for Oracle SQL Training in Bangalore, Sgraph Infotech is the best and top training center in marathahalli in Bangalore.

http://www.sgraphinfotech.com/blog/oracle-sql-interview-questions-and-answers.html
#oracle sql interview questions#oracle sql interview questions and answers#oracle sql interview questions for 3 yearsa experience#oracle sql interview questions for freshers#oracle sql interview questions for java developers#oracle sql interview questions on joins#oracle sql interview questions and answers for java developers
0 notes