#pyspark training course
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
How to Read and Write Data in PySpark
The Python application programming interface known as PySpark serves as the front end for Apache Spark execution of big data operations. The most crucial skill required for PySpark work involves accessing and writing data from sources which include CSV, JSON and Parquet files.
In this blog, you’ll learn how to:
Initialize a Spark session
Read data from various formats
Write data to different formats
See expected outputs for each operation
Let’s dive in step-by-step.
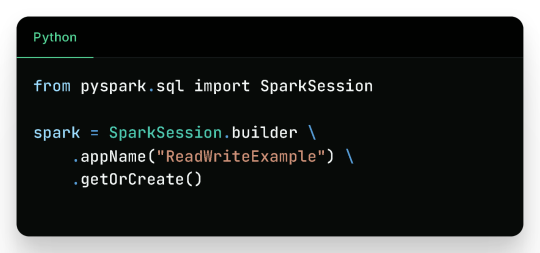
Getting Started
Before reading or writing, start by initializing a SparkSession.
Reading Data in PySpark
1. Reading CSV Files
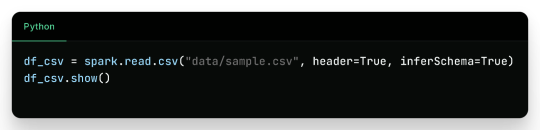
Sample CSV Data (sample.csv):

Output:

2. Reading JSON Files
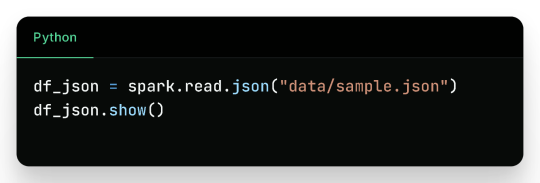
Sample JSON (sample.json):

Output:

3. Reading Parquet Files
Parquet is optimized for performance and often used in big data pipelines.

Assuming the parquet file has similar content:
Output:
4. Reading from a Database (JDBC)

Sample Table employees in MySQL:

Output:

Writing Data in PySpark
1. Writing to CSV
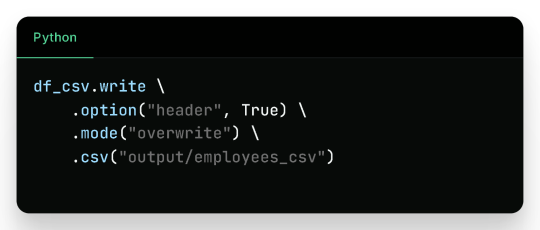
Output Files (folder output/employees_csv/):

Sample content:

2. Writing to JSON

Sample JSON output (employees_json/part-*.json):
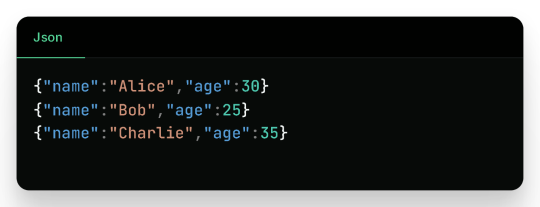
3. Writing to Parquet
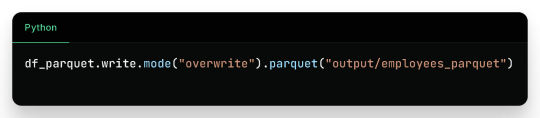
Output:
Binary Parquet files saved inside output/employees_parquet/
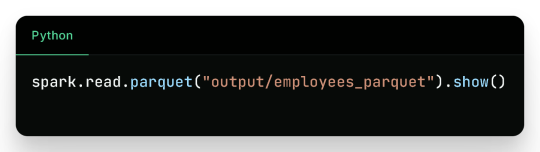
You can verify the contents by reading it again:
4. Writing to a Database
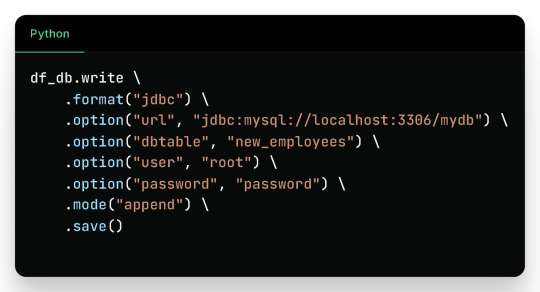
Check the new_employees table in your database — it should now include all the records.
Write Modes in PySpark
Mode
Description
overwrite
Overwrites existing data
append
Appends to existing data
ignore
Ignores if the output already exists
error
(default) Fails if data exists
Real-Life Use Case
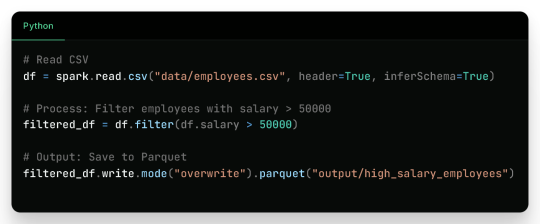
Filtered Output:
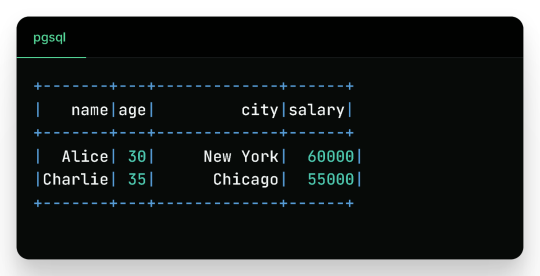
Wrap-Up
Reading and writing data in PySpark is efficient, scalable, and easy once you understand the syntax and options. This blog covered:
Reading from CSV, JSON, Parquet, and JDBC
Writing to CSV, JSON, Parquet, and back to Databases
Example outputs for every format
Best practices for production use
Keep experimenting and building real-world data pipelines — and you’ll be a PySpark pro in no time!
🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: [email protected]
🌍Visit Us: AccentFuture
#apache pyspark training#best pyspark course#best pyspark training#pyspark course online#pyspark online classes#pyspark training#pyspark training online
0 notes
Text
Data engineer training and placement in Pune - JVM Institute
Kickstart your career with JVM Institute's top-notch Data Engineer Training in Pune. Expert-led courses, hands-on projects, and guaranteed placement support to transform your future!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#Data engineer training and placement in Pune#Big Data courses in Pune#PySpark Courses in Pune
0 notes
Text
Master PySpark for High-Speed Data Processing Online!
youtube
0 notes
Text
Python Training institute in Hyderabad
Best Python Training in Hyderabad by RS Trainings
Python is one of the most popular and versatile programming languages in the world, renowned for its simplicity, readability, and broad applicability across various domains like web development, data science, artificial intelligence, and more. If you're looking to learn Python or enhance your Python skills, RS Trainings offers the best Python training in Hyderabad, guided by industry IT experts. Recognized as the best place for better learning, RS Trainings is committed to delivering top-notch education that equips you with practical skills and knowledge.

Why Choose RS Trainings for Python?
1. Expert Instructors: Our Python training program is led by seasoned industry professionals who bring a wealth of experience and insights. They are adept at simplifying complex concepts and providing real-world examples to ensure you gain a deep understanding of Python.
2. Comprehensive Curriculum: The curriculum is meticulously designed to cover everything from the basics of Python to advanced topics. You'll learn about variables, data types, control structures, functions, modules, file handling, object-oriented programming, web development frameworks like Django and Flask, and data analysis libraries like Pandas and NumPy.
3. Hands-on Learning: We emphasize a practical approach to learning. Our training includes numerous hands-on exercises, coding assignments, and real-time projects that help you apply the concepts you learn in class, ensuring you gain practical experience.
4. Flexible Learning Options: RS Trainings offers both classroom and online training options to accommodate different learning preferences and schedules. Whether you are a working professional or a student, you can find a batch that fits your timetable.
5. Career Support: Beyond just training, we provide comprehensive career support, including resume building, interview preparation, and job placement assistance. Our aim is to help you smoothly transition into a successful career in Python programming.
Course Highlights:
Introduction to Python: Get an overview of Python and its applications, understanding why it is a preferred language for various domains.
Core Python Concepts: Dive into the core concepts, including variables, data types, control structures, loops, and functions.
Object-Oriented Programming: Learn about object-oriented programming in Python, covering classes, objects, inheritance, and polymorphism.
Web Development: Explore web development using popular frameworks like Django and Flask, and build your own web applications.
Data Analysis: Gain proficiency in data analysis using libraries like Pandas, NumPy, and Matplotlib.
Real-world Projects: Work on real-world projects that simulate industry scenarios, enhancing your practical skills and understanding.
Who Should Enroll?
Aspiring Programmers: Individuals looking to start a career in programming.
Software Developers: Developers wanting to add Python to their skill set.
Data Scientists and Analysts: Professionals aiming to leverage Python for data analysis and machine learning.
Web Developers: Web developers interested in using Python for backend development.
Students and Enthusiasts: Anyone with a passion for learning programming and Python.
Enroll Today!
Join RS Trainings, the best Python training institute in Hyderabad, and embark on a journey to master one of the most powerful programming languages. Our expert-led training, practical approach, and comprehensive support ensure you are well-prepared to excel in your career.
Visit our website or contact us to learn more about our Python training program, upcoming batches, and enrollment details. Elevate your programming skills with RS Trainings – the best place for better learning in Hyderabad!
#python training#python online training#python training in Hyderabad#python training institute in Hyderabad#python course online Hyderabad#pyspark course online
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
PySpark Courses in Pune - JVM Institute
In today’s dynamic landscape, data reigns supreme, reshaping businesses across industries. Those embracing Data Engineering technologies are gaining a competitive edge by amalgamating raw data with advanced algorithms. Master PySpark with expert-led courses at JVM Institute in Pune. Learn big data processing, real-time analytics, and more. Join now to boost your career!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#PySpark Courses in Pune#PySpark Courses in PCMC#Pune
0 notes
Text
Best Azure Data Engineer Course In Ameerpet | Azure Data
Understanding Delta Lake in Databricks
Introduction
Delta Lake, an open-source storage layer developed by Databricks, is designed to address these challenges. It enhances Apache Spark's capabilities by providing ACID transactions, schema enforcement, and time travel, making data lakes more reliable and efficient. In modern data engineering, managing large volumes of data efficiently while ensuring reliability and performance is a key challenge.

What is Delta Lake?
Delta Lake is an optimized storage layer built on Apache Parquet that brings the reliability of a data warehouse to big data processing. It eliminates the limitations of traditional data lakes by adding ACID transactions, scalable metadata handling, and schema evolution. Delta Lake integrates seamlessly with Azure Databricks, Apache Spark, and other cloud-based data solutions, making it a preferred choice for modern data engineering pipelines. Microsoft Azure Data Engineer
Key Features of Delta Lake
1. ACID Transactions
One of the biggest challenges in traditional data lakes is data inconsistency due to concurrent read/write operations. Delta Lake supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable data updates without corruption. It uses Optimistic Concurrency Control (OCC) to handle multiple transactions simultaneously.
2. Schema Evolution and Enforcement
Delta Lake enforces schema validation to prevent accidental data corruption. If a schema mismatch occurs, Delta Lake will reject the data, ensuring consistency. Additionally, it supports schema evolution, allowing modifications without affecting existing data.
3. Time Travel and Data Versioning
Delta Lake maintains historical versions of data using log-based versioning. This allows users to perform time travel queries, enabling them to revert to previous states of data. This is particularly useful for auditing, rollback, and debugging purposes. Azure Data Engineer Course
4. Scalable Metadata Handling
Traditional data lakes struggle with metadata scalability, especially when handling billions of files. Delta Lake optimizes metadata storage and retrieval, making queries faster and more efficient.
5. Performance Optimizations (Data Skipping and Caching)
Delta Lake improves query performance through data skipping and caching mechanisms. Data skipping allows queries to read only relevant data instead of scanning the entire dataset, reducing processing time. Caching improves speed by storing frequently accessed data in memory.
6. Unified Batch and Streaming Processing
Delta Lake enables seamless integration of batch and real-time streaming workloads. Structured Streaming in Spark can write and read from Delta tables in real-time, ensuring low-latency updates and enabling use cases such as fraud detection and log analytics.
How Delta Lake Works in Databricks?
Delta Lake is tightly integrated with Azure Databricks and Apache Spark, making it easy to use within data pipelines. Below is a basic workflow of how Delta Lake operates: Azure Data Engineering Certification
Data Ingestion: Data is ingested into Delta tables from multiple sources (Kafka, Event Hubs, Blob Storage, etc.).
Data Processing: Spark SQL and PySpark process the data, applying transformations and aggregations.
Data Storage: Processed data is stored in Delta format with ACID compliance.
Query and Analysis: Users can query Delta tables using SQL or Spark.
Version Control & Time Travel: Previous data versions are accessible for rollback and auditing.
Use Cases of Delta Lake
ETL Pipelines: Ensures data reliability with schema validation and ACID transactions.
Machine Learning: Maintains clean and structured historical data for training ML models. Azure Data Engineer Training
Real-time Analytics: Supports streaming data processing for real-time insights.
Data Governance & Compliance: Enables auditing and rollback for regulatory requirements.
Conclusion
Delta Lake in Databricks bridges the gap between traditional data lakes and modern data warehousing solutions by providing reliability, scalability, and performance improvements. With ACID transactions, schema enforcement, time travel, and optimized query performance, Delta Lake is a powerful tool for building efficient and resilient data pipelines. Its seamless integration with Azure Databricks and Apache Spark makes it a preferred choice for data engineers aiming to create high-performance and scalable data architectures.
Trending Courses: Artificial Intelligence, Azure AI Engineer, Informatica Cloud IICS/IDMC (CAI, CDI),
Visualpath stands out as the best online software training institute in Hyderabad.
For More Information about the Azure Data Engineer Online Training
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text
Mastering Big Data Tools: Scholarnest's Databricks Cloud Training

In the ever-evolving landscape of data engineering, mastering the right tools is paramount for professionals seeking to stay ahead. Scholarnest, a leading edtech platform, offers comprehensive Databricks Cloud training designed to empower individuals with the skills needed to navigate the complexities of big data. Let's explore how this training program, rich in keywords such as data engineering, Databricks, and PySpark, sets the stage for a transformative learning journey.
Diving into Data Engineering Mastery:
Data Engineering Course and Certification:
Scholarnest's Databricks Cloud training is structured as a comprehensive data engineering course. The curriculum is curated to cover the breadth and depth of data engineering concepts, ensuring participants gain a robust understanding of the field. Upon completion, learners receive a coveted data engineer certification, validating their expertise in handling big data challenges.
Databricks Data Engineer Certification:
The program places a special emphasis on Databricks, a leading big data analytics platform. Participants have the opportunity to earn the Databricks Data Engineer Certification, a recognition that holds substantial value in the industry. This certification signifies proficiency in leveraging Databricks for efficient data processing, analytics, and machine learning.
PySpark Excellence Unleashed:
Best PySpark Course Online:
A highlight of Scholarnest's offering is its distinction as the best PySpark course online. PySpark, the Python library for Apache Spark, is a pivotal tool in the data engineering arsenal. The course delves into PySpark's intricacies, enabling participants to harness its capabilities for data manipulation, analysis, and processing at scale.
PySpark Training Course:
The PySpark training course is thoughtfully crafted to cater to various skill levels, including beginners and those looking for a comprehensive, full-course experience. The hands-on nature of the training ensures that participants not only grasp theoretical concepts but also gain practical proficiency in PySpark.
Azure Databricks Learning for Real-World Applications:
Azure Databricks Learning:
Recognizing the industry's shift towards cloud-based solutions, Scholarnest's program includes Azure Databricks learning. This module equips participants with the skills to leverage Databricks in the Azure cloud environment, aligning their knowledge with contemporary data engineering practices.
Best Databricks Courses:
Scholarnest stands out for offering one of the best Databricks courses available. The curriculum is designed to cover the entire spectrum of Databricks functionalities, from data exploration and visualization to advanced analytics and machine learning.
Learning Beyond Limits:
Self-Paced Training and Certification:
The flexibility of self-paced training is a cornerstone of Scholarnest's approach. Participants can learn at their own speed, ensuring a thorough understanding of each concept before progressing. The self-paced model is complemented by comprehensive certification, validating the mastery of Databricks and related tools.
Machine Learning with PySpark:
Machine learning is seamlessly integrated into the program, providing participants with insights into leveraging PySpark for machine learning applications. This inclusion reflects the program's commitment to preparing professionals for the holistic demands of contemporary data engineering roles.
Conclusion:
Scholarnest's Databricks Cloud training transcends traditional learning models. By combining in-depth coverage of data engineering principles, hands-on PySpark training, and Azure Databricks learning, this program equips participants with the knowledge and skills needed to excel in the dynamic field of big data. As the industry continues to evolve, Scholarnest remains at the forefront, ensuring that professionals are not just keeping pace but leading the way in data engineering excellence.
#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#big data
1 note
·
View note
Text
Top 5 Data Engineering Tools Every Aspiring Data Engineer Should Master
Introduction:
The discipline of data engineering is changing quickly, with new tools and technologies appearing on a regular basis. In order to remain competitive in the field, any aspiring data engineer needs become proficient in five key data engineering tools, which we will discuss in this blog article.
Apache Spark:
An essential component of the big data processing industry is Apache Spark. It is perfect for a variety of data engineering activities, such as stream processing, machine learning, and ETL (Extract, Transform, Load) procedures, because to its blazingly quick processing speeds and flexible APIs.
AWS Glue, GCP Dataflow, Azure Data Factory:
Data engineering has been transformed by cloud-based ETL (Extract, Transform, Load) services like AWS Glue, GCP Dataflow, and Azure Data Factory, which offer serverless and scalable solutions for data integration and transformation. With the help of these services, you can easily load data into your target data storage, carry out intricate transformations, and ingest data from several sources. Data engineers can create successful and affordable cloud data pipelines by knowing how to use these cloud-based ETL services.
Apache Hadoop:
Apache Hadoop continues to be a fundamental tool in the field of data engineering, despite the rise in popularity of more recent technologies like Spark. Large-scale data sets are still often processed and stored using Hadoop's MapReduce processing framework and distributed file system (HDFS). Gaining a grasp of Hadoop is essential to comprehending the foundations of big data processing and distributed computing.
Airflow:
Any data engineering workflow relies heavily on data pipelines, and Apache Airflow is an effective solution for managing and coordinating intricate data pipelines. Workflows can be defined as code, tasks can be scheduled and carried out, and pipeline status can be readily visualized with Airflow. To guarantee the dependability and effectiveness of your data pipelines, you must learn how to build, implement, and oversee workflows using Airflow.
SQL:
Although it isn't a specialized tool, any data engineer must be proficient in SQL (Structured Query Language). Writing effective queries to extract, manipulate, and analyze data is a key skill in SQL, the language of data analysis. SQL is the language you'll use to communicate with your data, regardless of whether you're dealing with more recent big data platforms or more conventional relational databases.
Conclusion:
Gaining proficiency with these five data engineering tools will provide you a strong basis for success in the industry. But keep in mind that the field of data engineering is always changing, therefore the secret to your long-term success as a data engineer will be to remain inquisitive, flexible, and willing to learn new technologies. Continue investigating, testing, and expanding the realm of data engineering's potential!
Hurry Up! Enroll at JVM Institute Now and Secure 100% Placement!
#Best Data Engineering Courses Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#Data engineer training and placement in Pune#Big Data courses in Pune#PySpark Courses in Pune
0 notes
Text
Training Proposal: PySpark for Data Processing
Training Proposal: PySpark for Data Processing Introduction:This proposal outlines a 3-day PySpark training program designed for 10 participants. The course aims to equip data professionals with the skills to leverage Apache Spark using the Python API (PySpark) for efficient large-scale data processing[5]. Participants will gain hands-on experience with PySpark, covering fundamental concepts to…
0 notes
Text
Training Proposal: PySpark for Data Processing
Introduction:This proposal outlines a 3-day PySpark training program designed for 10 participants. The course aims to equip data professionals with the skills to leverage Apache Spark using the Python API (PySpark) for efficient large-scale data processing5. Participants will gain hands-on experience with PySpark, covering fundamental concepts to advanced techniques, enabling them to tackle…
0 notes
Text
https://bitaacademy.com/course/best-pyspark-training-in-chennai/
0 notes
Text
https://bitaacademy.com/course/best-pyspark-training-in-chennai/
0 notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes