#python scrapy
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
AI Automated Testing Course with Venkatesh (Rahul Shetty) Join our AI Automated Testing Course with Venkatesh (Rahul Shetty) and learn how to test software using smart AI tools. This easy-to-follow course helps you save time, find bugs faster, and grow your skills for future tech jobs. To know more about us visit https://rahulshettyacademy.com/
#ai generator tester#ai software testing#ai automated testing#ai in testing software#playwright automation javascript#playwright javascript tutorial#playwright python tutorial#scrapy playwright tutorial#api testing using postman#online postman api testing#postman automation api testing#postman automated testing#postman performance testing#postman tutorial for api testing#free api for postman testing#api testing postman tutorial#postman tutorial for beginners#postman api performance testing#automate api testing in postman#java automation testing#automation testing selenium with java#automation testing java selenium#java selenium automation testing#python selenium automation#selenium with python automation testing#selenium testing with python#automation with selenium python#selenium automation with python#python and selenium tutorial#cypress automation training
0 notes
Text
Unlock the Secrets of Python Web Scraping for Data-Driven Success
Ever wondered how to extract data from websites without manual effort? Python web scraping is the answer!
This blog covers everything you need to know to harness Python’s powerful libraries like BeautifulSoup, Scrapy, and Requests.
Whether you're scraping for research, monitoring prices, or gathering content, this guide will help you turn the web into a vast source of structured data.
Learn how to set up Python for scraping, handle errors, and ensure your scraping process is both legal and efficient.
If you're ready to dive into the world of information mining, this article is your go-to resource.
0 notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
Tapping into Fresh Insights: Kroger Grocery Data Scraping
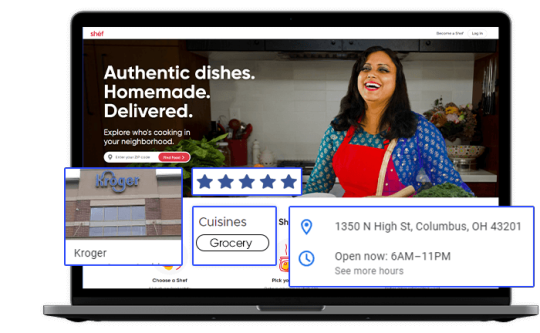
In today's data-driven world, the retail grocery industry is no exception when it comes to leveraging data for strategic decision-making. Kroger, one of the largest supermarket chains in the United States, offers a wealth of valuable data related to grocery products, pricing, customer preferences, and more. Extracting and harnessing this data through Kroger grocery data scraping can provide businesses and individuals with a competitive edge and valuable insights. This article explores the significance of grocery data extraction from Kroger, its benefits, and the methodologies involved.
The Power of Kroger Grocery Data
Kroger's extensive presence in the grocery market, both online and in physical stores, positions it as a significant source of data in the industry. This data is invaluable for a variety of stakeholders:
Kroger: The company can gain insights into customer buying patterns, product popularity, inventory management, and pricing strategies. This information empowers Kroger to optimize its product offerings and enhance the shopping experience.
Grocery Brands: Food manufacturers and brands can use Kroger's data to track product performance, assess market trends, and make informed decisions about product development and marketing strategies.
Consumers: Shoppers can benefit from Kroger's data by accessing information on product availability, pricing, and customer reviews, aiding in making informed purchasing decisions.
Benefits of Grocery Data Extraction from Kroger
Market Understanding: Extracted grocery data provides a deep understanding of the grocery retail market. Businesses can identify trends, competition, and areas for growth or diversification.
Product Optimization: Kroger and other retailers can optimize their product offerings by analyzing customer preferences, demand patterns, and pricing strategies. This data helps enhance inventory management and product selection.
Pricing Strategies: Monitoring pricing data from Kroger allows businesses to adjust their pricing strategies in response to market dynamics and competitor moves.
Inventory Management: Kroger grocery data extraction aids in managing inventory effectively, reducing waste, and improving supply chain operations.
Methodologies for Grocery Data Extraction from Kroger
To extract grocery data from Kroger, individuals and businesses can follow these methodologies:
Authorization: Ensure compliance with Kroger's terms of service and legal regulations. Authorization may be required for data extraction activities, and respecting privacy and copyright laws is essential.
Data Sources: Identify the specific data sources you wish to extract. Kroger's data encompasses product listings, pricing, customer reviews, and more.
Web Scraping Tools: Utilize web scraping tools, libraries, or custom scripts to extract data from Kroger's website. Common tools include Python libraries like BeautifulSoup and Scrapy.
Data Cleansing: Cleanse and structure the scraped data to make it usable for analysis. This may involve removing HTML tags, formatting data, and handling missing or inconsistent information.
Data Storage: Determine where and how to store the scraped data. Options include databases, spreadsheets, or cloud-based storage.
Data Analysis: Leverage data analysis tools and techniques to derive actionable insights from the scraped data. Visualization tools can help present findings effectively.
Ethical and Legal Compliance: Scrutinize ethical and legal considerations, including data privacy and copyright. Engage in responsible data extraction that aligns with ethical standards and regulations.
Scraping Frequency: Exercise caution regarding the frequency of scraping activities to prevent overloading Kroger's servers or causing disruptions.
Conclusion
Kroger grocery data scraping opens the door to fresh insights for businesses, brands, and consumers in the grocery retail industry. By harnessing Kroger's data, retailers can optimize their product offerings and pricing strategies, while consumers can make more informed shopping decisions. However, it is crucial to prioritize ethical and legal considerations, including compliance with Kroger's terms of service and data privacy regulations. In the dynamic landscape of grocery retail, data is the key to unlocking opportunities and staying competitive. Grocery data extraction from Kroger promises to deliver fresh perspectives and strategic advantages in this ever-evolving industry.
#grocerydatascraping#restaurant data scraping#food data scraping services#food data scraping#fooddatascrapingservices#zomato api#web scraping services#grocerydatascrapingapi#restaurantdataextraction
4 notes
·
View notes
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes
Text
How Python Can Be Used in Finance: Applications, Benefits & Real-World Examples

In the rapidly evolving world of finance, staying ahead of the curve is essential. One of the most powerful tools at the intersection of technology and finance today is Python. Known for its simplicity and versatility, Python has become a go-to programming language for financial professionals, data scientists, and fintech companies alike.
This blog explores how Python is used in finance, the benefits it offers, and real-world examples of its applications in the industry.
Why Python in Finance?
Python stands out in the finance world because of its:
Ease of use: Simple syntax makes it accessible to professionals from non-programming backgrounds.
Rich libraries: Packages like Pandas, NumPy, Matplotlib, Scikit-learn, and PyAlgoTrade support a wide array of financial tasks.
Community support: A vast, active user base means better resources, tutorials, and troubleshooting help.
Integration: Easily interfaces with databases, Excel, web APIs, and other tools used in finance.
Key Applications of Python in Finance
1. Data Analysis & Visualization
Financial analysis relies heavily on large datasets. Python’s libraries like Pandas and NumPy are ideal for:
Time-series analysis
Portfolio analysis
Risk assessment
Cleaning and processing financial data
Visualization tools like Matplotlib, Seaborn, and Plotly allow users to create interactive charts and dashboards.
2. Algorithmic Trading
Python is a favorite among algo traders due to its speed and ease of prototyping.
Backtesting strategies using libraries like Backtrader and Zipline
Live trading integration with brokers via APIs (e.g., Alpaca, Interactive Brokers)
Strategy optimization using historical data
3. Risk Management & Analytics
With Python, financial institutions can simulate market scenarios and model risk using:
Monte Carlo simulations
Value at Risk (VaR) models
Stress testing
These help firms manage exposure and regulatory compliance.
4. Financial Modeling & Forecasting
Python can be used to build predictive models for:
Stock price forecasting
Credit scoring
Loan default prediction
Scikit-learn, TensorFlow, and XGBoost are popular libraries for machine learning applications in finance.
5. Web Scraping & Sentiment Analysis
Real-time data from financial news, social media, and websites can be scraped using BeautifulSoup and Scrapy. Python’s NLP tools (like NLTK, spaCy, and TextBlob) can be used for sentiment analysis to gauge market sentiment and inform trading strategies.
Benefits of Using Python in Finance
✅ Fast Development
Python allows for quick development and iteration of ideas, which is crucial in a dynamic industry like finance.
✅ Cost-Effective
As an open-source language, Python reduces licensing and development costs.
✅ Customization
Python empowers teams to build tailored solutions that fit specific financial workflows or trading strategies.
✅ Scalability
From small analytics scripts to large-scale trading platforms, Python can handle applications of various complexities.
Real-World Examples
💡 JPMorgan Chase
Developed a proprietary Python-based platform called Athena to manage risk, pricing, and trading across its investment banking operations.
💡 Quantopian (acquired by Robinhood)
Used Python for developing and backtesting trading algorithms. Users could write Python code to create and test strategies on historical market data.
💡 BlackRock
Utilizes Python for data analytics and risk management to support investment decisions across its portfolio.
💡 Robinhood
Leverages Python for backend services, data pipelines, and fraud detection algorithms.
Getting Started with Python in Finance
Want to get your hands dirty? Here are a few resources:
Books:
Python for Finance by Yves Hilpisch
Machine Learning for Asset Managers by Marcos López de Prado
Online Courses:
Coursera: Python and Statistics for Financial Analysis
Udemy: Python for Financial Analysis and Algorithmic Trading
Practice Platforms:
QuantConnect
Alpaca
Interactive Brokers API
Final Thoughts
Python is transforming the financial industry by providing powerful tools to analyze data, build models, and automate trading. Whether you're a finance student, a data analyst, or a hedge fund quant, learning Python opens up a world of possibilities.
As finance becomes increasingly data-driven, Python will continue to be a key differentiator in gaining insights and making informed decisions.
Do you work in finance or aspire to? Want help building your first Python financial model? Let me know, and I’d be happy to help!
#outfit#branding#financial services#investment#finance#financial advisor#financial planning#financial wellness#financial freedom#fintech
0 notes
Text
How to Integrate WooCommerce Scraper into Your Business Workflow
In today’s fast-paced eCommerce environment, staying ahead means automating repetitive tasks and making data-driven decisions. If you manage a WooCommerce store, you’ve likely spent hours handling product data, competitor pricing, and inventory updates. That’s where a WooCommerce Scraper becomes a game-changer. Integrated seamlessly into your workflow, it can help you collect, update, and analyze data more efficiently, freeing up your time and boosting operational productivity.

In this blog, we’ll break down what a WooCommerce scraper is, its benefits, and how to effectively integrate it into your business operations.
What is a WooCommerce Scraper?
A WooCommerce scraper is a tool designed to extract data from WooCommerce-powered websites. This data could include:
Product titles, images, descriptions
Prices and discounts
Reviews and ratings
Stock status and availability
Such a tool automates the collection of this information, which is useful for e-commerce entrepreneurs, data analysts, and digital marketers. Whether you're monitoring competitors or syncing product listings across multiple platforms, a WooCommerce scraper can save hours of manual work.
Why Businesses Use WooCommerce Scrapers
Before diving into the integration process, let’s look at the key reasons businesses rely on scraping tools:
Competitor Price Monitoring
Stay competitive by tracking pricing trends across similar WooCommerce stores. Automated scrapers can pull this data daily, helping you optimize your pricing strategy in real time.
Bulk Product Management
Import product data at scale from suppliers or marketplaces. Instead of manually updating hundreds of SKUs, use a scraper to auto-populate your database with relevant information.
Enhanced Market Research
Get a snapshot of what’s trending in your niche. Use scrapers to gather data about top-selling products, customer reviews, and seasonal demand.
Inventory Tracking
Avoid stockouts or overstocking by monitoring inventory availability from your suppliers or competitors.
How to Integrate a WooCommerce Scraper Into Your Workflow
Integrating a WooCommerce scraper into your business processes might sound technical, but with the right approach, it can be seamless and highly beneficial. Whether you're aiming to automate competitor tracking, streamline product imports, or maintain inventory accuracy, aligning your scraper with your existing workflow ensures efficiency and scalability. Below is a step-by-step guide to help you get started.
Step 1: Define Your Use Case
Start by identifying what you want to achieve. Is it competitive analysis? Supplier data syncing? Or updating internal catalogs? Clarifying this helps you choose the right scraping strategy.
Step 2: Choose the Right Scraper Tool
There are multiple tools available, ranging from browser-based scrapers to custom-built Python scripts. Some popular options include:
Octoparse
ParseHub
Python-based scrapers using BeautifulSoup or Scrapy
API integrations for WooCommerce
For enterprise-level needs, consider working with a provider like TagX, which offers custom scraping solutions with scalability and accuracy in mind.
Step 3: Automate with Cron Jobs or APIs
For recurring tasks, automation is key. Set up cron jobs or use APIs to run scrapers at scheduled intervals. This ensures that your database stays up-to-date without manual intervention.
Step 4: Parse and Clean Your Data
Raw scraped data often contains HTML tags, formatting issues, or duplicates. Use tools or scripts to clean and structure the data before importing it into your systems.
Step 5: Integrate with Your CMS or ERP
Once cleaned, import the data into your WooCommerce backend or link it with your ERP or PIM (Product Information Management) system. Many scraping tools offer CSV or JSON outputs that are easy to integrate.
Common Challenges in WooCommerce Scraping (And Solutions)
Changing Site Structures
WooCommerce themes can differ, and any update might break your script. Solution: Use dynamic selectors or AI-powered tools that adapt automatically.
Rate Limiting and Captchas
Some sites use rate limiting or CAPTCHAs to block bots. Solution: Use rotating proxies, headless browsers like Puppeteer, or work with scraping service providers.
Data Duplication or Inaccuracy
Messy data can lead to poor business decisions. Solution: Implement deduplication logic and validation rules before importing data.
Tips for Maintaining an Ethical Scraping Strategy
Respect Robots.txt Files: Always check the site’s scraping policy.
Avoid Overloading Servers: Schedule scrapers during low-traffic hours.
Use the Data Responsibly: Don’t scrape copyrighted or sensitive data.
Why Choose TagX for WooCommerce Scraping?
While it's possible to set up a basic WooCommerce scraper on your own, scaling it, maintaining data accuracy, and handling complex scraping tasks require deep technical expertise. TagX’s professionals offer end-to-end scraping solutions tailored specifically for e-commerce businesses. Whether you're looking to automate product data extraction, monitor competitor pricing, or implement web scraping using AI at scale. Key Reasons to Choose TagX:
AI-Powered Scraping: Go beyond basic extraction with intelligent scraping powered by machine learning and natural language processing.
Scalable Infrastructure: Whether you're scraping hundreds or millions of pages, TagX ensures high performance and minimal downtime.
Custom Integration: TagX enables seamless integration of scrapers directly into your CMS, ERP, or PIM systems, ensuring a streamlined workflow.
Ethical and Compliant Practices: All scraping is conducted responsibly, adhering to industry best practices and compliance standards.
With us, you’re not just adopting a tool—you’re gaining a strategic partner that understands the nuances of modern eCommerce data operations.
Final Thoughts
Integrating a WooCommerce scraper into your business workflow is no longer just a technical choice—it’s a strategic advantage. From automating tedious tasks to extracting market intelligence, scraping tools empower businesses to operate faster and smarter.
As your data requirements evolve, consider exploring web scraping using AI to future-proof your automation strategy. And for seamless implementation, TagX offers the technology and expertise to help you unlock the full value of your data.
0 notes
Text
The Role of AI in Modern Software Testing Practices
AI is reshaping the way software testing is done. With AI automated testing, businesses can achieve higher efficiency, better accuracy, and faster software releases. Whether it’s AI software testing, AI generator testers, or AI-driven automation, the future of software testing is AI-powered.
#ai generator tester#ai software testing#ai automated testing#ai in testing software#playwright automation javascript#playwright javascript tutorial#playwright python tutorial#scrapy playwright tutorial#api testing using postman#online postman api testing#postman automation api testing#postman automated testing#postman performance testing#postman tutorial for api testing#free api for postman testing#api testing postman tutorial#postman tutorial for beginners#postman api performance testing#automate api testing in postman#java automation testing#automation testing selenium with java#automation testing java selenium#java selenium automation testing#python selenium automation#selenium with python automation testing#selenium testing with python#automation with selenium python#selenium automation with python#python and selenium tutorial#cypress automation training
0 notes
Text
🏡 Real Estate Web Scraping — A Simple Way to Collect Property Info Online

Looking at houses online is fun… but trying to keep track of all the details? Not so much.
If you’ve ever searched for homes or rental properties, you know how tiring it can be to jump from site to site, writing down prices, addresses, and details. Now imagine if there was a way to automatically collect that information in one place. Good news — there is!
It’s called real estate web scraping, and it makes life so much easier.
🤔 What Is Real Estate Web Scraping?
Real estate web scraping is a tool that helps you gather information from property websites — like Zillow, Realtor.com, Redfin, or local listing sites — all without doing it by hand.
Instead of copying and pasting, the tool goes to the website, reads the page, and pulls out things like:
The home’s price
Location and zip code
Square footage and number of rooms
Photos
Description
Contact info for the seller or agent
And it puts all that data in a nice, clean file you can use.
🧑💼 Who Is It For?
Real estate web scraping is useful for anyone who wants to collect a lot of property data quickly:
Buyers and investors looking for the best deals
Real estate agents tracking listings in their area
Developers building property websites or apps
People comparing prices in different cities
Marketing teams trying to find leads
It saves time and gives you a better view of what’s happening in the market.
🛠️ How Can You Do It?
If you’re good with code, there are tools like Python, Scrapy, and Selenium that let you build your own scraper.
But if you’re not into tech stuff, no worries. There are ready-made tools that do everything for you. One of the easiest options is this real estate web scraping solution. It works in the cloud, is beginner-friendly, and gives you the data you need without the stress.
🛑 Is It Legal?
Great question — and yes, as long as you’re careful.
Scraping public information (like listings on a website) is generally okay. Just make sure to:
Don’t overload the website with too many requests
Avoid collecting private info
Follow the website’s rules (terms of service)
Be respectful — don’t spam or misuse the data
Using a trusted tool (like the one linked above) helps keep things safe and easy.
💡 Why Use Real Estate Scraping?
Here are some real-life examples:
You’re a property investor comparing house prices in 10 cities — scraping gives you all the prices in one spreadsheet.
You’re a developer building a housing app — scraping provides live listings to show your users.
You’re just curious about trends — scraping lets you track how prices change over time.
It’s all about saving time and seeing the full picture.
✅ In Short…
Real estate web scraping helps you collect a lot of property data from the internet without doing it all manually. It’s fast, smart, and incredibly helpful—whether you’re buying, building, or just exploring.
And the best part? You don’t need to be a tech expert. This real estate web scraping solution makes it super simple to get started.
Give it a try and see how much easier your real estate research can be.
1 note
·
View note
Text
Automate Web Scraping: Python & Scrapy Tutorial
Automating Web Scraping Tasks with Python and Scrapy 1. Introduction Web scraping is the process of extracting data from websites, web pages, and online documents. It is a crucial technique for data collection in various industries such as e-commerce, marketing, and data analysis. Automating web scraping tasks with tools like Python and Scrapy can save significant time and effort, allowing you…
0 notes
Text
How to Track Restaurant Promotions on Instacart and Postmates Using Web Scraping

Introduction
With the rapid growth of food delivery services, companies such as Instacart and Postmates are constantly advertising for their restaurants to entice customers. Such promotions can range from discounts and free delivery to combinations and limited-time offers. For restaurants and food businesses, tracking these promotions gives them a competitive edge to better adjust their pricing strategies, identify trends, and stay ahead of their competitors.
One of the topmost ways to track promotions is using web scraping, which is an automated way of extracting relevant data from the internet. This article examines how to track restaurant promotions from Instacart and Postmates using the techniques, tools, and best practices in web scraping.
Why Track Restaurant Promotions?
1. Contest Research
Identify promotional strategies of competitors in the market.
Compare their discounting rates between restaurants.
Create pricing strategies for competitiveness.
2. Consumer Behavior Intuition
Understand what kinds of promotions are the most patronized by customers.
Deducing patterns that emerge determine what day, time, or season discounts apply.
Marketing campaigns are also optimized based on popular promotions.
3. Distribution Profit Maximization
Determine the optimum timing for promotion in restaurants.
Analyzing competitors' discounts and adjusting is critical to reducing costs.
Maximize the Return on investments, and ROI of promotional campaigns.
Web Scraping Techniques for Tracking Promotions
Key Data Fields to Extract
To effectively monitor promotions, businesses should extract the following data:
Restaurant Name – Identify which restaurants are offering promotions.
Promotion Type – Discounts, BOGO (Buy One Get One), free delivery, etc.
Discount Percentage – Measure how much customers save.
Promo Start & End Date – Track duration and frequency of offers.
Menu Items Included – Understand which food items are being promoted.
Delivery Charges - Compare free vs. paid delivery promotions.
Methods of Extracting Promotional Data
1. Web Scraping with Python
Using Python-based libraries such as BeautifulSoup, Scrapy, and Selenium, businesses can extract structured data from Instacart and Postmates.
2. API-Based Data Extraction
Some platforms provide official APIs that allow restaurants to retrieve promotional data. If available, APIs can be an efficient and legal way to access data without scraping.
3. Cloud-Based Web Scraping Tools
Services like CrawlXpert, ParseHub, and Octoparse offer automated scraping solutions, making data extraction easier without coding.
Overcoming Anti-Scraping Measures
1. Avoiding IP Blocks
Use proxy rotation to distribute requests across multiple IP addresses.
Implement randomized request intervals to mimic human behavior.
2. Bypassing CAPTCHA Challenges
Use headless browsers like Puppeteer or Playwright.
Leverage CAPTCHA-solving services like 2Captcha.
3. Handling Dynamic Content
Use Selenium or Puppeteer to interact with JavaScript-rendered content.
Scrape API responses directly when possible.
Analyzing and Utilizing Promotion Data
1. Promotional Dashboard Development
Create a real-time dashboard to track ongoing promotions.
Use data visualization tools like Power BI or Tableau to monitor trends.
2. Predictive Analysis for Promotions
Use historical data to forecast future discounts.
Identify peak discount periods and seasonal promotions.
3. Custom Alerts for Promotions
Set up automated email or SMS alerts when competitors launch new promotions.
Implement AI-based recommendations to adjust restaurant pricing.
Ethical and Legal Considerations
Comply with robots.txt guidelines when scraping data.
Avoid excessive server requests to prevent website disruptions.
Ensure extracted data is used for legitimate business insights only.
Conclusion
Web scraping allows tracking restaurant promotions at Instacart and Postmates so that businesses can best optimize their pricing strategies to maximize profits and stay ahead of the game. With the help of automation, proxies, headless browsing, and AI analytics, businesses can beautifully keep track of and respond to the latest promotional trends.
CrawlXpert is a strong provider of automated web scraping services that help restaurants follow promotions and analyze competitors' strategies.
0 notes
Text
Unlock SEO & Automation with Python
In today’s fast-paced digital world, marketers are under constant pressure to deliver faster results, better insights, and smarter strategies. With automation becoming a cornerstone of digital marketing, Python has emerged as one of the most powerful tools for marketers who want to stay ahead of the curve.
Whether you’re tracking SEO performance, automating repetitive tasks, or analyzing large datasets, Python offers unmatched flexibility and speed. If you're still relying solely on traditional marketing platforms, it's time to step up — because Python isn't just for developers anymore.
Why Python Is a Game-Changer for Digital Marketers
Python’s growing popularity lies in its simplicity and versatility. It's easy to learn, open-source, and supports countless libraries that cater directly to marketing needs. From scraping websites for keyword data to automating Google Analytics reports, Python allows marketers to save time and make data-driven decisions faster than ever.
One key benefit is how Python handles SEO tasks. Imagine being able to monitor thousands of keywords, track competitors, and audit websites in minutes — all without manually clicking through endless tools. Libraries like BeautifulSoup, Scrapy, and Pandas allow marketers to extract, clean, and analyze SEO data at scale. This makes it easier to identify opportunities, fix issues, and outrank competitors efficiently.
Automating the Routine, Empowering the Creative
Repetitive tasks eat into a marketer's most valuable resource: time. Python helps eliminate the grunt work. Need to schedule social media posts, generate performance reports, or pull ad data across platforms? With just a few lines of code, Python can automate these tasks while you focus on creativity and strategy.
In Dehradun, a growing hub for tech and education, professionals are recognizing this trend. Enrolling in a Python Course in Dehradun not only boosts your marketing skill set but also opens up new career opportunities in analytics, SEO, and marketing automation. Local training programs often offer real-world marketing projects to ensure you gain hands-on experience with tools like Jupyter, APIs, and web scrapers — critical assets in the digital marketing toolkit.
Real-World Marketing Use Cases
Python's role in marketing isn’t just theoretical — it’s practical. Here are a few real-world scenarios where marketers are already using
Python to their advantage:
Content Optimization: Automate keyword research and content gap analysis to improve your blog and web copy.
Email Campaign Analysis: Analyze open rates, click-throughs, and conversions to fine-tune your email strategies.
Ad Spend Optimization: Pull and compare performance data from Facebook Ads, Google Ads, and LinkedIn to make smarter budget decisions.
Social Listening: Monitor brand mentions or trends across Twitter and Reddit to stay responsive and relevant.
With so many uses, Python is quickly becoming the Swiss army knife for marketers. You don’t need to become a software engineer — even a basic understanding can dramatically improve your workflow.
Getting Started with Python
Whether you're a fresh graduate or a seasoned marketer, investing in the right training can fast-track your career. A quality Python training in Dehradun will teach you how to automate marketing workflows, handle SEO analytics, and visualize campaign performance — all with practical, industry-relevant projects.
Look for courses that include modules on digital marketing integration, data handling, and tool-based assignments. These elements ensure you're not just learning syntax but applying it to real marketing scenarios. With Dehradun's increasing focus on tech education, it's a great place to gain this in-demand skill.
Python is no longer optional for forward-thinking marketers. As SEO becomes more data-driven and automation more essential, mastering Python gives you a clear edge. It simplifies complexity, drives efficiency, and helps you make smarter, faster decisions.
Now is the perfect time to upskill. Whether you're optimizing search rankings or building powerful marketing dashboards, Python is your key to unlocking smarter marketing in 2025 and beyond.
Python vs Ruby, What is the Difference? - Pros & Cons
youtube
#python course#python training#education#python#pythoncourseinindia#pythoninstitute#pythoninstituteinindia#pythondeveloper#Youtube
0 notes
Text
Monitor Competitor Pricing with Food Delivery Data Scraping

In the highly competitive food delivery industry, pricing can be the deciding factor between winning and losing a customer. With the rise of aggregators like DoorDash, Uber Eats, Zomato, Swiggy, and Grubhub, users can compare restaurant options, menus, and—most importantly—prices in just a few taps. To stay ahead, food delivery businesses must continually monitor how competitors are pricing similar items. And that’s where food delivery data scraping comes in.
Data scraping enables restaurants, cloud kitchens, and food delivery platforms to gather real-time competitor data, analyze market trends, and adjust strategies proactively. In this blog, we’ll explore how to use web scraping to monitor competitor pricing effectively, the benefits it offers, and how to do it legally and efficiently.
What Is Food Delivery Data Scraping?
Data scraping is the automated process of extracting information from websites. In the food delivery sector, this means using tools or scripts to collect data from food delivery platforms, restaurant listings, and menu pages.
What Can Be Scraped?
Menu items and categories
Product pricing
Delivery fees and taxes
Discounts and special offers
Restaurant ratings and reviews
Delivery times and availability
This data is invaluable for competitive benchmarking and dynamic pricing strategies.
Why Monitoring Competitor Pricing Matters
1. Stay Competitive in Real Time
Consumers often choose based on pricing. If your competitor offers a similar dish for less, you may lose the order. Monitoring competitor prices lets you react quickly to price changes and stay attractive to customers.
2. Optimize Your Menu Strategy
Scraped data helps identify:
Popular food items in your category
Price points that perform best
How competitors bundle or upsell meals
This allows for smarter decisions around menu engineering and profit margin optimization.
3. Understand Regional Pricing Trends
If you operate across multiple locations or cities, scraping competitor data gives insights into:
Area-specific pricing
Demand-based variation
Local promotions and discounts
This enables geo-targeted pricing strategies.
4. Identify Gaps in the Market
Maybe no competitor offers free delivery during weekdays or a combo meal under $10. Real-time data helps spot such gaps and create offers that attract value-driven users.
How Food Delivery Data Scraping Works
Step 1: Choose Your Target Platforms
Most scraping projects start with identifying where your competitors are listed. Common targets include:
Aggregators: Uber Eats, Zomato, DoorDash, Grubhub
Direct restaurant websites
POS platforms (where available)
Step 2: Define What You Want to Track
Set scraping goals. For pricing, track:
Base prices of dishes
Add-ons and customization costs
Time-sensitive deals
Delivery fees by location or vendor
Step 3: Use Web Scraping Tools or Custom Scripts
You can either:
Use scraping tools like Octoparse, ParseHub, Apify, or
Build custom scripts in Python using libraries like BeautifulSoup, Selenium, or Scrapy
These tools automate the extraction of relevant data and organize it in a structured format (CSV, Excel, or database).
Step 4: Automate Scheduling and Alerts
Set scraping intervals (daily, hourly, weekly) and create alerts for major pricing changes. This ensures your team is always equipped with the latest data.
Step 5: Analyze the Data
Feed the scraped data into BI tools like Power BI, Google Data Studio, or Tableau to identify patterns and inform strategic decisions.
Tools and Technologies for Effective Scraping
Popular Tools:
Scrapy: Python-based framework perfect for complex projects
BeautifulSoup: Great for parsing HTML and small-scale tasks
Selenium: Ideal for scraping dynamic pages with JavaScript
Octoparse: No-code solution with scheduling and cloud support
Apify: Advanced, scalable platform with ready-to-use APIs
Hosting and Automation:
Use cron jobs or task schedulers for automation
Store data on cloud databases like AWS RDS, MongoDB Atlas, or Google BigQuery
Legal Considerations: Is It Ethical to Scrape Food Delivery Platforms?
This is a critical aspect of scraping.
Understand Platform Terms
Many websites explicitly state in their Terms of Service that scraping is not allowed. Scraping such platforms can violate those terms, even if it’s not technically illegal.
Avoid Harming Website Performance
Always scrape responsibly:
Use rate limiting to avoid overloading servers
Respect robots.txt files
Avoid scraping login-protected or personal user data
Use Publicly Available Data
Stick to scraping data that’s:
Publicly accessible
Not behind paywalls or logins
Not personally identifiable or sensitive
If possible, work with third-party data providers who have pre-approved partnerships or APIs.
Real-World Use Cases of Price Monitoring via Scraping
A. Cloud Kitchens
A cloud kitchen operating in three cities uses scraping to monitor average pricing for biryani and wraps. Based on competitor pricing, they adjust their bundle offers and introduce combo meals—boosting order value by 22%.
B. Local Restaurants
A family-owned restaurant tracks rival pricing and delivery fees during weekends. By offering a free dessert on orders above $25 (when competitors don’t), they see a 15% increase in weekend orders.
C. Food Delivery Startups
A new delivery aggregator monitors established players’ pricing to craft a price-beating strategy, helping them enter the market with aggressive discounts and gain traction.
Key Metrics to Track Through Price Scraping
When setting up your monitoring dashboard, focus on:
Average price per cuisine category
Price differences across cities or neighborhoods
Top 10 lowest/highest priced items in your segment
Frequency of discounts and offers
Delivery fee trends by time and distance
Most used upsell combinations (e.g., sides, drinks)
Challenges in Food Delivery Data Scraping (And Solutions)
Challenge 1: Dynamic Content and JavaScript-Heavy Pages
Solution: Use headless browsers like Selenium or platforms like Puppeteer to scrape rendered content.
Challenge 2: IP Blocking or Captchas
Solution: Rotate IPs with proxies, use CAPTCHA-solving tools, or throttle request rates.
Challenge 3: Frequent Site Layout Changes
Solution: Use XPaths and CSS selectors dynamically, and monitor script performance regularly.
Challenge 4: Keeping Data Fresh
Solution: Schedule automated scraping and build change detection algorithms to prioritize meaningful updates.
Final Thoughts
In today’s digital-first food delivery market, being reactive is no longer enough. Real-time competitor pricing insights are essential to survive and thrive. Data scraping gives you the tools to make informed, timely decisions about your pricing, promotions, and product offerings.
Whether you're a single-location restaurant, an expanding cloud kitchen, or a new delivery platform, food delivery data scraping can help you gain a critical competitive edge. But it must be done ethically, securely, and with the right technologies.
0 notes
Text
Data Scraping Made Simple: What It Really Means
Data Scraping Made Simple: What It Really Means
In the digital world, data scraping is a powerful way to collect information from websites automatically. But what exactly does that mean—and why is it important?
Let’s break it down in simple terms.
What Is Data Scraping?
Data scraping (also called web scraping) is the process of using bots or scripts to extract data from websites. Instead of copying and pasting information manually, scraping tools do the job automatically—much faster and more efficiently.
You can scrape product prices, news headlines, job listings, real estate data, weather reports, and more.
Imagine visiting a website with hundreds of items. Now imagine a tool that can read all that content and save it in a spreadsheet in seconds. That’s what data scraping does.
Why Is It So Useful?
Businesses, researchers, and marketers use data scraping to:
Track competitors' prices
Monitor customer reviews
Gather contact info for leads
Collect news for trend analysis
Keep up with changing market data
In short, data scraping helps people get useful information without wasting time.
Is Data Scraping Legal?
It depends. Public data (like product prices or news articles) is usually okay to scrape, but private or copyrighted content is not. Always check a website’s terms of service before scraping it.
Tools for Data Scraping
There are many tools that make data scraping easy:
Beautiful Soup (for Python developers)
Octoparse (no coding needed)
Scrapy (for advanced scraping tasks)
SERPHouse APIs (for SEO and search engine data)
Some are code-based, others are point-and-click tools. Choose what suits your need and skill level.
Final Thoughts
What is data scraping? It’s the smart way to extract website content for business, research, or insights. With the right tools, it saves time, increases productivity, and opens up access to valuable online data.
Just remember: scrape responsibly.
#serphouse#google serp api#serp scraping api#google search api#seo#api#google#bing#data scraping#web scraping
0 notes
Text
Scrape Product Info, Images & Brand Data from E-commerce | Actowiz
Introduction
In today’s data-driven world, e-commerce product data scraping is a game-changer for businesses looking to stay competitive. Whether you're tracking prices, analyzing trends, or launching a comparison engine, access to clean and structured product data is essential. This article explores how Actowiz Solutions helps businesses scrape product information, images, and brand details from e-commerce websites with precision, scalability, and compliance.
Why Scraping E-commerce Product Data Matters

E-commerce platforms like Amazon, Walmart, Flipkart, and eBay host millions of products. For retailers, manufacturers, market analysts, and entrepreneurs, having access to this massive product data offers several advantages:
- Price Monitoring: Track competitors’ prices and adjust your pricing strategy in real-time.
- Product Intelligence: Gain insights into product listings, specs, availability, and user reviews.
- Brand Visibility: Analyze how different brands are performing across marketplaces.
- Trend Forecasting: Identify emerging products and customer preferences early.
- Catalog Management: Automate and update your own product listings with accurate data.
With Actowiz Solutions’ eCommerce data scraping services, companies can harness these insights at scale, enabling smarter decision-making across departments.
What Product Data Can Be Scraped?

When scraping an e-commerce website, here are the common data fields that can be extracted:
✅ Product Information
Product name/title
Description
Category hierarchy
Product specifications
SKU/Item ID
Price (Original/Discounted)
Availability/Stock status
Ratings & reviews
✅ Product Images
Thumbnail URLs
High-resolution images
Zoom-in versions
Alternate views or angle shots
✅ Brand Details
Brand name
Brand logo (if available)
Brand-specific product pages
Brand popularity metrics (ratings, number of listings)
By extracting this data from platforms like Amazon, Walmart, Target, Flipkart, Shopee, AliExpress, and more, Actowiz Solutions helps clients optimize product strategy and boost performance.
Challenges of Scraping E-commerce Sites

While the idea of gathering product data sounds simple, it presents several technical challenges:
Dynamic Content: Many e-commerce platforms load content using JavaScript or AJAX.
Anti-bot Mechanisms: Rate-limiting, captchas, IP blocking, and login requirements are common.
Frequent Layout Changes: E-commerce sites frequently update their front-end structure.
Pagination & Infinite Scroll: Handling product listings across pages requires precise navigation.
Image Extraction: Downloading, renaming, and storing image files efficiently can be resource-intensive.
To overcome these challenges, Actowiz Solutions utilizes advanced scraping infrastructure and intelligent algorithms to ensure high accuracy and efficiency.
Step-by-Step: How Actowiz Solutions Scrapes E-commerce Product Data

Let’s walk through the process that Actowiz Solutions follows to scrape and deliver clean, structured, and actionable e-commerce data:
1. Define Requirements
The first step involves understanding the client’s specific data needs:
Target websites
Product categories
Required data fields
Update frequency (daily, weekly, real-time)
Preferred data delivery formats (CSV, JSON, API)
2. Website Analysis & Strategy Design
Our technical team audits the website’s structure, dynamic loading patterns, pagination system, and anti-bot defenses to design a customized scraping strategy.
3. Crawler Development
We create dedicated web crawlers or bots using tools like Python, Scrapy, Playwright, or Puppeteer to extract product listings, details, and associated metadata.
4. Image Scraping & Storage
Our bots download product images, assign them appropriate filenames (using SKU or product title), and store them in cloud storage like AWS S3 or GDrive. Image URLs can also be returned in the dataset.
5. Brand Attribution
Products are mapped to brand names by parsing brand tags, logos, and using NLP-based classification. This helps clients build brand-level dashboards.
6. Data Cleansing & Validation
We apply validation rules, deduplication, and anomaly detection to ensure only accurate and up-to-date data is delivered.
7. Data Delivery
Data can be delivered via:
REST APIs
S3 buckets or FTP
Google Sheets/Excel
Dashboard integration
All data is made ready for ingestion into CRMs, ERPs, or BI tools.
Supported E-Commerce Platforms

Actowiz Solutions supports product data scraping from a wide range of international and regional e-commerce websites, including:
Amazon
Walmart
Target
eBay
AliExpress
Flipkart
BigCommerce
Magento
Rakuten
Etsy
Lazada
Wayfair
JD.com
Shopify-powered sites
Whether you're focused on electronics, fashion, grocery, automotive, or home décor, Actowiz can help you extract relevant product and brand data with precision.
Use Cases: How Businesses Use Scraped Product Data

Retailers
Compare prices across platforms to remain competitive and win the buy-box.
🧾 Price Aggregators
Fuel price comparison engines with fresh, accurate product listings.
📈 Market Analysts
Study trends across product categories and brands.
🎯 Brands
Monitor third-party sellers, counterfeit listings, or unauthorized resellers.
🛒 E-commerce Startups
Build initial catalogs quickly by extracting competitor data.
📦 Inventory Managers
Sync product stock and images with supplier portals.
Actowiz Solutions tailors the scraping strategy according to the use case and delivers the highest ROI on data investment.
Benefits of Choosing Actowiz Solutions

✅ Scalable Infrastructure
Scrape millions of products across multiple websites simultaneously.
✅ IP Rotation & Anti-Bot Handling
Bypass captchas, rate-limiting, and geolocation barriers with smart proxies and user-agent rotation.
✅ Near Real-Time Updates
Get fresh data updated daily or in real-time via APIs.
✅ Customization & Flexibility
Select your data points, target pages, and preferred delivery formats.
✅ Compliance-First Approach
We follow strict guidelines and ensure scraping methods respect site policies and data usage norms.
Security and Legal Considerations
Actowiz Solutions emphasizes ethical scraping practices and ensures compliance with data protection laws such as GDPR, CCPA, and local regulations. Additionally:
Only publicly available data is extracted.
No login-restricted or paywalled content is accessed without consent.
Clients are guided on proper usage and legal responsibility for the scraped data.
Frequently Asked Questions
❓ Can I scrape product images in high resolution?
Yes. Actowiz Solutions can extract multiple image formats, including zoomable HD product images and thumbnails.
❓ How frequently can data be updated?
Depending on the platform, we support real-time, hourly, daily, or weekly updates.
❓ Can I scrape multiple marketplaces at once?
Absolutely. We can design multi-site crawlers that collect and consolidate product data across platforms.
❓ Is scraped data compatible with Shopify or WooCommerce?
Yes, we can deliver plug-and-play formats for Shopify, Magento, WooCommerce, and more.
❓ What if a website structure changes?
We monitor site changes proactively and update crawlers to ensure uninterrupted data flow.
Final Thoughts
Scraping product data from e-commerce websites unlocks a new layer of market intelligence that fuels decision-making, automation, and competitive strategy. Whether it’s tracking competitor pricing, enriching your product catalog, or analyzing brand visibility — the possibilities are endless.
Actowiz Solutions brings deep expertise, powerful infrastructure, and a client-centric approach to help businesses extract product info, images, and brand data from e-commerce platforms effortlessly. Learn More
0 notes
Text

Postman API Testing Training - Rahul Shetty Academy Join the Postman API Testing Training at Rahul Shetty Academy. Learn postman automated testing, postman performance testing, and master API testing with hands-on experience. This postman tutorial for API testing is perfect for beginners and professionals. Enroll now to enhance your testing skills. Visit Our Website at:- www.rahulshettyacademy.com
#ai generator tester#ai software testing#ai automated testing#ai in testing software#playwright automation javascript#playwright javascript tutorial#playwright python tutorial#scrapy playwright tutorial#api testing using postman#online postman api testing#postman automation api testing#postman automated testing#postman performance testing#postman tutorial for api testing#free api for postman testing#api testing postman tutorial#postman tutorial for beginners#postman api performance testing#automate api testing in postman
0 notes