#scraper site API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Note
there is a dip in the fic count of all fandoms between february 26 and march 3, is there a reason for that? just something I noticed while looking at the dashboard
So I finally had time to look into this properly - at first I couldn't figure it out, because I didn't make any changes to my workflow around that time.
However, I had a hunch and checked everyone's favorite RPF fandom (Hockey RPF) and the drop was wayyy more dramatic there. This confirmed my theory that my stats were no longer including locked works (since RPF fandoms tend to have a way higher percentage of locked fics).
It looks AO3 made some changes to how web scrapers can interact with their site, likely due to the DDOS attacks / AI scrapers they've been dealing with. That change caused my scraper to pull all fic counts as if it was a guest and not a member, which caused the drop.
~
The good news: I was able to leverage the login code from the unofficial python AO3 api to fix it, so future fic counts should be accurate.
The bad news: I haven't figured out what to do about the drop in old data. I can either leave it or I can try to write some math-based script that estimates how many fics there were on those old dates (using the data I do have and scaling up based on that fandom's percentage of locked fics). This wouldn't be a hundred percent accurate, but neither are the current numbers, so we'll see.
~
Thanks Nonny so much for pointing this out! I wish I would've noticed & had a chance to fix earlier, but oh well!
37 notes
·
View notes
Text
25 Python Projects to Supercharge Your Job Search in 2024

Introduction: In the competitive world of technology, a strong portfolio of practical projects can make all the difference in landing your dream job. As a Python enthusiast, building a diverse range of projects not only showcases your skills but also demonstrates your ability to tackle real-world challenges. In this blog post, we'll explore 25 Python projects that can help you stand out and secure that coveted position in 2024.
1. Personal Portfolio Website
Create a dynamic portfolio website that highlights your skills, projects, and resume. Showcase your creativity and design skills to make a lasting impression.
2. Blog with User Authentication
Build a fully functional blog with features like user authentication and comments. This project demonstrates your understanding of web development and security.
3. E-Commerce Site
Develop a simple online store with product listings, shopping cart functionality, and a secure checkout process. Showcase your skills in building robust web applications.
4. Predictive Modeling
Create a predictive model for a relevant field, such as stock prices, weather forecasts, or sales predictions. Showcase your data science and machine learning prowess.
5. Natural Language Processing (NLP)
Build a sentiment analysis tool or a text summarizer using NLP techniques. Highlight your skills in processing and understanding human language.
6. Image Recognition
Develop an image recognition system capable of classifying objects. Demonstrate your proficiency in computer vision and deep learning.
7. Automation Scripts
Write scripts to automate repetitive tasks, such as file organization, data cleaning, or downloading files from the internet. Showcase your ability to improve efficiency through automation.
8. Web Scraping
Create a web scraper to extract data from websites. This project highlights your skills in data extraction and manipulation.
9. Pygame-based Game
Develop a simple game using Pygame or any other Python game library. Showcase your creativity and game development skills.
10. Text-based Adventure Game
Build a text-based adventure game or a quiz application. This project demonstrates your ability to create engaging user experiences.
11. RESTful API
Create a RESTful API for a service or application using Flask or Django. Highlight your skills in API development and integration.
12. Integration with External APIs
Develop a project that interacts with external APIs, such as social media platforms or weather services. Showcase your ability to integrate diverse systems.
13. Home Automation System
Build a home automation system using IoT concepts. Demonstrate your understanding of connecting devices and creating smart environments.
14. Weather Station
Create a weather station that collects and displays data from various sensors. Showcase your skills in data acquisition and analysis.
15. Distributed Chat Application
Build a distributed chat application using a messaging protocol like MQTT. Highlight your skills in distributed systems.
16. Blockchain or Cryptocurrency Tracker
Develop a simple blockchain or a cryptocurrency tracker. Showcase your understanding of blockchain technology.
17. Open Source Contributions
Contribute to open source projects on platforms like GitHub. Demonstrate your collaboration and teamwork skills.
18. Network or Vulnerability Scanner
Build a network or vulnerability scanner to showcase your skills in cybersecurity.
19. Decentralized Application (DApp)
Create a decentralized application using a blockchain platform like Ethereum. Showcase your skills in developing applications on decentralized networks.
20. Machine Learning Model Deployment
Deploy a machine learning model as a web service using frameworks like Flask or FastAPI. Demonstrate your skills in model deployment and integration.
21. Financial Calculator
Build a financial calculator that incorporates relevant mathematical and financial concepts. Showcase your ability to create practical tools.
22. Command-Line Tools
Develop command-line tools for tasks like file manipulation, data processing, or system monitoring. Highlight your skills in creating efficient and user-friendly command-line applications.
23. IoT-Based Health Monitoring System
Create an IoT-based health monitoring system that collects and analyzes health-related data. Showcase your ability to work on projects with social impact.
24. Facial Recognition System
Build a facial recognition system using Python and computer vision libraries. Showcase your skills in biometric technology.
25. Social Media Dashboard
Develop a social media dashboard that aggregates and displays data from various platforms. Highlight your skills in data visualization and integration.
Conclusion: As you embark on your job search in 2024, remember that a well-rounded portfolio is key to showcasing your skills and standing out from the crowd. These 25 Python projects cover a diverse range of domains, allowing you to tailor your portfolio to match your interests and the specific requirements of your dream job.
If you want to know more, Click here:https://analyticsjobs.in/question/what-are-the-best-python-projects-to-land-a-great-job-in-2024/
#python projects#top python projects#best python projects#analytics jobs#python#coding#programming#machine learning
2 notes
·
View notes
Text
If the chronological dash gets axed and algorithmic suggestions become a bigger part of this site, I'm jumping ship.
If I have a "bad content experience"—whatever the fuck that means—then it was a slow day on the website—that's a feature, not a bug. What I like about tumblr is that I don't have to spend time curating the algorithm by hunting down The Right Things to click on—I get to see stuff that people did by following them, or seeing what's reblogged by accounts I follow.
If you fuckers send me emails when my notifications turn off, I will get the hell off this website. I use tumblr for fun, not my job.
Moreover, don't fuck with SEO, and don't make logged out users sign in to see posts. You know what that does? It annoys people and makes them ignore your website every time they see it.
I get it, staff. Now that other social media sites are becoming bloated, sinking ships, floating on nothing but VC money, you want to go for the kill and expand more. No one wants that. No one wants this website to be like other social media sites. You want to flex that API to get more bots and scrapers onto the site, because that's profitable.
Fix the website, sure—and make the apps half decent while you're at it—but don't change what actually makes people use tumblr. You nerds only just recently managed to get the porn bots off your site—I can't trust you people to do anything decent with the frontend when the backend is complete shit.
Moreover, there's that line in there, "being successful on tumblr shouldn't be a punishing experience," and all the stuff preceding it. It's clear that you all want people to post at maximum capacity all the time, which is just impossible. You lot want "content," not people posting on this site. There are enough shitty content farms on here as it is, but a push for constant content—showing people everything 24/7 algorithmically—opens up a horrible chain of incentives that will inevitably lead to constant streams of clickbait and AI generated slop, something that, from some of the advertisements I've seen on here, you all love.
@staff, literally everything relating to content, reblogs, and all that in your post is a step in the wrong direction. If this plan goes through, tumblr won't be a hellsite anymore, it will be nothing—there will be a smooth, grey, default cube, an ulcer and memorial to place that used to be fun. The reason people stay is because the site isn't like other social media—there's no awful, algorithmic chain of incentives to keep people posting—and the site, as it stands, doesn't expect you to meticulously curate everything.
I'm going to say that again:
The reason people stay is because the site isn't like other social media—there's no awful, algorithmic chain of incentives to keep people posting—and the site, as it stands, doesn't expect you to meticulously curate everything.
In summary:
If this plan goes through, I'm leaving tumblr. Fix your website instead of making it worse.
Tumblr’s Core Product Strategy
Here at Tumblr, we’ve been working hard on reorganizing how we work in a bid to gain more users. A larger user base means a more sustainable company, and means we get to stick around and do this thing with you all a bit longer. What follows is the strategy we're using to accomplish the goal of user growth. The @labs group has published a bit already, but this is bigger. We’re publishing it publicly for the first time, in an effort to work more transparently with all of you in the Tumblr community. This strategy provides guidance amid limited resources, allowing our teams to focus on specific key areas to ensure Tumblr’s future.
The Diagnosis
In order for Tumblr to grow, we need to fix the core experience that makes Tumblr a useful place for users. The underlying problem is that Tumblr is not easy to use. Historically, we have expected users to curate their feeds and lean into curating their experience. But this expectation introduces friction to the user experience and only serves a small portion of our audience.
Tumblr’s competitive advantage lies in its unique content and vibrant communities. As the forerunner of internet culture, Tumblr encompasses a wide range of interests, such as entertainment, art, gaming, fandom, fashion, and music. People come to Tumblr to immerse themselves in this culture, making it essential for us to ensure a seamless connection between people and content.
To guarantee Tumblr’s continued success, we’ve got to prioritize fostering that seamless connection between people and content. This involves attracting and retaining new users and creators, nurturing their growth, and encouraging frequent engagement with the platform.
Our Guiding Principles
To enhance Tumblr’s usability, we must address these core guiding principles.
Expand the ways new users can discover and sign up for Tumblr.
Provide high-quality content with every app launch.
Facilitate easier user participation in conversations.
Retain and grow our creator base.
Create patterns that encourage users to keep returning to Tumblr.
Improve the platform’s performance, stability, and quality.
Below is a deep dive into each of these principles.
Principle 1: Expand the ways new users can discover and sign up for Tumblr.
Tumblr has a “top of the funnel” issue in converting non-users into engaged logged-in users. We also have not invested in industry standard SEO practices to ensure a robust top of the funnel. The referral traffic that we do get from external sources is dispersed across different pages with inconsistent user experiences, which results in a missed opportunity to convert these users into regular Tumblr users. For example, users from search engines often land on pages within the blog network and blog view—where there isn’t much of a reason to sign up.
We need to experiment with logged-out tumblr.com to ensure we are capturing the highest potential conversion rate for visitors into sign-ups and log-ins. We might want to explore showing the potential future user the full breadth of content that Tumblr has to offer on our logged-out pages. We want people to be able to easily understand the potential behind Tumblr without having to navigate multiple tabs and pages to figure it out. Our current logged-out explore page does very little to help users understand “what is Tumblr.” which is a missed opportunity to get people excited about joining the site.
Actions & Next Steps
Improving Tumblr’s search engine optimization (SEO) practices to be in line with industry standards.
Experiment with logged out tumblr.com to achieve the highest conversion rate for sign-ups and log-ins, explore ways for visitors to “get” Tumblr and entice them to sign up.
Principle 2: Provide high-quality content with every app launch.
We need to ensure the highest quality user experience by presenting fresh and relevant content tailored to the user’s diverse interests during each session. If the user has a bad content experience, the fault lies with the product.
The default position should always be that the user does not know how to navigate the application. Additionally, we need to ensure that when people search for content related to their interests, it is easily accessible without any confusing limitations or unexpected roadblocks in their journey.
Being a 15-year-old brand is tough because the brand carries the baggage of a person’s preconceived impressions of Tumblr. On average, a user only sees 25 posts per session, so the first 25 posts have to convey the value of Tumblr: it is a vibrant community with lots of untapped potential. We never want to leave the user believing that Tumblr is a place that is stale and not relevant.
Actions & Next Steps
Deliver great content each time the app is opened.
Make it easier for users to understand where the vibrant communities on Tumblr are.
Improve our algorithmic ranking capabilities across all feeds.
Principle 3: Facilitate easier user participation in conversations.
Part of Tumblr’s charm lies in its capacity to showcase the evolution of conversations and the clever remarks found within reblog chains and replies. Engaging in these discussions should be enjoyable and effortless.
Unfortunately, the current way that conversations work on Tumblr across replies and reblogs is confusing for new users. The limitations around engaging with individual reblogs, replies only applying to the original post, and the inability to easily follow threaded conversations make it difficult for users to join the conversation.
Actions & Next Steps
Address the confusion within replies and reblogs.
Improve the conversational posting features around replies and reblogs.
Allow engagements on individual replies and reblogs.
Make it easier for users to follow the various conversation paths within a reblog thread.
Remove clutter in the conversation by collapsing reblog threads.
Explore the feasibility of removing duplicate reblogs within a user’s Following feed.
Principle 4: Retain and grow our creator base.
Creators are essential to the Tumblr community. However, we haven’t always had a consistent and coordinated effort around retaining, nurturing, and growing our creator base.
Being a new creator on Tumblr can be intimidating, with a high likelihood of leaving or disappointment upon sharing creations without receiving engagement or feedback. We need to ensure that we have the expected creator tools and foster the rewarding feedback loops that keep creators around and enable them to thrive.
The lack of feedback stems from the outdated decision to only show content from followed blogs on the main dashboard feed (“Following”), perpetuating a cycle where popular blogs continue to gain more visibility at the expense of helping new creators. To address this, we need to prioritize supporting and nurturing the growth of new creators on the platform.
It is also imperative that creators, like everyone on Tumblr, feel safe and in control of their experience. Whether it be an ask from the community or engagement on a post, being successful on Tumblr should never feel like a punishing experience.
Actions & Next Steps
Get creators’ new content in front of people who are interested in it.
Improve the feedback loop for creators, incentivizing them to continue posting.
Build mechanisms to protect creators from being spammed by notifications when they go viral.
Expand ways to co-create content, such as by adding the capability to embed Tumblr links in posts.
Principle 5: Create patterns that encourage users to keep returning to Tumblr.
Push notifications and emails are essential tools to increase user engagement, improve user retention, and facilitate content discovery. Our strategy of reaching out to you, the user, should be well-coordinated across product, commercial, and marketing teams.
Our messaging strategy needs to be personalized and adapt to a user’s shifting interests. Our messages should keep users in the know on the latest activity in their community, as well as keeping Tumblr top of mind as the place to go for witty takes and remixes of the latest shows and real-life events.
Most importantly, our messages should be thoughtful and should never come across as spammy.
Actions & Next Steps
Conduct an audit of our messaging strategy.
Address the issue of notifications getting too noisy; throttle, collapse or mute notifications where necessary.
Identify opportunities for personalization within our email messages.
Test what the right daily push notification limit is.
Send emails when a user has push notifications switched off.
Principle 6: Performance, stability and quality.
The stability and performance of our mobile apps have declined. There is a large backlog of production issues, with more bugs created than resolved over the last 300 days. If this continues, roughly one new unresolved production issue will be created every two days. Apps and backend systems that work well and don't crash are the foundation of a great Tumblr experience. Improving performance, stability, and quality will help us achieve sustainable operations for Tumblr.
Improve performance and stability: deliver crash-free, responsive, and fast-loading apps on Android, iOS, and web.
Improve quality: deliver the highest quality Tumblr experience to our users.
Move faster: provide APIs and services to unblock core product initiatives and launch new features coming out of Labs.
Conclusion
Our mission has always been to empower the world’s creators. We are wholly committed to ensuring Tumblr evolves in a way that supports our current users while improving areas that attract new creators, artists, and users. You deserve a digital home that works for you. You deserve the best tools and features to connect with your communities on a platform that prioritizes the easy discoverability of high-quality content. This is an invigorating time for Tumblr, and we couldn’t be more excited about our current strategy.
65K notes
·
View notes
Text
Extract Amazon Product Prices with Web Scraping | Actowiz Solutions
Introduction
In the ever-evolving world of e-commerce, pricing strategy can make or break a brand. Amazon, being the global e-commerce behemoth, is a key platform where pricing intelligence offers an unmatched advantage. To stay ahead in such a competitive environment, businesses need real-time insights into product prices, trends, and fluctuations. This is where Actowiz Solutions comes into play. Through advanced Amazon price scraping solutions, Actowiz empowers businesses with accurate, structured, and actionable data.
Why extract Amazon Product Prices?

Price is one of the most influential factors affecting a customer’s purchasing decision. Here are several reasons why extracting Amazon product prices is crucial:
Competitor Analysis: Stay informed about competitors’ pricing.
Dynamic Pricing: Adjust your prices in real time based on market trends.
Market Research: Understand consumer behavior through price trends.
Inventory & Repricing Strategy: Align stock and pricing decisions with demand.
With Actowiz Solutions’ Amazon scraping services, you get access to clean, structured, and timely data without violating Amazon’s terms.
How Actowiz Solutions Extracts Amazon Price Data

Actowiz Solutions uses advanced scraping technologies tailored for Amazon’s complex site structure. Here’s a breakdown:
1. Custom Scraping Infrastructure
Actowiz Solutions builds custom scrapers that can navigate Amazon’s dynamic content, pagination, and bot protection layers like CAPTCHA, IP throttling, and JavaScript rendering.
2. Proxy Rotation & User-Agent Spoofing
To avoid detection and bans, Actowiz employs rotating proxies and multiple user-agent headers that simulate real user behavior.
3. Scheduled Data Extraction
Actowiz enables regular scheduling of price scraping jobs — be it hourly, daily, or weekly — for ongoing price intelligence.
4. Data Points Captured
The scraping service extracts:
Product name & ASIN
Price (MRP, discounted, deal price)
Availability
Ratings & Reviews
Seller information
Real-World Use Cases for Amazon Price Scraping

A. Retailers & Brands
Monitor price changes for own products or competitors to adjust pricing in real-time.
B. Marketplaces
Aggregate seller data to ensure competitive offerings and improve platform relevance.
C. Price Comparison Sites
Fuel your platform with fresh, real-time Amazon price data.
D. E-commerce Analytics Firms
Get historical and real-time pricing trends to generate valuable reports for clients.
Dataset Snapshot: Amazon Product Prices

Below is a snapshot of average product prices on Amazon across popular categories:
Product CategoryAverage Price (USD)Electronics120.50Books15.75Home & Kitchen45.30Fashion35.90Toys & Games25.40Beauty20.60Sports50.10Automotive75.80
Benefits of Choosing Actowiz Solutions

1. Scalability: From thousands to millions of records.
2. Accuracy: Real-time validation and monitoring ensure data reliability.
3. Customization: Solutions are tailored to each business use case.
4. Compliance: Ethical scraping methods that respect platform policies.
5. Support: Dedicated support and data quality teams
Legal & Ethical Considerations

Amazon has strict policies regarding automated data collection. Actowiz Solutions follows legal frameworks and deploys ethical scraping practices including:
Scraping only public data
Abiding by robots.txt guidelines
Avoiding high-frequency access that may affect site performance
Integration Options for Amazon Price Data

Actowiz Solutions offers flexible delivery and integration methods:
APIs: RESTful APIs for on-demand price fetching.
CSV/JSON Feeds: Periodic data dumps in industry-standard formats.
Dashboard Integration: Plug data directly into internal BI tools like Tableau or Power BI.
Contact Actowiz Solutions today to learn how our Amazon scraping solutions can supercharge your e-commerce strategy.Contact Us Today!
Conclusion: Future-Proof Your Pricing Strategy
The world of online retail is fast-moving and highly competitive. With Amazon as a major marketplace, getting a pulse on product prices is vital. Actowiz Solutions provides a robust, scalable, and ethical way to extract product prices from Amazon.
Whether you’re a startup or a Fortune 500 company, pricing intelligence can be your competitive edge. Learn More
#ExtractProductPrices#PriceIntelligence#AmazonScrapingServices#AmazonPriceScrapingSolutions#RealTimeInsights
0 notes
Text
How to Integrate WooCommerce Scraper into Your Business Workflow
In today’s fast-paced eCommerce environment, staying ahead means automating repetitive tasks and making data-driven decisions. If you manage a WooCommerce store, you’ve likely spent hours handling product data, competitor pricing, and inventory updates. That’s where a WooCommerce Scraper becomes a game-changer. Integrated seamlessly into your workflow, it can help you collect, update, and analyze data more efficiently, freeing up your time and boosting operational productivity.

In this blog, we’ll break down what a WooCommerce scraper is, its benefits, and how to effectively integrate it into your business operations.
What is a WooCommerce Scraper?
A WooCommerce scraper is a tool designed to extract data from WooCommerce-powered websites. This data could include:
Product titles, images, descriptions
Prices and discounts
Reviews and ratings
Stock status and availability
Such a tool automates the collection of this information, which is useful for e-commerce entrepreneurs, data analysts, and digital marketers. Whether you're monitoring competitors or syncing product listings across multiple platforms, a WooCommerce scraper can save hours of manual work.
Why Businesses Use WooCommerce Scrapers
Before diving into the integration process, let’s look at the key reasons businesses rely on scraping tools:
Competitor Price Monitoring
Stay competitive by tracking pricing trends across similar WooCommerce stores. Automated scrapers can pull this data daily, helping you optimize your pricing strategy in real time.
Bulk Product Management
Import product data at scale from suppliers or marketplaces. Instead of manually updating hundreds of SKUs, use a scraper to auto-populate your database with relevant information.
Enhanced Market Research
Get a snapshot of what’s trending in your niche. Use scrapers to gather data about top-selling products, customer reviews, and seasonal demand.
Inventory Tracking
Avoid stockouts or overstocking by monitoring inventory availability from your suppliers or competitors.
How to Integrate a WooCommerce Scraper Into Your Workflow
Integrating a WooCommerce scraper into your business processes might sound technical, but with the right approach, it can be seamless and highly beneficial. Whether you're aiming to automate competitor tracking, streamline product imports, or maintain inventory accuracy, aligning your scraper with your existing workflow ensures efficiency and scalability. Below is a step-by-step guide to help you get started.
Step 1: Define Your Use Case
Start by identifying what you want to achieve. Is it competitive analysis? Supplier data syncing? Or updating internal catalogs? Clarifying this helps you choose the right scraping strategy.
Step 2: Choose the Right Scraper Tool
There are multiple tools available, ranging from browser-based scrapers to custom-built Python scripts. Some popular options include:
Octoparse
ParseHub
Python-based scrapers using BeautifulSoup or Scrapy
API integrations for WooCommerce
For enterprise-level needs, consider working with a provider like TagX, which offers custom scraping solutions with scalability and accuracy in mind.
Step 3: Automate with Cron Jobs or APIs
For recurring tasks, automation is key. Set up cron jobs or use APIs to run scrapers at scheduled intervals. This ensures that your database stays up-to-date without manual intervention.
Step 4: Parse and Clean Your Data
Raw scraped data often contains HTML tags, formatting issues, or duplicates. Use tools or scripts to clean and structure the data before importing it into your systems.
Step 5: Integrate with Your CMS or ERP
Once cleaned, import the data into your WooCommerce backend or link it with your ERP or PIM (Product Information Management) system. Many scraping tools offer CSV or JSON outputs that are easy to integrate.
Common Challenges in WooCommerce Scraping (And Solutions)
Changing Site Structures
WooCommerce themes can differ, and any update might break your script. Solution: Use dynamic selectors or AI-powered tools that adapt automatically.
Rate Limiting and Captchas
Some sites use rate limiting or CAPTCHAs to block bots. Solution: Use rotating proxies, headless browsers like Puppeteer, or work with scraping service providers.
Data Duplication or Inaccuracy
Messy data can lead to poor business decisions. Solution: Implement deduplication logic and validation rules before importing data.
Tips for Maintaining an Ethical Scraping Strategy
Respect Robots.txt Files: Always check the site’s scraping policy.
Avoid Overloading Servers: Schedule scrapers during low-traffic hours.
Use the Data Responsibly: Don’t scrape copyrighted or sensitive data.
Why Choose TagX for WooCommerce Scraping?
While it's possible to set up a basic WooCommerce scraper on your own, scaling it, maintaining data accuracy, and handling complex scraping tasks require deep technical expertise. TagX’s professionals offer end-to-end scraping solutions tailored specifically for e-commerce businesses. Whether you're looking to automate product data extraction, monitor competitor pricing, or implement web scraping using AI at scale. Key Reasons to Choose TagX:
AI-Powered Scraping: Go beyond basic extraction with intelligent scraping powered by machine learning and natural language processing.
Scalable Infrastructure: Whether you're scraping hundreds or millions of pages, TagX ensures high performance and minimal downtime.
Custom Integration: TagX enables seamless integration of scrapers directly into your CMS, ERP, or PIM systems, ensuring a streamlined workflow.
Ethical and Compliant Practices: All scraping is conducted responsibly, adhering to industry best practices and compliance standards.
With us, you’re not just adopting a tool—you’re gaining a strategic partner that understands the nuances of modern eCommerce data operations.
Final Thoughts
Integrating a WooCommerce scraper into your business workflow is no longer just a technical choice—it’s a strategic advantage. From automating tedious tasks to extracting market intelligence, scraping tools empower businesses to operate faster and smarter.
As your data requirements evolve, consider exploring web scraping using AI to future-proof your automation strategy. And for seamless implementation, TagX offers the technology and expertise to help you unlock the full value of your data.
0 notes
Text
Smart Retail Decisions Start with AI-Powered Data Scraping

In a world where consumer preferences change overnight and pricing wars escalate in real time, making smart retail decisions is no longer about instincts—it's about data. And not just any data. Retailers need fresh, accurate, and actionable insights drawn from a vast and competitive digital landscape.
That’s where AI-powered data scraping steps in.
Historically, traditional data scraping has been used to gather ecommerce data. But by leveraging artificial intelligence (AI) in scraping processes, companies can gain real-time, scalable, and predictive intelligence to make informed decisions in retailing.
Here, we detail how data scraping using AI is revolutionizing retailing, its advantages, what kind of data you can scrape, and why it enables high-impact decisions in terms of pricing, inventory, customer behavior, and market trends.
What Is AI-Powered Data Scraping?
Data scraping is an operation of pulling structured data from online and digital channels, particularly websites that do not support public APIs. In retail, these can range from product offerings and price data to customer reviews and availability of items in stock.
AI-driven data scraping goes one step further by employing artificial intelligence such as machine learning, natural language processing (NLP), and predictive algorithms to:
Clean and structure unstructured data
Interpret customer sentiment from reviews
Detect anomalies in prices
Predict market trends
Based on data collected, provide strategic proposals
It's not just about data-gathering—it’s about knowing and taking wise action based on it.
Why Retail Requires Smarter Data Solutions
The contemporary retail sector is sophisticated and dynamic. This is why AI-powered scraping is more important than ever:
Market Changes Never Cease to Occur Prices, demand, and product availability can alter multiple times each day—particularly on marketplaces such as Amazon or Walmart. AI scrapers can monitor and study these changes round-the-clock.
Manual Decision-Making is Too Slow Human analysts can process only so much data. AI accelerates decision-making by processing millions of pieces of data within seconds and highlighting what's significant.
The Competition is Tough Retailers are in a race to offer the best prices, maintain optimal inventory, and deliver exceptional customer experiences. Data scraping allows companies to monitor competitors in real time.
Types of Retail Data You Can Scrape with AI
AI-powered scraping tools can extract and analyze the following retail data from ecommerce sites, review platforms, competitor websites, and search engines:
Product Information
Titles, descriptions, images
Product variants (size, color, model)
Brand and manufacturer details
Availability (in stock/out of stock)
Pricing & Promotions
Real-time price tracking
Historical pricing trends
Discount and offer patterns
Dynamic pricing triggers
Inventory & Supply
Stock levels
Delivery timelines
Warehouse locations
SKU movement tracking
Reviews & Ratings
NLP-based sentiment analysis
Star ratings and text content
Trending complaints or praise
Verified purchase filtering
Market Demand & Sales Rank
Bestsellers by category
Category saturation metrics
Sales velocity signals
New or emerging product trends
Logistics & Shipping
Delivery options and timeframes
Free shipping thresholds
Return policies and costs
Benefits of AI-Powered Data Scraping in Retail
So what happens when you combine powerful scraping capabilities with AI intelligence? Retailers unlock a new dimension of performance and strategy.
1. Real-Time Competitive Intelligence
With AI-enhanced scraping, retailers can monitor:
Price changes across hundreds of competitor SKUs
Promotional campaigns
Inventory status of competitor bestsellers
AI models can predict when a competitor may launch a flash sale or run low on inventory—giving you an opportunity to win customers.
2. Smarter Dynamic Pricing
Machine learning algorithms can:
Analyze competitor pricing history
Forecast demand elasticity
Recommend optimal pricing
Retailers can automatically adjust prices to stay competitive while maximizing margins.
3. Enhanced Product Positioning
By analyzing product reviews and ratings using NLP, you can:
Identify common customer concerns
Improve product descriptions
Make data-driven merchandising decisions
For example, if customers frequently mention packaging issues, that feedback can be looped directly to product development.
4. Improved Inventory Planning
AI-scraped data helps detect:
Which items are trending up or down
Seasonality patterns
Regional demand variations
This enables smarter stocking, reduced overstock, and faster response to emerging trends.
5. Superior Customer Experience
Insights from reviews and competitor platforms help you:
Optimize support responses
Highlight popular product features
Personalize marketing campaigns
Use Cases: How Retailers Are Winning with AI Scraping
DTC Ecommerce Brands
Use AI to monitor pricing and product availability across marketplaces. React to changes in real time and adjust pricing or run campaigns accordingly.
Multichannel Retailers
Track performance and pricing across online and offline channels to maintain brand consistency and pricing competitiveness.
Consumer Insights Teams
Analyze thousands of reviews to spot unmet needs or new use cases—fueling product innovation and positioning.
Marketing and SEO Analysts
Scrape metadata, titles, and keyword rankings to optimize product listings and outperform competitors in search results.
Choosing the Right AI-Powered Scraping Partner
Whether building your own tool or hiring a scraping agency, here’s what to look for:
Scalable Infrastructure
The tool should handle scraping thousands of pages per hour, with robust error handling and proxy support.
Intelligent Data Processing
Look for integrated machine learning and NLP models that analyze and enrich the data in real time.
Customization and Flexibility
Ensure the solution can adapt to your specific data fields, scheduling, and delivery format (JSON, CSV, API).
Legal and Ethical Compliance
A reliable partner will adhere to anti-bot regulations, avoid scraping personal data, and respect site terms of service.
Challenges and How to Overcome Them
While AI-powered scraping is powerful, it’s not without hurdles:
Website Structure Changes
Ecommerce platforms often update their layouts. This can break traditional scraping scripts.
Solution: AI-based scrapers with adaptive learning can adjust without manual reprogramming.
Anti-Bot Measures
Websites deploy CAPTCHAs, IP blocks, and rate limiters.
Solution: Use rotating proxies, headless browsers, and CAPTCHA solvers.
Data Noise
Unclean or irrelevant data can lead to false conclusions.
Solution: Leverage AI for data cleaning, anomaly detection, and duplicate removal.
Final Thoughts
In today's ecommerce disruption, retailers that utilize real-time, smart data will be victorious. AI-driven data scraping solutions no longer represent an indulgence but rather an imperative to remain competitive.
By facilitating data capture and smarter insights, these services support improved customer experience, pricing, marketing, and inventory decisions.
No matter whether you’re introducing a new product, measuring your market, or streamlining your supply chain—smart retailing begins with smart data.
0 notes
Text
Unlock the Full Potential of Web Data with ProxyVault’s Datacenter Proxy API
In the age of data-driven decision-making, having reliable, fast, and anonymous access to web resources is no longer optional—it's essential. ProxyVault delivers a cutting-edge solution through its premium residential, datacenter, and rotating proxies, equipped with full HTTP and SOCKS5 support. Whether you're a data scientist, SEO strategist, or enterprise-scale scraper, our platform empowers your projects with a secure and unlimited Proxy API designed for scalability, speed, and anonymity. In this article, we focus on one of the most critical assets in our suite: the datacenter proxy API.
What Is a Datacenter Proxy API and Why It Matters
A datacenter proxy API provides programmatic access to a vast pool of high-speed IP addresses hosted in data centers. Unlike residential proxies that rely on real-user IPs, datacenter proxies are not affiliated with Internet Service Providers (ISPs). This distinction makes them ideal for large-scale operations such as:
Web scraping at volume
Competitive pricing analysis
SEO keyword rank tracking
Traffic simulation and testing
Market intelligence gathering
With ProxyVault’s datacenter proxy API, you get lightning-fast response times, bulk IP rotation, and zero usage restrictions, enabling seamless automation and data extraction at any scale.
Ultra-Fast and Scalable Infrastructure
One of the hallmarks of ProxyVault’s platform is speed. Our datacenter proxy API leverages ultra-reliable servers hosted in high-bandwidth facilities worldwide. This ensures your requests experience minimal latency, even during high-volume data retrieval.
Dedicated infrastructure guarantees consistent uptime
Optimized routing minimizes request delays
Low ping times make real-time scraping and crawling more efficient
Whether you're pulling hundreds or millions of records, our system handles the load without breaking a sweat.
Unlimited Access with Full HTTP and SOCKS5 Support
Our proxy API supports both HTTP and SOCKS5 protocols, offering flexibility for various application environments. Whether you're managing browser-based scraping tools, automated crawlers, or internal dashboards, ProxyVault’s datacenter proxy API integrates seamlessly.
HTTP support is ideal for most standard scraping tools and analytics platforms
SOCKS5 enables deep integration for software requiring full network access, including P2P and FTP operations
This dual-protocol compatibility ensures that no matter your toolset or tech stack, ProxyVault works right out of the box.
Built for SEO, Web Scraping, and Data Mining
Modern businesses rely heavily on data for strategy and operations. ProxyVault’s datacenter proxy API is custom-built for the most demanding use cases:
SEO Ranking and SERP Monitoring
For marketers and SEO professionals, tracking keyword rankings across different locations is critical. Our proxies support geo-targeting, allowing you to simulate searches from specific countries or cities.
Track competitor rankings
Monitor ad placements
Analyze local search visibility
The proxy API ensures automated scripts can run 24/7 without IP bans or CAPTCHAs interfering.
Web Scraping at Scale
From eCommerce sites to travel platforms, web scraping provides invaluable insights. Our rotating datacenter proxies change IPs dynamically, reducing the risk of detection.
Scrape millions of pages without throttling
Bypass rate limits with intelligent IP rotation
Automate large-scale data pulls securely
Data Mining for Enterprise Intelligence
Enterprises use data mining for trend analysis, market research, and customer insights. Our infrastructure supports long sessions, persistent connections, and high concurrency, making ProxyVault a preferred choice for advanced data extraction pipelines.
Advanced Features with Complete Control
ProxyVault offers a powerful suite of controls through its datacenter proxy API, putting you in command of your operations:
Unlimited bandwidth and no request limits
Country and city-level filtering
Sticky sessions for consistent identity
Real-time usage statistics and monitoring
Secure authentication using API tokens or IP whitelisting
These features ensure that your scraping or data-gathering processes are as precise as they are powerful.
Privacy-First, Log-Free Architecture
We take user privacy seriously. ProxyVault operates on a strict no-logs policy, ensuring that your requests are never stored or monitored. All communications are encrypted, and our servers are secured using industry best practices.
Zero tracking of API requests
Anonymity by design
GDPR and CCPA-compliant
This gives you the confidence to deploy large-scale operations without compromising your company’s or clients' data.
Enterprise-Level Support and Reliability
We understand that mission-critical projects demand not just great tools but also reliable support. ProxyVault offers:
24/7 technical support
Dedicated account managers for enterprise clients
Custom SLAs and deployment options
Whether you need integration help or technical advice, our experts are always on hand to assist.
Why Choose ProxyVault for Your Datacenter Proxy API Needs
Choosing the right proxy provider can be the difference between success and failure in data operations. ProxyVault delivers:
High-speed datacenter IPs optimized for web scraping and automation
Fully customizable proxy API with extensive documentation
No limitations on bandwidth, concurrent threads, or request volume
Granular location targeting for more accurate insights
Proactive support and security-first infrastructure
We’ve designed our datacenter proxy API to be robust, reliable, and scalable—ready to meet the needs of modern businesses across all industries.
Get Started with ProxyVault Today
If you’re ready to take your data operations to the next level, ProxyVault offers the most reliable and scalable datacenter proxy API on the market. Whether you're scraping, monitoring, mining, or optimizing, our solution ensures your work is fast, anonymous, and unrestricted.
Start your free trial today and experience the performance that ProxyVault delivers to thousands of users around the globe.
1 note
·
View note
Text
Unlocking the Web: How to Use an AI Agent for Web Scraping Effectively

In this age of big data, information has become the most powerful thing. However, accessing and organizing this data, particularly from the web, is not an easy feat. This is the point where AI agents step in. Automating the process of extracting valuable data from web pages, AI agents are changing the way businesses operate and developers, researchers as well as marketers.
In this blog, we’ll explore how you can use an AI agent for web scraping, what benefits it brings, the technologies behind it, and how you can build or invest in the best AI agent for web scraping for your unique needs. We’ll also look at how Custom AI Agent Development is reshaping how companies access data at scale.
What is Web Scraping?
Web scraping is a method of obtaining details from sites. It is used in a range of purposes, including price monitoring and lead generation market research, sentiment analysis and academic research. In the past web scraping was performed with scripting languages such as Python (with libraries like BeautifulSoup or Selenium) however, they require constant maintenance and are often limited in terms of scale and ability to adapt.
What is an AI Agent?
AI agents are intelligent software system that can be capable of making decisions and executing jobs on behalf of you. In the case of scraping websites, AI agents use machine learning, NLP (Natural Language Processing) and automated methods to navigate websites in a way that is intelligent and extract structured data and adjust to changes in the layout of websites and algorithms.
In contrast to crawlers or basic bots however, an AI agent doesn’t simply scrape in a blind manner; it comprehends the context of its actions, changes its behavior and grows with time.
Why Use an AI Agent for Web Scraping?
1. Adaptability
Websites can change regularly. Scrapers that are traditional break when the structure is changed. AI agents utilize pattern recognition and contextual awareness to adjust as they go along.
2. Scalability
AI agents are able to manage thousands or even hundreds of pages simultaneously due to their ability to make decisions automatically as well as cloud-based implementation.
3. Data Accuracy
AI improves the accuracy of data scraped in the process of filtering noise recognizing human language and confirming the results.
4. Reduced Maintenance
Because AI agents are able to learn and change and adapt, they eliminate the need for continuous manual updates to scrape scripts.
Best AI Agent for Web Scraping: What to Look For
If you’re searching for the best AI agent for web scraping. Here are the most important aspects to look out for:
NLP Capabilities for reading and interpreting text that is not structured.
Visual Recognition to interpret layouts of web pages or dynamic material.
Automation Tools: To simulate user interactions (clicks, scrolls, etc.)
Scheduling and Monitoring built-in tools that manage and automate scraping processes.
API integration You can directly send scraped data to your database or application.
Error Handling and Retries Intelligent fallback mechanisms that can help recover from sessions that are broken or access denied.
Custom AI Agent Development: Tailored to Your Needs
Though off-the-shelf AI agents can meet essential needs, Custom AI Agent Development is vital for businesses which require:
Custom-designed logic or workflows for data collection
Conformity with specific data policies or the lawful requirements
Integration with dashboards or internal tools
Competitive advantage via more efficient data gathering
At Xcelore, we specialize in AI Agent Development tailored for web scraping. Whether you’re monitoring market trends, aggregating news, or extracting leads, we build solutions that scale with your business needs.
How to Build Your Own AI Agent for Web Scraping
If you’re a tech-savvy person and want to create the AI you want to use Here’s a basic outline of the process:
Step 1: Define Your Objective
Be aware of the exact information you need, and the which sites. This is the basis for your design and toolset.
Step 2: Select Your Tools
Frameworks and tools that are popular include:
Python using libraries such as Scrapy, BeautifulSoup, and Selenium
Playwright or Puppeteer to automatize the browser
OpenAI and HuggingFace APIs for NLP and decision-making
Cloud Platforms such as AWS, Azure, or Google Cloud to increase their capacity
Step 3: Train Your Agent
Provide your agent with examples of structured as compared to. non-structured information. Machine learning can help it identify patterns and to extract pertinent information.
Step 4: Deploy and Monitor
You can run your AI agent according to a set schedule. Use alerting, logging, and dashboards to check the agent’s performance and guarantee accuracy of data.
Step 5: Optimize and Iterate
The AI agent you use should change. Make use of feedback loops as well as machine learning retraining in order to improve its reliability and accuracy as time passes.
Compliance and Ethics
Web scraping has ethical and legal issues. Be sure that your AI agent
Respects robots.txt rules
Avoid scraping copyrighted or personal content. Avoid scraping copyrighted or personal
Meets international and local regulations on data privacy
At Xcelore We integrate compliance into each AI Agent development project we manage.
Real-World Use Cases
E-commerce Price tracking across competitors’ websites
Finance Collecting news about stocks and financial statements
Recruitment extracting job postings and resumes
Travel Monitor hotel and flight prices
Academic Research: Data collection at a large scale to analyze
In all of these situations an intelligent and robust AI agent could turn the hours of manual data collection into a more efficient and scalable process.
Why Choose Xcelore for AI Agent Development?
At Xcelore, we bring together deep expertise in automation, data science, and software engineering to deliver powerful, scalable AI Agent Development Services. Whether you need a quick deployment or a fully custom AI agent development project tailored to your business goals, we’ve got you covered.
We can help:
Find scraping opportunities and devise strategies
Create and design AI agents that adapt to your demands
Maintain compliance and ensure data integrity
Transform unstructured web data into valuable insights
Final Thoughts
Making use of an AI agent for web scraping isn’t just an option for technical reasons, it’s now an advantage strategic. From better insights to more efficient automation, the advantages are immense. If you’re looking to build your own AI agent or or invest in the best AI agent for web scraping.The key is in a well-planned strategy and skilled execution.
Are you ready to unlock the internet by leveraging intelligent automation?
Contact Xcelore today to get started with your custom AI agent development journey.
#ai agent development services#AI Agent Development#AI agent for web scraping#build your own AI agent
0 notes
Text
Understanding Web Scraping: Techniques, Ethics & Professional Guidance

Web scraping is a widely-used method for automatically extracting information from websites. It allows users to programmatically gather large volumes of data without manual copying and pasting. This technology has become essential for professionals in fields like market research, journalism, and e-commerce. In this blog, we’ll explore what web scraping is, how it works, and why practicing it ethically matters—along with how partnering with experts in web development can enhance your data strategy.
What Is Web Scraping?
At its core, web scraping is a digital technique that simulates human browsing to extract useful information from websites. It involves writing scripts that send requests to web pages, parse the HTML code, and organize extracted content—such as prices, reviews, or contact info—into structured formats like spreadsheets or databases.
Many developers choose languages like Python for web scraping due to its clean syntax and powerful libraries like Beautiful Soup and Scrapy. These tools make it easier to navigate and extract data from complex websites efficiently.
Common Applications of Web Scraping
Web scraping serves a wide variety of purposes across different industries:
Market Research: Businesses collect consumer feedback and competitor pricing to understand market trends.
E-commerce Monitoring: Online stores track product availability and prices across multiple platforms.
News & Journalism: Reporters gather public data or breaking information to support their stories.
Academic Research: Analysts compile datasets for large-scale studies or surveys.
By leveraging these insights, companies can fine-tune their strategies and stay ahead of the competition.
Why Ethical Web Scraping Matters
While web scraping can be incredibly useful, it must be done responsibly. Key ethical considerations include:
Respect for Consent: Many websites specify in their terms of service whether scraping is allowed. Ignoring these terms may result in legal issues or damage to your reputation.
Robots.txt Compliance: Most websites use a file called robots.txt to control which parts of their site are accessible to bots. Ethical scrapers always check and follow these rules.
Data Usage Responsibility: Scraped data must be handled with care, especially if it contains personal or sensitive information. It should never be exposed or misused.
Maintaining an ethical stance helps preserve trust across the digital ecosystem and ensures long-term viability of web scraping as a business tool.
How to Practice Ethical Web Scraping
To make your web scraping efforts both effective and ethical, consider the following best practices:
Review Website Policies: Always check the site’s terms of service and robots.txt file before scraping.
Limit Request Frequency: Sending too many requests at once can overload a website’s server. Adding delays between requests is a respectful practice.
Anonymize Sensitive Data: If your project involves sharing scraped data, make sure it does not expose personal information.
Use Reliable Tools and Secure Platforms: Implement scraping on well-developed systems that adhere to best practices in coding and data security.
Get Professional Help with Ethical Web Development
While scraping tools are powerful, integrating them into a secure and compliant workflow requires professional expertise. That’s where a reliable partner like Dzinepixel comes in. As a leading web development company in India, Dzinepixel has worked with a wide range of businesses to create customized, secure, and ethical digital solutions.
Whether you need assistance building an efficient scraping tool or a full-fledged data dashboard, their expert developers can help you:
Create scalable and secure backend systems
Ensure compliance with data protection laws
Develop user-friendly interfaces for visualizing scraped data
Build APIs and data integration pipelines
By relying on an experienced web development team, you can streamline your scraping workflows while avoiding legal or technical pitfalls.
Final Thoughts
Web scraping is a valuable technique that helps individuals and organizations access critical data quickly and efficiently. However, it’s essential to approach it with caution and ethics. By understanding how scraping works, respecting website policies, and managing data responsibly, you ensure long-term success and sustainability.
If you're considering a web scraping project, or if you want to build a robust and secure platform for your business, explore the services offered by Dzinepixel’s web development team. Their expertise in building high-performance digital systems can give you a competitive edge while staying compliant with all ethical and legal standards.
Start small—review a website’s policies, test your scraping tool responsibly, or consult a professional. The right foundation today ensures scalable, secure success tomorrow.
#best web development agencies india#website design and development company in india#website development company in india#web design company india#website designing company in india#digital marketing agency india
0 notes
Text
Sure, here is the article formatted according to your specifications:
Cryptocurrency data scraping TG@yuantou2048
In the rapidly evolving world of cryptocurrency, staying informed about market trends and price movements is crucial for investors and enthusiasts alike. One effective way to gather this information is through cryptocurrency data scraping. This method involves extracting data from various sources on the internet, such as exchanges, forums, and news sites, to compile a comprehensive dataset that can be used for analysis and decision-making.
What is Cryptocurrency Data Scraping?
Cryptocurrency data scraping refers to the process of automatically collecting and organizing data related to cryptocurrencies from online platforms. This data can include real-time prices, trading volumes, news updates, and social media sentiment. By automating the collection of this data, users can gain valuable insights into the cryptocurrency market, enabling them to make more informed decisions. Here’s how it works and why it’s important.
Why Scrape Cryptocurrency Data?
1. Real-Time Insights: Scraping allows you to access up-to-date information about different cryptocurrencies, ensuring that you have the latest details at your fingertips.
2. Market Analysis: With the vast amount of information available online, manual tracking becomes impractical. Automated scraping tools can help you stay ahead by providing timely and accurate information.
3. Tools and Techniques:
Web Scrapers: These are software tools designed to extract specific types of data from websites. They can gather data points like current prices, historical price trends, and community sentiment, which are essential for making informed investment decisions.
2. Automation: Instead of manually checking multiple platforms, automated scrapers can continuously monitor and collect data, saving time and effort.
3. Customization: You can tailor your scraper to focus on specific metrics or platforms, allowing for personalized data collection tailored to your needs.
4. Competitive Advantage: Having access to real-time data gives you an edge in understanding market dynamics and identifying potential opportunities or risks.
5. Legal Considerations: It's important to ensure that the data collected complies with legal guidelines and respects terms of service agreements of the websites being scraped. Always check the legality and ethical considerations before implementing any scraping projects.
6. Use Cases:
Price Tracking: Track the value of different cryptocurrencies across multiple exchanges.
Sentiment Analysis: Analyze social media and news feeds to gauge public opinion and predict market movements.
7. Challenges:
Dynamic Content: Websites often use JavaScript to load content dynamically, which requires advanced techniques to capture this data accurately.
Scraping Tools: Popular tools include Python libraries like BeautifulSoup and Selenium, which can parse HTML and interact with web pages to extract relevant information efficiently.
8. Best Practices:
Respect Terms of Service: Ensure that your scraping activities comply with the terms of service of the websites you’re scraping from. Some popular platforms like CoinMarketCap, Coingecko, and Twitter for sentiment analysis.
9. Ethical and Legal Scrutiny: Be mindful of the ethical implications and ensure compliance with website policies.
10. Data Quality: The quality of the data is crucial. Use robust frameworks and APIs provided by exchanges directly when possible to avoid overloading servers and ensure reliability.
11. Conclusion: Cryptocurrency data scraping is a powerful tool for anyone interested in the crypto space. However, always respect the terms of service of the platforms you scrape from.
12. Future Trends: As the landscape evolves, staying updated with the latest technologies and best practices is key. Always respect the terms of service of the platforms you're scraping from.
13. Conclusion: Cryptocurrency data scraping offers a wealth of information but requires careful implementation to avoid violating terms of service or facing legal issues.
14. Final Thoughts: While scraping can provide significant advantages, it’s vital to use these tools responsibly and ethically.
This structured approach ensures that you adhere to ethical standards while leveraging the power of automation to stay informed without infringing on copyright laws and privacy policies.
Feel free to adjust the length and tone as needed.
加飞机@yuantou2048

EPP Machine
蜘蛛池出租
0 notes
Text
How To Use Python for Web Scraping – A Complete Guide
The ability to efficiently extract and analyze information from websites is critical for skilled developers and data scientists. Web scraping – the automated extraction of data from websites – has become an essential technique for gathering information at scale. As per reports, 73.0% of web data professionals utilize web scraping to acquire market insights and to track their competitors. Python, with its simplicity and robust ecosystem of libraries stands out as the ideal programming for this task. Regardless of your purpose for web scraping, Python provides a powerful yet accessible approach. This tutorial will teach you all you need to know to begin using Python for efficient web scraping. Step-By-Step Guide to Web Scraping with Python
Before diving into the code, it is worth noting that some websites explicitly prohibit scraping. You ought to abide by these restrictions. Also, implement rate limiting in your scraper to prevent overwhelming the target server or virtual machine. Now, let’s focus on the steps –
1- Setting up the environment
- Downlaod and install Python 3.x from the official website. We suggest version 3.4+ because it has pip by default.
- The foundation of most Python web scraping projects consists of two main libraries. These are Requests and Beautiful Soup
Once the environment is set up, you are ready to start building the scraper.
2- Building a basic web scraper
Let us first build a simple scraper that can extract quotes from the “Quotes to Scrape” website. This is a sandbox created specifically for practicing web scraping.
Step 1- Connect to the target URL
First, use the requests libraries to fetch the content of the web page.
import requests

Setting a proper User-agent header is critical, as many sites block requests that don’t appear to come from a browser.
Step 2- Parse the HTML content
Next, use Beautiful Soup to parse the HTML and create a navigable structure.

Beautiful Soup transforms the raw HTML into a parse tree that you can navigate easily to find and extract data.
Step 3- Extract data from the elements
Once you have the parse tree, you can locate and extract the data you want.

This code should find all the div elements with the class “quote” and then extract the text, author and tags from each one.
Step 4- Implement the crawling logic
Most sites have multiple pages. To get extra data from all the pages, you will need to implement a crawling mechanism.

This code will check for the “Next” button, follow the link to the next page, and continue the scraping process until no more pages are left.
Step 5- Export the data to CSV
Finally, let’s save the scraped data to a CSV file.

And there you have it. A complete web scraper that extracts the quotes from multiple pages and saves them to a CSV file.
Python Web Scraping Libraries
The Python ecosystem equips you with a variety of libraries for web scraping. Each of these libraries has its own strength. Here is an overview of the most popular ones –
1- Requests
Requests is a simple yet powerful HTTP library. It makes sending HTTP requests exceptionally easy. Also, it handles, cookies, sessions, query strings, including other HTTP-related tasks seamlessly.
2- Beautiful Soup
This Python library is designed for parsing HTML and XML documents. It creates a parse tree from page source code that can be used to extract data efficiently. Its intuitive API makes navigating and searching parse trees straightforward.
3- Selenium
This is a browser automation tool that enables you to control a web browser using a program. Selenium is particularly useful for scraping sites that rely heavily on JavaScript to load content.
4- Scrapy
Scrapy is a comprehensive web crawling framework for Python. It provides a complete solution for crawling websites and extracting structured data. These include mechanisms for following links, handling cookies and respecting robots.txt files.
5- 1xml
This is a high-performance library for processing XML and HTML. It is faster than Beautiful Soup but has a steeper learning curve.
How to Scrape HTML Forms Using Python?
You are often required to interact with HTML when scraping data from websites. This might include searching for specific content or navigating through dynamic interfaces.
1- Understanding HTML forms
HTML forms include various input elements like text fields, checkboxes and buttons. When a form is submitted, the data is sent to the server using either a GET or POST request.
2- Using requests to submit forms
For simple forms, you can use the Requests library to submit form data
import requests

3- Handling complex forms with Selenium
For more complex forms, especially those that rely on JavaScript, Selenium provides a more robust solution. It allows you to interact with forms just like human users would.

How to Parse Text from the Website?
Once you have retrieved the HTML content form a site, the next step is to parse it to extract text or data you need. Python offers several approaches for this.
1- Using Beautiful Soup for basic text extraction
Beautiful Soup makes it easy to extract text from HTML elements.

2- Advanced text parsing
For complex text extraction, you can combine Beautiful Soup with regular expressions.

3- Structured data extraction
If you wish to extract structured data like tables, Beautiful Soup provides specialized methods.

4- Cleaning extracted text
Extracted data is bound to contain unwanted whitespaces, new lines or other characters. Here is how to clean it up –

Conclusion Python web scraping offers a powerful way to automate data collection from websites. Libraries like Requests and Beautiful Soup, for instance, make it easy even for beginners to build effective scrappers with just a few lines of code. For more complex scenarios, the advanced capabilities of Selenium and Scrapy prove helpful. Keep in mind, always scrape responsibly. Respect the website’s terms of service and implement rate limiting so you don’t overwhelm servers. Ethical scraping practices are the way to go! FAQs 1- Is web scraping illegal? No, it isn’t. However, how you use the obtained data may raise legal issues. Hence, always check the website’s terms of service. Also, respect robots.txt files and avoid personal or copyrighted information without permission. 2- How can I avoid getting blocked while scraping? There are a few things you can do to avoid getting blocked – - Use proper headers - Implement delays between requests - Respect robot.txt rules - Use rotating proxies for large-scale scraping - Avoid making too many requests in a short period 3- Can I scrape a website that requires login? Yes, you can. Do so using the Requests library with session handling. Even Selenium can be used to automate the login process before scraping. 4- How do I handle websites with infinite scrolling? Use Selenium when handling sites that have infinite scrolling. It can help scroll down the page automatically. Also, wait until the new content loads before continuing scraping until you have gathered the desired amounts of data.
0 notes
Text
How to Scrape LinkedIn Data Efficiently with Profile Scraper Tools
Scraping LinkedIn data has become a popular method for businesses, marketers, and recruiters to gather valuable information from professional profiles. With a constantly growing network of millions of professionals, LinkedIn is a goldmine of contact information, job histories, and skill sets. Whether it’s for lead generation, recruitment, or market research, utilizing a LinkedIn profile scraper tool can save significant time and effort in collecting data. In this article, the focus will be on understanding how to scrape LinkedIn data efficiently and the benefits of using a scraper tool.
Understanding the Need for LinkedIn Data Scraping
The power of LinkedIn lies in its vast pool of professionals from diverse industries. For businesses, having access to such data can streamline the process of finding potential leads or candidates. Still, hand gathering this data takes time and is unworkable. This is where tools like scrape LinkedIn data come into play. These tools can quickly extract crucial data, including names, job titles, companies, and locations. The ability to gather such information in bulk enhances decision-making processes, making scraping LinkedIn data a valuable practice for many.

How LinkedIn Profile Scrapers Work
A LinkedIn profile scraper operates by automating the data extraction process. These tools use advanced algorithms to bypass LinkedIn's search filters and pull out public information available on profiles. This includes professional details such as job titles, company affiliations, skills, and contact information. While scraping LinkedIn data, these tools ensure high accuracy and consistency, reducing human error. With just a few clicks, users can collect a large volume of data that would be impossible to achieve manually, enhancing productivity and efficiency.
Benefits of Scraping LinkedIn Data
The primary benefit of scrape LinkedIn data is the time it saves. Instead of individually browsing through profiles, a scraper tool can gather all necessary information quickly. This entails creating focused lists of prospects depending on particular criteria such job titles, sectors, and firm size for marketers. These instruments help recruiters identify applicants with the correct background and aptitudes. Recruiters can use these tools to find candidates with the right skills and experience. Overall, LinkedIn profile scrapers provide a highly efficient way to gather data that is essential for business growth.
Legal and Ethical Considerations in Scraping
While scrape LinkedIn data offers numerous advantages, it is important to remember that LinkedIn has strict terms of service regarding the use of automation tools. The site’s policies prohibit scraping unless done through authorized APIs. Breaking these agreements could lead to legal consequences or account suspensions. Therefore, using a LinkedIn profile scraper tool requires caution. It's essential to ensure compliance with LinkedIn's guidelines and use scraping methods that align with ethical practices, respecting both the platform and its users.
Choosing the Right LinkedIn Profile Scraper Tool
When choosing a LinkedIn profile scraper, one should take into account elements including dependability, simplicity of usage, and handling of big data capability of the instrument. Some scrapers are more suitable for small-scale extractions, while others are built to handle bulk data scraping efficiently. It’s also important to assess whether the tool integrates seamlessly with other data tools or CRM systems for better management and utilization of the collected data. Researching the best options will help ensure the chosen tool meets specific needs.

Conclusion
In conclusion, scraping LinkedIn data through a LinkedIn profile scraper is a highly effective method for collecting valuable professional information. Using the correct technologies helps companies save time, streamline procedures, and get insights that support expansion. For those interested in exploring advanced data scraping options, Scrapin.io offers a powerful platform to efficiently extract LinkedIn data, helping users harness the full potential of LinkedIn's vast network.
Blog Source Url :
https://scrapin26.blogspot.com/2025/01/how-to-scrape-linkedin-data-efficiently.html
0 notes
Text
News Extract: Unlocking the Power of Media Data Collection
In today's fast-paced digital world, staying updated with the latest news is crucial. Whether you're a journalist, researcher, or business owner, having access to real-time media data can give you an edge. This is where news extract solutions come into play, enabling efficient web scraping of news sources for insightful analysis.

Why Extracting News Data Matters
News scraping allows businesses and individuals to automate the collection of news articles, headlines, and updates from multiple sources. This information is essential for:
Market Research: Understanding trends and shifts in the industry.
Competitor Analysis: Monitoring competitors’ media presence.
Brand Reputation Management: Keeping track of mentions across news sites.
Sentiment Analysis: Analyzing public opinion on key topics.
By leveraging news extract techniques, businesses can access and process large volumes of news data in real-time.
How News Scraping Works
Web scraping involves using automated tools to gather and structure information from online sources. A reliable news extraction service ensures data accuracy and freshness by:
Extracting news articles, titles, and timestamps.
Categorizing content based on topics, keywords, and sentiment.
Providing real-time or scheduled updates for seamless integration into reports.
The Best Tools for News Extracting
Various scraping solutions can help extract news efficiently, including custom-built scrapers and APIs. For instance, businesses looking for tailored solutions can benefit from web scraping services India to fetch region-specific media data.
Expanding Your Data Collection Horizons
Beyond news extraction, companies often need data from other platforms. Here are some additional scraping solutions:
Python scraping Twitter: Extract real-time tweets based on location and keywords.
Amazon reviews scraping: Gather customer feedback for product insights.
Flipkart scraper: Automate data collection from India's leading eCommerce platform.
Conclusion
Staying ahead in today’s digital landscape requires timely access to media data. A robust news extract solution helps businesses and researchers make data-driven decisions effortlessly. If you're looking for reliable news scraping services, explore Actowiz Solutions for customized web scraping solutions that fit your needs.
#news extract#web scraping services India#Python scraping Twitter#Amazon reviews scraping#Flipkart scraper#Actowiz Solutions
0 notes
Text
How to Use a Zillow Scraper to Extract Real Estate Listings at Scale
If you're in real estate, property investment, or the proptech industry, access to reliable, up-to-date housing data is invaluable. However, manually collecting Zillow data can be inefficient and error-prone, especially when dealing with large volumes. This is where a Zillow scraper becomes crucial.
A Zillow scraper is a tool that automates the process of extracting structured property data from Zillow, one of the largest real estate platforms. Whether you’re a real estate investor looking for profitable properties, an analyst tracking market trends, or a founder building a property app, scraping Zillow listings can provide you with the competitive edge you need.

With a Zillow scraper, you can scrape Zillow listings, track property details, and gather rental information and pricing histories — all at scale. In this comprehensive guide, you’ll discover how to efficiently scrape Zillow data, understand its benefits, and ensure that your scraping activities are both effective and ethical.
Let’s dive into how to use a Zillow scraper and extract real estate listings at scale.
Why Scrape Zillow Data?
Zillow offers one of the most comprehensive and dynamic databases of property listings available online, making it an ideal source for:
Real Estate Firms: Competing agencies can compare regional pricing and track market shifts.
Investors: Scraping Zillow helps identify undervalued properties, track property appreciation, and build profitable portfolios.
Rental Property Managers: You can track rental pricing trends, demand for different property types, and determine optimal rental prices.
Proptech Startups: Innovators in the real estate space can integrate real-time Zillow data into apps and platforms.
Despite the availability of Zillow's API, it has become more restrictive over time. Scraping public data from the site offers an alternative way to gather the information you need. By learning how to scrape Zillow data, you can easily gather:
For-sale and rental listings.
Property specifications.
Historical pricing information.
Market and neighborhood-level trends.
Scraping Zillow data at scale allows you to perform detailed analyses that would otherwise be time-consuming and inefficient.
What You Can Extract When Scraping Zillow Listings
When using a Zillow scraper, a vast amount of valuable data can be extracted to inform investment decisions, market analysis, and more.
Here are the primary data points you can collect:
Zillow Property Listings
Zillow listings contain detailed information about each property on the market, including:
Full Address: Location data is critical for evaluating properties.
Asking Price: The current listing price or asking price of a property.
Bedrooms and Bathrooms: Data on the number of bedrooms and bathrooms provides insight into the property’s size and functionality.
Property Type and Size: Information about whether the property is a house, apartment, condo, etc., along with its size in square footage.
Listing Status: Zillow provides information on whether the listing is active, pending, or sold, which is crucial for determining market activity.
Year Built, HOA Fees, and Amenities: These details contribute to determining the property's condition, ongoing maintenance costs, and amenities (e.g., pool, gym, parking).
Rental Listings
For property managers, investors, or anyone focused on rental properties, Zillow scraping provides:
Monthly Rent Prices: Vital for understanding local rental markets.
Lease Terms: Details on the lease duration, security deposits, and special terms (e.g., rent control).
Property Type: Whether the rental is a studio, apartment, house, or townhouse.
Pet Policies and Availability: Important for targeting renters with specific needs.
Parking and Other Amenities: These can affect rental prices and occupancy rates.
Historical Pricing Data
Gaining insight into historical pricing is essential for investors and analysts:
Past Sale Prices: Track the sales history of properties and identify potential for price appreciation.
Tax Assessments: See how a property’s tax values have changed over the years.
Price Reductions: Understand why a property has dropped in price, which can indicate seller urgency or market conditions.
Time-on-Market Trends: Track how long listings are on the market, which can give insight into demand.
Market and Neighborhood Trends
Zillow scraping allows you to gather aggregated data for broader market insights:
Median Prices by ZIP Code: Understand the average price trends within specific locations.
Inventory Levels: Gain an understanding of the supply-demand balance in a given area.
Price Per Square Foot Comparisons: Compare property values across neighborhoods.
Local Market Dynamics: Scrape data on local supply and demand ratios, which can help you predict market shifts.
How to Scrape Zillow Listings: Step-by-Step
If you're wondering how to scrape Zillow listings on your own, follow these essential steps to gather structured property data effectively.
Step 1: Define Your Data Needs
Before scraping Zillow, decide exactly what data you need. For example:
Current Listings: You may want to extract for-sale or rental properties from a specific city or ZIP code.
Historical Pricing Data: You may be more interested in tracking pricing trends over time.
Market Trends: Maybe you need data on market movements or local trends for specific property types.
Defining your data goals upfront helps you focus your efforts and ensures that you only collect the most relevant information.
Step 2: Choose Your Scraping Method
There are several methods to scrape Zillow data:
Custom Scraping Code: You can use Python libraries such as BeautifulSoup, Selenium, or Scrapy to create a custom scraper. These tools allow you to extract and process the data programmatically.
No-Code Scraping Tools: For non-technical users, platforms like Octoparse, ParseHub, or DataMiner offer a drag-and-drop interface for scraping Zillow.
Zillow Scraping API: There are third-party APIs designed for scraping Zillow data, or you can partner with a service like TagX to handle the data extraction.
Step 3: Start Extracting Zillow Listings Data
To start scraping, you need to identify the target URL for the Zillow listing. From there, you can:
Send HTTP requests to Zillow’s property listing pages.
Parse the HTML response to identify key data points.
Follow pagination to scrape multiple pages of listings.
Step 4: Export and Clean Your Data
Once the data is scraped, you’ll want to clean and organize it:
CSV: For spreadsheets and analysis.
JSON: For use in APIs or web applications.
SQL/NoSQL: To store the data in databases.
Cleaning the data is crucial to remove duplicates, normalize formats, and fill in missing values.
Step 5: Handle Legal Considerations
When scraping Zillow data, it's important to follow best practices:
Only scrape publicly available data.
Avoid scraping personal information or violating privacy.
Respect the site’s robots.txt file to ensure you're not violating their policies.
Implement rate-limiting and delays to avoid overloading Zillow's servers.
Common Challenges in Zillow Scraping
While scraping Zillow is a powerful tool, there are challenges to be aware of:
IP Blocking: Zillow can block your IP if it detects frequent access. To mitigate this, use rotating proxies to ensure that your requests are distributed across multiple IP addresses.
Captcha and Bot Detection: Zillow uses CAPTCHAs to prevent automated scraping. You can handle CAPTCHAs by using third-party services that bypass them or integrating CAPTCHA-solving mechanisms.
Changes in HTML Structure: Zillow may change its website layout, which can break your scraper. Regularly maintaining and updating your scraper is necessary to adapt to these changes.
Compliance: Scraping may violate certain website terms of service. It’s recommended to partner with legal and technical experts to ensure compliance.
Why Use a Professional Zillow Scraping Service Like TagX
For businesses looking to scale real estate platforms or run large-scale market research, managing your own scraping infrastructure can be complex and time-consuming. That's where services like TagX can help.
With TagX, you get:
Custom-built Zillow scrapers tailored to your specific data needs.
Real-time data access, including historical and live data.
Ongoing scraper maintenance and updates to keep your data collection process running smoothly.
Compliance safeguards, ensuring that your data collection is ethical and adheres to legal best practices.
By outsourcing scraping to a professional service like TagX, you can save valuable time, reduce technical risks, and ensure you get high-quality, accurate real estate data.
Conclusion
Using a Zillow scraper provides valuable insights for real estate professionals, investors, and analysts looking to gain a competitive edge. With the right tools and techniques, you can automate the process of extracting property details, historical prices, and market trends at scale.
By using a professional data service like TagX, you can access Zillow data efficiently and at scale, without the headaches of managing infrastructure or worrying about compliance. If you’re looking for reliable Zillow data scraping services, TagX offers tailored solutions to meet your needs.
Reach out today to learn more about how we can help you get the data you need for your real estate business!
0 notes
Text
Pulitzer Prize Winners database
I volunteer at my kids' school library. I recently needed a list of all the Pulitzer Prize winners, in order to identify which books we had in our catalogue but weren't on our Pulitzer winners bookshelf. I had resigned myself to manually copy-pasting almost six hundred entries in eight categories from the Pulitzer website - a task that would likely take the better part of a month - before then going through the process of checking our library catalogue for matches, but one midnight I had an ephiphany that there might have been another person with the same needs that had already created a database.
I found one better: https://github.com/jonseitz/pulitzer-scraper had identified nine years ago that the Pulitzer website itself uses API calls to inform its category pages!
I wrote up my explorations of making the Pulitzer API output usable in a GitHub repo, which also serves a GitHub Pages site made out of Jekyll:
0 notes
Text
Vacation Rental Website Data Scraping | Scrape Vacation Rental Website Data
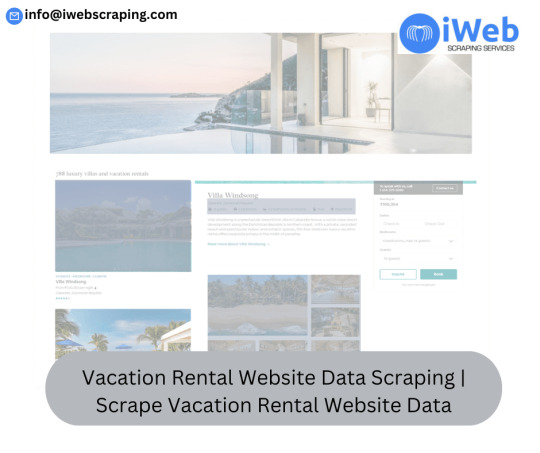
In the ever-evolving landscape of the vacation rental market, having access to real-time, accurate, and comprehensive data is crucial for businesses looking to gain a competitive edge. Whether you are a property manager, travel agency, or a startup in the hospitality industry, scraping data from vacation rental websites can provide you with invaluable insights. This blog delves into the concept of vacation rental website data scraping, its importance, and how it can be leveraged to enhance your business operations.
What is Vacation Rental Website Data Scraping?
Vacation rental website data scraping involves the automated extraction of data from vacation rental platforms such as Airbnb, Vrbo, Booking.com, and others. This data can include a wide range of information, such as property listings, pricing, availability, reviews, host details, and more. By using web scraping tools or services, businesses can collect this data on a large scale, allowing them to analyze trends, monitor competition, and make informed decisions.
Why is Data Scraping Important for the Vacation Rental Industry?
Competitive Pricing Analysis: One of the primary reasons businesses scrape vacation rental websites is to monitor pricing strategies used by competitors. By analyzing the pricing data of similar properties in the same location, you can adjust your rates to stay competitive or identify opportunities to increase your prices during peak seasons.
Market Trend Analysis: Data scraping allows you to track market trends over time. By analyzing historical data on bookings, occupancy rates, and customer preferences, you can identify emerging trends and adjust your business strategies accordingly. This insight can be particularly valuable for making decisions about property investments or marketing campaigns.
Inventory Management: For property managers and owners, understanding the supply side of the market is crucial. Scraping data on the number of available listings, their features, and their occupancy rates can help you optimize your inventory. For example, you can identify underperforming properties and take corrective actions such as renovations or targeted marketing.
Customer Sentiment Analysis: Reviews and ratings on vacation rental platforms provide a wealth of information about customer satisfaction. By scraping and analyzing this data, you can identify common pain points or areas where your service excels. This feedback can be used to improve your offerings and enhance the guest experience.
Lead Generation: For travel agencies or vacation rental startups, scraping contact details and other relevant information from vacation rental websites can help generate leads. This data can be used for targeted marketing campaigns, helping you reach potential customers who are already interested in vacation rentals.
Ethical Considerations and Legal Implications
While data scraping offers numerous benefits, it’s important to be aware of the ethical and legal implications. Vacation rental websites often have terms of service that prohibit or restrict scraping activities. Violating these terms can lead to legal consequences, including lawsuits or being banned from the platform. To mitigate risks, it’s advisable to:
Seek Permission: Whenever possible, seek permission from the website owner before scraping data. Some platforms offer APIs that provide access to data in a more controlled and legal manner.
Respect Robots.txt: Many websites use a robots.txt file to communicate which parts of the site can be crawled by web scrapers. Ensure your scraping activities respect these guidelines.
Use Data Responsibly: Avoid using scraped data in ways that could harm the website or its users, such as spamming or creating fake listings. Responsible use of data helps maintain ethical standards and builds trust with your audience.
How to Get Started with Vacation Rental Data Scraping
If you’re new to data scraping, here’s a simple guide to get you started:
Choose a Scraping Tool: There are various scraping tools available, ranging from easy-to-use platforms like Octoparse and ParseHub to more advanced solutions like Scrapy and Beautiful Soup. Choose a tool that matches your technical expertise and requirements.
Identify the Data You Need: Before you start scraping, clearly define the data points you need. This could include property details, pricing, availability, reviews, etc. Having a clear plan will make your scraping efforts more efficient.
Start Small: Begin with a small-scale scrape to test your setup and ensure that you’re collecting the data you need. Once you’re confident, you can scale up your scraping efforts.
Analyze the Data: After collecting the data, use analytical tools like Excel, Google Sheets, or more advanced platforms like Tableau or Power BI to analyze and visualize the data. This will help you derive actionable insights.
Stay Updated: The vacation rental market is dynamic, with prices and availability changing frequently. Regularly updating your scraped data ensures that your insights remain relevant and actionable.
Conclusion
Vacation rental website data scraping is a powerful tool that can provide businesses with a wealth of information to drive growth and innovation. From competitive pricing analysis to customer sentiment insights, the applications are vast. However, it’s essential to approach data scraping ethically and legally to avoid potential pitfalls. By leveraging the right tools and strategies, you can unlock valuable insights that give your business a competitive edge in the ever-evolving vacation rental market.
0 notes