#spark rdd cache
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Top 30+ Spark Interview Questions

Apache Spark, the lightning-fast open-source computation platform, has become a cornerstone in big data technology. Developed by Matei Zaharia at UC Berkeley's AMPLab in 2009, Spark gained prominence within the Apache Foundation from 2014 onward. This article aims to equip you with the essential knowledge needed to succeed in Apache Spark interviews, covering key concepts, features, and critical questions.
Understanding Apache Spark: The Basics
Before delving into interview questions, let's revisit the fundamental features of Apache Spark:
1. Support for Multiple Programming Languages:
Java, Python, R, and Scala are the supported programming languages for writing Spark code.
High-level APIs in these languages facilitate seamless interaction with Spark.
2. Lazy Evaluation:
Spark employs lazy evaluation, delaying computation until absolutely necessary.
3. Machine Learning (MLlib):
MLlib, Spark's machine learning component, eliminates the need for separate engines for processing and machine learning.
4. Real-Time Computation:
Spark excels in real-time computation due to its in-memory cluster computing, minimizing latency.
5. Speed:
Up to 100 times faster than Hadoop MapReduce, Spark achieves this speed through controlled partitioning.
6. Hadoop Integration:
Smooth connectivity with Hadoop, acting as a potential replacement for MapReduce functions.
Top 30+ Interview Questions: Explained
Question 1: Key Features of Apache Spark
Apache Spark supports multiple programming languages, lazy evaluation, machine learning, multiple format support, real-time computation, speed, and seamless Hadoop integration.
Question 2: Advantages Over Hadoop MapReduce
Enhanced speed, multitasking, reduced disk-dependency, and support for iterative computation.
Question 3: Resilient Distributed Dataset (RDD)
RDD is a fault-tolerant collection of operational elements distributed and immutable in memory.
Question 4: Functions of Spark Core
Spark Core acts as the base engine for large-scale parallel and distributed data processing, including job distribution, monitoring, and memory management.
Question 5: Components of Spark Ecosystem
Spark Ecosystem comprises GraphX, MLlib, Spark Core, Spark Streaming, and Spark SQL.
Question 6: API for Implementing Graphs in Spark
GraphX is the API for implementing graphs and graph-parallel computing in Spark.
Question 7: Implementing SQL in Spark
Spark SQL modules integrate relational processing with Spark's functional programming API, supporting SQL and HiveQL.
Question 8: Parquet File
Parquet is a columnar format supporting read and write operations in Spark SQL.
Question 9: Using Spark with Hadoop
Spark can run on top of HDFS, leveraging Hadoop's distributed replicated storage for batch and real-time processing.
Question 10: Cluster Managers in Spark
Apache Mesos, Standalone, and YARN are cluster managers in Spark.
Question 11: Using Spark with Cassandra Databases
Spark Cassandra Connector allows Spark to access and analyze data in Cassandra databases.
Question 12: Worker Node
A worker node is a node capable of running code in a cluster, assigned tasks by the master node.
Question 13: Sparse Vector in Spark
A sparse vector stores non-zero entries using parallel arrays for indices and values.
Question 14: Connecting Spark with Apache Mesos
Configure Spark to connect with Mesos, place the Spark binary package in an accessible location, and set the appropriate configuration.
Question 15: Minimizing Data Transfers in Spark
Minimize data transfers by avoiding shuffles, using accumulators, and broadcast variables.
Question 16: Broadcast Variables in Spark
Broadcast variables store read-only cached versions of variables on each machine, reducing the need for shipping copies with tasks.
Question 17: DStream in Spark
DStream, or Discretized Stream, is the basic abstraction in Spark Streaming, representing a continuous stream of data.
Question 18: Checkpoints in Spark
Checkpoints in Spark allow programs to run continuously and recover from failures unrelated to application logic.
Question 19: Levels of Persistence in Spark
Spark offers various persistence levels for storing RDDs on disk, memory, or a combination of both.
Question 20: Limitations of Apache Spark
Limitations include the lack of a built-in file management system, higher latency, and no support for true real-time data stream processing.
Question 21: Defining Apache Spark
Apache Spark is an easy-to-use, highly flexible, and fast processing framework supporting cyclic data flow and in-memory computing.
Question 22: Purpose of Spark Engine
The Spark Engine schedules, monitors, and distributes data applications across the cluster.
Question 23: Partitions in Apache Spark
Partitions in Apache Spark split data logically for more efficient and smaller divisions, aiding in faster data processing.
Question 24: Operations of RDD
RDD operations include transformations and actions.
Question 25: Transformations in Spark
Transformations are functions applied to RDDs, creating new RDDs. Examples include Map() and filter().
Question 26: Map() Function
The Map() function repeats over every line in an RDD, splitting them into a new RDD.
Question 27: Filter() Function
The filter() function creates a new RDD by selecting elements from an existing RDD based on a specified function.
Question 28: Actions in Spark
Actions bring back data from an RDD to the local machine, including functions like reduce() and take().
Question 29: Difference Between reduce() and take()
reduce() repeatedly applies a function until only one value is left, while take() retrieves all values from an RDD to the local node.
Question 30: Coalesce() and Repartition() in MapReduce
Coalesce() and repartition() modify the number of partitions in an RDD, with Coalesce() being part of repartition().
Question 31: YARN in Spark
YARN acts as a central resource management platform, providing scalable operations across the cluster.
Question 32: PageRank in Spark
PageRank in Spark is an algorithm in GraphX measuring the importance of each vertex in a graph.
Question 33: Sliding Window in Spark
A Sliding Window in Spark specifies each batch of Spark streaming to be processed, setting batch intervals and processing several batches.
Question 34: Benefits of Sliding Window Operations
Sliding Window operations control data packet transfer, combine RDDs within a specific window, and support windowed computations.
Question 35: RDD Lineage
RDD Lineage is the process of reconstructing lost data partitions, aiding in data recovery.
Question 36: Spark Driver
Spark Driver is the program running on the master node, declaring transformations and actions on data RDDs.
Question 37: Supported File Systems in Spark
Spark supports Amazon S3, HDFS, and Local File System as file systems.
If you like to read more about it please visit
https://analyticsjobs.in/question/what-is-apache-spark/
0 notes
Text
Hadoop and Spark: Pioneers of Big Data in the Data Science Realm
Introduction:
In the realm of data science, the sheer volume, velocity, and variety of data have given rise to the phenomenon known as big data. Managing and analysing vast datasets necessitates specialised tools and technologies. This article explores big data and delves into two prominent technologies, Hadoop and Spark, integral parts of any comprehensive data scientist course, that play pivotal roles in handling the complexities of big data analytics.
Understanding Big Data:
Big data refers to datasets that are too large and complex to be processed by traditional data management and analysis tools. The three Vs—Volume, velocity, and variety—characterise big data. Volume refers to the massive amount of data generated, Velocity denotes the speed at which data is generated and processed, and Variety encompasses the diverse sources and formats of data.
Specialised technologies are required to harness the potential insights from big data, and two of the most prominent ones are Hadoop and Spark, as extensively covered in a Data Science Course in Mumbai.
Hadoop: The Distributed Processing Powerhouse
Hadoop, an open-source framework, is synonymous with big data processing.
Created by the Apache Software Foundation, Hadoop facilitates the distribution of large data sets' storage and processing across clusters of standard hardware. It comprises two primary elements: the HDFS for data storage and the MapReduce programming model for efficient data processing.
1. Hadoop Distributed File System (HDFS):
At the core of Hadoop is its distributed file system, HDFS. HDFS breaks down vast datasets into smaller segments, usually 128 MB or 256 MB, and disperses these segments throughout various nodes in a cluster. This enables parallel processing, making it possible to analyse massive datasets concurrently, a key topic in any data science course.
2. MapReduce Programming Model:
Hadoop employs the MapReduce programming model for distributed data processing. MapReduce breaks down a computation into two phases—Map and Reduce. The Map phase processes and filters the input data, while the Reduce phase aggregates and summarises the results. This parallelised approach allows Hadoop to process vast amounts of data efficiently.
While Hadoop revolutionised big data processing, the evolution of technology led to the emergence of Apache Spark.
Spark: The High-Performance Data Processing Engine
Apache Spark, an open-source, fast, and general-purpose cluster-computing framework, addresses some of the limitations of Hadoop, providing quicker and more versatile extensive data processing capabilities.
1. In-Memory Processing:
One of Spark's key differentiators is its ability to perform in-memory processing, reducing the need to read and write to disk. Consequently, Spark outpaces Hadoop's MapReduce in terms of speed, particularly for repetitive algorithms and dynamic data analysis, due to its more efficient processing capabilities.
2. Versatility with Resilient Distributed Datasets (RDDs):
Spark brings forth the notion of Resilient Distributed Datasets (RDDs), a robust and fault-tolerant array of elements designed for parallel processing. RDDs can be cached in memory, enabling iterative computations and enhancing the overall speed and efficiency of data processing.
3. Advanced Analytics and Machine Learning Libraries:
Spark offers high-level APIs in Scala, Java, Python, and R, making it accessible to a broader audience. Additionally, Spark includes libraries for machine learning (MLlib) and graph processing (GraphX), expanding its utility beyond traditional batch processing.
Comparing Hadoop and Spark:
While both Hadoop and Spark are integral components of the extensive data ecosystem, they cater to different use cases and have distinct advantages.
Hadoop Advantages:
Well-suited for batch processing of large datasets.
Proven reliability in handling massive-scale distributed storage and processing.
Spark Advantages:
Significantly faster than Hadoop, especially for iterative algorithms and interactive data analysis.
Versatile with support for batch processing, interactive queries, streaming, and machine learning workloads.
Conclusion:
In the ever-expanding landscape of data science, big data technologies like Hadoop and Spark, critical components in a Data Science Course in Mumbai, are crucial in unlocking insights from vast and complex datasets. With its distributed file system and MapReduce paradigm, Hadoop laid the foundation for scalable data processing. Spark brought about advancements that address the evolving needs of the data-driven era. As part of a data science course, understanding these technologies equips data scientists and analysts with the capability to derive significant insights, thus fueling innovation and guiding decision-making across various sectors.
0 notes
Text
Streamlining Big Data Analytics with Apache Spark

Apache Spark is a powerful open-source data processing framework designed to streamline big data analytics. It's specifically built to handle large-scale data processing and analytics tasks efficiently. Here are some key aspects of how Apache Spark streamlines big data analytics:
In-Memory Processing: One of the significant advantages of Spark is its ability to perform in-memory data processing. It stores data in memory, which allows for much faster access and processing compared to traditional disk-based processing systems. This is particularly beneficial for iterative algorithms and machine learning tasks.
Distributed Computing: Spark is built to perform distributed computing, which means it can distribute data and processing across a cluster of machines. This enables it to handle large datasets and computations that would be impractical for a single machine.
Versatile Data Processing: Spark provides a wide range of libraries and APIs for various data processing tasks, including batch processing, real-time data streaming, machine learning, and graph processing. This versatility makes it a one-stop solution for many data processing needs.
Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structure in Spark. They are immutable, fault-tolerant, and can be cached in memory for fast access. This simplifies the process of handling data and makes it more fault-tolerant.
Ease of Use: Spark provides APIs in several programming languages, including Scala, Java, Python, and R, making it accessible to a wide range of developers and data scientists. This ease of use has contributed to its popularity.
Integration: Spark can be easily integrated with other popular big data tools, like Hadoop HDFS, Hive, HBase, and more. This ensures compatibility with existing data infrastructure.
Streaming Capabilities: Spark Streaming allows you to process real-time data streams. It can be used for applications like log processing, fraud detection, and real-time dashboards.
Machine Learning Libraries: Spark's MLlib provides a scalable machine learning library, which simplifies the development of machine learning models on large datasets.
Graph Processing: GraphX, a library for graph processing, is integrated into Spark. It's useful for tasks like social network analysis and recommendation systems.
Community Support: Spark has a vibrant and active open-source community, which means that it's continuously evolving and improving. You can find numerous resources, tutorials, and documentation to help with your big data analytics projects.
Performance Optimization: Spark provides various mechanisms for optimizing performance, including data partitioning, caching, and query optimization.
1 note
·
View note
Text
Important libraries for data science and Machine learning.
Python has more than 137,000 libraries which is help in various ways.In the data age where data is looks like the oil or electricity .In coming days companies are requires more skilled full data scientist , Machine Learning engineer, deep learning engineer, to avail insights by processing massive data sets.
Python libraries for different data science task:
Python Libraries for Data Collection
Beautiful Soup
Scrapy
Selenium
Python Libraries for Data Cleaning and Manipulation
Pandas
PyOD
NumPy
Spacy
Python Libraries for Data Visualization
Matplotlib
Seaborn
Bokeh
Python Libraries for Modeling
Scikit-learn
TensorFlow
PyTorch
Python Libraries for Model Interpretability
Lime
H2O
Python Libraries for Audio Processing
Librosa
Madmom
pyAudioAnalysis
Python Libraries for Image Processing
OpenCV-Python
Scikit-image
Pillow
Python Libraries for Database
Psycopg
SQLAlchemy
Python Libraries for Deployment
Flask
Django
Best Framework for Machine Learning:
1. Tensorflow :
If you are working or interested about Machine Learning, then you might have heard about this famous Open Source library known as Tensorflow. It was developed at Google by Brain Team. Almost all Google’s Applications use Tensorflow for Machine Learning. If you are using Google photos or Google voice search then indirectly you are using the models built using Tensorflow.
Tensorflow is just a computational framework for expressing algorithms involving large number of Tensor operations, since Neural networks can be expressed as computational graphs they can be implemented using Tensorflow as a series of operations on Tensors. Tensors are N-dimensional matrices which represents our Data.
2. Keras :
Keras is one of the coolest Machine learning library. If you are a beginner in Machine Learning then I suggest you to use Keras. It provides a easier way to express Neural networks. It also provides some of the utilities for processing datasets, compiling models, evaluating results, visualization of graphs and many more.
Keras internally uses either Tensorflow or Theano as backend. Some other pouplar neural network frameworks like CNTK can also be used. If you are using Tensorflow as backend then you can refer to the Tensorflow architecture diagram shown in Tensorflow section of this article. Keras is slow when compared to other libraries because it constructs a computational graph using the backend infrastructure and then uses it to perform operations. Keras models are portable (HDF5 models) and Keras provides many preprocessed datasets and pretrained models like Inception, SqueezeNet, Mnist, VGG, ResNet etc
3.Theano :
Theano is a computational framework for computing multidimensional arrays. Theano is similar to Tensorflow , but Theano is not as efficient as Tensorflow because of it’s inability to suit into production environments. Theano can be used on a prallel or distributed environments just like Tensorflow.
4.APACHE SPARK:
Spark is an open source cluster-computing framework originally developed at Berkeley’s lab and was initially released on 26th of May 2014, It is majorly written in Scala, Java, Python and R. though produced in Berkery’s lab at University of California it was later donated to Apache Software Foundation.
Spark core is basically the foundation for this project, This is complicated too, but instead of worrying about Numpy arrays it lets you work with its own Spark RDD data structures, which anyone in knowledge with big data would understand its uses. As a user, we could also work with Spark SQL data frames. With all these features it creates dense and sparks feature label vectors for you thus carrying away much complexity to feed to ML algorithms.
5. CAFFE:
Caffe is an open source framework under a BSD license. CAFFE(Convolutional Architecture for Fast Feature Embedding) is a deep learning tool which was developed by UC Berkeley, this framework is mainly written in CPP. It supports many different types of architectures for deep learning focusing mainly on image classification and segmentation. It supports almost all major schemes and is fully connected neural network designs, it offers GPU as well as CPU based acceleration as well like TensorFlow.
CAFFE is mainly used in the academic research projects and to design startups Prototypes. Even Yahoo has integrated caffe with Apache Spark to create CaffeOnSpark, another great deep learning framework.
6.PyTorch.
Torch is also a machine learning open source library, a proper scientific computing framework. Its makers brag it as easiest ML framework, though its complexity is relatively simple which comes from its scripting language interface from Lua programming language interface. There are just numbers(no int, short or double) in it which are not categorized further like in any other language. So its ease many operations and functions. Torch is used by Facebook AI Research Group, IBM, Yandex and the Idiap Research Institute, it has recently extended its use for Android and iOS.
7.Scikit-learn
Scikit-Learn is a very powerful free to use Python library for ML that is widely used in Building models. It is founded and built on foundations of many other libraries namely SciPy, Numpy and matplotlib, it is also one of the most efficient tool for statistical modeling techniques namely classification, regression, clustering.
Scikit-Learn comes with features like supervised & unsupervised learning algorithms and even cross-validation. Scikit-learn is largely written in Python, with some core algorithms written in Cython to achieve performance. Support vector machines are implemented by a Cython wrapper around LIBSVM.
Below is a list of frameworks for machine learning engineers:
Apache Singa is a general distributed deep learning platform for training big deep learning models over large datasets. It is designed with an intuitive programming model based on the layer abstraction. A variety of popular deep learning models are supported, namely feed-forward models including convolutional neural networks (CNN), energy models like restricted Boltzmann machine (RBM), and recurrent neural networks (RNN). Many built-in layers are provided for users.
Amazon Machine Learning is a service that makes it easy for developers of all skill levels to use machine learning technology. Amazon Machine Learning provides visualization tools and wizards that guide you through the process of creating machine learning (ML) models without having to learn complex ML algorithms and technology. It connects to data stored in Amazon S3, Redshift, or RDS, and can run binary classification, multiclass categorization, or regression on said data to create a model.
Azure ML Studio allows Microsoft Azure users to create and train models, then turn them into APIs that can be consumed by other services. Users get up to 10GB of storage per account for model data, although you can also connect your own Azure storage to the service for larger models. A wide range of algorithms are available, courtesy of both Microsoft and third parties. You don’t even need an account to try out the service; you can log in anonymously and use Azure ML Studio for up to eight hours.
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license. Models and optimization are defined by configuration without hard-coding & user can switch between CPU and GPU. Speed makes Caffe perfect for research experiments and industry deployment. Caffe can process over 60M images per day with a single NVIDIA K40 GPU.
H2O makes it possible for anyone to easily apply math and predictive analytics to solve today’s most challenging business problems. It intelligently combines unique features not currently found in other machine learning platforms including: Best of Breed Open Source Technology, Easy-to-use WebUI and Familiar Interfaces, Data Agnostic Support for all Common Database and File Types. With H2O, you can work with your existing languages and tools. Further, you can extend the platform seamlessly into your Hadoop environments.
Massive Online Analysis (MOA) is the most popular open source framework for data stream mining, with a very active growing community. It includes a collection of machine learning algorithms (classification, regression, clustering, outlier detection, concept drift detection and recommender systems) and tools for evaluation. Related to the WEKA project, MOA is also written in Java, while scaling to more demanding problems.
MLlib (Spark) is Apache Spark’s machine learning library. Its goal is to make practical machine learning scalable and easy. It consists of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as lower-level optimization primitives and higher-level pipeline APIs.
mlpack, a C++-based machine learning library originally rolled out in 2011 and designed for “scalability, speed, and ease-of-use,” according to the library’s creators. Implementing mlpack can be done through a cache of command-line executables for quick-and-dirty, “black box” operations, or with a C++ API for more sophisticated work. Mlpack provides these algorithms as simple command-line programs and C++ classes which can then be integrated into larger-scale machine learning solutions.
Pattern is a web mining module for the Python programming language. It has tools for data mining (Google, Twitter and Wikipedia API, a web crawler, a HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, clustering, SVM), network analysis and visualization.
Scikit-Learn leverages Python’s breadth by building on top of several existing Python packages ��� NumPy, SciPy, and matplotlib — for math and science work. The resulting libraries can be used either for interactive “workbench” applications or be embedded into other software and reused. The kit is available under a BSD license, so it’s fully open and reusable. Scikit-learn includes tools for many of the standard machine-learning tasks (such as clustering, classification, regression, etc.). And since scikit-learn is developed by a large community of developers and machine-learning experts, promising new techniques tend to be included in fairly short order.
Shogun is among the oldest, most venerable of machine learning libraries, Shogun was created in 1999 and written in C++, but isn’t limited to working in C++. Thanks to the SWIG library, Shogun can be used transparently in such languages and environments: as Java, Python, C#, Ruby, R, Lua, Octave, and Matlab. Shogun is designed for unified large-scale learning for a broad range of feature types and learning settings, like classification, regression, or explorative data analysis.
TensorFlow is an open source software library for numerical computation using data flow graphs. TensorFlow implements what are called data flow graphs, where batches of data (“tensors”) can be processed by a series of algorithms described by a graph. The movements of the data through the system are called “flows” — hence, the name. Graphs can be assembled with C++ or Python and can be processed on CPUs or GPUs.
Theano is a Python library that lets you to define, optimize, and evaluate mathematical expressions, especially ones with multi-dimensional arrays (numpy.ndarray). Using Theano it is possible to attain speeds rivaling hand-crafted C implementations for problems involving large amounts of data. It was written at the LISA lab to support rapid development of efficient machine learning algorithms. Theano is named after the Greek mathematician, who may have been Pythagoras’ wife. Theano is released under a BSD license.
Torch is a scientific computing framework with wide support for machine learning algorithms that puts GPUs first. It is easy to use and efficient, thanks to an easy and fast scripting language, LuaJIT, and an underlying C/CUDA implementation. The goal of Torch is to have maximum flexibility and speed in building your scientific algorithms while making the process extremely simple. Torch comes with a large ecosystem of community-driven packages in machine learning, computer vision, signal processing, parallel processing, image, video, audio and networking among others, and builds on top of the Lua community.
Veles is a distributed platform for deep-learning applications, and it’s written in C++, although it uses Python to perform automation and coordination between nodes. Datasets can be analyzed and automatically normalized before being fed to the cluster, and a REST API allows the trained model to be used in production immediately. It focuses on performance and flexibility. It has little hard-coded entities and enables training of all the widely recognized topologies, such as fully connected nets, convolutional nets, recurent nets etc.
1 note
·
View note
Text
Pyspark Tutorial
What is the purpose of PySpark?
· PySpark allows you to easily integrate and interact with Resilient Distributed Datasets (RDDs) in Python.
· PySpark is a fantastic framework for working with large datasets because of its many capabilities.
· PySpark provides a large selection of libraries, making Machine Learning and Real-Time Streaming Analytics easy.
· PySpark combines Python's ease of use with Apache Spark's capabilities for taming Big Data.
· The power of technologies like Apache Spark and Hadoop has been developed as a result of the emergence of Big Data.
· A data scientist can efficiently manage enormous datasets, and any Python developer can do the same.
Python Big Data Concepts
Python is a high-level programming language that supports a wide range of programming paradigms, including object-oriented programming (OOPs), asynchronous programming, and functional programming.
When it comes to Big Data, functional programming is a crucial paradigm. It uses parallel programming, which means you can run your code on many CPUs or on completely other machines. The PySpark ecosystem has the capability to distribute functioning code over a cluster of machines.
Python's standard library and built-ins contain functional programming basic notions for programmers.
The essential principle of functional programming is that data manipulation occurs through functions without any external state management. This indicates that your code avoids using global variables and does not alter data in-place, instead returning new data. The lambda keyword in Python is used to expose anonymous functions.
The following are some of PySpark key features:
· PySpark is one of the most used frameworks for working with large datasets. It also works with a variety of languages.
· Disk persistence and caching: The PySpark framework has excellent disk persistence and caching capabilities.
· Fast processing: When compared to other Big Data processing frameworks, the PySpark framework is rather quick.
· Python is a dynamically typed programming language that makes it easy to work with Resilient Distributed Datasets.
What exactly is PySpark?
PySpark is supported by two types of evidence:
· The PySpark API includes a large number of examples.
· The Spark Scala API transforms Scala code, which is a very legible and work-based programming language, into Python code and makes it understandable for PySpark projects.
Py4J allows a Python program to communicate with a JVM-based software. PySpark can use it to connect to the Spark Scala-based Application Programming Interface.
Python Environment in PySpark
Self-Hosted: You can create a collection or clump on your own in this situation. You can use metal or virtual clusters in this environment. Some suggested projects, such as Apache Ambari, are appropriate for this purpose. However, this procedure is insufficiently rapid.
Cloud Service Providers: Spark clusters are frequently employed in this situation. Self-hosting takes longer than this environment. Electronic MapReduce (EMR) is provided by Amazon Web Services (AWS), while Dataproc is provided by Good Clinical Practice (GCP).
Spark solutions are provided by Databricks and Cloudera, respectively. It's one of the quickest ways to get PySpark up and running.
Programming using PySpark
Python, as we all know, is a high-level programming language with several libraries. It is extremely important in Machine Learning and Data Analytics. As a result, PySpark is a Python-based Spark API. Spark has some great features, such as rapid speed, quick access, and the ability to be used for streaming analytics. Furthermore, the Spark and Python frameworks make it simple for PySpark to access and analyse large amounts of data.
RDDs (Resilient Distributed Datasets): RDDs (Resilient Distributed Datasets) are a key component of the PySpark programming framework. This collection can't be changed and only goes through minor transformations. Each letter in this abbreviation has a specific meaning. It has a high level of resiliency since it can tolerate errors and recover data. It's scattered because it spreads out over a clump of other nodes. The term "dataset" refers to a collection of data values.
PySpark's Benefits
This section can be broken down into two pieces. First and foremost, you will learn about the benefits of utilizing Python in PySpark, as well as the benefits of PySpark itself.
It is simple to learn and use because it is a high-level and coder-friendly language.
It is possible to use a simple and inclusive API.
Python provides a wonderful opportunity for the reader to visualize data.
Python comes with a large number of libraries. Matplotlib, Pandas, Seaborn, NumPy, and others are some of the examples.
0 notes
Text
Spark Scala Training
Rainbow Training Institute provides the Best Apache Spark Scala Online Training Course Certification. We are Offering Spark and Scala Course classroom training And Scala Online Training in Hyderabad.we will deliver courses 100% Practical and Spark scala Real-Time project training. Complete Suite of spark Scala training videos.
In this Spark Tutorial, we will see an outline of Spark and scala in Big Data. We will begin with a prologue to Apache Spark and scala online training Programming. At that point we will move to know the Spark History. Besides, we will realize why Spark is required. A short time later, will cover all major of Spark segments. Moreover, we will find out about Spark's center deliberation and Spark RDD. For increasingly nitty gritty bits of knowledge, we will likewise cover sparkle highlights, Spark restrictions, and Spark Use cases.

Prologue to Spark Programming
What is Spark? Flash Programming is only a broadly useful and exceptionally quick bunch processing stage. At the end of the day, it is an open source, wide range information preparing motor. That uncovers advancement API's, which likewise qualifies information laborers to achieve spilling, AI or SQL remaining tasks at hand which request rehashed access to informational collections. Nonetheless, Spark can perform group preparing and stream handling. Cluster preparing alludes, to the handling of the recently gathered activity in a solitary group. Though stream handling intends to manage Spark gushing information.
Additionally, it is planned so that it incorporates with all the Big information devices. Like sparkle can get to any Hadoop information source, additionally can run on Hadoop groups. Besides, Apache Spark stretches out Hadoop MapReduce to the following level. That likewise incorporates iterative questions and stream handling.
One progressively basic conviction about Spark is that it is an augmentation of Hadoop. Despite the fact that that isn't valid. Be that as it may, Spark is autonomous of Hadoop since it has its own group the executives framework. Fundamentally, it utilizes Hadoop for capacity reason as it were.
In spite of the fact that, there is one sparkle's key component that it has in-memory bunch calculation capacity. Likewise speeds up an application.
Essentially, Apache Spark and Scala offers significant level APIs to clients, for example, Java, Scala, Python, and R. In spite of the fact that, Spark is written in Scala still offers rich APIs in Scala, Java, Python, just as R. We can say, it is an instrument for running flash applications.
Above all, by contrasting Spark and Hadoop, it is multiple times quicker than Hadoop In-Memory mode and multiple times quicker than Hadoop On-Disk mode.
Spark and Scala training Tutorial – History
From the outset, in 2009 Apache Spark was presented in the UC Berkeley R&D Lab, which is currently known as AMPLab. A short time later, in 2010 it became open source under BSD permit. Further, the sparkle was given to Apache Software Foundation, in 2013. At that point in 2014, it became top-level Apache venture.
Why Spark?
As we probably am aware, there was no universally useful registering motor in the business, since
To perform bunch handling, we were utilizing Hadoop MapReduce.
Additionally, to perform stream handling, we were utilizing Apache Storm/S4.
In addition, for intelligent handling, we were utilizing Apache Impala/Apache Tez.
To perform chart handling, we were utilizing Neo4j/Apache Giraph.
Henceforth there was no ground-breaking motor in the business, that can procedure the information both continuously and group mode. Likewise, there was a necessity that one motor can react in sub-second and act in-memory handling.
In this manner, Apache Spark programming enters, it is an amazing open source motor. Since, it offers continuous stream preparing, intelligent handling, chart handling, in-memory handling just as clump preparing. Indeed, even with extremely quick speed, convenience and standard interface. Essentially, these highlights make the distinction among Hadoop and Spark. Likewise makes a colossal examination between Spark versus Storm.
Apache Spark Components
In this Apache Spark Tutorial, we examine Spark Components. It puts the guarantee for quicker information handling just as simpler improvement. It is conceivable in light of its segments. All these Spark parts settled the issues that happened while utilizing Hadoop MapReduce.
Presently we should examine each Spark Ecosystem Component individually
a. Spark Core
Sparkle Core is an essential issue of Spark. Essentially, it gives an execution stage to all the Spark applications. In addition, to help a wide exhibit of utilizations, Spark Provides a summed up stage.
b. Spark SQL
On the highest point of Spark, Spark SQL empowers clients to run SQL/HQL inquiries. We can process organized just as semi-organized information, by utilizing Spark SQL. In addition, it offers to run unmodified inquiries up to multiple times quicker on existing organizations. To learn Spark SQL in detail, pursue this connection.
c. Spark Streaming
Fundamentally, crosswise over live spilling, Spark Streaming empowers an amazing intelligent and information examination application. In addition, the live streams are changed over into miniaturized scale groups those are executed over flash center. Learn Spark Streaming in detail.
d. Spark MLlib
AI library conveys the two efficiencies just as the top notch calculations. Additionally, it is the most sizzling decision for an information researcher. Since it is equipped for in-memory information preparing, that improves the presentation of iterative calculation radically.
e. Spark GraphX
Essentially, Spark GraphX is the chart calculation motor based over Apache Spark that empowers to process diagram information at scale.
f. SparkR
Fundamentally, to utilize Apache Spark from R. It is R bundle that gives light-weight frontend. Also, it enables information researchers to dissect enormous datasets. Likewise permits running employments intelligently on them from the R shell. In spite of the fact that, the primary thought behind SparkR was to investigate various procedures to coordinate the ease of use of R with the versatility of Spark. Pursue the connection to learn SparkR in detail.
Versatile Distributed Dataset – RDD
The key reflection of Spark is RDD. RDD is an abbreviation for Resilient Distributed Dataset. It is the basic unit of information in Spark. Fundamentally, it is a disseminated assortment of components crosswise over group hubs. Likewise performs parallel activities. Additionally, Spark RDDs are unchanging in nature. In spite of the fact that, it can create new RDD by changing existing Spark RDD.Learn about Spark RDDs in detail.
a. Approaches to make Spark RDD
Fundamentally, there are 3 different ways to make Spark RDDs
I. Parallelized assortments
By summoning parallelize strategy in the driver program, we can make parallelized assortments.
ii. Outside datasets
One can make Spark RDDs, by calling a textFile strategy. Consequently, this technique takes URL of the document and peruses it as an assortment of lines.
iii. Existing RDDs
Additionally, we can make new RDD in flash, by applying change activity on existing RDDs.
To gain proficiency with each of the three different ways to make RDD in detail, pursue the connection.
b. Flash RDDs activities
There are two sorts of activities, which Spark RDDs bolsters:
I. Change Operations
It makes another Spark RDD from the current one. In addition, it passes the dataset to the capacity and returns new dataset.
ii. Activity Operations
In Apache Spark, Action returns conclusive outcome to driver program or compose it to the outside information store.
Learn RDD Operations in detail.
c. Shining Features of Spark RDD
There are different points of interest of utilizing RDD. Some of them are
I. In-memory calculation
Essentially, while putting away information in RDD, information is put away in memory for whatever length of time that you need to store. It improves the presentation by a request for sizes by keeping the information in memory.
ii. Apathetic Evaluation
Flash Lazy Evaluation implies the information inside RDDs are not assessed in a hurry. Essentially, simply after an activity triggers every one of the progressions or the calculation is performed. In this way, it confines how much work it needs to do. learn Lazy Evaluation in detail.
iii. Adaptation to internal failure
In the event that any laborer hub comes up short, by utilizing ancestry of activities, we can re-register the lost parcel of RDD from the first one. Henceforth, it is conceivable to recoup lost information effectively. Learn Fault Tolerance in detail.
iv. Permanence
Permanence implies once we make a RDD, we can not control it. In addition, we can make another RDD by playing out any change. Likewise, we accomplish consistency through permanence.
v. Steadiness
In-memory, we can store the every now and again utilized RDD. Likewise, we can recover them legitimately from memory without going to circle. It brings about the speed of the execution. Also, we can play out various tasks on similar information. It is just conceivable by putting away the information expressly in memory by calling persevere() or store() work.
Learn Persistence and Caching Mechanism in detail.
vi. Apportioning
Fundamentally, RDD segment the records intelligently. Likewise, appropriates the information crosswise over different hubs in the bunch. Additionally, the legitimate divisions are just for handling and inside it has no division. Consequently, it gives parallelism.
vii. Parallel
While we talk about parallel preparing, RDD forms the information parallelly over the bunch.
viii. Area Stickiness
To figure segments, RDDs are fit for characterizing position inclination. Besides, situation inclination alludes to data about the area of RDD. In spite of the fact that, the DAGScheduler places the segments so that assignment is near information however much as could reasonably be expected. Also, it accelerates calculation.
ix. Coarse-grained Operation
For the most part, we apply coarse-grained changes to Spark RDD. It implies the activity applies to the entire dataset not on the single component in the informational collection of RDD in Spark.
x. Composed
There are a few kinds of Spark RDD. For example, RDD [int], RDD [long], RDD [string].
xi. No restriction
There are no restrictions to utilize the quantity of Spark RDD. We can utilize any no. of RDDs. Fundamentally, the cutoff relies upon the size of plate and memory.
In this Apache Spark and Scala Online Training, we spread most Features of Spark RDD to study RDD Features pursue this connection.
#Spark and Scala Training#spark scala online training#scala online training#Spark Scala Training in Hyderabad
0 notes
Text
300+ TOP PYSPARK Interview Questions and Answers
PYSPARK Interview Questions for freshers experienced :-
1. What is Pyspark? Pyspark is a bunch figuring structure which keeps running on a group of item equipment and performs information unification i.e., perusing and composing of wide assortment of information from different sources. In Spark, an undertaking is an activity that can be a guide task or a lessen task. Flash Context handles the execution of the activity and furthermore gives API’s in various dialects i.e., Scala, Java and Python to create applications and quicker execution when contrasted with MapReduce. 2. How is Spark not quite the same as MapReduce? Is Spark quicker than MapReduce? Truly, Spark is quicker than MapReduce. There are not many significant reasons why Spark is quicker than MapReduce and some of them are beneath: There is no tight coupling in Spark i.e., there is no compulsory principle that decrease must come after guide. Spark endeavors to keep the information “in-memory” however much as could be expected. In MapReduce, the halfway information will be put away in HDFS and subsequently sets aside longer effort to get the information from a source yet this isn’t the situation with Spark. 3. Clarify the Apache Spark Architecture. How to Run Spark applications? Apache Spark application contains two projects in particular a Driver program and Workers program. A group supervisor will be there in the middle of to communicate with these two bunch hubs. Sparkle Context will stay in contact with the laborer hubs with the assistance of Cluster Manager. Spark Context resembles an ace and Spark laborers resemble slaves. Workers contain the agents to run the activity. In the event that any conditions or contentions must be passed, at that point Spark Context will deal with that. RDD’s will dwell on the Spark Executors. You can likewise run Spark applications locally utilizing a string, and on the off chance that you need to exploit appropriated conditions you can take the assistance of S3, HDFS or some other stockpiling framework. 4. What is RDD? RDD represents Resilient Distributed Datasets (RDDs). In the event that you have enormous measure of information, and isn’t really put away in a solitary framework, every one of the information can be dispersed over every one of the hubs and one subset of information is called as a parcel which will be prepared by a specific assignment. RDD’s are exceptionally near information parts in MapReduce. 5. What is the job of blend () and repartition () in Map Reduce? Both mix and repartition are utilized to change the quantity of segments in a RDD however Coalesce keeps away from full mix. On the off chance that you go from 1000 parcels to 100 segments, there won’t be a mix, rather every one of the 100 new segments will guarantee 10 of the present allotments and this does not require a mix. Repartition plays out a blend with mix. Repartition will result in the predefined number of parcels with the information dispersed utilizing a hash professional. 6. How would you determine the quantity of parcels while making a RDD? What are the capacities? You can determine the quantity of allotments while making a RDD either by utilizing the sc.textFile or by utilizing parallelize works as pursues: Val rdd = sc.parallelize(data,4) val information = sc.textFile(“path”,4) 7. What are activities and changes? Changes make new RDD’s from existing RDD and these changes are sluggish and won’t be executed until you call any activity. Example:: map(), channel(), flatMap(), and so forth., Activities will return consequences of a RDD. Example:: lessen(), tally(), gather(), and so on., 8. What is Lazy Evaluation? On the off chance that you make any RDD from a current RDD that is called as change and except if you consider an activity your RDD won’t be emerged the reason is Spark will defer the outcome until you truly need the outcome in light of the fact that there could be a few circumstances you have composed something and it turned out badly and again you need to address it in an intuitive manner it will expand the time and it will make un-essential postponements. Additionally, Spark improves the required figurings and takes clever choices which is beyond the realm of imagination with line by line code execution. Sparkle recoups from disappointments and moderate laborers. 9. Notice a few Transformations and Actions Changes map (), channel(), flatMap() Activities diminish(), tally(), gather() 10. What is the job of store() and continue()? At whatever point you need to store a RDD into memory with the end goal that the RDD will be utilized on different occasions or that RDD may have made after loads of complex preparing in those circumstances, you can exploit Cache or Persist. You can make a RDD to be continued utilizing the persevere() or store() works on it. The first occasion when it is processed in an activity, it will be kept in memory on the hubs. When you call persevere(), you can indicate that you need to store the RDD on the plate or in the memory or both. On the off chance that it is in-memory, regardless of whether it ought to be put away in serialized organization or de-serialized position, you can characterize every one of those things. reserve() resembles endure() work just, where the capacity level is set to memory as it were.

11. What are Accumulators? Collectors are the compose just factors which are introduced once and sent to the specialists. These specialists will refresh dependent on the rationale composed and sent back to the driver which will total or process dependent on the rationale. No one but driver can get to the collector’s esteem. For assignments, Accumulators are compose as it were. For instance, it is utilized to include the number blunders seen in RDD crosswise over laborers. 12. What are Broadcast Variables? Communicate Variables are the perused just shared factors. Assume, there is a lot of information which may must be utilized on various occasions in the laborers at various stages. 13. What are the enhancements that engineer can make while working with flash? Flash is memory serious, whatever you do it does in memory. Initially, you can alter to what extent flash will hold up before it times out on every one of the periods of information region information neigh borhood process nearby hub nearby rack neighborhood Any. Channel out information as ahead of schedule as could be allowed. For reserving, pick carefully from different capacity levels. Tune the quantity of parcels in sparkle. 14. What is Spark SQL? Flash SQL is a module for organized information handling where we exploit SQL questions running on the datasets. 15. What is a Data Frame? An information casing resembles a table, it got some named sections which composed into segments. You can make an information outline from a document or from tables in hive, outside databases SQL or NoSQL or existing RDD’s. It is practically equivalent to a table. 16. How might you associate Hive to Spark SQL? The principal significant thing is that you need to place hive-site.xml record in conf index of Spark. At that point with the assistance of Spark session object we can develop an information outline as, 17. What is GraphX? Ordinarily you need to process the information as charts, since you need to do some examination on it. It endeavors to perform Graph calculation in Spark in which information is available in documents or in RDD’s. GraphX is based on the highest point of Spark center, so it has got every one of the abilities of Apache Spark like adaptation to internal failure, scaling and there are numerous inbuilt chart calculations too. GraphX binds together ETL, exploratory investigation and iterative diagram calculation inside a solitary framework. You can see indistinguishable information from the two charts and accumulations, change and unite diagrams with RDD effectively and compose custom iterative calculations utilizing the pregel API. GraphX contends on execution with the quickest diagram frameworks while holding Spark’s adaptability, adaptation to internal failure and convenience. 18. What is PageRank Algorithm? One of the calculation in GraphX is PageRank calculation. Pagerank measures the significance of every vertex in a diagram accepting an edge from u to v speaks to a supports of v’s significance by u. For exmaple, in Twitter if a twitter client is trailed by numerous different clients, that specific will be positioned exceptionally. GraphX accompanies static and dynamic executions of pageRank as techniques on the pageRank object. 19. What is Spark Streaming? At whatever point there is information streaming constantly and you need to process the information as right on time as could reasonably be expected, all things considered you can exploit Spark Streaming. 20. What is Sliding Window? In Spark Streaming, you need to determine the clump interim. In any case, with Sliding Window, you can indicate what number of last clumps must be handled. In the beneath screen shot, you can see that you can indicate the clump interim and what number of bunches you need to process. 21. Clarify the key highlights of Apache Spark. Coming up next are the key highlights of Apache Spark: Polyglot Speed Multiple Format Support Lazy Evaluation Real Time Computation Hadoop Integration Machine Learning 22. What is YARN? Like Hadoop, YARN is one of the key highlights in Spark, giving a focal and asset the executives stage to convey adaptable activities over the bunch. YARN is a conveyed holder chief, as Mesos for instance, while Spark is an information preparing instrument. Sparkle can keep running on YARN, a similar way Hadoop Map Reduce can keep running on YARN. Running Spark on YARN requires a double dispersion of Spark as based on YARN support. 23. Do you have to introduce Spark on all hubs of YARN bunch? No, in light of the fact that Spark keeps running over YARN. Flash runs autonomously from its establishment. Sparkle has a few alternatives to utilize YARN when dispatching employments to the group, as opposed to its very own inherent supervisor, or Mesos. Further, there are a few arrangements to run YARN. They incorporate ace, convey mode, driver-memory, agent memory, agent centers, and line. 24. Name the parts of Spark Ecosystem. Spark Core: Base motor for huge scale parallel and disseminated information handling Spark Streaming: Used for handling constant spilling information Spark SQL: Integrates social handling with Spark’s useful programming API GraphX: Graphs and chart parallel calculation MLlib: Performs AI in Apache Spark 25. How is Streaming executed in Spark? Clarify with precedents. Sparkle Streaming is utilized for handling constant gushing information. Along these lines it is a helpful expansion deeply Spark API. It empowers high-throughput and shortcoming tolerant stream handling of live information streams. The crucial stream unit is DStream which is fundamentally a progression of RDDs (Resilient Distributed Datasets) to process the constant information. The information from various sources like Flume, HDFS is spilled lastly handled to document frameworks, live dashboards and databases. It is like bunch preparing as the information is partitioned into streams like clusters. 26. How is AI executed in Spark? MLlib is adaptable AI library given by Spark. It goes for making AI simple and adaptable with normal learning calculations and use cases like bunching, relapse separating, dimensional decrease, and alike. 27. What record frameworks does Spark support? The accompanying three document frameworks are upheld by Spark: Hadoop Distributed File System (HDFS). Local File framework. Amazon S3 28. What is Spark Executor? At the point when SparkContext associates with a group chief, it obtains an Executor on hubs in the bunch. Representatives are Spark forms that run controls and store the information on the laborer hub. The last assignments by SparkContext are moved to agents for their execution. 29. Name kinds of Cluster Managers in Spark. The Spark system underpins three noteworthy sorts of Cluster Managers: Standalone: An essential administrator to set up a group. Apache Mesos: Generalized/regularly utilized group administrator, additionally runs Hadoop MapReduce and different applications. YARN: Responsible for asset the board in Hadoop. 30. Show some utilization situations where Spark beats Hadoop in preparing. Sensor Data Processing: Apache Spark’s “In-memory” figuring works best here, as information is recovered and joined from various sources. Real Time Processing: Spark is favored over Hadoop for constant questioning of information. for example Securities exchange Analysis, Banking, Healthcare, Telecommunications, and so on. Stream Processing: For preparing logs and identifying cheats in live streams for cautions, Apache Spark is the best arrangement. Big Data Processing: Spark runs upto multiple times quicker than Hadoop with regards to preparing medium and enormous estimated datasets. 31. By what method can Spark be associated with Apache Mesos? To associate Spark with Mesos: Configure the sparkle driver program to associate with Mesos. Spark paired bundle ought to be in an area open by Mesos. Install Apache Spark in a similar area as that of Apache Mesos and design the property ‘spark.mesos.executor.home’ to point to the area where it is introduced. 32. How is Spark SQL not the same as HQL and SQL? Flash SQL is a unique segment on the Spark Core motor that supports SQL and Hive Query Language without changing any sentence structure. It is conceivable to join SQL table and HQL table to Spark SQL. 33. What is ancestry in Spark? How adaptation to internal failure is accomplished in Spark utilizing Lineage Graph? At whatever point a progression of changes are performed on a RDD, they are not assessed promptly, however languidly. At the point when another RDD has been made from a current RDD every one of the conditions between the RDDs will be signed in a diagram. This chart is known as the ancestry diagram. Consider the underneath situation Ancestry chart of every one of these activities resembles: First RDD Second RDD (applying map) Third RDD (applying channel) Fourth RDD (applying check) This heredity diagram will be helpful on the off chance that if any of the segments of information is lost. Need to set spark.logLineage to consistent with empower the Rdd.toDebugString() gets empowered to print the chart logs. 34. What is the contrast between RDD , DataFrame and DataSets? RDD : It is the structure square of Spark. All Dataframes or Dataset is inside RDDs. It is lethargically assessed permanent gathering objects RDDS can be effectively reserved if a similar arrangement of information should be recomputed. DataFrame : Gives the construction see ( lines and segments ). It tends to be thought as a table in a database. Like RDD even dataframe is sluggishly assessed. It offers colossal execution due to a.) Custom Memory Management – Data is put away in off load memory in twofold arrangement .No refuse accumulation because of this. Optimized Execution Plan – Query plans are made utilizing Catalyst analyzer. DataFrame Limitations : Compile Time wellbeing , i.e no control of information is conceivable when the structure isn’t known. DataSet : Expansion of DataFrame DataSet Feautures – Provides best encoding component and not at all like information edges supports arrange time security. 35. What is DStream? Discretized Stream (DStream) Apache Spark Discretized Stream is a gathering of RDDS in grouping . Essentially, it speaks to a flood of information or gathering of Rdds separated into little clusters. In addition, DStreams are based on Spark RDDs, Spark’s center information reflection. It likewise enables Streaming to flawlessly coordinate with some other Apache Spark segments. For example, Spark MLlib and Spark SQL. 36. What is the connection between Job, Task, Stage ? Errand An errand is a unit of work that is sent to the agent. Each stage has some assignment, one undertaking for every segment. The Same assignment is done over various segments of RDD. Occupation The activity is parallel calculation comprising of numerous undertakings that get produced in light of activities in Apache Spark. Stage Each activity gets isolated into littler arrangements of assignments considered stages that rely upon one another. Stages are named computational limits. All calculation is impossible in single stage. It is accomplished over numerous stages. 37. Clarify quickly about the parts of Spark Architecture? Flash Driver: The Spark driver is the procedure running the sparkle setting . This driver is in charge of changing over the application to a guided diagram of individual strides to execute on the bunch. There is one driver for each application. 38. How might you limit information moves when working with Spark? The different manners by which information moves can be limited when working with Apache Spark are: Communicate and Accumilator factors 39. When running Spark applications, is it important to introduce Spark on every one of the hubs of YARN group? Flash need not be introduced when running a vocation under YARN or Mesos in light of the fact that Spark can execute over YARN or Mesos bunches without influencing any change to the group. 40. Which one will you decide for an undertaking – Hadoop MapReduce or Apache Spark? The response to this inquiry relies upon the given undertaking situation – as it is realized that Spark utilizes memory rather than system and plate I/O. In any case, Spark utilizes enormous measure of RAM and requires devoted machine to create viable outcomes. So the choice to utilize Hadoop or Spark changes powerfully with the necessities of the venture and spending plan of the association. 41. What is the distinction among continue() and store() endure () enables the client to determine the capacity level while reserve () utilizes the default stockpiling level. 42. What are the different dimensions of constancy in Apache Spark? Apache Spark naturally endures the mediator information from different mix tasks, anyway it is regularly proposed that clients call persevere () technique on the RDD on the off chance that they intend to reuse it. Sparkle has different tirelessness levels to store the RDDs on circle or in memory or as a mix of both with various replication levels. 43. What are the disservices of utilizing Apache Spark over Hadoop MapReduce? Apache Spark’s in-memory ability now and again comes a noteworthy barrier for cost effective preparing of huge information. Likewise, Spark has its own record the board framework and consequently should be incorporated with other cloud based information stages or apache hadoop. 44. What is the upside of Spark apathetic assessment? Apache Spark utilizes sluggish assessment all together the advantages: Apply Transformations tasks on RDD or “stacking information into RDD” isn’t executed quickly until it sees an activity. Changes on RDDs and putting away information in RDD are languidly assessed. Assets will be used in a superior manner if Spark utilizes sluggish assessment. Lazy assessment advances the plate and memory utilization in Spark. The activities are activated just when the information is required. It diminishes overhead. 45. What are advantages of Spark over MapReduce? Because of the accessibility of in-memory handling, Spark executes the preparing around 10 to multiple times quicker than Hadoop MapReduce while MapReduce utilizes diligence stockpiling for any of the information handling errands. Dissimilar to Hadoop, Spark gives inbuilt libraries to play out numerous errands from a similar center like cluster preparing, Steaming, Machine learning, Interactive SQL inquiries. Be that as it may, Hadoop just backings cluster handling. Hadoop is very plate subordinate while Spark advances reserving and in-memory information stockpiling. 46. How DAG functions in Spark? At the point when an Action is approached Spark RDD at an abnormal state, Spark presents the heredity chart to the DAG Scheduler. Activities are separated into phases of the errand in the DAG Scheduler. A phase contains errand dependent on the parcel of the info information. The DAG scheduler pipelines administrators together. It dispatches task through group chief. The conditions of stages are obscure to the errand scheduler.The Workers execute the undertaking on the slave. 47. What is the hugeness of Sliding Window task? Sliding Window controls transmission of information bundles between different PC systems. Sparkle Streaming library gives windowed calculations where the changes on RDDs are connected over a sliding window of information. At whatever point the window slides, the RDDs that fall inside the specific window are consolidated and worked upon to create new RDDs of the windowed DStream. 48. What are communicated and Accumilators? Communicate variable: On the off chance that we have an enormous dataset, rather than moving a duplicate of informational collection for each assignment, we can utilize a communicate variable which can be replicated to every hub at one timeand share similar information for each errand in that hub. Communicate variable assistance to give a huge informational collection to every hub. Collector: Flash capacities utilized factors characterized in the driver program and nearby replicated of factors will be produced. Aggregator are shared factors which help to refresh factors in parallel during execution and offer the outcomes from specialists to the driver. 49. What are activities ? An activity helps in bringing back the information from RDD to the nearby machine. An activity’s execution is the aftereffect of all recently made changes. lessen() is an activity that executes the capacity passed over and over until one esteem assuming left. take() move makes every one of the qualities from RDD to nearby hub. 50. Name kinds of Cluster Managers in Spark. The Spark system bolsters three noteworthy kinds of Cluster Managers: Independent : An essential administrator to set up a bunch. Apache Mesos : Summed up/ordinarily utilized group director, additionally runs Hadoop MapReduce and different applications. PYSPARK Questions and Answers Pdf Download Read the full article
0 notes
Text
Google Analytics (GA) like Backend System Architecture
There are numerous way of designing a backend. We will take Microservices route because the web scalability is required for Google Analytics (GA) like backend. Micro services enable us to elastically scale horizontally in response to incoming network traffic into the system. And a distributed stream processing pipeline scales in proportion to the load.
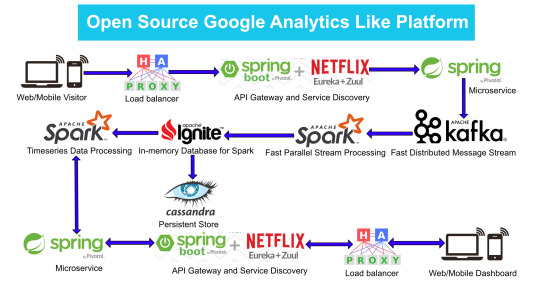
Here is the High Level architecture of the Google Analytics (GA) like Backend System.
Components Breakdown
Web/Mobile Visitor Tracking Code
Every web page or mobile site tracked by GA embed tracking code that collects data about the visitor. It loads an async script that assigns a tracking cookie to the user if it is not set. It also sends an XHR request for every user interaction.
HAProxy Load Balancer
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers. It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
A backend can contain one or many servers in it — generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
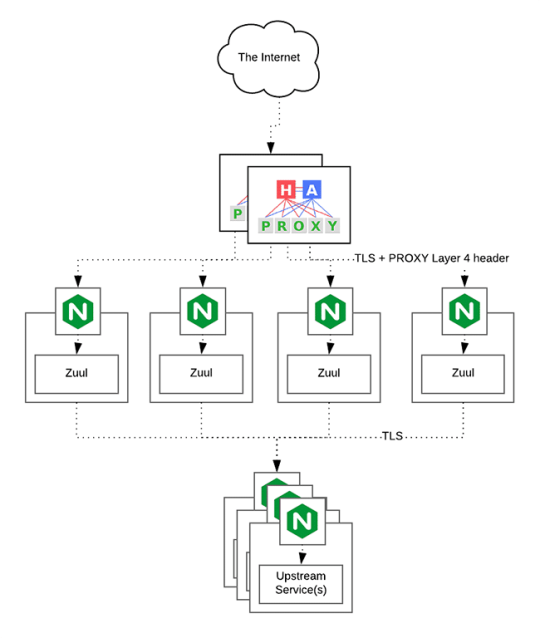
HAProxy routes the requests coming from Web/Mobile Visitor site to the Zuul API Gateway of the solution. Given the nature of a distributed system built for scalability and stateless request and response handling we can distribute the Zuul API gateways spread across geographies. HAProxy performs load balancing (layer 4 + proxy) across our Zuul nodes. High-Availability (HA ) is provided via Keepalived.
Spring Boot & Netflix OSS Eureka + Zuul
Zuul is an API gateway and edge service that proxies requests to multiple backing services. It provides a unified “front door” to the application ecosystem, which allows any browser, mobile app or other user interface to consume services from multiple hosts. Zuul is integrated with other Netflix stack components like Hystrix for fault tolerance and Eureka for service discovery or use it to manage routing rules, filters and load balancing across your system. Most importantly all of those components are well adapted by Spring framework through Spring Boot/Cloud approach.
An API gateway is a layer 7 (HTTP) router that acts as a reverse proxy for upstream services that reside inside your platform. API gateways are typically configured to route traffic based on URI paths and have become especially popular in the microservices world because exposing potentially hundreds of services to the Internet is both a security nightmare and operationally difficult. With an API gateway, one simply exposes and scales a single collection of services (the API gateway) and updates the API gateway’s configuration whenever a new upstream should be exposed externally. In our case Zuul is able to auto discover services registered in Eureka server.
Eureka server acts as a registry and allows all clients to register themselves and used for Service Discovery to be able to find IP address and port of other services if they want to talk to. Eureka server is a client as well. This property is used to setup Eureka in highly available way. We can have Eureka deployed in a highly available way if we can have more instances used in the same pattern.
Spring Boot Microservices
Using a microservices approach to application development can improve resilience and expedite the time to market, but breaking apps into fine-grained services offers complications. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain. With microservices, the code is broken into independent services that run as separate processes.
Scalability is the key aspect of microservices. Because each service is a separate component, we can scale up a single function or service without having to scale the entire application. Business-critical services can be deployed on multiple servers for increased availability and performance without impacting the performance of other services. Designing for failure is essential. We should be prepared to handle multiple failure issues, such as system downtime, slow service and unexpected responses. Here, load balancing is important. When a failure arises, the troubled service should still run in a degraded functionality without crashing the entire system. Hystrix Circuit-breaker will come into rescue in such failure scenarios.
The microservices are designed for scalability, resilience, fault-tolerance and high availability and importantly it can be achieved through deploying the services in a Docker Swarm or Kubernetes cluster. Distributed and geographically spread Zuul API gateways route requests from web and mobile visitors to the microservices registered in the load balanced Eureka server.
The core processing logic of the backend system is designed for scalability, high availability, resilience and fault-tolerance using distributed Streaming Processing, the microservices will ingest data to Kafka Streams data pipeline.
Apache Kafka Streams
Apache Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications.
It allows:
Publishing and subscribing to streams of records
Storing streams of records in a fault-tolerant, durable way
It provides a unified, high-throughput, low-latency, horizontally scalable platform that is used in production in thousands of companies.
Kafka Streams being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) are what we need — not to mention Kafka being a reliable and mature messaging system.
Kafka is run as a cluster on one or more servers that can span multiple datacenters spread across geographies. Those servers are usually called brokers.
Kafka uses Zookeeper to store metadata about brokers, topics and partitions.
Kafka Streams is a pretty fast, lightweight stream processing solution that works best if all of the data ingestion is coming through Apache Kafka. The ingested data is read directly from Kafka by Apache Spark for stream processing and creates Timeseries Ignite RDD (Resilient Distributed Datasets).
Apache Spark
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
It provides a high-level abstraction called a discretized stream, or DStream, which represents a continuous stream of data.
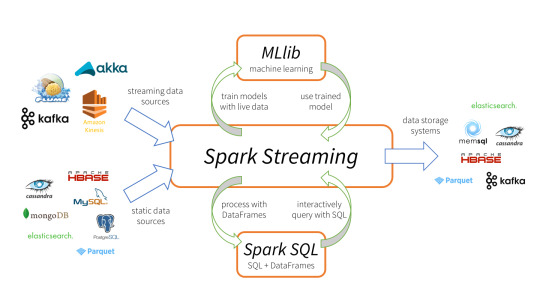
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Datasets).
Apache Spark is a perfect choice in our case. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
In our scenario Spark streaming process Kafka data streams; create and share Ignite RDDs across Apache Ignite which is a distributed memory-centric database and caching platform.
Apache Ignite
Apache Ignite is a distributed memory-centric database and caching platform that is used by Apache Spark users to:
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
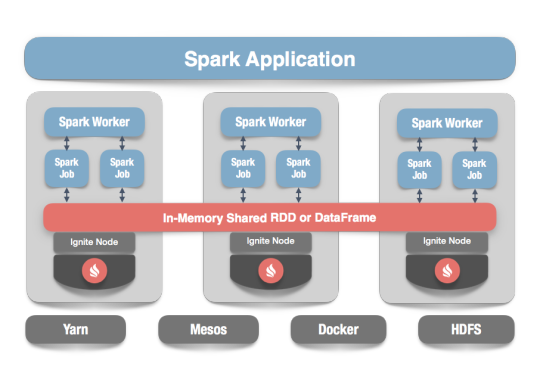
More easily share state and data among Spark jobs.
Apache Ignite is designed for transactional, analytical, and streaming workloads, delivering in-memory performance at scale. Apache Ignite provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications.
The way an Ignite RDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Apache Cassandra
We will use Apache Cassandra as storage for persistence writes from Ignite.
Apache Cassandra is a highly scalable and available distributed database that facilitates and allows storing and managing high velocity structured data across multiple commodity servers without a single point of failure.
The Apache Cassandra is an extremely powerful open source distributed database system that works extremely well to handle huge volumes of records spread across multiple commodity servers. It can be easily scaled to meet sudden increase in demand, by deploying multi-node Cassandra clusters, meets high availability requirements, and there is no single point of failure.
Apache Cassandra has best write and read performance.
Characteristics of Cassandra:
It is a column-oriented database
Highly consistent, fault-tolerant, and scalable
The data model is based on Google Bigtable
The distributed design is based on Amazon Dynamo
Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes.
In our scenario we will configure Ignite to work in write-behind mode: normally, a cache write involves putting data in memory, and writing the same into the persistence source, so there will be 1-to-1 mapping between cache writes and persistence writes. With the write-behind mode, Ignite instead will batch the writes and execute them regularly at the specified frequency. This is aimed at limiting the amount of communication overhead between Ignite and the persistent store, and really makes a lot of sense if the data being written rapidly changes.
Analytics Dashboard
Since we are talking about scalability, high availability, resilience and fault-tolerance, our analytics dashboard backend should be designed in a pretty similar way we have designed the web/mobile visitor backend solution using HAProxy Load Balancer, Zuul API Gateway, Eureka Service Discovery and Spring Boot Microservices.
The requests will be routed from Analytics dashboard through microservices. Apache Spark will do processing of time series data shared in Apache Ignite as Ignite RDDs and the results will be sent across to the dashboard for visualization through microservices
0 notes
Link
Aparche Spark streaming con Python y PySpark ##udemycourses ##UdemyFreeDiscountCoupons #Aparche #con #PySpark #Python #Spark #Streaming Aparche Spark streaming con Python y PySpark De qué trata este curso: Este curso cubre todos los aspectos fundamentales de Apache Spark streaming con Python, y te enseña todo lo que necesitas saber sobre el desarrollo de aplicaciones Apache Spark. Al final de este curso, obtendrás un conocimiento profundo sobre Apache Spark streaming, así como habilidades generales de manejo y análisis de big data para ayudar a tu empresa o proyecto a adaptar Apache Spark para la construcción de un pipeline de procesamiento de big data y aplicaciones de análisis de datos. Este curso sera absolutamente critico para cualquiera que quiera dominar Data Science hoy en día. ¿Qué aprenderás en estas clases? En particular, aprenderás: Sobre la arquitectura de Apache Spark. Como desarrollar aplicaciones Apache Spark streaming con PySpark usando transformaciones RDD, acciones y Spark SQL. Serás capaz de trabajar con la abstracción principal de Apache Spark, RDDs o conjuntos de datos distribuidos y resilientes (RDD) para procesar y analizar grandes conjuntos de datos. Técnicas avanzadas para optimizar y mejorar los trabajos Apache Spark al usar particiones, almacenamiento en cache y persistencia de RDDs. Escalar aplicaciones Spark Streaming para banda ancha y velocidad de procesamiento. Analizar datos estructurados y semiestructurados utilizando conjuntos de datos (Datasets) y Dataframes, y entender a detalle el funcionamiento de Spark SQL. Como integrar Spark Streaming con herramientas de computo de clusters tales como Apache Kafka. Conectar tu Spark Stream con una fuente de datos tal como Amazon Web Services (AWS). Técnicas avanzadas para optimizar y mejorar, trabajos de Apache Spark mediante el particionado, almacenamiento en caché y la persistencia de RDDs. Sobre buenas prácticas de trabajo con Apache Spark. Repaso del ecosistema Big Data ¿Por qué debería aprender Apache Spark en streaming? Spark Streaming se está volviendo increíblemente popular. Según IBM, el noventa por ciento de los datos en el mundo de hoy se ha creado solo en los últimos dos años. Nuestra salida actual de datos es de aproximadamente 2.5 quintillones de bytes por día. El mundo está siendo inmerso en datos, cada día más. Como tal, el análisis de marcos de datos estáticos de datos no dinámicos se convierte en el enfoque menos práctico de cada vez más problemas. Aquí es donde entra la transmisión de datos, la capacidad de procesar datos casi tan pronto como se producen, reconociendo la dependencia del tiempo de los datos. Apache Spark streaming nos brinda una capacidad ilimitada para crear aplicaciones de vanguardia. También es una de las tecnologías más convincentes de la última década en términos de su interrupción en el mundo del big data. Spark proporciona computación en clúster en memoria que aumenta considerablemente la velocidad de los algoritmos iterativos y las tareas de minería de datos interactiva. Spark también es un potente motor para transmitir datos y procesarlos. La sinergia entre ellos hace de Spark una herramienta ideal para procesar gigantescos chimeneas de datos. Toneladas de compañías, incluidas las de Fortune 500, están adaptando la transmisión de Apache Spark para extraer el significado de flujos de datos masivos. Hoy en día, tienes acceso a esa misma tecnología de big data en tu escritorio. ¿En qué lenguaje de programación se enseña este curso de Apache Spark streaming? Apache Spark streaming se imparte en Python. Python es actualmente uno de los lenguajes de programación más populares del mundo! Su gran comunidad de datos, que ofrece vastas cantidades de juegos de herramientas y características, la convierte en una herramienta poderosa para el procesamiento de datos. Al utilizar PySpark (la API de Python para Spark), podrá interactuar con la abstracción principal de Apache Spark Streaming, RDDs, así como con otros componentes de Spark, como Spark SQL y mucho más. ¡Aprendamos cómo escribir programas de transmisión de Apache Spark Streaming con PySpark para procesar fuentes de big data hoy! ¡30 días de garantía de devolución de dinero! Udemy brinda una garantía de devolución de dinero de 30 días para este curso de Apache Spark streaming. Si no estás satisfecho, simplemente solicita un reembolso dentro de los 30 días. Obtendrás un reembolso completo sin preguntas en absoluto. ¿Está listo para llevar tus habilidades de análisis de big data y tu carrera al siguiente nivel, toma este curso ahora? Aprenderás Spark en 4 horas. Para quién es este curso: Desarrolladores de Python que buscan mejorar en Data Streaming Gerentes o Ingenieros Senior en Equipos de Ingeniería de Datos Desarrolladores Spark ansiosos por ampliar sus habilidades. Who this course is for: Cualquier persona que quiera entender completamente cómo funciona Apache Spark, y cómo se usa Apache Spark en la industria. Ingenieros de software que deseen desarrollar aplicaciones con Apache Spark 2.0 utilizando Spark Core y Spark SQL. Científicos de datos o ingenieros de datos que quieran avanzar en su carrera mejorando sus habilidades de procesamiento de Big Data. 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/aparche-spark-streaming-con-python-y-pyspark/
0 notes
Text
8 Performance Optimization Techniques Using Spark
Due to its fast, easy-to-use capabilities, Apache Spark helps to Enterprises process data faster, solving complex data problems quickly.
We all know that during the development of any program, taking care of the performance is equally important. A Spark job can be optimized by many techniques so let’s dig deeper into those techniques one by one. Apache Spark optimization helps with in-memory data computations. The bottleneck for these spark optimization computations can be CPU, memory or any resource in the cluster.
1. Serialization
Serialization plays an important role in the performance for any distributed application. By default, Spark uses Java serializer.
Spark can also use another serializer called ‘Kryo’ serializer for better performance.
Kryo serializer is in compact binary format and offers processing 10x faster than Java serializer.
To set the serializer properties:
conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
Code:
val conf = new SparkConf().setMaster(…).setAppName(…)
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
Serialization plays an important role in the performance of any distributed application and we know that by default Spark uses the Java serializer on the JVM platform. Instead of Java serializer, Spark can also use another serializer called Kryo. The Kryo serializer gives better performance as compared to the Java serializer.
Kryo serializer is in a compact binary format and offers approximately 10 times faster speed as compared to the Java Serializer. To set the Kryo serializer as part of a Spark job, we need to set a configuration property, which is org.apache.spark.serializer.KryoSerializer.
2. API selection
Spark introduced three types of API to work upon – RDD, DataFrame, DataSet
RDD is used for low level operation with less optimization
DataFrame is best choice in most cases due to its catalyst optimizer and low garbage collection (GC) overhead.
Dataset is highly type safe and use encoders. It uses Tungsten for serialization in binary format.
We know that Spark comes with 3 types of API to work upon -RDD, DataFrame and DataSet.
RDD is used for low-level operations and has less optimization techniques.
DataFrame is the best choice in most cases because DataFrame uses the catalyst optimizer which creates a query plan resulting in better performance. DataFrame also generates low labor garbage collection overhead.
DataSets are highly type safe and use the encoder as part of their serialization. It also uses Tungsten for the serializer in binary format.
Code:
val df = spark.read.json(“examples/src/main/resources/people.json”)
case class Person(name: String, age: Long)
// Encoders are created for case classes
val caseClassDS = Seq(Person(“Andy”, 32)).toDS()
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = “examples/src/main/resources/people.json”
val peopleDS = spark.read.json(path).as[Person]
3. Advance Variable
Broadcasting plays an important role while tuning Spark jobs.
Broadcast variable will make small datasets available on nodes locally.
When you have one dataset which is smaller than other dataset, Broadcast join is highly recommended.
To use the Broadcast join: (df1. join(broadcast(df2)))
Spark comes with 2 types of advanced variables – Broadcast and Accumulator.
Broadcasting plays an important role while tuning your spark job. Broadcast variable will make your small data set available on each node, and that node and data will be treated locally for the process.
Want more?
Subscribe to receive articles on topics of your interest, straight to your inbox.
Success!
First Name
Last Name
Email
Subscribe
Suppose you have a situation where one data set is very small and another data set is quite large, and you want to perform the join operation between these two. In that case, we should go for the broadcast join so that the small data set can fit into your broadcast variable. The syntax to use the broadcast variable is df1.join(broadcast(df2)). Here we have a second dataframe that is very small and we are keeping this data frame as a broadcast variable.
Code:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
val accum = sc.longAccumulator(“My Accumulator”)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
accum.value
res2: Long = 10
4. Cache and Persist
Spark provides its own caching mechanisms like persist() and cache().
cache() and persist() will store the dataset in memory.
When you have a small dataset which needs be used multiple times in your program, we cache that dataset.
Cache() – Always in Memory
Persist() – Memory and disks
Spark provides its own caching mechanism like Persist and Caching. Persist and Cache mechanisms will store the data set into the memory whenever there is requirement, where you have a small data set and that data set is being used multiple times in your program. If we apply RDD.Cache() it will always store the data in memory, and if we apply RDD.Persist() then some part of data can be stored into the memory some can be stored on the disk.
5. ByKey Operation
Shuffles are heavy operation which consume a lot of memory.
While coding in Spark, the user should always try to avoid shuffle operation.
High shuffling may give rise to an OutOfMemory Error; To avoid such an error, the user can increase the level of parallelism.
Use reduceByKey instead of groupByKey.
Partition the data correctly.
As we know during our transformation of Spark we have many ByKey operations. ByKey operations generate lot of shuffle. Shuffles are heavy operation because they consume a lot of memory. While coding in Spark, a user should always try to avoid any shuffle operation because the shuffle operation will degrade the performance. If there is high shuffling then a user can get the error out of memory. Inthis case, to avoid that error, a user should increase the level of parallelism. Instead of groupBy, a user should go for the reduceByKey because groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much. Therefore, reduceByKey is faster as compared to groupByKey. Whenever any ByKey operation is used, the user should partition the data correctly.
6. File Format selection
Spark supports many formats, such as CSV, JSON, XML, PARQUET, ORC, AVRO, etc.
Spark jobs can be optimized by choosing the parquet file with snappy compression which gives the high performance and best analysis.
Parquet file is native to Spark which carries the metadata along with its footer.
Spark comes with many file formats like CSV, JSON, XML, PARQUET, ORC, AVRO and more. A Spark job can be optimized by choosing the parquet file with snappy compression. Parquet file is native to Spark which carry the metadata along with its footer as we know parquet file is native to spark which is into the binary format and along with the data it also carry the footer it’s also carries the metadata and its footer so whenever you create any parquet file, you will see .metadata file on the same directory along with the data file.
Code:
val peopleDF = spark.read.json(“examples/src/main/resources/people.json”)
peopleDF.write.parquet(“people.parquet”)
val parquetFileDF = spark.read.parquet(“people.parquet”)
val usersDF = spark.read.format(“avro”).load(“examples/src/main/resources/users.avro”)
usersDF.select(“name”, “favorite_color”).write.format(“avro”).save(“namesAndFavColors.avro”)
7. Garbage Collection Tuning
JVM garbage collection can be a problem when you have large collection of unused objects.
The first step in GC tuning is to collect statistics by choosing – verbose while submitting spark jobs.
In an ideal situation we try to keep GC overheads < 10% of heap memory.
As we know underneath our Spark job is running on the JVM platform so JVM garbage collection can be a problematic when you have a large collection of an unused object so the first step in tuning of garbage collection is to collect statics by choosing the option in your Spark submit verbose. Generally, in an ideal situation we should keep our garbage collection memory less than 10% of heap memory.
8. Level of Parallelism
Parallelism plays a very important role while tuning spark jobs.
Every partition ~ task requires a single core for processing.
There are two ways to maintain the parallelism:
Repartition: Gives equal number of partitions with high shuffling
Coalesce: Generally reduces the number of partitions with less shuffling.
In any distributed environment parallelism plays very important role while tuning your Spark job. Whenever a Spark job is submitted, it creates the desk that will contain stages, and the tasks depend upon partition so every partition or task requires a single core of the system for processing. There are two ways to maintain the parallelism – Repartition and Coalesce. Whenever you apply the Repartition method it gives you equal number of partitions but it will shuffle a lot so it is not advisable to go for Repartition when you want to lash all the data. Coalesce will generally reduce the number of partitions and creates less shuffling of data.
These factors for spark optimization, if properly used, can –
Eliminate the long-running job process
Correction execution engine
Improve performance time by managing resources
For more information and if you have any additional questions, please feel free to reach out to our Spark experts at Syntelli.
SIMILAR POSTS
How Predictive Analytics in Finance Can Accelerate Data-Driven Enterprise Transformation
As the U.S. economy faces unprecedented challenges, predictive analytics in financial services is necessary to accommodate customers’ immediate needs while preparing for future changes. These future changes may amount to enterprise transformation, a fundamental...
read more
7 Reasons to Start Using Customer Intelligence in Your Healthcare Organization
Healthcare organizations face an array of challenges regarding customer communication and retention. Customer intelligence can be a game-changer for small and large organizations due to its ability to understand customer needs and preferences. When it comes to data,...
read more
The Future of Analytics in Higher Education with Artificial Intelligence
The future is sooner than you would have expected – it is now. Contrary to concerns about Artificial Intelligence (AI) in everyday activities, ethical AI can enhance a balanced, accessible, scalable, and inclusive learning system. With the increasingly limited...
read more
The post 8 Performance Optimization Techniques Using Spark appeared first on Syntelli Solutions Inc..
https://www.syntelli.com/eight-performance-optimization-techniques-using-spark
0 notes
Text
Spark Persistance Storage Levels
All different persistence (persist() method) storage level Spark supports are available at org.apache.spark.storage.StorageLevel class. The storage level specifies how and where to persist or cache a Spark RDD, DataFrame and Dataset.
All these Storage levels are passed as an argument to the persist() method of the Spark/Pyspark RDD, DataFrame and Dataset.
For example
import…
View On WordPress
0 notes
Text
Spark Kernel
<a href="https://adrenaline-studios.com">social media marketing</a>
The Spark core is the core engine for large-scale parallel and
distributed data processing. The kernel is responsible for:
● memory management and failure recovery ● Planning, distribution and tracking of cluster tasks ● interaction with data storage systems Spark introduces the concept of RDD (sustainable distributed dataset) - immutable fault tolerant distributed collection of objects that you can handle in parallel. RDD can contain objects of any type; RDD created by loading an external dataset or distributing a collection from main program (driver program). RDD supports two types of operations: ● Transformations are operations (for example, display, filtering, Association, etc.) committed on RDD; result of transformation becomes a new RDD containing its result. ● Actions are operations (for example, reduction, counting, etc.) that return value obtained as a result of some calculations in RDD. Transformations in Spark are carried out in a "lazy" mode - that is, the result is not calculated immediately after transformation. Instead, they simply “remember” the operation to be performed and the data set (e.g. file) over which need to perform an operation. Transforms are calculated only when the action is called, and its result is returned to the main program. Thanks This design improves Spark's performance. For example, if a large file was converted in various ways and transferred to the first action, then Spark will process and will return the result only for the first row, and will not work out this way entire file.
By default, every transformed RDD can be re-calculated whenever when you perform a new action on it. However, RDD is also possible for a long time. store in memory using the storage or caching method; in this case Spark will keep the necessary elements on the cluster, and you will be able to request them much faster.
0 notes
Text
Hadoop Learnings
Hadoop Overview
Inspired by GFS (Google File System).
Rack awareness: The idea of where nodes are located, relative to one another.
3 way replication: Typical replication factor is 3. Copies each block to 3 different servers in the cluster. 1st copy of the block is placed on the same node as the client. 2nd copy is placed on a node residing on a different rack. 3rd copy is placed on a different node in the same rack as the 2nd copy.
Data Integrity: Maintained through E2E checksums. If checksum fails, namenode re-replicates the block to another datanode.
Self healing: Detects bad blocks and auto rebalances. (Checksum by datanode every 3 weeks after the block is created).
Use scale-out model based on inexpensive commodity servers with internal JBOD ("Just a bunch of disks") rather than RAID to achieve large-scale storage.
Hadoop Components
HDFS: Distributed and replicated file system.
Map/Reduce: API that simplifies distributed data processing.
This minimalistic design— just a filesystem and job scheduler—allows Hadoop to complement the relational database. Instead of creating a schema and loading structured data into it, Hadoop lets you load any file into HDFS and use Map/Reduce to process and structure the data later.
HDFS provides redundant and reliable storage for massive amounts of data. File sizes are typically very large, and to reflect that, Hadoop’s default block size is 64MB (compare this with Oracle’s 8KB). So if the input file size is 640 MB, HDFS will break it into 10 blocks each. Ex: if file size is 50MB, HDFS is optimized to create a block of 50MB instead of default 64MB.
HDFS daemon services
Namenode: It’s like a bookkeeper that maintains which file is stored as multiple blocks in which data nodes. Note that data never travels via name node. Used to be SPOF but starting Hadoop 2.0, that’s been addressed. Default Java heap size of name node is 1GB. Kerberos used for authentication.
Secondary namenode: The SecondaryNameNode is NOT a failover NameNode. NameNode keeps information about files and blocks in memory and writes metadata changes to edit log. Secondary NameNode periodically constructs a checkpoint by combining a prior snapshot of the file system metadata and edit log into a new snapshot. The new snapshot is transmitted back to the name node. SecondaryNameNode only exists when high availability is not configured. One more namenode is used as standby when configured in HA where secondary name node is not needed. The standby name node can be used for checkpointing and takes over when primary name node fails.
Job Tracker
Data nodes
Task trackers
Sustained high throughput is given priority over low latency to maximize throughput of large scans. HDFS provides reliability by copying each block to at least three different servers in the cluster. The replication doesn’t just provide failover in case a node crashes, it also allows multiple jobs to process the same data in parallel on different servers.
Deploy namenode and jobtracker on the master node, and deploy datanodes and task trackers on multiple slave nodes.
Map Reduce
1.0 - Original map reduce that uses task tracker and job tracker daemons.
2.0 - YARN (Yet Another Resource Negotiator). YARN splits up the two major functionalities of the JobTracker, resource management and job scheduling/monitoring, into separate daemons as Resource manager, application master, and node manager
Map/Reduce is a method to distribute processing jobs across the servers. Jobs are split into small, mostly independent tasks. Each task is responsible for processing data in one block, and whenever possible it will run on a server that stores that block locally. The design maximizes parallelism by eliminating locks and latches.
As the name suggests, Map/Reduce has two phases: map and reduce. Map tasks filter and modify the data. This is analogous to the “where” portion of a query and to non-aggregating functions applied to the data. The reduce phase applies the data aggregation: group by and aggregating functions such as sum and average.
When to use HDFS
Very large files
Batch Processing
Streaming data access:
Read data in bigger volume, Write once, read many times. Sequential reads.
Cost Effective: Commodity H/W instead of expensive commercial solutions.
Behavioural Data: Application examples - Ad Targeting, Recommendation Engine.
When NOT to use HDFS
Low Latency
Lot of small files
Parallel writes, random reads
Transactional data
Hadoop Distributions
Open Source: Apache
Commercial: Cloudera, Hortonworks, MapR
Cloud: AWS
Hadoop processes run in different JVMs and JVMs do not share state.
Hadoop ecosystem Overview
Hive: Apache Hive is data warehouse infrastructure built on top of Hadoop that can compile SQL queries into Map Reduce jobs and run the jobs in the cluster. Think of Hive query as Oracle query with large parallel operations across a very large Oracle RAC but without cache fusion. A normal Oracle operation consists of two sets of PX processes, producers and consumers, and a PX coordinator. For Hive, the producer is Hadoop Mapper, the consumer is Hadoop Reducer and the PX coordinator is Hadoop Job Tracker.
PIG: Hive is SQL like query language that generates map reduce jobs for batch processing, not interactive. Developed at Facebook. Mostly used with HBase. PIG developed at Yahoo is ETL library for Hadoop that compiles Pig latin scripts into map reduce jobs. Also allows to create UDF (user defined function). There are no if statements or for loops in Pig Latin. Pig Latin instead focuses on data flow and is used for ETL.
Oozie: Workflow scheduler library to schedule recurring jobs on Hadoop.
Sqoop (SQL to Hadoop): Utility to transfer data between HDFS and RDBMS.
Flume: Library for working with log data. Typically used to ingest log files from real time systems into HDFS.
Zookeeper: Centralized service for distributed coordination, developed at Yahoo Research.
Impala: Need for speed. Interactive Hive. In memory and column store. Does not generate map reduce jobs. Faster query results. Ships with Cloudera distribution.
Mahout: Used to perform predictive analytics through Machine learning and data mining.
Spark: Fast In memory Hive based on RDDs. Open source Apache library compared to Cloudera distributed Impala. Useful for ETL and graph algorithms. Spark solves similar problems as Hadoop MapReduce does but with a fast in-memory approach and a clean functional style API.
HBase (Columnar like Cassandra): HBase is an open source, non-relational, columnar distributed database modeled after Google's BigTable and runs on top of HDFS. Recommended for large scans and analytics in Hadoop ecosystem. Not recommended for low latency serving. In terms of CAP, it’s CP with strong consistency and typical implementation needs at least 5 nodes. In terms of drawbacks, it doesn’t have data types (everything treated as bytes) and no sorting and no indexing other than the row keys.
In HBase a master node manages the cluster and region servers store portions of the tables and perform the work on the data.
In HBase, data is physically sharded into what are known as regions. When data is added to HBase, it’s first written to a write-ahead log (WAL) known as the HLog. Once written to the HLog, the data is then stored in an in-memory MemStore. Once the data in memory exceeds a certain threshold, it’s flushed as an HFile to disk. As the number of HFiles increases with MemStore flushes, HBase will merge several smaller files into a few larger ones, to reduce the overhead of reads. This is known as compaction.
0 notes
Text
Big Data Architect with net2source
The position listed below is not with New York Interviews but with net2sourceNew York Interviews is a private organization that works in collaboration with government agencies to promote emerging careers. Our goal is to connect you with supportive resources to supplement your skills in order to attain your dream career. New York Interviews has also partnered with industry leading consultants & training providers that can assist during your career transition. We look forward to helping you reach your career goals! If you any questions please visit our contact page to connect with us directlyNet2Source, Inc. is one of the fastest growing IT Consulting company across the USA. N2S is headquartered at NJ, USA with its branch offices in Asia Pacific Region. N2S offers a wide gamut of consulting solutions customized to client needs including staffing, training and technology.Job Summary: Job Title: Big Data ArchitectLocation: NYC, NYJob Description Must Have Skills: Apache Spark Core/Streaming/SparkSQL and Hbase Big Data Architect Apache Spark Core/Streaming/Spark SQL and HBase, Spark's RDD, DataFrames and datasets API's, and query performance debugging and optimization, core Spark internals, such as caching, memory management, storage versus execution memory, shuffling, partitioning, checkpointing. About Net2Source, Inc. Net2Source is an employer-of-choice for over 1000 consultants across the globe. We recruit top-notch talent for over 40 Fortune and Government clients coast-to-coast across the U.S. We are one of the fastest-growing companies in the U.S. and this may be your opportunity to join us! Want to read more about Net2Source? , Visit us at www.net2source.comRegards, - provided by Dice(BIG DATA over 5 year(s) ) AND (APACHE ) AND (SPARK ) AND (SQL ) AND (HBASE ) AND (API ) Associated topics: data analytic, data architect, data integration, data integrity, data quality, data scientist, data warehouse, data warehousing, etl, teradata BigDataArchitectwithnet2source from Job Portal http://www.jobisite.com/extrJobView.htm?id=75428
0 notes
Text
Big Data Architect with net2source
The position listed below is not with New York Interviews but with net2sourceNew York Interviews is a private organization that works in collaboration with government agencies to promote emerging careers. Our goal is to connect you with supportive resources to supplement your skills in order to attain your dream career. New York Interviews has also partnered with industry leading consultants & training providers that can assist during your career transition. We look forward to helping you reach your career goals! If you any questions please visit our contact page to connect with us directlyNet2Source, Inc. is one of the fastest growing IT Consulting company across the USA. N2S is headquartered at NJ, USA with its branch offices in Asia Pacific Region. N2S offers a wide gamut of consulting solutions customized to client needs including staffing, training and technology.Job Summary: Job Title: Big Data ArchitectLocation: NYC, NYJob Description Must Have Skills: Apache Spark Core/Streaming/SparkSQL and Hbase Big Data Architect Apache Spark Core/Streaming/Spark SQL and HBase, Spark's RDD, DataFrames and datasets API's, and query performance debugging and optimization, core Spark internals, such as caching, memory management, storage versus execution memory, shuffling, partitioning, checkpointing. About Net2Source, Inc. Net2Source is an employer-of-choice for over 1000 consultants across the globe. We recruit top-notch talent for over 40 Fortune and Government clients coast-to-coast across the U.S. We are one of the fastest-growing companies in the U.S. and this may be your opportunity to join us! Want to read more about Net2Source? , Visit us at www.net2source.comRegards, - provided by Dice(BIG DATA over 5 year(s) ) AND (APACHE ) AND (SPARK ) AND (SQL ) AND (HBASE ) AND (API ) Associated topics: data analytic, data architect, data integration, data integrity, data quality, data scientist, data warehouse, data warehousing, etl, teradata BigDataArchitectwithnet2source from Job Portal http://www.jobisite.com/extrJobView.htm?id=75428
0 notes