#sql alias join
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
𝗨𝗻𝗹𝗲𝗮𝘀𝗵 𝘁𝗵𝗲 𝗣𝗼𝘄𝗲𝗿 𝗼𝗳 𝗗𝗮𝘁𝗮 𝘄𝗶𝘁𝗵 𝗣𝗼𝘄𝗲𝗿 𝗕𝗜 𝗢𝗻𝗹𝗶𝗻𝗲 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗮𝘁 𝗡𝗮𝗿𝗲𝘀𝗵-𝗜𝗧!

Enroll now : https://nareshit.com/courses/power-bi-online-training
Course Overview
Naresh IT offers top-notch Power BI training, both online and in the classroom, aimed at equipping participants with an in-depth grasp of Microsoft Power BI, a premier business intelligence and data visualization platform. Our course delves into crucial facets of data analysis, visualization, and reporting utilizing Power BI. Through hands-on sessions, students will master the creation of dynamic dashboards, data source connectivity, and the extraction of actionable insights. Join Naresh IT for unrivaled expertise in Power BI.
Learn software skills with real experts, either in live classes with videos or without videos, whichever suits you best.
Description
The Power BI course begins with an introduction to business intelligence and the role of Power BI in transforming raw data into meaningful insights. Participants will learn about the Power BI ecosystem, including Power BI Desktop, Power BI Service, and Power BI Mobile. The course covers topics such as data loading, data transformation, creating visualizations, and sharing reports. Practical examples, hands-on projects, and real-world scenarios will be used to reinforce theoretical concepts.
Course Objectives
The primary objectives of the Power BI course are as follows:
Introduction to Business Intelligence and Power BI: Provide an overview of business intelligence concepts and the features of Power BI.
Power BI Ecosystem: Understand the components of the Power BI ecosystem, including Power BI Desktop, Service, and Mobile.
Data Loading and Transformation: Learn the process of loading data into Power BI and transforming it for analysis and visualization.
Data Modeling: Gain skills in creating data models within Power BI to establish relationships and hierarchies.
Creating Visualizations: Explore the various visualization options in Power BI and create interactive and informative reports and dashboards.
Advanced Analytics: Understand how to leverage advanced analytics features in Power BI, including DAX (Data Analysis Expressions) for calculations.
Power BI Service: Learn about the cloud-based service for sharing, collaborating, and publishing Power BI reports.
Data Connectivity: Explore the options for connecting Power BI to various data sources, including databases, cloud services, and Excel.
Sharing and Collaboration: Understand how to share Power BI reports with others, collaborate on datasets, and use workspaces.
Security and Compliance: Explore security measures and compliance considerations when working with sensitive data in Power BI.
Prerequisites
Basic understanding of data analysis concepts.
Familiarity with Microsoft Excel and its functions.
Knowledge of relational databases and SQL.
Understanding of data visualization principles.
Awareness of business intelligence (BI) concepts and tools.
Experience with basic data modeling and transformation techniques.
Course Curriculum
SQL (Structured Query Language)
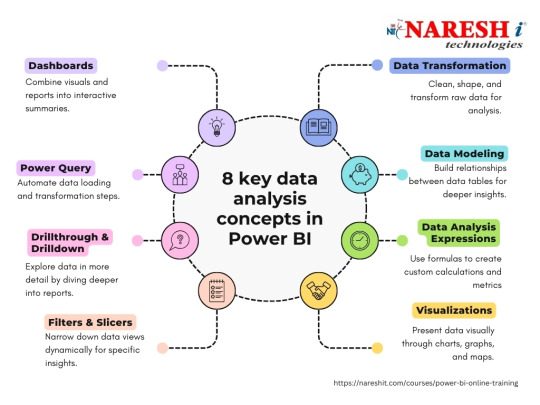
What is SQL?
What is Database?
Difference between SQL and Database
Types of SQL Commands
Relationships in SQL
Comments in SQL
Alias in SQL
Database Commands
Datatypes in SQL
Table Commands
Constraints in SQL
Operators in SQL
Clauses in SQL
Functions in SQL
JOINS
Set operators
Sub Queries
Views
Synonyms
Case Statements
Window Functions
Introduction to Power BI
Power BI Introduction
Power BI Desktop (Power Query, Power Pivot, Power View, Data Modelling)
Power BI Service
Flow of Work in Power BI
Power BI Architecture
Power BI Desktop Installation
Installation through Microsoft Store
Download and Installation of Power BI Desktop
Power Query Editor / Power Query
Overview of Power Query Editor
Introduction of Power Query
UI of Power Query Editor
How to Open Power Query Editor
File Tab
Inbuilt Column Transformations
Inbuilt Row Transformations
Query Options
Home Tab Options
Transform Tab Options
Add Column Tab
Combine Queries (Merge and Append Queries)
View Tab Options
Tools Tab Options
Help Tab Options
Filters in Power Query
Data Modelling / Model View
What is InMemory Columnar database and advantages
What is Traditional database
Difference between InMemory Columnar database and Traditional database
xVelocity In-memory Analytics Engine (Vertipaq Engine)
Data Connectivity modes in Power BI
What is Data Modelling?
What are a Relationships?
Types of Relationships/Cardinalities
One-to-One, One-to-many, Many-to-One, Many-to-Many
Why do we need a Relationship?
How to create a relationship in Power BI
Edit existing relationship
Delete relationship
AutoDetect Relationship
Make Relationship Active or Inactive
Cross filter direction (Single, Both)
Assume Referential Integrity
Apply Security Filter in Both Directions
Dimension Column, Fact Column.
Dimension table, Fact Table
What is Schema?
Types of Schemas and Advantages
Power View / Report View

Introduction to Power View
What and why Visualizations?
UI of Report View/Power View
Difference between Numeric data, Categorical data, Series of data
Difference between Quantitative data and Qualitative data
Categorical data Visuals
Numeric and Series of Data
Tabular Data
Geographical Data
KPI Data
Filtering data
Filters in Power View
Drill Reports
Visual Interactions
Grouping
Sorting
Bookmarks in Power BI
Selection Pane in Power BI
Buttons in Power BI
Tooltips
Power BI Service
Power BI Architecture
How to Sign into Power BI Service account
Power Bi Licences (Pro & Premium Licences)
Team Collaboration in Power BI using Workspace
Sharing Power BI Content using Basic Sharing, Content Packs and Apps
Refreshing the Data Source
Deployment Pipelines
Row Level Security (RLS)
#PowerBI#PowerBIDesktop#DataVisualization#DataAnalytics#BusinessIntelligence#PowerBIAI#DataStorytelling
0 notes
Text
Homework 5 Managing Data(bases) using SQL solved
Objective: Create SELECT statements involving multiple tables by using joins Problem 1: Create a query displaying the employee_id, start_date, end_date and department_name using the old SQL join syntax (Where clause). Alias the departments table with d and the job_history table with jh. Order it by employee_id and start_date. Problem 2: Rewrite the previous query using the new SQL join syntax…

View On WordPress
0 notes
Text
Homework 5 Managing Data(bases) using SQL
Objective: Create SELECT statements involving multiple tables by using joins Problem 1: Create a query displaying the employee_id, start_date, end_date and department_name using the old SQL join syntax (Where clause). Alias the departments table with d and the job_history table with jh. Order it by employee_id and start_date. Problem 2: Rewrite the previous query using the new SQL join syntax…

View On WordPress
0 notes
Text
[Python] PySpark to M, SQL or Pandas
Hace tiempo escribí un artículo sobre como escribir en pandas algunos códigos de referencia de SQL o M (power query). Si bien en su momento fue de gran utilidad, lo cierto es que hoy existe otro lenguaje que representa un fuerte pie en el análisis de datos.
Spark se convirtió en el jugar principal para lectura de datos en Lakes. Aunque sea cierto que existe SparkSQL, no quise dejar de traer estas analogías de código entre PySpark, M, SQL y Pandas para quienes estén familiarizados con un lenguaje, puedan ver como realizar una acción con el otro.
Lo primero es ponernos de acuerdo en la lectura del post.
Power Query corre en capas. Cada linea llama a la anterior (que devuelve una tabla) generando esta perspectiva o visión en capas. Por ello cuando leamos en el código #“Paso anterior” hablamos de una tabla.
En Python, asumiremos a "df" como un pandas dataframe (pandas.DataFrame) ya cargado y a "spark_frame" a un frame de pyspark cargado (spark.read)
Conozcamos los ejemplos que serán listados en el siguiente orden: SQL, PySpark, Pandas, Power Query.
En SQL:
SELECT TOP 5 * FROM table
En PySpark
spark_frame.limit(5)
En Pandas:
df.head()
En Power Query:
Table.FirstN(#"Paso Anterior",5)
Contar filas
SELECT COUNT(*) FROM table1
spark_frame.count()
df.shape()
Table.RowCount(#"Paso Anterior")
Seleccionar filas
SELECT column1, column2 FROM table1
spark_frame.select("column1", "column2")
df[["column1", "column2"]]
#"Paso Anterior"[[Columna1],[Columna2]] O podría ser: Table.SelectColumns(#"Paso Anterior", {"Columna1", "Columna2"} )
Filtrar filas
SELECT column1, column2 FROM table1 WHERE column1 = 2
spark_frame.filter("column1 = 2") # OR spark_frame.filter(spark_frame['column1'] == 2)
df[['column1', 'column2']].loc[df['column1'] == 2]
Table.SelectRows(#"Paso Anterior", each [column1] == 2 )
Varios filtros de filas
SELECT * FROM table1 WHERE column1 > 1 AND column2 < 25
spark_frame.filter((spark_frame['column1'] > 1) & (spark_frame['column2'] < 25)) O con operadores OR y NOT spark_frame.filter((spark_frame['column1'] > 1) | ~(spark_frame['column2'] < 25))
df.loc[(df['column1'] > 1) & (df['column2'] < 25)] O con operadores OR y NOT df.loc[(df['column1'] > 1) | ~(df['column2'] < 25)]
Table.SelectRows(#"Paso Anterior", each [column1] > 1 and column2 < 25 ) O con operadores OR y NOT Table.SelectRows(#"Paso Anterior", each [column1] > 1 or not ([column1] < 25 ) )
Filtros con operadores complejos
SELECT * FROM table1 WHERE column1 BETWEEN 1 and 5 AND column2 IN (20,30,40,50) AND column3 LIKE '%arcelona%'
from pyspark.sql.functions import col spark_frame.filter( (col('column1').between(1, 5)) & (col('column2').isin(20, 30, 40, 50)) & (col('column3').like('%arcelona%')) ) # O spark_frame.where( (col('column1').between(1, 5)) & (col('column2').isin(20, 30, 40, 50)) & (col('column3').contains('arcelona')) )
df.loc[(df['colum1'].between(1,5)) & (df['column2'].isin([20,30,40,50])) & (df['column3'].str.contains('arcelona'))]
Table.SelectRows(#"Paso Anterior", each ([column1] > 1 and [column1] < 5) and List.Contains({20,30,40,50}, [column2]) and Text.Contains([column3], "arcelona") )
Join tables
SELECT t1.column1, t2.column1 FROM table1 t1 LEFT JOIN table2 t2 ON t1.column_id = t2.column_id
Sería correcto cambiar el alias de columnas de mismo nombre así:
spark_frame1.join(spark_frame2, spark_frame1["column_id"] == spark_frame2["column_id"], "left").select(spark_frame1["column1"].alias("column1_df1"), spark_frame2["column1"].alias("column1_df2"))
Hay dos funciones que pueden ayudarnos en este proceso merge y join.
df_joined = df1.merge(df2, left_on='lkey', right_on='rkey', how='left') df_joined = df1.join(df2, on='column_id', how='left')Luego seleccionamos dos columnas df_joined.loc[['column1_df1', 'column1_df2']]
En Power Query vamos a ir eligiendo una columna de antemano y luego añadiendo la segunda.
#"Origen" = #"Paso Anterior"[[column1_t1]] #"Paso Join" = Table.NestedJoin(#"Origen", {"column_t1_id"}, table2, {"column_t2_id"}, "Prefijo", JoinKind.LeftOuter) #"Expansion" = Table.ExpandTableColumn(#"Paso Join", "Prefijo", {"column1_t2"}, {"Prefijo_column1_t2"})
Group By
SELECT column1, count(*) FROM table1 GROUP BY column1
from pyspark.sql.functions import count spark_frame.groupBy("column1").agg(count("*").alias("count"))
df.groupby('column1')['column1'].count()
Table.Group(#"Paso Anterior", {"column1"}, {{"Alias de count", each Table.RowCount(_), type number}})
Filtrando un agrupado
SELECT store, sum(sales) FROM table1 GROUP BY store HAVING sum(sales) > 1000
from pyspark.sql.functions import sum as spark_sum spark_frame.groupBy("store").agg(spark_sum("sales").alias("total_sales")).filter("total_sales > 1000")
df_grouped = df.groupby('store')['sales'].sum() df_grouped.loc[df_grouped > 1000]
#”Grouping” = Table.Group(#"Paso Anterior", {"store"}, {{"Alias de sum", each List.Sum([sales]), type number}}) #"Final" = Table.SelectRows( #"Grouping" , each [Alias de sum] > 1000 )
Ordenar descendente por columna
SELECT * FROM table1 ORDER BY column1 DESC
spark_frame.orderBy("column1", ascending=False)
df.sort_values(by=['column1'], ascending=False)
Table.Sort(#"Paso Anterior",{{"column1", Order.Descending}})
Unir una tabla con otra de la misma característica
SELECT * FROM table1 UNION SELECT * FROM table2
spark_frame1.union(spark_frame2)
En Pandas tenemos dos opciones conocidas, la función append y concat.
df.append(df2) pd.concat([df1, df2])
Table.Combine({table1, table2})
Transformaciones
Las siguientes transformaciones son directamente entre PySpark, Pandas y Power Query puesto que no son tan comunes en un lenguaje de consulta como SQL. Puede que su resultado no sea idéntico pero si similar para el caso a resolver.
Analizar el contenido de una tabla
spark_frame.summary()
df.describe()
Table.Profile(#"Paso Anterior")
Chequear valores únicos de las columnas
spark_frame.groupBy("column1").count().show()
df.value_counts("columna1")
Table.Profile(#"Paso Anterior")[[Column],[DistinctCount]]
Generar Tabla de prueba con datos cargados a mano
spark_frame = spark.createDataFrame([(1, "Boris Yeltsin"), (2, "Mikhail Gorbachev")], inferSchema=True)
df = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]], columns=["CustomerID", "Name"])
Table.FromRecords({[CustomerID = 1, Name = "Bob", Phone = "123-4567"]})
Quitar una columna
spark_frame.drop("column1")
df.drop(columns=['column1']) df.drop(['column1'], axis=1)
Table.RemoveColumns(#"Paso Anterior",{"column1"})
Aplicar transformaciones sobre una columna
spark_frame.withColumn("column1", col("column1") + 1)
df.apply(lambda x : x['column1'] + 1 , axis = 1)
Table.TransformColumns(#"Paso Anterior", {{"column1", each _ + 1, type number}})
Hemos terminado el largo camino de consultas y transformaciones que nos ayudarían a tener un mejor tiempo a puro código con PySpark, SQL, Pandas y Power Query para que conociendo uno sepamos usar el otro.
#spark#pyspark#python#pandas#sql#power query#powerquery#notebooks#ladataweb#data engineering#data wrangling#data cleansing
0 notes
Text
SQL에서 "조인(Join)"은 두 개 이상의 테이블에서 열을 결합하여 데이터를 조회하는 과정을 말합니다. 조인을 사용하면 관련된 데이터가 여러 테이블에 분산되어 있을 때 이를 통합하여 조회할 수 있습니다. ��양한 종류의 조인이 있으며, 각각 특정한 유형의 결과를 반환합니다.
주요 조인 유형:
SQL에서 "조인(Join)"은 두 개 이상의 테이블에서 열을 결합하여 데이터를 조회하는 과정을 말합니다. 조인을 사용하면 관련된 데이터가 여러 테이블에 분산되어 있을 때 이를 통합하여 조회할 수 있습니다. 다양한 종류의 조인이 있으며, 각각 특정한 유형의 결과를 반환합니다.
주요 조인 유형:
내부 조인 (INNER JOIN):
두 테이블 간에 일치하는 행만 반환합니다. 즉, 양쪽 테이블 모두에서 일치하는 데이터가 있는 경우에만 해당 행들이 결과에 포함됩니다.
구문:sqlCopy codeSELECT columns FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
외부 조인 (OUTER JOIN):
외부 조인은 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN으로 나뉩니다.
LEFT (OUTER) JOIN: 왼쪽 테이블의 모든 행과 오른쪽 테이블에서 일치하는 행을 반환합니다. 오른쪽 테이블에 일치하는 행이 없는 경우 NULL 값으로 반환합니다.
RIGHT (OUTER) JOIN: 오른쪽 테이블의 모든 행과 왼쪽 테이블에서 일치하는 행을 반환합니다. 왼쪽 테이블에 일치하는 행이 없는 경우 NULL 값으로 반환합니다.
FULL (OUTER) JOIN: 왼쪽과 오른쪽 테이블 모두에서 일치하는 행을 반환합니다. 어느 한쪽에만 있는 행도 포함되며, 일치하는 행이 없는 쪽은 NULL 값으로 반환합니다.
크로스 조인 (CROSS JOIN):
두 테이블 간의 모든 가능한 조합을 반환합니다. 이는 두 테이블의 각 행이 다른 테이블의 모든 행과 결합됩니다.
구문:sqlCopy codeSELECT columns FROM table1 CROSS JOIN table2;
자체 조인 (SELF JOIN):
테이블이 자기 자신과 조인되는 경우입니다. 이는 별칭(Alias)을 사용하여 동일한 테이블을 두 번 참조함으로써 수행됩니다.
표준 조인 (ANSI SQL-92 조인 구문):
표준 조인은 SQL-92 표준에서 도입된 조인 구문으로, 조인을 명확하게 표현할 수 있게 해줍니다. 표준 조인 구문은 조인의 종류를 명시적으로 기술하여 가독성과 관리의 용이성을 높입니다.
예를 들어, INNER JOIN은 다음과 같이 표현됩니다:sqlCopy codeSELECT columns FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
표준 조인 구문은 특히 조인의 유형을 명확하게 하여 복잡한 쿼리에서 의도를 분명히 드러내는 데 유용합니다.
조인을 사용하면 데이터베이스 내 여러 테이블 간의 관계를 기반으로 복잡한 쿼리를 생성하고, 필요한 데이터를 효율적으로 추출할 수 있습니다.
표준 조인 (ANSI SQL-92 조인 구문):
표준 조인은 SQL-92 표준에서 도입된 조인 구문으로, 조인을 명확하게 표현할 수 있게 해줍니다. 표준 조인 구문은 조인의 종류를 명시적으로 기술하여 가독성과 관리의 용이성을 높입니다.
예를 들어, INNER JOIN은 다음과 같이 표현됩니다:sqlCopy codeSELECT columns FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
표준 조인 구문은 특히 조인의 유형을 명확하게 하여 복잡한 쿼리에서 의도를 분명히 드러내는 데 유용합니다.
조인을 사용하면 데이터베이스 내 여러 테이블 간의 관계를 기반으로 복잡한 쿼리를 생성하고, 필요한 데이터를 효율적으로 추출할 수 있습니다.
0 notes
Text
Create SELECT statements involving multiple tables by using joins
Problem 1: Create a query displaying the employee_id, start_date, end_date and department_name using the old SQL join syntax (Where clause). Alias the departments table with d and the job_history table with jh. Order it by employee_id and start_date. Problem 2: Rewrite the previous query using the new SQL join syntax (From clause). Problem 3: Rewrite the previous query using the following syntax…

View On WordPress
0 notes
Text
Introduction to SQL
Introduction to SQL
One of the key concepts involved in data management is the programming language SQL (Structured Query Language). This language is widely known and used for database management by many individuals and companies around the world. SQL is used to perform creation, retrieval, updating, and deletion (CRUD) tasks on databases, making it very easy to store and query data. SQL was developed in the 1970’s by Raymond Boyce and Donald Chamberlin. It was initially created for use within IBM’s database management system but has since been developed further and become available to the public. Oracle has released an open-source system called MySQL where individuals in the public can write their own SQL to perform queries, which is a great place to start!
Types of Commands
There are three types of commands in SQL:
Data Definition Language (DDL)- DDL defines a database through create, drop, and alter table commands, as well as establishing keys (primary, foreign, etc.)
Data Control Language (DCL)- DCL controls who has access to the data.
Data Manipulation Language (DML)- DML commands are used to query a database.
Steps to Create a Table
The first step to creating a table is making a plan of what variables will be in the table as well as the type of variable. Once a plan is in place, the CREATE TABLE command is used and the variables are listed with their type and length. Then, one must identify which attributes will allow null values and which columns should be unique. At the end, all primary and foreign keys need to be identified. INSERT INTO commands are then used to fill the empty table with rows of data. If a table need to be edited, the ALTER TABLE command can be used. If it needs to be deleted, then DROP TABLE can be used to do so. Sometimes it is helpful to drop a table at the beginning of a session in case there has already been a table created with the table name one is trying to use.
SQL Query Hierarchy
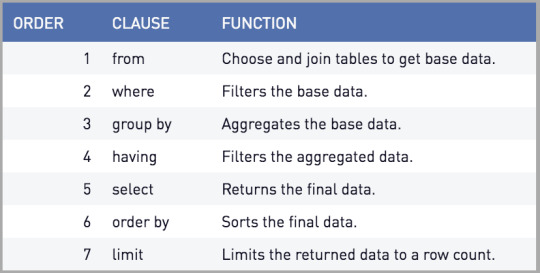
Querying data is essentially asking it a question or asking it for a specified output. Nearly all DML queries begin with the same commands. First, one must identify which columns they would like to the output to contain. This is established by listing the column names after SELECT with commas in between. Aggregate function may be used in this part as well, such as SUM or COUNT. However, if an aggregate function is used, a GROUP BY must also be used (expanded upon later). Next, one must identify the table from which these columns are coming from. To do this, the table name is written after the clause FROM, and an alias may be used if multiple tables are being joined, or just to stay organized. This is also the location where one would identify any tables that are being joined, as well as the column on which they are being joined. SELECT and FROM are the two commands necessary to query data. If there are any filters one would like to use on the data that do not require an aggregation, the WHERE clause comes next. This is where the filter can be applied to the data. If aggregate functions were used in the SELECT command, a GROUP BY command would be used after WHERE. One or more columns can be used in a GROUP BY to group the data by a field (or multiple). Next, a HAVING clause is used to filter data if the filter is based on an aggregate, such as AVG. If one wants the query returned in a sorted manner, the ORDER BY command can be used to sort it in ascending or descending order. If one wants the order to be descending, DESC must be written after ORDER BY. Finally, LIMIT can be used to the limit the number of rows of data returned. These are the steps one would take when writing a query, however, the clauses are processed in a different order by the computer. The order in which they are processed by the computer is as follows: FROM, WHERE, GROUP BY, HAVING, SELECT, ORDER BY, LIMIT. It is also important to note that all these commands are used to query data, so the tables must already be created to perform these operations.
Is it Worth Learning SQL?
The short answer is- absolutely! SQL is a very commonly used programming language across the world; it is universal. Also, it is subjectively easy to learn, especially compared to coding. It is incredibly powerful when dealing with databases. The steps provided above are only for simple queries, though they are very useful. Much more advanced queries are possible with SQL, such as nested queries. If you want to get started with SQL, Data Camp offers excellent beginner courses as well as other online platforms. Because Oracle’s MySQL is open-source and easy to use, it is a great place to practice.
1 note
·
View note
Text
100%OFF | SQL Server Interview Questions and Answers

If you are looking forward to crack SQL Server interviews then you are at the right course.
Working in SQL Server and cracking SQL Server interviews are different ball game. Normally SQL Server professionals work on repetitive tasks like back ups , custom reporting and so on. So when they are asked simple questions like Normalization , types of triggers they FUMBLE.
Its not that they do not know the answer , its just that they need a revision. That’s what this course exactly does. Its prepares you for SQL Server interview in 2 days.
Below are the list of questions with answers , demonstration and detailed explanation. Happy learning. Happy job hunting.
SQL Interview Questions & Answers – Part 1 :-
Question 1 :- Explain normalization ?
Question 2 :- How to implement normalization ?
Question 3 :- What is denormalization ?
Question 4 :- Explain OLTP vs OLAP ?
Question 5 :- Explain 1st,2nd and 3rd Normal form ?
Question 6 :- Primary Key vs Unique key ?
Question 7 :- Differentiate between Char vs Varchar ?
Question 8 :- Differentiate between Char vs NChar ?
Question 9 :- Whats the size of Char vs NChar ?
Question 10 :- What is the use of Index ?
Question 11 :- How does it make search faster?
Question 12 :- What are the two types of Indexes ?
Question 13 :- Clustered vs Non-Clustered index
Question 14 :- Function vs Stored Procedures
Question 15 :- What are triggers and why do you need it ?
Question 16 :- What are types of triggers ?
Question 17 :- Differentiate between After trigger vs Instead Of ?
Question 18 :- What is need of Identity ?
Question 19 :- Explain transactions and how to implement it ?
Question 20 :- What are inner joins ?
Question 21 :- Explain Left join ?
Question 22 :- Explain Right join ?
Question 23 :- Explain Full outer joins ?
Question 24 :- Explain Cross joins ?
SQL Interview Questions & Answers – Part 2 :-
Question 25:-Why do we need UNION ?
Question 26:-Differentiate between Union vs Union All ?
Question 27:-can we have unequal columns in Union?
Question 28:-Can column have different data types in Union ?
Question 29:- Which Aggregate function have you used ?
Question 30:- When to use Group by ?
Question 31:- Can we select column which is not part of group by ?
Question 32:- What is having clause ?
Question 33:- Having clause vs Where clause
Question 34:- How can we sort records ?
Question 35:- Whats the default sort ?
Question 36:- How can we remove duplicates ?
Question 37:- Select the first top X records ?
Question 38:- How to handle NULLS ?
Question 39:- What is use of wild cards ?
Question 40:- What is the use of Alias ?
Question 41:- How to write a case statement ?
Question 42:- What is self reference tables ?
Question 43:- What is self join ?
Question 44:- Explain the between clause ?
SQL Interview Questions & Answers – Part 3 :-
Question 45:- Explain SubQuery?
Question 46:- Can inner Subquery return multiple results?
Question 47:- What is Co-related Query?
Question 48:- Differentiate between Joins and SubQuery?
Question 49:- Performance Joins vs SubQuery?
SQL Interview Questions & Answers – Part 4 :-
Question 50:- Find NTH Highest Salary in SQL.
SQL Interview Questions & Answers – Part 5
Question 51:- Select the top nth highest salary using correlated Queries?
Question 52:- Select top nth using using TSQL
Question 53:- Performance comparison of all the methods.
[ENROLL THE COURSE]
21 notes
·
View notes
Text
Sql Inquiry Interview Questions
The function MATTER()returns the number of rows from the field e-mail. The driver HAVINGworks in similar means WHERE, except that it is applied except all columns, but also for the established produced by the driver GROUP BY. This statement copies data from one table and inserts it right into an additional, while the information enters both tables have to match. SQL aliases are needed to give a temporary name to a table or column. These are guidelines for restricting the sort of data that can be stored in a table. The activity on the data will certainly not be carried out if the set limitations are gone against. Obviously, this isn't an extensive list of inquiries you might be asked, however it's a excellent beginning point. We have actually likewise obtained 40 real chance & data interview concerns asked by FANG & Wall Street. The very first step of analytics for many workflows involves fast cutting as well as dicing of data in SQL. That's why being able to compose fundamental queries effectively is a very essential ability. Although numerous might think that SQL merely involves SELECTs and Signs up with, there are lots of other operators and information involved for effective SQL workflows. Used to establish benefits, functions, and also approvals for different users of the database (e.g. the GRANT and also WITHDRAW statements). Made use of to query the database for info that matches the specifications of the request (e.g. the SELECT declaration). Utilized to change the documents present in a data source (e.g. the INSERT, UPDATE, and ERASE statements). The SELECT declaration is made use of to choose information from a database. Given the tables above, compose a query that will certainly determine the total commission by a salesperson. A LEFT OUTER JOIN B amounts B RIGHT EXTERNAL SIGN UP WITH A, with the columns in a various order. The INSERT statement includes brand-new rows of data to a table. Non-Clustered Indexes, or simply indexes, are created beyond the table. SQL Server supports 999 Non-Clustered per table and also each Non-Clustered can have up to 1023 columns. A Non-Clustered Index does not support the Text, nText and Image data kinds. A Clustered Index kinds as well as stores the data in the table based upon keys. Data source normalization is the process of arranging the fields as well as tables of a relational database to decrease redundancy as well as dependence. Normalization generally includes separating large tables into smaller sized tables as well as specifying partnerships amongst them. Normalization is a bottom-up strategy for database design. In this post, we share 65 SQL Web server interview concerns and response to those inquiries. SQL is progressing rapidly and also is one of the commonly made use of query languages for data extraction and analysis from relational databases. Despite the outburst of NoSQL in recent times, SQL is still making its back to become the extensive interface for data extraction as well as analysis. Simplilearn has many courses in SQL which can help you obtain fundamental as well as deep expertise in SQL and eventually become a SQL expert. There are much more innovative attributes that include producing stored procedures or SQL manuscripts, views, and establishing approvals on data source objects. Sights are utilized for security objectives due to the fact that they supply encapsulation of the name of the table. Information is in the online table, not stored permanently. In some cases for safety and security objectives, accessibility to the table, table structures, and also table relationships are not provided to the database individual. All they have is accessibility to a sight not knowing what tables in fact exist in the database. A Clustered Index can be defined just as soon as per table in the SQL Web Server Database, because the information rows can be sorted in only one order. Text, nText and also Image information are not permitted as a Gathered index. An Index is one of the most powerful techniques to collaborate with this massive info. ROWID is an 18-character long pseudo column connected with each row of a data source table. The main trick that is created on more than one column is known as composite primary key. Car increment allows the customers to produce a serial number to be created whenever a brand-new document is put into the table. It aids to maintain the main vital unique for each row or document. If you are utilizing Oracle then VEHICLE INCREMENT keyword need to be utilized otherwise utilize the IDENTIFICATION key words when it comes to the SQL Server. Information integrity is the total precision, completeness, and uniformity of information kept in a data source.

RDBMS is a software that stores the data right into the collection of tables in a partnership based upon typical fields between the columns of the table. Relational Database Management System is among the very best as well as frequently utilized databases, consequently SQL abilities are necessary in most of the job duties. In this SQL Meeting Questions and also solutions blog site, you will certainly find out one of the most frequently asked questions on SQL. Right here's a transcript/blog blog post, as well as here's a web link to the Zoom webinar. If you're hungry to begin addressing problems and also get solutions TODAY, register for Kevin's DataSciencePrep program to get 3 issues emailed to you every week. Or, you can produce a database utilizing the SQL Server Administration Studio. Right-click on Data sources, pick New Database and comply with the wizard actions. These SQL interview concerns and solutions are inadequate to pass out your interviews carried out by the top organization brand names. So, it is highly suggested to keep method of your academic knowledge in order to boost your efficiency. Remember, " method makes a man best". This is necessary when the inquiry contains 2 or more tables or columns with intricate names. In this case, for convenience, pseudonyms are made use of in the question. The SQL alias only exists throughout of the inquiry. INNER JOIN- obtaining documents with the very same values in both tables, i.e. getting the crossway of tables. SQL constraints are defined when developing or customizing a table. https://geekinterview.net Database tables are insufficient for obtaining the data successfully in case of a substantial amount of information. In order to get the information swiftly, we need to index the column in a table. As an example, in order to maintain information integrity, the numerical columns/sells should not accept alphabetic information. The distinct index makes certain the index vital column has one-of-a-kind values and it uses immediately if the primary secret is defined. In case, the special index has numerous columns after that the mix of values in these columns should be one-of-a-kind. As the name indicates, complete sign up with returns rows when there are matching rows in any kind of among the tables. It integrates the results of both left and right table records as well as it can return huge result-sets. The foreign secret is used to link 2 tables with each other and also it is a field that describes the primary key of another table. Structured Query Language is a shows language for accessing as well as adjusting Relational Database Management Solution. SQL is commonly used in preferred RDBMSs such as SQL Web Server, Oracle, as well as MySQL. The smallest device of execution in SQL is a question. A SQL query is used to pick, upgrade, and erase information. Although ANSI has actually established SQL criteria, there are many different versions of SQL based on various kinds of databases. Nonetheless, to be in compliance with the ANSI criterion, they need to at least sustain the major commands such as DELETE, INSERT, UPDATE, IN WHICH, and so on
1 note
·
View note
Text
Integrating Power BI with Azure Synapse Analytics for real-time data insights-NareshIT

Enroll now : https://nareshit.com/courses/power-bi-online-training
Course Overview
Naresh IT offers top-notch Power BI training, both online and in the classroom, aimed at equipping participants with an in-depth grasp of Microsoft Power BI, a premier business intelligence and data visualization platform. Our course delves into crucial facets of data analysis, visualization, and reporting utilizing Power BI. Through hands-on sessions, students will master the creation of dynamic dashboards, data source connectivity, and the extraction of actionable insights. Join Naresh IT for unrivaled expertise in Power BI.
Learn software skills with real experts, either in live classes with videos or without videos, whichever suits you best.
Description
The Power BI course begins with an introduction to business intelligence and the role of Power BI in transforming raw data into meaningful insights. Participants will learn about the Power BI ecosystem, including Power BI Desktop, Power BI Service, and Power BI Mobile. The course covers topics such as data loading, data transformation, creating visualizations, and sharing reports. Practical examples, hands-on projects, and real-world scenarios will be used to reinforce theoretical concepts.
Course Objectives
The primary objectives of the Power BI course are as follows:
Introduction to Business Intelligence and Power BI: Provide an overview of business intelligence concepts and the features of Power BI.
Power BI Ecosystem: Understand the components of the Power BI ecosystem, including Power BI Desktop, Service, and Mobile.
Data Loading and Transformation: Learn the process of loading data into Power BI and transforming it for analysis and visualization.
Data Modeling: Gain skills in creating data models within Power BI to establish relationships and hierarchies.
Creating Visualizations: Explore the various visualization options in Power BI and create interactive and informative reports and dashboards.
Advanced Analytics: Understand how to leverage advanced analytics features in Power BI, including DAX (Data Analysis Expressions) for calculations.
Power BI Service: Learn about the cloud-based service for sharing, collaborating, and publishing Power BI reports.
Data Connectivity: Explore the options for connecting Power BI to various data sources, including databases, cloud services, and Excel.
Sharing and Collaboration: Understand how to share Power BI reports with others, collaborate on datasets, and use workspaces.
Security and Compliance: Explore security measures and compliance considerations when working with sensitive data in Power BI.
Prerequisites
Basic understanding of data analysis concepts.
Familiarity with Microsoft Excel and its functions.
Knowledge of relational databases and SQL.
Understanding of data visualization principles.
Awareness of business intelligence (BI) concepts and tools.
Experience with basic data modeling and transformation techniques.
Course Curriculum
SQL (Structured Query Language)
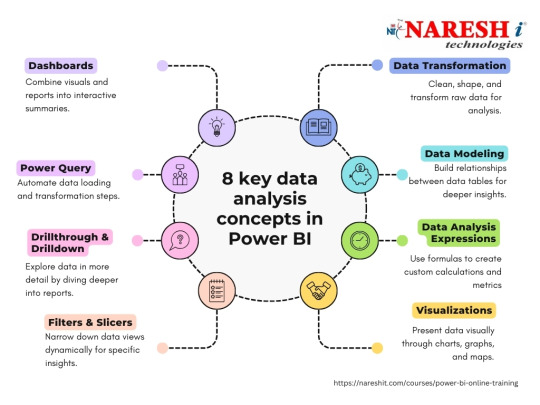
What is SQL?
What is Database?
Difference between SQL and Database
Types of SQL Commands
Relationships in SQL
Comments in SQL
Alias in SQL
Database Commands
Datatypes in SQL
Table Commands
Constraints in SQL
Operators in SQL
Clauses in SQL
Functions in SQL
JOINS
Set operators
Sub Queries
Views
Synonyms
Case Statements
Window Functions
Introduction to Power BI
Power BI Introduction
Power BI Desktop (Power Query, Power Pivot, Power View, Data Modelling)
Power BI Service
Flow of Work in Power BI
Power BI Architecture
Power BI Desktop Installation
Installation through Microsoft Store
Download and Installation of Power BI Desktop
Power Query Editor / Power Query
Overview of Power Query Editor
Introduction of Power Query
UI of Power Query Editor
How to Open Power Query Editor
File Tab
Inbuilt Column Transformations
Inbuilt Row Transformations
Query Options
Home Tab Options
Transform Tab Options
Add Column Tab
Combine Queries (Merge and Append Queries)
View Tab Options
Tools Tab Options
Help Tab Options
Filters in Power Query
Data Modelling / Model View
What is InMemory Columnar database and advantages
What is Traditional database
Difference between InMemory Columnar database and Traditional database
xVelocity In-memory Analytics Engine (Vertipaq Engine)
Data Connectivity modes in Power BI
What is Data Modelling?
What are a Relationships?
Types of Relationships/Cardinalities
One-to-One, One-to-many, Many-to-One, Many-to-Many
Why do we need a Relationship?
How to create a relationship in Power BI
Edit existing relationship
Delete relationship
AutoDetect Relationship
Make Relationship Active or Inactive
Cross filter direction (Single, Both)
Assume Referential Integrity
Apply Security Filter in Both Directions
Dimension Column, Fact Column.
Dimension table, Fact Table
What is Schema?
Types of Schemas and Advantages
Power View / Report View

Introduction to Power View
What and why Visualizations?
UI of Report View/Power View
Difference between Numeric data, Categorical data, Series of data
Difference between Quantitative data and Qualitative data
Categorical data Visuals
Numeric and Series of Data
Tabular Data
Geographical Data
KPI Data
Filtering data
Filters in Power View
Drill Reports
Visual Interactions
Grouping
Sorting
Bookmarks in Power BI
Selection Pane in Power BI
Buttons in Power BI
Tooltips
Power BI Service
Power BI Architecture
How to Sign into Power BI Service account
Power Bi Licences (Pro & Premium Licences)
Team Collaboration in Power BI using Workspace
Sharing Power BI Content using Basic Sharing, Content Packs and Apps
Refreshing the Data Source
Deployment Pipelines
Row Level Security (RLS)
#PowerBI#PowerBIDesktop#DataVisualization#DataAnalytics#BusinessIntelligence#PowerBIAI#DataStorytelling
0 notes
Text
Sql Interview Questions
If a WHERE clause is used in cross join after that the inquiry will certainly function like an INTERNAL SIGN UP WITH. A DISTINCT restraint ensures that all values in a column are various. This supplies uniqueness for the column and also assists identify each row distinctively. It promotes you to manipulate the data stored in the tables by using relational drivers. Instances of the relational data source administration system are Microsoft Gain access to, MySQL, SQLServer, Oracle database, etc. One-of-a-kind crucial restriction uniquely identifies each document in the data source. https://geekinterview.net This vital provides uniqueness for the column or set of columns. A database arrow is a control framework that permits traversal of documents in a data source. Cursors, on top of that, promotes handling after traversal, such as access, addition as well as deletion of database documents. They can be considered as a reminder to one row in a set of rows. An alias is a feature of SQL that is sustained by a lot of, otherwise all, RDBMSs. It is a temporary name designated to the table or table column for the purpose of a specific SQL inquiry. Furthermore, aliasing can be employed as an obfuscation technique to protect the actual names of database fields. A table pen name is also called a relationship name. students; Non-unique indexes, on the other hand, are not utilized to enforce restrictions on the tables with which they are linked. Rather, non-unique indexes are made use of solely to improve query performance by keeping a sorted order of data worths that are used regularly. A database index is a data structure that offers quick lookup of data in a column or columns of a table. It boosts the speed of operations accessing data from a data source table at the cost of additional creates as well as memory to keep the index information framework. Prospects are most likely to be asked standard SQL interview concerns to progress degree SQL concerns relying on their experience and different other aspects. The listed below list covers all the SQL meeting concerns for betters in addition to SQL interview questions for knowledgeable degree candidates as well as some SQL question meeting concerns. SQL provision helps to restrict the outcome set by offering a problem to the query. A clause assists to filter the rows from the entire set of records. Our SQL Meeting Questions blog site is the one-stop source where you can improve your meeting prep work. It has a set of leading 65 concerns which an interviewer intends to ask throughout an interview procedure. Unlike primary vital, there can be numerous distinct restrictions specified per table. The code syntax for UNIQUE is rather comparable to that of PRIMARY SECRET and can be utilized mutually. A lot of modern data source management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 as well as Amazon Redshift are based upon RDBMS. SQL clause is specified to restrict the result set by providing problem to the query. This typically filterings system some rows from the whole collection of records. Cross join can be defined as a cartesian product of both tables included in the join. The table after sign up with contains the same number of rows as in the cross-product of number of rows in the two tables. Self-join is set to be query made use of to contrast to itself. This is utilized to contrast values in a column with other worths in the exact same column in the same table. PEN NAME ES can be utilized for the same table contrast. This is a key words used to inquire information from even more tables based upon the partnership between the areas of the tables. A international trick is one table which can be associated with the main key of another table. Partnership requires to be produced in between 2 tables by referencing international key with the main key of another table. A Distinct essential restraint uniquely recognized each record in the data source. It begins with the fundamental SQL interview questions and later on remains to sophisticated inquiries based on your conversations and also solutions. These SQL Interview concerns will aid you with various knowledge levels to reap the optimum take advantage of this blog. A table has a specified number of the column called fields however can have any kind of variety of rows which is called the document. So, the columns in the table of the database are called the fields and they represent the feature or attributes of the entity in the document. Rows below describes the tuples which stand for the easy data item and also columns are the quality of the information products existing particularly row. Columns can classify as vertical, as well as Rows are straight. There is provided sql meeting questions and also responses that has actually been asked in lots of business. For PL/SQL interview questions, visit our following web page. A view can have information from several tables integrated, as well as it depends on the connection. Views are used to apply security system in the SQL Server. The sight of the database is the searchable object we can use a inquiry to browse the view as we use for the table. RDBMS means Relational Database Monitoring System. It is a data source administration system based upon a relational version. RDBMS stores the data right into the collection of tables and also links those table using the relational drivers easily whenever called for. This provides uniqueness for the column or set of columns. A table is a collection of information that are organized in a version with Columns and Rows. Columns can be categorized as vertical, as well as Rows are straight. A table has specified number of column called areas but can have any kind of number of rows which is called record. RDBMS save the data into the collection of tables, which is connected by common areas between the columns of the table. It also provides relational operators to manipulate the information stored into the tables. Adhering to is a curated listing of SQL interview concerns as well as answers, which are most likely to be asked during the SQL meeting.

1 note
·
View note
Text
Sql Inquiry Meeting Questions
The feature COUNT()returns the variety of rows from the area e-mail. The operator HAVINGworks in much the same means WHERE, except that it is used not for all columns, but for the established created by the operator TEAM BY. This statement copies data from one table and also inserts it right into one more, while the information enters both tables need to match. SQL pen names are required to provide a short-lived name to a table or column. These are rules for restricting the sort of information that can be kept in a table. The action on the data will certainly not be executed if the established limitations are broken. Naturally, this isn't an exhaustive list of questions you may be asked, yet it's a excellent starting point. We have actually likewise obtained 40 actual chance & stats meeting inquiries asked by FANG & Wall Street. The very first step of analytics for a lot of process includes fast cutting as well as dicing of data in SQL. That's why being able to create basic inquiries efficiently is a extremely vital ability. Although lots of might assume that SQL just includes SELECTs and also Signs up with, there are several other operators as well as information included for powerful SQL operations. Used to set opportunities, functions, and also authorizations for different users of the data source (e.g. the GRANT as well as WITHDRAW declarations). Made use of to inquire the data source for info that matches the specifications of the demand (e.g. the SELECT statement). Utilized to alter the documents present in a data source (e.g. the INSERT, UPDATE, as well as DELETE declarations). The SELECT statement is utilized to choose information from a database. Provided the tables above, write a inquiry that will calculate the complete commission by a sales representative. A LEFT OUTER SIGN UP WITH B is equivalent to B RIGHT OUTER JOIN A, with the columns in a different order. The INSERT declaration includes new rows of data to a table. Non-Clustered Indexes, or simply indexes, are produced beyond the table. SQL Web server supports 999 Non-Clustered per table and each Non-Clustered can have up to 1023 columns. A Non-Clustered Index does not sustain the Text, nText and also Image information kinds. A Clustered Index types as well as shops the data in the table based upon secrets. Database normalization is the procedure of organizing the fields and tables of a relational database to decrease redundancy as well as reliance. Normalization usually involves splitting huge tables into smaller tables as well as defining connections amongst them. Normalization is a bottom-up strategy for database layout. In this article, we share 65 SQL Web server meeting inquiries as well as response to those inquiries. SQL is advancing rapidly and also is one of the widely made use of question languages for data removal and also analysis from relational data sources. Despite the outburst of NoSQL in recent times, SQL is still making its back to become the widespread user interface for data removal and also analysis. Simplilearn has lots of courses in SQL which can assist you obtain fundamental and deep understanding in SQL and also ultimately become a SQL professional. There are much more innovative features that consist of developing kept treatments or SQL manuscripts, views, and also setting approvals on database things. Views are made use of for security functions since they offer encapsulation of the name of the table. Data is in the digital table, not stored permanently. Sometimes for protection purposes, access to the table, table structures, and also table partnerships are not provided to the data source individual. All they have is accessibility to a sight not knowing what tables really exist in the database. A Clustered Index can be defined just once per table in the SQL Web Server Data Source, due to the fact that the information rows can be sorted in only one order. Text, nText and Photo information are not enabled as a Clustered index. An Index is among one of the most powerful methods to collaborate with this massive details. ROWID is an 18-character lengthy pseudo column attached with each row of a data source table. The main secret that is developed on greater than one column is referred to as composite main secret. Auto increment allows the users to develop a serial number to be produced whenever a brand-new record is inserted right into the table. It assists to maintain the primary key unique for every row or document. If you are making use of Oracle after that VEHICLE INCREMENT keyword need to be made use of or else make use of the IDENTITY key phrase in the case of the SQL Server. Information stability is the total accuracy, efficiency, as well as uniformity of data saved in a database. RDBMS is a software application that saves the data into the collection of tables in a partnership based upon typical fields between the columns of the table. https://geekinterview.net Relational Data Source Management System is one of the best as well as frequently used databases, therefore SQL skills are essential in most of the task roles. In this SQL Meeting Questions and also solutions blog, you will discover one of the most frequently asked questions on SQL. Right here's a transcript/blog blog post, as well as below's a link to the Zoom webinar. If you're starving to begin addressing issues as well as obtain solutions TODAY, sign up for Kevin's DataSciencePrep program to get 3 troubles emailed to you weekly. Or, you can produce a data source making use of the SQL Server Management Studio. Right-click on Databases, choose New Data source as well as comply with the wizard actions. These SQL meeting concerns and responses are not enough to lose consciousness your meetings performed by the top organization brands. So, it is extremely suggested to keep technique of your theoretical understanding in order to improve your efficiency. Bear in mind, " technique makes a male perfect". This is needed when the query contains two or even more tables or columns with complicated names. In this situation, for comfort, pseudonyms are utilized in the inquiry. The SQL alias only exists for the duration of the inquiry. INTERNAL JOIN- obtaining documents with the exact same worths in both tables, i.e. getting the crossway of tables. SQL restraints are defined when developing or changing a table. Data source tables are not enough for obtaining the data effectively in case of a massive amount of data. In order to get the data promptly, we require to index the column in a table. As an example, in order to maintain data stability, the numerical columns/sells should decline alphabetical information. The unique index makes sure the index vital column has unique worths as well as it uses automatically if the main secret is specified. In case, the distinct index has numerous columns after that the combination of values in these columns should be unique. As the name indicates, full sign up with returns rows when there are matching rows in any type of among the tables. It incorporates the outcomes of both left and appropriate table documents and it can return large result-sets. The international key is used to connect 2 tables together as well as it is a field that refers to the main key of an additional table.

Structured Question Language is a shows language for accessing as well as manipulating Relational Database Monitoring Solution. SQL is widely made use of in preferred RDBMSs such as SQL Web Server, Oracle, and MySQL. The tiniest unit of execution in SQL is a query. A SQL inquiry is used to select, upgrade, as well as delete data. Although ANSI has actually developed SQL criteria, there are several variations of SQL based upon various sorts of databases. Nonetheless, to be in conformity with the ANSI requirement, they require to at the very least sustain the major commands such as DELETE, INSERT, UPDATE, WHERE, and so on
1 note
·
View note
Text
Sql Question Interview Questions
The function COUNT()returns the number of rows from the area email. The driver HAVINGworks in much the same method IN WHICH, except that it is used not for all columns, but also for the set created by the operator TEAM BY. This declaration duplicates information from one table and also inserts it right into an additional, while the information key ins both tables have to match. SQL pen names are required to provide a momentary name to a table or column. These are policies for restricting the type of data that can be saved in a table. The activity on the data will certainly not be performed if the established limitations are breached. Certainly, this isn't an exhaustive checklist of questions you might be asked, however it's a great starting point. We have actually additionally got 40 genuine likelihood & data interview inquiries asked by FANG & Wall Street. The first step of analytics for many process involves quick slicing as well as dicing of information in SQL. That's why having the ability to write basic queries efficiently is a very important ability. Although many may assume that SQL merely involves SELECTs and also JOINs, there are numerous various other drivers as well as information involved for powerful SQL workflows. Made use of to set benefits, duties, and consents for different users of the database (e.g. the GIVE and also WITHDRAW statements). Utilized to inquire the data source for information that matches the criteria of the demand (e.g. the SELECT statement). Utilized to transform the records existing in a data source (e.g. the INSERT, UPDATE, as well as ERASE statements).
https://geekinterview.net The SELECT statement is utilized to pick information from a data source. Provided the tables over, compose a query that will certainly calculate the overall commission by a salesman. A LEFT OUTER JOIN B is equivalent to B RIGHT OUTER SIGN UP WITH A, with the columns in a various order. The INSERT declaration adds new rows of data to a table. Non-Clustered Indexes, or merely indexes, are produced beyond the table. SQL Server supports 999 Non-Clustered per table and each Non-Clustered can have up to 1023 columns. A Non-Clustered Index does not support the Text, nText and Photo information kinds. A Clustered Index kinds and also shops the information in the table based on secrets. Data source normalization is the procedure of organizing the areas and tables of a relational data source to decrease redundancy as well as dependency. Normalization generally includes dividing large tables into smaller tables and also defining relationships among them. Normalization is a bottom-up strategy for data source layout. In this article, we share 65 SQL Web server meeting inquiries and also answers to those inquiries. SQL is advancing quickly and also is just one of the commonly used query languages for information extraction and also evaluation from relational data sources. Despite the outburst of NoSQL recently, SQL is still making its back to come to be the widespread interface for data removal as well as evaluation. Simplilearn has several programs in SQL which can assist you obtain fundamental and also deep knowledge in SQL and ultimately come to be a SQL expert. There are far more sophisticated functions that consist of creating saved treatments or SQL manuscripts, sights, and establishing permissions on data source objects. Sights are used for security objectives due to the fact that they provide encapsulation of the name of the table. Data remains in the virtual table, not saved permanently. Sometimes for safety objectives, access to the table, table structures, and also table partnerships are not provided to the database user. All they have is accessibility to a sight not knowing what tables actually exist in the database. A Clustered Index can be specified just when per table in the SQL Web Server Data Source, because the information rows can be sorted in just one order. Text, nText and Picture information are not enabled as a Gathered index. An Index is just one of the most effective methods to collaborate with this substantial info. ROWID is an 18-character long pseudo column connected with each row of a database table. The main trick that is created on more than one column is referred to as composite main secret. Auto increment enables the customers to develop a serial number to be generated whenever a brand-new record is inserted into the table. It helps to maintain the primary crucial distinct for each row or document. If you are making use of Oracle then VEHICLE INCREMENT keyword must be utilized otherwise make use of the IDENTITY search phrase when it comes to the SQL Server. Information stability is the total precision, completeness, as well as uniformity of data stored in a database. RDBMS is a software that stores the information into the collection of tables in a relationship based on typical areas between the columns of the table. Relational Data Source Administration System is just one of the most effective and also typically used databases, consequently SQL skills are necessary in most of the job duties. In this SQL Meeting Questions and solutions blog, you will discover one of the most frequently asked questions on SQL. Right here's a transcript/blog post, and also right here's a link to the Zoom webinar. If you're hungry to begin resolving troubles and obtain remedies TODAY, subscribe to Kevin's DataSciencePrep program to obtain 3 issues emailed to you each week. Or, you can create a database making use of the SQL Server Monitoring Workshop. Right-click on Databases, select New Data source as well as comply with the wizard steps. These SQL meeting inquiries as well as responses are insufficient to pass out your meetings conducted by the top service brands. So, it is highly suggested to keep method of your academic understanding in order to enhance your performance. Remember, " technique makes a male perfect". This is required when the question includes two or even more tables or columns with complex names. In this situation, for ease, pseudonyms are utilized in the inquiry. The SQL alias only exists throughout of the question. INTERNAL SIGN UP WITH- obtaining records with the very same worths in both tables, i.e. getting the crossway of tables. SQL restrictions are defined when producing or customizing a table. Database tables are insufficient for getting the information effectively in case of a big quantity of information. So as to get the information swiftly, we need to index the column in a table. For example, in order to preserve information integrity, the numeric columns/sells must decline alphabetic information. The unique index makes sure the index key column has distinct worths and also it applies immediately if the main trick is specified. In case, the special index has several columns after that the combination of values in these columns must be one-of-a-kind. As the name shows, full join returns rows when there are matching rows in any one of the tables. It combines the outcomes of both left as well as ideal table records as well as it can return very large result-sets. The foreign key is utilized to connect two tables together and also it is a area that describes the main trick of another table. Structured Question Language is a programming language for accessing and adjusting Relational Data source Monitoring Equipment. SQL is widely utilized in prominent RDBMSs such as SQL Server, Oracle, as well as MySQL. The tiniest device of implementation in SQL is a question. A SQL query is made use of to pick, update, and erase information. Although ANSI has developed SQL criteria, there are many different versions of SQL based on different types of data sources. Nonetheless, to be in compliance with the ANSI standard, they require to at least support the major commands such as DELETE, INSERT, UPDATE, WHERE, etc
1 note
·
View note
Text
[PowerQuery] Pandas and SQL to M
En múltiples oportunidades me encontré con personas que se dedican a data engineering o data analytics con python y por requerimiento/necesidad necesitan utilizar herramientas microsoft de movimiento de datos o Power Bi para presentarlos. Lo cierto es que dichas personas suelen detestar ese pedido puesto que esos puestos prefieren un trabajo más back que la demostración de tableros o herramientas de microsoft.
Ciertamente hoy microsoft ha implementado e impulsa Power Query para todo lo que es transformación de datos al punto que puede ser usado en SSIS, SSAS, Power Automate, Power Apps, Power Bi y DataFlows (en Power Platform y Data Factory).
El impulso por el lenguage de transformación es cada vez más fuerte y está pasando de ser un lenguaje de un rol de Bi a roles de data analyst y data engineer.
Por ello cree este post que nos ayudará a conocer como realizar las funciones básicas de SQL y principalmente Pandas (librería de python)
Lo primero a destacar es que Power Query corre en capas. Cada linea llama a la anterior (que devuelve una tabla) generando esta perspectiva o visión en capas. Por ello cuando leamos en el código #"Paso anterior" hablamos de una tabla.
Conozcamos los ejemplos que serán listados en el siguiente orden: SQL, Python, Power Query.
Cinco primeras filas
En SQL:
SELECT TOP 5 * FROM table
En Pandas:
df.head()
En Power Query:
Table.FirstN(#"Paso Anterior",5)
Contar filas
SELECT COUNT(*) FROM table1
df.shape()
Table.RowCount(#"Paso Anterior")
Seleccionar filas
SELECT column1, column2 FROM table1
df[["column1", "column2"]]
#"Paso Anterior"[[Columna1],[Columna2]] O podría ser: Table.SelectColumns(#"Paso Anterior", {"Columna1", "Columna2"} )
Filtrar filas
SELECT column1, column2 FROM table1 WHERE column1 = 2
df[['column1', 'column2']].loc[df['column1'] == 2]
Table.SelectRows(#"Paso Anterior", each [column1] == 2 )
Varios filtros de filas
SELECT * FROM table1 WHERE column1 > 1 AND column2 < 25
df.loc[(df['column1'] > 1) & (df['column2'] < 25)] O con operadores OR y NOT df.loc[(df['column1'] > 1) | ~(df['column2'] < 25)]
Table.SelectRows(#"Paso Anterior", each [column1] > 1 and column2 < 25 ) O con operadores OR y NOT Table.SelectRows(#"Paso Anterior", each [column1] > 1 or not ([column1] < 25 ) )
Filtros con operadores complejos
SELECT * FROM table1 WHERE column1 BETWEEN 1 and 5 AND column2 IN (20,30,40,50) AND column3 LIKE '%arcelona%'
df.loc[(df['colum1'].between(1,5)) & (df['column2'].isin([20,30,40,50])) & (df['column3'].str.contains('arcelona'))]
Table.SelectRows(#"Paso Anterior", each ([column1] > 1 and [column1] < 5) and List.Contains({20,30,40,50}, [column2]) and Text.Contains([column3], "arcelona") )
Join tables
SELECT t1.column1, t2.column1 FROM table1 t1 LEFT JOIN table2 t2 ON t1.column_id = t2.column_id
Hay dos funciones que pueden ayudarnos en este proceso merge y join.
df_joined = df1.merge(df2, left_on='lkey', right_on='rkey', how='left') df_joined = df1.join(df2, on='column_id', how='left')Luego seleccionamos dos columnas df_joined.loc[['column1_df1', 'column1_df2']]
En Power Query vamos a ir eligiendo una columna de antemano y luego añadiendo la segunda.
#"Origen" = #"Paso Anterior"[[column1_t1]] #"Paso Join" = Table.NestedJoin(#"Origen", {"column_t1_id"}, table2, {"column_t2_id"}, "Prefijo", JoinKind.LeftOuter) #"Expansion" = Table.ExpandTableColumn(#"Paso Join", "Prefijo", {"column1_t2"}, {"Prefijo_column1_t2"})
Group By
SELECT column1, count(*) FROM table1 GROUP BY column1
df.groupby('column1')['column1'].count()
Table.Group(#"Paso Anterior", {"column1"}, {{"Alias de count", each Table.RowCount(_), type number}})
Filtrando un agrupado
SELECT store, sum(sales) FROM table1 GROUP BY store HAVING sum(sales) > 1000
df_grouped = df.groupby('store')['sales'].sum() df_grouped.loc[df_grouped > 1000]
#”Grouping” = Table.Group(#"Paso Anterior", {"store"}, {{"Alias de sum", each List.Sum([sales]), type number}}) #"Final" = Table.SelectRows( #"Grouping" , each [Alias de sum] > 1000 )
Ordenar descendente por columna
SELECT * FROM table1 ORDER BY column1 DESC
df.sort_values(by=['column1'], ascending=False)
Table.Sort(#"Paso Anterior",{{"column1", Order.Descending}})
Unir una tabla con otra de la misma característica
SELECT * FROM table1 UNION SELECT * FROM table2
En Pandas tenemos dos opciones conocidas, la función append y concat.
df.append(df2) pd.concat([df1, df2])
Table.Combine({table1, table2})
Transformaciones
Las siguientes transformaciones son directamente entre Pandas y Power Query puesto que no son tan comunes en un lenguaje de consulta como SQL.
Analizar el contenido de una tabla
df.describe()
Table.Profile(#"Paso Anterior")
Chequear valores únicos de las columnas
df.value_counts()
Table.Profile(#"Paso Anterior")[[Column],[DistinctCount]]
Generar Tabla de prueba con datos cargados a mano
df = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]], columns=["CustomerID", "Name"])
Table.FromRecords({[CustomerID = 1, Name = "Bob", Phone = "123-4567"]})
Quitar una columna
df.drop(columns=['column1']) df.drop(['column1'], axis=1)
Table.RemoveColumns(#"Paso Anterior",{"column1"})
Aplicar transformaciones sobre una columna
df.apply(lambda x : x['column1'] + 1 , axis = 1)
Table.TransformColumns(#"Paso Anterior", {{"column1", each _ + 1, type number}})
Hemos terminado el largo camino de consultas y transformaciones que nos ayudarían a tener un mejor tiempo a puro código con Power Query y no andar buscando que botones tocar.
#python#sql#powerquery#power query#dataflows#data analysis#data analytics#pandas#tsql#data engineering#data transformation#power bi#bi#data science#python cordoba#python argentina#sql cordoba#sql argentina#power bi cordoba#power bi argentina
1 note
·
View note
Text
Join Multiple Tables in SQL Part 02
youtube
The left and right outer joins are the same as the inner join but differ slightly in that the left outer join shows only those rows or individuals that are both customers and employees, who will see the higher date or information from the employee table. This is similar to the inner join, where only those values or rows that appeared in both tables would have their rows returned to the result set. The left and right outer joins are the same type of join, with the difference being which table comes first. An example of this is to find all product information regardless of whether or not the product is associated with a product subcategory. This is done by selecting the column names from production. product p and adding in the name column from production. Product or ps and giving it an alias of product for category.
0 notes
Text
Join Multiple Tables in SQL Part 02
youtube
The left and right outer joins are the same as the inner join but differ slightly in that the left outer join shows only those rows or individuals that are both customers and employees, who will see the higher date or information from the employee table. This is similar to the inner join, where only those values or rows that appeared in both tables would have their rows returned to the result set. The left and right outer joins are the same type of join, with the difference being which table comes first. An example of this is to find all product information regardless of whether or not the product is associated with a product subcategory. This is done by selecting the column names from production. product p and adding in the name column from production. Product or ps and giving it an alias of product for category.
0 notes