#sqlqueries
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Top SQL Interview Questions and Answers for Freshers and Professionals

SQL is the foundation of data-driven applications. Whether you’re applying for a data analyst, backend developer, or database administrator role, having a solid grip on SQL interview questions is essential for cracking technical rounds.
In this blog post, we’ll go over the most commonly asked SQL questions along with sample answers to help you prepare effectively.
📘 Want a complete, updated list of SQL interview questions? 👉 Check out: SQL Interview Questions & Answers – Freshy Blog
🔹 What is SQL?
SQL (Structured Query Language) is used to communicate with and manipulate databases. It is the standard language for relational database management systems (RDBMS).
🔸 Most Common SQL Interview Questions
1. What is the difference between WHERE and HAVING clause?
WHERE: Filters rows before grouping
HAVING: Filters groups after aggregation
2. What is a Primary Key?
A primary key is a unique identifier for each record in a table and cannot contain NULL values.
3. What are Joins in SQL?
Joins are used to combine rows from two or more tables based on a related column. Types include:
INNER JOIN
LEFT JOIN
RIGHT JOIN
FULL OUTER JOIN
🔸 Intermediate to Advanced SQL Questions
4. What is the difference between DELETE, TRUNCATE, and DROP?
DELETE: Removes rows (can be rolled back)
TRUNCATE: Removes all rows quickly (cannot be rolled back)
DROP: Deletes the table entirely
5. What is a Subquery?
A subquery is a query nested inside another query. It is used to retrieve data for use in the main query.
6. What is normalization?
Normalization is the process of organizing data to reduce redundancy and improve integrity.
🚀 Get a full breakdown with examples, tips, and pro-level questions: 👉 https://www.freshyblog.com/sql-interview-questions-answers/
🔍 Bonus Questions to Practice
What is the difference between UNION and UNION ALL?
What are indexes and how do they improve performance?
How does a GROUP BY clause work with aggregate functions?
What is a stored procedure and when would you use one?
✅ Tips to Crack SQL Interviews
Practice writing queries by hand
Focus on real-world database scenarios
Understand query optimization basics
Review basic RDBMS concepts like constraints and keys
Final Thoughts
Whether you're a fresher starting out or an experienced developer prepping for technical rounds, mastering these SQL interview questions is crucial for acing your next job opportunity.
📚 Access the full SQL interview guide here: 👉 https://www.freshyblog.com/sql-interview-questions-answers/
#SQLInterviewQuestions#SQLQueries#DatabaseInterview#DataAnalytics#BackendDeveloper#FreshyBlog#SQLForFreshers#TechJobs
0 notes
Text
Dynamic Where Condition usage in Database queries

Learn how to implement dynamic WHERE conditions in database queries to build flexible, efficient, and secure SQL statements. This technique allows developers to apply filters based on user input or runtime conditions, enhancing performance and customizability in data-driven applications.
#SQLQueries#DynamicWhereClause#DatabaseDevelopment#SQLTips#QueryOptimization#BackendDevelopment#DatabaseProgramming#CodingBestPractices#SQLInjectionPrevention#WebDevelopment
0 notes
Text
Dynamic Where Condition usage in Database queries

Learn how to implement dynamic WHERE conditions in database queries to build flexible, efficient, and secure SQL statements. This technique allows developers to apply filters based on user input or runtime conditions, enhancing performance and customizability in data-driven applications.
#SQLQueries#DynamicWhereClause#DatabaseDevelopment#SQLTips#QueryOptimization#BackendDevelopment#DatabaseProgramming#CodingBestPractices#SQLInjectionPrevention#WebDevelopment
0 notes
Text
Dynamic Where Condition usage in Database queries

Learn how to implement dynamic WHERE conditions in database queries to build flexible, efficient, and secure SQL statements. This technique allows developers to apply filters based on user input or runtime conditions, enhancing performance and customizability in data-driven applications.
#SQLQueries#DynamicWhereClause#DatabaseDevelopment#SQLTips#QueryOptimization#BackendDevelopment#DatabaseProgramming#CodingBestPractices#SQLInjectionPrevention#WebDevelopment
0 notes
Text
Dynamic Where Condition usage in Database queries

Learn how to implement dynamic WHERE conditions in database queries to build flexible, efficient, and secure SQL statements. This technique allows developers to apply filters based on user input or runtime conditions, enhancing performance and customizability in data-driven applications.
#SQLQueries#DynamicWhereClause#DatabaseDevelopment#SQLTips#QueryOptimization#BackendDevelopment#DatabaseProgramming#CodingBestPractices#SQLInjectionPrevention#WebDevelopment
0 notes
Text
SQL
Quizzes
#quizsquestion#language#programming#SQL#DatabaseManagement#DataAnalysis#SQLQueries#DataScience#TechTutorials#Programming#DataVisualization#LearnSQL#CodingTips
0 notes
Text
Mastering SQL for ETL Testing, Business Analysts, and Advanced Querying
#SQL#ETLTesting#DataAnalysis#SQLforBusinessAnalysts#SQLJoins#SQLSubqueries#FutureTechSkills#SQLQueries#DatabaseTesting#BusinessIntelligence#DataDriven#DataValidation#LearnSQL
1 note
·
View note
Text
SQL Assignments with Solutions - SQL Assignments for Beginners
SQL Assignments for Beginners - We have over ten years of experience and have completed over a thousand SQL assignments with solutions.
https://udaipurwebdesigner.com/sql-assignments-with-solutions/
#UdaipurWebDesigner#SQLLearning#SQLPractice#BeginnerSQL#SQLExercises#DatabaseFundamentals#LearnSQLFromHome#FreeSQLResources#SQLSolutions#SQLForBeginners#CodingChallenges#DataAnalysis#LearnToCode#SQLQueries#DatabaseManagement#SQLJobs
0 notes
Text
NL2SQL With Gemini And BigQuery: A Step-by-Step Guide
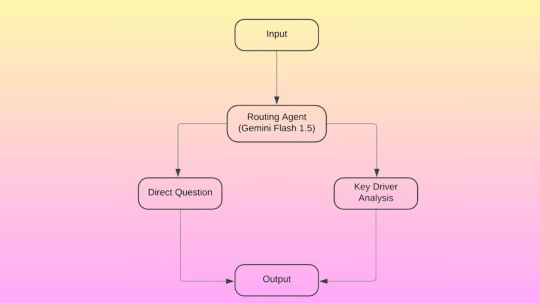
Conversion of natural language to SQL
Beginning to use Gemini and BigQuery for NL2SQL (natural language to SQL)
The intriguing new technology known as Natural Language to SQL, or NL2SQL, was created by combining the classic Structured Query Language (SQL) with Natural Language Processing (NLP). It converts inquiries written in common human language into structured SQL queries.
The technology has enormous potential to change how we engage with data, which is not surprising.
With the help of NL2SQL, non-technical users like marketers, business analysts, and other subject matter experts can engage with databases, examine data, and obtain insights independently without requiring specific SQL expertise. Even SQL experts can save time by using NL2SQL to create sophisticated queries, which allows them to devote more time to strategic analysis and decision-making.
On the ground, how does that appear? Imagine having instant access to a chat interface where you can ask inquiries and receive real-time replies, or
“How many units were sold overall this month?”
“What are the main factors influencing the shift in APAC sales when comparing Q1 and Q2 sales?”
In the past, this would have required an expert to extract information from databases and turn it into business insights. By lowering obstacles to data access, it can democratize analytics by utilizing NL2SQL.
However, a number of obstacles prevent NL2SQL from being extensively used. We’ll look at NL2SQL solutions on Google Cloud and implementation best practices in this blog.
Data quality issues in practical applications
Let us first examine some of the factors that contribute to the difficulty of implementing NL2SQL.
Real-world production data poses a number of difficulties, even if NL2SQL performs best in controlled settings and straightforward queries. These difficulties include:
Data formatting variations: The same information can be expressed in a variety of ways, such as “Male,” “male,” or “M” for gender, or “1000,” “1k,” or “1000.0” for monetary amounts. Additionally, many organizations use poorly defined acronyms of their own.
Semantic ambiguity: Large Language Models (LLMs) frequently lack domain-specific schema comprehension, which results in semantic ambiguity. This can cause user queries to be misinterpreted, for example, when the same column name has many meanings.
Syntactic rigidity: If semantically correct queries don’t follow SQL’s stringent syntax, they may fail.
Unique business metrics: NL2SQL must manage intricate business computations and comprehend table relationships via foreign keys. To translate the question effectively, one must have a sophisticated understanding of the tables that need to be connected and modeled together. Additionally, there is no one standard approach to determine the business KPIs that each corporation should use in the final narrative report.
Client difficulties
Users’ questions are frequently unclear or complicated, so it’s not only the data that can be unclear or poorly formatted. These three frequent issues with user inquiries may make NL2SQL implementation challenging.
Ambiguous questions: Even questions that appear to be clear-cut can be unclear. For example, a query looking for the “total number of sold units month to date” may need to specify which date field to use and whether to use average_total_unit or running_total_unit, etc. The perfect NL2SQL solution will actively ask the user to select the correct column and use their input when creating the SQL query.
Underspecified questions: Another issue is queries that are not detailed enough. For example, a user’s question concerning “the return rate of all products under my team in Q4” does not provide enough details, such as which team should fully grasp the question. An optimal NL2SQL solution should identify areas of ambiguity in the initial input and ask follow-up questions to obtain a comprehensive representation of the query.
Complex queries that require a multi-step analysis: Numerous questions require several stages of analysis. Consider figuring out the main causes of variations in sales from quarter to quarter, for instance: A good NL2SQL solution should be able to deconstruct the study into digestible parts, produce interim summaries, and then create a thorough final report that answers the user’s question.
Dealing with the difficulties
In order to address these issues, Google designed Gemini Flash 1.5 as a routing agent that can categorize queries according to their level of complexity. It can enhance its results by applying methods like contribution analysis models, ambiguity checks, vector embeddings, and semantic searches after the question has been classified.
It reacts to instructions in a JSON format using Gemini. Gemini can act as a routing agent, for instance, by responding to the few-shot prompt.
Direct inquiries
The right column names in scope can be clarified for direct inquiries by utilizing in-context learning, draft SQL ambiguity checks, and user feedback loops. Additionally, simple questions can be guaranteed to generate SQL that is clear.
For straightforward inquiries, its method does the following:
Gathers quality question/SQL pairings.
Keeps samples in BigQuery rows.
Enables the question to have vector embeddings
Leverages BigQuery vector search to extract related examples based on the user’s query.
Adds the table structure, question, and example as the LLM context.
Produces a draft SQL
Executes a loop that includes a SQL ambiguity check, user feedback, refinement, and syntax validation.
Performs the SQL
Uses natural language to summarize the data.
Gemini appears to perform well on tasks that check for SQL ambiguity, according to its heuristic testing. Google started by creating a draft SQL model that had all of the table structure and context-related questions. This allowed Gemini to ask the user follow-up questions to get clarification.
Key driver analysis
Key driver analysis is another name for multi-step reasoning-based data analysis in which analysts must separate and organize data according to every possible combination of attributes (e.g., product categories, distribution channels, and geographies). Google suggests combining Gemini and BigQuery contribution analysis for this use case.
Key driver analysis adds the following steps to the ones done with direct questions:
The routing agent refers users to a key driver analysis special handling page when they ask a query about it.
From ground truth stored in a BigQuery vector database, the agent retrieves similar question/SQL embedding pairings using BigQuery ML vector search.
After that, it creates and verifies the CREATE MODEL statement in order to construct a report on contribution analysis.
Lastly, the SQL that follows is executed in order to obtain the contribution analysis report:
The final report appears as follows:
With Gemini, you can further condense the report in natural language:
Implementing NL2SQL on Google Cloud
Even though this can sound difficult, Google Cloud provides a comprehensive set of tools to assist you in putting an effective NL2SQL solution into place. Let’s examine it.
BigQuery vector search is used for embedding and retrieval
By using BigQuery for embedding storage and retrieval, it is possible to quickly find instances and context that are semantically meaningful for better SQL production. Vertex AI’s text embedding API or BigQuery’s ML.GENERATE_EMBEDDING function can be used to create embeddings. It is simple to match user queries and SQL pairs when BigQuery is used as a vector database because of its inherent vector search.
Contribution analysis using BigQuery
Contribution analysis modeling can find statistically significant differences throughout a dataset, including test and control data, to identify areas of the data that are producing unanticipated changes. A section of the data based on a combination of dimension values is called a region.
To help answer “why?” questions, the recently unveiled contribution analysis preview from BigQuery ML enables automated explanations and insight development of multi-dimensional data at scale. Regarding your data, “What happened?” and “What’s changed?”
The contribution analysis models in BigQuery, in summary, facilitate the generation of many queries using NL2SQL, hence increasing overall efficiency.
Ambiguity checks with Gemini
The process of translating natural language inquiries into structured SQL queries is known as NL2SQL, and it is often unidirectional. Gemini can assist in lowering ambiguity and enhancing the output statements in order to boost performance.
When a question, table, or column schema is unclear, you may utilize Gemini 1.5 Flash to get user input by asking clarifying questions. This will help you improve and refine the SQL query that is produced. Additionally, Gemini and in-context learning can be used to expedite the creation of SQL queries and results summaries in natural language.
Top NL2SQL techniques
For an advantage in your own NL2SQL endeavor, take a look at the following advice.
Start by determining which questions require attention: Depending on the final report’s goal, answering a question may seem straightforward, but getting the intended response and storyline frequently requires several steps of reasoning. Before your experiment, gather the expected natural language ground truth, SQL, and your query.
Data purification and preparation are essential, and using LLMs does not replace them. As needed, establish new table views and make sure that useful descriptions or metadata are used in place of business domain acronyms. Before going on to more complicated join-required questions, start with straightforward ones that just need one table.
Practice iteration and SQL refinement with user feedback: Google’s heuristic experiment demonstrates that iteration with feedback is more effective following the creation of an initial draft of your SQL.
For queries with multiple steps, use a custom flow: Multi-dimensional data explanations and automated insight development can be made possible by BigQuery contribution analysis models.
Next up?
A big step toward making data more accessible and useful for everyone is the combination of NL2SQL, LLMs, and data analytic methods. Enabling users to communicate with databases through natural language can democratize data access and analysis, opening up improved decision-making to a larger group of people in every company.
Data, size, and value can now be rationalized more easily than ever thanks to exciting new innovations like BigQuery contribution analysis and Gemini.
Read more on govindhtech.com
#NL2SQL#Gemini#BigQuery#NaturalLanguage#SQL#SQLqueries#LLM#API#BigQueryML#Gemini1.5#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
How Sql AI Empowers Data Analysts to Retrieve Insights Faster
Data analysts often need to write complex SQL queries to retrieve insights from databases, but manually crafting these queries can be time-consuming and prone to errors. Sql AI provides a powerful solution by enabling analysts to generate SQL queries using natural language, simplifying data access.
Problem Statement: Crafting SQL queries requires in-depth knowledge of SQL syntax, which can be challenging for analysts who are not experts in database management. Writing queries manually also increases the risk of errors, leading to delays in retrieving data.
Application: Sql AI allows data analysts to type in natural language requests, such as "show total sales by product for the last quarter," and converts them into optimized SQL queries. This feature makes data retrieval faster and more intuitive, allowing analysts to focus on interpreting the results rather than spending time writing code.
Outcome: By using Sql AI, data analysts can retrieve data insights much more efficiently, reducing the time spent on query creation and minimizing errors. This leads to quicker decision-making and better overall productivity.
Industry Examples:
E-Commerce: Data analysts in e-commerce companies use Sql AI to quickly generate queries that analyze sales trends and customer behavior.
Healthcare: Analysts in healthcare organizations use Sql AI to generate reports on patient data, improving healthcare outcomes through better data analysis.
Finance: Financial analysts use the platform to access transaction data and generate reports on account activity, aiding in fraud detection and financial planning.
Additional Scenarios: Sql AI can also be used by marketers for campaign analysis, HR departments for employee data insights, and small businesses to generate inventory reports.
Discover how Sql AI can help you retrieve insights faster and improve your data analysis workflow. Get started today at https://aiwikiweb.com/product/sql-ai/
#DataAnalysis#SqlAI#AIinData#NaturalLanguageSQL#BusinessIntelligence#SQLQueries#ECommerceAnalytics#DataDrivenDecisions#SQLAutomation#DataInsights
0 notes
Text
SQL Queries Execution Order - JigNect Technologies
Enhance your SQL knowledge by understanding the order in which queries are executed. Discover how SQL processes statements for better query writing.
0 notes
Text
A Beginner's Guide to Database Management

SQL, or Structured Query Language, is a powerful tool used in database management and manipulation. It provides a standardized method for accessing and managing databases, enabling users to store, retrieve, update, and delete data efficiently. SQL operates through a variety of commands, such as SELECT, INSERT, UPDATE, DELETE, and JOIN, allowing users to perform complex operations on relational databases. Its simplicity and flexibility make it an essential skill for beginners in data management and analysis. With SQL, users can interact with databases seamlessly, extracting valuable insights and ensuring data integrity across various applications and platforms. For the more information visit our website -
#software engineering#coding#programming#SQLBeginner#DatabaseManagement#SQLTutorial#LearnSQL#StructuredQueryLanguage#SQLCommands#DatabaseFundamentals#DataManipulation#SQLSyntax#SQLQueries#Databasecourse
0 notes
Text
SQL Assignment Help
If you find yourself grappling with SQL assignments, seek solace in SQL Assignment Help services. These specialized services are tailored to assist students and professionals in mastering Structured Query Language concepts and overcoming the challenges posed by complex assignments. With SQL Assignment Help, you gain access to expert guidance and solutions, ensuring a comprehensive understanding of database management and query optimization. Navigate through intricate SQL queries, database design, and data manipulation with confidence, as these services provide timely and accurate assistance. Empower your SQL skills, meet academic requirements, and boost your confidence in handling database-related challenges with the dedicated support offered by SQL Assignment Help.
#SQLAssignmentHelp#SQLHelp#SQLTutor#SQLHomework#DatabaseAssignmentHelp#SQLQueries#SQLLearning#SQLProblems#SQLTips
0 notes
Text

Teradata SQL Online Certification Training | H2k Infosys
Introduction:
Teradata SQL refers to the structured query language (SQL) dialect used specifically with Teradata Database, a popular data warehousing solution. SQL is a domain-specific language used for managing and querying relational databases. Teradata SQL is tailored to work efficiently with the Teradata Database, which is known for its parallel processing capabilities and its ability to handle large-scale data processing.
Key aspects of Teradata SQL:
Parallel Processing: Teradata is designed for parallel processing, meaning it can divide tasks among multiple processors to handle large volumes of data more efficiently.

Why Choose H2k Infosys for this Teradata SQL Training
H2k Infosys provides 100% job oriented Teradata training online and onsite training to individuals and corporate teams.
Our Teradata certification training is instructor-led, face-to-face training with live classes.
We incorporate real-time project work in our Teradata training which helps our students gain practical, hands-on experience.
Our faculty are accomplished data professionals in their rights with many years of industrial and teaching experience.
During our Teradata SQL training H2k infosys, we conduct several mock interviews to help you gain the confidence to face real interviews.
After completion of the course, we assist you in preparing your resume.
We also provide you with recruiter driven job placement assistance Future of Teradata SQL:
Integration with Cloud Services: Teradata is working on enhancing its cloud offerings. This includes the integration with popular cloud platforms like AWS, Azure, and Google Cloud. The future may see more seamless integration and optimization for cloud-based deployments.
Advanced Analytics and Machine Learning: Teradata has been expanding its capabilities in advanced analytics and machine learning. Expect more features and functionalities geared towards data science applications.
Focus on Hybrid and Multi-Cloud Environments: As organizations increasingly adopt hybrid and multi-cloud strategies, Teradata may continue to evolve to support these complex environments.
Optimization for IoT and Streaming Data: With the proliferation of IoT devices and the importance of real-time data processing, Teradata may develop features to handle streaming data and IoT workloads more efficiently.
AI-Driven Automation and Optimization: Automation and AI-driven features may become more prominent in Teradata SQL to help optimize queries, workload management, and performance tuning.
Tags: H2kinfosys, Teradata SQL Online Certification Training | H2k Infosys, Teradata Database, For Basic Level, Teradata SQL Aggregates, data warehousing, data engineering, real-time project work training.
#TeradataSQLTraining#TeradataCertification#SQLCertification#DataWarehousingTraining#DatabaseCertification#OnlineLearning#ITTraining#SQLQueries#DatabaseSkills#DataAnalyticsTraining#TeradataDatabase#TechCertification#SQLSkills#DataManagement#OnlineCourse#TeradataAnalytics#DatabaseDevelopment#SQLCourse#DataWarehousingSkills
0 notes
Text

#DataAnalysts#DataAnalysis#DataInsights#DecisionMaking#DataProcessing#DataVisualization#ExcelAnalysis#SQLQueries#PythonAnalysis#RProgramming#DataTools#StatisticalAnalysis#DataVisualizationTools#ETLTools#DataCleaning#MachineLearning#TechnicalSkills#BusinessStrategies#DataManagement#microsoftedu
1 note
·
View note
Text
youtube
0 notes