#targeted ai solutions legit
Text
Targeted AI Solutions Review – Real Info About AI Solutions
Welcome to my Targeted AI Solutions Review Post. This is a real user-based Targeted AI Solutions Review where I will focus on the features, upgrades, demo, pricing and bonus how Targeted AI Solutions can help you, and my opinion. Unlock Local Marketing’s Future and Business Growth with the End of Expensive Consultants. Just Smart AI Solutions
Total AI Solutions is ready to help you realise your goal. Consider having access to top-tier marketing and company development assistance whenever you want, without having to pay the high rates of conventional consultants. Total AI Solutions provides a cost-effective, AI-powered solution that is accessible 24 hours a day, seven days a week. It’s all offered via an easy-to-use chat interface, making it as simple as texting a buddy. Total AI Solutions provides more than simply guidance. It offers focused tactics supported by data-driven insights to assist you in implementing changes quickly and seeing results quicker. Stop pondering what you should do next. Total AI Solutions gives the assistance you need, when you want it, to propel your company forward.

<<Get Amplify with my Special Bonus Bundle to Get More Traffic, Leads & Commissions >>
Targeted AI Solutions Review: What Is Targeted AI Solutions?
Targeted AI Solutions is created by IM Wealth Builders, expert product builders known for their innovation and pragmatism. Their creative goods have made them famous in internet marketing. Imagine having a 24/7 staff of digital marketing and company development experts at your disposal. Imagine a future where strategic advice, creative content, and faultless execution in expanding your company or improving client services are simply the norm. As an experienced company owner, I’ve felt the pain of obtaining top-tier knowledge that drives growth. Traditional path? It takes time and money to hire expensive experts. DIY method? The many obligations you handle everyday make life daunting.
Targeted AI Solutions Review: Overview
Creator: Matt Garrett
Product: Targeted AI Solutions
Date Of Launch: 2024-Jan-04
Time Of Launch: 11:00 EDT
Front-End Price: $17
Product Type: Software (online)
Support: Effective Response
Discount : Get The Best Discount Right Now!
Recommended: Highly Recommended
Skill Level Required: All Levels
Refund: YES, 30 Days Money-Back Guarantee
Targeted AI Solutions Review: Key Features
The 12 Marketing Titans Council: Dive into the minds of 12 AI experts, each a maestro in a crucial domain of business growth and digital marketing. From SEO virtuosos to social media mavens, they constitute your council of digital dominance.
Customized Strategies from AI Maestros: These aren’t mere aides. They are AI-powered strategists delivering personalized, actionable plans finely tuned to your business objectives.
24/7 Support: Your business never sleeps, and neither do our AI experts. They stand ready around the clock, ensuring you have support whenever inspiration strikes or challenges arise.
Cost-Effective Expertise: Bid farewell to exorbitant consultant fees. Total AI Solutions offers the wisdom of top-tier marketing experts at a fraction of the cost.
Adaptable Wisdom: As your business evolves, so does our AI. Our platform scales its expertise to meet your expanding needs, guaranteeing you stay ahead of the curve.
Swift Strategy Implementation: Translate advice into action with agility. Our AI experts furnish detailed, easy-to-implement strategies, accelerating your journey to success.
Universal Relevance: Irrespective of your industry, Total AI Solutions is primed to elevate your business. Our AI expertise is versatile, adaptable, and universally applicable.
User-Friendly Interface: Engage with our AI experts through an intuitive chat interface. No steep learning curve, just straightforward, effective communication.
Targeted AI Solutions Review: Can Do For You
Easy Accessibility Expert: Ensuring your digital presence is inclusive and accessible to all
Google Business Guru: Optimizing your visibility and impact on Google
Citation Champion: Mastering the art of business listings for maximum reach
Reputation Guardian: Safeguarding and enhancing your online reputation
Video Marketing Magician: Conjuring compelling video content that captivates and converts
Website Wizard and Designer: Crafting and beautifying your digital storefront
AI Services Virtuoso: Unleashing the power of AI for innovative solutions
On-Page & Technical SEO Sensei: Fine-tuning your website for peak search engine performance
Link Building Luminary: Constructing a network of quality links to boost your SEO
Social Media and Content Marketing Maverick: Driving engagement and brand loyalty through social media and content
Pay Per Click Ads Ace: Maximizing your ROI on ad spend
Security Solutions Sentinel: Fortifying your digital assets against threats
Targeted AI Solutions Review: Who Should Use It?
Business Owners
Bloggers
Content Creators
Digital Agencies
Educators and Trainers
Entertainment Industry Professional
Influence’s and Celebrities
Marketing Professionals
Photographers & Videographers
Social Media Marketer
Technology Users
Targeted AI Solutions Review: OTO’S And Pricing
Front-End Price: Targeted AI Solutions ($17)
OTO 1: TAIS Additional Niche Experts Library ($27/47)
OTO 2: TAIS Niche Expert Creation Module ($67)
OTO 3: TAIS Niche Experts Client Access ($97)
OTO 4: TAIS Bespoke Experts Lifetime License Buyout ($147)
Targeted AI Solutions Review: Free Bonuses
Bonus 1: Email Crafter AI Software (Value $197)
AI-Powered Email Writer.
Automatically create complete email sequences in a single click
Enter a URL, or describe your content, and Email Crafter will analyze it and write your emails
Whitelabel email template system: add your email sequences and emails for your users to use
We host it: nothing to download, you can be up and running in minutes.
Create a single email, or 100’s of emails in 1 go.
One-click copy system to easily take emails from the app into your autoresponder.
200+ Emails in 26 different email sequences. 1,000 Emails available soon.
1-click regeneration of produced emails
End-user email sequences: users can write their email prompts or give the app their writing as an example, then let the app write emails in their voice
Bonus 2: AI Enhanced List Building Launchpad – 30-Day Playbook! (Value $197)
Teach Businesses How to Build an Email List So They Can Generate More Leads, Customers, and Revenue!
In the ever-evolving digital landscape, the difference between businesses that thrive and those that merely survive is often the effectiveness of their online strategy. The AI Enhanced List Building Launchpad 30-Day Playbook isn’t just a guide; it’s a promise. A promise that by the end of these 30 days, your business will be able to turn on your “email list profit faucet” any time you want to drive revenue like never before.
Bonus 3: Full Commercial Licence Included (Value $197)
That means you generate content, training, guidance, ads, social media posts, e-books, and more with your Digital Marketing Experts. You can use the power of the AI experts to build your own business AND you can give, sell rent, or offer as service-generated content!
Three video series covering
How To Start A Consultancy Business (4 videos)
How To Find And Close Clients (3 videos)
How To Sell Marketing And Digital Services (11 videos)
Conclusion
Targeted AI Solutions will revolutionise corporate development by seamlessly integrating artificial intelligence with innovation for entrepreneurs and marketers. This innovative platform removes obstacles to profit-driven knowledge by providing personalised, strategic consultations from top experts at any time and place. Targeted AI Solutions offers lifelong access to superior digital skills at a very low price. Success stories and a money-back guarantee make this platform essential for aspiring people in all fields. Take advantage of this disruptive innovation at its present price before rates raise.
Frequently Asked Questions (FAQ)
Q. Can I use Targeted AI Solutions on Mac?
Absolutely, Targeted AI Solutions is a web-based app accessible on a computer with an internet connection.
Q. What else do I need to make this work?
Targeted AI Solutions use the OpenAI API. So you will need an Open AI account and an API key. The account is free with over 3 million tokens for 3 months included.
Q. Do I need to purchase credits?
Targeted AI Solutions uses Open AI extensively. Start by creating a free Open AI account with 1.5 million characters of credit. After your initial credits run out, token use is pay-as-you-go. Around $1 every 350,000 characters, tokens are cheap.
Q. Does this software support all countries?
While the application’s user interface is in English, our experts have the flexibility to respond in any requested language or your local language if necessary. Regardless, our experts will always tailor their responses specifically to your location.
Q. What exactly does the AI do?
AI drives the 12 professionals, who each have a distinct skill set for offering digital services to local clientele. SEO, Google My Business, Citation Management, Reputation Management, etc. By communicating directly with these professionals, the AI helps you understand consumer behaviour, learn new skills, improve service delivery, build successful marketing campaigns, generate documentation, create social media content, and more.
Q. Why is Targeted AI Solutions such a low price?
Special launch pricing. This application should engage as many individuals as feasible. We think Targeted AI Solutions is great software and that users would agree. We want testimonials and comments as part of the deal. Help us market and develop the software.
Q. What kind of license do I get with software?
You get full access and a commercial license. That means you can sell or distribute any content generated by your experts.
Q. Does this app work in any niche or business?
Absolutely, Your specialists are designed for local business. They work with home, commercial, healthcare, beauty and well-being, legal, hospitality, transport, and other businesses.
Q. How do I get my bonuses?
The bonuses are integrated into the app. Navigate to the bottom of the home page and access the “Bonuses” menu item.
<<Get Amplify with my Special Bonus Bundle to Get More Traffic, Leads & Commissions >>
Check Out My Other Reviews Here! – Amplify App Review, AI NexaSites Review, $1K PAYDAYS Review, FaceSwap Review, Chat Bot AI Review.
Thank for reading my Targeted AI Solutions Review till the end. Hope it will help you to make purchase decision perfectly.
#buy targeted ai solutions#get targeted ai solutions#How to make money online#make money online#Make Money Online 2024#make money tutorials#targeted ai solutions#targeted ai solutions app by Matt Garrett#targeted ai solutions app review#targeted ai solutions bonus#targeted ai solutions demo#targeted ai solutions discount#targeted ai solutions legit#targeted ai solutions oto#targeted ai solutions preview#targeted ai solutions review#targeted ai solutions scam
0 notes
Note
Notice how the rising stories from China and in villages across India are reporting that families are still mass killing their baby girls make the pro aborts quiet? They claim to be feminists but the choice is always at the expense of a baby girl being murdered for being a girl. Always. There’s no place on earth where baby boys are being mass killed in a system that tells families that boys have no value.
Now those countries are killing themselves because they don’t have any women left to marry their sons too. There’s already kidnapping from nearby areas but that’s not sustainable. On top of that, boys in primary school who consume content like Tat3 or these masculinity podcasts are academically falling faster because they’re more concerned over being “masculine and dominant” over the female teachers and classmates. The future seems to be full of single, violent, unintelligent/uneducated men who hate women because the girls who haven’t been killed in the womb or as infants are accomplished and educated but vastly outnumbered. Males will use every excuse to justify their hatred from religion like islam to just being violent. There would be pick mes that support those men tho. I watched a tiktok of a woman at the gym (who I think either had her account banned or went private) say the worst things for her male viewers. The worst I saw was how she said that men should return women back to god (so kill us) and the comments (the males) all agreed. But even so, she won’t be protected by them because at the end of the day, being a woman means you have a target on your back that will only get bigger as time goes on. So I hope pro aborts are happy that they think giving the choice to kill babies were worth it. Because this world despises women, even in the womb so that choice will always kill us.
They're quiet about it because they can't shove them abortion as the solution of this problem ¯\_(ツ)_/¯ pro abortion aren't solution focused, they just want to elevate abortion as the be all and end all of reproductive justice. But what are they gonna do when women are going to profit off access to abortion to have safer sex elective abortion? They'll go *shocked face Pikachu ", that's all
Female redpilled grifter are trendy because pandering to incels is very profitable. The good news is that it's pretty much a phase and that most of these women will get over in ~10 years or tone down their act big time (à la Lauren Southern), the bad news is that they will always be a new flock of idiot to take over the torch AND having the audience to follow.
Even here in France we have them red pill trad chicks associated to far right movement saying slut shaming is good and that feminism is the devil (Thaïs d'Escufon is a piece of work lol), and they are fairly popular in their nice. Just sprinkle "woke" here and there and they reach 100k+ views every few days.
She (Thaïs) once made a collab video with a french manosphere scrote, and they humiliated her asking her to pick some coffee and basically putting her down into her 'female place', and french twitter clowned her saying "well that's what sd was asking for ¯\_(ツ)_/¯". There was also an audio leak from this french Nationalist vocal chatroom where she threw a fit bc apparently nationalist scrotes were interested dating Asian or African wife bc they were "more traditional". She was fuming bc it was a cultural and racial waste 💀 (FYI she's a legit White supremacist. But also a VERY dumb one. She once posted on Twitter an AI image of these "perfect man & woman" and used the fact they were White to argue that White people were objectively the prettiest 💀 .... girl didn't get that AI wasn't "neutral")
It's was very interesting to see her seething at seeing her White men lusting after women. You'd think with all the attention she gets, she'd have a ring on her finger yet, but homegirl is in her mid 20, still not married, but patronizing men peepee to keep them on check (which is a lost cause of course bc most men are animals). This dissonance is very weird... She's very much like Pearl. There has to be something very off with them or their surrounding if they can't find a man. I mean, according to their own logic of "women main purpose to breed to pursue the (white) race".
5 notes
·
View notes
Text
Affiliate Begins With AI legit or hype?
In today’s rapidly evolving digital marketing landscape, one technology is rising above all others—Artificial Intelligence (AI). For affiliate marketers, staying ahead of the competition has become a matter of leveraging AI effectively. The role of AI in affiliate marketing is more than just a trend; it’s a revolution that’s reshaping how businesses promote products, engage audiences, and generate revenue. As digital marketing continues to shift, the message is clear: the future of affiliate marketing begins with AI, and those who embrace it will thrive in this highly competitive field.

The Importance of Staying Ahead in Affiliate Marketing
Affiliate marketing has always been a dynamic industry, constantly adapting to new technologies, platforms, and consumer behaviors. Whether you’re a seasoned marketer or just stepping into the world of affiliate marketing, the ability to stay ahead of the curve is critical for success. The competition is fierce, and only those who innovate will capture attention, drive traffic, and convert sales. This is where AI steps in, providing tools and capabilities that no human team can match in terms of speed, accuracy, and scale.
✅ WATCH THE VIDEO ✅
AI is no longer a futuristic concept but a present reality that is transforming how marketers operate. In a space where every click counts, every conversion matters, and customer expectations are higher than ever, using AI-powered tools is no longer optional but necessary.
What is AI in Affiliate Marketing?
Artificial Intelligence in affiliate marketing refers to the use of machine learning algorithms, data analytics, and automation technologies to streamline and enhance the processes involved in affiliate marketing. From automating content creation and email marketing to optimizing ad placements and audience targeting, AI’s reach is vast. But at its core, AI's main role is to process and analyze massive amounts of data, providing actionable insights that improve marketing strategies and increase conversion rates.
AI in affiliate marketing offers several advantages, such as:
Data-Driven Insights: AI algorithms process large sets of data to provide real-time insights into customer behavior, preferences, and buying patterns. This helps marketers make informed decisions and adjust campaigns for better performance.
Automation of Routine Tasks: Time-consuming tasks like audience segmentation, lead nurturing, and content scheduling can be fully automated using AI. This frees up marketers to focus on strategy and creativity.
Predictive Analytics: AI-powered tools can predict future trends, enabling marketers to anticipate what products or services will be in demand and optimize their promotional efforts accordingly.
Personalization at Scale: With AI, personalization is not limited to small customer segments but can be applied to individual users, creating a highly customized and engaging experience.
Enhanced Customer Engagement: Chatbots and AI-powered communication tools can engage customers instantly, providing answers and solutions in real time, leading to better user experiences and increased conversions.
How AI is Revolutionizing Affiliate Marketing
AI is revolutionizing affiliate marketing by turning data into a goldmine of actionable insights. Let’s explore the key areas where AI is making the most significant impact:
Hyper-Targeted Content Creation
Content remains king, but AI has transformed how content is created and targeted. By analyzing user data, AI tools can generate hyper-targeted content designed to resonate with specific audience segments. This allows affiliate marketers to create personalized messages that speak directly to the needs, desires, and pain points of individual users. Whether it’s blog posts, social media ads, or email campaigns, AI helps optimize the content creation process for higher engagement and better conversions.
For example, AI-driven tools like GPT-4 can analyze top-performing content in a specific niche and create similar content tailored to your audience. By learning from millions of data points, these tools can predict what type of content will perform best for your target demographic, helping marketers consistently produce high-quality, relevant content that converts.
Advanced Audience Targeting
Audience targeting is the cornerstone of successful affiliate marketing. Traditionally, marketers relied on manual methods to segment audiences based on demographics or behaviors. But AI takes audience targeting to a whole new level. Using sophisticated algorithms, AI can identify and categorize audiences based on much more complex factors, including behavioral patterns, purchase histories, and even social media activity.
AI-driven audience segmentation tools allow affiliate marketers to create hyper-specific groups based on a range of data points, ensuring that each marketing message reaches the right audience at the right time. This leads to more personalized user experiences and higher conversion rates. By leveraging AI, marketers can refine their targeting strategies continuously, improving the effectiveness of their campaigns over time.
Predictive Analytics for Smarter Marketing
One of the most powerful applications of AI in affiliate marketing is predictive analytics. AI tools can process historical data and identify patterns to predict future behaviors and trends. This is particularly valuable in affiliate marketing, where the ability to anticipate market shifts or changing consumer preferences can mean the difference between success and failure.
By using predictive analytics, affiliate marketers can make informed decisions about which products to promote, which audiences to target, and how to allocate resources effectively. For example, if an AI tool predicts that a certain product category is about to experience a surge in demand, marketers can adjust their campaigns to focus on those products, maximizing their potential profits.
Real-Time Data Optimization
AI allows affiliate marketers to optimize their campaigns in real time. Instead of waiting weeks or months to assess the success of a campaign, AI-powered tools provide immediate feedback, enabling marketers to adjust their strategies on the fly. This level of responsiveness is crucial in the fast-paced world of digital marketing, where trends can change overnight.
✅==> Click Here to Buy at an Exclusively Discounted Price Now!✅
AI tools analyze performance metrics like click-through rates, conversion rates, and engagement levels, identifying areas that need improvement. Based on these insights, marketers can make data-driven adjustments to their campaigns, such as changing ad copy, tweaking targeting parameters, or reallocating budgets. This continuous optimization ensures that campaigns are always performing at their highest potential.
Automating Routine Tasks
One of the most significant benefits of AI is its ability to automate routine tasks, allowing marketers to focus on higher-level strategy and creativity. AI-powered tools can handle tasks like email marketing, lead nurturing, and even customer service through chatbots. This not only saves time but also ensures consistency and accuracy across all marketing efforts.
For example, AI-driven email marketing platforms can automatically segment your audience, personalize email content, and schedule campaigns based on user behavior. Chatbots powered by AI can handle customer inquiries in real time, providing instant answers and resolving issues without human intervention. This level of automation allows affiliate marketers to scale their efforts without compromising on quality.
Boosting Conversion Rates with Personalization
Personalization is a proven method for increasing conversion rates, and AI takes it to the next level by enabling personalized experiences at scale. By analyzing user data, AI tools can create unique marketing experiences for each individual user, tailoring recommendations, offers, and content to their specific preferences.
For example, AI-driven recommendation engines can suggest products to users based on their browsing history or past purchases, increasing the likelihood of conversion. Personalized email campaigns can deliver highly relevant content to users, improving engagement and driving sales. The result is a more personalized customer journey that leads to higher conversion rates and greater customer satisfaction.
The Future of Affiliate Marketing with AI
The integration of AI into affiliate marketing is still in its early stages, but the future is incredibly promising. As AI technology continues to evolve, we can expect even more advanced tools and capabilities to emerge, further transforming the affiliate marketing landscape.
In the near future, AI could enable entirely automated marketing campaigns that require minimal human intervention, with algorithms optimizing every aspect of the process, from content creation to audience targeting. Virtual reality and augmented reality, combined with AI, could offer immersive, personalized shopping experiences that engage users on a deeper level, leading to even higher conversion rates.
Conclusion
Affiliate marketing has always been about staying ahead of the curve, and the future of the industry undoubtedly lies in the power of AI. From automating routine tasks to providing data-driven insights and personalized experiences, AI is transforming how affiliate marketers operate.
The time to embrace AI is now. Those who leverage this technology will not only keep up with the competition but lead the way into a new era of marketing success. In the world of affiliate marketing, it’s clear: Affiliate begins with AI, and the future belongs to those who master it.
Affiliate Disclosure: Affiliate Links are used in this content i will receive a little commission if you puchase any product using one of the links in this post. but there are no additional cost for you
0 notes
Text
Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card
Independent adviser Steven van Belleghem presents an absorbing eyes on the chump acquaintance of the day afterwards tomorrow in this IDG webinar. He sees two capital affidavit why the agenda era is about to accept a absolute breakthrough. First of all, Covid-19 has accustomed the apple a blast advance in agenda because there were no added options. And second, we can apprentice from beforehand revolutions (industrial, steam, accumulation production) that deployment sears to abundant heights as the aftereffect of a recession.

12 Pay with GasBuddy App Review: Is It a Legit Way to Save Money? – manage sears credit card | manage sears credit card
In aggregate with accessible technologies as AI, 5G, breakthrough accretion and robotics Steven van Belleghem sees a CX (customer experience) that is predictive, faster than absolute time, aggressive alone and convenient.
His advice? Alpha apperception the ultimate CX and about-face architect the action to accomplish that goal.
At Genesys we absolutely accede and are acquisitive to airing through this action calm with you. Let us biking forth the three advance advance Steven recommends and appearance what is already possible.

Former CD/Game Exchange (The Record Exchange), Cleveland Heights, Ohio – manage sears credit card | manage sears credit card
Integration is key, abnormally back we allocution about data. A lot or organizations still accept actual disparaged abstracts because siloed systems. Integrating systems for CRM, agenda marketing, sales and chump account is footfall one. But appropriately important is to be able to chase the babble with the chump from access to channel. If your chump grabs the buzz and vents his complaint – can your abettor see that this being acclimated the webform yesterday, beatific an email that morning and a absolute bulletin via Twitter? Or does the chump accept to alpha cogent his adventure from scratch?
If you accept a accurate omnichannel acquaintance centermost all this advice is at the fingertips of your agents, allotment them to bear a alone acquaintance absorption at the specific catechism and bearings for the customer.
Integrated abstracts is additionally the abject of advantageous intelligence to abutment acceptable administration decisions on annihilation from business to sales to acquaintance centermost management. For instance, based on actual abstracts Genesys Predictive Engagement can adjudge the best moment to access a website company with an action or abetment to apprehend the about-face from anticipation to buyer.

Target Red Card Login – Manage My RedCard – manage sears credit card | manage sears credit card
In our appearance the chump is consistently in the lead, which includes the best of advice channel. You charge to be there area the chump expects you to be, whether it is on the phone, chat, email or on a concrete location.
Connecting them to the appropriate ability should be accessible and intuitive. No amaranthine IVR choices but AI apprenticed accent acceptance in aggregate with skills-based acquisition for instance, ensuring the best accessible abettor gets to acknowledgment the issue. On top of this we can additionally bear predictive routing; acquisition based on predefined KPI’s. Predictive acquisition is AI assisted and will arbitrate abilities based acquisition if the aftereffect of that acquisition accommodation will advance the authentic KPI.
It sounds actual futuristic: but that best abettor ability be a bot. With accent acceptance it is accessible to actualize a chatty self-service action for almost simple, alternating requests. A acceptable archetype is in this video area a chump is accustomed by her buzz cardinal and asked if she calls about her best contempo order. The bot understands her acknowledgment and reacts by initiating the acknowledgment action including a acceptance email. Another acceptable archetype is a animal abettor handing off the processing of a acclaim agenda acquittal to an automatic process, based on accent acceptance and argument to speech, appropriately ensuring aegis and acquiescence of the banking transaction.

Ten Things To Expect When Attending Sears Credit Card Number | sears credit card number – manage sears credit card | manage sears credit card
But it keeps accepting bigger back bodies and bots are absolutely teaming together. This is what Steven van Belleghem calls Augmented Intelligence area the abettor handles the alternation and is accurate by suggestions from the system. Through accent and argument assay the arrangement can retrieve accordant advice from the ability abject while the abettor talks to the customer. It helps acknowledgment questions but can additionally advance up advertise and cantankerous advertise opportunities.
These are aloof a few examples of what is already accessible at this moment. Share your eyes today of the chump acquaintance you appetite to be able to action the day afterwards tomorrow and we will advice you body it.
Just call, mail or accelerate me a message.

www.searscard.com Login |Make Payment – Sears Credit Card Customer .. | manage sears credit card
Terrence Hotting, Senior Solution Adviser at Genesys [email protected] 31 6 297 268 92
Copyright © 2020 IDG Communications, Inc.
Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card – manage sears credit card
| Allowed to my own website, in this period I’m going to provide you with in relation to keyword. And from now on, this is the primary photograph:

Quick Ways To Make A Sears Credit Card Payment | BrokeMeNot – manage sears credit card | manage sears credit card
Think about photograph over? is usually in which incredible???. if you think maybe consequently, I’l l provide you with several impression all over again below:
So, if you’d like to get these magnificent pics about (Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card), click save icon to store the photos to your laptop. They’re all set for down load, if you appreciate and want to grab it, click save symbol on the post, and it will be instantly down loaded to your computer.} Finally if you want to gain unique and latest photo related to (Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card), please follow us on google plus or save the site, we try our best to give you regular update with fresh and new photos. We do hope you like keeping right here. For most upgrades and recent information about (Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card) graphics, please kindly follow us on twitter, path, Instagram and google plus, or you mark this page on book mark area, We try to provide you with up-date regularly with fresh and new images, like your surfing, and find the best for you.
Here you are at our website, articleabove (Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card) published . Today we’re pleased to announce we have discovered an incrediblyinteresting nicheto be discussed, that is (Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card) Most people attempting to find info about(Seven Facts You Never Knew About Manage Sears Credit Card | manage sears credit card) and definitely one of them is you, is not it?

All You Need to Know about the Sears MasterCard – Tally – manage sears credit card | manage sears credit card

Sears Credit Card Offers – Kmart – manage sears credit card | manage sears credit card

How Apple Pay works under the hood? | by Prashant Ram | codeburst – manage sears credit card | manage sears credit card

Sears Credit Offers Members – Sears – manage sears credit card | manage sears credit card

How to Access a Sears Credit Card Account | LoveToKnow – manage sears credit card | manage sears credit card

www.searscard | manage sears credit card
from WordPress https://www.cardsvista.com/seven-facts-you-never-knew-about-manage-sears-credit-card-manage-sears-credit-card/
via IFTTT
0 notes
Text
AI competitions don’t produce useful models

By LUKE OAKDEN-RAYNER
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
The dataset has been released for a competition, which obviously lead to the usual friendly rivalry on Twitter:
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle

Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!

If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.

Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:

In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:
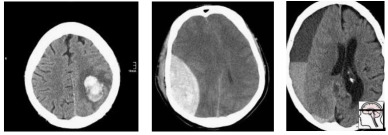
Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.

These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).

So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.

Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.

Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?

So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?

As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?

They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
AI competitions don’t produce useful models published first on https://wittooth.tumblr.com/
0 notes
Text
AI competitions don’t produce useful models

By LUKE OAKDEN-RAYNER
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
The dataset has been released for a competition, which obviously lead to the usual friendly rivalry on Twitter:
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle

Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!

If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.
Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:

In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:
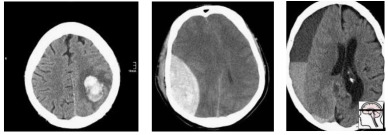
Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.

These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).
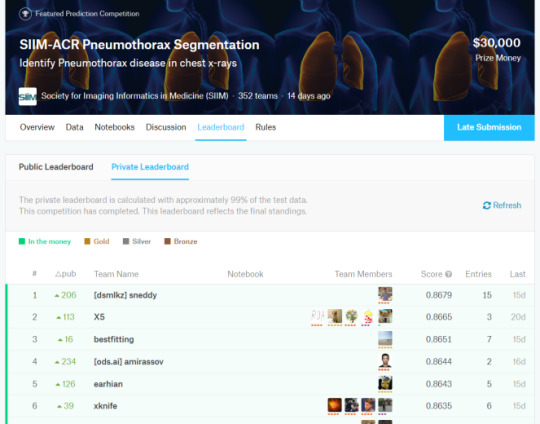
So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.
Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.
Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?

So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?

As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?

They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
AI competitions don’t produce useful models published first on https://venabeahan.tumblr.com
0 notes
Text
Thin Content & SEO | How to Avoid a Google Thin Content Penalty
We live in a world of information overload. If 10 years ago it was hard to find content at all, now there’s way too much of it! Which one is good? Which one is bad? We don’t know.
While this subject is very complex, it’s clear that Google is attempting to solve these content issues in its search results. One of the biggest issues they’ve encountered in the digital marketing world is what they call thin content.
But what exactly is thin content? Should you worry about it? Can it affect your website’s SEO in a negative way? Well, thin content can get your site manually penalized but it can also sometimes send your website in Google’s omitted results. If you want to avoid these issues, keep reading!
What Is Thin Content & How Does It Affect SEO?
Is Thin Content Still a Problem in 2019?
How Does Thin Content Affect SEO?
Where Is Thin Content Found Most Often?
How to Identify Thin Content Pages
How to Fix Thin Content Issues & Avoid a Google Penalty
Make sure your site looks legit
Add more content & avoid similar titles
Don’t copy content
Web design, formatting & ads
Video, images, text, audio, etc.
Deindex/remove useless pages
1. What Is Thin Content & How Does It Affect SEO?
Thin content is an OnPage SEO issue that has been defined by Google as content with no added value.
When you’re publishing content on your website and it doesn’t improve the quality of a search results page at least a little bit, you’re publishing thin content.
For a very dull example, when you search Google for a question such as “What color is the sky?” and there’s an article out there saying “The sky is blue!”, if you publish an article with the same answer you would be guilty of adding no value.
So does it mean that this article is thin content because there are other articles about thin content out there?
Well.. no. Why? Because I’m adding value to it. First, I’m adding my own opinion, which is crucial. Then, I’m trying to structure it as logically as possible, address as many important issues as I can and cover gaps which I have identified from other pieces.
Sometimes, you might not have something new to say, but you might have a better way of saying it. To go back to our example, you could say something like “The sky doesn’t really have a color but is perceived as blue by the human eye because of the way light scatters through the atmosphere.”
Of course, you would probably have to add at least another 1500 words to that to make it seem like it’s not thin. It’s true. Longer content tends to rank better in Google, with top positions averaging about 2000 words.
How your content should be to rank
Sometimes, you might add value through design or maybe even through a faster website. There are multiple ways through which you can add value. We’ll talk about them soon.
From the Google Webmaster Guidelines page we can extract 4 types of practices which are strictly related to content quality. However, they are not easy to define!
Automatically generated content: Simple. It’s content created by robots to replace regular content, written by humans. Don’t do it. But… some AI content marketing tools have become so advanced that it’s hard to distinguish between real and automatically generated content. Humans can write poorly too. Don’t expect a cheap freelancer who writes 1000 words for $1 to have good grammar and copy. A robot might be better. But theoretically, that’s against the rules.
Thin affiliate pages: If you’re publishing affiliate pages which don’t include reviews or opinions, you’re not providing any new value to the users compared to what the actual store is already providing on their sales page.
Scraped or copied content: The catch here is to have original content. If you don’t have original content, you shouldn’t be posting it to claim it’s yours. However, even when you don’t claim it’s yours, you can’t expect Google to rank it better than the original source. Maybe there can be a reason (better design, faster website) but, generally, nobody would say it’s fair. Scraping is a no no and Google really hates it.
Doorway pages: Doorway pages are pages created to target and rank for a variety of very similar queries. While this is bad in Google’s eyes, the search giant doesn’t provide an alternative to doorway pages. If you have to target 5-10 similar queries (let’s say if you’re doing local SEO for a client), you might pull something off with one page, but if you have to target thousands of similar queries, you won’t be able to do it. A national car rental service, for example, will always have pages which could be considered doorways.
If you want, you can listen to Matt Cutts’ explanation from this video.
youtube
As you can see, it all revolves around value. The content that you publish must have some value to the user. If it’s just there because you want traffic, then you’re doing it wrong.
But value can sometimes be hard to define. For some, their content might seem as the most valuable, while for others it might seem useless. For example, one might write “Plumbing services New York, $35 / hour, Phone number”. The other might write “The entire history of plumbing, How to do it yourself, Plumbing services New York, $35 / hour, Phone number.”
Which one is more relevant? Which one provides more value? It really depends on the user’s intent. If the user just wants a plumber, they don’t want to hear about all the history. They just want a phone number and a quick, good service.
However, what’s important to understand is that there is always a way to add value.
In the end, it’s the search engine that decides, but there are some guidelines you can follow to make sure Google sees your content as valuable. Keep reading and you’ll find out all about them. But first, let’s better understand why thin content is still an issue and how it actually affects search engine optimization.
1.1 Is Thin Content Still a Problem in 2019?
The thin content purge started on February 23, 2011 with the first Panda Update. At first, Google introduced the thin content penalty because many people were generating content automatically or were creating thousands of irrelevant pages.
The series of further updates were successful and many websites with low quality content got penalized or deranked. This pushed site owners to write better content.
Unfortunately, today this mostly translates to longer content. The more you write, the more value you can provide, right? We know it’s not necessarily the case, but as I’ve said, longer content does tend to rank better in Google. Be it because the content makes its way up there or because the search engine is biased towards it… it’s hard to tell.
But there’s also evidence that long form content gets more shares on social media. This can result in more backlinks, which translates to better rankings. So it’s not directly the fact that the content is long, but rather an indirect factor related to it.
It’s kind of ironic, as Google sometimes uses its answer boxes to give a very ‘thin’ answer to questions that might require more context to be well understood.
However, in 2019 it’s common SEO knowledge that content must be of high quality. The issue today shifts to the overload of content that is constantly being published. Everything is, at least to some extent, qualitative.
But it’s hard to get all the information from everywhere and you don’t always know which source to rely on or trust. That’s why content curation has been doing so well lately.
This manifests itself in other areas, especially where there’s a very tough competition, such as eCommerce.
1.2 How Does Thin Content Affect SEO?
Google wants to serve its users the best possible content it can. If Google doesn’t do that, then its users won’t return to Google and could classify it as a poor quality service. And that makes the search engine unhappy.
Google generally applies a manual action penalty to websites it considers to contain thin content. You will see it in the Google Search Console (former Google Webmaster Tools) and it looks like this:
However, your site can still be affected by thin content even if you don’t get a warning from Google in your Search Console account. That’s because you’re diluting your site’s value and burning through your crawl budget.
The problem that search engines have is that they constantly have to crawl a lot of pages. The more pages you give it to crawl, the more work it has to do.
If the pages the search engine crawls are not useful for the users, then Google will have a problem with wasting its time on your content.
1.3 Where Is Thin Content Found Most Often?
Thin content is found most of the time on bigger websites. For the sake of helping people that really need help, let’s exclude spammy affiliate websites and automated blogs from this list.
Big websites, like eCommerce stores, often have a hard time coming up with original, high quality content for all their pages, especially for thousands of product pages.
In the example above, you can see that although the Product Details section under the image is expanded, there’s no content there. This means that users don’t have any details at all about the dress. All they know is that it’s a dress, it’s black and it costs about $20.
This doesn’t look too bad when you’re looking as a human at a single page, but when you’re a search engine and take a look at thousands and thousands of pages just like this one, then you begin to see the issue.
The solution here is to add some copy. Think of what users want to know about your product. Make sure you add the details about everything they might want to know and make them easily accessible!
Sometimes, thin content makes its way into eCommerce sites unnoticed. For example, you might have a category page which hosts a single product. Compared to all your other categories or competitor websites,that can be seen as thin content.
2. How to Identify Thin Content Pages
If we are referring merely to its size, then thin content can be easily identified using the cognitiveSEO Tool’s Site Audit.
Did you know?
Identifying thin content is actually really easy with a tool like cognitiveSEO Site Audit. The tool has a Thin Content section where you can easily find the pages with issues.
It’s as simple as that! Once you have your list, you can export it and start adding some content to those pages. This will improve their chances to make it to the top of the search results.
However, you also want to take a look at the duplicate content section in the Site Audit tool. This can also lead to a lot of indexation & content issues.
Extremely similar pages can be “combined” using canonical tags. Sometimes it can be a good idea to remove them completely from the search engine results.
3. How to Fix Thin Content Issues & Avoid a Google Penalty
Sometimes, you can fix thin content issues easily, especially if you get a manual penalty warning. At least if your website isn’t huge. If you have thousands of pages, it might take a while till you can fix them.
Here’ s a happy ending case from one of Doug Cunnington’s students:
youtube
However, the “penalty” can also come from the algorithm and you won’t even know it’s there because there is no warning. It’s not actually a penalty, it’s just the fact that Google won’t rank your pages because of their poor quality.
When that’s the case, it might not be as easy to get things fixed as in the video above.
In order to avoid getting these penalties, here’s a few things that you should consider when you write content.
3.1 Make sure your site looks legit
First of all, if your website looks shady, then you have a higher chance of getting a manual penalty on your website. If someone from Google reviews your website and decides it looks spammy at a first glance, they will be more likely to consider penalizing it.
To avoid this, make sure you:
Use an original template and customize it a little bit
Have a logo or some sort of original branding
Provide an about page and contact details
3.2 Add more content & avoid very similar titles
The best way to show Google that your pages are worth taking a look at is to not leave them empty. In 2019, I hope we all know that for good OnPage SEO we need to add a little bit more content.
Your pages should have at least 300 words of copy. Notice how I say copy, not words. If you’re there to sell, write copy. Even on an eCommerce product page.
If you’re not sure what to write about, you can always use the CognitiveSEO Keyword Tool & Content Assistant. It will give you ideas on what you should write on your pages to make them relevant for the query you want them to rank on.
Automatically generated titles can also quickly trigger Google’s alarms. If you review multiple products from the same brand and your titles are like this:
Nike Air Max 520 Review
Nike Air Max 620 Review
Nike Air Max 720 Review
then you can see how it might be an issue. Do those articles provide any value or are they all the same except for one digit?
It’s important to have the keywords in your title, but you can also try to add some diversity to them. It’s not always very hard to do. A good example could be:
Nike Air Max 520 Review | Best bang for the buck
Nike Air Max 620 | A Comprehensive Review Regarding Comfort
Nike Air Max 720 | Review After 2 Weeks of Wearing Them at The Gym
But Adrian, I have an eCommerce site with over 2000 products, I can’t write original titles for all of them!
That’s why I said that content isn’t the only way you can provide value with. If you can’t change the titles and content, improve some other areas.
However, the truth is that there’s someone out there who does optimize and show love to all their titles, even if there are 2000 of them. So why shouldn’t they be rewarded for it?
Usually, very similar titles are a result of content duplication issues. If you have a product that comes in 100 different colors, you don’t necessarily need to have 100 different pages with 100 unique titles and copy. You can just make them 1 single page where users can select their color without having to go to another URL.
Combining pages can also be done via canonical tags, although it’s recommended to only keep this for duplicate content. Pages with different colors can count as duplicate content, as only one word is different, so the similarity is 99.9%.
Make sure that the pages that get canonicalized don’t provide organic search traffic. For example, if people search for “blue dress for ladies” then it’s a good idea to have a separate page that can directly rank for that query instead of canonicalizing it to the black version.
A proper faceted navigation can help you solve all these SEO issues.
3.3 Don’t copy content
Copying content from other websites will definitely make your site look bad in Google’s eyes.
Again, this happens mostly on eCommerce websites, where editors get the descriptions directly from the producer’s official website. Many times they also duplicate pages in order to save time and just change a couple of words.
On the long run, this will definitely get you into duplicate content issues, which can become very hard to fix once they’re out of control. It will also tell Google that your site endorses competitors. By using their copy, you’re considering it valuable, right?
3.4 Web design, formatting & ads
Sometimes, you can identify gaps in web design or formatting. That’s not easy to do, as you’ll have to manually take a look at your competitor’s websites. Here are some questions you should ask yourself:
Are competitors presenting their information in an unpleasant manner? Do they have too many pop-ups, too many ads or very nasty designs?
Then that’s obviously where you can make a difference. This doesn’t give you the right not to have an original copy, but it might have a greater impact.
Source: premiumcoding.com
3.5 Video, images, text, audio, etc.
Big, successful eCommerce businesses which have an entire community supporting them and backing them up have used this technique for a long time: video content.
This might work better in some niches, such as tech. In Romania, cel.ro has a very bad reputation with delivery and quality, yet it still has a decent amount of market share due to its strong video content marketing strategy.
If you want to improve the value of your page, make sure you add images, videos or whatever you think might better serve your user. If you’re a fashion store, images might be your priority, while if you’re an electronics store, the product specifications should be more visible instead.
3.6 Deindex useless pages
Sometimes, when you have a lot of very similar pages that host thin content with no added value, the only viable solution is to remove those pages completely.
This can be done in a number of ways. However, the best ones are:
Removing the content altogether
Using canonical tags to combine them
Using robots.txt & noindex
However, you’ll have to choose carefully which method you use. Remember, you don’t want to remove those pages with search demand from the search engines!
Source: Moz.com
This can determine you to switch the focus from optimizing individual product pages to optimizing category pages.
Conclusion
Thin content is definitely bad for your website. It’s always better to avoid an issue from the beginning than to have to fix it later on. This saves you both time and money.
However, you’ll have to know about these issues early on, before you even start setting up your website and content marketing strategy. Hopefully, this article helped you have a better understanding on the topic.
Have you ever faced thin content issues on your websites in your digital marketing journey? How do you identify it? And how did you solve these content issues? Let us know in the comments section below!
The post Thin Content & SEO | How to Avoid a Google Thin Content Penalty appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
from Marketing https://cognitiveseo.com/blog/22582/thin-content-google-penalty-seo/
via http://www.rssmix.com/
0 notes
Text
Thin Content & SEO | How to Avoid a Google Thin Content Penalty
We live in a world of information overload. If 10 years ago it was hard to find content at all, now there’s way too much of it! Which one is good? Which one is bad? We don’t know.
While this subject is very complex, it’s clear that Google is attempting to solve these content issues in its search results. One of the biggest issues they’ve encountered in the digital marketing world is what they call thin content.
But what exactly is thin content? Should you worry about it? Can it affect your website’s SEO in a negative way? Well, thin content can get your site manually penalized but it can also sometimes send your website in Google’s omitted results. If you want to avoid these issues, keep reading!
What Is Thin Content & How Does It Affect SEO?
Is Thin Content Still a Problem in 2019?
How Does Thin Content Affect SEO?
Where Is Thin Content Found Most Often?
How to Identify Thin Content Pages
How to Fix Thin Content Issues & Avoid a Google Penalty
Make sure your site looks legit
Add more content & avoid similar titles
Don’t copy content
Web design, formatting & ads
Video, images, text, audio, etc.
Deindex/remove useless pages
1. What Is Thin Content & How Does It Affect SEO?
Thin content is an OnPage SEO issue that has been defined by Google as content with no added value.
When you’re publishing content on your website and it doesn’t improve the quality of a search results page at least a little bit, you’re publishing thin content.
For a very dull example, when you search Google for a question such as “What color is the sky?” and there’s an article out there saying “The sky is blue!”, if you publish an article with the same answer you would be guilty of adding no value.
So does it mean that this article is thin content because there are other articles about thin content out there?
Well.. no. Why? Because I’m adding value to it. First, I’m adding my own opinion, which is crucial. Then, I’m trying to structure it as logically as possible, address as many important issues as I can and cover gaps which I have identified from other pieces.
Sometimes, you might not have something new to say, but you might have a better way of saying it. To go back to our example, you could say something like “The sky doesn’t really have a color but is perceived as blue by the human eye because of the way light scatters through the atmosphere.”
Of course, you would probably have to add at least another 1500 words to that to make it seem like it’s not thin. It’s true. Longer content tends to rank better in Google, with top positions averaging about 2000 words.
How your content should be to rank
Sometimes, you might add value through design or maybe even through a faster website. There are multiple ways through which you can add value. We’ll talk about them soon.
From the Google Webmaster Guidelines page we can extract 4 types of practices which are strictly related to content quality. However, they are not easy to define!
Automatically generated content: Simple. It’s content created by robots to replace regular content, written by humans. Don’t do it. But… some AI content marketing tools have become so advanced that it’s hard to distinguish between real and automatically generated content. Humans can write poorly too. Don’t expect a cheap freelancer who writes 1000 words for $1 to have good grammar and copy. A robot might be better. But theoretically, that’s against the rules.
Thin affiliate pages: If you’re publishing affiliate pages which don’t include reviews or opinions, you’re not providing any new value to the users compared to what the actual store is already providing on their sales page.
Scraped or copied content: The catch here is to have original content. If you don’t have original content, you shouldn’t be posting it to claim it’s yours. However, even when you don’t claim it’s yours, you can’t expect Google to rank it better than the original source. Maybe there can be a reason (better design, faster website) but, generally, nobody would say it’s fair. Scraping is a no no and Google really hates it.
Doorway pages: Doorway pages are pages created to target and rank for a variety of very similar queries. While this is bad in Google’s eyes, the search giant doesn’t provide an alternative to doorway pages. If you have to target 5-10 similar queries (let’s say if you’re doing local SEO for a client), you might pull something off with one page, but if you have to target thousands of similar queries, you won’t be able to do it. A national car rental service, for example, will always have pages which could be considered doorways.
If you want, you can listen to Matt Cutts’ explanation from this video.
youtube
As you can see, it all revolves around value. The content that you publish must have some value to the user. If it’s just there because you want traffic, then you’re doing it wrong.
But value can sometimes be hard to define. For some, their content might seem as the most valuable, while for others it might seem useless. For example, one might write “Plumbing services New York, $35 / hour, Phone number”. The other might write “The entire history of plumbing, How to do it yourself, Plumbing services New York, $35 / hour, Phone number.”
Which one is more relevant? Which one provides more value? It really depends on the user’s intent. If the user just wants a plumber, they don’t want to hear about all the history. They just want a phone number and a quick, good service.
However, what’s important to understand is that there is always a way to add value.
In the end, it’s the search engine that decides, but there are some guidelines you can follow to make sure Google sees your content as valuable. Keep reading and you’ll find out all about them. But first, let’s better understand why thin content is still an issue and how it actually affects search engine optimization.
1.1 Is Thin Content Still a Problem in 2019?
The thin content purge started on February 23, 2011 with the first Panda Update. At first, Google introduced the thin content penalty because many people were generating content automatically or were creating thousands of irrelevant pages.
The series of further updates were successful and many websites with low quality content got penalized or deranked. This pushed site owners to write better content.
Unfortunately, today this mostly translates to longer content. The more you write, the more value you can provide, right? We know it’s not necessarily the case, but as I’ve said, longer content does tend to rank better in Google. Be it because the content makes its way up there or because the search engine is biased towards it… it’s hard to tell.
But there’s also evidence that long form content gets more shares on social media. This can result in more backlinks, which translates to better rankings. So it’s not directly the fact that the content is long, but rather an indirect factor related to it.
It’s kind of ironic, as Google sometimes uses its answer boxes to give a very ‘thin’ answer to questions that might require more context to be well understood.
However, in 2019 it’s common SEO knowledge that content must be of high quality. The issue today shifts to the overload of content that is constantly being published. Everything is, at least to some extent, qualitative.
But it’s hard to get all the information from everywhere and you don’t always know which source to rely on or trust. That’s why content curation has been doing so well lately.
This manifests itself in other areas, especially where there’s a very tough competition, such as eCommerce.
1.2 How Does Thin Content Affect SEO?
Google wants to serve its users the best possible content it can. If Google doesn’t do that, then its users won’t return to Google and could classify it as a poor quality service. And that makes the search engine unhappy.
Google generally applies a manual action penalty to websites it considers to contain thin content. You will see it in the Google Search Console (former Google Webmaster Tools) and it looks like this:
However, your site can still be affected by thin content even if you don’t get a warning from Google in your Search Console account. That’s because you’re diluting your site’s value and burning through your crawl budget.
The problem that search engines have is that they constantly have to crawl a lot of pages. The more pages you give it to crawl, the more work it has to do.
If the pages the search engine crawls are not useful for the users, then Google will have a problem with wasting its time on your content.
1.3 Where Is Thin Content Found Most Often?
Thin content is found most of the time on bigger websites. For the sake of helping people that really need help, let’s exclude spammy affiliate websites and automated blogs from this list.
Big websites, like eCommerce stores, often have a hard time coming up with original, high quality content for all their pages, especially for thousands of product pages.
In the example above, you can see that although the Product Details section under the image is expanded, there’s no content there. This means that users don’t have any details at all about the dress. All they know is that it’s a dress, it’s black and it costs about $20.
This doesn’t look too bad when you’re looking as a human at a single page, but when you’re a search engine and take a look at thousands and thousands of pages just like this one, then you begin to see the issue.
The solution here is to add some copy. Think of what users want to know about your product. Make sure you add the details about everything they might want to know and make them easily accessible!
Sometimes, thin content makes its way into eCommerce sites unnoticed. For example, you might have a category page which hosts a single product. Compared to all your other categories or competitor websites,that can be seen as thin content.
2. How to Identify Thin Content Pages
If we are referring merely to its size, then thin content can be easily identified using the cognitiveSEO Tool’s Site Audit.
Did you know?
Identifying thin content is actually really easy with a tool like cognitiveSEO Site Audit. The tool has a Thin Content section where you can easily find the pages with issues.
It’s as simple as that! Once you have your list, you can export it and start adding some content to those pages. This will improve their chances to make it to the top of the search results.
However, you also want to take a look at the duplicate content section in the Site Audit tool. This can also lead to a lot of indexation & content issues.
Extremely similar pages can be “combined” using canonical tags. Sometimes it can be a good idea to remove them completely from the search engine results.
3. How to Fix Thin Content Issues & Avoid a Google Penalty
Sometimes, you can fix thin content issues easily, especially if you get a manual penalty warning. At least if your website isn’t huge. If you have thousands of pages, it might take a while till you can fix them.
Here’ s a happy ending case from one of Doug Cunnington’s students:
youtube
However, the “penalty” can also come from the algorithm and you won’t even know it’s there because there is no warning. It’s not actually a penalty, it’s just the fact that Google won’t rank your pages because of their poor quality.
When that’s the case, it might not be as easy to get things fixed as in the video above.
In order to avoid getting these penalties, here’s a few things that you should consider when you write content.
3.1 Make sure your site looks legit
First of all, if your website looks shady, then you have a higher chance of getting a manual penalty on your website. If someone from Google reviews your website and decides it looks spammy at a first glance, they will be more likely to consider penalizing it.
To avoid this, make sure you:
Use an original template and customize it a little bit
Have a logo or some sort of original branding
Provide an about page and contact details
3.2 Add more content & avoid very similar titles
The best way to show Google that your pages are worth taking a look at is to not leave them empty. In 2019, I hope we all know that for good OnPage SEO we need to add a little bit more content.
Your pages should have at least 300 words of copy. Notice how I say copy, not words. If you’re there to sell, write copy. Even on an eCommerce product page.
If you’re not sure what to write about, you can always use the CognitiveSEO Keyword Tool & Content Assistant. It will give you ideas on what you should write on your pages to make them relevant for the query you want them to rank on.
Automatically generated titles can also quickly trigger Google’s alarms. If you review multiple products from the same brand and your titles are like this:
Nike Air Max 520 Review
Nike Air Max 620 Review
Nike Air Max 720 Review
then you can see how it might be an issue. Do those articles provide any value or are they all the same except for one digit?
It’s important to have the keywords in your title, but you can also try to add some diversity to them. It’s not always very hard to do. A good example could be:
Nike Air Max 520 Review | Best bang for the buck
Nike Air Max 620 | A Comprehensive Review Regarding Comfort
Nike Air Max 720 | Review After 2 Weeks of Wearing Them at The Gym
But Adrian, I have an eCommerce site with over 2000 products, I can’t write original titles for all of them!
That’s why I said that content isn’t the only way you can provide value with. If you can’t change the titles and content, improve some other areas.
However, the truth is that there’s someone out there who does optimize and show love to all their titles, even if there are 2000 of them. So why shouldn’t they be rewarded for it?
Usually, very similar titles are a result of content duplication issues. If you have a product that comes in 100 different colors, you don’t necessarily need to have 100 different pages with 100 unique titles and copy. You can just make them 1 single page where users can select their color without having to go to another URL.
Combining pages can also be done via canonical tags, although it’s recommended to only keep this for duplicate content. Pages with different colors can count as duplicate content, as only one word is different, so the similarity is 99.9%.
Make sure that the pages that get canonicalized don’t provide organic search traffic. For example, if people search for “blue dress for ladies” then it’s a good idea to have a separate page that can directly rank for that query instead of canonicalizing it to the black version.
A proper faceted navigation can help you solve all these SEO issues.
3.3 Don’t copy content
Copying content from other websites will definitely make your site look bad in Google’s eyes.
Again, this happens mostly on eCommerce websites, where editors get the descriptions directly from the producer’s official website. Many times they also duplicate pages in order to save time and just change a couple of words.
On the long run, this will definitely get you into duplicate content issues, which can become very hard to fix once they’re out of control. It will also tell Google that your site endorses competitors. By using their copy, you’re considering it valuable, right?
3.4 Web design, formatting & ads
Sometimes, you can identify gaps in web design or formatting. That’s not easy to do, as you’ll have to manually take a look at your competitor’s websites. Here are some questions you should ask yourself:
Are competitors presenting their information in an unpleasant manner? Do they have too many pop-ups, too many ads or very nasty designs?
Then that’s obviously where you can make a difference. This doesn’t give you the right not to have an original copy, but it might have a greater impact.
Source: premiumcoding.com
3.5 Video, images, text, audio, etc.
Big, successful eCommerce businesses which have an entire community supporting them and backing them up have used this technique for a long time: video content.
This might work better in some niches, such as tech. In Romania, cel.ro has a very bad reputation with delivery and quality, yet it still has a decent amount of market share due to its strong video content marketing strategy.
If you want to improve the value of your page, make sure you add images, videos or whatever you think might better serve your user. If you’re a fashion store, images might be your priority, while if you’re an electronics store, the product specifications should be more visible instead.
3.6 Deindex useless pages
Sometimes, when you have a lot of very similar pages that host thin content with no added value, the only viable solution is to remove those pages completely.
This can be done in a number of ways. However, the best ones are:
Removing the content altogether
Using canonical tags to combine them
Using robots.txt & noindex
However, you’ll have to choose carefully which method you use. Remember, you don’t want to remove those pages with search demand from the search engines!
Source: Moz.com
This can determine you to switch the focus from optimizing individual product pages to optimizing category pages.
Conclusion
Thin content is definitely bad for your website. It’s always better to avoid an issue from the beginning than to have to fix it later on. This saves you both time and money.
However, you’ll have to know about these issues early on, before you even start setting up your website and content marketing strategy. Hopefully, this article helped you have a better understanding on the topic.
Have you ever faced thin content issues on your websites in your digital marketing journey? How do you identify it? And how did you solve these content issues? Let us know in the comments section below!
The post Thin Content & SEO | How to Avoid a Google Thin Content Penalty appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
0 notes
Text
Thin Content & SEO | How to Avoid a Google Thin Content Penalty
We live in a world of information overload. If 10 years ago it was hard to find content at all, now there’s way too much of it! Which one is good? Which one is bad? We don’t know.
While this subject is very complex, it’s clear that Google is attempting to solve these content issues in its search results. One of the biggest issues they’ve encountered in the digital marketing world is what they call thin content.
But what exactly is thin content? Should you worry about it? Can it affect your website’s SEO in a negative way? Well, thin content can get your site manually penalized but it can also sometimes send your website in Google’s omitted results. If you want to avoid these issues, keep reading!
What Is Thin Content & How Does It Affect SEO?
Is Thin Content Still a Problem in 2019?
How Does Thin Content Affect SEO?
Where Is Thin Content Found Most Often?
How to Identify Thin Content Pages
How to Fix Thin Content Issues & Avoid a Google Penalty
Make sure your site looks legit
Add more content & avoid similar titles
Don’t copy content
Web design, formatting & ads
Video, images, text, audio, etc.
Deindex/remove useless pages
1. What Is Thin Content & How Does It Affect SEO?
Thin content is an OnPage SEO issue that has been defined by Google as content with no added value.
When you’re publishing content on your website and it doesn’t improve the quality of a search results page at least a little bit, you’re publishing thin content.
For a very dull example, when you search Google for a question such as “What color is the sky?” and there’s an article out there saying “The sky is blue!”, if you publish an article with the same answer you would be guilty of adding no value.
So does it mean that this article is thin content because there are other articles about thin content out there?
Well.. no. Why? Because I’m adding value to it. First, I’m adding my own opinion, which is crucial. Then, I’m trying to structure it as logically as possible, address as many important issues as I can and cover gaps which I have identified from other pieces.
Sometimes, you might not have something new to say, but you might have a better way of saying it. To go back to our example, you could say something like “The sky doesn’t really have a color but is perceived as blue by the human eye because of the way light scatters through the atmosphere.”
Of course, you would probably have to add at least another 1500 words to that to make it seem like it’s not thin. It’s true. Longer content tends to rank better in Google, with top positions averaging about 2000 words.
How your content should be to rank
Sometimes, you might add value through design or maybe even through a faster website. There are multiple ways through which you can add value. We’ll talk about them soon.
From the Google Webmaster Guidelines page we can extract 4 types of practices which are strictly related to content quality. However, they are not easy to define!
Automatically generated content: Simple. It’s content created by robots to replace regular content, written by humans. Don’t do it. But… some AI content marketing tools have become so advanced that it’s hard to distinguish between real and automatically generated content. Humans can write poorly too. Don’t expect a cheap freelancer who writes 1000 words for $1 to have good grammar and copy. A robot might be better. But theoretically, that’s against the rules.
Thin affiliate pages: If you’re publishing affiliate pages which don’t include reviews or opinions, you’re not providing any new value to the users compared to what the actual store is already providing on their sales page.
Scraped or copied content: The catch here is to have original content. If you don’t have original content, you shouldn’t be posting it to claim it’s yours. However, even when you don’t claim it’s yours, you can’t expect Google to rank it better than the original source. Maybe there can be a reason (better design, faster website) but, generally, nobody would say it’s fair. Scraping is a no no and Google really hates it.
Doorway pages: Doorway pages are pages created to target and rank for a variety of very similar queries. While this is bad in Google’s eyes, the search giant doesn’t provide an alternative to doorway pages. If you have to target 5-10 similar queries (let’s say if you’re doing local SEO for a client), you might pull something off with one page, but if you have to target thousands of similar queries, you won’t be able to do it. A national car rental service, for example, will always have pages which could be considered doorways.
If you want, you can listen to Matt Cutts’ explanation from this video.
youtube
As you can see, it all revolves around value. The content that you publish must have some value to the user. If it’s just there because you want traffic, then you’re doing it wrong.
But value can sometimes be hard to define. For some, their content might seem as the most valuable, while for others it might seem useless. For example, one might write “Plumbing services New York, $35 / hour, Phone number”. The other might write “The entire history of plumbing, How to do it yourself, Plumbing services New York, $35 / hour, Phone number.”
Which one is more relevant? Which one provides more value? It really depends on the user’s intent. If the user just wants a plumber, they don’t want to hear about all the history. They just want a phone number and a quick, good service.
However, what’s important to understand is that there is always a way to add value.
In the end, it’s the search engine that decides, but there are some guidelines you can follow to make sure Google sees your content as valuable. Keep reading and you’ll find out all about them. But first, let’s better understand why thin content is still an issue and how it actually affects search engine optimization.
1.1 Is Thin Content Still a Problem in 2019?
The thin content purge started on February 23, 2011 with the first Panda Update. At first, Google introduced the thin content penalty because many people were generating content automatically or were creating thousands of irrelevant pages.
The series of further updates were successful and many websites with low quality content got penalized or deranked. This pushed site owners to write better content.
Unfortunately, today this mostly translates to longer content. The more you write, the more value you can provide, right? We know it’s not necessarily the case, but as I’ve said, longer content does tend to rank better in Google. Be it because the content makes its way up there or because the search engine is biased towards it… it’s hard to tell.
But there’s also evidence that long form content gets more shares on social media. This can result in more backlinks, which translates to better rankings. So it’s not directly the fact that the content is long, but rather an indirect factor related to it.
It’s kind of ironic, as Google sometimes uses its answer boxes to give a very ‘thin’ answer to questions that might require more context to be well understood.
However, in 2019 it’s common SEO knowledge that content must be of high quality. The issue today shifts to the overload of content that is constantly being published. Everything is, at least to some extent, qualitative.
But it’s hard to get all the information from everywhere and you don’t always know which source to rely on or trust. That’s why content curation has been doing so well lately.
This manifests itself in other areas, especially where there’s a very tough competition, such as eCommerce.
1.2 How Does Thin Content Affect SEO?
Google wants to serve its users the best possible content it can. If Google doesn’t do that, then its users won’t return to Google and could classify it as a poor quality service. And that makes the search engine unhappy.
Google generally applies a manual action penalty to websites it considers to contain thin content. You will see it in the Google Search Console (former Google Webmaster Tools) and it looks like this:
However, your site can still be affected by thin content even if you don’t get a warning from Google in your Search Console account. That’s because you’re diluting your site’s value and burning through your crawl budget.
The problem that search engines have is that they constantly have to crawl a lot of pages. The more pages you give it to crawl, the more work it has to do.
If the pages the search engine crawls are not useful for the users, then Google will have a problem with wasting its time on your content.
1.3 Where Is Thin Content Found Most Often?
Thin content is found most of the time on bigger websites. For the sake of helping people that really need help, let’s exclude spammy affiliate websites and automated blogs from this list.
Big websites, like eCommerce stores, often have a hard time coming up with original, high quality content for all their pages, especially for thousands of product pages.
In the example above, you can see that although the Product Details section under the image is expanded, there’s no content there. This means that users don’t have any details at all about the dress. All they know is that it’s a dress, it’s black and it costs about $20.
This doesn’t look too bad when you’re looking as a human at a single page, but when you’re a search engine and take a look at thousands and thousands of pages just like this one, then you begin to see the issue.
The solution here is to add some copy. Think of what users want to know about your product. Make sure you add the details about everything they might want to know and make them easily accessible!
Sometimes, thin content makes its way into eCommerce sites unnoticed. For example, you might have a category page which hosts a single product. Compared to all your other categories or competitor websites,that can be seen as thin content.
2. How to Identify Thin Content Pages
If we are referring merely to its size, then thin content can be easily identified using the cognitiveSEO Tool’s Site Audit.
Did you know?
Identifying thin content is actually really easy with a tool like cognitiveSEO Site Audit. The tool has a Thin Content section where you can easily find the pages with issues.
It’s as simple as that! Once you have your list, you can export it and start adding some content to those pages. This will improve their chances to make it to the top of the search results.
However, you also want to take a look at the duplicate content section in the Site Audit tool. This can also lead to a lot of indexation & content issues.
Extremely similar pages can be “combined” using canonical tags. Sometimes it can be a good idea to remove them completely from the search engine results.
3. How to Fix Thin Content Issues & Avoid a Google Penalty
Sometimes, you can fix thin content issues easily, especially if you get a manual penalty warning. At least if your website isn’t huge. If you have thousands of pages, it might take a while till you can fix them.
Here’ s a happy ending case from one of Doug Cunnington’s students:
youtube
However, the “penalty” can also come from the algorithm and you won’t even know it’s there because there is no warning. It’s not actually a penalty, it’s just the fact that Google won’t rank your pages because of their poor quality.
When that’s the case, it might not be as easy to get things fixed as in the video above.
In order to avoid getting these penalties, here’s a few things that you should consider when you write content.
3.1 Make sure your site looks legit
First of all, if your website looks shady, then you have a higher chance of getting a manual penalty on your website. If someone from Google reviews your website and decides it looks spammy at a first glance, they will be more likely to consider penalizing it.
To avoid this, make sure you:
Use an original template and customize it a little bit
Have a logo or some sort of original branding
Provide an about page and contact details
3.2 Add more content & avoid very similar titles
The best way to show Google that your pages are worth taking a look at is to not leave them empty. In 2019, I hope we all know that for good OnPage SEO we need to add a little bit more content.
Your pages should have at least 300 words of copy. Notice how I say copy, not words. If you’re there to sell, write copy. Even on an eCommerce product page.
If you’re not sure what to write about, you can always use the CognitiveSEO Keyword Tool & Content Assistant. It will give you ideas on what you should write on your pages to make them relevant for the query you want them to rank on.
Automatically generated titles can also quickly trigger Google’s alarms. If you review multiple products from the same brand and your titles are like this:
Nike Air Max 520 Review
Nike Air Max 620 Review
Nike Air Max 720 Review
then you can see how it might be an issue. Do those articles provide any value or are they all the same except for one digit?
It’s important to have the keywords in your title, but you can also try to add some diversity to them. It’s not always very hard to do. A good example could be:
Nike Air Max 520 Review | Best bang for the buck
Nike Air Max 620 | A Comprehensive Review Regarding Comfort
Nike Air Max 720 | Review After 2 Weeks of Wearing Them at The Gym
But Adrian, I have an eCommerce site with over 2000 products, I can’t write original titles for all of them!
That’s why I said that content isn’t the only way you can provide value with. If you can’t change the titles and content, improve some other areas.
However, the truth is that there’s someone out there who does optimize and show love to all their titles, even if there are 2000 of them. So why shouldn’t they be rewarded for it?
Usually, very similar titles are a result of content duplication issues. If you have a product that comes in 100 different colors, you don’t necessarily need to have 100 different pages with 100 unique titles and copy. You can just make them 1 single page where users can select their color without having to go to another URL.
Combining pages can also be done via canonical tags, although it’s recommended to only keep this for duplicate content. Pages with different colors can count as duplicate content, as only one word is different, so the similarity is 99.9%.
Make sure that the pages that get canonicalized don’t provide organic search traffic. For example, if people search for “blue dress for ladies” then it’s a good idea to have a separate page that can directly rank for that query instead of canonicalizing it to the black version.
A proper faceted navigation can help you solve all these SEO issues.
3.3 Don’t copy content
Copying content from other websites will definitely make your site look bad in Google’s eyes.
Again, this happens mostly on eCommerce websites, where editors get the descriptions directly from the producer’s official website. Many times they also duplicate pages in order to save time and just change a couple of words.
On the long run, this will definitely get you into duplicate content issues, which can become very hard to fix once they’re out of control. It will also tell Google that your site endorses competitors. By using their copy, you’re considering it valuable, right?
3.4 Web design, formatting & ads
Sometimes, you can identify gaps in web design or formatting. That’s not easy to do, as you’ll have to manually take a look at your competitor’s websites. Here are some questions you should ask yourself:
Are competitors presenting their information in an unpleasant manner? Do they have too many pop-ups, too many ads or very nasty designs?
Then that’s obviously where you can make a difference. This doesn’t give you the right not to have an original copy, but it might have a greater impact.
Source: premiumcoding.com
3.5 Video, images, text, audio, etc.
Big, successful eCommerce businesses which have an entire community supporting them and backing them up have used this technique for a long time: video content.
This might work better in some niches, such as tech. In Romania, cel.ro has a very bad reputation with delivery and quality, yet it still has a decent amount of market share due to its strong video content marketing strategy.
If you want to improve the value of your page, make sure you add images, videos or whatever you think might better serve your user. If you’re a fashion store, images might be your priority, while if you’re an electronics store, the product specifications should be more visible instead.
3.6 Deindex useless pages
Sometimes, when you have a lot of very similar pages that host thin content with no added value, the only viable solution is to remove those pages completely.
This can be done in a number of ways. However, the best ones are:
Removing the content altogether
Using canonical tags to combine them
Using robots.txt & noindex
However, you’ll have to choose carefully which method you use. Remember, you don’t want to remove those pages with search demand from the search engines!
Source: Moz.com
This can determine you to switch the focus from optimizing individual product pages to optimizing category pages.
Conclusion
Thin content is definitely bad for your website. It’s always better to avoid an issue from the beginning than to have to fix it later on. This saves you both time and money.
However, you’ll have to know about these issues early on, before you even start setting up your website and content marketing strategy. Hopefully, this article helped you have a better understanding on the topic.
Have you ever faced thin content issues on your websites in your digital marketing journey? How do you identify it? And how did you solve these content issues? Let us know in the comments section below!
The post Thin Content & SEO | How to Avoid a Google Thin Content Penalty appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
from Marketing https://cognitiveseo.com/blog/22582/thin-content-google-penalty-seo/
via http://www.rssmix.com/
0 notes
Text
Spanish Car Manufacturer SEAT Joins Alastria Consortium to Develop Blockchain Products
Spanish automobile manufacturer SEAT has joined Alastria consortium to work on the development of blockchain-based products. Cointelegraph in Spanish reported the news Jan. 16.
Founded in 1950, SEAT is a state-owned industrial company and Spain’s largest car manufacturer. SEAT’s turnover reportedly reached a record figure of 9.552 billion euro ($10.878 billion) in 2017, which is 11.1% more than the year prior.
Per the recent announcement, SEAT joined Alastria, a multi-industry, semi-public consortium backed by a national network of more than 70 companies and establishments. These include such major players as banks BBVA and Banco Santander, telecommunications provider Telefónica, energy firm Repsol and professional services company Accenture. The goal of the alliance is to promote the advancement and development of blockchain technology.
As part of the collaboration, SEAT plans to test the benefits of blockchain in the field of finance, aiming to improve and optimize the existing processes and facilitate supply chain management.
SEAT president Luca de Meo reportedly said that the company is “convinced of the relevance that blockchain technology will have in the future.”
In the meantime, SEAT and Telefónica have already begun jointly working on a proof-of-concept of a blockchain product that will track vehicle parts throughout the supply chain of SEAT’s factory located in Martorell, Spain.
Last month, American car manufacturing giant General Motors (GM) filed a blockchain patent for a solution to manage data from autonomous vehicles.
In September, German automobile manufacturer Porsche AG announced that it will increase its investments in startups — with a focus on blockchain and artificial intelligence (AI) — by around $176 million over the next five years. The investments target “early and growth” stage businesses that relate to “customer experience, mobility and digital lifestyle,” as well as future technologies including blockchain, AI, and virtual and augmented reality.
window.fbAsyncInit = function() { FB.init({ appId : '1922752334671725', xfbml : true, version : 'v2.9' }); FB.AppEvents.logPageView(); }; (function(d, s, id){ var js, fjs = d.getElementsByTagName(s)[0]; if (d.getElementById(id)) {return;} js = d.createElement(s); js.id = id; js.src = "http://connect.facebook.net/en_US/sdk.js"; js.async = true; fjs.parentNode.insertBefore(js, fjs); }(document, 'script', 'facebook-jssdk')); !function(f,b,e,v,n,t,s) {if(f.fbq)return;n=f.fbq=function(){n.callMethod? n.callMethod.apply(n,arguments):n.queue.push(arguments)}; if(!f._fbq)f._fbq=n;n.push=n;n.loaded=!0;n.version='2.0'; n.queue=[];t=b.createElement(e);t.async=!0; t.src=v;s=b.getElementsByTagName(e)[0]; s.parentNode.insertBefore(t,s)}(window,document,'script', 'https://connect.facebook.net/en_US/fbevents.js'); fbq('init', '1922752334671725'); fbq('track', 'PageView');
This news post is collected from Cointelegraph
Recommended Read
New & Hot
The Calloway Software – Secret Weapon To Make Money From Crypto Trading (Proofs Inside)
The modern world is inextricably linked to the internet. We spend a lot of time in virtual reality, and we're no longer ...
User rating:
9.6
Free Spots are Limited Get It Now Hurry!
Read full review
Editors' Picks 2
BinBot Pro – Its Like Printing Money On Autopilot (Proofs Inside)
Do you live in a country like USA or Canada where using automated trading systems is a problem? If you do then now we ...
User rating:
9.5
Demo & Pro Version Get It Now Hurry!
Read full review
The post Spanish Car Manufacturer SEAT Joins Alastria Consortium to Develop Blockchain Products appeared first on Review: Legit or Scam?.
Read more from → https://legit-scam.review/spanish-car-manufacturer-seat-joins-alastria-consortium-to-develop-blockchain-products
0 notes
Text
10 SEO Trends to Look Out for in 2019
Search Engines are one of our beloved figure, which helps us to explore, learn, and enlighten us across all the items of one’s wish list. Anytime and anywhere you can insert your thoughts or query into the search box, and the system just makes you relief and happy, when you got the exact information you’re eagerly looking for. Search Engines are always made you feel connected.
And because of these huge people dependent on search engines for facts and info, Search Engines are expected to maintain quality content and recommendations when selecting sites on their SERPs (Search Engine Result Pages). And competition is at its peak. Getting your Website to make an appearance in the First or foremost page and position, is dependent on the content you are providing to offer the world and helping these Search Engines by making them comprehend the message you have in the mind that you think would be the best solution to offer the puzzled searchers.
According to the research on predicting the SEO trends and future in 2019 says, it’s going to be more difficult to rank high on SERPs in the coming years. A structured database may show more result info than organic results can. Due to the introduction of featured snippets, smaller sites which are more properly structured answers can rank well than huge content one. Search engines are updated from time to time and getting smarter. And now the answers are mostly right there on the SERPs itself. The foremost features that rundown are assembled that would be a trend in 2019.
Snippets Feature
For instance, in the Google search engine when we enter something in the search box, you’ll get to see a more competitive space than before. Such one as, Adwords ads. When someone research on any kind of commercial queries the SERP’s first space will be occupied by images or block images or quartet of text ads are positioned prior to the organic search results.
For common information and facts the search result page includes:
Knowledge Graphs,
“People also ask” reference boxes,
Related Images,
Related trending news,
YouTube Videos, etc.
These snippets will be a major part in full filling the researcher’s demands as in basic answers. And these newest features are made the work of researchers more simple by allowing them to see more relevant or related questions that to be made by users on the next pace on the ‘People also ask’ snippet.
Mobile First Index
Mobile is the most prominent device used by most of the users around the world. Mobile devices are getting upgraded and that is placed to be on one of the needed features in the Google search engine. In March 2018, Google Search Engine Company announced the rundown called Mobile-first index. Just a few months later on this feature release, Google launched the mobile speed update. Loading speed it became a factor in calculating the mobile site ranking. A lightning fast mobile UX site fetches you the Golden SEO ticket.
It is predicted that 63.4% of mobile phone internet users would be in the year 2019 worldwide.
Around 80% of adults own smartphone in the year 2018.
Brand and its Reputation
When Business comes, it is very important to create, build and maintain the brand and reputation. Not for the popularity thing but for the brand to be recognized by the people around you. To receives, these SERPs trustworthiness is not as easy as promoting the brand. It has to create a tangible an impact on SERPs decision on the place and position placement. One easy and common way to gain your brand’s reliability through by Backlinking. By this way, external sites link to your site, which is like Google ask voting for your site. The number of link vote your site gets, the more legit your website’s presence in the SERP. It is not always helping hand especially in for newer brands in the screen, but it is one of good and gradual promoting type.
Providing quality content
It was quite enough to just make an appearance on the internet to simply churn out content and search engines signals your site could be a helpful resource for users in back the days. But now in 2019, due to the increase in content presence and competition in the market, the quality of the content plays a crucial role. Also, the internet has shed its training and development for a long while.
The new update of Google broad core algorithm has a new feature as in to evaluate the websites that meeting the company’s EAT standards. The acronym of EAT stands for Expertise – Authoritativeness – Trustworthiness. EAT step up the competition about offering your web visitors fetching blog posts by thorough Knowledge bases, and engaging news and video materials. Remember to provide internal links of other web pages on your website, which drives traffics. All these ways are good at getting your site noticed and signaling to Search Engines to direct people out at your place.
Voice Search
It is one of the expected updated features in Search Engine and everybody saw coming. The huge the mobile internet grows, with that new features like voice searching also developed by removing the old good typing searches. It is expected that Web browsing will go screen-less by 2020, a trend to keep optimizing. Each year brings new technological development and the ways of understanding and exactly listings are being categorized. Adjusting your target keywords to reflect how someone talks and search of your thoughts, rather than typing it.
To improve the voice search engine for users to get specific results in their researched queries. For that, use Long tail Keywords, highly descriptive search phrases. These long tail keywords often turn into questions by AI assistance like Alexa, Siri, Google assistance etc.
Protect your user’s data
Have you ever noticed the little pop message on the right upper corner of your browser or a lock icon that appears in the left corner of the URL bar? And, this super alarm sometimes starts on a corner the frantically waves a red flag says, “Not Secure”. A not reassuring welcome to the site.
Due to the increase in cyber security issues in this competitive world, protecting the users’ personal information is one of the major tasks to every website especially if the website is collecting customer insights. The General Data Protection Regulation, that progress full effects in May 2018 is a European Union measure implemented to ramp up personal data privacy by restricting what companies can do with those details that they hold and gather from the users.
Explore beyond the Search Engine
It is true, yes people are looking beyond the most common and popular search engines for the required facts. One of that such other content provider to pay attention is Amazon. A survey of consumers conducted by Kenshoo shows 56% of people usually head straight to Amazon content provider before looking elsewhere. This a special significant statistic for eCommerce sellers, everywhere to take that note of.
Another platform that distributes facts and details to pay attention is YouTube. Even though we know it was a subsidiary product of Google. Because more people are heading to video sharing platform before they are trying their work on Google’s conventional search page, it is also a way to expand the online presence of your content and brand in this internet area. By 2021, the online video platform is expected to account for 80% of overall online traffic.
User Experience
The User Experience of a website has the capability to make or break a deal of any website’s traffic. Thus, for business owners who want to keep making a profit with their brand and sites will have to do their best to guarantee smooth UX (User Experience)/customer experience. That includes an appealing appearance, easy-to-understand contents, intuitive design, lower page load time, Compact layout, easy map line, and absolutely no technical issues. A website appearance gives a better impression to any business than any kind of advertisement.
It is the nature of people to visit straightly to the website of brands they know or the recently visited site which they had most satisfactory information, the cause of reliable information they are in need of and the appearance of the site also determines the visitors’ level and frequency to a website. Use your powerful assets to bloom your reputation.
Marketing with Influencers
It is always said to be great to have a famous person to vouch for your brand for you in the market. Especially for the competitive business, where the increase in competition and you want your business to know at least the brand was there in the market by the common people. To get the people’s attention and attraction there are lot many ways, yet one of the easiest ways is that to make the influenced people talk in behalf of your brand. To make that possible, first, you have to find and connect with the influenced people. One advantage is that you can find them pretty easily in the social media platforms, so finding doesn’t a matter yet get their approval to what you and your brand do it really matters.
AI in Search Engines
AI (Artificial Intelligence), the fast-growing innovative technology has a massive amount of potential in it and its time to time new updates and new technological development impacts the business and consumers in numerous ways. It is still wondered how businesses are actively adapting to AI, as the uncertainty it carries around may cause huge loss. But when compared to the profit and upgrades it fetches in business minimize the risk factor. Businesses are actively looking to the ways to use and implement AI in their work. That same for the Search engines, popular search engines are already adopted AI feature in their work-space like deep learning. If the search engines would found the inevitable help of AI, it will have effects in SEO rankings.
For example, if AI could be integrated into SEO ranking algorithms of any search engines it could be aided in more effectively to sniff out websites practicing.
This coming year has immense development and competition in SEO algorithms and ranking.
The post 10 SEO Trends to Look Out for in 2019 appeared first on Broxer.
10 SEO Trends to Look Out for in 2019 published first on Broxer.com
0 notes
Text
Misinformed: A Roundtable on Social Media and the Shaping of Public Discourse
February 5 2018
https://www.eventbrite.co.uk/e/ucl-ias-lies-misinformed-a-roundtable-on-social-media-and-the-shaping-of-public-discourse-tickets-41517585215#
The UCL Institute of Advanced Studies will be hosting a roundtable discussion on media and politics in the age of the viral post, troll farm and automated botnet. How has the new digital media environment changed the ways we form opinions, elect representatives, challenge governments, create divides and bridge them? Bringing together researchers in political science, digital culture, journalism, and social media analysis, the roundtable will address the specific challenges posed by the ascendancy of platforms like Facebook, Twitter, and YouTube to democratic societies, and about the possibilities these technologies might open up.
Panel:
David Benigson, CEO, Signal Media
Anastasia Denisova, Communication and Media Research Institute, University of Westminster
Lisa-Maria Neudert, Oxford Internet Institute, University of Oxford (tbc)
Gregory Whitfield, Institute of Advanced Studies, UCL
Thoughts: This panel generally talked about filter bubbles and fake news. What I found the most interesting was definitely what Anastasia Denisova said about memes and bots. I also enjoyed the discussion about the intention behind Facebook’s new newsfeed. This was quite a fluid discussion, so I wasn’t able to catch exactly who said what in all situations! Also, they are not recorded here in chronological order, rather, I looked through my notes and grouped them into categories.
Notes
3 big technological trends that have changed since 5 years ago:
1) computational power - startups can access to the same ^ as global firms
2) accessibility and availability of data to mine and understand what people think / political leaning
willingness as consumers to give away info about ourselves online - vs old polls
3) esp helpful for signal media: merging sophistication of ML and AI
categories of influence
partisan influence - political parties
foreign influence, external (bonnets?)
more consumer driven, pop type of 1. content being generated, 2. channels they’re being published on, 3. form being used to convey the message = media brands to keep up with
quest for higher quality info
as much about media literacy as it is about trust in info
news is more and more consumed on social directly
—> source doesn’t matter so much on social anymore?
comment threads deserve attention: interdisciplinary way to look at how comments work, what info they work about, etc
political role of memes (Anastasia Denisova)
memes become a bit more important in like russia where it’s censored, because you don’t need to use your own voice (it’s anonymous / there is a lack of ownership) + you can just put out a message in an allegorical / metaphorical way (v interesting), not as much in western countries
memes keep the convo going even in absence of any more offline things happening
—> strong, influential informational environment.
use their minds, use creativity, lets you interpret, interact with other people etc
subliminal messages that technology constructs for us - not just content - who uses these things, how they are coded in the actual language
agency, authorship, gender that are embedded in these practices
memes - anonymity, lack of ownership (good for against censorship), very sexist.
issue: filter bubbles
can literally segment populations, and target individuals who might be more susceptible
aren’t the filter bubbles going to get larger? where is the space for different views?
social constructs where we are just being fed stuff we want to click on
siloing happenstance - interacting more and more with people we agree with —> causal in link of increased partisanship
role of bots (Anastasia Denisova)
Are usually extremely simple - generally not conversational, and plainly engage with content by liking and retweeting
But this generates visibility and endorsement
by racking up the numbers/notes, gives the content more credibility
the number of clicks is itself capital, a driver? it creates spaces of permission for new types of behaviour (which is unprecedented), because it gives an illusion of consensus (apparent consensus), giving people permission to think that their view is shared by many / ok / legit.
—> Algorithms amplify this by having it show up more prominently on their feed, increasing chance of exposure
—> People gravitate toward it, and then when its someone i know sharing it i immediately drop my guard.
People are most likely to click on an article that 1. has an extreme/attention grabbing headline, and/or 2. reinforces their POV. —> Platform/media/algorithms exploit this with clickbait. No longer a sustainable strategy?
companies increasingly coming to a conclusion that this isn’t going to get people on their network for good + to stay
facebook is rolling out a new newsfeed - claims that they want more meaningful content on platform (more about friends and family)
expect time spent + engagement to go down
ACTUALLY more a PR thing for FB, they knew about this for 6-7 years and did nothing, only responding in fear of regulation
rather than being affirmative of what quality engagement looks like, this is a cop out
their R&D is about what will make you click on more posts — and you are more likely to click on content by friends/family
issue: the social media companies (ie. Facebook) that put together your media diet have a lot of power.
What their platforms enable:
ability to get a sense of someone, and use these platforms to influence the conversation
personalised messaging: advertisers can tweak their message depending on who the audience is (compared to TV ads)?
—> filter bubbles
—> psychological manipulation (esp. for more susceptible people)
Social media is not a conceptual space, these are big companies - we need to understand their business models
issue: a lot of the propaganda going on is very subtle - hard to distinguish from normal content. it’s also hard to distinguish between “fake news” and biased reporting. hard to realise their intention.
media losing trust of its users / erosion of trust in news
trump: more about sowing confusion and chaos than swaying the vote?
is the daily mail just very right leaning, or is it fake news?
lots of fake news in china related to healthcare (bizarre) - take this and you will get xxx etc
solution to fake news?
need to arm people with clarity about who’s produced it, whose made money off it, has it been fact checked by human, is there any quality nutritional score we can give it? way to assess the value in some way through bread crumb-y indicators that this is a fake news thing?
process of scoring the quality of content of a piece
fact checking tech organisations rising
quest for human editorial/curation is getting stronger, responding to rise of algorithm bots
actually, there may not be anything extraordinarily new to worry about in the new social media world we live in.
partisanship has always existed, this is just a new way of expressing it
do the number of clicks and views actually translate into taken as absolute truth + affect voting etc?
difficult to tell what certain kinds of voters actually believe, esp low info voters (conspiracy theories?)
political science experiments: people are not as terrifyingly wrong about political things as we might think they are
when asked in ^, people often don’t answer the question accurately, experience it as whose side are you on, as if it’s an opportunity to voice alliance to side you’re on - rather than experiencing question as about facts
viewing the way people use social media as effective attachment with their group > honest engagement with world around them
aligning with the group of people you agree with politically + consuming those things solidify your belonging with that group. it will narrow down personal window of yours, but doesn’t show whether it will push you more left or right. will increase amount of info that you think you know support your bias?
but increases in group solidarity and involvement shouldn’t be as worrying a phenomenon of rightward drift of right wing people —> need to look at different causes of this
radical voices might get more exposure than they would have in past, but we shouldn’t worry too much
additional resources mentioned:
reuters institution of journalism in oxford http://www.digitalnewsreport.org/
weapons of math destruction
0 notes
Text
AI competitions don’t produce useful models

By LUKE OAKDEN-RAYNER
A huge new CT brain dataset was released the other day, with the goal of training models to detect intracranial haemorrhage. So far, it looks pretty good, although I haven’t dug into it in detail yet (and the devil is often in the detail).
The dataset has been released for a competition, which obviously lead to the usual friendly rivalry on Twitter:
Of course, this lead to cynicism from the usual suspects as well.
And the conversation continued from there, with thoughts ranging from “but since there is a hold out test set, how can you overfit?” to “the proposed solutions are never intended to be applied directly” (the latter from a previous competition winner).
As the discussion progressed, I realised that while we “all know” that competition results are more than a bit dubious in a clinical sense, I’ve never really seen a compelling explanation for why this is so.
Hopefully that is what this post is, an explanation for why competitions are not really about building useful AI systems.
DISCLAIMER: I originally wrote this post expecting it to be read by my usual readers, who know my general positions on a range of issues. Instead, it was spread widely on Twitter and HackerNews, and it is pretty clear that I didn’t provide enough context for a number of statements made. I am going to write a follow-up to clarify several things, but as a quick response to several common criticisms:
I don’t think AlexNet is a better model than ResNet. That position would be ridiculous, particularly given all of my published work uses resnets and densenets, not AlexNets.
I think this miscommunication came from me not defining my terms: a “useful” model would be one that works for the task it was trained on. It isn’t a model architecture. If architectures are developed in the course of competitions that are broadly useful, then that is a good architecture, but the particular implementation submitted to the competition is not necessarily a useful model.
The stats in this post are wrong, but they are meant to be wrong in the right direction. They are intended for illustration of the concept of crowd-based overfitting, not accuracy. Better approaches would almost all require information that isn’t available in public leaderboards. I may update the stats at some point to make them more accurate, but they will never be perfect.
I was trying something new with this post – it was a response to a Twitter conversation, so I wanted to see if I could write it in one day to keep it contemporaneous. Given my usual process is spending several weeks and many rewrites per post, this was a risk. I think the post still serves its purpose, but I don’t personally think the risk paid off. If I had taken even another day or two, I suspect I would have picked up most of these issues before publication. Mea culpa.
Let’s have a battle

Nothing wrong with a little competition.*
So what is a competition in medical AI? Here are a few options:
getting teams to try to solve a clinical problem
getting teams to explore how problems might be solved and to try novel solutions
getting teams to build a model that performs the best on the competition test set
a waste of time
Now, I’m not so jaded that I jump to the last option (what is valuable to spend time on is a matter of opinion, and clinical utility is only one consideration. More on this at the end of the article).
But what about the first three options? Do these models work for the clinical task, and do they lead to broadly applicable solutions and novelty, or are they only good in the competition and not in the real world?
(Spoiler: I’m going to argue the latter).
Good models and bad models
Should we expect this competition to produce good models? Let’s see what one of the organisers says.
Cool. Totally agree. The lack of large, well-labeled datasets is the biggest major barrier to building useful clinical AI, so this dataset should help.
But saying that the dataset can be useful is not the same thing as saying the competition will produce good models.
So to define our terms, let’s say that a good model is a model that can detect brain haemorrhages on unseen data (cases that the model has no knowledge of).
So conversely, a bad model is one that doesn’t detect brain haemorrhages in unseen data.
These definitions will be non-controversial. Machine Learning 101. I’m sure the contest organisers agree with these definitions, and would prefer their participants to be producing good models rather than bad models. In fact, they have clearly set up the competition in a way designed to promote good models.
It just isn’t enough.
Epi vs ML, FIGHT!

If only academic arguments were this cute
ML101 (now personified) tells us that the way to control overfitting is to use a hold-out test set, which is data that has not been seen during model training. This simulates seeing new patients in a clinical setting.
ML101 also says that hold-out data is only good for one test. If you test multiple models, then even if you don’t cheat and leak test information into your development process, your best result is probably an outlier which was only better than your worst result by chance.
So competition organisers these days produce hold-out test sets, and only let each team run their model on the data once. Problem solved, says ML101. The winner only tested once, so there is no reason to think they are an outlier, they just have the best model.
Not so fast, buddy.
Let me introduce you to Epidemiology 101, who claims to have a magic coin.
Epi101 tells you to flip the coin 10 times. If you get 8 or more heads, that confirms the coin is magic (while the assertion is clearly nonsense, you play along since you know that 8/10 heads equates to a p-value of <0.05 for a fair coin, so it must be legit).
Unbeknownst to you, Epi101 does the same thing with 99 other people, all of whom think they are the only one testing the coin. What do you expect to happen?
If the coin is totally normal and not magic, around 5 people will find that the coin is special. Seems obvious, but think about this in the context of the individuals. Those 5 people all only ran a single test. According to them, they have statistically significant evidence they are holding a “magic” coin.
Now imagine you aren’t flipping coins. Imagine you are all running a model on a competition test set. Instead of wondering if your coin is magic, you instead are hoping that your model is the best one, about to earn you $25,000.
Of course, you can’t submit more than one model. That would be cheating. One of the models could perform well, the equivalent of getting 8 heads with a fair coin, just by chance.
Good thing there is a rule against it submitting multiple models, or any one of the other 99 participants and their 99 models could win, just by being lucky…
Multiple hypothesis testing
The effect we saw with Epi101’s coin applies to our competition, of course. Due to random chance, some percentage of models will outperform other ones, even if they are all just as good as each other. Maths doesn’t care if it was one team that tested 100 models, or 100 teams.
Even if certain models are better than others in a meaningful sense^, unless you truly believe that the winner is uniquely able to ML-wizard, you have to accept that at least some other participants would have achieved similar results, and thus the winner only won because they got lucky. The real “best performance” will be somewhere back in the pack, probably above average but below the winner^^.
Epi101 says this effect is called multiple hypothesis testing. In the case of a competition, you have a ton of hypotheses – that each participant was better than all others. For 100 participants, 100 hypotheses.
One of those hypotheses, taken in isolation, might show us there is a winner with statistical significance (p<0.05). But taken together, even if the winner has a calculated “winning” p-value of less than 0.05, that doesn’t mean we only have a 5% chance of making an unjustified decision. In fact, if this was coin flips (which is easier to calculate but not absurdly different), we would have a greater than 99% chance that one or more people would “win” and come up with 8 heads!
That is what an AI competition winner is; an individual who happens to get 8 heads while flipping fair coins.
Interestingly, while ML101 is very clear that running 100 models yourself and picking the best one will result in overfitting, they rarely discuss this “overfitting of the crowds”. Strange, when you consider that almost all ML research is done of heavily over-tested public datasets …
So how do we deal with multiple hypothesis testing? It all comes down to the cause of the problem, which is the data. Epi101 tells us that any test set is a biased version of the target population. In this case, the target population is “all patients with CT head imaging, with and without intracranial haemorrhage”. Let’s look at how this kind of bias might play out, with a toy example of a small hypothetical population:

In this population, we have a pretty reasonable “clinical” mix of cases. 3 intra-cerebral bleeds (likely related to high blood pressure or stroke), and two traumatic bleeds (a subdural on the right, and an extradural second from the left).
Now let’s sample this population to build our test set:

Randomly, we end up with mostly extra-axial (outside of the brain itself) bleeds. A model that performs well on this test will not necessarily work as well on real patients. In fact, you might expect a model that is really good at extra-axial bleeds at the expense of intra-cerebral bleeds to win.
But Epi101 doesn’t only point out problems. Epi101 has a solution.
So powerful
There is only one way to have an unbiased test set – if it includes the entire population! Then whatever model does well in the test will also be the best in practice, because you tested it on all possible future patients (which seems difficult).
This leads to a very simple idea – your test results become more reliable as the test set gets larger. We can actually predict how reliable test sets are using power calculations.

These are power curves. If you have a rough idea of how much better your “winning” model will be than the next best model, you can estimate how many test cases you need to reliably show that it is better.
So to find out if you model is 10% better than a competitor, you would need about 300 test cases. You can also see how exponentially the number of cases needed grows as the difference between models gets narrower.
Let’s put this into practice. If we look at another medical AI competition, the SIIM-ACR pneumothorax segmentation challenge, we see that the difference in Dice scores (ranging between 0 and 1) is negligible at the top of the leaderboard. Keep in mind that this competition had a dataset of 3200 cases (and that is being generous, they don’t all contribute to the Dice score equally).
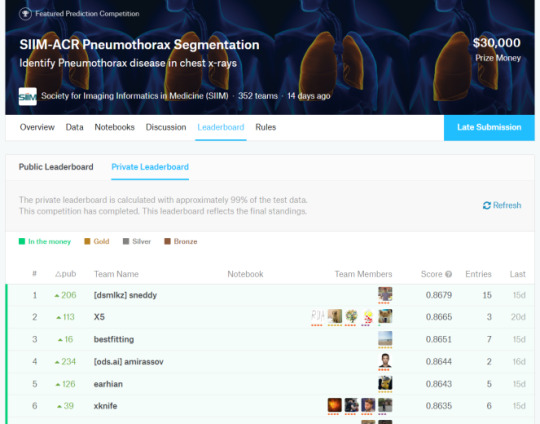
So the difference between the top two was 0.0014 … let’s chuck that into a sample size calculator.
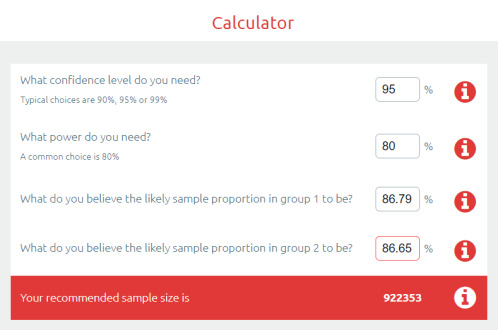
Ok, so to show a significant difference between these two results, you would need 920,000 cases.
But why stop there? We haven’t even discussed multiple hypothesis testing yet. This absurd number of cases needed is simply if there was ever only one hypothesis, meaning only two participants.
If we look at the leaderboard, there were 351 teams who made submissions. The rules say they could submit two models, so we might as well assume there were at least 500 tests. This has to produce some outliers, just like 500 people flipping a fair coin.
Epi101 to the rescue. Multiple hypothesis testing is really common in medicine, particularly in “big data” fields like genomics. We have spent the last few decades learning how to deal with this. The simplest reliable way to manage this problem is called the Bonferroni correction^^.
The Bonferroni correction is super simple: you divide the p-value by the number of tests to find a “statistical significance threshold” that has been adjusted for all those extra coin flips. So in this case, we do 0.05/500. Our new p-value target is 0.0001, any result worse than this will be considered to support the null hypothesis (that the competitors performed equally well on the test set). So let’s plug that in our power calculator.
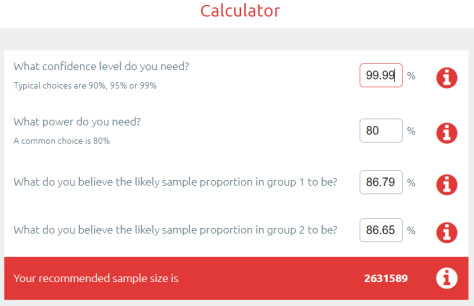
Cool! It only increased a bit… to 2.6 million cases needed for a valid result :p
Now, you might say I am being very unfair here, and that there must be some small group of good models at the top of the leaderboard that are not clearly different from each other^^^. Fine, lets be generous. Surely no-one will complain if I compare the 1st place model to the 150th model?

So still more data than we had. In fact, I have to go down to the 192nd placeholder to find a result where the sample size was enough to produce a “statistically significant” difference.
But maybe this is specific to the pneumothorax challenge? What about other competitions?
In MURA, we have a test set of 207 x-rays, with 70 teams submitting “no more than two models per month”, so lets be generous and say 100 models were submitted. Running the numbers, the “first place” model is only significant versus the 56th placeholder and below.
In the RSNA Pneumonia Detection Challenge, there were 3000 test images with 350 teams submitting one model each. The first place was only significant compared to the 30th place and below.
And to really put the cat amongst the pigeons, what about outside of medicine?

As we go left to right in ImageNet results, the improvement year on year slows (the effect size decreases) and the number of people who have tested on the dataset increases. I can’t really estimate the numbers, but knowing what we know about multiple testing does anyone really believe the SOTA rush in the mid 2010s was anything but crowdsourced overfitting?
So what are competitions for?

They obviously aren’t to reliably find the best model. They don’t even really reveal useful techniques to build great models, because we don’t know which of the hundred plus models actually used a good, reliable method, and which method just happened to fit the under-powered test set.
You talk to competition organisers … and they mostly say that competitions are for publicity. And that is enough, I guess.
AI competitions are fun, community building, talent scouting, brand promoting, and attention grabbing.
But AI competitions are not to develop useful models.
* I have a young daughter, don’t judge me for my encyclopaedic knowledge of My Little Pony.**
** not that there is anything wrong with My Little Pony***. Friendship is magic. There is just an unsavoury internet element that matches my demographic who is really into the show. I’m no brony.
*** barring the near complete white-washing of a children’s show about multi-coloured horses.
^ we can actually understand model performance with our coin analogy. Improving the model would be equivalent to bending the coin. If you are good at coin bending, doing this will make it more likely to land on heads, but unless it is 100% likely you still have no guarantee to “win”. If you have a 60%-chance-of-heads coin, and everyone else has a 50% coin, you objectively have the best coin, but your chance of getting 8 heads out of 10 flips is still only 17%. Better than the 5% the rest of the field have, but remember that there are 99 of them. They have a cumulative chance of over 99% that one of them will get 8 or more heads.
^^ people often say the Bonferroni correction is a bit conservative, but remember, we are coming in skeptical that these models are actually different from each other. We should be conservative.
^^^ do please note, the top model here got $30,000 and the second model got nothing. The competition organisers felt that the distinction was reasonable.
Luke Oakden-Rayner is a radiologist (medical specialist) in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
AI competitions don’t produce useful models published first on https://wittooth.tumblr.com/
0 notes
Link
Facebook’s admission to the UK parliament this week that it had unearthed unquantified thousands of dark fake ads after investigating fakes bearing the face and name of well-known consumer advice personality, Martin Lewis, underscores the massive challenge for its platform on this front. Lewis is suing the company for defamation over its failure to stop bogus ads besmirching his reputation with their associated scams.
Lewis decided to file his campaigning lawsuit after reporting 50 fake ads himself, having been alerted to the scale of the problem by consumers contacting him to ask if the ads were genuine or not. But the revelation that there were in fact associated “thousands” of fake ads being run on Facebook as a clickdriver for fraud shows the company needs to change its entire system, he has now argued.
In a response statement after Facebook’s CTO Mike Schroepfer revealed the new data-point to the DCMS committee, Lewis wrote: “It is creepy to hear that there have been 1,000s of adverts. This makes a farce of Facebook’s suggestion earlier this week that to get it to take down fake ads I have to report them to it.”
“Facebook allows advertisers to use what is called ‘dark ads’. This means they are targeted only at set individuals and are not shown in a time line. That means I have no way of knowing about them. I never get to hear about them. So how on earth could I report them? It’s not my job to police Facebook. It is Facebook’s job — it is the one being paid to publish scams.”
As Schroepfer told it to the committee, Facebook had removed the additional “thousands” of ads “proactively” — but as Lewis points out that action is essentially irrelevant given the problem is systemic. “A one off cleansing, only of ads with my name in, isn’t good enough. It needs to change its whole system,” he wrote.
In a statement on the case, a Facebook spokesperson told us: “We have also offered to meet Martin Lewis in person to discuss the issues he’s experienced, explain the actions we have taken already and discuss how we could help stop more bad ads from being placed.”
The committee raised various ‘dark ads’-related issues with Schroepfer — asking how, as with the Lewis example, a person could complain about an advert they literally can’t see?
The Facebook CTO avoided a direct answer but essentially his reply boiled down to: People can’t do anything about this right now; they have to wait until June when Facebook will be rolling out the ad transparency measures it trailed earlier this month — then he claimed: “You will basically be able to see every running ad on the platform.”
But there’s a very big different between being able to technically see every ad running on the platform — and literally being able to see every ad running on the platform. (And, well, pity the pair of eyeballs that were condemned to that Dantean fate… )
In its PR about the new tools Facebook says a new feature — called “view ads” — will let users see the ads a Facebook Page is running, even if that Page’s ads haven’t appeared in an individual’s News Feed. So that’s one minor concession. However, while ‘view ads’ will apply to every advertiser Page on Facebook, a Facebook user will still have to know about the Page, navigate to it and click to ‘view ads’.
What Facebook is not launching is a public, searchable archive of all ads on its platform. It’s only doing that for a sub-set of ads — specially those labeled “Political Ad”.
Clearly the Martin Lewis fakes wouldn’t fit into that category. So Lewis won’t be able to run searches against his name or face in future to try to identify new dark fake Facebook ads that are trying to trick consumers into scams by misappropriating his brand. Instead, he’d have to employ a massive team of people to click “view ads” on every advertiser Page on Facebook — and do so continuously, so long as his brand lasts — to try to stay ahead of the scammers.
So unless Facebook radically expands the ad transparency tools it has announced thus far it’s really not offering any kind of fix for the dark fake ads problem at all. Not for Lewis. Nor indeed for any other personality or brand that’s being quietly misused in the hidden bulk of scams we can only guess are passing across its platform.
Kremlin-backed political disinformation scams are really just the tip of the iceberg here. But even in that narrow instance Facebook estimated there had been 80,000 pieces of fake content targeted at just one election.
What’s clear is that without regulatory invention the burden of proactive policing of dark ads and fake content on Facebook will keep falling on users — who will now have to actively sift through Facebook Pages to see what ads they’re running and try to figure out if they look legit.
Yet Facebook has 2BN+ users globally. The sheer number of Pages and advertisers on its platform renders “view ads” an almost entirely meaningless addition, especially as cyberscammers and malicious actors are also going to be experts at setting up new accounts to further their scams — moving on to the next batch of burner accounts after they’ve netted each fresh catch of unsuspecting victims.
The committee asked Schroepfer whether Facebook retains money from advertisers it ejects from its platform for running ‘bad ads’ — i.e. after finding they were running an ad its terms prohibit. He said he wasn’t sure, and promised to follow up with an answer. Which rather suggests it doesn’t have an actual policy. Mostly it’s happy to collect your ad spend.
“I do think we are trying to catch all of these things pro-actively. I won’t want the onus to be put on people to go find these things,” he also said, which is essentially a twisted way of saying the exact opposite: That the onus remains on users — and Facebook is simply hoping to have a technical capacity that can accurately review content at scale at some undefined moment in the future.
“We think of people reporting things, we are trying to get to a mode over time — particularly with technical systems — that can catch this stuff up front,” he added. “We want to get to a mode where people reporting bad content of any kind is the sort of defense of last resort and that the vast majority of this stuff is caught up front by automated systems. So that’s the future that I am personally spending my time trying to get us to.”
Trying, want to, future… aka zero guarantees that the parallel universe he was describing will ever align with the reality of how Facebook’s business actually operates — right here, right now.
In truth this kind of contextual AI content review is a very hard problem, as Facebook CEO Mark Zuckerberg has himself admitted. And it’s by no means certain the company can develop robust systems to properly police this kind of stuff. Certainly not without hiring orders of magnitude more human reviewers than it’s currently committed to doing. It would need to employ literally millions more humans to manually check all the nuanced things AIs simply won’t be able to figure out.
Or else it would need to radically revise its processes — as Lewis has suggested — to make them a whole lot more conservative than they currently are — by, for example, requiring much more careful and thorough scrutiny of (and even pre-vetting) certain classes of high risk adverts. So yes, by engineering in friction.
In the meanwhile, as Facebook continues its lucrative business as usual — raking in huge earnings thanks to its ad platform (in its Q1 earnings this week it reported a whopping $11.97BN in revenue) — Internet users are left performing unpaid moderation for a massively wealthy for-profit business while simultaneously being subject to the bogus and fraudulent content its platform is also distributing at scale.
There’s a very clear and very major asymmetry here — and one European lawmakers at least look increasingly wise to.
Facebook frequently falling back on pointing to its massive size as the justification for why it keeps failing on so many types of issues — be it consumer safety or indeed data protection compliance — may even have interesting competition-related implications, as some have suggested.
On the technical front, Schroepfer was asked specifically by the committee why Facebook doesn’t use the facial recognition technology it has already developed — which it applies across its user-base for features such as automatic photo tagging — to block ads that are using a person’s face without their consent.
“We are investigating ways to do that,” he replied. “It is challenging to do technically at scale. And it is one of the things I am hopeful for in the future that would catch more of these things automatically. Usually what we end up doing is a series of different features would figure out that these ads are bad. It’s not just the picture, it’s the wording. What can often catch classes — what we’ll do is catch classes of ads and say ‘we’re pretty sure this is a financial ad, and maybe financial ads we should take a little bit more scrutiny on up front because there is the risk for fraud’.
“This is why we took a hard look at the hype going around cryptocurrencies. And decided that — when we started looking at the ads being run there, the vast majority of those were not good ads. And so we just banned the entire category.”
That response is also interesting, given that many of the fake ads Lewis is complaining about (which incidentally often point to offsite crypto scams) — and indeed which he has been complaining about for months at this point — fall into a financial category.
If Facebook can easily identify classes of ads using its current AI content review systems why hasn’t it been able to proactively catch the thousands of dodgy fake ads bearing Lewis’ image?
Why did it require Lewis to make a full 50 reports — and have to complain to it for months — before Facebook did some ‘proactive’ investigating of its own?
And why isn’t it proposing to radically tighten the moderation of financial ads, period?
The risks to individual users here are stark and clear. (Lewis writes, for example, that “one lady had over £100,000 taken from her”.)
Again it comes back to the company simply not wanting to slow down its revenue engines, nor take the financial hit and business burden of employing enough humans to review all the free content it’s happy to monetize. It also doesn’t want to be regulated by governments — which is why it’s rushing out its own set of self-crafted ‘transparency’ tools, rather than waiting for rules to be imposed on it.
Committee chair Damian Collins concluded one round of dark ads questions for the Facebook CTO by remarking that his overarching concern about the company’s approach is that “a lot of the tools seem to work for the advertiser more than they do for the consumer”. And, really, it’s hard to argue with that assessment.
This is not just an advertising problem either. All sorts of other issues that Facebook had been blasted for not doing enough about can also be explained as a result of inadequate content review — from hate speech, to child protection issues, to people trafficking, to ethnic violence in Myanmar, which the UN has accused its platform of exacerbating (the committee questioned Schroepfer on that too, and he lamented that it is “awful”).
In the Lewis fake ads case, this type of ‘bad ad’ — as Facebook would call it — should really be the most trivial type of content review problem for the company to fix because it’s an exceeding narrow issue, involving a single named individual. (Though that might also explain why Facebook hasn’t bothered; albeit having ‘total willingness to trash individual reputations’ as your business M.O. doesn’t make for a nice PR message to sell.)
And of course it goes without saying there are far more — and far more murky and obscure — uses of dark ads that remain to be fully dragged into the light where their impact on people, societies and civilized processes can be scrutinized and better understood. (The difficulty of defining what is a “political ad” is another lurking loophole in the credibility of Facebook’s self-serving plan to ‘clean up’ its ad platform.)
Schroepfer was asked by one committee member about the use of dark ads to try to suppress African American votes in the US elections, for example, but he just reframed the question to avoid answering it — saying instead that he agrees with the principle of “transparency across all advertising”, before repeating the PR line about tools coming in June. Shame those “transparency” tools look so well designed to ensure Facebook’s platform remains as shadily opaque as possible.
Whatever the role of US targeted Facebook dark ads in African American voter suppression, Schroepfer wasn’t at all comfortable talking about it — and Facebook isn’t publicly saying. Though the CTO confirmed to the committee that Facebook employs people to work with advertisers, including political advertisers, to “help them to use our ad systems to best effect”.
“So if a political campaign were using dark advertising your people helping support their use of Facebook would be advising them on how to use dark advertising,” astutely observed one committee member. “So if somebody wanted to reach specific audiences with a specific message but didn’t want another audience to [view] that message because it would be counterproductive, your people who are supporting these campaigns by these users spending money would be advising how to do that wouldn’t they?”
“Yeah,” confirmed Schroepfer, before immediately pointing to Facebook’s ad policy — claiming “hateful, divisive ads are not allowed on the platform”. But of course bad actors will simply ignore your policy unless it’s actively enforced.
“We don’t want divisive ads on the platform. This is not good for us in the long run,” he added, without shedding so much as a chink more light on any of the bad things Facebook-distributed dark ads might have already done.
At one point he even claimed not to know what the term ‘dark advertising’ meant — leading the committee member to read out the definition from Google, before noting drily: “I’m sure you know that.”
Pressed again on why Facebook can’t use facial recognition at scale to at least fix the Lewis fake ads — given it’s already using the tech elsewhere on its platform — Schroepfer played down the value of the tech for these types of security use-cases, saying: “The larger the search space you use, so if you’re looking across a large set of people the more likely you’ll have a false positive — that two people tend to look the same — and you won’t be able to make automated decisions that said this is for sure this person.
“This is why I say that it may be one of the tools but I think usually what ends up happening is it’s a portfolio of tools — so maybe it’s something about the image, maybe the fact that it’s got ‘Lewis’ in the name, maybe the fact that it’s a financial ad, wording that is consistent with a financial ads. We tend to use a basket of features in order to detect these things.”
That’s also an interesting response since it was a security use-case that Facebook selected as the first of just two sample ‘benefits’ it presents to users in Europe ahead of the choice it is required (under EU law) to offer people on whether to switch facial recognition technology on or keep it turned off — claiming it “allows us to help protect you from a stranger using your photo to impersonate you”…
Yet judging by its own CTO’s analysis, Facebook’s face recognition tech would actually be pretty useless for identifying “strangers” misusing your photographs — at least without being combined with a “basket” of other unmentioned (and doubtless equally privacy-hostile) technical measures.
So this is yet another example of a manipulative message being put out by a company that is also the controller of a platform that enables all sorts of unknown third parties to experiment with and distribute their own forms of manipulative messaging at vast scale, thanks to a system designed to facilitate — nay, embrace — dark advertising.
What face recognition technology is genuinely useful for is Facebook’s own business. Because it gives the company yet another personal signal to triangulate and better understand who people on its platform are really friends with — which in turn fleshes out the user-profiles behind the eyeballs that Facebook uses to fuel its ad targeting, money-minting engines.
For profiteering use-cases the company rarely sits on its hands when it comes to engineering “challenges”. Hence its erstwhile motto to ‘move fast and break things’ — which has now, of course, morphed uncomfortably into Zuckerberg’s 2018 mission to ‘fix the platform’; thanks, in no small part, to the existential threat posed by dark ads which, up until very recently, Facebook wasn’t saying anything about at all. Except to claim it was “crazy” to think they might have any influence.
And now, despite major scandals and political pressure, Facebook is still showing zero appetite to “fix” its platform — because the issues being thrown into sharp relief are actually there by design; this is how Facebook’s business functions.
“We won’t prevent all mistakes or abuse, but we currently make too many errors enforcing our policies and preventing misuse of our tools. If we’re successful this year then we’ll end 2018 on a much better trajectory,” wrote Zuckerberg in January, underlining how much easier it is to break stuff than put things back together — or even just make a convincing show of fiddling with sticking plaster.
from Social – TechCrunch https://ift.tt/2vUlg3j
Original Content From: https://techcrunch.com
0 notes
Text
Video Friday: Giant Robotic Chair, Underwater AI, and Robot Holiday Mischief
Your weekly selection of awesome robot videos
Image: KAIST HuboLab/Rainbow Robotics/YouTube
FX-2 Giant Human Riding Robot from KAIST HuboLab.
Video Friday is your weekly selection of awesome robotics videos, collected by your Automaton bloggers. We’ll also be posting a weekly calendar of upcoming robotics events for the next two months; here’s what we have so far (send us your events!):
IEEE IRC 2018 – January 31-2, 2018 – Laguna Hills, Calif.
HRI 2018 – March 5-8, 2018 – Chicago, Ill.
Let us know if you have suggestions for next week, and enjoy today’s videos.
DRC Hubo (and some
humans) are helping relay the Olympic torch to PyeongChang:
[ DRC Hubo ]
This is the FX-2 Giant Human Riding Robot from KAIST HuboLab and Rainbow Robotics, and that’s all I know about it.
[ Rainbow Robotics ]
Yuichiro Katsumoto, a “gadget creator” based in Singapore, wrote in to share this video of the robotic kinetic typography that he’s been working on for the last year. It’s mesmerizing.
[ Yuichiro Katsumoto ]
Thanks Yuichiro!
Oceans makeup 70% of the Earth’s surface, yet we know very little about them. MIT students taking class 2.680: Unmanned Marine Vehicle Autonomy, Sensing and Communications aim to deepen our understanding by developing artificial intelligence for use on autonomous marine vehicles. Their software is put to the ultimate test while running missions of the Charles River.
Someone should tell MIT that the Charles River is not the ocean, though.
[ MIT ]
FZI Living Lab has the best robot holiday parties EVER.
Note: Please do not try to host a party like this unless you’re a trained professional and are willing to invite me.
[ FZI Living Labs ]
Thanks Arne!
Look who’s been eating our chocolates. The Meca500, the only industrial robot that can fit in gift box. Happy Holidays!
More importantly, it can fit in a gift box along with a big pile of chocolates.
[ Mecademic ]
Robotnik brings us one of the more… unusual… holiday videos:
[ Robotnik ]
The high probability of hardware failures prevents many advanced robots (e.g., legged robots) from being confidently deployed in real-world situations (e.g., post-disaster rescue). Instead of attempting to diagnose the failures, robots could adapt by trial-and-error in order to be able to complete their tasks. In that case, damage recovery can be seen as a Reinforcement Learning (RL) problem. However, the best RL algorithms for robotics require resetting the robot and the environment to an initial state after each episode, that is, the robot is not learning autonomously. In addition, most of the RL methods for robotics do not scale well with complex robots (e.g., walking robots) and either cannot be used at all or take too long to converge to a solution (e.g., hours of learning). In this paper, we introduce a novel learning algorithm called “Reset-free Trial-and-Error’” (RTE) that (1) breaks the complexity by pre-generating hundreds of possible behaviors with a dynamics simulator of the intact robot, and (2) allows complex robots to quickly recover from damage while completing their tasks and taking the environment into account.
By Konstantinos Chatzilygeroudis, Vassilis Vassiliades, and Jean-Baptiste Mouret. Full paper at the link below.
[ arXiv ]
Several NCCR Robotics laboratories have been collaborating on this integrative demo project, targeted at rescue missions.
[ NCCR Robotics ]
These small bots are capable of doing useful task by way of external actuation. Shown here are 1 and 2mm “bots”. Applications include micro transportation, micro manipulation and more. Potential use cases include crystal harvesting, manufacture of bio sensors, lab on chip, cell manipulation and surgery.
[ University of Sydney ACFR ]
Simone Giertz takes on bubble wrap with a $100k robot arm.
Er, I really feel like the Kuka arm should just be totally wrecking this competition. Why is is moving sooo slooowly?
[ Simone Giertz ]
CMU senior undergrad Alan Jaffe demos his final project, which was to getting a robotic arm to assist a virtual disabled person who needs help with eating.
[ CMU ]
Why do I have to say this every year? If you are a company that makes robots that can do cool things, don’t make a holiday card using animations of your robots doing cool things that they should be able to do in real life.
[ Yaskawa ]
This video shows the ability of iCub to work safely in sharing environment with human. Taking inspiration from peripersonal space representations in humans, we present a framework on the iCub humanoid robot that dynamically maintains such a protective safety zone, composed of the following main components: an architecture for human keypoints estimation in 3D, an adaptive peripersonal space representation, and a controller dynamically incorportating human keypoints as obstacles into a reaching task.
The video is based on the work presented in Nguyen, P. D.; Hoffmann, M.; Roncone, A.; Pattacini, U. & Metta, G. (2018), Compact real-time avoidance on a humanoid robot for human-robot interaction, in ’Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction (HRI)’. [conditionally accepted].
I hope you gave that iCub a proper hug after all of those avoidance experiments.
[ iCub ]
TJBot is an open-source platform built around the Raspberry Pi for exploring artificial intelligence (AI) with IBM Watson. Create recipes on IBM Cloud to hold conversations with TJBot, ask it to dance, turn on a light, or analyze a Tweet.
Watson, tell me a joke that is actually funny.
[ SparkFun ]
TinyWhoop FPV drones look like they’re way more fun to play with than their size would suggest:
You can get a complete ready-to-fly TinyWhoop kit (including the FPV goggles) for just $350.
[ TinyWhoop ] via [ Team BlackSheep ]
How close are we to a Star Wars droid reality? That’s the question we posed to Paul G. Allen’s technical advisor Jeff Kramer. As a Star Wars fan with an extensive background in robotics, he knows a thing or two about beloved characters like C-3P0, R2-D2 and BB-8 and how some of their technological advances can be seen in present day robotics.
[ Vulcan ]
In case you don’t get enough Agility Robotics video by reading this blog, here’s another 12 minutes worth of footage and interviews from Motherboard:
[ Motherboard ]
The U.S. Army Research Laboratory is working on a concept to 3-D print custom unmanned aircraft systems on-demand. Join us for an inside look at a project that has Soldiers and Marines using science and technology to bring important mission capabilities to the fight.
[ ARL ]
Kurt Leucht performs exploration research and technology development for NASA KSC, and he’s one of the very few people legit qualified to give a talk entitled “Writing Apps For Mars!”
Mobile app developers and other software developers typically take great pride in their final products. But how does the onboard software for a Mars rover, for example, compare to a good mobile app or business app?
Is it simple and easy to use? Is it efficient? What platform does it run on? How does it typically perform? Does it work seamlessly offline? What language is it written in? Is it supportable and upgradable? Is it designed with the user in mind? How is it developed and tested?
This presentation will explore all these questions and more in an effort to understand the similarities and the major differences between typical business software and software that is designed for the NASA Mars rovers.
[ Oredev ]
Thanks Kurt!
In the latest episode of Robots in Depth, Per Sjöborg interviews Ian Bernstein, of Sphero and now Misty Robotics:
Ian Bernstein is the founder of several robotics companies including Sphero. Hi shares his experience from completing 5 successful rounds of financing, raising 17 million dollars in the 5th one. He also talks about building a world-wide distribution network and the complexity of combining software and hardware development. We then discuss what is happening in robotics and where future successes may come from, including the importance of Kickstarter and Indiegogo. If you view this episode, you will also learn which day of the week people don’t play with their Sphero :-).
[ Robots in Depth ]
Video Friday: Giant Robotic Chair, Underwater AI, and Robot Holiday Mischief syndicated from http://ift.tt/2Bq2FuP
0 notes
Text
Following $120 Million Funding Round, Waves Token Price Jumps Over 30%
Global blockchain platform Waves has raised $120 million in a private funding round for its new project called Vostok, according to an official blog post published Dec. 19.
The Vostok project is a “universal blockchain solution” that combines two basic components — its own private blockchain platform, and the Vostok system integrator, a tool for developing and optimizing the platform.
The Vostok blockchain is focused on the deployment of Waves technologies for commercial and government IT systems. The new product will reportedly help the Waves Platform to develop new technologies such as artificial intelligence (AI), Internet of Things (IoT), and blockchain in order to “support a truly open and decentralised web.”
The private funding round was led by London-based financial services firm Dolfin, as reported by financial trading news website Finance Magnates. Waves started developing Vostok earlier in 2018 and is reportedly planning to launch the platform in early 2019, targeting European and Asian markets at the initial launch stage.
Denis Nagy, CEO of Dolfin, commented that attracting private funding in the blockchain industry is “often problematic due to the lack of financial infrastructure.” According to Nagy, the recent private funding round is based on a model that is “familiar to private equity investors,” and was developed together with Vostok.
Founded in 2016, the Waves Platform is a blockchain platform that allows users to build their own custom tokens and is touted to become the “fastest blockchain in the world.” According to Finance Magnates, the platform is faster than the Bitcoin (BTC) and Ethereum (ETH) blockchains, processing 6.1 million transactions daily at its peak.
Following the funding news, the Waves (WAVES) token saw a price spike of more than 30 percent earlier today. Ranked the 19th largest cryptocurrency by market cap, the Waves token is trading at $3.99, with a market capitalization of around $399 million at press time. Waves coin is up more than 104 percent over the past seven days, according to CoinMarketCap.
Waves 24-hour price chart. Source: CoinMarketCap
window.fbAsyncInit = function() { FB.init({ appId : '1922752334671725', xfbml : true, version : 'v2.9' }); FB.AppEvents.logPageView(); }; (function(d, s, id){ var js, fjs = d.getElementsByTagName(s)[0]; if (d.getElementById(id)) {return;} js = d.createElement(s); js.id = id; js.src = "http://connect.facebook.net/en_US/sdk.js"; js.async = true; fjs.parentNode.insertBefore(js, fjs); }(document, 'script', 'facebook-jssdk')); !function(f,b,e,v,n,t,s) {if(f.fbq)return;n=f.fbq=function(){n.callMethod? n.callMethod.apply(n,arguments):n.queue.push(arguments)}; if(!f._fbq)f._fbq=n;n.push=n;n.loaded=!0;n.version='2.0'; n.queue=[];t=b.createElement(e);t.async=!0; t.src=v;s=b.getElementsByTagName(e)[0]; s.parentNode.insertBefore(t,s)}(window,document,'script', 'https://connect.facebook.net/en_US/fbevents.js'); fbq('init', '1922752334671725'); fbq('track', 'PageView');
This news post is collected from Cointelegraph
Recommended Read
New & Hot
The Calloway Software – Secret Weapon To Make Money From Crypto Trading (Proofs Inside)
The modern world is inextricably linked to the internet. We spend a lot of time in virtual reality, and we're no longer ...
User rating:
9.6
Free Spots are Limited Get It Now Hurry!
Read full review
Editors' Picks 2
BinBot Pro – Its Like Printing Money On Autopilot (Proofs Inside)
Do you live in a country like USA or Canada where using automated trading systems is a problem? If you do then now we ...
User rating:
9.5
Demo & Pro Version Get It Now Hurry!
Read full review
The post Following $120 Million Funding Round, Waves Token Price Jumps Over 30% appeared first on Review: Legit or Scam?.
Read more from → https://legit-scam.review/following-120-million-funding-round-waves-token-price-jumps-over-30-2
0 notes
Last Seen Blogs




