#using jquery to perform calculations in a table
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
How to calculate sum of column in jquery
How to calculate sum of column in jquery
In this article, we learn about how to calculate sum of column in jquery, or you can also say how to calculate the value when giving input to the column. In this article we will jquery version 3.X and bootstrap version 4 to give some feel to our form. You will learn about each function() , parse column data in this article. Below is the basic html code which includes cdn in their…
View On WordPress
#"calculate sum total of column in jquery#calculate sum total of column in jquery how to calculate total in jquery#how to calculate sum of column values in javascript#how to calculate total in jquery#how to dynamically add row and calculate sum using jquery#javascript sum table row values#jquery datatable sum of particular column#update column value in html table using jquery#using jquery to perform calculations in a table
0 notes
Text
Hire me under false pretences, then fire me under more fallacies? Welp; OK then
First post; TL;DR at the end
Background.init()
After leaving 6th form (college for my family over the pond), I started a job as a Full Stack Java Developer for a small company in the city I currently reside, study and work (more on that later). For those not in the know, a "Full Stack" Developer, is someone that develops the application/website that controls an application, the middleware "brain", and the back-end, usually a Database of some kind.
In the contract, it stated that "All development projects developed within Notarealcompany's offices are the sole property of the company". I was new to the scene and assumed this was the norm (turns out it is - Important later).
The Story.main()
My "Training" was minimalistic, and expectations were insanely high. I was placed on a client project within the first month, and was told that this was to be a trial by fire. Oh boy.
Having spoken to the client, their expectations had already been set by the owner; let's call him Berk (Berk is an English term for moron); "Whatever you need, our developers can accommodate". Their requirements were as follows;
The Intranet software MUST match the production, public site in functionality, including JQuery and other technologies I was unfamiliar with
MUST accommodate their inventory and shipping database, including prior version functionality (which included loading a 400k+ database table into a webpage in one shot)
MUST look seamless on ALL internal assets, regardless of browser (THIS is important)
ABSOLUTELY MUST USE THE STRONGEST SECURITY MONEY CAN BUY (without requiring external sources)
Having asked what the oldest machine on their network was, I realised it was a nightmare given form. They wanted advanced webtoys to work on WINDOWS XP SP1 (which did not, and does not, support HTML5, let alone the version of JavaScript/JQuery the main website does).
I was given a time-line of 2 months to build this by the client, who were already under the impression that all would be ok.
Having spent a few days researching and prototyping, it was clear that their laundry list of demands was impossible. I told them in plenty of time, providing evidence with Virtual Machines, using their "golden images". The website looked clunky, the database loader crashed the entire machine, the JavaScript flat-out refused to work.
Needless to say, they weren't happy. I was ordered to fix the issue, or "my ass is out on the street".
Spending every waking moment outside of work, I build something that, still to this day, I am insanely proud of. The Database was built robust; built to British and German security standards around Information Security. The Password management system was NUKE-proof (I calculated it would take until the Sun died to crack a single password), and managed to get the Database to load into the page flawlessly, using "pagination", the same technology Amazon uses to slide through pages, and AJAX (not important; my fellow devs will know). I managed to get the project completed a DAY before the deadline. Gave the customer a deadline, and plugged their live data into it. Everything worked fine, BUT, their DB had multiple duplicate records, with no way to filter through them. I told them that I could fix this issue with a 100% success rate, and would build dupe-protection into the software (it was easy); without losing pertinent information. The SQL script was dirty, but functional.
Shortly after completing the project, I was told it was "too slow". Now bare in mind; the longest action took 0.0023 of a second; EVEN ON XP. Never the less, I built it faster, giving benchmarking data for the before and after (only 0.0001 of a seconds improvement).
Shortly after, I was told to pack my "shit", as I'd failed my peer review.
The nightmare continues
Because I'd built the software outside of work, on my own time, on my own devices; they had no rights over it, as the only version they saw were the second-to-last, and final commits from my private github.
Shortly after leaving, I'm served papers, summoning me to court for "corporate espionage". Wait, WHAT?
Turned up to court with all relevant documents, a copy of my development system on an ISO for evidence, and a court-issued solicitor. Their claim, was that I'd purposely engineered the application to be insecure, causing their client to be hacked, losing an inordinate amount of money. They presented the source code as "evidence", citing that the password functionality for the management interface was using MD5 (you can google an MD5 hash and find out what it is; see here: https://md5.gromweb.com/?md5=1f3870be274f6c49b3e31a0c6728957f
I show the court the source code I have from the final version (which had only been altered once within work premises to improve speed and provide benchmarking information). They then accuse me of theft, despite showing IP-trace information from Git, the commit hashes from Github, correlating with my PC, and all the time logs from editing and committing (all out of hours).
The Aftermath
To cut an already long story short; I got a payout for defamation of character and time wasted, they paid all the court costs, and was let go with the summons removed from my record.
The story doesn't end there though...
Currently, I am doing a Degree in Information Security, and working for a Managed Service Provider for security products and monitoring. I was asked to do a site visit and perform;
Full "Black Box" Penetration Test (I'm given no knowledge on the network to be attacked, and can use almost any means to gain access)
Full Compliance test for PCI DSS (Payment card industry for Debit/Credit payments)
GDPR (Information storage and management)
ISO 27001 FULL audit
All in all, this is a very highly paid job. Sat in the car park with a laptop, I gained FULL ADMIN ACCESS within about 20 minutes, cloned the access cards to my phone over the air, and locked their systems down (all within the contract). Leaving for the day, I compile a report with pure glee. Their contract with us stipulates that the analyst on site would remain to remediate any and all issues, would have total jurisdiction over the network whilst on job, and would return 6 months later for further assessment and remedy and and all issues persistent or new.
The report put the company on blast; outlining every single fault, every blind spot, and provided evidence of previous compromise. The total cost of repairs was more than the company was willing to pay (they were able, I saw the finances after all). The company went into liquidation, but not before trying to have me fired for having a prior vendetta. The legal team for my current employers not-so-politely tore them to shreds, suing for defamation of character (sounds familiar right?), forcing them to liquidate even more assets than they intended; ultimately costing them their second home.
TL;DR: Got a job, got told I was fired after doing an exemplary job; then had the company liquidated due to MANY flaws when working for their security contractors.
submitted by /u/BenignReaver [link] [comments] ****** (source) story by (/u/BenignReaver)
315 notes
·
View notes
Text
Primefacs icefaces usage

#Primefacs icefaces usage update#
Once you start to use the components in PrimeFaces for things other than trivial showcase examples you quickly run into a lot of problems and limitations (I'm grateful for PrimeFaces, but thought I would provide a little constructive feedback).One of the questions from the above dialog that we (ICEsoft) have perhaps not fully addressed already is why we felt it necessary to fork the PrimeFaces project in the first place. I also hope that 2.2/2.3 focuses more on fixing up bugs and making the component library more useable in general. Post on Primefaces forum that is quite revelent : Thanks Mathieu for correcting the spelling of the article! ) ĭear Icefaces, Primefaces and Richfaces users, if you see some improvements please post a comment. If a winner should be decided it would be Richfaces since I have been quite disappointed by Primefaces. Richfaces is between Primefaces and Icefaces closest to Primefaces. Icefaces has clearly the worst performance on datatable on all test. Primefaces has the best datatable implementation although buggy (I hope Primefaces 2.2 will correct all the issues). To be complete the generic components (tab, tree.) have to be tested too in order to make a robust conclusion. Richfaces : 9400 requests ~900MB : ~100KBĬonclusionThe page used for the test is quite simple and does not reflect a real page nor the global performance of these frameworks.I took the JVM memory consumption and the number of requests done : You can basically have three time more users with Primeface than Icefaces (considering it is growing lineary)īecause Icefaces OOM my JVM very quickly without a cookie manager I did a very simple calculation on session size. Test setup : Core 2 Duo 3Ghz 64bits, 2GB dedicated to the JVM. Server loadI have created a simple unit test which executes 10 concurrent threads with a cookies manager. So the question is, why does it do that when we don't need them?
#Primefacs icefaces usage update#
Knowing that I put an id only on the components i needed to update that means JSF autogenerate the other Ids by itself. The table contains ids and classes only on rows.īut what if the data changes on the server side (delete or add) ? An user action on the paginator doesn't update it. The paginator is updated on the client side. The Icefaces paginator block is quite big, more than the datatable block. The table contains ids and classes on all cells. Icefaces and Richfaces send the paginator and the table. Richfaces can gain 80KB by using JQuery min and be below 200KB. Icefaces and Richfaces don't used minified JS. Creating an unit test with HtmlUnit is quite simple and I did not met issue requesting Icefaces, Primefaces and Richfaces for the purpose of this article. Page size benchmarkI'm measuring the page size and the ajax response size with HtmlUnit. The datable is binded to an ajax paginator which display books 15 by 15. Test setupThe datatable will display a list of books with 3 columns : ISBN, author and title. I will focus on efficiency : page size, ajax request/response size, server load, and not on features. In this article I will bench the datatables of 3 JSF2 components frameworks :
0 notes
Text
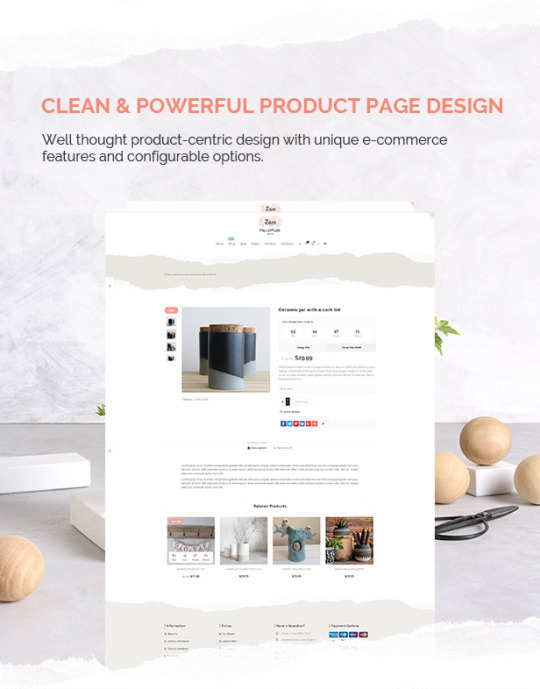
Zass - WooCommerce Theme for Handmade Artists and Artisans
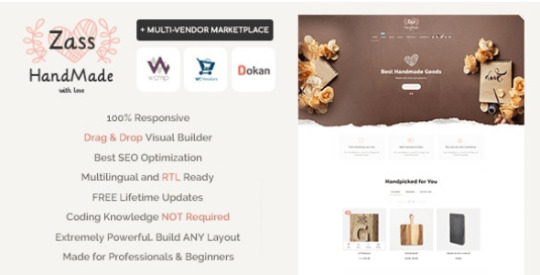


Zass is the perfect WordPress / WooCommerce theme for handmade artists and artisans. Whether you look to build a fully functional Etsy Style online shop, blog or portfolio for your handmade business – Zass is the right choice for you. With it’s extremely powerful custom e-commerce features, unlimited portfolio styles, different blog styles and unlimited colors, backgrounds and layouts – it’s the last theme you’ll ever need.




NEW: WC MARKETPLACE MULTI VENDOR
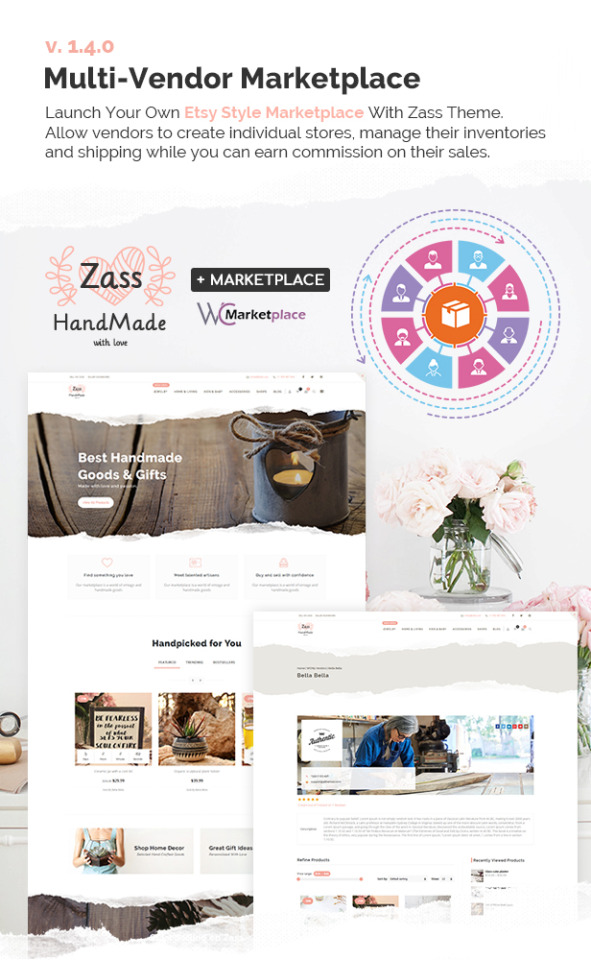
NEW: v. 1.7.0 NOW FULLY COMPATIBLE WITH WC VENDORS / WC VENDORS PRO
NEW: v. 2.5.0 NOW FULLY COMPATIBLE WITH DOKAN MULTI-VENDOR
WHY PEOPLE LOVE ZASS THEME FOR HANDMADE PRODUCTS & BLOG
THEME KEY FEATURES: - FULLY RESPONSIVE AND OPTIMIZED - RETINA READY - SEO OPTIMIZED - BLOG VARIANTS - UNLIMITED PORTFOLIO VARIANTS - 4 TYPES OF PORTFOLIO GALLERY DISPLAY - HEADER STYLES - PAGE OPTIONS - LAYOUT OVERWRITES ON PAGES AND POSTS - GOOGLE RICH SNIPPETS READY - FULL WOOCOMMERCE INTEGRATION ON STEROIDS - CUSTOM BBPRESS INTEGRATION - VISUAL COMPOSER – DRAG AND DROP PAGE BUILDER INCLUDED – (SAVE $34) - REVOLUTION SLIDER INCLUDED – (SAVE $25) - BUILT-IN GROUPON-STYLE OFFERS WITH COUNTDOWN – (SAVE $20) - 100% WPML READY - 100% RTL READY - UNLIMITED PORTFOLIOS - TONS OF SHORTCODES - UNLIMITED COLORS AND BACKGROUNDS - WISHLIST INTEGRATED - CUSTOM PRODUCTS QUICK VIEW FEATURE – (SAVE $18) - FULLSCREEN VIDEO BACKGROUNDS WITH OR WITHOUT SOUND - FULLSCREEN BACKGROUND SLIDESHOWS - CUSTOM MENUS - POWERFUL CUSTOM MEGA MENU - 3 TYPES OF PRODUCT LISTINGS - POWERFUL AJAX SEARCH SUGGESTIONS - BUILT-IN PRICE FILTER - SAVING CALCULATION ON OFFERS - UNLIMITED SIDEBARS - POST CAROUSELS - POST GRIDS - POST SLIDERS - POST FORMATS SUPPORTED - PORTFOLIO WITH RELATED PROJECTS - GRID, SLIDESHOW AND MASONRY GALLERIES - CUSTOM WIDGET AREAS - WIDGETIZED COLLAPSIBLE PRE-HEADER - WIDGETIZED OFF-CANVAS SIDEBAR - WIDGETIZED FOOTER - SOCIAL MEDIA SHARE FUNCTIONALITY - ALL (600+) GOOGLE FONTS - 7 ICON FONTS - SLIDING SIDEBLOCKS - ICON TEASERS WITH LIGHTBOX - ICON BOXES - GOOGLE MAPS WITH DRIVING DIRECTIONS (SAVE $14) - PAYMENT OPTIONS WIDGET - UP-TO 6 POST/PAGE FEATURED IMAGES - PRODUCT IMAGES WITH ANY ASPECT RATIO - CLOUZOOM ON PRODUCTS AND PORTFOLIO - TESTED WITH ALL MAJOR PLUGINS - HIGHLY CUSTOMIZABLE - CHARTS AND PROGRESS BARS - CUSTOM FEATURES COSTS $300+ IF PURCHASED AS PLUGINS - CONSTANTLY IMPROVED - MENU LABELS - MENU ICONS - DEDICATED SUPPORT FORUMS - CUSTOM CONTENT SLIDER - CUSTOM PRODUCTS (DEALS) SLIDER - CUSTOM TYPING TEXT ROTATOR - CUSTOM TEAR-OFF PAPER EFFECT and so much more, that just can’t be listed here! THEME UPDATES Changelog Zass WP theme v. 3.9.2 – 16.06.2021 - Fix: Blog category description position when masonry layout is used. - Update: WooCommerce 5.4.1 compatibility - Update: Revolution Slider v. 6.5.0 - Update: Wishlist 3.0.22 compatibility improvements Changelog Zass WP theme v. 3.9.1 – 22.04.2021 IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: Latest WC Marketplace compatibility - Fix: WC Marketplace new endpoints bredcrumb - Fix: Parallax background for latest WP Bakery Page Builder - Tweak: Various CSS and JS performance improvements Changelog Zass WP theme v. 3.9.0 – 12.03.2021 IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Added: Set product category description position: top or bottom of the category page - Fix: Now proper retrieving of all portfolio categories on the projects shortcode - Fix: product slider countdowns - Fix: jQuery deprecation warnings - Tweak: Major Performance improvements - Update: WordPress 5.7 compatibility - Update: WPBakery Page Builder v. 6.6 - Update: WooCommerce 5.1 compatibility - Update: Revolution Slider v. 6.4.3 Changelog Zass WP theme v. 3.8.2 – 23.12.2020 IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WPBakery Page Builder v. 6.5 - Update: WooCommerce 4.8.0 compatibility - Update: Revolution Slider v. 6.3.3 - Update: Video background v. 3.3.8 improvements - Update: Better compatibility with official WooCommerce plugins - Fix: Product attribute table spacing - Fix: WooCommerce Products per page dropdown - Fix: Content slider resizing when stretch row set inside slides - Fix: Supersized background slider - Tweak: Various CSS and JS performance improvements Changelog Zass WP theme v. 3.8.1 – 04.12.2020 IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WPBakery Page Builder v. 6.4.2 - Update: Upcoming WordPress 5.6 and new jQuery compatibility - Update: WooCommerce 4.7.1 compatibility - Update: Revolution Slider v. 6.3.1 - New: Full support for the official WooCommerce Product Bundles plugin - Tweak: Various CSS and JS performance improvements Changelog Zass WP theme v. 3.8.0 – 25.09.2020 - Update: WPBakery Page Builder v. 6.4.1 - Update: WooCommerce 4.5.2 compatibility - Update: Envato Market Plugin v. 2.0.5 - Tweak: Removed ucfirst from breadcrumb to improve non UTF-8 colated databases compatibility - Tweak: Various CSS and JS performance improvements Changelog Zass WP theme v. 3.7.9 – 27.08.2020 - Update: Revolution Slider v. 6.2.22 - Update: WPBakery Page Builder 6.3.0 - Tweak: Various CSS and JS performance improvements and fixes Changelog Zass WP theme v. 3.7.8 – 20.08.2020 - Update: WooCommerce 4.4.1 compatibility - Tweak: Various CSS and JS performance improvements and bug fixes Changelog Zass WP theme v. 3.7.7 – 11.08.2020 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WordPress 5.5 compatibility - Update: WooCommerce 4.3.2 compatibility - Update: Revolution Slider v. 6.2.17 - Tweak: Popular posts widget reworked from scratch to avoid crashes on some server configurations - Update: PHP 7.4 compatibility Changelog Zass WP theme v. 3.7.6 – 27.05.2020 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 4.1.1 compatibility - Update: Revolution Slider 6.2.6 - Update: WPBakery Page Builder 6.2.0 Changelog Zass WP theme v. 3.7.5 – 17.04.2020 - Tweak: Improved compatibility with latest versions of Facebook for WooCommerce. - Fix: Theme Options export when child theme is active - Tweak: CSS and JS performance improvements Changelog Zass WP theme v. 3.7.4.1 – 13.03.2020 - Fix: Latest plugin version can not be installed properly Changelog Zass WP theme v. 3.7.4 – 11.03.2020 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 4.0 compatibility - Update: Revolution Slider 6.1.8 - Fix: Top bar menu overlapping icons on mobile devices Changelog Zass WP theme v. 3.7.3 – 28.02.2020 - Fix: Bug in Convert Plus inline forms when posts are displayed without sidebar - Tweak: Minor performance improvements Changelog Zass WP theme v. 3.7.2 – 08.02.2020 - Update: Revolution 6.1.8 - Update: WooCommerce 3.9.1 compatibility - Tweak: Better layout on tablets for YITH Wishlist - Tweak: Better countdown compatibility for different locales in Serbian and Brasilian-Portuguese - Fix: Default template error on new blog posts Changelog Zass WP theme v. 3.7.1 – 29.01.2020 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 3.9+ compatibility - Update: WP Bakery Page Builder 6.1 - Upgrade: Font Awesome to version 5+ - Update: Revolution Slider 6.1.6 - Update: Wishlist 3.0.5+ compatibility improvements - Fix: Currency issue, related with WooCommerce multilingual and WPML - Fix: PHP error in quick view when products don't have a featured image - Fix: YITH Wishlist mobile layout - Fix: Missing icons for the new FontAwesome 5+ - Fix: Notifications container on WooCommerce pages - Tweak: Improved mobile layout on cart page - Tweak: Minor CSS and JS performance improvements - Fix: Social share icons Changelog Zass WP theme v. 3.7.0 – 11.12.2019 - Fix: Products grid in latest native Safari Browser (MacBook and iMac) - Fix: Login/Register tabs on My Account when carousel style enabled - Tweak: Hidden system comments by Action Scheduler on pages - Update: Wishlist 2.2.17 compatibility - Update: Revolution Slider 6.1.5 - Update: WooCommerce 3.8.1 compatibility Changelog Zass WP theme v. 3.6.9 – 16.11.2019 - Fix: Search button position Changelog Zass WP theme v. 3.6.8 – 11.11.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 3.8 compatibility - Update: EnvatoMarket plugin 2.0.3 compatibility - Update: Wishlist 2.2.15 compatibility - Update: Revolution Slider 6.1.3 - Fix: Cart widget subtotal overlaping products in sidebar Changelog Zass WP theme v. 3.6.7 – 04.10.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Fix: translation issues with countdown for BR, CN and TW - Fix: quickview variations image change and single product on mobile variations - Fix JS error when "redirect to cart after adding to cart" is enabled in WooCommerce and "Ajax add to cart" is enabled - Fix: JS error in latest WooCommerce version causing conflict with Product Categories dropdown widget - Tweak: various small design improvements - Tweak: Performance improvements - Updated Owl Carousel to latest version (2.3.4) - Added option to not select any font from the theme. Can be used to set fonts manually or with third party plugins Changelog Zass WP theme v. 3.6.6 – 14.08.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 3.7 compatibility - Update: Slider Revolution 6.0.9 - Update: YITH Wishlist 2.2.13 compatibility Changelog Zass WP theme v. 3.6.5 – 07.08.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Fix: Vendor Shop name in WC Marketplace Vendors List shortcode Changelog Zass WP theme v. 3.6.4 – 30.07.2019 - Fix: Variations in cart on mobiles - Update: WPBakery Page Builder 6.0.5 - Update: Slider Revolution 6.0.7 - Update: YITH Wishlist 2.2.12 compatibility Changelog Zass WP theme v. 3.6.3 – 27.06.2019 - Fix: tabs on WCMp dashboard - Tweak: Improved Performance - Tweak: Improved compatibility with Dokan Multi Vendor - New: Option to disable carousel on login/register form Changelog Zass WP theme v. 3.6.2 – 17.06.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Fix: updated WCMp vendor list shortcode to show vendor shop name instead of username - Update: WP Bakery Page Builder v. 6.0.3 - Update: WooCommerce 3.6.3 compatibility - Update: YITH Wishlist 2.2.11 compatibility Changelog Zass WP theme v. 3.6.1 – 27.05.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Tweak: Removed addThis script and replaced with custom share links - Tweak: Performance improvements Changelog Zass WP theme v. 3.6.0 – 22.05.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 3.6.3 compatibility - Update: WP Bakery Page Builder v. 6.0.2 - Tweak: Refactored theme code and plugins to comply with latest WordPress standards and requirements Changelog Zass WP theme v. 3.5.8 – 18.04.2019 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 3.6.1 compatibility - Fix: Added "prev" and "next" in translation - Fix: Header account icon on transparen header - Fix: Improved RTL styles on product page Changelog Zass WP theme v. 3.5.6 – 31.03.2019 - Update: WooCommerce 3.5.7 - Fix: Improved RTL styles on product page Changelog Zass WP theme v. 3.5.5 – 14.03.2019 - Fix: PHP 7.3 compact() fix - Update: WooCommerce 3.5.6 - Update: WordPRess 5.1.1 - Update: YITH Wishlist 2.2.8 - Update: Revolution Slider 5.4.8.3 Changelog Zass WP theme v. 3.5.4 – 04.03.2019 - Update: WooCommerce 3.5.5 compatibility fix - Improved RTL styles Changelog Zass WP theme v. 3.5.3 – 13.02.2019 - Update: WooCommerce 3.5.4 compatibility fix - Update: Revolution Slider 5.4.8.2. - Update: WP Bakery Page Builder v. 5.7 - Fix: Possible issue with displaying product categories twice on shop and category pages - Fix: Home page slider - fullwidth after import - Fix: WooCommerce plugin detection on WP Multisite Changelog Zass WP theme v. 3.5.1 – 18.01.2019 - Update: Latest Dokan version vendor dashboard styling issues - Update: Minor CSS optimizations Changelog Zass WP theme v. 3.5.0 – 15.01.2019 - Update: WooCommerce 3.5.3 compatibility - Update: YITH Wishlist 2.2.7 compatibility - Tweak: Improved RTL styles Changelog Zass WP theme v. 3.4.9.1 – 10.01.2019 - Tweak: RTL styles tweaks and improvements Changelog Zass WP theme v. 3.4.9 – 08.01.2019 - Tweak: Improved RTL styles Changelog Zass WP theme v. 3.4.8 – 04.01.2019 - Tweak: Improved RTL styles for sticky header - Fix: Mobile styles for Quick View Changelog Zass WP theme v. 3.4.7 – 20.12.2018 - Tweak: Improved RTL styles Changelog Zass WP theme v. 3.4.6 – 01.12.2018 - Update: WooCommerce 3.5.2 compatibility fixes - Update: WPBakery Page Builder updated to the latest version Changelog Zass WP theme v. 3.4.5 – 07.11.2018 *IMPORTANT: Update required for both theme files AND the theme plugin (Appearance > Install Plugins > Zass Plugin) - Update: WooCommerce 3.5.1 compatibility update - Tweak: Improved styling for Dokan "More Products by Seller" tab in product single page - Tweak: Improved bbPress styles for mobiles - Tweak: Minor CSS and JS improvements and optimizations Changelog Zass WP theme v. 3.4.3 – 26.10.2018 - Update: WooCommerce 3.5.0 Read the full article
0 notes
Text
How to Choose the Best React Drag and Drop? Top 15 Free Libraries to Set Up
New Post has been published on https://flatlogic.com/blog/how-to-choose-the-best-react-drag-and-drop-top-15-free-libraries-to-set-up/
How to Choose the Best React Drag and Drop? Top 15 Free Libraries to Set Up
What is Drag and Drop? Drag and Drop types Basic Concepts How to choose the Drag and Drop? Typescript vs Javascript How to build a custom React Draggable Component? How do I drag and drop in React dnd? React Drag and Drop Library List Wrapping Up About Flatlogic
User experience is crucial when you interact with your website or web app. Though it may seem that choosing a drag and drop element is no big deal, after all, it’s just a basic functionality component! But, the drag and drop module lets you transfer the items between drag handlers, tables and lists, touch devices, animations, previews, and placeholders, thus resolving the simple but still integral step that allows you to ‘take an object’ and drag it to another location.
What is Drag and Drop?
Drag and drop is an action carried out by the user in order to move one or another element to a different place in UI. There are lots of well-known applications where you use the drag and drop function as the basic one, let’s remind ourselves of just a few of them: Trello, Jira, Zapier, Monday, and others, where we one way or another using drag and drop to move things.
This simple action may be comfy not only as a part of the modern user experience, especially for those people who have disabilities or some difficulties with performing manual-type actions.
But why does such a simple element take quite a while to develop? The answer is simple: it takes a lot of code to build high-quality, neat and clean JavaScript forms. And it is much faster to run any ready-made library where you can easily borrow some pieces of code.
Check out React Material Admin Full!
Material UI No jQuery and Bootstrap! Fully Documented Codebase
Drag And Drop Types
There are dozens of open-source libraries that help to create draggable and movable elements (e.g. lists, cards, tables, etc) in your React app. And, this option can simplify the UX route, in comparison to the process of filling in forms, and shortens the time of one or another formal action.
The most common use cases for drag-and-drop in React include: uploading files; replacing the components within created lists and rearranging images and assets.
Basic Concepts
DragDrop Container: where you held and then taken out the component (data)
Children: the content of dataItem; DragDropContext: is the place where drag-and-drop is carried out;
Droppable: the component which allows draggable components to be able to drop at the targeted area;
Draggable: the component which will be replaced;
As well as Droppable, it requires several properties to make the component displaceable;
onDragStart: onDragStart component occurs when the user starts to drag an element;
onDragEnd: the component known as DragEnd occurs after the action has been accomplished;
DataTransfer: the component that can hold data about the dragged object;
DropTarget: component that contains drop data;
How to Choose a Good Drag and Drop?
Surely, this is a relatively controversial question, because if you have enough time at your disposal, you may start coding on your own. Moreover, if you’re a junior programmer, we would not recommend that you use any ready libraries, but try to figure out the problem using your own code. Yes, bugs are inevitable, though after each challenge there will surely be progress.
In Flatlogic we create web & mobile application templates built with React, Vue, Angular and React Native to help you develop web & mobile apps faster. Go and check out yourself! See our themes!
Typescript vs. Javascript Library
The vast majority of drag and drop libraries are written with the help of Typescript prevalence because Typescript is known for being structured, highly secure, and more consistent than vanilla Javascript. At the same time, it takes longer to compile the code in TypeScript, whereas JavaScript is more easy and flexible in terms of development.
Do you like this article? You can read also:
React Pagination Guide And Best React Pagination Libraries
So, if you are an old-school adherent, who is devoted to JS, you should understand that you need to know Typescript peculiarities to write with it. Plus, the size of the code will increase, because Typescript requires extremely detailed and accurate coding.
How to Build Custom Draggable Components in React?
To enable dragging on the component we need to proceed this path:
First off, create a drag component (drop area), in other words — container, where you will further drag dataItem. Set the draggable attribute on the dataItem
Handle onDragStart event Add here event.dataTransfer.setData
event.dataTransfer.setData component will contain some data, dataItem Create a function startDrag event Create a dropTarget component; it will call an event handler when dataItem with children will be dropped in Handle onDragOver event Create event.preventDefault() function that will enable the dropping process of the component Handle onDrop event Set the consent function – getData
Call the dropped component onItemDropped
Finally, return the components to their initial state,
<div onDragOver=dragOver onDrop=drop> props.children </div>);
Voila! This way your component will be ‘transferred’ from the container to the DropTarget.
How to Make Drag and Drop With React dnd library?
React Drag’n’Drops Libraries List
1. React Beautiful Dnd
React beautiful dnd is the most popular library to build React Drag and Drop lists easily. It has already won the heart of 23.8k developers on GitHub, thanks to its high performance. It has a clean and powerful API that is easy to work with and it fits well with any modern browser.
GitHub
2. React Drag and Drop Container
Here the name of the library speaks for itself. React Drag Drop container offers functionality for mouse and touch devices; i.e. it allows you to set up a draggable element, drop a target for it, plus, it highlights the drop target when dragging over it (highlightClassName). Also, you can drag an element copy of the element, or let the element disappear while dragging (disappearDraggedElement).
GitHub
3. Draggable
Another well-deserved library, does not perform any sorting behaviour while dragging, it has the following modulers: Droppable, Sortable, and Swappable. Draggable itself does not perform any sorting behaviour while dragging, but does the heavy lifting, e.g. creates mirror, emits events, manages sensor events, makes elements draggable.
GitHub
4. React Grid Layout
React Grid Layout library has 13,5k stars on GitHub. Inside you will get a fluid layout with sensible breakpoints, static widgets, draggable and resizable widgets. You can drag the elements, and resize them. The closest similar instrument is called Packery, though this is a bin-packing layout library using jQuery, which React Grid Layout doesn’t use.
: React-Grid-Layout works well with complex grid layouts that require drag-and-drop, such as dashboards which can be resized(e.g., looker, data visualization products, etc.)
: Because of the clunky API, React-Grid-Layout may need more calculations and it’s obviously a better fit for large-scale apps.
5. React Dropzone
React Dropzone is an example of simple HTML5 drag and drop zone with React.js. It requires a standard installation process with npm command and using a module bundler like Webpack or Browserify. React Dropzone has 8.2 Github stars and is based on Javascript.
GitHub
6. React DND
React DND got 15.9k stars on GitHub, and was written mainly with the help of TypeScript, as well as JavaScript and CSS. It has the sort option, group option, delay option, delayOnTouchOnly option, swapThreshold option, and many other essential features for implementing drag and drop components. React DND works well with grids, one-dimensional lists, but it’s harder to work with than for instance the well-known react-beautiful-dnd when you need to customize something individually.
GitHub
7. React SortableJS
React sortable is one more brilliant instrument made with Javascript and HTML, commonly used for creating drag-and-drop lists. It has all the basic functionalities of sorting/delaying/swapping/inverting and lots of others. Available on all touch modern browsers and touch devices.
GitHub
8. Interact.js
Snap, resize, customize your drag and drop elements with Interact.js. The library has also an advanced version, check it here. It also supports evoking simultaneous interactions; interaction with SVG and works well with desktop and mobile versions of Chrome, Firefox, and Opera as well as Internet Explorer 9+. Sharp has 10.2 k on GitHub and
GitHub
9. React Kanban
React Kanban is a relatively young but super pluggable library positioning itself as ‘one more Kanban/Trello board lib for React’. Kanban was written with the help of JavaScript, SCSS and HTML. But, be careful using this library with lots of cards (more than 1k), cause then you may face some performance hurdles. In this case, virtual lists may become the solution.
GitHub
10. Juggle and Drop
Juggle and Drop is an instrument to manage your tasks made with pure Javascript, with the help of React, redux, MLAB, express mongodb, Google Analytics. With Juggle and Drop you can add, edit, delete cards and lists; clone the component, navigate to the root directory, and other.
GitHub
11. React Motion
One more highly recommended and really powerful package for working with animation functions in JS. This package has 19.7k on GitHub, and 612,446 installations according to NPM. And among others, it has sorting lists with drag and drop. How to get started? npm install — save react-motion and keep working!
GitHub
12. React Smooth DnD
The React-smooth drag and drop package is a super lightweight and highly customizable library for React with 1,5k stars on GitHub and with lots of configuration options covering d&d scenarios. The cardboard and fonts look really neat and pleasant to the eye.
GitHub
13. Nested DND
Nested DND in juicy colors helps to drag a part of the stack with the items lying on top of the dragged one. Drop it on top of any plays, and see how simple and intuitive it is.
GitHub
14. React Nestable
React Nestable, an example of JavaScript drag and drop library, is a drag & drop hierarchical list made with a neat bit of deduction. This package is finalizing our list of open-source drag and drop libraries recommended while building the dnd option.
GitHub
15. React Files Drag and Drop
One more relatively fresh library to manage and customize your inner drag and drop component easily is React-files-drag-and-drop. It has a list of basic properties and was developed with TypeScript and CSS language.
GitHub
Check more examples of React drag and drop on codesandox or here.
Wrapping Up
Now you know enough about React DnD libraries and it is high time to explore further the rest of the documentation in detail! Stay motivated, don’t be afraid of making mistakes, and debugging them! Well, this is a good place to tell: if you’ve never made a mistake,�� you’ve probably never done anything.
About Flatlogic
At Flatlogic, we carefully craft dashboard templates on React, Vue, Bootstrap and React Native to bootstrap coding. We are mentioned in the Clutch top-performing agencies from all over the world. In the last 6 years, we have successfully completed more than 50 templates and large-scaled custom development projects for small startups and large enterprises. We love our work and know that only beauty (beautifully designed templates 🙂 ) can save the world.
Suggested Posts:
Top 30 Open Source And Paid React Charts + Examples React Table Guide And Best React Table Examples Best React Open Source Projects
The post How to Choose the Best React Drag and Drop? Top 15 Free Libraries to Set Up appeared first on Flatlogic Blog.
1 note
·
View note
Quote
Bootstrap, the most popular front-end framework built to design modern, responsive, and dynamic interfaces for professional design web pages, is currently undertaking a major update, Bootstrap 5. Bootstrap is a free and open-source collection of CSS and JavaScript/jQuery code used for creating dynamic layout websites and web applications. Being a tool for creating front-end design, it consists of a series of HTML- and CSS-based design templates for different components of a website or application such as forms, buttons, navigation, modals, typography and other interface components with helpful JavaScript extensions. It doesn’t matter if you are a beginner to web development or an experienced developer, Bootstrap is a powerful tool for whatever type of website and web application you are trying to build. In addition, Bootstrap provides an out-of-the-box solution with hundreds of third-party components that you can integrate with it which allows you to build a prototype fast to materialize your ideal website without spending a lot of time. Which in the end you might end up customizing to build the final design of your website or web application as most of the configuration is already set up for you. Bootstrap 4 is currently on version 4.4.1 which now has a lot of vital features such as cards, flexbox, Sass integration and powerful plugins built on jQuery. After more than 4 years of progress since the alpha version of Bootstrap 4 was released on August 19, 2015; an update is being developed in the background for the version 5 upgrade. The Startup app will be updated to Bootstrap 5 as soon as the framework is updated. Also, we’ll update the Bootstrap templates gallery. In this article, let’s take a look at Bootstrap 5’s major updates including the release date, integration, and modification. Online Email Template Builder With Postcards you can create and edit email templates online without any coding skills! Includes more than 100 components to help you create custom emails templates faster than ever before. Try FreeOther Products Table of Contents hide Bootstrap Version 5: What Should We Expect? jQuery Removed Switch to Vanilla JavaScript Responsive Font Sizes Drop Internet Explorer 10 and 11 Support Change Gutter Width Unit of Measurement Remove Card Decks Navbar Optimization Custom SVG Icon Library Switching from Jekyll to Hugo Class Updates Conclusion Bootstrap Version 5: What Should We Expect? Bootstrap 5’s official Github project tracking board has more than 765 tasks being shipped with more than 83 pull requests and 311 issues. If we base the release date from the previous development timeframe (Bootstrap 4 to Bootstrap 4.1) the development team took about 3 months to complete Bootstrap 4.1 to Bootstrap 4.2 took about 8 months. We might expect Bootstrap 5 in the first half of 2020. Bootstrap hasn’t confirmed the official release date yet. In hindsight, there is a list of changes that we expect on version 5 such as the removal of jQuery which is a major lift for this version and the drop of Internet Explorer 10 and 11 support. The following are some of the expected changes in Bootstrap 5: jQuery was removed Switch to Vanilla JavaScript Responsive Font Sizes Drop Internet Explorer 10 and 11 support Change of gutter width unit of measurement Removed Card Decks Navbar Optimization Custom SVG icon library Switching from Jekyll to Hugo Class updates jQuery Removed <img class="size-full wp-image-591166" src="https://ift.tt/2XlELhF" alt="Bootstrap 5: What's new about it?" width="960" height="540" srcset="https://ift.tt/2XlELhF 960w, https://ift.tt/3aFtsEC 747w, https://ift.tt/2R8Dvu8 768w, https://ift.tt/2Rc8TrL 5w, https://ift.tt/349EUWy 300w" sizes="(max-width: 960px) 100vw, 960px">jQuery is a library that offers a general-purpose abstraction layer for classic web scripting that is efficient in almost any web development requirements. Its extensible nature allows you to access elements in a document without writing a lot of JavaScript, modify the appearance of your content in a web page which developers take advantage of to bridge the gap across all browsers, change the content of a document, respond to a user’s interaction, retrieve information from a server without refreshing a page through AJAX, add animation to your web page, simplify common JavaScript tasks and the list goes on. While Bootstrap has been using jQuery for more than 8 years, jQuery has become quite a large and bloated framework that requires websites using it to download and add trivial load time for a library that may not be used by any other plugin except Bootstrap itself. As JavaScript frameworks like Angular, Vue and React dominate the web development community nowadays, jQuery has been losing its popularity as most of these modern frameworks work through the virtual DOM and not on the DOM directly that leads to much faster performance. Although it might sound absurd, it turns out it is much more proficient and anyone using these frameworks will have better control and maintenance over their code than those who use jQuery. Moving forward, any jQuery querying features will have to be done with pure or vanilla JavaScript code in Bootstrap 5 which will help with the file size or weight of the framework. Switch to Vanilla JavaScript <img class="size-full wp-image-591169" src="https://ift.tt/3dTH8hi" alt="Bootstrap JavaScript" width="960" height="540" srcset="https://ift.tt/3dTH8hi 960w, https://ift.tt/2xO4V1K 747w, https://ift.tt/2V192iW 768w, https://ift.tt/2xP0eVr 5w, https://ift.tt/3bSWAsm 300w" sizes="(max-width: 960px) 100vw, 960px">JavaScript is the programming language of the web. Most modern websites are powered by JavaScript and all modern web browsers on desktops, consoles, tablets, games and mobile phones include JavaScript interpreters, which makes JavaScript the most universal programming language in the world. Create Websites with Our Online Builders With Startup App and Slides App you can build unlimited websites using the online website editor which includes ready-made designed and coded elements, templates and themes. Try Startup App Try Slides AppOther Products The removal of jQuery support in Bootstrap 5 gives way to writing efficient vanilla JavaScript code without worrying about the size or adding up any other non-essential functions. While jQuery has been around for a long time, it is completely impossible to use jQuery alone because for the most part, what jQuery does is add a $ object to the global scope, with a lot of functions in it. Even more slick libraries like prototype are not an alternative to JavaScript, but exist only as extra tools to solve common problems. If you know how JavaScript works from the root, this major change won’t affect you much but for some developers who only know how to use jQuery, this might be a good chance to learn the language. Responsive Font Sizes <img class="size-full wp-image-591170" src="https://ift.tt/2RbHsy2" alt="Bootstrap Responsive Font Sizes" width="974" height="661" srcset="https://ift.tt/2RbHsy2 974w, https://ift.tt/2UGxKWJ 747w, https://ift.tt/2Xa7MfP 768w, https://ift.tt/3aKiOfN 5w, https://ift.tt/3dXOUXl 300w" sizes="(max-width: 974px) 100vw, 974px">Designing a website that looks good across multiple platforms or viewports has been quite challenging for some developers. Media queries have been a great tool to solve typography common problems that allow developers to control the appearance of typographies on web pages by specifying specific font sizes for the typography elements on a specific viewport. Bootstrap 5 will enable responsive font sizes by default which will automatically resize the typography element according to the size of the user’s viewport through RFS engine or Responsive Font Sizes. According to RFS repository, RFS is a unit resizing engine which was originally developed to resize font sizes. RFS offers the ability to resize basically every value for any CSS property with units, like margin, padding, border-radius or box-shadow. It is a preprocessor or postprocessor-powered-mechanism that automatically calculates the appropriate font-size values based on the user’s screen size or viewport. It works on known preprocessors or postprocessor tools such as Sass, Less, Stylus or PostCSS. As an example, assuming that you have a hero-title class which is a class for your h1 tag element that you want to use for your main title on the hero section. Using Sass the following mixin will do the trick: 1 2 3 .hero-title { @include font-size(4rem); } This will be compiled to this: 1 2 3 4 5 6 7 8 .hero-title { font-size: calc(1.525rem + 3.3vw); } @media (min-width: 1200px) { .hero-title { font-size: 4rem; } } Drop Internet Explorer 10 and 11 Support <img class="size-full wp-image-591171" src="https://ift.tt/2xKEGJr" alt="Drop of Internet Explorer 10 and 11 Support" width="960" height="540" srcset="https://ift.tt/2xKEGJr 960w, https://ift.tt/2wU6HhN 747w, https://ift.tt/2V1e4Mh 768w, https://ift.tt/2UKgGPu 5w, https://ift.tt/2JDQX55 300w" sizes="(max-width: 960px) 100vw, 960px">In 1995, Microsoft released the Internet Explorer which blew everyone’s mind because for the first time there was a browser that supported CSS and Java applets that made it one of the most widely used web browsers back in 2003 with 95% usage share. Fast forward to 2020, Internet Explorer is no longer relevant with Chrome, Firefox, and Edge. In fact, it became one of the web designer’s nightmares since it doesn’t support modern JavaScript standards. In order to work with Internet Explorer, be it 10 or 11, JavaScript codes need to be compiled to ES5 instead of ES6, which increases the size of your projects up to 30%. This obviously limits your ability to use the features of ES6 or newer JavaScript standards. What’s even worse is it doesn’t support a lot of modern CSS properties which limits your modern web design potential. In Bootstrap 5, the Bootstrap team decided to drop the support for Internet Explorer 10 and 11 which is a pretty good move as it will enable web designers and developers focus more on designing modern web pages without having to worry about breaking any piece of codes on old browsers or increasing the size of every project. Change Gutter Width Unit of Measurement <img class="size-full wp-image-591172" src="https://ift.tt/2wf7GIR" alt="Change of gutter width unit of measurement" width="1920" height="1029" srcset="https://ift.tt/2wf7GIR 1920w, https://ift.tt/3dVLODl 1280w, https://ift.tt/2UGHGj8 747w, https://ift.tt/3bSWBfU 768w, https://ift.tt/2JBPf4i 1536w, https://ift.tt/2JH4PM4 5w, https://ift.tt/2RbXTdL 300w" sizes="(max-width: 1920px) 100vw, 1920px">CSS offers ways to specify sizes or lengths of elements using various units of measurement such as px, em, rem, % vw, and vh. While pixels or px is considered to be widely known and used for its absolute units, relative to DPI and resolution of the viewing device, it does not change based on any other element which is not good for modern responsive web design. Bootstrap has been using px for its gutter width for quite a long time which will no longer be the case in Bootstrap 5. According to the fixes made on Bootstrap 5’s official Github project tracking board, the gutter width will now be on rem instead of px. Rem stands for “root em” which means equal to the calculated value of font-size on the root element. For instance, 1 rem is equal to the font size of the HTML element (most browsers have a default value of 16px). Remove Card Decks <img class="size-full wp-image-591173" src="https://ift.tt/2UHcAHW" alt="Bootstrap Remove Card Decks" width="1199" height="486" srcset="https://ift.tt/2UHcAHW 1199w, https://ift.tt/39ExfRb 747w, https://ift.tt/2JBP6hg 768w, https://ift.tt/2x1QxCM 5w, https://ift.tt/3dYlBny 300w" sizes="(max-width: 1199px) 100vw, 1199px">In Bootstrap 4, in order for you to be able to set equal width and height cards that aren’t attached to one another, you need to use card decks as shown below. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Card title This is a longer card with supporting text below as a natural lead-in to additional content. This content is a little bit longer. Last updated 3 mins ago Card title This card has supporting text below as a natural lead-in to additional content. Last updated 3 mins ago Card title This is a wider card with supporting text below as a natural lead-in to additional content. This card has even longer content than the first to show that equal height action. Last updated 3 mins ago In Bootstrap 5, the Bootstrap team removed the card decks since the new grid system offers more responsive control. Hence, removing unnecessary extra classes that can be solved via grid. Navbar Optimization <img class="size-full wp-image-591174" src="https://ift.tt/2X9MEqb" alt="Navbar Optimization" width="1179" height="228" srcset="https://ift.tt/2X9MEqb 1179w, https://ift.tt/3dPU8oh 747w, https://ift.tt/3bSWCjY 768w, https://ift.tt/2JCyLsA 300w" sizes="(max-width: 1179px) 100vw, 1179px">The Bootstrap navbar component is a principal part of Bootstrap that gets used all the time. In previous versions of Bootstrap, you need to have a decent amount of markup in order to make it work. However, in Bootstrap 4 they simplified this through the use of a nav or div HTML element and unordered list. The navbar class is the default class that always needs to appear on the component. By default, Bootstrap 4 uses inline-block on its display option but in Bootstrap 5, it was removed. They also used flex shorthand and removed the brand margin caused by requiring containers in navbars. Aside from this, they have also implemented a dark dropdown via dropdown-menu-dark class that turns the dropdown into a black background which we usually see on navbar dropdown items. Custom SVG Icon Library <img class="size-full wp-image-591175" src="https://ift.tt/2x3dCoN" alt="Bootstrap Custom SVG Icon Library" width="1163" height="711" srcset="https://ift.tt/2x3dCoN 1163w, https://ift.tt/3aLAM1p 747w, https://ift.tt/2JHJ9PT 768w, https://ift.tt/2V5mKRA 5w, https://ift.tt/2UKgHD2 300w" sizes="(max-width: 1163px) 100vw, 1163px">In version 3 of Bootstrap, there are 250 reusable icon components in the font format called “Glyphicons” created to provide iconography to input groups, alert, dropdowns and to other useful Bootstrap components. However, in Bootstrap 4 it was totally scrapped and web designers and developers need to rely on free icon fonts like Font Awesome or use their own custom SVG icons in order to add value to their web design. In Bootstrap 5, there’s a brand new SVG icon library crafted carefully by Mark Otto, co-founder of Bootstrap. Before the official release of Bootstrap 5, these icons can now be added and used to your project at this moment of time. You can visit this page to learn more. Switching from Jekyll to Hugo <img class="size-full wp-image-591176" src="https://ift.tt/34cLlbF" alt="Switching from Jekyll to Hugo" width="960" height="540" srcset="https://ift.tt/34cLlbF 960w, https://ift.tt/3dYfjUW 747w, https://ift.tt/2JHx4tP 768w, https://ift.tt/2xSfJvS 5w, https://ift.tt/3bPobdO 300w" sizes="(max-width: 960px) 100vw, 960px">Jekyll is a free and open-source static site generator. If you know how WordPress, Joomla or Drupal works, then, you probably have an idea of how it works. Jekyll is used to build websites with easy to use navigation, website components and generates all the content at once. Jekyll basically provides page templates such as navigation and footers that will reflect on all of your web pages. These templates are merged with other files with definite information (for instance, a file for each blog post on your website) to generate full HTML pages for website users to see. Bootstrap 4 has been a great tool to integrate with Jekyll through Sass (Syntactically Awesome Style Sheets) but in Bootstrap 5, a major switch from Jekyll to Hugo is anticipated. Hugo is described as “A Fast and Flexible Static Site Generator built with love by spf13 in GoLang”. Similar to Jekyll, it is a static site generator but written in Go language. A possible reason for the switch is that Hugo is lightning fast, easy to use and configurable. Compared with Jekyll, it has a great integration with the popular web host and can organize your content with any URL structure. Class Updates <img class="size-full wp-image-591177" src="https://ift.tt/3bSWDo2" alt="Class Updates" width="1209" height="357" srcset="https://ift.tt/3bSWDo2 1209w, https://ift.tt/2x5U6I9 747w, https://ift.tt/34bZQfD 768w, https://ift.tt/3bQaIT6 300w" sizes="(max-width: 1209px) 100vw, 1209px">Of course, Bootstrap 5 will not be interesting without the new Bootstrap CSS class. Bootstrap 4 has more than 1,500 CSS classes. There will be some CSS class that will no longer be available in the new version and some CSS class that will be added. Some of the CSS classes that are already removed, according to the Bootstrap 5’s official Github project tracking board are: form-row form-inline list-inline card-deck Here are some new Bootstrap 5 CSS class added: gx-* classes control the horizontal/column gutter width gy-* classes control the vertical/row gutter width g-* classes control the horizontal & vertical gutter width row-cols-auto Conclusion One of the frustrating experiences of being a developer is reinventing the base HTML, CSS, and JavaScript for each project. While some prefer to write their own code, it still makes sense to just use an existing framework like Bootstrap. With all the new updates coming in Bootstrap 5, it’s safe to say that the Bootstrap team is making huge steps to make the framework lightweight, simple, useful and faster for the developer’s benefit. If you use Bootstrap in your projects, then you will probably love Startup app – Bootstrap Builder. It is a great development tool with lots of ready-made designed and coded templates and themes for faster deployment of your projects.
http://damianfallon.blogspot.com/2020/04/bootstrap-5-whats-new-about-it-and_75.html
0 notes
Text
Tech 101: Python vs JavaScript—What’s the Difference?
Python and JavaScript are two programming languages, both of which you’ll hear plenty about as you start exploring potential careers in tech. But even though they’re often mentioned in comparison with each other, it’s not really a contest. Both languages are powerful tools for building websites, web applications, and software programs. Each has its own strengths (that sometimes overlaps with the other), but some distinct differences, too.
If you’re ready to learn what the deal is with Python vs JavaScript once and for all, let’s take a look at the two languages head-to-head and see what they’re all about.
Table of Contents
1. What is JavaScript?
2. What is Python?
3. Python vs JavaScript—Which One Should You Choose?
4. Python vs JavaScript—How Long Does it Take to Learn, Where Can You Learn, and Who’s Hiring?
1. What is JavaScript?
JavaScript is a scripting language used to create and control dynamic website content.
OK, but what does that mean? Let’s break that definition apart. First up, what is a scripting language?
JavaScript is a Scripting Language
TLDR: Scripting languages tell computer programs (like websites or web applications) to “do something,” so you, the person sitting at the keyboard or holding your phone, don’t have to.
Scripting languages are just another type of coding languages. They’re used to make things easier for users by automating website and app processes that you’d otherwise need to execute on your own, each and every time. Without scripting, any live changes or updates on web pages you visit would require manually reloading the page, or you’d have to go through a series of static menus to get to the content you’re after. When anything on a web page or web app animates, refreshes, or adjusts automatically according to your input, it’s often a scripting language that makes it happen.
(an example of JavaScript code used to build an interactive tip calculator)
JavaScript is a Scripting Language that A LOT of People Use
TLDR: JavaScript is the industry standard used by everyone from Google and Facebook to entry level web developers.
JavaScript is one of several scripting languages, but it’s more than that—it’s the industry standard scripting language. You’ll find that the digital giants like Google, Facebook, Youtube, Wikipedia, and Amazon use it according to web technology survey site W3Techs. When your Facebook timeline updates on your screen or Google suggests search terms based on the few letters you’ve typed into your search bar, that’s JavaScript doing its job.
At the same time, JavaScript is flexible and scalable enough that a beginning developer can use it to make a website for their friend’s flower shop. The takeaway here: from tech titans to aspiring coding students, JavaScript is a must-know (or at least should know) used to bring “dynamic website content” (think animation, scrolling photos, interactive forms) to otherwise static websites. This also means JavaScript is commonly used by front end developers (website developers who work on the visible parts of websites that users interact with in their web browsers) since it’s what makes everything that much more user-friendly and, well, visually pleasing.
JavaScript is Everywhere
TLDR: JavaScript comes built-in to modern web browsers, so it doesn’t require additional downloads or compilers to use.
JavaScript is such a commonly used programming language for websites and applications that it’s become an indispensable part of making the web work—which means all major web browsers (Chrome, Firefox, Safari, etc.) come equipped with engines that can render JavaScript. In other words, whenever you visit a website using a web browser, that browser will be able to process any JavaScript content you come across.
So what does that mean for developers? Less work. The bonus here is that JS commands can be typed directly into an HTML document, and web browsers will be able to understand them automatically. This means coding with JavaScript doesn’t require downloading any additional programs or compilers—if you have a modern web browser, it will have a developer menu with JavaScript built-in.
Don’t Forget About JavaScript Libraries and Frameworks
TLDR: JavaScript libraries and frameworks give developers pre-written JavaScript code for basic JS functions, speeding up the coding process. You’re going to want to use them.
The raw JavaScript language on its own is referred to by developers as “vanilla JavaScript.” And while you can certainly code JavaScript functions using nothing more than vanilla JavaScript, JS offers a number of tools that can make a JavaScript developer’s life considerably easier. You’ll hear them called either JavaScript libraries or JavaScript frameworks. These tools include JavaScript libraries like jQuery, and JavaScript frameworks like AngularJS and ReactJS.
JavaScript libraries are collections of JS code snippets that can be used to perform routine JavaScript tasks. Rather than reinvent the wheel every time you need to add one of these routine features to a JavaScript project, you can use pre written snippets from libraries like jQuery instead.
JavaScript frameworks are collections of JS libraries that not only include JS code snippets, but also provide developers with a template (you know, a “framework”) for arranging the JavaScript code on their website.
(back to top)
2. What is Python?
“Python is an interpreted, object-oriented, high-level programming language with dynamic semantics.”
This is the Python Software Foundation’s thumbnail definition, and no, it’s not clear at all. But don’t panic! Let’s break down what it actually means.
Python is an Object-Oriented Programming Language
TLDR: While JavaScript is a scripting language, Python is an object-oriented programming language—a type of coding language that lets developers build sites and apps with virtual building blocks (i.e. objects).
One of the keys to the Python vs JavaScript discussion is to understand their foundational differences. JavaScript is a scripting language, while Python is part of a class of coding languages called “object-oriented” languages.
But we still need a non-jargony definition.
Remember how scripting languages like JavaScript tell websites and web applications to “do something?” You can visualize this as the scripting language handing a script to the computer program it’s attached to, which the program then reads and acts on.
Object oriented languages (like Python) take a different approach—these languages allow programmers to create virtual objects in their code and give each of these objects unique attributes and abilities. All of the objects a developer creates are then able to interact with each other or perform actions on their own.
An object oriented programming language gives developers a virtual set of building blocks. Each block (or object) is defined by its shape, size, and type of behavior (e.g. can if be stacked on top of a different kind of block? Can other kinds of blocks be stacked on top of it? Where is it placed right now?). Meanwhile, groups of objects can be given instructions—for instance a programmer might instruct a group of “A” blocks to build a tower, while telling a group of “B” blocks to create steps leading to the top of the tower.
Through this object model, object oriented programming languages like Python reduce complexity for developers by mimicking real world building dynamics and giving programmers a clear structure to work with. Objects can be isolated and maintained separately from the rest of their code (making it easier to locate and repair bugs), and—once created—they can be easily reused in future programs.
(an example of Python code for a virtual Magic 8 Ball)
So What is Python Used For?
TLDR: Python can be used to develop software from the ground up, but it can also be used for scripting purposes, similar to JavaScript.
According to the Python Software Foundation, Python serves two common purposes. It can be used for full scale software development (i.e. to create an entire software program), but—due to its easy to learn, object oriented syntax (where programmers work directly with objects as their building blocks)—Python also makes an ideal “scripting or glue language to connect existing components (of a website or software application) together.”
Sound similar to JavaScript? Well, it is. Even though it’s not a bonafide scripting language, Python CAN be used to to script functions (just like JavaScript—a scripting language—can be used for more general purpose programming tasks). The lesson here is that, jargon and definitions aside, coding isn’t black and white—the ultimate test for a language and its use is…well, it’s usefulness.
If a programmer finds the best solution for scripting their project is using Python, then they should use Python. At the same time, if JavaScript is the ideal tool for coding the mobile application you’re building, then JavaScript it is!
One point to clarify when it comes to Python and scripting: Python is more likely to be used for “server side” scripting than “client side” (server side being the “under the hood” databases and web servers that allow websites and apps to “work,” while client side includes the parts of a site or app you see on your screen as a “client” or user), but this doesn’t mean Python can’t also make scripting appearances on the client side. Similarly, JavaScript is a client side (or front end) mainstay, but is perfectly capable of being used on the server side, too.
And Python Also Has Libraries and Frameworks
Finally, just like JavaScript, Python has its own libraries and frameworks that are used to make Python coding easier. These libraries and frameworks function the same way as the JavaScript examples outlined above, and you can take a look at some of Python’s libraries here and Python’s frameworks here.
(back to top)
3. Python vs JavaScript—Which One Should You Choose?
TLDR: Picking a programming language (ANY programming language) and starting to learn it is more important than the specific language, but if you’re looking to decide between Python or JavaScript, we give the slight edge to JS—only because it lends itself so well to entry level web work.
Now that you have a basic understanding of both languages, we can get back to comparing them head on.
Is one language inherently better than the other?
If you had to pick one to start with, which should it be?
And if you do pick one, how long does it take to learn, where can you learn it, and what kind of jobs can you expect to qualify for?
How to Choose: A Quickstart Guide
Step 1: What Does Your Company (or Your Ideal Company) Use?
As far as which language is better, it ultimately depends on your specific situation and what you’ll be using the language for—if you’re applying for a job at a company that uses Python, then Python is the language you should focus on. If you have your heart set on a JavaScript developer role well… you know which one to choose.
Step 2: If You Just Want to Learn Your First Programming Language, Start Anywhere That Feels Right
But what if you’re starting from square one and aren’t far enough along to have a specific job in mind yet? The first, most critical piece of advice is to pick a language, any language, and start learning—taking that first step of getting started with coding is way more important than the particular language you pick. And, after you learn your first language, there’s nothing stopping you from learning more (and each successive one will only be easier to get the hang of).
Step 3: If You’re Trying to Decide Between JavaScript and Python and You Really Want Guidance, Learn JavaScript
However, if Python vs JavaScript stands out as your choice between starting points we personally give the edge to JavaScript. Front end web development is a direct entry point to tech (and one that lends itself particularly well to freelance side hustles and junior web developer positions), and JavaScript is a fundamental front end language. Yes, you can do front end work with Python too, but when looking at Python vs JavaScript, JS is such a clear jumping off point to front end development that we have to recommend it.
Of course—since learning to code in general is the most important thing—there’s absolutely nothing wrong with learning Python, so let’s finish up by running down how long it takes to learn each language, where you can learn them, and what kind of jobs rely heavily on Python and JavaScript skills respectively.
(back to top)
4. Python vs JavaScript—How Long Does it Take to Learn, Where Can You Learn, and Who’s Hiring?
Learning JavaScript
TLDR: Learning JavaScript basics should generally take a matter of months (up to a year). You can start learning with online tutorials, or take a deeper dive with Skillcrush’s Front End Developer Blueprint course.
How Much Time It’ll Take
While the learning curve for JavaScript might feel a little steeper than the most fundamental front end development skills (languages like HTML and CSS, which can be learned in under a month), you can still expect to learn JS basics in a matter of months, not years—and that’s true whether you learn through online classes or teach yourself through book study. We go into detail on the time frame and differences between learning methods (online classes, in-person courses, book learning) in our How Hard is it to Learn JavaScript article, but generally speaking, JavaScript professionals agree that a few months is the timeframe for learning JavaScript basics.
Where to Learn It
You can get a jump on JS fundamentals with tutorials from sites like Learn JS and Lynda. And when you’re ready to learn everything it takes to use JavaScript as a working front end developer, think about signing up for our Skillcrush Front End Developer Blueprint. This online course is designed to be completed in three months by spending just an hour a day on the materials, getting you well on your way to becoming a web professional.
Learning Python
TLDR: Like JavaScript, Python basics can be learned in a matter of months, and the Python Software Foundation has a robust user’s guide.
How Much Time It’ll Take
And when it comes to how long it will take to get familiar with Python basics? Similar to JavaScript, public consensus agrees on somewhere between a month and a year. Again, that’s months, not years, which means there’s no time like right now to start learning.
Where to Learn It
If you’re looking for resources to help you learn Python, you should head directly to the Python Software Foundation’s Beginner’s Guide. This free resource has extensive tutorials for Python beginners, including material for tailored specifically to beginners with no programming experience, and material for beginners with some programming experience. And if you’re looking for even more Python learning resources, try sites like learnpython.org and python-guide.org. We’re also in the process of gauging interest in a Skillcrush Python course—you can sign up to be the first to know when it launches.
Python and JavaScript Jobs
Wondering what kind of jobs Python and JavaScript skills will qualify you for? As of writing, Indeed.com lists over 40,000 JavaScript related job postings, and more than 65,000 Python listings.
Current JavaScript jobs including plenty of front end oriented roles (consistent with JavaScript’s reputation) and Indeed reports an average salary of $61,880 for entry level JavaScript developer positions.
Indeed’s Python jobs also include junior positions like quality assurance engineers and entry level software engineers, with a decent amount of specialized and higher level positions like machine learning/artificial intelligence engineers mixed in (due to Python’s more general purpose orientation). Meanwhile, Indeed reports an average junior Python developer salary at $80,786.
If you’re ready to start learning the skills it takes to work as a web developer, check out our Skillcrush Front End Developer and Web Developer Blueprint courses. These online classes are designed to be completed in three months by spending only an hour a day on the materials, and will set you up with all the skills you’ll need to break into tech.
(back to top)
from Web Developers World https://skillcrush.com/2019/03/15/python-vs-javascript/
0 notes
Text
The Best JavaScript and CSS Libraries for 2017
Our mission at Tutorialzine is to keep you up to date with the latest and coolest trends in web development. Over the last year, we presented you a number of interesting libraries and resources, that we thought are worth checking out. That's why in this article we decided to share with you a collection of those, that stood out the most.
Wrapper for indexedDB and WebSQL that improves the ability of web apps to store data locally for offline use. Writing and reading is done in a similar fashion to localStorage but many types of data can be saved instead of only strings. It also offers a dual API, which gives developers the choice to use either callbacks or promises. You can find more about it in our Make IndexedDB a Breeze With LocalForage article.
AOS is a CSS library that allows you to add on scroll animation effects. The library is highly customizable, very tiny, easy to use (install via CDN), and most importantly performs well, which can be an issue with other animate on scroll libraries.
MJML is a simple XML-like language that provides simple markup syntax with various stylized components that can be compiled to email-friendly HTML. This way we don't have to manually code entire layouts out of tables and legacy in-line styles. It also offers a rich set of standardized components with various customization options. For more detailed information, you can check our Building Responsive Emails with MJML tutorial.
The editor engine behind Microsoft's Electron based Visual Studio Code. It has everything you'd expect out of a modern code editor - syntax highlighting for many languages, multiple cursors, keyboard shortcuts, code completion, etc. Monaco is open-sourced so it can be used to power any editor project you have in mind.
This futuristic library allows you to create virtual reality experiences using only good ol' web technologies. After you've created your 3D world in HTML, A-frame will take it and split it into two screens with slightly different viewing angles. Now, you can run your demo on your mobile phone using Google Cardboard or another headset and have some serious VR fun.
Bootstrap 4 brings many changes and new features to the grid system we are all so familiar with from version 3. The new version of the framework brings forth a lot of great changes, including a flexbox-based grid system, new and restyled components, and faster ES6 JavaScript plugins. Another cool new feature is the auto-layout mode. It allows developers to leave out the size of columns, making them automatically distribute the space in that row.
Prettier is an opinionated JavaScript formatter inspired by refmt with advanced support for language features from ES2017, JSX, and Flow. It removes all original formatting and ensures that all outputted JavaScript conforms to a consistent style.
Library for running browser JavaScript code in the GPU. With GPU.js you can execute complex calculations much quicker by compiling specially written JS into shader language that can run on the GPU via WebGL. If WebGL isn't available the functions fallback to regular JavaScript.
This is an updated version of the popular Node.js request library. It is a more lightweight HTTP client solution that is built on top of the browser's native Fetch API and shimmed for Node.js. When compressed R2's size is only 16K, compared to request's ~500K footprint.
Puppeteer is a high-level Node.js API for working with the new headless Chrome feature. It is an official Google project maintained by the Chrome DevTools team. In a headless environment you can generate screenshots and PDFs, navigate between links and app states, automate user input and form validation testing and scrape data from websites. You can read more about it in our article Automating Google Chrome with Node.js where we try out some of its features.
Push is the fastest library for managing JavaScript desktop notifications. It is based on the powerful Notification API but also acts as a reliable cross-browser solution, falling back to older implementations if the user’s browser does not have support for the new API. For a closer look you can check our The Easiest Way To Show Browser Notifications tutorial.
Draggable is a simple, easy to use, modular drag and drop library by Shopify. It provides excellent drag and drop functionality with fast DOM reordering, clean API and accessible markup. Draggable comes with additional modules that can be included to add more features like sorting, swapping and other utilities.
A library that showcases modern mobile devices created with pure CSS. It includes some of the most popular mobile devices like iPhone 8, iPadPro, MacBook and Samsung Galaxy S8. The designs are elegant and high-quality and can be used for landing or screenshot pages.
Card is a tiny vanilla JS project (with a jQuery version) that will make your credit card forms much more fun and interactive. After a quick installation, the library will take your form and transform it into an animated CSS-only credit card that gets filled as users input their data.
Webpack is a powerful open-source module bundler and preprocessor that can handle a large variety of tasks. Over the last few years it has become the prefered javascript bundler for most developers. It can create single bundle or multiple chunks that are loaded asynchronously at runtime, has a highly modular plugin system, and allows advanced code splitting.
Deeplearn.js is an open-source library that brings performant machine learning building blocks to the web. It offers two APIs, an immediate execution model and a deferred execution model. This library can be used for everything from education to model understanding and art projects. For a closer look on machine learning, check our 10 Machine Learning Examples in JavaScript article.
KeystoneJS is a powerful CMS framework, build on Express and MongoDB. It allows you to easily create dynamic projects with well-structured routes, templates and models. It offers a good-looking admin UI, helpful API utilities, session management, email sending, extensions, and much more. It also offers a command line tool for creating a new project and setting up all of its assets.
Popper is a JavaScript library for adding tooltips and popovers to HTML elements. It offers a large number of customization options and is fully modular with separate plugins for every feature. Popper is really small in size, has absolutely no dependencies and is very easy to use. It is used by companies like Twitter in Bootstrap 4, Microsoft in WebClipper and Atlassian in AtlasKit.
Apollo Client is a fully-featured GraphQL client that can be used with every frontend platform. It is easy to get started with, built for modern, interactive React apps, amazingly small - under 25kb compressed, community-focused and is extremely adaptable to fit your needs.
Animate.css is a cross-browser library for CSS animations. It is really easy to use and offers a large number of different animation effects like bounce, pulse, swing, fade, flip and many more. It can be used for emphasis, home pages, sliders or anywhere you like to add some cool and fun animation effects.
Presenting Bootstrap Studio
a revolutionary tool that developers and designers use to create beautiful interfaces using the Bootstrap Framework.
Learn more
via Tutorialzine http://ift.tt/2ynzkhI
0 notes
Text
Top Chiropractor Southport Gold Coast Nearby
.ui-tabs {display: table; } .ui-tabs-nav {display: table;} a.ui-tabs-anchor { font-family: Tahoma; font-size: 15px; color: #B52700; } div.ui-tabs-panel { font-family: Tahoma; font-size: 14px; font-weight: normal; color: #B35B22; }
Top Chiropractor Southport Gold Coast Nearby.
Chiropractors utilize quite a few treatment procedures, besides manual adjustments to take care of patients. Before you see a chiropractor, you need to know their areas of expertise. Chiropractors are practitioners that are well trained to take care of these injuries.
When you stop by the chiropractor for the initial consultation, there are specific things which they will discuss with you to figure out the treatment which you need and there are particular affairs that you should ask them about to be able to establish that they’re the correct person to give you the therapy.
Sports chiropractors may also supply suggestions and suggestions for greater sleep, training, and diet.
They are expected to have in-depth knowledge and understanding of different common sports-related injuries. As mentioned, they are known for their understanding of injuries and common issues related to various sports.
Chiropractors use wide range of methods to correct spinal misalignments. People who aren’t aware regarding the chiropractor will surely talk anything, that’s why folks should need to have adequate knowledge regarding chiropractor so they can get relief of the pains they’re afflicted by.
Surfers Paradise Chiropractic Health & Wellness Center chiropractors utilize a more thorough way of spinal analysis, a system a lot more complex in comparison to what other chiropractors utilize. A Surfers Paradise Chiropractic Health & Wellness Center chiropractors utilizes this thorough diagnostic info to spot and correct misalignments.
Call (07) 553 997 98 To Set An Appointment With The Top Southport Gold Coast Chiropractors Nearby
Now you have to work out which listed chiropractor is going to be the ideal one for you. Chiropractors are those who treat conditions regarding the musculoskeletal system. They may use other forms of treatment to offer the patient faster results.
Many chiropractors can also help you in living a much healthier life generally by offering counseling services. Qualified chiropractors have trained for five years as a way to gain an exhaustive comprehension of the human body’s anatomy and chemistry.
Chiropractors can assist you in different ways too. Your chiropractor is a specialist in trying to find subtle changes in your posture and movement that could indicate any issues. An excellent chiropractor will not have the capability to provide you with a thorough explanation of the situation over the telephone, and this is a great thing. Understanding how to choose the best chiropractor just requires a bit common sense, and this might save a bundle in the future.
Even when you don’t feel as if you’re hurt, it’s important to find a doctor within one day of the incident. It assists the doctor easily locate the subluxations. It gets especially aggravating once the health care provider won’t keep you up to date.
Surfers Paradise Chiropractic Health & Wellness Center Chiropractors understand where to deal with a patient, which direction to correct and they also understand when to stop. They also do not perform the same treatment to every patient.
Be sure that you’re taking care of your body by picking the chiropractor that’s going to manage it like it were his own. If you aren’t sure whether you require chiropractic care, don’t hesitate to call or visit our office today. Normal chiropractic care can lower the consequences of training. Yet, in your kitchen, you might have exactly what you have to offer you optimum wellbeing.
Following an entire analysis, the doctor is about to do the adjustment. A chiropractic doctor is only one of the options offered for all those of you who are worried about your wellbeing. It is getting increasingly hard to find a health doctor who doesn’t observe the advantage of chiropractic care.
We’re interested in helping patients and we’re interested in assisting you to develop a healthy lifestyle. It’s also incredibly rewarding to have the ability to help patients on a personal level.
To Set An Appointment With Top Southport Gold Coast Chiropractors Nearby Call (07) 553 997 98 Surfers Paradise Chiropractic Health & Wellness Center 12 Thomas Drive, Chevron Island QLD 4217
Surfers Paradise Chiropractic Health And Wellness Center
Route
Your location: No route could be calculated.
Top Chiropractor Southport Gold Coast Nearby
To Set An Appointment Complete Form Below
[contact-form-7]
jQuery(document).ready(function() { jQuery( "#tabs_3346" ).tabs({ collapsible: true, active: false }); jQuery( ".scroller_3346" ).width(jQuery( ".scroller_3346" ).width()+1); //jQuery( ".scroller_3346" ).width('100%'); //jQuery( ".scroller_3346 ul" ).width('100%'); jQuery( "#tabs_3346" ).tabs({ collapsible: false }); //var n = jQuery(".scroller_3346 ul li").length; //var w = (100/n-1); //jQuery(".scroller_3346 ul li").width(w+'%'); });
The post Top Chiropractor Southport Gold Coast Nearby appeared first on Chiropractors Gold Coast.
from Chiropractors Gold Coast http://ift.tt/2f87FxH
0 notes
Text
Top Chiropractor Southport Gold Coast Nearby
.ui-tabs {display: table; } .ui-tabs-nav {display: table;} a.ui-tabs-anchor { font-family: Tahoma; font-size: 15px; color: #B52700; } div.ui-tabs-panel { font-family: Tahoma; font-size: 14px; font-weight: normal; color: #B35B22; }
Top Chiropractor Southport Gold Coast Nearby.
Chiropractors utilize quite a few treatment procedures, besides manual adjustments to take care of patients. Before you see a chiropractor, you need to know their areas of expertise. Chiropractors are practitioners that are well trained to take care of these injuries.
When you stop by the chiropractor for the initial consultation, there are specific things which they will discuss with you to figure out the treatment which you need and there are particular affairs that you should ask them about to be able to establish that they’re the correct person to give you the therapy.
Sports chiropractors may also supply suggestions and suggestions for greater sleep, training, and diet.
They are expected to have in-depth knowledge and understanding of different common sports-related injuries. As mentioned, they are known for their understanding of injuries and common issues related to various sports.
Chiropractors use wide range of methods to correct spinal misalignments. People who aren’t aware regarding the chiropractor will surely talk anything, that’s why folks should need to have adequate knowledge regarding chiropractor so they can get relief of the pains they’re afflicted by.
Surfers Paradise Chiropractic Health & Wellness Center chiropractors utilize a more thorough way of spinal analysis, a system a lot more complex in comparison to what other chiropractors utilize. A Surfers Paradise Chiropractic Health & Wellness Center chiropractors utilizes this thorough diagnostic info to spot and correct misalignments.
Call (07) 553 997 98 To Set An Appointment With The Top Southport Gold Coast Chiropractors Nearby
Now you have to work out which listed chiropractor is going to be the ideal one for you. Chiropractors are those who treat conditions regarding the musculoskeletal system. They may use other forms of treatment to offer the patient faster results.
Many chiropractors can also help you in living a much healthier life generally by offering counseling services. Qualified chiropractors have trained for five years as a way to gain an exhaustive comprehension of the human body’s anatomy and chemistry.
Chiropractors can assist you in different ways too. Your chiropractor is a specialist in trying to find subtle changes in your posture and movement that could indicate any issues. An excellent chiropractor will not have the capability to provide you with a thorough explanation of the situation over the telephone, and this is a great thing. Understanding how to choose the best chiropractor just requires a bit common sense, and this might save a bundle in the future.
Even when you don’t feel as if you’re hurt, it’s important to find a doctor within one day of the incident. It assists the doctor easily locate the subluxations. It gets especially aggravating once the health care provider won’t keep you up to date.
Surfers Paradise Chiropractic Health & Wellness Center Chiropractors understand where to deal with a patient, which direction to correct and they also understand when to stop. They also do not perform the same treatment to every patient.
Be sure that you’re taking care of your body by picking the chiropractor that’s going to manage it like it were his own. If you aren’t sure whether you require chiropractic care, don’t hesitate to call or visit our office today. Normal chiropractic care can lower the consequences of training. Yet, in your kitchen, you might have exactly what you have to offer you optimum wellbeing.
Following an entire analysis, the doctor is about to do the adjustment. A chiropractic doctor is only one of the options offered for all those of you who are worried about your wellbeing. It is getting increasingly hard to find a health doctor who doesn’t observe the advantage of chiropractic care.
We’re interested in helping patients and we’re interested in assisting you to develop a healthy lifestyle. It’s also incredibly rewarding to have the ability to help patients on a personal level.
To Set An Appointment With Top Southport Gold Coast Chiropractors Nearby Call (07) 553 997 98 Surfers Paradise Chiropractic Health & Wellness Center 12 Thomas Drive, Chevron Island QLD 4217
Surfers Paradise Chiropractic Health And Wellness Center
Route
Your location: No route could be calculated.
Top Chiropractor Southport Gold Coast Nearby
To Set An Appointment Complete Form Below
[contact-form-7]
jQuery(document).ready(function() { jQuery( "#tabs_3346" ).tabs({ collapsible: true, active: false }); jQuery( ".scroller_3346" ).width(jQuery( ".scroller_3346" ).width()+1); //jQuery( ".scroller_3346" ).width('100%'); //jQuery( ".scroller_3346 ul" ).width('100%'); jQuery( "#tabs_3346" ).tabs({ collapsible: false }); //var n = jQuery(".scroller_3346 ul li").length; //var w = (100/n-1); //jQuery(".scroller_3346 ul li").width(w+'%'); });
The post Top Chiropractor Southport Gold Coast Nearby appeared first on Chiropractors Gold Coast.
from Chiropractors Gold Coast http://chiropractorsgoldcoast.net.au/top-chiropractor-southport-gold-coast-nearby/
0 notes
Text
How to Do a Content Audit [Updated for 2017]
Posted by Everett
//<![CDATA[ (function($) { // code using $ as alias to jQuery $(function() { // Hide the hypotext content. $('.hypotext-content').hide(); // When a hypotext link is clicked. $('a.hypotext.closed').click(function (e) { // custom handling here e.preventDefault(); // Create the class reference from the rel value. var id = '.' + $(this).attr('rel'); // If the content is hidden, show it now. if ( $(id).css('display') == 'none' ) { $(id).show('slow'); if (jQuery.ui) { // UI loaded $(id).effect("highlight", {}, 1000); } } // If the content is shown, hide it now. else { $(id).hide('slow'); } }); // If we have a hash value in the url. if (window.location.hash) { // If the anchor is within a hypotext block, expand it, by clicking the // relevant link. console.log(window.location.hash); var anchor = $(window.location.hash); var hypotextLink = $('#' + anchor.parents('.hypotext-content').attr('rel')); console.log(hypotextLink); hypotextLink.click(); // Wait until the content has expanded before jumping to anchor. //$.delay(1000); setTimeout(function(){ scrollToAnchor(window.location.hash); }, 1000); } }); function scrollToAnchor(id) { var anchor = $(id); $('html,body').animate({scrollTop: anchor.offset().top},'slow'); } })(jQuery); //]]>
This guide provides instructions on how to do a content audit using examples and screenshots from Screaming Frog, URL Profiler, Google Analytics (GA), and Excel, as those seem to be the most widely used and versatile tools for performing content audits.
{Expand for more background}
It's been almost three years since the original “How to do a Content Audit – Step-by-Step” tutorial was published here on Moz, and it’s due for a refresh. This version includes updates covering JavaScript rendering, crawling dynamic mobile sites, and more.
It also provides less detail than the first in terms of prescribing every step in the process. This is because our internal processes change often, as do the tools. I’ve also seen many other processes out there that I would consider good approaches. Rather than forcing a specific process and publishing something that may be obsolete in six months, this tutorial aims to allow for a variety of processes and tools by focusing more on the basic concepts and less on the specifics of each step.
We have a DeepCrawl account at Inflow, and a specific process for that tool, as well as several others. Tapping directly into various APIs may be preferable to using a middleware product like URL Profiler if one has development resources. There are also custom in-house tools out there, some of which incorporate historic log file data and can efficiently crawl websites like the New York Times and eBay. Whether you use GA or Adobe Sitecatalyst, Excel, or a SQL database, the underlying process of conducting a content audit shouldn’t change much.
TABLE OF CONTENTS
What is an SEO content audit?
What is the purpose of a content audit?
How & why “pruning” works
How to do a content audit
The inventory & audit phase
Step 1: Crawl all indexable URLs
Crawling roadblocks & new technologies
Crawling very large websites
Crawling dynamic mobile sites
Crawling and rendering JavaScript
Step 2: Gather additional metrics
Things you don’t need when analyzing the data
The analysis & recommendations phase
Step 3: Put it all into a dashboard
Step 4: Work the content audit dashboard
The reporting phase
Step 5: Writing up the report
Content audit resources & further reading
What is a content audit?
A content audit for the purpose of SEO includes a full inventory of all indexable content on a domain, which is then analyzed using performance metrics from a variety of sources to determine which content to keep as-is, which to improve, and which to remove or consolidate.
What is the purpose of a content audit?
A content audit can have many purposes and desired outcomes. In terms of SEO, they are often used to determine the following:
How to escape a content-related search engine ranking filter or penalty
Content that requires copywriting/editing for improved quality
Content that needs to be updated and made more current
Content that should be consolidated due to overlapping topics
Content that should be removed from the site
The best way to prioritize the editing or removal of content
Content gap opportunities
Which content is ranking for which keywords
Which content should be ranking for which keywords
The strongest pages on a domain and how to leverage them
Undiscovered content marketing opportunities
Due diligence when buying/selling websites or onboarding new clients
While each of these desired outcomes and insights are valuable results of a content audit, I would define the overall “purpose” of one as:
The purpose of a content audit for SEO is to improve the perceived trust and quality of a domain, while optimizing crawl budget and the flow of PageRank (PR) and other ranking signals throughout the site.
Often, but not always, a big part of achieving these goals involves the removal of low-quality content from search engine indexes. I’ve been told people hate this word, but I prefer the “pruning” analogy to describe the concept.
How & why “pruning” works
{Expand for more on pruning}
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove. Optimizing crawl budget and the flow of PR is self-explanatory to most SEOs. But how does a content audit improve the perceived trust and quality of a domain? By removing low-quality content from the index (pruning) and improving some of the content remaining in the index, the likelihood that someone arrives on your site through organic search and has a poor user experience (indicated to Google in a variety of ways) is lowered. Thus, the quality of the domain improves. I’ve explained the concept here and here.
Others have since shared some likely theories of their own, including a larger focus on the redistribution of PR.
Case study after case study has shown the concept of “pruning” (removing low-quality content from search engine indexes) to be effective, especially on very large websites with hundreds of thousands (or even millions) of indexable URLs. So why do content audits work? Lots of reasons. But really...
Does it matter?
¯\_(ツ)_/¯
How to do a content audit
Just like anything in SEO, from technical and on-page changes to site migrations, things can go horribly wrong when content audits aren’t conducted properly. The most common example would be removing URLs that have external links because link metrics weren’t analyzed as part of the audit. Another common mistake is confusing removal from search engine indexes with removal from the website.
Content audits start with taking an inventory of all content available for indexation by search engines. This content is then analyzed against a variety of metrics and given one of three “Action” determinations. The “Details” of each Action are then expanded upon.
The variety of combinations of options between the “Action” of WHAT to do and the “Details” of HOW (and sometimes why) to do it are as varied as the strategies, sites, and tactics themselves. Below are a few hypothetical examples:
You now have a basic overview of how to perform a content audit. More specific instructions can be found below.
The process can be roughly split into three distinct phases:
Inventory & audit
Analysis & recommendations
Summary & reporting
The inventory & audit phase
Taking an inventory of all content, and related metrics, begins with crawling the site.
One difference between crawling for content audits and technical audits:
Technical SEO audit crawls are concerned with all crawlable content (among other things).
Content audit crawls for the purpose of SEO are concerned with all indexable content.
{Expand for more on crawlable vs. indexable content}
The URL in the image below should be considered non-indexable. Even if it isn’t blocked in the robots.txt file, with a robots meta tag, or an X-robots header response –– even if it is frequently crawled by Google and shows up as a URL in Google Analytics and Search Console –– the rel =”canonical” tag shown below essentially acts like a 301 redirect, telling Google not to display the non-canonical URL in search results and to apply all ranking calculations to the canonical version. In other words, not to “index” it.
I'm not sure “index” is the best word, though. To “display” or “return” in the SERPs is a better way of describing it, as Google surely records canonicalized URL variants somewhere, and advanced site: queries seem to show them in a way that is consistent with the "supplemental index" of yesteryear. But that's another post, more suitably written by a brighter mind like Bill Slawski.
A URL with a query string that canonicalizes to a version without the query string can be considered “not indexable.”
A content audit can safely ignore these types of situations, which could mean drastically reducing the amount of time and memory taken up by a crawl.
Technical SEO audits, on the other hand, should be concerned with every URL a crawler can find. Non-indexable URLs can reveal a lot of technical issues, from spider traps (e.g. never-ending empty pagination, infinite loops via redirect or canonical tag) to crawl budget optimization (e.g. How many facets/filters deep to allow crawling? 5? 6? 7?) and more.
It is for this reason that trying to combine a technical SEO audit with a content audit often turns into a giant mess, though an efficient idea in theory. When dealing with a lot of data, I find it easier to focus on one or the other: all crawlable URLs, or all indexable URLs.
Orphaned pages (i.e., with no internal links / navigation path) sometimes don’t turn up in technical SEO audits if the crawler had no way to find them. Content audits should discover any indexable content, whether it is linked to internally or not. Side note: A good tech audit would do this, too.
Identifying URLs that should be indexed but are not is something that typically happens during technical SEO audits.
However, if you're having trouble getting deep pages indexed when they should be, content audits may help determine how to optimize crawl budget and herd bots more efficiently into those important, deep pages. Also, many times Google chooses not to display/index a URL in the SERPs due to poor content quality (i.e., thin or duplicate).
All of this is changing rapidly, though. URLs as the unique identifier in Google’s index are probably going away. Yes, we’ll still have URLs, but not everything requires them. So far, the word “content” and URL has been mostly interchangeable. But some URLs contain an entire application’s worth of content. How to do a content audit in that world is something we’ll have to figure out soon, but only after Google figures out how to organize the web’s information in that same world. From the looks of things, we still have a year or two.
Until then, the process below should handle most situations.
Step 1: Crawl all indexable URLs
A good place to start on most websites is a full Screaming Frog crawl. However, some indexable content might be missed this way. It is not recommended that you rely on a crawler as the source for all indexable URLs.
In addition to the crawler, collect URLs from Google Analytics, Google Webmaster Tools, XML Sitemaps, and, if possible, from an internal database, such as an export of all product and category URLs on an eCommerce website. These can then be crawled in “list mode” separately, then added to your main list of URLs and deduplicated to produce a more comprehensive list of indexable URLs.
Some URLs found via GA, XML sitemaps, and other non-crawl sources may not actually be “indexable.” These should be excluded. One strategy that works here is to combine and deduplicate all of the URL “lists,” and then perform a crawl in list mode. Once crawled, remove all URLs with robots meta or X-Robots noindex tags, as well as any URL returning error codes and those that are blocked by the robots.txt file, etc. At this point, you can safely add these URLs to the file containing indexable URLs from the crawl. Once again, deduplicate the list.
Crawling roadblocks & new technologies
Crawling very large websites
First and foremost, you do not need to crawl every URL on the site. Be concerned with indexable content. This is not a technical SEO audit.
{Expand for more about crawling very large websites}
Avoid crawling unnecessary URLs
Some of the things you can avoid crawling and adding to the content audit in many cases include:
Noindexed or robots.txt-blocked URLs
4XX and 5XX errors
Redirecting URLs and those that canonicalize to a different URL
Images, CSS, JavaScript, and SWF files
Segment the site into crawlable chunks
You can often get Screaming Frog to completely crawl a single directory at a time if the site is too large to crawl all at once.
Filter out URL patterns you plan to remove from the index
Let’s say you’re auditing a domain on WordPress and you notice early in the crawl that /tag/ pages are indexable. A quick site:domain.com inurl:tag search on Google tells you there are about 10 million of them. A quick look at Google Analytics confirms that URLs in the /tag/ directory are not responsible for very much revenue from organic search. It would be safe to say that the “Action” on these URLs should be “Remove” and the “Details” should read something like this: Remove /tag/ URLs from the indexed with a robots noindex,follow meta tag. More advice on this strategy can be found here.
Upgrade your machine
Install additional RAM on your computer, which is used by Screaming Frog to hold data during the crawl. This has the added benefit of improving Excel performance, which can also be a major roadblock.
You can also install Screaming Frog on Amazon Web Server (AWS), as described in this post on iPullRank.
Tune up your tools
Screaming Frog provides several ways for SEOs to get more out of the crawler. This includes adjusting the speed, max threads, search depth, query strings, timeouts, retries, and the amount of RAM available to the program. Leave at least 3GB off limits to the spider to avoid catastrophic freezing of the entire machine and loss of data. You can learn more about tuning up Screaming Frog here and here.
Try other tools
I’m convinced that there's a ton of wasted bandwidth on most content audit projects due to strategists releasing a crawler and allowing it to chew through an entire domain, whether the URLs are indexable or not. People run Screaming Frog without saving the crawl intermittently, without adding more RAM availability, without filtering out the nonsense, or using any of the crawl customization features available to them.
That said, sometimes SF just doesn’t get the job done. We also have a process specific to DeepCrawl, and have used Botify, as well as other tools. They each have their pros and cons. I still prefer Screaming Frog for crawling and URL Profiler for fetching metrics in most cases.
Crawling dynamic mobile sites
This refers to a specific type of mobile setup in which there are two code-bases –– one for mobile and one for desktop –– but only one URL. Thus, the content of a single URL may vary significantly depending on which type of device is visiting that URL. In such cases, you will essentially be performing two separate content audits. Proceed as usual for the desktop version. Below are instructions for crawling the mobile version.
{Expand for more on crawling dynamic websites}
Crawling a dynamic mobile site for a content audit will require changing the User-Agent of the crawler, as shown here under Screaming Frog’s “Configure ---> HTTP Header” menu:
The important thing to remember when working on mobile dynamic websites is that you're only taking an inventory of indexable URLs on one version of the site or the other. Once the two inventories are taken, you can then compare them to uncover any unintentional issues.
Some examples of what this process can find in a technical SEO audit include situations in which titles, descriptions, canonical tags, robots meta, rel next/prev, and other important elements do not match between the two versions of the page. It's vital that the mobile and desktop version of each page have parity when it comes to these essentials.
It's easy for the mobile version of a historically desktop-first website to end up providing conflicting instructions to search engines because it's not often “automatically changed” when the desktop version changes. A good example here is a website I recently looked at with about 20 million URLs, all of which had the following title tag when loaded by a mobile user (including Google): BRAND NAME - MOBILE SITE. Imagine the consequences of that once a mobile-first algorithm truly rolls out.
Crawling and rendering JavaScript
One of the many technical issues SEOs have been increasingly dealing with over the last couple of years is the proliferation of websites built on JavaScript frameworks and libraries like React.js, Ember.js, and Angular.js.
{Expand for more on crawling Javascript websites}
Most crawlers have made a lot of progress lately when it comes to crawling and rendering JavaScript content. Now, it’s as easy as changing a few settings, as shown below with Screaming Frog.
When crawling URLs with #! , use the “Old AJAX Crawling Scheme.” Otherwise, select “JavaScript” from the “Rendering” tab when configuring your Screaming Frog SEO Spider to crawl JavaScript websites.
How do you know if you’re dealing with a JavaScript website?
First of all, most websites these days are going to be using some sort of JavaScript technology, though more often than not (so far) these will be rendered by the “client” (i.e., by your browser). An example would be the .js file that controls the behavior of a form or interactive tool.
What we’re discussing here is when the JavaScript is used “server-side” and needs to be executed in order to render the page.
JavaScript libraries and frameworks are used to develop single-page web apps and highly interactive websites. Below are a few different things that should alert you to this challenge:
The URLs contain #! (hashbangs). For example: http://ift.tt/2nQK6ch (AJAX)
Content-rich pages with only a few lines of code (and no iframes) when viewing the source code.
What looks like server-side code in the meta tags instead of the actual content of the tag. For example:
You can also use the BuiltWith Technology Profiler or the Library Detector plugins for Chrome, which shows JavaScript libraries being used on a page in the address bar.
Not all websites built primarily with JavaScript require special attention to crawl settings. Some websites use pre-rendering services like Brombone or Prerender.io to serve the crawler a fully rendered version of the page. Others use isomorphic JavaScript to accomplish the same thing.
Step 2: Gather additional metrics
Most crawlers will give you the URL and various on-page metrics and data, such as the titles, descriptions, meta tags, and word count. In addition to these, you’ll want to know about internal and external links, traffic, content uniqueness, and much more in order to make fully informed recommendations during the analysis portion of the content audit project.
Your process may vary, but we generally try to pull in everything we need using as few sources as possible. URL Profiler is a great resource for this purpose, as it works well with Screaming Frog and integrates easily with all of the APIs we need.
Once the Screaming Frog scan is complete (only crawling indexable content) export the “Internal All” file, which can then be used as the seed list in URL Profiler (combined with any additional indexable URLs found outside of the crawl via GSC, GA, and elsewhere).
This is what my URL Profiler settings look for a typical content audit for a small- or medium-sized site. Also, under “Accounts” I have connected via API keys to Moz and SEMrush.
Once URL Profiler is finished, you should end up with something like this:
Screaming Frog and URL Profiler: Between these two tools and the APIs they connect with, you may not need anything else at all in order to see the metrics below for every indexable URL on the domain.
The risk of getting analytics data from a third-party tool
We've noticed odd data mismatches and sampled data when using the method above on large, high-traffic websites. Our internal process involves exporting these reports directly from Google Analytics, sometimes incorporating Analytics Canvas to get the full, unsampled data from GA. Then VLookups are used in the spreadsheet to combine the data, with URL being the unique identifier.
Metrics to pull for each URL:
Indexed or not?
If crawlers are set up properly, all URLs should be “indexable.”
A non-indexed URL is often a sign of an uncrawled or low-quality page.
Content uniqueness
Copyscape, Siteliner, and now URL Profiler can provide this data.
Traffic from organic search
Typically 90 days
Keep a consistent timeframe across all metrics.
Revenue and/or conversions
You could view this by “total,” or by segmenting to show only revenue from organic search on a per-page basis.
Publish date
If you can get this into Google Analytics as a custom dimension prior to fetching the GA data, it will help you discover stale content.
Internal links
Content audits provide the perfect opportunity to tighten up your internal linking strategy by ensuring the most important pages have the most internal links.
External links
These can come from Moz, SEMRush, and a variety of other tools, most of which integrate natively or via APIs with URL Profiler.
Landing pages resulting in low time-on-site
Take this one with a grain of salt. If visitors found what they want because the content was good, that’s not a bad metric. A better proxy for this would be scroll depth, but that would probably require setting up a scroll-tracking “event.”
Landing pages resulting in Low Pages-Per-Visit
Just like with Time-On-Site, sometimes visitors find what they’re looking for on a single page. This is often true for high-quality content.
Response code
Typically, only URLs that return a 200 (OK) response code are indexable. You may not require this metric in the final data if that's the case on your domain.
Canonical tag
Typically only URLs with a self-referencing rel=“canonical” tag should be considered “indexable.” You may not require this metric in the final data if that's the case on your domain.
Page speed and mobile-friendliness
Again, URL Profiler comes through with their Google PageSpeed Insights API integration.
Before you begin analyzing the data, be sure to drastically improve your mental health and the performance of your machine by taking the opportunity to get rid of any data you don’t need. Here are a few things you might consider deleting right away (after making a copy of the full data set, of course).
Things you don’t need when analyzing the data
{Expand for more on removing unnecessary data}
URL Profiler and Screaming Frog tabs Just keep the “combined data” tab and immediately cut the amount of data in the spreadsheet by about half.
Content Type Filtering by Content Type (e.g., text/html, image, PDF, CSS, JavaScript) and removing any URL that is of no concern in your content audit is a good way to speed up the process.
Technically speaking, images can be indexable content. However, I prefer to deal with them separately for now.
Filtering unnecessary file types out like I've done in the screenshot above improves focus, but doesn’t improve performance very much. A better option would be to first select the file types you don’t want, apply the filter, delete the rows you don’t want, and then go back to the filter options and “(Select All).”
Once you have only the content types you want, it may now be possible to simply delete the entire Content Type column.
Status Code and Status You only need one or the other. I prefer to keep the Code, and delete the Status column.
Length and Pixels You only need one or the other. I prefer to keep the Pixels, and delete the Length column. This applies to all Title and Meta Description columns.
Meta Keywords Delete the columns. If those cells have content, consider removing that tag from the site.
DNS Safe URL, Path, Domain, Root, and TLD You should really only be working on a single top-level domain. Content audits for subdomains should probably be done separately. Thus, these columns can be deleted in most cases.
Duplicate Columns You should have two columns for the URL (The “Address” in column A from URL Profiler, and the “URL” column from Screaming Frog). Similarly, there may also be two columns each for HTTP Status and Status Code. It depends on the settings selected in both tools, but there are sure to be some overlaps, which can be removed to reduce the file size, enhance focus, and speed up the process.
Blank Columns Keep the filter tool active and go through each column. Those with only blank cells can be deleted. The example below shows that column BK (Robots HTTP Header) can be removed from the spreadsheet.
[You can save a lot of headspace by hiding or removing blank columns.]
Single-Value Columns If the column contains only one value, it can usually be removed. The screenshot below shows our non-secure site does not have any HTTPS URLs, as expected. I can now remove the column. Also, I guess it’s probably time I get that HTTPS migration project scheduled.
Hopefully by now you've made a significant dent in reducing the overall size of the file and time it takes to apply formatting and formula changes to the spreadsheet. It’s time to start diving into the data.
The analysis & recommendations phase
Here's where the fun really begins. In a large organization, it's tempting to have a junior SEO do all of the data-gathering up to this point. I find it useful to perform the crawl myself, as the process can be highly informative.
Step 3: Put it all into a dashboard
Even after removing unnecessary data, performance could still be a major issue, especially if working in Google Sheets. I prefer to do all of this in Excel, and only upload into Google Sheets once it's ready for the client. If Excel is running slow, consider splitting up the URLs by directory or some other factor in order to work with multiple, smaller spreadsheets.
Creating a dashboard can be as easy as adding two columns to the spreadsheet. The first new column, “Action,” should be limited to three options, as shown below. This makes filtering and sorting data much easier. The “Details” column can contain freeform text to provide more detailed instructions for implementation.
Use Data Validation and a drop-down selector to limit Action options.
Step 4: Work the content audit dashboard
All of the data you need should now be right in front of you. This step can’t be turned into a repeatable process for every content audit. From here on the actual step-by-step process becomes much more open to interpretation and your own experience. You may do some of them and not others. You may do them a little differently. That's all fine, as long as you're working toward the goal of determining what to do, if anything, for each piece of content on the website.
A good place to start would be to look for any content-related issues that might cause an algorithmic filter or manual penalty to be applied, thereby dragging down your rankings.
Causes of content-related penalties
These typically fall under three major categories: quality, duplication, and relevancy. Each category can be further broken down into a variety of issues, which are detailed below.
{Expand to learn more about quality, duplication, and relevancy issues}
Typical low-quality content
Poor grammar, written primarily for search engines (includes keyword stuffing), unhelpful, inaccurate...
Completely irrelevant content
OK in small amounts, but often entire blogs are full of it.
A typical example would be a "linkbait" piece circa 2010.
Thin/short content
Glossed over the topic, too few words, or all image-based content.
Curated content with no added value
Comprised almost entirely of bits and pieces of content that exists elsewhere.
Misleading optimization
Titles or keywords targeting queries for which content doesn't answer or deserve to rank.
Generally not providing the information the visitor was expecting to find.
Duplicate content
Internally duplicated on other pages (e.g., categories, product variants, archives, technical issues, etc.).
Externally duplicated (e.g., manufacturer product descriptions, product descriptions duplicated in feeds used for other channels like Amazon, shopping comparison sites and eBay, plagiarized content, etc.)
Stub pages (e.g., "No content is here yet, but if you sign in and leave some user-generated-content, then we'll have content here for the next guy." By the way, want our newsletter? Click an AD!)
Indexable internal search results
Too many indexable blog tag or blog category pages
And so on and so forth...
It helps to sort the data in various ways to see what’s going on. Below are a few different things to look for if you’re having trouble getting started.
{Expand to learn more about what to look for}
Sort by duplicate content risk
URL Profiler now has a native duplicate content checker. Other options are Copyscape (for external duplicate content) and Siteliner (for internal duplicate content).
Which of these pages should be rewritten?
Rewrite key/important pages, such as categories, home page, top products
Rewrite pages with good link and social metrics
Rewrite pages with good traffic
After selecting "Improve" in the Action column, elaborate in the Details column:
"Improve these pages by writing unique, useful content to improve the Copyscape risk score."
Which of these pages should be removed/pruned?
Remove guest posts that were published elsewhere
Remove anything the client plagiarized
Remove content that isn't worth rewriting, such as:
No external links, no social shares, and very few or no entrances/visits
After selecting "Remove" from the Action column, elaborate in the Details column:
"Prune from site to remove duplicate content. This URL has no links or shares and very little traffic. We recommend allowing the URL to return 404 or 410 response code. Remove all internal links, including from the sitemap."
Which of these pages should be consolidated into others?
Presumably none, since the content is already externally duplicated.
Which of these pages should be left “As-Is”?
Important pages which have had their content stolen
Sort by entrances or visits (filtering out any that were already finished)
Which of these pages should be marked as "Improve"?
Pages with high visits/entrances but low conversion, time-on-site, pageviews per session, etc.
Key pages that require improvement determined after a manual review of the page.
Which of these pages should be marked as "Consolidate"?
When you have overlapping topics that don't provide much unique value of their own, but could make a great resource when combined.
Mark the page in the set with the best metrics as "Improve" and in the Details column, outline which pages are going to be consolidated into it. This is the canonical page.
Mark the pages that are to be consolidated into the canonical page as "Consolidate" and provide further instructions in the Details column, such as:
Use portions of this content to round out /canonicalpage/ and then 301 redirect this page into /canonicalpage/
Update all internal links.
Campaign-based or seasonal pages that could be consolidated into a single "Evergreen" landing page (e.g., Best Sellers of 2012 and Best Sellers of 2013 ---> Best Sellers).
Which of these pages should be marked as "Remove"?
Pages with poor link, traffic, and social metrics related to low-quality content that isn't worth updating
Typically these will be allowed to 404/410.
Irrelevant content
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Out-of-date content that isn't worth updating or consolidating
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Which of these pages should be marked as "Leave As-Is"?
Pages with good traffic, conversions, time on site, etc. that also have good content.
These may or may not have any decent external links.
Taking the hatchet to bloated websites
For big sites, it's best to use a hatchet-based approach as much as possible, and finish up with a scalpel in the end. Otherwise, you'll spend way too much time on the project, which eats into the ROI.
This is not a process that can be documented step-by-step. For the purpose of illustration, however, below are a few different examples of hatchet approaches and when to consider using them.
{Expand for examples of hatchet approaches}
Parameter-based URLs that shouldn't be indexed
Defer to the technical audit, if applicable. Otherwise, use your best judgment:
e.g., /?sort=color, &size=small
Assuming the tech audit didn't suggest otherwise, these pages could all be handled in one fell swoop. Below is an example Action and example Details for such a page:
Action = Remove
Details = Rel canonical to the base page without the parameter
Internal search results
Defer to the technical audit if applicable. Otherwise, use your best judgment:
e.g., /search/keyword-phrase/
Assuming the tech audit didn't suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
Blog tag pages
Defer to the technical audit if applicable. Otherwise:
e.g., /blog/tag/green-widgets/ , blog/tag/blue-widgets/
Assuming the tech audit didn't suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
E-commerce product pages with manufacturer descriptions
In cases where the "Page Type" is known (i.e., it's in the URL or was provided in a CMS export) and Risk Score indicates duplication:
e.g., /product/product-name/
Assuming the tech audit didn't suggest otherwise:
Action = Improve
Details = Rewrite to improve product description and avoid duplicate content
E-commerce category pages with no static content
In cases where the "Page Type" is known:
e.g. /category/category-name/ or category/cat1/cat2/
Assuming NONE of the category pages have content:
Action = Improve
Details = Write 2–3 sentences of unique, useful content that explains choices, next steps, or benefits to the visitor looking to choose a product from the category.
Out-of-date blog posts, articles, and other landing pages
In cases where the title tag includes a date, or...
In cases where the URL indicates the publishing date:
Action = Improve
Details = Update the post to make it more current, if applicable. Otherwise, change Action to "Remove" and customize the Strategy based on links and traffic (i.e., 301 or 404).
Content marked for improvement should lay out more specific instructions in the “Details” column, such as:
Update the old content to make it more relevant
Add more useful content to “beef up” this thin page
Incorporate content from overlapping URLs/pages
Rewrite to avoid internal duplication
Rewrite to avoid external duplication
Reduce image sizes to speed up page load
Create a “responsive” template for this page to fit on mobile devices
Etc.
Content marked for removal should include specific instructions in the “Details” column, such as:
Consolidate this content into the following URL/page marked as “Improve”
Then redirect the URL
Remove this page from the site and allow the URL to return a 410 or 404 HTTP status code. This content has had zero visits within the last 360 days, and has no external links. Then remove or update internal links to this page.
Remove this page from the site and 301 redirect the URL to the following URL marked as “Improve”... Do not incorporate the content into the new page. It is low-quality.
Remove this archive page from search engine indexes with a robots noindex meta tag. Continue to allow the page to be accessed by visitors and crawled by search engines.
Remove this internal search result page from the search engine indexed with a robots noindex meta tag. Once removed from the index (about 15–30 days later), add the following line to the #BlockedDirectories section of the robots.txt file: Disallow: /search/.
As you can see from the many examples above, sorting by “Page Type” can be quite handy when applying the same Action and Details to an entire section of the website.
After all of the tool set-up, data gathering, data cleanup, and analysis across dozens of metrics, what matters in the end is the Action to take and the Details that go with it.
URL, Action, and Details: These three columns will be used by someone to implement your recommendations. Be clear and concise in your instructions, and don’t make decisions without reviewing all of the wonderful data-points you’ve collected.
Here is a sample content audit spreadsheet to use as a template, or for ideas. It includes a few extra tabs specific to the way we used to do content audits at Inflow.
WARNING!
As Razvan Gavrilas pointed out in his post on Cognitive SEO from 2015, without doing the research above you risk pruning valuable content from search engine indexes. Be bold, but make highly informed decisions:
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove.
The reporting phase
The content audit dashboard is exactly what we need internally: a spreadsheet crammed with data that can be sliced and diced in so many useful ways that we can always go back to it for more insight and ideas. Some clients appreciate that as well, but most are going to find the greater benefit in our final content audit report, which includes a high-level overview of our recommendations.
Counting actions from Column B
It is useful to count the quantity of each Action along with total organic search traffic and/or revenue for each URL. This will help you (and the client) identify important metrics, such as total organic traffic for pages marked to be pruned. It will also make the final report much easier to build.
Step 5: Writing up the report
Your analysis and recommendations should be delivered at the same time as the audit dashboard. It summarizes the findings, recommendations, and next steps from the audit, and should start with an executive summary.
Here is a real example of an executive summary from one of Inflow's content audit strategies:
As a result of our comprehensive content audit, we are recommending the following, which will be covered in more detail below:
Removal of about 624 pages from Google index by deletion or consolidation:
203 Pages were marked for Removal with a 404 error (no redirect needed)
110 Pages were marked for Removal with a 301 redirect to another page
311 Pages were marked for Consolidation of content into other pages
Followed by a redirect to the page into which they were consolidated
Rewriting or improving of 668 pages
605 Product Pages are to be rewritten due to use of manufacturer product descriptions (duplicate content), these being prioritized from first to last within the Content Audit.
63 "Other" pages to be rewritten due to low-quality or duplicate content.
Keeping 226 pages as-is
No rewriting or improvements needed
These changes reflect an immediate need to "improve or remove" content in order to avoid an obvious content-based penalty from Google (e.g. Panda) due to thin, low-quality and duplicate content, especially concerning Representative and Dealers pages with some added risk from Style pages.
The content strategy should end with recommended next steps, including action items for the consultant and the client. Below is a real example from one of our documents.
We recommend the following three projects in order of their urgency and/or potential ROI for the site:
Project 1: Remove or consolidate all pages marked as “Remove”. Detailed instructions for each URL can be found in the "Details" column of the Content Audit Dashboard.
Project 2: Copywriting to improve/rewrite content on Style pages. Ensure unique, robust content and proper keyword targeting.
Project 3: Improve/rewrite all remaining pages marked as “Improve” in the Content Audit Dashboard. Detailed instructions for each URL can be found in the "Details" column
Content audit resources & further reading
Understanding Mobile-First Indexing and the Long-Term Impact on SEO by Cindy Krum This thought-provoking post begs the question: How will we perform content inventories without URLs? It helps to know Google is dealing with the exact same problem on a much, much larger scale.
Here is a spreadsheet template to help you calculate revenue and traffic changes before and after updating content.
Expanding the Horizons of eCommerce Content Strategy by Dan Kern of Inflow An epic post about content strategies for eCommerce businesses, which includes several good examples of content on different types of pages targeted toward various stages in the buying cycle.
The Content Inventory is Your Friend by Kristina Halvorson on BrainTraffic Praise for the life-changing powers of a good content audit inventory.
Everything You Need to Perform Content Audits
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from Blogger http://ift.tt/2nuDWkD via SW Unlimited
0 notes
Text
How to Do a Content Audit [Updated for 2017]
Posted by Everett
//<![CDATA[ (function($) { // code using $ as alias to jQuery $(function() { // Hide the hypotext content. $('.hypotext-content').hide(); // When a hypotext link is clicked. $('a.hypotext.closed').click(function (e) { // custom handling here e.preventDefault(); // Create the class reference from the rel value. var id = '.' + $(this).attr('rel'); // If the content is hidden, show it now. if ( $(id).css('display') == 'none' ) { $(id).show('slow'); if (jQuery.ui) { // UI loaded $(id).effect("highlight", {}, 1000); } } // If the content is shown, hide it now. else { $(id).hide('slow'); } }); // If we have a hash value in the url. if (window.location.hash) { // If the anchor is within a hypotext block, expand it, by clicking the // relevant link. console.log(window.location.hash); var anchor = $(window.location.hash); var hypotextLink = $('#' + anchor.parents('.hypotext-content').attr('rel')); console.log(hypotextLink); hypotextLink.click(); // Wait until the content has expanded before jumping to anchor. //$.delay(1000); setTimeout(function(){ scrollToAnchor(window.location.hash); }, 1000); } }); function scrollToAnchor(id) { var anchor = $(id); $('html,body').animate({scrollTop: anchor.offset().top},'slow'); } })(jQuery); //]]>
This guide provides instructions on how to do a content audit using examples and screenshots from Screaming Frog, URL Profiler, Google Analytics (GA), and Excel, as those seem to be the most widely used and versatile tools for performing content audits.
{Expand for more background}
It's been almost three years since the original “How to do a Content Audit – Step-by-Step” tutorial was published here on Moz, and it’s due for a refresh. This version includes updates covering JavaScript rendering, crawling dynamic mobile sites, and more.
It also provides less detail than the first in terms of prescribing every step in the process. This is because our internal processes change often, as do the tools. I’ve also seen many other processes out there that I would consider good approaches. Rather than forcing a specific process and publishing something that may be obsolete in six months, this tutorial aims to allow for a variety of processes and tools by focusing more on the basic concepts and less on the specifics of each step.
We have a DeepCrawl account at Inflow, and a specific process for that tool, as well as several others. Tapping directly into various APIs may be preferable to using a middleware product like URL Profiler if one has development resources. There are also custom in-house tools out there, some of which incorporate historic log file data and can efficiently crawl websites like the New York Times and eBay. Whether you use GA or Adobe Sitecatalyst, Excel, or a SQL database, the underlying process of conducting a content audit shouldn’t change much.
TABLE OF CONTENTS
What is an SEO content audit?
What is the purpose of a content audit?
How & why “pruning” works
How to do a content audit
The inventory & audit phase
Step 1: Crawl all indexable URLs
Crawling roadblocks & new technologies
Crawling very large websites
Crawling dynamic mobile sites
Crawling and rendering JavaScript
Step 2: Gather additional metrics
Things you don’t need when analyzing the data
The analysis & recommendations phase
Step 3: Put it all into a dashboard
Step 4: Work the content audit dashboard
The reporting phase
Step 5: Writing up the report
Content audit resources & further reading
What is a content audit?
A content audit for the purpose of SEO includes a full inventory of all indexable content on a domain, which is then analyzed using performance metrics from a variety of sources to determine which content to keep as-is, which to improve, and which to remove or consolidate.
What is the purpose of a content audit?
A content audit can have many purposes and desired outcomes. In terms of SEO, they are often used to determine the following:
How to escape a content-related search engine ranking filter or penalty
Content that requires copywriting/editing for improved quality
Content that needs to be updated and made more current
Content that should be consolidated due to overlapping topics
Content that should be removed from the site
The best way to prioritize the editing or removal of content
Content gap opportunities
Which content is ranking for which keywords
Which content should be ranking for which keywords
The strongest pages on a domain and how to leverage them
Undiscovered content marketing opportunities
Due diligence when buying/selling websites or onboarding new clients
While each of these desired outcomes and insights are valuable results of a content audit, I would define the overall “purpose” of one as:
The purpose of a content audit for SEO is to improve the perceived trust and quality of a domain, while optimizing crawl budget and the flow of PageRank (PR) and other ranking signals throughout the site.
Often, but not always, a big part of achieving these goals involves the removal of low-quality content from search engine indexes. I’ve been told people hate this word, but I prefer the “pruning” analogy to describe the concept.
How & why “pruning” works
{Expand for more on pruning}
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove. Optimizing crawl budget and the flow of PR is self-explanatory to most SEOs. But how does a content audit improve the perceived trust and quality of a domain? By removing low-quality content from the index (pruning) and improving some of the content remaining in the index, the likelihood that someone arrives on your site through organic search and has a poor user experience (indicated to Google in a variety of ways) is lowered. Thus, the quality of the domain improves. I’ve explained the concept here and here.
Others have since shared some likely theories of their own, including a larger focus on the redistribution of PR.
Case study after case study has shown the concept of “pruning” (removing low-quality content from search engine indexes) to be effective, especially on very large websites with hundreds of thousands (or even millions) of indexable URLs. So why do content audits work? Lots of reasons. But really...
Does it matter?
¯\_(ツ)_/¯
How to do a content audit
Just like anything in SEO, from technical and on-page changes to site migrations, things can go horribly wrong when content audits aren’t conducted properly. The most common example would be removing URLs that have external links because link metrics weren’t analyzed as part of the audit. Another common mistake is confusing removal from search engine indexes with removal from the website.
Content audits start with taking an inventory of all content available for indexation by search engines. This content is then analyzed against a variety of metrics and given one of three “Action” determinations. The “Details” of each Action are then expanded upon.
The variety of combinations of options between the “Action” of WHAT to do and the “Details” of HOW (and sometimes why) to do it are as varied as the strategies, sites, and tactics themselves. Below are a few hypothetical examples:
You now have a basic overview of how to perform a content audit. More specific instructions can be found below.
The process can be roughly split into three distinct phases:
Inventory & audit
Analysis & recommendations
Summary & reporting
The inventory & audit phase
Taking an inventory of all content, and related metrics, begins with crawling the site.
One difference between crawling for content audits and technical audits:
Technical SEO audit crawls are concerned with all crawlable content (among other things).
Content audit crawls for the purpose of SEO are concerned with all indexable content.
{Expand for more on crawlable vs. indexable content}
The URL in the image below should be considered non-indexable. Even if it isn’t blocked in the robots.txt file, with a robots meta tag, or an X-robots header response –– even if it is frequently crawled by Google and shows up as a URL in Google Analytics and Search Console –– the rel =”canonical” tag shown below essentially acts like a 301 redirect, telling Google not to display the non-canonical URL in search results and to apply all ranking calculations to the canonical version. In other words, not to “index” it.
I'm not sure “index” is the best word, though. To “display” or “return” in the SERPs is a better way of describing it, as Google surely records canonicalized URL variants somewhere, and advanced site: queries seem to show them in a way that is consistent with the "supplemental index" of yesteryear. But that's another post, more suitably written by a brighter mind like Bill Slawski.
A URL with a query string that canonicalizes to a version without the query string can be considered “not indexable.”
A content audit can safely ignore these types of situations, which could mean drastically reducing the amount of time and memory taken up by a crawl.
Technical SEO audits, on the other hand, should be concerned with every URL a crawler can find. Non-indexable URLs can reveal a lot of technical issues, from spider traps (e.g. never-ending empty pagination, infinite loops via redirect or canonical tag) to crawl budget optimization (e.g. How many facets/filters deep to allow crawling? 5? 6? 7?) and more.
It is for this reason that trying to combine a technical SEO audit with a content audit often turns into a giant mess, though an efficient idea in theory. When dealing with a lot of data, I find it easier to focus on one or the other: all crawlable URLs, or all indexable URLs.
Orphaned pages (i.e., with no internal links / navigation path) sometimes don’t turn up in technical SEO audits if the crawler had no way to find them. Content audits should discover any indexable content, whether it is linked to internally or not. Side note: A good tech audit would do this, too.
Identifying URLs that should be indexed but are not is something that typically happens during technical SEO audits.
However, if you're having trouble getting deep pages indexed when they should be, content audits may help determine how to optimize crawl budget and herd bots more efficiently into those important, deep pages. Also, many times Google chooses not to display/index a URL in the SERPs due to poor content quality (i.e., thin or duplicate).
All of this is changing rapidly, though. URLs as the unique identifier in Google’s index are probably going away. Yes, we’ll still have URLs, but not everything requires them. So far, the word “content” and URL has been mostly interchangeable. But some URLs contain an entire application’s worth of content. How to do a content audit in that world is something we’ll have to figure out soon, but only after Google figures out how to organize the web’s information in that same world. From the looks of things, we still have a year or two.
Until then, the process below should handle most situations.
Step 1: Crawl all indexable URLs
A good place to start on most websites is a full Screaming Frog crawl. However, some indexable content might be missed this way. It is not recommended that you rely on a crawler as the source for all indexable URLs.
In addition to the crawler, collect URLs from Google Analytics, Google Webmaster Tools, XML Sitemaps, and, if possible, from an internal database, such as an export of all product and category URLs on an eCommerce website. These can then be crawled in “list mode” separately, then added to your main list of URLs and deduplicated to produce a more comprehensive list of indexable URLs.
Some URLs found via GA, XML sitemaps, and other non-crawl sources may not actually be “indexable.” These should be excluded. One strategy that works here is to combine and deduplicate all of the URL “lists,” and then perform a crawl in list mode. Once crawled, remove all URLs with robots meta or X-Robots noindex tags, as well as any URL returning error codes and those that are blocked by the robots.txt file, etc. At this point, you can safely add these URLs to the file containing indexable URLs from the crawl. Once again, deduplicate the list.
Crawling roadblocks & new technologies
Crawling very large websites
First and foremost, you do not need to crawl every URL on the site. Be concerned with indexable content. This is not a technical SEO audit.
{Expand for more about crawling very large websites}
Avoid crawling unnecessary URLs
Some of the things you can avoid crawling and adding to the content audit in many cases include:
Noindexed or robots.txt-blocked URLs
4XX and 5XX errors
Redirecting URLs and those that canonicalize to a different URL
Images, CSS, JavaScript, and SWF files
Segment the site into crawlable chunks
You can often get Screaming Frog to completely crawl a single directory at a time if the site is too large to crawl all at once.
Filter out URL patterns you plan to remove from the index
Let’s say you’re auditing a domain on WordPress and you notice early in the crawl that /tag/ pages are indexable. A quick site:domain.com inurl:tag search on Google tells you there are about 10 million of them. A quick look at Google Analytics confirms that URLs in the /tag/ directory are not responsible for very much revenue from organic search. It would be safe to say that the “Action” on these URLs should be “Remove” and the “Details” should read something like this: Remove /tag/ URLs from the indexed with a robots noindex,follow meta tag. More advice on this strategy can be found here.
Upgrade your machine
Install additional RAM on your computer, which is used by Screaming Frog to hold data during the crawl. This has the added benefit of improving Excel performance, which can also be a major roadblock.
You can also install Screaming Frog on Amazon Web Server (AWS), as described in this post on iPullRank.
Tune up your tools
Screaming Frog provides several ways for SEOs to get more out of the crawler. This includes adjusting the speed, max threads, search depth, query strings, timeouts, retries, and the amount of RAM available to the program. Leave at least 3GB off limits to the spider to avoid catastrophic freezing of the entire machine and loss of data. You can learn more about tuning up Screaming Frog here and here.
Try other tools
I’m convinced that there's a ton of wasted bandwidth on most content audit projects due to strategists releasing a crawler and allowing it to chew through an entire domain, whether the URLs are indexable or not. People run Screaming Frog without saving the crawl intermittently, without adding more RAM availability, without filtering out the nonsense, or using any of the crawl customization features available to them.
That said, sometimes SF just doesn’t get the job done. We also have a process specific to DeepCrawl, and have used Botify, as well as other tools. They each have their pros and cons. I still prefer Screaming Frog for crawling and URL Profiler for fetching metrics in most cases.
Crawling dynamic mobile sites
This refers to a specific type of mobile setup in which there are two code-bases –– one for mobile and one for desktop –– but only one URL. Thus, the content of a single URL may vary significantly depending on which type of device is visiting that URL. In such cases, you will essentially be performing two separate content audits. Proceed as usual for the desktop version. Below are instructions for crawling the mobile version.
{Expand for more on crawling dynamic websites}
Crawling a dynamic mobile site for a content audit will require changing the User-Agent of the crawler, as shown here under Screaming Frog’s “Configure ---> HTTP Header” menu:
The important thing to remember when working on mobile dynamic websites is that you're only taking an inventory of indexable URLs on one version of the site or the other. Once the two inventories are taken, you can then compare them to uncover any unintentional issues.
Some examples of what this process can find in a technical SEO audit include situations in which titles, descriptions, canonical tags, robots meta, rel next/prev, and other important elements do not match between the two versions of the page. It's vital that the mobile and desktop version of each page have parity when it comes to these essentials.
It's easy for the mobile version of a historically desktop-first website to end up providing conflicting instructions to search engines because it's not often “automatically changed” when the desktop version changes. A good example here is a website I recently looked at with about 20 million URLs, all of which had the following title tag when loaded by a mobile user (including Google): BRAND NAME - MOBILE SITE. Imagine the consequences of that once a mobile-first algorithm truly rolls out.
Crawling and rendering JavaScript
One of the many technical issues SEOs have been increasingly dealing with over the last couple of years is the proliferation of websites built on JavaScript frameworks and libraries like React.js, Ember.js, and Angular.js.
{Expand for more on crawling Javascript websites}
Most crawlers have made a lot of progress lately when it comes to crawling and rendering JavaScript content. Now, it’s as easy as changing a few settings, as shown below with Screaming Frog.
When crawling URLs with #! , use the “Old AJAX Crawling Scheme.” Otherwise, select “JavaScript” from the “Rendering” tab when configuring your Screaming Frog SEO Spider to crawl JavaScript websites.
How do you know if you’re dealing with a JavaScript website?
First of all, most websites these days are going to be using some sort of JavaScript technology, though more often than not (so far) these will be rendered by the “client” (i.e., by your browser). An example would be the .js file that controls the behavior of a form or interactive tool.
What we’re discussing here is when the JavaScript is used “server-side” and needs to be executed in order to render the page.
JavaScript libraries and frameworks are used to develop single-page web apps and highly interactive websites. Below are a few different things that should alert you to this challenge:
The URLs contain #! (hashbangs). For example: example.com/page#!key=value (AJAX)
Content-rich pages with only a few lines of code (and no iframes) when viewing the source code.
What looks like server-side code in the meta tags instead of the actual content of the tag. For example:
You can also use the BuiltWith Technology Profiler or the Library Detector plugins for Chrome, which shows JavaScript libraries being used on a page in the address bar.
Not all websites built primarily with JavaScript require special attention to crawl settings. Some websites use pre-rendering services like Brombone or Prerender.io to serve the crawler a fully rendered version of the page. Others use isomorphic JavaScript to accomplish the same thing.
Step 2: Gather additional metrics
Most crawlers will give you the URL and various on-page metrics and data, such as the titles, descriptions, meta tags, and word count. In addition to these, you’ll want to know about internal and external links, traffic, content uniqueness, and much more in order to make fully informed recommendations during the analysis portion of the content audit project.
Your process may vary, but we generally try to pull in everything we need using as few sources as possible. URL Profiler is a great resource for this purpose, as it works well with Screaming Frog and integrates easily with all of the APIs we need.
Once the Screaming Frog scan is complete (only crawling indexable content) export the “Internal All” file, which can then be used as the seed list in URL Profiler (combined with any additional indexable URLs found outside of the crawl via GSC, GA, and elsewhere).
This is what my URL Profiler settings look for a typical content audit for a small- or medium-sized site. Also, under “Accounts” I have connected via API keys to Moz and SEMrush.
Once URL Profiler is finished, you should end up with something like this:
Screaming Frog and URL Profiler: Between these two tools and the APIs they connect with, you may not need anything else at all in order to see the metrics below for every indexable URL on the domain.
The risk of getting analytics data from a third-party tool
We've noticed odd data mismatches and sampled data when using the method above on large, high-traffic websites. Our internal process involves exporting these reports directly from Google Analytics, sometimes incorporating Analytics Canvas to get the full, unsampled data from GA. Then VLookups are used in the spreadsheet to combine the data, with URL being the unique identifier.
Metrics to pull for each URL:
Indexed or not?
If crawlers are set up properly, all URLs should be “indexable.”
A non-indexed URL is often a sign of an uncrawled or low-quality page.
Content uniqueness
Copyscape, Siteliner, and now URL Profiler can provide this data.
Traffic from organic search
Typically 90 days
Keep a consistent timeframe across all metrics.
Revenue and/or conversions
You could view this by “total,” or by segmenting to show only revenue from organic search on a per-page basis.
Publish date
If you can get this into Google Analytics as a custom dimension prior to fetching the GA data, it will help you discover stale content.
Internal links
Content audits provide the perfect opportunity to tighten up your internal linking strategy by ensuring the most important pages have the most internal links.
External links
These can come from Moz, SEMRush, and a variety of other tools, most of which integrate natively or via APIs with URL Profiler.
Landing pages resulting in low time-on-site
Take this one with a grain of salt. If visitors found what they want because the content was good, that’s not a bad metric. A better proxy for this would be scroll depth, but that would probably require setting up a scroll-tracking “event.”
Landing pages resulting in Low Pages-Per-Visit
Just like with Time-On-Site, sometimes visitors find what they’re looking for on a single page. This is often true for high-quality content.
Response code
Typically, only URLs that return a 200 (OK) response code are indexable. You may not require this metric in the final data if that's the case on your domain.
Canonical tag
Typically only URLs with a self-referencing rel=“canonical” tag should be considered “indexable.” You may not require this metric in the final data if that's the case on your domain.
Page speed and mobile-friendliness
Again, URL Profiler comes through with their Google PageSpeed Insights API integration.
Before you begin analyzing the data, be sure to drastically improve your mental health and the performance of your machine by taking the opportunity to get rid of any data you don’t need. Here are a few things you might consider deleting right away (after making a copy of the full data set, of course).
Things you don’t need when analyzing the data
{Expand for more on removing unnecessary data}
URL Profiler and Screaming Frog tabs Just keep the “combined data” tab and immediately cut the amount of data in the spreadsheet by about half.
Content Type Filtering by Content Type (e.g., text/html, image, PDF, CSS, JavaScript) and removing any URL that is of no concern in your content audit is a good way to speed up the process.
Technically speaking, images can be indexable content. However, I prefer to deal with them separately for now.
Filtering unnecessary file types out like I've done in the screenshot above improves focus, but doesn’t improve performance very much. A better option would be to first select the file types you don’t want, apply the filter, delete the rows you don’t want, and then go back to the filter options and “(Select All).”
Once you have only the content types you want, it may now be possible to simply delete the entire Content Type column.
Status Code and Status You only need one or the other. I prefer to keep the Code, and delete the Status column.
Length and Pixels You only need one or the other. I prefer to keep the Pixels, and delete the Length column. This applies to all Title and Meta Description columns.
Meta Keywords Delete the columns. If those cells have content, consider removing that tag from the site.
DNS Safe URL, Path, Domain, Root, and TLD You should really only be working on a single top-level domain. Content audits for subdomains should probably be done separately. Thus, these columns can be deleted in most cases.
Duplicate Columns You should have two columns for the URL (The “Address” in column A from URL Profiler, and the “URL” column from Screaming Frog). Similarly, there may also be two columns each for HTTP Status and Status Code. It depends on the settings selected in both tools, but there are sure to be some overlaps, which can be removed to reduce the file size, enhance focus, and speed up the process.
Blank Columns Keep the filter tool active and go through each column. Those with only blank cells can be deleted. The example below shows that column BK (Robots HTTP Header) can be removed from the spreadsheet.
[You can save a lot of headspace by hiding or removing blank columns.]
Single-Value Columns If the column contains only one value, it can usually be removed. The screenshot below shows our non-secure site does not have any HTTPS URLs, as expected. I can now remove the column. Also, I guess it’s probably time I get that HTTPS migration project scheduled.
Hopefully by now you've made a significant dent in reducing the overall size of the file and time it takes to apply formatting and formula changes to the spreadsheet. It’s time to start diving into the data.
The analysis & recommendations phase
Here's where the fun really begins. In a large organization, it's tempting to have a junior SEO do all of the data-gathering up to this point. I find it useful to perform the crawl myself, as the process can be highly informative.
Step 3: Put it all into a dashboard
Even after removing unnecessary data, performance could still be a major issue, especially if working in Google Sheets. I prefer to do all of this in Excel, and only upload into Google Sheets once it's ready for the client. If Excel is running slow, consider splitting up the URLs by directory or some other factor in order to work with multiple, smaller spreadsheets.
Creating a dashboard can be as easy as adding two columns to the spreadsheet. The first new column, “Action,” should be limited to three options, as shown below. This makes filtering and sorting data much easier. The “Details” column can contain freeform text to provide more detailed instructions for implementation.
Use Data Validation and a drop-down selector to limit Action options.
Step 4: Work the content audit dashboard
All of the data you need should now be right in front of you. This step can’t be turned into a repeatable process for every content audit. From here on the actual step-by-step process becomes much more open to interpretation and your own experience. You may do some of them and not others. You may do them a little differently. That's all fine, as long as you're working toward the goal of determining what to do, if anything, for each piece of content on the website.
A good place to start would be to look for any content-related issues that might cause an algorithmic filter or manual penalty to be applied, thereby dragging down your rankings.
Causes of content-related penalties
These typically fall under three major categories: quality, duplication, and relevancy. Each category can be further broken down into a variety of issues, which are detailed below.
{Expand to learn more about quality, duplication, and relevancy issues}
Typical low-quality content
Poor grammar, written primarily for search engines (includes keyword stuffing), unhelpful, inaccurate...
Completely irrelevant content
OK in small amounts, but often entire blogs are full of it.
A typical example would be a "linkbait" piece circa 2010.
Thin/short content
Glossed over the topic, too few words, or all image-based content.
Curated content with no added value
Comprised almost entirely of bits and pieces of content that exists elsewhere.
Misleading optimization
Titles or keywords targeting queries for which content doesn't answer or deserve to rank.
Generally not providing the information the visitor was expecting to find.
Duplicate content
Internally duplicated on other pages (e.g., categories, product variants, archives, technical issues, etc.).
Externally duplicated (e.g., manufacturer product descriptions, product descriptions duplicated in feeds used for other channels like Amazon, shopping comparison sites and eBay, plagiarized content, etc.)
Stub pages (e.g., "No content is here yet, but if you sign in and leave some user-generated-content, then we'll have content here for the next guy." By the way, want our newsletter? Click an AD!)
Indexable internal search results
Too many indexable blog tag or blog category pages
And so on and so forth...
It helps to sort the data in various ways to see what’s going on. Below are a few different things to look for if you’re having trouble getting started.
{Expand to learn more about what to look for}
Sort by duplicate content risk
URL Profiler now has a native duplicate content checker. Other options are Copyscape (for external duplicate content) and Siteliner (for internal duplicate content).
Which of these pages should be rewritten?
Rewrite key/important pages, such as categories, home page, top products
Rewrite pages with good link and social metrics
Rewrite pages with good traffic
After selecting "Improve" in the Action column, elaborate in the Details column:
"Improve these pages by writing unique, useful content to improve the Copyscape risk score."
Which of these pages should be removed/pruned?
Remove guest posts that were published elsewhere
Remove anything the client plagiarized
Remove content that isn't worth rewriting, such as:
No external links, no social shares, and very few or no entrances/visits
After selecting "Remove" from the Action column, elaborate in the Details column:
"Prune from site to remove duplicate content. This URL has no links or shares and very little traffic. We recommend allowing the URL to return 404 or 410 response code. Remove all internal links, including from the sitemap."
Which of these pages should be consolidated into others?
Presumably none, since the content is already externally duplicated.
Which of these pages should be left “As-Is”?
Important pages which have had their content stolen
Sort by entrances or visits (filtering out any that were already finished)
Which of these pages should be marked as "Improve"?
Pages with high visits/entrances but low conversion, time-on-site, pageviews per session, etc.
Key pages that require improvement determined after a manual review of the page.
Which of these pages should be marked as "Consolidate"?
When you have overlapping topics that don't provide much unique value of their own, but could make a great resource when combined.
Mark the page in the set with the best metrics as "Improve" and in the Details column, outline which pages are going to be consolidated into it. This is the canonical page.
Mark the pages that are to be consolidated into the canonical page as "Consolidate" and provide further instructions in the Details column, such as:
Use portions of this content to round out /canonicalpage/ and then 301 redirect this page into /canonicalpage/
Update all internal links.
Campaign-based or seasonal pages that could be consolidated into a single "Evergreen" landing page (e.g., Best Sellers of 2012 and Best Sellers of 2013 ---> Best Sellers).
Which of these pages should be marked as "Remove"?
Pages with poor link, traffic, and social metrics related to low-quality content that isn't worth updating
Typically these will be allowed to 404/410.
Irrelevant content
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Out-of-date content that isn't worth updating or consolidating
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Which of these pages should be marked as "Leave As-Is"?
Pages with good traffic, conversions, time on site, etc. that also have good content.
These may or may not have any decent external links.
Taking the hatchet to bloated websites
For big sites, it's best to use a hatchet-based approach as much as possible, and finish up with a scalpel in the end. Otherwise, you'll spend way too much time on the project, which eats into the ROI.
This is not a process that can be documented step-by-step. For the purpose of illustration, however, below are a few different examples of hatchet approaches and when to consider using them.
{Expand for examples of hatchet approaches}
Parameter-based URLs that shouldn't be indexed
Defer to the technical audit, if applicable. Otherwise, use your best judgment:
e.g., /?sort=color, &size=small
Assuming the tech audit didn't suggest otherwise, these pages could all be handled in one fell swoop. Below is an example Action and example Details for such a page:
Action = Remove
Details = Rel canonical to the base page without the parameter
Internal search results
Defer to the technical audit if applicable. Otherwise, use your best judgment:
e.g., /search/keyword-phrase/
Assuming the tech audit didn't suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
Blog tag pages
Defer to the technical audit if applicable. Otherwise:
e.g., /blog/tag/green-widgets/ , blog/tag/blue-widgets/
Assuming the tech audit didn't suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
E-commerce product pages with manufacturer descriptions
In cases where the "Page Type" is known (i.e., it's in the URL or was provided in a CMS export) and Risk Score indicates duplication:
e.g., /product/product-name/
Assuming the tech audit didn't suggest otherwise:
Action = Improve
Details = Rewrite to improve product description and avoid duplicate content
E-commerce category pages with no static content
In cases where the "Page Type" is known:
e.g. /category/category-name/ or category/cat1/cat2/
Assuming NONE of the category pages have content:
Action = Improve
Details = Write 2–3 sentences of unique, useful content that explains choices, next steps, or benefits to the visitor looking to choose a product from the category.
Out-of-date blog posts, articles, and other landing pages
In cases where the title tag includes a date, or...
In cases where the URL indicates the publishing date:
Action = Improve
Details = Update the post to make it more current, if applicable. Otherwise, change Action to "Remove" and customize the Strategy based on links and traffic (i.e., 301 or 404).
Content marked for improvement should lay out more specific instructions in the “Details” column, such as:
Update the old content to make it more relevant
Add more useful content to “beef up” this thin page
Incorporate content from overlapping URLs/pages
Rewrite to avoid internal duplication
Rewrite to avoid external duplication
Reduce image sizes to speed up page load
Create a “responsive” template for this page to fit on mobile devices
Etc.
Content marked for removal should include specific instructions in the “Details” column, such as:
Consolidate this content into the following URL/page marked as “Improve”
Then redirect the URL
Remove this page from the site and allow the URL to return a 410 or 404 HTTP status code. This content has had zero visits within the last 360 days, and has no external links. Then remove or update internal links to this page.
Remove this page from the site and 301 redirect the URL to the following URL marked as “Improve”... Do not incorporate the content into the new page. It is low-quality.
Remove this archive page from search engine indexes with a robots noindex meta tag. Continue to allow the page to be accessed by visitors and crawled by search engines.
Remove this internal search result page from the search engine indexed with a robots noindex meta tag. Once removed from the index (about 15–30 days later), add the following line to the #BlockedDirectories section of the robots.txt file: Disallow: /search/.
As you can see from the many examples above, sorting by “Page Type” can be quite handy when applying the same Action and Details to an entire section of the website.
After all of the tool set-up, data gathering, data cleanup, and analysis across dozens of metrics, what matters in the end is the Action to take and the Details that go with it.
URL, Action, and Details: These three columns will be used by someone to implement your recommendations. Be clear and concise in your instructions, and don’t make decisions without reviewing all of the wonderful data-points you’ve collected.
Here is a sample content audit spreadsheet to use as a template, or for ideas. It includes a few extra tabs specific to the way we used to do content audits at Inflow.
WARNING!
As Razvan Gavrilas pointed out in his post on Cognitive SEO from 2015, without doing the research above you risk pruning valuable content from search engine indexes. Be bold, but make highly informed decisions:
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove.
The reporting phase
The content audit dashboard is exactly what we need internally: a spreadsheet crammed with data that can be sliced and diced in so many useful ways that we can always go back to it for more insight and ideas. Some clients appreciate that as well, but most are going to find the greater benefit in our final content audit report, which includes a high-level overview of our recommendations.
Counting actions from Column B
It is useful to count the quantity of each Action along with total organic search traffic and/or revenue for each URL. This will help you (and the client) identify important metrics, such as total organic traffic for pages marked to be pruned. It will also make the final report much easier to build.
Step 5: Writing up the report
Your analysis and recommendations should be delivered at the same time as the audit dashboard. It summarizes the findings, recommendations, and next steps from the audit, and should start with an executive summary.
Here is a real example of an executive summary from one of Inflow's content audit strategies:
As a result of our comprehensive content audit, we are recommending the following, which will be covered in more detail below:
Removal of about 624 pages from Google index by deletion or consolidation:
203 Pages were marked for Removal with a 404 error (no redirect needed)
110 Pages were marked for Removal with a 301 redirect to another page
311 Pages were marked for Consolidation of content into other pages
Followed by a redirect to the page into which they were consolidated
Rewriting or improving of 668 pages
605 Product Pages are to be rewritten due to use of manufacturer product descriptions (duplicate content), these being prioritized from first to last within the Content Audit.
63 "Other" pages to be rewritten due to low-quality or duplicate content.
Keeping 226 pages as-is
No rewriting or improvements needed
These changes reflect an immediate need to "improve or remove" content in order to avoid an obvious content-based penalty from Google (e.g. Panda) due to thin, low-quality and duplicate content, especially concerning Representative and Dealers pages with some added risk from Style pages.
The content strategy should end with recommended next steps, including action items for the consultant and the client. Below is a real example from one of our documents.
We recommend the following three projects in order of their urgency and/or potential ROI for the site:
Project 1: Remove or consolidate all pages marked as “Remove”. Detailed instructions for each URL can be found in the "Details" column of the Content Audit Dashboard.
Project 2: Copywriting to improve/rewrite content on Style pages. Ensure unique, robust content and proper keyword targeting.
Project 3: Improve/rewrite all remaining pages marked as “Improve” in the Content Audit Dashboard. Detailed instructions for each URL can be found in the "Details" column
Content audit resources & further reading
Understanding Mobile-First Indexing and the Long-Term Impact on SEO by Cindy Krum This thought-provoking post begs the question: How will we perform content inventories without URLs? It helps to know Google is dealing with the exact same problem on a much, much larger scale.
Here is a spreadsheet template to help you calculate revenue and traffic changes before and after updating content.
Expanding the Horizons of eCommerce Content Strategy by Dan Kern of Inflow An epic post about content strategies for eCommerce businesses, which includes several good examples of content on different types of pages targeted toward various stages in the buying cycle.
The Content Inventory is Your Friend by Kristina Halvorson on BrainTraffic Praise for the life-changing powers of a good content audit inventory.
Everything You Need to Perform Content Audits
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Quote
Bootstrap, the most popular front-end framework built to design modern, responsive, and dynamic interfaces for professional design web pages, is currently undertaking a major update, Bootstrap 5. Bootstrap is a free and open-source collection of CSS and JavaScript/jQuery code used for creating dynamic layout websites and web applications. Being a tool for creating front-end design, it consists of a series of HTML- and CSS-based design templates for different components of a website or application such as forms, buttons, navigation, modals, typography and other interface components with helpful JavaScript extensions. It doesn’t matter if you are a beginner to web development or an experienced developer, Bootstrap is a powerful tool for whatever type of website and web application you are trying to build. In addition, Bootstrap provides an out-of-the-box solution with hundreds of third-party components that you can integrate with it which allows you to build a prototype fast to materialize your ideal website without spending a lot of time. Which in the end you might end up customizing to build the final design of your website or web application as most of the configuration is already set up for you. Bootstrap 4 is currently on version 4.4.1 which now has a lot of vital features such as cards, flexbox, Sass integration and powerful plugins built on jQuery. After more than 4 years of progress since the alpha version of Bootstrap 4 was released on August 19, 2015; an update is being developed in the background for the version 5 upgrade. The Startup app will be updated to Bootstrap 5 as soon as the framework is updated. Also, we’ll update the Bootstrap templates gallery. In this article, let’s take a look at Bootstrap 5’s major updates including the release date, integration, and modification. Online Email Template Builder With Postcards you can create and edit email templates online without any coding skills! Includes more than 100 components to help you create custom emails templates faster than ever before. Try FreeOther Products Table of Contents hide Bootstrap Version 5: What Should We Expect? jQuery Removed Switch to Vanilla JavaScript Responsive Font Sizes Drop Internet Explorer 10 and 11 Support Change Gutter Width Unit of Measurement Remove Card Decks Navbar Optimization Custom SVG Icon Library Switching from Jekyll to Hugo Class Updates Conclusion Bootstrap Version 5: What Should We Expect? Bootstrap 5’s official Github project tracking board has more than 765 tasks being shipped with more than 83 pull requests and 311 issues. If we base the release date from the previous development timeframe (Bootstrap 4 to Bootstrap 4.1) the development team took about 3 months to complete Bootstrap 4.1 to Bootstrap 4.2 took about 8 months. We might expect Bootstrap 5 in the first half of 2020. Bootstrap hasn’t confirmed the official release date yet. In hindsight, there is a list of changes that we expect on version 5 such as the removal of jQuery which is a major lift for this version and the drop of Internet Explorer 10 and 11 support. The following are some of the expected changes in Bootstrap 5: jQuery was removed Switch to Vanilla JavaScript Responsive Font Sizes Drop Internet Explorer 10 and 11 support Change of gutter width unit of measurement Removed Card Decks Navbar Optimization Custom SVG icon library Switching from Jekyll to Hugo Class updates jQuery Removed <img class="size-full wp-image-591166" src="https://ift.tt/2XlELhF" alt="Bootstrap 5: What's new about it?" width="960" height="540" srcset="https://ift.tt/2XlELhF 960w, https://ift.tt/3aFtsEC 747w, https://ift.tt/2R8Dvu8 768w, https://ift.tt/2Rc8TrL 5w, https://ift.tt/349EUWy 300w" sizes="(max-width: 960px) 100vw, 960px">jQuery is a library that offers a general-purpose abstraction layer for classic web scripting that is efficient in almost any web development requirements. Its extensible nature allows you to access elements in a document without writing a lot of JavaScript, modify the appearance of your content in a web page which developers take advantage of to bridge the gap across all browsers, change the content of a document, respond to a user’s interaction, retrieve information from a server without refreshing a page through AJAX, add animation to your web page, simplify common JavaScript tasks and the list goes on. While Bootstrap has been using jQuery for more than 8 years, jQuery has become quite a large and bloated framework that requires websites using it to download and add trivial load time for a library that may not be used by any other plugin except Bootstrap itself. As JavaScript frameworks like Angular, Vue and React dominate the web development community nowadays, jQuery has been losing its popularity as most of these modern frameworks work through the virtual DOM and not on the DOM directly that leads to much faster performance. Although it might sound absurd, it turns out it is much more proficient and anyone using these frameworks will have better control and maintenance over their code than those who use jQuery. Moving forward, any jQuery querying features will have to be done with pure or vanilla JavaScript code in Bootstrap 5 which will help with the file size or weight of the framework. Switch to Vanilla JavaScript <img class="size-full wp-image-591169" src="https://ift.tt/3dTH8hi" alt="Bootstrap JavaScript" width="960" height="540" srcset="https://ift.tt/3dTH8hi 960w, https://ift.tt/2xO4V1K 747w, https://ift.tt/2V192iW 768w, https://ift.tt/2xP0eVr 5w, https://ift.tt/3bSWAsm 300w" sizes="(max-width: 960px) 100vw, 960px">JavaScript is the programming language of the web. Most modern websites are powered by JavaScript and all modern web browsers on desktops, consoles, tablets, games and mobile phones include JavaScript interpreters, which makes JavaScript the most universal programming language in the world. Create Websites with Our Online Builders With Startup App and Slides App you can build unlimited websites using the online website editor which includes ready-made designed and coded elements, templates and themes. Try Startup App Try Slides AppOther Products The removal of jQuery support in Bootstrap 5 gives way to writing efficient vanilla JavaScript code without worrying about the size or adding up any other non-essential functions. While jQuery has been around for a long time, it is completely impossible to use jQuery alone because for the most part, what jQuery does is add a $ object to the global scope, with a lot of functions in it. Even more slick libraries like prototype are not an alternative to JavaScript, but exist only as extra tools to solve common problems. If you know how JavaScript works from the root, this major change won’t affect you much but for some developers who only know how to use jQuery, this might be a good chance to learn the language. Responsive Font Sizes <img class="size-full wp-image-591170" src="https://ift.tt/2RbHsy2" alt="Bootstrap Responsive Font Sizes" width="974" height="661" srcset="https://ift.tt/2RbHsy2 974w, https://ift.tt/2UGxKWJ 747w, https://ift.tt/2Xa7MfP 768w, https://ift.tt/3aKiOfN 5w, https://ift.tt/3dXOUXl 300w" sizes="(max-width: 974px) 100vw, 974px">Designing a website that looks good across multiple platforms or viewports has been quite challenging for some developers. Media queries have been a great tool to solve typography common problems that allow developers to control the appearance of typographies on web pages by specifying specific font sizes for the typography elements on a specific viewport. Bootstrap 5 will enable responsive font sizes by default which will automatically resize the typography element according to the size of the user’s viewport through RFS engine or Responsive Font Sizes. According to RFS repository, RFS is a unit resizing engine which was originally developed to resize font sizes. RFS offers the ability to resize basically every value for any CSS property with units, like margin, padding, border-radius or box-shadow. It is a preprocessor or postprocessor-powered-mechanism that automatically calculates the appropriate font-size values based on the user’s screen size or viewport. It works on known preprocessors or postprocessor tools such as Sass, Less, Stylus or PostCSS. As an example, assuming that you have a hero-title class which is a class for your h1 tag element that you want to use for your main title on the hero section. Using Sass the following mixin will do the trick: 1 2 3 .hero-title { @include font-size(4rem); } This will be compiled to this: 1 2 3 4 5 6 7 8 .hero-title { font-size: calc(1.525rem + 3.3vw); } @media (min-width: 1200px) { .hero-title { font-size: 4rem; } } Drop Internet Explorer 10 and 11 Support <img class="size-full wp-image-591171" src="https://ift.tt/2xKEGJr" alt="Drop of Internet Explorer 10 and 11 Support" width="960" height="540" srcset="https://ift.tt/2xKEGJr 960w, https://ift.tt/2wU6HhN 747w, https://ift.tt/2V1e4Mh 768w, https://ift.tt/2UKgGPu 5w, https://ift.tt/2JDQX55 300w" sizes="(max-width: 960px) 100vw, 960px">In 1995, Microsoft released the Internet Explorer which blew everyone’s mind because for the first time there was a browser that supported CSS and Java applets that made it one of the most widely used web browsers back in 2003 with 95% usage share. Fast forward to 2020, Internet Explorer is no longer relevant with Chrome, Firefox, and Edge. In fact, it became one of the web designer’s nightmares since it doesn’t support modern JavaScript standards. In order to work with Internet Explorer, be it 10 or 11, JavaScript codes need to be compiled to ES5 instead of ES6, which increases the size of your projects up to 30%. This obviously limits your ability to use the features of ES6 or newer JavaScript standards. What’s even worse is it doesn’t support a lot of modern CSS properties which limits your modern web design potential. In Bootstrap 5, the Bootstrap team decided to drop the support for Internet Explorer 10 and 11 which is a pretty good move as it will enable web designers and developers focus more on designing modern web pages without having to worry about breaking any piece of codes on old browsers or increasing the size of every project. Change Gutter Width Unit of Measurement <img class="size-full wp-image-591172" src="https://ift.tt/2wf7GIR" alt="Change of gutter width unit of measurement" width="1920" height="1029" srcset="https://ift.tt/2wf7GIR 1920w, https://ift.tt/3dVLODl 1280w, https://ift.tt/2UGHGj8 747w, https://ift.tt/3bSWBfU 768w, https://ift.tt/2JBPf4i 1536w, https://ift.tt/2JH4PM4 5w, https://ift.tt/2RbXTdL 300w" sizes="(max-width: 1920px) 100vw, 1920px">CSS offers ways to specify sizes or lengths of elements using various units of measurement such as px, em, rem, % vw, and vh. While pixels or px is considered to be widely known and used for its absolute units, relative to DPI and resolution of the viewing device, it does not change based on any other element which is not good for modern responsive web design. Bootstrap has been using px for its gutter width for quite a long time which will no longer be the case in Bootstrap 5. According to the fixes made on Bootstrap 5’s official Github project tracking board, the gutter width will now be on rem instead of px. Rem stands for “root em” which means equal to the calculated value of font-size on the root element. For instance, 1 rem is equal to the font size of the HTML element (most browsers have a default value of 16px). Remove Card Decks <img class="size-full wp-image-591173" src="https://ift.tt/2UHcAHW" alt="Bootstrap Remove Card Decks" width="1199" height="486" srcset="https://ift.tt/2UHcAHW 1199w, https://ift.tt/39ExfRb 747w, https://ift.tt/2JBP6hg 768w, https://ift.tt/2x1QxCM 5w, https://ift.tt/3dYlBny 300w" sizes="(max-width: 1199px) 100vw, 1199px">In Bootstrap 4, in order for you to be able to set equal width and height cards that aren’t attached to one another, you need to use card decks as shown below. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Card title This is a longer card with supporting text below as a natural lead-in to additional content. This content is a little bit longer. Last updated 3 mins ago Card title This card has supporting text below as a natural lead-in to additional content. Last updated 3 mins ago Card title This is a wider card with supporting text below as a natural lead-in to additional content. This card has even longer content than the first to show that equal height action. Last updated 3 mins ago In Bootstrap 5, the Bootstrap team removed the card decks since the new grid system offers more responsive control. Hence, removing unnecessary extra classes that can be solved via grid. Navbar Optimization <img class="size-full wp-image-591174" src="https://ift.tt/2X9MEqb" alt="Navbar Optimization" width="1179" height="228" srcset="https://ift.tt/2X9MEqb 1179w, https://ift.tt/3dPU8oh 747w, https://ift.tt/3bSWCjY 768w, https://ift.tt/2JCyLsA 300w" sizes="(max-width: 1179px) 100vw, 1179px">The Bootstrap navbar component is a principal part of Bootstrap that gets used all the time. In previous versions of Bootstrap, you need to have a decent amount of markup in order to make it work. However, in Bootstrap 4 they simplified this through the use of a nav or div HTML element and unordered list. The navbar class is the default class that always needs to appear on the component. By default, Bootstrap 4 uses inline-block on its display option but in Bootstrap 5, it was removed. They also used flex shorthand and removed the brand margin caused by requiring containers in navbars. Aside from this, they have also implemented a dark dropdown via dropdown-menu-dark class that turns the dropdown into a black background which we usually see on navbar dropdown items. Custom SVG Icon Library <img class="size-full wp-image-591175" src="https://ift.tt/2x3dCoN" alt="Bootstrap Custom SVG Icon Library" width="1163" height="711" srcset="https://ift.tt/2x3dCoN 1163w, https://ift.tt/3aLAM1p 747w, https://ift.tt/2JHJ9PT 768w, https://ift.tt/2V5mKRA 5w, https://ift.tt/2UKgHD2 300w" sizes="(max-width: 1163px) 100vw, 1163px">In version 3 of Bootstrap, there are 250 reusable icon components in the font format called “Glyphicons” created to provide iconography to input groups, alert, dropdowns and to other useful Bootstrap components. However, in Bootstrap 4 it was totally scrapped and web designers and developers need to rely on free icon fonts like Font Awesome or use their own custom SVG icons in order to add value to their web design. In Bootstrap 5, there’s a brand new SVG icon library crafted carefully by Mark Otto, co-founder of Bootstrap. Before the official release of Bootstrap 5, these icons can now be added and used to your project at this moment of time. You can visit this page to learn more. Switching from Jekyll to Hugo <img class="size-full wp-image-591176" src="https://ift.tt/34cLlbF" alt="Switching from Jekyll to Hugo" width="960" height="540" srcset="https://ift.tt/34cLlbF 960w, https://ift.tt/3dYfjUW 747w, https://ift.tt/2JHx4tP 768w, https://ift.tt/2xSfJvS 5w, https://ift.tt/3bPobdO 300w" sizes="(max-width: 960px) 100vw, 960px">Jekyll is a free and open-source static site generator. If you know how WordPress, Joomla or Drupal works, then, you probably have an idea of how it works. Jekyll is used to build websites with easy to use navigation, website components and generates all the content at once. Jekyll basically provides page templates such as navigation and footers that will reflect on all of your web pages. These templates are merged with other files with definite information (for instance, a file for each blog post on your website) to generate full HTML pages for website users to see. Bootstrap 4 has been a great tool to integrate with Jekyll through Sass (Syntactically Awesome Style Sheets) but in Bootstrap 5, a major switch from Jekyll to Hugo is anticipated. Hugo is described as “A Fast and Flexible Static Site Generator built with love by spf13 in GoLang”. Similar to Jekyll, it is a static site generator but written in Go language. A possible reason for the switch is that Hugo is lightning fast, easy to use and configurable. Compared with Jekyll, it has a great integration with the popular web host and can organize your content with any URL structure. Class Updates <img class="size-full wp-image-591177" src="https://ift.tt/3bSWDo2" alt="Class Updates" width="1209" height="357" srcset="https://ift.tt/3bSWDo2 1209w, https://ift.tt/2x5U6I9 747w, https://ift.tt/34bZQfD 768w, https://ift.tt/3bQaIT6 300w" sizes="(max-width: 1209px) 100vw, 1209px">Of course, Bootstrap 5 will not be interesting without the new Bootstrap CSS class. Bootstrap 4 has more than 1,500 CSS classes. There will be some CSS class that will no longer be available in the new version and some CSS class that will be added. Some of the CSS classes that are already removed, according to the Bootstrap 5’s official Github project tracking board are: form-row form-inline list-inline card-deck Here are some new Bootstrap 5 CSS class added: gx-* classes control the horizontal/column gutter width gy-* classes control the vertical/row gutter width g-* classes control the horizontal & vertical gutter width row-cols-auto Conclusion One of the frustrating experiences of being a developer is reinventing the base HTML, CSS, and JavaScript for each project. While some prefer to write their own code, it still makes sense to just use an existing framework like Bootstrap. With all the new updates coming in Bootstrap 5, it’s safe to say that the Bootstrap team is making huge steps to make the framework lightweight, simple, useful and faster for the developer’s benefit. If you use Bootstrap in your projects, then you will probably love Startup app – Bootstrap Builder. It is a great development tool with lots of ready-made designed and coded templates and themes for faster deployment of your projects.
http://damianfallon.blogspot.com/2020/04/bootstrap-5-whats-new-about-it-and_5.html
0 notes
Text
How to Do a Content Audit [Updated for 2017]
Posted by Everett
https://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js //
This guide provides instructions on how to do a content audit using examples and screenshots from Screaming Frog, URL Profiler, Google Analytics (GA), and Excel, as those seem to be the most widely used and versatile tools for performing content audits.
{Expand for more background}
It’s been almost three years since the original “How to do a Content Audit – Step-by-Step” tutorial was published here on Moz, and it’s due for a refresh. This version includes updates covering JavaScript rendering, crawling dynamic mobile sites, and more.
It also provides less detail than the first in terms of prescribing every step in the process. This is because our internal processes change often, as do the tools. I’ve also seen many other processes out there that I would consider good approaches. Rather than forcing a specific process and publishing something that may be obsolete in six months, this tutorial aims to allow for a variety of processes and tools by focusing more on the basic concepts and less on the specifics of each step.
We have a DeepCrawl account at Inflow, and a specific process for that tool, as well as several others. Tapping directly into various APIs may be preferable to using a middleware product like URL Profiler if one has development resources. There are also custom in-house tools out there, some of which incorporate historic log file data and can efficiently crawl websites like the New York Times and eBay. Whether you use GA or Adobe Sitecatalyst, Excel, or a SQL database, the underlying process of conducting a content audit shouldn’t change much.
TABLE OF CONTENTS
What is an SEO content audit?
What is the purpose of a content audit?
How & why “pruning” works
How to do a content audit
The inventory & audit phase
Step 1: Crawl all indexable URLs
Crawling roadblocks & new technologies
Crawling very large websites
Crawling dynamic mobile sites
Crawling and rendering JavaScript
Step 2: Gather additional metrics
Things you don’t need when analyzing the data
The analysis & recommendations phase
Step 3: Put it all into a dashboard
Step 4: Work the content audit dashboard
The reporting phase
Step 5: Writing up the report
Content audit resources & further reading
What is a content audit?
A content audit for the purpose of SEO includes a full inventory of all indexable content on a domain, which is then analyzed using performance metrics from a variety of sources to determine which content to keep as-is, which to improve, and which to remove or consolidate.
What is the purpose of a content audit?
A content audit can have many purposes and desired outcomes. In terms of SEO, they are often used to determine the following:
How to escape a content-related search engine ranking filter or penalty
Content that requires copywriting/editing for improved quality
Content that needs to be updated and made more current
Content that should be consolidated due to overlapping topics
Content that should be removed from the site
The best way to prioritize the editing or removal of content
Content gap opportunities
Which content is ranking for which keywords
Which content should be ranking for which keywords
The strongest pages on a domain and how to leverage them
Undiscovered content marketing opportunities
Due diligence when buying/selling websites or onboarding new clients
While each of these desired outcomes and insights are valuable results of a content audit, I would define the overall “purpose” of one as:
The purpose of a content audit for SEO is to improve the perceived trust and quality of a domain, while optimizing crawl budget and the flow of PageRank (PR) and other ranking signals throughout the site.
Often, but not always, a big part of achieving these goals involves the removal of low-quality content from search engine indexes. I’ve been told people hate this word, but I prefer the “pruning” analogy to describe the concept.
How & why “pruning” works
{Expand for more on pruning}
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove. Optimizing crawl budget and the flow of PR is self-explanatory to most SEOs. But how does a content audit improve the perceived trust and quality of a domain? By removing low-quality content from the index (pruning) and improving some of the content remaining in the index, the likelihood that someone arrives on your site through organic search and has a poor user experience (indicated to Google in a variety of ways) is lowered. Thus, the quality of the domain improves. I’ve explained the concept here and here.
Others have since shared some likely theories of their own, including a larger focus on the redistribution of PR.
Case study after case study has shown the concept of “pruning” (removing low-quality content from search engine indexes) to be effective, especially on very large websites with hundreds of thousands (or even millions) of indexable URLs. So why do content audits work? Lots of reasons. But really…
Does it matter?
¯\_(ツ)_/¯
How to do a content audit
Just like anything in SEO, from technical and on-page changes to site migrations, things can go horribly wrong when content audits aren’t conducted properly. The most common example would be removing URLs that have external links because link metrics weren’t analyzed as part of the audit. Another common mistake is confusing removal from search engine indexes with removal from the website.
Content audits start with taking an inventory of all content available for indexation by search engines. This content is then analyzed against a variety of metrics and given one of three “Action” determinations. The “Details” of each Action are then expanded upon.
The variety of combinations of options between the “Action” of WHAT to do and the “Details” of HOW (and sometimes why) to do it are as varied as the strategies, sites, and tactics themselves. Below are a few hypothetical examples:
You now have a basic overview of how to perform a content audit. More specific instructions can be found below.
The process can be roughly split into three distinct phases:
Inventory & audit
Analysis & recommendations
Summary & reporting
The inventory & audit phase
Taking an inventory of all content, and related metrics, begins with crawling the site.
One difference between crawling for content audits and technical audits:
Technical SEO audit crawls are concerned with all crawlable content (among other things).
Content audit crawls for the purpose of SEO are concerned with all indexable content.
{Expand for more on crawlable vs. indexable content}
The URL in the image below should be considered non-indexable. Even if it isn’t blocked in the robots.txt file, with a robots meta tag, or an X-robots header response –– even if it is frequently crawled by Google and shows up as a URL in Google Analytics and Search Console –– the rel =”canonical” tag shown below essentially acts like a 301 redirect, telling Google not to display the non-canonical URL in search results and to apply all ranking calculations to the canonical version. In other words, not to “index” it.
I’m not sure “index” is the best word, though. To “display” or “return” in the SERPs is a better way of describing it, as Google surely records canonicalized URL variants somewhere, and advanced site: queries seem to show them in a way that is consistent with the “supplemental index” of yesteryear. But that’s another post, more suitably written by a brighter mind like Bill Slawski.
A URL with a query string that canonicalizes to a version without the query string can be considered “not indexable.”
A content audit can safely ignore these types of situations, which could mean drastically reducing the amount of time and memory taken up by a crawl.
Technical SEO audits, on the other hand, should be concerned with every URL a crawler can find. Non-indexable URLs can reveal a lot of technical issues, from spider traps (e.g. never-ending empty pagination, infinite loops via redirect or canonical tag) to crawl budget optimization (e.g. How many facets/filters deep to allow crawling? 5? 6? 7?) and more.
It is for this reason that trying to combine a technical SEO audit with a content audit often turns into a giant mess, though an efficient idea in theory. When dealing with a lot of data, I find it easier to focus on one or the other: all crawlable URLs, or all indexable URLs.
Orphaned pages (i.e., with no internal links / navigation path) sometimes don’t turn up in technical SEO audits if the crawler had no way to find them. Content audits should discover any indexable content, whether it is linked to internally or not. Side note: A good tech audit would do this, too.
Identifying URLs that should be indexed but are not is something that typically happens during technical SEO audits.
However, if you’re having trouble getting deep pages indexed when they should be, content audits may help determine how to optimize crawl budget and herd bots more efficiently into those important, deep pages. Also, many times Google chooses not to display/index a URL in the SERPs due to poor content quality (i.e., thin or duplicate).
All of this is changing rapidly, though. URLs as the unique identifier in Google’s index are probably going away. Yes, we’ll still have URLs, but not everything requires them. So far, the word “content” and URL has been mostly interchangeable. But some URLs contain an entire application’s worth of content. How to do a content audit in that world is something we’ll have to figure out soon, but only after Google figures out how to organize the web’s information in that same world. From the looks of things, we still have a year or two.
Until then, the process below should handle most situations.
Step 1: Crawl all indexable URLs
A good place to start on most websites is a full Screaming Frog crawl. However, some indexable content might be missed this way. It is not recommended that you rely on a crawler as the source for all indexable URLs.
In addition to the crawler, collect URLs from Google Analytics, Google Webmaster Tools, XML Sitemaps, and, if possible, from an internal database, such as an export of all product and category URLs on an eCommerce website. These can then be crawled in “list mode” separately, then added to your main list of URLs and deduplicated to produce a more comprehensive list of indexable URLs.
Some URLs found via GA, XML sitemaps, and other non-crawl sources may not actually be “indexable.” These should be excluded. One strategy that works here is to combine and deduplicate all of the URL “lists,” and then perform a crawl in list mode. Once crawled, remove all URLs with robots meta or X-Robots noindex tags, as well as any URL returning error codes and those that are blocked by the robots.txt file, etc. At this point, you can safely add these URLs to the file containing indexable URLs from the crawl. Once again, deduplicate the list.
Crawling roadblocks & new technologies
Crawling very large websites
First and foremost, you do not need to crawl every URL on the site. Be concerned with indexable content. This is not a technical SEO audit.
{Expand for more about crawling very large websites}
Avoid crawling unnecessary URLs
Some of the things you can avoid crawling and adding to the content audit in many cases include:
Noindexed or robots.txt-blocked URLs
4XX and 5XX errors
Redirecting URLs and those that canonicalize to a different URL
Images, CSS, JavaScript, and SWF files
Segment the site into crawlable chunks
You can often get Screaming Frog to completely crawl a single directory at a time if the site is too large to crawl all at once.
Filter out URL patterns you plan to remove from the index
Let’s say you’re auditing a domain on WordPress and you notice early in the crawl that /tag/ pages are indexable. A quick site:domain.com inurl:tag search on Google tells you there are about 10 million of them. A quick look at Google Analytics confirms that URLs in the /tag/ directory are not responsible for very much revenue from organic search. It would be safe to say that the “Action” on these URLs should be “Remove” and the “Details” should read something like this: Remove /tag/ URLs from the indexed with a robots noindex,follow meta tag. More advice on this strategy can be found here.
Upgrade your machine
Install additional RAM on your computer, which is used by Screaming Frog to hold data during the crawl. This has the added benefit of improving Excel performance, which can also be a major roadblock.
You can also install Screaming Frog on Amazon Web Server (AWS), as described in this post on iPullRank.
Tune up your tools
Screaming Frog provides several ways for SEOs to get more out of the crawler. This includes adjusting the speed, max threads, search depth, query strings, timeouts, retries, and the amount of RAM available to the program. Leave at least 3GB off limits to the spider to avoid catastrophic freezing of the entire machine and loss of data. You can learn more about tuning up Screaming Frog here and here.
Try other tools
I’m convinced that there’s a ton of wasted bandwidth on most content audit projects due to strategists releasing a crawler and allowing it to chew through an entire domain, whether the URLs are indexable or not. People run Screaming Frog without saving the crawl intermittently, without adding more RAM availability, without filtering out the nonsense, or using any of the crawl customization features available to them.
That said, sometimes SF just doesn’t get the job done. We also have a process specific to DeepCrawl, and have used Botify, as well as other tools. They each have their pros and cons. I still prefer Screaming Frog for crawling and URL Profiler for fetching metrics in most cases.
Crawling dynamic mobile sites
This refers to a specific type of mobile setup in which there are two code-bases –– one for mobile and one for desktop –– but only one URL. Thus, the content of a single URL may vary significantly depending on which type of device is visiting that URL. In such cases, you will essentially be performing two separate content audits. Proceed as usual for the desktop version. Below are instructions for crawling the mobile version.
{Expand for more on crawling dynamic websites}
Crawling a dynamic mobile site for a content audit will require changing the User-Agent of the crawler, as shown here under Screaming Frog’s “Configure —> HTTP Header” menu:
The important thing to remember when working on mobile dynamic websites is that you’re only taking an inventory of indexable URLs on one version of the site or the other. Once the two inventories are taken, you can then compare them to uncover any unintentional issues.
Some examples of what this process can find in a technical SEO audit include situations in which titles, descriptions, canonical tags, robots meta, rel next/prev, and other important elements do not match between the two versions of the page. It’s vital that the mobile and desktop version of each page have parity when it comes to these essentials.
It’s easy for the mobile version of a historically desktop-first website to end up providing conflicting instructions to search engines because it’s not often “automatically changed” when the desktop version changes. A good example here is a website I recently looked at with about 20 million URLs, all of which had the following title tag when loaded by a mobile user (including Google): BRAND NAME – MOBILE SITE. Imagine the consequences of that once a mobile-first algorithm truly rolls out.
Crawling and rendering JavaScript
One of the many technical issues SEOs have been increasingly dealing with over the last couple of years is the proliferation of websites built on JavaScript frameworks and libraries like React.js, Ember.js, and Angular.js.
{Expand for more on crawling Javascript websites}
Most crawlers have made a lot of progress lately when it comes to crawling and rendering JavaScript content. Now, it’s as easy as changing a few settings, as shown below with Screaming Frog.
When crawling URLs with #! , use the “Old AJAX Crawling Scheme.” Otherwise, select “JavaScript” from the “Rendering” tab when configuring your Screaming Frog SEO Spider to crawl JavaScript websites.
How do you know if you’re dealing with a JavaScript website?
First of all, most websites these days are going to be using some sort of JavaScript technology, though more often than not (so far) these will be rendered by the “client” (i.e., by your browser). An example would be the .js file that controls the behavior of a form or interactive tool.
What we’re discussing here is when the JavaScript is used “server-side” and needs to be executed in order to render the page.
JavaScript libraries and frameworks are used to develop single-page web apps and highly interactive websites. Below are a few different things that should alert you to this challenge:
The URLs contain #! (hashbangs). For example: example.com/page#!key=value (AJAX)
Content-rich pages with only a few lines of code (and no iframes) when viewing the source code.
What looks like server-side code in the meta tags instead of the actual content of the tag. For example:
You can also use the BuiltWith Technology Profiler or the Library Detector plugins for Chrome, which shows JavaScript libraries being used on a page in the address bar.
Not all websites built primarily with JavaScript require special attention to crawl settings. Some websites use pre-rendering services like Brombone or Prerender.io to serve the crawler a fully rendered version of the page. Others use isomorphic JavaScript to accomplish the same thing.
Step 2: Gather additional metrics
Most crawlers will give you the URL and various on-page metrics and data, such as the titles, descriptions, meta tags, and word count. In addition to these, you’ll want to know about internal and external links, traffic, content uniqueness, and much more in order to make fully informed recommendations during the analysis portion of the content audit project.
Your process may vary, but we generally try to pull in everything we need using as few sources as possible. URL Profiler is a great resource for this purpose, as it works well with Screaming Frog and integrates easily with all of the APIs we need.
Once the Screaming Frog scan is complete (only crawling indexable content) export the “Internal All” file, which can then be used as the seed list in URL Profiler (combined with any additional indexable URLs found outside of the crawl via GSC, GA, and elsewhere).
This is what my URL Profiler settings look for a typical content audit for a small- or medium-sized site. Also, under “Accounts” I have connected via API keys to Moz and SEMrush.
Once URL Profiler is finished, you should end up with something like this:
Screaming Frog and URL Profiler: Between these two tools and the APIs they connect with, you may not need anything else at all in order to see the metrics below for every indexable URL on the domain.
The risk of getting analytics data from a third-party tool
We’ve noticed odd data mismatches and sampled data when using the method above on large, high-traffic websites. Our internal process involves exporting these reports directly from Google Analytics, sometimes incorporating Analytics Canvas to get the full, unsampled data from GA. Then VLookups are used in the spreadsheet to combine the data, with URL being the unique identifier.
Metrics to pull for each URL:
Indexed or not?
If crawlers are set up properly, all URLs should be “indexable.”
A non-indexed URL is often a sign of an uncrawled or low-quality page.
Content uniqueness
Copyscape, Siteliner, and now URL Profiler can provide this data.
Traffic from organic search
Typically 90 days
Keep a consistent timeframe across all metrics.
Revenue and/or conversions
You could view this by “total,” or by segmenting to show only revenue from organic search on a per-page basis.
Publish date
If you can get this into Google Analytics as a custom dimension prior to fetching the GA data, it will help you discover stale content.
Internal links
Content audits provide the perfect opportunity to tighten up your internal linking strategy by ensuring the most important pages have the most internal links.
External links
These can come from Moz, SEMRush, and a variety of other tools, most of which integrate natively or via APIs with URL Profiler.
Landing pages resulting in low time-on-site
Take this one with a grain of salt. If visitors found what they want because the content was good, that’s not a bad metric. A better proxy for this would be scroll depth, but that would probably require setting up a scroll-tracking “event.”
Landing pages resulting in Low Pages-Per-Visit
Just like with Time-On-Site, sometimes visitors find what they’re looking for on a single page. This is often true for high-quality content.
Response code
Typically, only URLs that return a 200 (OK) response code are indexable. You may not require this metric in the final data if that’s the case on your domain.
Canonical tag
Typically only URLs with a self-referencing rel=“canonical” tag should be considered “indexable.” You may not require this metric in the final data if that’s the case on your domain.
Page speed and mobile-friendliness
Again, URL Profiler comes through with their Google PageSpeed Insights API integration.
Before you begin analyzing the data, be sure to drastically improve your mental health and the performance of your machine by taking the opportunity to get rid of any data you don’t need. Here are a few things you might consider deleting right away (after making a copy of the full data set, of course).
Things you don’t need when analyzing the data
{Expand for more on removing unnecessary data}
URL Profiler and Screaming Frog tabs Just keep the “combined data” tab and immediately cut the amount of data in the spreadsheet by about half.
Content Type Filtering by Content Type (e.g., text/html, image, PDF, CSS, JavaScript) and removing any URL that is of no concern in your content audit is a good way to speed up the process.
Technically speaking, images can be indexable content. However, I prefer to deal with them separately for now.
Filtering unnecessary file types out like I’ve done in the screenshot above improves focus, but doesn’t improve performance very much. A better option would be to first select the file types you don’t want, apply the filter, delete the rows you don’t want, and then go back to the filter options and “(Select All).”
Once you have only the content types you want, it may now be possible to simply delete the entire Content Type column.
Status Code and Status You only need one or the other. I prefer to keep the Code, and delete the Status column.
Length and Pixels You only need one or the other. I prefer to keep the Pixels, and delete the Length column. This applies to all Title and Meta Description columns.
Meta Keywords Delete the columns. If those cells have content, consider removing that tag from the site.
DNS Safe URL, Path, Domain, Root, and TLD You should really only be working on a single top-level domain. Content audits for subdomains should probably be done separately. Thus, these columns can be deleted in most cases.
Duplicate Columns You should have two columns for the URL (The “Address” in column A from URL Profiler, and the “URL” column from Screaming Frog). Similarly, there may also be two columns each for HTTP Status and Status Code. It depends on the settings selected in both tools, but there are sure to be some overlaps, which can be removed to reduce the file size, enhance focus, and speed up the process.
Blank Columns Keep the filter tool active and go through each column. Those with only blank cells can be deleted. The example below shows that column BK (Robots HTTP Header) can be removed from the spreadsheet.
[You can save a lot of headspace by hiding or removing blank columns.]
Single-Value Columns If the column contains only one value, it can usually be removed. The screenshot below shows our non-secure site does not have any HTTPS URLs, as expected. I can now remove the column. Also, I guess it’s probably time I get that HTTPS migration project scheduled.
Hopefully by now you’ve made a significant dent in reducing the overall size of the file and time it takes to apply formatting and formula changes to the spreadsheet. It’s time to start diving into the data.
The analysis & recommendations phase
Here’s where the fun really begins. In a large organization, it’s tempting to have a junior SEO do all of the data-gathering up to this point. I find it useful to perform the crawl myself, as the process can be highly informative.
Step 3: Put it all into a dashboard
Even after removing unnecessary data, performance could still be a major issue, especially if working in Google Sheets. I prefer to do all of this in Excel, and only upload into Google Sheets once it’s ready for the client. If Excel is running slow, consider splitting up the URLs by directory or some other factor in order to work with multiple, smaller spreadsheets.
Creating a dashboard can be as easy as adding two columns to the spreadsheet. The first new column, “Action,” should be limited to three options, as shown below. This makes filtering and sorting data much easier. The “Details” column can contain freeform text to provide more detailed instructions for implementation.
Use Data Validation and a drop-down selector to limit Action options.
Step 4: Work the content audit dashboard
All of the data you need should now be right in front of you. This step can’t be turned into a repeatable process for every content audit. From here on the actual step-by-step process becomes much more open to interpretation and your own experience. You may do some of them and not others. You may do them a little differently. That’s all fine, as long as you’re working toward the goal of determining what to do, if anything, for each piece of content on the website.
A good place to start would be to look for any content-related issues that might cause an algorithmic filter or manual penalty to be applied, thereby dragging down your rankings.
Causes of content-related penalties
These typically fall under three major categories: quality, duplication, and relevancy. Each category can be further broken down into a variety of issues, which are detailed below.
{Expand to learn more about quality, duplication, and relevancy issues}
Typical low-quality content
Poor grammar, written primarily for search engines (includes keyword stuffing), unhelpful, inaccurate…
Completely irrelevant content
OK in small amounts, but often entire blogs are full of it.
A typical example would be a “linkbait” piece circa 2010.
Thin/short content
Glossed over the topic, too few words, or all image-based content.
Curated content with no added value
Comprised almost entirely of bits and pieces of content that exists elsewhere.
Misleading optimization
Titles or keywords targeting queries for which content doesn’t answer or deserve to rank.
Generally not providing the information the visitor was expecting to find.
Duplicate content
Internally duplicated on other pages (e.g., categories, product variants, archives, technical issues, etc.).
Externally duplicated (e.g., manufacturer product descriptions, product descriptions duplicated in feeds used for other channels like Amazon, shopping comparison sites and eBay, plagiarized content, etc.)
Stub pages (e.g., “No content is here yet, but if you sign in and leave some user-generated-content, then we’ll have content here for the next guy.” By the way, want our newsletter? Click an AD!)
Indexable internal search results
Too many indexable blog tag or blog category pages
And so on and so forth…
It helps to sort the data in various ways to see what’s going on. Below are a few different things to look for if you’re having trouble getting started.
{Expand to learn more about what to look for}
Sort by duplicate content risk
URL Profiler now has a native duplicate content checker. Other options are Copyscape (for external duplicate content) and Siteliner (for internal duplicate content).
Which of these pages should be rewritten?
Rewrite key/important pages, such as categories, home page, top products
Rewrite pages with good link and social metrics
Rewrite pages with good traffic
After selecting “Improve” in the Action column, elaborate in the Details column:
“Improve these pages by writing unique, useful content to improve the Copyscape risk score.”
Which of these pages should be removed/pruned?
Remove guest posts that were published elsewhere
Remove anything the client plagiarized
Remove content that isn’t worth rewriting, such as:
No external links, no social shares, and very few or no entrances/visits
After selecting “Remove” from the Action column, elaborate in the Details column:
“Prune from site to remove duplicate content. This URL has no links or shares and very little traffic. We recommend allowing the URL to return 404 or 410 response code. Remove all internal links, including from the sitemap.”
Which of these pages should be consolidated into others?
Presumably none, since the content is already externally duplicated.
Which of these pages should be left “As-Is”?
Important pages which have had their content stolen
Sort by entrances or visits (filtering out any that were already finished)
Which of these pages should be marked as “Improve”?
Pages with high visits/entrances but low conversion, time-on-site, pageviews per session, etc.
Key pages that require improvement determined after a manual review of the page.
Which of these pages should be marked as “Consolidate”?
When you have overlapping topics that don’t provide much unique value of their own, but could make a great resource when combined.
Mark the page in the set with the best metrics as “Improve” and in the Details column, outline which pages are going to be consolidated into it. This is the canonical page.
Mark the pages that are to be consolidated into the canonical page as “Consolidate” and provide further instructions in the Details column, such as:
Use portions of this content to round out /canonicalpage/ and then 301 redirect this page into /canonicalpage/
Update all internal links.
Campaign-based or seasonal pages that could be consolidated into a single “Evergreen” landing page (e.g., Best Sellers of 2012 and Best Sellers of 2013 —> Best Sellers).
Which of these pages should be marked as “Remove”?
Pages with poor link, traffic, and social metrics related to low-quality content that isn’t worth updating
Typically these will be allowed to 404/410.
Irrelevant content
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Out-of-date content that isn’t worth updating or consolidating
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Which of these pages should be marked as “Leave As-Is”?
Pages with good traffic, conversions, time on site, etc. that also have good content.
These may or may not have any decent external links.
Taking the hatchet to bloated websites
For big sites, it’s best to use a hatchet-based approach as much as possible, and finish up with a scalpel in the end. Otherwise, you’ll spend way too much time on the project, which eats into the ROI.
This is not a process that can be documented step-by-step. For the purpose of illustration, however, below are a few different examples of hatchet approaches and when to consider using them.
{Expand for examples of hatchet approaches}
Parameter-based URLs that shouldn’t be indexed
Defer to the technical audit, if applicable. Otherwise, use your best judgment:
e.g., /?sort=color, &size=small
Assuming the tech audit didn’t suggest otherwise, these pages could all be handled in one fell swoop. Below is an example Action and example Details for such a page:
Action = Remove
Details = Rel canonical to the base page without the parameter
Internal search results
Defer to the technical audit if applicable. Otherwise, use your best judgment:
e.g., /search/keyword-phrase/
Assuming the tech audit didn’t suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
Blog tag pages
Defer to the technical audit if applicable. Otherwise:
e.g., /blog/tag/green-widgets/ , blog/tag/blue-widgets/
Assuming the tech audit didn’t suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
E-commerce product pages with manufacturer descriptions
In cases where the “Page Type” is known (i.e., it’s in the URL or was provided in a CMS export) and Risk Score indicates duplication:
e.g., /product/product-name/
Assuming the tech audit didn’t suggest otherwise:
Action = Improve
Details = Rewrite to improve product description and avoid duplicate content
E-commerce category pages with no static content
In cases where the “Page Type” is known:
e.g. /category/category-name/ or category/cat1/cat2/
Assuming NONE of the category pages have content:
Action = Improve
Details = Write 2–3 sentences of unique, useful content that explains choices, next steps, or benefits to the visitor looking to choose a product from the category.
Out-of-date blog posts, articles, and other landing pages
In cases where the title tag includes a date, or…
In cases where the URL indicates the publishing date:
Action = Improve
Details = Update the post to make it more current, if applicable. Otherwise, change Action to “Remove” and customize the Strategy based on links and traffic (i.e., 301 or 404).
Content marked for improvement should lay out more specific instructions in the “Details” column, such as:
Update the old content to make it more relevant
Add more useful content to “beef up” this thin page
Incorporate content from overlapping URLs/pages
Rewrite to avoid internal duplication
Rewrite to avoid external duplication
Reduce image sizes to speed up page load
Create a “responsive” template for this page to fit on mobile devices
Etc.
Content marked for removal should include specific instructions in the “Details” column, such as:
Consolidate this content into the following URL/page marked as “Improve”
Then redirect the URL
Remove this page from the site and allow the URL to return a 410 or 404 HTTP status code. This content has had zero visits within the last 360 days, and has no external links. Then remove or update internal links to this page.
Remove this page from the site and 301 redirect the URL to the following URL marked as “Improve”… Do not incorporate the content into the new page. It is low-quality.
Remove this archive page from search engine indexes with a robots noindex meta tag. Continue to allow the page to be accessed by visitors and crawled by search engines.
Remove this internal search result page from the search engine indexed with a robots noindex meta tag. Once removed from the index (about 15–30 days later), add the following line to the #BlockedDirectories section of the robots.txt file: Disallow: /search/.
As you can see from the many examples above, sorting by “Page Type” can be quite handy when applying the same Action and Details to an entire section of the website.
After all of the tool set-up, data gathering, data cleanup, and analysis across dozens of metrics, what matters in the end is the Action to take and the Details that go with it.
URL, Action, and Details: These three columns will be used by someone to implement your recommendations. Be clear and concise in your instructions, and don’t make decisions without reviewing all of the wonderful data-points you’ve collected.
Here is a sample content audit spreadsheet to use as a template, or for ideas. It includes a few extra tabs specific to the way we used to do content audits at Inflow.
WARNING!
As Razvan Gavrilas pointed out in his post on Cognitive SEO from 2015, without doing the research above you risk pruning valuable content from search engine indexes. Be bold, but make highly informed decisions:
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove.
The reporting phase
The content audit dashboard is exactly what we need internally: a spreadsheet crammed with data that can be sliced and diced in so many useful ways that we can always go back to it for more insight and ideas. Some clients appreciate that as well, but most are going to find the greater benefit in our final content audit report, which includes a high-level overview of our recommendations.
Counting actions from Column B
It is useful to count the quantity of each Action along with total organic search traffic and/or revenue for each URL. This will help you (and the client) identify important metrics, such as total organic traffic for pages marked to be pruned. It will also make the final report much easier to build.
Step 5: Writing up the report
Your analysis and recommendations should be delivered at the same time as the audit dashboard. It summarizes the findings, recommendations, and next steps from the audit, and should start with an executive summary.
Here is a real example of an executive summary from one of Inflow’s content audit strategies:
As a result of our comprehensive content audit, we are recommending the following, which will be covered in more detail below:
Removal of about 624 pages from Google index by deletion or consolidation:
203 Pages were marked for Removal with a 404 error (no redirect needed)
110 Pages were marked for Removal with a 301 redirect to another page
311 Pages were marked for Consolidation of content into other pages
Followed by a redirect to the page into which they were consolidated
Rewriting or improving of 668 pages
605 Product Pages are to be rewritten due to use of manufacturer product descriptions (duplicate content), these being prioritized from first to last within the Content Audit.
63 “Other” pages to be rewritten due to low-quality or duplicate content.
Keeping 226 pages as-is
No rewriting or improvements needed
These changes reflect an immediate need to “improve or remove” content in order to avoid an obvious content-based penalty from Google (e.g. Panda) due to thin, low-quality and duplicate content, especially concerning Representative and Dealers pages with some added risk from Style pages.
The content strategy should end with recommended next steps, including action items for the consultant and the client. Below is a real example from one of our documents.
We recommend the following three projects in order of their urgency and/or potential ROI for the site:
Project 1: Remove or consolidate all pages marked as “Remove”. Detailed instructions for each URL can be found in the “Details” column of the Content Audit Dashboard.
Project 2: Copywriting to improve/rewrite content on Style pages. Ensure unique, robust content and proper keyword targeting.
Project 3: Improve/rewrite all remaining pages marked as “Improve” in the Content Audit Dashboard. Detailed instructions for each URL can be found in the “Details” column
Content audit resources & further reading
Understanding Mobile-First Indexing and the Long-Term Impact on SEO by Cindy Krum This thought-provoking post begs the question: How will we perform content inventories without URLs? It helps to know Google is dealing with the exact same problem on a much, much larger scale.
Here is a spreadsheet template to help you calculate revenue and traffic changes before and after updating content.
Expanding the Horizons of eCommerce Content Strategy by Dan Kern of Inflow An epic post about content strategies for eCommerce businesses, which includes several good examples of content on different types of pages targeted toward various stages in the buying cycle.
The Content Inventory is Your Friend by Kristina Halvorson on BrainTraffic Praise for the life-changing powers of a good content audit inventory.
Everything You Need to Perform Content Audits
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
from Moz Blog https://moz.com/blog/content-audit via IFTTT
from Blogger http://imlocalseo.blogspot.com/2017/03/how-to-do-content-audit-updated-for-2017.html via IFTTT
from IM Local SEO https://imlocalseo.wordpress.com/2017/03/22/how-to-do-a-content-audit-updated-for-2017/ via IFTTT
from Gana Dinero Colaborando | Wecon Project https://weconprojectspain.wordpress.com/2017/03/22/how-to-do-a-content-audit-updated-for-2017/ via IFTTT
from WordPress https://mrliberta.wordpress.com/2017/03/22/how-to-do-a-content-audit-updated-for-2017/ via IFTTT
0 notes
Text
How to Do a Content Audit [Updated for 2017]
Posted by Everett
//<![CDATA[ (function($) { // code using $ as alias to jQuery $(function() { // Hide the hypotext content. $('.hypotext-content').hide(); // When a hypotext link is clicked. $('a.hypotext.closed').click(function (e) { // custom handling here e.preventDefault(); // Create the class reference from the rel value. var id = '.' + $(this).attr('rel'); // If the content is hidden, show it now. if ( $(id).css('display') == 'none' ) { $(id).show('slow'); if (jQuery.ui) { // UI loaded $(id).effect("highlight", {}, 1000); } } // If the content is shown, hide it now. else { $(id).hide('slow'); } }); // If we have a hash value in the url. if (window.location.hash) { // If the anchor is within a hypotext block, expand it, by clicking the // relevant link. console.log(window.location.hash); var anchor = $(window.location.hash); var hypotextLink = $('#' + anchor.parents('.hypotext-content').attr('rel')); console.log(hypotextLink); hypotextLink.click(); // Wait until the content has expanded before jumping to anchor. //$.delay(1000); setTimeout(function(){ scrollToAnchor(window.location.hash); }, 1000); } }); function scrollToAnchor(id) { var anchor = $(id); $('html,body').animate({scrollTop: anchor.offset().top},'slow'); } })(jQuery); //]]>
This guide provides instructions on how to do a content audit using examples and screenshots from Screaming Frog, URL Profiler, Google Analytics (GA), and Excel, as those seem to be the most widely used and versatile tools for performing content audits.
{Expand for more background}
It's been almost three years since the original “How to do a Content Audit – Step-by-Step” tutorial was published here on Moz, and it’s due for a refresh. This version includes updates covering JavaScript rendering, crawling dynamic mobile sites, and more.
It also provides less detail than the first in terms of prescribing every step in the process. This is because our internal processes change often, as do the tools. I’ve also seen many other processes out there that I would consider good approaches. Rather than forcing a specific process and publishing something that may be obsolete in six months, this tutorial aims to allow for a variety of processes and tools by focusing more on the basic concepts and less on the specifics of each step.
We have a DeepCrawl account at Inflow, and a specific process for that tool, as well as several others. Tapping directly into various APIs may be preferable to using a middleware product like URL Profiler if one has development resources. There are also custom in-house tools out there, some of which incorporate historic log file data and can efficiently crawl websites like the New York Times and eBay. Whether you use GA or Adobe Sitecatalyst, Excel, or a SQL database, the underlying process of conducting a content audit shouldn’t change much.
TABLE OF CONTENTS
What is an SEO content audit?
What is the purpose of a content audit?
How & why “pruning” works
How to do a content audit
The inventory & audit phase
Step 1: Crawl all indexable URLs
Crawling roadblocks & new technologies
Crawling very large websites
Crawling dynamic mobile sites
Crawling and rendering JavaScript
Step 2: Gather additional metrics
Things you don’t need when analyzing the data
The analysis & recommendations phase
Step 3: Put it all into a dashboard
Step 4: Work the content audit dashboard
The reporting phase
Step 5: Writing up the report
Content audit resources & further reading
What is a content audit?
A content audit for the purpose of SEO includes a full inventory of all indexable content on a domain, which is then analyzed using performance metrics from a variety of sources to determine which content to keep as-is, which to improve, and which to remove or consolidate.
What is the purpose of a content audit?
A content audit can have many purposes and desired outcomes. In terms of SEO, they are often used to determine the following:
How to escape a content-related search engine ranking filter or penalty
Content that requires copywriting/editing for improved quality
Content that needs to be updated and made more current
Content that should be consolidated due to overlapping topics
Content that should be removed from the site
The best way to prioritize the editing or removal of content
Content gap opportunities
Which content is ranking for which keywords
Which content should be ranking for which keywords
The strongest pages on a domain and how to leverage them
Undiscovered content marketing opportunities
Due diligence when buying/selling websites or onboarding new clients
While each of these desired outcomes and insights are valuable results of a content audit, I would define the overall “purpose” of one as:
The purpose of a content audit for SEO is to improve the perceived trust and quality of a domain, while optimizing crawl budget and the flow of PageRank (PR) and other ranking signals throughout the site.
Often, but not always, a big part of achieving these goals involves the removal of low-quality content from search engine indexes. I’ve been told people hate this word, but I prefer the “pruning” analogy to describe the concept.
How & why “pruning” works
{Expand for more on pruning}
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove. Optimizing crawl budget and the flow of PR is self-explanatory to most SEOs. But how does a content audit improve the perceived trust and quality of a domain? By removing low-quality content from the index (pruning) and improving some of the content remaining in the index, the likelihood that someone arrives on your site through organic search and has a poor user experience (indicated to Google in a variety of ways) is lowered. Thus, the quality of the domain improves. I’ve explained the concept here and here.
Others have since shared some likely theories of their own, including a larger focus on the redistribution of PR.
Case study after case study has shown the concept of “pruning” (removing low-quality content from search engine indexes) to be effective, especially on very large websites with hundreds of thousands (or even millions) of indexable URLs. So why do content audits work? Lots of reasons. But really...
Does it matter?
¯\_(ツ)_/¯
How to do a content audit
Just like anything in SEO, from technical and on-page changes to site migrations, things can go horribly wrong when content audits aren’t conducted properly. The most common example would be removing URLs that have external links because link metrics weren’t analyzed as part of the audit. Another common mistake is confusing removal from search engine indexes with removal from the website.
Content audits start with taking an inventory of all content available for indexation by search engines. This content is then analyzed against a variety of metrics and given one of three “Action” determinations. The “Details” of each Action are then expanded upon.
The variety of combinations of options between the “Action” of WHAT to do and the “Details” of HOW (and sometimes why) to do it are as varied as the strategies, sites, and tactics themselves. Below are a few hypothetical examples:
You now have a basic overview of how to perform a content audit. More specific instructions can be found below.
The process can be roughly split into three distinct phases:
Inventory & audit
Analysis & recommendations
Summary & reporting
The inventory & audit phase
Taking an inventory of all content, and related metrics, begins with crawling the site.
One difference between crawling for content audits and technical audits:
Technical SEO audit crawls are concerned with all crawlable content (among other things).
Content audit crawls for the purpose of SEO are concerned with all indexable content.
{Expand for more on crawlable vs. indexable content}
The URL in the image below should be considered non-indexable. Even if it isn’t blocked in the robots.txt file, with a robots meta tag, or an X-robots header response –– even if it is frequently crawled by Google and shows up as a URL in Google Analytics and Search Console –– the rel =”canonical” tag shown below essentially acts like a 301 redirect, telling Google not to display the non-canonical URL in search results and to apply all ranking calculations to the canonical version. In other words, not to “index” it.
I'm not sure “index” is the best word, though. To “display” or “return” in the SERPs is a better way of describing it, as Google surely records canonicalized URL variants somewhere, and advanced site: queries seem to show them in a way that is consistent with the "supplemental index" of yesteryear. But that's another post, more suitably written by a brighter mind like Bill Slawski.
A URL with a query string that canonicalizes to a version without the query string can be considered “not indexable.”
A content audit can safely ignore these types of situations, which could mean drastically reducing the amount of time and memory taken up by a crawl.
Technical SEO audits, on the other hand, should be concerned with every URL a crawler can find. Non-indexable URLs can reveal a lot of technical issues, from spider traps (e.g. never-ending empty pagination, infinite loops via redirect or canonical tag) to crawl budget optimization (e.g. How many facets/filters deep to allow crawling? 5? 6? 7?) and more.
It is for this reason that trying to combine a technical SEO audit with a content audit often turns into a giant mess, though an efficient idea in theory. When dealing with a lot of data, I find it easier to focus on one or the other: all crawlable URLs, or all indexable URLs.
Orphaned pages (i.e., with no internal links / navigation path) sometimes don’t turn up in technical SEO audits if the crawler had no way to find them. Content audits should discover any indexable content, whether it is linked to internally or not. Side note: A good tech audit would do this, too.
Identifying URLs that should be indexed but are not is something that typically happens during technical SEO audits.
However, if you're having trouble getting deep pages indexed when they should be, content audits may help determine how to optimize crawl budget and herd bots more efficiently into those important, deep pages. Also, many times Google chooses not to display/index a URL in the SERPs due to poor content quality (i.e., thin or duplicate).
All of this is changing rapidly, though. URLs as the unique identifier in Google’s index are probably going away. Yes, we’ll still have URLs, but not everything requires them. So far, the word “content” and URL has been mostly interchangeable. But some URLs contain an entire application’s worth of content. How to do a content audit in that world is something we’ll have to figure out soon, but only after Google figures out how to organize the web’s information in that same world. From the looks of things, we still have a year or two.
Until then, the process below should handle most situations.
Step 1: Crawl all indexable URLs
A good place to start on most websites is a full Screaming Frog crawl. However, some indexable content might be missed this way. It is not recommended that you rely on a crawler as the source for all indexable URLs.
In addition to the crawler, collect URLs from Google Analytics, Google Webmaster Tools, XML Sitemaps, and, if possible, from an internal database, such as an export of all product and category URLs on an eCommerce website. These can then be crawled in “list mode” separately, then added to your main list of URLs and deduplicated to produce a more comprehensive list of indexable URLs.
Some URLs found via GA, XML sitemaps, and other non-crawl sources may not actually be “indexable.” These should be excluded. One strategy that works here is to combine and deduplicate all of the URL “lists,” and then perform a crawl in list mode. Once crawled, remove all URLs with robots meta or X-Robots noindex tags, as well as any URL returning error codes and those that are blocked by the robots.txt file, etc. At this point, you can safely add these URLs to the file containing indexable URLs from the crawl. Once again, deduplicate the list.
Crawling roadblocks & new technologies
Crawling very large websites
First and foremost, you do not need to crawl every URL on the site. Be concerned with indexable content. This is not a technical SEO audit.
{Expand for more about crawling very large websites}
Avoid crawling unnecessary URLs
Some of the things you can avoid crawling and adding to the content audit in many cases include:
Noindexed or robots.txt-blocked URLs
4XX and 5XX errors
Redirecting URLs and those that canonicalize to a different URL
Images, CSS, JavaScript, and SWF files
Segment the site into crawlable chunks
You can often get Screaming Frog to completely crawl a single directory at a time if the site is too large to crawl all at once.
Filter out URL patterns you plan to remove from the index
Let’s say you’re auditing a domain on WordPress and you notice early in the crawl that /tag/ pages are indexable. A quick site:domain.com inurl:tag search on Google tells you there are about 10 million of them. A quick look at Google Analytics confirms that URLs in the /tag/ directory are not responsible for very much revenue from organic search. It would be safe to say that the “Action” on these URLs should be “Remove” and the “Details” should read something like this: Remove /tag/ URLs from the indexed with a robots noindex,follow meta tag. More advice on this strategy can be found here.
Upgrade your machine
Install additional RAM on your computer, which is used by Screaming Frog to hold data during the crawl. This has the added benefit of improving Excel performance, which can also be a major roadblock.
You can also install Screaming Frog on Amazon Web Server (AWS), as described in this post on iPullRank.
Tune up your tools
Screaming Frog provides several ways for SEOs to get more out of the crawler. This includes adjusting the speed, max threads, search depth, query strings, timeouts, retries, and the amount of RAM available to the program. Leave at least 3GB off limits to the spider to avoid catastrophic freezing of the entire machine and loss of data. You can learn more about tuning up Screaming Frog here and here.
Try other tools
I’m convinced that there's a ton of wasted bandwidth on most content audit projects due to strategists releasing a crawler and allowing it to chew through an entire domain, whether the URLs are indexable or not. People run Screaming Frog without saving the crawl intermittently, without adding more RAM availability, without filtering out the nonsense, or using any of the crawl customization features available to them.
That said, sometimes SF just doesn’t get the job done. We also have a process specific to DeepCrawl, and have used Botify, as well as other tools. They each have their pros and cons. I still prefer Screaming Frog for crawling and URL Profiler for fetching metrics in most cases.
Crawling dynamic mobile sites
This refers to a specific type of mobile setup in which there are two code-bases –– one for mobile and one for desktop –– but only one URL. Thus, the content of a single URL may vary significantly depending on which type of device is visiting that URL. In such cases, you will essentially be performing two separate content audits. Proceed as usual for the desktop version. Below are instructions for crawling the mobile version.
{Expand for more on crawling dynamic websites}
Crawling a dynamic mobile site for a content audit will require changing the User-Agent of the crawler, as shown here under Screaming Frog’s “Configure ---> HTTP Header” menu:
The important thing to remember when working on mobile dynamic websites is that you're only taking an inventory of indexable URLs on one version of the site or the other. Once the two inventories are taken, you can then compare them to uncover any unintentional issues.
Some examples of what this process can find in a technical SEO audit include situations in which titles, descriptions, canonical tags, robots meta, rel next/prev, and other important elements do not match between the two versions of the page. It's vital that the mobile and desktop version of each page have parity when it comes to these essentials.
It's easy for the mobile version of a historically desktop-first website to end up providing conflicting instructions to search engines because it's not often “automatically changed” when the desktop version changes. A good example here is a website I recently looked at with about 20 million URLs, all of which had the following title tag when loaded by a mobile user (including Google): BRAND NAME - MOBILE SITE. Imagine the consequences of that once a mobile-first algorithm truly rolls out.
Crawling and rendering JavaScript
One of the many technical issues SEOs have been increasingly dealing with over the last couple of years is the proliferation of websites built on JavaScript frameworks and libraries like React.js, Ember.js, and Angular.js.
{Expand for more on crawling Javascript websites}
Most crawlers have made a lot of progress lately when it comes to crawling and rendering JavaScript content. Now, it’s as easy as changing a few settings, as shown below with Screaming Frog.
When crawling URLs with #! , use the “Old AJAX Crawling Scheme.” Otherwise, select “JavaScript” from the “Rendering” tab when configuring your Screaming Frog SEO Spider to crawl JavaScript websites.
How do you know if you’re dealing with a JavaScript website?
First of all, most websites these days are going to be using some sort of JavaScript technology, though more often than not (so far) these will be rendered by the “client” (i.e., by your browser). An example would be the .js file that controls the behavior of a form or interactive tool.
What we’re discussing here is when the JavaScript is used “server-side” and needs to be executed in order to render the page.
JavaScript libraries and frameworks are used to develop single-page web apps and highly interactive websites. Below are a few different things that should alert you to this challenge:
The URLs contain #! (hashbangs). For example: http://ift.tt/2nQK6ch (AJAX)
Content-rich pages with only a few lines of code (and no iframes) when viewing the source code.
What looks like server-side code in the meta tags instead of the actual content of the tag. For example:
You can also use the BuiltWith Technology Profiler or the Library Detector plugins for Chrome, which shows JavaScript libraries being used on a page in the address bar.
Not all websites built primarily with JavaScript require special attention to crawl settings. Some websites use pre-rendering services like Brombone or Prerender.io to serve the crawler a fully rendered version of the page. Others use isomorphic JavaScript to accomplish the same thing.
Step 2: Gather additional metrics
Most crawlers will give you the URL and various on-page metrics and data, such as the titles, descriptions, meta tags, and word count. In addition to these, you’ll want to know about internal and external links, traffic, content uniqueness, and much more in order to make fully informed recommendations during the analysis portion of the content audit project.
Your process may vary, but we generally try to pull in everything we need using as few sources as possible. URL Profiler is a great resource for this purpose, as it works well with Screaming Frog and integrates easily with all of the APIs we need.
Once the Screaming Frog scan is complete (only crawling indexable content) export the “Internal All” file, which can then be used as the seed list in URL Profiler (combined with any additional indexable URLs found outside of the crawl via GSC, GA, and elsewhere).
This is what my URL Profiler settings look for a typical content audit for a small- or medium-sized site. Also, under “Accounts” I have connected via API keys to Moz and SEMrush.
Once URL Profiler is finished, you should end up with something like this:
Screaming Frog and URL Profiler: Between these two tools and the APIs they connect with, you may not need anything else at all in order to see the metrics below for every indexable URL on the domain.
The risk of getting analytics data from a third-party tool
We've noticed odd data mismatches and sampled data when using the method above on large, high-traffic websites. Our internal process involves exporting these reports directly from Google Analytics, sometimes incorporating Analytics Canvas to get the full, unsampled data from GA. Then VLookups are used in the spreadsheet to combine the data, with URL being the unique identifier.
Metrics to pull for each URL:
Indexed or not?
If crawlers are set up properly, all URLs should be “indexable.”
A non-indexed URL is often a sign of an uncrawled or low-quality page.
Content uniqueness
Copyscape, Siteliner, and now URL Profiler can provide this data.
Traffic from organic search
Typically 90 days
Keep a consistent timeframe across all metrics.
Revenue and/or conversions
You could view this by “total,” or by segmenting to show only revenue from organic search on a per-page basis.
Publish date
If you can get this into Google Analytics as a custom dimension prior to fetching the GA data, it will help you discover stale content.
Internal links
Content audits provide the perfect opportunity to tighten up your internal linking strategy by ensuring the most important pages have the most internal links.
External links
These can come from Moz, SEMRush, and a variety of other tools, most of which integrate natively or via APIs with URL Profiler.
Landing pages resulting in low time-on-site
Take this one with a grain of salt. If visitors found what they want because the content was good, that’s not a bad metric. A better proxy for this would be scroll depth, but that would probably require setting up a scroll-tracking “event.”
Landing pages resulting in Low Pages-Per-Visit
Just like with Time-On-Site, sometimes visitors find what they’re looking for on a single page. This is often true for high-quality content.
Response code
Typically, only URLs that return a 200 (OK) response code are indexable. You may not require this metric in the final data if that's the case on your domain.
Canonical tag
Typically only URLs with a self-referencing rel=“canonical” tag should be considered “indexable.” You may not require this metric in the final data if that's the case on your domain.
Page speed and mobile-friendliness
Again, URL Profiler comes through with their Google PageSpeed Insights API integration.
Before you begin analyzing the data, be sure to drastically improve your mental health and the performance of your machine by taking the opportunity to get rid of any data you don’t need. Here are a few things you might consider deleting right away (after making a copy of the full data set, of course).
Things you don’t need when analyzing the data
{Expand for more on removing unnecessary data}
URL Profiler and Screaming Frog tabs Just keep the “combined data” tab and immediately cut the amount of data in the spreadsheet by about half.
Content Type Filtering by Content Type (e.g., text/html, image, PDF, CSS, JavaScript) and removing any URL that is of no concern in your content audit is a good way to speed up the process.
Technically speaking, images can be indexable content. However, I prefer to deal with them separately for now.
Filtering unnecessary file types out like I've done in the screenshot above improves focus, but doesn’t improve performance very much. A better option would be to first select the file types you don’t want, apply the filter, delete the rows you don’t want, and then go back to the filter options and “(Select All).”
Once you have only the content types you want, it may now be possible to simply delete the entire Content Type column.
Status Code and Status You only need one or the other. I prefer to keep the Code, and delete the Status column.
Length and Pixels You only need one or the other. I prefer to keep the Pixels, and delete the Length column. This applies to all Title and Meta Description columns.
Meta Keywords Delete the columns. If those cells have content, consider removing that tag from the site.
DNS Safe URL, Path, Domain, Root, and TLD You should really only be working on a single top-level domain. Content audits for subdomains should probably be done separately. Thus, these columns can be deleted in most cases.
Duplicate Columns You should have two columns for the URL (The “Address” in column A from URL Profiler, and the “URL” column from Screaming Frog). Similarly, there may also be two columns each for HTTP Status and Status Code. It depends on the settings selected in both tools, but there are sure to be some overlaps, which can be removed to reduce the file size, enhance focus, and speed up the process.
Blank Columns Keep the filter tool active and go through each column. Those with only blank cells can be deleted. The example below shows that column BK (Robots HTTP Header) can be removed from the spreadsheet.
[You can save a lot of headspace by hiding or removing blank columns.]
Single-Value Columns If the column contains only one value, it can usually be removed. The screenshot below shows our non-secure site does not have any HTTPS URLs, as expected. I can now remove the column. Also, I guess it’s probably time I get that HTTPS migration project scheduled.
Hopefully by now you've made a significant dent in reducing the overall size of the file and time it takes to apply formatting and formula changes to the spreadsheet. It’s time to start diving into the data.
The analysis & recommendations phase
Here's where the fun really begins. In a large organization, it's tempting to have a junior SEO do all of the data-gathering up to this point. I find it useful to perform the crawl myself, as the process can be highly informative.
Step 3: Put it all into a dashboard
Even after removing unnecessary data, performance could still be a major issue, especially if working in Google Sheets. I prefer to do all of this in Excel, and only upload into Google Sheets once it's ready for the client. If Excel is running slow, consider splitting up the URLs by directory or some other factor in order to work with multiple, smaller spreadsheets.
Creating a dashboard can be as easy as adding two columns to the spreadsheet. The first new column, “Action,” should be limited to three options, as shown below. This makes filtering and sorting data much easier. The “Details” column can contain freeform text to provide more detailed instructions for implementation.
Use Data Validation and a drop-down selector to limit Action options.
Step 4: Work the content audit dashboard
All of the data you need should now be right in front of you. This step can’t be turned into a repeatable process for every content audit. From here on the actual step-by-step process becomes much more open to interpretation and your own experience. You may do some of them and not others. You may do them a little differently. That's all fine, as long as you're working toward the goal of determining what to do, if anything, for each piece of content on the website.
A good place to start would be to look for any content-related issues that might cause an algorithmic filter or manual penalty to be applied, thereby dragging down your rankings.
Causes of content-related penalties
These typically fall under three major categories: quality, duplication, and relevancy. Each category can be further broken down into a variety of issues, which are detailed below.
{Expand to learn more about quality, duplication, and relevancy issues}
Typical low-quality content
Poor grammar, written primarily for search engines (includes keyword stuffing), unhelpful, inaccurate...
Completely irrelevant content
OK in small amounts, but often entire blogs are full of it.
A typical example would be a "linkbait" piece circa 2010.
Thin/short content
Glossed over the topic, too few words, or all image-based content.
Curated content with no added value
Comprised almost entirely of bits and pieces of content that exists elsewhere.
Misleading optimization
Titles or keywords targeting queries for which content doesn't answer or deserve to rank.
Generally not providing the information the visitor was expecting to find.
Duplicate content
Internally duplicated on other pages (e.g., categories, product variants, archives, technical issues, etc.).
Externally duplicated (e.g., manufacturer product descriptions, product descriptions duplicated in feeds used for other channels like Amazon, shopping comparison sites and eBay, plagiarized content, etc.)
Stub pages (e.g., "No content is here yet, but if you sign in and leave some user-generated-content, then we'll have content here for the next guy." By the way, want our newsletter? Click an AD!)
Indexable internal search results
Too many indexable blog tag or blog category pages
And so on and so forth...
It helps to sort the data in various ways to see what’s going on. Below are a few different things to look for if you’re having trouble getting started.
{Expand to learn more about what to look for}
Sort by duplicate content risk
URL Profiler now has a native duplicate content checker. Other options are Copyscape (for external duplicate content) and Siteliner (for internal duplicate content).
Which of these pages should be rewritten?
Rewrite key/important pages, such as categories, home page, top products
Rewrite pages with good link and social metrics
Rewrite pages with good traffic
After selecting "Improve" in the Action column, elaborate in the Details column:
"Improve these pages by writing unique, useful content to improve the Copyscape risk score."
Which of these pages should be removed/pruned?
Remove guest posts that were published elsewhere
Remove anything the client plagiarized
Remove content that isn't worth rewriting, such as:
No external links, no social shares, and very few or no entrances/visits
After selecting "Remove" from the Action column, elaborate in the Details column:
"Prune from site to remove duplicate content. This URL has no links or shares and very little traffic. We recommend allowing the URL to return 404 or 410 response code. Remove all internal links, including from the sitemap."
Which of these pages should be consolidated into others?
Presumably none, since the content is already externally duplicated.
Which of these pages should be left “As-Is”?
Important pages which have had their content stolen
Sort by entrances or visits (filtering out any that were already finished)
Which of these pages should be marked as "Improve"?
Pages with high visits/entrances but low conversion, time-on-site, pageviews per session, etc.
Key pages that require improvement determined after a manual review of the page.
Which of these pages should be marked as "Consolidate"?
When you have overlapping topics that don't provide much unique value of their own, but could make a great resource when combined.
Mark the page in the set with the best metrics as "Improve" and in the Details column, outline which pages are going to be consolidated into it. This is the canonical page.
Mark the pages that are to be consolidated into the canonical page as "Consolidate" and provide further instructions in the Details column, such as:
Use portions of this content to round out /canonicalpage/ and then 301 redirect this page into /canonicalpage/
Update all internal links.
Campaign-based or seasonal pages that could be consolidated into a single "Evergreen" landing page (e.g., Best Sellers of 2012 and Best Sellers of 2013 ---> Best Sellers).
Which of these pages should be marked as "Remove"?
Pages with poor link, traffic, and social metrics related to low-quality content that isn't worth updating
Typically these will be allowed to 404/410.
Irrelevant content
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Out-of-date content that isn't worth updating or consolidating
The strategy will depend on link equity and traffic as to whether it gets redirected or simply removed.
Which of these pages should be marked as "Leave As-Is"?
Pages with good traffic, conversions, time on site, etc. that also have good content.
These may or may not have any decent external links.
Taking the hatchet to bloated websites
For big sites, it's best to use a hatchet-based approach as much as possible, and finish up with a scalpel in the end. Otherwise, you'll spend way too much time on the project, which eats into the ROI.
This is not a process that can be documented step-by-step. For the purpose of illustration, however, below are a few different examples of hatchet approaches and when to consider using them.
{Expand for examples of hatchet approaches}
Parameter-based URLs that shouldn't be indexed
Defer to the technical audit, if applicable. Otherwise, use your best judgment:
e.g., /?sort=color, &size=small
Assuming the tech audit didn't suggest otherwise, these pages could all be handled in one fell swoop. Below is an example Action and example Details for such a page:
Action = Remove
Details = Rel canonical to the base page without the parameter
Internal search results
Defer to the technical audit if applicable. Otherwise, use your best judgment:
e.g., /search/keyword-phrase/
Assuming the tech audit didn't suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
Blog tag pages
Defer to the technical audit if applicable. Otherwise:
e.g., /blog/tag/green-widgets/ , blog/tag/blue-widgets/
Assuming the tech audit didn't suggest otherwise:
Action = Remove
Details = Apply a noindex meta tag. Once they are removed from the index, disallow /search/ in the robots.txt file.
E-commerce product pages with manufacturer descriptions
In cases where the "Page Type" is known (i.e., it's in the URL or was provided in a CMS export) and Risk Score indicates duplication:
e.g., /product/product-name/
Assuming the tech audit didn't suggest otherwise:
Action = Improve
Details = Rewrite to improve product description and avoid duplicate content
E-commerce category pages with no static content
In cases where the "Page Type" is known:
e.g. /category/category-name/ or category/cat1/cat2/
Assuming NONE of the category pages have content:
Action = Improve
Details = Write 2–3 sentences of unique, useful content that explains choices, next steps, or benefits to the visitor looking to choose a product from the category.
Out-of-date blog posts, articles, and other landing pages
In cases where the title tag includes a date, or...
In cases where the URL indicates the publishing date:
Action = Improve
Details = Update the post to make it more current, if applicable. Otherwise, change Action to "Remove" and customize the Strategy based on links and traffic (i.e., 301 or 404).
Content marked for improvement should lay out more specific instructions in the “Details” column, such as:
Update the old content to make it more relevant
Add more useful content to “beef up” this thin page
Incorporate content from overlapping URLs/pages
Rewrite to avoid internal duplication
Rewrite to avoid external duplication
Reduce image sizes to speed up page load
Create a “responsive” template for this page to fit on mobile devices
Etc.
Content marked for removal should include specific instructions in the “Details” column, such as:
Consolidate this content into the following URL/page marked as “Improve”
Then redirect the URL
Remove this page from the site and allow the URL to return a 410 or 404 HTTP status code. This content has had zero visits within the last 360 days, and has no external links. Then remove or update internal links to this page.
Remove this page from the site and 301 redirect the URL to the following URL marked as “Improve”... Do not incorporate the content into the new page. It is low-quality.
Remove this archive page from search engine indexes with a robots noindex meta tag. Continue to allow the page to be accessed by visitors and crawled by search engines.
Remove this internal search result page from the search engine indexed with a robots noindex meta tag. Once removed from the index (about 15–30 days later), add the following line to the #BlockedDirectories section of the robots.txt file: Disallow: /search/.
As you can see from the many examples above, sorting by “Page Type” can be quite handy when applying the same Action and Details to an entire section of the website.
After all of the tool set-up, data gathering, data cleanup, and analysis across dozens of metrics, what matters in the end is the Action to take and the Details that go with it.
URL, Action, and Details: These three columns will be used by someone to implement your recommendations. Be clear and concise in your instructions, and don’t make decisions without reviewing all of the wonderful data-points you’ve collected.
Here is a sample content audit spreadsheet to use as a template, or for ideas. It includes a few extra tabs specific to the way we used to do content audits at Inflow.
WARNING!
As Razvan Gavrilas pointed out in his post on Cognitive SEO from 2015, without doing the research above you risk pruning valuable content from search engine indexes. Be bold, but make highly informed decisions:
Content audits allow SEOs to make informed decisions on which content to keep indexed “as-is,” which content to improve, and which to remove.
The reporting phase
The content audit dashboard is exactly what we need internally: a spreadsheet crammed with data that can be sliced and diced in so many useful ways that we can always go back to it for more insight and ideas. Some clients appreciate that as well, but most are going to find the greater benefit in our final content audit report, which includes a high-level overview of our recommendations.
Counting actions from Column B
It is useful to count the quantity of each Action along with total organic search traffic and/or revenue for each URL. This will help you (and the client) identify important metrics, such as total organic traffic for pages marked to be pruned. It will also make the final report much easier to build.
Step 5: Writing up the report
Your analysis and recommendations should be delivered at the same time as the audit dashboard. It summarizes the findings, recommendations, and next steps from the audit, and should start with an executive summary.
Here is a real example of an executive summary from one of Inflow's content audit strategies:
As a result of our comprehensive content audit, we are recommending the following, which will be covered in more detail below:
Removal of about 624 pages from Google index by deletion or consolidation:
203 Pages were marked for Removal with a 404 error (no redirect needed)
110 Pages were marked for Removal with a 301 redirect to another page
311 Pages were marked for Consolidation of content into other pages
Followed by a redirect to the page into which they were consolidated
Rewriting or improving of 668 pages
605 Product Pages are to be rewritten due to use of manufacturer product descriptions (duplicate content), these being prioritized from first to last within the Content Audit.
63 "Other" pages to be rewritten due to low-quality or duplicate content.
Keeping 226 pages as-is
No rewriting or improvements needed
These changes reflect an immediate need to "improve or remove" content in order to avoid an obvious content-based penalty from Google (e.g. Panda) due to thin, low-quality and duplicate content, especially concerning Representative and Dealers pages with some added risk from Style pages.
The content strategy should end with recommended next steps, including action items for the consultant and the client. Below is a real example from one of our documents.
We recommend the following three projects in order of their urgency and/or potential ROI for the site:
Project 1: Remove or consolidate all pages marked as “Remove”. Detailed instructions for each URL can be found in the "Details" column of the Content Audit Dashboard.
Project 2: Copywriting to improve/rewrite content on Style pages. Ensure unique, robust content and proper keyword targeting.
Project 3: Improve/rewrite all remaining pages marked as “Improve” in the Content Audit Dashboard. Detailed instructions for each URL can be found in the "Details" column
Content audit resources & further reading
Understanding Mobile-First Indexing and the Long-Term Impact on SEO by Cindy Krum This thought-provoking post begs the question: How will we perform content inventories without URLs? It helps to know Google is dealing with the exact same problem on a much, much larger scale.
Here is a spreadsheet template to help you calculate revenue and traffic changes before and after updating content.
Expanding the Horizons of eCommerce Content Strategy by Dan Kern of Inflow An epic post about content strategies for eCommerce businesses, which includes several good examples of content on different types of pages targeted toward various stages in the buying cycle.
The Content Inventory is Your Friend by Kristina Halvorson on BrainTraffic Praise for the life-changing powers of a good content audit inventory.
Everything You Need to Perform Content Audits
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from Blogger http://ift.tt/2mrxo6L via IFTTT
0 notes
Text
Find Top Southport Sports Massage Therapists Near Me
.ui-tabs {display: table; } .ui-tabs-nav {display: table;} a.ui-tabs-anchor { font-family: Tahoma; font-size: 15px; color: #B52700; } div.ui-tabs-panel { font-family: Tahoma; font-size: 14px; font-weight: normal; color: #B35B22; }
Find Top Southport Sports Massage Therapists Near Me.
In regards to sports massage you will see it can help increase athletic performance and decrease muscle fatigue. Apart from soothing overused muscles, sports massages also utilize techniques to stop future sports injuries. It is a type of therapy that is meant to soothe tired as well as strained body parts.
It has been used by professional athletes for years to gain a competitive edge over their competition! Deep tissue massage is useful in treating spasms together with muscle tension.
Sports massage can help decrease the danger of muscle swelling, enabling you to perform at your peak in any respect times. It aims to get the athlete in fit shape and ensure superior performance. It is one of the most popular western therapeutic approaches to massage. It can help reduce this risk while increasing flexibility.
With this comparison, an individual can get to understand how these massages are not the same as one another and will also help you pick the one which suits you the very best. Swedish massage refers to several distinct techniques designed particularly to relax muscles. It is the perfect place to start. It has come a long way over the centuries.
Using foot massage machines for diabetics is among the simplest methods to supply care for diabetic feet. The demand for variety arises from an exceptional environment which exists in each provider. So there’s more demand for pampering the body once a while, and a massage is an ideal means to do so. Absolutely anything else you’re not sure of!
As soon as you get one be ready to share as others may want to utilize it as well. Showing you look after your employees goes a ways towards developing a team that will go the additional mile for your organization. Swedish massage is the most frequently offered and best-known sort of massage.
Call (07) 553 997 98 To Set An Appointment With Find Top Southport Sports Massage Therapists Near Me
The practitioner often is unclothed and the customer. Your therapist will take some time to attach with you individually as a way to address your specific needs. When thinking about an expert massage therapist, it is necessary to find a therapist with the experience and understanding who will be able to help you accomplish your goals.
Currently, there are plenty of sports massage therapists all around the world. Our massage therapists concentrate on results to deliver durable muscle pain relief. Certified prenatal massage therapists could be trusted, since they are well attentive to the scenario.
While a highly beneficial therapy for certain injuries, bear in mind that deep tissue massage isn’t terribly relaxing, and you can be sore for a couple days afterward. Injuries, physique, postural distortions, and pain tolerance all element into the kind of treatment you might require. Then only, appropriate treatment can be planned.
There are a number of advantages to massage. It enables me to gain (slowly) my flexibility back along with preventing any probable injuries. There are a number of psychological benefits also.
By treating the source of the matter after possible, athletes can avoid chronic issues. It’s directed toward the regions of the body which is going to be involved in the exertion.
By finding the opportunity to care for your entire body, your entire body will subsequently reward you in return by setting your head and soul free to fulfill its fullest potential. Instead of stretching, as a result, the muscles ought to be compressed. It isn’t recommended for when you’re experiencing body aches and fever.
To Set An Appointment With The Best Surfers Paradise Massage Therapist Near Me Call (07) 553 997 98 Surfers Paradise Chiropractic Health & Wellness Center 12 Thomas Drive, Chevron Island QLD 4217 and learn more at Top 10 Surfers Paradise Chiropractors For Back Pain Near Me
Surfers Paradise Chiropractic Health And Wellness Center
Route
Your location: No route could be calculated.
Find Top Southport Sports Massage Therapists Near Me
To Set An Appointment Complete Form Below
[contact-form-7]
jQuery(document).ready(function() { jQuery( "#tabs_3258" ).tabs({ collapsible: true, active: false }); jQuery( ".scroller_3258" ).width(jQuery( ".scroller_3258" ).width()+1); //jQuery( ".scroller_3258" ).width('100%'); //jQuery( ".scroller_3258 ul" ).width('100%'); jQuery( "#tabs_3258" ).tabs({ collapsible: false }); //var n = jQuery(".scroller_3258 ul li").length; //var w = (100/n-1); //jQuery(".scroller_3258 ul li").width(w+'%'); });
The post Find Top Southport Sports Massage Therapists Near Me appeared first on Chiropractors Gold Coast.
from Chiropractors Gold Coast http://ift.tt/2ubrvtw
0 notes