#what is postgres
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Note
Welcome back campers, to this weeks episode of TOTAL, DRAMA, HELLSITE! On this weeks episode, me and my handy Chef Hex will be cooking up a delicious meal of parpy goodness! But the campers will have to roll a single... WITH A PROMPT! The first one to get a proper Roleplay going gets the immunity marshmallow. Now watch out, cuz this ones gonna be a doozy, dudes!
Your September 2nd PARPdate: "Remember that time on TDI where they called god to make it rain? That happened" Edition.
News this month is sorta slow- those of you In The Know already know this, but Hex is being forced to move again. This hasn't impacted Dev TOO much, honestly, and I'm gonna break down WHY in this wonderful little post!
Ok so if you remember the August update, you likely recall us showing off our shiny new mod features and how we can now play funny roleplay police state in order to nail rulebreakers and bandodgers.
If you're also a huge Bubblehead (which is what you're called), you're also likely familiar with this bastard:
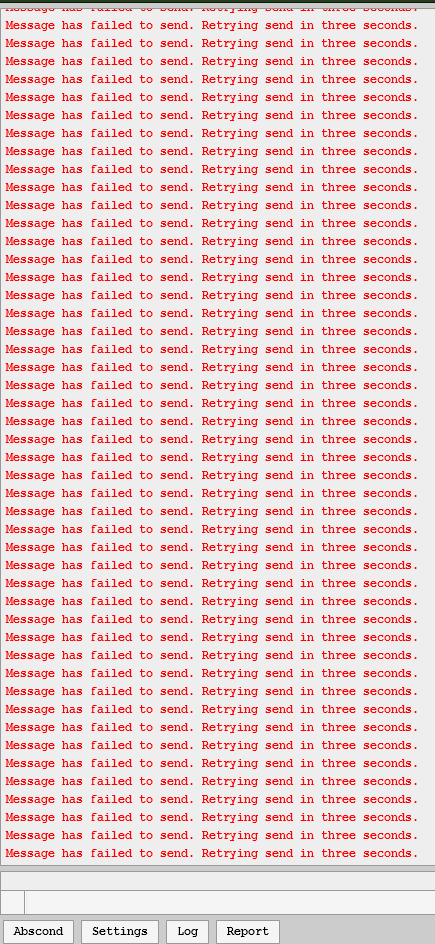
(Image description: The red miles, basically. Its a message failed message repeated like ninety times in a row in red font. Thanks to Alienoid from the server for posting this screenshot for me to steal!)
This is because, somehow, these new mod features almost completely broke Dreambubble in ways that make no sense (the new features use Redis, but for some reason their introduction is making PostGres, a completely different system, go absolutely haywire)
So, Hex decided to move forward with their pet project to rewrite Dreambubble. Normally, this would mean a development delay on Parp2 and I'd feel pretty bad about laying this on yalls feet after two years of parplessness.
But hey wait isn't this literally just how they made parp last time.
The answer is yes! The previous Msparp version was built using what is now Dreambubble as a skeleton, evolving on itself into the rickety but lovable RP site we knew before she tragically passed away last February after choking to death on fresh air. As such, Dev is actually going pretty good! Hex has been COOKING through the bones for Dreambubble 2, getting a ton of barebones stuff working right off the bat:

(Image description: A barebones but functional chat window using Felt theme; complete with system connection messages, text preview, and quirking)
Along with our first new feature preview in a while: PUSH NOTIFICATIONS!

(Image description: A felt-theme settings menu showing the ability to turn on and off push notifications, as well as a browser popup in the bottom corner showing that it's been activated)
These are also working on Android! What this does is it pings you when the chat you're in gets a new message, operating on a system level instead of a site level so you don't even need to have the tab, or the browser, open to keep up with your chats! This is gonna be especially useful for mobile users, since this means they can navigate away and use their phone for other things, and their phone'll just ping them when their partners' next message comes through. (These are gonna be off by default, btw. You'll have to turn them on yourself on a per-chat basis in the final release)
It should also be noted that we've Snagged Ourselves A UI Guy recently from the userbase, so we've got a dedicated Make It Look Good person for when things get closer to launch!
That's all for this update, though. Absolutely thrilled to be showing off some progress after the restart. Hopefully we'll have even more to show off next month!
Until then, cheers!
24 notes
·
View notes
Text
Opening up an incognito tab because it's just soooo embarrassing that I have to look up what the syntax for uuids in postgres is. I can't let anyone know I googled this for some reason
4 notes
·
View notes
Text
Me during a job interview: "I love this job because I love solving puzzles!"
Me when I actually do the job: "WHAT DO YOU MEAN I NEED AN OPEN TRANSACTION TO OPEN A TRANSACTION YOU PIECE OF SHIT POSTGRES KOBOLD, WHAT KIND OF SPHINX RIDDLE IS THIS???"
#I am about to flip my shit what is this api#i am 80% sure the api is fine whats not fine is the NONEXISTANT DOCUMENTATION
6 notes
·
View notes
Text
if my goal with this project was just "make a website" I would just slap together some html, css, and maybe a little bit of javascript for flair and call it a day. I'd probably be done in 2-3 days tops. but instead I have to practice and make myself "employable" and that means smashing together as many languages and frameworks and technologies as possible to show employers that I'm capable of everything they want and more. so I'm developing apis in java that fetch data from a postgres database using spring boot with authentication from spring security, while coding the front end in typescript via an angular project served by nginx with https support and cloudflare protection, with all of these microservices running in their own docker containers.
basically what that means is I get to spend very little time actually programming and a whole lot of time figuring out how the hell to make all these things play nice together - and let me tell you, they do NOT fucking want to.
but on the bright side, I do actually feel like I'm learning a lot by doing this, and hopefully by the time I'm done, I'll have something really cool that I can show off
8 notes
·
View notes
Note
One of the current pluralkit devs here, heard about lighthouse today and I absolutely love what you're doing with this!! we've wanted some private forums/journals for a while now and this might be the tool for that.
What did you use to make this site? Techwise I mean. I'm not asking for the source code, just curious as to what stack you used since I'm a webdev nerd and like to look into these kinds of things.
Nw if you'd rather not answer!! Like I said I'm curious. I see a cool thing and want to know how it's made. Seriously, thank you for making this available for others to use!!
Heya! I’m glad you’ve found Lighthouse useful.
As for a stack, we started with PERN, but then we never got around to actually using React on the web side of things. So the stack is more like PEN lol. Postgres-Express-Node. The front end is primarily done with EJS templating, jQuery and/or vanilla JavaScript.
Have a happy and safe holiday!
9 notes
·
View notes
Text
A thing I've been looking into at work lately is collation, and specifically sorting. We want to compare in-memory implementations of things to postgres implementations, which means we need to reproduce postgres sorting in Haskell. Man it's a mess.
By default postgres uses glibc to sort. So we can use the FFI to reproduce it.
This mostly works fine, except if the locale says two things compare equal, postgres falls back to byte-comparing them. Which is also fine I guess, we can implement that too, but ugh.
Except also, this doesn't work for the mac user, so they can't reproduce test failures in the test suite we implemented this in.
How does postgres do sorting on mac? Not sure.
So we figured we'd use libicu for sorting. Postgres supports that, haskell supports it (through text-icu), should be fine. I'm starting off with a case-insensitive collation.
In postgres, you specify a collation through a string like en-u-ks-level2-numeric-true. (Here, en is a language, u is a separator, ks and numeric are keys and level2 and true are values. Some keys take multiple values, so you just have to know which strings are keys I guess?) In Haskell you can do it through "attributes" or "rules". Attributes are type safe but don't support everything you might want to do with locales. Rules are completely undocumented in text-icu, you pass in a string and it parses it. I'm pretty sure the parsing is implemented in libicu itself but it would be nice if text-icu gave you even a single example of what they look like.
But okay, I've got a locale in Haskell that I think should match the postgres one. Does it? Lolno
So there's a function collate for "compare these two strings in this locale", and a function sortKey for "get the sort key of this string in this locale". It should be that "collate l a b" is the same as "compare (sortKey l a) (sortKey l b)", but there are subtle edge cases where this isn't the case, like for example when a is the empty string and b is "\0". Or any string whose characters are all drawn from a set that includes NUL, lots of other control codes, and a handful of characters somewhere in the Arabic block. In these cases, collate says they're equal but sortKey says the empty string is smaller. But pg gets the same results as collate so fine, go with that.
Also seems like text-icu and pg disagree on which blocks get sorted before which other blocks, or something? At any rate I found a lot of pairs of (latin, non-latin) where text-icu sorts the non-latin first and pg sorts it second. So far I've solved this by just saying "only generate characters in the basic multilingual plane, and ignore anything in (long list of blocks)".
(Collations have an option for choosing which order blocks get sorted in, but it's not available with attributes. I haven't bothered to try it with rules, or with the format pg uses to specify them.)
I wonder how much of this is to do with using different versions of libicu. For Haskell we use a nix shell, which is providing version 72.1. Our postgres comes from a docker image and is using 63.1. When I install libicu on our CI images, they get 67.1 (and they can't reproduce the collate/sortKey bug with the arabic characters, so fine, remove them from the test set).
(I find out version numbers locally by doing lsof and seeing that the files are named like .so.63.1. Maybe ldd would work too? But because pg is in docker I don't know where the binary is. On CI I just look at the install logs.)
I wonder if I can get 63.1 in our nix shell. No, node doesn't support below 69. Fine, let's try 69. Did you know chromium depends on libicu? My laptop's been compiling chromium for many hours now.
7 notes
·
View notes
Text
I'm in tech and I agree that there are some things that LLMs can do better (and certainly faster) than I can.
1. Provide workable solutions to well-described (but fairly straightforward) problems. For example "using jq (a json query language tool) take two json files and combine them in this manner...."
2. Identify and fix format issues: "what changes are required to make this string valid json?"
3. Doing boring chores. "Using this sample data, suggest a well normalised database structure. Write a script that creates a Postgres database, and creates the tables decided above. Write a second script that accepts json objects that look like EXAMPLE and adds them into the database."
However, while there is a risk my employer will decide that LLMs can reduce the workforce significantly, 99% of what I do can't be done by LLMs yet and I can't see how that would change.
LLMs have the ability to draw on the expertise and documentation created by millions of people. They can synthesise that knowledge to provide answers to fairly casually askef questions. But they have no *understanding* of the content they're synthesising, which is why they can't give correct answers to questions like "what is 2+2?" or "how many times does the letter r appear in strawberry?" Those questions require *understanding* of the premise of the question. "Infer, based on hundreds of millions of pages of documentation and examples, how to use this tool to do that thing" is a much easier ask.
The other thing about having no understanding is that they can't create anything truly new. They can create new art in the style of the grand masters, compose music, write stories... But only in a derivative sense. LLMs possess no mind, so they can't *imagine* anything. Users who use LLMs to realise their own art are missing out on the value of learning how to create their art themselves. Just as I am missing out on the value of learning how to use the tool jq to manipulate json files which would enable me to answer my own question.
LLMs have such a large environmental footprint, that they're morally dubious at best. It should be alarming that LLM proponents are telling us to just use these tools without worrying about the environment, because we aren't doing enough to fix climate change anyway. "Leave solving the future to LLMs?!" LLMs aren't going to solve climate change, they're incapable of *understanding* and *innovating*. We already know how to save ourselves from climate change, but the wealthy and powerful don't want to because it would require them to be less rich and powerful.
The trillion dollar problem is literally "how do we change our current society such that leadership requires the ability to lead, a commitment to listen to experts and does not result in the leader getting buckets of money from bribes and lobbying?" preferably without destroying the supply chain and killing hundreds of thousands.
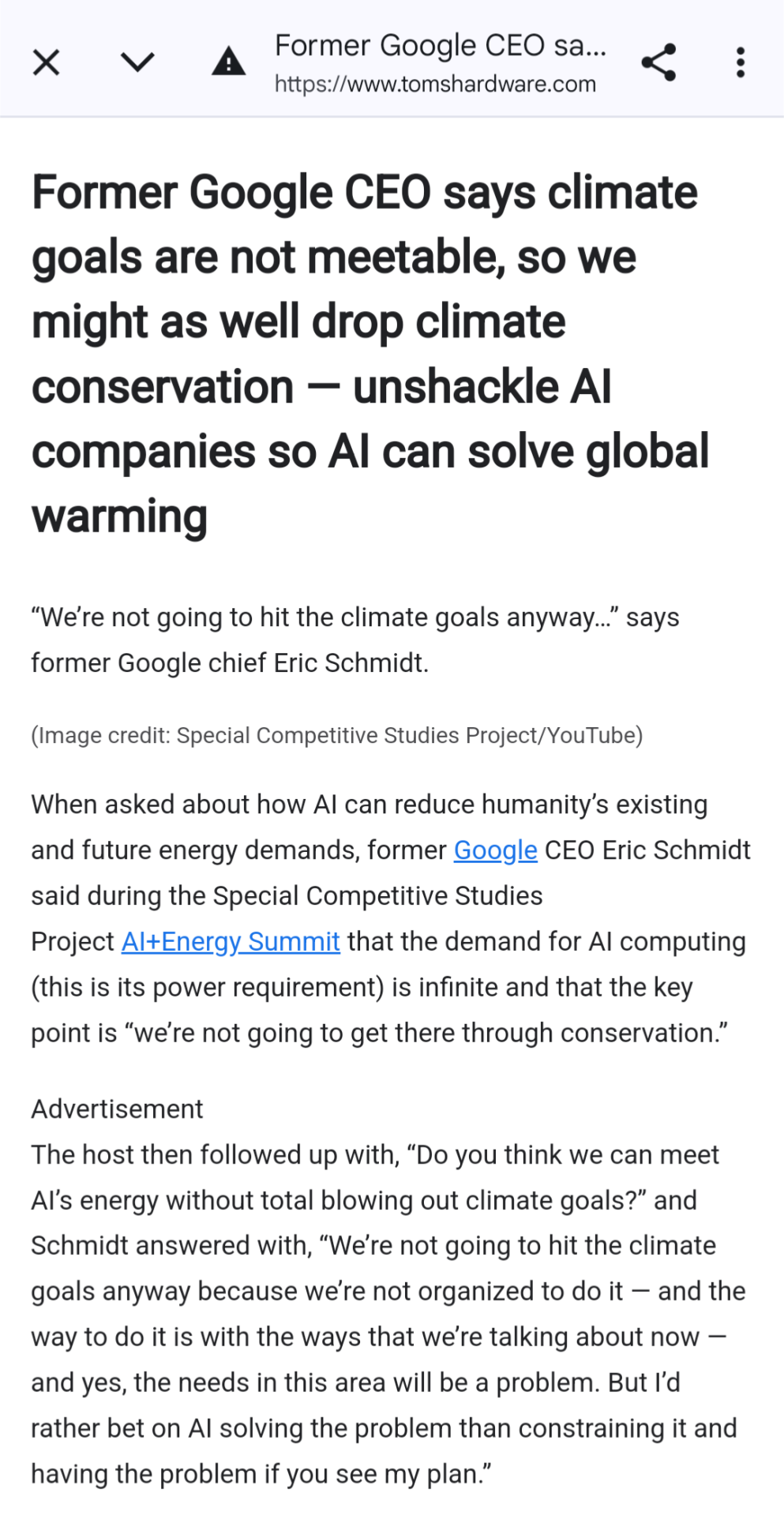
so like I said, I work in the tech industry, and it's been kind of fascinating watching whole new taboos develop at work around this genAI stuff. All we do is talk about genAI, everything is genAI now, "we have to win the AI race," blah blah blah, but nobody asks - you can't ask -
What's it for?
What's it for?
Why would anyone want this?
I sit in so many meetings and listen to genuinely very intelligent people talk until steam is rising off their skulls about genAI, and wonder how fast I'd get fired if I asked: do real people actually want this product, or are the only people excited about this technology the shareholders who want to see lines go up?
like you realize this is a bubble, right, guys? because nobody actually needs this? because it's not actually very good? normal people are excited by the novelty of it, and finance bro capitalists are wetting their shorts about it because they want to get rich quick off of the Next Big Thing In Tech, but the novelty will wear off and the bros will move on to something else and we'll just be left with billions and billions of dollars invested in technology that nobody wants.
and I don't say it, because I need my job. And I wonder how many other people sitting at the same table, in the same meeting, are also not saying it, because they need their jobs.
idk man it's just become a really weird environment.
33K notes
·
View notes
Text
Databricks Revolutionizes Data and AI Landscape with New Operational Database, Free Education, and No-Code Pipelines
San Francisco, CA – June 12, 2025 – Databricks, the pioneering Data and AI company, today unveiled a suite of transformative innovations at its Data + AI Summit, setting a new benchmark for how enterprises and individuals interact with data and artificial intelligence. The announcements include the launch of Lakebase, a groundbreaking operational database built for AI; a significant $100 million investment in global data and AI education coupled with the Databricks Free Edition; and the introduction of Lakeflow Designer, empowering data analysts to build production-grade pipelines without coding. These advancements underscore Databricks’ commitment to democratizing data and AI, accelerating innovation, and closing the critical talent gap in the industry.
Databricks Unveils Lakebase: A New Class of Operational Database for AI Apps and Agents

What is it?
Databricks announced the launch of Lakebase, a first-of-its-kind fully-managed Postgres database built for AI. This new operational database layer seamlessly integrates into the company’s Data Intelligence Platform, allowing developers and enterprises to build data applications and AI agents faster and more easily on a single multi-cloud platform. Lakebase is powered by Neon technology and is designed to unify analytics and operations by bringing operational data to the lakehouse, continuously autoscaling compute to support demanding agent workloads.
When is the Launch Planned?
Lakebase is now available in Public Preview, marking a significant step towards its full availability.
Who Introduced?
Ali Ghodsi, Co-founder and CEO of Databricks, introduced Lakebase, stating, “We’ve spent the past few years helping enterprises build AI apps and agents that can reason on their proprietary data with the Databricks Data Intelligence Platform. Now, with Lakebase, we’re creating a new category in the database market: a modern Postgres database, deeply integrated with the lakehouse and today’s development stacks.”
Why Does This Matter? Motivation: The Driving Forces Behind
Operational databases (OLTP) represent a $100-billion-plus market, yet their decades-old architecture struggles with the demands of modern, rapidly changing applications. They are often difficult to manage, expensive, and prone to vendor lock-in. AI introduces a new set of requirements: every data application, agent, recommendation, and automated workflow needs fast, reliable data at the speed and scale of AI agents. This necessitates the convergence of operational and analytical systems to reduce latency and provide real-time information for decision-making. Fortune 500 companies are ready to replace outdated systems, and Lakebase offers a solution built for the demands of the AI era.
Business Strategies
The launch of Lakebase is a strategic move to create a new category in the database market, emphasizing a modern Postgres database deeply integrated with the lakehouse and today’s development stacks. This strategy aims to empower developers to build faster, scale effortlessly, and deliver the next generation of intelligent applications, directly addressing the evolving needs of the AI era.
Key benefits of Lakebase include:
Separated compute and storage: Built on Neon technology, it offers independent scaling, low latency (<10 ms), high concurrency (>10K QPS), and high availability transactional needs.
Built on open source: Leveraging widely adopted Postgres with its rich ecosystem, ideal for workflows built on agents as all frontier LLMs have been trained on vast database system information.
Built for AI: Enables launch in under a second and pay-for-what-you-use pricing. Its unique branching capability allows low-risk development by creating copy-on-write database clones for developer testing and agent-based development.
Integrated with the lakehouse: Provides automatic data sync to and from lakehouse tables, an online feature store for model serving, and integration with Databricks Apps and Unity Catalog.
Enterprise ready: Fully managed by Databricks, based on hardened compute infrastructure, encrypted data at rest, and supports high availability, point-in-time recovery, and integration with Databricks enterprise features.
Lakebase Momentum
Digital leaders are already experiencing the value, with hundreds of enterprises having participated in the Private Preview. “At Heineken, our goal is to become the best-connected brewer. To do that, we needed a way to unify all of our datasets to accelerate the path from data to value,” stated Jelle Van Etten, Head of Global Data Platform at Heineken. Anjan Kundavaram, Chief Product Officer at Fivetran, added, “Lakebase removes the operational burden of managing transactional databases. Our customers can focus on building applications instead of worrying about provisioning, tuning and scaling.” David Menninger, Executive Director, ISG Software Research, highlighted that “By offering a Postgres-compatible, lakehouse-integrated system designed specifically for AI-native and analytical workloads, Databricks is giving customers a unified, developer-friendly stack that reduces complexity and accelerates innovation.”
Partner Ecosystem
A robust partner network, including Accenture, Airbyte, Alation, Fivetran, and many others, supports Lakebase customers in data integration, business intelligence, and governance.
Read More : Databricks Revolutionizes Data and AI Landscape with New Operational Database, Free Education, and No-Code Pipelines
#Databricks#Data & AI#Lakebase#Operational Database#AI Applications#Free AI Education#Lakeflow Designer#No-Code Pipelines#Data Engineering#Machine Learning#Data Cloud#AI Talent Gap
0 notes
Text
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series
New Post has been published on https://thedigitalinsider.com/soham-mazumdar-co-founder-ceo-of-wisdomai-interview-series/
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series

Soham Mazumdar is the Co-Founder and CEO of WisdomAI, a company at the forefront of AI-driven solutions. Prior to founding WisdomAI in 2023, he was Co-Founder and Chief Architect at Rubrik, where he played a key role in scaling the company over a 9-year period. Soham previously held engineering leadership roles at Facebook and Google, where he contributed to core search infrastructure and was recognized with the Google Founder’s Award. He also co-founded Tagtile, a mobile loyalty platform acquired by Facebook. With two decades of experience in software architecture and AI innovation, Soham is a seasoned entrepreneur and technologist based in the San Francisco Bay Area.
WisdomAI is an AI-native business intelligence platform that helps enterprises access real-time, accurate insights by integrating structured and unstructured data through its proprietary “Knowledge Fabric.” The platform powers specialized AI agents that curate data context, answer business questions in natural language, and proactively surface trends or risks—without generating hallucinated content. Unlike traditional BI tools, WisdomAI uses generative AI strictly for query generation, ensuring high accuracy and reliability. It integrates with existing data ecosystems and supports enterprise-grade security, with early adoption by major firms like Cisco and ConocoPhillips.
You co-founded Rubrik and helped scale it into a major enterprise success. What inspired you to leave in 2023 and build WisdomAI—and was there a particular moment that clarified this new direction?
The enterprise data inefficiency problem was staring me right in the face. During my time at Rubrik, I witnessed firsthand how Fortune 500 companies were drowning in data but starving for insights. Even with all the infrastructure we built, less than 20% of enterprise users actually had the right access and know-how to use data effectively in their daily work. It was a massive, systemic problem that no one was really solving.
I’m also a builder by nature – you can see it in my path from Google to Tagtile to Rubrik and now WisdomAI. I get energized by taking on fundamental challenges and building solutions from the ground up. After helping scale Rubrik to enterprise success, I felt that entrepreneurial pull again to tackle something equally ambitious.
Last but not least, the AI opportunity was impossible to ignore. By 2023, it became clear that AI could finally bridge that gap between data availability and data usability. The timing felt perfect to build something that could democratize data insights for every enterprise user, not just the technical few.
The moment of clarity came when I realized we could combine everything I’d learned about enterprise data infrastructure at Rubrik with the transformative potential of AI to solve this fundamental inefficiency problem.
WisdomAI introduces a “Knowledge Fabric” and a suite of AI agents. Can you break down how this system works together to move beyond traditional BI dashboards?
We’ve built an agentic data insights platform that works with data where it is – structured, unstructured, and even “dirty” data. Rather than asking analytics teams to run reports, business managers can directly ask questions and drill into details. Our platform can be trained on any data warehousing system by analyzing query logs.
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc.
Unlike conventional tools designed primarily for analysts, our conversational interface empowers business users to get answers directly, while our multi-agent architecture enables complex queries across diverse data systems.
You’ve emphasized that WisdomAI avoids hallucinations by separating GenAI from answer generation. Can you explain how your system uses GenAI differently—and why that matters for enterprise trust?
Our AI-Ready Context Model trains on the organization’s data to create a universal context understanding that answers questions with high semantic accuracy while maintaining data privacy and governance. Furthermore, we use generative AI to formulate well-scoped queries that allow us to extract data from the different systems, as opposed to feeding raw data into the LLMs. This is crucial for addressing hallucination and safety concerns with LLMs.
You coined the term “Agentic Data Insights Platform.” How is agentic intelligence different from traditional analytics tools or even standard LLM-based assistants?
Traditional BI stacks slow decision-making because every question has to fight its way through disconnected data silos and a relay team of specialists. When a chief revenue officer needs to know how to close the quarter, the answer typically passes through half a dozen hands—analysts wrangling CRM extracts, data engineers stitching files together, and dashboard builders refreshing reports—turning a simple query into a multi-day project.
Our platform breaks down those silos and puts the full depth of data one keystroke away, so the CRO can drill from headline metrics all the way to row-level detail in seconds.
No waiting in the analyst queue, no predefined dashboards that can’t keep up with new questions—just true self-service insights delivered at the speed the business moves.
How do you ensure WisdomAI adapts to the unique data vocabulary and structure of each enterprise? What role does human input play in refining the Knowledge Fabric?
Working with data where and how it is – that’s essentially the holy grail for enterprise business intelligence. Traditional systems aren’t built to handle unstructured data or “dirty” data with typos and errors. When information exists across varied sources – databases, documents, telemetry data – organizations struggle to integrate this information cohesively.
Without capabilities to handle these diverse data types, valuable context remains isolated in separate systems. Our platform can be trained on any data warehousing system by analyzing query logs, allowing it to adapt to each organization’s unique data vocabulary and structure.
You’ve described WisdomAI’s development process as ‘vibe coding’—building product experiences directly in code first, then iterating through real-world use. What advantages has this approach given you compared to traditional product design?
“Vibe coding” is a significant shift in how software is built where developers leverage the power of AI tools to generate code simply by describing the desired functionality in natural language. It’s like an intelligent assistant that does what you want the software to do, and it writes the code for you. This dramatically reduces the manual effort and time traditionally required for coding.
For years, the creation of digital products has largely followed a familiar script: meticulously plan the product and UX design, then execute the development, and iterate based on feedback. The logic was clear because investing in design upfront minimizes costly rework during the more expensive and time-consuming development phase. But what happens when the cost and time to execute that development drastically shrinks? This capability flips the traditional development sequence on its head. Suddenly, developers can start building functional software based on a high-level understanding of the requirements, even before detailed product and UX designs are finalized.
With the speed of AI code generation, the effort involved in creating exhaustive upfront designs can, in certain contexts, become relatively more time-consuming than getting a basic, functional version of the software up and running. The new paradigm in the world of vibe coding becomes: execute (code with AI), then adapt (design and refine).
This approach allows for incredibly early user validation of the core concepts. Imagine getting feedback on the actual functionality of a feature before investing heavily in detailed visual designs. This can lead to more user-centric designs, as the design process is directly informed by how users interact with a tangible product.
At WisdomAI, we actively embrace AI code generation. We’ve found that by embracing rapid initial development, we can quickly test core functionalities and gather invaluable user feedback early in the process, live on the product. This allows our design team to then focus on refining the user experience and visual design based on real-world usage, leading to more effective and user-loved products, faster.
From sales and marketing to manufacturing and customer success, WisdomAI targets a wide spectrum of business use cases. Which verticals have seen the fastest adoption—and what use cases have surprised you in their impact?
We’ve seen transformative results with multiple customers. For F500 oil and gas company, ConocoPhillips, drilling engineers and operators now use our platform to query complex well data directly in natural language. Before WisdomAI, these engineers needed technical help for even basic operational questions about well status or job performance. Now they can instantly access this information while simultaneously comparing against best practices in their drilling manuals—all through the same conversational interface. They evaluated numerous AI vendors in a six-month process, and our solution delivered a 50% accuracy improvement over the closest competitor.
At a hyper growth Cyber Security company Descope, WisdomAI is used as a virtual data analyst for Sales and Finance. We reduced report creation time from 2-3 days to just 2-3 hours—a 90% decrease. This transformed their weekly sales meetings from data-gathering exercises to strategy sessions focused on actionable insights. As their CRO notes, “Wisdom AI brings data to my fingertips. It really democratizes the data, bringing me the power to go answer questions and move on with my day, rather than define your question, wait for somebody to build that answer, and then get it in 5 days.” This ability to make data-driven decisions with unprecedented speed has been particularly crucial for a fast-growing company in the competitive identity management market.
A practical example: A chief revenue officer asks, “How am I going to close my quarter?” Our platform immediately offers a list of pending deals to focus on, along with information on what’s delaying each one – such as specific questions customers are waiting to have answered. This happens with five keystrokes instead of five specialists and days of delay.
Many companies today are overloaded with dashboards, reports, and siloed tools. What are the most common misconceptions enterprises have about business intelligence today?
Organizations sit on troves of information yet struggle to leverage this data for quick decision-making. The challenge isn’t just about having data, but working with it in its natural state – which often includes “dirty” data not cleaned of typos or errors. Companies invest heavily in infrastructure but face bottlenecks with rigid dashboards, poor data hygiene, and siloed information. Most enterprises need specialized teams to run reports, creating significant delays when business leaders need answers quickly. The interface where people consume data remains outdated despite advancements in cloud data engines and data science.
Do you view WisdomAI as augmenting or eventually replacing existing BI tools like Tableau or Looker? How do you fit into the broader enterprise data stack?
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc. Our approach transforms the interface where people consume data, which has remained outdated despite advancements in cloud data engines and data science.
Looking ahead, where do you see WisdomAI in five years—and how do you see the concept of “agentic intelligence” evolving across the enterprise landscape?
The future of analytics is moving from specialist-driven reports to self-service intelligence accessible to everyone. BI tools have been around for 20+ years, but adoption hasn’t even reached 20% of company employees. Meanwhile, in just twelve months, 60% of workplace users adopted ChatGPT, many using it for data analysis. This dramatic difference shows the potential for conversational interfaces to increase adoption.
We’re seeing a fundamental shift where all employees can directly interrogate data without technical skills. The future will combine the computational power of AI with natural human interaction, allowing insights to find users proactively rather than requiring them to hunt through dashboards.
Thank you for the great interview, readers who wish to learn more should visit WisdomAI.
#2023#adoption#agent#agents#ai#AI AGENTS#ai code generation#AI innovation#ai tools#Amazon#Analysis#Analytics#approach#architecture#assistants#bi#bi tools#bigquery#bridge#Building#Business#Business Intelligence#CEO#challenge#chatGPT#Cisco#Cloud#cloud data#code#code generation
0 notes
Note
Hey steve real quick question, on my normal browser whenever I get onto dreambubble and everything seems to immediately go to the blue screen saying that something went wrong, but whenever I go onto incognito it seems to work just fine, is this something to do with the site or is this a sealthy way to ban someone off of the site?
(If the latter idk what i did since i didn't break any of the rules)
Nah she's just Mad Fucky right now.
Those new mod features kinda fucked the site up a lil in some confusing ways (the new features use Redis, but for some reason its PostGres that's spiking up and crashing things). Hex is cooking up a solution in the background though, with occasional updates in the drambuggles channel in the server. I'll announce it here when it's ready!
4 notes
·
View notes
Text
Is ChatGPT Easy to Use? Here’s What You Need to Know
Introduction: A Curious Beginning I still remember the first time I stumbled upon ChatGPT my heart raced at the thought of talking to an AI. I was a fresh-faced IT enthusiast, eager to explore how a “gpt chat” interface could transform my workflow. Yet, as excited as I was, I also felt a tinge of apprehension: Would I need to learn a new programming language? Would I have to navigate countless settings? Spoiler alert: Not at all. In this article, I’m going to walk you through my journey and show you why ChatGPT is as straightforward as chatting with a friend. By the end, you’ll know exactly “how to use ChatGPT” in your day-to-day IT endeavors whether you’re exploring the “chatgpt app” on your phone or logging into “ChatGPT online” from your laptop.
What Is ChatGPT, Anyway?
If you’ve heard of “chat openai,” “chat gbt ai,” or “chatgpt openai,” you already know that OpenAI built this tool to mimic human-like conversation. ChatGPT sometimes written as “Chat gpt”—is an AI-powered chatbot that understands natural language and responds with surprisingly coherent answers. With each new release remember buzz around “chatgpt 4”? OpenAI has refined its approach, making the bot smarter at understanding context, coding queries, creative brainstorming, and more.
GPT Chat: A shorthand term some people use, but it really means the same as ChatGPT just another way to search or tag the service.
ChatGPT Online vs. App: Although many refer to “chatgpt online,” you can also download the “chatgpt app” on iOS or Android for on-the-go access.
Free vs. Paid: There’s even a “chatgpt gratis” option for users who want to try without commitment, while premium plans unlock advanced features.
Getting Started: Signing Up for ChatGPT Online
1. Creating Your Account
First things first head over to the ChatGPT website. You’ll see a prompt to sign up or log in. If you’re wondering about “chat gpt free,” you’re in luck: OpenAI offers a free tier that anyone can access (though it has usage limits). Here’s how I did it:
Enter your email (or use Google/Microsoft single sign-on).
Verify your email with the link they send usually within seconds.
Log in, and voila, you’re in!
No complex setup, no plugin installations just a quick email verification and you’re ready to talk to your new AI buddy. Once you’re “ChatGPT online,” you’ll land on a simple chat window: type a question, press Enter, and watch GPT 4 respond.
Navigating the ChatGPT App
While “ChatGPT online” is perfect for desktop browsing, I quickly discovered the “chatgpt app” on my phone. Here’s what stood out:
Intuitive Interface: A text box at the bottom, a menu for adjusting settings, and conversation history links on the side.
Voice Input: On some versions, you can tap the microphone icon—no need to type every query.
Seamless Sync: Whatever you do on mobile shows up in your chat history on desktop.
For example, one night I was troubleshooting a server config while waiting for a train. Instead of squinting at the station’s Wi-Fi, I opened the “chat gpt free” app on my phone, asked how to tweak a Dockerfile, and got a working snippet in seconds. That moment convinced me: whether you’re using “chatgpt online” or the “chatgpt app,” the learning curve is minimal.
Key Features of ChatGPT 4
You might have seen “chatgpt 4” trending this iteration boasts numerous improvements over earlier versions. Here’s why it feels so effortless to use:
Better Context Understanding: Unlike older “gpt chat” bots, ChatGPT 4 remembers what you asked earlier in the same session. If you say, “Explain SQL joins,” and then ask, “How does that apply to Postgres?”, it knows you’re still talking about joins.
Multi-Turn Conversations: Complex troubleshooting often requires back-and-forth questions. I once spent 20 minutes configuring a Kubernetes cluster entirely through a multi-turn conversation.
Code Snippet Generation: Want Ruby on Rails boilerplate or a Python function? ChatGPT 4 can generate working code that requires only minor tweaks. Even if you make a mistake, simply pasting your error output back into the chat usually gets you an explanation.
These features mean that even non-developers say, a project manager looking to automate simple Excel tasks can learn “how to use ChatGPT” with just a few chats. And if you’re curious about “chat gbt ai” in data analytics, hop on and ask ChatGPT can translate your plain-English requests into practical scripts.
Tips for First-Time Users
I’ve coached colleagues on “how to use ChatGPT” in the last year, and these small tips always come in handy:
Be Specific: Instead of “Write a Python script,” try “Write a Python 3.9 script that reads a CSV file and prints row sums.” The more detail, the more precise the answer.
Ask Follow-Up Questions: Stuck on part of the response? Simply type, “Can you explain line 3 in more detail?” This keeps the flow natural—just like talking to a friend.
Use System Prompts: At the very start, you can say, “You are an IT mentor. Explain in beginner terms.” That “meta” instruction shapes the tone of every response.
Save Your Favorite Replies: If you stumble on a gem—say, a shell command sequence—star it or copy it to a personal notes file so you can reference it later.
When a coworker asked me how to connect a React frontend to a Flask API, I typed exactly that into the chat. Within seconds, I had boilerplate code, NPM install commands, and even a short security note: “Don’t forget to add CORS headers.” That level of assistance took just three minutes, demonstrating why “gpt chat” can feel like having a personal assistant.
Common Challenges and How to Overcome Them
No tool is perfect, and ChatGPT is no exception. Here are a few hiccups you might face and how to fix them:
Occasional Inaccuracies: Sometimes, ChatGPT can confidently state something that’s outdated or just plain wrong. My trick? Cross-check any critical output. If it’s a code snippet, run it; if it’s a conceptual explanation, ask follow-up questions like, “Is this still true for Python 3.11?”
Token Limits: On the “chatgpt gratis” tier, you might hit usage caps or get slower response times. If you encounter this, try simplifying your prompt or wait a few minutes for your quota to reset. If you need more, consider upgrading to a paid plan.
Overly Verbose Answers: ChatGPT sometimes loves to explain every little detail. If that happens, just say, “Can you give me a concise version?” and it will trim down its response.
Over time, you learn how to phrase questions so that ChatGPT delivers exactly what you need quickly—no fluff, just the essentials. Think of it as learning the “secret handshake” to get premium insights from your digital buddy.
Comparing Free and Premium Options
If you search “chat gpt free” or “chatgpt gratis,” you’ll see that OpenAI’s free plan offers basic access to ChatGPT 3.5. It’s great for light users students looking for homework help, writers brainstorming ideas, or aspiring IT pros tinkering with small scripts. Here’s a quick breakdown: FeatureFree Tier (ChatGPT 3.5)Paid Tier (ChatGPT 4)Response SpeedStandardFaster (priority access)Daily Usage LimitsLowerHigherAccess to Latest ModelChatGPT 3.5ChatGPT 4 (and beyond)Advanced Features (e.g., Code)LimitedFull accessChat History StorageShorter retentionLonger session memory
For someone just dipping toes into “chat openai,” the free tier is perfect. But if you’re an IT professional juggling multiple tasks and you want the speed and accuracy of “chatgpt 4” the upgrade is usually worth it. I switched to a paid plan within two weeks of experimenting because my productivity jumped tenfold.
Real-World Use Cases for IT Careers
As an IT blogger, I’ve seen ChatGPT bridge gaps in various IT roles. Here are some examples that might resonate with you:
Software Development: Generating boilerplate code, debugging error messages, or even explaining complex algorithms in simple terms. When I first learned Docker, ChatGPT walked me through building an image, step by step.
System Administration: Writing shell scripts, explaining how to configure servers, or outlining best security practices. One colleague used ChatGPT to set up an Nginx reverse proxy without fumbling through documentation.
Data Analysis: Crafting SQL queries, parsing data using Python pandas, or suggesting visualization libraries. I once asked, “How to use chatgpt for data cleaning?” and got a concise pandas script that saved hours of work.
Project Management: Drafting Jira tickets, summarizing technical requirements, or even generating risk-assessment templates. If you ever struggled to translate technical jargon into plain English for stakeholders, ChatGPT can be your translator.
In every scenario, I’ve found that the real magic isn’t just the AI’s knowledge, but how quickly it can prototype solutions. Instead of spending hours googling or sifting through Stack Overflow, you can ask a direct question and get an actionable answer in seconds.
Security and Privacy Considerations
Of course, when dealing with AI, it’s wise to think about security. Here’s what you need to know:
Data Retention: OpenAI may retain conversation data to improve their models. Don’t paste sensitive tokens, passwords, or proprietary code you can’t risk sharing.
Internal Policies: If you work for a company with strict data guidelines, check whether sending internal data to a third-party service complies with your policy.
Public Availability: Remember that anyone else could ask ChatGPT similar questions. If you need unique, private solutions, consult official documentation or consider an on-premises AI solution.
I routinely use ChatGPT for brainstorming and general code snippets, but for production credentials or internal proprietary logic, I keep those aspects offline. That balance lets me benefit from “chatgpt openai” guidance without compromising security.
Is ChatGPT Right for You?
At this point, you might be wondering, “Okay, but is it really easy enough for me?” Here’s my honest take:
Beginners who have never written a line of code can still ask ChatGPT to explain basic IT concepts no jargon needed.
Intermediate users can leverage the “chatgpt app” on mobile to troubleshoot on the go, turning commute time into learning time.
Advanced professionals will appreciate how ChatGPT 4 handles multi-step instructions and complex code logic.
If you’re seriously exploring a career in IT, learning “how to use ChatGPT” is almost like learning to use Google in 2005: essential. Sure, there’s a short learning curve to phrasing your prompts for maximum efficiency, but once you get the hang of it, it becomes second nature just like typing “ls -la” into a terminal.
Conclusion: Your Next Steps
So, is ChatGPT easy to use? Absolutely. Between the intuitive “chatgpt app,” the streamlined “chatgpt online” interface, and the powerful capabilities of “chatgpt 4,” most users find themselves up and running within minutes. If you haven’t already, head over to the ChatGPT website and create your free account. Experiment with a few prompts maybe ask it to explain “how to use chatgpt” and see how it fits into your daily routine.
Remember:
Start simple. Ask basic questions, then gradually dive deeper.
Don’t be afraid to iterate. If an answer isn’t quite right, refine your prompt.
Keep security in mind. Never share passwords or sensitive data.
Whether you’re writing your first “gpt chat” script, drafting project documentation, or just curious how “chat gbt ai” can spice up your presentations, ChatGPT is here to help. Give it a try, and in no time, you’ll wonder how you ever managed without your AI sidekick.
1 note
·
View note
Text
How to Become a Pathologist in Australia: Your Step-by-Step Guide
Are you fascinated by diagnosing diseases, working behind the scenes in healthcare, and combining science with real-world impact? If so, a career in pathology could be the ideal choice for you. One of the most common questions among aspiring students is: How do you become a pathologist in Australia?
In this article, we break down the exact steps, required education, and pathology training pathways available in Australia—especially for international students looking to enter the medical profession.
What Does a Pathologist Do?
Pathologists are medical doctors who study the cause and nature of diseases by examining blood, tissue, and bodily fluids. Their findings help diagnose illnesses, guide treatment, and even assist in preventing disease outbreaks.
There are several types of pathologists, each with a specific focus:
Anatomical Pathologists – Specialize in biopsies and surgical specimens
Clinical Pathologists – Focus on laboratory testing, including blood and fluid analysis
Forensic Pathologists – Involved in legal investigations and determine causes of unnatural deaths
How to Become a Pathologist in Australia
Here’s a simplified step-by-step guide tailored for international students:
1. Complete a Bachelor’s Degree (3–4 years)
Begin with an undergraduate degree in a relevant science field such as biology, biomedical science, or health science.
2. Study Medicine (MD or MBBS) – 4 to 6 years
Enroll in a recognized Australian medical school. This is where you build your foundational clinical knowledge.
ApplyOn can assist you in applying to top-ranked Australian universities for both undergraduate and medical programs.
3. Internship & Residency (1–2 years)
After completing your medical degree, you must work as a supervised intern in a hospital setting. This is a necessary step to gain full registration with the Medical Board of Australia.
4. Specialist Pathology Training (5 years)
This is the stage where formal pathology training begins. You will:
Undergo supervised training in accredited hospitals and pathology labs
Rotate through multiple specialties such as microbiology, hematology, anatomical pathology, and more
5. Fellowship and Licensing
Once training is completed and the final RCPA exams are passed, you’ll be awarded Fellowship status. This allows you to practice independently as a licensed pathologist in Australia.
Why Choose Australia for Pathology Training?
Internationally recognized medical education system
Access to advanced hospitals, laboratories, and research infrastructure
Clear post-study pathways under the Skilled Occupation List (SOL)
Strong job demand across both public and private healthcare sectors
Entry Requirements for International Students
To begin your journey in pathology, you will typically need:
A strong academic record in science (at high school or undergraduate level)
Proof of English proficiency (IELTS or TOEFL)
Competitive GAMSAT or UCAT scores (for medical school entry)
Demonstrated interest in diagnostics, research, and medical science
Plan Your Career in Pathology with ApplyOn
At ApplyOn, we support aspiring international students from start to finish—whether you're planning your undergraduate degree or preparing for medical school and beyond. We help with:
University and program selection
Documentation and application preparation
Scholarship exploration
Visa and compliance support
Guidance through your entire education journey
Start your journey today — Visit https://applyon.com.au to explore top medicine and pathology training programs in Australia.
FAQs: Pathology Career in Australia
Q1. How long does it take to become a pathologist in Australia? It typically takes around 13–15 years, including undergraduate study, medical school, internship, and specialist training.
Q2. Can international students become pathologists in Australia? Yes. Many Australian universities accept international students for both undergraduate and postgraduate medical programs. ApplyOn can help you through the entire application and visa process.
Q3. Is pathology a good career in Australia? Absolutely. With a national shortage of qualified pathologists and a growing healthcare system, it is a secure, respected, and well-compensated career path.
0 notes
Link
“The era of AI-native, agent-driven applications is reshaping what a database must do,” said Ali Ghodsi, Co-Founder and CEO at Databricks. Databricks, the Data and AI company, announced its intent to acquire Neon, a leading serverless Postgres company. As the $100-billion-plus database market braces for unprecedented disruption driven by AI, Databricks plans to continue innovating and investing in Neon’s database and developer experience for existing and new Neon customers and partners.
0 notes
Text
Text to SQL LLM: What is Text to SQL And Text to SQL Methods
SQL LLM text
How text-to-SQL approaches help AI write good SQL
SQL is vital for organisations to acquire quick and accurate data-driven insights for decision-making. Google uses Gemini to generate text-to-SQL from natural language. This feature lets non-technical individuals immediately access data and boosts developer and analyst productivity.
How is Text to SQL?
A feature dubbed “text-to-SQL” lets systems generate SQL queries from plain language. Its main purpose is to remove SQL code by allowing common language data access. This method maximises developer and analyst efficiency while letting non-technical people directly interact with data.
Technology underpins
Recent Text-to-SQL improvements have relied on robust large language models (LLMs) like Gemini for reasoning and information synthesis. The Gemini family of models produces high-quality SQL and code for Text-to-SQL solutions. Based on the need, several model versions or custom fine-tuning may be utilised to ensure good SQL production, especially for certain dialects.
Google Cloud availability
Current Google Cloud products support text-to-SQL:
BigQuery Studio: available via Data Canvas SQL node, SQL Editor, and SQL Generation.
Cloud SQL Studio has “Help me code” for Postgres, MySQL, and SQLServer.
AlloyDB Studio and Cloud Spanner Studio have “Help me code” tools.
AlloyDB AI: This public trial tool connects to the database using natural language.
Vertex AI provides direct access to Gemini models that support product features.
Text-to-SQL Challenges
Text-to-SQL struggles with real-world databases and user queries, even though the most advanced LLMs, like Gemini 2.5, can reason and convert complex natural language queries into functional SQL (such as joins, filters, and aggregations). The model needs different methods to handle critical problems. These challenges include:
Provide Business-Specific Context:
Like human analysts, LLMs need a lot of “context” or experience to write appropriate SQL. Business case implications, semantic meaning, schema information, relevant columns, data samples—this context may be implicit or explicit. Specialist model training (fine-tuning) for every database form and alteration is rarely scalable or cost-effective. Training data rarely includes semantics and business knowledge, which is often poorly documented. An LLM won't know how a cat_id value in a table indicates a shoe without context.
User Intent Recognition
Natural language is less accurate than SQL. An LLM may offer an answer when the question is vague, causing hallucinations, but a human analyst can ask clarifying questions. The question “What are the best-selling shoes?” could mean the shoes are most popular by quantity or revenue, and it's unclear how many responses are needed. Non-technical users need accurate, correct responses, whereas technical users may benefit from an acceptable, nearly-perfect query. The system should guide the user, explain its decisions, and ask clarifying questions.
LLM Generation Limits:
Unconventional LLMs are good at writing and summarising, but they may struggle to follow instructions, especially for buried SQL features. SQL accuracy requires careful attention to specifications, which can be difficult. The many SQL dialect changes are difficult to manage. MySQL uses MONTH(timestamp_column), while BigQuery SQL uses EXTRACT(MONTH FROM timestamp_column).
Text-to-SQL Tips for Overcoming Challenges
Google Cloud is constantly upgrading its Text-to-SQL agents using various methods to improve quality and address the concerns identified. These methods include:
Contextual learning and intelligent retrieval: Provide data, business concepts, and schema. After indexing and retrieving relevant datasets, tables, and columns using vector search for semantic matching, user-provided schema annotations, SQL examples, business rule implementations, and current query samples are loaded. This data is delivered to the model as prompts using Gemini's long context windows.
Disambiguation LLMs: To determine user intent by asking the system clarifying questions. This usually involves planning LLM calls to see if a question can be addressed with the information available and, if not, to create follow-up questions to clarify purpose.
SQL-aware Foundation Models: Using powerful LLMs like the Gemini family with targeted fine-tuning to ensure great and dialect-specific SQL generation.
Verification and replenishment: LLM creation non-determinism. Non-AI methods like query parsing or dry runs of produced SQL are used to get a predicted indication if something crucial was missed. When provided examples and direction, models can typically remedy mistakes, thus this feedback is sent back for another effort.
Self-Reliability: Reducing generation round dependence and boosting reliability. After creating numerous queries for the same question (using different models or approaches), the best is chosen. Multiple models agreeing increases accuracy.
The semantic layer connects customers' daily language to complex data structures.
Query history and usage pattern analysis help understand user intent.
Entity resolution can determine user intent.
Model finetuning: Sometimes used to ensure models supply enough SQL for dialects.
Assess and quantify
Enhancing AI-driven capabilities requires robust evaluation. Although BIRD-bench and other academic benchmarks are useful, they may not adequately reflect workload and organisation. Google Cloud has developed synthetic benchmarks for a variety of SQL engines, products, dialects, and engine-specific features like DDL, DML, administrative requirements, and sophisticated queries/schemas. Evaluation uses offline and user metrics and automated and human methods like LLM-as-a-judge to deliver cost-effective performance understanding on ambiguous tasks. Continuous reviews allow teams to quickly test new models, prompting tactics, and other improvements.
#SQLLLM#TexttoSQLLLM#TexttoSQL#VertexAI#TexttoSQLMethods#ChallengesofTexttoSQL#technology#technews#news#technologynews#technologytrends#govindhtech
0 notes
Text
The past 15 years have witnessed a massive change in the nature and complexity of web applications. At the same time, the data management tools for these web applications have undergone a similar change. In the current web world, it is all about cloud computing, big data and extensive users who need a scalable data management system. One of the common problems experienced by every large data web application is to manage big data efficiently. The traditional RDBM databases are insufficient in handling Big Data. On the contrary, NoSQL database is best known for handling web applications that involve Big Data. All the major websites including Google, Facebook and Yahoo use NoSQL for data management. Big Data companies like Netflix are using Cassandra (NoSQL database) for storing critical member data and other relevant information (95%). NoSQL databases are becoming popular among IT companies and one can expect questions related to NoSQL in a job interview. Here are some excellent books to learn more about NoSQL. Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement (By: Eric Redmond and Jim R. Wilson ) This book does what it is meant for and it gives basic information about seven different databases. These databases include Redis, CouchDB, HBase, Postgres, Neo4J, MongoDB and Riak. You will learn about the supporting technologies relevant to all of these databases. It explains the best use of every single database and you can choose an appropriate database according to the project. If you are looking for a database specific book, this might not be the right option for you. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence (By: Pramod J. Sadalage and Martin Fowler ) It offers a hands-on guide for NoSQL databases and can help you start creating applications with NoSQL database. The authors have explained four different types of databases including document based, graph based, key-value based and column value database. You will get an idea of the major differences among these databases and their individual benefits. The next part of the book explains different scalability problems encountered within an application. It is certainly the best book to understand the basics of NoSQL and makes a foundation for choosing other NoSQL oriented technologies. Professional NoSQL (By: Shashank Tiwari ) This book starts well with an explanation of the benefits of NoSQL in large data applications. You will start with the basics of NoSQL databases and understand the major difference among different types of databases. The author explains important characteristics of different databases and the best-use scenario for them. You can learn about different NoSQL queries and understand them well with examples of MongoDB, CouchDB, Redis, HBase, Google App Engine Datastore and Cassandra. This book is best to get started in NoSQL with extensive practical knowledge. Getting Started with NoSQL (By: Gaurav Vaish ) If you planning to step into NoSQL databases or preparing it for an interview, this is the perfect book for you. You learn the basic concepts of NoSQL and different products using these data management systems. This book gives a clear idea about the major differentiating features of NoSQL and SQL databases. In the next few chapters, you can understand different types of NoSQL storage types including document stores, graph databases, column databases, and key-value NoSQL databases. You will even come to know about the basic differences among NoSQL products such as Neo4J, Redis, Cassandra and MongoDB. Data Access for Highly-Scalable Solutions: Using SQL, NoSQL, and Polyglot Persistence (By: John Sharp, Douglas McMurtry, Andrew Oakley, Mani Subramanian, Hanzhong Zhang ) It is an advanced level book for programmers involved in web architecture development and deals with the practical problems in complex web applications. The best part of this book is that it describes different real-life
web development problems and helps you identify the best data management system for a particular problem. You will learn best practices to combine different data management systems and get maximum output from it. Moreover, you will understand the polyglot architecture and its necessity in web applications. The present web environment requires an individual to understand complex web applications and practices to handle Big Data. If you are planning to start high-end development and get into the world of NoSQL databases, it is best to choose one of these books and learn some practical concepts about web development. All of these books are full of practical information and can help you prepare for different job interviews concerning NoSQL databases. Make sure to do the practice section and implement these concepts for a better understanding.
0 notes