#what is trigger in sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text

► TAGGING SYSTEM
FOR MOST TYPES OF POST THE TAG FORMAT WILL BE SELECT ___; (semicolon included)
ex, SELECT music; or SELECT ships; or SELECT selfships.
>> for the most part i will only tag original posts this way. if im reblogging something the tags will be straightforward. so art will be tagged as #art and fandom without fuss.
ex. #art, #jjk etc.
>> i use a bastardized version of SQL to tag my posts bc it's easy for me to remember and generally uncomplicated to filter (from what ive tested at least)

FOR TRIGGER TAGGING:
anything that discusses something at depth will be tagged with ___ cw
ex. incest cw, grooming cw.
anything that is mostly joking or describes something in less than a sentence will be tagged. ___ mention
ex. incest mention, noncon mention.
FOR FANDOM TAGGING:
ALL ENCOMPASSING WRITING TAG IS THE SAME:
# writing tag.
FICS WILL BE DIVIDED BY.
# WHERE ___ -> length.
# where small; for anything under 1k, # where medium for anything 1-4k #where long for anything 4k+
# SELECT * FROM ___ -> general fandom tag.
# WHERE CHARACTER; -> general character (or ship name)
# WHERE CHARACTER1 AND CHARACTER 2; -> character pair tag.
# WHERE MULTI; -> multi character posts.
# FROM ___ -> my fic tag / tag for fic specific asks etc.
# SELECT meta; -> meta / commentary
# SELECT general; - ask tag for general asks (unrelated to fandom), general posts / catch-all
# SELECT SILLY general; -> funnies tag / hoarding tag for funny asks.
# SELECT MAX(LOVE); -> favorites tag.
# SELECT recs; -> recommendation tag.
# SELECT MIN(BS); ->discourse tag
# UNIQUE(PRAISE); -> hall of fame tag.
# UNIQUE(KEEP); -> posts i want to refer back to.
# ZERO. TXT -> general talking / inquiry tag.
#zero.txt#SELECT general;#SELECT SILLY general;#SELECT MAX(LOVE);#SELECT MIN(BS);#SELECT meta;#SELECT recs;#SELECT * FROM bllk#SELECT * FROM lads#SELECT * FROM jjk#SELECT * FROM wbk#SELECT * FROM bnha#SELECT * FROM hsr#SELECT music;#SELECT ships;#SELECT selfships;#WHERE small;#WHERE medium;#WHERE long;#UNIQUE(KEEP);#hall of fame
19 notes
·
View notes
Note
HEY i read your rambles on the authority skilltober drawing and i just wanna say that id love to read your thoughts on authority and volition's dynamic!! if you want to share them obviously lmao
hi anon!!! you sent this in 6 weeks ago, I am so sorry :( hopefully you still see this
I am! extremely excited to dump about these two!! just needed to have the time/energy to and then it took forever hgkjh
it's gonna be long so putting a break here :) but there are quote screenshots *and* doodles under the cut
first off, a bunch of this stuff is in this post about them, this Volition skilltober post, and this Authority skilltober post, but now it's all together. so if you've seen some of this commentary or screenshots before... that's why
so ... going to sort this into canon and headcanons.
CANON:
we get: all volition and authority interactions I can find!
them agreeing:

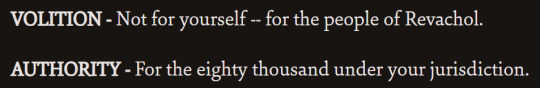








them disagreeing:



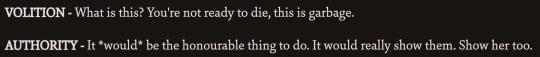



this ones not really agreeing or disagreeing ig:
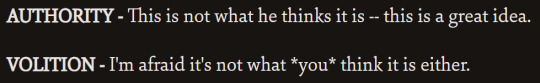
this one, the authority passive only fires if volition's doesn't. they're covering for eachotherrr.
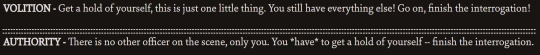
I ran a very complicated SQL query to find all the instances of them having dialogue right after another, but it doesn't account for when the dialogue is separated by a variable check (eg. the sorry cop dialogue needs to check if you have the sorry cop thought). so I did what anyone would do and spent 3 hours making a far more convoluted query to iterate through the variable chains until they reached another line of dialogue. Which for some reason was a lot more easy in theory than in execution. And every time I messed it up it would sit for like 15 minutes and then bomb my computer with 10 million rows of dialogue. And sure, maybe twice I accidentally made it trace through every single dialogue path possible in the game recursively which. required killing it because it blew up. but it eventually WORKED and that's what matters.
So these quotes! Basically. They agree on stuff plenty, backing eachother up against bad ideas presented by Harry, other skills, or other people. but they also bicker a lot, trying to shut down eachother's ideas. Volition is the voice of reason in a lot of these, mostly just his desire not to die out of sheer willpower, as well as shutting down a few of Authority's more impulsive suggestions. But there is one where Volition disagrees with Authority, telling you to keep pushing on the stickbug issue despite the fact that he's only doing it to be stubborn and is actively making the situation worse... I think Authority helps balance against the extreme stubbornness Volition sometimes takes too far.
Here are a couple of them referring to eachother's specialties...


Authority is also extremely anti narcotics and encourages you to do the right thing (like declining Evrart's bribe) which I'm sure Volition would be happy with, until Authority takes it too far and encourages you to drink and smoke more because it's better than narcotics, and starts encouraging you to basically fabricate situations where you can pretend to be honourable for karma coupons. Which. Sigh.
That's them! They're on the same page and everything is going great right up until it's not.
Also Authority triggers the only instance of healing *all* morale damage in the whole game... :)
Of note is also when Volition *doesn't* chime in. Volition is well aware of the gun idea during the Hardies fail, even before you are, and makes no move to stop it. (Also, the back and forth during that fail when Volition tells you to give the gun back is. hgkh. I can't think of any other instance of Volition trying to override some bad decision and the skill in question talking/fighting back. If it does happen, it must be pretty rare.) He also doesn't stop you during the Authority fail dancing in the church, just urges you to go apologize after the damage is done (despite stopping you from making a racist comment during an encyclopedia fail a different time).
They also do take over for eachother from time to time! Especially with Kim asserting his authority, both of them do it several times. Authority obviously has the eyebrow standoff, but the check to not wipe coal off your face is an Authority check. The check to refuse to drink water after you faint is Volition, as well as Volition will allow you to tell Kim you don't need to be supervised.
HEADCANONS:
YES behold. my headcanons about them.
skill parents... the two of them are the ones all the other skills go to if they need help, or to break up a fight, or to hide from if they're being irresponsible
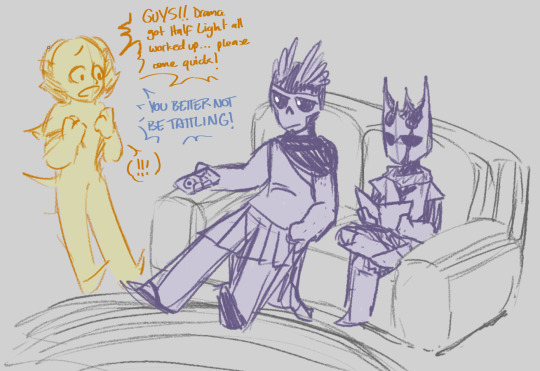
one sided rivalry!! volition just wants to keep everything together and authority took that personally. he's far more invested in asserting himself over volition than the other way around -- volition just wants authority to listen to him. we've got volition at 10 skill points and authority at 8, and authority is cooperative right up until Harry takes too much morale damage and volition's points dip below authority's, and then all bets are off.

ouh I love these two. when they get along, they work together wonderfully and do a great job running the ship together. and when they don't it turns into a mess! :) they absolutely fight over who has to (or gets to, depending) resolve an issue when something comes up while they're fighting. or will defer to the other one if they're separate (go talk to authority > go ask volition loop)
Authority is like this absolute force of nature that can't stand being told no, or anything or anyone getting in his way, and will use intimidation or force or whatever he has to to get his way. And Volition is this wall of willpower that will completely dig his heels in at the first sign of anyone trying to force him to do something he doesn't want to do, and continue to be unrelentingly stubborn about it until the bitter end. Unstoppable force vs immovable object. Authority's desire to control everything is only matched by Volition's desire for control over himself. Like I am not convinced Volition would be able to put self preservation above his stubbornness. And it's this eternal standoff until something (either of their skill points dropping/raising) changes the playing field. They're awful for each other sometimes but they're the only ones who can balance each other out a bit. I'm so normal about them.
I will say with regards to my morale critical volition, which I have many thoughts about constantly... that authority is so much more attuned to volition's strength relative to his own that he often realizes way before the others that morale is getting low. :) may make some mini comics about them because writing is much more fickle... and I like drawing them.
okay... that's far more than anyone could have possibly wanted about these two idiots, I think. hope u enjoyed anon, ty for asking about them!!!
18 notes
·
View notes
Text
SQL Temporary Table | Temp Table | Global vs Local Temp Table
Q01. What is a Temp Table or Temporary Table in SQL? Q02. Is a duplicate Temp Table name allowed? Q03. Can a Temp Table be used for SELECT INTO or INSERT EXEC statement? Q04. What are the different ways to create a Temp Table in SQL? Q05. What is the difference between Local and Global Temporary Table in SQL? Q06. What is the storage location for the Temp Tables? Q07. What is the difference between a Temp Table and a Derived Table in SQL? Q08. What is the difference between a Temp Table and a Common Table Expression in SQL? Q09. How many Temp Tables can be created with the same name? Q10. How many users or who can access the Temp Tables? Q11. Can you create an Index and Constraints on the Temp Table? Q12. Can you apply Foreign Key constraints to a temporary table? Q13. Can you use the Temp Table before declaring it? Q14. Can you use the Temp Table in the User-Defined Function (UDF)? Q15. If you perform an Insert, Update, or delete operation on the Temp Table, does it also affect the underlying base table? Q16. Can you TRUNCATE the temp table? Q17. Can you insert the IDENTITY Column value in the temp table? Can you reset the IDENTITY Column of the temp table? Q18. Is it mandatory to drop the Temp Tables after use? How can you drop the temp table in a stored procedure that returns data from the temp table itself? Q19. Can you create a new temp table with the same name after dropping the temp table within a stored procedure? Q20. Is there any transaction log created for the operations performed on the Temp Table? Q21. Can you use explicit transactions on the Temp Table? Does the Temp Table hold a lock? Does a temp table create Magic Tables? Q22. Can a trigger access the temp tables? Q23. Can you access a temp table created by a stored procedure in the same connection after executing the stored procedure? Q24. Can a nested stored procedure access the temp table created by the parent stored procedure? Q25. Can you ALTER the temp table? Can you partition a temp table? Q26. Which collation will be used in the case of Temp Table, the database on which it is executing, or temp DB? What is a collation conflict error and how you can resolve it? Q27. What is a Contained Database? How does it affect the Temp Table in SQL? Q28. Can you create a column with user-defined data types (UDDT) in the temp table? Q29. How many concurrent users can access a stored procedure that uses a temp table? Q30. Can you pass a temp table to the stored procedure as a parameter?
#sqlinterview#sqltemptable#sqltemporarytable#sqltemtableinterview#techpointinterview#techpointfundamentals#techpointfunda#techpoint#techpointblog
4 notes
·
View notes
Text
Sorry, you have been blocked You are unable to access playnileonline.com Why have I been blocked? This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
What can I do to resolve this? You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
Cloudflare Ray ID: 951c23455eb2c9cf • Your IP: Click to reveal • Performance & security by Cloudflare
0 notes
Text
Unlocking the Power of Delta Live Tables in Data bricks with Kadel Labs
Introduction
In the rapidly evolving landscape of big data and analytics, businesses are constantly seeking ways to streamline data processing, ensure data reliability, and improve real-time analytics. One of the most powerful solutions available today is Delta Live Tables (DLT) in Databricks. This cutting-edge feature simplifies data engineering and ensures efficiency in data pipelines.
Kadel Labs, a leader in digital transformation and data engineering solutions, leverages Delta Live Tables to optimize data workflows, ensuring businesses can harness the full potential of their data. In this article, we will explore what Delta Live Tables are, how they function in Databricks, and how Kadel Labs integrates this technology to drive innovation.
Understanding Delta Live Tables
What Are Delta Live Tables?
Delta Live Tables (DLT) is an advanced framework within Databricks that simplifies the process of building and maintaining reliable ETL (Extract, Transform, Load) pipelines. With DLT, data engineers can define incremental data processing pipelines using SQL or Python, ensuring efficient data ingestion, transformation, and management.
Key Features of Delta Live Tables
Automated Pipeline Management
DLT automatically tracks changes in source data, eliminating the need for manual intervention.
Data Reliability and Quality
Built-in data quality enforcement ensures data consistency and correctness.
Incremental Processing
Instead of processing entire datasets, DLT processes only new data, improving efficiency.
Integration with Delta Lake
DLT is built on Delta Lake, ensuring ACID transactions and versioned data storage.
Monitoring and Observability
With automatic lineage tracking, businesses gain better insights into data transformations.
How Delta Live Tables Work in Databricks
Databricks, a unified data analytics platform, integrates Delta Live Tables to streamline data lake house architectures. Using DLT, businesses can create declarative ETL pipelines that are easy to maintain and highly scalable.
The DLT Workflow
Define a Table and Pipeline
Data engineers specify data sources, transformation logic, and the target Delta table.
Data Ingestion and Transformation
DLT automatically ingests raw data and applies transformation logic in real-time.
Validation and Quality Checks
DLT enforces data quality rules, ensuring only clean and accurate data is processed.
Automatic Processing and Scaling
Databricks dynamically scales resources to handle varying data loads efficiently.
Continuous or Triggered Execution
DLT pipelines can run continuously or be triggered on-demand based on business needs.
Kadel Labs: Enhancing Data Pipelines with Delta Live Tables
As a digital transformation company, Kadel Labs specializes in deploying cutting-edge data engineering solutions that drive business intelligence and operational efficiency. The integration of Delta Live Tables in Databricks is a game-changer for organizations looking to automate, optimize, and scale their data operations.
How Kadel Labs Uses Delta Live Tables
Real-Time Data Streaming
Kadel Labs implements DLT-powered streaming pipelines for real-time analytics and decision-making.
Data Governance and Compliance
By leveraging DLT’s built-in monitoring and validation, Kadel Labs ensures regulatory compliance.
Optimized Data Warehousing
DLT enables businesses to build cost-effective data warehouses with improved data integrity.
Seamless Cloud Integration
Kadel Labs integrates DLT with cloud environments (AWS, Azure, GCP) to enhance scalability.
Business Intelligence and AI Readiness
DLT transforms raw data into structured datasets, fueling AI and ML models for predictive analytics.
Benefits of Using Delta Live Tables in Databricks
1. Simplified ETL Development
With DLT, data engineers spend less time managing complex ETL processes and more time focusing on insights.
2. Improved Data Accuracy and Consistency
DLT automatically enforces quality checks, reducing errors and ensuring data accuracy.
3. Increased Operational Efficiency
DLT pipelines self-optimize, reducing manual workload and infrastructure costs.
4. Scalability for Big Data
DLT seamlessly scales based on workload demands, making it ideal for high-volume data processing.
5. Better Insights with Lineage Tracking
Data lineage tracking in DLT provides full visibility into data transformations and dependencies.
Real-World Use Cases of Delta Live Tables with Kadel Labs
1. Retail Analytics and Customer Insights
Kadel Labs helps retailers use Delta Live Tables to analyze customer behavior, sales trends, and inventory forecasting.
2. Financial Fraud Detection
By implementing DLT-powered machine learning models, Kadel Labs helps financial institutions detect fraudulent transactions.
3. Healthcare Data Management
Kadel Labs leverages DLT in Databricks to improve patient data analysis, claims processing, and medical research.
4. IoT Data Processing
For smart devices and IoT applications, DLT enables real-time sensor data processing and predictive maintenance.
Conclusion
Delta Live Tables in Databricks is transforming the way businesses handle data ingestion, transformation, and analytics. By partnering with Kadel Labs, companies can leverage DLT to automate pipelines, improve data quality, and gain actionable insights.
With its expertise in data engineering, Kadel Labs empowers businesses to unlock the full potential of Databricks and Delta Live Tables, ensuring scalable, efficient, and reliable data solutions for the future.
For businesses looking to modernize their data architecture, now is the time to explore Delta Live Tables with Kadel Labs!
0 notes
Text
How to Optimize ETL Pipelines for Performance and Scalability

As data continues to grow in volume, velocity, and variety, the importance of optimizing your ETL pipeline for performance and scalability cannot be overstated. An ETL (Extract, Transform, Load) pipeline is the backbone of any modern data architecture, responsible for moving and transforming raw data into valuable insights. However, without proper optimization, even a well-designed ETL pipeline can become a bottleneck, leading to slow processing, increased costs, and data inconsistencies.
Whether you're building your first pipeline or scaling existing workflows, this guide will walk you through the key strategies to improve the performance and scalability of your ETL pipeline.
1. Design with Modularity in Mind
The first step toward a scalable ETL pipeline is designing it with modular components. Break down your pipeline into independent stages — extraction, transformation, and loading — each responsible for a distinct task. Modular architecture allows for easier debugging, scaling individual components, and replacing specific stages without affecting the entire workflow.
For example:
Keep extraction scripts isolated from transformation logic
Use separate environments or containers for each stage
Implement well-defined interfaces for data flow between stages
2. Use Incremental Loads Over Full Loads
One of the biggest performance drains in ETL processes is loading the entire dataset every time. Instead, use incremental loads — only extract and process new or updated records since the last run. This reduces data volume, speeds up processing, and decreases strain on source systems.
Techniques to implement incremental loads include:
Using timestamps or change data capture (CDC)
Maintaining checkpoints or watermark tables
Leveraging database triggers or logs for change tracking
3. Leverage Parallel Processing
Modern data tools and cloud platforms support parallel processing, where multiple operations are executed simultaneously. By breaking large datasets into smaller chunks and processing them in parallel threads or workers, you can significantly reduce ETL run times.
Best practices for parallelism:
Partition data by time, geography, or IDs
Use multiprocessing in Python or distributed systems like Apache Spark
Optimize resource allocation in cloud-based ETL services
4. Push Down Processing to the Source System
Whenever possible, push computation to the database or source system rather than pulling data into your ETL tool for processing. Databases are optimized for query execution and can filter, sort, and aggregate data more efficiently.
Examples include:
Using SQL queries for filtering data before extraction
Aggregating large datasets within the database
Using stored procedures to perform heavy transformations
This minimizes data movement and improves pipeline efficiency.
5. Monitor, Log, and Profile Your ETL Pipeline
Optimization is not a one-time activity — it's an ongoing process. Use monitoring tools to track pipeline performance, identify bottlenecks, and collect error logs.
What to monitor:
Data throughput (rows/records per second)
CPU and memory usage
Job duration and frequency of failures
Time spent at each ETL stage
Popular tools include Apache Airflow for orchestration, Prometheus for metrics, and custom dashboards built on Grafana or Kibana.
6. Use Scalable Storage and Compute Resources
Cloud-native ETL tools like AWS Glue, Google Dataflow, and Azure Data Factory offer auto-scaling capabilities that adjust resources based on workload. Leveraging these platforms ensures you’re only using (and paying for) what you need.
Additionally:
Store intermediate files in cloud storage (e.g., Amazon S3)
Use distributed compute engines like Spark or Dask
Separate compute and storage to scale each independently
Conclusion
A fast, reliable, and scalable ETL pipeline is crucial to building robust data infrastructure in 2025 and beyond. By designing modular systems, embracing incremental and parallel processing, offloading tasks to the database, and continuously monitoring performance, data teams can optimize their pipelines for both current and future needs.
In the era of big data and real-time analytics, even small performance improvements in your ETL workflow can lead to major gains in efficiency and insight delivery. Start optimizing today to unlock the full potential of your data pipeline.
0 notes
Text
Master SQL with the Best Online Course in Hyderabad – Offered by Gritty Tech
SQL (Structured Query Language) is the backbone of data handling in modern businesses. Whether you're aiming for a career in data science, software development, or business analytics, SQL is a must-have skill. If you're based in Hyderabad or even outside but seeking the best SQL online course that delivers practical learning with real-world exposure, Gritty Tech has crafted the perfect program for you For More…
What Makes Gritty Tech's SQL Course Stand Out?
Practical, Job-Focused Curriculum
Gritty Tech’s SQL course is meticulously designed to align with industry demands. The course content is structured around the real-time requirements of IT companies, data-driven businesses, and startups.
You'll start with the basics of SQL and gradually move to advanced concepts such as:
Writing efficient queries
Managing large datasets
Building normalized databases
Using SQL with business intelligence tools
SQL for data analytics and reporting
Every module is project-based. This means you won’t just learn the theory—you’ll get your hands dirty with practical assignments that mirror real-world tasks.
Learn from Industry Experts
The faculty at Gritty Tech are not just trainers; they are seasoned professionals from top MNCs and startups. Their teaching combines theory with examples drawn from years of hands-on experience. They understand what companies expect from an SQL developer and prepare students accordingly.
Each mentor brings valuable insights into how SQL works in day-to-day business scenarios—whether it's managing millions of records in a customer database or optimizing complex queries in a financial system.
Interactive and Flexible Online Learning
Learning online doesn’t mean learning alone. Gritty Tech ensures you’re part of a vibrant student community where peer interaction, discussion forums, and collaborative projects are encouraged.
Key features of their online delivery model include:
Live instructor-led sessions with real-time query solving
Access to session recordings for future reference
Weekly challenges and hackathons to push your skills
1:1 mentorship to clarify doubts and reinforce learning
You can choose batch timings that suit your schedule, making this course ideal for both working professionals and students.
Comprehensive Module Coverage
The course is divided into logical modules that build your expertise step by step. Here's an overview of the key topics covered:
Introduction to SQL and RDBMS
Understanding data and databases
Relational models and primary concepts
Introduction to MySQL and PostgreSQL
Data Definition Language (DDL)
Creating and modifying tables
Setting primary and foreign keys
Understanding constraints and data types
Data Manipulation Language (DML)
Inserting, updating, and deleting records
Transaction management
Working with auto-commits and rollbacks
Data Query Language (DQL)
SELECT statements in depth
Filtering data with WHERE clause
Using ORDER BY, GROUP BY, and HAVING
Advanced SQL Queries
JOINS: INNER, LEFT, RIGHT, FULL OUTER
Subqueries and nested queries
Views and materialized views
Indexing and performance tuning
Stored Procedures and Triggers
Creating stored procedures for reusable logic
Using triggers to automate actions
SQL in Real Projects
Working with business databases
Creating reports and dashboards
Integrating SQL with Excel and BI tools
Interview Preparation & Certification
SQL interview Q&A sessions
Mock technical interviews
Industry-recognized certification on course completion
Real-Time Projects and Case Studies
Nothing beats learning by doing. At Gritty Tech, every student works on multiple real-time projects, such as:
Designing a complete eCommerce database
Building a report generation system for a retail chain
Analyzing customer data for a telecom company
Creating dashboards with SQL-backed queries for business decisions
These projects simulate real job roles and ensure you're not just certified but genuinely skilled.
Placement Assistance and Resume Building
Gritty Tech goes the extra mile to help you land your dream job. They offer:
Resume and LinkedIn profile optimization
Personalized career guidance
Referrals to hiring partners
Mock interview practice with real-time feedback
Graduates of Gritty Tech have successfully secured jobs as Data Analysts, SQL Developers, Business Intelligence Executives, and more at top companies.
Affordable Pricing with Installment Options
Quality education should be accessible. Gritty Tech offers this high-value SQL course at a very competitive price. Students can also opt for EMI-based payment options. There are often discounts available for early registration or referrals.
Support After Course Completion
Your learning doesn't stop when the course ends. Gritty Tech provides post-course support where you can:
Revisit lectures and materials
Get help with ongoing SQL projects at work
Stay connected with alumni and mentors
They also host webinars, advanced workshops, and alumni meetups that keep you updated and networked.
Who Should Join This Course?
This SQL course is ideal for:
College students and fresh graduates looking to boost their resume
Working professionals in non-technical roles aiming to switch to tech
Data enthusiasts and aspiring data scientists
Business analysts who want to strengthen their data querying skills
Developers who wish to enhance their backend capabilities
No prior coding experience is required. The course begins from scratch, making it beginner-friendly while progressing toward advanced topics for experienced learners.
0 notes
Text
How to Assess Oracle EBS Customizations Before Cloud Migration
Migrating from Oracle E-Business Suite (EBS) to Oracle Cloud Applications (Fusion) isn’t just a technical upgrade—it’s a transformation. One of the most critical and often underestimated parts of this journey is assessing customizations. Over the years, organizations have tailored their EBS environments with custom reports, workflows, forms, and extensions to meet specific business needs. But not everything needs to move to the cloud. Some customizations become obsolete, while others can now be addressed with built-in cloud functionality.
This blog outlines a practical approach to assessing your EBS customizations before migrating to Oracle Cloud, helping you reduce technical debt, streamline operations, and align with modern best practices.
1. Identify All Existing Customizations
Before deciding what to migrate, you need a full inventory of what’s customized in your EBS environment. This includes:
Custom Forms (FMBs)
Custom Reports (RDFs, BI Publisher, Discoverer)
Workflows and Alerts
PL/SQL packages, procedures, triggers
Custom menus, responsibilities, and profiles
Third-party integrations
Use tools like Oracle Application Object Library (AOL) tables, custom code repositories, or Oracle-provided utilities (like Customization Analyzer or EBS Upgrade Companion) to extract and document this data.
2. Classify and Categorize the Customizations
Once identified, classify the customizations into categories such as:
Mandatory (business-critical)
Nice to have
Obsolete or redundant
Replaced by standard cloud functionality
This helps stakeholders prioritize what needs to be rebuilt, replaced, or retired.
3. Evaluate Business Relevance in the Cloud Context
Many EBS customizations were created due to gaps in standard functionality. But Oracle Cloud Applications are built with industry best practices, modern capabilities, and built-in analytics. Before deciding to rebuild a customization:
Ask why it was created
Check if similar functionality is now standard in Oracle Cloud
Consider whether adapting business processes to the cloud's standard flow is a better option
This approach reduces custom development and long-term maintenance efforts.
4. Map Customizations to Cloud Equivalents
For viable customizations, determine how they can be translated in the cloud: EBS CustomizationOracle Cloud EquivalentForms (FMBs)Visual Builder Apps, Page Composer, App ComposerPL/SQL CodeGroovy Scripts, REST APIs, Cloud FunctionsWorkflowsBPM Workflows, Approval RulesReports (RDF)BI Publisher, OTBI, Fusion Analytics
Understanding these mappings helps scope the effort required and guides design decisions in the cloud environment.
5. Document, Rationalize, and Get Stakeholder Buy-in
Create a detailed Customization Assessment Register that includes:
Custom object name
Purpose
Business owner
Migration decision (Migrate, Replace, Retire)
Notes on implementation approach
Review it with stakeholders and functional leads to ensure alignment before proceeding with design or development in the cloud.
Conclusion
Assessing Oracle EBS customizations is a vital early step in your cloud migration journey. It ensures you're not just copying legacy complexity into a modern platform. By identifying, classifying, and evaluating your customizations thoughtfully, you can take full advantage of Oracle Cloud’s built-in capabilities, reduce future maintenance, and create a cleaner, more agile system.
Start early, collaborate with your business users, and think cloud-first—your future self will thank you.
0 notes
Text
Combining Azure Data Factory with Azure Event Grid for Event-Driven Workflows

Traditional data pipelines often run on schedules — every 15 minutes, every hour, etc. But in a real-time world, that isn’t always enough. When latency matters, event-driven architectures offer a more agile solution.
Enter Azure Data Factory (ADF) + Azure Event Grid — a powerful duo for building event-driven data workflows that react to file uploads, service messages, or data changes instantly.
Let’s explore how to combine them to build more responsive, efficient, and scalable pipelines.
⚡ What is Azure Event Grid?
Azure Event Grid is a fully managed event routing service that enables your applications to react to events in near real-time. It supports:
Multiple event sources: Azure Blob Storage, Event Hubs, IoT Hub, custom apps
Multiple event handlers: Azure Functions, Logic Apps, WebHooks, and yes — Azure Data Factory
🎯 Why Use Event Grid with Azure Data Factory?
BenefitDescription🕒 Real-Time TriggersTrigger ADF pipelines the moment a file lands in Blob Storage — no polling needed🔗 Decoupled ArchitectureKeep data producers and consumers independent⚙️ Flexible RoutingRoute events to different pipelines, services, or queues based on metadata💰 Cost-EffectivePay only for events received — no need for frequent pipeline polling
🧱 Core Architecture Pattern
Here’s how the integration typically looks:pgsqlData Source (e.g., file uploaded to Blob Storage) ↓ Event Grid ↓ ADF Webhook Trigger (via Logic App or Azure Function) ↓ ADF Pipeline runs to ingest/transform data
🛠 Step-by-Step: Setting Up Event-Driven Pipelines
✅ 1. Enable Event Grid on Blob Storage
Go to your Blob Storage account
Navigate to Events > + Event Subscription
Select Event Type: Blob Created
Choose the endpoint — typically a Logic App, Azure Function, or Webhook
✅ 2. Create a Logic App to Trigger ADF Pipeline
Use Logic Apps if you want simple, no-code integration:
Use the “When a resource event occurs” Event Grid trigger
Add an action: “Create Pipeline Run (Azure Data Factory)”
Pass required parameters (e.g., file name, path) from the event payload
🔁 You can pass the blob path into a dynamic dataset in ADF for ingestion or transformation.
✅ 3. (Optional) Add Routing Logic
Use conditional steps in Logic Apps or Functions to:
Trigger different pipelines based on file type
Filter based on folder path, metadata, or event source
📘 Use Case Examples
📁 1. File Drop in Data Lake
Event Grid listens to Blob Created
Logic App triggers ADF pipeline to process the new file
🧾 2. New Invoice Arrives via API
Custom app emits event to Event Grid
Azure Function triggers ADF pipeline to pull invoice data into SQL
📈 3. Stream Processing with Event Hubs
Event Grid routes Event Hub messages to ADF or Logic Apps
Aggregated results land in Azure Synapse
🔐 Security and Best Practices
Use Managed Identity for authentication between Logic Apps and ADF
Use Event Grid filtering to avoid noisy triggers
Add dead-lettering to Event Grid for failed deliveries
Monitor Logic App + ADF pipeline failures with Azure Monitor Alerts
🧠 Wrapping Up
Event-driven architectures are key for responsive data systems. By combining Azure Event Grid with Azure Data Factory, you unlock the ability to trigger pipelines instantly based on real-world events — reducing latency, decoupling your system, and improving efficiency.
Whether you’re reacting to file uploads, streaming messages, or custom app signals, this integration gives your pipelines the agility they need.
Want an infographic to go with this blog? I can generate one in your preferred visual style.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
B2B Buyer Intent Data Game-Changers: Unlocking Smarter Lead Generation with Acceligize
The Rise of Intent Data in Modern B2B Marketing In today’s highly competitive B2B landscape, understanding who your buyers are is no longer enough. To drive true demand generation success, brands must uncover what those buyers are actively researching, when they are in-market, and why they’re searching in the first place. That’s where B2B buyer intent data has become a game-changer.
By tapping into behavioral signals across digital channels, buyer intent data allows businesses to identify prospects who are actively evaluating solutions—well before they fill out a form or respond to outreach. At Acceligize, we help forward-thinking B2B organizations harness this intelligence to drive more targeted, personalized, and high-converting marketing campaigns.

What Is Buyer Intent Data—and Why Does It Matter in B2B? Buyer intent data refers to the digital footprints left behind when prospects research topics, visit competitor sites, engage with industry content, or participate in relevant online activities. This data signals potential purchase intent—and when captured effectively, it reveals which companies are “in-market” right now.
Unlike traditional lead scoring, which relies heavily on historical or firmographic information, intent data provides real-time insight into active buying behavior. For B2B companies, this changes everything: it shortens sales cycles, enhances account prioritization, and dramatically improves pipeline quality.
Acceligize: Powering Demand Generation with Intent Intelligence At Acceligize, we’ve embedded buyer intent intelligence into the core of our B2B demand generation solutions. Our advanced data ecosystem aggregates and analyzes billions of intent signals across content networks, search behavior, and media engagement. This allows our clients to:
Identify high-potential accounts earlier in the buying journey
Deliver personalized messaging tailored to specific interests and research topics
Prioritize outreach to leads that are more likely to convert
Align marketing and sales teams with a shared understanding of buyer readiness
By focusing on behavior-based triggers rather than assumptions, we enable businesses to meet prospects with exactly what they need, exactly when they need it.
B2B Buyer Intent Data Trends to Watch in 2025 The use of intent data is evolving rapidly—and staying ahead requires awareness of key trends:
AI-Driven Predictive Analytics: More companies are combining AI and machine learning with intent data to forecast buying signals with greater accuracy. Acceligize integrates AI layers to recommend content, channels, and timing based on intent scoring models.
Hyper-Personalization at Scale: Intent data fuels deeper personalization across campaigns. With real-time insights, marketers can craft content journeys that feel tailored to the individual, even within large ABM programs.
Intent-Based ABM: Account-Based Marketing is no longer just about targeting ideal customers—it’s about targeting the right accounts at the right time. Acceligize’s ABM strategies leverage intent to prioritize account lists dynamically and optimize outreach efficiency.
Cross-Channel Signal Integration: From webinars to search engines, buyer activity spans multiple touchpoints. Acceligize tracks and unifies signals across channels to create a comprehensive view of intent that’s actionable across platforms.
How Intent Data Accelerates Pipeline and ROI B2B marketers who leverage intent data consistently see better performance across the funnel. Why? Because they focus resources where the interest already exists. Acceligize’s intent-powered campaigns have helped clients achieve:
Up to 3x increase in MQL-to-SQL conversion rates
Reduced cost-per-lead (CPL) by targeting only in-market accounts
Improved sales velocity and shorter deal cycles
Higher account engagement and nurturing efficiency
Get more insights@ https://acceligize.com/our-solutions/
When intent data is applied strategically, it’s not just a performance booster—it becomes a competitive advantage.
Final Thoughts: Ready to Leverage Intent Like a Game-Changer? The future of B2B lead generation is not about casting wider nets—it’s about casting smarter ones. Buyer intent data is changing the rules of engagement, and those who harness it effectively will dominate their market.
At Acceligize, we help our clients turn intent insights into impactful demand generation results. Whether you're launching a new ABM initiative, enhancing your sales outreach, or optimizing your digital campaigns, our intent-driven approach ensures you’re always one step ahead of the buyer—and the competition.
Read More@ https://acceligize.com/featured-blogs/b2b-buyer-intent-data-game-changers/
#b2b#b2b lead generation#b2b saas#b2b services#b2bbusiness#b2bdatabase#b2bmarketing#b2bsales#digital painting#Acceligize#Acceligize b2b demand generation
0 notes
Text
Real-time Data Processing with Azure Stream Analytics
Introduction
The current fast-paced digital revolution demands organizations to handle occurrences in real-time. The processing of real-time data enables organizations to detect malicious financial activities and supervise sensor measurements and webpage user activities which enables quicker and more intelligent business choices.
Microsoft’s real-time analytics service Azure Stream Analytics operates specifically to analyze streaming data at high speed. The introduction explains Azure Stream Analytics system architecture together with its key features and shows how users can construct effortless real-time data pipelines.
What is Azure Stream Analytics?
Algorithmic real-time data-streaming functions exist as a complete serverless automation through Azure Stream Analytics. The system allows organizations to consume data from different platforms which they process and present visual data through straightforward SQL query protocols.
An Azure data service connector enables ASA to function as an intermediary which processes and connects streaming data to emerging dashboards as well as alarms and storage destinations. ASA facilitates processing speed and immediate response times to handle millions of IoT device messages as well as application transaction monitoring.
Core Components of Azure Stream Analytics
A Stream Analytics job typically involves three major components:
1. Input
Data can be ingested from one or more sources including:
Azure Event Hubs – for telemetry and event stream data
Azure IoT Hub – for IoT-based data ingestion
Azure Blob Storage – for batch or historical data
2. Query
The core of ASA is its SQL-like query engine. You can use the language to:
Filter, join, and aggregate streaming data
Apply time-window functions
Detect patterns or anomalies in motion
3. Output
The processed data can be routed to:
Azure SQL Database
Power BI (real-time dashboards)
Azure Data Lake Storage
Azure Cosmos DB
Blob Storage, and more
Example Use Case
Suppose an IoT system sends temperature readings from multiple devices every second. You can use ASA to calculate the average temperature per device every five minutes:

This simple query delivers aggregated metrics in real time, which can then be displayed on a dashboard or sent to a database for further analysis.
Key Features
Azure Stream Analytics offers several benefits:
Serverless architecture: No infrastructure to manage; Azure handles scaling and availability.
Real-time processing: Supports sub-second latency for streaming data.
Easy integration: Works seamlessly with other Azure services like Event Hubs, SQL Database, and Power BI.
SQL-like query language: Low learning curve for analysts and developers.
Built-in windowing functions: Supports tumbling, hopping, and sliding windows for time-based aggregations.
Custom functions: Extend queries with JavaScript or C# user-defined functions (UDFs).
Scalability and resilience: Can handle high-throughput streams and recovers automatically from failures.
Common Use Cases
Azure Stream Analytics supports real-time data solutions across multiple industries:
Retail: Track customer interactions in real time to deliver dynamic offers.
Finance: Detect anomalies in transactions for fraud prevention.
Manufacturing: Monitor sensor data for predictive maintenance.
Transportation: Analyze traffic patterns to optimize routing.
Healthcare: Monitor patient vitals and trigger alerts for abnormal readings.
Power BI Integration
The most effective connection between ASA and Power BI serves as a fundamental feature. Asustream Analytics lets users automatically send data which Power BI dashboards update in fast real-time. Operations teams with managers and analysts can maintain ongoing key metric observation through ASA since it allows immediate threshold breaches to trigger immediate action.
Best Practices
To get the most out of Azure Stream Analytics:
Use partitioned input sources like Event Hubs for better throughput.
Keep queries efficient by limiting complex joins and filtering early.
Avoid UDFs unless necessary; they can increase latency.
Use reference data for enriching live streams with static datasets.
Monitor job metrics using Azure Monitor and set alerts for failures or delays.
Prefer direct output integration over intermediate storage where possible to reduce delays.
Getting Started
Setting up a simple ASA job is easy:
Create a Stream Analytics job in the Azure portal.
Add inputs from Event Hub, IoT Hub, or Blob Storage.
Write your SQL-like query for transformation or aggregation.
Define your output—whether it’s Power BI, a database, or storage.
Start the job and monitor it from the portal.
Conclusion
Organizations at all scales use Azure Stream Analytics to gain processing power for real-time data at levels suitable for business operations. Azure Stream Analytics maintains its prime system development role due to its seamless integration of Azure services together with SQL-based declarative statements and its serverless architecture.
Stream Analytics as a part of Azure provides organizations the power to process ongoing data and perform real-time actions to increase operational intelligence which leads to enhanced customer satisfaction and improved market positioning.
#azure data engineer course#azure data engineer course online#azure data engineer online course#azure data engineer online training#azure data engineer training#azure data engineer training online#azure data engineering course#azure data engineering online training#best azure data engineer course#best azure data engineer training#best azure data engineering courses online#learn azure data engineering#microsoft azure data engineer training
0 notes
Text
How to Hire the Right MySQL Engineer: Skills to Look For

For any business that handles structured data a solid database foundation serves as the key. MySQL continues to dominate the market as one of the most reliable and widely utilized relational database systems. Whether it’s managing e-commerce transactions, user profiles, or analytics, having the right talent can have a significant impact on performance and scalability.
That’s why several tech companies are considering hiring database engineers with MySQL proficiency. This helps to manage the growing database needs. But how do you know that you are hiring the right fit for the job? In this article we will breakdown what you need to look for when you set out to hire these experts.
Key Technical and Practical Skills Every Business Should Prioritize
Strong knowledge of SQL and database design
Fundamental SQL expertise is a must when hiring MySQL engineers. Your ideal applicant ought to:
Create secure and optimized SQL queries.
Recognize data modelling and normalization.
Understand performance indexing techniques.
Have the ability to create triggers and stored procedures.
These abilities allow a MySQL engineer to increase speed and storage efficiency, which is essential for rapidly expanding tech companies.
Experience in performance tuning and troubleshooting
Performance issues arise as your data grows. A proficient MySQL developer ought to be able to:
Find and fix slow queries.
Keep an eye on and maximize database load.
Make use of programs such as MySQLTuner, EXPLAIN, and performance schema.
Set up the server's parameters for best performance.
In SaaS setups or real-time applications where latency is a concern, this becomes even more crucial.
Data backup, security, and recovery skills
A business can be destroyed by data breaches or loss. A trustworthy MySQL developer will:
Configure automated backup plans.
Put user roles and permissions into practice.
Secure connections and encrypt data.
Create scenarios for catastrophe recovery.
These abilities guarantee data security and regulatory compliance, which is particularly important for the high-security, healthcare, and financial sectors.
Integration and collaboration capabilities
MySQL engineers don't work alone. They frequently work along with software developers and backend teams. You might also have to:
Fill positions like hiring backend developers to assist with application-side logic.
Employ database engineers for distributed or more complicated settings.
Hire software developers to create data-driven, scalable products.
A MySQL engineer with cross-departmental collaboration skills guarantees more efficient operations and agile delivery.
Familiarity with modern tools and frameworks
Present-day MySQL programmers must to be knowledgeable about:
ORMs such as Eloquent, Sequelize, or Hibernate.
Cloud-based solutions like Google Cloud SQL and AWS RDS.
Tools for monitoring such as Prometheus or Datadog.
Pipelines for CI/CD database updates.
For the majority of tech businesses that use cloud-native solutions, this demonstrates adaptability in contemporary development settings.
Closing Remarks
If you are serious about your data infrastructure, you should hire MySQL developers. Seek applicants that have excellent technical proficiency together with teamwork and problem-solving abilities. Results can be increased by matching your MySQL specialist with the appropriate team, such as hiring software engineers, regardless of whether you're managing a legacy system or scaling a SaaS platform. Choosing the proper database hiring is a commercial choice for tech firms, not just a backend one.
0 notes
Text
Microsoft Dynamics 365 CRM Training | MS Dynamics CRM Training
How Canvas Apps Improve Dynamics 365 CRM Customization
Introduction
Microsoft Dynamics CRM Training Customization to streamline customer relationships, sales, and service processes. However, standard CRM functionalities may not always meet unique business needs. This is where Canvas Apps for Dynamics 365 CRM come in. These low-code applications allow businesses to customize CRM interfaces, automate workflows, and create tailored solutions without requiring extensive coding knowledge.
What Are Canvas Apps in Power Apps?
Canvas Apps, part of Microsoft Power Apps for CRM, provide a drag-and-drop interface to build custom applications. Unlike Model-Driven Apps, which follow a structured data model, Canvas Apps offer complete UI flexibility, allowing users to design screens, integrate data sources, and build applications that fit specific business processes.
Key Features of Canvas Apps
Drag-and-drop design interface for easy customization. Seamless integration with Dynamics 365 CRM, SharePoint, Excel, and third-party applications. Responsive mobile and desktop applications for on-the-go access. Built-in AI capabilities to enhance decision-making.
By using Canvas Apps for Dynamics 365 CRM, businesses can create custom CRM dashboards, automate workflows, and improve data management.

How Canvas Apps Improve Dynamics 365 CRM Customization
1. Customizing CRM Interfaces for a Better User Experience
One of the biggest limitations of traditional MS Dynamics 365 CRM Customization is UI rigidity. Standard CRM screens may not always match business workflows, leading to inefficiencies and user frustration.
Canvas Apps allow businesses to design custom UI elements based on their specific needs. Users can create interactive dashboards, custom data entry forms, and optimized navigation experiences. With a touch-friendly and mobile-responsive design, employees can access CRM data seamlessly on any device.
This results in a more intuitive and user-friendly Microsoft Dynamics CRM Training system, improving productivity and adoption rates.
2. Automating Workflows for Improved Efficiency
Manual data entry and repetitive tasks can slow down CRM operations. Dynamics 365 CRM Workflow Automation with Canvas Apps helps businesses streamline processes and reduce errors.
Create automated lead tracking systems to update sales records in real-time. Build approval workflows that trigger emails and notifications based on CRM actions. Integrate with Power Automate to execute tasks like data validation, invoice generation, and follow-up scheduling.
By leveraging Microsoft Power Apps for CRM, businesses can eliminate inefficiencies and focus on high-value tasks.
3. Enhancing Data Visualization and Reporting
CRM systems collect vast amounts of customer, sales, and service data. However, without proper visualization tools, extracting insights can be challenging.
Canvas Apps enable real-time data dashboards, displaying insights using charts, graphs, and reports. Users can customize CRM views to display only relevant metrics, improving decision-making. Integration with Power BI allows advanced analytics, predictive modeling, and KPI tracking.
By using Canvas Apps for Microsoft Dynamics CRM Online Training, organizations gain better data control and reporting capabilities.
4. Extending CRM Functionalities with Third-Party Integrations
Every business relies on multiple tools beyond CRM, such as ERP systems, HR platforms, and marketing automation tools. Canvas Apps bridge the gap by enabling seamless integrations.
Connect CRM with Microsoft Teams, Outlook, SharePoint, and SAP. Fetch and update records from SQL databases, Excel, and third-party APIs. Use AI-driven chatbots within CRM for automated customer interactions.
These integrations enhance CRM functionality, ensuring a unified and connected business ecosystem.
5. Mobile Accessibility for On-the-Go Productivity
Sales and service teams often need Microsoft Dynamics 365 Training Courses access outside the office. Canvas Apps provide a mobile-first solution to keep employees connected.
Sales reps can update leads, log calls, and check customer history from their mobile devices. Field service agents can capture on-site data, generate invoices, and manage appointments. Managers can approve workflows, view performance dashboards, and make data-driven decisions remotely.
With Canvas Apps for Dynamics 365 CRM, organizations enable mobile workforce efficiency like never before.
Conclusion
Canvas Apps revolutionize MS Dynamics 365 CRM Customization by offering flexibility, automation, and enhanced user experiences. With Dynamics CRM Online Training custom UI, automated workflows, real-time data visualization, and mobile accessibility, businesses can unlock the full potential of their CRM systems. By leveraging Microsoft Power Apps for CRM, organizations can increase efficiency, improve customer interactions, and drive better business outcomes.
Trending Courses are : D365 Functional (F & O), Prompt Engineering, Generative AI (GenAI), Microsoft Dynamics AX Retail Management.
Visualpath is the Leading and Best Software Online Training Institute in Hyderabad. Avail complete Microsoft Dynamics CRM Certification Worldwide. You will get the best course at an affordable cost.
WhatsApp: https://wa.me/c/917032290546
Visit: https://www.visualpath.in/online-microsoft-dynamics-crm.html
#D365#MSDynamics#Dynamics365#Microsoft#Education#visualpath#softwarecourses#dynamics#dynamics365crm#demovideo#microsoftpowerapps#ITCourses#ITskills#MicrosoftDynamics365#onlinetraining#powerappscrm#CRM#software#student#NewTechnology#career
0 notes
Text
What is HarmonyOS NEXT - RelationalStore?
Relational databases provide a universal operational interface for applications, with SQLite as the persistent storage engine at the underlying level, supporting the database features of SQLite, including but not limited to transactions, indexes, views, triggers, foreign keys, parameterized queries, and precompiled SQL statements.
Applicable scenarios: In scenarios where complex relational data is stored, such as the student information of a class, which needs to include names, student IDs, subject grades, etc., or the employee information of a company, which needs to include names, job IDs, positions, etc. Due to the strong correspondence between data, the complexity is higher than that of key value data. In this case, a relational database needs to be used to persistently store the data.
constraint qualification ·The default logging mode of the system is WAL (Write Ahead Log) mode, and the default disk dropping mode is FULL mode. ·There are 4 read connections and 1 write connection in the database. When a thread obtains a free read connection, it can perform a read operation. When there is no free read connection and there is a free write connection, the write connection will be used as a read connection. ·To ensure data accuracy, the database can only support one write operation at a time. ·After the application is uninstalled, the relevant database files and temporary files on the device will be automatically cleared. ·Basic data types supported by ArkTS side: number、string、 Binary type data boolean。 ·To ensure successful insertion and reading of data, it is recommended that one piece of data should not exceed 2M. Exceeding this size, insertion successful, read failed.
Basic concepts: ·Predicate: A term used in a database to represent the properties, characteristics, or relationships between data entities, primarily used to define the operating conditions of the database. ·Result set: refers to the set of results obtained by the user after querying, which can be accessed for data. The result set provides a flexible way of accessing data, making it easier for users to obtain the data they want.
code example SQLiteUtil [code] export default class SQLiteUtil { static getCreateTableSql(tableName: string, columns: ColumnInfo[]): string { let sql = CREATE TABLE IF NOT EXISTS ${tableName} (; columns.forEach((element, index) => { if (index == 0) { //Splicing the first element, default as primary key sql += ${element.name} ${DataType[element.type]} PRIMARY KEY AUTOINCREMENT,; } else if (index == columns.length - 1) { //Last element concatenation statement sql += ${element.name} ${DataType[element.type]} NOT NULL);; } else { sql += ${element.name} ${DataType[element.type]} NOT NULL,; } }); return sql; } }
export interface ColumnInfo { name: string; type: DataType; }
export enum DataType { NULL = 'NULL', INTEGER = 'INTEGER', REAL = 'REAL', TEXT = 'TEXT', BLOB = 'BLOB' } [/code] RelationalStoreService [code] import SQLiteUtil, { ColumnInfo, DataType } from '../ChicKit/data/SQLiteUtil' import relationalStore from '@ohos.data.relationalStore' import { common } from '@kit.AbilityKit'; import Logger from '../utils/Logger'; import AppError from '../models/AppError'; import Schedule from '../entities/Schedule'; import { BusinessError } from '@kit.BasicServicesKit'; import { ValuesBucket, ValueType } from '@ohos.data.ValuesBucket'; import { DataModel } from '../ChicKit/data/DataModel'; import Target from '../entities/Target'; import Plan from '../entities/Plan';
const RelationalStoreName = 'shijianxu.db'
export default class RelationalStoreService { static rdbStore: relationalStore.RdbStore;
/**
Initialize relational database
@param context */ static init(context: common.UIAbilityContext) { // RelationalStore configuration let storeConfig: relationalStore.StoreConfig = { // Database file name name: RelationalStoreName, //security level securityLevel: relationalStore.SecurityLevel.S1 } relationalStore.getRdbStore(context, storeConfig, (err, store) => { if (err) { Logger.error(RelationalStoreService init error, error=${JSON.stringify(new AppError(err))}) return; } else { RelationalStoreService.rdbStore = store RelationalStoreService.createScheduleTable() RelationalStoreService.createTargetTable() RelationalStoreService.createPlanTable() } }); } /**
Create schedule table */ static createScheduleTable() { //Table Fields const columns: ColumnInfo[] = Schedule.getColumns() // Retrieve the SQL statement for creating a table const sql = SQLiteUtil.getCreateTableSql(Schedule.TableName, columns) // Create Data Table RelationalStoreService.rdbStore.executeSql(sql, (err) => { if (err) { Logger.error(RelationalStoreService createScheduleTable error, error=${JSON.stringify(new AppError(err))}) return; } }); } /**
Create target table */ static createTargetTable() { //表字段 const columns: ColumnInfo[] = Target.getColumns() // 获取创建表SQL语句 const sql = SQLiteUtil.getCreateTableSql(Target.TableName, columns) // 创建数据表 RelationalStoreService.rdbStore.executeSql(sql, (err) => { if (err) { Logger.error(RelationalStoreService createTargetTable error, error=${JSON.stringify(new AppError(err))}) return; } }); } /**
Create plan table */ static createPlanTable() { //表字段 const columns: ColumnInfo[] = Plan.getColumns() // 获取创建表SQL语句 const sql = SQLiteUtil.getCreateTableSql(Plan.TableName, columns) // 创建数据表 RelationalStoreService.rdbStore.executeSql(sql, (err) => { if (err) { Logger.error(RelationalStoreService createPlanTable error, error=${JSON.stringify(new AppError(err))}) return; } }); } /**
insert data
@param tableName
@param values */ static insert(tableName: string, values: ValuesBucket) { RelationalStoreService.rdbStore.insert(tableName, values, (err: BusinessError, rowId: number) => { if (err) { Logger.error(RelationalStoreService insert error, error=${JSON.stringify(new AppError(err))}) return; } else { return rowId } }) } /**
delete
@param predicates
@returns delete count */ static delete(predicates: relationalStore.RdbPredicates):number{ return RelationalStoreService.rdbStore.deleteSync(predicates) } /**
update
@param values
@param predicates
@returns update count */ static update(values: ValuesBucket,predicates: relationalStore.RdbPredicates):number{ let rows: number = RelationalStoreService.rdbStore.updateSync(values, predicates, relationalStore.ConflictResolution.ON_CONFLICT_REPLACE); return rows } static querySync(predicates: relationalStore.RdbPredicates, columns: ColumnInfo[]): DataModel[] { let dataList: DataModel[] = [] try { let columnsStringArray: string[] = [] columns.forEach(element => { columnsStringArray.push(element.name) }); const resultSet = RelationalStoreService.rdbStore.querySync(predicates, columnsStringArray) resultSet.columnNames // resultSet.getColumnName('') // resultSet.getValue() //循环处理结果,循环条件:当所在行不是最后一行 while (!resultSet.isAtLastRow) { //去往下一行 resultSet.goToNextRow() let schedule: DataModel = {} columns.forEach(element => { switch (element.type) { case DataType.INTEGER: schedule[element.name] = resultSet.getLong(resultSet.getColumnIndex(element.name)) break; case DataType.REAL: schedule[element.name] = resultSet.getDouble(resultSet.getColumnIndex(element.name)) break; case DataType.TEXT: schedule[element.name] = resultSet.getString(resultSet.getColumnIndex(element.name)) break; case DataType.BLOB: schedule[element.name] = resultSet.getBlob(resultSet.getColumnIndex(element.name)) break; } }) dataList.push(schedule) } } catch (err) { Logger.error(RelationalStoreService querySync error, error=${JSON.stringify(new AppError(err))}) } return dataList } } [/code]
0 notes
Text
How to Prevent Business Logic Vulnerabilities in Laravel Apps
Introduction
Business Logic Vulnerabilities (BLVs) are some of the most subtle and critical issues that developers can overlook in Laravel applications. These vulnerabilities can lead to unauthorized access, data manipulation, and other serious security risks if not addressed properly.

In this blog post, we will dive deep into Business Logic vulnerabilities in Laravel, show you common examples, and walk you through the steps to prevent them with practical coding solutions. We’ll also introduce our Website Vulnerability Scanner tool to help you scan your Laravel application for vulnerabilities in real time.
What Are Business Logic Vulnerabilities?
Business Logic vulnerabilities occur when an application’s business rules, workflows, or logic can be bypassed or manipulated by an attacker. Unlike traditional security issues such as SQL injection or cross-site scripting (XSS), these vulnerabilities are often more complex because they are based on the specific design of your application.
Example: Insecure Transaction Logic
Consider a banking application where users are allowed to withdraw money. If the system doesn't properly validate the user's account balance before processing the withdrawal, a user could manipulate the application logic to withdraw more money than they actually have.
How to Prevent Business Logic Vulnerabilities in Laravel
Laravel is a powerful framework, but it’s essential to carefully design and validate the logic of your application to avoid vulnerabilities.
1. Enforcing Authorization at Every Level
To prevent unauthorized access, always ensure that authorization checks are performed at each level of your application. For instance, a user should only be able to access their own data, and not that of other users.
public function viewUserProfile($id) { $user = User::findOrFail($id); // Check if the current user is the owner if (auth()->user()->id !== $user->id) { abort(403, 'Unauthorized action.'); } return view('profile', compact('user')); }
This example ensures that only the user who owns the profile can access it.
2. Using Request Validation
Always validate user inputs, especially when dealing with critical business operations like payments, transfers, or product purchases.
$request->validate([ 'amount' => 'required|numeric|min:10', // Minimum withdrawal of 10 units 'recipient_id' => 'required|exists:users,id', ]); // Process the transfer if validation passes $transaction = Transaction::create([ 'user_id' => auth()->id(), 'amount' => $request->input('amount'), 'recipient_id' => $request->input('recipient_id'), ]);
This ensures that no invalid or malicious data is processed by your application.
3. Implementing Rate Limiting
Rate limiting can prevent attackers from abusing your endpoints and triggering unwanted actions. Laravel provides an easy way to set up rate limiting.
use Illuminate\Cache\RateLimiter; public function register() { RateLimiter::for('login', function (Request $request) { return Limit::perMinute(5)->by($request->email); }); }
In this example, users are limited to five login attempts per minute, preventing brute-force attacks or abuse of business logic.
Use Our Free Website Security Checker
To assist in identifying Business Logic vulnerabilities, we offer a free tool for a Website Security test that you can use on your Laravel project. This tool scans your application for various security risks, including Business Logic vulnerabilities, and provides a detailed report of potential issues.
Check your Laravel app now!

Screenshot of the free tools webpage where you can access security assessment tools.
Sample Vulnerability Report
Once you've scanned your site, the tool will generate a vulnerability assessment report, which provides detailed information about identified risks. Here's an example of a report that highlights potential Business Logic flaws.

An Example of a vulnerability assessment report generated with our free tool, providing insights into possible vulnerabilities.
Conclusion
Business Logic Vulnerabilities in Laravel can pose significant risks to your application’s security and integrity. By carefully validating inputs, enforcing proper authorization checks, and limiting abuse, you can protect your Laravel applications from these vulnerabilities.
Don't forget to regularly use our Free Website Security Scanner tool to scan your applications for vulnerabilities and secure your Laravel project.
For more in-depth articles and security tips, visit the Pentest Testing Corp Blog.
Additional Resources:
Prevent Buffer Overflow in OpenCart
Fix Weak SSL/TLS Configuration in OpenCart
Prevent Command Injection in TypeScript
This blog post provides practical coding examples and highlights the importance of securing business logic in Laravel applications. With the added value of our Website Security Checker, you can now actively assess your application's vulnerabilities.
1 note
·
View note
Text
How AWS WAF Works with AWS Lambda for Dynamic Security?
In today’s evolving cybersecurity landscape, web applications need robust protection against cyber threats. AWS Web Application Firewall (AWS WAF) is a powerful security tool that safeguards applications from common attacks like SQL injection, cross-site scripting (XSS), and DDoS attacks. When combined with AWS Lambda, AWS WAF becomes even more dynamic, allowing businesses like Edgenexus Limited to automate security responses in real time. This article explores how AWS WAF and AWS Lambda work together to strengthen web application security.
Understanding AWS Web Application Firewall (AWS WAF)
AWS Web Application Firewall (AWS WAF) is a cloud-based security service designed to protect web applications from malicious traffic. It enables businesses to define custom rules that filter incoming requests, blocking threats based on predefined security parameters. Companies like Edgenexus Limited leverage AWS WAF to create a secure online environment, preventing unauthorized access and mitigating risks. By integrating AWS WAF with other AWS services, organizations can enhance protection against evolving cyber threats.
What is AWS Lambda and How It Enhances Security?
AWS Lambda is a serverless computing service that automatically executes code in response to specific triggers. It eliminates the need for manual intervention, making it a valuable addition to AWS WAF security strategies. By using AWS Lambda, businesses like Edgenexus Limited can automate security tasks such as updating firewall rules, analyzing traffic patterns, and responding to threats in real time. This dynamic approach ensures that web applications remain secure without requiring constant human monitoring.
How AWS WAF and AWS Lambda Work Together?
When combined, AWS WAF and AWS Lambda create a highly flexible security solution. AWS WAF monitors and filters HTTP/S requests, while AWS Lambda can be triggered to perform additional security actions based on detected threats. For instance, if AWS WAF identifies suspicious traffic, AWS Lambda can automatically update rules, notify security teams, or block malicious IP addresses. This automated process helps businesses like Edgenexus Limited maintain a proactive security posture without manual intervention.
Automating Security Responses with AWS WAF and AWS Lambda
Automation is a key benefit of integrating AWS WAF with AWS Lambda. By using Lambda functions, businesses can automate security responses based on predefined conditions. If AWS WAF detects repeated unauthorized access attempts, AWS Lambda can dynamically adjust firewall rules or send alerts. For companies like Edgenexus Limited, this means improved security efficiency, reduced response time, and a proactive defense system that adapts to emerging threats without human intervention.
Use Cases of AWS WAF and AWS Lambda for Web Security
Many organizations, including Edgenexus Limited, use AWS WAF and AWS Lambda for enhanced web security. A common use case is automatic IP blacklisting, where AWS Lambda updates AWS WAF rules to block suspicious IP addresses detected by traffic analysis. Another use case is real-time threat analysis, where AWS Lambda processes AWS WAF logs to identify attack patterns and adjust security measures dynamically. AWS Lambda can also enforce geo-blocking by restricting access based on geographic locations identified as high-risk. By leveraging these capabilities, businesses can ensure continuous protection for their web applications.
Benefits of Using AWS WAF and AWS Lambda Together
Integrating AWS WAF with AWS Lambda offers multiple advantages. One major benefit is real-time security updates, where AWS Lambda responds instantly to AWS WAF alerts, ensuring quick mitigation of threats. Another advantage is cost-efficiency, as AWS Lambda’s serverless nature eliminates the need for additional infrastructure costs. Scalability is another key benefit, allowing the security solution to automatically scale with traffic demands, making it ideal for businesses like Edgenexus Limited. Additionally, AWS Lambda enables customization, allowing organizations to create tailored security rules that fit their specific needs. With these benefits, AWS WAF and AWS Lambda provide a dynamic and scalable security framework for modern web applications.
How Edgenexus Limited Implements AWS WAF and AWS Lambda?
At Edgenexus Limited, AWS WAF and AWS Lambda are integrated into a comprehensive cybersecurity strategy. By leveraging automated security responses, the company enhances web application security while reducing manual workloads. AWS Lambda-driven automation ensures continuous monitoring and rapid threat response, protecting sensitive data and maintaining compliance with industry standards. Businesses looking to improve their cloud security can benefit significantly from this approach, ensuring long-term resilience against cyber threats.
Conclusion
The combination of AWS Web Application Firewall (AWS WAF) and AWS Lambda provides a powerful, automated security solution for web applications. With real-time monitoring, automatic rule updates, and scalable protection, organizations can stay ahead of evolving threats. Businesses like Edgenexus Limited are already leveraging this integration to strengthen cybersecurity defenses, ensuring reliable protection for their web applications. By adopting AWS WAF and AWS Lambda, companies can enhance security efficiency, minimize risks, and focus on growing their digital presence safely.
0 notes