#yahoo data scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Why Businesses Need Reliable Web Scraping Tools for Lead Generation.
The Importance of Data Extraction in Business Growth
Efficient data scraping tools are essential for companies looking to expand their customer base and enhance their marketing efforts. Web scraping enables businesses to extract valuable information from various online sources, such as search engine results, company websites, and online directories. This data fuels lead generation, helping organizations find potential clients and gain a competitive edge.
Not all web scraping tools provide the accuracy and efficiency required for high-quality data collection. Choosing the right solution ensures businesses receive up-to-date contact details, minimizing errors and wasted efforts. One notable option is Autoscrape, a widely used scraper tool that simplifies data mining for businesses across multiple industries.

Why Choose Autoscrape for Web Scraping?
Autoscrape is a powerful data mining tool that allows businesses to extract emails, phone numbers, addresses, and company details from various online sources. With its automation capabilities and easy-to-use interface, it streamlines lead generation and helps businesses efficiently gather industry-specific data.
The platform supports SERP scraping, enabling users to collect information from search engines like Google, Yahoo, and Bing. This feature is particularly useful for businesses seeking company emails, websites, and phone numbers. Additionally, Google Maps scraping functionality helps businesses extract local business addresses, making it easier to target prospects by geographic location.
How Autoscrape Compares to Other Web Scraping Tools
Many web scraping tools claim to offer extensive data extraction capabilities, but Autoscrape stands out due to its robust features:
Comprehensive Data Extraction: Unlike many free web scrapers, Autoscrape delivers structured and accurate data from a variety of online sources, ensuring businesses obtain quality information.
Automated Lead Generation: Businesses can set up automated scraping processes to collect leads without manual input, saving time and effort.
Integration with External Tools: Autoscrape provides seamless integration with CRM platforms, marketing software, and analytics tools via API and webhooks, simplifying data transfer.
Customizable Lead Lists: Businesses receive sales lead lists tailored to their industry, each containing 1,000 targeted entries. This feature covers sectors like agriculture, construction, food, technology, and tourism.
User-Friendly Data Export: Extracted data is available in CSV format, allowing easy sorting and filtering by industry, location, or contact type.
Who Can Benefit from Autoscrape?
Various industries rely on web scraping tools for data mining and lead generation services. Autoscrape caters to businesses needing precise, real-time data for marketing campaigns, sales prospecting, and market analysis. Companies in the following sectors find Autoscrape particularly beneficial:
Marketing Agencies: Extract and organize business contacts for targeted advertising campaigns.
Real Estate Firms: Collect property listings, real estate agencies, and investor contact details.
E-commerce Businesses: Identify potential suppliers, manufacturers, and distributors.
Recruitment Agencies: Gather data on potential job candidates and hiring companies.
Financial Services: Analyze market trends, competitors, and investment opportunities.
How Autoscrape Supports Business Expansion
Businesses that rely on lead generation services need accurate, structured, and up-to-date data to make informed decisions. Autoscrape enhances business operations by:
Improving Customer Outreach: With access to verified emails, phone numbers, and business addresses, companies can streamline their cold outreach strategies.
Enhancing Market Research: Collecting relevant data from SERPs, online directories, and Google Maps helps businesses understand market trends and competitors.
Increasing Efficiency: Automating data scraping processes reduces manual work and ensures consistent data collection without errors.
Optimizing Sales Funnel: By integrating scraped data with CRM systems, businesses can manage and nurture leads more effectively.

Testing Autoscrape: Free Trial and Accessibility
For businesses unsure about committing to a web scraper tool, Autoscrapeoffers a free account that provides up to 100 scrape results. This allows users to evaluate the platform's capabilities before making a purchase decision.
Whether a business requires SERP scraping, Google Maps data extraction, or automated lead generation, Autoscrape delivers a reliable and efficient solution that meets the needs of various industries. Choosing the right data scraping tool is crucial for businesses aiming to scale operations and enhance their customer acquisition strategies.
Investing in a well-designed web scraping solution like Autoscrape ensures businesses can extract valuable information quickly and accurately, leading to more effective marketing and sales efforts.
0 notes
Text
Mastering Web Scraping: Techniques for Yahoo Sports News
Yahoo News is an important news website that not only provides aggregated content from major news media, but is also committed to developing original content and improving the quality and influence of its news by hiring senior reporters and dispatching reporters to the White House press corps. At the same time, Yahoo News is also an important part of Yahoo’s diversified network services.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
VeryUtils AI Marketing Tools is your all-in-one Marketing platform. VeryUtils AI Marketing Tools includes Email Scraper, Email Sender, Email Verifier, Whatsapp Sender, SMS Sender, Social Media Marketing etc. tools.
VeryUtils AI Marketing Tools is your all-in-one Marketing platform. VeryUtils AI Marketing Tools includes Email Scraper, Email Sender, Email Verifier, Whatsapp Sender, SMS Sender, Social Media Marketing etc. tools. You can use VeryUtils AI Marketing Tools to find and connect with the people that matter to your business.
Artificial Intelligence (AI) Marketing Tools are revolutionizing almost every field, including marketing. Many companies of various scales rely on VeryUtils AI Marketing Tools to promote their brands and businesses. They should be a part of any business plan, whether you're an individual or an organization, and they have the potential to elevate your marketing strategy to a new level.
VeryUtils AI Marketing Tools are software platforms that help automate decision-making based on collected and analyzed data, making it easier to target buyers and increase sales.
VeryUtils AI Marketing Tools can handle vast amounts of information from various sources like search engines, social media, and email. Everyone knows that data is key to marketing, and AI takes it a step further while also saving a significant amount of money and time.
✅ Types of marketing tools The different types of marketing tools you'll need fall under the following categories:
Email marketing
Social media marketing
Content marketing
SEO
Direct mail
Lead generation
Lead capture and conversion
Live chat
Design and visuals
Project management
SMS marketing
Analytics and tracking
Brand marketing
Influencer and affiliate marketing
Loyalty and rewards
✅ VeryUtils AI Marketing Tools for Every Business. VeryUtils AI Marketing Tools include the following components:
Email Collection Tools (Hunt email addresses from Google, Bing, Yahoo, LinkedIn, Facebook, Amazon, Instagram, Google Maps, etc.)
Email Sending Automation Tools
Phone Number Collection Tools
WhatsApp Automation Tools (coming soon)
Social Media Auto Posting Robot (coming soon)
SMS Marketing (upon request)
Custom Development of any tools to best meet your specific requirements.
VeryUtils AI Marketing Tools can help you tackle the manual parts of marketing, precisely locate your customers from the vast internet, and promote your products to these customers.
✅ 1. Email Collection Tools Do you need to scrape email addresses from web pages, and don’t know how to do it or don’t have a tool capable?
VeryUtils AI Marketing Tools has a powerful multi-threaded email scraper which can harvest email addresses from webpages, it also has proxy support so each request is randomly assigned a proxy from from your list to keep your identity hidden or prevent sites blocking your by IP address due to too many queries.
The VeryUtils AI Marketing Tools email harvester also works with https URL’s so it can work with sites like FaceBook and Twitter that require a secure connection. It also has an adjustable user-agent option, so you can set your user-agent to Googlebot to work with sites like SoundCloud.com or you can set it as a regular browser or even mobile device for compatibility with most sites. When exporting you also have the option to save the URL along with the scraped email address so you know where each email came from as well as filter options to extract only specific emails.
Because the Email Grabber function is multi-threaded, you can also select the number of simultaneous connections as well as the timeout so you can configure it for any connection type regardless if you have a powerful server or a home connection. Another unique thing the email grabber can do is extract emails from files stored locally on your computer, if you have a .txt file or .sql database which contains various information along with emails you can simply load the file in to VeryUtils AI Marketing Tools and it will extract all emails from the file!
If you need to harvest URL’s to scrape email addresses from, then VeryUtils AI Marketing Tools has a powerful Search Engine Harvester with 30 different search engines such as Google, Bing, Yahoo, AOL, Blekko, Lycos, AltaVista as well as numerous other features to extract URL lists such as the Internal External Link Extractor and the Sitemap Scraper.
Also recently added is an option to scrape emails by crawling a site. What this does is allows you to enter a domain name and select how many levels deep you wish to crawl the site, for example 4 levels. It will then fetch the emails and all internal links on the site homepage, then visit each of those pages finding all the emails and fetching the internal links from those pages and so on. This allows you to drill down exacting emails from a specific website.
So this makes it a great email finder software for extracting published emails. If the emails are not published on the pages, you can use the included Whois Scraper Addon to scrape the domains registrant email and contact details.
Find email addresses & automatically send AI-personalized cold emails
Use our search email address tool to find emails and turn your contacts into deals with the right cold emailing.
Easy setup with your current email provider
Deep AI-personalization with Chat GPT (soon)
Safe sending until reply
High deliverability
Smart scheduling of email sequences
Complete A/B testing for best results
Create and edit templates
Email tracking and analytics
-- Bulk Email Verifier Make cold mailing more effective with email verification process that will guarantee 97% deliverability
-- Collect email addresses from Internet Email Collection Tools can automatically collect email addresses of your target customers from platforms like Google, Bing, Yahoo, LinkedIn, Facebook, Amazon, Instagram, Google Maps, etc., making it convenient to reach out to these potential clients.
-- Collect email addresses from email clients Email Collection Tools can also extract email addresses from email clients like Microsoft Outlook, Thunderbird, Mailbird, Mailbird, Foxmail, Gmail, etc.
-- Collect email addresses from various file formats Email Collection Tools can extract email addresses from various file formats such as Text, PDF, Word, Excel, PowerPoint, ZIP, 7Z, HTML, EML, EMLX, ICS, MSG, MBOX, PST, VCF.
-- Various tools and custom development services
-- Domain Search Find the best person to contact from a company name or website.
-- Email Finder Type a name, get a verified email address. Our high match rate helps you get the most from your lists.
-- Email Verifier Avoid bounces and protect your sender reputation.
-- Find emails by domain Find all email addresses on any domain in a matter of minutes.
-- Find emails by company Use VeryUtils AI Marketing Tools to find just the companies you need by industry, company size, location, name and more.
-- Get emails from names Know your lead's name and company domain but not their email? We can find it for you. Use this feature to complete your prospects lists with quality contacts.
-- Find potential customers based on information Use key parameters like prospect's job position, location, industry or skills to find only relevant leads for your business.
✅ 2. Email Marketing Tools
VeryUtils AI Marketing Tools provides Fast and Easy Email Sender software to help you winning the business. All the email tools you need to hit the inbox. Discover our easy-to-use software for sending your email marketing campaigns, newsletters, and automated emails.
-- Easy to use Only two steps, importing a mail list file, select email account and template, the software will start email sending automatically.
-- Fast to run The software will automatically adjust the number of threads according to the network situation, to maximize the use of network resources.
-- Real-time display email sending status
Displaying the number of total emails
Displaying the number of sent emails
Displaying the number of success emails
Displaying the number of failure emails
Displaying the different sending results through different colors.
Displaying the time used of email sending.
-- Enhance ROI with the industry-leading email marketing platform Take your email marketing to a new level, and deliver your next major campaign and drive sales in less time.
-- Easy for beginners, powerful for professional marketers Our email marketing platform makes it easy for marketers of any type of business to effortlessly send professional, engaging marketing emails. VeryUtils AI Marketing Tools are designed to help you sell more products - regardless of the complexity of your business.
-- Being a leader in deliverability means your emails get seen Unlike other platforms, VeryUtils AI Marketing Tools ensure your marketing emails are delivered. We rank high in email deliverability, meaning more of your emails reach your customers, not just their spam folders.
-- Leverage our powerful AI and data tools to make your marketing more impactful The AI in VeryUtils AI Marketing Tools can be the next expert marketer on your team. VeryUtils AI Marketing Tools analyze your product information and then generate better-performing email content for you. Generate professionally written, brand-consistent marketing emails with just a click of a button.
-- Get started easily with personalized onboarding services Receive guidance and support from an onboarding specialist. It's real-time, hands-on, and already included with your subscription.
-- We offer friendly 24/7 customer service Our customer service team is available at all times, ready to support you.
-- Collaborate with our experts to launch your next major campaign Bring your questions to our expert community and find the perfect advice for your campaigns. We also offer exclusive customer success services.
✅ FAQs:
What is email marketing software? Email marketing software is a marketing tool companies use to communicate commercial information to customers. Companies may use email marketing services to introduce new products to customers, promote upcoming sales events, share content, or perform any other action aimed at promoting their brand and engaging with customers.
What does an email marketing platform do? Email marketing platforms like VeryUtils AI Marketing Tools simplify the process of creating and sending email marketing campaigns. Using email marketing tools can help you create and manage audience groups, configure email marketing campaigns, and monitor their performance, all on one platform.
How effective is email marketing? Email marketing can be a powerful part of any company's marketing strategy. By leveraging effective email marketing tools, you can interact with your audience by creating personalized messages tailored to their interests. Additionally, using email marketing tools is a very cost-effective way of marketing your business.
What are the types of email marketing campaigns? There are many types of email marketing campaigns. However, there are four main types of marketing emails, including:
Promotional emails: These emails promote a company's products or services, often by advertising sales, discounts, seasonal events, company events, etc.
Product update emails: These emails inform customers about new or updated products.
Digital newsletters: Digital newsletters are regularly sent to a company's email list to inform customers of company or industry updates by providing interesting articles or relevant news.
Transactional emails: These emails are typically triggered by a customer's action. For example, if a customer purchases a product, they may receive a confirmation email or a follow-up email requesting their feedback.
How to optimize email marketing campaigns? When executing a successful email marketing strategy, there are several best practices to follow:
Create short, attention-grabbing subject lines: The subject line is the first copy your reader will see, so ensure it's enticing and meaningful. Spend time optimizing your subject line to improve click-through rates.
Keep it concise: When writing the email body, it's important to keep the content concise. You may only have your reader's attention for a short time, so it's crucial to craft a message that is clear, concise, and to the point.
Make it easy to read: Utilize headings, subheadings, bold text, font, and short paragraphs to make your email skimmable and easy to digest.
Fast loading visuals and images: Including images and visuals make email content more interesting and help break up the text. However, it's important that all elements load properly.
Include a call to action (CTA): Every email marketing content should include a call to action, whether you want the reader to shop the sale on your website or read your latest blog post.
How to start email marketing? Email marketing can serve as a cornerstone of any company's digital marketing strategy. If you don't already have an email marketing strategy in place or you're interested in improving your company's email marketing campaigns, use VeryUtils AI Marketing Tools. With our email marketing services, you can quickly and easily organize audience groups, segment customers, write and design emails, set timing preferences and triggers, and evaluate your performance.
0 notes
Link
Google Maps is the Mapping Service developed by Google itself. Google Maps Provide services like Satellite Imagery, Street Maps, 360 degrees’ panoramic view of streets view, and you can see all the traffic conditions also from the Google Maps.
Google Maps is a Web-Based service which provides all the information regarding sites and the regions. Google Maps provide street view comparison the photos taken from the vehicle. A route will give you the information regarding the street and a view from different locations.
Google Maps allow to see the users from different views like horizontal & Vertical view of the cities around the world. So Google Maps is a guide to the person who is new in the city and he can search the good place according to his requirements from Google Maps.
0 notes
Text
Let’s Save Yahoo! Answers!
So as you all might be aware, the incredible well of human knowledge known as Yahoo! Answers will be shut down on May 4th. They will be scrubbing all of the data from their servers, millions of hilarious Qs and As will be lost to history. MBMBaM will never be the same!
But there is still time! There is still HOPE!
The Internet Archive at archive.org already has over 5 million Y!A pages archived in their Wayback Machine and you can do your part to add to it.
HERE is an article explaining couple of easy ways you can help save your favourite questions and answers for posterity! You can either install a browser extension that will help you easily save any page you want with single click. Or you can use this covenient form, where you just paste the URL you want to archive. All that you need to do then is to dive deep into the treasure troves of this incredible website and start archiving!
Internet Archive is an invaluable project, that does this sort of thing for thousands of web pages, that would otherwise be lost forever. You should absolutely consider donating to them! They are hosting over 70 petabytes of data! That’s expensive! Do you know how much a petabyte is? No? Don’t worry, Yahoo! Answers got you! (That’s right! It’s a Wayback Machine link! I just archived that question for future generations! Took me like 5 seconds!)
There’s also a separate archival project run by the Archive Team. There might be ways you can help them as well, but it’s gonna be a bit more involved (they’ll be running scrapers on the site). Keep an eye on their wiki or join their IRC chat and ask how you can help.
Let’s get saving!
#yahoo answers#save yahoo answers#yahoo! answers#yahoo#answers#mbmbam#mcelroys#griffin mcelroy#mcelroy family
171 notes
·
View notes
Text
How To Use An AliExpress Scraper For Scraping AliExpress Data?

What is an AliExpress API?
A web scraper is used to scrape AliExpress product data. A web scraper is a computer bot that gathers similar material and compiles it into a single document. You choose the pricing points of things, product numbers, or AliExpress URLs you want the scraper to look for, and then the bot will start working. The AliExpress Scraper collects the requested information in the form of Links. Those Links will direct you to the shortest way to the shopping cart.
In short, a data scraper looks for information in HTML documents. HTML is the universal language in today’s online world. The scraper is a good digital translator because humans have a bigger challenge interpreting its language. An API (Application Programming Interface) is a communication interface that connects various software packages that aren't designed to function together.
When you use the scraping bot to create a scraping request, the API sends it to the AliExpress platform, which extracts the relevant data and feeds it within your software directly.
Is E-Commerce Scraper Necessary for AliExpress?
An AliExpress API is an excellent tool for massive price monitoring of competitors as just a company owner or worker of a marketing organization. You can use a web scraping API to build up a consistent procedure of pricing extraction or just specify your settings to inform the change in dataset since you last extracted it. And that's how beneficial a web scraping API can be.
Furthermore, employing an AliExpress API for business purposes simplifies your task. An AliExpress API can also help you understand what customers purchase, the problems they have with specific products, and the things that may sell more if they were better marketed. Gaining observations about what customers wish to buy will maintain a competitive-edge in the market, even in a highly competed online market.
Which are Different Ways of Using an AliExpress Data Scraper?
You can extract useful data on a specific item or compare the prices of several products to find the best discounts using the AliExpress API. You would believe that using an API will ruin your financial account, depending on how easy the shopping is. But a digital bot makes you more aware of your online selections and keeps you informed of the best deals on important (or non-essential) items. You could consider using the AliExpress CSV scraper and API for commercial practices in addition to the requirements indicated above.
A scraping API can be very useful in evaluating all the factors and many more. In a competitive e-commerce world, keeping an eye on the market ensures you create a competitive-edge in the market. Your organization will always be aware of all the companies selling on AliExpress as well as the actual prices of products due to an AliExpress API.
Web scraping is more useful than crawling for your needs. Crawling refers to searching for information on Google, Yahoo, and nearly any other website, whereas AliExpress scraping is specific to that website. Crawling is done on a wider scale.
AliExpress Product Scraper
At iWeb Scraping, we have created a data collection tool that is both efficient and cost-effective. Our data collecting system is made up of a web scraping service that can fetch information from every website on the internet and an open API that can be used by any software. Our API works through any website and is well-documented to make it simple to use.
You're prepared to go along with the push of a button. To give you the fastest scraping possible experience, we use numerous proxies from our contract manufacturer.
Conclusion
Web scraping will assist you in discovering adjustments in different prices or innovative products introduced by competitors. You may simply predict market trends with Web scraper, which will aid you in developing a simple market strategy. You may create an optimum price with the utilization of a web scraper, which will help you get more buyers. Using a web scraper, you may also keep record of your data in one spot.
Looking for Scraping AliExpress products? Contact iWeb Scraping today!
#WebScrapingServices#AliExpressScraper#AliExpressScraperPython#AliExpressAPIPython#AliexpressDataScraping
1 note
·
View note
Text
Data Extraction Software - Leads Extraction Tips
The third layer of defense is a long term block of the whole community segment. This type of block is probably going triggered by an administrator and solely occurs if a scraping tool is sending a very excessive number of requests.
This may be carried out both manually or by utilizing software program tools called data extraction software. These software instruments are often preferred as they're quicker, more highly effective and therefore extra handy. The largest public identified incident of a search engine being scraped happened in 2011 when Microsoft was caught scraping unknown key phrases from Google for their own, rather new Bing service. () But even this incident didn't result in a court docket case.

The goal of both internet scraping and APIs is to entry web information. Once internet scrapers extract the user’s desired data, they usually additionally restructure the information right into a extra convenient format such as an Excel spreadsheet.
The error FileNotFoundError occurs because you both don't know where a file actually is in your pc. Or, even should you do, you don't know tips on how to inform your Python program the place it's. Don't try to fix different elements of your code that are not related to specifying filenames or paths. Well, there isn't any getting around the truth that at the programmatic layer, opening a file is distinct from studying its contents. Here's a brief snippet of Python code to open that file and print out its contents to display – notice that this Python code has to be run in the identical directory that the example.txt file exists in.
Google Scraper – A Python module to scrape totally different search engines like google and yahoo by utilizing proxies (socks4/5, http proxy). The tool contains asynchronous networking support and is able to control real browsers to mitigate detection. Even bash scripting can be utilized together with cURL as command line device to scrape a search engine. The quality of IPs, methods of scraping, key phrases requested and language/nation requested can significantly affect the attainable most rate. To scrape a search engine successfully the two main elements are time and amount.
No matter where you might be, Adobe Acrobat takes the effort out of making an Excel spreadsheet from a PDF file. Now, you don’t need to fret about inputting numbers, formatting cells, or losing time. Learn tips on how to easily export your PDF records data to editable Excel paperwork with Adobe Acrobat. For instance, you could use an internet scraper to extract product knowledge information from Amazon since they do not provide an API so that you can entry this data. In these situations, web scraping would allow you to entry the data as long as it is out there on a website.
Use the PDF to Excel converter on your browser or cellular system to transform your PDF files into fully editable spreadsheets regardless of where you are. When you change your PDF to the XLS or XLSX file format with Acrobat, you'll be able to rest simple understanding that your whole columns, layouts, and formatting carry over.
1 note
·
View note
Text
A useful tool to get news from Yahoo Sports
Yahoo Sports is a sports news and information website operated by Yahoo!. It provides comprehensive coverage of various sports, including football, basketball, baseball, hockey, soccer, and more. Users can find the latest scores, statistics, standings, and news for their favorite teams and players.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Yahoo Groups - Scraping in Chrome
What is scraping? It’s where you use a bot to cruse the internet for you and collect data into a spreadsheet. Bots can work a lot faster than you and don’t get tired or distracted so if you’ve got a lot of data to collect scraping makes your life easier.
Now it’s the end of 2019 and you’ve got a yahoo group full of old Fanfic Files that you’d like to download before it’s gone forever. Sure you can download everything by hand or use a custom script to scrape it perfectly into folders quickly but lets be honest, you ain’t got time for that shit - mentally or physically. Your best bet is using a free scraping tool and leave it going while you’re at work so you can come home to 1,000s of ancient fandom fics. Sure this inelegant solution will perform so slowly you’ll wonder if it’s a geriatric, overweight snail powered by farts but f*ck it, at least you won’t have to sit at the computer clicking on every single htm and txt file in your yahoo group right?
Here are some helpful steps below the break.

Step One:
Create a folder for your downloads. With Chrome’s settings you can then switch your download folder to this new folder.
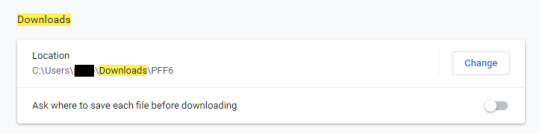
Trust me, you don’t want your thousands of historical fic mixing in with all the other porn crap in your downloads folder. The scraping won’t be maintaining subfolder file structure so you’ll have all your group’s files in one heap of a mess. Possibly half of them helpfully named ‘Chapter_One.htm’ The less sorting you have to do later the better.
Step Two:
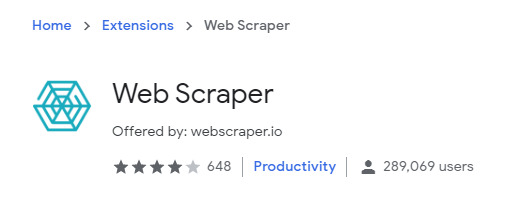
Install a browser extension scraper. In this case we’re using Chrome’s Web Scraper:
Once installed you can access it on any webpage by opening Chrome’s developer tools using F12 and selecting ‘Web Scraper’ from the tool’s menu bar. Note: You’ll want to dock the developer tools window to the bottom of the screen using the buttons I’ve highlighted below. vvv
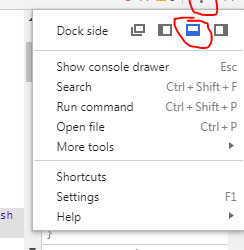
If you want more details on how to use Web Scraper, click on the blue web symbol that will appear to the right of your address bar in Chrome. You’ll find tutorials and documentation. I didn’t read any of it. Why any of you are listening to me is a mystery. But if you’re happy with the blind leading the blind, jump to our next step.
Step Three:
Now we can import your Sitemap for scraping. Start by navigating in Chrome to the yahoo groups file page. Something like, https://groups.yahoo.com/neo/groups/awesomefanfic/files
Open the Web Scraper in developer tools (F12) for this page, if you haven’t already, and click “create new sitemap”>“Import Sitemap”
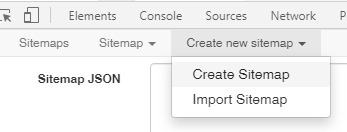
Then paste the following code into the "Sitemap JSON” field:
{"_id":"testscrape1","startUrl":["YOUR FILES"],"selectors":[{"id":"folderName","type":"SelectorLink","parentSelectors":["_root"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"subfolder","type":"SelectorLink","parentSelectors":["folderName"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"subfiles","type":"SelectorLink","parentSelectors":["subfiles"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"Files","type":"SelectorText","parentSelectors":["folderName"],"selector":".yg-list-title a","multiple":true,"regex":"","delay":0},{"id":"subFiles","type":"SelectorLink","parentSelectors":["subfolder"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"SubFileNames","type":"SelectorText","parentSelectors":["subfolder"],"selector":".yg-list-title a","multiple":true,"regex":"","delay":0},{"id":"dummy","type":"SelectorText","parentSelectors":["subFiles"],"selector":".yg-list-title a","multiple":true,"regex":"","delay":0}]}
You’ll going to need to change where it says “YOUR FILES” to your yahoo group’s files page. Copy it from the address bar. It will look something like: "startUrl": ["https://groups.yahoo.com/neo/groups/awesomefanfic/files"]
You may want to rename your Sitemap in the second field. Otherwise it will be named “testscrape1″
Once you’ve made your changes, hit the import button and you’re ready to start scraping.
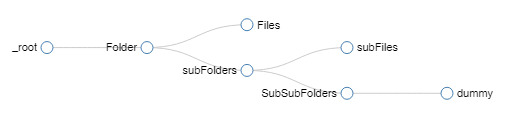
Note: This imported JSON code provides a Sitemap structure designed to download all the documents up to a level two subfolder and place them all into that download folder. It will also create a spreadsheet record of each file’s location.
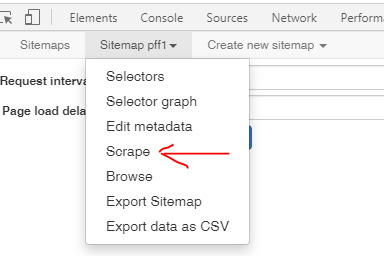
Step Four:
Now we Scrape.
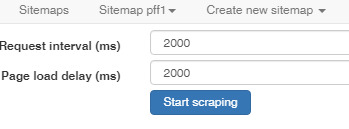
Once it starts scraping it will open a new window and slowly (SOOO SLOWLY) start downloading your old files. Note: Do NOT close Web Scraper window while it is running a scrape or you will have to start again from beginning. Again, it will not be downloading folders so all the files will be dumped in one big heap. Luckily the spreadsheet it creates showing where every file came from, will help.

Step Five:
Once you’ve walked the dog, gone to work, eaten a feast for the elder gods, and danced with your coven at midnight the scraping should be about done (results dependent on number of grizzled files to download). The Web Scraper window should close on it’s own. You’re tomb-of-ancient-knowledge will be ready in the location you specified in step one. It’s possible the Scrape missed some hoary files because yahoo was refusing to open a folder or the file was in a deeper subfolder than level two (the bot checking for subfolders is why this scrape is so slow so I didn’t go deeper). For best results you will need to review the scraped file data and compare it to what you downloaded. Use “Export data as CSV” and then use your new spreadsheet to rebuild your file structure and check for any missing files. NOTHING listed in the “dummy” column will be downloaded. You will have download everything in that column (and deeper) manually.
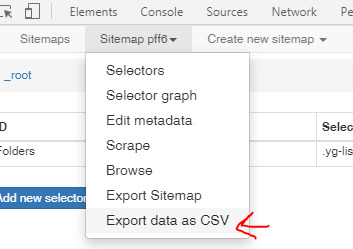
With luck, only a handful of files will need to be downloaded manually after your review. Treasure your prize and if you’re a mod of the group, help save the files for the gen z fic readers by sharing your hoard on Hugo-award-winning AO3.
Bonus (Expert Mode):
Using the spreadsheet and batch file scripts you can recreate your file structure quickly and move the files into the new folders. A few changes will turn your list of urls into folder locations on your PC and bam! You’ve got a everything organized again! A few things to watch for: 1. You will have to remove spaces and special characters from folder names. 2. File names should be in double quotes in your batch file or have all spaces removed. 3. Files with the same name from different folders (Like chapter1.htm) should probably be done manually before running the batch to move the rest.
-------------------------------
Thank you for reading.
Don’t like my jokes or my solution? Feel free to call me out and post better solutions here. Hope this helps!
10 notes
·
View notes
Text
Walmart Product Data Scraping Services | Walmart Product Data Scraper

Within this blog post, we will elucidate the disparities between web crawling and web scraping while delving into the primary benefits and practical applications of each technique.
What is Web Crawling?

Web crawling, often referred to as indexing, involves the utilization of bots, also known as crawlers, to index information found on web pages. This process mirrors the activities of search engines, encompassing the comprehensive examination of a webpage as a unified entity for indexing purposes. During the website crawling procedure, bots meticulously traverse through every page and link, extending their search until the final element of the website to locate any available information.
Major search engines such as Google, Bing, Yahoo, statistical agencies, and prominent online aggregators predominantly employ web crawlers. The output of web crawling tends to capture generalized information, whereas web scraping is more directed at extracting specific segments of datasets.
What is Web Scraping?

Web scraping, or web data extraction, shares similarities with web crawling, primarily identifying and pinpointing targeted data from web pages. However, the key distinction lies in that web scraping, especially through professional web scraping services, operates with a predefined understanding of the data set's structure, such as an HTML element configuration for fixed web pages, from which data extraction is intended.
It is powered by automated bots called 'scrapers'; web scraping offers an automated mechanism for harvesting distinct datasets. Once the desired information is acquired, it can be harnessed for various purposes, including comparison, verification, and analysis, in alignment with a given business's specific objectives and requirements.
Widely Seen Use Cases of Web Scraping
Web scraping finds versatile applications across various domains, serving as a powerful tool for data acquisition and analysis. Some common use cases include:
Academic Research: Researchers extract data from online publications, websites, and forums for analysis and insights.
Content Aggregation: Content platforms use web scraping to aggregate articles, blog posts, and other content for distribution.
Financial Data Extraction: Investment firms utilize web scraping to gather financial data, stock prices, and market performance metrics.
Government Data Access: Web scraping aids in accessing public data like census statistics, government reports, and legislative updates.
Healthcare Analysis: Researchers extract medical data for studies, pharmaceutical companies analyze drug information, and health organizations track disease trends.
Job Market Insights: Job boards scrape job listings and employer data to provide insights into employment trends and company hiring practices.
Language Processing: Linguists and language researchers scrape text data for studying linguistic patterns and developing language models.
Lead Generation: Sales teams use web scraping to extract contact information from websites and directories for potential leads.
Market Research: Web scraping helps in gathering market trends, customer reviews, and product details to inform strategic decisions.
News Aggregation: Web scraping aggregates news articles and headlines from various sources, creating comprehensive news platforms.
Price Monitoring: E-commerce businesses employ web scraping to track competitor prices and adjust their own pricing strategies accordingly.
Real Estate Analysis: Real estate professionals can scrape property listings and historical data for property value trends and investment insights.
Social Media Monitoring: Brands track their online presence by scraping social media platforms for mentions, sentiment analysis, and engagement metrics.
Travel Planning: Travel agencies leverage travel data scraping services to extract valuable information, including flight and hotel prices, enabling them to curate competitive travel packages for their customers. This approach, combined with hotel data scraping services, empowers travel agencies to offer well-informed and attractive options that cater to the unique preferences and budgets of travelers.
Weather Data Collection: Meteorologists and researchers gather weather data from multiple sources for accurate forecasts and climate studies.
These are just a few examples of how web scraping is utilized across various industries to gather, analyze, and leverage data for informed decision-making and strategic planning.
Advantages of Each Available Option
Advantages of Web Scraping
Web scraping, the process of extracting data from websites, offers several critical benefits across various domains. Here are some of the main advantages of web scraping:
Academic and Research Purposes: Researchers can use web scraping to gather data for academic studies, social science research, sentiment analysis, and other scientific investigations.
Competitive Intelligence: Web scraping enables you to monitor competitors' websites, gather information about their products, pricing strategies, customer reviews, and marketing strategies. This information can help you make informed decisions to stay competitive.
Content Aggregation: Web scraping allows you to automatically collect and aggregate content from various sources, which can help create news summaries, comparison websites, and data-driven content.
Data Collection and Analysis: Web scraping allows you to gather large amounts of data from websites quickly and efficiently. This data can be used for analysis, research, and decision-making in various fields, such as business, finance, market research, and academia.
Financial Analysis: Web scraping can provide valuable financial data, such as stock prices, historical data, economic indicators, and company financials, which can be used for investment decisions and financial modeling.
Government and Public Data: Government websites often publish data related to demographics, public health, and other social indicators. Web scraping can automate the process of collecting and updating this information.
Job Market Analysis: Job portals and career websites can be scraped to gather information about job listings, salary trends, required skills, and other insights related to the job market.
Lead Generation: In sales and marketing, web scraping can collect contact information from potential leads, including email addresses, phone numbers, and job titles, which can be used for outreach campaigns.
Machine Learning and AI Training: Web scraping can provide large datasets for training machine learning and AI models, especially in natural language processing (NLP), image recognition, and sentiment analysis.
Market Research: Web scraping can help you gather insights about consumer preferences, trends, and sentiment by analyzing reviews, comments, and discussions on social media platforms, forums, and e-commerce websites.
Price Monitoring: E-commerce businesses can use web scraping to monitor competitor prices, track price fluctuations, and adjust their pricing strategies to remain competitive.
Real-time Data: You can access real-time or near-real-time data by regularly scraping websites. This is particularly useful for tracking stock prices, weather updates, social media trends, and other time-sensitive information.
It's important to note that while web scraping offers numerous benefits, there are legal and ethical considerations to be aware of, including respecting website terms of use, robots.txt guidelines, and privacy regulations. Always ensure that your web scraping activities comply with relevant laws and regulations.
Advantages of Web Crawling
Web crawling, a fundamental aspect of web scraping, involves systematically navigating and retrieving information from various websites. Here are the advantages of web crawling in more detail:
Automated Data Extraction: With web crawling, you can automate the process of data extraction, reducing the need for manual copying and pasting. This automation saves time and minimizes errors that can occur during manual data entry.
Competitive Intelligence: Web crawling helps businesses gain insights into their competitors' strategies, pricing, product offerings, and customer reviews. This information assists in making informed decisions to stay ahead in the market.
Comprehensive Data Gathering: Web crawling allows you to systematically explore and collect data from a vast number of web pages. It helps you cover a wide range of sources, ensuring that you have a comprehensive dataset for analysis.
Content Aggregation: Web crawling is a foundational process for content aggregation websites, news aggregators, and price comparison platforms. It helps gather and present relevant information from multiple sources in one place.
Data Enrichment: Web crawling can be used to enrich existing datasets with additional information, such as contact details, addresses, and social media profiles.
E-commerce Insights: Retail businesses can use web crawling to monitor competitors' prices, product availability, and customer reviews. This data aids in adjusting pricing strategies and understanding market demand.
Financial Analysis: Web crawling provides access to financial data, stock market updates, economic indicators, and company reports. Financial analysts use this data to make informed investment decisions.
Improved Search Engines: Search engines like Google use web crawling to index and rank web pages. By crawling and indexing new content, search engines ensure that users find the most relevant and up-to-date information.
Machine Learning and AI Training: Web crawling provides the data required to train machine learning and AI models, enabling advancements in areas like natural language processing, image recognition, and recommendation systems.
Market and Sentiment Analysis: By crawling social media platforms, forums, and review sites, you can analyze customer sentiment, opinions, and trends. This analysis can guide marketing strategies and product development.
Real-time Updates: By continuously crawling websites, you can obtain real-time or near-real-time updates on data, such as news articles, stock prices, social media posts, and more. This is particularly useful for industries that require up-to-the-minute information.
Research and Academia: In academic and research settings, web crawling is used to gather data for studies, analysis, and scientific research. It facilitates data-driven insights in fields such as social sciences, linguistics, and more.
Structured Data Collection: Web crawling enables you to retrieve structured data, such as tables, lists, and other organized formats. This structured data can be easily processed, analyzed, and integrated into databases.
While web crawling offers numerous advantages, it's essential to conduct it responsibly, respecting website terms of use, robots.txt guidelines, and legal regulations. Additionally, efficient web crawling requires handling issues such as duplicate content, handling errors, and managing the frequency of requests to avoid overloading servers.
How does the output vary?
The contrast in output between web crawling and web scraping lies in their primary outcomes. In the context of web crawling, the critical output usually consists primarily of lists of URLs. While additional fields or information may be present, URLs dominate as the primary byproduct.
In contrast, the output encompasses more than just URLs when it comes to web scraping. The scope of web scraping is more expansive, encompassing various fields, such as:
Product and stock prices
Metrics like views, likes, and shares reflect social engagement
Customer reviews
Star ratings for products, offering insights into competitor offerings
Aggregated images sourced from industry advertising campaigns
Chronological records of search engine queries and their corresponding search engine results
The broader scope of web scraping yields a diverse range of information, extending beyond URL lists.
Common Challenges in Both Web Crawling and Web Scraping
CAPTCHAs and Anti-Scraping Measures: Some websites employ CAPTCHAs and anti-scraping measures to prevent automated access. Overcoming these obstacles while maintaining data quality is a significant challenge.
Data Quality and Consistency: Both web crawling and web scraping can encounter issues with inconsistent or incomplete data. Websites may have varying structures or layouts, leading to difficulty in extracting accurate and standardized information.
Data Volume and Storage: Large-scale scraping and crawling projects generate substantial data. Efficiently storing and managing this data is essential to prevent data loss and ensure accessibility.
Dependency on Website Stability: Both processes rely on the stability of the websites being crawled or scraped. If a target website experiences downtime or technical issues, it can disrupt data collection.
Dynamic Content: Websites increasingly use JavaScript to load content dynamically, which can be challenging to scrape or crawl. Special techniques are required to handle such dynamic content effectively.
Efficiency and Performance: Balancing the efficiency and speed of the crawling or scraping process while minimizing the impact on target websites' servers can be a delicate challenge.
IP Blocking and Rate Limiting: Websites may detect excessive or aggressive crawling or scraping activities as suspicious and block or throttle the IP addresses involved. Overcoming these limitations without affecting the process is a common challenge.
Legal and Ethical Concerns: Ensuring compliance with copyright, data privacy regulations, and terms of use while collecting and using scraped or crawled data is a shared challenge.
Parsing and Data Extraction: Extracting specific data elements accurately from HTML documents can be complex due to variations in website structures and content presentation.
Proxy Management: To mitigate IP blocking and rate limiting issues, web crawling and scraping may require effective proxy management to distribute requests across different IP addresses.
Robots.txt and Terms of Use: Adhering to websites' robots.txt rules and terms of use is crucial to maintain ethical and legal scraping and crawling practices. However, interpreting these rules and ensuring compliance can be complex.
Website Changes: Websites frequently update their designs, structures, or content, which can break the crawling or scraping process. Regular maintenance is needed to adjust scrapers and crawlers to these changes.
Navigating these shared challenges requires technical expertise, ongoing monitoring, adaptability, and a strong understanding of ethical and legal considerations.
Conclusion
In summary, 'web crawling' involves indexing data, whereas 'web scraping' involves extracting data. For individuals interested in web scraping, Actowiz Solutions provides advanced options. Web Unlocker utilizes Machine Learning algorithms to gather open-source target data efficiently. Meanwhile, Web Scraper IDE is a fully automated web scraper requiring no coding, directly delivering data to your email inbox. For more information, contact Actowiz Solutions now! You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
0 notes
Text
How Web Scraping Is Used To Extract Yahoo Finance Data: Stock Prices, Bids, Price Change And More?

The stock market is a massive database for technological companies, with millions of records that are updated every second! Because there are so many companies that provide financial data, it's usually done through Real-time web scraping API, and APIs always have premium versions. Yahoo Finance is a dependable source of stock market information. It is a premium version because Yahoo also has an API. Instead, you can get free access to any company's stock information on the website.
Although it is extremely popular among stock traders, it has persisted in a market when many large competitors, including Google Finance, have failed. For those interested in following the stock market, Yahoo provides the most recent news on the stock market and firms.
Steps to Scrape Yahoo Finance
Create the URL of the search result page from Yahoo Finance.
Download the HTML of the search result page using Python requests.
Scroll the page using LXML-LXML and let you navigate the HTML tree structure by using Xpaths. We have defined the Xpaths for the details we need for the code.
Save the downloaded information to a JSON file.+

We will extract the following data fields:
Previous close
Open
Bid
Ask
Day’s Range
52 Week Range
Volume
Average volume
Market cap
Beta
PE Ratio
1yr Target EST
You will need to install Python 3 packages for downloading and parsing the HTML file.
The Script
from lxml import html import requests import json import argparse from collections import OrderedDict def get_headers(): return {"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "accept-encoding": "gzip, deflate, br", "accept-language": "en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7", "cache-control": "max-age=0", "dnt": "1", "sec-fetch-dest": "document", "sec-fetch-mode": "navigate", "sec-fetch-site": "none", "sec-fetch-user": "?1", "upgrade-insecure-requests": "1", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"} def parse(ticker): url = "http://finance.yahoo.com/quote/%s?p=%s" % (ticker, ticker) response = requests.get( url, verify=False, headers=get_headers(), timeout=30) print("Parsing %s" % (url)) parser = html.fromstring(response.text) summary_table = parser.xpath( '//div[contains(@data-test,"summary-table")]//tr') summary_data = OrderedDict() other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}?formatted=true&lang=en-US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&corsDomain=finance.yahoo.com".format( ticker) summary_json_response = requests.get(other_details_json_link) try: json_loaded_summary = json.loads(summary_json_response.text) summary = json_loaded_summary["quoteSummary"]["result"][0] y_Target_Est = summary["financialData"]["targetMeanPrice"]['raw'] earnings_list = summary["calendarEvents"]['earnings'] eps = summary["defaultKeyStatistics"]["trailingEps"]['raw'] datelist = [] for i in earnings_list['earningsDate']: datelist.append(i['fmt']) earnings_date = ' to '.join(datelist) for table_data in summary_table: raw_table_key = table_data.xpath( './/td[1]//text()') raw_table_value = table_data.xpath( './/td[2]//text()') table_key = ''.join(raw_table_key).strip() table_value = ''.join(raw_table_value).strip() summary_data.update({table_key: table_value}) summary_data.update({'1y Target Est': y_Target_Est, 'EPS (TTM)': eps, 'Earnings Date': earnings_date, 'ticker': ticker, 'url': url}) return summary_data except ValueError: print("Failed to parse json response") return {"error": "Failed to parse json response"} except: return {"error": "Unhandled Error"} if __name__ == "__main__": argparser = argparse.ArgumentParser() argparser.add_argument('ticker', help='') args = argparser.parse_args() ticker = args.ticker print("Fetching data for %s" % (ticker)) scraped_data = parse(ticker) print("Writing data to output file") with open('%s-summary.json' % (ticker), 'w') as fp: json.dump(scraped_data, fp, indent=4)
Executing the Scraper
Assuming the script is named yahoofinance.py. If you type in the code name in the command prompt or terminal with a -h.
python3 yahoofinance.py -h usage: yahoo_finance.py [-h] ticker positional arguments: ticker optional arguments: -h, --help show this help message and exit
The ticker symbol, often known as a stock symbol, is used to identify a corporation.
To find Apple Inc stock data, we would make the following argument:
python3 yahoofinance.py AAPL
This will produce a JSON file named AAPL-summary.json in the same folder as the script.
This is what the output file would look like:
{ "Previous Close": "293.16", "Open": "295.06", "Bid": "298.51 x 800", "Ask": "298.88 x 900", "Day's Range": "294.48 - 301.00", "52 Week Range": "170.27 - 327.85", "Volume": "36,263,602", "Avg. Volume": "50,925,925", "Market Cap": "1.29T", "Beta (5Y Monthly)": "1.17", "PE Ratio (TTM)": "23.38", "EPS (TTM)": 12.728, "Earnings Date": "2020-07-28 to 2020-08-03", "Forward Dividend & Yield": "3.28 (1.13%)", "Ex-Dividend Date": "May 08, 2020", "1y Target Est": 308.91, "ticker": "AAPL", "url": "http://finance.yahoo.com/quote/AAPL?p=AAPL" }
This code will work for fetching the stock market data of various companies. If you wish to scrape hundreds of pages frequently, there are various things you must be aware of.
Why Perform Yahoo Finance Data Scraping?

If you're working with stock market data and need a clean, free, and trustworthy resource, Yahoo Finance might be the best choice. Different company profile pages have the same format, thus if you construct a script to scrape data from a Microsoft financial page, you could use the same script to scrape data from an Apple financial page.
If anyone is unable to choose how to scrape Yahoo finance data then it is better to hire an experienced web scraping company like Web Screen Scraping.
For any queries, contact Web Screen Scraping today or Request for a free Quote!!
0 notes
Video
youtube
https://creativebeartech.com/product/search-engine-scraper-and-email-extractor-by-creative-bear-tech/ - Our Search Engine Scraper is a cutting-edge lead generation software like no other! It will enable you to scrape niche-relevant business contact details from the search engines, social media and business directories. At the moment, our Search Engine Scraper can scrape: your own list of website urls Google Bing Yahoo Ask Ecosia AOL So DuckDuckGo! Yandex Trust Pilot Google Maps LinkedIn Yelp Yellow Pages (yell.com UK Yellow Pages and YellowPages.com USA Yellow Pages) Twitter Facebook and Instagram That’s a hell of a lot of websites under one roof! The software will literally go out and crawl these sites and find all the websites related to your keywords and your niche! You may have come across individual scrapers such as Google Maps Scraper, Yellow Pages Scraper, E-Mail Extractors, Web Scrapers, LinkedIn Scrapers and many others. The problem with using individual scrapers is that your collected data will be quite limited because you are harvesting it from a single website source. Theoretically, you could use a dozen different website scrapers, but it would be next to impossible to amalgamate the data into a centralised document. Our software combines all the scrapers into a single software. This means that you can scrape different website sources at the same time and all the scraped business contact details will be collated into a single depository (Excel file). Not only will this save you a lot of money from having to go out and buy website scrapers for virtually every website source and social media platform, but it will also allow you to harvest very comprehensive B2B marketing lists for your business niche.
1 note
·
View note
Text
A useful tool to get news from Yahoo Sports
Yahoo Sports is a sports news and information website operated by Yahoo!. It provides comprehensive coverage of various sports, including football, basketball, baseball, hockey, soccer, and more. Users can find the latest scores, statistics, standings, and news for their favorite teams and players.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
The Benefits Of A Professional Ranking Report
SEO is vital for any sort of website. Due to the reality that many people use on-line engines like google for you to locate products and services, plus a steady circulation of unfastened visitors coming from search engines will usually be welcome, numerous primary SEO strategies desires for use on any net web page. Though, sporting out SEO capabilities will no longer be enough. Enhancing pages or producing inbound links will not make feel, except in cases in which you're able to see improvements and the outcomes of rating reviews. If you need more information about google search scraper please visit this site.
Rank tracking is truly a technique of retaining an eye fixed on net web page placements. While you are executing this quite regularly, for instance every day, then you may effortlessly recognize extensive upgrades in net web page positions. Those changes will be resulting from search engine optimization sports or perhaps search engine algorithm modifications. Web page role have to no longer be the handiest parameter being checked. Web page rank in addition to numerous back links may also be a very good indication of web page popularity and SEO actions.
It need to be clearly clean that the positions of web page can alternate. A few less vast variances might be regular and take vicinity due to volatility of rating algorithms and additionally due to the fact competing web pages will trade. If a SEO method is efficient then this needs to be proven in a slow way as the pages climb up the hunt outcomes. Useless to mention, the rating by myself could be already established after you choose key phrases and broaden pages.
It's far feasible to manually music the position of net pages, but this isn't always advocated. For every page and associated keywords you'll have to test the location on google; calculate the range of lower back links the usage of yahoo website explorer and so forth. This can be extraordinarily time-consuming. therefore, the nice strategy is to make use of committed SEO solutions which comprise a ranking record as the final search engine optimization step. A further benefit of utilizing such gear is the reality that every one the data is stored in a database to do comparisons at a later date and additionally to display photograph.
0 notes
Text
Idle thought on Tumblr backups
I've seen rumblings again of people exchanging contact info and methods for backing up your Tumblr, out of some vague sense of foreboding that the next great fandom migration will soon be upon us/Yahoo is going to pull the plug on Tumblr any day now/a lot of things are going to blow up if net neutrality gets axed. I hesitate to predict the future, but here's a thought if you're in backup mode:
If Tumblr goes, all the fic and art and meta posted exclusively to Tumblr goes with it. Don't just save your own stuff. Download a web scraper and make local copies of your friends' blogs, your favorite artists' art tags, your favorite fic aggregators, your favorite meta blogs. Download random shit you think has community importance or fandom-history value. Save anything you can't bear to see disappear down the memory hole.
Reposting any of it elsewhere on the web is ethically sticky, but if nothing else, keep the local backups. For your own sake, and for the sake of anyone you might be able to rescue from catastrophic data loss if they didn't get their own shit backed up in time.
I realize that Tumblr especially tends to have a low original-content-to-reblogs radio, that backing up entire blogs could eat up storage space, and that not everything you want to back up will be tagged. But still, save what you can't bear to lose. I've been playing with Tumblr's API, looking for a reliable way to request only posts the blogger has contributed to somehow (i.e. original posts + reblogs with comments). Naturally Tumblr's API is a steaming pile of manure that can't even accomplish that simple task without barfing up a torrent of false positives from pre-2015 reblogs, but I'll keep you guys posted on what I can come up with in terms of fine-grained backup options. I might also tinker with the Tumblr-to-Wordpress import plugin, which is generally pretty good but has some issues with mangling video embeds and formatting photosets weirdly. It'd be cool to fix them, and maybe experiment with some bells and whistles like extracting "tag commentary" into a separate metadata field. Stay tuned.
101 notes
·
View notes