#Data Extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
I would be extremely pleased if someone else told Jasper to turn down his music, as he apparently refuses to listen to me.
12 notes
·
View notes
Text
🚗 How Can Real-Time Car Rental Data Scraping from #Turo Enhance Your Business Strategy?

In the rapidly evolving #mobility and #carsharing space, having access to real-time rental data is key to staying ahead of market trends. Here's how #carrentaldata scraping from platforms like #Turo can benefit your business: 📊 Track dynamic #pricingmodels and rental rates by region 📈 Monitor trending #vehicletypes and availability 📍 Analyze #locationbased demand for smarter fleet distribution
🧠 Understand seasonal trends for effective #strategicplanning
📉 Benchmark against competitors to adjust #pricingstrategy Whether you're in #automotive, #rentalservices, or #mobilityanalytics, this data provides actionable insights to fine-tune offerings and boost profitability.
2 notes
·
View notes
Text

2 notes
·
View notes
Text
Market Research with Web Data Solutions – Dignexus
6 notes
·
View notes
Text

Lensnure Solution provides top-notch Food delivery and Restaurant data scraping services to avail benefits of extracted food data from various Restaurant listings and Food delivery platforms such as Zomato, Uber Eats, Deliveroo, Postmates, Swiggy, delivery.com, Grubhub, Seamless, DoorDash, and much more. We help you extract valuable and large amounts of food data from your target websites using our cutting-edge data scraping techniques.
Our Food delivery data scraping services deliver real-time and dynamic data including Menu items, restaurant names, Pricing, Delivery times, Contact information, Discounts, Offers, and Locations in required file formats like CSV, JSON, XLSX, etc.
Read More: Food Delivery Data Scraping
#data extraction#lensnure solutions#web scraping#web scraping services#food data scraping#food delivery data scraping#extract food ordering data#Extract Restaurant Listings Data
2 notes
·
View notes
Text
In search for a Scanner SDK?
With the Docutain SDK you can integrate ready-to-use Scanner and Data Extraction components in your apps for Android, iOS and Windows in less than 1 day!
Try it out: https://sdk.docutain.com
2 notes
·
View notes
Text
How to Extract Amazon Product Prices Data with Python 3
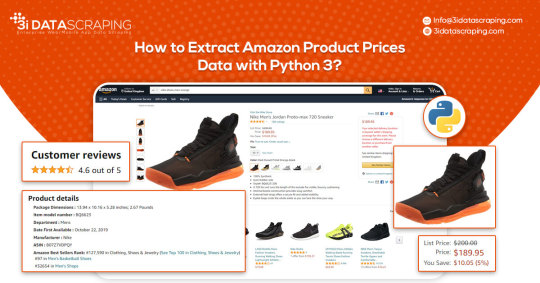
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
We scraped thousands of posts from popular subreddits to uncover real opinions, pros, and cons of moving to New York. Here's what the data tells us.
0 notes
Text

Scraping stopped by hCaptcha? Here’s your cheat sheet for doing it ethically, effectively, and without breaking a sweat. Let PromptCloud help you get back to clean, compliant data. Read more here: https://shorturl.at/Q52nE
#hCaptcha #WebScraping #DataExtraction #AIandAutomation
0 notes
Text
A Guide To Modern Data Extraction Services
As data surges with rapid technological breakthroughs and expanding industry capabilities, access to higher volume, laser-accurate, highly relevant and mission critical information becomes imperative to thrive in the market. In this guide, you’ll discover how modern data extraction services can transform your business and catapult you ahead of the competition. We cover everything from choosing the right strategy to implementing best practices and exploring how finding an ideal partner for your business can be game-changing.
What is Modern Data Extraction?
Modern data extraction harnesses cutting-edge technologies to efficiently collect, process, and analyze vast amounts of data from diverse sources. It employs AI-driven algorithms, machine learning, and cloud computing to deliver insights with unprecedented speed and accuracy. The goal is to empower businesses with timely, comprehensive, and actionable insights for strategic decision-making.
Businesses extract target data from various sources. The most common data sources are:
Websites: Critical information is available directly from various online sources.
Documents: Data from a wide range of document types, including emails, spreadsheets, PDFs, and images.
Databases: Structured and semi-structured data available in relational and non-relational databases.
Multimedia: Insights from visual and audio media content.
Custom: Tailored data is accessed from APIs, local drives, social media, and other unique sources.
Customer Data: Leverage your own treasure trove of customer interactions and behaviours.
Data Vendors: Augment your insights with specialized data from trusted providers.
Manual Data Collection: Complement automated processes with human-gathered intelligence.
Evolution of Data Extraction: Traditional to Modern
Technological advancements have driven the evolution of data extraction over the past decade. The market size is expected to grow from USD 2.33 billion in 2023 to USD 5.13 billion by 2030, with a compound annual growth rate (CAGR) of 11.9% (MMR).
Initially, data extraction relied heavily on manual processes, with large teams dedicating countless hours to painstaking data entry and basic extraction tasks. With the wave of globalization, these operations shifted offshore, taking advantage of cost efficiencies while maintaining the human-centric approach to data handling.
Alongside these manual efforts, early automation solutions emerged. However, their capabilities were limited, often requiring significant human oversight and intervention. This hybrid approach, combining manual with nascent automated tools, has characterized the data extraction landscape for years, and it has struggled to keep pace with the growing needs of the industry.
As digital transformation came into full swing, the volume and complexity of data skyrocketed. This growth catalyzed innovations in programming, giving rise to sophisticated computer algorithms for retrieving, modifying, and storing data. Enter the era of ETL (Extract, Transform, Load) processing and advanced data automation:
Extract: Extracting data from a variety of sources
Transform: Transforming the data per business rules
Load: Loading and storing data in the desired format
The flexibility of these automated workflows has created variations like ELT (Extract, Load, Transform) and ELTL (Extract, Load, Transform, Load), each tailored to specific industry needs and use cases.
Despite these advancements, new challenges have emerged in data management and scalability.
As businesses have expanded, the volume, variety, and velocity of extracted data have increased, overwhelming traditional systems. This has demanded more trailblazing approaches to data storage and processing.
To address these challenges, a trifecta of modern data storage solutions has emerged: data lakes, data warehouses, and data lakehouses. Each plays a crucial role in revolutionizing data management, offering unique advantages for different data needs.
Data lakes: Store vast amounts of raw, unprocessed data in its native format.
Data warehouses: Offer a structured approach to handling large volumes of data from multiple sources.
Data lakehouses: Combine the flexibility of data lakes with the performance features of data warehouses.
Complementing these storage solutions, cloud computing further redefined the data management landscape. By offering scalable infrastructure and on-demand resources, cloud platforms empower organizations to handle massive datasets and complex extraction tasks without significant upfront investments or commitments. Cloud-native data solutions leverage distributed computing to deliver unparalleled performance, reliability, and cost-efficiency.
This technological shift enabled organizations to process massive datasets and execute complex extraction tasks without substantial initial capital expenditure. The cloud’s elasticity and pay-as-you-go model democratized access to advanced data processing capabilities, facilitating the development and deployment of sophisticated data extraction technologies across various industries and organization sizes.
Understanding Modern Data Extraction Technologies
Modern data extraction technologies now leverage unprecedented data storage capacities and computing power to implement transformative strategies:
Automation: Identify repetitive tasks, streamline processes, reduce costs and process vast datasets with minimal manual intervention
Artificial Intelligence (AI) / Machine Learning (ML): Enhance decision-making, learn from patterns, and uncover hidden insights and continuous performance improvement through exposure to new data. AI/ML goes beyond rules-based logic to handle more complex situations, such as recognizing and maintaining relationships between interconnected data points across multiple data sources, building robust datasets from unstructured data or enabling advanced master data management without the need for explicit pre-defined rules
Natural Language Processing (NLP): Transform unstructured text data into actionable intelligence, mimicking human language understanding
Generative AI: Create human-like content, generate innovative solutions that can enhance big data quality, build intuition from currently available sources and checkpoints, provide deeper insights into performance and resolve inconsistencies with precision without human intervention and understand the context to produce relevant outputs across various domains
Artificial General Intelligence (AGI): While still largely theoretical, AI systems aim to match or exceed human-level intelligence. Development of AGI could revolutionize data extraction by enabling systems to understand and adapt to complex, novel situations without specific programming.
How Modern Data Extraction Changed Business Intelligence
AI and Natural Language Processing (NLP): NLP techniques extract valuable insights from unstructured text data at scale, enabling sophisticated sentiment analysis, topic modeling, and entity recognition. This capability transforms raw textual data into structured, actionable intelligence. Read more on: Introduction to News Crawlers: Powering Data Insights
Real-time Web Data Harvesting: Advanced web scraping techniques now enable the extraction of live data from dynamic websites. This provides crucial, up-to-the-minute insights for time-sensitive industries such as finance and e-commerce, facilitating rapid decision-making based on current market conditions. Read more on: Web Data Extraction: Techniques, Tools, and Applications
Intelligent Document Processing (IDP): AI-driven IDP systems automate the capture, classification, and extraction of data from diverse document types. Unlike traditional logic-based algorithms, these intelligent systems understand the context and build relationships between various data points, significantly enhancing the accuracy and depth of extracted information.
Generative AI in Data Augmentation: Emerging applications leverage generative models to create synthetic datasets for training models, eliminating the need for extensive labeling operations, augment existing data, provide summarization from vast resources of raw data, and assist in query formulation with human-like prompting, enabling users to “talk” to their data through visualizations, charts, or conversational interfaces. This technology expands the scope and quality of available data, enabling more robust analysis and model training.
Big Data and Cloud Computing Integration: The synergy between big data technologies and cloud computing enables real-time processing of vast datasets. This integration facilitates advanced analytics and drives the development of increasingly sophisticated extraction algorithms, all while optimizing infrastructure management, costs, processing speed, and data growth.
Custom Large Language Models (LLMs): Large Language Models, a subset of the AI/ML field, have fueled the evolution of Generative AI by exhibiting cognitive abilities to understand, process, and augment data with near-human intelligence. Building a custom LLM is equivalent to designing your own encyclopedia. Focused on your business needs, these models can help precisely identify areas of improvement, craft data-driven strategies, build resources to empower data use cases and enhance decision-making processes through intelligent automation and predictive analytics.
Retrieval-Augmented Generation (RAGs): Another breakthrough in enhancing capabilities for LLMs is the RAGs architecture. It blends the abilities of Information RAG Systems and Natural Language Generation to provide relevant and up-to-date insights. Imagine your custom LLMs (or encyclopedia for your business) always serving current data. An advanced responsibility is served by integrating RAGs with your LLMs.
Current Industry Challenges in Data Extraction
The transformative impact of modern data extraction technologies on business is undeniable. Yet, the accelerated evolution of these advanced solutions presents a paradox: as capabilities expand, so too does the complexity of implementation and integration. This complexity creates challenges in three key areas:
Business Challenges
Cost Management: Balancing investment in advanced extraction tools against potential ROI in a data-driven market.
Resource Allocation: Addressing the shortage of skilled data engineers and specialists while managing growing extraction needs.
Infrastructure Readiness: Upgrading systems to handle high-volume, real-time data extraction without disrupting operations.
Knowledge Gaps: Keeping teams updated on evolving extraction techniques, from web scraping to API integrations to Generative AI.
Decision-Making Complexity: Choosing between in-house solutions and third-party data extraction services in a crowded market.
Content Challenges
Unstructured Data: Extracting valuable insights from diverse sources like social media, emails, PDFs, etc. given the complex structure of embedded data that remains often inaccessible.
Data Freshness: Ensuring extracted data remains relevant in industries that require real-time data to serve their customer needs.
Ethical and Legal Considerations: Navigating data privacy regulations (GDPR, CCPA) while maintaining robust extraction practices.
Data Variety and Velocity: Handling the increasing diversity of data formats and the speed of data generation.
Technical Challenges
Data Quality: Maintaining accuracy and consistency when extracting from multiple and disparate sources.
Data Volume: Scaling extraction processes to handle terabytes of data without compromising performance or storage.
Scalability: Developing extraction systems that can grow with business needs and adapt to new data sources.
Flexibility: Fine-tuning data pipelines to accommodate changing requirements to meet business needs.
Integration with Existing Systems: Seamlessly incorporating extracted data into legacy systems and business intelligence tools.
Adopting Data Extraction Services in 2024
In 2024, an age of urgency, enterprises need efficient, plug-and-play data extraction solutions. As companies navigate the data-driven force, choosing the right extraction strategy is crucial.
Key pillars of a robust strategy include:
Identifying Your Business Needs
Assessing What Data is Essential to Your Business Goals: Determine which data directly supports your objectives. This could be business data enrichment, social media data stream, online news aggregation, or automated processing of millions of documents. Knowing what matters most helps focus your extraction efforts on the valuable sources.
Determining the Frequency, Volume, and Type of Data Required: Consider how often you need data updates, how much data you’re dealing with, and in what format it’s available. This could range from real-time streams to periodic updates or large historical datasets.
Choosing the Right Solution
Evaluating Vendors and Technologies Based on Your Specific Requirements: Carefully assess potential solutions. The key function to target is their strategic capabilities and partnership strength — this helps in aligning objectives from the outset and setting you up for streamlined operations. Additional areas are technology stack, integration ease, end-to-end data management support, and the ability to handle your critical data types. This ensures the chosen solution fits your business needs and technical capabilities.
Comparing In-house vs. Outsourced Data Extraction Solutions: Decide whether to manage extraction internally or outsource. In-house offers more control but requires significant resources. Outsourcing provides expert knowledge with less upfront investment. Weigh these options to find the best fit for your needs.
Working with Best Practices
Compatibility with Existing Workflows: The solution should ensure smooth integration with your current systems. This minimizes disruption and allows teams to use extracted data effectively without major process changes.
Data Quality and Accuracy: The solution should implement strong validation processes to support data integrity. This ensures your extracted data is accurate, complete, and consistent, enhancing decision-making and building trust in the data across your organization.
Scalability and Flexibility: The solution should provide scalability to meet your future needs. It should handle increasing data volumes without performance issues and adapt to changing business requirements and new technologies.
Data Security and Compliance: The solution should prioritize safeguarding your data. It should employ encryption, strict access controls, and regular audits to comply with regulations like GDPR and CCPA. This reduces risk and enhances your reputation as a trusted partner.
Continuous Improvement: The solution should have room for learning and improvements. It should support regular review and optimization of your processes. This includes monitoring performance, gathering user feedback, and staying informed about new trends to ensure your strategy remains effective and aligned with your goals.
Forage AI: Your One-Stop Data Automation Partner
We understand that managing the complexities of data extraction can seem overwhelming. At Forage AI, we specialize in providing robust solutions to these complex challenges. Our comprehensive suite of modern data extraction solutions address all the aspects discussed above and more. We design our full spectrum of services to be relevant to your data needs.
Multi-Modal Data Extraction: Our robust solutions use advanced techniques for data extraction from the web and documents. Coupled with battle-tested, multi-layered QA, you can unlock a treasure trove of insights.
Change Detection: Our bespoke solutions monitor, extract and report real-time changes, ensuring your data stays fresh and accurate.
Data Governance: We are GDPR and CCPA compliant, ensuring your data is secure and meets all regulatory standards.
Automation and NLP: We know exactly when and how to integrate these technologies to enhance your business processes. Our advanced techniques help preprocess and clean data going from noisy raw data to preparing high-value datasets.
Generative AI Integration: We stay at the forefront of innovation by wisely integrating Generative AI into our solutions, bringing new levels of automation and efficiency. Our approach is measured and responsible — carefully addressing common pitfalls like data bias and ensuring compliance with industry standards. By embracing this technology strategically, we deliver cutting-edge features while maintaining the accuracy, security, and reliability your business depends on.
Data Delivery Assurance: We provide full coverage with no missing data, and resilient data pipelines with SLAs in place.
Tailored Approach: We create custom plans relevant to your processes. This allows for tight data management, and flexibility to integrate with existing data systems.
True Partnership: We launch quickly, work closely with you, and focus on your success.
Final Thoughts
As we ride the waves of relentless innovation in 2024, where yesterday’s cutting-edge is today’s status quo, the critical role of modern data extraction services in driving business success becomes increasingly apparent. The evolution from manual processes to sophisticated AI-driven techniques represents a paradigm shift in how organizations acquire, process, and leverage information. This transformation offers unprecedented opportunities for gaining deeper insights, facilitating data-driven decision-making, and maintaining a competitive edge in an increasingly complex market environment.
The efficacy of these advanced data extraction methodologies hinges on access to high-quality, relevant data sources. Organizations must recognize that the value derived from data extraction technologies is directly proportional to the quality and relevance of the input data. As such, investing in premium data sources and maintaining robust data governance practices are essential components of a successful data strategy.
The future trajectory of data extraction technologies is promising, with emergent fields such as Generative AI and advanced Natural Language Processing techniques poised to further expand the capabilities of data extraction systems. However, it is crucial to recognize that the key to unlocking the full potential of these technologies lies not merely in their adoption, but in their strategic implementation and integration within existing business processes.
Those who successfully harness the power of advanced data extraction technologies will be well-positioned to thrive in an increasingly data-driven global economy, gaining actionable insights that drive innovation, enhance decision-making, and create sustainable competitive advantages.
Take the Next Step
Transform your business intelligence capabilities with Forage AI’s tailored data automation solutions. Our expert team stands ready to work with you through the complexities of modern data acquisition and analysis. Schedule a consultation today to explore how Forage AI’s advanced extraction techniques can unlock the full potential of your data assets and position your organization at the forefront of your industry.

#artificial intelligence#Web data extraction#data extraction#Data extraction services#machine learning#startup
0 notes
Text

#ecommerce#marketing#branding#data scraping#data solutions#data extraction#sephora#ulta beauty#nykaa#amazon
2 notes
·
View notes
Text
🏡 Looking to make smarter real estate decisions in 2025? It starts with the right data.

At Actowiz Solutions, we specialize in #RERAdataextraction combined with #propertylistingscraping from top platforms like Zillow, #99acres, and #MagicBricks. 🔍 Our services help you: ✅ Collect verified project approvals & legal compliance data ✅ Monitor real-time property prices, listings & availability ✅ Track builder reputation, reviews, and historical projects ✅ Analyze location trends, PIN-code serviceability & property appreciation ✅ Support investment, lending, and market research with structured insights 💡 Whether you're a real estate investor, #proptechstartup, builder, or consultancy — reliable RERA + #marketplacedata offers a #competitiveedge you can't afford to miss.
1 note
·
View note
Text
Beauty filters: Digital privilege and data exposure
Beyond promoting heteronormative beauty standards through content visibility, the digital world continuously reinforces the aesthetic privilege through beauty filters. These filters operate by detecting a face through the camera and enabling users to modify their images by adjusting colors, adding stickers, editing facial structure and body proportions (Schipper, 2018, as cited in Lavrence & Cambre, 2020). With the advanced technology, these filters have been developed to precisely scan users’ faces and offer users with features to comprehensively and structurally reconfigure their facial attributes (Lavrence & Cambre, 2020).

It’s no surprise that these filters quickly attract users' attention and preference. That is because they boost users’ confidence by receiving positive social engagement with their conventionally prettier images. However, there is a growing wave of criticism around the beautifying effect of filters. For instance, Arata, a frequent Snapchat filter user, showed her frustration when her selfie was unrealistically adjusted to “stereotypical form of beauty” (Barker, 2020, p. 209). This highlights a significant issue of how filters systematically modify users’ features to align with the Western beauty norms, such as white skin, thin face shape, large eyes and plump lips (Barker, 2020, p. 209).
Therefore, the platform has rapidly evolved filter technology to provide more “realistic” images. Instead of exaggerating Western beauty ideals, the algorithms tend to refine users’ facial features in a way that is hard to see but still enhances their attractiveness. Peres Martins (2017) shared that Snapchat’s new filter “barely changed anything but enough” for her to notice that she did look prettier (as cited in Barker, 2020, p. 211). Or the development of fotor.com, a beauty filter website that provides advanced tools to transform selfies into "natural" beauty images. Consequently, it quickly satisfies digital users since it advocates the most “realistic” and diverse beauty appearance yet yielding lots of social engagement.

However, the deadly point is that, in order to create such a natural and “real” appearance, the platform algorithm must maximize their efforts in collecting and analyzing users’ biometric data. In other words, the more seamlessly a filter blends with reality, the deeper the algorithm digs into our facial details. That is because machines convert things that we see, such as facial contrast, eyes, nose and lip into computational language, allowing algorithms to identify and manipulate users’ facial features from different angles (Rettberg, 2017, pp. 89-90).

As our facial identities are continuously being captured and stored online (Retberg, 2017, p. 89), the risk of biometric data misuse grows significantly. There will be a potential chance that these data could be illegally sold, leaked or stolen, which could lead to a digital exposure crisis. Then, it might be used for unauthorized deep fake content, which can directly harm the users’ privacy and reputation.

It is clear that filters might seem like something fun but they are gradually reinforcing narrow beauty ideals and quietly stealing personal data. The more we use, the more freely we allow the system to use our biometric data. So next time, better thought twice while scrolling through several filters for your own safety.
References
Barker, J. (2020). Making-up on mobile: The pretty filters and ugly implications of Snapchat. Fashion, Style & Popular Culture, 7, 207-221.
Lavrence, C., & Cambre, C. (2020). “Do I Look Like My Selfie?”: Filters and the digital-forensic gaze. Social Media + Society, 6(4). https://doi.org/10.1177/2056305120955182
Rettberg, J. W. (2017). Biometric Citizens: Adapting our selfies to machine vision. In A, Kuntsman (Eds.), Selfie citizenship (pp. 89–96). Springer International Publishing. https://doi.org/10.1007/978-3-319-45270-8_10
0 notes
Text
Intelligent Document Processing (IDP) is a cutting-edge technology that leverages AI, machine learning, and OCR to automate the extraction, processing, and analysis of data from documents. From invoices and contracts to customer forms and emails, IDP transforms unstructured and semi-structured data into actionable insights, reducing manual effort and errors. Its applications span industries such as finance, healthcare, logistics, and legal, enabling organizations to streamline workflows, enhance accuracy, and improve operational efficiency. Explore the transformative potential of IDP and its role in driving digital transformation.
#IDP#Intelligent Document Processing#AI#machine learning#OCR#document automation#data extraction#workflow automation#digital transformation.
1 note
·
View note
Text
youtube
🪪🔀📝Effortlessly extract key details like first name, last name, passport number, address, and other information from passports of any nationality using AlgoDocs’ intelligent AI data extraction tool. Export and save captured data to Excel, JSON, or XML.
Sign up for AlgoDocs free-forever plan today.
0 notes