#yolov2
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Video
instagram
Making a program with #yoloV2 on OF turning #objectdetection to #midi #machinelearning #AI #notreally (at London, United Kingdom) https://www.instagram.com/p/Bm_RsdhDgaF/?utm_source=ig_tumblr_share&igshid=tqfka6rq48uj
1 note
·
View note
Photo

Neural Networks using Keras and TensorFlow in Python.Learn Artificial Neural Networks in Python. Bulding deep learning models using Keras & Tensorflow| Python.Interested poeple can share me your details. Check our Info : www.incegna.com Reg Link for Programs : http://www.incegna.com/contact-us Follow us on Facebook : www.facebook.com/INCEGNA/? Follow us on Instagram : https://www.instagram.com/_incegna/ For Queries : [email protected] #deepelearning,#artificialneuralnetworks,#keras,#tensirflow,#python,#computervision,#LSTM,#RNN,#ConvNets,#VGG-16,#R-CNN,#YOLOv2,#v3,#scikit,#theano,#gradientdescent https://www.instagram.com/p/B-d8xYSgvnI/?igshid=t5dm62ukoxxd
#deepelearning#artificialneuralnetworks#keras#tensirflow#python#computervision#lstm#rnn#convnets#vgg#r#yolov2#v3#scikit#theano#gradientdescent
0 notes
Photo


Added a realtime pixelization filter example to the Tiny YOLOv2 on Unity Barracuda repository. https://github.com/keijiro/TinyYOLOv2Barracuda
7 notes
·
View notes
Text
A 40cm-square patch that renders you invisible to person-detecting AIs

Researchers from KU Leuven have published a paper showing how they can create a 40cm x 40cm "patch" that fools a convoluted neural network classifier that is otherwise a good tool for identifying humans into thinking that a person is not a person -- something that could be used to defeat AI-based security camera systems. They theorize that the could just print the patch on a t-shirt and get the same result.
The researchers' key point is that the training data for classifiers consists of humans who aren't trying to fool it -- that is, the training is non-adversarial -- while the applications for these systems are often adversarial (such as being used to evaluate security camera footage whose subjects might be trying to defeat the algorithm). It's like designing a lock always unlocks when you use the key -- but not testing to see if it unlocks if you don't have the key, too.
The attack can reliably defeat YOLOv2, a popular machine-learning classifier, and they hypothesize that it could be applied to other classifiers as well.
I've been writing about these adversarial examples for years, and universally, they represent devastating attacks on otherwise extremely effective classifiers. It's an important lesson about the difference between adversarial and non-adversarial design: the efficacy of a non-adversarial system is no guarantee of adversarial efficacy.
https://boingboing.net/2019/04/25/tee-of-invisibility.html
847 notes
·
View notes
Text
第10回議事録(1)
第10回プロジェクト(1)
日時 6月18 日(金) 金曜2限
場所 225号室
出席 全員
内容
現状まとめ
(武田)
現在の進捗
中間発表で公開するのを目標に
挙手を感知する→ZOOM APIでメッセージを送信を目標に進めていて、挙手感知は完了しました。APIのアクセストークンを受け取るのに手こずりましたが今日できたので最悪でも来週中にはできそうです。
中間発表の見通し
•名前といまプロジェクトで自���がやっていること
•なぜZOOMを快適にしようと思ったのか
•現時点でのアイディア
•現在の進捗(ここで挙手通知の実行例画像)
•次の目標と最終発表への目標
(若林、村上)
中間発表の見通し
・自分たちがサッカーの無回転シュートをopenposeを使って分析していること
・素人と無回転を蹴れる人の違いを説明
・最終的な目標
・現状どこまでできているか
現状
素人とプロとの蹴り方の違いの分析の仕方に迷っている。
(宮崎、菊池)
現在の進捗
シュートフォームを分析中。
yoloでボールの軌道を解析中。
いろいろな人のサンプルを集めている。
中間発表の見通し
なぜ3ポイントに着目したか
シュートが上手い人との比較
分析した動画見せてを説明する。
(遊佐)
現状:
先生に教えていただいた方法でリアルタイム解析の実用的な認識の速度と精度が得られるようになってきました。mobilenet_thinやmobilenet_v2_smallでは手首が認識されなくなるため(おそらく精度の問題)、cmuで実行しています。現在、resizeの値を変えて実用的な速度を保ちつつ精度を向上させられるベストなバランスを検討中です。
中間発表の見通し:
1.目的・背景
2.最終的に実現したいこと
3.現在の状況(リアルタイムに動きを解析している映像or画像)
4.今後の課題・取り組みの方向性
を説明します。
(亀井)
現状
身近な人たちの歩行姿勢を撮り、cmuにかけて分析している
分析した動画とexcel表からその人の歩行姿勢の特徴を探っている
これと並行して、理想の姿勢や歩行についてネットで公開されている論文等をいくつか閲覧
中間発表の見通し
1.分析をしようと思った理由
2.歩行や姿勢についての論文から一般にどのような特徴があると言われているか
3.実際にどうなのかの検証(サンプル数は20人から25人を予定)
4.身近な人たちの結果から傾向を探りまとめる
5.最終発表に向けてのイメージ
(このまま分析を続けるor何らかの形でアイデアを出力し有用性を持たせる)
(佐野)
現状
本を購入。
本に書いてある理想のフォームと自分のフォームの違いを分析中。
中間発表の見通し
・分析をしようと思った理由
・理想のフォームとは
・理想のフォームと自分のフォームの違い
・今後の課題
困っていること
動画を解析しようとするとエラーが出る。
もう一度インストールしなおしてみる。
(井上)
現在の進捗
Jetson Nanoを使って、ラズパイカメラのリアルタイム映像から物体検出または骨格推定することはできている。外部機器を制御する方法として、Tiny YOLOV2・MQTTブローカー・Node-REDを組み合わせる方法があるが、上手くできるかわからない。中間発表ではLED等を使ってプロトタイプを作成しようか考えている。
中間発表の見通し
1. Jetson Nanoについて
2. 最終的に実現したいこと
3. 現在の状況(リアルタイム映像の解析動画)
4. 今後の課題と見通し
0 notes
Photo

via @createwithAI
[link] Invisibility cloak https://t.co/rdx9GRsxLd Adversarial Examplesの考え方を用いて、監視カメラのオブジェクト認識アルゴリズム(YOLOv2)をだます服。ビデオデモも。 pic.twitter.com/CCpKy0mwqx
— Create with AI (@createwithAI) May 1, 2020
0 notes
Photo

"[R] YOLACT: Real-time Instance Segmentation"- Detail: Paper - Codetl;dr: Instance Segmentation slow, YOLACT make fast (29.8 COCO mAP, 33.5 Titan Xp fps).Hi all, my paper was recently accepted ICCV 2019 Oral so I thought I'd post it here. (Note: fps numbers were rebenchmarked for ICCV and I haven't updated it elsewhere).Today, object detection has several methods that do well (e.g., Faster R-CNN+++, RetinaNet), and several that do well enough but are also fast (e.g., YOLOv2-3, SSD). On the other hand, the same isn't true for instance segmentation. We have good methods (e.g., Mask R-CNN and its derivatives, Retina-Mask), but no fast methods that do well enough on a complex dataset like COCO.YOLACT changes this. We obtain 29.8 mAP (30.1 after a stupid bug fix, but the paper's out now >.>) on COCO at 33.5 fps on a single Titan Xp, making YOLACT the best fast instance segmention method out at the moment. And it's simple: predict a set of k basis masks (prototypes) over the whole image and in parallel predict a set of k linear combination coefficients (mask coefficients) for each detection. Then to generate masks for a detection, just multiply the mask coefficients into the prototypes and add (which can be implemented as one matrix multiplication per image). This whole process takes ~5-6 ms to add a masks to any existing object detector.I also came up with "Fast NMS", a close approximation to traditional per-class NMS that's 12ms faster.Feel free to AMA.. Caption by dbolya. Posted By: www.eurekaking.com
0 notes
Text
YOLO on the NVIDIA Jetson Nano

2019年4月に発売されたNVIDIAのシングルボード・コンピュータ Jetson Nano(*1)を使ってYOLO(*2)の実行性能を調べてみた。
ModelGFLOPs fpsCfg Weights YOLOv229.475 4 yolov2.cfg yolov2.weights YOLOv2-tiny 5.412 15 yolov2-tiny.cfg yolov2-tiny.weights YOLOv3 65.864 2 yolov3.cfg yolov3.weights YOLOv3-tiny 5.571 15 yolov3-tiny.cfg yolov3-tiny.weights
何れのモデルもDarknetフレームワーク(*3)上で実行(演算精度はFP32)。使用したリポジトリは下記 https://github.com/AlexeyAB/darknet
モデルの総演算量(GFLOPs)はDarknetツールによるモデルパース時の出力値を転記
実行性能(fps)は「USB Cam入力 → CNN推論 → Post処理(バウンダリBox描画等)→ 表示」の一連の演算に対するフレームレート。ビデオストリーム・サイズは640x480
モデルの入力サイズ(Cfg)は416x416
訓練済みウェイトパラメータ(Weights)のデータセットはCOCO、分類は80クラス
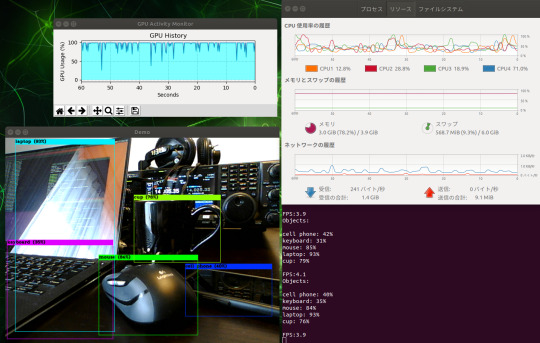
YOLOv2実行中のコンソール

USB CamはSony PlayStation®Eye(60fps@640×480, 120fps@ 320×240)
(*1) Jetson Nanoは組み込みシステム向けにニューラルネットワークの推論演算をアクセラレートすることを狙ったシングルボード・コンピュータ。Jetsonシリーズの最廉価モデルの位置づけで、発売価格99ドル。FP16(半精度浮動小数点数)モードにおける公称ピーク性能は472GFLOPs。開発キットの主なハードウェアスペックは以下。
CPU 64-bit Quad-core ARM A57 @1.43GHz GPU 128-core NVIDIA Maxwell @921MHz Memory 4GB 64-bit LPDDR4 @1600MHz | 25.6GB/s Video Encoder 4kp30 | (4x) 1080p30 | (2x) 1080p60 Video Decoder 4kp60 | (2x) 4kp30 | (8x) 1080p30 | (4x) 1080p60 USB (4x) USB3.0 A (Host) | USB2.0 Micro B (Device) Camera MIPI CSI-2 x2 (15-position Flex Connector) Display HDMI | DisplayPort Networking Gigabit Ethernet (RJ45, PoE) Wireless M.2 Key-E with PCIe x 1 Storege MicroSD card (16GB UHS-1 recommended minimum) 40-Pin Header UART | SPI | I2C | I2S | Audio Clock | GPIOs Power 5V DC (μUSB, Barrel Jack, PoE) - 5W | 10W Size 80x100mm
開発用ソフトウェア環境としてはUbuntu 18.04をベースとする「JETPACK 4.2 SDK」が準備されており、CUDA, cuDNN, OpenCV, TensorRT, Python3.6/2.7等々の深層学習向けライブラリ群が同梱される。 サーバ側の学習環境はNVIDIA GPU上にCUDA+cuDNN+...+オープンソース・フレームワーク(TensorFlow, PyTorch, Caffe, etc.)で構築されるのが常だから、学習環境と推論環境とがこれらのエコシステムを介してシームレスに繋がるのがJetson開発環境の一番の“売り”と言えると思う。 (推論用ハードウェア性能だけで言えば、3月に発売されたGoogle Coral “Edge TPU”の方が速いし電力効率でも勝っている。一方、Googleの開発環境は上で述べた“地続き感”には乏しい) [参考URL] https://blogs.nvidia.co.jp/2019/04/02/jetson-nano-ai-computing/ https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit
(*2) YOLOは深層学習にもとづく物体検出アルゴリズムのひとつ。与えられた画像中の複数の物体に対し、分類クラスとバウンダリ・ボックス座標の信頼度確率を回帰問題として同時に解く実装がなされている。SSD(別種の物体検出アルゴリズム)と共にハードウェアのベンチマーク指標として用いられることも多い。YOLOの能力を知るには以下のTED「コンピューターはいかに物体を即座に認識できるようになったのか 」を見ていただくのが手っ取り早い。 [参考URL] https://www.ted.com/talks/joseph_redmon_how_a_computer_learns_to_recognize_objects_instantly?language=ja#t-5153 https://pjreddie.com/darknet/yolo/ https://arxiv.org/abs/1612.08242 https://www.slideshare.net/DeepLearningJP2016/dl-reading-paper20170804pdf
(*3) Darknetは深層学習用オープンソース・フレームワークのひとつ。Cで実装されている。開発者のJoseph RedmonはYOLOの作者でもある。Darknet/YOLOの実に明快なライセンス条件はここを参照。
0 notes
Text
OpenCV/Speech Recognition
OpenCV

On previous uses of image recognition CNNs, i had to place the whiteboard in a certain position, as i was using image segmentation at a post webcam, but pre model level. This meant that any misalignments would input an incorrect image and cause false predictions. While this worked ok for my initial ventures into neural networks, for a final piece the input to be less cumbersome, as an important aspect of design for this project is for it to be pick up and play. I want to combat this by using some form of image tracking/detection, so the users can be anywhere in the webcams view and still have this input detected correctly. I’ll add more important posts to this link, as well as relevant pages from the reading list.
https://www.pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
https://medium.com/@manivannan_data/how-to-train-yolov2-to-detect-custom-objects-9010df784f36
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
http://papers.nips.cc/paper/5638-faster-r-cnn-towards-real-time-object-detection-with-region-proposal-networks.pdf
Speech recognition
I’ve also began looking into using speech recognition instead of the OpenCV/machine learning implementation. I think speech recognition may end up being less obtrusive, while being a cheaper and more accessible option. I could run a simple webpage on a users mobile device, allowing them to control the robots after speaking into their microphone.
0 notes
Text
Détection d'objets YOLOv2 à partir du modèle ONNX dans MATLAB
Détection d'objets YOLOv2 à partir du modèle ONNX dans MATLAB
Détection d'objets YOLOv2 à partir du modèle ONNX dans MATLAB
Une fois que j'ai eu le réseau formé, j'ai ensuite évalué ses performances sur les données de test selon les étapes ci-dessous.
Étape 1: Créez un tableau pour stocker les résultats et initialisez un lecteur vidéo déployable pour afficher le flux d'images.
résultats = table('Taille',[height(TestData) 3], ... 'VariableTypes', {'cellule',…
View On WordPress
0 notes
Photo

via @ksasao
PCとかラズパイとか不要で本当にこれだけでTiny YOLOv2が動いちゃうんですよ!!! pic.twitter.com/MA7ttqnUh1
— ミクミンP/Kazuhiro Sasao (@ksasao) April 28, 2019
0 notes
Photo

"[P]PyTorch implementation of and Yolov2 and Yolov3"- Detail: We create a repo that implement yolo series detector in pytorch, which include yolov2, yolov3, tiny yolov2 and tiny yolov3.It has the following features:Include both yolov2 and yolov3Good performance. Trained with this implementation, yolov2 has a mAP of 77.6%(544x544), yolov3 has a mAP of 79.6%(544x544) on Pascal VOC2007 Test.Train as fast as darknetA lot of efficient backbones on hand, like tiny yolov2, tiny yolov3, mobilenet, mobilenetv2, shufflenet(g2), shufflenetv2(1x), squeezenext(1.0-SqNxt-23v5), light xception, xception etc. When trained with this implementation from scratch, tiny yolov2 can get a mAP of 57.5%(416x416), tiny yolov3 can ge a mAP of 61.3%(416x416)Credit:I got a lot of code from lightnet whose code is really beautiful. Caption by jackson_ditred. Posted By: www.eurekaking.com
0 notes
Text
Automatic thyroid nodule recognition and diagnosis in ultrasound imaging with the YOLOv2 neural network
Abstract
Background
In this study, images of 2450 benign thyroid nodules and 2557 malignant thyroid nodules were collected and labeled, and an automatic image recognition and diagnosis system was established by deep learning using the YOLOv2 neural network. The performance of the system in the diagnosis of thyroid nodules was evaluated, and the application value of artificial intelligence in clinical practice was investigated.
Methods
The ultrasound images of 276 patients were retrospectively selected. The diagnoses of the radiologists were determined according to the Thyroid Imaging Reporting and Data System; the images were automatically recognized and diagnosed by the established artificial intelligence system. Pathological diagnosis was the gold standard for the final diagnosis. The performances of the established system and the radiologists in diagnosing the benign and malignant thyroid nodules were compared.
Results
The artificial intelligence diagnosis system correctly identified the lesion area, with an area under the receiver operating characteristic (ROC) curve of 0.902, which is higher than that of the radiologists (0.859). This finding indicates a higher diagnostic accuracy (p = 0.0434). The sensitivity, positive predictive value, negative predictive value, and accuracy of the artificial intelligence diagnosis system for the diagnosis of malignant thyroid nodules were 90.5%, 95.22%, 80.99%, and 90.31%, respectively, and the performance did not significantly differ from that of the radiologists (p > 0.05). The artificial intelligence diagnosis system had a higher specificity (89.91% vs 77.98%, p = 0.026).
Conclusions
Compared with the performance of experienced radiologists, the artificial intelligence system has comparable sensitivity and accuracy for the diagnosis of malignant thyroid nodules and better diagnostic ability for benign thyroid nodules. As an auxiliary tool, this artificial intelligence diagnosis system can provide radiologists with sufficient assistance in the diagnosis of benign and malignant thyroid nodules.
http://bit.ly/2QydUaO
0 notes
Photo

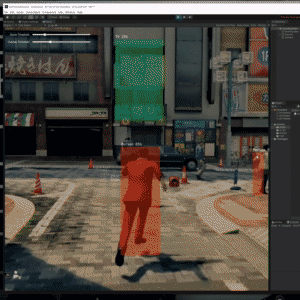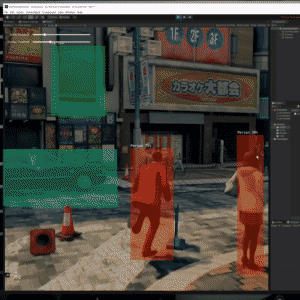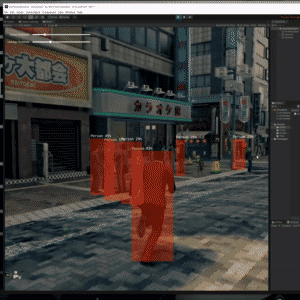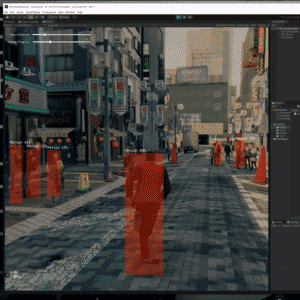
Trying the Tiny YOLOv2 object detector with gameplay footage. https://github.com/keijiro/TinyYOLOv2Barracuda
6 notes
·
View notes