#yolov8
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
SciTech Chronicles. . . . . . . . .April 3rd, 2025
#NIRCam#infrared#size#air-low#turbulence#simulation#hypersonic#fermentation#microgravity#radiation#Miso#AI#threats#YOLOv8#DeepSORT#capabilities#AtmoSense#acoustic#electromagnetic
0 notes
Text
YOLOv8: Bước nhảy vọt trong công nghệ nhận diện đối tượng
🌟 YOLOv8: Bước nhảy vọt trong công nghệ nhận diện đối tượng! 🚀
🔥 Nếu bạn đang tìm kiếm một giải pháp tối ưu trong lĩnh vực AI nhận diện đối tượng, thì YOLOv8 chính là cái tên không thể bỏ qua! Với hiệu suất vượt trội, tốc độ xử lý nhanh 💨 và độ chính xác cao 🎯, YOLOv8 hứa hẹn mang lại trải nghiệm tuyệt vời cho các ứng dụng từ an ninh, y tế, đến tự động hóa.
👉 Vậy YOLOv8 có gì nổi bật? ✨ Nhanh hơn, chính xác hơn: Được cải tiến từ các phiên bản trước, YOLOv8 mang lại hiệu quả xử lý dữ liệu lớn mà không làm giảm hiệu năng. ✨ Tối ưu cho thiết bị thực tế: Hoạt động mượt mà trên cả các thiết bị có cấu hình thấp. ✨ Ứng dụng đa dạng: Từ nhận diện khuôn mặt, phương tiện giao thông 🚗, đến phát hiện vật thể trong video trực tiếp.
💡 Đừng bỏ lỡ cơ hội tìm hiểu sâu hơn! Click ngay để khám phá bài viết chi tiết và cách YOLOv8 đang cách mạng hóa công nghệ AI: 👉 YOLOv8: Nhận diện đối tượng với hiệu suất vượt trội
❤️ Cùng chia sẻ để lan tỏa kiến thức và công nghệ đến nhiều người hơn nhé!
Khám phá thêm những bài viết giá trị tại aicandy.vn
3 notes
·
View notes
Video
youtube
Advancing precision agriculture: A comparative analysis of YOLOv8 for mu...
0 notes
Text
Step-by-Step Breakdown of AI Video Analytics Software Development: Tools, Frameworks, and Best Practices for Scalable Deployment
AI Video Analytics is revolutionizing how businesses analyze visual data. From enhancing security systems to optimizing retail experiences and managing traffic, AI-powered video analytics software has become a game-changer. But how exactly is such a solution developed? Let’s break it down step by step—covering the tools, frameworks, and best practices that go into building scalable AI video analytics software.

Introduction: The Rise of AI in Video Analytics
The explosion of video data—from surveillance cameras to drones and smart cities—has outpaced human capabilities to monitor and interpret visual content in real-time. This is where AI Video Analytics Software Development steps in. Using computer vision, machine learning, and deep neural networks, these systems analyze live or recorded video streams to detect events, recognize patterns, and trigger automated responses.
Step 1: Define the Use Case and Scope
Every AI video analytics solution starts with a clear business goal. Common use cases include:
Real-time threat detection in surveillance
Customer behavior analysis in retail
Traffic management in smart cities
Industrial safety monitoring
License plate recognition
Key Deliverables:
Problem statement
Target environment (edge, cloud, or hybrid)
Required analytics (object detection, tracking, counting, etc.)
Step 2: Data Collection and Annotation
AI models require massive amounts of high-quality, annotated video data. Without clean data, the model's accuracy will suffer.
Tools for Data Collection:
Surveillance cameras
Drones
Mobile apps and edge devices
Tools for Annotation:
CVAT (Computer Vision Annotation Tool)
Labelbox
Supervisely
Tip: Use diverse datasets (different lighting, angles, environments) to improve model generalization.
Step 3: Model Selection and Training
This is where the real AI work begins. The model learns to recognize specific objects, actions, or anomalies.
Popular AI Models for Video Analytics:
YOLOv8 (You Only Look Once)
OpenPose (for human activity recognition)
DeepSORT (for multi-object tracking)
3D CNNs for spatiotemporal activity analysis
Frameworks:
TensorFlow
PyTorch
OpenCV (for pre/post-processing)
ONNX (for interoperability)
Best Practice: Start with pre-trained models and fine-tune them on your domain-specific dataset to save time and improve accuracy.
Step 4: Edge vs. Cloud Deployment Strategy
AI video analytics can run on the cloud, on-premises, or at the edge depending on latency, bandwidth, and privacy needs.
Cloud:
Scalable and easier to manage
Good for post-event analysis
Edge:
Low latency
Ideal for real-time alerts and privacy-sensitive applications
Hybrid:
Initial processing on edge devices, deeper analysis in the cloud
Popular Platforms:
NVIDIA Jetson for edge
AWS Panorama
Azure Video Indexer
Google Cloud Video AI
Step 5: Real-Time Inference Pipeline Design
The pipeline architecture must handle:
Video stream ingestion
Frame extraction
Model inference
Alert/visualization output
Tools & Libraries:
GStreamer for video streaming
FFmpeg for frame manipulation
Flask/FastAPI for inference APIs
Kafka/MQTT for real-time event streaming
Pro Tip: Use GPU acceleration with TensorRT or OpenVINO for faster inference speeds.
Step 6: Integration with Dashboards and APIs
To make insights actionable, integrate the AI system with:
Web-based dashboards (using React, Plotly, or Grafana)
REST or gRPC APIs for external system communication
Notification systems (SMS, email, Slack, etc.)
Best Practice: Create role-based dashboards to manage permissions and customize views for operations, IT, or security teams.
Step 7: Monitoring and Maintenance
Deploying AI models is not a one-time task. Performance should be monitored continuously.
Key Metrics:
Accuracy (Precision, Recall)
Latency
False Positive/Negative rate
Frame per second (FPS)
Tools:
Prometheus + Grafana (for monitoring)
MLflow or Weights & Biases (for model versioning and experiment tracking)
Step 8: Security, Privacy & Compliance
Video data is sensitive, so it’s vital to address:
GDPR/CCPA compliance
Video redaction (blurring faces/license plates)
Secure data transmission (TLS/SSL)
Pro Tip: Use anonymization techniques and role-based access control (RBAC) in your application.
Step 9: Scaling the Solution
As more video feeds and locations are added, the architecture should scale seamlessly.
Scaling Strategies:
Containerization (Docker)
Orchestration (Kubernetes)
Auto-scaling with cloud platforms
Microservices-based architecture
Best Practice: Use a modular pipeline so each part (video input, AI model, alert engine) can scale independently.
Step 10: Continuous Improvement with Feedback Loops
Real-world data is messy, and edge cases arise often. Use real-time feedback loops to retrain models.
Automatically collect misclassified instances
Use human-in-the-loop (HITL) systems for validation
Periodically retrain and redeploy models
Conclusion
Building scalable AI Video Analytics Software is a multi-disciplinary effort combining computer vision, data engineering, cloud computing, and UX design. With the right tools, frameworks, and development strategy, organizations can unlock immense value from their video data—turning passive footage into actionable intelligence.
0 notes
Text

In today’s tech landscape, the average VPS just doesn’t cut it for everyone. Whether you're a machine learning enthusiast, video editor, indie game developer, or just someone with a demanding workload, you've probably hit a wall with standard CPU-based servers. That’s where GPU-enabled VPS instances come in. A GPU VPS is a virtual server that includes access to a dedicated Graphics Processing Unit, like an NVIDIA RTX 3070, 4090, or even enterprise-grade cards like the A100 or H100. These are the same GPUs powering AI research labs, high-end gaming rigs, and advanced rendering farms. But thanks to the rise of affordable infrastructure providers, you don’t need to spend thousands to tap into that power. At LowEndBox, we’ve always been about helping users find the best hosting deals on a budget. Recently, we’ve extended that mission into the world of GPU servers. With our new Cheap GPU VPS Directory, you can now easily discover reliable, low-cost GPU hosting solutions for all kinds of high-performance tasks. So what exactly can you do with a GPU VPS? And why should you rent one instead of buying hardware? Let’s break it down. 1. AI & Machine Learning If you’re doing anything with artificial intelligence, machine learning, or deep learning, a GPU VPS is no longer optional, it’s essential. Modern AI models require enormous amounts of computation, particularly during training or fine-tuning. CPUs simply can’t keep up with the matrix-heavy math required for neural networks. That’s where GPUs shine. For example, if you’re experimenting with open-source Large Language Models (LLMs) like Mistral, LLaMA, Mixtral, or Falcon, you’ll need a GPU with sufficient VRAM just to load the model—let alone fine-tune it or run inference at scale. Even moderately sized models such as LLaMA 2–7B or Mistral 7B require GPUs with 16GB of VRAM or more, which many affordable LowEndBox-listed hosts now offer. Beyond language models, researchers and developers use GPU VPS instances for: Fine-tuning vision models (like YOLOv8 or CLIP) Running frameworks like PyTorch, TensorFlow, JAX, or Hugging Face Transformers Inference serving using APIs like vLLM or Text Generation WebUI Experimenting with LoRA (Low-Rank Adaptation) to fine-tune LLMs on smaller datasets The beauty of renting a GPU VPS through LowEndBox is that you get access to the raw horsepower of an NVIDIA GPU, like an RTX 3090, 4090, or A6000, without spending thousands upfront. Many of the providers in our Cheap GPU VPS Directory support modern drivers and Docker, making it easy to deploy open-source AI stacks quickly. Whether you’re running Stable Diffusion, building a custom chatbot with LLaMA 2, or just learning the ropes of AI development, a GPU-enabled VPS can help you train and deploy models faster, more efficiently, and more affordably. 2. Video Rendering & Content Creation GPU-enabled VPS instances aren’t just for coders and researchers, they’re a huge asset for video editors, 3D animators, and digital artists as well. Whether you're rendering animations in Blender, editing 4K video in DaVinci Resolve, or generating visual effects with Adobe After Effects, a capable GPU can drastically reduce render times and improve responsiveness. Using a remote GPU server also allows you to offload intensive rendering tasks, keeping your local machine free for creative work. Many users even set up a pipeline using tools like FFmpeg, HandBrake, or Nuke, orchestrating remote batch renders or encoding jobs from anywhere in the world. With LowEndBox’s curated Cheap GPU List, you can find hourly or monthly rentals that match your creative needs—without having to build out your own costly workstation. 3. Cloud Gaming & Game Server Hosting Cloud gaming is another space where GPU VPS hosting makes a serious impact. Want to stream a full Windows desktop with hardware-accelerated graphics? Need to host a private Minecraft, Valheim, or CS:GO server with mods and enhanced visuals? A GPU server gives you the headroom to do it smoothly. Some users even use GPU VPSs for game development, testing their builds in environments that simulate the hardware their end users will have. It’s also a smart way to experiment with virtualized game streaming platforms like Parsec or Moonlight, especially if you're developing a cloud gaming experience of your own. With options from providers like InterServer and Crunchbits on LowEndBox, setting up a GPU-powered game or dev server has never been easier or more affordable. 4. Cryptocurrency Mining While the crypto boom has cooled off, GPU mining is still very much alive for certain coins, especially those that resist ASIC centralization. Coins like Ethereum Classic, Ravencoin, or newer GPU-friendly tokens still attract miners looking to earn with minimal overhead. Renting a GPU VPS gives you a low-risk way to test your mining setup, compare hash rates, or try out different software like T-Rex, NBMiner, or TeamRedMiner, all without buying hardware upfront. It's a particularly useful approach for part-time miners, researchers, or developers working on blockchain infrastructure. And with LowEndBox’s flexible, budget-focused listings, you can find hourly or monthly GPU rentals that suit your experimentation budget perfectly. Why Rent a GPU VPS Through LowEndBox? ✅ Lower CostEnterprise GPU hosting can get pricey fast. We surface deals starting under $50/month—some even less. For example: Crunchbits offers RTX 3070s for around $65/month. InterServer lists setups with RTX 4090s, Ryzen CPUs, and 192GB RAM for just $399/month. TensorDock provides hourly options, with prices like $0.34/hr for RTX 4090s and $2.21/hr for H100s. Explore all your options on our Cheap GPU VPS Directory. ✅ No Hardware CommitmentRenting gives you flexibility. Whether you need GPU power for just a few hours or a couple of months, you don’t have to commit to hardware purchases—or worry about depreciation. ✅ Easy ScalabilityWhen your project grows, so can your resources. Many GPU VPS providers listed on LowEndBox offer flexible upgrade paths, allowing you to scale up without downtime. Start Exploring GPU VPS Deals Today Whether you’re training models, rendering video, mining crypto, or building GPU-powered apps, renting a GPU-enabled VPS can save you time and money. Start browsing the latest GPU deals on LowEndBox and get the computing power you need, without the sticker shock. We've included a couple links to useful lists below to help you make an informed VPS/GPU-enabled purchasing decision. https://lowendbox.com/cheap-gpu-list-nvidia-gpus-for-ai-training-llm-models-and-more/ https://lowendbox.com/best-cheap-vps-hosting-updated-2020/ https://lowendbox.com/blog/2-usd-vps-cheap-vps-under-2-month/ Read the full article
0 notes
Text
YOLO V/s Embeddings: A comparison between two object detection models
YOLO-Based Detection Model Type: Object detection Method: YOLO is a single-stage object detection model that divides the image into a grid and predicts bounding boxes, class labels, and confidence scores in a single pass. Output: Bounding boxes with class labels and confidence scores. Use Case: Ideal for real-time applications like autonomous vehicles, surveillance, and robotics. Example Models: YOLOv3, YOLOv4, YOLOv5, YOLOv8 Architecture
YOLO processes an image in a single forward pass of a CNN. The image is divided into a grid of cells (e.g., 13×13 for YOLOv3 at 416×416 resolution). Each cell predicts bounding boxes, class labels, and confidence scores. Uses anchor boxes to handle different object sizes. Outputs a tensor of shape [S, S, B*(5+C)] where: S = grid size (e.g., 13×13) B = number of anchor boxes per grid cell C = number of object classes 5 = (x, y, w, h, confidence) Training Process
Loss Function: Combination of localization loss (bounding box regression), confidence loss, and classification loss.
Labels: Requires annotated datasets with labeled bounding boxes (e.g., COCO, Pascal VOC).
Optimization: Typically uses SGD or Adam with a backbone CNN like CSPDarknet (in YOLOv4/v5). Inference Process
Input image is resized (e.g., 416×416). A single forward pass through the model. Non-Maximum Suppression (NMS) filters overlapping bounding boxes. Outputs detected objects with bounding boxes. Strengths
Fast inference due to a single forward pass. Works well for real-time applications (e.g., autonomous driving, security cameras). Good performance on standard object detection datasets. Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high-dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high- dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
1 note
·
View note
Text
Building a Real-Time Object Detection System with YOLOv8: A Hands-On Guide
1. Introduction Real-time object detection is one of the most impactful technologies in computer vision, with applications ranging from surveillance to autonomous vehicles. YOLOv8, the latest iteration of the You Only Look Once (YOLO) series, offers state-of-the-art performance in speed and accuracy, making it an ideal choice for building real-time object detection systems. This guide will walk…
0 notes
Text
Real-Time QR Code Detection Using YOLO: A Step-by-Step Guide

Introduction
Quick Response (QR) codes are everywhere—from product packaging to payment gateways. Detecting them efficiently in real-time is crucial for various applications, such as automated checkout systems, digital payments, and augmented reality. One of the best ways to achieve this is by leveraging YOLO (You Only Look Once), a deep-learning-based object detection model that is both fast and accurate.
In this guide, we will walk through the key steps of using YOLO for real-time QR code detection, explaining the process conceptually without delving into coding details. If you want to get started with a dataset, check out this QR Code Detection YOLO dataset.
Why Use YOLO for QR Code Detection?
YOLO represents an advanced deep learning framework specifically developed for real-time object detection. In contrast to conventional techniques that analyze an image repeatedly, YOLO evaluates the entire image in one go, resulting in exceptional efficiency. The following points illustrate why YOLO is particularly suitable for QR code detection:
Speed: It enables real-time image processing, making it ideal for mobile and embedded systems.
Accuracy: YOLO is capable of identifying small objects, such as QR codes, with remarkable precision.
Flexibility: It can be trained on tailored datasets, facilitating the detection of QR codes across various environments and conditions.
Step-by-Step Guide to Real-Time QR Code Detection Using YOLO
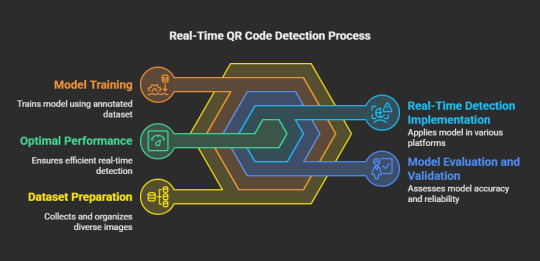
Assemble and Organize the Dataset
The initial phase in training a YOLO model for QR code detection involves the collection of a varied dataset. This dataset must encompass images featuring QR codes under different lighting scenarios, orientations, and backgrounds. You may utilize pre-existing datasets or generate your own by manually capturing images. A well-structured dataset is essential for achieving model precision.
Label the QR Codes
After preparing the dataset, the subsequent step is to annotate it. This process entails marking the QR codes in each image with annotation tools such as LabelImg or Roboflow. The objective is to create bounding boxes around the QR codes, which will act as ground truth data for the model's training.
Train the YOLO Model
To initiate the training of the YOLO model, a deep learning framework such as Darknet, TensorFlow, or PyTorch is required. During the training process, the model acquires the ability to detect QR codes based on the annotated dataset. Important considerations include:
Selecting the appropriate YOLO version (YOLOv4, YOLOv5, or YOLOv8) according to your computational capabilities and accuracy requirements.
Fine-tuning hyperparameters to enhance performance.
Implementing data augmentation techniques to bolster generalization across various conditions.
Evaluate and Validate the Model
Following the training phase, it is imperative to assess the model's performance using previously unseen images. Evaluation metrics such as precision, recall, and mean Average Precision (mAP) are instrumental in gauging the model's effectiveness in detecting QR codes. Should the results indicate a need for improvement, fine-tuning and retraining may enhance the model's accuracy.
Implement the Model for Real-Time Detection
Upon successful validation, the trained YOLO model can be implemented for real-time QR code detection across various platforms, including:
Web applications (for instance, integration with a web camera interface)
Mobile applications (such as QR code scanning features in shopping applications)
Embedded systems (including IoT devices and smart kiosks)
Enhance for Optimal Performance
To ensure efficiency in real-time applications, it is crucial to optimize the model. Strategies may include:
Minimizing model size through quantization and pruning techniques
Leveraging hardware acceleration via GPUs or TPUs
Utilizing efficient inference engines like TensorRT or OpenVINO .These measures contribute to seamless and rapid QR code detection.
Final Thoughts
Real-time detection of QR codes utilizing YOLO represents an effective method that merges rapidity with precision. By adhering to the aforementioned steps—data gathering, annotation, training, validation, and deployment—you can create a resilient QR code detection system customized to your requirements. Whether your project involves a mobile application, an automated payment solution, or an intelligent retail system, YOLO provides a dependable technique to improve QR code recognition in practical scenarios. With Globose Technology Solution, you can further enhance your development process and leverage advanced technologies for better performance.
For an accessible dataset, consider exploring the QR Code Detection YOLO Dataset. Wishing you success in your development endeavors!
0 notes
Text
LatentAI: Industrial Edge AI With Dell And NVIDIA Hardware

LatentAI: Using NVIDIA and Dell AI to Boost Edge AI. What is the connection between driverless cars, military activities, and oil rigs?
What is the connection between autonomous machines and oil rigs? They both deploy on-site AI solutions in situations where access to cloud networks is restricted or nonexistent, which may sound like a poor preamble to a joke.
Waiting for data to reach a cloud resource hundreds of kilometers distant is impracticable, whether you are developing AI models in demanding conditions or monitoring equipment on an oil rig located far offshore. By enabling real-time data processing at the source and providing quick and effective operations where they’re most required, LatentAI, a firm that specializes in edge AI, helps address this issue.
Industrial Edge AI’s Challenge: On-Site, Real-Time Processing
Consider an oil rig, where safety requires continuous monitoring of analog instruments. Data must be gathered and analyzed promptly away to avoid dangerous situations or expensive equipment breakdowns. The issue? High-bandwidth internet connections are becoming more limited as these rigs move farther offshore. Delays might result in failure or more downtime if that data is sent to the cloud for analysis.
These are the types of settings where industrial edge AI flourishes, where an operation’s success or failure depends on real-time adaptability and decision-making.
Why Industrial Edge AI Needs Purpose-Built Hardware
The proper infrastructure is necessary for industrial edge AI to operate, particularly in settings with computational and physical difficulties. As previously stated, cloud solutions are sometimes unworkable in the field, particularly for situations with limited resources and ruggedness. With its technology, LatentAI overcomes that limitation by designing, refining, and implementing the most effective AI models on specialized edge hardware. Processing at the data, not simply close to it, is necessary for industrial edge solutions.
Through compilation and compression, the LatentAI Efficient Inference Platform (LEIP) technology lowers the computational and storage requirements for AI models. This procedure reduces the size, speed, and energy consumption of the models without compromising their accuracy.
Additionally, LEIP uses all available hardware acceleration to optimize the model and increase inference performance. LEIP handles the compilation process to create an AI runtime for on-site inference, or it may execute the AI model on conventional CPU-only hardware if a GPU is available. With NVIDIA RTX Ada Generation GPUs and the NVIDIA IGX Orin and NVIDIA Jetson platforms for industrial edge AI applications, LEIP operates on conventional x86-based workstation computers.
LatentAI evaluated LEIP technology on the Precision 5690 with the NVIDIA RTX 5000 Ada Generation Laptop GPU, and found that it performed up to 300 times quicker than CPU training with the most accurate (slowest) recipe, Yolov8.
LatentAI makes it possible for effective AI deployment in practical settings by concentrating on hardware model improvement.
Bringing AI to the Edge
Matching the best model with the right devices is the key to successful AI deployment. Additionally, the hardware must be just as capable as the software in settings like manufacturing floors or oil fields.
This is the market segment for tough gadgets. These gadgets, which fall into the semi-rugged or totally rugged categories, are made to withstand harsh environments. Specifically, fully robust gadgets are designed to withstand harsh environments without sacrificing performance. The Pro tough 13, Latitude 7230, and Latitude 7030 offer fully tough laptop and tablet options.
This means these devices have been MIL-STD 810G drop, shock, and vibration tested. They also have an IP65 rating for dust and water tight sealing. Other features like glove-compatible touchpads, screens with up to 1400 nits of backlight to ensure viewability in direct sunlight, dual hot-swappable batteries, and a powerful CPU setup help ensure your technology meets your needs when on an oil rig or in other harsh environments.
These robust laptops and tablets, when combined with LatentAI’s LEIP and edge processing capabilities, may cut down your training time from months to minutes.
A Collaboration for the Future of Industrial Edge AI
In collaboration with Dell and NVIDIA, LatentAI optimizes the hardware’s computing power, which is necessary for on-site settings where traditional solutions are insufficient.
Industries have changed as a result of the internet. The way choices are made in real time on the ground is now being redefined by edge AI. Even in the most distant or dangerous situations, LatentAI is developing systems that analyze data locally, bypassing cloud infrastructures.
Read more on govindhtech.com
#LatentAI#IndustrialEdgeAI#Dell#NVIDIAHardware#DellAI#AImodels#edgeAI#NVIDIARTX5000Ada#NVIDIA#Collaboration#BringingAI#Hardware#RealTimeProcessing#Technology#technews#news#govindhtech
0 notes
Text
2025 Guide to 20+ Hands-On AI and ML Projects with Source Code
INTRODUCTION:
Looking to dive deep into the world of Artificial Intelligence and Machine Learning? Whether you’re just getting started or sharpening your skills, this list of 20+ exciting projects will guide you through some of the most fascinating applications of AI. Covering areas like healthcare, agriculture, natural language processing, computer vision, and predictive analytics, these projects offer hands-on experience with real-world data and problems. Each project includes source code so you can jump right in!

Why These Projects Matter
AI is reshaping industries, from transforming healthcare diagnoses to creating smarter farming solutions and enhancing customer service. But to truly understand how these systems work, you need hands-on experience. Working on projects not only hones your technical skills but also gives you something tangible to showcase to potential employers or collaborators.
Key Skills You’ll Develop
Here’s a quick look at what you’ll learn while working through these projects:
Data Preprocessing: Essential skills for handling and preparing data, including data cleaning, augmentation, and feature engineering.
Model Selection and Training: How to choose, build, and train models, such as CNNs, Transformers, and YOLO.
Hyperparameter Tuning: Fine-tuning models to optimise accuracy with techniques like dropout, batch normalisation, and early stopping.
Deployment and Real-Time Inference: How to deploy models with interactive interfaces (e.g., Gradio, Streamlit) to make real-time predictions.
Model Evaluation: Analysing performance metrics such as accuracy, precision, recall, and F1-score to ensure reliability.
Tools You’ll Need
Most of these projects use popular ML and AI libraries that make building, training, and deploying models a breeze:
Python: A must-have for AI projects, using libraries like Numpy, Pandas, and Matplotlib for data manipulation and visualisation.
TensorFlow & Keras: Perfect for building and training deep learning models.
PyTorch: Great for deep learning, especially for tasks involving complex image and text data.
Scikit-Learn: Ideal for traditional ML algorithms, data preprocessing, and model evaluation.
OpenCV: For image processing in computer vision projects.
Gradio and Streamline: Tools to create interactive apps and real-time demos for your models.
Getting Started
Pick a Project that Excites You: Choose one based on your interest and experience level. For beginners, start with something like Vegetable Classification or Blood Cell Classification. Advanced users can explore Voice Cloning or Semantic Search.
Set Up Your Environment: Google Colab is a great option for training models without needing powerful hardware. For local environments, install Python, TensorFlow, and PyTorch.
Study the Code and Documentation: Carefully go through the code and documentation. Check out the library documentation for any new functions you encounter.
Experiment and Modify: Once you’ve built a project, try making it your own by tuning hyperparameters, using different datasets, or experimenting with new models.
Showcase Your Work: Deploy your projects on GitHub or create a portfolio. Share them on LinkedIn or Medium to connect with the AI community!
24 Inspiring AI & ML Projects to Try
Below, you’ll find a collection of projects that range from beginner to advanced levels, covering a variety of fields to give you well-rounded exposure to the world of AI.
1. Voice Cloning Application Using RVC
Overview: Create a realistic voice clone using RVC models. This project guides you through the steps to collect data, train the model, and generate a customizable voice clone that replicates tone, pitch, and accent.
Perfect For: Those interested in NLP, voice tech, or audio engineering.
Tools: RVC, Deep Learning Models, Google Colab
2. Automatic Eye Cataract Detection Using YOLOv8
Overview: Build a fast, accurate YOLOv8 model to detect cataracts in eye images, supporting healthcare professionals in diagnosing cataracts quickly.
Perfect For: Medical imaging researchers, healthcare tech enthusiasts.
Tools: YOLOv8, Gradio, TensorFlow/Keras
3. Crop Disease Detection Using YOLOv8
Overview: Designed for real-time use, this project uses YOLOv8 to detect and classify diseases in plants, helping farmers identify issues early and take action to protect their crops.
Perfect For: Those interested in agriculture, AI enthusiasts.
Tools: YOLOv8, Gradio, Google Colab
4. Vegetable Classification with Parallel CNN Model
Overview: This project automates vegetable sorting using a Parallel CNN model, improving efficiency in the food industry.
Perfect For: Beginners in ML, food industry professionals.
Tools: TensorFlow/Keras, Python
5. Banana Leaf Disease Detection Using Vision Transformer
Overview: Detects diseases on banana leaves early with a Vision Transformer model, a powerful approach to prevent crop losses.
Perfect For: Agricultural tech enthusiasts, AI learners.
Tools: Vision Transformer, TensorFlow/Keras
6. Leaf Disease Detection Using Deep Learning
Overview: Train CNN models like VGG16 and EfficientNet to detect leaf diseases, helping farmers promote healthier crops.
Perfect For: Botanists, agricultural researchers.
Tools: VGG16, EfficientNet, TensorFlow/Keras
7. Glaucoma Detection Using Deep Learning
Overview: This project uses CNNs to detect early signs of glaucoma in eye images, aiding in early intervention and preventing vision loss.
Perfect For: Healthcare researchers, AI enthusiasts.
Tools: CNN, TensorFlow/Keras, Python
8. Blood Cell Classification Using Deep Learning
Overview: Classify blood cell images with CNNs, EfficientNetB4, and VGG16 to assist in medical research and diagnostics.
Perfect For: Medical researchers, beginners.
Tools: CNN, EfficientNet, TensorFlow/Keras
9. Skin Cancer Detection Using Deep Learning
Overview: Detects skin cancer early using CNN models like DenseNet121 and EfficientNetB4, helping improve diagnostic accuracy.
Perfect For: Healthcare providers, dermatologists.
Tools: DenseNet121, EfficientNet, TensorFlow/Keras
10. Cervical Cancer Detection Using Deep Learning
Overview: Use EfficientNetB0 to classify cervical cell images, assisting in early detection of cervical cancer.
Perfect For: Pathologists, AI researchers.
Tools: EfficientNetB0, TensorFlow/Keras
11. Nutritionist Generative AI Doctor Using Gemini
Overview: An AI-powered nutritionist that uses the Gemini model to offer diet insights tailored to user needs.
Perfect For: Nutritionists, health tech developers.
Tools: Gemini Pro, Python
12. Chatbots with Generative AI Models
Overview: Build advanced chatbots with GPT-3.5-turbo and GPT-4 for customer service or personal assistants.
Perfect For: Customer service, business owners.
Tools: GPT-3.5-turbo, GPT-4, OpenAI API
13. Insurance Pricing Forecast Using XGBoost Regressor
Overview: Use XGBoost to forecast healthcare costs, aiding insurance companies in setting premiums.
Perfect For: Finance professionals, data scientists.
Tools: XGBoost, Python
14. Linear Regression Modeling for Soccer Player Performance Prediction in the EPL
Overview: Predict EPL player performance using linear regression on player stats like goals, assists, and time on field.
Perfect For: Sports analysts, data scientists.
Tools: Linear Regression, Python
15. Complete CNN Image Classification Models for Real Time Prediction
Overview: Create a real-time image classification model for applications like quality control or face recognition.
Perfect For: AI developers, image processing engineers.
Tools: CNN, TensorFlow/Keras
16. Predictive Analytics on Business License Data Using Deep Learning
Overview: Analyze patterns in business licenses to uncover trends and insights, using DNN.
Perfect For: Business analysts, entrepreneurs.
Tools: DNN, Pandas, Numpy, TensorFlow
17. Image Generation Model Fine Tuning With Diffusers Models
Overview: Get creative with AI by fine-tuning models for realistic image synthesis, using Diffusers.
Perfect For: Content creators, AI enthusiasts.
Tools: Diffusers, Stable Diffusion, Gradio
18.Question Answer System Training With Distilbert Base Uncased
Overview: Build a question-answering system with DistilBERT, optimized for high accuracy.
Perfect For: NLP developers, educational platforms.
Tools: DistilBERT, Hugging Face Transformers
19. Semantic Search Using Msmarco Distilbert Base & Faiss Vector Database
Overview: Speed up search results with a semantic search system that uses DistilBERT and Faiss.
Perfect For: Search engines, e-commerce.
Tools: Faiss, DistilBERT, Transformers
20. Document Summarization Using Sentencepiece Transformers
Overview: Automatically create summaries of lengthy documents, streamlining information access.
Perfect For: Content managers, researchers.
Tools: Sentencepiece, Transformers
21. Customer Service Chatbot Using LLMs
Overview: Create a chatbot for customer service using advanced LLMs to provide human-like responses.
Perfect For: Customer support teams, business owners.
Tools: LLMs, Transformers
22. Real-Time Human Pose Detection With YOLOv8 Models
Overview: Use YOLOv8 to identify human poses in real time, ideal for sports analysis and safety applications.
Perfect For: Sports analysts, fitness trainers.
Tools: YOLOv8, COCO Dataset
23.Real-Time License Plate Detection Using YOLOv8 and OCR Model
Overview: Detect license plates in real-time for traffic monitoring and security.
Perfect For: Security, smart city developers.
Tools: YOLOv8, OCR
24. Medical Image Segmentation With UNET
Overview: Improve medical image analysis by applying UNET for segmentation tasks.
Perfect For: Radiologists, healthcare researchers.
Tools: UNET, TensorFlow/Keras
This collection of projects not only provides technical skills but also enhances problem-solving abilities, giving you the chance to explore the possibilities of AI in various industries. Enjoy coding and happy learning!
0 notes
Text
Danh sách bài viết trên AIcandy.vn
Học tập toàn diện: Kết nối lý thuyết, thực hành và dữ liệu thực tế
Kiến thức nền tảng trí tuệ nhân tạo
Trí tuệ nhân tạo (AI): Lịch sử phát triển và ứng dụng thực tiễn
Từ điển AI cho người mới bắt đầu: Giải thích các khái niệm chính
Khám phá sự khác biệt giữa AI, ML và DL
Tổng quan 4 phương pháp học máy chính trong trí tuệ nhân tạo
Hồi quy tuyến tính: Kỹ thuật cơ bản và ứng dụng trong học máy
K-Means Clustering: Ưu điểm, nhược điểm và khi nào nên sử dụng
Khám phá K-nearest neighbors cho phân loại và hồi quy
Phân loại dữ liệu là gì? Giải thích đơn giản và ví dụ thực tế
Random Forest: Giải thích chi tiết và ứng dụng
SVM trong xử lý dữ liệu phi tuyến tính: Kỹ thuật kernel và ứng dụng
Mạng nơ-ron nhân tạo: Công nghệ đột phá trong trí tuệ nhân tạo
Convolutional Neural Networks (CNN) trong Deep Learning
Recurrent Neural Network (RNN): Ứng dụng và cách hoạt động
Tăng tốc huấn luyện mô hình với phương pháp Gradient Descent
Các phương pháp đánh giá hiệu suất mô hình Machine Learning
Tìm hiểu phân loại hình ảnh trong AI: Cách thức và ứng dụng
Tìm hiểu nhận diện đối tượng trong AI: Cách thức và ứng dụng
Xử lý ngôn ngữ tự nhiên: Công nghệ phân tích ngôn ngữ bằng AI
Giới thiệu chi tiết về học tăng cường: Phương pháp và ứng dụng
MobileNet: Mô hình hiệu quả trên thiết bị di động
Mô hình ResNet: Đột phá trong nhận diện hình ảnh
SSD: Giải pháp hiệu quả cho bài toán phát hiện đối tượng
EfficientNet: Cách mạng hóa mạng neural hiện đại
DenseNet: Cấu trúc, nguyên lý và ưu điểm trong mạng nơ-ron sâu
Tìm hiểu mô hình YOLOv5: Hiệu quả trong nhận diện đối tượng
YOLOv8: Nhận diện đối tượng với hiệu suất vượt trội
RetinaNet: Cải tiến mạnh mẽ trong công nghệ phát hiện đối tượng
GoogleNet: Cột mốc đột phá trong lĩnh vực trí tuệ nhân tạo
AlexNet: Bước đột phá trong trí tuệ nhân tạo
Tìm hiểu mô hình FaceNet cho bài toán nhận diện khuôn mặt
Imbalanced Dataset: Thách thức và giải pháp trong Machine Learning
PyTorch trong học máy cho người mới bắt đầu
Từ lý thuyết đến thực hành AI-ML
Ứng dụng mạng MobileNet vào phân loại hình ảnh
Ứng dụng mạng GoogleNet vào phân loại hình ảnh
Ứng dụng mạng DenseNet vào phân loại hình ảnh
Ứng dụng mạng AlexNet vào phân loại hình ảnh
Ứng dụng mạng Efficientnet vào phân loại hình ảnh
Ứng dụng mạng ResNet-18 vào phân loại hình ảnh
Ứng dụng mạng ResNet-50 vào phân loại hình ảnh
Hướng dẫn chi tiết cách huấn luyện dữ liệu tùy chỉnh với YOLO5
Hướng dẫn chi tiết cách huấn luyện dữ liệu tùy chỉnh với YOLO8
Ứng dụng mạng SSD300 vào nhận diện đối tượng
Ứng dụng mạng RetinaNet vào nhận diện đối tượng
Cách dự đoán giá cổ phiếu hiệu quả bằng mô hình LSTM
Ứng dụng Machine Learning vào chơi game Flappy Bird
Triển khai phân loại hình ảnh trên thiết bị Android
Triển khai nhận diện đối tượng trên thiết bị Android với YOLO
Hướng dẫn triển khai phân loại hình ảnh trên Website miễn phí
Kho dữ liệu dành cho học máy
Tổng hợp công cụ hỗ trợ phát triển AI, ML, DL
1 note
·
View note
Text

This projects aim is to explore computer vision to examine the feasibility of providing live positional graphics on horse races through a computer vision model. Starting with learning, explaining and documenting machine learning and computer vision fundamentals so that both me and the reader can build a basic understanding. From there in the literature review state of the art models focused on multiple object tracking in horse racing are reviewed and explained, to understand the main challenges facing such an implementation. Finally, I implement my own object detection model using YoloV8, and a custom dataset made by myself. Given the project constraints and limitations, I was able to train a fairly accurate model, and discuss the results.
Joe Holloway
0 notes
Text
Color-Changing Melon Detection Model: Leveraging YOLOv8-CML
Key Takeaways Chen et al. (2024) have developed a lightweight detection model, YOLOv8-CML, for Color-changing melon in intelligent agriculture. The model introduces several innovations, including the Faster-Block and C2f structure, to reduce memory access and computation. The redesigned detection head and the α-IoU loss function improve recognition accuracy and efficiency. YOLOv8-CML achieves a…
0 notes
Video
youtube
Training YOLOv8 Object Detection Model in Python on Google Colab | Step-...
0 notes