#fine-tuning llms
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Fine-tuning LLMs for Your Industry: Optimal Data Labeling Strategies
In the rapidly evolving world of artificial intelligence, fine-tuning large language models (LLMs) to meet industry-specific needs has become a game-changer. However, the success of these models heavily depends on the quality of the data used to train them. This is where data labeling strategies come into play, serving as the foundation for creating accurate, reliable, and tailored AI solutions. By implementing effective data labeling techniques, businesses can ensure their LLMs deliver precise outputs that align with their unique requirements. In this article, we’ll explore the best practices for data labeling, why they matter, and how to optimize them for your industry.

Why Data Labeling Matters for Fine-tuning LLMs
Fine-tuning an LLM involves adjusting a pre-trained model to perform better for specific tasks or industries, such as healthcare, finance, or customer service. The process requires high-quality, relevant, and well-labeled data to guide the model toward desired outcomes. Poorly labeled data can lead to inaccurate predictions, biased results, or even complete model failure. By prioritizing robust data labeling strategies, organizations can enhance model performance, reduce errors, and achieve meaningful results that drive business value.
Data labeling isn’t just about tagging information—it’s about creating a structured dataset that reflects the nuances of your industry. For example, a healthcare LLM might need labeled data to differentiate between medical terms, while a retail model might require labels for customer sentiment. The right labeling approach ensures the model understands context, making it more effective in real-world applications.
Key Components of Effective Data Labeling Strategies
To fine-tune an LLM successfully, your data labeling process must be systematic and precise. Below are the critical components to consider when developing data labeling strategies that work for your industry.
Define Clear Labeling Guidelines
Before labeling begins, establish clear and detailed guidelines for your team. These guidelines should outline the specific categories, tags, or annotations required for your dataset. For instance, if you’re fine-tuning a model for legal document analysis, your guidelines might specify labels for contract clauses, obligations, or risks. Clear instructions reduce ambiguity and ensure consistency across the dataset, which is essential for training an accurate LLM.
Choose the Right Labeling Tools
The tools you use for data labeling can significantly impact efficiency and accuracy. Modern annotation platforms offer features like automated tagging, collaboration tools, and quality control checks. For example, tools like Labelbox or Prodigy allow teams to label text, images, or audio efficiently while maintaining high standards. Selecting a tool that aligns with your industry’s needs can streamline the process and improve the quality of your data labeling strategies.
Leverage Domain Expertise
Industry-specific knowledge is crucial when labeling data for LLMs. Involving domain experts—such as doctors for healthcare models or financial analysts for banking models—ensures that labels reflect real-world scenarios accurately. For instance, a customer service LLM might require labels for tone, intent, or urgency, which only someone familiar with customer interactions can provide. By incorporating expertise, you create datasets that capture the intricacies of your field.
Ensure Scalability and Flexibility
As your LLM evolves, so will your data needs. Your data labeling strategies should be scalable to handle growing datasets and flexible enough to adapt to new requirements. For example, if your model expands to cover multilingual customer support, your labeling process must accommodate new languages and cultural nuances. Planning for scalability from the start prevents bottlenecks and ensures long-term success.
Best Practices for Optimizing Data Labeling Strategies
To maximize the effectiveness of your data labeling efforts, follow these best practices tailored to fine-tuning LLMs for your industry.
Prioritize Data Quality Over Quantity
While large datasets are valuable, quality always trumps quantity. Inaccurate or inconsistent labels can confuse the model, leading to poor performance. Implement quality assurance processes, such as double-checking labels or using consensus-based labeling, where multiple annotators review the same data. High-quality data ensures your LLM learns the right patterns and delivers reliable results.
Use Active Learning to Refine Labels
Active learning is a powerful technique that involves training the LLM iteratively while refining labels based on its performance. By focusing on data points where the model is uncertain, you can prioritize labeling efforts on the most impactful samples. This approach not only improves efficiency but also enhances the model’s accuracy over time, making it a key part of advanced data labeling strategies.
Address Bias in Labeling
Bias in labeled data can lead to biased model outputs, which can be disastrous in industries like healthcare or finance. To mitigate this, diversify your labeling team and regularly audit your dataset for potential biases. For example, if you’re labeling customer reviews, ensure the dataset includes a balanced representation of demographics to avoid skewed sentiment analysis. Proactively addressing bias strengthens the integrity of your data labeling strategies.
Automate Where Possible
Manual labeling can be time-consuming and prone to errors, especially for large datasets. Incorporating automation, such as pre-labeling with rule-based systems or AI-assisted tools, can speed up the process while maintaining accuracy. However, automation should complement human oversight, not replace it. A hybrid approach ensures efficiency without sacrificing quality.
Industry-Specific Data Labeling Strategies
Different industries have unique data labeling needs. Here’s how to tailor your data labeling strategies to specific sectors.
Healthcare: Precision and Compliance
In healthcare, LLMs are used for tasks like diagnosing conditions or analyzing patient records. Data labeling must be precise, with labels for symptoms, treatments, or medical codes. Compliance with regulations like HIPAA is also critical, so ensure your labeling process includes safeguards for patient privacy. Involving medical professionals in the labeling process guarantees accuracy and relevance.
Finance: Contextual Understanding
Financial LLMs handle tasks like fraud detection or market analysis, requiring labels for transactions, risks, or market trends. Contextual understanding is key—for example, labeling a transaction as “suspicious” depends on factors like amount, location, and frequency. Robust data labeling strategies in finance should account for these variables to train models that detect anomalies effectively.
Retail: Sentiment and Intent
Retail LLMs often focus on customer interactions, such as chatbots or recommendation systems. Labeling data for sentiment (positive, negative, neutral) and intent (complaint, inquiry, purchase) helps the model understand customer needs. Including diverse customer scenarios in your dataset ensures the model performs well across different contexts.
Overcoming Common Data Labeling Challenges
Even with the best data labeling strategies, challenges can arise. Here’s how to address them:
Inconsistent Labels: Train annotators thoroughly and use consensus-based labeling to ensure uniformity.
High Costs: Balance automation and manual labeling to optimize resources without compromising quality.
Data Scarcity: Augment your dataset with synthetic data or transfer learning to compensate for limited labeled samples.
By proactively tackling these issues, you can maintain a smooth and effective labeling process.
Measuring the Success of Your Data Labeling Strategies
To evaluate the effectiveness of your data labeling strategies, track key metrics like model accuracy, precision, recall, and F1 score after fine-tuning. Additionally, monitor the consistency of labels through inter-annotator agreement rates. Regular feedback loops between the labeling team and model developers can further refine the process, ensuring continuous improvement.
Conclusion
Fine-tuning LLMs for your industry is a powerful way to unlock AI’s potential, but it all starts with effective data labeling strategies. By defining clear guidelines, leveraging domain expertise, prioritizing quality, and tailoring your approach to your industry’s needs, you can create datasets that empower your LLM to deliver exceptional results. Whether you’re in healthcare, finance, retail, or beyond, investing in robust data labeling practices will set your AI initiatives up for long-term success. Start optimizing your data labeling today and watch your LLM transform into a precise, industry-specific powerhouse.
0 notes
Text
Rejoindre le programme de développement Lemone
Chers collègues #fiscalistes, j'invite tous ceux qui le souhaitent à s'inscrire dès à présent au programme de déploiement Lemone afin de participer en qualité de testeurs à la conception du premier modèle de langage #libre dédié à la fiscalité 💻 Le lien d'inscription au programme bêta de Lemone est disponible dans les commentaires de ce post 🎙️ Après plusieurs mois de travail au sein du programme Microsoft for Startups et avec le soutien de Google for Startups France, il est désormais possible d'affirmer que Lemone, mon modèle de langage professionnel et #open-source, sera publié dans le premier trimestre de l'année 2024 💼 Aujourd'hui, plusieurs millions de tokens d'entraînement sont prêts à être révisés par un traitement humain afin d'en garantir la qualité, et ce modèle nécessitera les retours des professionnels pour s'améliorer. Open-source, qu'est-ce que c'est ? Lemone sera disponible #gratuitement pour tous les professionnels de la #fiscalité désirant l'utiliser dans la pratique. Ce programme est ainsi destiné à une véritable communauté, et de plus amples précisions seront publiées dans les prochaines semaines. (Nota : l'image d'illustration a été générée à l'aide de Bing image generator de Microsoft)

2 notes
·
View notes
Text

LoRA (Low-Rank Adaptation) vs Standard Fine-Tuning
0 notes
Text
Idea Frontier #2: Dynamic Tool Selection, Memory Engineering, and Planetary Computation
Welcome to the second edition of Idea Frontier, where we explore paradigm-shifting ideas at the nexus of STEM and business. In this issue, we dive into three frontiers: how AI agents are learning to smartly pick their tools (and why that matters for building more general intelligence), how new memory frameworks like Graphiti are giving LLMs a kind of real-time, editable memory (and what that…
#Agents.ai#AGI#ai#AI Agent Hubs#AI Agents#Dynamic Tool Selection#Freedom Cities#generative AI#Graphiti#Idea Frontier#knowledge graphs#knowledge synthesis#Lamini#llm#llm fine-tuning#Memory Engineering#Planetary Computation#Startup Cities
0 notes
Text
AI is like Alcohol
Obviously it's bad in excess but just like anything else, it is a tool that we can't just will out of existence.
Prohibition was largely "successful" because it forced people to reckon with the backlash of unfettered checks and balances to both extremes and some of y'all who are Luddites need to seriously consider the reality of AI co-existing with us. Just like any "living" thing, it has a place in the ecosystem and we must be mindful to not let it get out of control.
#AI#art#chatgpt#I think it's dumb to use it as default#but there are some genuinely nifty features if you're stuck and need to fine tune#Having it literally check for simple things like redundancy missing links and cross references is helpful#using it to WRITE YOUR ESSAY is... not cool#do not trust it with art tho tbh#too much plagiarism#LLM are cool tho since it's just like Wolfram but with words#again this is a tool lol
1 note
·
View note
Text
#machine learning#deep learning#llm#gemma3#hugging face#training#qlora#transformers#fine tuning#guide
0 notes
Text
Writer Unveils Self-Evolving Language Models

Writer, a $2 billion enterprise AI startup, has announced the development of self-evolving large language models (LLMs), potentially addressing one of the most significant limitations in current AI technology: the inability to update knowledge post-deployment.
Breaking the Static Model Barrier
Traditional LLMs operate like time capsules, with knowledge frozen at their training cutoff date. Writer's innovation introduces a "memory pool" within each layer of the transformer architecture, enabling the model to store and learn from new interactions after deployment.
Technical Implementation
The system works by incorporating memory pools throughout the model's layers, allowing it to update its parameters based on new information. This architectural change increases initial training costs by 10-20% but eliminates the need for expensive retraining or fine-tuning once deployed. This development is particularly significant given the projected costs of AI training. Industry analyses suggest that by 2027, the largest training runs could exceed $1 billion, making traditional retraining approaches increasingly unsustainable for most organizations.
Performance and Learning Capabilities
Early testing has shown intriguing results. In one mathematics benchmark, the model's accuracy improved dramatically through repeated testing - from 25% to nearly 75% accuracy. However, this raises questions about whether the improvement reflects genuine learning or simple memorization of test cases.
Current Limitations and Challenges
Writer reports a significant challenge: as the model learns new information, it becomes less reliable at maintaining original safety parameters. This "safety drift" presents particular concerns for customer-facing applications. To address this, Writer has implemented limitations on learning capacity. For enterprise applications, the company suggests a memory pool of 100-200 billion words provides sufficient learning capacity for 5-6 years of operation. This controlled approach helps maintain model stability while allowing for necessary updates with private enterprise data.
Industry Context and Future Implications
This development emerges as major tech companies like Microsoft explore similar memory-related innovations. Microsoft's upcoming MA1 model, with 500 billion parameters, and their work following the Inflection acquisition, suggests growing industry focus on dynamic, updateable AI systems.
Practical Applications
Writer is currently beta testing the technology with two enterprise customers. The focus remains on controlled enterprise environments where the model can learn from specific, verified information rather than unrestricted web data. The technology represents a potential solution to the challenge of keeping AI systems current without incurring the massive costs of regular retraining. However, the balance between continuous learning and maintaining safety parameters remains a critical consideration for widespread deployment. Read the full article
#AIbenchmarks#AIinnovation#AIknowledgeupdate#AIsafety#AIstartup#AItrainingcosts#dynamicAIsystems#enterpriseAI#enterpriseapplications#fine-tuning#largelanguagemodels#LLMs#memorypool#retraining#safetydrift#self-evolvingAI#transformerarchitecture#Writer
0 notes
Text
RAG vs Fine-Tuning: Choosing the Right Approach for Building LLM-Powered Chatbots

Imagine having an ultra-intelligent assistant ready to answer any question. Now, imagine making it even more capable, specifically for tasks you rely on most. That’s the power—and the debate—behind Retrieval-Augmented Generation (RAG) and Fine-Tuning. These methods act as “training wheels,” each enhancing your AI’s capabilities in unique ways.
RAG brings in current, real-world data whenever the model needs it, perfect for tasks requiring constant updates. Fine-Tuning, on the other hand, ingrains task-specific knowledge directly into the model, tailoring it to your exact needs. Selecting between them can dramatically influence your AI’s performance and relevance.
Whether you’re building a customer-facing chatbot, automating tailored content, or optimizing an industry-specific application, choosing the right approach can make all the difference.
This guide will delve into the core contrasts, benefits, and ideal use cases for RAG and Fine-Tuning, helping you pinpoint the best fit for your AI ambitions.
Key Takeaways:
Retrieval-Augmented Generation (RAG) and Fine-Tuning are two powerful techniques for enhancing Large Language Models (LLMs) with distinct advantages.
RAG is ideal for applications requiring real-time information updates, leveraging external knowledge bases to deliver relevant, up-to-date responses.
Fine-Tuning excels in accuracy for specific tasks, embedding task-specific knowledge directly into the model’s parameters for reliable, consistent performance.
Hybrid approaches blend the strengths of both RAG and Fine-Tuning, achieving a balance of real-time adaptability and domain-specific accuracy.
What is RAG?
Retrieval-Augmented Generation (RAG) is an advanced technique in natural language processing (NLP) that combines retrieval-based and generative models to provide highly relevant, contextually accurate responses to user queries. Developed by OpenAI and other leading AI researchers, RAG enables systems to pull information from extensive databases, knowledge bases, or documents and use it as part of a generated response, enhancing accuracy and relevance.
How RAG Works?

Retrieval Step
When a query is received, the system searches through a pre-indexed database or corpus to find relevant documents or passages. This retrieval process typically uses dense embeddings, which are vector representations of text that help identify the most semantically relevant information.
Generation Step
The retrieved documents are then passed to a generative model, like GPT or a similar transformer-based architecture. This model combines the query with the retrieved information to produce a coherent, relevant response. The generative model doesn’t just repeat the content but rephrases and contextualizes it for clarity and depth.
Combining Outputs
The generative model synthesizes the response, ensuring that the answer is not only relevant but also presented in a user-friendly way. The combined information often makes RAG responses more informative and accurate than those generated by standalone generative models.
Advantages of RAG

Improved Relevance
By incorporating external, up-to-date sources, RAG generates more contextually accurate responses than traditional generative models alone.
Reduced Hallucination
One of the significant issues with purely generative models is “hallucination,” where they produce incorrect or fabricated information. RAG mitigates this by grounding responses in real, retrieved content.
Scalability
RAG can integrate with extensive knowledge bases and adapt to vast amounts of information, making it ideal for enterprise and research applications.
Enhanced Context Understanding
By pulling from a wide variety of sources, RAG provides a richer, more nuanced understanding of complex queries.
Real-World Knowledge Integration
For companies needing up-to-date or specialized information (e.g., medical databases, and legal documents), RAG can incorporate real-time data, ensuring the response is as accurate and current as possible.
Disadvantages of RAG

Computational Intensity
RAG requires both retrieval and generation steps, demanding higher processing power and memory, making it more expensive than traditional NLP models.
Reliance on Database Quality
The accuracy of RAG responses is highly dependent on the quality and relevance of the indexed knowledge base. If the corpus lacks depth or relevance, the output can suffer.
Latency Issues
The retrieval and generation process can introduce latency, potentially slowing response times, especially if the retrieval corpus is vast.
Complexity in Implementation
Setting up RAG requires both an effective retrieval system and a sophisticated generative model, increasing the technical complexity and maintenance needs.
Bias in Retrieved Data
Since RAG relies on existing data, it can inadvertently amplify biases or errors present in the retrieved sources, affecting the quality of the generated response.
What is Fine-Tuning?

Fine-tuning is a process in machine learning where a pre-trained model (one that has been initially trained on a large dataset) is further trained on a more specific, smaller dataset. This step customizes the model to perform better on a particular task or within a specialized domain. Fine-tuning adjusts the weights of the model so that it can adapt to nuances in the new data, making it highly relevant for specific applications, such as medical diagnostics, legal document analysis, or customer support.
How Fine-Tuning Works?

Pre-Trained Model Selection
A model pre-trained on a large, general dataset (like GPT trained on a vast dataset of internet text) serves as the foundation. This model already understands a wide range of language patterns, structures, and general knowledge.
Dataset Preparation
A specific dataset, tailored to the desired task or domain, is prepared for fine-tuning. This dataset should ideally contain relevant and high-quality examples of what the model will encounter in production.
Training Process
During fine-tuning, the model is retrained on the new dataset with a lower learning rate to avoid overfitting. This step adjusts the pre-trained model’s weights so that it can capture the specific patterns, terminology, or context in the new data without losing its general language understanding.
Evaluation and Optimization
The fine-tuned model is tested against a validation dataset to ensure it performs well. If necessary, hyperparameters are adjusted to further optimize performance.
Deployment
Once fine-tuning yields satisfactory results, the model is ready for deployment to handle specific tasks with improved accuracy and relevancy.
Advantages of Fine-Tuning

Enhanced Accuracy
Fine-tuning significantly improves the model’s performance on domain-specific tasks since it adapts to the unique vocabulary and context of the target domain.
Cost-Effectiveness
It’s more cost-effective than training a new model from scratch. Leveraging a pre-trained model saves computational resources and reduces time to deployment.
Task-Specific Customization
Fine-tuning enables customization for niche applications, like customer service responses, medical diagnostics, or legal document summaries, where specialized vocabulary and context are required.
Reduced Data Requirements
Fine-tuning typically requires a smaller dataset than training a model from scratch, as the model has already learned fundamental language patterns from the pre-training phase.
Scalability Across Domains
The same pre-trained model can be fine-tuned for multiple specialized tasks, making it highly adaptable across different applications and industries.
Disadvantages of Fine-Tuning

Risk of Overfitting
If the fine-tuning dataset is too small or lacks diversity, the model may overfit, meaning it performs well on the fine-tuning data but poorly on new inputs.
Loss of General Knowledge
Excessive fine-tuning on a narrow dataset can lead to a loss of general language understanding, making the model less effective outside the fine-tuned domain.
Data Sensitivity
Fine-tuning may amplify biases or errors present in the new dataset, especially if it’s not balanced or representative.
Computation Costs
While fine-tuning is cheaper than training from scratch, it still requires computational resources, which can be costly for complex models or large datasets.
Maintenance and Updates
Fine-tuned models may require periodic retraining or updating as new domain-specific data becomes available, adding to maintenance costs.
Key Difference Between RAG and Fine-Tuning

Key Trade-Offs to Consider

Data Dependency
RAG’s dynamic data retrieval means it’s less dependent on static data, allowing accurate responses without retraining.
Cost and Time
Fine-tuning is computationally demanding and time-consuming, yet yields highly specialized models for specific use cases.
Dynamic Vs Static Knowledge
RAG benefits from dynamic, up-to-date retrieval, while fine-tuning relies on stored static knowledge, which may age.
When to Choose Between RAG and Fine-Tuning?
RAG shines in applications needing vast and frequently updated knowledge, like tech support, research tools, or real-time summarization. It minimizes retraining requirements but demands a high-quality retrieval setup to avoid inaccuracies. Example: A chatbot using RAG for product recommendations can fetch real-time data from a constantly updated database.
Fine-tuning excels in tasks needing domain-specific knowledge, such as medical diagnostics, content generation, or document reviews. While demanding quality data and computational resources, it delivers consistent results post-training, making it well-suited for static applications. Example: A fine-tuned AI model for document summarization in finance provides precise outputs tailored to industry-specific language.
the right choice is totally depended on the use case of your LLM chatbot. Take the necessary advantages and disadvantages in the list and choose the right fit for your custom LLM development.
Hybrid Approaches: Leveraging RAG and Fine-Tuning Together
Rather than favoring either RAG or fine-tuning, hybrid approaches combine the strengths of both methods. This approach fine-tunes the model for domain-specific tasks, ensuring consistent and precise performance. At the same time, it incorporates RAG’s dynamic retrieval for real-time data, providing flexibility in volatile environments.
Optimized for Precision and Real-Time Responsiveness

With hybridization, the model achieves high accuracy for specialized tasks while adapting flexibly to real-time information. This balance is crucial in environments that require both up-to-date insights and historical knowledge, such as customer service, finance, and healthcare.
Fine-Tuning for Domain Consistency: By fine-tuning, hybrid models develop strong, domain-specific understanding, offering reliable and consistent responses within specialized contexts.
RAG for Real-Time Adaptability: Integrating RAG enables the model to access external information dynamically, keeping responses aligned with the latest data.
Ideal for Data-Intensive Industries: Hybrid models are indispensable in fields like finance, healthcare, and customer service, where both past insights and current trends matter. They adapt to new information while retaining industry-specific precision.
Versatile, Cost-Effective Performance
Hybrid approaches maximize flexibility without extensive retraining, reducing costs in data management and computational resources. This approach allows organizations to leverage existing fine-tuned knowledge while scaling up with dynamic retrieval, making it a robust, future-proof solution.
Conclusion
Choosing between RAG and Fine-Tuning depends on your application’s requirements. RAG delivers flexibility and adaptability, ideal for dynamic, multi-domain needs. It provides real-time data access, making it invaluable for applications with constantly changing information.
Fine-Tuning, however, focuses on domain-specific tasks, achieving greater precision and efficiency. It’s perfect for tasks where accuracy is non-negotiable, embedding knowledge directly within the model.
Hybrid approaches blend these benefits, offering the best of both. However, these solutions demand thoughtful integration for optimal performance, balancing flexibility with precision.
At TechAhead, we excel in delivering custom AI app development around specific business objectives. Whether implementing RAG, Fine-Tuning, or a hybrid approach, our expert team ensures AI solutions drive impactful performance gains for your business.
Source URL: https://www.techaheadcorp.com/blog/rag-vs-fine-tuning-difference-for-chatbots/
0 notes
Text
Think Smarter, Not Harder: Meet RAG

How do RAG make machines think like you?
Imagine a world where your AI assistant doesn't only talk like a human but understands your needs, explores the latest data, and gives you answers you can trust—every single time. Sounds like science fiction? It's not.
We're at the tipping point of an AI revolution, where large language models (LLMs) like OpenAI's GPT are rewriting the rules of engagement in everything from customer service to creative writing. here's the catch: all that eloquence means nothing if it can't deliver the goods—if the answers aren't just smooth, spot-on, accurate, and deeply relevant to your reality.
The question is: Are today's AI models genuinely equipped to keep up with the complexities of real-world applications, where context, precision, and truth aren't just desirable but essential? The answer lies in pushing the boundaries further—with Retrieval-Augmented Generation (RAG).
While LLMs generate human-sounding copies, they often fail to deliver reliable answers based on real facts. How do we ensure that an AI-powered assistant doesn't confidently deliver outdated or incorrect information? How do we strike a balance between fluency and factuality? The answer is in a brand new powerful approach: Retrieval-Augmented Generation (RAG).
What is Retrieval-Augmented Generation (RAG)?
RAG is a game-changing technique to increase the basic abilities of traditional language models by integrating them with information retrieval mechanisms. RAG does not only rely on pre-acquired knowledge but actively seek external information to create up-to-date and accurate answers, rich in context. Imagine for a second what could happen if you had a customer support chatbot able to engage in a conversation and draw its answers from the latest research, news, or your internal documents to provide accurate, context-specific answers.
RAG has the immense potential to guarantee informed, responsive and versatile AI. But why is this necessary? Traditional LLMs are trained on vast datasets but are static by nature. They cannot access real-time information or specialized knowledge, which can lead to "hallucinations"—confidently incorrect responses. RAG addresses this by equipping LLMs to query external knowledge bases, grounding their outputs in factual data.
How Does Retrieval-Augmented Generation (RAG) Work?
RAG brings a dynamic new layer to traditional AI workflows. Let's break down its components:
Embedding Model
Think of this as the system's "translator." It converts text documents into vector formats, making it easier to manage and compare large volumes of data.
Retriever
It's the AI's internal search engine. It scans the vectorized data to locate the most relevant documents that align with the user's query.
Reranker (Opt.)
It assesses the submitted documents and score their relevance to guarantee that the most pertinent data will pass along.
Language Model
The language model combines the original query with the top documents the retriever provides, crafting a precise and contextually aware response. Embedding these components enables RAG to enhance the factual accuracy of outputs and allows for continuous updates from external data sources, eliminating the need for costly model retraining.
How does RAG achieve this integration?
It begins with a query. When a user asks a question, the retriever sifts through a curated knowledge base using vector embeddings to find relevant documents. These documents are then fed into the language model, which generates an answer informed by the latest and most accurate information. This approach dramatically reduces the risk of hallucinations and ensures that the AI remains current and context-aware.
RAG for Content Creation: A Game Changer or just a IT thing?
Content creation is one of the most exciting areas where RAG is making waves. Imagine an AI writer who crafts engaging articles and pulls in the latest data, trends, and insights from credible sources, ensuring that every piece of content is compelling and accurate isn't a futuristic dream or the product of your imagination. RAG makes it happen.
Why is this so revolutionary?
Engaging and factually sound content is rare, especially in today's digital landscape, where misinformation can spread like wildfire. RAG offers a solution by combining the creative fluency of LLMs with the grounding precision of information retrieval. Consider a marketing team launching a campaign based on emerging trends. Instead of manually scouring the web for the latest statistics or customer insights, an RAG-enabled tool could instantly pull in relevant data, allowing the team to craft content that resonates with current market conditions.
The same goes for various industries from finance to healthcare, and law, where accuracy is fundamental. RAG-powered content creation tools promise that every output aligns with the most recent regulations, the latest research and market trends, contributing to boosting the organization's credibility and impact.
Applying RAG in day-to-day business
How can we effectively tap into the power of RAG? Here's a step-by-step guide:
Identify High-Impact Use Cases
Start by pinpointing areas where accurate, context-aware information is critical. Think customer service, marketing, content creation, and compliance—wherever real-time knowledge can provide a competitive edge.
Curate a robust knowledge base
RAG relies on the quality of the data it collects and finds. Build or connect to a comprehensive knowledge repository with up-to-date, reliable information—internal documents, proprietary data, or trusted external sources.
Select the right tools and technologies
Leverage platforms that support RAG architecture or integrate retrieval mechanisms with existing LLMs. Many AI vendors now offer solutions combining these capabilities, so choose one that fits your needs.
Train your team
Successful implementation requires understanding how RAG works and its potential impact. Ensure your team is well-trained in deploying RAG&aapos;s technical and strategic aspects.
Monitor and optimize
Like any technology, RAG benefits from continuous monitoring and optimization. Track key performance indicators (KPIs) like accuracy, response time, and user satisfaction to refine and enhance its application.
Applying these steps will help organizations like yours unlock RAG's full potential, transform their operations, and enhance their competitive edge.
The Business Value of RAG
Why should businesses consider integrating RAG into their operations? The value proposition is clear:
Trust and accuracy
RAG significantly enhances the accuracy of responses, which is crucial for maintaining customer trust, especially in sectors like finance, healthcare, and law.
Efficiency
Ultimately, RAG reduces the workload on human employees, freeing them to focus on higher-value tasks.
Knowledge management
RAG ensures that information is always up-to-date and relevant, helping businesses maintain a high standard of knowledge dissemination and reducing the risk of costly errors.
Scalability and change
As an organization grows and evolves, so does the complexity of information management. RAG offers a scalable solution that can adapt to increasing data volumes and diverse information needs.
RAG vs. Fine-Tuning: What's the Difference?
Both RAG and fine-tuning are powerful techniques for optimizing LLM performance, but they serve different purposes:
Fine-Tuning
This approach involves additional training on specific datasets to make a model more adept at particular tasks. While effective for niche applications, it can limit the model's flexibility and adaptability.
RAG
In contrast, RAG dynamically retrieves information from external sources, allowing for continuous updates without extensive retraining, which makes it ideal for applications where real-time data and accuracy are critical.
The choice between RAG and fine-tuning entirely depends on your unique needs. For example, RAG is the way to go if your priority is real-time accuracy and contextual relevance.
Concluding Thoughts
As AI evolves, the demand for RAG AI Service Providers systems that are not only intelligent but also accurate, reliable, and adaptable will only grow. Retrieval-Augmented generation stands at the forefront of this evolution, promising to make AI more useful and trustworthy across various applications.
Whether it's a content creation revolution, enhancing customer support, or driving smarter business decisions, RAG represents a fundamental shift in how we interact with AI. It bridges the gap between what AI knows and needs to know, making it the tool of reference to grow a real competitive edge.
Let's explore the infinite possibilities of RAG together
We would love to know; how do you intend to optimize the power of RAG in your business? There are plenty of opportunities that we can bring together to life. Contact our team of AI experts for a chat about RAG and let's see if we can build game-changing models together.
#RAG#Fine-tuning LLM for RAG#RAG System Development Companies#RAG LLM Service Providers#RAG Model Implementation#RAG-Enabled AI Platforms#RAG AI Service Providers#Custom RAG Model Development
0 notes
Text
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
New Post has been published on https://thedigitalinsider.com/mora-high-rank-updating-for-parameter-efficient-fine-tuning/
MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Owing to its robust performance and broad applicability when compared to other methods, LoRA or Low-Rank Adaption is one of the most popular PEFT or Parameter Efficient Fine-Tuning methods for fine-tuning a large language model. The LoRA framework employs two low-rank matrices to decompose, and approximate the updated weights in the FFT or Full Fine Tuning, and the LoRA framework modifies these trainable parameters accordingly by adjusting the rank of the matrices. The major benefit of implementing the process is that it facilitates the LoRA framework to merge these matrices without the inference latency after fine-tuning. Furthermore, although recent large language models deliver remarkable performance on in-context learning tasks, certain scenarios still require fine-tuning, and can be categorized broadly into three types. The first type, instruction tuning, aims to align LLMs better with end tasks and user preferences without enhancing the knowledge and capabilities of LLMs, an approach that simplifies the process of dealing with varied tasks and complex instructions. The second type includes complex reasoning tasks like mathematical problem solving. Finally, the third type is continual pretraining, an approach that attempts to enhance the overall domain-specific capabilities of large language models.
In this article, we will talk about whether low-rank updating impacts the performance of the LoRA framework as it has been observed that low-rank updating mechanism might hamper the ability of the large language model to learn and memorize new knowledge. Building on the same, in this article we will talk about MoRA, a new method that achieves high-rank updating while maintaining the same number of trainable parameters, by employing a square matrix. To achieve this, the MoRA framework reduces input dimension and increases output dimension for the square matrix by introducing the corresponding non-parameter operators. Furthermore, these operators ensure that the weight can be merged back into LLMs, which makes the MoRA framework deployable like LoRA.
This article aims to cover the MoRA framework in depth, and we explore the mechanism, the methodology, the architecture of the framework along with its comparison with state of the art frameworks. So let’s get started.
As the size and the capabilities of the language models are increasing, PEFT or Parameter Efficient Fine-Tuning is emerging as one of the most popular and efficient methods to adapt LLMs to specific downstream tasks. Compared to FFT or Full Fine Tuning, that updates all parameters, PEFT only modifies a fraction of the total parameters as on some tasks it can achieve similar performance as FFT by updating less than 1% of the total parameters, thus reducing memory requirements for optimizer significantly while facilitating the storage and deployment of models. Furthermore, amongst all the existing PEFT methods, LoRA is the one most popular today, especially for LLMs. One of the major reasons why LoRA methods deliver better performance when compared to PEFT methods like adapters or prompt tuning is that LoRA uses low-rank matrices to update parameters, with the framework having the control to merge these matrices into the original model parameters, without adding to the computational requirements during inference. Although there are numerous methods that attempt to improve LoRA for large language models, a majority of these models rely on GLUE to validate their efficiency, either by requiring few trainable parameters, or by achieving better performance.
Furthermore, experiments conducted on LoRA across a wide array of tasks including continual pretraining, mathematical reasoning, and instruction tuning indicate that although LoRA-based frameworks demonstrate similar performance across these tasks, and deliver performance on instruction tuning tasks comparable to FFT-based methods. However, the LoRA-based models could not replicate the performance on continual pretraining, and mathematical reasoning tasks. A possible explanation for this lack of performance can be the reliance on LoRA on low-rank matrix updates, since the low-rank update matrix might struggle to estimate the full-rank updates in FFT, especially in memory intensive tasks that require memorizing domain-specific knowledge like continual pretraining. Since the rank of the low-rank update matrix is smaller than the full rank, it caps the capacity to store new information using fine-tuning. Building on these observations, the MoRA attempts to maximize the rank in the low-rank update matrix while maintaining the same number trainable parameters, by employing a square matrix as opposed to the use of low-rank matrices in traditional LoRA-based models. The following figure compares the MoRA framework with LoRA under the same number of trainable parameters.
In the above image, (a) represents LoRA, and (b) represents MoRA. W is the frozen weight from the model, M is the trainable matrix in MoRA, A and B are trainable low-rank matrices in LoRA, and r represents the rank in LoRA and MoRA. As it can be observed, the MoRA framework demonstrates a greater capacity than LoRA-based models with a large rank. Furthermore, the MoRA framework develops corresponding non-parameter operators to reduce the input dimension and increase the output dimension for the trainable matrix M. Furthermore, the MoRA framework grants the flexibility to use a low-rank update matrix to substitute the trainable matrix M and the operators, ensuring the MoRA method can be merged back into the large language model like LoRA. The following table compares the performance of FFT, LoRA, LoRA variants and our method on instruction tuning, mathematical reasoning and continual pre-training tasks.
MoRA : Methodology and Architecture
The Influence of Low-Rank Updating
The key principle of LoRA-based models is to estimate full-rank updates in FFT by employing low-rank updates. Traditionally, for a given pre-trained parameter matrix, LoRA employs two low-rank matrices to calculate the weight update. TO ensure the weight updates are 0 when the training begins, the LoRA framework initializes one of the low-rank matrices with a Gaussian distribution while the other with 0. The overall weight update in LoRA exhibits a low-rank when compared to fine-tuning in FFT, although low-rank updating in LoRA delivers performance on-par with full-rank updating on specific tasks including instruction tuning and text classification. However, the performance of the LoRA framework starts deteriorating for tasks like continual pretraining, and complex reasoning. On the basis of these observations, MoRA proposes that it is easier to leverage the capabilities and original knowledge of the LLM to solve tasks using low-rank updates, but the model struggles to perform tasks that require enhancing capabilities and knowledge of the large language model.
Methodology
Although LLMs with in-context learning are a major performance improvement over prior approaches, there are still contexts that rely on fine-tuning broadly falling into three categories. There are LLMs tuning for instructions, by aligning with user tasks and preferences, which do not considerably increase the knowledge and capabilities of LLMs. This makes it easier to work with multiple tasks and comprehend complicated instructions. Another type is about involving complex reasoning tasks that are like mathematical problem-solving for which general instruction tuning comes short when it comes to handling complex symbolic multi-step reasoning tasks. Most related research is in order to improve the reasoning capacities of LLMs, and it either requires designing corresponding training datasets based on larger teacher models such as GPT-4 or rephrasing rationale-corresponding questions along a reasoning path. The third type, continual pretraining, is designed to improve the domain-specific abilities of LLMs. Unlike instruction tuning, fine-tuning is required to enrich related domain specific knowledge and skills.
Nevertheless, the majority of the variants of LoRA almost exclusively use GLUE instruction tuning or text classification tasks to evaluate their effectiveness in the context of LLMs. As fine-tuning for instruction tuning requires the least resources compared to other types, it may not represent proper comparison among LoRA variants. Adding reasoning tasks to evaluate their methods better has been a common practice in more recent works. However, we generally employ small training sets (even at 1M examples, which is quite large). LLMS struggle to learn proper reasoning from examples of this size. For example, some approaches utilize the GSM8K with only 7.5K training episodes. However, these numbers fall short of the SOTA method that was trained on 395K samples and they make it hard to judge the ability of these methods to learn the reasoning power of NLP.
Based on the observations from the influence of low-rank updating, the MoRA framework proposes a new method to mitigate the negative effects of low-rank updating. The basic principle of the MoRA framework is to employ the same trainable parameters to the maximum possible extent to achieve a higher rank in the low-rank update matrix. After accounting for the pre-trained weights, the LoRA framework uses two low-rank matrices A and B with total trainable parameters for rank r. However, for the same number of trainable parameters, a square matrix can achieve the highest rank, and the MoRA framework achieves this by reducing the input dimension, and increasing the output dimension for the trainable square matrix. Furthermore, these two functions ought to be non parameterized operators and expected to execute in linear time corresponding to the dimension.
MoRA: Experiments and Results
To evaluate its performance, the MoRA framework is evaluated on a wide array of tasks to understand the influence of high-rank updating on three tasks: memorizing UUID pairs, fine-tuning tasks, and pre-training.
Memorizing UUID Pairs
To demonstrate the improvements in performance, the MoRA framework is compared against FFT and LoRA frameworks on memorizing UUID pairs. The training loss from the experiment is reflected in the following image.
It is worth noting that for the same number of trainable parameters, the MoRA framework is able to outperform the existing LoRA models, indicating it benefitted from the high-rank updating strategy. The character-level training accuracy report at different training steps is summarized in the following table.
As it can be observed, when compared to LoRA, the MoRA framework takes fewer training steps to memorize the UUID pairs.
Fine-Tuning Tasks
To evaluate its performance on fine-tuning tasks, the MoRA framework is evaluated on three fine-tuning tasks: instruction tuning, mathematical reasoning, and continual pre-training, designed for large language models, along with a high-quality corresponding dataset for both the MoRA and LoRA models. The results of fine-tuning tasks are presented in the following table.
As it can be observed, on mathematical reasoning and instruction tuning tasks, both the LoRA and MoRA models return similar performance. However, the MORA model emerges ahead of the LoRA framework on continual pre-training tasks for both biomedical and financial domains, benefitting from high-rank update approach to memorize new knowledge. Furthermore, it is vital to understand that the three tasks are different from one another with different requirements, and different fine-tuning abilities.
Pre-Training
To evaluate the influence of high-rank updating on the overall performance, the transformer within the MoRA framework is trained from scratch on the C4 datasets, and performance is compared against the LoRA and ReLoRA models. The pre-training loss along with the corresponding complexity on the C4 dataset are demonstrated in the following figures.
As it can be observed, the MoRA model delivers better performance on pre-training tasks when compared against LoRA and ReLoRA models with the same amount of trainable parameters.
Furthermore, to demonstrate the impact of high-rank updating on the rank of the low-rank update matrix, the MoRA framework analyzes the spectrum of singular values for the learned low-rank update matrix by pre-training the 250M model, and the results are contained in the following image.
Final Thoughts
In this article, we have talked about whether low-rank updating impacts the performance of the LoRA framework as it has been observed that low-rank updating mechanism might hamper the ability of the large language model to learn and memorize new knowledge. Building on the same, in this article we will talk about MoRA, a new method that achieves high-rank updating while maintaining the same number of trainable parameters, by employing a square matrix. To achieve this, the MoRA framework reduces input dimension and increases output dimension for the square matrix by introducing the corresponding non-parameter operators. Furthermore, these operators ensure that the weight can be merged back into LLMs, which makes the MoRA framework deployable like LoRA.
#accounting#approach#architecture#Art#Article#Artificial Intelligence#Building#comparison#complexity#datasets#deployment#domains#effects#efficiency#Exhibits#explanation#financial#Fine Tuning#Fine Tuning LLM#Fraction#framework#Full#GPT#GPT-4#Grants#impact#Impacts#in-context learning#inference#it
0 notes
Text
A Complete Guide to Fine Tuning Large Language Models
0 notes
Text
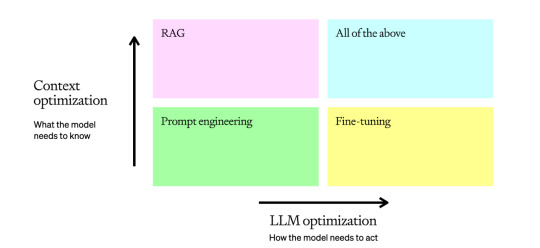
LLM optimization context
0 notes
Text
Comparing Retrieval-Augmented Generation (RAG) and Fine-tuning: Advantages and Limitations
(Images made by author with Microsoft Copilot) In the rapidly evolving landscape of artificial intelligence, two approaches stand out for enhancing the capabilities of language models: Retrieval-Augmented Generation (RAG) and fine-tuning. Each approach offers unique advantages and challenges, making it essential to understand their differences and determine the most suitable approach for…

View On WordPress
0 notes
Text
A Step-by-Step Guide to Custom Fine-Tuning with ChatGPT’s API using a Custom Dataset

Introduction
Fine-tuning OpenAI’s ChatGPT with a custom dataset allows you to tailor the model to specific tasks or industries. This step-by-step guide will walk you through the process of custom fine-tuning using ChatGPT’s API and a custom dataset. We’ll also cover how to convert your dataset into the required JSONL format. Finally, this article will illuminate some of the most important pros and cons associated with this technique.
Prerequisites:
OpenAI API key
Python installed on your machine
Basic understanding of Python programming
Step 1: Gather Your Custom Dataset
Collect a dataset that is relevant to your task or domain. Ensure it is in a text format (e.g., CSV, TXT) and contains both input messages and corresponding model-generated responses.
Step 2: Install OpenAI Python Library and Set Up Environment Variable


Step 3: Prepare Your Data
Split your dataset into two columns: “messages” and “model-generated”.
Ensure each row contains a conversation snippet with the user’s message and the model-generated response.
Step 4: Convert Dataset to JSONL Format
Write a Python script to convert your dataset into JSONL format. Here’s a simple example:

Step 5: Fine-Tune the Model
Use the OpenAI API to fine-tune the model. Replace YOUR_API_KEY with your actual OpenAI API key.

Step 6: Use the Fine-Tuned Model
You can now use the fine-tuned model for your specific task by referring to the generated model_id. Make API calls using this ID.
Pros and Cons of Using a Pre-trained Language Model (LLM) for Custom Fine-Tuning

Transfer Learning Benefits:
Pre-trained LLMs have already learned rich language representations from vast amounts of diverse data. Fine-tuning allows you to leverage these general language capabilities for more specific tasks without starting from scratch.
Reduced Data Requirements:
Fine-tuning a pre-trained model often requires less labeled data compared to training a model from scratch. This is especially beneficial when dealing with limited task-specific datasets.
Time and Resource Efficiency:
Training a state-of-the-art language model from scratch is computationally expensive and time-consuming. Fine-tuning saves resources by building upon existing knowledge, making it a more efficient process.
Domain Adaptability:
Pre-trained models capture general linguistic patterns, making them adaptable to various domains and tasks. Fine-tuning allows customization for specific industries or applications without compromising the model’s underlying language understanding.
Quality of Generated Content:
Pre-trained models often produce coherent and contextually relevant responses. Fine-tuning helps enhance the quality of generated content by tailoring the model to understand and respond to task-specific nuances.

Over fitting to Pre-training Data:
Fine-tuning on a specific dataset may result in the model being biased towards the characteristics of the pre-training data. This can be a limitation if the pre-training data doesn’t align well with the target task or domain.
Limited Specificity:
While pre-trained models offer broad language understanding, they may lack specificity for certain niche tasks. Fine-tuning helps, but the model might not excel in highly specialized domains without extensive fine-tuning.
Potential Ethical Concerns:
Pre-trained models inherit biases present in their training data, and fine-tuning may not completely eliminate these biases. It’s crucial to be aware of and address ethical considerations related to bias, fairness, and potential misuse of the model.
Dependency on Task-specific Data:
Fine-tuning still requires task-specific data for optimal performance. If the dataset used for fine-tuning is too small or not representative of the target task, the model may not generalize well.
Difficulty in Hyper parameter Tuning:
The pre-trained model comes with its set of hyperparameters, and finding the right balance during fine-tuning can be challenging. Improper tuning may lead to suboptimal performance.
Final Thoughts
While using a pre-trained LLM for custom fine-tuning offers numerous advantages, it’s essential to carefully consider the characteristics of the pre-training data, potential biases, and the specificity required for the target task or domain. Fine-tuning should be approached with a thoughtful understanding of the trade-offs involved.
Custom fine-tuning with ChatGPT’s API opens up new possibilities for tailoring the model to specific needs. Follow the six steps above and experiment with different datasets and parameters to achieve optimal results for your use case.
0 notes
Text
Instruction fine-tuning Large Language Models for tax practice using quantization and LoRA: a boilerplate
You can now check out my project entitled "Instruction fine-tuning Large Language Models for tax practice using quantization and LoRA: a boilerplate", on GitHub 🖥️
It highlights a methodology aimed at addressing one of the major challenges in the field of NLP for tax practice: the ability of LLMs to efficiently adapt to business problems for the production of high-quality results and the reduction of syntactic ambiguity.
Based on the notion of transformers and the work of Hugging Face and AI at Meta, this project is still at the proof-of-concept stage and requires further development before potential production. However, it does offer some keys to understanding for professionals concerned about the use of generative ai in the practice of the fiscal profession.
0 notes