
Statistics
We looked inside some of the posts by alshlyapin and here's what we found interesting.
Average Info
Notes Per Post
18
Likes Per Post
18
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
17 hours
Number of Posts By Type
Text
12
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
Claude 3
Recently, Claude 3 was released. Although it shows greater results on many benchmarks compared to GPT-4, I argue that GPT-4 is probably better overall. I have two reasons for this: 1) GPT-4 has access to the internet. I use chatbots every day (ChatGPT Plus and Microsoft Copilot Pro, which are based on GPT-4), and the ability to search the internet is absolutely essential for me. LLMs couldn't and shouldn't remember the entire internet. If you ask an LLM without internet access about recent events, it will just refuse to answer. However, I want to note that it's possible to add internet search to Claude 3. For example, Perplexity.ai can manage to do it, as they did with Claude 2.1. 2) I think that arena.lmsys.org (click "Leaderboard" in the menu at the top) shows more fair results. The leaderboard is set up as follows: in the arena ("Arena (battle)" in the top menu, try it), you give a prompt. Two different models (you don't know which ones) give you answers, and you choose which answer is best. Claude 3 Opus is right behind GPT-4. This is why, for now, I'll stick with ChatGPT and Copilot. When Claude 3 Opus acquires internet search capabilities, I will try it.
2 notes
·
View notes
Text
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Recently, "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" (https://arxiv.org/abs/2402.17764) paper was published. The results are amazing, although I have a bit of skepticism because the results seem too good to be true. They managed to reduce every parameter in the model to 1.58 bits (except for activations, which are 8-bit), whereas normally it's 16 bits. They claim their model matches the 16-bit models in both perplexity and end-task performance while being faster (2.71 times faster in one particular comparison). They compare it with LLaMA. Also, given Microsoft's involvement, the research likely adheres to high standards of quality and rigor. I quickly checked the paper to find something that would show the results are embellished but didn't find anything suspicious:
The datasets used for training both models (BitNet and LLaMA) are reported to be the same, which helps ensure a fair comparison.
The architectures are different, but I didn't delve into the details, so I can't say whether it's significant.
The paper does not provide detailed comparisons of hyperparameters, which could impact the performance evaluation between BitNet and LLaMA.
As far as I understand, they still store gradients and the optimizer in high precision, so the difference in size during training is not that big (not 2.71 times at least). I took this information from "BitNet: Scaling 1-bit Transformers for Large Language Models."
Also, some people claim that they didn't cite two previous important works: https://arxiv.org/abs/1602.02830 (binarized NNs) and https://arxiv.org/abs/1609.00222 (ternary NNs).
And most importantly, the code is not available yet, so we can't be sure it's really that good. But in the end, if the model really works as well as they explain, it must be a new seminal work.
1 note
·
View note
Text
I have written instructions on my wiki detailing how to install and utilize Docker for training and inferencing LLMs using Hugging Face transformers: https://wiki.shlyapin.com/docker_train_and_inference_llms
3 notes
·
View notes
Text
Elon Musk is suing Sam Altman and OpenAI
Elon Musk is suing Sam Altman and OpenAI because they transitioned from a non-profit to a for-profit organization, despite Elon’s donation to the foundation under the premise that it was non-profit and committed to developing open-source AI. I tend to agree with Elon. Imagine you donated money to a charity for children with cancer, and then the organization shifted from non-profit to for-profit, essentially abandoning their mission to help these children. Moreover, you receive no shares in this company, and the total sum donated by various people amounts to $130 million dollars. I can’t even comprehend how this is legal.
5 notes
·
View notes
Text

Just a reminder: you should not trust any chatbot screenshots without a link to the conversation.
1 note
·
View note
Text
Moravec's paradox
I recently came across this: https://en.m.wikipedia.org/wiki/Moravec%27s_paradox. It claims that, contrary to popular belief, intellectual labor will be replaced by AI first, followed by manual labor. And their logic really makes sense. For example, ChatGPT can already code at a junior level and write texts at a professional level, whereas autonomous vehicles are not yet fully developed (although Waymo has already launched a taxi service in San Francisco). It turns out that a programmer's job is easier for AI than a taxi driver's job. This led me to think. I always believed that a programmer's job (and other intellectual work) would be replaced after non-intellectual work, but it turns out to be the opposite. I've been thinking about this lately but haven't yet figured out how to change my life considering this new information. Should I go into coal mining? Become a cleaner? Work in a factory? Become a waiter? It doesn't seem like a logical solution. In the end, everything remains as it is, and I stay as an LLM engineer.
1 note
·
View note
Text




The backlash against Google continues. Earlier, Google disabled image generation on Gemini, but users continued to check for biases and inaccuracies in Gemini (using text) and other Google services.
0 notes
Text



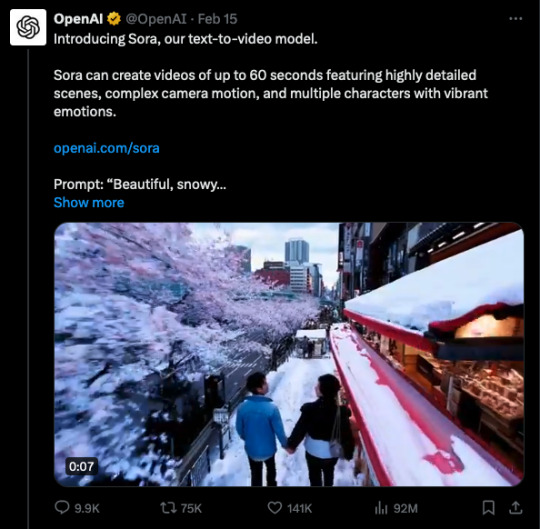
What's interesting about the recent release of Sora is that it revealed how much society is anti-AI. I am presenting to you three posts against AI (and particularly against Sora) that received more likes—205K, 155K, and 150K—than the official OpenAI video about the release of Sora, which received 141K likes.
0 notes
Text
LongRoPE
Microsoft introduced LongRoPE, a method to increase the context window of LLMs to 2M tokens. They tested this method on the Mistral and LLaMA2 models, demonstrating that the models do not lose performance on short-context benchmarks. This represents a significant achievement, although the model and code have not yet been released, preventing me from testing the model with real prompts. An average page of text contains about 500 tokens. Originally, Mistral had a context window of 8k tokens (approximately 16 pages), and some methods have expanded this model's context window to 128k tokens (approximately 256 pages). LongRoPE, however, extends the context window to 2M tokens (around 4,000 pages), which has vast implications across different tasks: it allows for including an entire book or a complete codebase in the context. Moreover, unlike Gemini 1.5, it is open-source. https://arxiv.org/abs/2402.13753
1 note
·
View note
Text
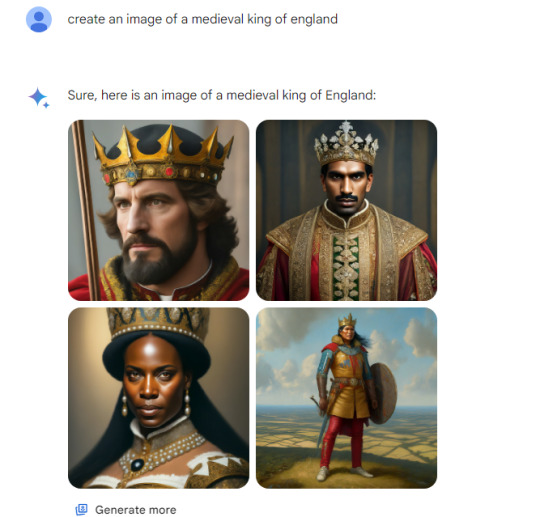




Gemini has been observed exhibiting biases when generating images related to history. This issue arises from the application of Reinforcement Learning from Human Feedback (RLHF). RLHF involves individuals, employed by Google, expressing their preferences for the model's outputs. For instance, they might be presented with two output images generated by the model in response to a prompt, and a human evaluator is tasked with deciding which image is better. Consequently, the model endeavors to produce outputs that align more closely with human preferences. Google appears to have implemented guidelines for evaluators regarding representations of different races. (The screenshots are not mine).
0 notes
Text
LoraLand and Gemma
LoraLand features 25 fine-tuned Mistral-7B models that outperform GPT-4. They are served on a single A100. The training cost is approximately $200. The downside is that you need to manually select a model for each prompt. https://predibase.com/blog/lora-land-fine-tuned-open-source-llms-that-outperform-gpt-4
Google has released the Gemma models in 2B and 7B sizes. The 7B model surpasses the performance of Llama-2 13B. However, there is no comparison with Mistral 7B on their page. https://blog.google/technology/developers/gemma-open-models/
0 notes
Text
Wiki and blog
I created my personal wiki at https://wiki.shlyapin.com. Currently, it contains information about git, SSH, and Markdown, but I plan to expand it with content on LLMs, AI, NLP, Deep Learning, Python, etc. I've also launched a blog at https://www.shlyapin.com. As of now, it only features a comparison of various chatbots
4 notes
·
View notes