
Statistics
We looked inside some of the posts by christophwagner and here's what we found interesting.
Average Info
Notes Per Post
182
Likes Per Post
134
Reblog Per Post
48
Reply Per Post
0
Time Between Posts
3 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
How to Become a Better Programmer in 30 Minutes a Day
What if I told you that there is a surefire way to level up your coding skills in as little as six weeks, and it would only take you about 30 minutes of time per day? Would you do it? Or is that too much to ask?
Think about it: what’s the biggest obstacle standing between you and that big idea that you have? That awesome app that you’d like to code, but you’re not sure that you have the skills or the persistence to finish? Or that day at your job that you don’t have drop everything in order to put out yet another fire and focus on building something really worthwhile?
You might say “I don’t know enough to build that <app/project/feature>. I need to study more.” I say you’re wrong. Chances are you know already much more than you need to. What you’re lacking is practice. A good coder is not someone who knows how to do everything. A good coder is someone who can figure out how to do anything.
The point is this: amateurs study, professionals practice. They practice every day. Sure, studying new research and reading up on theory has its place. But you don’t become better at your craft by studying. You become better by practicing.
Yes, there is a place for studying, for reading books and blogs and working through all the tutorials you can find on the web. I’m not arguing that studying is not important. All I’m saying is that it’s overrated. What matters in real life is whether you can apply what you know. And the only way to find out is by doing it.
Imagine this scenario: you’re in the hospital, and you’re scheduled for open heart surgery. There are two surgeons available: the first one has graduated from Harvard Medical School. He’s read every book there is on open heart surgery, and he can go to great lengths elaborating on every single detail of it. The other one used to patch together soldier on the battlefield with a piece string and a hot needle, but he’s operated on thousands of patients and has a 99% success rate. Which one would you choose?
What do successful athletes do when they prepare for a big game or an upcoming tournament? Ponder over strategy books? No, they practice.
What do successful musicians do when they prepare for their next concert? Read about a bunch of music theory? No, they practice.
What do successful chess players do when preparing for an upcoming match? Well, being chess players, they probably will be reading a bunch of books and studying popular openings, but I assure you, they are still going to practice, by playing as many games against a simulator (or a real person) as possible.
“Okay”, you say, “I get it. But where can I get that practice? No one will hire me without experience, and I won’t get experience without a job. So I’m stuck!”
Not really. One way to get consistent problem solving practice is by writing very small, very limited programs every day. Programs so small that you can write them in a single file.
This is what websites like CodeWars or HackerRank are for. They have giant collections of practice problems in many different languages, neatly organized into categories and rated by difficulty level. In some circles, this is referred to as “code golf”. Other people call these practice problems “katas”, borrowing a term from martial arts (specifically, Karate).
A kata in Karate is a practice set. It’s the equivalent of a musician practicing scales in order to improve the finger dexterity, or an actor practicing tongue twisters to improve their enunciation. In the same way, programmers should be practicing katas to improve their problem solving skills. Practice is what sets the professional and the amateur apart.
The Chinese word for “Kung Fu” (功夫 or “gōng fū”) really means “hard work” or “effort over time”. There is no shortcut around this. Only by trying, and failing, and trying again can you develop your programming Kung Fu. The master has failed more times than the student has even tried. The pathway to mastery is practice.
So, here’s how you become a better programmer: take 30 minutes each day and try to solve at least one kata in that time. That’s all I ask. 30 minutes, no more, no less. If you can’t finish it in that time, doesn’t matter. You gave it a shot, and that counts. You can try it again tomorrow. Or try a different one. Keep trying until you find something you can solve. Then try another one.
If you can keep this up even for just a month, I promise you will start seeing the results in your everyday work. You will write better, cleaner, more effective code, and you’ll start enjoying it. You’ll be more familiar with the standard library of your language, and you won’t have to go “gee, I wonder if there is already a function for this…” each time you hit a minor road bump in your day job. Your programming muscles will literally start to bulge, and bugs will begin to tremble in fear when they see you coming.
Within three months you will have solved enough problems that the lower levels will start to feel boring to you, and you’ll start looking at the higher levels in order to get a better challenge. Within a year you’ll have leveled up significantly, and you may find yourself pondering over algorithm books in order to master the advanced level katas. You’ll be looking back at code you wrote one year ago, and you will laugh at your old self and the silly mistakes you used to make.
30 minutes a day is all it takes. Can you invest that much in your future?
2 notes
·
View notes
Text
I added a CodeMentor badge to my website
That was a LOT more work than I'd like to admit. Seriously, it took me several hours. And I'll explain why. But first, let's see the result:

Sweet, isn't it? Now, let me walk you through the process of creating it.
First of all, I needed a CodeWars icon in font format. Why is that, you ask? Well, that's how the theme I'm using on my website works. Each of the badges is a link, which has the icon inserted into it from a custom font. I tried using an image, but it wouldn't work. It would just break the layout, and the highlighting didn't work either (note how the icons subtly change color when they are hovered over).
Iconoclastic
So, where do I get a font that includes a CodeWars icon? The website isn't nearly as popular as Google, Github, or Facebook, so obviously, no icon was included in the theme. But looking at how the theme implemented the icons, I found an interesting lead: the font it was using was called "Fontello". The Fontello website explained that it isn't really a fixed font set (like FontAwesome), but rather, a custom font generator, that lets you upload your own icons and turn them into a webfont. Neat!
Okay, so I now I knew how I could make a font with that icon in it, but where do I get the icon? The Fontello website only accepts SVG files. But the site favicon is an ICO file. SVG is a vector file format, but ICO is a pixel-based format. Not helpful. Thankfully, I had the idea to check out the “badge” feature on Codewars. Actually, that’s where I started this whole journey – I wanted to add a badge to my website, but I didn’t like any of the formats they provided, because they wouldn’t look clean in my theme.
If you go to your user profile and add "/badges" to the end of the URL, you’ll see a collection of badges that you can add to your website. And those happen to be in SVG format, AND they include the CodeWars logo!

Don’t badger me, bro!
Alright, but the problem is, it's not just the logo. There's a bunch of other stuff that I can't use! How do I get rid of that?
Well, that's when I remembered that SVG files are just plain text files, like HTML. In fact, SVG has a very similar syntax to HTML, and you can actually inspect SVG files using Chrome's web inspector, which helpfully even highlights the corresponding elements in the image.

From here, I could see that the icon was just a single <path> element. Good. I could download this file, and remove all the other extraneous stuff, and then I'd only be left with the logo itself. So far so good. But the logo is still in a square box, and being created from only a single path, I could not easily remove that. That's when I had to dive deeper. Time to learn us some SVG!
Okay, okay, I'm only kidding. Well... sort of. After looking up the Paths Tutorial on MDN, I quickly gave up on the idea of just editing this by hand, even with Atom's awesome SVG previewer. I needed a graphical editor. A quick Google search led me to MacSVG, which is both free AND gives you full control over the source code, while still providing helpful tools to arrange things graphically.
I'll spare you a bunch of extremely detailed and complicated fiddling with this editor. Safe to say I spent about an hour or two just whipping the outer shape of the logo into a circle. In the process, I actually learned quite a bit about how SVG paths work, and the practical difference between Bezier curves and elliptical arcs. But eventually, I had my round Codewars logo, and I had it in SVG format!

So, next, I uploaded this file to Fontello, downloaded my new font, and added it to my website theme. I'll spare you the details of another half hour or so of annoying fiddling, but in the end, it worked. Well, sorta. After reloading the site (which looked fine in the preview) in Chrome, all the other badges had disappeared, and only the CodeWars badge remained. But when I loaded the site in Safari, it looked fine, just as expected. I supposed I’ll try to fix this eventually, but after all that work, I needed a little break.
0 notes
Text
Having Fun with Proccesing.js: Langton’s Ant
The other day I solved an interesting problem on CodeWars, called Langton’s Ant. It’s a type of cellular automaton that runs on a 2-dimensional infinite grid and moves according to two very simple rules:
If the current field is colored white, make it black, turn 90 degrees to the right, and move one step forward.
If the current field is colored black, make it white, turn 90 degrees to the left, and move one step forward.
While the CodeWars problem only required you to compute a few iterations of the ant’s movement and return the resulting state of the grid, I thought it would be interesting to make a visual version that runs in the browser.
After a bit of research, I finally settled on Processing.js. Initially I had avoided it, because I did not want to learn yet another language, but after wasting a whole day trying to do pixel graphics with the Canvas API, I figured I might as well give it a shot.
Turns out it’s a near perfect fit for this exercise, and not just because it provides a point primitive, which the Canvas API does not. Processing is a very simple, C-like language that is optimized for 2D graphics. The basic program structure is extremely simple: there is a setup() function and a draw() function. The former is called once at the start of your program, while the latter is called repeatedly in order to update the screen.
But enough of the theory, let’s see the result:

JS Bin on jsbin.com
The interesting thing about Langton’s Ant is that despite its incredibly simple rules, it produces some rather interesting behavior. For a few minutes, it seems to run around the center aimlessly, until suddenly, it starts creating a sort of “highway” leading to the lower right hand corner.
If you leave it running long enough, it will eventually hit the edge of the screen and stop there, because I didn’t implement any overflow behavior, so the code will just crash at this point. One way to solve this would perhaps be by shifting the offset of the grid in the canvas, or scaling down the size of the pixels. I might try implementing that next time.
UPDATE: The new version now automatically scales the resolution once the ant hits the borders of the screen. However, once the ant starts building its highway, it will inevitably run out of space eventually.
The other interesting thing, from a computer science perspective, is the fact that the Ant works like a 2-dimensional Turing Machine. That means that given the right input (i.e. a pre-populated grid), it can compute the solution to any algorithmic problem (if given enough time).
Another idea I’d like to pursue in the future is generalizing the ant to 3 dimensions, by giving it the ability to rotate around all 3 axes (and yes, that is indeed the correct plural form of “axis”). This would mean I’d have to introduce more colors (two per axis). I’m curious to see if that same emergent behavior also works in 3D.
1 note
·
View note
Text
Elixir and Phoenix – A Review
So I've been spending some time recently learning about Elixir and Phoenix. I thought I'd share my experiences here, maybe someone will find it useful. If you've never heard of it, Elixir is a new(-ish) programming language that borrows a lot of syntax from Ruby. However, even though it looks quite similar on the surface, it's really a very different language.
Ruby is a object oriented, multi-paradigm language (meaning it supports imperative and functional programming styles). It's also interpreted, meaning that there is no compilation step. This is what makes many of the advanced features in Ruby work, but it's also the reason why it is rather slow compared to languages like Java or C, which involve a compilation step.
Elixir is similar to Java, in the sense that there is a compiler, but instead of machine code, it produces byte code that runs on a virtual machine. In the case of Elixir, this virtual machine is Erlang, a language created over 30 years ago by the Swedish telecom company Ericsson for use in their telecommunications equipment.
It turns out that Erlang has many features that are very desirable for building web applications, such as high performance, fault tolerance, and the ability to support many millions of simultaneous connections. It also has very good support for multi-core CPUs, something that is more and more important these days, now that even the smartphone in your pocket likely has multiple cores. However, Erlang's syntax is quite dated, so Elixir aims to bring Erlang into the 21st century.
Phoenix on the other hand is a web framework for Elixir. It's heavily inspired by Ruby on Rails and indeed shares many of the same features. However, it is generally at least an order of magnitude faster. Instead of taking several milliseconds, it can answer most requests in a matter of microseconds.
There is a cost, however, and that's learning a new programming paradigm. Elixir is a functional programming language, meaning that there are no objects, only functions. Furthermore, functions have to be "pure" in the mathematical sense, that is, they can have no side effects.
All data in Elixir is immutable by default, meaning it cannot be changed. If you want to make changes to a variable, you need to return a new copy that includes the changes. If this sounds expensive to you, then keep in mind that the developers thought of this and heavily optimized the compiler for this use case, so in practice, this is much faster that you'd think. Behind the scenes, the language uses many tricks to make this incredibly cheap. For example, inserting an element at the beginning of a linked list does not need to copy the entire list – since the tail of the list is guaranteed to never change, the new list can be constructed by simply making a new head and linking it to the old list.
The advantage of having immutable data is that it allows for easy parallelization. The biggest problem that languages like Ruby have with parallelization is when data needs to be shared between two threads. If two separate threads want to access the same data (say, one wants to read and another wants to write), that creates a conflict. They have to synchronize somehow, so that one thread has to wait until the other is done before accessing the shared data. This can lead to many difficult-to-resolve bugs.
In Elixir, everything is immutable, so there is no problem sharing data between threads. If one thread wants to make changes, it automatically gets its own copy of the data.
While it takes a bit of practice, but after a while it's not that difficult thinking only in functions. A web server is really just a collection of functions (AWS lambda makes that pretty clear). A request, consisting of HTTP method, URL, headers and body (for POST/PUT/PATCH) goes in, HTML comes out. Since HTTP is by definition a stateless protocol, the functional paradigm is a perfect match for this use case.
Of course, in a web app, it usually takes many steps to produce the desired response. Phoenix gives you the tools to compose your functions out of many smaller functions, and it also provides a convention to help organize them in a sensible way.
Similar to Rails, Phoenix uses the MVC (Model, View, Controller) pattern, but it introduces a few more layers to keep things neat. In Phoenix, every controller has a single view module, which in turn can have several templates. Any helper functions that are used in the view (which go into a helper module in Rails) go into the view module, assuring that they are only available to the templates that need them, not application-wide like in Rails.
Phoenix also adds a new layer of abstraction between controllers and models (called a “context”), which absorbs all the database queries. This fixes a big problem with Rails, where models often grow tremendously large because they have to deal with both business logic and database logic. Phoenix draws a clear line, separating the business logic from the database code.
Another interesting aspect of Phoenix is the idea of pipelines, which fixes another big problem of Rails: middleware. If you've ever worked on a large Rails app, it can be quite difficult figuring out exactly what filters are run for a request and in what order. Even more so if you have an application that has both an HTML frontend and an API — In this case, you often want a different set of filters to apply for API requests than you have for HTML requests. Phoenix solves this by letting you combine all the filters (which it calls "plugs") into a pipeline and then giving you a way to decide which pipeline a request should be routed through. If it's a browser request, you send it through the :browser pipeline. If it’s an API request, you send it through the :api pipeline. Neat.
All in all, it makes for quite an interesting framework. While I wouldn't exactly recommend it to someone brand new to web programming (Rails is much more beginner friendly than Phoenix), it's easy enough to pick up for someone with a few years of Rails on their back. It does take some getting used to, however – especially Ecto, the persistence layer, feels rather clunky compared to elegance of Rails's ActiveRecord (although it is no less powerful). However, the enormous performance gain might well be worth making the switch for. A single app server running Elixir and Phoenix can easily replace 10 Rails servers (and probably have room left to grow). I'm looking forward to learn more in the future.
0 notes
Text
Quick Meteor Tip: Using Inline Objects (and Arrays) in Blaze Templates
The other day, I was working on my upcoming Meteor Tutorial, and I found myself wanting to pass a literal object to a template for testing purposes. This happens more often than you'd think — for instance, the excellent dburles:google-maps package takes a single options parameter in order to support the bewildering amount of configuration settings available through the Google Maps API:
{{> googleMap name="map" options=mapOptions}}
The correct solution, of course, is to create a mapOptions helper on the template containing the map, which then return an object. Sometimes, however, you just want to test something real quick and would like to be able to pass a literal object right in the template.
If you follow your instinct, however, and write something like
{{> template param={ foo: "bar", things: [1, 2, 3] } }}
You'll find out very quickly that Spacebars doesn't support that kind of construct. However, after fooling around a bit with a suggestion made in the comments, I was able to figure out a workaround for this. I wrote two global template helpers as follows:
// This allows us to write inline objects in Blaze templates // like so: {{> template param=(object key="value") }} // => The template's data context will look like this: // { param: { key: "value" } } Template.registerHelper('object', function({ hash }) { return hash; }); // This allows us to write inline arrays in Blaze templates // like so: {{> template param=(array 1 2 3) }} // => The template's data context will look like this: // { param: [1, 2, 3] } Template.registerHelper('array', function() { return Array.from(arguments).slice(0, arguments.length-1); });
With these, you can now pass a literal object to any Meteor template as follows:
{{> template param=(object foo="bar") }}
Will result in the template's param looking like this:
{ foo: "bar" }
You can also pass literal arrays:
{{> template things=(array 1 2 3) }}
This will result in the template's data looking like this:
{ things: [1, 2, 3] }
Both helpers can be combined:
{{> template param=(object foo="bar" things=(array 1 2 3)) }}
Will result in the template's data context looking like this:
{ param: { foo: "bar", things: [1, 2, 3] } }
If this was useful, please let me know in the comments below.
0 notes
Text
Tests? We Don't Have Budget for That
The other week, someone forwarded me this article on the TopTal engineering blog. It was an interesting read, if only for the warm, fuzzy feeling of familiarity that arises when you realize that even someone who works for a company that prides itself in hiring only the top 3% of developers has to deal with the same issues as yourself.
For my last few projects, I was forced to work without automated testing and honestly, it was embarrassing to have the client email me after a code push to say that the application was breaking in places where I hadn’t even touched the code.
Right there with you, pal. This is something pretty much every developer with a modicum of experience can sympathize with. I think it’s safe to say that if you’ve never run into this problem before, you either have never worked on real life project before, or you’re a certified genius on the level of Donald Knuth, who writes a mathematical proof that his code is error free. In other words, you’re a unicorn. Most likely though, it’s the former.
What’s The Issue?
So, why is it that even the top 3% of developers have to deal with this?
Often, the client doesn’t really understand what testing is, or why it has value for the application. Clients tend to be more concerned with rapid product delivery and therefore see programmatic testing as counterproductive.
If that’s the case, it’s either the sales team’s fault for setting the wrong expectations, or it’s the developer’s fault for not explaining the value of tests properly. Either way, it’s a sales issue, not an engineering issue.
Or, it may be as simple as the client not having the budget to pay for the extra time needed to implement these tests.
In that case, maybe the client should be using off-the-shelf software instead of having a custom solution built for them.
Let’s just imagine for a second the following situation: a client walks into a car dealer’s showroom, and talks to the nearest salesperson. The following conversation ensues:
Client: “I need a new car for my family. We just got our first child and I have to replace the convertible because only has two seats.”
Salesperson: “Well, you came to the right place. All our cars have a 5 star crash safety rating.”
Client: “Well, that’s neat, but they’re so expensive. Can’t I just buy a cheaper car without a crash test rating?"
That’s literally the equivalent of what the client is asking. If you wouldn’t get on an airplane without knowing that it has undergone extensive safety testing, then why would you run your business on an app that has no tests?
At this point, of course, the comparison starts getting a little wonky. Most cars are obviously mass-produced, and therefore the money required for testing is spread out over the entire production series. But let’s say you have the money to have a custom car built for you. Would you really insist that no testing be done to it whatsoever, because “there is no budget for that”?
Obviously, not all apps are the same. Maybe the client just needs a static website. Or a landing page for collecting emails. In that case, it probably doesn’t need a lot of tests. But in that case, why pay for custom development at all? Just have someone customize Wordpress for you and you’re done. However, if you’re having an app built that you plan to run your business on, then you absolutely, positively need tests.
It’s really surprising to what degree people still believe that the rules of traditional engineering don’t apply to software engineering. As if somehow, by virtue of using a computer, the laws of the physical universe don’t apply anymore. They do. A computer is just a physical machine. It’s susceptible to influences from the physical world. Heck, the very act of programming it to do something is an influence from the physical world. The physical world is non-deterministic and occasionally produces random events. Humans make mistakes. Are you willing to bet your business against that?
No? Well, then you DO have the budget for tests.
1 note
·
View note
Text
Last week I tried "real" TDD, and it was beautiful
If you've been coding for more than a few weeks, I'm sure you've heard of Test-Driven Development, or TDD for short. The idea, of course, is deceptively simple: instead of writing code iteratively and testing it by hand, you write the test first, and then you write the code that makes it pass.
After discussing this principle with one of my mentees at theFirehoseProject, he sent me an article he found, penned by the venerable Bob Martin, in which he elucidates on the The 3 Rules of TDD. They are:
You are not allowed to write any production code unless it is to make a failing unit test pass.
You are not allowed to write any more of a unit test than is sufficient to fail; and compilation failures are failures.
You are not allowed to write any more production code than is sufficient to pass the one failing unit test.
I've been struggling with learning "real" TDD for a few years now. I chalk up most of that struggle to bad habits, which have a tendency to expand themselves. Unless you make a real commitment to change, you somehow keep finding yourself in situations where everyone else has the same avoidance habits as you.
TDD? Yes, we do that. But we write the tests afterwards. At least usually. Well, sometimes. When we have time. — Someone, at every company, every day
Now, we all know that "when we have time" in practice almost always means "never". And so, even after 5 years on the job, it's no surprise that when you find yourself thrown on the next project, even though the code is deployed to production, the tests either aren't working, hopelessly outdated, or completely non-existent. At best, there's some poor schmuck who gets paid to test the entire site by hand every time there's a deploy. True story.
Testing really is the ugly stepchild of the industry. Everyone just pays it lip service, but no one ever invites it to the party. And I'll be the first to admit that my previous encounters with TDD have often been all but fulfilling. In fact, they were mostly frustrating (I'm looking at you, RSpec). But after reading Bob Martin's 3 rules, and the advantages of following them, I couldn't help but feel a surge of motivation roll over me, followed by the desire to give it another try. Good thing I had just received a programming challenge in the mail for a job I was interviewing for. There wasn't going to be any better reason to try it than that, so I decided to give it go.
Giving it a spin
So, with the 3 rules firmly in mind, I set out to finish this challenge. Without revealing too much, it was basically a simple JSON API server with 4 endpoints, 2 POST and 2 GET. There was one collection, a POST call to create a new element in it, and a GET call to retrieve the entire collection (POST /collection and GET /collection, respectively). The other two calls were to retrieve summary statistics on the entire collection (GET /collection/summary) and to delete the entire collection (POST /collection/clear). The last one kind of broke the REST principle, but let's not be sticklers about that right now.
As Uncle Bob demanded, of course, I started with the tests. Well, I admit that I may have set up a very basic Express app skeleton first, but I definitely wrote the first test before writing any of the endpoints. Then, using supertest, I wrote a test for the first endpoint, POST /collection. Reading right off the specification I got, I outlined the following test stubs:
app = require '../src/app' request = require 'supertest' describe 'Collection API', -> describe 'POST /collection', -> describe 'GET /collection', -> describe 'GET /collection/summary', -> describe 'POST /collection/clear', ->
Of course, none of that will fail, so I added the following test case:
describe 'POST /collection', -> it 'creates a new item', -> request(app) .post('/collection') .send() .expect(200) .expect('Content-Type', 'application/json')
Keeping in mind rule number 2, I stopped here, even though you may have noticed I'm not even POSTing any data yet. This was already sufficient to fail, because after all, my server didn't even know about the /collection endpoint yet. In fact, I realized, just writing expect(200) would have been enough, checking the content type should have come later. In fact, I realized at this point, all I should have written was this (let's ignore for a moment the fact that the status code should be 201 — I was just working off of the requirements here):
it 'responds with status code 200', -> request(app) .post('/collection') .expect(200)
And so I went on to rule number 3, and wrote exactly enough production code to make this test pass:
app.post '/events', (request, response) -> response.json path: 'POST /events'
First round accomplished! That really wasn't so hard.
I'll spare you the intimate details about the rest of the journey. I think these examples are enough to get the idea. After the realization that my first step was already too big, I tried really hard to pace myself on the next iterations, doing my best to literally only write enough of a test to make the production code fail. It's a strange feeling if you've been used to doing it differently. It somehow feels like your progress is much slower, because you're taking such small steps. However, a few hours later, it really started paying off: by this time, I would have normally gotten bored and take a long-ish break to read HackerNews or catch up on Facebook or some other nonsense, but instead, I was motivated to keep going, since my code was literally all working, and I could prove it, thanks to my growing number of tests.
By the end of the afternoon, I had the entire app working according to specs, and 33 unit tests to prove my work. I was feeling great! There was only one small thing: I hadn't even added a database yet, because I had no idea how to write a test for that. In fact, my server was storing everything sent to in an array in memory, because of rule #3 ("You are not allowed to write any more production code than is sufficient to pass the one failing unit test."). However, having a database backend was definitely one of the requirements.
Now what?
I took some time that evening to think about whether it was possible to test for this, but couldn't come up with a good answer. Obviously, retaining state between tests is a no-no (that was how the requirement was worded: "we need a database to persist data between runs).
I briefly considered writing a test that actually starts the server from the command line (in another thread), runs the first part of the suite, and then terminates the server without erasing data, only to start another instance, verify that the data is still there, and then delete it. But that seemed just a bit too involved. So at this point, I decided to cheat, and I simply added the database backend without having a failing test that I needed to make work. However, after that was done, I still had my suite of 33 tests that I could run against the server to make sure everything is still working.
Overall, this was a really fun experiment, and I think I gained a new appreciation for TDD. I'll certainly try this approach again for any new project that I'll be working on. Now if only the 3 rules could help with that one project that's already in production, but doesn't have any tests whatsoever...
2 notes
·
View notes
Text
A Picture Says More Than a Thousand Words
When Apple first introduced Emojis, I was skeptical. After all, we’d all been accustomed to using text-based emoticons for about a decade and they worked (reasonably) well. Most people, at least in my age group, had no difficult understanding expressions like :) and ;). If it ain’t broken, don’t fix it, right? And after all, having to access a special keyboard to type those image-based emojis didn’t even save you any taps — it requires at least two taps to switch the keyboard and then back again.
Well, sometimes it’s not about fixing something that’s not broken, but rather about creating new opportunities. Or at least, that’s what I discovered when one fine day, I was trying to organize my life by creating a bunch of to-do lists in Apple’s (then new) Reminders app. I can’t remember exactly what sparked this idea, but when contemplating what lists I needed and how to name them, it suddenly occurred to me that I could use emojis in the name, in order to make my lists easier to find.
Rather than having to read all the titles, it occurred to me, if I used descriptive emojis, all I would have to do is look at the pictures to quickly find the list I was looking for. And for some weird reason, looking at pictures seems to require less cognitive effort than reading a bunch of text.

After a few minutes of deliberation, I came up with the scheme on the left. The “To Do” list is my default list, which acts as an inbox — this is where I add new to-dos whenever I think of them. Siri uses that list as well, whenever I ask her to remind me of something. Every week, usually on Sundays, I go through that list and prioritize everything, moving the tasks for the upcoming week into the “This Week” list. Every morning, I pick out the tasks I want to accomplish that day and move them into the “Today” list.
Apart from that, I have a few more “special” lists, for things that are also to-dos, but not urgent or need scheduling. The “Eat” list, for instance, is where I save the name of restaurants I’m planning to try out some day. The “Listen” list is where I gather the names of musical artists and podcasts that I plan on checking out. I trust that the “Read” list needs no further explanation.
But it doesn’t stop here. Emojis can be used anywhere where you can type text, so I’ve started using them in the calendar app as well. For instance, when scheduling a phone call, I’ll put the “📞” emoji as the first character in the title, followed by the name of the person I’ll be talking to. If I have an online meeting, I use “💻” instead. For scheduled errands that require driving, “🚗” is a great choice. Meeting someone for a drink? “🍻” works great. You get the idea. And while it may seem like a childish idea at first, you only need to switch to the calendar’s week view to appreciate the power of these little pictures.
Even though I’ve been doing this for about a year now, I still find new, creative uses for emojis. For instance, one of my friends uses them in his git commit messages to indicate the type of commit (“🐛” for bugfix, “➕” for a new feature, “⬆️” for upgrading dependencies, “🚧” for work in progress, “👕” for linting code, etc.). Again, when looking at a single commit, this doesn’t seem to make any sense whatsoever, but you only have to take one step back and look at the commit log, and the value instantly becomes clear.
Have you found any creative uses for emojis? Let’s hear them!
0 notes
Text
How To: Get a Push Notification When Your Heroku App is Deployed
If you’re like me, you probably have at least a few apps deployed on Heroku. And if you are taking advantage of their GitHub integration, there's a good chance you have at least one app that deploys automatically whenever you push to a certain branch. And if that's the case, you may have realized that there's a small, but important problem with that: when you push to GitHub, you no longer know when the app has finished deploying, because the whole post-deploy process now happens in the background, rather than in your terminal.
Sure, you can always log into your Heroku Dashboard, open the app, navigate to the "Activity" tab, and watch the progress from there, but who has time for that?

That’s right: nobody. So, here's the patented, "lazy programmer" solution: you set up a deploy hook. Heroku already supports several channels out of the box, such as Email, IRC, Basecamp, Campfire, and HipChat, but what if you use Slack, or you prefer a push notification instead? Well, then this guide is for you.
Without further ado, let's get started!
First, you're going to sign up for a free account at Zapier. This is a service very similar to IFTTT, but while the latter seems to be more prolific in their marketing, Zapier’s engineers have been busy creating more API integrations. Unfortunately, neither of the two list Heroku as supported service. But fear not, we can still make this work, because Heroku was nice enough to also provide a HTTP hook.
Second, you'll need some way to receive notifications. In this guide, I'll be using Pushover for that purpose, but you can also use InstaPush, Basecamp, or Slack for this purpose. Or, if you’re old school, you can even have an SMS send to your phone (come on now, it’s 2016, time to ditch that feature phone and get with it, grandpa).
Once you've created your account on Zapier, you'll see the dashboard, with a big orange "Make a New Zap" button. Click it. You should see the following screen:

Type “webhook” into the search box, and select “Webhooks by Zapier” from the autocomplete dropdown. You should see the following screen:

Select “Catch Hook” and click the “Save + Continue” button. You’ll see this screen next:

We don’t need this part, so just click the “Continue” button. Now you will see this:

The textbox contains a randomly generated URL, which is where Zapier will receive notifications from Heroku. Copy this URL to your clipboard and click “Ok, I did this”. Zapier is now waiting for Heroku to send it some sample data to verify that the hook is working.
Next, we'll have to do some setup in Heroku. Log into your Heroku dashboard, open your app, and under "Resources", type "Deploy Hooks" into the search box and add the add-on from there. Paste the URL you copied into the input box and click the "Save and Test" button. Now, go back to Zapier. It should now tell you that the test was successful. On to the next step!

Click "Continue", select “Push Notification” on the next screen, and then select the Pushover account to use (or set up a new one).

Finally, here comes the fun part: this is where you set up the push notification. Pushover supports a lot of options. You can play around with these or just use the settings from my screenshot:

Note that if you set a URL, clicking on a push notification will take you to that URL right away. In other words, if you put the placeholder for your app’s URL in that field, tapping on the push notification will take you straight to your app. Neat!
Lastly, Zapier will ask you to test this step by sending a push notification to your account:
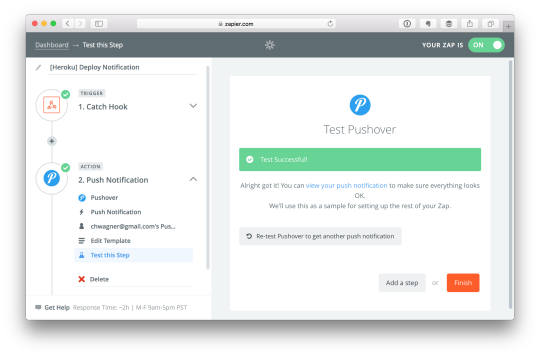
All you need to do now is set a name for this trigger and save it by clicking “Finish”. Voila, Heroku will now send you a push notification anytime your app is deployed.
UPDATE: As luck would have it, Zapier deployed a completely new UI for creating and editing Zaps just two days after publishing this article. I will update it soon with new screenshots.
UPDATE 2: Just revised the article and updated it with current screenshots. Enjoy!
0 notes
Text
Exercism just helped me ace a job interview
So the other day I blogged about how practice helps improve your code game. Well, I already have a success story to share! I'm currently in the process of interviewing with TopTal, a company that prides itself on hiring only the top 3% of freelancers. I had my second round inteview this week, and surprise, surprise! it was a live coding test.
So I was on Skype with a very friendly fellow from Brazil, and after a few minutes of smalltalk, he asked me to share my screen, and then he gave me my first task. Once he confirmed that I had understood what he was asking, he set a timer for 20 minutes. Alright, go time!
A few years ago I would have been super nervous. Even a few weeks ago, I might have just started tripping all over myself trying to figure out what to do first – write the code? Write some tests? Wait, what's the syntax again?
When I code Rails I normally use RSpec (old habits die hard), but that's way too heavy for a little test, and it tends to break down when you least expect it. I got 20 minutes, there's no time to babysit my test framework!
Thankfully, I had taken my own advice and worked on a few Exercisms this week. So, instead of going into panic mode, I just calmly explained to my interviewer that I'd just copy and paste the setup code for the test, and then write a test according to his requirements. There were a few test cases given in the problem setting, so I simply wrote a test method for each of them, which let me think about the interface to my code before I even wrote it.
Then I showed him that the tests were failing, and explained that now I was going to make them work now. Then I opened up the other file and started writing the actual code. From here on out, it was just like solving another exercism. Since I had practiced this all week, all of this happened pretty much on autopilot.
And that's exactly what you want in a situation like this. Knowing all the motions you need to go through my heart makes you feel calm and collected, and look cool as a cucumber. While my hands were busy banging out the test cases, my subconscious mind was already working on a solution. And by the time I was ready to write the first line of code, I already had my attack planned out.
Long story short, I finished the first problem in under 10 minutes, and the second in 3. Not being nervous had a LOT to do with it. The interviewer congratulated me and told me I'm moving on to the next round.
So, what are YOU waiting for? Go practice!
4 notes
·
View notes
Text
How to Level Up Your Coding Skills in 20 Minutes a Day
Okay, hands up if you got into coding because of an inspiration. Did you start this journey because you had an idea for an app that you wanted to build? Now that you're three, four, five months down the rabbit hole, how is that inspiration holding up? Not so well? I see.
Have you spent the last three weeks repeatedly banging your head against the wall because there was some problem that you just COULD NOT solve? And then when you tried working on a different part of your app, within a day or two you ran into another brick wall? Is your code starting to resemble a maze and you can't seem to find the exit anymore?
Trust me, I've been there. It sucks. It makes you doubt yourself, doubt your intelligence, and it just wants to make you give up, doesn't it? But then, when you've had some time to recharge, like, say, after a vacation or a fun weekend out with your friends, it's right there again: that inspiration, that vision that you had, that made you get into this whole thing in the first place. But now it almost feels like it's taunting you. Like a fata morgana that you just can't reach, no matter how hard to you try.
Unfortunately, that happens to a LOT of people. It happened to me as well. Fortunately, there's a solution, but it requires that you're willing to face an uncomfortable truth. Are you ready to hear it?
You. Just. Don't. Practice. Enough.
Admit it. You kinda thought you could just learn a bit of Ruby or JavaScript, take that bootcamp, and then wing it until your awesome app hits the front page of Product Hunt or Tech Crunch, and then you'd be rolling in dough like good ol' Scrooge McDuck.

He's judging you.
Well, I don't blame you, since that's what all those bootcamp advertisements basically promised you. But if you think about it, it becomes obvious pretty quick: it's a bit like walking into a NBA pro tournament after playing hoops all day with your buddies at summer camp, and expecting to beat Kobe Bryant at a penalty shootout. It's just not very likely to happen.
Now, what's the difference between you and Kobe Bryant? That's right: HE'S HAD MORE PRACTICE. Plain and simple. That's the bad news and the good news. Bad, because it means that the rolling in dough part might just have to wait for a while longer. Good, because it means you can DO something about it.
You practice.
How do you practice? Well, first of all, you do it every day. Do you think Kobe takes a day off from practicing free throws, just because he's already done it like a million times? I bet you he doesn't. The key is making your practice a daily habit. It should be as automatic as making coffee when you get up, or brushing your teeth before bed.
Second, what makes practice different from a tournament? The stakes are much lower. Instead of having thousands of spectators watch your every move (and millions on TV), you practice in an empty gym, at 6 in the morning, when nobody's around. Let's translate that into coding terms. Your app, the thing that got you into this whole thing in the first place, that's the tournament. This is prime time. It's where all your knowledge, skills and preparation come together to make something amazing happen.
So, where's the empty gym at 6 in the morning? Right here:
CodeWars.com
CodeCombat.com
Exercism.io
All of these sites let you practice your coding skills by solving short, focused problems by writing throwaway code (i.e., code that you don't really have to maintain later). Two of these, CodeWars and Exercism, let you see other people's solutions (AFTER solving a problem yourself), and discuss your code with other members. The third, CodeCombat, is actually aimed at middle school kids, but it's fun for grownups nevertheless. Plus, it starts getting more challening a few worlds into the game. At the very least, it's a fun way to practice the basics if a particularly difficult problem on one of the other sites kicked your ass.
If you're serious about learning coding, these sites should be at the top of your bookmark list. They should be the first thing that pops up when you just type their first letter into your browser's address bar. If you want to get better at coding, make a commitment to attempt to solve at LEAST one problem on any of those sites each day. Even if you don't feel like it. Even if it seems too hard. Try and spent at LEAST 20 minutes coming up with solutions, even if none of them work. Do you think Kobe started out by hitting every single throw?
Yeah, neither did I.
161 notes
·
View notes
Text
Atom: Disable weird popups when navigating in Vim-Mode on Mac OS X
I've recently decided to give GitHub's Atom Text Editor another chance, after the long await 1.0 release. Of course, as a long time Vim user, the first package I installed was vim-mode, along with ex-mode to make me feel right at home. So far, so good.
Most Vim commands worked perfectly, even advanced motion commands like ciw or daW are working like they're supposed to. However, one thing that bothered me was a weird popup that would appear every so often when navigating using the l key, as demonstrated on the GitHub issue that was filed regarding this problem:

Thanks to GitHub user @rastasheep, however, there appears to be a solution:
Mac OS X Lion introduced a new, iOS-like context menu when you press and hold a key that enables you to choose a character from a menu of options. If you are on Lion try it by pressing and holding down e in any app that uses the default NSTextField for input.
It's a nice feature and continues the blending of Mac OS X and iOS features. However,it's a nightmare to deal with in Atom if you're running vim mode, as it means you cannot press and hold h/j/k/l to move through your file. You have to repeatedly press the keys to navigate.
defaults write com.github.atom ApplePressAndHoldEnabled -bool false
Alternately, if you want this feature disabled globally, you can enter this:
defaults write -g ApplePressAndHoldEnabled -bool false
In either case you'll need to restart Atom for the change to take place.
Happy coding!
1 note
·
View note
Text
Don’t Learn CoffeeScript Until You Understand JavaScript (Part 3)
In the last part of this series, we've taken a deeper look at JavaScript's prototypal inheritance model, and how it differs from the "classic" OOP model championed by languages such as Ruby, Python, Java, and C++. In this part, we'll take a look at how this knowledge can make you better at writing CoffeeScript. You might also be interested in part 1, which discusses my motivation for doing this.
CoffeeScript, while bearing many (intentional) similarities to JavaScript, is a complete programming language in its own right, and includes a full self hosting compiler, as is par for the course. However, that compiler, does not of emit machine code (such as C/C++) or bytecode (such as Java). Instead it produces plain, 100% human readable (though not optimized) JavaScript. Therefore, anything you can do in CoffeeScript, you can do in JavaScript. As the CoffeeScript homepage states:
The golden rule of CoffeeScript is: "It's just JavaScript"
You could compare CoffeeScript with a preprocessor, but that would not be entirely correct. A preprocessor can only add things to the language (like macros), but CoffeeScript removes a significant amount as well — such as semicolons, curly braces, the === operator, just to name a few. Basically, the goal of CoffeeScript is to fix JavaScript's most egregious bugs and design flaws, and expose the simple and beautiful core underneath it.
A Better JavaScript
The most distinctive syntactic differences to JavaScript are immediately obvious: semicolons are not required (and not inserted automatically in surprising ways either). Curly braces are (mostly) unnecessary, too. CoffeeScript instead requires you to indent your code properly in order to create blocks, just as in Python. Finally, parentheses for function calls are optional as well, at least as long as there is at least one argument. Argument-less function calls still require parentheses, however (so they can be distinguished from accessing the function itself). Finally, function literals are written using a single (->) or double arrow (=>) to separate the parameter list from the function body. All in all, CoffeeScript looks like a mixture of Ruby and Python, except for the somewhat unusual (but elegant) function syntax.
To anyone who has used CoffeeScript before, it comes as no surprise that the next iteration of JavaScript, ES6, contains a lot of syntax improvements that are almost 100% identical to what CoffeeScript had for the last few years.
Okay, so how does knowing JavaScript make you better at CoffeeScript?
Since JavaScript is now one of the world's most popular programming languages, there's a lot of code out there that's already written in it. A LOT. Therefore, chances are that if you're going to write anything in CoffeeScript, more often than not, you'll be either integrating with other JavaScript code, leveraging existing libraries written in JavaScript, or (most likely) both. It makes sense, therefore, to at least familiarize yourself with some of the patterns that are common in JavaScript, and how CoffeeScript implements some of its "magic" features in plain old JS. Let's start, shall we?
Everything is an Expression
CoffeeScript implements Ruby's philosophy of "everything is an expression". So you can do stuff like this:
over_18 = if user.age > 18 then false else true
This compiles to the following JavaScript:
var over_18; over_18 = (function() { if (user.age < 18) { return false; } else { return true; } })();
Granted, an experienced JavaScript developer could have made this a one-liner, too:
var over_18 = (user.age >= 18);
But it's not quite as readable, and might take most junior devs a few minutes and some head scratching before they get that the result is always a boolean. The CoffeeScript version is marginally longer, but MUCH easier to read.
By the way, you'll find this pattern extremely often in JavaScript code that was generated by the CoffeeScript compiler. CoffeeScript makes use of this any time it needs to turn something into an expression that's ordinarily a statement, for instance, the switch statement.
Keeping it Classy
Inheritance in JavaScript has always been a bit messy, so CoffeeScript decided to introduce some nice syntactic sugar for it (which then promptly made it into the next release of JavaScript, ES6).
class Animal constructor: (@name) -> move: (meters) -> alert @name + " moved #{meters}m."
This is a lot more straightforward and easier on the eye than the traditional JavaScript way of doing the same thing:
function Animal(name) { this.name = name; } Animal.prototype.move = function(meters) { return alert(this.name + " moved " + meters + "m."); };
Of course, in order to really make use of this pattern, you need to also be able to recognize it in existing JavaScript code. In other words, when you see something like the second example, your brain should go "oh, that's a class in CoffeeScript, and and move is an instance method." Bonus points for extending a JavaScript "class" using CoffeeScript.
Fat Arrows, Two Ways
The this keyword is probably one of the most misunderstood parts of JavaScript, yet one of the most frequently used ones at the same time. It really pays off to spend some time to get to know it better, including the tools you need to bend it to your will (call/apply and bind). I promise you'll have much fewer mystery bugs and your day will be a lot more productive.
Since manipulating the scope of this is such a frequent requirement, CoffeeScript brings some additional syntax to make things more pleasant. By using a "fat arrow" => instead of a regular one when defining a function, a function will automatically inherit its parent's scope's this. In other words, no more
var self = this; $('#whatever').on('click', function(event) { self.setColor(event.target.value); // or something involving `this` });
However, things get a little confusing when using the fat arrow for defining methods on objects, as opposed to anonymous functions.
foo = foo: 'bar' test: => console.log @foo class Foo foo: 'bar' test: => console.log @foo foo.test() test = (new Foo).test test()
This is compiled to the following JavaScript:
var Foo, foo, test, bind = function(fn, me){ return function(){ return fn.apply(me, arguments); }; }; foo = { foo: 'bar', test: (function(_this) { return function() { return console.log(_this.foo); }; })(this) }; Foo = (function() { function Foo() { this.test = bind(this.test, this); } Foo.prototype.foo = 'bar'; Foo.prototype.test = function() { return console.log(this.foo); }; return Foo; })(); foo.test(); test = (new Foo).test; test();
This code will produce the following output:
undefined bar
Even though we used the fat arrow both times, and we called the first function with the proper object reference, and the second one without, only the latter did what we expected. Why is that?
If you look closely, you'll see what happened: in the first declaration, CoffeeScript still uses the this from the surrounding scope (which is, in this case, empty). In other words, the function is bound at the time it's declared. In the second part, however, the function is not bound until an instance of the class is created. Only when the constructor is executed, the function is bound to the current instance. Unfortunately, the CoffeeScript docs don't do a very good job at explaining this (in fact, it's not mentioned at all).
Summary
CoffeeScript vastly reduces the amount of clutter in your code, and enforces good habits by requiring proper code indentation. However, since we can't live exclusively on CoffeeScript island, we have venture out into JavaScript land from time to time, and collaborate with its denizens. Therefore, knowing the local customs and idioms is extremely helpful, even if you don't plan on making your life there.
3 notes
·
View notes
Text
This Meteor has crashed
So about a year ago I started working on a side project, because I was bored at work and I kept hearing about this new framework called Meteor, which supposedly made building Single Page Apps stupidly simple.
I started my app somewhere around version 0.5. Turns out it really was deceptively simple to get a working app, and I made progress very quickly. Over the summer and the fall, new versions of the framework kept getting released, but updating was usually a breeze. That is, until the big 1.0 rolled around.
This one was a bitch to install. The entire packaging system had changed, from being an unofficial hack to being part of the platform. It took months until I finally found the time to complete the migration.
Last weekend I took the project out again to do some work. But upon starting the server, it failed with the following error message:
TypeError: Object # has no method 'host'
The error was not coming from any of my own code, rather, from somewhere deep inside the framework. Googling for the error message yielded only one result, a StackOverflow question with zero answers.
At a loss, I went on IRC, where someone in #meteor suggested I try meteor reset. I did, but alas, it changed nothing. It also made me wonder what on earth this command does? Overall, Meteor is pretty opaque as it is, and this just added another notch to the tally. It seems the maintainers do not want to bother "ordinary" developers with the complexity of the internal workings of the magic, and instead prefer them to learn a variety of arcane incantations.
Update
Finally, in a last hope effort, I noticed that I had a node_modules directory in my Meteor project, which was left from some experiments I did with the json-server module. As soon as I deleted it, the server started up cleanly again.
Of course, this makes some amount of sense, since Meteor's strategy is to bundle any and all JavaScript code it finds in your project, unless it's in the server directory. It's really a shame that the developers not only eschew the standard NPM packaging system, but haven't even thought about providing a safeguard to prevent accidents like this one. This certainly puts a dent into the comet's shiny exterior.
0 notes
Text
Don’t Learn CoffeeScript Until You Understand JavaScript (Part 2)
In the last part, I talked about my motivation for re-learning JavaScript. In this part, I'll tell you how I went about it. The third part will be about how being better at JavaScript will make you better at CoffeeScript as well.
After the sobering conclusion that I didn't really know how to write JavaScript very well, I decided to fix this once and for all. It just seemed to make sense. Web application had (and still have) been consistently getting more front-end heavy, and after serving as a sideshow for almost 15 years, JavaScript was getting ready for prime time. Everyone was investing in it, and Google was leading the charge. But where to start?
"Let's ask Google," I thought. They should know.
Well, I don't remember exactly what I typed into Google, but I do remember the most important resources I found. The first was JavaScript Garden. After having struggled for months tripping over each and every of JavaScript's weird idiosyncracies, each of them often costing me a few hours, or sometimes up to a day of coding, I finally had a complete compendium of ALL the bugs and wrinkles in JavaScript, and how to work around them. This resource should definitely be in every JavaScript coder's bookmarks. It also helped me to finally disabuse myself of the notion that I actually understood JavaScript in some way, just because I had been a Java programmer for two and a half years, and JavaScript's syntax is similar to Java's. This was my extraction from the Matrix of false belief.
Now, the next step was finding a resource to help me re-learn JavaScript, from the ground up. My Nebuchadnezzar, if you will. This came in the form of the excellent (and free!) Eloquent JavaScript by Marijn Haverbeke. This wonderful book teaches JavaScript as a first programming language, and it does so with impeccable style and attention to detail. Especially chapter 6 was extremely helpful in overcoming my preconceived notions about how JavaScript's object orientation should work, and instead understand how it actually does work.

The Nebuchadnezzar
I'm not going to lie to you though — this chapter is still rather dense, and you might need to read it and re-read it a couple of times. In order to better process what I learned and deepen my own understanding, I then signed up to give a talk about the JavaScript object model at one of the weekly tech talks held at our company.
Here's the TL;DR: JavaScript features prototypal inheritance, which is in stark contrast to the classic class-based inheritance used by almost all other object oriented languages. In prototype-based inheritance, there are no classes. Instead, there are only objects (what is called instances in other languages). Anytime you write {} in JavaScript, you've created an object. Since functions are values, you can outfit your object with methods simply by attaching function-valued properties. If a function is called via an object , the this keyword inside the function body will be bound to the object the function was called on:
var person = {name: "Simon"}; person.speak = function (line) { console.log(this.name + " says '" + line + "'"); } person.speak("Jump in the air!"); // → Simon says 'Jump in the air!'
Objects, Prototypes, Oh My...
Now, how does inheritance work without classes? Simple: it works just like in a real world. Each object has an ancestor, the so-called prototype. By default, if an object's prototype isn't otherwise specified, it will be Object.prototype. This default prototype contains methods that are common to all JavaScript objects, such as the well-known .toString(), or .hasOwnProperty(). Anytime you create an object using the literal notation {...}, its prototype is going to be Object.prototype.
One way to imagine this is to literally visualize objects being people, and the prototype being their parent (since objects don't reproduce sexually, they'll only have one parent instead of two). An object inherits all of its parent's properties, but has the option to modify (i.e. override) them.

JavaScript: a class-less system
Now, we know from experience that certain objects in JavaScript have additional methods, which are only available on objects of that type. For instance, arrays have a .forEach() method, functions have .call() and .apply(), and strings have .toUpperCase() and .toLowerCase(), among others. It would make sense then, that all arrays would share a common Array prototype, functions have a Function prototype, and strings have String prototype. And indeed that is the case (you can find the prototype of an object using Object.getPrototypeOf()):
Object.getPrototypeOf([])) == Array.prototype; // → true Object.getPrototypeOf(function() {})) == Function.prototype; // → true Object.getPrototypeOf('') == String.prototype; // → TypeError: Object.getPrototypeOf called on non-object // Oh JavaScript...
And all of those prototypes actually contain the methods we mentioned above:
Array.prototype.hasOwnProperty('forEach'); // → true Function.prototype.hasOwnProperty('call'); // → true Function.prototype.hasOwnProperty('apply'); // → true String.prototype.hasOwnProperty('toUpperCase'); // → true String.prototype.hasOwnProperty('toLowerCase'); // → true
Inheriting Prototypes
Now, inheritance traditionally works in multiple levels: Class A can inherit from class B which can inherit from class C, which makes all methods (and properties) of class C available in class A, as long as they aren't overridden somewhere along the line (either in class B or in class A itself).
The same goes for prototypal inheritance. For example, an array's prototype is Array.prototype, which is an object. All objects, if not otherwise specified, have Object.prototype as their prototype, and Array.prototype is an object — therefore, its prototype must be Object.prototype:
Object.getPrototypeOf(Array.prototype) == Object.prototype; // → true
Okay. I know what you're thinking. "Does it have to be Object.prototype? Couldn't it be something else?"
Yes, it could. There could be another prototype nestled in between. And another, and another... before we finally get to Object.prototype. This is what's known as a prototype chain. And understanding the prototype chain is essential to solve the mystery of how JavaScript's classes work. This chain defines how JavaScript resolves properties on objects.
For instance, an empty array [] has the following prototype chain:
[] → Array.prototype → Object.prototype
Any property or method that we might call on an array has to be defined somewhere in that chain. Let's say we call [].toString(). JavaScript will first look in the array object itself, but it will come up empty. Next, it will start traversing the prototype chain, going one level up to the ancestor, Array.prototype. As it happens, Array.prototype contains a .toString() method (which thus overrides the default .toString() implementation from Object.prototype). The runtime found a match, so it will execute that function.

Not that kind of prototype chain
Let's say we try another method, one that is implemented on Object.prototype, but not Array.prototype. .hasOwnProperty() is such a method. In this case, the runtime would come up empty in Array.prototype, and traverse the chain another level up, looking in Object.prototype, where this method is defined. It finds a match there, and executes the function.
If the interpreter has finished traversing the entire prototype chain, but still comes up empty, it will consider that property to be undefined. Of course, if you tried to call it as a method (by providing an argument list), this will cause the well-known TypeError: undefined is not a function.
Before we move on, let's finish this off with an example showing how to set up a prototype chain yourself. We'll be creating some ancestors for Simon. Let's start with his grandpa:
var simonsGrandpa = {name: "Simon's Grandpa"}; simonsGrandpa.speak = function (line) { console.log(this.name + " says '" + line + "'"); } simonsGrandpa.speak("How do you do?"); // → Simon's Grandpa says 'How do you do?'
Next, we'll create his dad. You'll see that he inherits some of his behavior from Simon's grandpa, but he also learns a new trick:
var simonsDad = Object.create(simonsGrandpa); simonsDad.name = "Simon's Dad"; simonsDad.proclaim = function() { this.speak("But I would walk 500 miles"); } simonsDad.speak("Fine and dandy."); // → Simon's Dad says 'Fine and dandy.' simonsDad.proclaim() // → Simon's Dad says 'But I would walk 500 miles'
Finally, here's Simon:
var simon = Object.create(simonsDad); simon.name = "Simon";
Simon inherits everything from his dad and his granddad:
simon.speak("Jump in the air!"); // → Simon says 'Jump in the air!' simon.proclaim(); // → Simon says 'But I would walk 500 miles'
Now, let's teach Simon something new, by modifying a behavior he learned from his dad. In order to do this, we need to access the version of proclaim from Simon's prototype:
simon.proclaim = function() { Object.getPrototypeOf(this).proclaim(); this.speak("And I would walk 500 more"); } simon.proclaim() // → Simon's Dad says 'But I would walk 500 miles' // → Simon says 'And I would walk 500 more'
Whoops! What happened here? What's Simon's dad doing here? Well, remember that this in JavaScript is always set to the object a method was invoked on. In this case, that's Simon's prototype, i.e. his dad. In order to have that method work on Simon instead, we need to use .call() or .apply(), and specify the target object explicitly:
simon.proclaim = function() { Object.getPrototypeOf(this).proclaim.apply(this); this.speak("And I would walk 500 more"); } simon.proclaim() // → Simon says 'But I would walk 500 miles' // → Simon says 'And I would walk 500 more'
Prototype, meet Constructor, Constructor, meet Prototype
The next and final piece to this puzzle is the constructor. If you have spent any time at all around JavaScript, you will have noticed that you can create objects of a specific type using the same notation that's used in other languages. For example, you can create an array using new Array(). That looks a lot like we're instantiating a class, doesn't it?
Yes. And no. Let me explain. What the new operator is doing is simply calling a function as a constructor. What happens behind the scenes is this: the runtime allocates a new, empty object, setting its prototype to the constructor function's .prototype property. Then, it invokes the constructor function, with this set to the newly created object. The constructor function can then make any modifications to the object that it wishes. The following examples illustrates that:
function Person(name) { this.name = name; } console.log(Person.prototype); // → '{}' Person.prototype.speak = function(line) { console.log(this.name + " says '" + line + "'"); }; var simon = new Person('Simon'); simon.speak("Stick out your tongue!"); // → Simon says 'Stick out your tongue!'
So there you have it: this is the essence of prototypal inheritance. In the next part, I'll talk about how being good a JavaScript makes you better at CoffeeScript. If you have any questions, comments, or suggestions, please share them below.
2 notes
·
View notes
Text
Don't Learn CoffeeScript Until You Understand JavaScript (Part 1)
When I first found out about CoffeeScript a few years ago, I was immediately hooked. Here was a language that looked a lot like Ruby, in fact, it borrowed almost all the syntax from Ruby, and mixed in a little bit of Python just for aesthetic effect. It promised to get rid of the most annoying bugs and wrinkles in JavaScript, while making it look like a language I already knew and loved. It had a sane syntax for defining classes, array comprehensions, and a variety of other goodies I had come to love. THIS was going to be the end of my shitty JavaScript days.
I couldn't have been more wrong.
Let me set the scene for you: at that point in my life, I was working as a Rails engineer in a very corporate setting, but ironically, most of my day-to-day work was actually spent writing JavaScript. By some strange twist of fate, even though I was hired because I knew Ruby, the majority of the tickets I was assigned where 100% frontend. Which meant JavaScript. Which I was in no way or shape qualified to do. It's not that I didn't know JavaScript — technically, it was the language I had the most experience in, seeing as I had made a switch from Java to Ruby midway through my career.
I just didn't know how to write JavaScript well.
Consequently, the front end code I was banging out quickly turned into a hot mess. It all had started so innocently: just a little jQuery typeahead over here, a little jQuery UI calendar over there. An action button that validated the form input and sent it to the server for further processing. Nothing fancy. But fast forward about eight months, and I was dealing with over 300 lines of spaghetti code, everything tightly coupled, and if you changed something on one end, it would break on another.
Unfortunately, due to management somehow consistently firing or losing the most competent senior engineers, there was no one around that I could ask for guidance, either. So I had to help myself. And as it frequently happens when you desperately need help, but you're not sure what KIND of help, I found the wrong help. It went by the name of CoffeeScript.
When I first clicked the link that lead to the CoffeeScript website, my tired eyes were lighting up. THIS I could do. THIS was going to be the solution. CoffeeScript would save my ass, by allowing me to write code in a way I already knew, without having to waste hours of my day figuring out which of JavaScript's many bugs I just just ran into.

I would just rewrite my 300 lines of spaghetti code in CoffeeScript, and because I no longer had to worry about all the nasty JavaScript bugs, it was going to work SO much better and be SO much more maintainable.
Yeah right.
After spending a few weeks trying to re-code the entire front-end code in CoffeeScript, I came to a very sobering conclusion. My 300+ line JavaScript mess was now a 200 line CoffeeScript mess. It was still tightly coupled. It was still breaking as soon as I started making modifications. And it still barely made sense, even to me. Mostly, it was just JavaScript, but with function replaced by pointy arrows. Because that was the only way I had gotten it to work with the other libraries I was using.
It slowly dawned on me that CoffeeScript is, in the end, still "just JavaScript". It's just syntactic sugar, designed to work around the most egregious flaws in the language. All the fancy constructs, like classes and array comprehensions — at the end of the day, they just mapped to equivalent JavaScript code. And I realized that if I wanted my CoffeeScript code to cleanly interface with other JavaScript code, I'd actually have to understand how it all worked under the hood. I'd have take apart the engine and see what made it work. And that meant having to re-learn JavaScript, from scratch.

In the next part, I'm going to explain how I went about re-learning JavaScript, the resources I used, and the key insights I got.
5 notes
·
View notes
Text
CoffeeScript: entering multiple lines in the REPL
Finally found a solution to one of my most annoying complaints about the CoffeeScript REPL: turns out you can write code spanning multiple lines after all!
Just press Ctrl+V at the prompt to turn on multiline mode.
Thanks to Alex on StackOverflow for this.
0 notes