Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by exeton and here's what we found interesting.
Average Info
Notes Per Post
5
Likes Per Post
2
Reblog Per Post
3
Reply Per Post
0
Time Between Posts
5 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Supercharging Generative AI: The Power of NVIDIA RTX AI PCs and Cloud Workstations

Introduction
Generative AI is revolutionizing the world of Windows applications and gaming. It’s enabling dynamic NPCs, helping creators generate new art, and boosting gamers’ frame rates by up to 4x. But this is just the beginning. As the capabilities and use cases for generative AI grow, so does the demand for robust compute resources. Enter NVIDIA RTX AI PCs and workstations that tap into the cloud to supercharge these AI-driven experiences. Let’s dive into how hybrid AI solutions combine local and cloud-based computing to meet the evolving demands of AI workloads.
Hybrid AI: A Match Made in Tech Heaven
As AI adoption continues to rise, developers need versatile deployment options. Running AI locally on NVIDIA RTX GPUs offers high performance, low latency, and constant availability, even without internet connectivity. On the other hand, cloud-based AI can handle larger models and scale across multiple GPUs, serving many clients simultaneously. Often, a single application will leverage both approaches.
Hybrid AI harmonizes local PC and workstation compute power with cloud scalability, providing the flexibility to optimize AI workloads based on specific use cases, cost, and performance. This setup ensures that AI tasks run efficiently, whether they are local or cloud-based, all accelerated by NVIDIA GPUs and the comprehensive NVIDIA AI stack, including TensorRT and TensorRT-LLM.
Tools and Technologies Supporting Hybrid AI
NVIDIA offers a range of tools and technologies to support hybrid AI workflows for creators, gamers, and developers. Let’s explore how these innovations are transforming various industries.
Dream in the Cloud, Create Locally on RTX
Generative AI is a game-changer for artists, enabling them to ideate, prototype, and brainstorm new creations. One such solution, Generative AI by iStock — powered by NVIDIA Edify — provides a generative photography service built for artists. It trains on licensed content and compensates contributing artists.
Generative AI by iStock offers tools for exploring styles, modifying parts of an image, and expanding the canvas, allowing artists to quickly bring their ideas to life. Once the creative concept is ready, artists can switch to their local RTX-powered PCs and workstations. These systems provide AI acceleration in over 125 top creative apps, allowing artists to realize their full vision, whether they are using Photoshop, DaVinci Resolve, or Blender.
Bringing NPCs to Life with Hybrid ACE
Hybrid AI is also revolutionizing interactive PC gaming. NVIDIA ACE enables game developers to integrate state-of-the-art generative AI models into digital avatars on RTX AI PCs. Powered by AI neural networks, NVIDIA ACE allows developers to create NPCs that understand and respond to human player text and speech in real-time, enhancing the gaming experience.
Hybrid Developer Tools for Versatile AI Model Building
Hybrid AI also facilitates the development and fine-tuning of new AI models. NVIDIA AI Workbench allows developers to quickly create, test, and customize pretrained generative AI models and LLMs on RTX GPUs. With streamlined access to popular repositories like Hugging Face, GitHub, and NVIDIA NGC, AI Workbench simplifies the development process, enabling data scientists and developers to collaborate and migrate projects seamlessly.
When additional performance is needed, projects can scale to data centers, public clouds, or NVIDIA DGX Cloud. They can then be brought back to local RTX systems for inference and light customization. Pre-built Workbench projects support tasks such as document chat using retrieval-augmented generation (RAG) and customizing LLMs using fine-tuning.
The Hybrid RAG Workbench Project
The Hybrid RAG Workbench project provides a customizable application that developers can run locally or in the cloud. It allows developers to embed documents locally and run inference either on a local RTX system or a cloud endpoint hosted on NVIDIA’s API catalog. This flexibility supports various models, endpoints, and containers, ensuring developers can optimize performance based on their GPU of choice.
Conclusion
NVIDIA RTX AI PCs and workstations, combined with cloud-based solutions, offer a powerful platform for creators, gamers, and developers. By leveraging hybrid AI workflows, users can take advantage of the best of both worlds, achieving high performance, scalability, and flexibility in their AI-driven projects.
Generative AI is transforming gaming, videoconferencing, and interactive experiences of all kinds. Stay informed about the latest developments and innovations by subscribing to the AI Decoded newsletter. And if you found this article helpful, consider supporting us! Your support can make a significant difference in our progress and innovation!
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
1 note
·
View note
Text
NVIDIA CEO Predicts AI-Driven Future for Electric Grid

Introduction:
In a talk at the Edison Electric Institute, NVIDIA’s CEO, Jensen Huang, shared his vision for the transformative impact of generative AI on the future of electric utilities. The ongoing industrial revolution, powered by AI and accelerated computing, is set to revolutionize the way utilities operate and interact with their customers.
NVIDIA CEO on the Future of AI and Energy
Jensen Huang, the founder and CEO of NVIDIA, highlighted the critical role of electric grids and utilities in the next industrial revolution driven by AI. Speaking at the annual meeting of the Edison Electric Institute (EEI), Huang emphasized how AI will significantly enhance the energy sector.
“The future of digital intelligence is quite bright, and so the future of the energy sector is bright, too,” Huang remarked. Addressing an audience of over a thousand utility and energy industry executives, he explained how AI will be pivotal in improving the delivery of energy.
AI-Powered Productivity Boost
Like many industries, utilities will leverage AI to boost employee productivity. However, the most significant impact will be in the delivery of energy over the grid. Huang discussed how AI-powered smart meters could enable customers to sell excess electricity to their neighbors, transforming power grids into smart networks akin to digital platforms like Google.
“You will connect resources and users, just like Google, so your power grid becomes a smart network with a digital layer like an app store for energy,” he said, predicting unprecedented levels of productivity driven by AI.
AI Lights Up Electric Grids
Today’s electric grids are primarily one-way systems linking large power plants to numerous users. However, they are evolving into two-way, flexible networks that integrate solar and wind farms with homes and buildings equipped with solar panels, batteries, and electric vehicle chargers. This transformation requires autonomous control systems capable of real-time data processing and analysis, a task well-suited to AI and accelerated computing.
AI and Accelerated Computing for Electric Grids
AI applications across electric grids are growing, supported by a broad ecosystem of companies utilizing NVIDIA’s technologies. In a recent GTC session, Hubbell and Utilidata, a member of the NVIDIA Inception program, showcased a new generation of smart meters using the NVIDIA Jetson platform. These meters will process and analyze real-time grid data using AI models at the edge. Deloitte also announced its support for this initiative.
In another GTC session, Siemens Energy discussed its work with AI and NVIDIA Omniverse to create digital twins of transformers in substations, enhancing predictive maintenance and boosting grid resilience. Additionally, Siemens Gamesa used Omniverse and accelerated computing to optimize turbine placements for a large wind farm.
Maria Pope, CEO of Portland General Electric, praised these advancements: “Deploying AI and advanced computing technologies developed by NVIDIA enables faster and better grid modernization and we, in turn, can deliver for our customers.”
NVIDIA’s Breakthroughs in Energy Efficiency
NVIDIA is significantly reducing the costs and energy required to deploy AI. Over the past eight years, the company has increased the energy efficiency of running AI inference on large language models by an astounding 45,000 times, as highlighted in Huang’s recent keynote at COMPUTEX.
The new NVIDIA Blackwell architecture GPUs offer 20 times greater energy efficiency than CPUs for AI and high-performance computing. Transitioning all CPU servers to GPUs for these tasks could save 37 terawatt-hours annually, equivalent to the electricity use of 5 million homes and a reduction of 25 million metric tons of carbon dioxide.
NVIDIA-powered systems dominated the latest Green500 ranking of the world’s most energy-efficient supercomputers, securing the top six spots and seven of the top ten.
Government Support for AI Adoption
A recent report urges governments to accelerate AI adoption as a crucial tool for driving energy efficiency across various industries. It highlighted several examples of utilities using AI to enhance the efficiency of the electric grid.
Exeton’s Perspective on AI and Electric Grids
At Exeton, we are committed to leveraging AI and advanced computing to drive innovation in the energy sector. Our cutting-edge solutions are designed to enhance grid efficiency, boost productivity, and reduce environmental impact.
www.exeton.com
With a focus on delivering superior technology and services, Exeton is at the forefront of the AI revolution in the energy industry. Our partnerships and collaborations with industry leaders like NVIDIA ensure that we remain at the cutting edge of grid modernization.
Final Thoughts
The future of the energy sector is undeniably intertwined with the advancements in AI and accelerated computing. As companies like NVIDIA continue to push the boundaries of technology, the electric grid will become more efficient, flexible, and sustainable.
For more insights into how Exeton is driving innovation in the energy sector, visit our website.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
1 note
·
View note
Text
Nvidia HGX vs DGX: Key Differences in AI Supercomputing Solutions

Nvidia HGX vs DGX: What are the differences?
Nvidia is comfortably riding the AI wave. And for at least the next few years, it will likely not be dethroned as the AI hardware market leader. With its extremely popular enterprise solutions powered by the H100 and H200 “Hopper” lineup of GPUs (and now B100 and B200 “Blackwell” GPUs), Nvidia is the go-to manufacturer of high-performance computing (HPC) hardware.
Nvidia DGX is an integrated AI HPC solution targeted toward enterprise customers needing immensely powerful workstation and server solutions for deep learning, generative AI, and data analytics. Nvidia HGX is based on the same underlying GPU technology. However, HGX is a customizable enterprise solution for businesses that want more control and flexibility over their AI HPC systems. But how do these two platforms differ from each other?




Nvidia DGX: The Original Supercomputing Platform
It should surprise no one that Nvidia’s primary focus isn’t on its GeForce lineup of gaming GPUs anymore. Sure, the company enjoys the lion’s share among the best gaming GPUs, but its recent resounding success is driven by enterprise and data center offerings and AI-focused workstation GPUs.
Overview of DGX
The Nvidia DGX platform integrates up to 8 Tensor Core GPUs with Nvidia’s AI software to power accelerated computing and next-gen AI applications. It’s essentially a rack-mount chassis containing 4 or 8 GPUs connected via NVLink, high-end x86 CPUs, and a bunch of Nvidia’s high-speed networking hardware. A single DGX B200 system is capable of 72 petaFLOPS of training and 144 petaFLOPS of inference performance.
Key Features of DGX
AI Software Integration: DGX systems come pre-installed with Nvidia’s AI software stack, making them ready for immediate deployment.
High Performance: With up to 8 Tensor Core GPUs, DGX systems provide top-tier computational power for AI and HPC tasks.
Scalability: Solutions like the DGX SuperPOD integrate multiple DGX systems to form extensive data center configurations.
Current Offerings
The company currently offers both Hopper-based (DGX H100) and Blackwell-based (DGX B200) systems optimized for AI workloads. Customers can go a step further with solutions like the DGX SuperPOD (with DGX GB200 systems) that integrates 36 liquid-cooled Nvidia GB200 Grace Blackwell Superchips, comprised of 36 Nvidia Grace CPUs and 72 Blackwell GPUs. This monstrous setup includes multiple racks connected through Nvidia Quantum InfiniBand, allowing companies to scale thousands of GB200 Superchips.
Legacy and Evolution
Nvidia has been selling DGX systems for quite some time now — from the DGX Server-1 dating back to 2016 to modern DGX B200-based systems. From the Pascal and Volta generations to the Ampere, Hopper, and Blackwell generations, Nvidia’s enterprise HPC business has pioneered numerous innovations and helped in the birth of its customizable platform, Nvidia HGX.
Nvidia HGX: For Businesses That Need More
Build Your Own Supercomputer
For OEMs looking for custom supercomputing solutions, Nvidia HGX offers the same peak performance as its Hopper and Blackwell-based DGX systems but allows OEMs to tweak it as needed. For instance, customers can modify the CPUs, RAM, storage, and networking configuration as they please. Nvidia HGX is actually the baseboard used in the Nvidia DGX system but adheres to Nvidia’s own standard.
Key Features of HGX
Customization: OEMs have the freedom to modify components such as CPUs, RAM, and storage to suit specific requirements.
Flexibility: HGX allows for a modular approach to building AI and HPC solutions, giving enterprises the ability to scale and adapt.
Performance: Nvidia offers HGX in x4 and x8 GPU configurations, with the latest Blackwell-based baseboards only available in the x8 configuration. An HGX B200 system can deliver up to 144 petaFLOPS of performance.
Applications and Use Cases
HGX is designed for enterprises that need high-performance computing solutions but also want the flexibility to customize their systems. It’s ideal for businesses that require scalable AI infrastructure tailored to specific needs, from deep learning and data analytics to large-scale simulations.
Nvidia DGX vs. HGX: Summary
Simplicity vs. Flexibility
While Nvidia DGX represents Nvidia’s line of standardized, unified, and integrated supercomputing solutions, Nvidia HGX unlocks greater customization and flexibility for OEMs to offer more to enterprise customers.
Rapid Deployment vs. Custom Solutions
With Nvidia DGX, the company leans more into cluster solutions that integrate multiple DGX systems into huge and, in the case of the DGX SuperPOD, multi-million-dollar data center solutions. Nvidia HGX, on the other hand, is another way of selling HPC hardware to OEMs at a greater profit margin.
Unified vs. Modular
Nvidia DGX brings rapid deployment and a seamless, hassle-free setup for bigger enterprises. Nvidia HGX provides modular solutions and greater access to the wider industry.
FAQs
What is the primary difference between Nvidia DGX and HGX?
The primary difference lies in customization. DGX offers a standardized, integrated solution ready for deployment, while HGX provides a customizable platform that OEMs can adapt to specific needs.
Which platform is better for rapid deployment?
Nvidia DGX is better suited for rapid deployment as it comes pre-integrated with Nvidia’s AI software stack and requires minimal setup.
Can HGX be used for scalable AI infrastructure?
Yes, Nvidia HGX is designed for scalable AI infrastructure, offering flexibility to customize and expand as per business requirements.
Are DGX and HGX systems compatible with all AI software?
Both DGX and HGX systems are compatible with Nvidia’s AI software stack, which supports a wide range of AI applications and frameworks.
Final Thoughts
Choosing between Nvidia DGX and HGX ultimately depends on your enterprise’s needs. If you require a turnkey solution with rapid deployment, DGX is your go-to. However, if customization and scalability are your top priorities, HGX offers the flexibility to tailor your HPC system to your specific requirements.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
GeForce RTX 50 Blackwell GB20X GPU Specs Unveiled

Last week, a trusted leaker known as Kopite7kimi hinted at unexpected changes in the configuration of NVIDIA’s upcoming GB203 GPU. Initially thought to feature 96 Streaming Multiprocessors (SMs), the design was revised to include 84 SMs. Despite efforts to gather more details at that time, the leaker didn’t provide complete configurations for the remaining GPUs. Today, however, we have a comprehensive list of all five upcoming Blackwell GB20X processors along with their specs.
GB203 GPU: Revised Expectations
The GB203 GPU was initially expected to come with 96 SMs. However, new information confirms it will have 84 SMs, arranged in a 7x6 configuration. This GPU will also support a 256-bit memory bus, which aligns it closely with the AD103 GPU, but with the added advantage of GDDR7 memory support. This marks a significant shift from earlier reports, reflecting NVIDIA’s ongoing adjustments to optimize performance and yield.
Detailed Configurations of Blackwell GB20X Processors
GB202 GPU
Expected Configuration: The GB202 GPU is anticipated to feature 12 Graphics Processing Clusters (GPCs) and 8 Texture Processing Clusters (TPC) per GPC, leading to a total of 192 SMs (assuming 2 SMs per TPC).
Memory Bus: NVIDIA plans to equip the GB202 with a 448-bit memory bus, although it inherently supports a 512-bit bus.
Product Implementation: For retail purposes, such as the RTX 5090, NVIDIA will likely use a cut-down version to ensure high manufacturing yields.
GB203 GPU
Confirmed Configuration: As mentioned, the GB203 will have 84 SMs, arranged in a 7x6 layout.
Memory Bus: This GPU will use a 256-bit memory bus.
New Features: It introduces GDDR7 memory support, enhancing its performance capabilities.
Comparing GB20X to the RTX 40 Series
It’s confirmed that not all Blackwell GB20X GPUs will share the same configurations as their RTX 40 series counterparts. However, at least one model will feature an identical core count. This variability indicates NVIDIA’s strategy to tailor each GPU to meet specific performance and market demands.
The Implications of the New Leaks
Enhanced Performance with GDDR7 Memory
The introduction of GDDR7 memory support across these new GPUs signifies a substantial performance boost. GDDR7 memory is expected to offer higher bandwidth and better power efficiency compared to GDDR6, making these GPUs highly suitable for demanding applications and gaming experiences.
Memory Bus Adjustments
The decision to equip the GB202 with a 448-bit memory bus, despite its 512-bit capability, suggests a strategic approach to balance performance and production efficiency. These adjustments aim to maximize yields while still delivering robust performance metrics.
Anticipated Market Impact
The unveiling of these configurations has stirred excitement in the tech community. Enthusiasts and professionals alike are eagerly awaiting the official release, expecting these GPUs to set new benchmarks in graphics performance. The inclusion of advanced memory technology and the strategic use of memory bus capabilities indicate NVIDIA’s commitment to pushing the envelope in GPU technology.
Conclusion
The recently leaked specifications of NVIDIA’s GeForce RTX 50 Blackwell GB20X GPUs have provided valuable insights into the future of graphics technology. With significant changes from initial expectations and the introduction of GDDR7 memory support, these GPUs are poised to deliver exceptional performance. As we await further official announcements, it’s clear that NVIDIA continues to innovate and adapt to meet the evolving demands of the market.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
AMD Introduces Ryzen 9 5900XT and Ryzen 7 5800XT Processors at Computex 2024

AMD has once again taken the tech world by storm at Computex 2024, revealing the much-anticipated Ryzen 9 5900XT and Ryzen 7 5800XT processors. These new additions to the Ryzen lineup are set to provide an exciting update to the AM4 socket, continuing AMD's legacy of innovation and performance in the CPU market.
But what makes these new processors stand out, and why should you care? Let's dive into the details.
A New Era for AM4: Ryzen 9 5900XT and Ryzen 7 5800XT
At Computex, AMD showcased not only the new AM5 Ryzen 9000 series but also the latest updates for the old-gen AM4 socket with the Ryzen 5000XT models. This dual announcement strategy underscores AMD's commitment to supporting a wide range of users, from those looking for the cutting-edge to those who are upgrading existing systems.
The Ryzen 5000XT series wasn't a complete surprise. Back in March, AMD hinted at this release during a special event in China. Although the specifics were kept under wraps, the anticipation was palpable among tech enthusiasts.
The Specs: What You Need to Know
During the pre-Computex briefing, AMD detailed two new SKUs:
Ryzen 9 5900XT: Featuring 16 cores, this processor boasts clock speeds up to 4.8 GHz. With a 105W TDP, it's built on the Zen 3 architecture, using Vermeer silicon.
Ryzen 7 5800XT: This 8-core processor also reaches clock speeds up to 4.8 GHz, sharing the same 105W TDP and Zen 3 architecture.
Despite what the naming might suggest, the 5900XT isn't a 12-core SKU but a 16-core powerhouse. Its boost clock speed is slightly lower than the 5950X by 100 MHz, yet it shares the same TDP, indicating a balance between power and efficiency. The 5800XT, on the other hand, claims the highest clock speed of any AM4 8-core CPU, maxing out at 4.8 GHz.
Competitive Pricing and Availability
AMD has priced these processors very competitively:
Ryzen 9 5900XT: $359
Ryzen 7 5800XT: $249
These new CPUs are set to launch in July 2024. This means that the AM4 platform, which first saw the light of day over seven years ago, will receive another significant update. The longevity of the AM4 socket is a testament to AMD's commitment to providing enduring value to their users.
What This Means for You
For those still on the AM4 platform, this release is a fantastic opportunity to upgrade without having to invest in a new motherboard. The Ryzen 9 5900XT and Ryzen 7 5800XT offer high performance at an accessible price point, making them an excellent choice for gamers, content creators, and anyone looking to boost their PC's capabilities.
Looking Ahead
AMD's dual launch strategy at Computex 2024 showcases their forward-thinking approach. By supporting both new and existing platforms, they're ensuring that every user has a path to powerful performance. Whether you're ready to jump to the AM5 Ryzen 9000 series or stick with and upgrade your AM4 system, AMD has you covered.
FAQs
Q: When will the Ryzen 9 5900XT and Ryzen 7 5800XT be available? A: These processors are expected to launch in July 2024.
Q: What is the TDP of the new Ryzen processors? A: Both the Ryzen 9 5900XT and Ryzen 7 5800XT have a TDP of 105W.
Q: How do the new Ryzen processors compare to the existing ones? A: The Ryzen 9 5900XT and Ryzen 7 5800XT offer higher clock speeds and core counts, providing better performance for a range of applications.
Q: What is the pricing of the new Ryzen processors? A: The Ryzen 9 5900XT is priced at $359, while the Ryzen 7 5800XT costs $249.
Wrapping Up
AMD continues to push the boundaries of what's possible with their Ryzen lineup. The introduction of the Ryzen 9 5900XT and Ryzen 7 5800XT processors is yet another step in their journey to deliver exceptional performance and value. Whether you're a long-time AMD user or considering making the switch, these new processors offer compelling reasons to upgrade.
For the latest updates and more in-depth reviews, keep an eye on our blog and stay tuned for our detailed performance benchmarks coming soon.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
Nvidia Surpasses Apple to Become the Second-Largest Public Company in the US

Nvidia, the trailblazing AI chipmaker, is on a remarkable ascent, capturing the attention of investors and tech enthusiasts alike. The company’s market capitalization recently surged to an impressive $3.019 trillion, nudging past Apple’s $2.99 trillion and positioning Nvidia as the second-largest publicly traded company in the United States, just behind Microsoft’s $3.15 trillion.
The Meteoric Rise of Nvidia
Nvidia’s journey to the top has been nothing short of extraordinary. This Santa Clara-based chipmaker has become synonymous with cutting-edge artificial intelligence technology, fueling its rapid growth and investor confidence. On Wednesday, Nvidia’s shares jumped by 5.2%, reaching approximately $1,224.4 per share, while Apple’s shares saw a modest increase of 0.8%, closing at $196. This surge not only propelled Nvidia past Apple but also set new records for the S&P 500 and Nasdaq indexes.
The AI Revolution and Nvidia’s Dominance
So, what’s driving Nvidia’s phenomenal success? The answer lies in the company’s strategic focus on artificial intelligence. Nvidia has been a significant beneficiary of the AI boom, with its stock skyrocketing by 147% this year alone, following an astounding 239% increase in 2023. This AI craze has captivated Wall Street, and Nvidia stands at the forefront of this technological revolution.
Upcoming Innovations: The Rubin AI Chip Platform
Nvidia’s CEO, Jensen Huang, recently announced plans to unveil the company’s most advanced AI chip platform, Rubin, in 2026. This new platform will follow the highly successful Blackwell chips, which have already been dubbed the “world’s most powerful chip.” The introduction of Rubin signifies Nvidia’s ongoing commitment to pushing the boundaries of AI technology and maintaining its market leadership.
Market Impact and Future Prospects
Nvidia’s influence extends far beyond its market cap. The company accounts for approximately 70% of AI semiconductor sales, and analysts believe there’s still room for growth. Angelo Zino, a senior equity analyst at CFRA Research, noted, “As we look ahead, we think NVDA is on pace to become the most valuable company, given the plethora of ways it can monetize AI and our belief that it has the largest addressable market expansion opportunity across the Tech sector.”
Making Shares More Accessible: 10-for-1 Stock Split
To make investing in Nvidia more accessible, the company announced a 10-for-1 stock split last month. This move will lower the price per share, making it easier for individual investors to buy into the high-flying semiconductor company. The split shares will start trading on June 10, offering more opportunities for people to become part of Nvidia’s exciting journey.
Conclusion: A Bright Future Ahead
Nvidia’s ascent to becoming the second-largest public company in the US is a testament to its innovative spirit and strategic focus on artificial intelligence. With the upcoming Rubin AI chip platform and a significant market share in AI semiconductors, Nvidia is well-positioned to continue its upward trajectory. As investors and tech enthusiasts watch closely, one thing is clear: Nvidia’s future looks incredibly promising.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
Revolutionizing Speed: NVIDIA CEO Sets the Pace Ahead of COMPUTEX

NVIDIA CEO Jensen Huang recently delivered an inspiring keynote ahead of COMPUTEX 2024 in Taipei. Emphasizing cost reduction and sustainability, Huang introduced new semiconductors, software, and systems aimed at revolutionizing data centers, factories, consumer devices, and robots. He underscored that generative AI is reshaping industries and unlocking new opportunities for innovation and growth.
A New Era in Computing

Pushing the Boundaries
Huang emphasized the continuous innovation cycle at NVIDIA. He introduced a new semiconductor roadmap with platforms set to debut annually. The upcoming Rubin platform, succeeding Blackwell, will feature advanced GPUs, the Arm-based Vera CPU, and cutting-edge networking solutions like NVLink 6 and the X1600 converged InfiniBand/Ethernet switch.
Sustainable and Efficient Computing

Building AI Factories
Leading computer manufacturers, particularly from Taiwan, are integrating NVIDIA’s GPUs and networking solutions to develop cloud, on-premises, and edge AI systems. The NVIDIA MGX modular reference design platform, supporting Blackwell and the GB200 NVL2 platform, facilitates large language model inference, retrieval-augmented generation, and data processing.
Next-Generation Networking

Empowering Developers with NVIDIA NIM
NVIDIA NIM allows developers to create generative AI applications effortlessly. NIM — inference microservices that provide models as optimized containers — can be deployed on clouds, data centers, or workstations. Enterprises can maximize their infrastructure investments with NIM, which significantly boosts generative AI token production on accelerated infrastructure.
Revolutionizing Consumer Experiences
NVIDIA’s RTX AI PCs, powered by RTX technologies, are set to transform consumer experiences with over 200 RTX AI laptops and more than 500 AI-powered apps and games. The RTX AI Toolkit and PC-based NIM inference microservices for the NVIDIA ACE digital human platform highlight NVIDIA’s dedication to making AI accessible.
AI Assistants and Robotics

Conclusion
Huang’s keynote emphasized the transformative potential of AI and accelerated computing. NVIDIA’s innovations are driving a new industrial revolution, making computing more efficient, sustainable, and accessible. The collaboration with global leaders and the continuous push for technological advancement underscores NVIDIA’s commitment to shaping the future of computing.
NVIDIA’s journey is a testament to the power of innovation and the relentless pursuit of excellence. As Huang concluded, “Thank you, Taiwan. I love you guys.”
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
How NVIDIA A100 GPUs Can Revolutionize Game Development

Gaming has evolved from a niche hobby to a booming multi-billion-dollar industry, with its market value expected to hit a whopping $625 billion by 2028. This surge is partly fueled by the rise of cloud gaming, enabling users to stream top titles via services like Xbox Cloud Gaming without the need for pricey hardware. Simultaneously, virtual reality (VR) gaming is gaining traction, with its market size projected to reach $71.2 billion by 2028.
With this growth, there’s a heightened demand for more realistic, immersive, and visually stunning games. Meeting these expectations requires immense graphic processing power, and each new generation of GPUs aims to deliver just that. Enter NVIDIA’s A100 GPU, a game-changer promising significant leaps in performance and efficiency that can transform your game development workflow.
In this article, we’ll explore how adopting NVIDIA A100 GPUs can revolutionize various aspects of game development and enable feats previously deemed impossible.
The Impact of GPUs on Game Development
Remember when video game graphics resembled simple cartoons? Those days are long gone, thanks to GPUs.
Initially, games relied on the CPU for all processing tasks, resulting in pixelated graphics and limited complexity. The introduction of dedicated GPUs in the 1980s changed everything. These specialized processors, with their parallel processing architecture, could handle the computationally intensive tasks of rendering graphics much faster, leading to smoother gameplay and higher resolutions.
The mid-90s saw the advent of 3D graphics, further cementing the GPU’s role. GPUs could now manipulate polygons and textures, creating immersive 3D worlds that captivated players. Techniques like texture filtering, anti-aliasing, and bump mapping brought realism and depth to virtual environments.
Shaders introduced in the early 2000s marked a new era. Developers could now write code to control how the GPU rendered graphics, leading to dynamic lighting, real-time shadows, and complex particle effects. Modern NVIDIA GPUs like the A100 continue to push these boundaries. Features like ray tracing, which simulates real-world light interactions, and AI-powered upscaling techniques further blur the lines between reality and virtual worlds. Handling massive datasets and complex simulations, they create dynamic weather systems and realistic physics, making games more lifelike than ever.
NVIDIA A100 GPU Architecture
Before diving deeper, let’s understand the NVIDIA A100 GPU architecture. Built on the revolutionary Ampere architecture, the NVIDIA A100 offers dramatic performance and efficiency gains over its predecessors. Key advancements include:
3rd Generation Tensor Cores: Providing up to 20x higher deep learning training and inference throughput over the previous Volta generation.
Tensor Float 32 (TF32) Precision: Accelerates AI training while maintaining accuracy. Combined with structural sparsity support, it offers optimal speedups.
HBM2e Memory: Delivers up to 80GB capacity and 2 TB/s bandwidth, making it the world’s fastest GPU memory system.
Multi-Instance GPU (MIG): Allows a single A100 GPU to be securely partitioned into up to seven smaller GPU instances for shared usage, accelerating multi-tenancy.
NVLink 3rd Gen Technology: Combines up to 16 A100 GPUs to operate as one giant GPU, with up to 600 GB/sec interconnect bandwidth.
PCIe Gen4 Support: Provides 64 GB/s host transfer speeds, doubling interface throughput over PCIe Gen3 GPUs.
NVIDIA A100 GPU for Game Development
When it comes to game development, the NVIDIA A100 GPU is a total game-changer, transforming what was once thought impossible. Let’s delve into how this GPU revolutionizes game design and workflows with massive improvements in AI, multitasking flexibility, and high-resolution rendering support.
AI-Assisted Content Creation
The NVIDIA A100 significantly accelerates neural networks through its 3rd generation Tensor Cores, enabling developers to integrate powerful AI techniques into content creation and testing workflows. Procedural content generation via machine learning algorithms can automatically produce game assets, textures, animations, and sounds from input concepts. The immense parameter space of neural networks allows for near-infinite content combinations. AI agents powered by the NVIDIA A100 can also autonomously play-test games to detect flaws and identify areas for improvement at a massive scale. Advanced systems can drive dynamic narrative storytelling, adapting moment-to-moment based on player actions.
Faster Iteration for Programmers
The NVIDIA A100 GPU delivers up to 5x faster build and run times, dramatically accelerating programming iteration speed. This is invaluable for developers, allowing them to code, compile, test, and debug game logic and systems much more rapidly. Fixing bugs or experimenting with new features is no longer hampered by lengthy compile wait times. Programmers can stay in their flow state and make quicker adjustments based on feedback. This faster turnaround encourages bold experimentation, dynamic team collaboration, and ultimately faster innovation.
Multi-Instance GPU Flexibility
The Multi-Instance GPU (MIG) capability enables a single NVIDIA A100 GPU to be securely partitioned into smaller separate GPU instances. Game studios can use MIG to right-size GPU resources for tasks. Lightweight processes can leverage smaller instances while more demanding applications tap larger pools of resources. Multiple development or testing workloads can run simultaneously without contention. MIG also provides flexible access for individuals or teams based on dynamic needs. By improving GPU utilization efficiency, studios maximize their return on NVIDIA A100 investment.
High-Resolution Gameplay
The incredible throughput of the NVIDIA A100 makes real-time rendering of complex 8K scenes feasible. Designers can build hyper-detailed assets and environments that retain clarity when viewed on next-gen displays. Support for high frame rate 8K output showcases the GPU’s comfortable headroom for future graphical demands. This also benefits game development workflows, as assets can be created at 8K resolutions during modeling or texturing for superior quality before downscaling to target mainstream resolutions.
Wrapping Up
The NVIDIA A100 GPU represents a monumental leap forward in game development, offering unprecedented levels of performance, efficiency, and flexibility. With its advanced Ampere architecture and cutting-edge features, the A100 is set to revolutionize workflows across all aspects of game creation, from cloud gaming to virtual reality.
One of the most significant advantages of the NVIDIA A100 is its ability to accelerate AI-assisted content creation, allowing developers to generate game assets, textures, animations, and sounds more efficiently than ever before. The NVIDIA A100’s Multi-Instance GPU capability is also great for studios to optimize GPU resources for various tasks, maximizing efficiency and productivity.
Are you ready to revolutionize your game development workflow?
Experience the power of the NVIDIA A100 GPU at EXETON! We offer flexible cloud solutions tailored to your specific needs, allowing you to tap into the A100’s potential without the upfront investment. Our NVIDIA A100 80 GB PCIe GPUs start at just $2.75/hr, so you only pay for what you use!
FAQs
How can NVIDIA A100 GPUs revolutionize game development?
The NVIDIA A100, built with the groundbreaking Ampere architecture and boasting 54 billion transistors, delivers unmatched speeds ideal for the most demanding computing workloads, including cutting-edge game development. With 80 GB of memory, the A100 can effectively accelerate game development workflows.
Is the NVIDIA A100 suitable for both 2D and 3D game development?
Yes, the NVIDIA A100 GPUs are suitable for both 2D and 3D game development, accelerating rendering, simulation, and AI tasks.
Does the NVIDIA A100 provide tools for game optimization and performance tuning?
While the NVIDIA A100 doesn’t provide specific tools, developers can leverage its capabilities for optimization using other software tools and frameworks.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
NVIDIA RTX 5090 New Rumored Specs: 28GB GDDR7 and 448-bit Bus

The rumor mill is buzzing with exciting news about NVIDIA’s upcoming flagship graphics card, the RTX 5090. Whispers suggest it will sport a 448-bit memory bus and a whopping 28GB of GDDR7 memory. This new configuration marks a significant shift from earlier speculations and promises a substantial boost in performance. Let’s dive into the details and see what this could mean for gamers and professionals alike.
The Latest Rumors: A Shift in Memory Configuration
The upcoming flagship Blackwell graphics card is said to feature a 448-bit memory bus, diverging from the 512-bit memory bus initially rumored for the GB202 graphics processor. This shift in configuration has caught the attention of tech enthusiasts and industry insiders.

Who Are the Sources?
Panzerlied, a well-known leaker who previously revealed the RTX 5090 Founder’s Edition PCB design, claimed it uses three parts. This has now been confirmed by another trusted source, Kopite7kimi. Panzerlied has further stated that the RTX 5090 will not use the full 512-bit bus but will settle for a 448-bit configuration. This implies the RTX 5090 might not utilize all 16 available memory modules but only 14.
What Does This Mean for the RTX 5090?
Assuming NVIDIA sticks to the 448-bit memory bus, the RTX 5090 is likely to feature 28GB of GDDR7 memory. Leaked memory speed information suggests that the bandwidth should reach 1568 GB/s, regardless of the memory capacity. This represents a 50% increase over the RTX 4090, making the RTX 5090 a formidable contender in the high-performance GPU market.
GeForce RTX 5090 Rumored Memory Specs
Here’s a breakdown of the rumored memory specs for the RTX 5090:
Memory Modules: 14x 8Gbit (2GB) GDDR7 modules
Total Capacity: 28GB
Speed: 28 Gbps
Maximum Memory Bandwidth: 1568 GB/s
Comparison to Previous Models
The 28GB specs on the new flagship might not look as impressive as the speculated 32GB. However, this configuration means that NVIDIA will still have room for potential “Ti/SUPER” upgrades in the future. The 512-bit memory bus might not be used by gaming GPUs but could instead be offered for ProViz RTX (formerly Quadro) series, which can utilize a larger memory capacity.
Historical Context: Memory Buses in Previous NVIDIA GPUs
The last time NVIDIA used a 448-bit memory bus was during the GTX 200 series era. Models like the GTX 260 and GTX 275 featured 896 MB of memory. The GTX 280 used a 512-bit bus. Subsequent launches saw the use of up to a 384-bit bus (GTX 400 series and newer).
Future Implications and Potential Upgrades
The decision to use a 448-bit memory bus in the RTX 5090 leaves NVIDIA with the flexibility to introduce future models with enhanced specs. Potential “Ti” or “SUPER” versions could leverage the full 512-bit bus, offering even greater performance and capacity. Additionally, the ProViz RTX series might benefit from the 512-bit configuration, catering to professional users who require extensive memory capacity for demanding applications.
Conclusion

FAQs
Q: When will the NVIDIA RTX 5090 be released? A: There’s no official release date yet, but it’s expected to be announced later this year.
Q: Will the RTX 5090 be available in a “Ti” or “SUPER” version? A: While not confirmed, the 448-bit memory bus configuration suggests that there might be room for future “Ti” or “SUPER” versions with enhanced specs.
Q: How does the 448-bit memory bus compare to the 512-bit bus? A: The 448-bit bus is slightly less capable than the 512-bit bus but still offers significant bandwidth improvements over previous models.
Q: What is the significance of the 28GB GDDR7 memory? A: The 28GB GDDR7 memory provides substantial capacity and speed improvements, ensuring better performance for demanding applications and games.
For more updates on the latest in GPU technology, stay tuned!
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
#nvidia#RTX 4090#4090 Specifications#RTX 4090 Specifications#exeton#gpu#RTX 4090 GPU#Nvidia RTX 5090#RTX 5090#Nvidia RTX 5090 GPU#RTX 5090 GPU#5090 Specifications#Nvidia RTX 5090 Specifications
0 notes
Text
Data Centers in High Demand: The AI Industry’s Unending Quest for More Capacity

The demand for data centers to support the booming AI industry is at an all-time high. Companies are scrambling to build the necessary infrastructure, but they’re running into significant hurdles. From parts shortages to power constraints, the AI industry’s rapid growth is stretching resources thin and driving innovation in data center construction.
The Parts Shortage Crisis
Data center executives report that the lead time to obtain custom cooling systems has quintupled compared to a few years ago. Additionally, backup generators, which used to be delivered in a month, now take up to two years. This delay is a major bottleneck in the expansion of data centers.
The Hunt for Suitable Real Estate
Finding affordable real estate with adequate power and connectivity is a growing challenge. Builders are scouring the globe and employing creative solutions. For instance, new data centers are planned next to a volcano in El Salvador to harness geothermal energy and inside shipping containers in West Texas and Africa for portability and access to remote power sources.
Case Study: Hydra Host’s Struggle
Earlier this year, data-center operator Hydra Host faced a significant hurdle. They needed 15 megawatts of power for a planned facility with 10,000 AI chips. The search for the right location took them from Phoenix to Houston, Kansas City, New York, and North Carolina. Each potential site had its drawbacks — some had power but lacked adequate cooling systems, while others had cooling but no transformers for additional power. New cooling systems would take six to eight months to arrive, while transformers would take up to a year.
Surge in Demand for Computational Power
The demand for computational power has skyrocketed since late 2022, following the success of OpenAI’s ChatGPT. The surge has overwhelmed existing data centers, particularly those equipped with the latest AI chips, like Nvidia’s GPUs. The need for vast numbers of these chips to create complex AI systems has put enormous strain on data center infrastructure.
Rapid Expansion and Rising Costs
The amount of data center space in the U.S. grew by 26% last year, with a record number of facilities under construction. However, this rapid expansion is not enough to keep up with demand. Prices for available space are rising, and vacancy rates are negligible.
Building Data Centers: A Lengthy Process
Jon Lin, the general manager of data-center services at Equinix, explains that constructing a large data facility typically takes one and a half to two years. The planning and supply-chain management involved make it challenging to quickly scale up capacity in response to sudden demand spikes.
Major Investments by Tech Giants

Supply Chain and Labor Challenges
The rush to build data centers has extended the time required to acquire essential components. Transceivers and cables now take months longer to arrive, and there’s a shortage of construction workers skilled in building these specialized facilities. AI chips, particularly Nvidia GPUs, are also in short supply, with lead times extending to several months at the height of demand.
Innovative Solutions to Power Needs

Portable Data Centers and Geothermal Energy
Startups like Armada are building data centers inside shipping containers, which can be deployed near cheap power sources like gas wells in remote Texas or Africa. In El Salvador, AI data centers may soon be powered by geothermal energy from volcanoes, thanks to the country’s efforts to create a more business-friendly environment.
Conclusion: Meeting the Unending Demand
The AI industry’s insatiable demand for data centers shows no signs of slowing down. While the challenges are significant — ranging from parts shortages to power constraints — companies are responding with creativity and innovation. As the industry continues to grow, the quest to build the necessary infrastructure will likely become even more intense and resourceful.
FAQs
1. Why is there such a high demand for data centers in the AI industry?
The rapid growth of AI technologies, which require significant computational power, has driven the demand for data centers.
2. What are the main challenges in building new data centers?
The primary challenges include shortages of critical components, suitable real estate, and sufficient power supply.
3. How long does it take to build a new data center?
It typically takes one and a half to two years to construct a large data facility due to the extensive planning and supply-chain management required.
4. What innovative solutions are companies using to meet power needs for data centers?
Companies are exploring options like modular nuclear reactors, geothermal energy, and portable data centers inside shipping containers.
5. How are tech giants like Amazon, Microsoft, and Google responding to the demand for data centers?
They are investing billions of dollars in new data centers to expand their capacity and meet the growing demand for AI computational power.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
3 notes
·
View notes
Text
NVIDIA RTX 5090 Founder’s Edition Rumored to Feature 16 GDDR7 Memory Modules in Denser Design

The NVIDIA RTX 5090 Founder’s Edition, the much-anticipated next-generation graphics card, is making waves with rumors of a significant overhaul in its memory configuration. Building on the legacy of the RTX 4090, the new flagship GPU is expected to feature the advanced Blackwell GB202 GPU and incorporate cutting-edge GDDR7 memory technology. Let’s delve into the details of what makes the RTX 5090 a potential game-changer in the world of graphics cards.
A New Memory Layout for Enhanced Performance
The memory layout of the upcoming RTX 5090 is poised to differ considerably from that of its predecessor, the RTX 4090. With a rumored 512-bit memory bus, the RTX 5090 is set to increase its memory capacity, necessitating more modules around the GPU. This enhancement is expected to boost the overall performance and efficiency of the graphics card.
A superimposed memory layout on RTX 4090 Founder Edition PCB would look like this:
The RTX 5090 is anticipated to support GDDR7 memory, arranged in a denser configuration than the current RTX 4090. The layout will transition from the previous 3–4–1–4 arrangement to a more compact 4–5–2–5 layout (clockwise). This new configuration will enable the board to support up to 16 memory modules, although it does not necessarily mean all modules will be utilized or confirm their individual capacities. If the RTX 5090 employs the same 2GB modules as its predecessors, it could potentially offer up to an impressive 32GB of memory.
Innovative PCB Design
Adding to the intrigue, the rumor mill suggests that the RTX 5090 will feature a unique three-PCB design. While the specifics of this design remain unclear, it’s worth noting that NVIDIA has a history of experimenting with non-standard PCB configurations. For instance, the unreleased RTX TITAN ADA GPU was supposed to have its PCB placed parallel to the PCI slot, with the PCIe interface on a separate PCB. This innovative approach indicates that NVIDIA continues to push the boundaries of traditional GPU design.
The proposed three-PCB design could imply a more modular and flexible architecture, potentially improving cooling efficiency and component accessibility. While the actual board has not been pictured, leaks of the prototype cooler suggest a quad-slot, triple-fan setup, indicating robust cooling capabilities to manage the high-performance components.

RTX TITAN ADA Prototype cooler, Source: Hayaka
Anticipated Launch and Market Impact
NVIDIA is expected to unveil its RTX 50 series later this year, possibly in the fourth quarter. As the launch date approaches, the frequency of leaks is likely to increase, particularly between June and August. During this period, NVIDIA typically engages with more partners, some of whom are already working on prototype cooler manufacturing. These prototypes often become the subject of leaks, providing enthusiasts with tantalizing glimpses of what’s to come.
The introduction of the RTX 5090 could set a new benchmark in the graphics card industry, offering unprecedented memory capacity and performance enhancements. Its advanced memory configuration and innovative design could make it a formidable contender in both gaming and professional applications, pushing the envelope of what’s possible with modern GPUs.
Conclusion
The NVIDIA RTX 5090 Founder’s Edition is shaping up to be a revolutionary addition to the world of graphics cards, with rumors pointing to a host of advanced features and design innovations. From its denser GDDR7 memory layout to the potential three-PCB configuration, the RTX 5090 promises to deliver significant performance gains. As we await the official unveiling, the excitement continues to build around what could be one of the most powerful GPUs ever created. Stay tuned for more updates as we approach the anticipated launch later this year.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
NVIDIA H100 vs. A100: Which GPU Reigns Supreme?

NVIDIA’s CEO, Jensen Huang, unveiled the NVIDIA H100 Tensor Core GPU at NVIDIA GTC 2022, marking a significant leap in GPU technology with the new Hopper architecture. But how does it compare to its predecessor, the NVIDIA A100, which has been a staple in deep learning? Let’s explore the advancements and differences between these two powerhouse GPUs.
NVIDIA H100: A Closer Look
The NVIDIA H100, based on the new Hopper architecture, is NVIDIA’s ninth-generation data center GPU, boasting 80 billion transistors. Marketed as “the world’s largest and most powerful accelerator,” it’s designed for large-scale AI and HPC models. Key features include:
Most Advanced Chip: The H100 is built with cutting-edge technology, making it highly efficient for complex tasks.
New Transformer Engine: Enhances network speeds by six times compared to previous versions.
Confidential Computing: Ensures secure processing of sensitive data.
2nd-Generation Secure Multi-Instance GPU (MIG): Extends capabilities by seven times over the A100.
4th-Generation NVIDIA NVLink: Connects up to 256 H100 GPUs with nine times the bandwidth.
New DPX Instructions: Accelerates dynamic programming by up to 40 times compared to CPUs and up to seven times compared to previous-generation GPUs.
NVIDIA asserts that the H100 and Hopper technology will drive future AI research, supporting massive AI models, deep recommender systems, genomics, and complex digital twins. Its enhanced AI inference capabilities cater to real-time applications like giant-scale AI models and chatbots.

NVIDIA A100: A Deep Dive
Introduced in 2020, the NVIDIA A100 Tensor Core GPU was heralded as the highest-performing elastic data center for AI, data analytics, and HPC. Based on the Ampere architecture, it delivers up to 20 times higher performance than its predecessor. The A100’s notable features include:
Multi-Instance GPU (MIG): Allows division into seven GPUs, adjusting dynamically to varying demands.
Third-Generation Tensor Core: Boosts throughput and supports a wide range of DL and HPC data types.
The A100’s ability to support cloud service providers (CSPs) during the digital transformation of 2020 and the pandemic was crucial, delivering up to seven times more GPU instances through its MIG virtualization and GPU partitioning capabilities.
Architecture Comparison NVIDIA Hopper
Named after the pioneering computer scientist Grace Hopper, the Hopper architecture significantly enhances the MIG capabilities by up to seven times compared to the previous generation. It introduces features that improve asynchronous execution, allowing memory copies to overlap with computation and reducing synchronization points. Designed to accelerate the training of Transformer models on H100 GPUs by six times, Hopper addresses the challenges of long training periods for large models while maintaining GPU performance.
NVIDIA Ampere
Described as the core of the world’s highest-performing elastic data centers, the Ampere architecture supports elastic computing at high acceleration levels. It’s built with 54 billion transistors, making it the largest 7nm chip ever created. Ampere offers L2 cache residency controls for data management, enhancing data center scalability. The third generation of NVLink® in Ampere doubles GPU-to-GPU bandwidth to 600 GB/s, facilitating large-scale application performance.
Detailed Specifications: H100 vs. A100

H100 Specifications:
8 GPCs, 72 TPCs (9 TPCs/GPC), 2 SMs/TPC, 144 SMs per full GPU
128 FP32 CUDA Cores per SM, 18432 FP32 CUDA Cores per full GPU
4 Fourth-Generation Tensor Cores per SM, 576 per full GPU
6 HBM3 or HBM2e stacks, 12 512-bit Memory Controllers
60MB L2 Cache
Fourth-Generation NVLink and PCIe Gen 5
Fabricated on TSMC’s 4N process, the H100 has 80 billion transistors and 395 billion parameters, providing up to nine times the speed of the A100. It’s noted as the first truly asynchronous GPU, extending A100’s asynchronous transfers across address spaces and growing the CUDA thread group hierarchy with a new level called the thread block cluster.
A100 Specifications:
8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
4 third-generation Tensor Cores/SM, 512 third-generation Tensor Cores per full GPU
6 HBM2 stacks, 12 512-bit memory controllers
The A100 is built on the A100 Tensor Core GPU SM architecture and the third-generation NVIDIA high-speed NVLink interconnect. With 54 billion transistors, it delivers five petaflops of performance, a 20x improvement over its predecessor, Volta. The A100 also includes fine-grained structured sparsity to double the compute throughput for deep neural networks.
Conclusion
When comparing NVIDIA’s H100 and A100 GPUs, it’s clear that the H100 brings substantial improvements and new features that enhance performance and scalability for AI and HPC applications. While the A100 set a high standard in 2020, the H100 builds upon it with advanced capabilities that make it the preferred choice for cutting-edge research and large-scale model training. Whether you choose the H100 or A100 depends on your specific needs, but for those seeking the latest in GPU technology, the H100 is the definitive successor.
FAQs
1- What is the main difference between NVIDIA H100 and A100?
The main difference lies in the architecture and capabilities. The H100, based on the Hopper architecture, offers enhanced performance, scalability, and new features like the Transformer Engine and advanced DPX instructions.
2- Which GPU is better for deep learning: H100 or A100?
The H100 is better suited for deep learning due to its advanced features and higher performance metrics, making it ideal for large-scale AI models.
3- Can the H100 GPU be used for gaming?
While the H100 is primarily designed for AI and HPC tasks, it can theoretically be used for gaming, though it’s not optimized for such purposes.
4- What are the memory specifications of the H100 and A100?
The H100 includes six HBM3 or HBM2e stacks with 12 512-bit memory controllers, whereas the A100 has six HBM2 stacks with 12 512-bit memory controllers.
5- How does the H100’s NVLink compare to the A100's?
The H100 features fourth-generation NVLink, which connects up to 256 GPUs with nine times the bandwidth, significantly outperforming the A100’s third-generation NVLink.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
Why NAS Servers Are the Perfect Storage Solution for Your Business — Exeton

What is NAS?
A Network Attached Storage (NAS) system is a high-capacity storage device connected to a network, allowing authorized users to store and retrieve data from a centralized location. Essentially, a NAS device is a container for hard drives with built-in intelligence for file sharing and authorization.

QUMULO ACTIVE LICENSE + 4X SUPERMICRO A+ ASG-1014S 216TB-2X100GBE
Why Do Organizations Use NAS?
NAS systems are versatile, flexible, and scalable. They can be pre-populated with disks or diskless, and typically include USB ports for connecting printers or external storage drives, offering additional options for all connected users.
Do You Need IT to Manage NAS?
Managing a NAS device is straightforward and can be done through a browser-based utility. You might not need an IT professional on standby, making it an excellent choice for small businesses. NAS devices can also be accessed remotely, serving as a private Dropbox or Google Drive with much more storage and no monthly cost.
How Does a NAS Device Work?
A NAS device runs on any platform or operating system, functioning as a bundle of hardware and software with an embedded operating system. It consists of a network interface card (NIC), a storage controller, drive bays, and a power supply, and can contain two to five hard drives for redundancy and fast file access.

QUMULO ACTIVE LICENSE + 4X SUPERMICRO A+ WIO 1114S-WN10RT ALL-NVME 30TB
Benefits of Using NAS
NAS systems are becoming popular for businesses due to their effectiveness, scalability, and low-cost storage solutions. Here are some key benefits:
Speed: NAS can store and transfer files quickly, with rapid backup for incremental changes.
Control: Companies maintain total control over their data without relying on third-party storage.
Ease of Use: NAS devices are user-friendly and simple to manage, often featuring streamlined setup scripts.
Reliable Access: Positioned on a dedicated network, NAS provides uninterrupted access to data, even during internet service interruptions.
NAS vs. SAN Protocols
NAS and Storage Area Networks (SANs) are both networked storage solutions but differ in their approaches:
NAS: A single-storage device serving files over Ethernet, ideal for unstructured data like audio, video, and documents. Uses TCP/IP for data transfer.
SAN: A complex network of devices handling block storage inside databases, ideal for structured data. Uses FC protocol or Ethernet-based ISCSI for storage networks.
From a user perspective, NAS appears as a single device managing files, while SAN presents as a disk to the client OS, housing critical databases.
Why Small Businesses Use NAS
Small businesses require low-cost, scalable storage with easy operation and robust data backup. Here are some examples:
Telecom: A leading telecom operator needed an easily managed backup solution within their budget to handle internal data generated by employees. They chose NAS for its low cost and high-capacity file-sharing capabilities.
Banking: A cloud-based platform provider for the mortgage finance industry needed a scalable storage solution for 30 billion small files. They found NAS efficient and cost-saving, allowing more focus on customer service.
Criminal Justice: A national prison system needed reliable storage for high-definition video surveillance. They implemented a NAS solution with larger capacity and room for expansion, meeting their preservation requirements.
HPE NAS Solutions
Hewlett Packard Enterprise (HPE) offers secure, tailored, and economically feasible NAS solutions for businesses of all sizes. Their platforms are resilient and self-protecting, with features like data encryption, sophisticated access controls, file access auditing, and deletion prevention to reduce security risks.
HPE StoreEasy: Designed to maximize capacity, simplify management, and scale as businesses grow, supporting tens of thousands of concurrent users and ensuring data security with built-in encryption.
HPE Apollo 4000 Systems: Intelligent data storage servers that offer accelerated performance, end-to-end security, and predictive analytics for storage-intensive workloads.
Conclusion
NAS systems provide an efficient, scalable, and cost-effective storage solution for businesses of all sizes. With their ease of use, speed, control, and reliable access, NAS devices are ideal for managing growing volumes of data. HPE’s NAS solutions offer secure and tailored options to meet diverse business needs, making them a perfect choice for modern data storage requirements.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
NVIDIA HGX AI Supercomputer Now Available at Exeton - Experience Next-Gen AI Computing

Exeton proudly announces a significant advancement in computing technology with the availability of the NVIDIA HGX AI Supercomputer. Tailored for high-caliber AI research and high-performance computing (HPC) tasks, the NVIDIA HGX is your gateway to achieving unparalleled computational speeds and efficiency.
The NVIDIA HGX AI platform is offered in several powerful configurations. Customers can choose from single baseboards with four H200 or H100 GPUs, or opt for the more expansive eight-GPU configurations which include combinations of H200, H100, B200, or B100 models. These setups are engineered to handle the most complex and demanding tasks across various industries including AI development, deep learning, and scientific research.
Central to the NVIDIA HGX B200 and B100 models are the innovative Blackwell Tensor Core GPUs. These are seamlessly integrated with high-speed interconnects to propel your data center into the next era of accelerated computing. Offering up to 15X more inference performance than its predecessors, the Blackwell-based HGX systems are ideal for running complex generative AI models, performing advanced data analytics, and managing intensive HPC operations.
The HGX H200 model takes performance to the next level, combining H200 Tensor Core GPUs with state-of-the-art interconnects for superior scalability and security. Capable of delivering up to 32 petaFLOPS of computational power, the HGX H200 sets a new benchmark as the world’s most potent accelerated scale-up server platform for AI and high-performance computing.
Exeton is excited to offer this revolutionary tool that redefines what is possible in AI and HPC. The NVIDIA HGX AI Supercomputer is not just a piece of technology; it is your partner in pushing the boundaries of what is computationally possible. Visit Exeton today and choose the NVIDIA HGX model that will drive your ambitions to new computational heights.
0 notes
Text
Exeton Launches Vector One, A New Single-GPU Desktop PC

The Exeton Vector One is now available for order. The new single-GPU desktop PC is built to tackle demanding AI/ML tasks, from fine-tuning Stable Diffusion to handling the complexities of Llama 2 7B. Exeton customers can now benefit from a more compact, quieter desktop PC at a price point of less than $5,500.
Vector One Specs
GPU: 1x NVIDIA GeForce RTX 4090, 24 GB, liquid-cooled
PROCESSOR: AMD Ryzen™ 9 7950X 16-core, 32-thread
SYSTEM RAM: 64 GB or 128 GB DDR5
STORAGE: OS — Up to 3.84 TB M.2 (NVMe) | Data — Up to 3 x 3.84 TB M.2 (NVMe)
NETWORK INTERFACE: 10Gb Ethernet
Key benefits of the Vector One
The Vector One offers Exeton customers a powerful deep learning solution to train neural networks right from their desktops.
Sleek Power that doesn’t Disturb
The Vector One has been meticulously designed with liquid cooling for both the CPU and GPU, ensuring optimal performance without the noise. Even under typical high workloads, it only emits a mere 39 dB SPL of sound, making it perfect for maintaining a quiet workspace.
Next-gen Graphics for Advanced AI/ML Tasks
Equipped with the cutting-edge NVIDIA GeForce RTX 4090 graphics card boasting 24 GB of VRAM, the Vector One stands ready to tackle demanding tasks. From fine-tuning Stable Diffusion to handling the complexities of Llama 2 7B, this machine ensures that high-intensity computations are a breeze.
Experience the Power of future-ready Architecture
At the heart of Vector One lies the state-of-the-art AMD Ryzen 9 7950X CPU, hosted on the advanced X670E chipset. This powerhouse supports both PCIe Gen 5 and DDR5 and offers up to twice the memory bandwidth of its predecessors. Dive into the future of computing with unrivaled speed and efficiency.
Delivering the Optimal Experience for AI/ML
Through rigorous research and experience, our engineers have crafted the ultimate system configuration tailored for AI/ML tasks. No more guesswork or configurations needed: the Vector One is fine-tuned to deliver unparalleled performance right out of the box. Additionally, every Vector One comes with a one-year warranty on hardware, with an option to extend to three years. For added peace of mind, choose to include dedicated technical support for Ubuntu and all ML frameworks and drivers that come pre-installed with your machine.
Pre-installed with the Software you Need

How to get started with Vector One
The Vector One is now available to purchase. Equipped with a single NVIDIA GeForce RTX 4090 graphics card boasting 24 GB of VRAM and pre-installed with Ubuntu, TensorFlow, PyTorch®, NVIDIA CUDA, and NVIDIA cuDNN, the Vector One is the optimal single-GPU desktop PC for deep learning. At less than $5,500, the desktop solution meets tighter budget requirements without sacrificing performance.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
NVIDIA Steps Up Its Game: Unveiling the Blackwell Architecture and the Powerhouse B200/B100 Accelerators

NVIDIA, a titan in the world of generative AI accelerators, is not one to rest on its laurels. Despite already dominating the accelerator market, the tech giant is determined to push the envelope further. With the unveiling of its next-generation Blackwell architecture and the B200/B100 accelerators, NVIDIA is set to redefine what’s possible in AI computing yet again.
As we witnessed the return of the in-person GTC for the first time in five years, NVIDIA’s CEO, Jensen Huang, took center stage to introduce an array of new enterprise technologies. However, it was the announcement of the Blackwell architecture that stole the spotlight. This move marks a significant leap forward, building upon the success of NVIDIA’s H100/H200/GH200 series.
Named after the American statistical and mathematical pioneer Dr. David Harold Blackwell, this architecture embodies NVIDIA’s commitment to innovation. Blackwell aims to elevate the performance of NVIDIA’s datacenter and high-performance computing (HPC) accelerators by integrating more features, flexibility, and transistors. This approach is a testament to NVIDIA’s strategy of blending hardware advancements with software optimization to tackle the evolving needs of high-performance accelerators.

With an impressive 208 billion transistors across the complete accelerator, NVIDIA’s first multi-die chip represents a bold step in unified GPU performance. The Blackwell GPUs are designed to function as a single CUDA GPU, thanks to the NV-High Bandwidth Interface (NV-HBI) facilitating an unprecedented 10TB/second of bandwidth. This architectural marvel is complemented by up to 192GB of HBM3E memory, significantly enhancing both the memory capacity and bandwidth.
However, it’s not just about packing more power into the hardware. The Blackwell architecture is engineered to dramatically boost AI training and inference performance while achieving remarkable energy efficiency. This ambition is evident in NVIDIA’s projections of a 4x increase in training performance and a staggering 30x surge in inference performance at the cluster level.
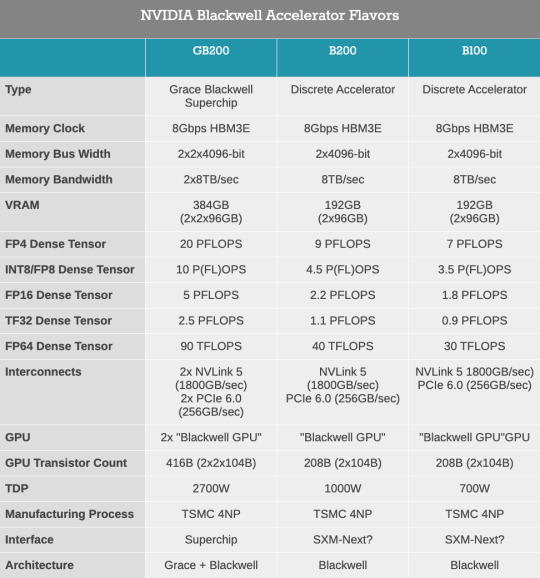
Moreover, NVIDIA is pushing the boundaries of precision with its second-generation transformer engine, capable of handling computations down to FP4 precision. This advancement is crucial for optimizing inference workloads, offering a significant leap in throughput for AI models.

In summary, NVIDIA’s Blackwell architecture and the B200/B100 accelerators represent a formidable advancement in AI accelerator technology. By pushing the limits of architectural efficiency, memory capacity, and computational precision, NVIDIA is not just maintaining its leadership in the AI space but setting new benchmarks for performance and efficiency. As we await the rollout of these groundbreaking products, the tech world watches with anticipation, eager to see how NVIDIA’s latest innovations will shape the future of AI computing.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
Nvidia Partners with Indonesia to Launch $200M AI Center in Global AI Expansion Effort

Nvidia's gaze turns to Indonesia, marking a significant leap in the global AI expansion saga. In a world where AI is no longer just buzz but a revolution, Nvidia's initiative to plant a $200M AI powerhouse in the heart of Indonesia is a game-changer. But what's this all about, and why should we keep our eyes peeled for this monumental project? Let's dive in and get the lowdown.
The Collaboration that Spells Future: Nvidia, a titan in AI and semiconductor innovation, has joined forces with Indonesia's government and the telecom titan, Indosat Ooredoo Hutchison, laying the foundation for what promises to be an AI mecca. This isn't just any partnership; it's a strategic move aiming at a grand slam in the AI arena.
Surakarta: The Chosen Ground: Picture this: Surakarta city, already buzzing with talent and tech, now set to be the epicenter of AI excellence. With a hefty $200 million investment, this AI center isn't just about hardware. It's where technology meets human genius, promising a fusion of telecommunication infrastructure and a human resource haven, all set against the backdrop of Central Java's vibrant community.
Why Surakarta, You Ask? Surakarta, affectionately known as Solo, isn't just chosen by chance. It's a city ready to leap into the future, boasting an arsenal of human resources and cutting-edge 5G infrastructure. According to Mayor Gibran Rakabuming Raka, Solo's readiness is not just about tech; it's about a community poised to embrace and lead in the AI revolution.
A Memorandum of Understanding with a Vision: Back in January 2022, Nvidia and the Indonesian government inked a deal not just on paper but on the future. This memorandum isn't just administrative; it's a commitment to empower over 20,000 university students and lecturers with AI prowess, sculpting Indonesia's next-gen AI maestros.
Riding the Wave of AI Frenzy: Post the unveiling of OpenAI's ChatGPT, the world hasn't just watched; it's leaped into the AI bandwagon, with the AI market ballooning from $134.89 billion to a staggering $241.80 billion in a year. Nvidia's move isn't just timely; it's a strategic chess move in a global AI match.
Beyond Borders: Nvidia's Southeast Asian Symphony: Indonesia's AI center is but a piece in Nvidia's grand Southeast Asian puzzle. From Singapore's collaboration for a new data center to initiatives with the Singapore Institute of Technology, Nvidia is weaving a network of AI excellence across the region, setting the stage for a tech renaissance.
A Global Race for AI Dominance: Nvidia's strides in Indonesia reflect a broader narrative. Giants like Google and Microsoft are not just spectators but active players, investing billions in AI ecosystems worldwide. This global sprint for AI supremacy is reshaping economies, technologies, and societies.
Tethering AI to Crypto: The AI craze isn't just confined to traditional tech realms. In the cryptosphere, firms like Tether are expanding their AI horizons, scouting for elite AI talent to pioneer new frontiers.
In Conclusion: Nvidia's foray into Indonesia with a $200M AI center is more than an investment; it's a testament to AI's transformative power and Indonesia's rising stature in the global tech arena. As we watch this partnership unfold, it's clear that the future of AI is not just being written; it's being coded, one innovation at a time.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes