
Statistics
We looked inside some of the posts by kracekumar and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
2 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Parameterize Python Tests
Introduction
A single test case follows a pattern. Setup the data, invoke the function or method with the arguments and assert the return data or the state changes. A function will have a minimum of one or more test cases for various success and failure cases.
Here is an example implementation of wc command for a single file that returns number of words, lines, and characters for an ASCII text file.
def wc_single(path, words=False, chars=False, lines=False): """Implement GNU/Linux `wc` command behavior for a single file. """ res = {} try: with open(path, 'r') as fp: # Consider, the file is a small file. content = fp.read() if words: lines = content.split('\n') res['words'] = sum([1 for line in lines for word in line.split(' ') if len(word.strip()) >= 1]) if chars: res['chars'] = len(content) if lines: res['lines'] = len(content.strip().split('\n')) return res except FileNotFoundError as exc: print(f'No such file {path}') return res
For the scope of the blog post, consider the implementation as sufficient and not complete. I'm aware; for example, the code would return the number of lines as 1 for the empty file. For simplicity, consider the following six test cases for wc_single function.
A test case with the file missing.
A test case with a file containing some data, with words, chars, lines set to True.
A test case with a file containing some data, with words alone set to True.
A test case with a file containing some data, with lines alone set to True.
A test case with a file containing some data, with chars alone set to True.
A test case with a file containing some data, with words, chars, lines alone set to True.
I'm skipping the combinatorics values for two of the three arguments to be True for simplicity.
Test Code
The file.txt content (don't worry about the comma after knows)
Welcome to the new normal. No one knows, what is new normal. Hang on!
wc output for file.txt
$wc file.txt 5 14 72 file.txt
Here is the implementation of the six test cases.
class TestWCSingleWithoutParameterized(unittest.TestCase): def test_with_missing_file(self): with patch("sys.stdout", new=StringIO()) as output: path = 'missing.txt' res = wc_single(path) assert f'No such file {path}' in output.getvalue().strip() def test_for_all_three(self): res = wc_single('file.txt', words=True, chars=True, lines=True) assert res == {'words': 14, 'lines': 5, 'chars': 72} def test_for_words(self): res = wc_single('file.txt', words=True) assert res == {'words': 14} def test_for_chars(self): res = wc_single('file.txt', chars=True) assert res == {'chars': 72} def test_for_lines(self): res = wc_single('file.txt', lines=True) assert res == {'lines': 5} def test_default(self): res = wc_single('file.txt') assert res == {}
The test case follows the pattern, setup the data, invoke the function with arguments, and asserts the return or printed value. Most of the testing code is a copy-paste code from the previous test case.
Parameterize
It's possible to reduce all six methods into a single test method with parameterized libray. Rather than having six methods, a decorator can inject the data for tests, expected value after the test. Here is how the code after parameterization.
def get_params(): """Return a list of parameters for each test case.""" missing_file = 'missing.txt' test_file = 'file.txt' return [('missing_file', {'path': missing_file}, f'No such file {missing_file}', True), ('all_three', {'path': test_file, 'words': True, 'lines': True, 'chars': True}, {'words': 14, 'lines': 5, 'chars': 72}, False), ('only_words', {'path': test_file, 'words': True}, {'words': 14}, False), ('only_chars', {'path': test_file, 'chars': True}, {'chars': 72}, False), ('only_lines', {'path': test_file, 'lines': True}, {'lines': 5}, False), ('default', {'path': test_file}, {}, False) ] class TestWCSingleWithParameterized(unittest.TestCase): @parameterized.expand(get_params()) def test_wc_single(self, _, kwargs, expected, stdout): with patch("sys.stdout", new=StringIO()) as output: res = wc_single(**kwargs) if stdout: assert expected in output.getvalue().strip() else: assert expected == res
The pytest runner output
pytest -s -v wc.py::TestWCSingleWithParameterized ============================================================================================================ test session starts ============================================================================================================= platform darwin -- Python 3.6.9, pytest-5.4.1, py-1.8.1, pluggy-0.13.1 -- /usr/local/Caskroom/miniconda/base/envs/hotbox/bin/python cachedir: .pytest_cache rootdir: /Users/user/code/snippets plugins: kubetest-0.6.4, cov-2.8.1 plugins: kubetest-0.6.4, cov-2.8.1 collected 6 items wc.py::TestWCSingleWithParameterized::test_wc_single_0_missing_file PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_1_all_three PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_2_only_words PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_3_only_chars PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_4_only_lines PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_5_default PASSED
What did @parameterized.expand do?
The decorator collected all the arguments to pass the test method, test_wc_single. When pytest runner ran the test class, the decorator injected a new function name following default rule, <func_name>_<param_number>_<first_argument_to_pass>. Then each item in the list returned by get_params to the test case, test_wc_single.
What did get_params return?
get_params returns a list(iterable). Each item in the list is a bunch of parameters for each test case.
('missing_file', {'path': missing_file}, f'No such file {missing_file}', True)
Each item in the list is a tuple containing the parameters for a test case. Let's take the first tuple as an example.
First item in the tuple is a function suffix used while printing the function name('missing_file'). The second value in the tuple is a dictionary containing the arguments to call the wc_single function({'path': missing_file}). Each test case passes a different number of arguments to the wc_single. Hence the second item in the first and second tuple has different keys in the dictionary. The third item in the tuple is the expected value to assert after calling the testing function(f'No such file {missing_file}'). The fourth item in the tuple determines what to assert after the function call, the return value, or stdout(True).
The principle is decorator will expand and pass each item in the iterable to the test method. Then how to receive the parameter and structure the code is up to the programmer.
Can I change the function name printed?
Yes, the parameterized.expand accepts a function as a value to the argument name_func, which can change each function name.
Here is the custom name function which suffixes the first argument for each test in the function name
def custom_name_func(testcase_func, param_num, param): return f"{testcase_func.__name__}_{parameterized.to_safe_name(param.args[0])}" class TestWCSingleWithParameterized(unittest.TestCase): @parameterized.expand(get_params(), name_func=custom_name_func) def test_wc_single(self, _, kwargs, expected, stdout): with patch("sys.stdout", new=StringIO()) as output: res = wc_single(**kwargs) if stdout: assert expected in output.getvalue().strip() else: assert expected == res
Test runner output
$pytest -s -v wc.py::TestWCSingleWithParameterized ... wc.py::TestWCSingleWithParameterized::test_wc_single_all_three PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_default PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_missing_file PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_only_chars PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_only_lines PASSED wc.py::TestWCSingleWithParameterized::test_wc_single_only_words PASSED
Is it possible to run a single test after parameterization?
Yes. You should give the full generated name and rather than actual method name in the code.
$pytest -s -v "wc.py::TestWCSingleWithParameterized::test_wc_single_all_three" ... wc.py::TestWCSingleWithParameterized::test_wc_single_all_three PASSED
Not like these
$pytest -s -v wc.py::TestWCSingleWithParameterized::test_wc_single ... =========================================================================================================== no tests ran in 0.24s ============================================================================================================ ERROR: not found: /Users/user/code/snippets/wc.py::TestWCSingleWithParameterized::test_wc_single (no name '/Users/user/code/snippets/wc.py::TestWCSingleWithParameterized::test_wc_single' in any of [<UnitTestCase TestWCSingleWithParameterized>]) $pytest -s -v "wc.py::TestWCSingleWithParameterized::test_wc_single_*" ... =========================================================================================================== no tests ran in 0.22s ============================================================================================================ ERROR: not found: /Users/user/code/snippets/wc.py::TestWCSingleWithParameterized::test_wc_single_* (no name '/Users/user/code/snippets/wc.py::TestWCSingleWithParameterized::test_wc_single_*' in any of [<UnitTestCase TestWCSingleWithParameterized>])
Does test failure give enough information to debug?
Yes, Here is an example of a test failure.
$pytest -s -v wc.py ... _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ self = <wc.TestWCSingleWithParameterized testMethod=test_wc_single_only_lines>, _ = 'only_lines', kwargs = {'lines': True, 'path': 'file.txt'}, expected = {'lines': 6}, stdout = False @parameterized.expand(get_params(), name_func=custom_name_func) def test_wc_single(self, _, kwargs, expected, stdout): with patch("sys.stdout", new=StringIO()) as output: res = wc_single(**kwargs) if stdout: assert expected in output.getvalue().strip() else: > assert expected == res E AssertionError: assert {'lines': 6} == {'lines': 5} E Differing items: E {'lines': 6} != {'lines': 5} E Full diff: E - {'lines': 5} E ? ^ E + {'lines': 6} E ? ^ wc.py:96: AssertionError
Pytest parametrize
pytest supports parametrizing test functions and not subclass methods of unittest.TestCase. parameterize library support all Python testing framework. You can mix and play with test functions, test classes, test methods. And pytest only supports UK spelling paramterize whereas parameterize library supports American spelling parameterize. Pytest refused to support both the spellings.
In recent PyCon 2020, there was a talk about pytest parametrize. It's crisp and provides a sufficient quick introduction to parametrization.
Why parameterize tests?
It follows DRY(Do not Repeat Yourself) principle.
Changing and managing the tests are easier.
In a lesser number of lines, you can test the code. At work, for a small sub-module, the unit tests took 660 LoC. After parameterization, tests cover only 440 LoC.
Happy parameterization!
Important links from the post:
Parameterized - https://github.com/wolever/parameterized
Pytest Parametrize - https://docs.pytest.org/en/latest/parametrize.html
PyCon 2020 Talk on Pytest Parametrize - https://www.youtube.com/watch?v=2R1HELARjUk
Complete code - https://gitlab.com/snippets/1977169
0 notes
Text
Incomplete data is useless - COVID-19 India data
The data is a representation of reality. When a value is missing in the piece of data, it makes it less useful and reliable. Every day, articles, a news report about COVID-19 discuss the new cases, recovered cases, and deceased cases. This information gives you a sense of hope or reality or confusion.
Regarding COVID-19, everyone believes or accepts specific details as fact like mortality rate is 2 to 3 percent, over the age of fifty, the chance of death is 30 to 50 percent. These are established based on previously affected places, and some details come out of the simulation. The mortality rate, deceased age distribution, patient age distribution, mode of spread differs from region to country. With accurate and complete data, one can understand the situation, make the decision, and update the facts.
Covid19India provides an API to details of all the COVID-19 cases. The dataset for the entire post comes from an API response on 18th April 2020. The APIs endpoints for the analysis are https://api.covid19india.org/raw_data.json, and https://api.covid19india.org/deaths_recoveries.json.
When one moves away cumulative data like total cases to specific data like age, gender, the details are largely missing and makes it difficult to comprehend what's going in the state. For all patients in India, only 11% of age brackets and 19.2% of gender details are available.
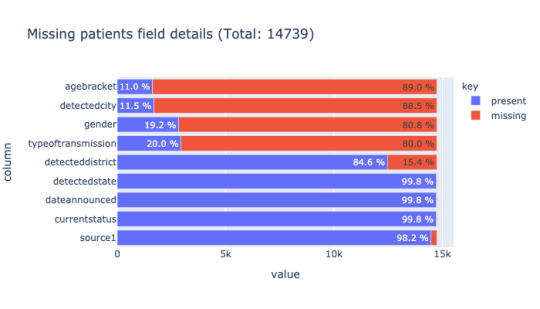
Analyzing missing data (empty value = '') state-wise reveals how each state reveals data. The below image is a comparison of missing data for the state of Karnataka and Maharashtra.
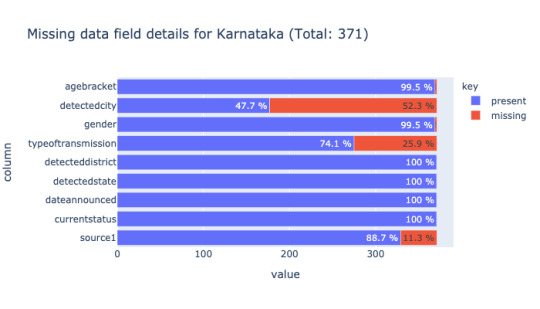
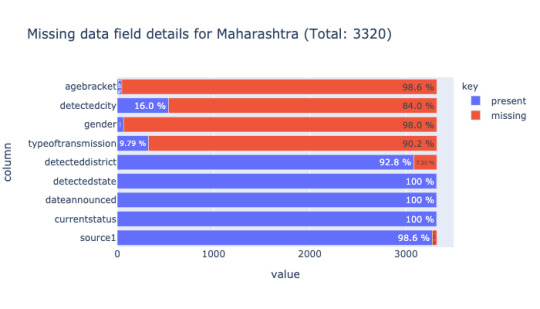
Looking further into each case, it's clear, Karnataka officials release date at the individual level such as age bracket, gender, other details in a tabular format(not machine-readable) compared to the State of Maharashtra. Maharashtra releases only cumulative data like the total number of new cases, the total number of recovered patients. Each state follows its format(not so useful). Next to Karnataka, Andhra Pradesh data contains more than 50% of age bracket and gender. The rest of the states except Kerala, to a certain extent, all have close to 90% of missing data for gender and age bracket.
With missing data, we can't identify which age group is dying in Maharashtra, which age group is most affected, does deceased age group vary across all states, is there a state where a considerable amount of young people are dying?
Karnataka Case
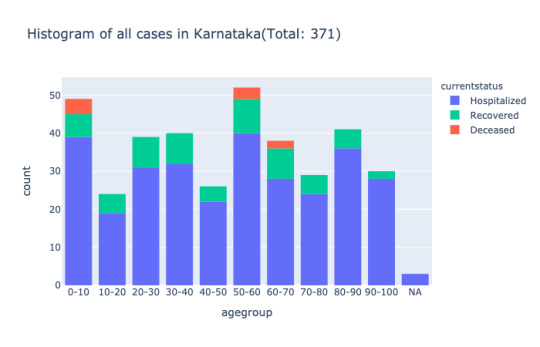
If we divide the age bracket in the range of ten like 40 - 50, all the age groups are more or less equally affected. There is no significant variation. You can also use arbitrary age groups like 0 to 45, 45 to 60, 60 to 75, 75+ as mentioned in the tweet.
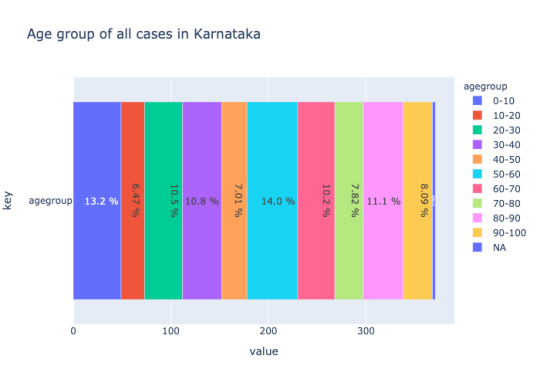
The raw_data.json API provides the status of the patients. The patient's status change numbers don't be match compared to the primary web application(covid19india.org). My guess is because of API update frequency.
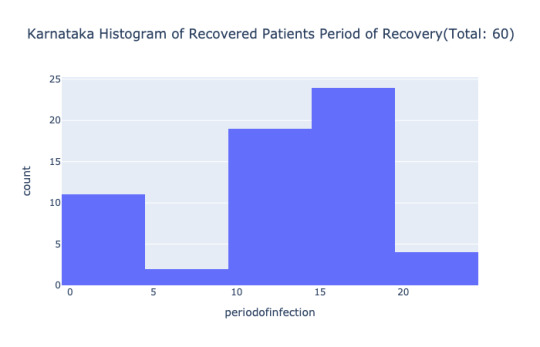
The patients in the age group 0-10 take more time to recover compared to the rest of the age group. The age group 10-20 less time to recover compared to the rest of the group. The two issues here. First, the dataset is small, only 60 cases. Second, the accuracy of dates makes a considerable difference; i.e dateannounced and statuschangedata in the API is crucial. If the data is available for the top three affected states like Maharashtra, Delhi, Gujarat, it would reveal which age group and gender are recovering fast and deceasing, in how many days the acute patients die.
Deceased Case
From the deaths_recoveries.json API, the age bracket is available for 39.6% of deceased cases. In Karnataka for

In the available data, the most number of deaths are in the age-group, 40-50 (44 deaths), and 20-30 (25 deaths). To get a better picture, one needs to compare with the population distributions as well. Without complete details, it's challenging to say the age group 20-30 mortality rate is 0.1%.
The mere number of deceased patients doesn't represent anything close to reality. Out of 13 deaths in Karnataka, age bracket and gender are available for 10 cases. All deceased cases are in the age bracket of 65 to 80, two females and eight males.
The small data suggests all corona related deaths happen with seven days of identification. Is this true for all states?
Conclusion
I'm aware; volunteers maintain the API. Their effort requires a special mention, and by analyzing the two sets of APIs, it's clear how hard it is to mark patients' status change. When the Government doesn't release the unique patient id, it's confusing, and local volunteer intuition and group knowledge takes over.
Every data points help us to know more about the pandemic. All the state governments need to release the complete data in a useable format. Remember, age and gender are necessary information, with more details like the existing respiratory condition, hospital allocated, the model can help in prioritizing the resources later. There is no replacement for testing and testing early. Without clean data, it's impossible to track the epidemic and associated rampage. We haven't seen the cases for re-infection yet. Several other factors contribute to one's survival, like a place of residence, access to insurance, socioeconomic status. We haven't moved further from numbers, the details like how crucial is a patient when identified, how each patient is recovering are never released in public.
By furnishing the incomplete data, the Government denies our choice of making an informed decision, and there is no independent verification for the claims on the pattern of the spread. In the prevailing conditions, the only way to understand the scenario is both qualitative and quantity (data) stories.
Code: Age Analysis, Death Recoveries
0 notes
Text
“Don’t touch your face” - Neural Network will warn you
A few days back, Keras creator, Francois Chollet tweeted
> A Keras/TF.js challenge: make a model that processes a webcam feed and detects when someone touches their face (triggering a loud beep)." The very next day, I tried the Keras yolov3 model available in the Github. It was trained on the coco80 dataset and could detect person but not the face touch.

V1 Training
The original Keras implementation lacked documentation to train from scratch or transfer learning. While looking for alternative implementation, I came across the PyTorch implemetation with complete documentation.
I wrote a simple python program to download images based on keyword.
> python face_touch_download.py --keyword "chin leaning" --limit 100 --dest chin_leaning
The script downloads 100 images and store the images in the directory. Next, I annotated the images using LabelImg in Yolo format. With close to 80 images, I trained the network on a single class facetouch for 100 epochs. The best of the weights couldn't identify any face touch on four images. Now, I wasn't clear should I train all classes(80 +1) or need more images with annotation.
V2 Training
Now, I downloaded two more sets of images using two different queries face touch and black face touch. After annotation, the dataset was close to 250 images. Then I decided to train along with a few other original classes of coco labels. I selected the first nine classes and face touch. Now, the annotated facetouch images need a change in class. For example, in V1, there was only one class(0), now those annotations are misleading because some other class takes up the number, now 0 means person and 9 means facetouch. Also, I picked random 500 images from the original coco dataset for training. After remapping the existing annotation and creating a new annotation, I trained the network for 200 epochs.
After training the network, I again ran the inference on four sample images - Dhanush rolling up mustache (1), another person rolling up mustache (2), Proust sitting in a chair leaning his face on the chin(3), and Virginia wolf leaning her face on the chin(4). The network labeled the person rolling up mustache, second image as face touch. First Victory! At the same time, the network was not predicting other images for classes person and face touch.

V3 Training
After re-reading the same documentation again, it was clear to me, the network needs more training images, and needn't be trained along with the rest of the classes. Now I deleted all the dataset v2 and annotations and came up with a list of keywords - face touch, black face touch, chin leaning. After annotation of close to 350 images, running the training, this time network was able to label two images - Another person rolling up mustache (2), Proust is sitting in a chair, leaning his face on the chin(3).
By now, it was clear to me that yolov3 can detect chin leaning and mustache as long as the rectangular box is of considerable size and next step.
Final Training
Now the list of keywords grew to ten. The new ones apart from previous ones are finger touching face, ear touch, finger touching forehead, headache, human thinking face, nose touching, rubbing eyes. The final dataset was close to 1000 images. After training the network for 400 epochs on the dataset, the network was able to identify face touch on videos, images, and webcam feed.
Classification (bounding box) on 17 images
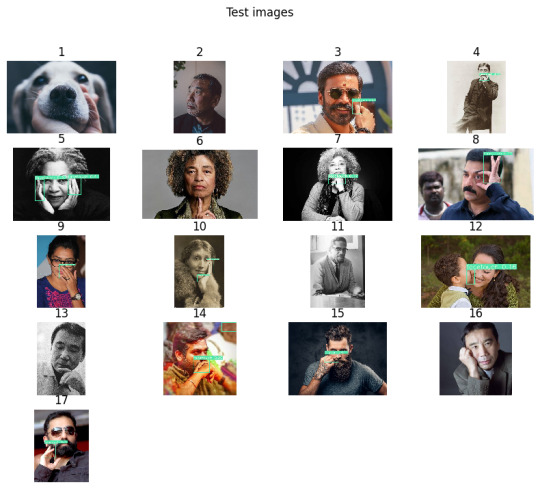
Out of 14 face touching images, the network able to box 11 images. The network couldn't box on two Murakami images.
Here is a youtube link to identifying facetouch on Salvoj Zizek clip - https://www.youtube.com/embed/n44WsmRiAvY.
youtube
Webcam
Now that, the network predicts anyone touching the face or trying to touch the face, you can run the program in the background, it warns you with the sound, Don't touch the face.
After installing the requirements, run the program,
> python detect.py --cfg cfg/yolov3-1cls.cfg --weights best_dataset_v5.pt --source 0
You're all set to hear the sound when you try to touch the face.
The repo contains a link to the trained model, dataset, and other instructions. Let me know your comments and issues.
I'm yet to understand how yolo works, so far, only read yolo v1 paper. The precision for the model is around ~0.6. I think it's possible to improve the precision of the model. Somewhere while transferring the image from the server, the results.png went missing.
Few Issues
If you run the detect.py with webcam source, the rendering sound is blocking code, you may notice a lag in the webcam feed.
Sometimes, the model predicts the mobile phone in front of the image as a face touch.
As shown in the images, if the face touch region is tiny like a single index finger over the chin, it doesn't predict, look at the below image titled 6.
The quality of the images was slightly issued because of the watermarks and focus angle. If the end deployment targets at the webcam, then it's better to train image with front face focus. There was no clean way to ensure or scrap the high-quality images. Do you know how to solve the problem or even this assumption is true?. Of course, good model should detect face touch from all sides and angles.
I haven't tried augmenting the dataset and training it.
The network may not run on edge devices, you may want to train using yolov3-tiny weights.
Yolo site: https://pjreddie.com/darknet/yolo/
PyTorch yolov3 implememtation: https://github.com/ultralytics/yolov3
Facetouch Repo: https://github.com/kracekumar/facetouch
While writing the code and debugging, I must have touched my face more than 100 times. It's part of evolution and habit, can't die in few days. Does wearing a mask with spikes help then?
0 notes
Text
1000 more whitelist sites in Kashmir, yet no Internet
Kashmir is under lockdown for more than 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200,200,200,200,200,200,200,200,200,200, 200 days. Last Friday(14th Feb, 2020), Government released a document with list of allowed whitelist sites at 2G speed. The text file with URLs extracted from the PDF - https://gitlab.com/snippets/1943725
In case you're not interested in tech details, analysis, or short of time, look at the summary section at the bottom.
DNS Query
The browser converts a domain name or URL into an IP address. This is step is called DNS querying.
I wrote the script to emulate the DNS request of the browser.
Out of 1464 entries in the PDF, only 90.9% (1331) of the URLs receive an answer(IP Address or sub-domain) for the DNS query. 9.1% (133) are either not domain names like (Airtel TV) and non-existent entities like www.unacademy.com.
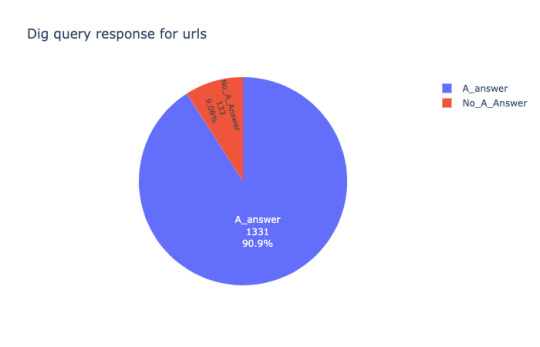
Out of 1331 DNS answers, except one URL all other DNS query answer contains at least one IP address. That means no further DNS query and all the webserver is reachable.
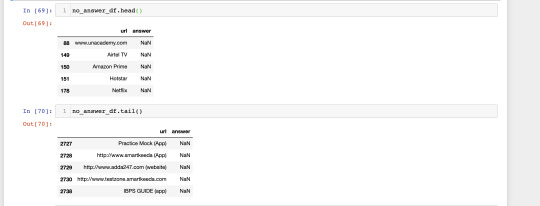
Out of 133 failed DNS queries, 113 are non-existent URLs/URIs(for simplicity you can assume non-existent hostname/sub-domain) like www.unacademy.com(the application is available at unacademy.com), http://www.testzone.smartkeeda.com, http://164.100.44.112/ficn/ and 22 entries are invalid like Gradeup (App), 122.182.251.118 precision biometrics.
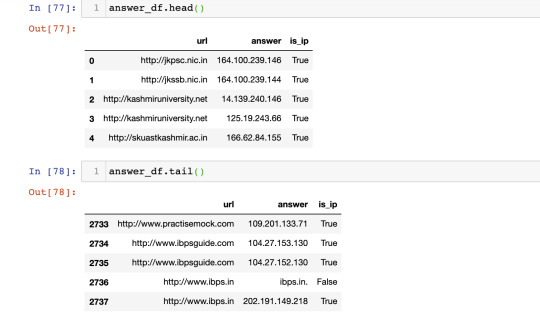
www.unacademy.com doesn't have 'A' address associated, and browser or resolver will fail, and http://unacademy.com only has the A address.

11 entries in the list are IP addresses without hostname like http://164.100.44.112/ficn/.
Four out of eleven IP addresses refuse to accept the HTTP GET request. Two of the IP address doesn't host any page, and two of the IP address refuse connection due to SSL Error, SSLCertVerificationError("hostname '59.163.223.219' doesn't match either of 'tin.tin.nsdl.com', 'onlineservices.tin.egov-nsdl.com".
All of the explicit IPs in the list are some sort of government service.
Whitelist group
Some of the entries in the PDF are from the same domain but with different sub-domain like example.com, api.example.com.
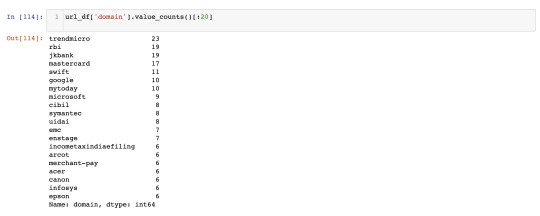
Analysis of the domain name association reveals, there are 23 URLs of trendmicro domain - a cybersecurity company, 19 URLs of rbi(reserve bank of India), 10 URLs of belonging to Google(Alphabet) product yet google.co.in is not on the list.
Spellings
In the last two PDFs, haj committee domain was misspelled. The misspelled still exists along with the correct spelling and irrelevant entry Haj_Committee.gov.in.
The new misspelled domains are www.scientificsmerican.com(scientific American?), flixcart.com(Flipkart?).
Product Names
It's unclear how the ISP will interpret the URL, http://Netflix. Netflix loads resources from the following places netflix.com, codex.nflxext.com, assets.nflxext.com, nflximg.com. Does the ISP download the netflix.com, figure out all the network calls, and whitelist all the network resources? Or they allow only the Netflix domain?
JIO chat mentioned in previous PDFs is missing in the current list.
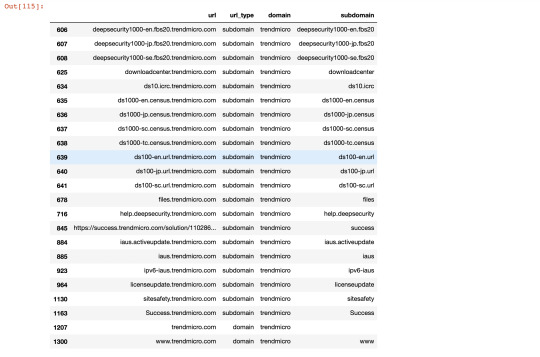
A classification of URLs from the PDF
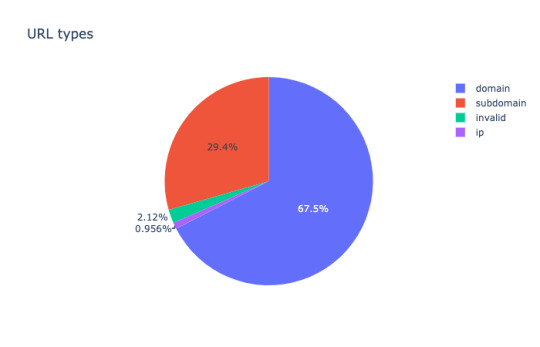
Site Reachability
Say if all the URLs DNS requests pass through(even though it's not), how many URLs will return a response to the browser? The source code available in GitLab
Only 74.6% entries are reachable - the browser receives a proper response (HTTP 200 response for GET request). 20 % of the websites fail to respond to HTTP GET requests due to various errors like SSL issues, non-existent site or technical misconfiguration, or unable to interpret the URL like Airtel TV.
6% URLs may or may not work since some of the URLs doesn't exist(https://www.khanacademy.org/math/in) or accept GET request(https://blazenet.citruspay.com/), but the domain or sub-domain or IP address exists, or issues redirect or don't accept GET request.

The domain http://aiman.co redirects to tumblr.com.
The list doesn't contain domain safexpay but the load balancer(going by the convention of naming), safexpay-341596490.ap-south-1.elb.amazonaws.com is in the list.
Do human agents verify these URLs before adding to the list?
Missing static content hosts
The Websites host JavaScripts, fonts, StyleSheet, static assets on third party services for fast load time. All cloud services provide a similar service. The important CDNs to load are present in the whitelist like googleapis.com, cdnjs.cloudflare.com, gstatic.com, fbcdn.net (facebook CDN),
Other popular services are missing like s3.amazonaws.com, nflxext.com, akamai.
All the problems mentioned in the post, to load static assets and in-general continue.
2G speed
I picked up random sites as a sample set(less than 100 websites - worth analysisng entire list); on average, each website makes 68 calls to load the home page, and an average size is 2.5 MB. These 68 network calls are from the mixed bag - same host, sub-domains, third party sites for JS, CSS, and images, etc.
Theoretical 2G speed is 40 kilobits per second. 2.5 G speed is 384kilobitss per second. Even when the browser can load all the resources in parallel, it may take exponential time and not linear time while deducing from higher speed to lower speed.
The browser opens only six connections to the host. If the server timeouts, the browser doesn't even retry.
In the chrome developer tool, there is no option to test a site in 2G. Allowed speed throttling is 3G, 4G.
In 20 Mbps speed, the browser takes 5 seconds to load a web page(consider all DNS queries pass through) of size 1.9 MB and, in a slow 3G connection, takes 13.79s in Chrome.
The real speed will be worse in 2G.
The chrome developer tools don't provide an option for simulating 2G speed. It is clear, no one test web sites in 2G speed. Airtel plans to shut down 2G service by mid of 2020 and reliance already shut down 2G service.
The process of whitelisting websites raises pertinent questions.
who chooses these websites?
what is the methodology to choose the websites?
what is the rationale of choosing 2G speed and banning VPN usage?
why even whitelist?
more
Summary
DNS query resolves a domain name into an IP address. Out of 1464 entries in the PDF, only 90.9% (1331) of the URLs receive an answer(IP Address or sub-domain) for the DNS query. 9.1% (133) are either not domain name like (Airtel TV) and non-existent entities like www.unacademy.com.
Out of 1330, except one URL all other DNS query answer contains at least one IP address.
Out of 133 failed DNS queries, 113 are non-existent URLs/URIs(for simplicity you can assume non-existent hostname/sub-domain) like www.unacademy.com(the application is available at unacademy.com), http://www.testzone.smartkeeda.com, http://164.100.44.112/ficn/ and 22 entries are invalid like Gradeup (App), 122.182.251.118 precision biometrics.
11 entries in the list are IP addresses without hostname like http://164.100.44.112/ficn/. Four out of eleven IP Addresses refuse to accept HTTP GET requests. Two of the IP address doesn't host any page, and two of the IP address refuse connection due to SSL Error, `SSLCertVerificationError("hostname '59.163.223.219' doesn't match either of 'tin.tin.nsdl.com,' 'onlineservices.tin.egov-nsdl.com".
Three entries are just hard to match keywords, unlike Airtel TV - umbrella, lancope, flexnetoperations.
In the last two PDF haj committee domain was misspelled. The misspelled still exists along with the correct spelling and irrelevant entry Haj_Committee.gov.in.
Scientific American and Flipkart are misspelled - www.scientificsmerican.com, flixcart.com.
There are 21 URLs of trendmicro domain,19 URLs of rbi,10 URLs of belonging to Google(Alphabet) product, yet google.co.in is not on the list.
74.6% entries are reachable - the browser receives proper response (HTTP 200 response for GET request). 20% of the website fails to respond to HTTP GET requests due to various errors like SSL issues, non-existent sites. 6% URLs may or may not work since some of the URLs don't exist, but the domain or sub-domain or IP address exist, or issues redirect or don't accept GET request.
Among the sample of URLs, on average, each website makes 68 calls to load the home page and an average size of 2.5 MB.
Some of the CDNs to load JavaScripts, fonts, StyleSheet, static assets are present in the whitelist like googleapis.com, cdnjs.cloudflare.com, gstatic.com, fbcdn.net (facebook CDN), Other popular services are missing like s3.amazonaws.com, nflxext.com, akamai.
The list doesn't contain domain safexpay but the load balancer(going by the convention of naming), safexpay-341596490.ap-south-1.elb.amazonaws.com is in the list.
All the problems mentioned in the post, https://kracekumar.com/post/190341665270/153-sites-allowed-in-kashmir-but-no-internet continues - whitelist sites can't provide complete access to the site and prevents the wholesome experience of the internet.
2G speed is 40 kilobits per second. 2.5 G speed is 384 kilobits per second. In the chrome developer tool, there is no option to test a site in 2G. Allowed speed throttlings are 3G, 4G. In a slow 3G connection, the chrome browser takes 13.79s to load a 1.9 MB size webpage. It is clear, no one test sites in 2G speed. Airtel plans to shut down 2G service by mid of 2020 and reliance already shut down 2G service.
Conclusion
> Internet (noun): an electronic communications network that connects computer networks and organizational computer facilities around the world
Overall, the internet cannot work by allowing only whitelist sites. Underhood, the browser makes calls to a plethora of locations mentioned by the developers and cannot function entirely and unusable from the beginning to the end.
Credits:
HashFyre for converting the PDF to text file using OCR.
Kingsly for pointing out DNS specific analysis - https://twitter.com/kracetheking/status/1229155303062745088?s=20
0 notes
Text
Capture all browser HTTP[s] calls to load a web page
How does one find out what network calls, browser requests to load web pages?
The simple method - download the HTML page, parse the page, find out all the network calls using web parsers like beautifulsoup.
The shortcoming in the method, what about the network calls made by your browser before requesting the web page? For example, firefox makes a call to ocsp.digicert.com to obtain revocation status on digital certificates. The protocol is Online Certificate Status Protocol.
The network tab in the browser dev tool doesn't display the network call to ocsp.digicert.com.
One of the ways to find out all the requests originating from the machine is by using a proxy.
Proxy
MITMProxy is a python interactive man-in-the-middle proxy for HTTP and HTTPS calls. Installation instructions here.
After installing the proxy, you can run the command mitmweb or mitmdump. Both will run the proxy in the localhost in the port 8080, with mitmweb, you get intuitive web UI to browse the request/response cycle and order of the web requests.
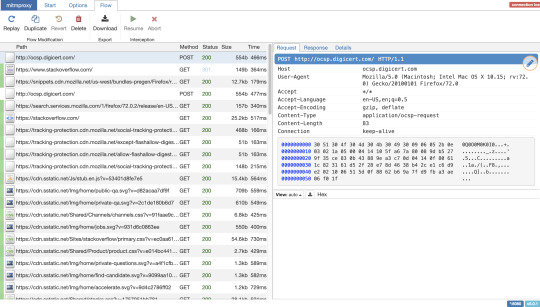
As the name indicate, "man in the middle," the proxy gives the ability to modify the request and response. To do so, a simple python script with a custom function can do the trick. The script accepts two python functions, request and response. After every request, request and after every response, response method will be called. There are other supported concepts like addons.
To extract the details of the request and response. Here is a small script, https://gitlab.com/snippets/1933443.
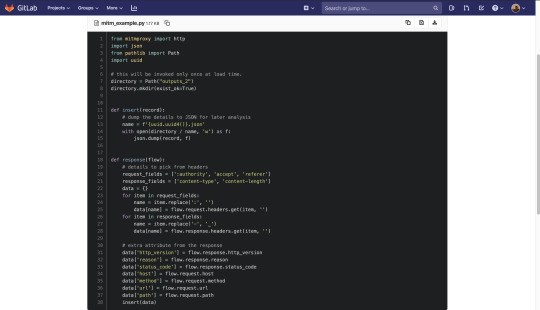
After receiving a successful response, the MITM invokes the function response; the function collects the details and dumps the details to the JSON file. uuid4 will ensure a unique file name for every function call.
Even though MITM provides an option to dump the response, it's in binary format and suited for data analysis. Next is to simulate the browser request.
Selenium
Selenium is one of the tools used by web-developers and testers for an end to end web testing. Selenium helps developers to test the code on the browser and assert the HTML elements on the same page.
To get selenium Python web driver working, one needs to install Java first, followed by geckodriver, and finally Python selenium driver(pip install selenium). Don't forget to place geckodriver in $PATH.
Code: https://gitlab.com/snippets/1933454
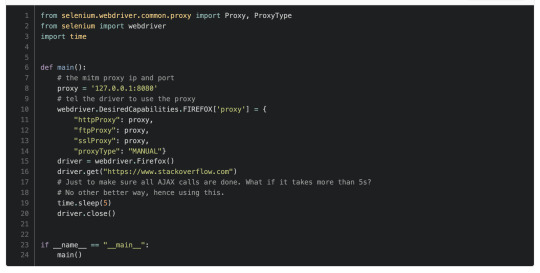
Run the MITM in a terminal, then selenium another terminal, the output directory must be filled with JSON files.
Here is how the directory looks
The sample JSON files output

0 notes
Text
153 sites allowed in Kashmir but no internet
Kashmir is locked down without the internet for more than 167 days as of 19th Jan 2020 since 5th Aug 2019. The wire recently published an article wherein the Government of India whitelisted 153 websites access in Kashmir. Below is the list extracted from the document . The internet shutdown is becoming common in recent days during protests.
Anyone with little knowledge to create a web application or work can say, every web application will make network calls to other sites to load JavaScript, Style sheets, Maps, Videos, Images, etc.
Accessing a Wikipedia page
The wikipedia.org is one of the whitelisted sites. If a user accesses the Freedom Page, they will see all the text in jumbled and image will be missing, since the image loads from wikimedia.org. wikimedia is not in the white listed sites. Even though you type one URL, your browser makes underhood requests to other sites.

Analysing these URLs
I wrote a small script to download all these sites' home page and parsed the HTML to extract the potential network calls while loading JavaScript, StyleSheets, images, media, WebSocket, Fonts, etc.
These whitelisted sites make network calls to 1469 unique locations, including their sites and external sites like cdn.jsdelivr.net, googletagmanager.com, maps.googleapis.com. That means, to make these whitelisted sites work, the ISP needs to whitelist thousand more sites.
The whitelist sites contain top-level domains like ac.in, gov.in, nic.in - meaning allow users to access all the government sites.Can ISP filters pass on the traffic to specific top-level domains?
For example, IRCTC uses CDN(Content Delivery Network) to load bootstrap CSS(styling the web elements), font from cdn.jsdeliver.net and googleapis, theme from cdn.jsdeliver.net, google analytics service from googleanalytics.com, loads AI-enabled chatbot from https://corover.mobi/. Failure to load all of these components will make the user unable to use the website - if not rendered by the browser, the site will be jumbled, the click actions on buttons will fail.
Other popular services that are missing in the whitelist - maps.googleapis.com, codex.nflxext.com, cdnjs.cloudflare.com, s.yimg.com, cdn.optimizely.com, code.jquery.com, gstatic.com, static.uacdn.net, cdn.sstatic.net, pixel.quantserve.com, nflxext.com, ssl-images-amazon.com, s3.amazonaws.com, rdbuz.com, oyoroomscdn.com, akamaized.net, etc.
Here is how amazon.in may look
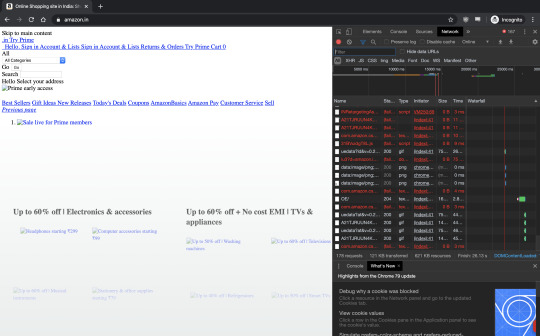
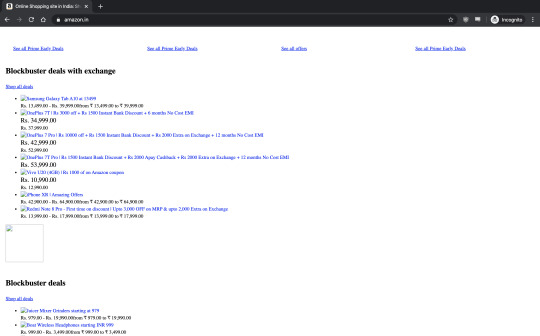
There is a typo in one of the whitelist sites, www.hajcommitee.gov.in, with a missing 't,' the correct URL is www.hajcommittee.gov.in. These two sites: https://www.jkpdd.gov.in/, https://www.jkpwdrb.nic.in, the browser fails to resolve.
Facebook, Twitter, Instagram, YouTube, WhatsApp, and other social media sites are blocked, whereas JioChat is allowed. The document mentions "JIO chat" does not specify the domain and application like www.
Conclusion
> Internet (noun): an electronic communications network that connects computer networks and organizational computer facilities around the world
Overall, the internet cannot work by allowing only whitelist sites. As said earlier, underhood, the browser makes calls to a plethora of locations mentioned by the developers and cannot function entirely and unusable from the beginning to the end.
0 notes
Text
How long do Python Postgres tools take to load data?
Data is crucial for all applications. While fetching a significant amount of data from database multiple times, faster data load times improve performance.
The post considers tools like SQLAlchemy statement, SQLAlchemy ORM, Pscopg2, psql for measuring latency. And to measure the python tool timing, jupyter notebook’s timeit is used. Psql is for the lowest time taken reference.
Table Structure
annotation=> \d data; Table "public.data" Column | Type | Modifiers --------+-----------+--------------------------------------------------- id | integer | not null default nextval('data_id_seq'::regclass) value | integer | label | integer | x | integer[] | y | integer[] | Indexes: "data_pkey" PRIMARY KEY, btree (id) "ix_data_label" btree (label) annotation=> select count(*) from data; count --------- 1050475 (1 row)
SQLAlchemy ORM Declaration
class Data(Base): __tablename__ = 'data' id = Column(Integer, primary_key=True) value = Column(Integer) # 0 => Training, 1 => test label = Column(Integer, default=0, index=True) x = Column(postgresql.ARRAY(Integer)) y = Column(postgresql.ARRAY(Integer))
SQLAlchemy ORM
def sa_orm(limit=20): sess = create_session() try: return sess.query(Data.value, Data.label).limit(limit).all() finally: sess.close()
Time taken
%timeit sa_orm(1) 28.9 ms ± 4.5 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
The time is taken in milliseconds to fetch 1, 20, 100, 1000, 10000 queries.
{1: 28.9, 20: 26.6, 100: 26.2, 1000: 29.5, 10000: 70.2}
SQLAlchemy Select statement
def sa_select(limit=20): tbl = Data.__table__ sess = create_session() try: stmt = select([tbl.c.value, tbl.c.label]).limit(limit) return sess.execute(stmt).fetchall() finally: sess.close()
Time Taken
The time is taken in milliseconds to fetch 1, 20, 100, 1000, 10000 queries.
{1: 24.7, 20: 24.5, 100: 24.9, 1000: 26.8, 10000: 39.6}
Pscopg2
Pscopg2 is one of the Postgres drivers. You can use pscopg2 along with SQLAlchemy or as a stand-alone tool.
def pscopg2_select(limit=20): conn = psycopg2.connect("dbname=db user=user password=password host=localhost") cur = conn.cursor() try: # Note: In prod, escape SQL queries. stmt = f"select value, label from data limit {limit}" cur.execute(stmt) return cur.fetchall() finally: cur.close() conn.close()
Pscopg2 Time Taken
The time is taken in milliseconds to fetch 1, 20, 100, 1000, 10000 queries.
{1: 17.0, 20: 16.9, 100: 17.3, 1000: 18.1, 10000: 30.1},
Psql
annotation=> explain (analyze, timing off) select label, value from data limit 10000; QUERY PLAN ------------------------------------------------------------------------------------------------ Limit (cost=0.00..322.22 rows=10000 width=8) (actual rows=10000 loops=1) -> Seq Scan on data (cost=0.00..33860.40 rows=1050840 width=8) (actual rows=10000 loops=1) Total runtime: 7.654 ms (3 rows) Time: 7.654 ms
Psql time taken
The time is taken in milliseconds to fetch 1, 20, 100, 1000, 10000 queries.
{1: 0.9, 20: 0.463, 100: 1.029, 1000: 1.643, 10000: 7.654}
All timings
{'pscopg2': {1: 17.0, 20: 16.9, 100: 17.3, 1000: 18.1, 10000: 30.1}, 'sa_orm': {1: 28.9, 20: 26.6, 100: 26.2, 1000: 29.5, 10000: 70.2}, 'sa_select': {1: 24.7, 20: 24.5, 100: 24.9, 1000: 26.8, 10000: 39.6}, 'sql_select': {1: 0.9, 20: 0.463, 100: 1.029, 1000: 1.643, 10000: 7.654}}
Chart of all the timings
Lower the bar, better for the performance.
As you can see, SQLAlchemy ORM is slowest, and pscyopg2 is fastest. SQLAlchemy select statement is close to the pscopg2 performance, provides a sweet spot for not writing SQL Queries and handling data at a high level.
0 notes
Text
Debugging Python multiprocessing program with strace
Debugging is a time consuming and brain draining process. It's essential part of learning and writing maintainable code. Every person has their way of debugging, approaches and tools. Sometimes you can view the traceback, pull the code from memory, and find a quick fix. Some other times, you opt different tricks like the print statement, debugger, and rubber duck method.
Debugging multi-processing bug in Python is hard because of various reasons.
The print statement is simple to start. When all the processes write the log to the same file, there is no guarantee of the order without synchronization. You need to use -u or sys.stdout.flush() or synchronizing the log statements using process ids or any identifier. Without PID it’s hard to know which process is stuck.
You can’t put pdb.set_trace() inside a multi-processing pool target function.
Let’s say a program reads a metadata file which contains a list of JSON files and total records. Files may have a total of 100 JSON records, but you may need only 5. In any case, the function can return first five or random five records.
Sample code
https://gist.github.com/kracekumar/20cfeec5dc99b084c879ce737f7c7214
The code is just for demonstrating the workflow and production code is not simple like above one.
Consider multiprocessing.Pool.starmap a function call with read_data as target and number of processes as 40.
Let’s say there are 80 files to process. Out of 80, 5 are problematic files(function takes ever to complete reading the data). Whatever be the position of five files, the processes continues forever, while other processes enter sleep state after completing the task.
Once you know the PID of the running process, you can look what system calls process calls using strace -s $PID. The process in running state was calling the system call read with same file name again and again. The while loop went on since the file had zero records and had only one file in the queue.
Strace looks like one below
https://gist.github.com/kracekumar/8cd44ff27b81e200343bc58d194dd595
You may argue a well-placed print may solve the problem. All times, you won't have the luxury to modify the running program or replicate the code in the local environment.
0 notes
Text
Notes from Root Conf Day 2 - 2017
On day 2, I spent a considerable amount of time networking and attend only four sessions.
Spotswap: running production APIs on Spot instance
Amazon EC2 spot instances are cheaper than on-demand server costs. Spot instances run when the bid price is greater than market/spot instance price.
Mapbox API server uses spot instances which are part of auto-scaling server
Auto scaling group is configured with min, desired, max parameters.
Latency should be low and cost effective
EC2 has three types of instances: On demand, reserved and spot. The spot instance comes from unused space and unstable pricing.
Spot market starts with bid price and market price.
In winter 2015 traffic increased and price also increased increased
To spin up a new machine with code takes almost two minutes
Our machine fleet encompasses of spot and on-demand instances
When one spot machine from the fleet goes down, and auto scaling group spins up an on-demand machine.
Race condition: several instances go down at same time.
Aggressive spin up in on-demand machines when market is volatile.
Tag EC2 machines going down and then spin up AWS lambda. When spot instance returns shit down a lambda or on-demand instance. Auto Scaling group can take care of this.
Savings 50% to 80%
Source code: https://github.com/mapbox/spotswap
No latency because over-provisioned
Set bid price as on-demand price.
Didn't try to increase spot instance before going on-demand
Cfconfig to deploy and Cloud formation template from AWS
Adventures with Postgres
Speaker: I’m an Accidental DBA
The talk is a story of a Postgres debugging.
Our services include Real-time monitoring, on demand business reporting to e-commerce players. 4000 stores and 10 million events per day. Thousands of customers in a single database.
Postgres 9.4, M4.xlarge,16GB, 750 GB disk space with Extensive monitoring
Reads don't block writes, Multi-Version Concurrency Model.
Two Clients A, B read X value as 3. When B updates the value X to 4, A reads the X value and gets back as 3. A reads the X value as 4 when B’s transaction succeeds.
Every transaction has a unique ID - XID.
XID - 32 bit, max transaction id is 4 billion.
After 2 billion no transaction happens.
All writes stop and server shutdown. Restarts in single user mode,
Read replicas work without any issue.
Our server reached 1 billion ids. 600k transaction per hour, so in 40 days transaction id will hit the maximum limit.
How to prevent?
Promote standby to master? But XID is also replicated.
Estimate the damage - txid_current - Current Transaction ID
Every insert and update is wrapped inside a transaction
Now add begin and commit for a group of statements, this bought some time.
With current rate, 60 days is left to hit max transaction limit.
TOAST - The Oversized Attribute Storage Technique
Aggressive maintenance. Config tweaks: autovacuum_workers, maintenance_work_mem, autovaccum_nap_time - knife to gun fight. Didn’t help
rds_superuser prevented from modifying pg system tables
Never thought about rds_superuser can be an issue.
VACUUM -- garbage-collect and optionally analyze a database
vacuum freeze (*) worked. Yay!
What may have caused issues - DB had a large number of tables. Thousands of tables
Better shard per customer
Understand the schema better
Configuration tweaks - max_workers, nap_time, cost_limit, maintenance_work_mem
Keep an eye out XID; Long-lived transactions are problem
Parallel vacuum introduced in 9.5
pg_visibility improvements in 9.6
Similar problem faced other companies like GetSentry
MySQL troubleshooting
Step 1 - Define the problem, know what is normal, read the manual
Step 2: collect diagnostics data (OS, MySQL). pt_stalk tool to collect diagnostics error
Lookup MySQL error log when DB misbehaves.
Check OOM killer
General performance issues - show global variables, show global status, show indexes, profile the query
Table corruption InnoDB, system can't startup. Worst strategy force recovery and start from backup.
Log message for table corruption is marked as crashed
Replication issues - show master status, my.cnf/my.ini, show global variables, show slave status
OTR Session - Micro Service
OTR - Off The Record session is a group discussion. Few folks come together and moderate the session. Ramya, Venkat, Ankit and Anand C where key in answering and moderating the session.
What is service and micro service? Micro is independent, self-contained and owned by the single team. Growing code base is unmanageable, and the number of deploys increases. So break them at small scale. Ease of coupling with other teams. No clear boundary
Advantages of Microservices - team size, easy to understand, scale it. Security aspects. Two pizza team, eight-member team. Able to pick up right tools for the job, and change the data store to experiment, fix perf issues.
How to verify your app needs micro service?
Functional boundary, behavior which is clear. Check out and Delivery
PDF/Document parsing is a good candidate for Micro Service, and parsing is CPU intensive. Don't create nano-service :-)
Failure is inevitable. Have logic for handling failures on another service. Say when MS 1 fails MS2 code base should handle gracefully.
Message queue Vs Simple REST service architecture. Sync Vs Async.The choice depends on the needs and functionality.
Service discovery? Service registry and discover from them.
Use swagger for API
Overwhelming tooling - you can start simple and add as per requirements
Good have to think from beginnings - how you deploy, build pipelines.
Auth for internal services - internal auth say Service level auth and user token for certain services. Convert monolithic to modular and then micro level.
API gateway to maintain different versions and rate limiting When to use role-based access and where does scope originate? Hard and no correct way. Experiment with one and move on.
Debugging in monolithic and micro service is different.
When you use vendor-specific software use mock service to test them. Also, use someone else micro service. Integration test for microservices are hard.
Use continuous delivery and don't make large number of service deployment in one release.
The discussion went on far for 2 hours! I moved out after an hour. Very exhaustive discussion on the topic.
1 note
·
View note
Text
Notes from Root Conf Day 1 - 2017
Root Conf is a conference on DevOps and Cloud Infrastructure. 2017 edition’s theme is service reliability. Following is my notes from Day 1.
State of the open source monitoring landscape
The speaker of the session is the co-founder of Icinga monitoring system. I missed first ten minutes of the talk. -The talk is a comparison of all available OSS options for monitoring, visualization.
Auto-discovery is hard.
As per 2015 monitoring tool usage survey, Nagios is widely used.
Nagios is reliable and stable.
Icinga 2 is a fork of Nagios, rewrite in c++. It’s modern, web 2.0 with APIs, extensions and multiple backends.
Sensu has limited features on OSS side and a lot of features on enterprise version. OSS version isn't useful much.
Zabbix is full featured, out of box monitoring system written in C. It provides logging and graphing features. Scaling is hard since all writes are written to single Postgres DB.
Riemann is stream processor and written in Clojure. The DSL stream processing language needs knowledge of Clojure. The system is stateless.
OpenNMS is a network monitoring tool written in Java and good for auto discovery. Using plugins for a non-Java environment is slow.
Graphite is flexible, a popular monitoring tool for time series database.
Prometheus is flexible rule-based alerting and time series database metrics.
Elastic comes with Elastic search, log stash, and kibana. It’s picking up a lot of traction. Elastic Stack is extensible using X-PACK feature.
Grafana is best for visualizing time series database. Easy to get started and combine multiple backends. - - Grafana annotations easy to use and tag the events.
There is no one tool which fits everyone's case. You have to start somewhere. So pick up a monitoring tool, see if it works for you else try the next one til you settle down.
Deployment strategies with Kubernetes
This was talk with a live demo.
Canary deployment: Route a small amount of traffic to a new host to test functioning.
If new hosts don't act normal roll back the deployment.
Blue Green Deployment is a procedure to minimize the downtime of the deployment. The idea is to have two set of machines with identical configuration but one with the latest code, rev 2 and other with rev 1. Once the machines with latest code act correctly, spin down the machines with rev 1 code.
Then a demo of kubectl with adding a new host to the cluster and roll back.
A little bot for big cause
The talk is on a story on developing, push to GitHub, merge and release. And shit hits the fan. Now, what to do?
The problem is developer didn’t get the code reviewed.
How can automation help here?
Enforcing standard like I unreviewed merge is reverted using GitHub API, Slack Bot, Hubot.
As soon as developer opens a PR, alice, the bot adds a comment to the PR with the checklist. When the code is merged, bot verifies the checklist, if items are unchecked, the bot reverts the merge.
The bot can do more work. DM the bot in the slack to issue commands and bot can interact with Jenkins to roll back the deployed code.
The bot can receive commands via slack personal message.
Necessary tooling and monitoring for performance critical applications
The talk is about collecting metrics for German E-commerce company Otto.
The company receives two orders/sec, million visitors per day. On an average, it takes eight clicks/pages to complete an order.
Monitor database, response time, throughput, requests/second, and measure state of the system
Metrics everywhere! We talk about metrics to decide and diagnose the problem.
Metrics is a Clojure library to measure and record the data to the external system.
The library offers various features like Counter, gauges, meters, timers, histogram percentile.
Rather than extracting data from the log file, measure details from the code and write to the data store.
Third party libraries are available for visualization.
The demo used d3.js application for annotation and visualization. In-house solution.
While measuring the metrics, measure from all possible places and store separately. If the web application makes a call to the recommendation engine, collect the metrics from the web application and recommendation for a single task and push to the data store.
What should be PID 1 in a container?
In older version of Docker, Docker doesn’t reap child process correctly. As a result, for every request, docker spawns a new application and never terminated. This is called PID 1 zombie problem.
This will eat all available PIDs in the container.
Use Sysctl-a | grep pid_max to find maximum available PIDs in the container.
In the bare metal machine, PID 1 is systemd or any init program.
If the first process in the container is bash, then is PID 1 zombie process doesn’t occur.
Using bash is to handle all signal handlers is messy.
Yelp came up with Yelp/dumb-init. Now, dumb-init is PID 1 and no more zombie processes.
Docker-1.13, introduced the flag, --init.
Another solution uses system as PID 1
Docker allows running system without privilege mode.
Running system as PID 1 has other useful features like managing logs.
‘Razor’ sharp provision for bare metal servers
I attended only first half of the talk, fifteen minutes.
When you buy physical rack space in a data server how will you install the OS? You’re in Bangalore and server is in Amsterdam.
First OS installation on bare metal is hard.
There comes Network boot!
PXELinux is a syslinux derivative to boot OS from NIC card.
Once the machine comes up, DHCP request is broadcasted, and DHCP server responds.
Cobbler helps in managing all services running the network.
DHCP server, TFTP server, and config are required to complete the installation.
Microkernel in placed in TFTP server.
Razor is a tool to automate provisioning bare metal installation.
Razor philosophy, consume the hardware resource like the virtual resource.
Razor components - Nodes, Tags, Repository, policy, Brokers, Hooks
FreeBSD is not a Linux distribution
FreeBSD is a complete OS, not a distribution
Who uses? NetFlix, WhatsApp, Yahoo!, NetApp and more
Great tools, mature release model, excellent documentation, friendly license.
Now a lot of forks NetBSD, FreeBSD, OpenBSD and few more
Good file system. UFS, and ZFS. UFS high performance and reliable. - If you don’t want to lose data use ZFS!
Jails - GNU/Linux copied this and called containers!
No GCC only llvm/clang.
FreeBSD is forefront in developing next generation tools.
Pluggable TCP stacks - BBR, RACK, CUBIC, NewReno
Firewalls - Ipfw , PF
Dummynet - live network emulation tool
FreeBSD can run Linux binaries in userspace. It maps GNU/Linux system call with FreeBSD.
It can run on 256 cores machine.
Hard Ware - NUMA, ARM64, Secure boot/UEFI
Politics - Democratically elected core team
Join the Mailing list and send patches, you will get a commit bit.
Excellent mentor program - GSoC copied our idea.
FreeBSD uses SVN and Git revision control.
Took a dig at GPLV2 and not a business friendly license.
Read out BSD license on the stage.
0 notes
Text
Book Review: The Culture Map
The Culture Map: Breaking Through the Invisible Boundaries of Global Business is a book on cultural differences in communication by Erin Meyer.
Last year, I spent three months in NYC. Whenever I entered food outlet or made an eye contact, all the conversation started with "How are you doing?". I replied, "I'm good and how are you doing?". Most of the times, I didn't receive a response. It was a sign. Pedestrians smile at you if you make an eye contact in the US. This doesn't happen back in India. Neither I'd dare to do it. That's considered crazy. You smile at someone whom you know or about to talk. Anything else is inviting problem.
The Culture Map is a book about how different culture perceives communication, persuasion, respect, politeness, leadership, decision-making and trust. The book documents all little details how neighboring countries like the UK and France differs. The book provides a relative scale how one culture compares to other. For example, confrontation in a debate in India is considered as outrageous whereas it is an essential aspect of the sound argument in France. French culture emphasis on thesis-antithesis-synthesis. Asian culture doesn't encourage open negative feedback in public.
If you're operating a business or working with multi-ethnicity people, understanding the cultural difference is a key ingredient of a fruitful outcome and pleasant experience. Knowing the difference will save you future trouble.
The book covers a lot of cultures differences in many countries, how to work in multi-cultural environment and decode culture difference. The book filled with a good amount of real-life stories and relative comparison of various culture.
Having worked and working with Canadians, Americans, Dutch, and Indians I'm surprised by author's effort in narrating the culture difference with solid backing. Next time when you encounter a communication gap, you will start thinking does culture play a role here? The book is absolute treasure trove on various cultures.
0 notes
Text
Book Review: Software Architecture with Python
The book Software Architecture with Python is by Anand B Pillai. The book explains various aspects of software architecture like testability, performance, scaling, concurrency and design patterns.
The book has ten chapters. The first chapter speaks about different architect roles like solution architect, enterprise architect, technical architect what is the role of an architect and difference between design and architecture. The book covers two lesser spoken topics debugging and code security which I liked. There is very few literature available in debugging. The author has provided real use cases of different debugging tips and tools without picking sides. The book has some good examples on OverFlowErrors in Python.
My favorite chapter in the book is 'Writing Applications that scale'. The author explains all the available concurrency primitives like threading, multiprocess, eventlet, twisted, gevent, asyncio, queues, semaphore, locks, etc. The author doesn't stop by explaining how to use them but paves the path to figuring out how to profile the code, find out where the bottleneck lies and when to use which concurrency primitives. This chapter is the longest in the book and deluged with examples and insights. The author's approach of using time command to measure the performance rather than sticking with wall-clock time gives the developer understanding of where programming is spending most of the time. The infamous GIL is explained!
The book covers vital details on implementing Python Design Patterns and how Python's dynamic nature brings joy while creating the creational, structural and design pattern. The showcased examples teach how Python metaclass works and it's simplicity. The author avoids the infamous gang of four patterns.
The book documents significantly scattered wisdom in Python and Software Architecture world in one place. The book strongly focuses on design pattern and concurrency. The in-depth coverage like concurrency is missing to other chapters. The book is must read for all Python developers.
The book is indeed a long read and solid one in size and content. Having said that book is pretty hands on and loaded with trivial and non-trivial examples. I won't be surprised if half the book covers the code snippets. The author hasn't shied away skipping code snippets for explaining any concept. The book introduces a plethora of tools for developing software, and at the same time references required literature.
0 notes
Text
RC checklist for Indian Applicants
One Sunny Sunday morning one can get up and question their self-existence, or one can ask every few days or few months what am I doing at the current job? The answer will push you to a place you have never been.
One can meticulously plan for extravagant programming tour or programmer’s pilgrimage for three months. Yes, that what my outlook of RC is! RC is a different place from a usual workplace, meetups, college or any educational institute. The two striking reasons are peers and social rules. If you haven't thought of attending it, give it a thought. I am jotting down the list of steps to ease the planning.
What is RC?
The Recurse Center is a free, three-month self-directed program for people who want to get better at programming.
Application Process
RC application process is straightforward. The applicant fills an online form with few details like programming experience, what are your plans at RC and few other details. The exact details are available at Apply Page. Once you submit the application, RC interviewer gets back to you in next few days about application status.
The first round for shortlisted candidate is casual Skype chat. The Skype chat is a step to get to know the applicant. The conversation lasts for few minutes to half an hour. The next round is pair programming round. You will pair up with an interviewer to add a simple feature to the code you submitted as part of the application process. The ideal duration is half an hour. Finally, you get the green card or red card. If you get a red card, you need to wait for six more months to apply. If you get a green card, you’re entitled to jump out of the chair or open a beer bottle and celebrate. You can read about the experience of a recurser on his interview process.
Choosing a batch
The application form has the drop down list of batches you’d like to attend. Normally, the drop down list contains next four batches with timelines. You will know how many days in advance to apply for a RC batch the bottom.
Book flight tickets and accommodation
First and foremost expense for the trip is purchasing flight tickets. You should book two-way flight ticket with or without the cancellation option. On an average, the flight tickets cost 70K INR (~1050 USD) for a two-way journey.
The trip is for three months, and the hotel stay is out of the equation since it's expensive. The other viable option is Airbnb. RC has a community mailing list for housing. You may get access to the list few weeks before the batch. But if you don't have a US visa you can't wait until the last moment. I’ll explain why this is important in a bit. Airbnb charges for the first month stay in advance for the three-month stay. If the user cancels the trip, Airbnb will refund the money with some deduction depending on terms and conditions.One can book Airbnb for the first month and upgrade/shift depending on the experience. Most of the times, Airbnb has a flat discount for one month stay.
By now you must have noticed the savings disappeared like melting of ice.
B-1/B-2 Visa - walking on the rope
Every year lakhs of people from the Indian Union travel to the USA for different purpose like education, business, family visit, conference, relocation, tourism, etc.. As per 2015 available stats on Wikipedia article, 1,175,153 tourists visited the USA. If you already have a US visa, skip this section.
Every purpose of the tour has a different class of visa. Here is an exhaustive list of visa types for immigrants and non-immigrants. All grad school students apply for non-immigrant F1 visa. The Recurse Center isn't typical education institute since you don't get a degree at the end of the stay. The motto of RC is Never Graduate. So you can’t apply for the F1 visa. The alternate option in front of the computer is B-1/B-2 visa.
B-1 visa is for business visitors, and B-2 is for pleasure. If your company is paying for the trip, apply for B-1 else apply for the B-2 visa. In the end, your visa carries a stamp stating B-1/B-2 visa type. The permit is valid for ten years.
Visa application
In the Tamil movie Vaaranam Aayiram - A thousand elephants, the hero shows up on US visa Center when he decides to fly to meet the girl whom he encountered on a train journey and fell in love with head over heels. That's one heck of a crazy scene! But the real life picture is entirely different. You need to apply for a visa online. The application process is time-consuming and takes multiple hours to fill. The application requires a bag full of references. Let me put down points I remember.
Date of journey and return
Purpose of visit - RC admission letter is suffice
Accommodation information
Flight details
Your last two employer name
Your point of contact in the USA
Your relative or friends address[es] in USA
Your trip sponsor information. If you're paying for the trip, itself
Your past crime records :-) Hopefully void!
During the online application process, your session must have expired multiple times. The applicant needs to select two dates for in-person interview. Everyone wants to have their interview as soon as possible. The number of visa interviewers is less than 20 in a Center, and one can speak to approximately 20 to 40 applicants in a day. Depending on which day of the year, which season the next available slot will fall in one to four weeks. During the education season, the interview slot fills up faster with minimum three weeks from date of application. The US travel site displays the turn around based on location.
The first day the applicant submits paper documents of residence, passport information. The Center takes candidate photo, collects fingerprints. The first day is tension free. The second-day applicant meets the interviewer for 10 minutes who will judge your intent and all the carried paper documents. This day is boxing day.
Criteria
Some people take off from the job and go to RC, some resign from the job and go to RC.
The visa clearance depends on what is your case out of two and other probabilities like marital status, loan, plans after RC, etc ...
US embassy loves people who travel for the business purpose. That should be the simple guess. What does that mean here? If your company pays for the trip, the chance of visa approval is high.
The prime concern for the interviewer is the applicant may disappear in the USA and never fly back. Hope you heard similar lines in the linked video. To break the fear, you need to answer the questions and show the proof of return. Now you must have understood why booking flight ticket is the must. As you know, the return flight ticket can be canceled and not a cohesive proof of return but showcases your plan.
So, What else can be a substantial evidence for flying back?
A loan like education loan, car loan, housing loan or personal loan.
The latest wedlock certificate.
A statement from the employer that you will join the current job after the short visit.
If you don't satisfy above three criteria and you're in the twenties, your visa request has the high probability of rejection. That’s the price you pay for being a free bird!
DS-160
An applicant can try twice consecutively for visa application. AFAIK for the third time, the applicant needs to wait for six months to apply. The interviewer for subsequent interviews are different, and there is a high chance of conversion on the second attempt. You need to fill out DS-160 application to get started on the application process and then pay 160 USD. You will receive the email notification at all phases. Once your payment is through, login to ustravel docs portal and pick up the interview slot. You can read step by step procedure on the site. Here is a document for the first-time traveler.
It took two attempts for me to get a US visa. So one of the safest bet is to obtain US visa for the conference or business and then later apply for RC if you have time. If you work in India focused startups, high chance the company won't send you to the USA. So you don't have USA visa.
The current political climate in the US may bring new rule during your transit to the USA. So odds are in all lands.
At the end of the interview, the concerned officer informs the status of the visa request. For the selected candidate, US embassy sends the visa affixed in the passport to one of the specified Collection Center in a week.
Timelines:
RC application process: 2 - 3 weeks
Visa application process first attempt: 2 weeks
Visa application process second attempt: 2 weeks
Visa delivery time: 1 week
Time to put down paper at the current company or relieve: 1 week to 3 months
So the applicant needs two to three months to complete all paperwork to attend RC. If you have US visa, you can fly next month to attend RC!
How much does it cost?
Economics played a crucial role in planning the trip.
I will provide two cost breakup. First one is from a fellow recurser Satabdi Das and second is mine.
She is not a vegetarian and stayed with an RC alumni who rented the other bedroom in his 2 Bedroom apartment in Brooklyn. Her commute time was between 25-30 minutes (25 minutes when I got the express train - A line) in A and C lines. Usually, she prepared her breakfast. In the beginning, she tried to cook dinner too, but that turned out to be a little time consuming, and there was no dearth of good and cheap options. Most of the meals used to be around $5 to $10 (rarely $10, if she felt like splurging) and sometimes even $2 (thanks to those yummy Chinese buns!). And she used to buy fruits almost weekly.
List of her most frequented places - Halal cart - Falafel sandwich - Hummus sandwich - NY Dosa - Chinese Buns from Golden Steamer - Sweet Green
Expenses:
Rent - 1185 per month = 3555
Commute - 115 per month = 345
Mobile Bill - 40 per month = 120
Food - 2000
Laundry - $3 per wash and dry.
Total $6020 (excluding the visa fee and plane fare and laundry cost)
Thanks Satabdi for sharing the expenses.
The second story is mine.
I am atheist vegetarian by choice and eat egg. I stayed in Brooklyn, traveled to RC by subway on A and C lines. The subway is operational throughout the clock. My Airbnb stay was a single room of 10*16 with queen size bed and dressing table in a three floored building. The room came with a shared kitchen, fridge, wifi, and toilet. Only two rooms were occupied, out of four rooms on the floor.
I mostly lived on fatty bread with peanut butter, French Sandwich, Falafel Sandwich, Dosa from NY Dosas,Dosa from Hampton Chutney,Veg Bowl from Sweet Green, Dollar Pizzas and fruits.
Three months expenses
Room Rent - 3000 (1000/month)
Subway - 345(115/month)
Food - 1700
Mobile Bill - 105 (35$/per month with unlimited calls, 4GB/4G data)
Misc - 200 (Laundry, Haircut, Sightseeing, etc ...)
Visa fee - 340 (Two attempts, Travel to Chennai)
Flights - 1000
Total = 6690 USD
With 1 USD as 67 INR, the trip cost was approximately 4.5 lakhs.
Hope the article gave a sense of trip planning. If you have any other doubts, feel free drop me an email.
Thank you Satabdi and Alicja Raszkowska for reviews and comments on the blog post.
0 notes
Text
Return Postgres data as JSON in Python
Postgres supports JSON and JSONB for a couple of years now. The support for JSON-functions landed in version 9.2. These functions let Postgres server to return JSON serialized data. This is a handy feature. Consider a case; Python client fetches 20 records from Postgres. The client converts the data returned by the server to tuple/dict/proxy. The application or web server converts tuple again back to JSON and sends to the client. The mentioned case is common in a web application. Not all API's fit in the mentioned. But there is a use case.
Postgres Example
Consider two tables, author and book with the following schema.
https://gist.github.com/kracekumar/322a2fd5ea09ee952e8a7720fd386184
Postgres function row_to_json convert a particular row to JSON data. Here is a list of authors in the table.
https://gist.github.com/kracekumar/3f4bcdd16d080b5a36436370823e0495
This is simple, let me show a query with an inner join. The book table contains a foreign key to author table. While returning list of books, including author name in the result is useful.
https://gist.github.com/kracekumar/eb9f1009743ccb47df2b3a5f078a4444
As you can see the query construction is verbose. The query has an extra select statement compared to a normal query. The idea is simple. First, do an inner join, then select the desired columns, and finally convert to JSON using row_to_json. row_to_json is available since version 9.2. The same functionality can be achieved using other function like json_build_object in 9.4. You can read more about it in the docs.
Python Example
Postgres drivers pyscopg2 and pg8000 handles JSON response, but the result is parsed and returned as a tuple/dictionary. What that means, if you execute raw SQL the returned JSON data is converted to Python dictionary using json.loads. Here is the function that facilitates the conversion in pyscopg2 and pg8000.
https://gist.github.com/kracekumar/2d1d0b468cafa5197f5e21734047c46d
The psycopg2 converts returned JSON data to list of tuples with a dictionary.
One way to circumvent the problem is to cast the result as text. The Python drivers don't parse the text. So the JSON format is preserved.
https://gist.github.com/kracekumar/b8a832cd036b54075a2715acf2086d62
Carefully view the printed results. The printed result is a list of tuple with a string.
For SQLAlchemy folks here is how you do it
https://gist.github.com/kracekumar/287178bcb26462a1b34ead4de10f0529
Another way to run SQL statement is to use text function.
The other workaround is to unregister the JSON converter. These two lines should do
import psycopg2.extensions as ext ext.string_types.pop(ext.JSON.values[0], None)
Here is a relevant issue in Pyscopg2.
0 notes
Text
RFCS We Love

A simple question can open a door for new exploration. While I was at RC, I tweeted "Is there any meetup group similar to papers we love for discussing RFCS?". In an interval of nine minutes, Jaseem replied: "Let's start one :)"
Is there any meetup group similar to @papers_we_love for discussing RFCs?
— kracekumar (@kracetheking) November 30, 2016
Above discussion on Twitter, lead to a new focus group RFCS We Love in Bangalore by Nemo, Jaseem, Avinash and Kracekumar. The first meetup held today, 28-01-2017. 15 interested and ethusiatic people attended the meetup. Anand and Govind presented RFC 3629 (UTF-8) and RFC 6238 (TOTP) respectively. The slides and videos links are available in GitHub README.
The Indian Union recognises two official languages, twenty-two scheduled languages with no national language. For the above mentioned reason, presenting Unicode as the first talk of the new experiment is apt, and I can't ask for a better start. It was a pure coincidence to have Unicode RFC in the first ever meetup. I don't know whether Anand, thought in the above lines.
If RFCS interests you, and you're in Bangalore, follow the group and join the meetup. If you're in any other city, you can start one too!
A journey of a thousand miles begins with a single step - Lao.
0 notes
Text
Expose jupyter notebook over the network
What is the Jupyter notebook?
The Jupyter Notebook is a web application that allows you to create and share documents that contain live code, equations, visualisations and explanatory text.
The definition is from the official site. I use IPython/Jupyter shell all time. If you haven't tried, spend 30 minutes and witness the power!
At times, I want to share some code snippet with folks in the same building during work, workshop or training. The Jupyter notebook configuration allows the user to expose the notebook cluster, terminal over the network or the internet. The notebook is available over the network with two changes in the configuration file. The first config value is IP other than default localhost. The second one is the password for users to connect to the notebook.
Run the command jupyter notebook --generate-config to generate the config file. The command creates configuration lies in the path ~/.jupyter/jupyter_notebook_config.py. By default, the server listens on localhost. Modify the IP address to local machine IP. You can use ifconfig to find out the IP and change the value of c.NotebookApp.ip to IP like # c.NotebookApp.ip = '192.168.0.101'.
Next, find the line which contains c.NotebookApp.password declaration. Then execute from the notebook.auth import passwd; passwd() in the IPython/Jupyter shell. The code is to generate password, and placed above the attribute assignment. Enter the password; copy the output and assign the output to the attribute c.NotebookApp.password. Now run the server and open the URL http://IP:8888 from another PC or mobile to browse notebooks after entering the correct password.
The IP address can be overridden using the flag --ip like jupyter notebook --ip 192.168.0.100
0 notes
Text
RC Return Statement
The Recurse Center is a free, three-month self-directed program for people who want to get better at programming. I attended fall batch 2 in 2016 from September to December. If you aren't aware of Recurse Centre, take a couple of minutes to go through recurse.com and read the rest of the piece.
Every day we open a significant amount of doors to get to desired places. Some doors are unique but look dull and plain, but the incredible universe behind the door hides excitement, adventures, gems, friends, and insights.
When I first walked into the door on the first day, I was blank and didn't know what to expect from RC. Over a period, I did program more, learned programming languages, lessons, picked up tools, thought process, made friends, etc...
Work
During twelve week experimentation, I worked on four projects.
I wrote a BitTorrent Client in Python.
Imon - Internet bandwidth monitor in Rust
I worked on Zulip to add reaction backend missing API.
Incomplete implementation of Amazon's DynamoDB paper in Erlang.
Learning
At RC I worked on tasks which were difficult to work at other times. Writing down what I learned is hard for various reasons. I am jotting down points I remember.
I picked up two new languages, Rust and Erlang which I am euphoric.
I rekindled my interest in system, network and distributed programming.
RC is the only place where I have seen folks aren't afraid to say I don't know. This attitude is valuable and activates the mind to discover. I picked up the habit of saying I don't know, what does that mean?.
I learned few things about compassion, empathy, kindness, gratitude and generosity and dropped a bit of arrogance.
How to prototype experimental projects like don't worry about file structures, modularity, optimization, right abstraction, etc ...
A better state of mind to focus on programming and curiosity to learn and discover.
I have previously pair programmed at work but never been fun. Now I have a clear expectation in pair programming and how to handle conflicts when it works and fails.
R0ml's talk on write all the code in a single file was intellectually stimulating. I practiced this technique in the project edht. It saved a considerable amount of time. I considered multiple times to refactor the code into multiple files but resisted. Question existing practices and assumptions to find out the real reason for existence and validate personal reasons.
Difficult times
I had my dark days(I am not talking about winter evenings), difficult time to concentrate and felt lost. Sometimes I spent the whole day staring at the code and debugging. I felt depressed when I couldn't make a progress. Reading Dynamo DB was hard, and paper is intended for a different set of audience. As a developer, every day I read documentations, man pages. The paper expects the reader familiar with concepts in distributed computing.
Next
It's been four weeks since the batch got over. Every day I am trying to learn something new in programming and learn from the Zulip discussions. Concentrating on everything going on in different streams is hard. That's how I think I can grow as a better programmer. Push the boundary of what you know, try to grasp and learn different topics.
What I think about RC
RC is a gift to programmers and three months is a sound investment in a programming career. The place and events teaches a lot of technical skills and non-technical skills. Social rules of RC is what makes the place welcoming and puts everyone at home. RC transforms everyone into better programmer or puts you on the track and make you feel better human being. I won't claim; I became a better programmer and but I can sense the difference in attitude and steps towards improving myself. RC shaped me as a better person! I believe to become a better programmer you need to be a better person.
I am honored to be part of RC and grateful it exists. Thanks for batchmates, alumni, and staff providing an opportunity to grow. Special Thanks to James Dennis who introduced me to Recurse Center (Hacker School at that time) and Suren, Punchagan for helping in RC planning.
It was hard to close the door on the last day knowing I will miss the cherished space.
0 notes