#yolov3
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
NTT Unveils Breakthrough AI Inference Chip for Real-Time 4K Video Processing at the Edge
New Post has been published on https://thedigitalinsider.com/ntt-unveils-breakthrough-ai-inference-chip-for-real-time-4k-video-processing-at-the-edge/
NTT Unveils Breakthrough AI Inference Chip for Real-Time 4K Video Processing at the Edge
In a major leap for edge AI processing, NTT Corporation has announced a groundbreaking AI inference chip that can process real-time 4K video at 30 frames per second—using less than 20 watts of power. This new large-scale integration (LSI) chip is the first in the world to achieve such high-performance AI video inferencing in power-constrained environments, making it a breakthrough for edge computing applications.
Revealed during NTT’s Upgrade 2025 summit in San Francisco, the chip is designed specifically for deployment in edge devices—hardware located physically close to the source of data, like drones, smart cameras, and sensors. Unlike traditional AI systems that rely on cloud computing for inferencing, this chip brings powerful AI capabilities directly to the edge, drastically reducing latency and eliminating the need to transmit ultra-high-definition video to centralized cloud servers for analysis.
Edge Computing vs. Cloud Computing: Why It Matters
In traditional cloud computing, data from devices like drones or cameras is sent to remote data centers—often located hundreds or thousands of miles away—where it’s processed and analyzed. While this approach offers virtually unlimited compute power, it introduces delays due to data transmission, which is problematic for real-time applications like autonomous navigation, security monitoring, and live decision-making.
By contrast, edge computing processes data locally, on or near the device itself. This reduces latency, preserves bandwidth, and enables real-time insights even in environments with limited or intermittent internet connectivity. It also enhances privacy and data security by minimizing the need to transmit sensitive data over public networks.
NTT’s new AI chip fully embraces this edge-first philosophy—delivering real-time 4K video analysis directly within the device, without relying on the cloud.
A New Era for Real-Time AI on Drones and Devices
With this chip installed, a drone can detect people or objects from up to 150 meters (492 feet)—the legal altitude limit for drones in Japan. That’s a dramatic improvement over traditional real-time AI systems, which are generally limited to a 30-meter range due to lower resolution or processing speed.
This advancement enables a host of new use cases, including:
Infrastructure inspections in hard-to-reach places
Disaster response in areas with limited connectivity
Agricultural monitoring across wide fields
Security and surveillance without constant cloud uplinks
All of this is achieved with a chip that consumes less than 20 watts—dramatically lower than the hundreds of watts required by GPU-powered AI servers, which are impractical for mobile or battery-powered systems.
Inside the Chip: NTT’s Proprietary AI Inference Engine
The LSI’s performance hinges on NTT’s custom-built AI inference engine, which ensures high-speed, accurate results while minimizing power use. Key innovations include:
Interframe correlation: By comparing sequential video frames, the chip reduces redundant calculations, improving efficiency.
Dynamic bit-precision control: This technique adjusts the numerical precision required on the fly, using fewer bits for simpler tasks, conserving energy without compromising accuracy.
Native YOLOv3 execution: The chip supports direct execution of You Only Look Once v3, one of the fastest real-time object detection algorithms in machine learning.
These combined features allow the chip to deliver robust AI performance in environments previously considered too power- or bandwidth-limited for advanced inferencing.
Path to Commercialization and the IOWN Vision
NTT plans to commercialize the chip within fiscal year 2025 through its operating company, NTT Innovative Devices Corporation.
Researchers are already exploring its integration into the Innovative Optical and Wireless Network (IOWN)—NTT’s next-generation infrastructure vision aimed at overhauling the digital backbone of modern society. Within IOWN’s Data-Centric Infrastructure (DCI), the chip would take advantage of the All-Photonics Network for ultra-low latency, high-speed communication, complementing the local processing power it brings to edge devices.
NTT is also collaborating with NTT DATA, Inc. to combine the chip’s capabilities with its Attribute-Based Encryption (ABE) technology, which enables secure, fine-grained access control over sensitive data. Together, these technologies will support AI applications that require both speed and security—such as in healthcare, smart cities, and autonomous systems.
A Legacy of Innovation and a Vision for the Future
This AI inference chip is the latest demonstration of NTT’s mission to empower a sustainable, intelligent society through deep technological innovation. As a global leader with over $92 billion in revenue, 330,000 employees, and $3.6 billion in annual R&D, NTT serves more than 75% of Fortune Global 100 companies and millions of consumers across 190 countries.
Whether it’s drones flying beyond the visual line of sight, cameras detecting events in real-time without cloud dependency, or securing data flows with attribute-based encryption, NTT’s new chip sets the stage for the next frontier in AI at the edge—where intelligence meets immediacy.
#000#2025#4K#access control#ai#ai at the edge#AI chip#ai inference#AI performance#AI systems#AI video#Algorithms#amp#Analysis#applications#approach#Artificial Intelligence#autonomous#autonomous systems#battery#battery-powered#billion#Cameras#chip#cities#Cloud#cloud computing#communication#Companies#computing
1 note
·
View note
Text
Assignment 2 ACV Object Detection
Requirement • Use the given pre-trained Yolov3 model to do the detection. • Set the threshold to 0.02 and 0.4 for each image (5 images in total). • Write a report: • 10 result images (5 for threshold 0.02, 5 for threshold 0.4). • The comparison of the threshold 0.02 and 0.4 (no more than 1 page). 2 Example You can check your correctness through the example image (ex.jpg). 3 ex.jpg threshold = 0.4…
0 notes
Text
YOLO V/s Embeddings: A comparison between two object detection models
YOLO-Based Detection Model Type: Object detection Method: YOLO is a single-stage object detection model that divides the image into a grid and predicts bounding boxes, class labels, and confidence scores in a single pass. Output: Bounding boxes with class labels and confidence scores. Use Case: Ideal for real-time applications like autonomous vehicles, surveillance, and robotics. Example Models: YOLOv3, YOLOv4, YOLOv5, YOLOv8 Architecture
YOLO processes an image in a single forward pass of a CNN. The image is divided into a grid of cells (e.g., 13×13 for YOLOv3 at 416×416 resolution). Each cell predicts bounding boxes, class labels, and confidence scores. Uses anchor boxes to handle different object sizes. Outputs a tensor of shape [S, S, B*(5+C)] where: S = grid size (e.g., 13×13) B = number of anchor boxes per grid cell C = number of object classes 5 = (x, y, w, h, confidence) Training Process
Loss Function: Combination of localization loss (bounding box regression), confidence loss, and classification loss.
Labels: Requires annotated datasets with labeled bounding boxes (e.g., COCO, Pascal VOC).
Optimization: Typically uses SGD or Adam with a backbone CNN like CSPDarknet (in YOLOv4/v5). Inference Process
Input image is resized (e.g., 416×416). A single forward pass through the model. Non-Maximum Suppression (NMS) filters overlapping bounding boxes. Outputs detected objects with bounding boxes. Strengths
Fast inference due to a single forward pass. Works well for real-time applications (e.g., autonomous driving, security cameras). Good performance on standard object detection datasets. Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high-dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high- dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
1 note
·
View note
Text
"Unlocking Object Detection in Images: A Hands-on Guide to YOLOv3"
1. Introduction Object detection is a pivotal task in computer vision, enabling machines to identify and locate objects within images or videos. Among various models, YOLOv3 stands out for its efficiency and accuracy, making it a favorite for real-time applications. This tutorial guides you through implementing YOLOv3, helping you unlock the potential of object detection. What You’ll Learn: –…
0 notes
Text
TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
Long Short-Term Memory (Neural Computation 1997)
Rich feature hierarchies for accurate object detection and semantic segmentation
Advances in Natural Language Processing (Science 2015)
Semi-supervised learning with Deep generative models (NIPS 2014)
ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION (ICLR 2015)
Machine learning: Trends, perspectives, and prospects
YOLOv3: An Incremental Improvement
Statistical Modeling : The Two Cultures
AutoML: A Survey of the State-of-the-Art
TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks
Mastering the game of Go with deep neural networks and tree search
Recent Trends in Deep Learning Based Natural Language Processing (2017)
Skip-gram/Distributed Representations of Words and Phrases and their Compositionality
Dropout as a Bayesian Approximation : Representing Model Uncertainty in Deep Learning
Gated RNN
On the Properties of Neural Machine Translation Encoder Decoder Approaches
TextRank: Bringing Order into Texts
YOLOv4: Optimal Speed and Accuracy of Object Detection
0 notes
Photo

Real-time Yolov3 Object Detection for Webcam and Video Using Tensorflow https://morioh.com/p/51c99ab97a3c #morioh #tensorflow #Yolov3
4 notes
·
View notes
Photo

How to Build an Object Tracker Using YOLOv3, Deep SORT and TensorFlow ☞ https://morioh.com/p/5f4db2fffbfa?f=5c21fb01c16e2556b555ab32 #tensorflow #yolov3 #python
1 note
·
View note
Text
#ComputerVision - Object Detection with #YoloV3 and #MobileNetSSD
#ComputerVision – Object Detection with #YoloV3 and #MobileNetSSD

Hi !
I have a ToDo in my list, to add some new drone demos. In order to do this, I was planning to perform some tests with pretrained models and use them. The 1st 2 in my list are Yolo and MobileNetSSD (see references).
YoloV3
Let’s start with one of the most popular object detection tools, YOLOV3. The official definition:
YOLO (You Only Look Once) is a real-time object…
View On WordPress
0 notes
Text
“Don’t touch your face” - Neural Network will warn you
A few days back, Keras creator, Francois Chollet tweeted
> A Keras/TF.js challenge: make a model that processes a webcam feed and detects when someone touches their face (triggering a loud beep)." The very next day, I tried the Keras yolov3 model available in the Github. It was trained on the coco80 dataset and could detect person but not the face touch.

V1 Training
The original Keras implementation lacked documentation to train from scratch or transfer learning. While looking for alternative implementation, I came across the PyTorch implemetation with complete documentation.
I wrote a simple python program to download images based on keyword.
> python face_touch_download.py --keyword "chin leaning" --limit 100 --dest chin_leaning
The script downloads 100 images and store the images in the directory. Next, I annotated the images using LabelImg in Yolo format. With close to 80 images, I trained the network on a single class facetouch for 100 epochs. The best of the weights couldn't identify any face touch on four images. Now, I wasn't clear should I train all classes(80 +1) or need more images with annotation.
V2 Training
Now, I downloaded two more sets of images using two different queries face touch and black face touch. After annotation, the dataset was close to 250 images. Then I decided to train along with a few other original classes of coco labels. I selected the first nine classes and face touch. Now, the annotated facetouch images need a change in class. For example, in V1, there was only one class(0), now those annotations are misleading because some other class takes up the number, now 0 means person and 9 means facetouch. Also, I picked random 500 images from the original coco dataset for training. After remapping the existing annotation and creating a new annotation, I trained the network for 200 epochs.
After training the network, I again ran the inference on four sample images - Dhanush rolling up mustache (1), another person rolling up mustache (2), Proust sitting in a chair leaning his face on the chin(3), and Virginia wolf leaning her face on the chin(4). The network labeled the person rolling up mustache, second image as face touch. First Victory! At the same time, the network was not predicting other images for classes person and face touch.

V3 Training
After re-reading the same documentation again, it was clear to me, the network needs more training images, and needn't be trained along with the rest of the classes. Now I deleted all the dataset v2 and annotations and came up with a list of keywords - face touch, black face touch, chin leaning. After annotation of close to 350 images, running the training, this time network was able to label two images - Another person rolling up mustache (2), Proust is sitting in a chair, leaning his face on the chin(3).
By now, it was clear to me that yolov3 can detect chin leaning and mustache as long as the rectangular box is of considerable size and next step.
Final Training
Now the list of keywords grew to ten. The new ones apart from previous ones are finger touching face, ear touch, finger touching forehead, headache, human thinking face, nose touching, rubbing eyes. The final dataset was close to 1000 images. After training the network for 400 epochs on the dataset, the network was able to identify face touch on videos, images, and webcam feed.
Classification (bounding box) on 17 images
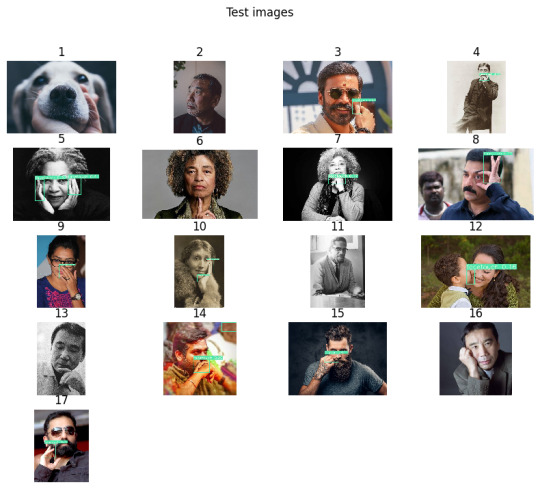
Out of 14 face touching images, the network able to box 11 images. The network couldn't box on two Murakami images.
Here is a youtube link to identifying facetouch on Salvoj Zizek clip - https://www.youtube.com/embed/n44WsmRiAvY.
youtube
Webcam
Now that, the network predicts anyone touching the face or trying to touch the face, you can run the program in the background, it warns you with the sound, Don't touch the face.
After installing the requirements, run the program,
> python detect.py --cfg cfg/yolov3-1cls.cfg --weights best_dataset_v5.pt --source 0
You're all set to hear the sound when you try to touch the face.
The repo contains a link to the trained model, dataset, and other instructions. Let me know your comments and issues.
I'm yet to understand how yolo works, so far, only read yolo v1 paper. The precision for the model is around ~0.6. I think it's possible to improve the precision of the model. Somewhere while transferring the image from the server, the results.png went missing.
Few Issues
If you run the detect.py with webcam source, the rendering sound is blocking code, you may notice a lag in the webcam feed.
Sometimes, the model predicts the mobile phone in front of the image as a face touch.
As shown in the images, if the face touch region is tiny like a single index finger over the chin, it doesn't predict, look at the below image titled 6.
The quality of the images was slightly issued because of the watermarks and focus angle. If the end deployment targets at the webcam, then it's better to train image with front face focus. There was no clean way to ensure or scrap the high-quality images. Do you know how to solve the problem or even this assumption is true?. Of course, good model should detect face touch from all sides and angles.
I haven't tried augmenting the dataset and training it.
The network may not run on edge devices, you may want to train using yolov3-tiny weights.
Yolo site: https://pjreddie.com/darknet/yolo/
PyTorch yolov3 implememtation: https://github.com/ultralytics/yolov3
Facetouch Repo: https://github.com/kracekumar/facetouch
While writing the code and debugging, I must have touched my face more than 100 times. It's part of evolution and habit, can't die in few days. Does wearing a mask with spikes help then?
0 notes
Photo

Deep learning is a subset of machine learning in artificial intelligence (AI) that has networks capable of learning unsupervised from data that is unstructured or unlabeled. Also known as deep neural learning
.
.
.
Register Now www.infogrex.com
Contact : 9347412456, 040 - 6771 4400/4444
.
.
. , ,, , , ,
#machinelearning#chennai#bangalore#hyderabad#mumbai#kolkata#lucknow#nagpur#ahmedabad#Delhi#DogBreedClassification#TextExtraction#Objectdetection#Inception#Resnet#YOLOv3#Faster-RCNN#datascience#pythonprogramming#pythonlanguage#thedevlife#womenintech#developer#programmer
0 notes
Photo
This is boss mode for object recognition AI. MAPs THAT RCNN

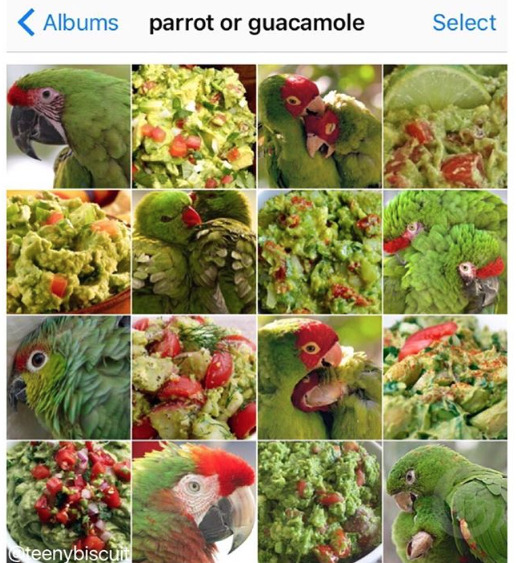
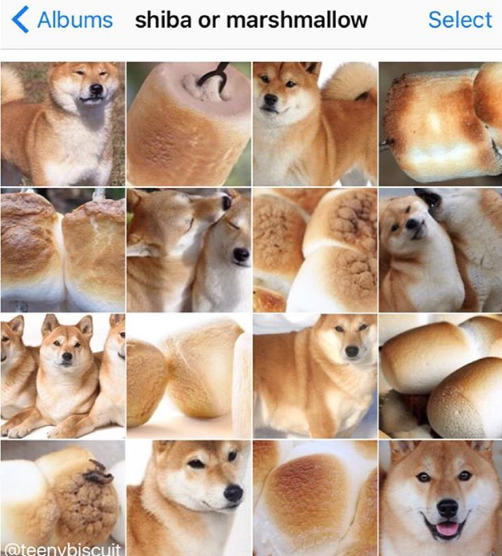




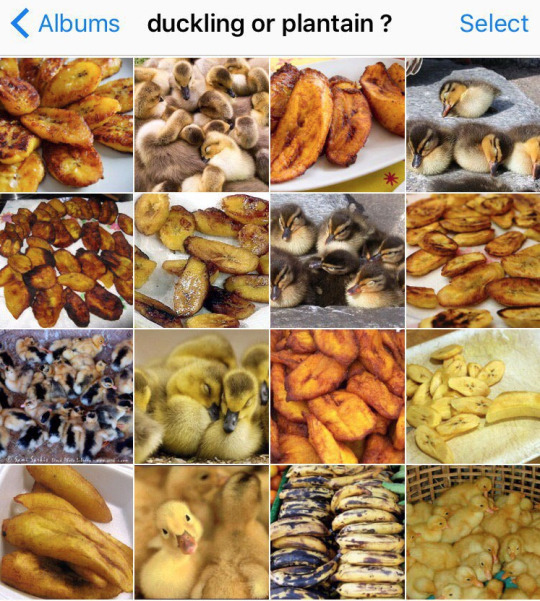

By Karen Zack (@teenybiscuit)
586K notes
·
View notes
Text
#art#machinelearning#deeplearning#artificialintelligence#datascience#iiot#sztucznainteligencja#data#MLsoGood#code#python#bigdata#MLart#algorithm#programmer#pytorch#DataScientist#Analytics#AI#VR#iot#TechCult#Digitalart#DigitalArtMarket#ArtMarket#DataArt#ArtTech#GAN#GANart#arttech
2 notes
·
View notes
Text
A Hands-On Guide to Object Detection in Images using YOLOv3
A Hands-On Guide to Object Detection in Images using YOLOv3 Introduction Object detection in images is a fundamental task in computer vision, with applications in various fields such as autonomous vehicles, surveillance systems, and healthcare. YOLOv3 (You Only Look Once) is a popular real-time object detection algorithm that has gained significant attention in recent years. In this tutorial,…
0 notes
Link
YOLOv3 is extremely fast and accurate. In mAP measured at .5 IOU YOLOv3 is on par with Focal Loss but about 4x faster. Moreover, you can easily tradeoff between speed and accuracy simply by changing the size of the model, no retraining required!

4 notes
·
View notes
Text
Yoloface-500k: ultra-light real-time face detection model, 500kb
https://github.com/dog-qiuqiu/MobileNetv2-YOLOV3#500kb%E7%9A%84yolo-face-detection Comments
4 notes
·
View notes