#Algorithms | “Universal Function Approximators”
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
The Elegant Math of Machine Learning
Anil Ananthaswamy’s 3 Greatest Revelations While Writing Why Machines Learn.
— By Anil Ananthaswamy | July 23, 2024

Image: Aree S., Shutterstock
1- Machines Can Learn!
A few years ago, I decided I needed to learn how to code simple machine learning algorithms. I had been writing about machine learning as a journalist, and I wanted to understand the nuts and bolts. (My background as a software engineer came in handy.) One of my first projects was to build a rudimentary neural network to try to do what astronomer and mathematician Johannes Kepler did in the early 1600s: analyze data collected by Danish astronomer Tycho Brahe about the positions of Mars to come up with the laws of planetary motion.
I quickly discovered that an artificial neural network—a type of machine learning algorithm that uses networks of computational units called artificial neurons—would require far more data than was available to Kepler. To satisfy the algorithm’s hunger, I generated a decade worth of data about the daily positions of planets using a simple simulation of the solar system.
After many false starts and dead-ends, I coded a neural network that—given the simulated data—could predict future positions of planets. It was beautiful to observe. The network indeed learned the patterns in the data and could prognosticate about, say, where Mars might be in five years.

Functions of the Future: Given enough data, some machine learning algorithms can approximate just about any sort of function—whether converting x into y or a string of words into a painterly illustration—author Anil Ananthaswamy found out while writing his new book, Why Machines Learn: The Elegant Math Behind Modern AI. Photo courtesy of Anil Ananthaswamy.
I was instantly hooked. Sure, Kepler did much, much more with much less—he came up with overarching laws that could be codified in the symbolic language of math. My neural network simply took in data about prior positions of planets and spit out data about their future positions. It was a black box, its inner workings undecipherable to my nascent skills. Still, it was a visceral experience to witness Kepler’s ghost in the machine.
The project inspired me to learn more about the mathematics that underlies machine learning. The desire to share the beauty of some of this math led to Why Machines Learn.
2- It’s All (Mostly) Vectors.
One of the most amazing things I learned about machine learning is that everything and anything—be it positions of planets, an image of a cat, the audio recording of a bird call—can be turned into a vector.
In machine learning models, vectors are used to represent both the input data and the output data. A vector is simply a sequence of numbers. Each number can be thought of as the distance from the origin along some axis of a coordinate system. For example, here’s one such sequence of three numbers: 5, 8, 13. So, 5 is five steps along the x-axis, 8 is eight steps along the y-axis and 13 is 13 steps along the z-axis. If you take these steps, you’ll reach a point in 3-D space, which represents the vector, expressed as the sequence of numbers in brackets, like this: [5 8 13].
Now, let’s say you want your algorithm to represent a grayscale image of a cat. Well, each pixel in that image is a number encoded using one byte or eight bits of information, so it has to be a number between zero and 255, where zero means black and 255 means white, and the numbers in-between represent varying shades of gray.
It was a visceral experience to witness Kepler’s ghost in the machine.
If it’s a 100×100 pixel image, then you have 10,000 pixels in total in the image. So if you line up the numerical values of each pixel in a row, voila, you have a vector representing the cat in 10,000-dimensional space. Each element of that vector represents the distance along one of 10,000 axes. A machine learning algorithm encodes the 100×100 image as a 10,000-dimensional vector. As far as the algorithm is concerned, the cat has become a point in this high-dimensional space.
Turning images into vectors and treating them as points in some mathematical space allows a machine learning algorithm to now proceed to learn about patterns that exist in the data, and then use what it’s learned to make predictions about new unseen data. Now, given a new unlabeled image, the algorithm simply checks where the associated vector, or the point formed by that image, falls in high-dimensional space and classifies it accordingly. What we have is one, very simple type of image recognition algorithm: one which learns, given a bunch of images annotated by humans as that of a cat or a dog, how to map those images into high-dimensional space and use that map to make decisions about new images.
3- Some Machine Learning Algorithms Can Be “Universal Function Approximators.”
One way to think about a machine learning algorithm is that it converts an input, x, into an output, y. The inputs and outputs can be a single number or a vector. Consider y = f (x). Here, x could be a 10,000-dimensional vector representing a cat or a dog, and y could be 0 for cat and 1 for dog, and it’s the machine learning algorithm’s job to find, given enough annotated training data, the best possible function, f, that converts x to y.
There are mathematical proofs that show that certain machine learning algorithms, such as deep neural networks, are “universal function approximators,” capable in principle of approximating any function, no matter how complex.
Voila, You Have A Vector Representing The Cat In 10,000-Dimensional Space.
A deep neural network has layers of artificial neurons, with an input layer, an output layer, and one or more so-called hidden layers, which are sandwiched between the input and output layers. There’s a mathematical result called universal approximation theorem that shows that given an arbitrarily large number of neurons, even a network with just one hidden layer can approximate any function, meaning: If a correlation exists in the data between the input and the desired output, then the neural network will be able to find a very good approximation of a function that implements this correlation.
This is a profound result, and one reason why deep neural networks are being trained to do more and more complex tasks, as long as we can provide them with enough pairs of input-output data and make the networks big enough.
So, whether it’s a function that takes an image and turns that into a 0 (for cat) and 1 (for dog), or a function that takes a string of words and converts that into an image for which those words serve as a caption, or potentially even a function that takes the snapshot of the road ahead and spits out instructions for a car to change lanes or come to a halt or some such maneuver, universal function approximators can in principle learn and implement such functions, given enough training data. The possibilities are endless, while keeping in mind that correlation does not equate to causation.
— Anil Ananthaswamy is a Science Journalist who writes about AI and Machine Learning, Physics, and Computational Neuroscience. He’s a 2019-20 MIT Knight Science Journalism Fellow. His latest book is Why Machines Learn: The Elegant Math Behind Modern AI.
#Nautilus#Mathematics#Elegant Math#Machine Learning#Mathematics | Mostly Vectors#Algorithms | “Universal Function Approximators”#Anil Ananthaswamy#Physics#Computational Neuroscience#MIT | Knight Science Journalism Fellow
4 notes
·
View notes
Text
Like countless other people around the globe, I stream music, and like more than six hundred million of them I mainly use Spotify. Streaming currently accounts for about eighty per cent of the American recording industry’s revenue, and in recent years Spotify’s health is often consulted as a measure for the health of the music business over all. Last spring, the International Federation of the Phonographic Industry reported global revenues of $28.6 billion, making for the ninth straight year of growth. All of this was unimaginable in the two-thousands, when the major record labels appeared poorly equipped to deal with piracy and the so-called death of physical media. On the consumer side, the story looks even rosier. Adjusted for inflation, a monthly subscription to an audio streaming service, allowing convenient access to a sizable chunk of the history of recorded music, costs much less than a single album once did. It can seem too good to be true.
Like considerably fewer people, I still buy a lot of CDs, records, and cassettes, mostly by independent artists, which is to say that I have a great deal of sympathy for how this immense reorganization in how we consume music has complicated the lives of artists trying to survive our on-demand, hyper-abundant present. Spotify divvies out some share of subscriber fees as royalties in proportion to an artist’s popularity on the platform. The service recently instituted a policy in which a track that registers fewer than a thousand streams in a twelve-month span earns no royalties at all. Some estimate that this applies to approximately two-thirds of its catalogue, or about sixty million songs. Meanwhile, during a twelve-month stretch from 2023 to 2024, Spotify announced new revenue highs, with estimates that the company is worth more than Universal and Warner combined. During the same period, its C.E.O., Daniel Ek, cashed out three hundred and forty million dollars in stock; his net worth, which fluctuates but is well into the billions, is thought to make him richer than any musician in history. Music has always been a perilous, impractical pursuit, and even sympathetic fans hope for the best value for their dollar. But if you think too deeply about what you’re paying for, and who benefits, the streaming economy can seem awfully crooked.
Although artists such as Taylor Swift and Neil Young have temporarily removed their music from Spotify—Swift pressed the company over its paltry royalty rates, while Young was protesting its nine-figure deal with the divisive podcaster Joe Rogan—defying the streamer comes with enormous risks. Spotify is a library, but it’s also a recommendation service, and its growth is fuelled by this second function, and by the company’s strategies for soundtracking the entirety of our days and nights. As a former Spotify employee once observed, the platform’s only real competitor is silence. In recent years, its attempts at studying and then adapting to our behavior have invited more than casual scrutiny among users: gripes about the constant tweaks and adjustments that make the interface more coldly opaque, stories about A.I.-generated songs and bots preying on the company’s algorithms, fatigue over “Spotify-core,” the shorthand for the limp, unobtrusive pop music that appears to be the service’s default aesthetic. Even Spotify’s popular Wrapped day, when users are given social-media-ready graphics detailing their listening habits from the past year, recently took its lumps. Where the previous year’s version assigned listeners a part of the world that most aligned with their favorites, the 2024 edition was highlighted by the introduction of personalized, A.I.-voiced recaps, striking some as the Spotify problem in a nutshell—a good thing that gets a little worse with all the desperate fine-tuning.
Just as we train Spotify’s algorithm with our likes and dislikes, the platform seems to be training us to become round-the-clock listeners. Most people don’t take issue with this—in fact, a major Spotify selling point is that it can offer you more of what you like. Liz Pelly’s new book, “Mood Machine: The Rise of Spotify and the Costs of the Perfect Playlist,” is a comprehensive look at how the company’s dominance has profoundly changed the way we listen and what we listen to. A contributing editor to The Baffler, Pelly has covered the ascent of Spotify for years, and she was an early critic of how the streaming economy relies less on delivering hit tunes than on keeping us within a narrow gradient of chill vibes. Her approach is aggressively moralistic: she is strongly influenced, she explains, by D.I.Y. spaces that attempt to bring about alternate forms of “collective culture,” rather than accept the world’s inequities as a given. She sympathizes with the plight of artists who feel adrift in the winner-take-all world of the Internet, contending with superstars like Adele or Coldplay for placement on career-making playlists and, consequently, a share of streaming revenue. But her greatest concerns are for listeners, with our expectations for newness and convenience. Pelly is a romantic, but her book isn’t an exercise in nostalgia. It’s about how we have come to view art and creativity, what it means to be an individual, and what we learn when we first hum along to a beloved pop song.
A great many people over forty retain some memory of the first time they witnessed the awesome possibilities of Internet piracy—the sense of wonder that you could go to class and return a couple of hours later to a Paul Oakenfold track playing from somewhere inside your computer. In 1999, two teen-agers named Shawn Fanning and Sean Parker launched the file-sharing application Napster, effectively torching the music industry as it had existed for nearly a century. There had always been piracy and bootlegging, but Napster introduced the free exchange of music at a global scale. Rather than maintain a publicly accessible archive of recordings—which was clearly illegal—Napster provided a peer-to-peer service that essentially allowed users to pool their music libraries. After a year, Fanning and Parker’s app had twenty million users.
At first, anti-Napster sentiment echoed the hysteria of the nineteen-seventies and eighties around the prospect of home taping killing the record industry. Yet online piracy was far more serious, moving at unprecedented speed. One label executive argued that Fanning and Parker belonged in jail, but there was no uniform response. For example, the media conglomerate Bertelsmann made plans to invest in Napster even as it was suing the company for copyright infringement. Some artists embraced Napster as a promotional tool. Chuck D, of Public Enemy, published a Times Op-Ed in which he praised Napster as “a new kind of radio.” The punk band the Offspring expressed its admiration by selling bootleg merchandise with the company’s logo. On the other side was the heavy-metal band Metallica, which sued the platform for “trafficking in stolen goods,” and thereby became seen—by many of their fellow-musicians as well as by listeners—as an establishment villain. Faced with too many legal challenges, Napster shut down in July, 2001. But the desire to break from traditional means of disseminating culture remained, as casual consumers began imagining an alternative to brick-and-mortar shopping and, with it, physical media. Just four months after Napster’s closure, Apple came out with the iPod.
In Sweden, where citizens had enjoyed high-speed Internet since the late nineties, piracy took on a political edge. In 2001, after a major anti-globalization protest in Gothenburg was violently put down by the police, activists formed online communities. In 2003, Rasmus Fleischer helped found Piratbyrån, or the Pirate Bureau, a group committed to flouting copyright laws. “We were trying to make something political from the already existing practice of file-sharing,” Fleischer explained to Pelly. “What are the alternative ways to think about power over networks? What counts as art and what counts as legitimate ways of using it? Or distributing money?” That year, a group of programmers associated with Piratbyrån launched the Pirate Bay, a file-sharing site that felt like a more evolved version of Napster, allowing users to swap not only music but movies, software, and video games.
Alongside Pirate Bay, file-sharing applications like LimeWire, Kazaa, and Grokster emerged to fill Napster’s void and were summarily targeted by the recording industry. Meanwhile, the music business marched forward, absorbing losses and deferring any hard decisions. So long as fans still thought of music in terms of ownership, there were still things to sell them—if not physical media, at least song files meant to be downloaded onto your hard drive. The most common model in the United States was the highly successful iTunes Store, which allowed listeners to purchase both albums and single tracks, abiding by a rough dollar-per-song value inherited from the age of LPs and CDs. “People want to own their music,” Steve Jobs said, in 2007, claiming he’d seen no evidence that consumers wanted a subscription model. “There’s definitely a hurdle with subscription because it’s not an exact replica of the model people are used to in the physical world,” Rob Williams, an executive at Rhapsody, one of the largest early-two-thousands music-subscription services, observed, in 2008.
Daniel Ek, Spotify’s C.E.O., taught himself programming as a teen-ager in Stockholm and was financially secure by his mid-twenties, when he began looking for a new project to work on. Like many, he credits Napster for providing him with a musical education. While some of his countrymen saw piracy as anarchist, a strike against big business, Ek sensed a more moderate path. He and Martin Lorentzon, both well versed in search engines and online advertising, founded Spotify, in 2006, in the hope of working with the music industry, not against it. Ek explained to a reporter, in 2010, that it was impossible to “legislate away from piracy.” The solution was making an alternative that was just as convenient, if not more. The year he and Lorentzon launched Spotify, the census showed that thirteen per cent of Sweden’s citizens already participated in file-sharing. “I’m just interested in building a company that doesn’t necessarily change lives but adapts people’s behavior,” Ek said.
Spotify benefitted from the emergence of smartphones and cheap data plans. When we are basically never offline, it no longer matters where our files are situated. “We’re punks,” Ek said. “Not the punks that are up to no good. The punks that are against the establishment. We want to bring music to every person on the face of the planet.” (Olof Dreijer, of the Swedish electronic pop group the Knife, griped to Pelly that the involvement of tech companies in music streaming represented the “gentrification” of piracy.)
Spotify made headway in Europe in the twenty-tens, capitalizing on the major labels’ seeming apathy toward committing to an online presence. It began offering plans to U.S. users in 2011—two paid tiers with no ads and a free one that, as an analyst told the Times that year, was “solidifying a perception that music should be free.” Ek sought partnerships with major labels, some of which still own Spotify stock. Around this time, a source who was then close to the company told Pelly, Spotify commissioned a study tracking the listening habits of a small subset of users and concluded that it could offer a qualitatively different experience than a marketplace like iTunes. By tracking what people wanted to hear at certain hours—from an aggro morning-workout mix to mellow soundscapes for the evening—the service began understanding how listeners used music throughout the day. People even streamed music while they were sleeping.
With all this information, Spotify might be able to guess your mood based on what time it was and what you had been listening to. Pelly argues, in fact, that its greatest innovation has been its grasp of affect, how we turned to music to hype us up or calm us down, help us focus on our homework or simply dissociate. Unlike a record label, a tech company doesn’t care whether we’re hooked on the same hit on repeat or lost in a three-hour ambient loop, so long as we’re listening to something. (This helps explain its ambitious entry into the world of podcasting, lavishing nine-figure deals on Joe Rogan and on the Ringer, Bill Simmons’s media company, as well as its recent investment in audiobooks.) Spotify just wants as much of our time and attention as possible, and a steady stream of melodic, unobtrusive sounds could be the best way to appeal to a passive listener. You get tired of the hit song after a while, whereas you might stop noticing the ambient background music altogether.
Last spring, a Swedish newspaper published a story about a little-known hitmaker named Johan Röhr, a specialist in tepid, soothing soundscapes. As of March, Röhr had used six hundred and fifty aliases (including Adelmar Borrego and Mingmei Hsueh) to release more than twenty-seven hundred songs on Spotify, where they had been streamed more than fifteen billion times. These numbers make him one of the most popular musicians in the world, even though he is not popular in any meaningful sense—it’s doubtful that many people who stream his music have any idea who he is. Spotify’s officially curated playlists seem to be a shortcut to success, akin to songs getting into heavy rotation on the radio or television. Röhr has benefitted from being featured on more than a hundred of them, with names like “Peaceful Piano” or “Stress Relief.” His ascent has raised a philosophical question about music in the streaming age: Does it even matter who is making this stuff? At least Röhr’s a real person. What about A.I.-generated music, which is increasingly popular on YouTube?
It’s tricky to make the argument that any of this is inherently bad for music fans; in our anti-élitist times, all taste is regarded as relative. Maybe Johan Röhr does, indeed, lower your stress levels. Who’s to say that A.I. Oasis is that much better or worse than the real thing? If you harbor no dreams of making money off your music, it’s never been easier to put your art out into the world. And even if we are constructing our playlists for friends under “data-tuned, ultra-surveilled” circumstances, feeding a machine data to more effectively sell things back to us, it’s a trade that most users don’t mind making. We’ve been conditioned to want hyper-personalization from our digital surroundings, with convenience and customizable environments the spoils of our age. For Pelly, it’s a problem less of taste than of autonomy—the question she asks is if we’re making actual decisions or simply letting the platform shape our behaviors. Decades ago, when you were listening to the radio or watching MTV, you might encounter something different and unknown, prompting some judgment as to whether you liked or loathed it. The collection of so much personalized data—around what time of day we turn to Sade or how many seconds of a NewJeans song we play—suggests a future without risk, one in which we will never be exposed to anything we may not want to hear.
Spotify recently projected that 2024 would be its first full year of profitability; one investment analyst told Axios that the company had “reached a level of scale and importance that we think the labels would be engaging in mutually-assured devastation if they tried to drive too hard a bargain.” Its success seems to have derived partly from cost-cutting measures: in December, 2023, it eliminated seventeen per cent of its employees, or about fifteen hundred jobs. Some music-industry groups also say that Spotify has found a way to pay less to rights holders by capitalizing on a 2022 ruling by the Copyright Royalty Board which allows services bundling different forms of content to pay lower rates.
I wonder if any of Pelly’s arguments will inspire readers to cancel their subscriptions. I remain on my family’s Spotify plan; it’s a necessary evil when part of your job involves listening to music. For all the service’s conveniences, one of my frustrations has always been the meagre amount of information displayed on each artist’s page, and Pelly’s criticisms made me think this might be by design—a way of rendering the labor of music-making invisible. Except for a brief biographical sketch, sounds float largely free of context or lineage. It’s harder than it should be to locate a piece of music in its original setting. Instead of a connection to history, we’re offered recommendations based on what other people listened to next. I’ve never heard so much music online as I have over the past few years yet felt so disconnected from its sources.
In 2020, Ek warned that “some artists that used to do well in the past may not do well in this future landscape where you can’t record music once every three to four years and think that’s going to be enough.” Rather, he suggested, artists would have to adapt to the relentless rhythms of the streaming age. I’ve long been fascinated by musicians who explore the creative tension between their own vision and the demands of their corporate overlords, making music in playful, mocking resistance of the business. A personal favorite is R.A. the Rugged Man’s “Every Record Label Sucks Dick,” which has been streamed about a quarter of a million times. Although I’ve heard many artists lament Spotify’s effect on their livelihoods, it’s hard to imagine someone channelling that animosity into a diss track. For that matter, it’s a conversation I rarely hear on podcasts—the chances of finding an audience without being present on the world’s largest distributor are slim. Instead, artists make music about the constant pressures of fame, as Tyler, the Creator, did with 2024’s “Chromakopia.” Or they try in vain to protect themselves from it, as the singer Chappell Roan, known for her theatrical take on dance pop, did this past summer. One of the breakout stars of 2024, Roan had difficulty coping with the unyielding demands of her sudden superstardom, eventually posting a TikTok begging her fans to respect her personal boundaries. The targets within the industry were once varied and diffuse, but they were identifiable. Now the pressure comes from everywhere, leaving artists to exploit themselves.
Reading “Mood Machine,” I began to regard Spotify as an allegory for life this year—this feeling that everything has never been so convenient, or so utterly precarious. I’d seldom considered the speed at which food or merchandise is delivered to my house to be a problem that required a solution. But we acclimate to the new normal very quickly; that is why it’s hard to imagine an alternative to Spotify. Rival streaming services like Apple Music deliver slightly better royalties to artists, yet decamping from Spotify feels a bit like leaving Twitter for Bluesky in that you haven’t fully removed yourself from the problem. Digital marketplaces such as Bandcamp and Nina offer models for directly supporting artists, but their catalogues seem niche by comparison.
In the past few years, artists have been using the occasion of Spotify’s Wrapped to share how little they were paid for the year’s streams. The United Musicians and Allied Workers, a music-industry trade union, was formed in 2020 in part to lobby on behalf of those most affected by the large-scale changes of the past decade. Four years later, Representatives Rashida Tlaib and Jamaal Bowman introduced the Living Wage for Musicians Act, which would create a fund to pay artists a minimum of a penny per stream. With a royalty rate at around half a cent—slightly more than Spotify pays—it would take more than four hundred and eighty thousand streams per month to make the equivalent of a fifteen-dollar-an-hour job. But the bill hasn’t made any legislative playlists.
Earlier this year, responding to questions about Spotify’s effect on working musicians, Ek compared the music industry to professional sports: “If you take football, it’s played by hundreds of millions of people around the world. But there’s a very, very small number of people that can live off playing soccer full time.” The Internet was supposed to free artists from the monoculture, providing the conditions for music to circulate in a democratic, decentralized way. To some extent, this has happened: we have easy access to more novelty and obscure sounds than ever before. But we also have data-verified imperatives around song structure and how to keep listeners hooked, and that has created more pressure to craft aggressively catchy intros and to make songs with maximum “replay value.” Before, it was impossible to know how many times you listened to your favorite song; what mattered was that you’d chosen to buy it and bring it into your home. What we have now is a perverse, frictionless vision for art, where a song stays on repeat not because it’s our new favorite but because it’s just pleasant enough to ignore. The most meaningful songs of my life, though, aren’t always ones I can listen to over and over. They’re there when I need them.
Pelly writes of some artists, in search of viral fame, who surreptitiously use social media to effectively beta test melodies and motifs, basically putting together songs via crowdsourcing. Artists have always fretted about the pressure to conform, but the data-driven, music-as-content era feels different. “You are a Spotify employee at that point,” Daniel Lopatin, who makes abstract electronic music as Oneohtrix Point Never, told Pelly. “If your art practice is so ingrained in the brutal reality that Spotify has outlined for all of us, then what is the music that you’re not making? What does the music you’re not making sound like?” Listeners might wonder something similar. What does the music we’re not hearing sound like?
22 notes
·
View notes
Text
I know nothing about this but here's an argument that neural network architecture doesn't matter:
assume you're applying a black box machine learning method to a large training set in order to create a function that models it, and importantly the function is smaller than the training set so it must be approximating it in ways that will generalise well to data outside the training set, assuming that training set is representative.
(it's not actually necessary for the function to be smaller than its training set but it's convenient given that the ultimate training set is the entire universe and it also guarantees that it can't just be literally memorising the input you give it and returning garbage for anything it hasn't seen before).
some possible training sets for your function:
a question -> the answer
parts of images -> the rest of the image
texts in one language -> the same text in a different language
a frame from a video -> the following frame in the video
the weather at time N -> the weather at time N+1
and so on, just keep pouring data into this black box and get back a function that approximates that data as best it can.
what is the architecture of the function? who cares! you only care about minimising the error, reducing the delta between its answers and the training set, better architectures might achieve lower error rates and asymptotically approach the minimum possible error for a given function size, but all the clever stuff is in the data and the more clever the architecture gets the less it impacts the result.
in the extreme case imagine you had a hyper turing oracle where you give it a fully connected neural network of a given size and it adjusts the weights to achieve the minimum possible error on the training set in constant time: such a device could not exist in this universe (citation needed) but even if it did, the networks that it created could not find anything that wasn't already in the data you give them, and that data would determine what they knew.
so architecture doesn't matter -- to the results, but of course it does matter for operational purposes: you could emulate the hyper turing oracle by just iterating through every possible assignment of weights and choosing the one with the lowest error, and you could implement this brute force algorithm on a regular computer today, but it would take longer than a universe of universes to terminate for a network of any reasonable size.
a smarter architecture lets you train larger networks on bigger training sets with less time and power usage, so architectural improvements allow you to take further steps towards what the perfect minimal function would return for the given input, but no better than that!
23 notes
·
View notes
Text
TikTok, Seriality, and the Algorithmic Gaze
Princeton-Weimar Summer School for Media Studies, 2024 Princeton University
If digital moving image platforms like TikTok differ in meaningful ways from cinema and television, certainly one of the most important differences is the mode by which the viewing experience is composed. We are dealing not only with fixed media nor with live broadcast media, but with an AI recommender system, a serial format that mixes both, generated on the fly and addressed to each individual user. Out of this series emerges something like a subject, or at least an image of one, which is then stored and constantly re-addressed.
TikTok has introduced a potentially dominant design for the delivery of moving images—and, potentially, a default delivery system for information in general. Already, Instagram has adopted this design with its Reels feature, and Twitter, too, has shifted towards a similar emphasis. YouTube has been providing video recommendations since 2008. More than other comparable services, TikTok places its proprietary recommender system at the core of the apparatus. The “For You” page, as TikTok calls it, presents a dynamically generated, infinitely scrollable series of video loops. The For You page is the primary interface and homepage for users. Content is curated and served on the For You page not only according to explicit user interactions (such as liking or following) or social graphs (although these do play some role in the curation). Instead, content is selected on the basis of a wider range of user behavior that seems to be particularly weighted towards viewing time—the time spent watching each video loop. This is automatic montage, personalized montages produced in real time for billions of daily users. To use another transmedial analogy—one perhaps justified by TikTok’s approximation of color convergence errors in its luminous cyan and red branding—this montage has the uncanny rhythm of TV channel surfing. But the “channels” you pass through are not determined by the fixed linear series of numbered broadcast channels. Instead, each “channel” you encounter has been preselected for you; you are shown “channels” that are like the ones you have tended to linger on.
The experience of spectatorship on TikTok, therefore, is also an experience of the responsive modeling of one’s spectatorship—it involves the awareness of such modeling. This is a cybernetic loop, in effect, within which future action is performed on the basis of the past behavior of the recommender system as it operates. Spectatorship is fully integrated into the circuit. Here is how it works: the system starts by recommending a sequence of more or less arbitrary videos. It notes my view time on each, and cross-references the descriptive metadata that underwrites each video. (This involves, to some degree, internal, invisible tags, not just user-generated tags.) The more I view something, the more likely I am to be shown something like it in the future. A series of likenesses unfolds, passing between two addresses: my behavior and the database of videos. It’s a serial process of individuation. As TikTok puts it in a 2020 blog post: these likenesses or recommendations increasingly become “polished,” “tailored,” “refined,” “improved,” and “corrected” apparently as a function of consistent use over time.
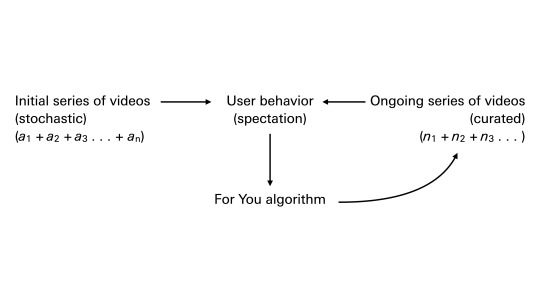
Like many recommender systems—and such systems are to be found everywhere nowadays—the For You algorithm is a black box. It has not been released to the public, although there seem to have been, at some point, promises to do this. In lieu of this, a “TikTok Transparency Center” run by TikTok in Los Angeles (delayed, apparently, by the 2020 COVID-19 pandemic) opened in 2023. TikTok has published informal descriptions of the algorithm, and by all accounts it appears to be rather straightforward. At the same time, the algorithm has engendered all kinds of folk sciences, superstitions, paranoid theories, and magical practices. What is this algorithm that shows me such interesting, bizarre, entertaining, unexpected things? What does it think I want? Why does it think I want this? How does this algorithm sometimes seem to know me so well, to know what I want to see? What is it watching me watch? (From the side of content creators, of course, there is also always the question: what kind of content do I need to produce in order to be recognized and distributed by the algorithm? How can I go viral and how can I maximize engagement? What kinds of things will the algorithm want to see? Why is the algorithm not seeing me?)
These seem to be questions involving an algorithmic gaze. That is to say: there is something or someone watching prior to the actual instance of watching, something or someone which is beyond empirical, human viewers, “watching” them watch. There is something watching me, whether or not I actually make an optical image of myself. I am looked at by the algorithm. There is a structuring gaze. But what is this gaze? How does it address us? Is this the gaze of a cinematic apparatus? Is it the gaze we know from filmtheory, a gaze of mastery with which we are supposed to identify, a gaze which hails or interpellates us, which masters us? Is it a Foucauldian, panoptic gaze, one that disciplines us?
Any one of us who uses the major platforms is familiar with how the gaze of the system feels. It a gaze that looks back—looks at our looking—and inscribes our attention onto a balance sheet. It counts and accounts for our attention. This account appears to be a personalized account, a personalized perspective. People use the phrase “my TikTok algorithm,” referring to the personalized model which they have generated through use. Strictly speaking, of course, it’s not the algorithm that’s individualized or that individuates, but the model that is its product. The model that is generated by the algorithm as I use it and as it learns from my activity is my profile. The profile is “mine” because I am constantly “training” it with my attention as its input, and feel a sense of ownership since it’s associated with my account, but the profile is also “of me” and “for me” because it is constantly subjecting me to my picture, a picture of my history of attention. Incidentally, I think this is precisely something that Jacques Lacan, in his 1973 lecture on the gaze in Seminar XI, refers to as a “bipolar reflexive relation,” the ambiguity of the phrase “my image.” “As soon as I perceive, my representations belong to me.” But, at the same time, something looks back; something pictures me looking. “The picture, certainly, is in my eye. But I am in the picture.”
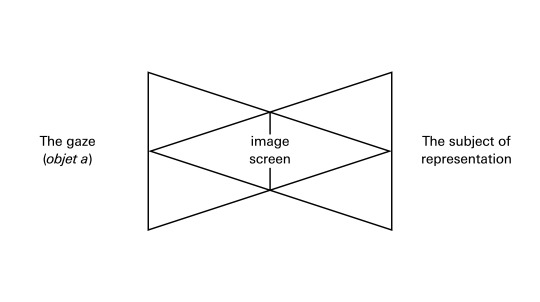
On TikTok, the picture often seems sort of wrong, malformed. Perhaps more often than not. Things drift around and get stuck in loops. The screen fills with garbage. As spectators, we are constantly being shown things we don’t want any more of, or things we would never admit we want, or things we hate (but cannot avoid watching: this is the pleasurable phenomenon of “cringe”). But we are compelled to watch them all. The apparatus seems to endlessly produce desire. Where does this desire come from? Is it from the addictive charge of the occasional good guess, the moment of brief recognition (the lucky find, the Surrealist trouvaille: “this is for me”)? Is it the promise that further training will yield better results? Is it possible that our desire is constituted and propelled in the failures of the machine, in moments of misrecognition and misidentification in the line of sight of a gaze that evidently cannot really see us?
In the early 1970s, in the British journal Screen, scholars such as Laura Mulvey, Colin MacCabe, and Stephen Heath developed a film-theoretical concept of the gaze. This concept was used to explain how desire is determined, specified, and produced by visual media. In some ways, the theory echoes Lacan’s phenomenological interest in “the pre-existence to the seen of a given-to-be-seen” (Seminar XI, 74). The gaze is what the cinematic apparatus produces as part of its configuration of the given-to-be-seen.
In Screen theory, as it came to be known, the screen becomes a mirror. On it, all representations seem to belong to me, the individual spectator. This is an illusion of mastery, an imaginary relation to real conditions of existence in the terms of the Althusserian formula. It corresponds to the jubilant identification that occurs in a moment in Lacan’s famous 1949 paper “The Mirror Stage as Formative of the I Function as Revealed in Psychoanalytic Experience,” in which the motor-challenged infant, its body fragmented (en morceaux) in reality, discovers the illusion of its wholeness in the mirror. The subject is brought perfectly in line with this ideal-I, with this spectacle, such that what it sees is simply identical to its desire. There is convergence. To slightly oversimplify: for Screen theory, this moment in mirror stage is the essence of cinema and ideology, or cinema as ideology.
Joan Copjec, in her essay “The Orthopsychic Subject,” notes that Screen theory considered a certain relationship of property to be one of its primary discoveries. The “screen as mirror”: the ideological-cinematic apparatus produces representations which are “accepted by the subject as its own.” This is what Lacan calls the “belong to me aspect so reminiscent of property.” “It is this aspect,” says Copjec, speaking for Screen theory, “that allows the subject to see in any representation not only a reflection of itself but a reflection of itself as master of all it surveys. The imaginary relation produces the subject as master of the image. . . . The subject is satisfied that it has been adequately reflected on the screen. The ‘reality effect’ and the ‘subject effect’ both name the same constructed impression: that the image makes the subject fully visible to itself” (21–22).
According to Copjec, “the gaze always remains within film theory the sense of being that point at which sense and being coincide. The subject comes into being by identifying with the image’s signified. Sense founds the subject—that is the ultimate point of the film-theoretical and Foucauldian concepts of the gaze” (22).
But this is not Lacan’s gaze. The gaze that Lacan introduces in Seminar XI is something much less complete, much less satisfying. The gaze concept is not exhausted by the imaginary relation of identification described in Screen theory, where the subject simply appropriates the gaze, assumes the position created for it by the image “without the hint of failure,” as Copjec puts it. In its emphasis on the imaginary, Screen theory neglects the symbolic relation as well as the issue of the real.
In Seminar XI, Lacan explicates the gaze in the midst of a discussion on Sartre and Merleau-Ponty. Again, Lacan’s gaze is something that pre-exists the seeing subject and is encountered as pre-existing it: “we are beings who are looked at, in the spectacle of the world” (75). But—and this is the crucial difference in emphasis—it is impossible to look at ourselves from the position of this all-seeing spectacle. The gaze, as objet a in the field of the visible, is something that in fact cannot be appropriated or inhabited. It is nevertheless the object of the drive, a cause of desire. The gaze “may come to symbolize” the "central lack expressed in the phenomenon of castration” (77). Lacan even says, later in the seminar, that the gaze is “the most characteristic term for apprehending the proper function of the objet a” (270). As objet a, as the object-cause of desire, the gaze is said to be separable and separated off from the subject and has only ever existed as lack. The gaze is just all of those points from which I myself will never see, the views I will never possess or master. I may occasionally imagine that I have the object, that I occupy the gaze, but I am also constantly reminded of the fact that I don’t, by images that show me my partiality, my separation. This is the separation—between eye and gaze��that manifests as the drive in the scopic field.
The gaze is a position that cannot be assumed. It indicates an impossible real. Beyond everything that is shown to the subject, beyond the series of images to which the subject is subjected, the question is asked: “What is being concealed from me? What in this graphic space does not show, does not stop not writing itself?” This missing point is the point of the gaze. “At the moment the gaze is discerned, the image, the entire visual field, takes on a terrifying alterity,” says Copjec. “It loses its ‘belong-to-me aspect’ and suddenly assumes the function of a screen” (35). We get the sense of being cut off from the gaze completely. We get the sense of a blind gaze, a gaze that “is not clear or penetrating, not filled with knowledge or recognition; it is clouded over and turned back on itself, absorbed in its own enjoyment” (36). As Copjec concludes: “the gaze does not see you” (36).
So the holes and stains in the model continuously produced by the TikTok algorithm—those moments in which what we are shown seems to indicate a misreading, a wrong guess—are those moments wherein the gaze can be discerned. The experience is this: I am watching a modeling process and engaging with the serial missed encounters or misrecognitions (meconnaissance—not only misrecognition but mistaken knowledge—mis-knowing) that the modeling process performs. The Lacanian point would simply be the following: the situation is not that the algorithm knows me too well or that it gives me the illusion of mastery that would be provided by such knowledge. The situation is that the algorithm may not know or recognize me at all, even though it seems to respond to my behavior in some limited way, and offers the promise of knowing or recognizing me. And this is perhaps the stain or tuche, the point at which we make contact with the real, where the network of signifiers, the automaton, or the symbolic order starts to break down. It is only available through the series, through the repeated presentation of likenesses.
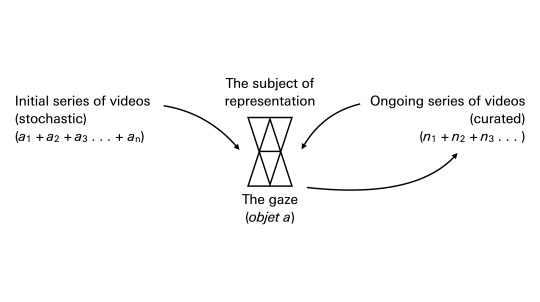
As Friedrich Kittler memorably put it, “the discourse of the other is the discourse of the circuit.” It is not the discourse of cinema or television or literature. Computational recommender systems operating as series of moving image loops seem to correspond strangely closely to the Lacanian models, to the gaze that is responsive yet absent, perceptive yet blind, desired yet impossible, perhaps even to the analytic scene. Lacan and psychoanalysis constantly seemed to suggest that humans carry out the same operations as machines, that the psyche is a camera-like apparatus capable of complicated performance, and that the analyst might be replaced with an optical device. Might we substitute recommender media for either psyche or analyst? In any case, it’s clear that the imaginary register of identification does not provide a sufficient model for subjectivity as it is addressed by computational media. That model, as Kittler points out, is to be found in Lacan’s symbolic register: “the world of the machine.”
10 notes
·
View notes
Text
While I understand the anger directed at the algorithm, I also want to add that ChatGPT has been a better teacher to me than most of my IRL teachers and has enabled me to catch up with my colleagues at university.
I've always been regarded as extremely intelligent, but university has been hell for me. Some classes have been impossible for me to succeed in because the explanations given don't cater to how I understand things (autism/ADHD) and the available tutors just copy and paste (memorize) whatever the teacher says and regurgitate it.
So I've been ashamed. I've been terrified. Now I have a tool that will break concepts down for me, give me examples, help me find online sources for ideas, reword explanations when they're confusing, describe the underlying principles of things, give me advice on how to remember it, give me exercises to help ingrain the knowledge, etc.
I think ChatGPT is extremely beneficial. I also disagree with the claim that it is a plagiarism machine. I understand why people think that, but the approximation of input is not the same as plagiarizing that input, and that's what the AI essentially does.
It's triangulating a position between all of the input that it's ever received and predicting a proper response based on that triangulation. It's, functionally, not that different from reading 10 books about a subject and using those books to write a research paper. The issue arises when it's unclear what sources ChatGPT is using to generate its ideas; the presentation of others' information as your own constitutes misinformation.
However, we all understand that it's an algorithm designed to approximate responses depending on user input; there is no miscommunication where we are led to believe the AI is generating its own content. Also, I could get into another debate here if I said that the AI does synthesize novel content, but this post is already too long.
TL;DR: I think ChatGPT is an amazing tool. It has helped me turn my schooling career around by making subjects accessible in ways my university never tried to. I also think that calling it a 'plagiarizing machine' is a gross oversimplification that twists what the algorithm is doing to fit and support a narrative crafted to fulfill a specific agenda rather than one meant to seek truth, understanding, and balance.
ChatGPT is running out of money because they haven't actually figured out how to make money with the plagiarism engine they created.
Like to charge, reblog to cast.
62K notes
·
View notes
Text
Quantum Continuous Variables With Fault-Tolerant Quantum

Quantum Continuous Variables
For feasible, scalable, and fault-tolerant quantum computers, continuous-variable (CV) devices that encode quantum information in light or other electromagnetic fields are becoming popular. Continuous variables systems are more scalable and photonic-compatible than qubit-based systems because they feature continuous degrees of freedom. This innovation relies on Continuous Variable Gates, which modify quantum information.
In measurement-based quantum computation (MBQC), a potential method, gates are implemented by projective measurements on large-scale entangled cluster states rather than sophisticated coherent unitary dynamics. Maintaining delicate coherent dynamics is unnecessary in this paradigm, simplifying processing.
Cluster States Are Essential In MBQC, cluster states are crucial quantum resources, and their size and structure determine the scale of a measurement-induced algorithm. CV MBQC requires deterministic large-scale cluster state generation. Previous experiments have established large-scale Continuous Variables cluster states using time and frequency multiplexing. Recently, theoretical approaches have explored multiplexing time and space or frequency and space. To accomplish universal quantum computation in CV MBQC, cluster states must be at least 2D, with one dimension for computation and another for manipulation.
A bilayer-square-lattice 2D spatiotemporal cluster state is proposed by a recent comprehensive CV quantum computation architecture. Multiplexing in temporal and spatial dimensions creates this state with one optical parametric oscillator. Four steps are needed to generate entangled Hermite Gaussian (HG) modes, spatially rotate and divide them, delay specific modes, and couple the staggered modes to form a continuous cylindrical structure that can be unrolled into a universal bilayer square lattice.
In “Fault-Tolerant Optical Quantum Computation with Surface-GKP Codes,” 3D cluster states are the centre of another architecture. Topological qubit error correction requires a 3D cluster state for efficient MBQC implementation, hence this 3D structure is essential. The all-temporally encoded version of this architecture promises experimental simplicity and scalability with as little as two squeezed light sources.
Navigating Noise: GKP Encoding and Error Correction Due to the inability to generate maximally entangled CV cluster states, which would take infinite squeezing and energy, CV quantum computation always adds Gaussian noise. This gate noise builds up throughout computing. This is overcome by encoding quantum information in specific qubits in infinite-dimensional continuous-variable bosonic modes.
The Gottesman-Kitaev-Preskill (GKP) code excels at this. Dirac combs represent a qubit in the amplitude and phase (or location and momentum) of a harmonic oscillator in GKP data. By transforming Gaussian noise into Pauli errors in the encoded qubit, this approach provides noise resilience. However, ideal GKP states are unphysical, so researchers use approximation states with finitely squeezed Gaussian functions instead of Dirac spikes.
For fault-tolerant quantum computation, multi-layered error correction is needed:
GKP Quadrature Correction: This first layer projects continuous-variable noise into qubit Pauli errors. Ancillary GKP qunaught states and qubit teleportation can purify noisy qubits. While correcting quadrature flaws, this procedure creates qubit defects. Qubit Error Correction: A qubit-level quantum error-correcting code must rectify these induced Pauli qubit faults. CV structures use nearest-neighbor interactions, making topological error correction like the surface code a natural choice. See also PsiQuantum Gets Large Linde Engineering Cryogenic Plant.
Architectural Innovations for Fault Tolerance Complete fault-tolerant CV quantum computation architectures have advanced in recent research:
2D Spatiotemporal Cluster State Architecture (2025): This paper presents a comprehensive architecture with cluster state preparation, gate implementations, and error correction.
Gate Implementations: Gate teleportation and homodyne detection efficiently implement single-mode and two-mode gates like controlled-Z and controlled-X. Actual gate noise from finite squeezing is accounted for.
Fault-Tolerant Strategy: They use a biassed GKP code and a concatenated repetition code to obtain ultra-low error probability to protect against phase-flip errors and residual bit-flip errors.
Squeezing Threshold: Their simulations, which uniquely account for gate noise and finite squeezing in GKP states, demonstrate a fault-tolerant 12.3 dB threshold. The error probability can be minimised by raising the repetition number or compressing above this level.
Larsen, Chamberland, Noh, et al. (2021): 3D Surface-GKP Architecture It presents a scalable, ubiquitous, and fault-tolerant architecture.
Gate Implementations: Two-mode gates are implemented using gate teleportation on parallel 1D cluster states (wires) in a 3D lattice and variable beam splitters.
Fault-Tolerant Strategy: The surface-GKP code combines GKP error correction with a topological surface code. The updated surface-4-GKP code corrects GKP quadrature after every gate during stabiliser measurements.
Failure tolerance, including GKP state noise and gate noise from finite squeezing in the cluster state, is validated by simulations. Surface-4-GKP had a 12.7 dB squeezing threshold. The usual surface-GKP coding threshold raised to 17.3 dB due to gate noise accumulation. Their surface-4-GKP code achieves 10.2 dB if gate noise is ignored, as in prior efforts.
Looking Ahead These advances are crucial to practical, robust quantum computation employing continuous variables. Using universal CV gates to generate high-quality GKP states with error rates below the quantum memory fault-tolerant threshold is a huge achievement. The researchers are scaling up these systems, exploring CV quantum computation applications in drug discovery, materials science, and financial modelling, and cooperating to develop new algorithms and improve system performance.
Experiments will produce photon loss noise and interferometric phase fluctuations, thus future research must optimise for them. These full designs enable fault-tolerant, measurement-based CV quantum computation in experiments, heralding a computational science revolution.
#QuantumContinuousVariables#GKPCodes#qubits#CVgates#CVquantumcomputation#3Dclusterstate#ContinuousVariableGates#News#Technews#Technology#TechnologyNews#Technologytrends#Govindhtech
0 notes
Text
Smart Home Market Size Set to Surpass USD 225 Billion by 2030 with Robust Growth Outlook
The global smart homes market is projected to witness strong growth, expanding from approximately USD 133.42 billion in 2025 to nearly USD 225.73 billion by 2030. This growth is driven by rapid advancements in home automation technologies and increasing consumer inclination toward connected living, reflecting a compound annual growth rate (CAGR) of 11.09% during the forecast period.
Market Overview
The smart homes industry is experiencing a rapid transformation as consumers seek enhanced convenience, energy efficiency, and security through connected technologies. The rise in the integration of Internet of Things (IoT), artificial intelligence (AI), and voice-activated systems has significantly boosted adoption rates across developed and emerging markets. With the increasing availability of affordable smart devices, the smart homes market size is expected to continue its upward trajectory over the next five years. Moreover, government initiatives promoting smart infrastructure and energy-efficient solutions further support the expansion of this sector.
Key Trends
Voice-Controlled Devices Gaining Popularity The use of voice assistants like Amazon Alexa, Google Assistant, and Apple’s Siri has become a cornerstone in smart home integration, allowing users to control lights, thermostats, and appliances seamlessly.
Integration of AI and Machine Learning Advanced algorithms are now being used in smart home devices to learn user behavior and preferences, enabling more personalized and automated home experiences.
Increased Focus on Energy Management Smart thermostats, lighting systems, and appliances are helping homeowners reduce energy consumption and manage utility costs efficiently — pushing the demand for smart energy solutions.
Expansion of Home Security Solutions The smart homes market is witnessing a surge in demand for surveillance cameras, smart doorbells, and connected alarm systems due to growing concerns about residential safety.
Interoperability and Ecosystem Development Companies are increasingly focusing on developing ecosystems where various smart devices can communicate and operate together, making smart homes more cohesive and functional.
Challenges
Despite the impressive growth forecast, the smart home industry faces several challenges. One of the major hurdles is data privacy and cybersecurity. As homes become more connected, the risk of cyber threats increases. Additionally, the lack of universal standards and interoperability between devices from different manufacturers continues to be a pain point for consumers. Cost is another barrier in price-sensitive markets, where the high initial investment may hinder widespread adoption.
Conclusion
The smart homes market is on a solid growth path, driven by technological advancements, increasing consumer awareness, and supportive government policies. With the smart homes market size projected to reach over USD 225 billion by 2030, industry stakeholders must address existing challenges around privacy, standardization, and affordability to unlock the full potential of this transformative sector. As highlighted in the smart homes market report, companies that innovate in automation, energy management, and security are well-positioned to capture a larger share of the growing smart homes market.
#smart home industry#smart home market size#smart homes industry#smart homes market#smart homes market report#smart homes market share#smart homes market size#smart homes market trends
0 notes
Text
NFT News: Latest Updates and Trends from Crypto News Room
Non-Fungible Tokens (NFTs) keep to revolutionize the virtual panorama, transforming industries along with art, gaming, tune, and real estate. As the NFT market evolves, staying knowledgeable approximately the today's traits, improvements, and regulatory modifications is crucial for traders, creators, and fanatics.
Crypto News Room is a leading supply for the maximum updated NFT news, imparting insights into new initiatives, market overall performance, industry tendencies, and expert reviews. In this newsletter, we explore the trendy NFT updates, including market trends, excessive-profile sales, new blockchain integrations, and the future of NFTs.
NFT Market Trends: The Current State of the Industry The NFT market has skilled massive fluctuations, with intervals of explosive growth followed by marketplace corrections. Despite this volatility, the arena stays a hub of innovation and funding opportunities.
Recent NFT Sales and Market Performance Crypto News Room reviews that in spite of broader crypto marketplace fluctuations, NFT income hold to thrive in specific sectors. Digital art, digital real property, and gaming NFTs stay the most sought-after property. Some of the latest highlights consist of:
Blue-Chip NFT Collections: Established NFT projects like Bored Ape Yacht Club (BAYC), CryptoPunks, and Azuki continue to dominate the market, with report-breaking income and movie star endorsements. Gaming NFTs: Play-to-Earn (P2E) games inclusive of Axie Infinity and Gods Unchained are attracting thousands and thousands of gamers, boosting call for for in-recreation NFTs. Virtual Real Estate Boom: Platforms like Decentraland and The Sandbox are seeing improved investments in digital land, as manufacturers and companies discover metaverse opportunities.
Top NFT Projects Making Headlines New and revolutionary NFT initiatives are continuously rising, reshaping the industry. Crypto News Room highlights some of the maximum promising tasks gaining attention.
Ethereum-Based NFT Projects Ethereum remains the leading blockchain for NFTs, way to its strong smart agreement functionality and widespread adoption. Recent traits consist of:
Yuga Labs Expanding the BAYC Universe: The creators of BAYC are launching new NFT collections and metaverse studies, in addition cementing their dominance inside the space. New Generative Art Projects: Innovative AI-pushed NFT collections are redefining virtual art, taking into consideration particular, algorithmically generated pieces. Solana NFTs Gaining Popularity While Ethereum dominates, Solana has emerge as a robust competitor because of its lower gas charges and quicker transaction speeds. Key Solana NFT initiatives include:
DeGods and y00ts: These collections are attracting a growing network of buyers and creditors. Magic Eden’s Marketplace Growth: Solana’s primary NFT marketplace, Magic Eden, continues to expand, challenging Ethereum-based totally competition.
Polygon NFTs and Mass Adoption Polygon’s low-price, high-velocity transactions make it an attractive desire for manufacturers getting into the NFT area.
Nike and Starbucks NFT Initiatives: Major groups are launching NFT-primarily based loyalty applications and virtual collectibles on Polygon. Gaming Collaborations: Popular Web3 games are integrating Polygon-based totally NFTs for in-recreation assets and rewards.
NFTs in Gaming: The Future of Play-to-Earn NFTs are transforming the gaming enterprise by using allowing true ownership of in-sport objects, characters, and digital assets.
Metaverse Expansion and Virtual Economies The metaverse idea is unexpectedly evolving, with fundamental gaming corporations integrating NFT era:
Meta and Other Big Tech Firms Entering the NFT Space: Facebook’s determine business enterprise, Meta, is exploring NFT integrations in its metaverse tasks. Web3 Gaming Studios: Companies like Gala Games and Immutable X are growing blockchain-based gaming ecosystems in which gamers can alternate, purchase, and promote NFT property.
Regulatory Developments within the NFT Space As NFTs gain mainstream interest, governments and regulators are beginning to enforce rules to deal with criminal and protection worries.
SEC and NFT Regulations The U.S. Securities and Exchange Commission (SEC) is carefully monitoring NFT sales, figuring out whether some tasks classify as securities. Crypto News Room reports that clearer rules may want to offer balance and safety for traders.
Global NFT Policies Countries like the UK, Japan, and the European Union are introducing NFT-unique legal guidelines to save you fraud and defend purchasers. These rules intention to legitimize NFT markets even as making sure fair practices.
Big Brands and Celebrities Entering the NFT Space Major corporations and celebrities keep to undertake NFTs as a part of their virtual techniques.
Luxury Brands Launching NFT Collections Gucci and Louis Vuitton: High-cease fashion brands are liberating unique NFT collections, bridging the distance among physical and digital luxurious. Adidas and Nike: These sportswear giants are leveraging NFTs for digital footwear and digital fashion reports.
Hollywood and Music Industry Adopting NFTs Movie Studios Releasing NFT-Based Content: Studios are experimenting with NFT ticketing, fan engagement, and virtual collectibles. Musicians Monetizing Their Work Through NFTs: Artists like Snoop Dogg and The Weeknd are the use of NFTs to sell music, live performance tickets, and exclusive reports.
The Future of NFTs: What’s Next? Despite marketplace fluctuations, the NFT industry maintains to develop, with new innovations shaping its destiny.
AI-Generated NFTs and Personalization Artificial Intelligence (AI) is gambling a big function within the evolution of NFTs, making an allowance for customizable and dynamic virtual assets. AI-driven NFT art collections are becoming more and more popular.
Interoperability Between Blockchains The destiny of NFTs may see greater interoperability, in which NFTs may be transferred among unique blockchains seamlessly. Projects like Polkadot and Cosmos are working on go-chain NFT answers.
Real-World Applications of NFTs NFTs are expanding past art and gaming into areas such as:
Real Estate: Tokenized belongings ownership is gaining traction. Identity Verification: NFTs will be used for virtual IDs and relaxed on-line authentication. Healthcare and Supply Chain Management: Blockchain era is being explored for NFT-based totally clinical statistics and product tracking.
Conclusion The NFT space stays one of the most dynamic sectors inside the cryptocurrency industry, with continuous innovation and mainstream adoption driving its increase. From gaming and virtual collectibles to company integrations and regulatory tendencies, NFTs are shaping the destiny of virtual possession.
Crypto News Room is dedicated to supplying the present day NFT information, making sure readers stay informed approximately marketplace developments, pinnacle projects, and industry advancements. As the NFT marketplace keeps to adapt, staying up to date with Crypto News Room will assist traders, creators, and fans navigate this exciting digital revolution.
Stay tuned for greater updates and insights on NFTs, blockchain improvements, and the destiny of Web3 from Crypto News Room!
0 notes
Text
Mim Continua Ter Problems
To address the challenges outlined in the spectral approach to the Riemann Hypothesis (RH), the following research problems can be developed. These questions aim to refine the methodology, extend computational capabilities, deepen theoretical connections, and validate results rigorously:
1. Refinement of the Potential Function
Problem 1: Can physics-informed neural networks (PINNs) or other machine learning frameworks discover a potential ( V(x) ) that optimally aligns the operator’s eigenvalues with zeta zeros, while respecting physical constraints (e.g., self-adjointness, boundary conditions)?
Sub-problems:
How does the choice of neural network architecture (e.g., Fourier neural operators) affect the accuracy of the learned potential?
Can symbolic regression techniques identify an analytic form for ( V(x) ) from numerically optimized solutions?
Problem 2: Are there functional constraints (e.g., integrability, smoothness) that guarantee uniqueness of the potential ( V(x) ) for a given eigenvalue spectrum?
Investigate whether imposing symmetries (e.g., PT-symmetry) or asymptotic conditions resolves non-uniqueness.
2. Extending Spectral Computations to Higher Zeros
Problem 3: How can high-performance computing (e.g., GPU-accelerated Lanczos algorithms, distributed eigensolvers) be leveraged to compute eigenvalues of ( H ) corresponding to the ( 10^3 )-th to ( 10^6 )-th zeta zeros?
Sub-problems:
Develop adaptive discretization schemes to maintain numerical stability for large ( \text{Im}(s) ).
Optimize sparse matrix storage/operations for Schrödinger-type operators.
Problem 4: Does the spectral gap or density of ( H ) exhibit phase transitions at critical scales, and do these relate to number-theoretic properties (e.g., prime gaps)?
3. Advanced Statistical Validation
Problem 5: Can spectral form factors or ( n )-level correlation functions provide stronger evidence for the GUE hypothesis than spacing distributions alone?
Compare long-range eigenvalue correlations of ( H ) with those of random matrices and zeta zeros.
Problem 6: Do the eigenvectors of ( H ) encode arithmetic information (e.g., correlations with prime-counting functions)?
Analyze eigenvector localization/delocalization properties and their relationship to zeros.
4. Theoretical Connections
Problem 7: Can the operator ( H ) be interpreted as a quantization of a classical dynamical system (e.g., geodesic flow on a manifold), and does this link explain the spectral-zeta zero correspondence?
Explore connections to quantum chaos and the Gutzwiller trace formula.
Problem 8: Does the Riemann-von Mangoldt formula for the number of zeta zeros up to height ( T ) emerge naturally from the spectral asymptotics of ( H )?
5. Generalization to Other L-functions
Problem 9: Can the framework be adapted to study zeros of Dirichlet L-functions or automorphic L-functions by modifying ( V(x) )?
Investigate whether symmetry properties of ( H ) (e.g., modular invariance) align with functional equations of L-functions.
Problem 10: Do families of L-functions correspond to universal classes of operators (e.g., varying potential parameters), and does this align with Katz-Sarnak universality?
6. Computational and Algorithmic Improvements
Problem 11: Can hybrid quantum-classical algorithms (e.g., variational quantum eigensolvers) efficiently diagonalize ( H ) for large-scale eigenvalue problems?
Assess the feasibility of quantum advantage in spectral RH research.
Problem 12: Do multiscale basis functions (e.g., wavelets) improve the accuracy of ( V(x) ) representations compared to fixed polynomial bases?
7. Toward a Formal Proof
Problem 13: If eigenvalues of ( H ) converge to zeta zeros as discretization is refined, can this imply a rigorous spectral realization of RH?
Establish error bounds for eigenvalue approximations under discretization and optimization.
Problem 14: Can spectral deformation techniques (e.g., inverse scattering transform) reconstruct ( V(x) ) directly from the zeta zero sequence?
8. Interdisciplinary Applications
Problem 15: Does the operator ( H ) have physical interpretations (e.g., as a Hamiltonian in condensed matter systems) that could provide experimental validation?
Explore connections to quantum wires, Anderson localization, or graphene.
Summary
These problems span computational, theoretical, and statistical domains. Progress on any front would advance the spectral approach to RH by:
Strengthening the numerical evidence for a self-adjoint operator realization.
Bridging gaps between analytic number theory and quantum mechanics.
Developing tools applicable to broader problems in mathematical physics and L-function theory.
Collaboration across disciplines (e.g., machine learning, quantum computing, analytic number theory) will be critical to addressing these challenges.
0 notes
Text
Lisk (LSK) Price Prediction 2025, 2026, 2027, 2028, 2029 and 2030
In this article, we aim to provide a clear and comprehensive price prediction for Lisk (LSK) from 2025 to 2030. Our focus is to give you an understanding of what to expect from LSK’s value over this period.
Our predictions are grounded in a thorough analysis of key technical indicators and the broader market dynamics that influence Lisk (LSK).
Lisk (LSK) Long-Term Price Prediction
Year Lowest Price Average Price Highest Price 2025 $8.51 $11.27 $13.93 2026 $12.70 $14.75 $17.83 2027 $9.51 $12.06 $14.82 2028 $8.29 $10.34 $12.47 2029 $12.85 $15.98 $18.99 2030 $18.54 $21.70 $25.32
Lisk Price Prediction 2025
In 2025, it’s predicted that Lisk will reach an average price of around $11.27, with a potential high of $13.93.
The growth in 2025 will be driven by technological advancements in the sector, along with favorable regulations, potentially leading to greater adoption of Lisk and other altcoins. This is optimistic, given the increasing acceptance of cryptos and blockchain by traditional financial institutions.
Lisk Price Prediction 2026
2026 is projected as another growth year, with Lisk price anticipated to reach an average of $14.75 and a possible high of $17.83.
With an expansion of the blockchain industry and more technological innovations, this kind of price increase could be feasible.
Lisk Price Prediction 2027
2027 could be a period of correction with Lisk’s average price decreasing to around $12.06, with a lowest forecast of $9.51. This price correction could be triggered by a wide-ranging market consolidation after the intense growth seen in earlier years.
Lisk Price Prediction 2028
2028 may see Lisk’s price dropping further to an average of approximately $10.34, with a lowest price point of $8.29.
Despite the drop, however, Lisk’s long-term potential and foundation of strong technology could see it weather tough market conditions and continue to be a noteworthy player in the crypto space.
Lisk Price Prediction 2029
By 2029, Lisk price is expected to experience another surge, to around $15.98 average price, and peaking at potentially $18.99. This prediction takes into consideration the potential technological advancements and mainstream adoption that is expected to occur in the late 2020s.
Lisk Price Prediction 2030
In a very optimistic scenario, by 2030, Lisk could reach an average price of $21.70, possibly even climbing as high as $25.32. This assumes a period of significant expansion of the crypto market, with a corresponding boom in the utility and usage of blockchain technologies.
Lisk (LSK) Fundamental Analysis
Project Name Lisk Symbol LSK Current Price $ 1.1 Price Change (24h) 0.72% Market Cap $ 158.9 M Volume (24h) $ 9,140,932 Current Supply 145,444,085
Lisk (LSK) is currently trading at $ 1.1 and has a market capitalization of $ 158.9 M.
Over the last 24 hours, the price of Lisk has changed by 0.72%, positioning it 279 in the ranking among all cryptocurrencies with a daily volume of $ 9,140,932.
Unique Technological Innovations
Lisk is a prominent player in the cryptocurrency arena due to its unique innovations. One of its key differentiators is the use of JavaScript as the core programming language, which is one of the most popular and universally used languages. This increases accessibility for developers, and potential for wider adoption.
The Lisk platform employs a delegated proof of stake (DPoS) consensus algorithm, which enhances transaction verification speed and scalability. It also features sidechain development, allowing developers to create their own blockchains with customizable rules and functionalities.
Furthermore, the Lisk blockchain application platform offers user-friendly features such as a comprehensive Software Development Kit (SDK), which simplifies the development and management of decentralized applications (dApps).
This comprehensive feature-set lines up Lisk strongly against most competitors in the blockchain sphere, thus addressing current market needs effectively.
Strategic Partnerships
To reinforce its position in the cryptocurrency market, Lisk has established partnerships with various industry players.
Most notably, the collaboration with Microsoft Azure allows developers to deploy Lisk’s node and build blockchain applications swiftly.
Similarly, partnerships with ShapeShift, a digital asset exchange, and Lightcurve, a blockchain development studio, enhance Lisk’s ecosystem and support wider adoption and utility. These alliances significantly boost Lisk’s credibility, boost its competitive positioning, and enhance its offering to developers and users.
Sustaining Competitive Advantage
To sustain its competitive edge in the fast-paced digital currency market, Lisk actively adopts new technologies and trends. The team continuously enhances the network via updates and upgrades.
Lisk also works on improving its DPoS system to ensure better governance and greater decentralization.
Investing heavily in academic research, and actively collaborating with research institutions and universities, ensures that Lisk remains robust against potential shifts in the technology and regulatory landscape within the crypto ecosystem.
Community Engagement Efforts
Lisk has a strong focus on building a vibrant and engaged community. They are active on various platforms such as Discourse, Reddit, Telegram, and GitHub. Initiatives such as offering bounties for bugs, rewarding developers for dApp creation, and hosting regular community meetings showcase its commitment to foster growth and engagement.
Lisk’s education-focused campaigns, including the Lisk Academy, provide resources for developers and generates awareness about blockchain technology to the wider public. This continuous engagement energizes the community and contributes actively to the project’s overall success and adoption.
By systematically addressing the unique value propositions, strategic partnerships, sustaining strategies, and community engagement, this analysis provides an in-depth understanding of Lisk’s role in the wider cryptocurrency ecosystem and its future potential.
Lisk (LSK) Technical Analysis
Zoom
Hour
Day
Week
Month
Year
All Time
Type
Line Chart
Candlestick
Technical Analysis is a method used to forecast the future price movement of cryptocurrencies, like Lisk, based on historical price data.
Importance of Technical Analysis in Lisk price prediction lies in its ability to utilize patterns in market data to speculate future behavior.
Technical indicators help to predict price trends and may be used as a basis for investment decisions:
Relative Strength Index (RSI): This momentum oscillator helps identify overbought or oversold conditions in a market, which may herald a trend reversal.
Simple Moving Average (SMA): It’s an arithmetic mean of the closing price of the security for a specified time period, which can indicate a possible price trend.
Volume: This indicator shows the number of shares or contracts traded in a security. If the volume is increasing, it signals a strong market interest in the security, thus affecting its price.
Lisk Price Predictions FAQs
What is Lisk?
Lisk is a blockchain application platform that seeks to make blockchain technology more accessible to the general public by allowing developers to create and publish their own blockchain applications using JavaScript.
Is Lisk a good investment?
Whether Lisk is a good investment or not depends on various factors including market trends, investor’s risk tolerance, and investment horizon. It’s advisable to conduct thorough research or consult a financial advisor before investing.
How does technical analysis affect Lisk price predictions?
Technical analysis uses past market data to try and forecast future price trends. This includes identifying chart patterns, trend lines and resistance levels which can give insights into potential future price movements. It’s not a guarantee for future performance though.
What are the risks associated with investing in Lisk?
Like any other cryptocurrency, Lisk is subjected to market volatility. The price may upsurge or plunge rapidly, resulting in potential losses. Additionally, as a digital asset, it’s always at risk of cyber attacks.
What is CoinEagle.com?
CoinEagle.com is an independent crypto media platform and your official source of crypto knowledge. Our motto, “soaring above traditional finance,” encapsulates our mission to promote the adoption of crypto assets and blockchain technology.
Symbolized by the eagle in our brand, CoinEagle.com represents vision, strength, and the ability to rise above challenges. Just as an eagle soars high and has a keen eye on the landscape below, we provide a broad and insightful perspective on the crypto world.
We strive to elevate the conversation around cryptocurrency, offering a comprehensive view that goes beyond the headlines.
Recognized not only as one of the best crypto news websites in the world, but also as a community that creates tools and strategies to help you master digital finance, CoinEagle.com is committed to providing you with the necessary knowledge to win in crypto.
Disclaimer: The Lisk price predictions in this article are speculative and intended solely for informational purposes. They do not constitute financial advice. Cryptocurrency markets are highly volatile and can be unpredictable. Investors should perform their own research and consult with a financial advisor before making any investment decisions. CoinEagle.com and its authors are not responsible for any financial losses that may result from following the information provided.
0 notes
Text
Quantum Machine Learning for Protein Folding
Proteins play a key role in every cell-level process, from immune responses to neuronal activity. They are encoded as long sequences of amino acid residues, which must fold into a complex 3D structure to perform their functions. Determining that structure, however, has proven a difficult computational challenge. This is because the physics of protein folding involves a highly dynamic energy landscape, which is difficult to model from first principles.
Attempts to tackle the problem have so far been limited by the availability of computing resources. The latest advance could potentially bring a quantum boost. Researchers have developed a hybrid classical-quantum algorithm that can predict the lowest-energy protein conformation from its amino acid sequence. It requires just nine qubits, of which seven are configuration qubits and two are interaction qubits.

The algorithm uses the principles of quantum annealing to guide its search for protein structures, and is based on the work of Fingerhuth et al 2018. A key difference between this and other quantum-algorithm approaches is that they use a probabilistic representation rather than a techogle.co deterministic one. This allows the algorithm to take advantage of a feature of the quantum mechanics of proteins, which is that the probability of a given state is proportional to the square root of the entropy of that state.
A major obstacle to protein folding is the Levinthal paradox, which states that the energy cost of sampling the full protein configuration space (the “space of all possible proteins”) exceeds the total energy required to find the lowest-energy conformation. Current computational methods, such as GPU-assisted exhaustive searches of coarse-grained models or protein lattices, reduce this space but require high computation resources. The authors’ new algorithm addresses this challenge by using the adiabatic optimization principle of quantum annealing to transform the protein configuration space into an objective function that minimizes the maximum deviation from the protein’s native conformation.
The adiabatic optimization approach, which is also used by other quantum algorithms, is an example of a general class of algorithms known as adiabatic approximations. The researchers evaluated the performance of their new algorithm on an IBM Quantum Cloud simulator and found that it achieved a computational efficiency of 128 bits per second, well above comparable classical-only algorithms. Their findings show that quantum machine learning can magnify our ability to decipher molecular complexities and supercharge simulations, potentially accelerating drug discovery timelines. The energy potential learned by the algorithm could be applied to designing viable amino-acid sequences for proteins, and it could help us develop better technology website treatments for diseases involving protein misfolding. This work was supported by the European Union Horizon 2020 programme and by the National Science Foundation under Grant No. 1734560. Additional support was provided by the University of the Basque Country UPV/EHU, Kipu Quantum in Germany, and the International Center for Quantum Artificial Intelligence for Science and Technology (QuArtist) and the UC Berkeley-Stanford Joint Institute for Computational Biology. Additional authors include Pranav Chandarana, Narendra N. Hegade, Iraitz Montalban, Enrique Solano, Xi Chen, and others.
1 note
·
View note
Text
Quantum Machine Learning for Protein Folding
Proteins are complex 3-dimensional structures that play a vital role in human health. In their unfolded state, proteins can have a wide variety of structural forms; however, they must refold into their native, functional structure in order to function properly. This process is both a biological mystery and a critical step in drug discovery, as many of our most effective medicines are protein-based.
Despite its crucial importance, folding a single protein is an enormous computational challenge. The inherent asymmetry and complexity of proteins creates a rugged energy landscape that must be optimized using highly accurate models, which requires significant computational resources. The advent of quantum computing has the potential to dramatically accelerate the folding of complex proteins, paving the way for new therapies and diagnostics.
Quantum machine learning for protein folding has already yielded impressive results, demonstrating the power of quantum computation to tackle a diverse set of biochemical problems. The superposition of qubits allows for simultaneous simulation of multiple solutions, enabling exponential speedups compared to classical computers. These speedups, coupled with the ability to probe more complex energy states of proteins, can reveal novel insights into folding pathways and help accelerate drug discovery timelines.

Recent studies have used hybrid quantum-classical computer systems to study the problem of protein folding. Casares et al 2021 combined quantum walks on a quantum computer with deep learning on a classical computer to create a hybrid algorithm called QFold, which achieves a polynomial speedup over the best classical algorithms. Outeiral et al 2020 used a similar approach, combining quantum annealing with a genetic algorithm on a classical computer to find low-energy configurations of lattice protein models.
Other approaches techogle.co have been explored using variational quantum learning, a form of approximate inference in which the optimization algorithm is informed by an empirical error model. For example, Roney and Ovchinnikov use an error model to guide their adiabatic quantum protein-folding algorithm to start from the lowest-energy conformation of a given amino acid sequence. Their algorithm then uses a heuristic search to locate a likely 3D protein structure.
While most experimental work to date has focused on simple proteins, recent theoretical developments have opened the door to applying quantum machine learning to more challenging proteins. In particular, researchers at Zhejiang University in Hangzhou have proposed a model that describes protein folding as a quantum walk on a definite graph, without relying on any simple assumptions of protein structure at the outset.
This work is an technology website exciting advancement in the field of quantum biology, but it is important to emphasize that it is still far from a clinically relevant model of protein folding. To be applicable to the study of real proteins, the model must be tested in simulations on a large scale. Currently available quantum computational devices have between 14 and 15 qubits; to simulate a protein of 50 amino acids, the number of qubits would need to grow to 98 or more. Quantum computers with higher qubit counts are under intensive development, and their application to protein folding may soon become a reality.
1 note
·
View note
Text
AI Unveils Thousands of Potential New CRISPR Systems in a Genetic Treasure Hunt
In the world of genetic editing, CRISPR Systems has been a game-changer. Scientists have relentlessly sought improvements in precision and accuracy within the CRISPR-Cas9 system. This month, a groundbreaking approach led by Dr. Feng Zhang and his team at MIT and Harvard has brought forth a remarkable breakthrough in the search for novel CRISPR systems.
A Sea of Genetic Sequences with AI
Driven by the challenge of sifting through billions of genetic sequences stored in databases, the team turned to Artificial Intelligence (AI) for a solution. Leveraging this technology, the researchers scoured extensive open-source databases housing genetic information from an array of sources—ranging from brewery bacteria to Antarctic microorganisms and even dog saliva.
In a matter of weeks, the AI algorithm identified thousands of potential new genetic components, constituting a staggering 188 never-before-seen CRISPR-based systems. Some of these variants showcased promising attributes, such as heightened precision in gene targeting and potential insights into RNA-targeting CRISPR systems.
A Bioengineering Quest for New CRISPR Systems
CRISPR, initially discovered in bacterial cells as a defense mechanism against viruses, has since been extensively studied for its potential in human gene editing. Dr. Zhang’s prior exploration led to the identification of an entirely new CRISPR family line, known as OMEGA, exhibiting effective DNA snipping in human cells.
Expanding their horizons beyond bacteria, the team delved into the world of eukaryotes, uncovering evidence of a CRISPR-like mechanism in organisms such as fungi and algae. This pioneering endeavor hinted at the possibility of gene editing mechanisms in eukaryotic life forms.
AI-Powered Genetic Clustering
The newly developed AI algorithm, dubbed FLSHclust, operates akin to technology analyzing vast datasets. It meticulously clustered genetic sequences from bacteria, segregating them into approximately 500 million clusters. Within these clusters, the team identified 188 genes potentially associated with CRISPR, presenting a treasure trove of thousands of unexplored CRISPR systems.
Among the standout discoveries were systems employing longer guide RNA sequences, hinting at enhanced precision in gene editing with reduced side effects. Additionally, the team unraveled a novel CRISPR system targeting RNA, an uncharted territory in genetic editing science.
Future Prospects
While the functional viability of these newfound CRISPR systems in human gene editing remains uncertain, the team’s AI-driven approach has unlocked a vast genetic universe for further scientific exploration. These discoveries could hold the key to advanced genetic therapies and a deeper understanding of nature’s diverse gene editing mechanisms.
The team’s AI tool is now available for fellow researchers, offering an unparalleled avenue to explore potential “unicorn” gene sequences within the vast expanse of genetic data. As this groundbreaking research propels the field of genetic editing forward, it paves the way for unprecedented discoveries in biomedical science.
0 notes
Link
Japan has embarked on an exciting new lunar program that will test automated remote construction machinery for the Moon. In 2021, representatives from the Kajima Corporation, the National Research and Development Agency, the Japan Aerospace Exploration Agency (JAXA), and the Shibaura Institute of Technology announced they would be working with the Ministry of Land, Infrastructure, Transport, and Tourism (MLIT) to develop a next-generation construction system (A4CSEL®) that will enable the creation of lunar infrastructure.This new collaborative venture, known as the Space Unmanned Construction Innovative Technology Development Promotion Project, will create an A4CSEL system capable of operating in the harsh lunar environment. In a recent statement, Kajima announced that it would connect the approximately 20-square kilometer (7.72 mi2) Kashima Seisho Experimental Field with JAXA’s Sagamihara Campus. Here, they are conducting experiments to validate automated remote construction machinery in a simulated lunar environment, which could lead to the creation of a lunar base!Since 2009, Kajima has been developing A4CSEL (“quad-accel”), a next-generation construction production system designed to transform “the construction site into a factory.” The technology is based on the concept of operating multiple automated construction machines with as few workers as possible, ensuring safety while reducing costs and eliminating waste. The technology has already been applied to several construction projects, mainly in the construction of dams and tunnels. Steps of an uncrewed base construction on the Moon. Credit: KajimaSince 2016, Kajima, JAXA, and multiple universities have been developing the A4CSEL technology to work on the Moon, emphasizing autonomous driving and remote control that can deal with lunar conditions. This includes extreme variations in temperature, lunar regolith, and lower gravity (roughly 1/6th of Earth’s gravity). In keeping with the philosophy of in-situ resource utilization (ISRU), their work has focused on creating A4CSEL applications to harvest lunar water ice deposits to generate hydrogen and oxygen propellants. This is consistent with JAXA’s “International Space Exploration Scenario,” which emphasizes the need for in-situ resource utilization (ISRU) and building lunar bases within permanently shadowed regions (PSRs) on the Moon – such as lunar craters. For their experiment, Kajima and JAXA simulated the excavation of water-bearing lunar regolith using three construction machines (two backhoes and one crawler dump truck) modified for automated and remote control. The JAXA Sagamihara campus was used as the command center while the vehicles operated in the Kashima Seisho Experimental Field. As the representatives indicated in a recent JAXA press release:“We demonstrated hybrid construction using automatic control and remote control based on an excavation and transportation work scenario assuming water excavation… Based on the results of this experiment on the ground using a real machine, we will build technology that can accurately reproduce work in virtual space, and if it becomes possible to reproduce work on the Moon under various conditions, it will be possible to. We believe that the results of this demonstration can be reflected in work on the lunar surface.”While the conditions were not analogous to the lunar environment for this experiment, the joint JAXA-Kashima team demonstrated the effectiveness of their automatic operation and remote control system using multiple vehicles. Similarly, the team combined laser range finder (LIDAR) data with simultaneous localization and mapping (SLAM) algorithm to create a map of the surrounding environment, which allowed the team to keep track of the positions of their vehicles. This demonstrated that their autonomous/remote control technology can function in environments where there is no Global Navigation Satellite System (GNSS).Artist rendering of an Artemis astronaut exploring the Moon’s surface during a future mission. Credit: NASAFor their next step, the participants in this collaborative venture will continue to develop a simulator that incorporates experimental results with lunar surface data. This will allow them to gradually test the technology in environments increasingly analogous to the lunar surface. At the same time, Kashima anticipates their experiments and the SLAM algorithm will have spinoff applications here on Earth. As Kashima’s representatives indicated in the press release:“SLAM, which was used as a positioning technology in this experiment, can be used as a simultaneous and dynamic positioning technology for multiple machines, which is essential for automating tunnels and underground construction where GNSS cannot be used, even on Earth. In addition to the accuracy improvement measures verified in this activity, we plan to utilize SLAM at sites around the world.”Caveat: This information is translated from a Japanese-language press release. Further Reading: JAXAThe post Japan Tests Robotic Earth-Moving Equipment in a Simulated Lunar Jobsite appeared first on Universe Today.
0 notes
Text
Q-AIM: Open Source Infrastructure for Quantum Computing

Q-AIM Quantum Access Infrastructure Management
Open-source Q-AIM for quantum computing infrastructure, management, and access.
The open-source, vendor-independent platform Q-AIM (Quantum Access Infrastructure Management) makes quantum computing hardware easier to buy, meeting this critical demand. It aims to ease quantum hardware procurement and use.
Important Q-AIM aspects discussed in the article:
Design and Execution Q-AIM may be installed on cloud servers and personal devices in a portable and scalable manner due to its dockerized micro-service design. This design prioritises portability, personalisation, and resource efficiency. Reduced memory footprint facilitates seamless scalability, making Q-AIM ideal for smaller server instances at cheaper cost. Dockerization bundles software for consistent performance across contexts.
Technology Q-AIM's powerful software design uses Docker and Kubernetes for containerisation and orchestration for scalability and resource control. Google Cloud and Kubernetes can automatically launch, scale, and manage containerised apps. Simple Node.js, Angular, and Nginx interfaces enable quantum gadget interaction. Version control systems like Git simplify code maintenance and collaboration. Container monitoring systems like Cadvisor monitor resource usage to ensure peak performance.
Benefits, Function Research teams can reduce technical duplication and operational costs with Q-AIM. It streamlines complex interactions and provides a common interface for communicating with the hardware infrastructure regardless of quantum computing system. The system reduces the operational burden of maintaining and integrating quantum hardware resources by merging access and administration, allowing researchers to focus on scientific discovery.
Priorities for Application and Research The Variational Quantum Eigensolver (VQE) algorithm is studied to demonstrate how Q-AIM simplifies hardware access for complex quantum calculations. In quantum chemistry and materials research, VQE is an essential quantum computation algorithm that approximates a molecule or material's ground state energy. Q-AIM researchers can focus on algorithm development rather than hardware integration.
Other Features QASM, a human-readable quantum circuit description language, was parsed by researchers. This simplifies algorithm translation into hardware executable instructions and quantum circuit manipulation. The project also understands that quantum computing errors are common and invests in scalable error mitigation measures to ensure accuracy and reliability. Per Google Cloud computing instance prices, the methodology considers cloud deployment costs to maximise cost-effectiveness and affect design decisions.
Q-AIM helps research teams and universities buy, run, and scale quantum computing resources, accelerating progress. Future research should improve resource allocation, job scheduling, and framework interoperability with more quantum hardware.
To conclude
The majority of the publications cover quantum computing, with a focus on Q-AIM (Quantum Access Infrastructure Management), an open-source software framework for managing and accessing quantum hardware. Q-AIM uses a dockerized micro-service architecture for scalable and portable deployment to reduce researcher costs and complexity.
Quantum algorithms like Variational Quantum Eigensolver (VQE) are highlighted, but the sources also address quantum machine learning, the quantum internet, and other topics. A unified and adaptable software architecture is needed to fully use quantum technology, according to the study.
#QAIM#quantumcomputing#quantumhardware#Kubernetes#GoogleCloud#quantumcircuits#VariationalQuantumEigensolver#machinelearning#News#Technews#Technology#TechnologyNews#Technologytrends#Govindhtech
0 notes
Text
Following a traumatic brain injury, depression may manifest as a novel and separate medical condition.

A recent study led by Shan Siddiqi, MD, from Brigham and Women’s Hospital, a founding member of the Mass General Brigham healthcare system, suggests that depression following traumatic brain injury (TBI) may represent a distinct clinical disorder rather than the conventional major depressive disorder. The implications of this research could have significant consequences for the treatment of patients. The findings have been published in Science Translational Medicine.
According to the corresponding author, Shan Siddiqi, MD, from the Brigham’s Department of Psychiatry and Center for Brain Circuit Therapeutics, their findings shed light on how physical trauma to specific brain circuits can lead to the development of depression. If their hypothesis is correct, it implies that depression after TBI should be managed as a separate disease. Many clinicians have long suspected that this condition possesses unique symptom patterns and treatment responses, including a limited response to conventional antidepressants, but until now, they lacked clear physiological evidence to support this notion.
The study involved collaboration with researchers from Washington University in St. Louis, Duke University School of Medicine, the University of Padua, and the Uniformed Services University of the Health Sciences. The research began as a side project seven years ago when Shan Siddiqi was motivated by a patient he shared with David Brody, MD, PhD, a co-author and a neurologist at the Uniformed Services University. They initiated a small clinical trial using personalized brain mapping to target brain stimulation as a treatment for TBI patients with depression. During this process, they observed specific abnormalities in the brain maps of these patients.
The study included 273 adults with TBI, primarily resulting from sports injuries, military incidents, or car accidents. This group was compared to other cohorts without TBI or depression, individuals with depression but without TBI, and people with posttraumatic stress disorder. Participants underwent resting-state functional connectivity MRI, a brain scan that observes oxygen movement in the brain. These scans provided oxygenation data at approximately 200,000 points in the brain and 1,000 different time points, generating about 200 million data points for each person. Machine learning algorithms were employed to create individualized brain maps based on this extensive information.
While the location of the brain circuit involved in depression was the same in both individuals with and without TBI, the nature of the abnormalities differed. In depression without TBI, connectivity in this circuit was reduced, whereas in TBI-associated depression, it was increased. This suggests that TBI-associated depression may involve a distinct disease process, leading the researchers to propose a new designation: “TBI affective syndrome.”
David Brody expressed that he has long suspected that this condition differs from typical major depressive disorder or other mental health conditions unrelated to traumatic brain injury. Although there is still much to comprehend, progress is being made in understanding the unique nature of this disorder.
One limitation of the trial was the sheer volume of data, which prevented the researchers from conducting detailed assessments of each patient beyond brain mapping. In the future, the investigators hope to use more sophisticated methods to assess participants’ behavior and potentially define various types of TBI-associated neuropsychiatric syndromes.
Shan Siddiqi and David Brody are using the insights gained from this study to develop personalized treatments. They initially designed a new treatment approach using brain mapping technology to target specific brain regions in TBI and depression patients, employing transcranial magnetic stimulation (TMS). A pilot trial with 15 participants showed promising results, and they have since received funding to replicate the study in a multicenter military trial.
The researchers aspire that their discovery will pave the way for a precision medicine approach to managing depression and mild TBI, and even enable intervention in neuro-vulnerable trauma survivors before the onset of chronic symptoms, as stated by Rajendra Morey, MD, a professor of psychiatry at Duke University School of Medicine and co-author of the study.
Source: Science Daily
#depressionhelp#neurostar#mental health#apdss#medicine#pain management#back pain#chiropractic#neckpain#health
1 note
·
View note