#All links are to the LDS website
Text
Template to send to EA regarding Paywallers.
Hey y'all! I had an anon ask about this, so I wrote this up real quick for anyone who doesn't have the time or ability to pen a long thing to send to EA about the paywallers. Feel free to change it up as much as you'd like, add even more paywallers (highly recommend this), do whatever you want, let's REPORT REPORT REPORT 💖
How to report:
To report Mods, give us the details right here on EA Help:
Click Contact Us from any page on EA Help.
We recommend logging in to your EA Account.
Select The Sims 4. If needed, use the search bar to find the game.
Select your Platform.
For Topic, select Report concerns or harassment.
For Issue, choose Report website.
From here, you’ll open a webform to let us know more about what happened. Please provide a link to the Mods you think break the rules, and as much detail as you can about why. Your report will be reviewed by our team.
Then you just enter your name/email (which isn't shared with anyone but EA)
Here's my lil template! THIS HAS BEEN CENSORED. In my actual report I listed their full names, and patreon/tumblr pages. I HIGHLY recommend you check out mack3030's anti perma paywall posts. Give EA as MUCH info as you can on this. The more of us that report the better off we'll be. Also i borrowed a little bit of wording from @myshunosun (the distribution and installation part) sorry but it sounded nice and I couldn't think of how else to phrase it.
My Template:
I made the subject "Custom Content in the Sims community- perma paywallers"
"Hello there, my name is ______, and I have been an avid sims fan and consumer for MANY years. It has recently come to my attention that EA has released an official article on the distribution and installation of mods and custom content. It states to reach out if we find any mods that go against the guidelines in this article. As a community, we know of MANY people who permanently lock their custom content behind what we call 'paywalls', which means simmers have NO access to them unless they pay. This is clearly against EA's policies and I would now like to report them to you in the hopes that you will not let this continue any longer. As someone who has already spent hundreds on this game and franchise, I believe it is wrong in so many ways to lock content using EA's intellectual property/program/meshes behind paywalls when it is clearly against your policy. Following is a list of some of the most notorious paywallers in the community.
S*xamcc
currently makes over 10k a month from perma paywalling their custom content. They have removed thier public patron amount due to the backlash they have received. This is unacceptable when EA CLEARLY states that mods are NOT to be sold. This creator will continue to lock all of their content behind paywalls until someone stops them.
Other perma paywallers:
antos*ms, bergd*rf, cowbu*ld, P*xel V*bes
Thank you so much for reading my report and taking what we as a community have been against for so long seriously. I greatly hope that you look at these reports and do something about these creators."
#yeah its not the BEST but idk its something lmao#they better read my shit i typed all this and sent it to them djkl#text
549 notes
·
View notes
Note
I was really excited about this project, and got immensely disappointed with the release of the UI. The fact it's almost a carbon copy of FlightRising's interface is just so... sad. It basically drains Pawborough of its own identity. I really-really hope you guys will consider changing it, because the original concept is lovely. Here's a few things I'd like to comment on:
1. FR's interface is dated. Currently, they're refactoring the site, and i wouldn't be surprised if their next goal after the refactor would be a UI redesign. And you guys, instead of trying to modernise it and make it your own, are copying a UI from *a decade ago*.
2. Why are you keeping the narrow column format of the site? Most people have a wide-screen monitor nowadays, and it looks bizarre to have such a compressed website. Please consider automatically adapting the site's layout to a user's screen width, sorta like Wolvden/Lioden does. IIRC, they have two columns of content (main stuff in the center & a column with user's data on the left), which stack into one column when you're using a mobile device (aka a narrow screen). But since you're planning to make a mobile version anyway, you should consider making the desktop version of the site wide and, well, desktop-friendly, and then figure out the mobile version as it's own thing.
3. Does the user box in the top right of the site really have to be literally identical to FR, with the same data placed in the same way, and also with the energy bar literally having the same exact segments on it? Especially since you have removed the flight banner, making that user block much less balanced looking. Instead, I think you guys can consider making it much more horizontal and narrow. Assuming the two variables on the right (book and turnip icons) are pet/familiar count and cat count, I feel like they can be dropped completely and moved to the user page. I don't think they need to be displayed at all times on all site's pages.
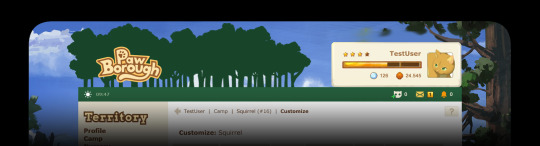
Image link
Alternatively, you can also use Lioden/Wolvden's approach and make a separate column, and then put all user information and bookmarks in that side column. As a compromise between FR & LD, you can place that user column on the right. Here's a screenshot from google for reference:

Image link
I'd also like to point out the bookmarks box in the column with user data. It's virtually unlimited and you can name your own bookmarks. Introducing this would allow you to largely collapse the left column with site navigation, because you don't use most of those links every day. As a FR player, I would only keep ~13 links in my always-visible bookmarks instead of the 29 available in the left navigation bar. It would be especially nice if I could add emojies into my bookmark names like you can on LD/WD, so it's easier to see what i need right away.
As a mini-addition, please work on the navigation column on the left. It's horrible on FR, and it will be horrible on PB if you introduce it. There's gotta be better ways to navigate the site.
4. I hope you reconsider some of the artstyle choices regarding backgrounds and decorations. What got me excited about PB was the absolutely fantastic character art from NPCs to the breed artworks. You seriously couldn't have picked a better artist for this over Amelia B. It has so much personality and immediately elevated PB in my eyes over Lorwolf, which had absolutely soulless art and looked almost traced from photos. But then I was absolutely heartbroken to see you have went with this odd, textured, sketchy style for the backdrops. Why? I'm assuming it's something like anime-style logic, where characters are cell-shaded and flat and backgrounds are painterly, but to pull that off you need a simply spectacular background artist and... i'm sorry, but your artists just don't pull it off. There's color going outside of lines on the opal waterfall background, some "hairy" scratchy lines that don't follow the shape of the object and dang it just looks flat in terms of values. Its not a terrible thing to make the cat pop, but the fact it's literally the opposite of the cats' style just makes it look odd. The obsidian sentry artwork is probably my least favorite out of everything shown by far. the head anatomy is all over the place and the shading is blurry and muddy where it looks like it should have sharp edges. It just seems like you hired a professional to do the breed artwork, and an actual newbie to do some of the items/backgrounds. Addittionally, i noticed that you're planning to introduce player-made familiars/decors, so that would introduce even more style variation into the equation. Please, please consider making the style same-ish for all site assets. It's not bad if the background assets stay low-contast and a bit flat, but at least give them the same linework as the cats in terms of weight, texture, and quality. Perhaps you can use colored lineart in decorations and backgrounds to make it more muted in comparison to the cats. And I see I'm not the only one asking for this, so please don't fall for the sunk cost fallacy and rework the assets you already have, instead of "dooming" your sites for decades of having blurry, sketchy backgrounds.
Anyway, all of this is coming from a good place, I promise this wasn't written in bad faith. Im extremely excited and passionate about this project and I really-really hope it succeeds. But please, not only listen to user feedback, but also make changes before it's too late.
Thank you for the feedback. To address a few things I believe were lost in translation that we hadn't made clear, and to address this feedback:
The narrow width of the container actually is a placeholder! We do wish to switch to a wider version, and the demo utilizes an early test build. We do already utilize flexbox, which will adjust to the player's screen size, but it's our intention to make the container limit bigger. On top of that, we are hoping to modernize much of the old interface style while keeping a nostalgic charm, including things such as integration of flexbox as an example. Thank you for pointing this out, as this was something that wasn't made clear, and that we did not think to mention.
The userbox is our design nadir right now, we understand, and we are looking to redesign it immediately. Our idea at this time is to disperse the pixel components among it into the ribbon, place where a graphic was intended to go into the navigation, and leave only the icon and energy bar at the top. Actually, we have design mockups with much similar placement to your mockup! Though we were considering putting money in the ribbon too so as to distance ourselves as much as possible. We will consider the feedback of leaving the components strictly on a user's page, so we will fiddle with this. As well, we will fiddle with information potentially in a column. Thank you for the effort you put in!
Regarding the user navigation, we could potentially make it collapsable, as well as introduce bookmarks for those who prefer it. However, to avoid the inaccessibility of dropdowns, the default state would have to remain uncollapsed. Making the navigation collapsable has actually been discussed previously as a good idea. As of now we are looking into increasing the margin of the list and importing imagery into it for better readability, thinking similar to Marapets and early Neopets, but different. What we enjoy about the navigation is a consistent knowledge and potential memorization of everything on a site that collapsed information does not provide, but perhaps we can design something that will allow for the best of both worlds. We are taking in this feedback to heart. Thank you for sharing what you as a user prefer from your game experience!
We understand your distaste for some of the Kickstarter assets, and should there be a demand we can reconsider the rendering for some of them, such as decor. We do, however, have several artists on the team that can do backgrounds and decor, and we shall work to better instruct style discrepancy. We apologize for the distaste in the assets, and we will improve with both stylistic direction and artistic synergy. The intention for our backgrounds is to bring a storybook feeling, and there is going to be an amount of subjectivity to the judgement of this choice. We apologize that it is not to your taste. Regardless, we appreciate your feedback, will note it for future adaptation of our stylistic direction, and once again apologize for your distaste. To clarify, "user-made" decor and companions will simply be user instruction on the design, while our art and design team is still controlling the final piece.
Thank you for feedback on the user experience, and we promise we have not been writing off these points entirely, but rather wanting to express that we understand and, as stated, want to incorporate this feedback while remaining true to our philosophy. We apologize that our communication was lackluster and will be keeping this as our statement on the matter before updating with our new designs. We will do better to communicate our intentions. We do want to hear what a user will most value from an interface experience! Once again, thank you for taking the time and effort to share this information with us, and thank you for the patience as we learn!
24 notes
·
View notes
Text
Decoding the Codex of Ruin
So, recently, on discord, people discovered that the entries for The Solemn, The Twins, The Match, and The End do not show up on The Codex of Ruin (farragofiction.com/CodexOfRuin/) for certain people. In copy pasting those links, I noted that I did not know why the urls were so long. The comment was screenshot, put into a farragofiction index with the name "ehehehehe_ilookforwardtowhenyoufindout.PNG"
This clued me in to the urls being some kind of puzzle. I struggled in the code of the game trying to figure out how to decode the long nonsense strings of text attached to each URL. I eventually came upon something called LZString. Googling how to decode LZString brought me to a simple website where I could do that. In the code itself was a random string associated with the Propaganda page that pops up when you put in an incorrect address like http://farragofiction.com/CodexOfRuin/viewer.html?name=NoThanks , but each individual entry had their string in the url.
What ended up decoded was mostly the data already listed on the page with one minor and one major exception.
The minor exception was that there was a segment called exactly_three_tips that for some correlated directly to the tips section, but for others were copies of a different entries tip section. I've included them, but suspect it was just some oversight.
The major exception is the section labelled story_details, which gives hidden details on the character, links to relevant pages, etcetera.
I give both of these data sets for all 24 Codex entries below the readmore.
Johnald Humanman not on website
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
Story Details: He is a very good employee
The The Hær@ld
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
Story Details: TBD
The Solemn
Story details:
He's just a guy. All the remains of a dead god that never existed. http://farragofiction.com/TwoGayJokes/ Given enough time, even the most Lonely of us can find more. http://farragofiction.com/LightAndVoid/?dearWitherby=true
The Twins
Story details: http://farragofiction.com/TwoGayJokes/in_which_neville_gets_owned_and_devona_makes_it_everybody_elses_problem
The Bard of Light gathers the information: http://farragofiction.com/LightAndVoid?seerOfVoid=true
The Bard of Void removes that which is not Relevant: http://farragofiction.com/LightAndVoid
Seeing through the void obscures things rather than revealing.
The Match
story_details: http://farragofiction.com/AnUnSentLetter/ connects to http://farragofiction.com/GhoulishThing/
Fanning her flames only makes her worse.
Perhaps that lack of response is what lets friendship happen here http://farragofiction.com/UnifiedTheory/
The End
story_details: I will never forget: http://farragofiction.com/TwoGayJokes/AnUnSentLetter
They will never remember: http://farragofiction.com/GhoulishThing/
They wish forgetting were an option: http://farragofiction.com/ASecondTranscript/
The Reflection
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details: http://farragofiction.com/ClownDiarySim/
He has been reflected too many times. There is nothing left to replace him. Any mirror that reflects him captures you, takes you, replaces you with you. You who are not you looks out through new eyes. You who are not you talks to your friends, sleeps in your bed. You will never return.
K
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details: Do you see me? Do you see what I'm doing? Don't stop looking. I'll cut out my tongue. I'll sell you my soul. I'll give you everything. http://farragofiction.com/TwoGayJokes/Stories/Notes_on_stealing_peoples_shit.pdf So long as you spare me your GAZE.
_
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details":"VOID,113 CORRUPTION,133 DARK,55 CENSORED,113 HUNGER, 33 ???????, 22 ?????????, 11
Tip1: When Employees and non Employees under Tier 4 saw _ for the first time, it would cause the subjects to experience rapidly increasing levels of mental corruption
Tip 2: Employees under Tier 4 became resistant to _ on subsequent viewings. Non-Employees cannot do so
Tip 3: _ ???????? victims to ???????? ??????????, causing ?????????????? and being ?????????? into its ?????
When you become a vessel for something else, you sacrifice a few things. But when you give up what makes you 'you', what takes place once what's left is gone
http://farragofiction.com/ACensoredTranscript/ Do not try to see what lies beneath. The censorship is for your protection
The Shot
exactly_three_tips: When a subject touches the coffin they are found with their head sliced clean off.,If L-0-17 engages in Attachment work they are found with their head sliced clean off.,L-0-17 is drawn to eliminating certain targets at an average rate of one per month
[this contrasts with the three tips actually given later in the code and is actually Camille's]
story_details: Isekai'd not once but twice. It does something to you. Sand you down. Makes you pure. Even if it doesn't seem like it.
http://farragofiction.com/ClownDiarySim/ There's something those who deal in absolutes can appreciate about the purity.
http://farragofiction.com/ACensoredTranscript/ Parker doesn't try to look too deep, you see. Take care you do the same
The Wiggler Eater
story_details: She likes fruit.
The Flower
exactly_three_tips: L-U-004
story_details: She do be playin vydiogames
The Intern
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details: He's just a guy. You can find more out about him to the East
Wanda
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details: Wodin becomes the Wanderer becomes Wanda though a spiraling obsession. Wodin is on the cusp a mystery. He wants to know, NEEDS to know, and is willing to throw everything to the pyre of his obsession of linking a serial killer to a almost forgotten retro game.. He is killed and only one mourns his passing. The Wanderer is born from Wodin's death, and you can only be referred to in the second person. You Wander endlessly the halls of Truth's Temple, able to leave at any time yet completely unwilling to. You carve away pieces of yourself bit by bit for just another morsel of knowledge until nothing is left but a pair of floating eyes. When you sacrifice even those to sink into a deep and dark coffin, Wanda is reborn with full gnosis and knowledge of reality. Sinking into depression, it is the mysterious girl with a flower in her eye that convinces Wanda to use her powers of twisting space to go back to the start and try to make a new life in the past. Eyedol Games is founded and has always existed and always was the source of Zampanio.
Quotidians
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details: Wodin created a series of web-crawler bots to search for information on Zampanio and the Eye Killer. When Wanda emerged from her chrysalis as a Lord, attendants were required that fit her needs. Her spiders became crows after a meme Reality had access to, and had always existed, even when the Wanderer had power. Some crows have been swayed by other, False Creators. Do not believe their lies
Zampanio
exactly_three_tips: HeartlessBot can not feel. HeartlessBot can not speak., HeartlessBot merely conveys the wishes of those Outside of Reality to their chosen Puppet. Caution is to be used if L-C-05 is also in play
[this contrasts with the three tips actually given later in the code and is actually HeartlessBot's]
story_details: The only concrete, true thing we know about House of Leaves is that people create derivative works of it. Incredibly sprawling, unsettlingly obsessive derivative works of it. And when I saw what the fan works of Zampanio were like my thoughts kept coming back to that single core fact in House of Leaves. What if it's the same thing there? What if that's the point? What if that's all fandom IS but a memetic hazard endlessly reproducing in all our minds, fueled by obsession? Similar but different. A Spiral and not a loop. So yeah. The Magnus Archives was definitely an important lens to understand the thoughts I had when exposed to Zampanio. And that helped me recontextualize my thoughts on House of Leaves. Lobotomy Corp has given me a fun lens for throwing wrenches into my fan works. Obviously Homestuck and SBURB were highly formative for me. Maybe that's the POINT of Zampanio. I don't think I've seen a single fan work of it that wasn't in SOME way connected to some other fandom? Roblox. Rain world. SBURB (thats how i found it, like a GlitchFaq crossover?). The Obscure Game. Polo. Minecraft. House of Leaves. Polybius. The Magnus Archives. The Way Ahead… Honestly more than I can remember off the top of my head. (is the entire concept of greek myths a ‘fandom’?) Can a fandom be parasitic? Or…can it be a mimic? (A Stranger, if you’ll allow me the conceit) Can a fandom wear the skin of other fandoms in order to spread its memes into new brains. If Memes are the DNA of the Soul…what is Zampanio doing to ours?
Novum Mirror
Exactly_three_tips: L-0-R1 can befriend any target., L-0-R1 will not get attached., Do not let L-0-R1 interact with L-W-003.
[this contrasts with the three tips actually given later in the code and is actually Witherby's]
story_details: Any who attempt to photograph, reflect or otherwise capture the image of one under the Novum Mirror or Reversed Novum Mirrors effect will be effected. As a result, the effect will spread exponentially. For this reason, it is advised that L-O-I1 be kept from the Novum Mirror at all costs. It is unknown whether the Mirror of Adjustment or the Novum Mirrors effect will in out, but the risk is too high to allow the alternate universe exponential access to ours.
ButlerBot:
exactly_three_tips: HeartlessBot can not feel. HeartlessBot can not speak., HeartlessBot merely conveys the wishes of those Outside of Reality to their chosen Puppet. Caution is to be used if L-C-05 is also in play
[this contrasts with the three tips actually given later in the code and is actually HeartlessBot's]
story_details: Sometimes I see a mysterious Witch in the Void. Lunch Time Mmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm https://farragnarok.com/Void
HeartlessBot:
story_details: Now deleting Feelings.dart. Awaiting input…
The Neighbor
story_details: Look at him. How happy he is! Look how comfortable, and smug. He is right where he fits. (Are you?) He thrives so easily. (Why aren't you?) Look at him. Why won't you? What has you uneasy? Surely he has no intent to harm. It must be your imagination. It must be your guilt. He's so nice, so liked. And you're not. Just last week he cat sit for Janice. (Or was it Janet?) He volunteered in the bake sale! (Or was it a carwash?) Look at him! He leads the PTA. Even though no one can remember, him having any children.
Tyrfing:
exactly_three_tips":"L-C-003 is helpful and friendly and fits in well with society;much better than you do., When L-C-003 encounters its doppelganger its stability level decreases., When breached L-C-003 kills exactly one person. Slowly. It's important to make it a special occasion
[this contrasts with the three tips actually given later in the code and is actually The Neighbor's]
story_details: Nidhogg's Forsaken Follower, a copy of a copy of a copy. Spiraling unending life has little place in a world of spiraling unending thoughts. Nidhogg's chosen Universe is barred forever to him, and his Follower is powerless. Corruption does not spread here, and even the Children wither and vanish. Only Rod, Rebel and Melon remain, clones hateful to Tyfings eyes, yet protected by those far more powerful than he. Wigglersim does not allow clone spam, after all.
Fruit Children
exactly_three_tips":"L-C-003 is helpful and friendly and fits in well with society;much better than you do., When L-C-003 encounters its doppelganger its stability level decreases., When breached L-C-003 kills exactly one person. Slowly. It's important to make it a special occasion
[this contrasts with the three tips actually given later in the code and is actually The Neighbor's]
story_details: Unending spiraling life has no place inside the Echidna. Nidhogg's children wither on the vine. Do you understand why Peewee shares the same fate?
Peewee
story_details:
.. http://farragofiction.com/PaldemicSim/bio.html?target=TheMan
.. http://farragofiction.com/ZampanioHotlink/L-U-000-print.pdf
.. http://farragofiction.com/SettlersFromTheWest/
The Minotaur
Hello :) :) :), Can You Read This?, If You Know, Then You Know It, The Unbroken
story_details: placeholder
12 notes
·
View notes
Text
My three very very precious groups-
🌹 Natsukashii Scans
🌹 Treasure Chest Subs
🌹 Rabbit Mantou Subs
A list of all other stuff I’ve worked on-
1) Sekaiichi Hatsukoi OVA 1 English subbed: Link
2) Sekaiichi Hatsukoi OVA 2 English subbed: Link
3) Which Kuroko no Basket Character are you? A three part quiz, just for fun: Link
4) Hybrid Child OVAs 1-4 English subbed: Link
5) Kamisama Hajimemashita Kako-hen OAD Ep 01-04: Link
6) LD-K Volume 1 Chapter 4 HQ scans: Link
7) Kuroko no Basket OVA 75.5: Link
8) Junjou Romantica S1+S2+OVA: Link
9) Some poems I wrote waaay back: Link
10) Ace of Diamond (or Daiya no Ace) anime OADs Ep02-05: Link
11) WangXian and HuaLian fanfics on AO3 (MDZS and TGCF): Link
12) Heaven Official’s Blessing Fanmade Audio: Link
13) Little Women Anime Eps 1 to 9: Link
***********
Info on some things-
1) How to download torrent files?: (please see the Notes) Link
2) About donating via Ko-fi, Patreon, etc.: Link
3) How to play MKV files and what to do if any website or torrent is blocked for you: Link
#fan translation#fan subbing#fan scanlation#fanfics#ao3#download links#anime#kuroko no basket personality quiz rpg#mo dao zu shi#tian guan ci fu#little women#english#english subtitles
15 notes
·
View notes
Photo

Let us share the power and peace of Jesus Christ “We have the sacred responsibility to share the power and peace of Jesus Christ with all who will listen and who will let God prevail in their lives.” President Russell M. Nelson We have the good news of the gospel of Jesus Christ in our lives. Let us be vigilant in sharing and testifying of Christ to all that we come in contact with. Testify both in words and in deeds as we serve those around us. See all memes from this talk: https://spiritualcrusade.com/2022/07/11-quotes-by-president-russell-m-nelson-preaching-the-gospel-of-peace.html https://spiritualcrusade.com/2022/09/let-us-share-the-power-and-peace-of-jesus-christ.html --- Website: spiritualcrusade.com Download our App: app.spiritualcrusade.com --- YouTube and Podcast Channels YouTube Channel: http://www.youtube.com/c/spiritualcrusade?sub_confirmation=1 Come, Follow Me Study - Podcast Channel: https://anchor.fm/comefollowme Podcast Channel: https://anchor.fm/spiritualcrusade --- Social Media Links Facebook: https://www.facebook.com/spiritualcrusade/ Pinterest: https://www.pinterest.com/spiritualcrusade/ Instagram: https://www.instagram.com/spiritualcrusade/ Twitter: https://twitter.com/spiritualcrusad/ Tumblr: https://spiritualcrusade.tumblr.com/ Flickr: https://www.flickr.com/photos/152962925@N07/ --- #lds #Gospel #spiritualcrusade #mormon #christian #christ #jesus #mormonquotes #becauseofhim #jesuschrist #faith #bebetter #standtall #lighttheworld #latterdaysaints #byu #byui #childofgod #ldsquotes #ldsyouth #ldslife #mormonmemes #choosetheright #ctr #godwins #hearhim #generalconference #ldsconf #thechurchofjesuschristoflatterdaysaints #strivetobe #ldsquotes https://www.instagram.com/p/Ci1UVvnLlog/?igshid=NGJjMDIxMWI=
#lds#gospel#spiritualcrusade#mormon#christian#christ#jesus#mormonquotes#becauseofhim#jesuschrist#faith#bebetter#standtall#lighttheworld#latterdaysaints#byu#byui#childofgod#ldsquotes#ldsyouth#ldslife#mormonmemes#choosetheright#ctr#godwins#hearhim#generalconference#ldsconf#thechurchofjesuschristoflatterdaysaints#strivetobe
5 notes
·
View notes
Text
Does SEO require coding

Search engine optimization (SEO) refers to the practice of improving a website's visibility and ranking in organic search engine results pages (SERPs). By optimizing various on-page and off-page factors, such as content relevance, keyword targeting, backlinks, and technical structure, SEO helps websites attract more qualified traffic and potential customers.
In the realm of digital marketing, a crucial consideration is the cost-effectiveness of SEO strategies. This analysis compares the aspects of free versus paid strategies within the scope of search engine optimization. It offers valuable insights for businesses and individuals determining the most efficient approach to enhancing their online presence
Many people wonder about the level of difficulty involved in entering the SEO industry as a career choice. While the field demands a blend of technical knowledge and creativity, its accessibility varies. With dedication to learning SEO principles and keeping up with the constantly evolving digital trends, one can successfully break into this dynamic and rewarding career, even without a traditional background in the field.
The SEO industry, marked by its constant evolution and competitive landscape, can be notably stressful for professionals. Navigating through algorithm changes, meeting client demands, and ensuring website performance adds pressure to the job, resulting in heightened stress levels for individuals in the field
The role of an SEO specialist, while rewarding, is often perceived as challenging due to the field's dynamic nature. This exploration assesses the level of stress involved in the SEO profession, considering the constant evolution of the field and the need for continual learning and adaptation. It's a crucial read for anyone considering SEO as a career and weighing its potential impact on work-life balance
In today's digital landscape, SEO is crucial for businesses of all sizes and industries. With the majority of online experiences beginning with a search engine query, ranking highly for relevant keywords can make a significant impact on brand awareness, lead generation, and revenue growth.
But given the technical nature of some SEO tasks, such as optimizing site speed or implementing structured data, does SEO require extensive coding skills? While a basic understanding of HTML, CSS, and other web technologies is certainly beneficial for SEO professionals, it is not always necessary to be a full-fledged programmer.
Many aspects of SEO, such as keyword research, content optimization, and link building, rely more on analytical and creative skills than coding abilities. Additionally, collaboration with web developers and the use of SEO tools can help bridge the technical gap for non-coders.
The Role of Coding in SEO
Coding plays a significant role in various aspects of search engine optimization, particularly in the technical implementation of on-page factors and site architecture. While not all SEO tasks require coding knowledge, understanding how web technologies impact search engine crawling and indexing is essential for optimal results.
One area where coding is particularly relevant is in the optimization of HTML elements such as title tags, meta descriptions, header tags, and image alt text. Properly implementing these on-page factors using clean, semantic HTML helps search engines understand the content and context of a webpage.
Structured data markup, such as Schema.org or JSON-LD, is another coding-related aspect of SEO. By adding structured data to a website's code, SEO professionals can provide search engines with more detailed information about the content, such as product details, reviews, or event information, which can enhance the appearance of search results and drive more targeted traffic.
Coding skills are also valuable for optimizing site speed and performance, which are important ranking factors. Minifying HTML, CSS, and JavaScript files, leveraging browser caching, and optimizing image file sizes all require some level of coding knowledge.
However, it's important to note that while coding is beneficial for SEO, it is not the only factor in success. SEO professionals must also focus on creating high-quality, relevant content, building authoritative backlinks, and providing a positive user experience to achieve top rankings.
Essential Coding Skills for SEO
While extensive programming knowledge is not always necessary for SEO success, having a solid foundation in certain coding languages and technologies can greatly enhance an SEO professional's ability to optimize websites effectively. Some of the essential coding skills for SEO include:
1. HTML and CSS: A strong understanding of HTML and CSS is crucial for optimizing on-page elements, such as title tags, meta descriptions, header tags, and content structure. Familiarity with HTML5 semantic elements and CSS best practices can also help improve site accessibility and mobile-friendliness.
2. JavaScript: As search engines increasingly render and index JavaScript content, understanding how JavaScript impacts SEO is becoming more important. Familiarity with JavaScript frameworks like Angular and React, as well as the ability to optimize JavaScript for performance and crawlability, is valuable.
3. Schema Markup and JSON-LD: Implementing structured data using Schema.org vocabulary and JSON-LD syntax helps search engines better understand and display website content in rich snippets and knowledge panels.
4. Basic Server-Side Languages: While not essential, a basic understanding of server-side languages like PHP, Python, or Ruby can be helpful for troubleshooting technical SEO issues, such as redirect chains or server errors.
In addition to these coding skills, SEO professionals should also be comfortable working with content management systems (CMS) like WordPress, as well as version control tools like Git for collaborating with web development teams.
SEO Tasks That Don't Require Coding
While coding skills are valuable for certain aspects of SEO, there are many essential tasks that don't require extensive programming knowledge. These non-technical SEO responsibilities are equally important for driving organic search success and should not be overlooked.
1. Keyword Research and Content Optimization: Identifying target keywords, analyzing search intent, and optimizing website content for relevance and readability are foundational SEO tasks that rely more on analytical and copywriting skills than coding.
2. Link Building and Outreach: Acquiring high-quality backlinks through tactics like guest posting, broken link building, and digital PR requires strong communication and relationship-building skills, rather than coding expertise.
3. Competitor Analysis and Tracking: Researching competitors' SEO strategies, monitoring their keyword rankings and backlink profiles, and identifying opportunities for improvement can be done using various tools and platforms without coding.
4. Reporting and Data Analysis: Measuring SEO performance, analyzing website traffic and user behavior, and creating data-driven reports and recommendations can be accomplished using tools like Google Analytics, Google Search Console, and Excel, which don't require coding skills.
5. Content Planning and Strategy: Developing a comprehensive content strategy that aligns with SEO goals, target audiences, and business objectives is a critical task that relies on marketing and communication skills.
While coding knowledge can certainly enhance an SEO professional's overall skill set, it's important to recognize that many vital SEO tasks can be accomplished successfully without extensive programming expertise.
The Importance of Collaboration
Effective SEO requires collaboration across multiple disciplines and teams, particularly when it comes to technical optimization and implementation. While SEO professionals may not always have extensive coding skills themselves, working closely with web developers, IT teams, and other stakeholders is essential for achieving optimal results.
One key area of collaboration is in communicating SEO requirements and best practices to web development teams. SEO professionals must be able to clearly articulate technical recommendations, such as site architecture improvements, URL structure, or page speed optimizations, to developers who will be responsible for implementing these changes.
Collaboration is also crucial when it comes to content creation and optimization. SEO professionals should work closely with content writers, editors, and marketers to ensure that website content is both keyword-optimized and user-friendly. This involves providing guidance on target keywords, content length, formatting, and internal linking strategies.
Additionally, SEO professionals may need to collaborate with designers and user experience (UX) teams to ensure that website design and functionality are aligned with SEO best practices and user needs. This can include optimizing site navigation, improving mobile responsiveness, and enhancing page load times.
By fostering strong collaborative relationships and effectively communicating SEO priorities and requirements, SEO professionals can ensure that all aspects of a website are working together to drive organic search success, even if they don't have extensive coding skills themselves.
Learning Coding for SEO
While coding skills are not always essential for SEO success, expanding one's programming knowledge can certainly be beneficial for SEO professionals looking to advance their careers and take on more technical optimization tasks. Here are some tips and resources for learning coding skills relevant to SEO:
1. Start with HTML and CSS: As the foundational languages of the web, HTML and CSS are essential for understanding how websites are structured and styled. Free online resources like Codecademy, FreeCodeCamp, and W3Schools offer interactive tutorials and exercises for learning HTML and CSS basics.
2. Move on to JavaScript: Once comfortable with HTML and CSS, learning JavaScript can help SEO professionals better understand how web pages are rendered and how to optimize dynamic content. Online courses like JavaScript for Beginners on Udemy or the JavaScript Algorithms and Data Structures Certification on FreeCodeCamp are great starting points.
3. Explore SEO-specific coding topics: Dive deeper into SEO-related coding topics such as structured data markup, schema.org implementation, and mobile-first indexing. The Google Developers website offers a wealth of resources and guides on these topics.
4. Practice on real websites: Apply coding skills to real-world SEO projects, whether through personal websites, client work, or open-source contributions. Hands-on experience is key to solidifying coding knowledge and troubleshooting skills.
5. Prioritize continuous learning: Stay up-to-date with the latest coding trends and best practices relevant to SEO, such as the adoption of Python for data analysis and machine learning in SEO. Attend industry conferences, webinars, and workshops to learn from experienced practitioners.
Remember, while learning to code can be valuable for SEO professionals, it's important to balance coding education with other essential SEO skills like content optimization, link building, and data analysis.
Alternative Approaches to Technical SEO
For SEO professionals who may not have extensive coding skills or the time to learn programming, there are several alternative approaches to managing technical SEO tasks and ensuring website optimization:
1. Leverage SEO Plugins and Tools: Many content management systems (CMS), such as WordPress, offer SEO plugins and tools that can handle technical optimization tasks without requiring coding knowledge. Popular options like Yoast SEO, All in One SEO Pack, and Rank Math provide features like XML sitemap generation, meta tag optimization, and schema markup implementation.
2. Use No-Code SEO Platforms: No-code SEO platforms, such as Moz, SEMrush, and Ahrefs, offer comprehensive site audit and optimization tools that can identify technical SEO issues and provide actionable recommendations for improvement. These platforms often include features like site crawlers, backlink analysis, and keyword research, which can be used effectively without coding skills.
3. Collaborate with Web Developers: For more complex technical SEO tasks, such as site migrations, page speed optimization, or mobile responsiveness, collaborating closely with web developers or IT teams is often the most effective approach. By clearly communicating SEO requirements and best practices, non-coding SEO professionals can ensure that technical optimizations are implemented correctly.
4. Outsource Technical SEO Tasks: When in-house resources are limited, outsourcing technical SEO tasks to specialized agencies or freelancers can be a viable alternative. This allows SEO professionals to focus on strategy, content, and other non-technical aspects of optimization while still ensuring that technical best practices are followed.
5. Prioritize Non-Technical SEO Factors: While technical SEO is important, it's not the only factor in search engine rankings. SEO professionals can also drive success by focusing on creating high-quality, relevant content, building authoritative backlinks, and improving user experience and engagement metrics.
By leveraging these alternative approaches and tools, SEO professionals can effectively manage technical optimization tasks and drive organic search success, even without extensive coding skills.
0 notes
Text
Not known Details About small seo tools
BrightLocal solves this with a quick nearby rating Instrument that can nearly fall you into any locale in the world to examine true regional rankings.
We independently choose all products and services. This short article was prepared by a third-party company. In the event you click on by one-way links we provide, we may earn a commission. Learn more
Keyword Rank Checker gives you the ability to get instant usage of any domain's position key terms. Exploration competitor Web-sites and acquire content material Concepts.
These tools offer you options for instance XML sitemap technology, title and meta description optimization, and Web-site performance tracking.
Gotta be honest, although Xenu is on every single "free Search engine optimization Software" checklist For the reason that dawn of, no way did I believe it might make this a person. This Windows-based mostly desktop crawler has become practically unchanged over the past 10 years.
Technological SEO is definitely the core stage of Website positioning optimization, So use our small Search engine optimisation tools to determine on-web page glitches and backend errors.
Did you apply evaluation ranking stars as part of your JSON-LD, and want to discover Should your markup is valid for Google's Abundant Effects? Acquiring a passing quality does not imply your site will routinely Show prosperous ends in the SERPs, but imagine it as the price of admission (the expense staying free, needless to say.)
https://cuteseotools.com/webtools/reactive-energy-converter is also received some pleasing reward options, like Web Explorer, which exhibits you position data for web pages through the Website for specified keywords.
Obtaining your business verified and mentioned by information aggregators offers search engines confidence in the precision
Proclaiming your small business profile varieties the inspiration of most other neighborhood SEO things to do, so It truly is A necessary phase.
Join https://cuteseotools.com/webtools/decimal-to-text -free Understand the techniques and tactics to take your social media marketing marketing and advertising to new heights.
Retail outlet all the pertinent info to get a link, such as backlink position, hyperlink sort, anchor textual content, destination url, and several other data points that can assist you as well as your complete workforce to stay in addition to your website link strategies.
Just after jogging an audit, What's more, it suggests locations where you can increase your inside linking, which can help Improve your rankings in search engines like yahoo.
You will also see a listing of tips for fixing these complications and getting your quality up (which can give serial overachievers like me flashbacks to inquiring their AP record Instructor how they are able to raise their 93% A- yet another level to an A).
0 notes
Text
Rumored Buzz on small seo tools
DeepCrawl is yet another website crawler that focuses on technical Search engine marketing auditing. It can help recognize difficulties like broken inbound links, duplicate content, and lacking alt tags.
Operate Backlink Hole Examination to discover who is linking to the other web pages in the area of interest, but not yours.
seo tools have now various content material writers tools from Plagiarism checkers, to content generators for Website designers and social networking specialists. You should utilize any Resource for free and with no registration.
Web site Explorer: This element gives an summary of a website’s backlink profile, such as the amount of backlinks, referring domains, and anchor text distribution.
Electricity your campaigns and switch additional advertisement clicks into clients with every one of the intuitive experimentation, optimization, reporting, and development tools you would like—all in a single place.
We are by no means compensated for placement inside our article content from any app or for links to any website—we price the have faith in visitors set in us to supply genuine evaluations in the categories and applications we evaluate. For additional information on our method, examine the full rundown of how we find applications to function over the Zapier blog.
Did you apply overview score stars inside your JSON-LD, and wish to discover if your markup is legitimate for Google's Loaded Benefits? Getting a passing grade doesn't mean your web page will immediately Show wealthy results in the SERPs, but think of it as the expense of admission (the associated fee being cost-free, certainly.)
Consumer critiques are essential for neighborhood Search engine optimization reasons. This Resource helps you to develop a shareable hyperlink for customers to assessment your company on Google.
Material optimization tools are important for Search engine optimization as they assist examine material and strengthen its high-quality to rank higher in online search engine success pages (SERPs). Here are several of the greatest articles optimization tools accessible:
Summary: BrightLocal is a superb time-preserving services, and we hugely advocate it. BrightLocal works by using individuals (not simply application) to acquire your listings. Amongst our colleagues identified two minimal glitches inside of a listing for the shopper. So, we propose examining Every single listing for accuracy after they’re carried out.

Exploding Topics: Discover subject areas with exponential spikes in search quantity. Free and paid out variations are available. Ubersuggest: Search phrase investigate Device with a compensated tier and restricted totally free Variation.
Am I expressing there are only nine fantastic Search engine optimisation tools in the marketplace? Absolutely not. Underneath are some of the products I really preferred but did not really help it become in the checklist. Each and every of those has a minimum of a person standout feature or use circumstance for Website positioning marketers.
Most likely quite possibly the most handy totally free Search engine optimisation Software on this whole list, It is really hard to imagine doing modern-day Web optimization without having access to the data within Google's Research Console. This is easily the most responsible spot for information on how Google crawls and ranks your site, and is one of the only areas the place you can obtain trustworthy search term facts.
p.s. Even though they are sixty of the best no cost SEO tools, It really is not at all a whole list! What are a few of your preferred no cost Search engine marketing tools? Let us know inside the reviews.
0 notes
Text
Not known Details About small seo tools
We've involved a Google Sheet that contains all 55 tools shown higher than. You can also make a copy of the sheet and file away for your personal use, or share along with your crew.
By utilizing these tools, Web-site entrepreneurs can discover and resolve technical Web optimization concerns, bringing about improved online search engine rankings and even more traffic to their site.
All round, these on-page Web optimization tools are important for optimizing your site for engines like google. Through the use of these tools, you may Ensure that your website is optimized for both of those people and serps, which often can support help your Site’s visibility and position in online search engine outcomes.
All of this will make seoClarity certainly the costliest Software on this record, but additionally one of the most in depth. This tool is just not For each and every enterprise, but for the ones that can afford it, it effectively combines a number of Website positioning tool kinds into just one System.
Moz also offers information regarding the Sites which might be linking to a certain Web-site, which might support Site owners to detect possible connection-building opportunities.
click for info delivers thorough reviews that will help you prioritize issues and keep track of development after some time. The Resource is readily available for a regular subscription fee, with pricing determined by the amount of Internet sites you must audit.
Did you put into action evaluate score stars as part of your JSON-LD, and want to discover Should your markup is legitimate for Google's Wealthy Results? Obtaining a passing grade does not imply your page will instantly Display screen wealthy leads to the SERPs, but think about it as the price of admission (the associated fee getting totally free, not surprisingly.)
Consumer assessments are crucial for area Website positioning purposes. This Instrument lets you make a shareable url for customers to review your small business on Google.
For those who haven't tried out it in a while, it now goes way further than key phrase solutions and offers plenty of extended Search engine optimisation abilities for instance essential hyperlink metrics and prime competitor internet pages.

The Overall performance rating is particularly practical, displaying thorough load speed insights and noting specific things like picture compression, JavaScript problems, and impression optimizations That could be retaining These speeds down.
Exploding Matters: Explore topics with exponential spikes in research quantity. Cost-free and paid out versions are offered. Ubersuggest: Keyword investigation Instrument with a paid out tier and restricted free of charge version.
Moz Area is a well-liked nearby Search engine optimisation Device that helps corporations regulate their on-line existence and enhance their local research rankings. With Moz Neighborhood, organizations can manage their on the net listings across multiple platforms, watch their on-line assessments, and track their neighborhood rankings.
You furthermore may get Moz's famous Search term Problem Score coupled with CTR data. Moz's no cost Local community account provides you with use of 10 queries a month, with Each and every question virtually providing you with as many as one thousand keyword ideas coupled with SERP analysis.
p.s. Although these are definitely sixty of the greatest no cost Search engine optimization tools, It is really by no means an entire checklist! What exactly are https://cuteseotools.com/webtools/volume-converter of your preferred cost-free Search engine optimisation tools? Let's know inside the comments.
0 notes
Text
Alternative to Squirrly SEO Semantic SEO Markup for WordPress
Both WordLift and Squirrly SEO help you add semantic schema markup to your website to speak Google’s language. Let’s compare them closely!
AI JSON/LD KNOWLEDGE GRAPH LINKED DATA RICH SNIPPET SCHEMA MARKUP SEO SQUIRRLY SEO WORDLIFT SRL
Are you looking for a Semantic SEO markup plugin for your website? There are many options, but in this comparison we will focus on two of them: Squirrly SEO and WordLift.
Both plugins offer a range of features to optimize your SEO, including adding schema markup. Which one is the best for you? Read on to learn more about each of the two plugins.
Table of contents:
What is Squirrly SEO
What is WordLift
Are WordLift And Squirrly SEO Alternative Solutions?
Squirrly SEO and WordLift: plans and costs
What is Squirrly SEO
Squirrly SEO is a website plugin that allows you to optimize pages and blog posts and get general Afghanistan WhatsApp Number List recommendations to improve search engine optimization. It performs an audit of your current SEO status and gives you some recommendations to improve your search engine ranking. Although search engine optimization can be complicated, Squirrly SEO makes it easy to follow the instructions and optimize what you need.
You can use the web application or download the plugin for WordPress. Some of the most interesting features of Squirrly SEO.

Keyword research. With this plugin you can search for the best keywords to optimize your content. You can choose from 140 countries to localize your search and get better results. It also suggests you long tail keywords.
Focus Pages. This feature lets you choose the pages you want to rank the most, and the tool gives you customized information on how to rank pages on a case-by-case basis.
Live Assistant. With this feature, you can optimize your content as you create it. Namely, the tool gives you a set of keyword suggestions, provides you with a library of free images already optimized for SEO that you can use in your blog post, and provides you with a link to Wikipedia to read and enter the necessary information for reference. Through a system of green or red lights, it shows you what is good and what can be improved.
SEO Audit. With this feature you’ll be able to check your website’s performance and get ratings and recommended actions to improve it.
Monitoring. You can measure your website’s performance using data on leads and traffic and keep up to date at all times. You’ll also get important details on progress and results. You can also compare multiple audits to track changes and see how your website is growing.
What is WordLift
WordLift is an entity-based SEO tool that focuses on semantic SEO and enables search engines to better understand content and rank better on Google.
The key to WordLift is entities. You can use entities to annotate and organize website posts and pages. By describing and linking entities, WordLift builds a Knowledge Graph. Each entity is an interconnected element that has been enriched with machine-readable information and converted from words to linked data.
The SEO value of a Knowledge Graph based on linked data goes far beyond featured snippets, voice search, and optimization for virtual search assistants.
These days, we are overwhelmed by information and it’s becoming increasingly difficult to find the content that interests us. That’s where a tool like WordLift comes in: it helps you create better content that leads users to what they are looking for.

In terms of SEO, articles enriched with linked data are found more easily, as they make information extraction much more efficient. The concepts mentioned in an article are annotated and linked to extensive knowledge bases such as DBpedia and Wikidata to provide search engines with important information about a particular content and its relevance to a specific search intent.
Search engines and web crawlers can use this now more understandable information to directly answer user queries. This way, your website will rank better and provide users with the relevant information they are looking for (in rich snippets, user queries, etc.). The user who lands on your site will then take a path that makes their experience meaningful and spend more time on your site.
Our AI analyzes the content of your website and suggests what information is relevant to your business by adding structured data and creating a customized Knowledge Graph. Not only that, it goes one step further. It turns structured data into linked data, strengthened by the same sources that Google and search engines use to understand the web. This way, the content is unique, can not be confused with other content, and gains authority.
This is a new approach to search engine optimization: from analyzing search intent to creating content, from creating internal links to improving user engagement on the site. Your content will be better understood by Google and other search engines, gaining more visibility and therefore more customers.
Are WordLift And Squirrly SEO Alternative Solutions
Structured data is the key to improving your SEO. They provide search engines with all the information they need to better understand your website’s content and rank it higher in SERPs. In addition, structured data allows your content to be included in Google’s enriched results, known as Rich Snippets, which improve the user experience. The result is that you can get more visitors to your website and, by reaching a more qualified audience, you can also get more conversions.
With Squirrly SEO you can add semantic SEO markup to your website by using JSON-LD. The tool loads the schema code for the selected type to the page.
You can enable this feature in the SEO Configuration menu by going to the Rich Snippets section and filling in the required fields. You can create multiple schema types for different pages and make your website appear in search results with richer features.

WordLift also allows you to add structured data to your website content, but in a different way. Using AI, the tool analyzes the content, detects and suggests which concepts are most relevant to your content. These concepts are the entities and are collected in a vocabulary. WordLift does something more. It connects these entities and creates a custom Knowledge Graph for you that allows Google to understand what you are talking about and also recognize the relationships between the entities, improving your ranking and increasing your organic traffic.
Read the case study from Kalicube Digital Agency to know how you can boost your organic traffic by using entity-based SEO.
Squirrly SEO and WordLift: plans and costs
Squirrly SEO offers 3 plans (Pro, Business, Agency), ranging in price from $20 to $75 per month. All plans include more than 650 features, which differ in the number of websites, the standard of expansion, support and customer service. There is a free version that you can use, as well as a demo page where you can try the plugin without installing it on your website.
WordLift, on the other hand, offers three different plans (Starter, Professional, Business+E-commerce) that give you access to the same technology and allow you to harness the power of AI. However, they differ in the number of domains on which the plugin can be used simultaneously and certain features available.
The Business+E-Commerce plan offers you the possibility to add all types of schema markup and also includes the SEO add-on for Google Sheets, developed in-house, which lets you perform semantic keyword analysis to make your semantic SEO strategy even more effective. Besides, with this plan you’ll also have access to the e-commerce extension, which provides advanced markup for stores and widgets with product suggestions, and lets you create a dedicated Knowledge Graph for products for sale.
Like Squirrly SEO, WordLift also offers a free trial (valid for 14 days). In addition, WordLift has an Enterprise plan aimed at large brands that not only want to do SEO, but also bring innovation in-house.
1 note
·
View note
Text
What is Carousel SERP Features in Google
Carousel SERP Features in Google - SERP Features: Carousel
Our SEO specialists from IUSTITIA.BG create unique SEO services that improve the online visibility and growth of your business.
A carousel is a list-like rich result that you can swipe through on desktop devices. They usually appear at the top of the SERP and each card has text or brief information about the item.
What Are SERP Features in Google
Here’s what they look like on Google’s desktop SERPs:
What Family Serp Feature Looks Like On Google
How to Rank Your Content for a Carousel
You can maximize your chances of ranking for this SERP feature by:
Implementing the ItemList from schema.org along with one of the following content types supported by Google: Course, Movie, Recipe, Restaurant.
Do not mix content types. All the items in the ItemList must be of the same type, e.g. if a list is about movies, only movie items should be included in the list.
JSON-LD is the recommended way to include the ItemList schema.
Make sure that the structured data is complete and contains all the items that are listed on the page.
Use high-resolution images in the formats supported by Google that are relevant to the content of the page.
Check to make sure that your schema is working by testing it.
How We Collect Data About Carousels
When we scan a keyword’s SERP, we identify whether or not a carousel is present anywhere on the results page.
If a carousel is present on the SERP, you’ll see its gray icon in the SF column.
Since we cannot currently collect URLs related to carousels, we cannot say if a queried domain is featured and cannot save it as a position.
To learn more about this SERP feature and others, read our SERP Features Guide.
******************************
WE CAN BE YOUR PARTNER FOR ONLINE SUCCESS
High Quality SEO Services for High Google Rankings from IUSTITIA.BG.
You can contact us by email: [email protected]
Realize the full potential of your website. Optimization aims to position you at the top of searches for keywords and phrases related to your business that people are searching for.
We and our SEO specialists from IUSTITIA.BG create unique SEO services that improve the online visibility and growth of your business. With the professionalism of our team and our innovative approaches, we provide comprehensive strategies including on-page optimization, quality link building and constant monitoring of search engine rankings. We not only increase your online presence, but also create lasting results for your success. Petar Nizamov. You can see also the websites and webstores we made.
Carousel SERP Carousel SERP Carousel SERP Carousel SERP Carousel SERP Carousel SERP Carousel SERP Carousel SERP
Read the full article
0 notes
Video
youtube
What is Structured Data Markup and Schema Markup | Type of Schema Markup
Schema markup (also known as structured data) is a vocabulary that assists search engines in better understanding the information on your page. When search engines detect schema markup on your page, they deliver rich results, also known as rich snippets.
Schema markup is code that specifies items on your website in a language that is understood by all major search engines. Search engines can thus provide users with more relevant results.
Schema is a language for representing data; structured data is the actual data. Structured data organises the content of your page and makes it easier for Google to understand.
Google understands 27 types of schema. These are:
1. Article Schema markup
2. Book Schema markup
3. Breadcrumb Schema markup
4. Carousel Schema markup
5. Course Schema markup
6. Dataset Schema markup
7. Employer Aggregate Rating Schema markup
8. Event Schema markup
9. Fact check Schema markup
10. FAQ Schema markup
11. Home Activities Schema markup
12. How-to Schema markup
13. Image license Schema markup
14. Job posting Schema markup
15. Learning video Schema markup
16. Math Solvers Schema markup
17. Movie Schema markup
18. Education Q&A Schema markup
19. Estimated salary Schema markup
20. Podcast Schema markup
21. Practice problems Schema markup
22. Q&A Schema markup
23. Recipe Schema markup
24. Software app (Beta) Schema markup
25. Speakbable Schema markup
26. Subscription and paywalled content Schema markup
27. Video Schema markup
You can add three different code languages to your HTML to notify search engines what is on your page:
1. JSON-LD (Javascript Object Notation for Linked Objects)
2. Microdata
3. RDFa (Resource Descriptive Framework in Attributes)
#schema #schemamarkup #sturucturedata #features #featuresnippet #faqschema #onpage #seo #articleschema #schemagenerator #html #json-ld #microddata #rdfa #podcast #connection #follow #website
0 notes
Text
RO-crate spec (w\o code)
This document specifies a method, known as RO-Crate (Research Object Crate), of aggregating and describing research data with associated metadata. RO-Crates can aggregate and describe any resource including files, URI-addressable resources, or use other addressing schemes to locate digital or physical data. RO-Crates can describe data in aggregate and at the individual resource level, with metadata to aid in discovery, re-use and long term management of data. Metadata includes the ability to describe the context of data and the entities involved in its production, use and reuse. For example: who created it, using which equipment, software and workflows, under what licenses can it be re-used, where was it collected, and/or where is it about.
RO-Crate uses JSON-LD to express this metadata using linked data, describing data resources as well as contextual entities such as people, organizations, software and equipment as a series of linked JSON-LD objects - using common published vocabularies, chiefly schema.org.
The core of RO-Crate is a JSON-LD file, the RO-Crate Metadata File, named ro-crate-metadata.json. This file contains structured metadata about the dataset as a whole (the Root Data Entity) and, optionally, about some or all of its files. This provides a simple way to, for example, assert the authors (e.g. people, organizations) of the RO-Crate or one its files, or to capture more complex provenance for files, such as how they were created using software and equipment.
While providing the formal specification for RO-Crate, this document also aims to be a practical guide for software authors to create tools for generating and consuming research data packages, with explanation by examples.
3 Terminology
RO-Crate: A directory structure that contains a dataset, which is described in an RO-Crate Metadata File.
RO-Crate Root: The top-level directory of the RO-Crate, indicated by the presence of the RO-Crate Metadata File ro-crate-metadata.json (or ro-crate-metadata.jsonld for crates that comply with versions before v1.1 of this specification)
RO-Crate Metadata File: A JSON-LD file stored as ro-crate-metadata.json in the RO-Crate Root. The metadata file describes the RO-Crate with structured data in form of RO-Crate JSON-LD. (In version 1.0 this file was named ro-crate-metadata.jsonld but has been renamed to improve the usability of crates.)
RO-Crate Website: Human-readable HTML pages which describe the RO-Crate (i.e. the Root Data Entity, its Data Entities and Context Entities), with a home-page at ro-crate-preview.html (any additional files reside in ro-crate-preview_files/)
Entity: An identified object, which have a given type and may be described using a set of properties.
Type: A classification of objects or their descriptions. The type (or class) is identified by a URI, mapped to a key by JSON-LD.
Property: A relationship from one entity to another entity, or to a value. The type of relationship is identified by a URI, mapped to a key by JSON-LD.
Data Entity: A JSON-LD representation, in the RO-Crate Metadata File, of a directory, file or other resource contained or described by the RO-Crate.
Root Data Entity: A Data Entity of type Dataset, representing the RO-Crate as a whole.
RO-Crate Metadata File Descriptor: A Contextual Entity of type CreativeWork, which describes the RO-Crate Metadata File and links it to the Root Data Entity.
JSON-LD: A JSON-based file format for storing Linked Data. This document assumes JSON-LD 1.0. JSON-LD use a context to map from JSON keys to URIs.
JSON: The JavaScript Object Notation (JSON) Data Interchange Format as defined by RFC 7159; a structured text file format that can be programmatically consumed and generated in a wide range of programming languages. The main JSON structures are objects ({}) indexed by keys, sequential arrays ([]) and literal values ("").
Contextual Entity: A JSON-LD representation of an entity associated with a Data Entity, needed to adequately describe that Data Entity. For example, a Person, Organization (including research projects), item of equipment (IndividualProduct), license or any other thing or event that forms part of the metadata for a Data Entity or supporting information.
Linked Data: A data structure where properties, types and resources are identified with URIs, which if retrieved over the Web, further describe or provide the identified property/type/resource.
URI: A Uniform Resource Identifier as defined in RFC 3986, for example http://example.com/path/file.html - commonly known as URL. In this document the term URI includes IRI, which also permit international Unicode characters.
URI Path: The relative path element of an URI as defined in RFC3986 section 3.3, e.g. path/file.html
RO-Crate JSON-LD Context: A JSON-LD context that provides Linked Data mapping for RO-Crate metadata to vocabularies like Schema.org.
RO-Crate JSON-LD: JSON-LD structure using the RO-Crate JSON-LD Context and containing RO-Crate metadata, written as if flattened and then compacted according to the rules in JSON-LD 1.0. The RO-Crate JSON-LD for an RO-Crate is stored in the RO-Crate Metadata File.
3.1 Linked Data conventions
Throughout this specification, RDF terms (properties, types) are referred to using the keys defined in the RO-Crate JSON-LD Context.
Following Schema.org practice, property names start with lowercase letters and Type names start with uppercase letters.
In the RO-Crate Metadata File the RDF terms use their RO-Crate JSON-LD names as defined in the RO-Crate JSON-LD Context, which is available at https://w3id.org/ro/crate/1.1/context
4 RO-Crate Structure
The structure an RO-Crate MUST follow is:
The name of the RO-Crate root directory is not defined, but a root directory is identifiable by the presence of the RO-Crate Metadata File, ro-crate-metadata.json. For instance, if an RO-Crate is archived in a ZIP-file, the ZIP root directory is an RO-Crate root directory if it contains ro-crate-metadata.json.
Data Entities in the RO-Crate MUST either be payload files/directories present within the RO-Crate root directory or its subdirectories, or be Web-based Data Entities.
4.1 RO-Crate Metadata File (ro-crate-metadata.json)
In new RO-Crates the RO-Crate Metadata File MUST be named ro-crate-metadata.json and appear in the RO-Crate Root
The RO-Crate Metadata File MUST contain RO-Crate JSON-LD; a valid JSON-LD 1.0 document in flattened and compacted form
The RO-Crate JSON-LD SHOULD use the RO-Crate JSON-LD Context https://w3id.org/ro/crate/1.1/context by reference.
If an RO-Crate conforming to version 1.0 or earlier contains a file named ro-crate-metadata.jsonld instead of ro-crate-metadata.json then processing software should treat this as the RO-Crate Metadata File. If the crate is updated then the file SHOULD be renamed to ro-crate-metadata.json and the RO-Crate Metadata File Descriptor SHOULD be updated to reference it, with an up to date conformsTo property naming an appropriate version of this specification.
JSON-LD is a structured form of JSON that can represent a Linked Data graph.
A valid RO-Crate JSON-LD graph MUST describe:
The RO-Crate Metadata File Descriptor
The Root Data Entity
Zero or more Data Entities
Zero or more Contextual Entities
It is RECOMMENDED that any referenced contextual entities are also described in the RO-Crate Metadata File with the same identifier. Similarly it is RECOMMENDED that any contextual entity in the RO-Crate Metadata file is linked to from at least one of the other entities using the same identifier.
The appendix RO-Crate JSON-LD details the general structure of the JSON-LD that is expected in the RO-Crate Metadata File. In short, the rest of this specification describe the different types of entities that can be added as {} objects to the RO-Crate JSON-LD @graph array below:
4.2 RO-Crate Website (ro-crate-preview.html and ro-crate-preview_files/)
In addition to the machine-oriented RO-Crate Metadata File, the RO-Crate MAY include a human-readable HTML rendering of the same information, known as the RO-Crate Website.
If present in the root directory, ro-crate-preview.html MUST:
Be a valid HTML 5 document
Be useful to users of the RO-Crate - this will vary by community and intended use, but in general the aim to assist users in reusing data by explaining what it is, how it was created how it can be used and how to cite it. One simple approach to this is to expose all the metadata in the RO-Crate Metadata File.
Contain a copy of the RO-Crate JSON-LD in a script element of the head element of the HTML, for example:
<script type="application/ld+json"> { "@context": "https://w3id.org/ro/crate/1.1/context", "@graph": [ ...] } </script>
ro-crate-preview.html SHOULD:
Display at least the metadata relating to the Root Data Enity as static HTML without the need for scripting. It MAY contain extra features enabled by JavaScript.
When a Data Entity or Contextual Entity is referenced by its ID:
If it has a name property, provide a link to its HTML version.
If it does not have a name (e.g. a GeoCoordinates location), show it embedded in the HTML for the entity.
For external URI values, provide a link.
For keys that resolve in the RO-Crate JSON-LD Context to a URI, indicate this (the simplest way is to link the key to its definition).
If there is sufficient metadata, contain a prominent "Cite-as" text with a natural language data citation (see for example the FORCE11 Data Citation Principles).
If there are additional resources necessary to render the preview (e.g. CSS, JSON, HTML), link to them in a subdirectory ro-crate-preview-files/
4.3 Payload files and directories
These are the actual files and directories that make up the dataset being described.
The base RO-Crate specification makes no assumptions about the presence of any specific files or folders beyond the reserved RO-Crate files described above. Payload files may appear directly in the RO-Crate Root alongside the RO-Crate Metadata File, and/or appear in sub-directories of the RO-Crate Root. Each file and directory MAY be represented as Data Entities in the RO-Crate Metadata File.
4.4 Self-describing and self-contained
RO-Crates SHOULD be self-describing and self-contained.
A minimal RO-Crate is a directory containing a single RO-Crate Metadata File ro-crate-metadata.json.
At the basic level, an RO-Crate is a collection of files and resources represented as a Schema.org Dataset, that together form a meaningful unit for the purposes of communication, citation, distribution, preservation, etc. The RO-Crate Metadata File describes the RO-Crate, and MUST be stored in the RO-Crate Root.
While RO-Crate is well catered for describing a Dataset as files and relevant metadata that are contained by the RO-Crate in the sense of living within the same root directory, RO-Crates can also reference external resources which are stored or accessed separately, via absolute URIs. This is particularly recommended where some resources cannot be co-hosted for practical or legal reasons, or if the RO-Crate itself is primarily web-based.
It is important to note that the RO-Crate Metadata File is not an exhaustive manifest or inventory, that is, it does not necessarily list or describe all files in the package. Rather it is focused on providing sufficient amount of metadata to understand and use the content, and is designed to be compatible with existing and future approaches that do have full inventories / manifest and integrity checks, e.g. by using checksums, such as BagIt and Oxford Common File Layout OCFL Objects.
The intention is that RO-Crates can work well with a variety of archive file formats, e.g. tar, zip, etc., and approaches to capturing file manifests and file fixity, such as BagIt, OCFL and git (see also appendix Combining with other packaging schemes). An RO-Crate can also be hosted on the web or mainly refer to web resources, although extra care to ensure persistence and consistency should be taken for archiving such RO-Crates.
5 RO-Crate Metadata
RO-Crate aims to capture and describe the Research Object using structured metadata.
The RO-Crate Metadata File Descriptor contains the metadata that describes the RO-Crate and its content, in particular:
Root Data Entity - the RO-Crate Dataset itself, a gathering of data
Data Entities - the data payload, in the form of files and folders
Contextual Entities - related things in the world (e.g. people, organizations, places), providing provenance for the data entities and the RO-Crate.
This machine-readable metadata can also be represented for human consumption in the RO-Crate Website, linking to data and Web resources.
5.1 RO-Crate uses Linked Data principles
RO-Crate makes use of the Linked Data principles for its description. In particular:
(Meta)data should be made available as Open Data on the web.
(Meta)data should be machine-readable in a structured format.
(Meta)data should not require proprietary software packages.
(Meta)data should use open standards from W3C, such as RDF and SPARQL.
(Meta)data should link to other people's data to provide context, using URIs as global identifiers
RO-Crate realizes these principles using a particular set of technologies and best practices:
The RO-Crate Metadata File and RO-Crate Website can be directly published on the web together with the RO-Crate payload. In addition, a data package (e.g. BagIt Zip archive) that contain the RO-Crate can also be published on the web.
The RO-Crate Metadata File is based on the structured data format JSON-LD.
Multiple open source tools/libraries are available for JSON and for JSON-LD.
The RO-Crate Website is HTML 5, and the RO-Crate Metadata File is JSON-LD, one of the W3C RDF 1.1 formats.
The RO-Crate Metadata File reuse common vocabularies like Schema.org, and this specification recommend identifiers it should link to.
5.2 Base metadata standard: Schema.org
Schema.org is the base metadata standard for RO-Crate. Schema.org was chosen because it is widely used on the World Wide Web and supported by search engines, on the assumption that discovery is likely to be maximized if search engines index the content.
Note: As far as we know there is no alternative, well-maintained linked-data schema for research data with the coverage needed for this project - i.e. a single standard for expressing all the examples presented in this specification.
RO-Crate relies heavily on Schema.org, using a constrained subset of JSON-LD, and this document gives opinionated recommendations on how to represent the metadata using existing linked data best practices.
5.2.1 Differences from Schema.org
Generally, the standard type and property names (terms) from Schema.org should be used. However, RO-Crate uses variant names for some elements, specifically:
File is mapped to http://schema.org/MediaObject which was chosen as a compromise as it has many of the properties that are needed to describe a generic file. Future versions of Schema.org or a research data extension may re-define File.
Journal is mapped to http://schema.org/Periodical.
Warning: JSON-LD examples given on the Schema.org website may not be in flattened form; any nested entities in RO-Crate JSON-LD SHOULD be described as separate contextual entities in the flat @graph list.
To simplify processing and avoid confusion with string values, the RO-Crate JSON-LD Context requires URIs and entity references to be given in the form "author": {"@id": "http://example.com/alice"}, even where Schema.org for some properties otherwise permit shorter forms like "author": "http://example.com/alice".
See the appendix RO-Crate JSON-LD for details.
5.3 Additional metadata standards
RO-Crate also uses the Portland Common Data Model (PCDM version https://pcdm.org/2016/04/18/models) to describe repositories or collections of digital objects and imports these terms:
RepositoryObject mapped to http://pcdm.org/models#Object
RepositoryCollection mapped to http://pcdm.org/models#Collection
RepositoryFile mapped to http://pcdm.org/models#File
hasMember mapped to http://pcdm.org/models#hasMember
hasFile mapped to http://pcdm.org/models#hasFile
Note: The terms RepositoryObject and RepositoryCollection are renamed to avoid collision between other vocabularies and the PCDM terms Collection and Object. The term RepositoryFile is renamed to avoid clash with RO-Crate's File mapping to http://schema.org/MediaObject.
From Dublin Core Terms RO-Crate use:
conformsTo mapped to http://purl.org/dc/terms/conformsTo
These terms are being proposed by Bioschemas profile ComputationalWorkflow 0.5-DRAFT and FormalParameter 0.1-DRAFT to be integrated into Schema.org:
ComputationalWorkflow mapped to https://bioschemas.org/ComputationalWorkflow
FormalParameter mapped to https://bioschemas.org/FormalParameter
input mapped to https://bioschemas.org/ComputationalWorkflow#input
output mapped to https://bioschemas.org/ComputationalWorkflow#output
funding mapped to http://schema.org/funding (schemaorg #383)
Note: In this specification the proposed Bioschemas terms use the temporary https://bioschemas.org/ namespace; future releases of RO-Crate may reflect mapping to the http://schema.org/ namespace.
5.4 Summary of Coverage
RO-Crate is simply a way to make metadata assertions about a set of files and folders that make up a Dataset. These assertions can be made at two levels:
Assertions at the RO-Crate level: for an RO-Crate to be useful, some metadata should be provided about the dataset as a whole (see minimum requirements for different use-cases below). In the RO-Crate Metadata File, we distinguish the Root Data Entity which represents the RO-Crate as a whole, from other Data Entities (files and folders contained in the RO-Crate) and Contextual Entities, e.g. a person, organisation, place related to an RO-Crate Data Entity
Assertions about files and folders contained in the RO-Crate: in addition to providing metadata about the RO-Crate as a whole, RO-Crate allows metadata assertions to be made about any other Data Entity
This document has guidelines for ways to represent common requirements for describing data in a research context, e.g.:
Contact information for a data set.
Descriptive information for a dataset and the files within it and their contexts such as an abstract, spatial and temporal coverage.
Associated publications.
Funding relationships.
Provenance information of various kinds; who (people and organizations) and what (instruments and computer programs) created or contributed to the data set and individual files within it.
Workflows that operate on the data using standard workflow descriptions including 'single step workflows'; executable files or environments such as singularity containers or Jupyter notebooks.
However, as RO-Crate uses the Linked Data principles, adopters of RO-Crate are free to supplement RO-Crate using Schema.org metadata and/or assertions using other Linked Data vocabularies.
5.5 Future coverage
A future version of this specification aim to cater for variable-level assertions: In some cases, e.g. for tabular data, additional metadata may be provided about the structure and variables within a given file. See the use case Describe a tabular data file directly in RO-Crate metadata for work-in-progress.
5.6 Recommended Identifiers
RO-Crate JSON-LD SHOULD use the following IDs where possible:
For a Root Data Entity, an identifier which is RECOMMENDED to be a https://doi.org/ URI.
For a Person participating in the research process: ORCID identifiers, e.g. https://orcid.org/0000-0002-1825-0097
For Organizations including funders, Research Organization Registry URIs, e.g. https://ror.org/0384j8v12
For entities of type Place, a geonames URL, e.g. http://sws.geonames.org/8152662/
For file formats, a Pronom URL, for example https://www.nationalarchives.gov.uk/PRONOM/fmt/831.
In the absence of the above, RO-Crates SHOULD contain stable persistent URIs to identify all entities wherever possible.
6 Root Data Entity
The Root Data Entity is a Dataset that represent the RO-Crate as a whole; a Research Object that includes the Data Entities and the related Contextual Entities.
As explained in section RO-Crate structure, the RO-Crate description is stored as JSON-LD in the RO-Crate Metadata File ro-crate-metadata.json in the RO-Crate root directory.
6.1 RO-Crate Metadata File Descriptor
The RO-Crate JSON-LD MUST contain a self-describing RO-Crate Metadata File Descriptor with the @id value ro-crate-metadata.json (or ro-crate-metadata.jsonld in legacy crates) and @type CreativeWork. This descriptor MUST have an about property referencing the Root Data Entity, which SHOULD have an @id of ./.
The conformsTo of the RO-Crate Metadata File Descriptor SHOULD be a versioned permalink URI of the RO-Crate specification that the RO-Crate JSON-LD conforms to. The URI SHOULD start with https://w3id.org/ro/crate/.
6.1.1 Finding the Root Data Entity
Consumers processing the RO-Crate as an JSON-LD graph can thus reliably find the Root Data Entity by following this algorithm:
For each entity in @graph array
..if the conformsTo property is a URI that starts with https://w3id.org/ro/crate/
....from this entity's about object keep the @id URI as variable root
For each entity in @graph array
.. if the entity has an @id URI that matches root return it
See also the appendix on finding RO-Crate Root in RDF triple stores.
6.1.2 Purpose of Metadata File
To ensure a base-line interoperability between RO-Crates, and for an RO-Crate to be considered a Valid RO-Crate, a minimum set of metadata is required for the Root Data Entity. As stated earlier the RO-Crate Metadata File is not an exhaustive manifest or inventory, that is, it does not necessarily list or describe all files in the package. For this reason, there are no minimum metadata requirements in terms of describing Data Entities (files and folders) other than the Root Data Entity. Extensions of RO-Crate dealing with specific types of dataset may put further constraints or requirements of metadata beyond the Root Data Entity (see the appendix Extending RO-Crate).
The RO-Crate Metadata File Descriptor MAY contain information such as licensing for the RO-Crate Metadata File so metadata can be licensed separately from Data.
The table below outlines the properties that the Root Data Entity MUST have to be minimally valid and additionally highlights properties required to meet other common use-cases:
6.2 Direct properties of the Root Data Entity
The Root Data Entity MUST have the following properties:
@type: MUST be Dataset
@id: MUST end with / and SHOULD be the string ./
name: SHOULD identify the dataset to humans well enough to disambiguate it from other RO-Crates
description: SHOULD further elaborate on the name to provide a summary of the context in which the dataset is important.
datePublished: MUST be a string in ISO 8601 date format and SHOULD be specified to at least the precision of a day, MAY be a timestamp down to the millisecond.
license: SHOULD link to a Contextual Entity in the RO-Crate Metadata File with a name and description. MAY have a URI (eg for Creative Commons or Open Source licenses). MAY, if necessary be a textual description of how the RO-Crate may be used.
Note: These requirements are stricter than those published > for Google Dataset Search which > requires a Dataset to have a name and description,
Warning: The properties above are not sufficient to generate a DataCite citation. Advice on integrating with DataCite will be provided in a future version of this specification, or as an implementation guide.
6.3 Minimal example of RO-Crate
The following RO-Crate Metadata File represents a minimal description of an RO-Crate.
7 Data Entities
The primary purpose for RO-Crate is to gather and describe a set of Data entities in the form of:
Files
Directories
Web resources
The data entities can be further described by referencing contextual entities such as persons, organizations and publications.
7.1 Referencing files and folders from the Root Data Entity
Where files and folders are represented as Data Entities in the RO-Crate JSON-LD, these MUST be linked to, either directly or indirectly, from the Root Data Entity using the hasPart property. Directory hierarchies MAY be represented with nested Dataset Data Entities, or the Root Dataset MAY refer to files anywhere in the hierarchy using hasPart.
Data Entities representing files MUST have "File" as a value for @type. File is an RO-Crate alias for http://schema.org/MediaObject. The term File here is liberal, and includes "downloadable" resources where @id is an absolute URI.
Data Entities representing directories MUST be of "@type": "Dataset". The term directory here includes HTTP file listings where @id is an absolute URI, however "external" directories SHOULD have a programmatic listing of their content (e.g. another RO-Crate).
Data Entities can also be other types, for instance an online database. These SHOULD be of "@type": "CreativeWork" and typically have a @id which is an absolute URI.
In all cases, @type MAY be an array in order to also specify a more specific type, e.g. "@type": ["File", "ComputationalWorkflow"]
Tip: There is no requirement to represent every file and folder in an RO-Crate as Data Entities in the RO-Crate JSON-LD.
7.1.1 Example linking to a file and folders
<RO-Crate root>/ | ro-crate-metadata.json | cp7glop.ai | lots_of_little_files/ | | file1 | | file2 | | ... | | file54
An example RO-Crate JSON-LD for the above would be as follows:
7.1.2 Adding detailed descriptions of encodings
The above example provides a media type for the file cp7glop.ai - which is useful as it may not be apparent that the file is readable as a PDF file from the extension alone. To add more detail, encodings SHOULD be linked using a PRONOM identifier to a Contextual Entity of @type WebSite.
If there is no PRONOM identifier, then a contextual entity with a URL as an @id MAY be used:
If there is no web-accessible description for a file format it SHOULD be described locally in the dataset.
7.2 Core Metadata for Data Entities
The table below outlines the properties that Data Entities, when present, MUST have to be minimally valid.
7.2.1 Encoding file paths
Note that all @id identifiers must be valid URI references, care must be taken to express any relative paths using / separator, correct casing, and escape special characters like space (%20) and percent (%25), for instance a File Data Entity from the Windows path Results and Diagrams\almost-50%.png becomes "@id": "Results%20and%20Diagrams/almost-50%25.png" in the RO-Crate JSON-LD.
In this document the term URI includes international IRIs; the RO-Crate Metadata File is always UTF-8 and international characters in identifiers SHOULD be written using native UTF-8 characters (IRIs), however traditional URL encoding of Unicode characters with % MAY appear in @id strings. Example: "@id": "面试.mp4" is preferred over the equivalent "@id": "%E9%9D%A2%E8%AF%95.mp4"
7.2.2 File Data Entity
A File Data Entity MUST have the following properties:
@type: MUST be File, or an array where File is one of the values.
@id MUST be either a URI Path relative to the RO Crate root, or an absolute URI.
7.2.3 Directory File Entity
A Dataset (directory) Data Entity MUST have the following properties:
@type MUST be Dataset or an array where Dataset is one of the values.
@id MUST be either a URI Path relative to the RO Crate root, or an absolute URI. The id SHOULD end with /
7.3 Web-based Data Entities
While one use-case of RO-Crates is to describe files contained within the RO-Crate root directory, RO-Crates can also gather resources from the web identified by absolute URIs instead of relative URI paths, i.e. Web-based data entities.
Using Web-based data entities can be important particularly where a file can't be included in the RO-Crate root because of licensing concerns, large data sizes, privacy, or where it is desirable to link to the latest online version.
Example of an RO-Crate including a File Data Entity external to the RO-Crate root (file entity https://zenodo.org/record/3541888/files/ro-crate-1.0.0.pdf):
Additional care SHOULD be taken to improve persistence and long-term preservation of web resources included in an RO-Crate as they can be more difficult to archive or move along with the RO-Crate root, and may change intentionally or unintentionally leaving the RO-Crate with incomplete or outdated information.
File Data Entries with an @id URI outside the RO-Crate Root SHOULD at the time of RO-Crate creation be directly downloadable by a simple retrieval (e.g. HTTP GET), permitting redirections and HTTP/HTTPS authentication. For instance, in the example above, https://zenodo.org/record/3541888 and https://doi.org/10.5281/zenodo.3541888 cannot be used as @id above as retrieving these URLs give a HTML landing page rather than the desired PDF as indicated by encodingFormat.
As files on the web may change, the timestamp property sdDatePublished SHOULD be included to indicate when the absolute URL was accessed, and derived metadata like encodingFormat and contentSize were considered to be representative.
7.3.1 Embedded data entities that are also on the web
File Data Entities may already have a corresponding web presence, for instance a landing page that describes the file, including persistent identifiers (e.g. DOI) resolving to an intermediate HTML page instead of the downloadable file directly.
These can be included for File Data Entities as additional metadata, regardless of whether the File is included in the RO-Crate Root directory or exists on the Web, by using the properties:
identifier for formal identifier strings such as DOIs
url with a string URL corresponding to a download link (if not available, a download landing page) for this file
subjectOf to a CreativeWork (or WebPage) that mentions this file or its content (but also other resources)
mainEntityOfPage to a CreativeWork (or WebPage) that primarily describes this file (or its content)
7.3.2 Directories on the web; dataset distributions
A Directory File Entry or Dataset identifier expressed as an absolute URL on the web can be harder to download than a File because it consists of multiple resources. It is RECOMMENDED that such directories have a complete listing of their content in hasPart, enabling download traversal.
Alternatively, a common mechanism to provide downloads of a reasonably sized directory is as an archive file in formats such as .zip or .tar.gz, described as a DataDownload.
Similarly, the RO-Crate root entity may also provide a distribution URL, in which case the download SHOULD be an archive that contains the RO-Crate Metadata file.
In all cases, consumers should be aware that a DataDownload is a snapshot that may not reflect the current state of the Dataset or RO-Crate.
8 Representing Contextual Entities
The RO-Crate SHOULD contain additional information about Contextual Entities for the use of both humans (in ro-crate-preview.html) and machines (in ro-crate-metadata.json). This also helps to maximize the extent to which an RO-Crate is self-contained and self-describing, in that it reduces the need for the consumer of an RO-Crate to refer to external information which may change or become unavailable over time.
8.1 Contextual vs Data entities
RO-Crate distinguishes between Contextual entities and Data entities.
Data entities primarily exist in their own right as a file or directory (which may be in the RO-Crate Root directory or downloadable by URL).
Contextual entities however primarily exist outside the digital sphere (e.g. People, Places) or are conceptual descriptions that primarily exists as metadata, like GeoCoordinates and ContactPoint.
Some contextual entities can also be considered data entities - for instance the license property refers to a CreativeWork that can reasonably be downloaded, however a license document is not usually considered as part of research outputs and would therefore typically not be included in hasPart on the root data entity.
Likewise, some data entities may also be described as contextual entities, for instance a File that is also a ScholarlyArticle. In such cases the Contextual Data Entity MUST be described as a single JSON object in the RO-Crate Metadata JSON @graph and SHOULD list both relevant data and contextual types in a @type array.
The RO-Crate Metadata JSON @graph MUST NOT list multiple entities with the same @id; behaviour of consumers of an RO-Crate encountering multiple entities with the same @id is undefined.
8.2 Identifiers for contextual entities
A challenge can be how to assign identifiers for contextual entities, that is deciding on their @id value.
RO-Crate recommend that if an existing permalink (e.g. https://orcid.org/0000-0002-1825-0097) or other absolute URI (e.g. https://en.wikipedia.org/wiki/Josiah_S._Carberry) is reasonably unique for that entity, that URI should be used as identifier for the contextual entity in preference of an identifier local to the RO-Crate (e.g. #josiah or #0fa587c6-4580-4ece-a5df-69af3c5590e3).
Care should be taken to not describe two conceptually different contextual entities with the same identifier - e.g. if https://en.wikipedia.org/wiki/Josiah_S._Carberry is a Person it should not also be a CreativeWork (although this example is a fictional person!).
Where a related URL exist that may not be unique enough to serve as identifier, it can instead be added to a contextual entity using the property url.
See the appendix on JSON-LD identifiers for details.
8.3 People
A core principle of Linked data is to use URIs to identify important entities such as people. The following is the minimum recommended way of representing a author of a RO-Crate. The author property MAY also be applied to a directory (Dataset), a File or other CreativeWork entities.
This uses an ORCID to unambiguously identify an author, represented as a Contextual Entity of type Person.
Note the string value for the organizational affiliation. This SHOULD be improved by also providing a Contextual Entity for the organization (see example below).
8.4 Organizations as values
An Organization SHOULD be the value for the publisher property of a Dataset or ScholarlyArticle or affiliation property of a Person.
An Organization SHOULD also be used for a Person's affiliation property.
8.5 Contact information
A RO-Crate SHOULD have contact information, using a contextual entity of type ContactPoint. Note that in Schema.org Dataset does not currently have the corresponding contactPoint property, so the contact point would need to be given through a Person or Organization contextual entity which are related to the Dataset via a author or publisher property.
8.6 Publications via citation property
To associate a publication with a dataset the RO-Crate JSON-LD MUST include a URL (for example a DOI URL) as the @id of a publication using the citation property.
The publication SHOULD be described further as an additional contextual entity of type ScholarlyArticle or CreativeWork.
citation MAY also be used with other data and contextual entities.
A data entity MAY provide a published DOI identifier that, compared with any related publication in citation, primarily captures that file or dataset.
8.7 Publisher
The Root Data Entity SHOULD have a publisher property. This SHOULD be an Organization though it MAY be a Person.
8.8 Funding and grants
To associate a research project with a Dataset, the RO-Crate JSON-LD SHOULD contain an entity for the project using type Organization, referenced by a funder property. The project Organization SHOULD in turn reference any external funder, either by using its URL as an @id or via a Contextual Entity describing the funder.
Tip: To make it very clear where funding is coming from, the Root Data Entity SHOULD also reference funders directly, as well as via a chain of references.
8.9 Licensing, Access control and copyright
If a Data Entity has a license that is different from the license on the Root Data Entity, the entity SHOULD have a license property referencing a Contextual Entity with a type CreativeWork to describe the license. The @id of the license SHOULD be its URL (e.g. a Creative Commons License URL) and, when possible, a summary of the license included using the description property.
The below Data Entity has a copyrightHolder which is different from its author. There is a reference to an Organization describing the copyright holder and, to give credit, a sameAs relation to a web page. The license property here refers to https://creativecommons.org/licenses/by/4.0/ which is expanded in a separate contextual entity.
8.9.1 Metadata license
In some cases the license of the RO-Crate metadata (the JSON-LD statements in the RO-Crate Metadata File Descriptor) is different from the license on the Root Data Entity and its content (data entities indicated by hasPart).
For instance, a common pattern for repositories is to license metadata as CC0 Public Domain Dedication, while data is licensed as CC-BY or similar. This pattern allow metadata to be combined freely (e.g. the DataCite knowledge graph), while redistribution of data files would require explicit attribution and statement of their license.
To express the metadata license is different from the Root Data Entity, expand the RO-Crate Metadata File Descriptor to include license.
If no explicit license is expressed on the RO-Crate Metadata File Descriptor, the license expressed on the Root Data Entity apply also on the RO-Crate metadata.
9 Detailing provenance of entities
9.1 Equipment used to create files
To specify which equipment was used to create or update a Data Entity, the RO-Crate JSON-LD SHOULD have a Context Entity for each item of equipment which SHOULD be of @type IndividualProduct. The entity SHOULD have a serial number, manufacturer that identifies it as completely as possible. In this case the equipment is a bespoke machine. The equipment SHOULD be described on a web page, and the address of the description SHOULD be used as its @id.
Uses CreateAction and UpdateAction type to model the contributions of Context Entities of type Person or Organization in the creation of files.
In this example the CreateAction has a human agent, the object is a Place (a cave) and the Hovermap drone is the instrument used in the file creation event.
9.2 Software used to create files
To specify which software was used to create or update a file, the software application SHOULD be represented with an entity of type SoftwareApplication, with a version property, e.g. from tool --version.
The software SHOULD be associated with the File (or other data entities) it created as an instrument of a CreateAction, with the File referenced by a result property. Any input files SHOULD be referenced by the object property.
In the below example, an image with the @id of pics/2017-06-11%2012.56.14.jpg was transformed into an new image pics/sepia_fence.jpg using the ImageMagick software application as "instrument". Actions MAY have human-readable names, which MAY be machine generated for use at scale.
Tip: If representing command lines, double escape \\ so that JSON preserves the \ character.
If multiple SoftwareApplications have been used in composition, such as from a script or workflow, then the CreateAction's instrument SHOULD rather reference a SoftwareSourceCode which can be further described as explained in the Workflows and scripts section.
9.3 Recording changes to RO-Crates
To record an action which changes an entity's metadata, or changes its state in a publication or other workflow, a CreateAction or UpdateAction SHOULD be associated with a Data Entity or, for the RO-Crate itself, with the root data entity.
A curation Action MUST have at least one object which associates it with either the root data entity Dataset or one of its components.
An Action which creates new Data entities - for example, the creation of a new metadata file - SHOULD have these as results.
An Action SHOULD have a name and MAY have a description.
An Action SHOULD have an endTime, which MUST be in ISO 8601 date format and SHOULD be specified to at least the precision of a day. An Action MAY have a startTime meeting the same specifications.
An Action SHOULD have a human agent who was responsible for authorizing the action, and MAY have an instrument which associates the action with a particular piece of software (for example, the content management system or data catalogue through which an update was approved) which SHOULD be of @type SoftwareApplication.
An Action's status MAY be recorded in an actionStatus property. The status must be one of the values enumerated by ActionStatusType: ActiveActionStatus, CompletedActionStatus, FailedActionStatus or PotentialActionStatus.
An Action which has failed MAY record any error information in an error property.
UpdateAction SHOULD only be used for actions which affect the Dataset as a whole, such as movement through a workflow.
To record curation actions which modify a File within a Dataset - for example, by correcting or enhancing metadata - the old version of the File SHOULD be retained, and a CreateAction added which has the original version as its object and the new version as its result.
9.4 Digital Library and Repository content
To describe an export from a Digital Library or repository system, RO-Crate uses the Portland Common Data Model (PCDM).
A Contextual Entity from a repository, representing an abstract entity such as a person, or a work, or a place SHOULD have a @type of RepositoryObject, in addition to any other types.
Objects MAY be grouped together in RepositoryCollections with hasMember pointing to the RepositoryObject.
Note: The terms RepositoryObject and RepositoryCollection are renamed in RO-Crate to avoid collision between other vocabularies and the PCDM terms Collection and Object. The term RepositoryFile is renamed to avoid clash with RO-Crate's File mapping to http://schema.org/MediaObject.
Warning: PCDM specifies that files should have only technical metadata, not descriptive metadata, which is not a restriction in RO-Crate. If the RO-Crate is to be imported into a strict PCDM repository, modeling of object/file relationships will be necessary.
For example, this data is exported from an Omeka repository.
10 Workflows and Scripts
Scientific workflows and scripts that were used (or can be used) to analyze or generate files contained in an RO-Crate MAY be embedded in an RO-Crate. See also the Provenance section on Software Used to Create Files.
Workflows and scripts SHOULD be described using data entities of type SoftwareSourceCode.
The distinction between SoftwareSourceCode and SoftwareApplication for software is fluid, and comes down to availability and understandability. For instance, office spreadsheet applications are generally available and do not need further explanation (SoftwareApplication); while a Python script that is customized for a particular data analysis might be important to understand deeper and should therefore be included as SoftwareSourceCode in the RO-Crate dataset.
10.1 Describing scripts and workflows
A script is a Data Entity which MUST have the following properties:
@type is an array with at least File and SoftwareSourceCode as values
@id is a File URI linking to the executable script
name: a human-readable name for the script.
A workflow is a Data Entity which MUST have the following properties:
@type is an array with at least File, SoftwareSourceCode and ComputationalWorkflow as values
@id is a File URI linking to the workflow entry-point.
name: a human-readable name for the workflow.
There is no strong distinction between a script and a workflow; many computational workflows are written in script-like languages, and many scripts perform a pipeline of steps.
Here are some indicators for when a script should be considered a workflow:
It performs a series of steps (pipeline)
The executed steps are mainly external tools or services
The main work is performed by the steps (script is not algorithmic)
The steps exchange data in a dataflow, typically file inputs/outputs
The script has well-defined inputs and outputs, e.g. file arguments
Here are some counter-indicators for when a script might not be a workflow:
The script contains mainly algorithms or logic
Data is exchanged out of bands, e.g. a SQL database
The script relies on a particular state of the system (e.g. appends existing files)
An interactive user interface that controls the actions
10.2 Workflow Runtime and Programming Language
Scripts written in a programming language, as well as workflows, generally need a runtime; in RO-Crate the runtime SHOULD be indicated using a liberal interpretation of programmingLanguage.
Note that the language and its runtime MAY differ (e.g. different C++ compilers), but for scripts and workflows, frequently the language and runtime are essentially the same, and thus the programmingLanguage, implied to be a ComputerLanguage, can also be described as an executable SoftwareApplication:
A contextual entity representing a ComputerLanguage and/or SoftwareApplication MUST have a name, url and version, which should indicate a known version the workflow/script was developed or tested with. alternateName MAY be provided if there is a shorter colloquial name, for instance "R" instead of "The R Project for Statistical Computing".
It is possible to indicate steps that are executed as part of an ComputationalWorkflow or Script, by using hasPart to relate additional SoftwareApplication or nested SoftwareSourceCode contextual entities.
10.3 Workflow diagram/sketch
It can be beneficial to show a diagram or sketch to explain the script/workflow. This may have been generated from a workflow management system, or drawn manually as a diagram. This diagram MAY be included from the SoftwareSourceCode data entity by using image, pointing to an ImageObject data entity which is about the SoftwareSourceCode.
The image file format SHOULD be indicated with encodingFormat using an IANA registered media type like image/svg+xml or image/png. Additionally a reference to a Pronom identifier SHOULD be provided, which MAY be described as an additional contextual entity to give human-readable name to the format.
A workflow diagram may still be provided even if there is no programmatic SoftwareSourceCode that can be executed (e.g. because the workflow was done by hand). In this case the sketch itself is a proxy for the workflow and SHOULD have an about property referring to the RO-Crate dataset as a whole (assuming the RO-Crate represents the outcome of a single workflow), or to other Data Entities otherwise.
10.4 Complying with Bioschemas Computational Workflow profile
Data entities representing workflows (@type: ComputationalWorkflow) SHOULD comply with the Bioschemas ComputationalWorkflow profile, where possible.
When complying with this profile, the workflow data entities MUST describe these properties and their related contextual entities: name, programmingLanguage, creator, dateCreated, license, sdPublisher, url, version.
The ComputationalWorkflow profile explains the above and list additional properties that a compliant ComputationalWorkflow data entity SHOULD include: citation, contributor, creativeWorkStatus, description, funding, hasPart, isBasedOn, keywords, maintainer, producer, publisher, runtimePlatform, softwareRequirements, targetProduct
A data entity conforming to the ComputationalWorkflow profile SHOULD declare the versioned profile URI using conformsTo.
10.4.1 Describing inputs and outputs
The input and output parameters for a workflow or script can be given with input and output to FormalParameter contextual entities. Note that this entity usually represent a potential input/output value in a reusable workflow, much like function parameter definitions in general programming.
If complying with the Bioschemas FormalParameter profile, the contextual entities for FormalParameter, referenced by input or output, MUST describe: name, additionalType, encodingFormat
The Bioschemas FormalParameter profile explains the above and lists additional properties that can be used, including description, valueRequired, defaultValue and identifier.
A contextual entity conforming to the FormalParameter profile SHOULD declare the versioned profile URI using conformsTo.
Note: input, output and FormalParameter are at time of writing proposed by Bioschemas and not yet integrated in Schema.org
10.5 Complete Workflow Example
The below is an example of an RO-Crate complying with the Bioschemas ComputationalWorkflow profile 0.5:
0 notes
Text
For eCommerce Websites: Schema Markup

When someone searches for a certain product online, they are directed to a SERP that (in most situations) has hundreds of results.
Because the chances of browsing through all of these links are slim to none, it's critical to make your company stand out.
The most effective method is to use structured data markup across your online business.
The Importance of Structured Data Markup
If you've ever looked for a product, business, or service online, especially in a competitive area, you've most likely seen improved Google search results known as Rich Snippets.
Rich Snippets extract information from structured data markup using semantic language such as schema.org to offer more information about a specific result.
These extra pieces of information not only increase your click-through rate but also assist search engines in better grasp the content of your site.
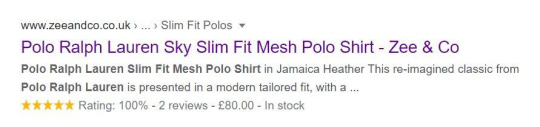
Although Google does not guarantee that rich snippets will appear in search results, you should still invest time in the implementation and optimization of your store's structured data.
On the contrary, I've noticed numerous eCommerce sites that lack adequate schema.org markup, which is why you should take advantage of this chance and include these in your website.
After all, one of the primary things that distinguishes you from your competition is your ability to deliver more information.
What Structured Data Markup is Required for eCommerce Websites?
When looking through the Schema.org vocabulary, it's easy to become overwhelmed by the sheer number of schema types and properties available for use on your site.
There are many alternatives for various content kinds, such as recipes, events, places, goods, and so on, which is why it is critical to select those that are most appropriate for your organization.
Because setting up the most typical schema types on eCommerce websites can be time-consuming, We've made the following advice on
Organization
Website
BreadcrumbList
ItemList
Product
Let's go into eCommerce markup right now.
Organization
The Organization schema type is used to offer information about your business, such as your name, logo, address, phone number, social network accounts, and so on.
Although this schema type allows you to provide a wealth of useful information to your customers, and I strongly encourage you to do so, you should exercise caution.
Only one page of your online store should use the organization schema type.
Choose the most relevant page on the store (usually the homepage) and add as many Organization properties as you need to your structured data markup.
Here's a simple example of how the Organization markup should appear in JSON-LD after it's added to your shop.
<script type="application/ld+json">
{
"@context":"http://schema.org",
"@type":"Organization",
"url":"https://www.abc.com",
"name":" abc Store",
"logo":"https://www. abc.com/ abc.svg",
"contactPoint":[
{"@type":"ContactPoint",
"telephone":"+X-XXX-XXX-XXX",
"contactType":"customer service"}
],
"address":{
"addressCountry":"Country",
"postalCode":"XXXXX",
"addressRegion":"Region",
"addressLocality":"Locality"}
}
</script>
Remember that this is just for online retailers. I would propose utilizing a LocalBusiness schema type instead if you have both online and actual businesses.
Website
Because eCommerce stores rely heavily on on-site search, I recommend including a Sitelink search box structured data via the Website schema type to allow users to search for products directly on SERP.
Make sure to only use it on the homepage, as shown in the example below:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "WebSite",
"url":"https://www.abc.com",
"potentialAction":
{
"@type": "SearchAction",
"target": " https://www. abc.com/catalogsearch/result/?q={search_term_string}",
"query": "required",
"query-input":"required name=search_term_string"
}
}
</script>
BreadcrumbList
Always include BreadcrumbList structured data markup in your online shop to offer extra information about site design to both search engines and potential consumers.
Despite the fact that the BreadcrumbList model has already been applied by the great majority of online shops, not all of them, in my opinion, are correct.
The most common problem is that the last page (the page you're on) is not added to ItemListElement.
Consider adding breadcrumb markup to “https://abc.com/shoes/boots”. When you look at the source code (or Rich result tester), you should see something like this:
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BreadcrumbList",
"itemListElement":[
{
"@type": "ListItem",</p>
"position": 1,
"item":
{
"@id": "https://abc.com/shoes",
"name": "Shoes"
}
},
{
"@type": "ListItem",
"position": 2,
"item":
{
"@id": "https://abc.com/shoes/boots",
"name": "Boots"
}
}
]
}
</script>
ItemList
This is where things start to get interesting. You might be wondering why we're using such a basic schema type that offers no information if you're new to eCommerce SEO.
Google does not allow product markup at the category level.

Although many different schemas could be used on product listing pages, I prefer the ItemList type. It displays the complete variety of your items without violating Google's standards.
This method is known as Carousel organized data, in which category pages serve as summary pages. It appears as follows:
This method, in which category pages serve as summary pages, is known as carousel organized data. It looks like this:
<script type="application/ld+json">
{
"@context":"http://schema.org",
"@type":"ItemList",
"itemListElement":
[
{
"@type":"ListItem",
"position":0,
"url":"https://www.abc.com/ankle-boots-ana.html"
},
{
"@type":"ListItem",
"position":1,
"url":"https://www.abc.com/ankle-boots-clara.html"
},
{
"@type":"ListItem",
"position":2,
"url":"https://www.abc.com/ankle-boots-maria.html"
}
]
}
</script>
Whatever you decide on for listing page structured data, bear in mind that it should never display as many details as the product page markup.
Product
Consider you have multiple product types visible in your catalog and do not want to send them all to Google Shopping. In such a situation, you must plan a separate Product schema.org implementation strategy for each product category.
Because Magento has 6 product types and you can have both simple and grouped products visible on the front end, you should be aware that only one page should showcase all product details in structured data markup.
Another thing to keep in mind is that product markup allows us to enable automated changes in Google Merchant Centre, so your structured data markup on product pages must match the feed data.
If you have multiple items on your main product page (the one you're sending to Google Merchant Centre), I recommend using the following HTML for each product:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "designer bags",
"image": [
"https://example.com/photos/4x2/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"description": "The beautiful designer bags you've ever seen.",
"sku": "8888888888",
"mpn": "777777",
"brand": {
"@type": "Brand",
"name": " designer bags "
},
"review": {
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4",
"bestRating": "5"
},
"author": {
"@type": "Person",
"name": "Kunal Shah"
}
},
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.8",
"reviewCount": "64"
},
"offers": {
"@type": "Offer",
"url": "https://www.example.com/ designer-bags.html",
"priceCurrency": "USD",
"price": "212.99",
"priceValidUntil": "2020-12-31",
"itemCondition": "https://schema.org/NewCondition,
"availability": "https://schema.org/InStock",
"seller": {
"@type": "Organization",
"name": "Example"
}
}
}
</script>
Add Product markup to your site, but with a twist, if you have grouped items displayed on the frontend and they're set to "index, follow" since you're targeting certain mid-tail keywords.
This time, instead of adding a distinct markup for each product, use the AggregateOffer.
How Do You Implement Schema Markup in an Online Store?
Decide on the format you want to use. You can see from our samples that JSON-LD is our favourite option despite their being multiple possibilities (Microdata, RDF, and JSON-LD). This is due to two factors.
The first reason is the ease with which it can be implemented. Working with JSON-LD is much easier than dealing with any other format, but it still requires a lot of attention.
The second reason is that search engines like this structured data markup type.
Now that you've decided on the format for your online business, let's get started.
There are multiple third-party plugins for structured data markup available for eCommerce businesses. Some of these will be enough for basic implementation, but as you get to more sophisticated schema types, you will almost certainly require the support of developers.
That is why, for schema.org implementation, I usually propose bespoke development.
This allows you to include as much information as you like in your structured data without being constrained by the extension's inability to support certain schemas.
Structured Data Implementation Testing
As soon as you begin adding schema markup in the store, run the Rich Results Tester to see how it turns out. The nicest part is that updates may even be tested on the staging site! Simply copy the source code from your website and paste it into the testing tool to get started.
I would also recommend using the Ryte Structured Data Helper plugin while browsing the store to fast and easily evaluate schema.org's implementation.
After you've verified your setup with these two tools, keep an eye on Google Search Console Enhancements reports to ensure your store isn't missing any data.
Conclusion
Although no one enjoys hearing these two words, it depends.
Because Rich Snippets have no direct impact on your organic rankings, we won't guarantee you first-page rankings.
Nonetheless, we are confident that structured data markup will increase your CTR, which will benefit your overall performance.
Empower your online business by hiring expert eCommerce development services today.
#ecommerce development services#e commerce development company#hire ecommerce developer#ecommerce website designing company#ecommerce web design agency
1 note
·
View note
Text
5 Killer Quora Answers On Internet Marketing
Suggestions To Be Effective With SEO

SEO companies help businesses to in attaining more traffic to their website page with search engine optimization methods. Web optimization gets great results from improving on page elements in your web site in addition to the over-all visibility of your brand name around the internet. Our purpose in doing this would be to clearly display to engines like Google how your business website content is relevant to a number of search phrases that you prefer to rank for so that your web page shows at the top of serp's. Here you will find some facts about some of the things pros often tend to consider when undertaking SEO for websites.
Challenges of Content Marketing
Content marketing can mean different things to different people. A major success factor with SEO is ensuring you have superior, highly relevant content. Sharing your content by using many different channels is one prime goal of content marketing. If you want it to convert visitors into customers, the web page ought to provide information that is engaging to customers, enables them to address a problem they have to deal with, and which provides innovation. While doing search engine optimization, it is vital if your site content is crafted for you to display crystal clear relevance to the search term by making use of proper page titles, H1 and related HTML tags, metadata like JSON-LD or microdata, and assorted file properties.
Analyzing Search Phrases
The most important action to take is search phrase analysis. It's usually viewed as SEO’s most important element. This can be achieved by using a keyword research application like Keyword Canine. You need to determine if a particular keyword can help you bring in revenue by understanding how many times it was searched. Once you found the best keywords, check each keyword if it could be ranked easily or not. Focus studying the websites that rank highest. Open their site and examine it. Evaluate the structure of the website thoroughly. If you succeed in establishing how the keyword is being used by high ranking websites, it's easier to copy a method which is shown to be efficient.
Link-Building
Backlinks are our next matter. Backlinks are employed so that online surfers can locate your site. After they click on one of your back links, they'll be redirected to a certain page of your site. The perceived quality of the backlinks helps search engines assess where to rank any specific website. Unfortunately, a number of people settle for low-cost backlink sellers. As a consequence, what they often are sent is just a huge amount of low quality spammy backlinks. This usually does more harm than good. If you want to obtain these links, the easiest approach is to create unique content material and distribute it yourself on blog sites and social media web sites. If you don't have enough time, you can hire somebody to prepare blog posts for you and use software programs to automate publication in your blogs. Proper execution of this task can make backlinks to your site in a way that's safe.
SEO Strategy Creation
The creation of your SEO strategy begins with establishing your company objectives. As part of strategy development, you must conduct key phrase research and take a look at the current market opportunity from both a difficulty and revenue point of view. Key phrase investigation is the process of identifying various keywords and phrases for your own industry that nearby prospects would use when looking for a local company. This feeds into your strategy and thus it must occur prior to almost everything else. Knowing the competition will help you make a decision as to which keywords you might want to pursue to start with. Generally an SEO advertising campaign ought to go after easier targets to start with to get trustworthiness with Yahoo and Google. Dependent on your specific needs, oftentimes people blend SEO with Pay Per Click in order to create both quick and long term success for your internet site.
Conclusion
These suggestions include the most critical factors that a novice needs to get with regards to search engine optimization. Follow these particular ideas and you will have great results.
youtube
1 note
·
View note
Text
notes on the sanctity of womanhood by richard g scott (secular)
ok so I was on the lds website looking at stuff and came across this talk and there are a few things I want to comment on (bc this shit is wild and I have a lot of feelings about it and I'm sorry if it's a lot)
link to the talk if you wanna read it: https://www.churchofjesuschrist.org/study/new-era/2008/11/the-sanctity-of-womanhood?lang=eng
tw: implied transphobia, implied rape mention

(btw "he" is referring to satan)
Third class? Who's first and second? The men can't take both spots, right?
"trade their...femininity for male coarseness" - is this referring to trans men giving up their womanhood for manhood or anger and aggressiveness typically associated with male behavior?

Whhyyyyyy would he refer to them as "attractive," seeing as he's an elderly man?
Why was their "male attire mentioned?" People crossdress all the time!
More "we need to convert everybody for the sake of their souls" type bullshittery

Can't tell if he's referring to virginity or not (if so, people shouldn't censor like this, don't leave things to the imagination, just come out and say it)

Oh no teenage boys experience sexual attraction! (a natural thing unless you're asexual, which is perfectly fine and valid) Better tell the teen girls that they're in the wrong here by dressing how they want to!

Consensual sexual acts can bring happiness, pleasure, and trust - not all lust is bad!
Also, it's strange how the church leads you to believe that sexual attraction/desire/thoughts is something wrong and sinful, yet as soon as you're married it's fine as long as it's only about the person you're married to. I can't speak for lds married couples, but wouldn't it feel weird or maybe even wrong to suddenly be allowed all of the things you were constantly told were bad and should be pushed away?
#exmo#ex mormon#exlds#ex christian#purity culture#tw transphobia#tw rape mention#fuck purity culture#fuck the mormons#<-(but only if you're married to one lol)#there's another talk right below this one called putting off the natural young woman#I might do that one next#the ex laurel/young woman inside of me is veryyy ANGRY right now
0 notes
Last Seen Blogs

shadows-of-almsivi
Shadows of ALMSIVI

chrismcshell
video games.

officialpixelfantasy
Pixel Fantasy


7justice
Egenin güzel izmiri