#Amazon Products data extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
youtube
#Scrape Amazon Products data#Amazon Products data scraper#Amazon Products data scraping#Amazon Products data collection#Amazon Products data extraction#Youtube
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
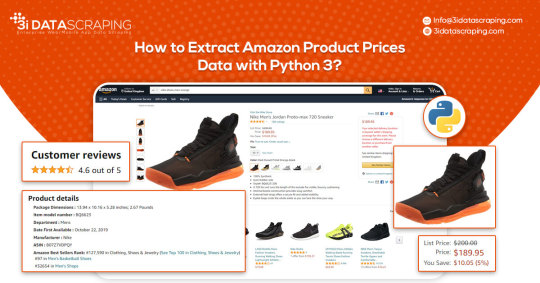
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Our Amazon product data scraping service helps you gather real-time pricing, reviews, ratings, and product details effortlessly. Stay ahead in eCommerce with accurate and structured data for market analysis, competitor research, and business growth. Get the best Amazon data extraction solutions today
0 notes
Text

The ASIN (Amazon Standard Identification Identifier) is a ten-digit number that is used to identify products on Amazon. This is unique to each product and is assigned when a new item is added to Amazon's stock. Except for books, which have an ISBN (International Standard Book Number) instead of an ASIN, almost every product on Amazon has an ASIN code. This Amazon product identifier is required before you may sell on Amazon. To achieve the best and most precise results, you can use an Amazon scraping tool to scrape Amazon product data.
0 notes
Text
0 notes
Note
Two questions about Siren:
After the revolution, did Atom make any attempt to reclaim the planet?
Did the authorities/general public ever find out about Siren?
No and no
So Atom was the type of corporation that didn't really have to care about bad PR in the public eye. They were like Amazon - demonstrably shit, but has that ever really stopped them? Their product, their geneweave technology, was their golden goose and proprietary technology. Maybe there might have been a headline in the news cycle for a day, "Atom fined for 'unethical' genetic experimentation" and then that would be that, buried under more news. People would move on, clients who already wanted to buy the products of that experimentation didn't care, etc.
Why not go back to Siren? Well because public perception is not the issue. Clients' perception is. You do NOT want your potential clients (mostly extraction & colonisation giants in the space exploration business) to know that your amazing unethical products that they pay top spacedollar for started a bloody revolutionary war, destroyed a colony on a promising planet, and killed many of your top technicians. You don't want to wave a neon sign at that incident. You want to bury it and forget it; the geneticists never made it off Siren, the data is lost, the planet still unnamed and unlabelled in official charts. Mounting a massive militarised reclamation mission would be flashy and expensive. Ishmael was made on Ceti, the planet from which the settlers came, and his genetic information is still there. Better to take that and try again, in a more controlled environment. Plus the Siren mission was partially funded by investors (usually future clients paying to have some say over the product - hey we want to union bust on a genetic level, can you do that for us?) and it wouldn't go down well with those investors to sidle up and ask for more money to clean up their oopsie ("what happened to all the money we gave you??" "oh the mission results were inconclusive")
33 notes
·
View notes
Text
In the old ranchlands of South Texas, dormant uranium mines are coming back online. A collection of new ones hope to start production soon, extracting radioactive fuel from the region’s shallow aquifers. Many more may follow.
These mines are the leading edge of what government and industry leaders in Texas hope will be a nuclear renaissance, as America’s latent nuclear sector begins to stir again.
Texas is currently developing a host of high-tech industries that require enormous amounts of electricity, from cryptocurrency mines and artificial intelligence to hydrogen production and seawater desalination. Now, powerful interests in the state are pushing to power it with next-generation nuclear reactors.
“We can make Texas the nuclear capital of the world,” said Reed Clay, president of the Texas Nuclear Alliance, former chief operating officer for Texas governor Greg Abbott’s office and former senior counsel to the Texas Office of the Attorney General. “There’s a huge opportunity.”
Clay owns a lobbying firm with heavyweight clients that include SpaceX, Dow Chemical, and the Texas Blockchain Council, among many others. He launched the Texas Nuclear Alliance in 2022 and formed the Texas Nuclear Caucus during the 2023 state legislative session to advance bills supportive of the nuclear industry.
The efforts come amid a national resurgence of interest in nuclear power, which can provide large amounts of energy without the carbon emissions that warm the planet. And it can do so with reliable consistency that wind and solar power generation lack. But it carries a small risk of catastrophic failure and requires uranium from mines that can threaten rural aquifers.
In South Texas, groundwater management officials have fought for almost 15 years against a planned uranium mine. Administrative law judges have ruled in their favor twice, finding potential for groundwater contamination. But in both cases those judges were overruled by the state’s main environmental regulator, the Texas Commission on Environmental Quality.
Now local leaders fear mining at the site appears poised to begin soon as momentum gathers behind America’s nuclear resurgence.
In October, Google announced the purchase of six small nuclear reactors to power its data centers by 2035. Amazon did the same shortly thereafter, and Microsoft has said it will pay to restart the Three Mile Island plant in Pennsylvania to power its facilities. Last month, President Joe Biden announced a goal to triple US nuclear capacity by 2050. American companies are racing to license and manufacture new models of nuclear reactors.
“It’s kind of an unprecedented time in nuclear,” said James Walker, a nuclear physicist and cofounder of New York-based NANO Nuclear Energy, a startup developing small-scale “microreactors” for commercial deployment around 2031.

The industry’s reemergence stems from two main causes, he said: towering tech industry energy demands and the war in Ukraine.
Previously, the US relied on enriched uranium from decommissioned Russian weapons to fuel its existing power plants and military vessels. When war interrupted that supply in 2022, American authorities urgently began to rekindle domestic uranium mining and enrichment.
“The Department of Energy at the moment is trying to build back a lot of the infrastructure that atrophied,” Walker said. “A lot of those uranium deposits in Texas have become very economical, which means a lot of investment will go back into those sites.”
In May, the White House created a working group to develop guidelines for deployment of new nuclear power projects. In June, the Department of Energy announced $900 million in funding for small, next-generation reactors. And in September it announced a $1.5 billion loan to restart a nuclear power plant in Michigan, which it called “a first-of-a-kind effort.”
“There’s an urgent desire to find zero-carbon energy sources that aren’t intermittent like renewables,” said Colin Leyden, Texas state director of the Environmental Defense Fund. “There aren’t a lot of options, and nuclear is one.”
Wind and solar will remain the cheapest energy sources, Leyden said, and a build-out of nuclear power would likely accelerate the retirement of coal plants.
The US hasn’t built a nuclear reactor in 30 years, spooked by a handful of disasters. In contrast, China has grown its nuclear power generation capacity almost 900 percent in the last 20 years, according to the World Nuclear Association, and currently has 30 reactors under construction.
Last year, Abbott ordered the state’s Public Utility Commission to produce a report “outlining how Texas will become the national leader in using advanced nuclear energy.” According to the report, which was issued in November, new nuclear reactors would most likely be built in ports and industrial complexes to power large industrial operations and enable further expansion.
“The Ports and their associated industries, like Liquified Natural Gas (LNG), carbon capture facilities, hydrogen facilities and cruise terminals, need additional generation sources,” the report said. Advanced nuclear reactors “offer Texas’ Ports a unique opportunity to enable continued growth.”
In the Permian Basin, the report said, reactors could power oil production as well as purification of oilfield wastewater “for useful purposes.” Or they could power clusters of data centers in Central and North Texas.
Already, Dow Chemical has announced plans to install four small reactors at its Seadrift plastics and chemical plant on a rural stretch of the middle Texas coast, which it calls the first grid-scale nuclear reactor for an industrial site in North America.
“I think the vast majority of these nuclear power plants are going to be for things like industrial use,” said Cyrus Reed, a longtime environmental lobbyist in the Texas Capitol and conservation director for the state’s Sierra Club chapter. “A lot of large industries have corporate goals of being low carbon or no carbon, so this could fill in a niche for them.”
The PUC report made seven recommendations for the creation of public entities, programs, and funds to support the development of a Texas nuclear industry. During next year’s state legislative session, legislators in the Nuclear Caucus will seek to make them law.
“It’s going to be a great opportunity for energy investment in Texas,” said Stephen Perkins, Texas-based chief operating officer of the American Conservation Coalition, a conservative environmental policy group. “We’re really going to be pushing hard for [state legislators] to take that seriously.”
However, Texas won’t likely see its first new commercial reactor come online for at least five years. Before a build-out of power plants, there will be a boom at the uranium mines, as the US seeks to reestablish domestic production and enrichment of uranium for nuclear fuel.
Texas Uranium
Ted Long, a former commissioner of Goliad County, can see the power lines of an inactive uranium mine from his porch on an old family ranch in the rolling golden savannah of South Texas. For years the mine has been idle, waiting for depressed uranium markets to pick up.
There, an international mining company called Uranium Energy Corp. plans to mine 420 acres of the Evangeline Aquifer between depths of 45 and 404 feet, according to permitting documents. Long, a dealer of engine lubricants, gets his water from a well 120 feet deep that was drilled in 1993. He lives with his wife on property that’s been in her family since her great-grandfather emigrated from Germany.
“I’m worried for groundwater on this whole Gulf Coast,” Long said. “This isn’t the only place they’re wanting to do this.”
As a public official, Long fought the neighboring mine for years. But he found the process of engaging with Texas’ environmental regulator, the Texas Commission on Environmental Quality, to be time-consuming, expensive, and ultimately fruitless. Eventually, he concluded there was no point.
“There’s nothing I can do,” he said. “I guess I’ll have to look for some kind of system to clean the water up.”
The Goliad mine is the smallest of five sites in South Texas held by UEC, which is based in Corpus Christi. Another company, enCore Energy, started uranium production at two South Texas sites in 2023 and 2024, and hopes to bring four more online by 2027.
Uranium mining goes back decades in South Texas, but lately it’s been dormant. Between the 1970s and 1990s, a cluster of open pit mines harvested shallow uranium deposits at the surface. Many of those sites left a legacy of aquifer pollution.
TCEQ records show active cases of groundwater contaminated with uranium, radium, arsenic, and other pollutants from defunct uranium mines and tailing impoundment sites in Live Oak County at ExxonMobil’s Ray Point site, in Karnes County at Conoco-Phillips’ Conquista Project, and at Rio Grande Resources’ Panna Maria Uranium Recovery Facility.
All known shallow deposits of uranium in Texas have been mined. The deeper deposits aren’t accessed by traditional surface mining, but rather a process called in-situ mining, in which solvents are pumped underground into uranium-bearing aquifer formations. Adjacent wells suck back up the resulting slurry, from which uranium dust will be extracted.
Industry describes in-situ mining as safer and more environmentally friendly than surface mining. But some South Texas water managers and landowners are concerned.
”We’re talking about mining at the same elevation as people get their groundwater,” said Terrell Graham, a board member of the Goliad County Groundwater Conservation District, which has been fighting a proposed uranium mine for almost 15 years. “There isn’t another source of water for these residents.”
“It Was Rigged, a Setup”
On two occasions, the district has participated in lengthy hearings and won favorable rulings in Texas’ administrative courts supporting concerns over the safety of the permits. But both times, political appointees at the TCEQ rejected judges’ recommendations and issued the permits anyway.
“We’ve won two administrative proceedings,” Graham said. “It’s very expensive, and to have the TCEQ commissioners just overturn the decision seems nonsensical.”
The first time was in 2010. UEC was seeking initial permits for the Goliad mine, and the groundwater conservation district filed a technical challenge claiming that permits risked contamination of nearby aquifers.
The district hired lawyers and geological experts for a three-day hearing on the permit in Austin. Afterwards, an administrative law judge agreed with some of the district’s concerns. In a 147-page opinion issued in September 2010, an administrative law judge recommended further geological testing to determine whether certain underground faults could transmit fluids from the mining site into nearby drinking water sources.
“If the Commission determines that such remand is not feasible or desirable then the ALJ recommends that the Mine Application and the PAA-1 Application be denied,” the opinion said.
But the commissioners declined the judge’s recommendation. In an order issued March 2011, they determined that the proposed permits “impose terms and conditions reasonably necessary to protect fresh water from pollution.”
“The Commission determines that no remand is necessary,” the order said.
The TCEQ issued UEC’s permits, valid for 10 years. But by that time, a collapse in uranium prices had brought the sector to a standstill, so mining never commenced.
In 2021, the permits came up for renewal, and locals filed challenges again. But again, the same thing happened.
A nearby landowner named David Michaelsen organized a group of neighbors to hire a lawyer and challenge UEC’s permit to inject the radioactive waste product from its mine more than half a mile underground for permanent disposal.
“It’s not like I’m against industry or anything, but I don’t think this is a very safe spot,” said Michaelsen, former chief engineer at the Port of Corpus Christi, a heavy industrial hub on the South Texas Coast. He bought his 56 acres in Goliad County in 2018 to build an upscale ranch house and retire with his wife.
In hearings before an administrative law judge, he presented evidence showing that nearby faults and old oil well shafts posed a risk for the injected waste to travel into potable groundwater layers near the surface.
In a 103-page opinion issued April 2024, an administrative law judge agreed with many of Michaelsen’s challenges, including that “site-specific evidence here shows the potential for fluid movement from the injection zone.”
“The draft permit does not comply with applicable statutory and regulatory requirements,” wrote the administrative law judge, Katerina DeAngelo, a former assistant attorney general of Texas in the environmental protection division. She recommended “closer inspection of the local geology, more precise calculations of the [cone of influence], and a better assessment of the faults.”
Michaelsen thought he had won. But when the TCEQ commissioners took up the question several months later, again they rejected all of the judge’s findings.
In a 19-page order issued in September, the commission concluded that “faults within 2.5 miles of its proposed disposal wells are not sufficiently transmissive or vertically extensive to allow migration of hazardous constituents out of the injection zone.” The old nearby oil wells, the commission found, “are likely adequately plugged and will not provide a pathway for fluid movement.”
“UEC demonstrated the proposed disposal wells will prevent movement of fluids that would result in pollution” of an underground source of drinking water, said the order granting the injection disposal permits.
“I felt like it was rigged, a setup,” said Michaelsen, holding his 4-inch-thick binder of research and records from the case. “It was a canned decision.”
Another set of permit renewals remains before the Goliad mine can begin operation, and local authorities are fighting it too. In August, the Goliad County Commissioners Court passed a resolution against uranium mining in the county. The groundwater district is seeking to challenge the permits again in administrative court. And in November, the district sued TCEQ in Travis County District Court seeking to reverse the agency’s permit approvals.
Because of the lawsuit, a TCEQ spokesperson declined to answer questions about the Goliad County mine site, saying the agency doesn’t comment on pending litigation.
A final set of permits remains to be renewed before the mine can begin production. However, after years of frustrations, district leaders aren’t optimistic about their ability to influence the decision.
Only about 40 residences immediately surround the site of the Goliad mine, according to Art Dohmann, vice president of the Goliad County Groundwater Conservation District. Only they might be affected in the near term. But Dohmann, who has served on the groundwater district board for 23 years, worries that the uranium, radium, and arsenic churned up in the mining process will drift from the site as years go by.
“The groundwater moves. It’s a slow rate, but once that arsenic is liberated, it’s there forever,” Dohmann said. “In a generation, it’s going to affect the downstream areas.”
UEC did not respond to a request for comment.
Currently, the TCEQ is evaluating possibilities for expanding and incentivizing further uranium production in Texas. It’s following instruction given last year, when lawmakers with the Nuclear Caucus added an item to TCEQ’s biannual budget ordering a study of uranium resources to be produced for state lawmakers by December 2024, ahead of next year’s legislative session.
According to the budget item, “The report must include recommendations for legislative or regulatory changes and potential economic incentive programs to support the uranium mining industry in this state.”
7 notes
·
View notes
Text
Excerpt from this story from Climate Home News:
The Amazon now holds nearly one-fifth of the world’s recently discovered oil and natural gas reserves, establishing itself as a new global frontier for the fossil fuel industry.
Almost 20 percent of global reserves identified between 2022 and 2024 are located in the region, primarily offshore along South America’s northern coast between Guyana and Suriname. This wealth has sparked increasing international interest from oil companies and neighbouring countries like Brazil, which is looking to exploit its own coastal resources.
In total, the Amazon region accounts for 5.3 billion barrels of oil equivalent (boe) of around 25 billion discovered worldwide during this period, according to Global Energy Monitor data, which tracks energy infrastructure development globally.
“The Amazon and adjacent offshore blocks account for a large share of the world’s recent oil and gas discoveries,” said Gregor Clark, lead of the Energy Portal for Latin America, an initiative of Global Energy Monitor. For him, however, this expansion is “inconsistent with international emissions targets and portends significant environmental and social consequences, both globally and locally.”
The region encompasses 794 oil and gas blocks – which are officially designated areas for exploration, though the existence of resources is not guaranteed. Nearly 70 percent of these Amazon blocks are either still under study or available for market bidding, meaning they remain unproductive.
In contrast, 60 percent of around 2,250 South American blocks outside the rainforest basin have already been awarded – authorized for reserve exploration and production – making the Amazon a promising avenue for further industry expansion, according to data from countries compiled by the Arayara International Institute up to July 2024. Of the entire Amazon territory, only French Guiana is devoid of oil blocks, as contracts have been banned by law there since 2017.
This new wave of oil exploration threatens a biome critical to the planet’s climate balance and the people who live there, coinciding with a global debate on reducing fossil fuel dependency.
“It’s no use talking about sustainable development if we keep exploiting oil,” said Guyanese Indigenous leader Mario Hastings. “We need real change that includes Indigenous communities and respects our rights.”
Across the eight Amazon countries analysed, 81 of all the awarded oil and gas blocks overlap with 441 ancestral lands, and 38 blocks were awarded within the limits of 61 protected natural areas. Hundreds of additional blocks are still under study or open for bids, the Arayara data shows.
5 notes
·
View notes
Text
Do you think Apple Products are overrated?
We all are very well aware of this fact that the security and the performance it offers is undeniably the best out of the best. Musicians, artist, film makers, businessman, students, everyone is crazy for it. Yet, Apple is criticized about the customer service like damage repair prices, sky touching prices of accessories, products at App Store, Storage limitations, Expandable Capacity, modifications or upgradability, battery, gaming experience.

So why is it yet overrated and people are going for this option. I was going through the internet and here is what I found out. I will summarize the whole thing in short,( in case if you plan to buy apple product, click here.)
So, The Ram Management is really impressive. Apple at 6gb or 8GB RAM, It beats any other 8GB Device variant whether it is Android or Windows. but in order to extract every ounce of the higher performance, it kills any background activity which sometime might lead to loss of unsaved data. Battery is really not at that level, charging time is still, I'd say not that better. Eco system is imressive.
And that is why artists prefer Apple products. Though it is very hard to upgrade Apple product and the price it costs is ridiculously high. Security is good, but so does limitation on supported games and apps.
However it is the best of the best productive product. And seamless connectivity with other Apple products makes the work of user easy, like it is so convenient that you will definitely love it. Camera is also competing against the DSLR's. So what is it that is left now.
But many people buy it just to show off. And the weightage of such buyers is much greater than deserving ones. Hence, it is now overrated. Because Linux is way way way better in resource management. Windows is much much better in upgradability, gaming and many other hardware beats Apple in benchmarks.
The cost is also another major factor that you can't really ignore. For servers Apple is really not preferred. Neither for competitive gaming.
We must know everything has their pros and cons. Apple is good. But it sometimes drives you crazy over little things. Like Lack of Storage, Closed Ecosystem, Limited upgradability and Software Compatibility.
It now totally depends up to you how you use it, what is your purpose. It is the user who decides whether it is worth it for him or not.
Thanks, That was my opinion, what's yours you can share with us. Also, I saw few leaked and rumored articles about Apple Fold Phones. Let's see what comes next. I am really excited to see what they offer this time.
If you are an Apple fan, here is something useful for you, : Airpods Exchange Offer Amazon
2 notes
·
View notes
Text
Use Amazon Review Scraping Services To Boost The Pricing Strategies
Use data extraction services to gather detailed insights from customer reviews. Our advanced web scraping services provide a comprehensive analysis of product feedback, ratings, and comments. Make informed decisions, understand market trends, and refine your business strategies with precision. Stay ahead of the competition by utilizing Amazon review scraping services, ensuring your brand remains attuned to customer sentiments and preferences for strategic growth.
2 notes
·
View notes
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
The ASIN (Amazon Standard Identification Identifier) is a ten-digit number that is used to identify products on Amazon. This is unique to each product and is assigned when a new item is added to Amazon's stock. Except for books, which have an ISBN (International Standard Book Number) instead of an ASIN, almost every product on Amazon has an ASIN code. This Amazon product identifier is required before you may sell on Amazon. To achieve the best and most precise results, you can use an Amazon scraping tool to scrape Amazon product data.
0 notes
Text
Amazon Product Data Scraping Services - Extract Amazon Product Data

In the vast realm of e-commerce, Amazon stands as a colossus, with millions of products spanning diverse categories. For businesses seeking to thrive in this competitive landscape, harnessing the power of Amazon product data is paramount. This is where Amazon product data scraping services come into play, offering a strategic advantage by extracting invaluable insights from the platform's wealth of information.
Understanding Amazon Product Data Scraping
Amazon product data scraping involves the automated extraction of information from Amazon's website. This process collects a wide array of data points, including product details, pricing information, customer reviews, seller rankings, and more. By systematically gathering and organizing this data, businesses gain comprehensive insights into market trends, competitor strategies, consumer preferences, and pricing dynamics.
The Value Proposition
Competitive Intelligence: With Amazon product data scraping, businesses can monitor competitors' product offerings, pricing strategies, and customer feedback. This enables them to identify market gaps, benchmark their performance, and refine their own strategies for greater competitiveness.
Market Research: By analyzing product trends, customer reviews, and ratings, businesses can gain a deeper understanding of market demands and consumer preferences. This data-driven approach helps in product development, marketing campaigns, and decision-making processes.
Price Optimization: Dynamic pricing is crucial in the ever-evolving e-commerce landscape. Amazon product data scraping allows businesses to track price fluctuations, identify optimal pricing points, and adjust their pricing strategies in real-time to maximize profitability and maintain competitiveness.
Enhanced Product Catalogs: By aggregating product data from Amazon, businesses can enrich their own product catalogs with comprehensive information, including descriptions, images, specifications, and customer reviews. This fosters transparency and trust among consumers, leading to higher conversion rates and customer satisfaction.
The Process in Action
Data Collection: Amazon product data scraping services utilize web scraping techniques to systematically retrieve data from Amazon's website. This includes product pages, search results, category listings, and more. Advanced scraping algorithms ensure accurate and timely data extraction while adhering to Amazon's terms of service.
Data Processing: Once the raw data is collected, it undergoes processing and normalization to ensure consistency and usability. This involves cleaning the data, removing duplicates, and structuring it into a format suitable for analysis and interpretation.
Analysis and Insights: The processed data is then analyzed using various statistical and machine learning techniques to extract actionable insights. These insights may include pricing trends, customer sentiment analysis, competitor benchmarks, and market segmentation.
Reporting and Visualization: Finally, the insights derived from Amazon product data scraping are presented to clients through intuitive dashboards, reports, and visualizations. This enables businesses to easily interpret the findings and make informed decisions to drive growth and profitability.
Compliance and Ethical Considerations
While Amazon product data scraping offers immense benefits, it's essential to ensure compliance with legal and ethical guidelines. Businesses must respect Amazon's terms of service and data usage policies to avoid potential legal repercussions. Additionally, respecting user privacy and data protection regulations is paramount to maintain trust and integrity.
Conclusion
In the dynamic world of e-commerce, access to accurate and timely data is indispensable for success. Amazon product data scraping services empower businesses with actionable insights to navigate the complexities of the online marketplace effectively. By leveraging the power of data, businesses can optimize their strategies, enhance their competitiveness, and drive sustainable growth in the digital age.
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes