#Amazon data scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
The Benefits of Using Amazon Scraping Tools for Market Research
Amazon is one of the largest e-commerce platforms in the world, with millions of products listed every day. With so much data available, Amazon can be a treasure trove for market research. Amazon scraping tools can help businesses extract valuable insights from Amazon product pages, reviews, and sales data. In this article, we will explore the benefits of using Amazon scraping tools for market research.
What are Amazon Scraping Tools?
Amazon scraping tools are software programs that extract data from Amazon product pages, reviews, and sales data. These tools can be used to extract various types of data, including:
Product information (e.g., description, specifications, images)
Reviews and ratings
Sales rankings
Pricing data
Benefits of Using Amazon Scraping Tools for Market Research
Identify Market Trends: Amazon scraping tools can help businesses identify market trends by analyzing sales data, reviews, and product listings.
Analyze Competitor Data: By scraping competitor data, businesses can gain insights into their pricing strategies, product offerings, and customer reviews.
Understand Customer Behavior: Amazon scraping tools can provide valuable insights into customer behavior, including purchasing habits and preferences.
Identify Product Opportunities: By analyzing Amazon product data, businesses can identify opportunities to develop new products or improve existing ones.
Improve Product Listings: Amazon scraping tools can help businesses optimize their product listings by analyzing top-performing listings and identifying key factors that contribute to their success.
How Amazon Scraping Tools Can Help with Market Research
Product Research: Amazon scraping tools can help businesses research products and identify opportunities to develop new products or improve existing ones.
Competitor Analysis: By scraping competitor data, businesses can gain insights into their pricing strategies, product offerings, and customer reviews.
Customer Insights: Amazon scraping tools can provide valuable insights into customer behavior, including purchasing habits and preferences.
Market Trend Analysis: Amazon scraping tools can help businesses identify market trends by analyzing sales data, reviews, and product listings.
Best Practices for Using Amazon Scraping Tools for Market Research
Choose a Reliable Tool: Choose an Amazon scraping tool that is reliable and provides accurate data.
Define Research Objectives: Define research objectives and identify the data that needs to be extracted.
Analyze Data: Analyze extracted data to identify trends, opportunities, and insights.
Monitor Competitor Activity: Monitor competitor activity to stay competitive and adjust market strategies accordingly.
Common Challenges in Using Amazon Scraping Tools for Market Research
Data Accuracy: Ensuring that extracted data is accurate and up-to-date can be a challenge.
IP Blocking: Amazon may block IP addresses that are scraping data excessively, which can disrupt market research.
Scalability: Handling large amounts of data can be a challenge, especially for businesses with limited resources.
Overcoming Challenges in Using Amazon Scraping Tools for Market Research
Use a Reliable Tool: Use a reliable Amazon scraping tool that provides accurate data and handles anti-scraping measures.
Rotate Proxies: Rotate proxies to avoid IP blocking and ensure that market research is not disrupted.
Optimize Data Storage: Optimize data storage to handle large amounts of data and ensure that data is easily accessible.
Conclusion
Amazon scraping tools can be a powerful tool for businesses looking to conduct market research. By providing valuable insights into customer behavior, market trends, and competitor activity, Amazon scraping tools can help businesses make informed decisions and stay competitive. By following best practices and overcoming challenges, businesses can unlock the potential of Amazon scraping tools and gain a competitive edge in the market.
1 note
·
View note
Text
How Web Scraping is Used for Amazon Keyword Research

In the ever-evolving world of e-commerce, Amazon stands as a global giant, with millions of products listed and a vast customer base. For sellers and businesses looking to succeed on this platform, Amazon keyword research is crucial. Keywords can make or break your product's visibility and sales. Fortunately, web scraping has emerged as a powerful tool to help sellers gain valuable insights into Amazon's keyword landscape, enabling them to optimize their listings and achieve better results.
Understanding Amazon Keyword Research
Amazon keyword research involves identifying the most relevant and high-impact keywords for your product listings. These keywords are essential for improving product visibility, driving organic traffic, and increasing sales. Amazon's search algorithm heavily relies on keywords to match customer queries with product listings. Thus, understanding which keywords are most effective for your product can significantly impact your success on the platform.
The Role of Web Scraping
Web scraping, also known as web harvesting or web data extraction, is a process that involves extracting data from websites. It is a versatile technique, with applications ranging from data analysis to market research. When it comes to Amazon keyword research, web scraping can be a game-changer. Here's how:
1. Extracting Competitor Keywords
Web scraping allows you to collect data from competitor product listings. By analyzing the titles, descriptions, and backend search terms of these listings, you can identify the keywords that are driving traffic and sales for similar products. This competitive keyword analysis is invaluable for fine-tuning your own product listings.
2. Analyzing Amazon Suggest and Auto-Complete
As you type a query in Amazon's search bar, you'll notice that it suggests relevant search terms. Web scraping can help you gather data on these suggestions, giving you insights into what customers are searching for. This can help you identify long-tail keywords that might have less competition but are highly relevant to your product.
3. Monitoring Keyword Rankings
Web scraping tools can be set up to periodically check the rankings of your product listings for specific keywords. This data provides insights into the effectiveness of your keyword optimization efforts. It helps you identify which keywords are driving the most traffic and conversions, allowing you to adjust your strategy accordingly.
4. Gathering Customer Reviews
Customer reviews often contain valuable keywords and phrases that buyers use to describe products. By scraping and analyzing these reviews, you can uncover additional relevant keywords to incorporate into your product listings. This can lead to improved product visibility and a better understanding of customer sentiment.
5. Tracking Seasonal and Trending Keywords
Web scraping can help you monitor shifts in keyword popularity. Seasonal and trending keywords can have a significant impact on your sales. By staying on top of these changes, you can adjust your keyword strategy to take advantage of new opportunities.
Web Scraping Tools for Amazon Keyword Research
Several web scraping tools are available that can streamline the process of gathering and analyzing Amazon keyword data. Some popular options include:
Scrapy: An open-source web scraping framework for Python, Scrapy is highly customizable and can be used to extract data from Amazon product listings efficiently.
Octoparse: This user-friendly web scraping tool offers point-and-click functionality, making it accessible to users with little to no programming experience.
ParseHub: ParseHub is a web scraping tool that allows you to extract data from websites with complex structures, making it suitable for scraping Amazon product listings and search results.
Import.io: This tool provides a simple way to turn web pages into data. You can use it to extract data from Amazon listings and reviews.
Legal and Ethical Considerations
It's essential to be aware of Amazon's terms of service and the legal and ethical considerations surrounding web scraping. Amazon may have specific rules regarding automated data collection, and it's crucial to comply with these guidelines to avoid potential repercussions.
In conclusion, web scraping is a powerful and versatile tool that can empower Amazon keyword research. By using web scraping to extract data from Amazon listings, suggest queries, customer reviews, and more, sellers and businesses can gain invaluable insights into the most effective keywords for their products. Armed with this knowledge, they can optimize their product listings and improve their visibility, ultimately leading to higher sales and success on the Amazon platform. However, it's crucial to use web scraping responsibly and ethically, while respecting Amazon's terms of service. When used correctly, web scraping can be a game-changer for Amazon keyword research.
0 notes
Text
Develop your own Amazon product scraper bot in Python
How to scrape data from amazon.com? Scraping amazon products details benefits to lots of things as product details, images, pricing, stock, rating, review, etc and it analyzes how particular brand being popular on amazon and competitive analysis. Read more
1 note
·
View note
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
youtube
#Scrape Amazon Products data#Amazon Products data scraper#Amazon Products data scraping#Amazon Products data collection#Amazon Products data extraction#Youtube
0 notes
Text
ShadowDragon sells a tool called SocialNet that streamlines the process of pulling public data from various sites, apps, and services. Marketing material available online says SocialNet can “follow the breadcrumbs of your target’s digital life and find hidden correlations in your research.” In one promotional video, ShadowDragon says users can enter “an email, an alias, a name, a phone number, a variety of different things, and immediately have information on your target. We can see interests, we can see who friends are, pictures, videos.”
The leaked list of targeted sites include ones from major tech companies, communication tools, sites focused around certain hobbies and interests, payment services, social networks, and more. The 30 companies the Mozilla Foundation is asking to block ShadowDragon scrapers are Amazon, Apple, BabyCentre, BlueSky, Discord, Duolingo, Etsy, Meta’s Facebook and Instagram, FlightAware, Github, Glassdoor, GoFundMe, Google, LinkedIn, Nextdoor, OnlyFans, Pinterest, Reddit, Snapchat, Strava, Substack, TikTok, Tinder, TripAdvisor, Twitch, Twitter, WhatsApp, Xbox, Yelp, and YouTube.
437 notes
·
View notes
Quote
In recent months, the signs and portents have been accumulating with increasing speed. Google is trying to kill the 10 blue links. Twitter is being abandoned to bots and blue ticks. There’s the junkification of Amazon and the enshittification of TikTok. Layoffs are gutting online media. A job posting looking for an “AI editor” expects “output of 200 to 250 articles per week.” ChatGPT is being used to generate whole spam sites. Etsy is flooded with “AI-generated junk.” Chatbots cite one another in a misinformation ouroboros. LinkedIn is using AI to stimulate tired users. Snapchat and Instagram hope bots will talk to you when your friends don’t. Redditors are staging blackouts. Stack Overflow mods are on strike. The Internet Archive is fighting off data scrapers, and “AI is tearing Wikipedia apart.” The old web is dying, and the new web struggles to be born.
AI is killing the old web, and the new web struggles to be born
67 notes
·
View notes
Text
How I'm Tracking My Manga Reading Backlog
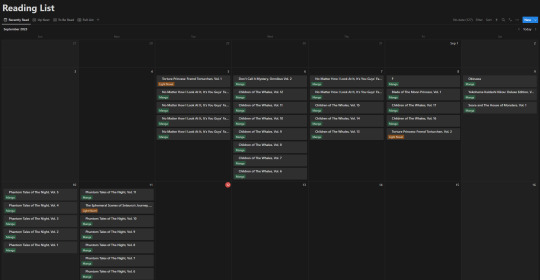
I'm bad at keeping up with reading sometimes. I'll read newer releases while still forgetting about some, want to re-read something even though I haven't started on another series, and leave droves of titles sitting on my shelves staring at me.
I got tired of that, and also tired of all these different tracking websites and apps that don't do what I want. So, with Notion and a few other tools, I've set out to make my own, and I like it! So I thought, hey, why not share how I'm doing it and see how other people keep track of their lists, so that's why I'm here. Enough rambling though, let me lead you through why I decided to make my own.
So, the number 1 challenge: Automation. In truth, it's far from perfect and is the price I pay for being lazy. But, I can automate a significant chunk of the adding process. I've yet to find a proper way to go from barcode scanning on my phone to my reading list, but I can go pretty easily from an amazon listing to the reading list. With it I grab: title, author, publisher, page count, and cover image.
So what do I use?
Well, it's a funky and interesting thing called 'Bardeen' that allows you to scrape webpages (among other things), collect and properly structure the desired information, and then feed it right into your Notion database. It's a little odd to try and figure out at first, but it's surprisingly intuitive in how it works! Once you have your template setup, you just head to the webpage (I've found Amazon the best option) and hit the button for the scraper you've built, and it puts it into Notion.
It saves an inordinate amount of time in populating fields by hand, and with the help of templates from Notion, means that the only fields left "empty" are the dated fields for tracking reading.

Thanks to Bardeen, the hardest (and really only) challenge is basically solved. Not "as" simple as a barcode, but still impressively close. Now, since the challenge is out of the way, how about some fun stuff?
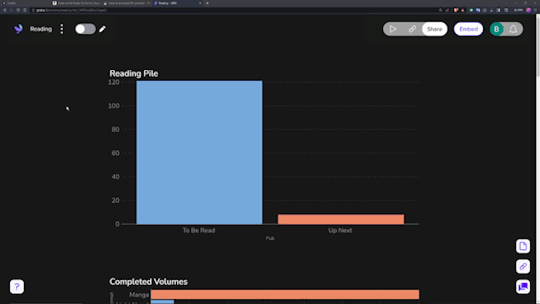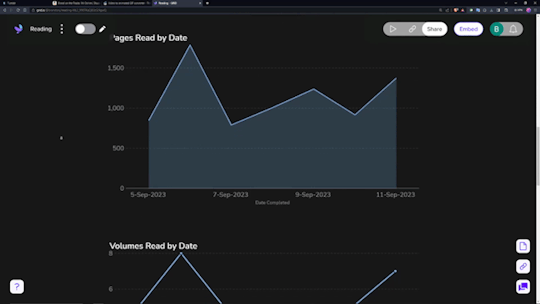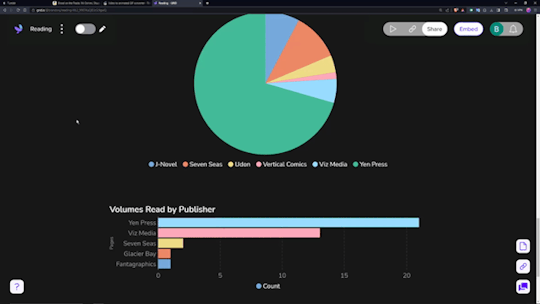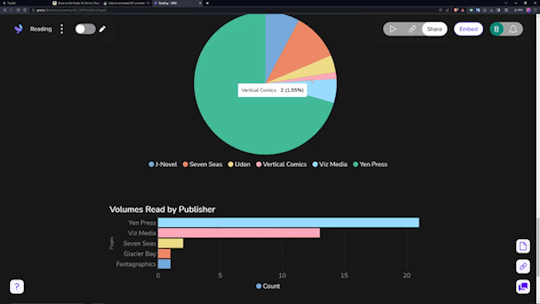
Data visualization is incredibly fun for all sorts of people. Getting to see a breakdown of all the little pieces that make up your reading habits is very interesting. Sadly, Notion doesn't have the ability to build charts from your own databases, so you need a tool.
The one I ended up settling on was 'Grid.is', as it has a "direct" integration/embed with Notion.
Sure, it has its own "limitations", but they pose absolutely zero concern as to how I want to set up my own data visualization. You can have (as far as I know) an unlimited number of graphs/charts on a single page, and you can choose to embed that page as a single entity, or go along and embed them as independent links. Either way, the graphs are really great and there's a lot of customization and options in regards to them. Also, incredibly thankful for the fact that there's an AI assistant to create the charts for you. The way that Notion data's read in is horrendous, so the AI makes it infinitely easier than what it appears as at first.
And yes, all those little popups and hover behaviors are preserved in the embeds.
Well, I suppose rather than talking about the tertiary tools, I should talk about what I'm doing with Notion itself, no?
Alright, so, like all Notion pages it starts with a database. It's the central core to keeping track of data and you can't do without it. Of course, data is no good if you can't have it properly organized, so how do I organize it?
With tags, of course! I don't have a massive amount of tags in place for the database, but I am considering adding more in terms of genre and whatnot. Regardless, what I have for the entries currently is: Title, Reading Status (TBR, Reading, Read, etc.), Author, Format (manga or LN), Date Started, Date Completed, Pages, and Publisher.
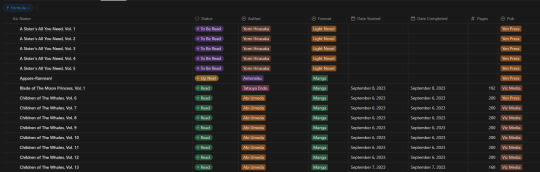
In addition to those "displayed" tags, I have two tertiary fields. The first is an image link so that entries can display an image in the appropriate view. The second, and a bit more of a pain, is a formula field used to create a proper "title" field so that Notion can sort effectively (they use lexicographic, so numbers end up sorted as letters instead). This is the poorly optimized Notion formula I used, as I don't have much experience with how they approach stuff like this. It just adds a leading zero to numbers less than 10 so that it can be properly sorted.

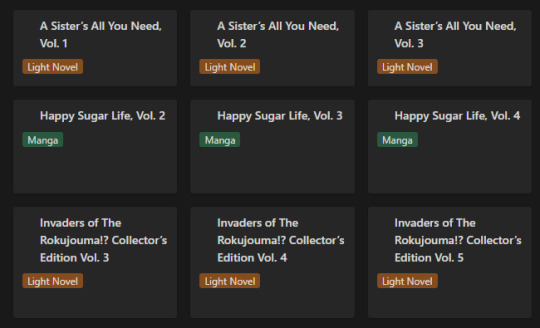
Of course this list view isn't my default view though, the calendar from the top of this post is. Most of the time though, I don't have it set to the monthly view, but rather weekly. Following up that view though, I've got my "up next" tab. This tab's meant to track all the titles/entries that I'm about to read. Things I'm planning to read today, tomorrow, or the day after. Sorta a three day sliding window to help me keep on top of the larger backlog and avoid being paralyzed by choice. It's also the only view that uses images currently.

Following that, I've got my "To Be Read" gallery. I wanted to use a kanban board but notion will only display each category as a single column, so I chose this view instead, which makes it much easier to get a better grasp of what's in the list. I've been considering adding images to this view, but I need to toy around with it some more. Either way, the point is to be able to take a wider look at what I've got left in my TBR and where I might go next.
So overall, I've ordered these views (though the list view I touch on "first" is actually the last of the views) in order from "most recent" to "least recent", if that makes any sense. Starting with where I've finished, moving to where I go next, what I have left, and then a grouping of everything for just in case.
It's certainly far from a perfect execution on a reading list/catalogue, but I think personally speaking that it checks off basically all of the boxes I required it to, and it gives me all the freedom that I could ever want - even if it means I have to put in a bit of elbow grease to make things work.
#anime and manga#manga#manga reader#manga list#reading list#reading backlog#light novel#notion#notion template
11 notes
·
View notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
IWeb Scraping scrapes the Amazon keywords data using a web scraping tool and helps sellers to list their products on the e-commerce platform.
For More Information:-
0 notes
Text
Dominate the E-Commerce Market with Amazon Product Data Scraping!

In today’s hyper-competitive digital marketplace, real-time access to product intelligence is key to driving better decisions and outperforming competitors. The Amazon Product Data Scraper by RealDataAPI enables businesses to extract rich, structured data across thousands of Amazon listings—instantly and at scale. ⚙️
🔍 Key Features: • Extract product titles, prices, ASINs, images, descriptions & specs • Monitor best sellers, variations, availability & ratings • Scrape by keyword, category, or ASINs • Ideal for price intelligence, catalog building, market research & competitor tracking
📈 “Accurate product data is your most valuable digital asset—fuel your decisions with precision.”
Whether you're managing an e-commerce platform, optimizing pricing, or building AI-based recommendation systems, this tool delivers reliable, scalable access to Amazon product intelligence.
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Extract Amazon Product Prices with Web Scraping | Actowiz Solutions
Introduction
In the ever-evolving world of e-commerce, pricing strategy can make or break a brand. Amazon, being the global e-commerce behemoth, is a key platform where pricing intelligence offers an unmatched advantage. To stay ahead in such a competitive environment, businesses need real-time insights into product prices, trends, and fluctuations. This is where Actowiz Solutions comes into play. Through advanced Amazon price scraping solutions, Actowiz empowers businesses with accurate, structured, and actionable data.
Why extract Amazon Product Prices?

Price is one of the most influential factors affecting a customer’s purchasing decision. Here are several reasons why extracting Amazon product prices is crucial:
Competitor Analysis: Stay informed about competitors’ pricing.
Dynamic Pricing: Adjust your prices in real time based on market trends.
Market Research: Understand consumer behavior through price trends.
Inventory & Repricing Strategy: Align stock and pricing decisions with demand.
With Actowiz Solutions’ Amazon scraping services, you get access to clean, structured, and timely data without violating Amazon’s terms.
How Actowiz Solutions Extracts Amazon Price Data

Actowiz Solutions uses advanced scraping technologies tailored for Amazon’s complex site structure. Here’s a breakdown:
1. Custom Scraping Infrastructure
Actowiz Solutions builds custom scrapers that can navigate Amazon’s dynamic content, pagination, and bot protection layers like CAPTCHA, IP throttling, and JavaScript rendering.
2. Proxy Rotation & User-Agent Spoofing
To avoid detection and bans, Actowiz employs rotating proxies and multiple user-agent headers that simulate real user behavior.
3. Scheduled Data Extraction
Actowiz enables regular scheduling of price scraping jobs — be it hourly, daily, or weekly — for ongoing price intelligence.
4. Data Points Captured
The scraping service extracts:
Product name & ASIN
Price (MRP, discounted, deal price)
Availability
Ratings & Reviews
Seller information
Real-World Use Cases for Amazon Price Scraping

A. Retailers & Brands
Monitor price changes for own products or competitors to adjust pricing in real-time.
B. Marketplaces
Aggregate seller data to ensure competitive offerings and improve platform relevance.
C. Price Comparison Sites
Fuel your platform with fresh, real-time Amazon price data.
D. E-commerce Analytics Firms
Get historical and real-time pricing trends to generate valuable reports for clients.
Dataset Snapshot: Amazon Product Prices

Below is a snapshot of average product prices on Amazon across popular categories:
Product CategoryAverage Price (USD)Electronics120.50Books15.75Home & Kitchen45.30Fashion35.90Toys & Games25.40Beauty20.60Sports50.10Automotive75.80
Benefits of Choosing Actowiz Solutions

1. Scalability: From thousands to millions of records.
2. Accuracy: Real-time validation and monitoring ensure data reliability.
3. Customization: Solutions are tailored to each business use case.
4. Compliance: Ethical scraping methods that respect platform policies.
5. Support: Dedicated support and data quality teams
Legal & Ethical Considerations

Amazon has strict policies regarding automated data collection. Actowiz Solutions follows legal frameworks and deploys ethical scraping practices including:
Scraping only public data
Abiding by robots.txt guidelines
Avoiding high-frequency access that may affect site performance
Integration Options for Amazon Price Data

Actowiz Solutions offers flexible delivery and integration methods:
APIs: RESTful APIs for on-demand price fetching.
CSV/JSON Feeds: Periodic data dumps in industry-standard formats.
Dashboard Integration: Plug data directly into internal BI tools like Tableau or Power BI.
Contact Actowiz Solutions today to learn how our Amazon scraping solutions can supercharge your e-commerce strategy.Contact Us Today!
Conclusion: Future-Proof Your Pricing Strategy
The world of online retail is fast-moving and highly competitive. With Amazon as a major marketplace, getting a pulse on product prices is vital. Actowiz Solutions provides a robust, scalable, and ethical way to extract product prices from Amazon.
Whether you’re a startup or a Fortune 500 company, pricing intelligence can be your competitive edge. Learn More
#ExtractProductPrices#PriceIntelligence#AmazonScrapingServices#AmazonPriceScrapingSolutions#RealTimeInsights
0 notes
Text
Naver Pricing Data Extraction For Retail Pricing Analysis
Introduction
In today's hypercompetitive retail landscape, staying ahead requires more than quality products and excellent customer service. The ability to make data-driven pricing decisions has become a critical factor separating industry leaders from those struggling to maintain market share. Among the various markets worldwide, South Korea's e-commerce ecosystem – dominated by platforms like Naver – presents unique opportunities for retailers seeking to optimize their pricing strategies through technological solutions.
Naver Pricing Data Extraction has emerged as a game-changing approach for businesses seeking competitive intelligence from South Korea's largest online marketplace. By leveraging advanced algorithms and automation, retailers can now access comprehensive insights that were previously unattainable or required prohibitively expensive manual research. This paradigm shift transforms how companies approach competitive price analysis, enabling more agile, responsive, and strategic decision-making.
Understanding the Korean E-commerce Landscape
To fully grasp the transformative impact of Naver Price Scraping, it's essential first to understand Naver's distinct role in the Korean digital ecosystem. Unlike Western markets—where platforms like Google dominate search, and Amazon leads the e-commerce space—Naver stands out as a multifaceted platform that seamlessly integrates search, online shopping, content creation, and community interaction into a unified experience.
With more than 30 million daily active users in a nation of roughly 51 million, Naver's marketplace offers a treasure trove of data related to consumer behavior, pricing trends, and product demand specific to the Korean market. For global retailers and brands aiming to expand into or strengthen their presence in this highly competitive and lucrative space, gaining insight into pricing dynamics within Naver is not just beneficial—it's essential.
The Evolution of Competitive Price Intelligence
Historically, businesses relied on manual and labor-intensive methods for competitive price monitoring. These traditional approaches involved store visits or browsing competitor websites, followed by manually entering prices into spreadsheets—a process that was not only time-consuming but also inherently flawed.
This legacy method was:
Inefficient: Requiring extensive human effort, these methods diverted valuable time and resources away from strategic initiatives.
Error-prone: Manual data entry increases the risk of inaccuracies, leading to flawed analysis and potentially costly decisions.
Limited Scope: With only a small segment of competitors and products being monitored, businesses lacked a holistic market view.
Reactive rather than proactive: Insights were delayed, offering a retrospective look at pricing trends rather than real-time data that could drive timely decisions.
The advent of Naver Product Data Scraping technologies has revolutionized how businesses approach price intelligence. Today’s advanced systems enable automated tracking of thousands of products across numerous competitors, delivering near-instantaneous updates on price fluctuations, stock availability, and promotional campaigns.
This transformation from manual tracking to automated, real-time analytics marks a pivotal advancement in competitive price intelligence, empowering businesses to act strategically with timely, accurate data.
How Naver Pricing Data Extraction Functions?
Naver Pricing Data Extraction is powered by advanced software that methodically traverses Naver's platform, pinpointing relevant product listings and extracting key structured data points, including:
Current selling prices
Historical price trends
Available stock levels
Promotional offers and discounts
Product specifications and features
Customer ratings and reviews
Shipping options and costs
Incorporating machine learning algorithms, advanced Naver Scraper For Retailers solutions can detect patterns, filter out irrelevant data, and standardize information from different sellers' unique presentation formats. This ensures that the extracted data remains consistent, accurate, and primed for further analysis.
The overall process of Naver Pricing Data Extraction typically follows these stages:
Target Identification: The first step is to define which specific products, categories, or competitors should be monitored. This helps set the scope of the data collection.
Data Collection: Automated bots visit predetermined pages at specified intervals, continuously gathering new data to ensure it stays up-to-date.
Data Extraction: During this phase, the platform identifies and captures relevant product details and pricing information.
Data Processing: Raw data is cleaned, standardized, and structured to make it usable for analysis, eliminating inconsistencies or irrelevant details.
Data Analysis: The cleaned data is analyzed to uncover trends, patterns, and anomalies. This step helps businesses understand price fluctuations, inventory changes, and customer behavior.
Insight Generation: Based on the analysis, actionable insights are generated. These insights offer recommendations that businesses can use to adjust their pricing strategies or improve inventory management.
Integration: The final step involves integrating the data into business intelligence systems, enabling seamless decision-making processes and real-time monitoring.
Modern Naver Competitor Pricing Tools handle this entire process automatically, providing businesses with continuous pricing intelligence without manual intervention. This approach empowers businesses to stay competitive by making real-time data-driven decisions.
Strategic Applications of Naver Product Data
Organizations utilizing tools to Scrape Naver Product Data technologies are uncovering a wide range of strategic applications that go beyond basic price matching. Some of the most impactful uses include:
1. Dynamic Pricing Optimization
Rather than simply reacting to competitor price changes, forward-thinking retailers leverage Naver's pricing intelligence to implement advanced dynamic pricing models. These models use complex algorithms that take into account multiple factors, such as:
Movements in competitor pricing
Fluctuations in demand based on time of day, seasonality, or market conditions
Real-time inventory levels
Specific customer segments and their price sensitivity
Profit margin objectives
Long-term market positioning strategies
By automating price adjustments within these well-defined parameters, businesses can maintain an optimal competitive position without constant manual intervention, resulting in more efficient operations and improved profit margins.
2. Assortment Planning and Category Management
Naver Product Catalog Scraping offers valuable insights into competitors' product assortments, allowing retailers to identify
Gaps in their current product offerings
Emerging product trends and new categories that are gaining popularity
Opportunities to introduce exclusive or differentiated items
Product features and attributes that resonate most with consumers
This data-driven intelligence empowers retailers to make more informed strategic decisions about which products to introduce, discontinue, or emphasize in marketing campaigns. This ultimately enhances their product portfolio and aligns it with customer demand.
3. Promotion Effectiveness Analysis
By monitoring promotional activities within Naver's marketplace, retailers can gather insights that help optimize their marketing efforts.
Specifically, they can assess:
Which promotional strategies generate the highest response rates?
The most effective discount thresholds for different product categories.
Competitor promotion schedules and promotional cycles.
The impact of promotions on the perceived value of regular pricing.
With these insights, retailers can plan more effective marketing campaigns, allocate budgets more efficiently, and adjust promotional tactics to maximize return on investment, ultimately boosting sales and brand visibility.
Transforming Pricing Strategy Through Data
Integrating Web Scraping For Pricing Strategy is revolutionizing how businesses approach pricing decisions. Traditional methods often relied on internal metrics like cost-plus formulas or basic competitive benchmarking. Modern, data-driven pricing strategies now incorporate much richer insights:
1. Value-Based Pricing Enhancement
With detailed market data from Naver, businesses gain a deeper understanding of their products' perceived value compared to competitors. This insight enables the development of more advanced value-based pricing strategies that account for:
Feature and specification differentials
Brand perception premiums
Service level differences
Customer experience factors
E-Commerce Data Extraction allows businesses to quantify these previously subjective elements, enabling the creation of pricing models that more accurately reflect actual market value.
2. Geographical Pricing Optimization
The Korean market's pricing sensitivity and competitive dynamics can differ significantly by region. Naver Price Scraping Services For E-Commerce Businesses with valuable insights into these regional variations, empowering retailers to implement location-specific pricing strategies that maximize competitiveness and profitability across various areas.
3. Elasticity Modeling
By accessing historical pricing data, businesses can develop sophisticated price elasticity models. Analyzing how demand reacts to price changes across different product categories allows retailers to forecast the potential revenue impact of pricing adjustments before implementing them—thereby reducing risk and enhancing financial outcomes.
Ethical and Legal Considerations
While the competitive advantages of Product Price Comparison technologies are evident, the implementation of these solutions requires a careful approach to legal and ethical considerations:
1. Compliance with Terms of Service
Platforms like Naver establish terms of service that govern automated data access. Responsible Naver price scraping services ensure full compliance with these terms by:
Adhering to rate limits
Properly identifying automated requests
Preventing server overload
Respecting robots.txt directives
2. Data Privacy Considerations
Ethical data extraction prioritizes publicly available information, avoiding any collection of personal customer data. Trusted providers maintain strict protocols to:
Filter out personally identifiable information (PII).
Ensure secure transmission and storage of the extracted data.
Implement appropriate data retention policies.
Adhere to relevant privacy regulations.
3. Intellectual Property Respect
Proper E-Commerce Data Extraction upholds intellectual property rights by:
Not extracting copyrighted content for republishing.
Focusing solely on factual data points rather than creative elements.
Using the data solely for analytical purposes instead of reproduction.
Implementing a Successful Naver Data Strategy
A structured approach is crucial for success for businesses aiming to maximize the potential of Naver Price Scraping Services For E-Commerce Businesses. The implementation process typically follows these key steps:
Define Clear Objectives
Identify Critical Data Points
Choose the Right Technology Solution
Integrate with Decision Processes
Continuously Refine Your Approach
How Retail Scrape Can Help You?
We specialize in offering advanced Naver Product Catalog Scraping solutions specifically tailored to your business's unique needs. Our team of data experts combines technical proficiency with a deep understanding of retail pricing dynamics, delivering actionable insights that generate measurable outcomes.
Our comprehensive approach includes:
Custom data extraction strategies designed around your specific competitive landscape.
Scalable solutions that evolve with your product catalog and competitive monitoring needs.
Advanced analytics dashboards provide an intuitive visualization of complex pricing trends.
Integration with your existing systems to streamline decision-making processes.
Regular consultation with pricing specialists to transform data into strategic action plans.
We recognize that every business has distinct requirements, which is why our Naver Scraper For Retailers solutions are fully customizable to align with your goals – whether you're aiming to optimize margins, expand market share, or strike the ideal balance between competitive positioning and profitability.
Conclusion
In today's data-driven retail environment, comprehensive market intelligence isn't just advantageous – it's essential. Product Price Comparison through automated data extraction provides the visibility needed to make informed, strategic pricing decisions that balance competitiveness with profitability.
As Korean e-commerce continues its rapid growth trajectory, retailers without robust Naver Pricing Data Extraction capabilities risk being outmaneuvered by more data-savvy competitors. The difference between success and struggle increasingly lies in how effectively companies harness this intelligence to inform their pricing strategies.
Ready to transform your pricing strategy with powerful Naver marketplace insights? Contact Retail Scrape today to discover how our customized data extraction solutions can give your business the competitive edge it needs.
Source : https://www.retailscrape.com/naver-pricing-data-extraction-retail-pricing-analysis.php
Originally Published By https://www.retailscrape.com/
#NaverPricingDataExtraction#NaverScraperForRetailers#NaverCompetitorPricing#NaversPricingIntelligence#NaverProductCatalogScraping#ECommerceDataExtraction#DataExtractionSolutions#RealTimeDataExtraction
0 notes
Text
Smart Retail Decisions Start with AI-Powered Data Scraping

In a world where consumer preferences change overnight and pricing wars escalate in real time, making smart retail decisions is no longer about instincts—it's about data. And not just any data. Retailers need fresh, accurate, and actionable insights drawn from a vast and competitive digital landscape.
That’s where AI-powered data scraping steps in.
Historically, traditional data scraping has been used to gather ecommerce data. But by leveraging artificial intelligence (AI) in scraping processes, companies can gain real-time, scalable, and predictive intelligence to make informed decisions in retailing.
Here, we detail how data scraping using AI is revolutionizing retailing, its advantages, what kind of data you can scrape, and why it enables high-impact decisions in terms of pricing, inventory, customer behavior, and market trends.
What Is AI-Powered Data Scraping?
Data scraping is an operation of pulling structured data from online and digital channels, particularly websites that do not support public APIs. In retail, these can range from product offerings and price data to customer reviews and availability of items in stock.
AI-driven data scraping goes one step further by employing artificial intelligence such as machine learning, natural language processing (NLP), and predictive algorithms to:
Clean and structure unstructured data
Interpret customer sentiment from reviews
Detect anomalies in prices
Predict market trends
Based on data collected, provide strategic proposals
It's not just about data-gathering—it’s about knowing and taking wise action based on it.
Why Retail Requires Smarter Data Solutions
The contemporary retail sector is sophisticated and dynamic. This is why AI-powered scraping is more important than ever:
Market Changes Never Cease to Occur Prices, demand, and product availability can alter multiple times each day—particularly on marketplaces such as Amazon or Walmart. AI scrapers can monitor and study these changes round-the-clock.
Manual Decision-Making is Too Slow Human analysts can process only so much data. AI accelerates decision-making by processing millions of pieces of data within seconds and highlighting what's significant.
The Competition is Tough Retailers are in a race to offer the best prices, maintain optimal inventory, and deliver exceptional customer experiences. Data scraping allows companies to monitor competitors in real time.
Types of Retail Data You Can Scrape with AI
AI-powered scraping tools can extract and analyze the following retail data from ecommerce sites, review platforms, competitor websites, and search engines:
Product Information
Titles, descriptions, images
Product variants (size, color, model)
Brand and manufacturer details
Availability (in stock/out of stock)
Pricing & Promotions
Real-time price tracking
Historical pricing trends
Discount and offer patterns
Dynamic pricing triggers
Inventory & Supply
Stock levels
Delivery timelines
Warehouse locations
SKU movement tracking
Reviews & Ratings
NLP-based sentiment analysis
Star ratings and text content
Trending complaints or praise
Verified purchase filtering
Market Demand & Sales Rank
Bestsellers by category
Category saturation metrics
Sales velocity signals
New or emerging product trends
Logistics & Shipping
Delivery options and timeframes
Free shipping thresholds
Return policies and costs
Benefits of AI-Powered Data Scraping in Retail
So what happens when you combine powerful scraping capabilities with AI intelligence? Retailers unlock a new dimension of performance and strategy.
1. Real-Time Competitive Intelligence
With AI-enhanced scraping, retailers can monitor:
Price changes across hundreds of competitor SKUs
Promotional campaigns
Inventory status of competitor bestsellers
AI models can predict when a competitor may launch a flash sale or run low on inventory—giving you an opportunity to win customers.
2. Smarter Dynamic Pricing
Machine learning algorithms can:
Analyze competitor pricing history
Forecast demand elasticity
Recommend optimal pricing
Retailers can automatically adjust prices to stay competitive while maximizing margins.
3. Enhanced Product Positioning
By analyzing product reviews and ratings using NLP, you can:
Identify common customer concerns
Improve product descriptions
Make data-driven merchandising decisions
For example, if customers frequently mention packaging issues, that feedback can be looped directly to product development.
4. Improved Inventory Planning
AI-scraped data helps detect:
Which items are trending up or down
Seasonality patterns
Regional demand variations
This enables smarter stocking, reduced overstock, and faster response to emerging trends.
5. Superior Customer Experience
Insights from reviews and competitor platforms help you:
Optimize support responses
Highlight popular product features
Personalize marketing campaigns
Use Cases: How Retailers Are Winning with AI Scraping
DTC Ecommerce Brands
Use AI to monitor pricing and product availability across marketplaces. React to changes in real time and adjust pricing or run campaigns accordingly.
Multichannel Retailers
Track performance and pricing across online and offline channels to maintain brand consistency and pricing competitiveness.
Consumer Insights Teams
Analyze thousands of reviews to spot unmet needs or new use cases—fueling product innovation and positioning.
Marketing and SEO Analysts
Scrape metadata, titles, and keyword rankings to optimize product listings and outperform competitors in search results.
Choosing the Right AI-Powered Scraping Partner
Whether building your own tool or hiring a scraping agency, here’s what to look for:
Scalable Infrastructure
The tool should handle scraping thousands of pages per hour, with robust error handling and proxy support.
Intelligent Data Processing
Look for integrated machine learning and NLP models that analyze and enrich the data in real time.
Customization and Flexibility
Ensure the solution can adapt to your specific data fields, scheduling, and delivery format (JSON, CSV, API).
Legal and Ethical Compliance
A reliable partner will adhere to anti-bot regulations, avoid scraping personal data, and respect site terms of service.
Challenges and How to Overcome Them
While AI-powered scraping is powerful, it’s not without hurdles:
Website Structure Changes
Ecommerce platforms often update their layouts. This can break traditional scraping scripts.
Solution: AI-based scrapers with adaptive learning can adjust without manual reprogramming.
Anti-Bot Measures
Websites deploy CAPTCHAs, IP blocks, and rate limiters.
Solution: Use rotating proxies, headless browsers, and CAPTCHA solvers.
Data Noise
Unclean or irrelevant data can lead to false conclusions.
Solution: Leverage AI for data cleaning, anomaly detection, and duplicate removal.
Final Thoughts
In today's ecommerce disruption, retailers that utilize real-time, smart data will be victorious. AI-driven data scraping solutions no longer represent an indulgence but rather an imperative to remain competitive.
By facilitating data capture and smarter insights, these services support improved customer experience, pricing, marketing, and inventory decisions.
No matter whether you’re introducing a new product, measuring your market, or streamlining your supply chain—smart retailing begins with smart data.
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes