#AmazonWebScraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text

Discover tips to overcome Amazon web scraping challenges, including IP blocking, captchas, and more. Learn effective strategies for successful data extraction.
Source: https://www.iwebdatascraping.com/effective-solutions-to-overcome-amazon-web-scraping-challenges.php
#AmazonWebScraping#WebScrapingEcommerceData#AmazonDataCollection#AmazonWebScraper#EcommerceDataScrapingServices
0 notes
Text
Amazon Web Scraping: Exploring Its Illegal and Unethical Dimensions
Introduction
In the age of e-commerce dominance, Amazon stands as a retail giant, offering a vast marketplace for both buyers and sellers. As businesses and individuals seek to gain a competitive edge on the platform, some turn to web scraping as a means of extracting valuable data. However, the practice of Amazon web scraping isn't without controversy, raising questions about its legality and ethics.
This article delves into the complex world of Amazon web scraping, shedding light on the illegal and unethical dimensions often accompanying this practice. While web scraping is not inherently illegal, it can cross legal boundaries when used to harvest sensitive data without consent or violating Amazon's terms of service.
We will explore the potential harm caused by unethical scraping, including the infringement of intellectual property rights, the disruption of fair competition, and the compromise of user privacy. Understanding these issues is crucial for individuals and businesses looking to engage in data extraction activities on Amazon's platform.
Join us as we navigate the maze of Amazon web scraping, unveiling the legal and ethical concerns that should be considered before embarking on such endeavors and how they may impact your business and online presence.
The Dark Side of Amazon Scraping: Understanding Illicit and Unethical Practices
Illegal and unethical use cases of Amazon scraping can have far-reaching consequences, not only for those who engage in such activities but also for the broader Amazon ecosystem and its users. It's essential to be aware of these practices to avoid legal troubles and maintain ethical conduct in the digital marketplace. Below, we'll explore these illegal and unethical use cases in more detail:
Price Manipulation
Some individuals or businesses scrape Amazon's product prices with the intent of manipulating prices, either on their listings or on other e-commerce platforms. This unethical practice can disrupt fair competition and deceive consumers. In many jurisdictions, such price-fixing is illegal and can lead to antitrust violations and substantial fines.
Unauthorized Data Extraction
Scraping sensitive data, such as customer information, product details, or sales data, without proper consent is illegal and unethical. It may violate privacy regulations, such as the General Data Protection Regulation (GDPR) and Amazon's terms of service. Unauthorized data extraction compromises the privacy and security of Amazon's users, potentially resulting in legal action and account suspension.
Review Manipulation
Some individuals scrape to manipulate product reviews on Amazon. This includes posting fake reviews, deleting genuine ones, or gaming the review system. Such manipulation is dishonest and can erode trust in the platform. Amazon actively works to combat review manipulation, and those caught engaging in such practices may face account suspension or legal consequences.
Intellectual Property Infringement
Scraping images, product descriptions, or copyrighted content from Amazon listings without proper authorization infringes on intellectual property rights. Amazon sellers invest time and resources in creating their listings, and unauthorized scraping and reusing of this content can lead to copyright infringement lawsuits and legal penalties.
Unfair Competition
Using scraped data to gain an unfair advantage in the marketplace, such as replicating successful products, exploiting competitors' strategies, or unfairly targeting their customer base, is considered unethical. Engaging in such practices can lead to legal disputes, damage your brand's reputation, and potential account suspension.
Web Traffic Hijacking
Some individuals scrape Amazon's product listings to redirect web traffic from Amazon to their website or another platform. This not only violates Amazon's policies but is also unethical as it diverts potential customers from the intended platform. It can lead to account suspension and loss of trust among Amazon's user base.
Fraudulent Activities
Scraping data intending to engage in fraudulent activities, such as identity theft, credit card fraud, or phishing, is illegal and morally wrong. These activities not only harm Amazon's users but also put you at risk of facing criminal charges and significant legal consequences.
Violation of Amazon's Terms of Service
Amazon has specific terms of service that prohibit certain scraping activities. Violating these terms can result in account suspension, termination, or other legal actions initiated by Amazon.
It's essential to recognize that while web scraping itself is not inherently illegal, how it is employed can make it illegal or unethical. Before engaging in any scraping activities related to Amazon, it is crucial to ensure strict compliance with the law, regulations, and Amazon's policies. Additionally, considering the potential harm scraping can cause to other users, businesses, and the platform is a responsible and ethical approach to data collection in the e-commerce ecosystem. Explore the responsible and ethical use of E-commerce Data Scraping Services to gather insights without causing harm to the digital ecosystem.
Efficiency in Data Extraction: Understanding the Speed of Web Scraping
Web scraping is a powerful technique for collecting data from websites. Still, it should be performed responsibly, considering various factors that affect the speed and efficiency of data extraction. Let's delve into these considerations:
Server Workload
One key factor that affects data extraction speed is the server load of the website being scraped. Heavy server loads can slow down the scraping process as the website's servers may need help to respond to a high volume of requests. Responsible web scrapers monitor server load and adjust their scraping rate to avoid overloading the servers, which could lead to IP blocking or other countermeasures.
Navigating Website Limits
Web scraping should respect the boundaries set by the website. This includes understanding and adhering to the website's terms of service, robots.txt file, and any other specific guidelines provided. Ignoring these boundaries can lead to legal issues and ethical concerns.
Optimizing Web Scraping Speed
Rate limiting, or setting the frequency of requests, is a crucial aspect of responsible web scraping. Scrapers should ensure that they only bombard a website with requests quickly. Setting an appropriate delay between requests not only helps avoid overloading the server but also reduces the risk of getting banned.
Honoring the Website's Integrity
Responsible web scrapers should ensure that their activities do not disrupt the normal functioning of the website. Web scraping should be conducted in a way that doesn't interfere with the experience of other users and doesn't cause unnecessary strain on the website's resources.
The Quest for Quality Amidst Quantity
It's essential to balance the quantity of data collected and the quality of that data. Extracting large volumes of data quickly may lead to inaccuracies, incomplete information, or even getting banned. Prioritizing data quality over quantity is a wise approach.
Ethics in Web Scraping Practices
Ethical considerations are paramount in web scraping. Engaging in scraping activities that could harm others, violate privacy, or deceive users is unethical. Responsible web scrapers should ensure that their activities are aligned with ethical principles and fair play.
Exploring Error Rates
Web scraping is only sometimes error-free. Pages may change in structure or content, causing scraping errors. Responsible scrapers should implement error-handling mechanisms to address these issues, such as retries, error logging, and notifications.
Detect and Evade
Websites often employ anti-scraping measures to detect and block scrapers. Responsible web scrapers should employ techniques to avoid detection, such as using rotating user agents, IP rotation, and CAPTCHA solving, while still adhering to ethical and legal boundaries.
Ensuring Data Persistence
If your web scraping is intended to be an ongoing process, it's crucial to maintain a good relationship with the website. This involves continuously monitoring scraping performance, adjusting to any changes on the website, and being prepared to adapt your scraping strategy to ensure long-term access to the data.
The speed of data extraction in web scraping depends on various factors, and responsible web scrapers take these factors into account to ensure their activities are efficient, ethical, and compliant with the rules and boundaries set by the websites they interact with. By doing so, they can achieve their data extraction goals while minimizing the risk of legal issues, ethical concerns, and disruptions to the websites they scrape.
Best Practices for Preventing Copyright Violations in Web Scraping Amazon Data
You are avoiding copyright infringement when web scraping from Amazon or any website is critical to ensure that you operate within the boundaries of copyright law. Amazon, like many websites, has its terms of service and content protection measures. Here are some specific steps to help you avoid copyright infringement while web scraping from Amazon:
Review Amazon's Terms of Service
Start by thoroughly reading Amazon's terms of service, user agreements, and any web scraping guidelines they may provide. Amazon's terms may specify which activities are allowed and which are prohibited.
Understand Amazon's Robots.txt File
Check Amazon's robots.txt file, which can be found at the root of their website (https://www.amazon.com/robots.txt). The robots.txt file may provide guidelines on which parts of the site are off-limits to web crawlers and scrapers. Adhere to these guidelines.
Use Amazon's API (if available)
Whenever possible, use Amazon's Application Programming Interface (API) to access their data. Amazon provides APIs for various services, and using them is often more compliant with their terms of service.
Scrape Only Publicly Accessible Data
Focus on scraping publicly accessible data that is not protected by copyright. Product information, prices, and availability are typically not copyrighted, but be cautious with descriptions and images, as they may be protected.
Respect Copyrighted Content
Avoid scraping and using copyrighted materials like product images, descriptions, and user-generated content without proper authorization or adherence to fair use principles. Seek permission or use these materials in a manner consistent with copyright law.
Attribute Sources
When displaying or sharing scraped data from Amazon, provide proper attribution and source information to acknowledge Amazon as the original content provider. This practice demonstrates good faith and respect for copyright.
Avoid Republishing Entire Content
Refrain from republishing entire product listings or substantial portions of Amazon's copyrighted content without authorization. Instead, summarize or quote selectively and link back to the source.
Use a Human-Like Scraping Pattern
Employ scraping techniques that mimic human browsing behavior, such as adding delays between requests, randomizing user agents, and avoiding aggressive or rapid scraping. This can help prevent being detected as a malicious bot.
Monitor and Adapt
Continuously monitor your scraping activities and adapt to any changes in Amazon's terms of service, website structure, or technology. Stay aware of any updates or changes in their policies.
Legal Consultation
If you are still determining the legality of your web scraping activities on Amazon, consider seeking legal advice from experts in copyright and web scraping law. Legal professionals can provide guidance specific to your situation.
It's essential to approach web scraping from Amazon or any e-commerce platform with caution and respect for copyright laws. By adhering to Amazon's terms of service, observing copyright regulations, and maintaining ethical web scraping practices, you can extract the necessary data while minimizing the risk of copyright infringement and legal issues.
Legal Considerations for Web Scraping on Amazon Marketplace
Web scraping laws can vary significantly from one country to another, and when it comes to the Amazon Marketplace, it's essential to understand the legal landscape in different jurisdictions. Amazon, as a global e-commerce platform, operates in numerous countries and regions, each with its legal framework regarding web scraping and data collection. Below is a broad overview of web scraping laws related to the Amazon Marketplace in different countries.
United States
In the United States, web scraping laws are primarily governed by federal copyright and computer fraud laws. While copyright laws protect original content and creative works, web scraping may infringe upon copyrights if not conducted responsibly. The Computer Fraud and Abuse Act (CFAA) can be used to prosecute scraping activities that involve unauthorized access to computer systems. Therefore, it's essential to respect Amazon's terms of service and legal boundaries when scraping its platform.
European Union
In the European Union, web scraping laws are influenced by data protection regulations, copyright laws, and the General Data Protection Regulation (GDPR). GDPR, in particular, imposes strict rules on the collection and processing of personal data, which includes customer information. Suppose you are scraping data from Amazon's EU websites. In that case, you must ensure that you comply with GDPR requirements, such as obtaining user consent for data processing and following the principles of data minimization.
United Kingdom
The UK, after leaving the EU, has adopted its data protection laws, including the UK GDPR. These regulations influence web scraping laws in the UK. It's crucial to respect user privacy and data protection rights when scraping data from Amazon UK or any other website.
Canada
In Canada, web scraping laws are influenced by the Copyright Act, which protects original literary, artistic, and dramatic works. While factual information may not be subject to copyright, scraping product descriptions or images without proper authorization can infringe upon copyrights. Additionally, Canada has data protection laws, like the Personal Information Protection and Electronic Documents Act (PIPEDA), which governs the handling of personal data.
Australia
Australia has copyright laws similar to those in the United States, which protect original works. However, facts and data are not generally subject to copyright. When scraping Amazon Australia, you should respect the terms of service and intellectual property rights while adhering to the Australian Privacy Principles (APPs) when handling personal data.
India
In India, web scraping laws are primarily influenced by copyright law, which protects original literary and artistic works. Web scraping that infringes upon copyrighted content may result in legal action. Data protection laws in India are evolving, with the Personal Data Protection Bill awaiting enactment.
China
China has specific regulations and guidelines for Internet information services and data privacy. When scraping Amazon China, be aware of these regulations, which may require user consent for collecting and processing personal data.
Japan
Japan's Personal Information Protection Act governs the handling of personal data, making it essential to adhere to data protection laws when scraping from Amazon Japan. Intellectual property laws also protect copyrighted content.
It's crucial to remember that web scraping laws can be complex and are subject to change. Before engaging in web scraping activities on Amazon Marketplace in different countries, it is advisable to consult with legal experts who are well-versed in the specific jurisdiction's laws. Additionally, it is essential to respect Amazon's terms of service, robots.txt guidelines, and any website-specific regulations to avoid legal issues and ethical concerns.
Web Scraping Ethics: Guidelines for Handling Nonpublic Data
Regarding web scraping, particularly for nonpublic information, it's crucial to exercise caution, responsibility, and compliance with legal and ethical standards. Nonpublic information can include sensitive data, proprietary information, personal details, or content not intended for public consumption. Here are some considerations to keep in mind when scraping nonpublic information:
Legal Compliance
Ensure that your web scraping activities comply with applicable laws, including copyright, data protection, and privacy regulations. Unauthorized scraping of nonpublic data can lead to legal action and severe consequences.
User Consent
When dealing with personal or sensitive data, always obtain informed consent from users before collecting their information. This consent should be freely given, specific, and unambiguous. Violating privacy regulations can result in hefty fines.
Terms of Service and User Agreements
Websites often have terms of service or user agreements that explicitly state their policies regarding data scraping. Respect these agreements and ensure your scraping activities align with their guidelines. Ignoring them can lead to legal disputes.
Robots.txt and Website Guidelines
Review the website's robots.txt file and any other guidelines provided. Nonpublic data is often protected from web scraping, and failure to adhere to these directives may result in blocking or legal action.
Selective Data Extraction
When scraping nonpublic information, extract only the data you genuinely need. Avoid collecting unnecessary data, as doing so can raise ethical and legal concerns.
Data Protection and Encryption
Implement robust data protection measures, such as encryption and secure storage, to safeguard any nonpublic data you collect. Failure to protect sensitive data can result in security breaches and legal liability.
Anonymization and De-identification
When working with personal data, consider anonymizing or de-identifying the information to remove any identifying elements. This can help protect individuals' privacy and minimize legal risks.
Minimize Impact on Servers
Nonpublic data scraping should be conducted with minimal impact on the server's resources. Avoid overloading the website with requests, which can disrupt its operation and result in potential legal action.
Ethical Use of Information
Scrutinize how you plan to use the nonpublic data you collect. Avoid using it for malicious purposes, such as fraud, identity theft, or harassment. Ethical use of information is a fundamental principle
Data Retention and Deletion
Define clear policies for data retention and deletion. Only keep nonpublic information for the necessary period and dispose of it securely when it is no longer required.
Continuous Monitoring and Updates
Regularly monitor your scraping activities and adjust them to any changes in the website's policies or data protection regulations. Stay informed and be prepared to adapt your approach accordingly.
Legal Advice
If you have concerns or uncertainties about scraping nonpublic information, it's advisable to seek legal counsel with expertise in data privacy and web scraping laws. Legal professionals can provide specific guidance based on your circumstances.
Scraping nonpublic information requires meticulous attention to legal, ethical, and privacy considerations. Failing to respect these considerations can result in legal consequences, damage to your reputation, and potential harm to individuals whose data is involved. Responsible web scraping practices are essential to balance data collection and ethical, lawful behavior.
Conclusion
Amazon web scraping presents a complex landscape of legal and ethical challenges. Understanding the potential risks and consequences is paramount for businesses and individuals looking to harness the power of web scraping while maintaining ethical integrity. To navigate this terrain with confidence and compliance, consider partnering with Actowiz Solutions. Our expertise in data extraction and commitment to responsible practices can help you achieve your data-driven goals while safeguarding against illegal and unethical pitfalls. Contact us today to explore how Actowiz Solutions can assist you in your web scraping endeavors and ensure you remain on the right side of the law and ethics. You can also reach us for all your mobile app scraping, instant data scraper and web scraping service requirements.
konw more: https://www.actowizsolutions.com/amazon-web-scraping-illegal-and-unethical-dimensions.php
#AmazonWebScraping#AmazonDataScraper#AmazonDataExtraction#ScrapeAmazonData#AmazonDataCollection#AmazonWebScraper
0 notes
Text
Web Scraping 102: Scraping Product Details from Amazon

Now that we understand the basics of web scraping, let's proceed with a practical guide. We'll walk through each step to extract data from an online ecommerce platform and save it in either Excel or CSV format. Since manually copying information online can be tedious, in this guide we'll focus on scraping product details from Amazon. This hands-on experience will deepen our understanding of web scraping in practical terms.
Before we start, make sure you have Python installed in your system, you can do that from this link: python.org. The process is very simple just install it like you would install any other application.
Install Anaconda using this link: https://www.anaconda.com/download . Be sure to follow the default settings during installation. For more guidance, please click here.
We can use various IDEs, but to keep it beginner-friendly, let's start with Jupyter Notebook in Anaconda. You can watch the video linked above to understand and get familiar with the software.
Now that everything is set let’s proceed:
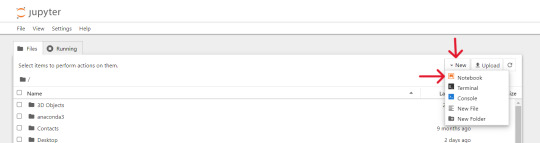
Open up the Anaconda software and you will find `jupyter notebook` option over there, just click and launch it or search on windows > jupyter and open it.
Steps for Scraping Amazon Product Detail's:
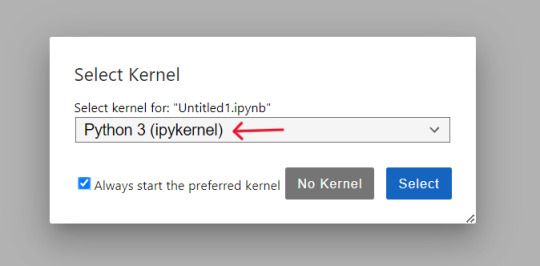
At first we will create and save our 'Notebook' by selecting kernel as 'python 3' if prompted, then we'll rename it to 'AmazonProductDetails' following below steps:

So, the first thing we will do is to import required python libraries using below commands and then press Shift + Enter to run the code every time:

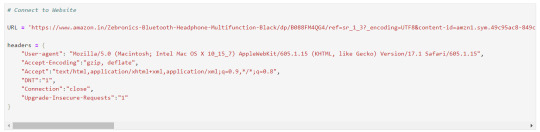
Let's connect to URL from which we want to extract the data and then define Headers to avoid getting our IP blocked.
Note : You can search `my user agent` on google to get your user agent details and replace it in below “User-agent”: “here goes your useragent line” below in headers.
Now that our URL is defined let's use the imported libraries and pull some data.
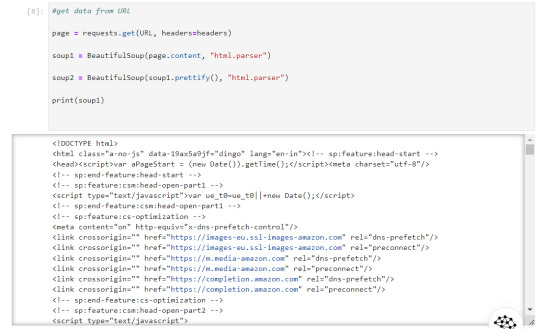
Now, let's start with scraping product title and price for that we need to use `inspect element` on the product URL page to find the ID associated to the element:
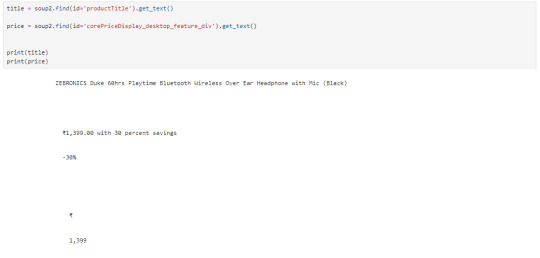
The data that we got is quite ugly as it has whitespaces and price are repeated let's trim the white space and just slice prices:

Let's create a timespan to keep note on when the data was extracted.

We need to save this data that we extracted, to a .csv or excel file. the 'w' below is use to write the data

Now you could see the file has been created at the location where the Anaconda app has been installed, in my case I had installed at path :"C:\Users\juver" and so the file is saved at path: "C:\Users\juver\AmazonProductDetailDataset"
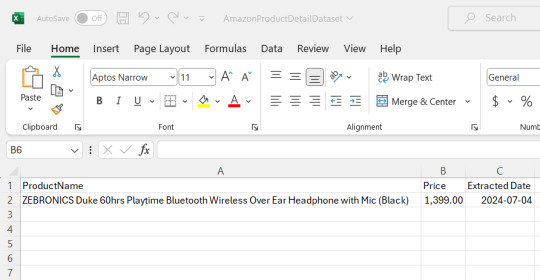
Instead of opening it by each time looking for path, let's read it in our notebook itself.

This way we could extract the data we need and save it for ourselves, by the time I was learning this basics, I came across this amazing post by Tejashwi Prasad on the same topic which I would highly recommend to go through.
Next, we’ll elevate our skills and dive into more challenging scraping projects soon.
0 notes
Text
What is Car Rental App Scraping Services?
Travelers always plan their journeys, they require rental cars at the right time and right place that makes it significant to be competitive, accurate, and agile to maximize the revenue. iWeb Scraping offers the Uber, Ola, Turo, Expedia, Car2Go car rental app scraping services in USA to level the competition as well as helps you lead the competition.
What is a Car Rental App?
Car rental hasn’t changed much in the last few decades. You can walk in to show your details, pay money, and walk away with the car keys. Even today, the procedure isn’t different. Though, you can use apps for locating car rental positions and a lot of companies have the apps which help accelerate the procedure. Vacationers and travelers frequently rent a car. It’s good when you could just get that over quickly.
The car rental segment revenue in 2019 is supposed to be $26,873m and this revenue is likely to show a yearly growth of 3.4% as per CAGR 2019-2023, which results in the market value of $30,686m by the year 2023.
Listing Of Data Fields
At iWeb Scraping, we can provide the following list of data fields with car rental app scraping services:
Pick Up
Drop
Journey Type
Departure Date
Departure Time
Return Date
Return Time
Car Type
Car Model Name
Car Images
Description
Fare
Per Day Rent
30 Days Rent
Price Includes
Damage Liability
Features
Reviews
Ratings
As travelers plan their own journeys, they need rental cars at the right place and right time which makes it important to be accurate, agile, and competitive daily to maximize the revenue. iWeb Scraping’s provides the best car rental app scraping services in India, USA, & UAE to benchmark the competition and makes you ahead in the competition and Web Scraping Services.
As competition rises with the increase of app-based car rental aggregators, active responses to the market shifts as well as changes have never been more important. A small or medium-sized business today gets it hard to arrange between day-to-day operations as well as building a strong revenue strategy that fuels the requirement of solutions which help cut the efforts drastically.
iWeb Scraping’s professional car rental app scraping services help you scrape all the data required from car rental apps like Uber, Ola, Turo, CarRentals, Enterprise Rent-A-Car, Expedia, Lyft, Hertz, Car2Go, Skyscanner, KAYAK, Rentalcars and more. So, you can get services like Uber Car Rental App Scraping, Ola Car Rental App Scraping, KAYAK Car Rental App Scraping and more.
0 notes
Link
Amazon, being the largest e-commerce company in the United States, has the world's largest product options. Amazon product data is important in a variety of ways, and web scraping Amazon data makes it simple to extract it.
1 note
·
View note
Link

Data Extraction Services from Amazon Website at Affordable Cost
3i Data Scraping has extraction tools for Scraping Amazon product listings which pulls out the listing of products, features, details, and clients’ requirements in the systematic way. We are having experience of many years and with our expert services, our first priority is always our work.
Total Solutions for Amazon Web Scraping
At 3i Data Scraping, We offer complete solutions for Amazon web scraping which consists of names, product features, images, and other information.
To extract data for Amazon you honestly need experienced professional for putting up all the information in orderly manner. From retail chains to big organizations, we help them in doing market research, preparing directory as well as inventories of most recent product through our software for scraping Amazon product listings.
Amazon Data Extraction in Finest Format with Structured Data
We obtain Amazon products from directories and databases, which are true, latest, and exact. We also offer add-on features for extraction of Amazon prices with the listing of product. Furthermore, this helps business grow through providing competitive prices and quote for the finest bargain online.
Visit Service : Amazon Website Data Scraping Services
#webscraping#datascraping#WebDataScraping#WebScrapingService#dataextractionservices#DataExtractfromWebsites#DataExtractionfromAmazon#AmazonWebScrapingServices#AmazonWebScraping#amazon#3idatascraping#3iDataScrapingService
0 notes
Text
Overcome Amazon Scraping: Beat IP Blocks, Captchas & More
Discover tips to overcome Amazon web scraping challenges, including IP blocking, captchas, and more. Learn effective strategies for successful data extraction.
Read more: https://www.iwebdatascraping.com/effective-solutions-to-overcome-amazon-web-scraping-challenges.php
#AmazonWebScraping#WebScrapingEcommerceData#AmazonDataCollection#AmazonWebScraper#EcommerceDataScrapingServices
0 notes
Text

Learn how to build an Amazon Price Tracker using Python to automatically monitor and receive alerts on price changes for products you are interested in buying
Know More: https://www.iwebdatascraping.com/amazon-price-tracker-with-python-for-real-time-price-monitoring.php
0 notes
Text
How To Create An Amazon Price Tracker With Python For Real-Time Price Monitoring
How To Create An Amazon Price Tracker With Python For Real-Time Price Monitoring?
In today's world of online shopping, everyone enjoys scoring the best deals on Amazon for their coveted electronic gadgets. Many of us maintain a wishlist of items we're eager to buy at the perfect price. With intense competition among e-commerce platforms, prices are constantly changing.
The savvy move here is to stay ahead by tracking price drops and seizing those discounted items promptly. Why rely on commercial Amazon price tracker software when you can create your solution for free? It is the perfect opportunity to put your programming skills to the test.
Our objective: develop a price tracking tool to monitor the products on your wishlist. You'll receive an SMS notification with the purchase link when a price drop occurs. Let's build your Amazon price tracker, a fundamental tool to satisfy your shopping needs.
About Amazon Price Tracker
An Amazon price tracker is a tool or program designed to monitor and track the prices of products listed on the Amazon online marketplace. Consumers commonly use it to keep tabs on price fluctuations for items they want to purchase. Here's how it typically works:
Product Selection: Users choose specific products they wish to track. It includes anything on Amazon, from electronics to clothing, books, or household items.
Price Monitoring: The tracker regularly checks the prices of the selected products on Amazon. It may do this by web scraping, utilizing Amazon's API, or other methods
Price Change Detection: When the price of a monitored product changes, the tracker detects it. Users often set thresholds, such as a specific percentage decrease or increase, to trigger alerts.
Alerts: The tracker alerts users if a price change meets the predefined criteria. This alert can be an email, SMS, or notification via a mobile app.
Informed Decisions: Users can use these alerts to make informed decisions about when to buy a product based on its price trends. For example, they may purchase a product when the price drops to an acceptable level.
Amazon price trackers are valuable tools for savvy online shoppers who want to save money by capitalizing on price drops. They can help users stay updated on changing market conditions and make more cost-effective buying choices.
Methods
Let's break down the process we'll follow in this blog. We will create two Python web scrapers to help us track prices on Amazon and send price drop alerts.
Step 1: Building the Master File
Our first web scraper will collect product name, price, and URL data. We'll assemble this information into a master file.
Step 2: Regular Price Checking
We'll develop a second web scraper to check the prices and perform hourly checks periodically. This Python script will compare the current prices with the data in the master file.
Step 3: Detecting Price Drops
Since Amazon sellers often use automated pricing, we expect price fluctuations. Our script will specifically look for significant price drops, let's say more than a 10% decrease.
Step 4: Alert Mechanism
Our script will send you an SMS price alert if a substantial price drop is detected. It ensures you'll be informed when it's the perfect time to grab your desired product at a discounted rate.
Let's kick off the process of creating a Python-based Amazon web scraper. We focus on extracting specific attributes using Python's requests, BeautifulSoup, and the lxml parser, and later, we'll use the csv library for data storage.
Here are the attributes we're interested in scraping from Amazon:
Product Name
Sale Price (not the listing price)
To start, we'll import the necessary libraries:
In the realm of e-commerce web scraping, websites like Amazon often harbor a deep-seated aversion to automated data retrieval, employing formidable anti-scraping mechanisms that can swiftly detect and thwart web scrapers or bots. Amazon, in particular, has a robust system to identify and block such activities. Incorporating headers into our HTTP requests is an intelligent strategy to navigate this challenge.
Now, let's move on to assembling our bucket list. In my instance, we've curated a selection of five items that comprise my personal bucket list, and we've included them within the program as a list. If your bucket list is more extensive, storing it in a text file and subsequently reading and processing the data using Python is prudent.
We will create two functions to extract Amazon pricing and product names that retrieve the price when called. For this task, we'll rely on Python's BeautifulSoup and lxml libraries, which enable us to parse the webpage and extract the e-commerce product data. To pinpoint the specific elements on the web page, we'll use Xpaths.
To construct the master file containing our scraped data, we'll utilize Python's csv module. The code for this process is below.
Here are a few key points to keep in mind:
The master file consists of three columns: product name, price, and the product URL.
We iterate through each item on our bucket list, parsing the necessary information from their URLs.
To ensure responsible web scraping and reduce the risk of detection, we incorporate random time delays between each request.
Once you execute the code snippets mentioned above, you'll find a CSV file as "master_data.csv" generated. It's important to note that you can run this program once to create the master file.
To develop our Amazon price tracking tool, we already have the essential master data to facilitate comparisons with the latest scraped information. Now, let's craft the second script, which will extract data from Amazon and perform comparisons with the data stored in the master file.
In this tracker script, we'll introduce two additional libraries:
The Pandas library will be instrumental for data manipulation and analysis, enabling us to work with the extracted data efficiently.
The Twilio library: We'll utilize Twilio for SMS notifications, allowing us to receive price alerts on our mobile devices.
Pandas: Pandas is a powerful open-source Python library for data analysis and manipulation. It's renowned for its versatile data structure, the pandas DataFrame, which facilitates the handling of tabular data, much like spreadsheets, within Python scripts. If you aspire to pursue a career in data science, learning Pandas is essential.
Twilio: Regarding programmatically sending SMS notifications, Twilio's APIs are a top choice. We opt for Twilio because it provides free credits, which suffice for our needs.
To streamline the scraper and ensure it runs every hour, we aim to automate the process. Given my full-time job, manually initiating the program every two hours is impractical. We prefer to set up a schedule that triggers the program's execution hourly.
To verify the program's functionality, manually adjust the price values within the master data file and execute the tracker program. You'll observe SMS notifications as a result of these modifications.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.
Know More: https://www.iwebdatascraping.com/amazon-price-tracker-with-python-for-real-time-price-monitoring.php
0 notes
Text
Discover the dark side of Amazon web scraping: Learn about its illegal and unethical aspects. Is it harming your business?
konw more: https://www.actowizsolutions.com/amazon-web-scraping-illegal-and-unethical-dimensions.php
#AmazonWebScraping#AmazonDataScraper#AmazonDataExtraction#ScrapeAmazonData#AmazonDataCollection#AmazonWebScraper
0 notes
Text

Amazon web scraping challenges involve overcoming IP blocking, CAPTCHA hurdles, dynamic content handling, website structure changes, and legal compliance issues.
Know more: https://www.iwebdatascraping.com/effective-solutions-to-overcome-amazon-web-scraping-challenges.php
#AmazonWebScraping#ScrapeAmazonData#AmazonDataScraper#ExtractAmazonData#AmazonDataCollection#AmazonDataExtraction
0 notes
Text
What Are Effective Solutions to Overcome Amazon Web Scraping Challenges?
Amazon web scraping challenges involve overcoming IP blocking, CAPTCHA hurdles, dynamic content handling, website structure changes, and legal compliance issues.
Know more: https://www.iwebdatascraping.com/effective-solutions-to-overcome-amazon-web-scraping-challenges.php
#AmazonWebScraping#ScrapeAmazonData#AmazonDataScraper#ExtractAmazonData#AmazonDataCollection#AmazonDataExtraction
0 notes
Text
How to Use ChatGPT for Automated Amazon Web Scraping: A Comprehensive Tutorial
This comprehensive tutorial will guide you through using ChatGPT to automate web scraping on Amazon.
know more: https://www.actowizsolutions.com/use-chatgpt-for-automated-amazon-web-scraping-tutorial.php
#AmazonWebScraping#WebScrapingAmazonData#AmazonScrapingChatgpt#AmazonDataCollection#AmazonDataScrapingTool
0 notes
Text

This comprehensive tutorial will guide you through using ChatGPT to automate web scraping on Amazon.
know more: https://www.actowizsolutions.com/use-chatgpt-for-automated-amazon-web-scraping-tutorial.php
#AmazonWebScraping#WebScrapingAmazonData#AmazonScrapingChatgpt#AmazonDataCollection#AmazonDataScrapingTool
0 notes
Text
Amazon Web Scraping: Exploring Its Illegal and Unethical Dimensions
Discover the dark side of Amazon web scraping: Learn about its illegal and unethical aspects. Is it harming your business?
konw more: https://www.actowizsolutions.com/amazon-web-scraping-illegal-and-unethical-dimensions.php
0 notes
Link
Amazon, being the largest e-commerce company in the United States, has the world's largest product options. Amazon product data is important in a variety of ways, and web scraping Amazon data makes it simple to extract it. You can use Amazon web scraper, to extract Amazon data.
1 note
·
View note