#Apache Flink
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Bigtable SQL Introduces Native Support for Real-Time Queries

Upgrades to Bigtable SQL offer scalable, fast data processing for contemporary analytics. Simplify procedures and accelerate business decision-making.
Businesses have battled for decades to use data for real-time operations. Bigtable, Google Cloud's revolutionary NoSQL database, powers global, low-latency apps. It was built to solve real-time application issues and is now a crucial part of Google's infrastructure, along with YouTube and Ads.
Continuous materialised views, an enhancement of Bigtable's SQL capabilities, were announced at Google Cloud Next this week. Maintaining Bigtable's flexible schema in real-time applications requires well-known SQL syntax and specialised skills. Fully managed, real-time application backends are possible with Bigtable SQL and continuous materialised views.
Bigtable has gotten simpler and more powerful, whether you're creating streaming apps, real-time aggregations, or global AI research on a data stream.
The Bigtable SQL interface is now generally available.
SQL capabilities, now generally available in Bigtable, has transformed the developer experience. With SQL support, Bigtable helps development teams work faster.
Bigtable SQL enhances accessibility and application development by speeding data analysis and debugging. This allows KNN similarity search for improved product search and distributed counting for real-time dashboards and metric retrieval. Bigtable SQL's promise to expand developers' access to Bigtable's capabilities excites many clients, from AI startups to financial institutions.
Imagine AI developing and understanding your whole codebase. AI development platform Augment Code gives context for each feature. Scalability and robustness allow Bigtable to handle large code repositories. This user-friendliness allowed it to design security mechanisms that protect clients' valuable intellectual property. Bigtable SQL will help onboard new developers as the company grows. These engineers can immediately use Bigtable's SQL interface to access structured, semi-structured, and unstructured data.
Equifax uses Bigtable to store financial journals efficiently in its data fabric. The data pipeline team found Bigtable's SQL interface handy for direct access to corporate data assets and easier for SQL-savvy teams to use. Since more team members can use Bigtable, it expects higher productivity and integration.
Bigtable SQL also facilitates the transition between distributed key-value systems and SQL-based query languages like HBase with Apache Phoenix and Cassandra.
Pega develops real-time decisioning apps with minimal query latency to provide clients with real-time data to help their business. As it seeks database alternatives, Bigtable's new SQL interface seems promising.
Bigtable is also previewing structured row keys, GROUP BYs, aggregations, and a UNPACK transform for timestamped data in its SQL language this week.
Continuously materialising views in preview
Bigtable SQL works with Bigtable's new continuous materialised views (preview) to eliminate data staleness and maintenance complexity. This allows real-time data aggregation and analysis in social networking, advertising, e-commerce, video streaming, and industrial monitoring.
Bigtable views update gradually without impacting user queries and are fully controllable. Bigtable materialised views accept a full SQL language with functions and aggregations.
Bigtable's Materialised Views have enabled low-latency use cases for Google Cloud's Customer Data Platform customers. It eliminates ETL complexity and delay in time series use cases by setting SQL-based aggregations/transformations upon intake. Google Cloud uses data transformations during import to give AI applications well prepared data with reduced latency.
Ecosystem integration
Real-time analytics often require low-latency data from several sources. Bigtable's SQL interface and ecosystem compatibility are expanding, making end-to-end solutions using SQL and basic connections easier.
Open-source Apache Large Table Washbasin Kafka
Companies utilise Google Cloud Managed Service for Apache Kafka to build pipelines for Bigtable and other analytics platforms. The Bigtable team released a new Apache Kafka Bigtable Sink to help clients build high-performance data pipelines. This sends Kafka data to Bigtable in milliseconds.
Open-source Apache Flink Connector for Bigtable
Apache Flink allows real-time data modification via stream processing. The new Apache Flink to Bigtable Connector lets you design a pipeline that modifies streaming data and publishes it to Bigtable using the more granular Datastream APIs and the high-level Apache Flink Table API.
BigQuery Continuous Queries are commonly available
BigQuery continuous queries run SQL statements continuously and export output data to Bigtable. This widely available capability can let you create a real-time analytics database using Bigtable and BigQuery.
Python developers may create fully-managed jobs that synchronise offline BigQuery datasets with online Bigtable datasets using BigQuery's Python frameworks' bigrames streaming API.
Cassandra-compatible Bigtable CQL Client Bigtable is previewed.
Apache Cassandra uses CQL. Bigtable CQL Client enables developers utilise CQL on enterprise-grade, high-performance Bigtable without code modifications as they migrate programs. Bigtable supports Cassandra's data migration tools, which reduce downtime and operational costs, and ecosystem utilities like the CQL shell.
Use migrating tools and Bigtable CQL Client here.
Using SQL power via NoSQL. This blog addressed a key feature that lets developers use SQL with Bigtable. Bigtable Studio lets you use SQL from any Bigtable cluster and create materialised views on Flink and Kafka data streams.
#technology#technews#govindhtech#news#technologynews#cloud computing#Bigtable SQL#Continuous Queries#Apache Flink#BigQuery Continuous Queries#Bigtable#Bigtable CQL Client#Open-source Kafka#Apache Kafka
0 notes
Text
Three-year-old Apache Flink flaw under active attack

Source: https://www.theregister.com/2024/05/24/apache_flink_flaw_cisa/
More info: https://nvd.nist.gov/vuln/detail/CVE-2020-17519
6 notes
·
View notes
Text
Unveiling Java's Multifaceted Utility: A Deep Dive into Its Applications
In software development, Java stands out as a versatile and ubiquitous programming language with many applications across diverse industries. From empowering enterprise-grade solutions to driving innovation in mobile app development and big data analytics, Java's flexibility and robustness have solidified its status as a cornerstone of modern technology.

Let's embark on a journey to explore the multifaceted utility of Java and its impact across various domains.
Powering Enterprise Solutions
Java is the backbone for developing robust and scalable enterprise applications, facilitating critical operations such as CRM, ERP, and HRM systems. Its resilience and platform independence make it a preferred choice for organizations seeking to build mission-critical applications capable of seamlessly handling extensive data and transactions.
Shaping the Web Development Landscape
Java is pivotal in web development, enabling dynamic and interactive web applications. With frameworks like Spring and Hibernate, developers can streamline the development process and build feature-rich, scalable web solutions. Java's compatibility with diverse web servers and databases further enhances its appeal in web development.
Driving Innovation in Mobile App Development
As the foundation for Android app development, Java remains a dominant force in the mobile app ecosystem. Supported by Android Studio, developers leverage Java's capabilities to craft high-performance and user-friendly mobile applications for a global audience, contributing to the ever-evolving landscape of mobile technology.
Enabling Robust Desktop Solutions
Java's cross-platform compatibility and extensive library support make it an ideal choice for developing desktop applications. With frameworks like Java Swing and JavaFX, developers can create intuitive graphical user interfaces (GUIs) for desktop software, ranging from simple utilities to complex enterprise-grade solutions.
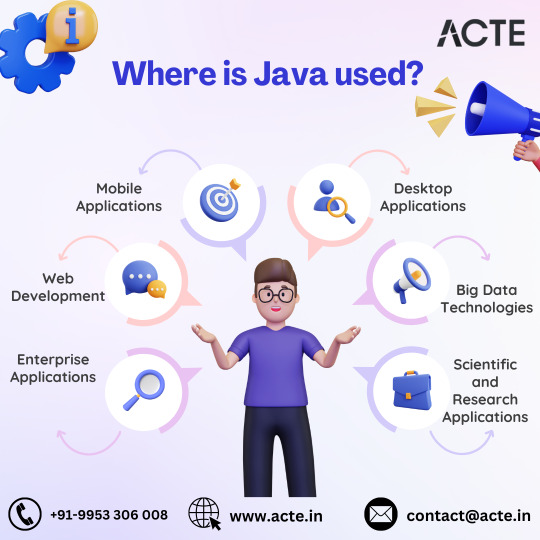
Revolutionizing Big Data Analytics
In big data analytics, Java is a cornerstone for various frameworks and tools to process and analyze massive datasets. Platforms like Apache Hadoop, Apache Spark, and Apache Flink leverage Java's capabilities to unlock valuable insights from vast amounts of data, empowering organizations to make data-driven decisions.
Fostering Innovation in Scientific Research
Java's versatility extends to scientific computing and research, where it is utilized to develop simulations, modeling tools, and data analysis software. Its performance and extensive library support make it an invaluable asset in bioinformatics, physics, and engineering, driving innovation and advancements in scientific research.
Empowering Embedded Systems
With its lightweight runtime environment, Java Virtual Machine (JVM), Java finds applications in embedded systems development. From IoT devices to industrial automation systems, Java's flexibility and reliability make it a preferred choice for building embedded solutions that require seamless performance across diverse hardware platforms.
In summary, Java's multifaceted utility and robustness make it an indispensable tool in the arsenal of modern software developers. Whether powering enterprise solutions, driving innovation in mobile app development, or revolutionizing big data analytics, Java continues to shape the technological landscape and drive advancements across various industries. As a versatile and enduring programming language, Java remains at the forefront of innovation, paving the way for a future powered by cutting-edge software solutions.
2 notes
·
View notes
Text
Big Data Technologies: Hadoop, Spark, and Beyond

In this era where every click, transaction, or sensor emits a massive flux of information, the term "Big Data" has gone past being a mere buzzword and has become an inherent challenge and an enormous opportunity. These are datasets so enormous, so complex, and fast-growing that traditional data-processing applications cannot handle them. The huge ocean of information needs special tools; at the forefront of this big revolution being Big Data Technologies- Hadoop, Spark, and beyond.
One has to be familiar with these technologies if they are to make some modern-day sense of the digital world, whether they be an aspiring data professional or a business intent on extracting actionable insights out of their massive data stores.
What is Big Data and Why Do We Need Special Technologies?
Volume: Enormous amounts of data (terabytes, petabytes, exabytes).
Velocity: Data generated and processed at incredibly high speeds (e.g., real-time stock trades, IoT sensor data).
Variety: Data coming in diverse formats (structured, semi-structured, unstructured – text, images, videos, logs).
Traditional relational databases and processing tools were not built to handle this scale, speed, or diversity. They would crash, take too long, or simply fail to process such immense volumes. This led to the emergence of distributed computing frameworks designed specifically for Big Data.
Hadoop: The Pioneer of Big Data Processing
Apache Hadoop was an advanced technological tool in its time. It had completely changed the facets of data storage and processing on a large scale. It provides a framework for distributed storage and processing of datasets too large to be processed on a single machine.
· Key Components:
HDFS (Hadoop Distributed File System): It is a distributed file system, where the data is stored across multiple machines and hence are fault-tolerant and highly scalable.
MapReduce: A programming model for processing large data sets with a parallel, distributed algorithm on a cluster. It subdivides a large problem into smaller ones that can be solved independently in parallel.
What made it revolutionary was the fact that Hadoop enabled organizations to store and process data they previously could not, hence democratizing access to massive datasets.
Spark: The Speed Demon of Big Data Analytics
While MapReduce on Hadoop is a formidable force, disk-based processing sucks up time when it comes to iterative algorithms and real-time analytics. And so came Apache Spark: an entire generation ahead in terms of speed and versatility.
· Key Advantages over Hadoop MapReduce:
In-Memory Processing: Spark processes data in memory, which is from 10 to 100 times faster than MapReduce-based operations, primarily in iterative algorithms (Machine Learning is an excellent example here).
Versatility: Several libraries exist on top of Spark's core engine:
Spark SQL: Structured data processing using SQL
Spark Streaming: Real-time data processing.
MLlib: Machine Learning library.
GraphX: Graph processing.
What makes it important, actually: Spark is the tool of choice when it comes to real-time analytics, complex data transformations, and machine learning on Big Data.
And Beyond: Evolving Big Data Technologies
The Big Data ecosystem is growing by each passing day. While Hadoop and Spark are at the heart of the Big Data paradigm, many other technologies help in complementing and extending their capabilities:
NoSQL Databases: (e.g., MongoDB, Cassandra, HBase) – The databases were designed to handle massive volumes of unstructured or semi-structured data with high scale and high flexibility as compared to traditional relational databases.
Stream Processing Frameworks: (e.g., Apache Kafka, Apache Flink) – These are important for processing data as soon as it arrives (real-time), crucial for fraud-detection, IoT Analytics, and real-time dashboards.
Data Warehouses & Data Lakes: Cloud-native solutions (example, Amazon Redshift, Snowflake, Google BigQuery, Azure Synapse Analytics) for scalable, managed environments to store and analyze big volumes of data often with seamless integration to Spark.
Cloud Big Data Services: Major cloud providers running fully managed services of Big Data processing (e.g., AWS EMR, Google Dataproc, Azure HDInsight) reduce much of deployment and management overhead.
Data Governance & Security Tools: As data grows, the need to manage its quality, privacy, and security becomes paramount.
Career Opportunities in Big Data
Mastering Big Data technologies opens doors to highly sought-after roles such as:
Big Data Engineer
Data Architect
Data Scientist (often uses Spark/Hadoop for data preparation)
Business Intelligence Developer
Cloud Data Engineer
Many institutes now offer specialized Big Data courses in Ahmedabad that provide hands-on training in Hadoop, Spark, and related ecosystems, preparing you for these exciting careers.
The journey into Big Data technologies is a deep dive into the engine room of the modern digital economy. By understanding and mastering tools like Hadoop, Spark, and the array of complementary technologies, you're not just learning to code; you're learning to unlock the immense power of information, shaping the future of industries worldwide.
Contact us
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Devant – Big Data Analytics Service Providers in India
Devant is among the top big data analytics service providers in India, offering robust and scalable solutions to help businesses unlock the full potential of their data. Our expert team specializes in collecting, processing, and analyzing vast volumes of structured and unstructured data to deliver meaningful insights. From real-time analytics and data warehousing to predictive modeling and data visualization, we provide end-to-end services that empower smarter business decisions. Devant ensures that your data becomes a strategic asset, driving efficiency, innovation, and growth.
As one of the most reliable big data analytics solution providers, we serve a wide range of industries including finance, healthcare, retail, logistics, and manufacturing. We leverage advanced technologies such as Hadoop, Spark, and Apache Flink to build high-performance analytics platforms tailored to your unique needs. Whether you’re aiming to optimize operations, understand customer behavior, or forecast market trends, Devant delivers solutions that are secure, scalable, and future-ready.
Contact us today and let Devant, your trusted big data analytics partner, help you make data-driven decisions that matter.

0 notes
Text
Top Trends Shaping the Future of Data Engineering Consultancy
In today’s digital-first world, businesses are rapidly recognizing the need for structured and strategic data management. As a result, Data Engineering Consultancy is evolving at an unprecedented pace. From cloud-native architecture to AI-driven automation, the future of data engineering is being defined by innovation and agility. Here are the top trends shaping this transformation.

1. Cloud-First Data Architectures
Modern businesses are migrating their infrastructure to cloud platforms like AWS, Azure, and Google Cloud. Data engineering consultants are now focusing on building scalable, cloud-native data pipelines that offer better performance, security, and flexibility.
2. Real-Time Data Processing
The demand for real-time analytics is growing, especially in sectors like finance, retail, and logistics. Data Engineering Consultancy services are increasingly incorporating technologies like Apache Kafka, Flink, and Spark to support instant data processing and decision-making.
3. Advanced Data Planning
A strategic approach to Data Planning is becoming central to successful consultancy. Businesses want to go beyond reactive reporting—they seek proactive, long-term strategies for data governance, compliance, and scalability.
4. Automation and AI Integration
Automation tools and AI models are revolutionizing how data is processed, cleaned, and analyzed. Data engineers now use machine learning to optimize data quality checks, ETL processes, and anomaly detection.
5. Data Democratization
Consultants are focusing on creating accessible data systems, allowing non-technical users to engage with data through intuitive dashboards and self-service analytics.
In summary, the future of Data Engineering Consultancy lies in its ability to adapt to technological advancements while maintaining a strong foundation in Data Planning. By embracing these trends, businesses can unlock deeper insights, enhance operational efficiency, and stay ahead of the competition in the data-driven era. Get in touch with Kaliper.io today!
0 notes
Text
The Data Engineering Evolution: Top Trends to Watch in 2025

Data engineering is the backbone of the data-driven world. It's the critical discipline that builds and maintains the robust pipelines and infrastructure essential for collecting, storing, transforming, and delivering data to data scientists, analysts, and business users. As data volumes explode and the demand for real-time insights intensifies, data engineering is evolving at an unprecedented pace.
As we move further into 2025, here are the top trends that are not just shaping, but fundamentally transforming, the data engineering landscape:
1. The AI/ML Infusion: Automation and Intelligence in Pipelines
Artificial Intelligence and Machine Learning are no longer just consumers of data; they are becoming integral to the data engineering process itself.
AI-Assisted Pipeline Development: Expect more tools leveraging AI to automate repetitive tasks like schema detection, data validation, anomaly detection, and even code generation for transformations. This empowers data engineers to focus on more complex architectural challenges rather than mundane scripting.
Intelligent Data Quality: AI will play a bigger role in real-time data quality monitoring and anomaly detection within pipelines. Instead of just flagging errors, AI systems will predict potential failures and even suggest resolutions.
Generative AI for Data Workflows: Generative AI's ability to understand natural language means it can assist in generating SQL queries, designing data models, and even documenting pipelines, significantly accelerating development cycles.
2. Real-Time Everything: The Demand for Instant Insights
The pace of business demands immediate insights, pushing data engineering towards real-time processing and streaming architectures.
Stream Processing Dominance: Technologies like Apache Kafka, Flink, and Spark Streaming will become even more central, enabling organizations to ingest, process, and analyze data as it's generated.
Edge Computing for Low Latency: As IoT devices proliferate, processing data closer to its source (at the "edge") will be crucial. This reduces latency, saves bandwidth, and enables faster decision-making for use cases like smart factories, autonomous vehicles, and real-time fraud detection.
Zero-ETL Architectures: The movement towards "zero-ETL" aims to minimize or eliminate data movement by enabling direct querying of operational databases or seamless integration with analytical stores, further reducing latency and complexity.
3. Data Mesh and Data Fabric: Decentralization and Interoperability
As data ecosystems grow, centralized data architectures struggle to keep up. Data Mesh and Data Fabric offer compelling alternatives.
Data Mesh: This paradigm promotes decentralized data ownership, treating data as a product owned by domain-specific teams. Data engineers will increasingly work within these domain teams, focusing on building "data products" that are discoverable, addressable, trustworthy, and secure.
Data Fabric: A data fabric acts as an integrated layer of data and analytics services across disparate data sources. It leverages active metadata, knowledge graphs, and AI to automate data discovery, integration, and governance, providing a unified view of data regardless of where it resides. Expect to see increasing synergy between Data Mesh and Data Fabric, with the latter often providing the underlying technical framework for the former.
4. Data Observability and Data Contracts: Building Trust and Reliability
With increased complexity, ensuring data quality and reliability becomes paramount.
Data Observability as a Must-Have: Moving beyond simple monitoring, data observability provides comprehensive insights into the health, quality, and lineage of data throughout its lifecycle. Tools will offer automated anomaly detection, root cause analysis, and proactive alerting to prevent "data downtime."
Data Contracts: Formalizing agreements between data producers and consumers (often referred to as "data contracts") will become a standard practice. These contracts define data schemas, quality expectations, and service level agreements (SLAs), fostering trust and enabling more robust, interconnected data systems.
5. Sustainability and Cost Optimization: Greener and Leaner Data
As data infrastructure scales, the environmental and financial costs become significant concerns.
Green Data Engineering: A growing focus on optimizing data pipelines and infrastructure for energy efficiency. This includes choosing cloud services with strong sustainability commitments, optimizing query performance, and adopting more efficient storage strategies.
FinOps for Data: Data engineers will increasingly be involved in cloud cost management (FinOps), optimizing resource allocation, identifying cost inefficiencies in data pipelines, and leveraging serverless architectures for pay-as-you-go pricing.
The data engineering role is evolving from primarily operational to increasingly strategic. Data engineers are becoming architects of data ecosystems, empowered by AI and automation, focused on delivering real-time, trustworthy, and scalable data solutions. Staying abreast of these trends is crucial for any data professional looking to thrive in the years to come.
0 notes
Text
How Modern Data Engineering Powers Scalable, Real-Time Decision-Making
In today's world, driven by technology, businesses have evolved further and do not want to analyze data from the past. Everything from e-commerce websites providing real-time suggestions to banks verifying transactions in under a second, everything is now done in a matter of seconds. Why has this change taken place? The modern age of data engineering involves software development, data architecture, and cloud infrastructure on a scalable level. It empowers organizations to convert massive, fast-moving data streams into real-time insights.
From Batch to Real-Time: A Shift in Data Mindset
Traditional data systems relied on batch processing, in which data was collected and analyzed after certain periods of time. This led to lagging behind in a fast-paced world, as insights would be outdated and accuracy would be questionable. Ultra-fast streaming technologies such as Apache Kafka, Apache Flink, and Spark Streaming now enable engineers to create pipelines that help ingest, clean, and deliver insights in an instant. This modern-day engineering technique shifts the paradigm of outdated processes and is crucial for fast-paced companies in logistics, e-commerce, relevancy, and fintech.
Building Resilient, Scalable Data Pipelines
Modern data engineering focuses on the construction of thoroughly monitored, fault-tolerant data pipelines. These pipelines are capable of scaling effortlessly to higher volumes of data and are built to accommodate schema changes, data anomalies, and unexpected traffic spikes. Cloud-native tools like AWS Glue and Google Cloud Dataflow with Snowflake Data Sharing enable data sharing and integration scaling without limits across platforms. These tools make it possible to create unified data flows that power dashboards, alerts, and machine learning models instantaneously.
Role of Data Engineering in Real-Time Analytics
Here is where these Data Engineering Services make a difference. At this point, companies providing these services possess considerable technical expertise and can assist an organization in designing modern data architectures in modern frameworks aligned with their business objectives. From establishing real-time ETL pipelines to infrastructure handling, these services guarantee that your data stack is efficient and flexible in terms of cost. Companies can now direct their attention to new ideas and creativity rather than the endless cycle of data management patterns.
Data Quality, Observability, and Trust
Real-time decision-making depends on the quality of the data that powers it. Modern data engineering integrates practices like data observability, automated anomaly detection, and lineage tracking. These ensure that data within the systems is clean and consistent and can be traced. With tools like Great Expectations, Monte Carlo, and dbt, engineers can set up proactive alerts and validations to mitigate issues that could affect economic outcomes. This trust in data quality enables timely, precise, and reliable decisions.
The Power of Cloud-Native Architecture
Modern data engineering encompasses AWS, Azure, and Google Cloud. They provide serverless processing, autoscaling, real-time analytics tools, and other services that reduce infrastructure expenditure. Cloud-native services allow companies to perform data processing, as well as querying, on exceptionally large datasets instantly. For example, with Lambda functions, data can be transformed. With BigQuery, it can be analyzed in real-time. This allows rapid innovation, swift implementation, and significant long-term cost savings.
Strategic Impact: Driving Business Growth
Real-time data systems are providing organizations with tangible benefits such as customer engagement, operational efficiency, risk mitigation, and faster innovation cycles. To achieve these objectives, many enterprises now opt for data strategy consulting, which aligns their data initiatives to the broader business objectives. These consulting firms enable organizations to define the right KPIs, select appropriate tools, and develop a long-term roadmap to achieve desired levels of data maturity. By this, organizations can now make smarter, faster, and more confident decisions.
Conclusion
Investing in modern data engineering is more than an upgrade of technology — it's a shift towards a strategic approach of enabling agility in business processes. With the adoption of scalable architectures, stream processing, and expert services, the true value of organizational data can be attained. This ensures that whether it is customer behavior tracking, operational optimization, or trend prediction, data engineering places you a step ahead of changes before they happen, instead of just reacting to changes.
1 note
·
View note
Text
Big Lake Storage: An Open Data Lakehouse on Google Cloud

Large Lake Storage
Built open, high-performance, enterprise Big Lake storage Lakehouses iceberg native
Businesses may use Apache Iceberg to develop open, high-performance, enterprise-grade data lakehouses on Google Cloud with recent Big Lake storage engine improvements. Customers no longer have to choose between completely managed, enterprise-grade storage management and open formats like Apache Iceberg.
Businesses want adaptive, open, and interoperable architectures that let several engines work on a single copy of data while data management is revolutionised. Apache Iceberg is a popular open table style. The latest Big Lake storage development offers Apache Iceberg access to Google's infrastructure, enabling open data lakehouses.
Major advances include:
BigLake Metastore is normally available: BigLake Metastore, formerly BigQuery, is now public. This completely managed, serverless, and scalable solution simplifies runtime metadata maintenance and operations for BigQuery and other Iceberg-compatible engines. Use of Google's global metadata management infrastructure reduces the need to control proprietary metastore implementation. BigLake Metastore is necessary for open interoperability.
Iceberg REST Catalogue API Preview Introduction: To complement the GA Custom Iceberg Catalogue, the Iceberg REST Catalogue (Preview) provides a standard REST interface for interoperability. Users, including Spark users, can use the BigLake metastore as a serverless Iceberg catalogue. The Custom Iceberg Catalogue lets Spark and other open-source engines connect with Apache Iceberg and BigQuery BigLake tables.
Google Cloud is simplifying lakehouse upkeep using Apache Iceberg and Google Cloud Storage management. Cloud Storage features like auto-class tiering, encryption, and automatic table maintenance including compaction and trash collection are supported. This enhances Iceberg data management in Cloud Storage.
BigQuery usually has Apache Iceberg BigLake tables: These publicly available tables combine BigQuery's scalable, real-time metadata with Iceberg formats' transparency. This enables BigQuery's Write API's high-throughput streaming ingestion and zero-latency reads at tens of GiB/second. It also has automatic table management (compaction, garbage collection), native Vertex AI interface, auto-reclustering speed improvements, and future fine-grained DML and multi-table transactions (coming soon in preview). These tables maintain Iceberg's openness while providing controlled, enterprise-ready functionality. BigLake automatically creates and registers an Apache Iceberg V2 metadata snapshot in its metastore. This snapshot updates automatically after edits.
BigLake natively supports Dataplex Universal Catalogue for AI-Powered Governance. This interface provides consistent and fine-grained access restrictions to apply Dataplex governance standards across engines. Direct Cloud Storage access supports table-level access control, whereas BigQuery can use Storage API connectors for open-source engines for finer control. Dataplex integration improves BigQuery and BigLake Iceberg table governance with search, discovery, profiling, data quality checks, and end-to-end data lineage. Dataplex simplifies data discovery with AI-generated insights and semantic search. End-to-end governance benefits are automatic and don't require registration.
The BigLake metastore enables interoperability with BigQuery, AlloyDB (preview), Spark, and Flink. This increased compatibility allows AlloyDB users to easily consume analytical BigLake tables for Apache Iceberg from within AlloyDB (Preview). PostgreSQL users can link real-time AlloyDB transactional data with rich analytical data for operational and AI-driven use cases.
CME Group Executive Director Zenul Pomal noted, “We needed teams throughout the company to access data in a consistent and secure way – regardless of where it stored or what technologies they were using.” They used Google's BigLake. BigLake from Google was clear. The uniform layer for accessing data and a fully managed experience with enterprise capabilities via BigQuery are available without moving or duplicating data, whether the data is in traditional tables or open table formats like Apache Iceberg. Metadata quality is critical as it explores gen AI applications. BigLake Metastore and Data Catalogue help us preserve high-quality metadata.
At Google Cloud Next '25, Google Cloud announced support for change data capture, multi-statement transactions, and fine-grained DML in the coming months.
Google Cloud is evolving BigLake into a comprehensive storage engine that uses open-source, third-party, and Google Cloud services by eliminating trade-offs between open and managed data solutions. This boosts data and AI innovation.
#BigLakestorage#widelyaccessible#BigLakeMetastore#BigQuery#ApacheIceberg#AlloyDB#technology#technologynews#technews#news#govindhtech
0 notes
Text
The Evolution of Hadoop: From Batch Processing to Real-Time Analytics
In today’s data-driven world, organisations generate vast amounts of data every second. Managing, storing, and analysing this data efficiently has become a necessity. Hadoop, an open-source framework, has played a crucial role in handling big data by offering scalable and distributed data processing capabilities. Over the years, Hadoop has evolved from a batch-processing system to a more advanced real-time analytics framework. This transformation has paved the way for businesses to make faster and more informed decisions.
Understanding the Foundation of Hadoop
Hadoop was developed to address the challenges posed by large-scale data processing. Initially, organisations struggled with traditional databases that could not handle the increasing volume, variety, and velocity. Hadoop emerged as a solution by introducing a distributed file system (HDFS) and a processing framework (MapReduce). These components enabled organisations to efficiently store and process massive datasets across multiple nodes.
MapReduce, the primary processing model in Hadoop’s early days, allowed batch data processing. However, this approach had limitations, especially in scenarios requiring real-time data insights. The need for faster data processing led to the evolution of Hadoop beyond batch-based analytics.
Transitioning from periodic data updates to continuous real-time analysis
Initially, Hadoop’s strength lay in batch processing, where large data sets were collected, stored, and processed periodically. While this was suitable for historical data analysis, businesses required more real-time insights to remain competitive. The increasing demand for real-time analytics led to the integration advanced technologies with Hadoop.
1. Introduction of Apache Spark
Apache Spark revolutionised the Hadoop ecosystem by introducing in-memory computing, making data processing significantly faster than traditional MapReduce. Spark’s ability to process data in real time improved analytics efficiency, making it a preferred choice for businesses dealing with streaming data.
2. Adoption of Apache Kafka and Flink
Hadoop is integrated with Apache Kafka and Apache Flink to handle continuous data streams. Kafka enabled real-time data ingestion, while Flink provided advanced stream processing capabilities. This shift allowed businesses to process and analyse data as it arrived, reducing latency and enhancing decision-making.
3. Advancements in Machine Learning and AI
With the rise of ML and AI, organisations needed faster and more scalable solutions for data processing. Hadoop evolved to support real-time machine learning applications, integrating with tools like TensorFlow and MLlib. This advancement enabled predictive analytics and automated decision-making in real-time scenarios.
The Role of Hadoop in Modern Data Science
The need for big data analytics keeps increasing, and Hadoop remains a key tool in data science. Professionals pursuing a data science course in Nagpur gain hands-on experience with Hadoop and its advanced frameworks. The course covers essential aspects such as data processing, analytics, and real-time insights, ensuring students stay ahead in the competitive job market.
Future Trends in Hadoop and Real-Time Analytics
The evolution of Hadoop is far from over. With technological advancements, the following trends are expected to shape the future of Hadoop and real-time analytics:
Integration with Cloud Computing – Organisations are shifting towards cloud-based Hadoop solutions to enhance scalability and flexibility.
Edge Computing and IoT Integration – The rise of IoT devices requires Hadoop to process data at the edge, reducing latency and improving real-time decision-making.
Enhanced Security and Privacy Measures – With data security in focus, Hadoop is enhancing its encryption and access control measures.
AI-Driven Automation – AI-powered tools automate Hadoop-based workflows, making data processing more efficient and cost-effective.
Hadoop’s journey from batch processing to real-time analytics has transformed how businesses handle data. With the integration of technologies like Apache Spark, Kafka, and machine learning frameworks, Hadoop has become a powerful tool for real-time decision-making. Enrolling in a data science course in Nagpur can help aspiring data scientists gain expertise in Hadoop and stay ahead in the ever-evolving analytics landscape.
The future of Hadoop is promising, with continuous innovations driving its capabilities beyond traditional data processing. Businesses that leverage these advancements will gain a competitive edge by making data-driven decisions faster and more efficiently than ever before.
0 notes
Text
Stateless vs Stateful Stream Processing With Kafka Streams and Apache Flink
http://securitytc.com/TKHfpR
0 notes
Text
Event Stream Processing: Powering the Next Evolution in Market Research.
What is Event Stream Processing?
At its core, Event Stream Processing is the technology that allows you to process and analyze data in motion. Unlike traditional batch processing, ESP enables organizations to ingest, filter, enrich, and analyze live data streams—in milliseconds. Technologies like Apache Kafka, Apache Flink, Spark Streaming, and proprietary platforms like Confluent and Azure Stream Analytics are powering this real-time revolution.
🌍 Overview of the Event Stream Processing Market
According to recent industry reports:
The global ESP market is projected to grow from $800M in 2022 to nearly $5.7B by 2032, with a CAGR exceeding 20%.
The drivers include growth in IoT devices, real-time analytics demand, AI/ML integration, and cloud-native infrastructure.
ESP is already being adopted in industries like finance, retail, telecom, and increasingly, in data-driven research sectors.
So how does this affect market research?
🧠 How ESP is Reshaping Market Research
The market research industry is undergoing a paradigm shift—from long cycles of surveys and focus groups to continuous consumer intelligence. ESP offers the foundation to make this real-time, automated, and infinitely scalable.
1. Always-On Consumer Listening
Traditional market research works in waves. ESP enables constant monitoring of consumer conversations, behaviors, and sentiments across social media, websites, mobile apps, and even connected devices.
2. Real-Time Behavioral Segmentation
Instead of waiting for post-campaign analysis, ESP enables dynamic audience segmentation based on live behavior. Imagine updating customer personas on the fly as users interact with a product or ad in real time.
3. Instant Trend Detection
With ESP, market researchers can spot emerging trends, spikes in brand mentions, or negative sentiment as it happens, giving companies the edge to react and innovate faster.
4. Improved Campaign Feedback Loops
By streaming campaign data into ESP systems, researchers can assess performance metrics like engagement, bounce rates, or purchase behavior in real time—enabling agile marketing and live optimization.
5. Enriching Traditional Research
Even classic survey research can be elevated. ESP can feed in contextual data (e.g., weather, location, digital footprint) to enhance response interpretation and modeling accuracy.
🚀 Emerging Use Cases
Use CaseESP in ActionSocial Listening at ScaleReal-time monitoring of tweets, posts, or mentions for brand perceptionVoice of the Customer (VoC)Processing live feedback from chat, call centers, or in-app surveysRetail Behavior AnalyticsStreaming in-store or ecommerce interaction data for buyer journey insightsAd Performance TrackingMeasuring campaign impact in real time and adjusting targeting dynamicallyGeo-Contextual SurveysTriggering location-based surveys in response to real-world events
🔍 Market Research Firms Tapping into ESP
Forward-thinking agencies and platforms are now building ESP pipelines into their solutions:
Nielsen is exploring real-time TV and digital media tracking.
Qualtrics and SurveyMonkey are integrating APIs and live data feeds to automate feedback systems.
Custom research agencies are partnering with ESP tech vendors to develop always-on insight platforms.
📈 Strategic Value for Researchers & Brands
Integrating ESP with market research doesn’t just speed things up—it changes the value proposition:Traditional ResearchESP-Enabled ResearchBatch, retrospectiveContinuous, real-timeManual analysisAutomated insightsSample-basedFull-data streamStatic reportsLive dashboardsReactive strategyProactive action
⚠️ Challenges to Consider
Data Overload: Without the right filters and models, ESP can create noise rather than insight.
Technical Skills Gap: Researchers may need to upskill or collaborate with data engineers.
Compliance Risks: Real-time processing must adhere to privacy laws like GDPR and CCPA.
Cost & Infrastructure: ESP requires robust architecture—cloud-native and scalable.
🔮 The Future: Market Research as a Streaming Platform
As ESP becomes more affordable and accessible via cloud platforms, we’ll see the rise of Insight-as-a-Stream—where brands and researchers subscribe to live feeds of behavioral, attitudinal, and transactional data, powered by AI and ESP pipelines.
In this new era, agility becomes a competitive advantage, and ESP is the engine behind it.
Final Thoughts
Event Stream Processing is no longer just for tech giants or financial firms—it’s the future backbone of modern market research. From real-time sentiment analysis to dynamic targeting and predictive behavioral modeling, ESP is enabling insights that are faster, smarter, and more actionable than ever before.
Market researchers who adopt ESP today won't just keep up—they'll lead. The Event Stream Processing market is poised for substantial growth, driven by technological advancements and the increasing need for real-time data analytics across various industries. For a detailed overview and more insights, you can refer to the full market research report by Mordor Intelligence: https://www.mordorintelligence.com/industry-reports/event-stream-processing-market
#event stream processing market#event stream processing market analysis#event stream processing research report#event stream processing market size#event stream processing market share#event stream processing market trends
0 notes
Text
Unlocking the Power of AI-Ready Customer Data

In today’s data-driven landscape, AI-ready customer data is the linchpin of advanced digital transformation. This refers to structured, cleaned, and integrated data that artificial intelligence models can efficiently process to derive actionable insights. As enterprises seek to become more agile and customer-centric, the ability to transform raw data into AI-ready formats becomes a mission-critical endeavor.
AI-ready customer data encompasses real-time behavior analytics, transactional history, social signals, location intelligence, and more. It is standardized and tagged using consistent taxonomies and stored in secure, scalable environments that support machine learning and AI deployment.
The Role of AI in Customer Data Optimization
AI thrives on quality, contextual, and enriched data. Unlike traditional CRM systems that focus on collecting and storing customer data, AI systems leverage this data to predict patterns, personalize interactions, and automate decisions. Here are core functions where AI is transforming customer data utilization:
Predictive Analytics: AI can forecast future customer behavior based on past trends.
Hyper-personalization: Machine learning models tailor content, offers, and experiences.
Customer Journey Mapping: Real-time analytics provide visibility into multi-touchpoint journeys.
Sentiment Analysis: AI reads customer feedback, social media, and reviews to understand emotions.
These innovations are only possible when the underlying data is curated and processed to meet the strict requirements of AI algorithms.
Why AI-Ready Data is a Competitive Advantage
Companies equipped with AI-ready customer data outperform competitors in operational efficiency and customer satisfaction. Here’s why:
Faster Time to Insights: With ready-to-use data, businesses can quickly deploy AI models without the lag of preprocessing.
Improved Decision Making: Rich, relevant, and real-time data empowers executives to make smarter, faster decisions.
Enhanced Customer Experience: Businesses can anticipate needs, solve issues proactively, and deliver customized journeys.
Operational Efficiency: Automation reduces manual interventions and accelerates process timelines.
Data maturity is no longer optional — it is foundational to innovation.
Key Steps to Making Customer Data AI-Ready
1. Centralize Data Sources
The first step is to break down data silos. Customer data often resides in various platforms — CRM, ERP, social media, call center systems, web analytics tools, and more. Use Customer Data Platforms (CDPs) or Data Lakes to centralize all structured and unstructured data in a unified repository.
2. Data Cleaning and Normalization
AI demands high-quality, clean, and normalized data. This includes:
Removing duplicates
Standardizing formats
Resolving conflicts
Filling in missing values
Data should also be de-duplicated and validated regularly to ensure long-term accuracy.
3. Identity Resolution and Tagging
Effective AI modeling depends on knowing who the customer truly is. Identity resolution links all customer data points — email, phone number, IP address, device ID — into a single customer view (SCV).
Use consistent metadata tagging and taxonomies so that AI models can interpret data meaningfully.
4. Privacy Compliance and Security
AI-ready data must comply with GDPR, CCPA, and other regional data privacy laws. Implement data governance protocols such as:
Role-based access control
Data anonymization
Encryption at rest and in transit
Consent management
Customers trust brands that treat their data with integrity.
5. Real-Time Data Processing
AI systems must react instantly to changing customer behaviors. Stream processing technologies like Apache Kafka, Flink, or Snowflake allow for real-time data ingestion and processing, ensuring your AI models are always trained on the most current data.
Tools and Technologies Enabling AI-Ready Data
Several cutting-edge tools and platforms enable the preparation and activation of AI-ready data:
Snowflake — for scalable cloud data warehousing
Segment — to collect and unify customer data across channels
Databricks — combines data engineering and AI model training
Salesforce CDP — manages structured and unstructured customer data
AWS Glue — serverless ETL service to prepare and transform data
These platforms provide real-time analytics, built-in machine learning capabilities, and seamless integrations with marketing and business intelligence tools.
AI-Driven Use Cases Empowered by Customer Data
1. Personalized Marketing Campaigns
Using AI-ready customer data, marketers can build highly segmented and personalized campaigns that speak directly to the preferences of each individual. This improves conversion rates and increases ROI.
2. Intelligent Customer Support
Chatbots and virtual agents can be trained on historical support interactions to deliver context-aware assistance and resolve issues faster than traditional methods.
3. Dynamic Pricing Models
Retailers and e-commerce businesses use AI to analyze market demand, competitor pricing, and customer buying history to adjust prices in real-time, maximizing margins.
4. Churn Prediction
AI can predict which customers are likely to churn by monitoring usage patterns, support queries, and engagement signals. This allows teams to launch retention campaigns before it’s too late.
5. Product Recommendations
With deep learning algorithms analyzing user preferences, businesses can deliver spot-on product suggestions that increase basket size and customer satisfaction.
Challenges in Achieving AI-Readiness
Despite its benefits, making data AI-ready comes with challenges:
Data Silos: Fragmented data hampers visibility and integration.
Poor Data Quality: Inaccuracies and outdated information reduce model effectiveness.
Lack of Skilled Talent: Many organizations lack data engineers or AI specialists.
Budget Constraints: Implementing enterprise-grade tools can be costly.
Compliance Complexity: Navigating international privacy laws requires legal and technical expertise.
Overcoming these obstacles requires a cross-functional strategy involving IT, marketing, compliance, and customer experience teams.
Best Practices for Building an AI-Ready Data Strategy
Conduct a Data Audit: Identify what customer data exists, where it resides, and who uses it.
Invest in Data Talent: Hire or train data scientists, engineers, and architects.
Use Scalable Cloud Platforms: Choose infrastructure that grows with your data needs.
Automate Data Pipelines: Minimize manual intervention with workflow orchestration tools.
Establish KPIs: Measure data readiness using metrics such as data accuracy, processing speed, and privacy compliance.
Future Trends in AI-Ready Customer Data
As AI matures, we anticipate the following trends:
Synthetic Data Generation: AI can create artificial data sets for training models while preserving privacy.
Federated Learning: Enables training models across decentralized data without sharing raw data.
Edge AI: Real-time processing closer to the data source (e.g., IoT devices).
Explainable AI (XAI): Making AI decisions transparent to ensure accountability and trust.
Organizations that embrace these trends early will be better positioned to lead their industries.
0 notes
Text
Onehouse opens up the lakehouse with Open Engines
Data lake vendor Onehouse on Thursday released Open Engines, a new capability on its platform which it says provides the ability to deploy open source engines on top of open data. Available in private preview, it initially supports Apache Flink for stream processing, Trino for distributed SQL queries for business intelligence and reporting, and Ray for machine learning (ML), AI, and data science…
0 notes
Text
Devant – Leading Big Data Analytics Service Providers in India
Devant is one of the top big data analytics service providers in India, delivering advanced data-driven solutions that empower businesses to make smarter, faster decisions. We specialize in collecting, processing, and analyzing large volumes of structured and unstructured data to uncover actionable insights. Our expert team leverages modern technologies such as Hadoop, Spark, and Apache Flink to create scalable, real-time analytics platforms that drive operational efficiency and strategic growth. From data warehousing and ETL pipelines to custom dashboards and predictive models, Devant provides end-to-end big data services tailored to your needs.
As trusted big data analytics solution providers, we serve a wide range of industries including finance, healthcare, retail, and logistics. Our solutions help organizations understand customer behavior, optimize business processes, and forecast trends with high accuracy. Devant’s consultative approach ensures that your data strategy aligns with your long-term business goals while maintaining security, compliance, and scalability. With deep expertise and a client-first mindset, we turn complex data into meaningful outcomes.Contact us today and let Devant be your go-to partner for big data success.

#devant#Data Analytics#Data Analytics Service Providers#Data Analytics Service#Big Data Analytics Service Providers in India
0 notes
Text

Java’s role in high-performance computing (HPC)
Java’s role in High-Performance Computing (HPC) has evolved significantly over the years. While traditionally, languages like C, C++, and Fortran dominated the HPC landscape due to their low-level control over memory and performance, Java has made inroads into this field thanks to various optimizations and frameworks.
Advantages of Java in HPC
Platform Independence — The Java Virtual Machine (JVM) allows Java applications to run on multiple architectures without modification.
Automatic Memory Management — Java’s garbage collection (GC) simplifies memory management, reducing the risk of memory leaks common in manually managed languages.
Multi-threading & Parallelism — Java provides built-in support for multithreading, making it easier to develop parallel applications.
JIT Compilation & Performance Optimizations — Just-In-Time (JIT) compilation helps Java achieve performance close to natively compiled languages.
Big Data & Distributed Computing — Java powers popular big data frameworks like Apache Hadoop, Apache Spark, and Flink, which are widely used for distributed HPC tasks.
Challenges of Java in HPC
Garbage Collection Overhead — While automatic memory management is beneficial, GC pauses can introduce latency, making real-time processing challenging.
Lower Native Performance — Even with JIT optimization, Java is generally slower than C or Fortran in numerical and memory-intensive computations.
Lack of Low-Level Control — Java abstracts many hardware-level operations, which can be a disadvantage in fine-tuned HPC applications.
Use Cases of Java in HPC
Big Data Processing — Apache Hadoop and Apache Spark, both written in Java/Scala, enable large-scale data processing.
Financial Computing — Many trading platforms use Java for risk analysis, Monte Carlo simulations, and algorithmic trading.
Bioinformatics — Java-based tools like Apache Mahout and BioJava support genomic and protein structure analysis.
Cloud-Based HPC — Java is widely used in cloud computing frameworks that provide scalable, distributed computing resources.
Java-Based HPC Frameworks & Libraries
Parallel Java (PJ2) — A library designed for parallel computing applications.
Java Grande Forum — A research initiative aimed at improving Java’s suitability for scientific computing.
MPJ Express — A Java implementation of Message Passing Interface (MPI) for distributed computing.
Future of Java in HPC
With ongoing developments like Project Panama (improving native interoperability), Project Valhalla (introducing value types for better memory efficiency), and optimized Garbage Collectors (ZGC, Shenandoah), Java is becoming a more viable option for high-performance computing tasks.
1 note
·
View note